
Abstract
The study aims to analyze and forecast Internet financial risks based on the model based on deep learning and the Back Propagation Neural Network (BPNN). First, the theory of Internet financial risks is introduced and a theoretical framework for analyzing and forecasting internet financial risks is established. Second, the theory of the BPNN and the algorithms based on deep learning are introduced. Then, the model based on the BPNN and deep learning is implemented to improve the early warning of Internet financial risks, analyze the data image of China's Gross Domestic Product (GDP), currency (M2), non-performing loan records, and the Shanghai Composite Index from 2006 to 2020, and forecast the risks in 2021. Through the model based on deep learning and BPNN, it can be found that the trends of the growth rate of China's GDP take on the shapes of V and L, and the trend of M2 is opposite to that of GDP. In the whole year, there is a low at the beginning and the end of the year, and the monthly non-performing loans and the Shanghai Composite Index decrease. The forecast made by the model is that there will be many fluctuations in 2021. At present, China’s economy just enters the era of the new normal, which helps to build a more scientific and sensitive early warning system for financial risks. The model based on the BPNN and deep learning greatly improves the timeliness of forecasts and has a positive impact on the stability of China’s financial environment.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the increasing instability of the international financial environment, the global financial market becomes turbulent, and the risks in China’s Internet finance also increase. During 2015, China’s financial market fluctuates greatly, which makes the Shanghai Composite Index drop by 30%, and the Shenzhen Component Index and the Growth Enterprise Market Index drop by nearly 40%, resulting in a loss of more than CNY 20 trillion (Song & Peng, 2019). In this case, Internet finance begins to illegally raise funds, which makes nearly 30% of the peer-to-peer (P2P) platforms meet with accidents, resulting in investment failures. During that period, China has not established the relevant Internet financial supervision mechanism, and the relevant warnings cannot be made in the face of risks, causing great losses (Wang et al., 2021; Wu & Wu, 2020). Due to globalization and the increasing frequency of businesses and trades between countries since the twenty-first century, the weak financial environment is on the verge of collapse, and how to establish effective mechanisms to deal with the risks that occur at any time become the main problem that every country should pay attention to. If a financial crisis happens in a country, it will not only cause the paralysis of the country’s financial system but also bring huge damage to the national economy. And it may even bring a crisis to society, national politics, and social security (Li et al., 2019).
Nowadays, China’s economy gradually tends to be stable, and the financial regulatory authorities have taken this opportunity to establish a set of scientific regulatory mechanisms, which should have the ability to evaluate and analyze the security of the internet financial system and warn risks. Chen et al. (2020) implemented a model based on a deep neural network to realize the evacuation simulation in subway stations. And the accuracy and training speed of the model are verified by combining with the model based on convolutional neural network (CNN) and the classification data set pre-training model (Chen et al., 2020). Huang et al. (2020) introduced a fuzzy c-means algorithm and comprehensive minority oversampling technology by taking China Securities Index 300 (CSI300) as an example and proposed a hybrid model of KFCM-KSMOTE-SVM for predicting extreme financial risks with a help of a support vector machine. The results show that the model is robust in predicting extreme financial risks (Huang et al., 2020). Cy et al. (2020) improved the adaptive genetic algorithm (NAGA) by combining it with the back propagation neural network (BPNN) to optimize the initial weights of the BPNN and overcome its shortcomings, such as easy to fall into a local minimum, slow convergence rate, and sample dependence. They used the historical automobile insurance claims data of insurance companies as samples, and the model based on NAGA-BPNN for simulation and prediction. Finally, the improved genetic algorithm (GA) is more advanced than the traditional algorithm in terms of convergence speed and prediction accuracy (Cy et al., 2020). Pawiak et al. (2020) introduced the Deep Genetic Hierarchical Learner Network Learner (DGHNL) method. The proposed method includes different types of learners, including the learners supported by the support vector machine (SVM), k-nearest neighbor (kNN), probabilistic neural network (PNN), and fuzzy systems. The StatlogGerman (1000 instances) credit approval dataset provided by the University of California (UCI) in the machine learning repository is used to test the effectiveness of the model in the field of credit scoring (CS), effectively improving the risk management ability of banks and other financial institutions (Pawiak et al., 2020). Zhou et al. (2019) believed that financial credit risk is one of the most significant risks faced by commercial banks. However, when there are massive financial data from various sources such as the Internet, mobile networks, or Internet of Things (IoT), the traditional statistical model and neural network model may not work. Therefore, they proposed a method based on big data and mining technology under the particle swarm optimization (PSO) of the BPNN for managing the financial risks of commercial banks (Zhou et al., 2019).
The main task of the study is to better predict and supervise the risks of the Internet finance system, and the model based on deep learning and the BPNN is introduced to improve the prediction accuracy of the system. The innovation is that all the data are from China, which makes the results of the study bear the Chinese characteristics and explores the current situation of its financial security and early warning programs. It is hoped that this study can provide a reference for the research on China's Internet financial security.
2 Theoretical Analysis and Modeling
2.1 Theory of the Internet Financial Risk
A very important internal attribute of Internet financial activities is the financial risk. And the main risks include credit risks, capital liquidity risks, and capital operation risks. If these risks cannot be reasonably removed, they will be transformed into internal risks in the Internet financial system (Chi et al., 2019; Qiu, 2021). In addition, there are also other factors, such as economic cycle changes, national economic policies, and international trades, which also cause risks to the Internet financial system. And the interest rates of the national regulatory system will inevitably decline if financial risks happen. Some risks are caused by uncertainties and the market regulatory system (Zhu & Liu, 2021). And the causes of financial risks can be explored subjectively and objectively. From the subjective aspect, the risk is caused by market management and government operation and it may be due to the change of the commodity tax rate and currency exchange rate in the market economy from the objective aspect (Liu, 2019; Wang & Wei, 2020). In finance, every action of senior managers may cause risks, so the implementation of the policies should be reviewed regularly. The Internet financial industry works with currency and credit. Credit refers to the circulation of goods by repaying the principles and interests. In the process of developing the market economy, commercial credit begins to disappear since the banking industry becomes increasingly prosperous (Gu, 2021; Su & Jiang, 2020). The Internet financial risks are complex, and different countries have different regulatory and control policies.
2.2 Model Based on the BPNN for the Early Warning of Internet Financial Risks
-
A.
Principle of the BPNN and the model based on the BPNN
The BPNN is frequently used for the study, and its principle is a multi-layer feedback network based on the error back propagation algorithm. It is also the most widely used neural network (Filippetto et al., 2021; Lu, 2020). Digital signals should be processed repeatedly to obtain the desired results in the model based on the BPNN. The process is divided into three layers, namely the input layer, the hidden layer, and the output layer. In the calculation, the digital signal first receives the signal from the input layer and then transmits it to the hidden layer. And the hidden layer processes and calculates the digital signal. Finally, the processed results are transmitted to the output layer and the results are output. The output results are compared with the expected values before the experiment. If there are many differences from the expected values, the results will be returned to be processed again (Lin et al., 2019). The results are transmitted from the output layer to the hidden layer, which decomposes the results of the digital signal to obtain the original digital signal and correct it. Then, the data are imported into the input layer, and the whole process starts again until the results obtained are satisfactory (Wang et al., 2020).
-
B.
Equations based on the BPNN
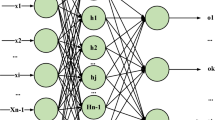
The algorithm based on the BPNN is composed of forward propagation and reverse propagation of a signal error. The signal is transferred from the input to the output and the weight and threshold are obtained (Song et al., 2019). Figure 1 shows the structure of the BPNN.

Structure of the BPNN
Entering the j-th node in the input layer is called xj, and the range of j is [1, M].
In the hidden layer, the weight from node i to node j in the output layer is generally represented by wij.
In the hidden layer, θi is the threshold of nodes.
In the hidden layer, the incentive function is generally expressed by \(\Phi\)(x).
Wki is the weight between the K node of the output layer and the i node of the hidden layer, and i = 1,…,q.
In the output layer, αk is the value of the K node, and the range of k is [1, L].
In the output layer, the excitation function is generally represented by \(\psi (x)\).
In the output layer, Ok is the output of the node.
First: forward propagation process of signals.
The input neti of the i-th node in the hidden layer.
The output yi of the i-th node in the hidden layer is:
The input netk of the K-th node in the output layer is:
The output Ok of the K-th node in the output layer is:
Second: the reverse propagation process of errors.
The back propagation of errors is as follows: the output error of neurons in each layer is calculated from the output layer, and then the weights and thresholds of each layer are adjusted according to the error gradient descent method so that the final output of the modified network can be close to the expected value (Chen & Chen, 2020).
For each sample p, the quadratic error criterion function is Ep:
The total error criterion function of the system for P training samples is:
According to the error gradient descent method, the correction \(\vartriangle w_{ki}\) of the output layer weight value, the correction \(\vartriangle a_{k}\) of the output layer threshold, the correction \(\vartriangle w_{ij}\) of the hidden layer weight value, and the correction \(\vartriangle \theta_{i}\) of the hidden layer threshold are corrected in turn.
The weight adjustment equation of the output layer is:
The threshold adjustment equation of the output layer is:
The weight adjustment equation of the hidden layer is:
The threshold adjustment equation of the hidden layer is:
and:
2.3 Financial Risk Warning System Based on Deep Learning
-
A.
The basic principle of the model based on deep learning
Deep learning uses the features of the factors to search for nonlinear factors to realize prediction. The essence of deep learning is to find the mathematical method of mapping relationship functions through observing data (Ghosh et al., 2019; Lu, 2020; Xie et al., 2021). In brief, deep learning is a supervised learning form that predicts variable Y through the characteristics of variable X. It includes a series of L nonlinear transformations acting on X. The output of each L transformation is called a layer, where the original input is X, and the output of the first transform is the first layer. Thus, the output Y is the output of the (L + 1) layer (Nayoga et al., 2021; Zhang & Lou, 2021). Layers 1 to L and the intermediate output layers are called hidden layers. Layer L is the depth of the model. Specifically, the deep neural network can be described as follows:
The activation function is a nonlinear transformation of weight data. The commonly used activation function is S (Karar et al., 2021). A vector with the same length is the number of neurons in layer L, so X = , then the structure of the deep prediction rule is the combination of univariate and semi-affine functions. Traditionally, researchers estimate factor Ft and learning coefficient are obtained through the two-step regression. Deep learning can estimate coefficients and potential factors (Mis et al., 2020).
-
B.
Early warning of internet financial risks
The model used for the experiment is collected from the China Securities Network under the China Capital Market Information Disclosure Platform. The website is China's authoritative financial and securities information website, which is the capital market professional information disclosure platform, covering the Shanghai Stock Exchange, Shenzhen Stock Exchange, the New Third Board, funds, bonds, regulators' information disclosure. Its advanced query function can obtain all the valuable data information contained in the originally listed companies. All the 16 indexes and the composite index are selected from the macroeconomic environment and financial industry evaluation. The specific indexes include the GDP growth rate, the M2 growth rate, the growth rate of total assets of banking and financial institutions, the ratio of non-performing loans of commercial banks, the monthly standard deviation of the Shanghai Composite Index, the monthly standard deviation of the Shenzhen Composite Index, and the monthly standard deviation of the national interbank lending rate (Pu et al., 2020; Weng et al., 2019).
2.3.1 Empirical Steps
The hyper-parameters of the model are set to train and predict the trend of GDP in 2021 according to the actual monthly growth rate of GDP from 2006 to 2020, and the change of M2 in 2021 is predicted according to the actual monthly growth data of M2 from 2006 to 2020 to make a judgment on the trend of economic development. According to the monthly statistical data of non-performing loans from 2006 to 2020, the non-performing loans in 2021 are predicted. And the actual standard deviation of the Shanghai Composite Index for 2006–2020 is used to predict the monthly data of the Shanghai Composite Index for 2021 and analyze the annual distribution of prediction deviation. The 2021 loan interest rate is predicted based on the standard deviation of the loan interest rate during 2006–2020. The input layer parameters of the model are the data of the past 15 years, and the hidden layer trains the output that conforms to the past trend as the output layer.
Input variables: the four different input variables are reviewed and they have a growing trend. In the first case, the input variables are 16 variables and the composite financial security index. In the second case, it has a square term, with a total of 32 variables (Weng et al., 2019).
Output variables: initial data should be sufficient and available at the beginning for obtaining a reliable regression estimation period.
Specifications of the training set: the rules of the two periods are explored. The first uses a fixed moving window to estimate the model and predict that in the next period. The second uses a cumulative moving window and predicts the next cycle from December 19 to the current. Thus, there are more data over time that can be used by the second rule (Qin et al., 2019; Zhao et al., 2020).
3 Results of the Data Analyzed by the Model
3.1 Data Analysis of M2 (Monthly Growth Rate) Based on the BPNN
Figure 2 below shows the monthly GDP growth rate from 2006 to 2020.

Monthly GDP growth rate from 2006 to 2020
The above chart is the monthly growth rate of China's GDP from 2006 to 2020. The GDP increases rapidly in 2007, but it decreases significantly due to the influence of the global economy since 2010, even falling to the bottom in 2012. With more national financial investment, the value-added of GDP rises rapidly. In this regard, many researchers and teams have to study the development trend of GDP in China in the process of economic development (V/L). And they find that the development trend presents V in the short term and L in the medium and long term of economic change. This indicates that China’s economy is gradually going stable.
Figure 3 shows the change and prediction of GDP from 2006 to 2021.

GDP statistics and prediction from 2005 to 2021 (a GDP forecast, b GDP statistics)
According to the data above, it can be found that the overall growth rate of GDP in 2021 is relatively high, but the growth rate remains less than 6.8. And GDP growth rate in 2021 is 6.8%, and the average predicted value is close to the real value.
Figure 4 shows the monthly growth rate of GDP.

Monthly variation and annual distribution of GDP from 2006 to 2020 (A: January, B: March, C: May, D: July, E: September, F: October, G: December. a GDP annual statistics; b monthly change of GDP)
Figure 4a shows China's monthly growth rate of GDP. During 2010, China's monthly growth rate of GDP reaches the highest. And then it gradually decreases, and there is a sign to continue. Figure 4b shows that growth rates of GDP have extreme values at the beginning and end of the year. In the beginning, the growth rate reaches the maximum, and it shows the minimum at the end of the year.
3.2 Data Analysis of the Monthly Growth Rate of M2 Based on the BPNN
Figure 5 shows the monthly growth rate of M2 from 2006 to 2020 and the prediction for 2021.

Monthly growth rate of M2 from 2006 to 2020 and the prediction for 2021 (a the monthly growth rate of M2, b Prediction for 2021)
Figure 5a shows the growth data of M2 from 2006 to 2020. M2 increases rapidly g in China since 2012, which is stimulated by a large number of funds. In 2014, the growth rate of M2 increases to 15%, and it slows down in 2016, indicating that there is only a growth in the first quarter. However, the epidemic, domestic and foreign capital flows make the monthly growth rate of M2 begin to decline in 2020. Figure 5b shows that the monthly growth rate of M2 is below 10% during 2018. In 2021, the monthly growth rate of M2 is stable in the first quarter and maintains at about 8.5%, which shows that China's socio-economic development is consistent with the forecast results.
Figure 6 shows the change in monthly growth rate and the annual distribution of M2 from 2006 to 2020.

Changes of monthly growth rate and annual distribution of M2 from 2006 to 2020 (a changes of the monthly growth rate of M2; b annual distribution from January to December; a change of the annual distribution of M2; b changes of the monthly growth rate of M2)
Figure 6a shows that during 2012, the monthly growth rate of M2 reaches the highest and slows down, and there is no sign of change. Figure 6b is the annual distribution map of M2. The data from January to December show that the two lowest points are in March and August, indicating that March and August are the money shortage months.
Figure 7 shows the monthly statistics of non-performing loans from 2006 to 2020 and the prediction for 2021.

Monthly statistics of non-performing loans from 2006 to 2020 and the prediction for 2021 (a monthly growth rate of non-performing loans, b prediction of non-performing loans in 2021)
Figure 7a shows that the number of non-performing loans decrease significantly since 2006. From 2007 to the first half of 2008 and the second half of 2011, there are three breaks. During this period, the relatively loose currency causes a surge in the base of loans, and the monthly growth rate of non-performing loans is low. Figure 7b shows that the trend of the growth rate of non-performing loans in the first half of 2021. The monthly growth rate of non-performing loans in 2021 will fluctuate greatly, and the maximum may be more than 10%, which is similar to the growth rate in 2008.
Figure 8 shows the monthly changes and annual distribution of M2 from 2006 to 2021.

Monthly changes and annual distribution of M2 from 2006 to 2021 (a changes of the monthly growth rate of M2; b annual distribution of M2 from January to December)
Figure 8a shows that the monthly growth rate of non-performing loans decreases since 2006, and there is no sign of reversal. Figure 8b shows the annual distribution of non-performing loans. During 2006–2020, the growth rate of non-performing loans has two peaks from January to December, and April and October are the fastest-growing months in terms of the changing trend.
Figure 9 shows that the data change of the Shanghai Composite Index.

Changes of the Shanghai Composite Index (a 2006–2021 Shanghai Composite Index monthly standard deviation; b prediction of the monthly standard deviation of Shanghai Composite Index in 2021; c trends in the monthly standard deviation of the Shanghai Composite Index from 2006 to 2021; d annual distribution of monthly standard deviation of Shanghai Composite Index from 2006 to 2021)
Figure 9 shows that the Shanghai Composite Index has two peaks. The first is in the first half of 2011, and the other in the second half of 2018, during which the A-share collapses. Figure 9b shows the prediction of the growth rate of the monthly standard deviation of the Shanghai Composite Index in 2021. It is found that the growth rate of the monthly standard deviation of the Shanghai Composite Index changes greatly in 2021. After the extreme value in 2011, it decreases month by month without any sign of reversal. The data show that the growth rate of the monthly standard deviation of the Shanghai Composite Index begins to increase from 2006 to 2020, which is in line with the saying in the industry: the annual market or Gold 9 silver 10.
Figure 10 shows the changes in national inter-bank interest rates.

Changes of interbank lending rates across the country (a standard deviation of the lending rates from 2006 to 2021); b prediction of the standard deviation of the lending rate in 2021; c the trend of the standard deviation of the lending rate from 2006 to 2021; d annual distribution of monthly standard deviation of the lending rates from 2006 to 2021)
Figure 10 shows that there are two peaks in the growth rate of the monthly standard deviation of inter-bank lending rates across the country during the second half of 2007 and the end of 2010, which indicates that there is a high demand for funds between inter-banks. Figure 10b shows the prediction of the monthly standard deviation of interbank lending rates across the country. The monthly standard deviation index of the interbank lending rate will increase in 2021 and the interbank lending rate will fluctuate greatly. The monthly standard deviation of the inter-bank lending rate reaches the peak in 2014, indicating that the lending rate fluctuates the most greatly in 2011 and then remains relatively stable. The monthly standard deviation of the inter-bank lending rate is distributed evenly, and appears a valley at the end of October, indicating that there is no large fluctuation in this period.
3.3 Data Analysis of the Internet Financial Security Based on the BPNN
Figure 11 shows the prediction of financial security under the model based on deep learning.

Prediction of the financial security
Figure 11 shows a one-step forecast of the Internet financial security composite index from 2006 to 2021 by using the model based on deep learning and the neural network. The test is the one-step prediction of the next month, so the point is close to the horizontal line at the end of the image. Figure 12 shows the financial risk prediction map implemented by the model based on deep learning.

Prediction and comparison of financial risks
Figure 12 shows the prediction of the Internet financial security composite index by the model based on deep learning from 2006 to 2021. Black points are the real values and red points are the prediction values. The model based on deep learning and the BPNN can predict the change of financial risks timely.
According to the experimental results of the prediction model proposed the results of evaluating the prediction model can be obtained. The root mean square error (RMSE) of the predicted values is between 0 and 1, the mean absolute percentage error (MAPE) of the predicted values is between 1 and 10%, and the mean absolute percentage error (MASE) of the predicted values is between 5 and 15%.
4 Discussion
The comparison shows that there are some problems in the Chinese Internet financial risk prediction system. Therefore, an early warning and supervision mechanism of financial risks in line with the nation’s conditions should be established: (1) A cross-industry and cross-domain prediction and supervision platform of internet financial risks should be established. And it can timely predict financial risks for different industries, which is necessary for the prediction and supervision of Internet financial risks. In addition, linkages and cooperation between different industries and regions should be strengthened to regulate financial risks. At the same time, the areas with the ability to supervise financial risks can stimulate those with lower supervision ability, so that the financial risk between different industries and regions can be transferred efficiently and accurately. (2) The early warning of the Internet financial risk mechanism should be optimized and improved and a more complete database of financial risks should be established. Before a risk prediction system is built, the analysis should be conducted from different perspectives (economic, cultural, social, and political) to select more appropriate indexes. When a complete risk prediction database is established, the risk data obtained should be correct, which can help the regulatory authorities to carry out relevant work timely. Besides, the type and source of financial risks should be analyzed to make timely responses. (3) Combined with the actual situation of China, a prediction and supervision model of Internet financial risks is implemented. First, the scope of the application, the advantages, and the disadvantages of the model are considered. The latest measurement methods and early warning means are achieved, and a scientific risk prediction and early warning model is developed according to the situation of China and the interdisciplinary research results like human intelligence, making the prediction and supervision model more scientific, accurate, and efficient. (4) The current socio-economic environment should be adjusted, the enthusiasm for bank credit should be improved, and financial support should be increased. First, debts should be resolutely eliminated, legal means should be strengthened to punish credit offenders, and the law should be used to maintain the normal operation of financial rights. It is necessary to improve the cooperation mechanism between the judiciary, financial management departments, and banks. Second, the social credit system should be strengthened, the honesty education for the people should be carried out, entrepreneurs should be encouraged to operate in good faith, market behavior should be standardized according to legal provisions, a safe and stable financial ecological environment should be created, and the basic work for China's socialist economic construction should be done timely and efficiently.
5 Conclusions
The model for predicting the Internet financial risks in China under deep learning and the BPNN is analyzed and forecasted. First, the model based on the BPNN algorithm and deep learning is implemented to predict financial risks according to the relevant theories of Internet financial risks. Then, the data are obtained through the model, and relevant analysis and predictions are made. The results show that the financial risks in China are high, which may influence the growth rate of GDP. Also, the monthly growth rate of GDP in 2021 will fluctuate greatly, and the GDP growth rate from 2016 to 2020 decreases greatly. The changing trend of M2 is opposite to that of GDP, showing extremes at the beginning and the end of the year. The monthly change of non-performing loans also decreases, and the prediction shows that there will be large fluctuations in 2021. The Shanghai Composite index is also similar with two peaks, which show that growth rates in 2021 will fluctuate considerably. According to the prediction of financial risks made by the model based on deep learning and the BPNN, the safety of the financial system is improved greatly.
However, there are still some limitations in this study, the external environment is not considered, making the results of the prediction not universal. In future research, the risk coefficient should be adjusted, and the influencing factors should not be considered comprehensively.
Change history
09 September 2024
A Correction to this paper has been published: https://doi.org/10.1007/s10614-024-10600-w
References
Chen, J., & Chen, Q. (2020). Application of deep learning and BP neural network sorting algorithm in financial news network communication. Journal of Intelligent and Fuzzy Systems, 38(3), 1–12.
Chen, Y., Hu, S., Mao, H., et al. (2020). Application of the best evacuation model of deep learning in the design of public structures. Image and Vision Computing, 102, 103975.
Chi, G., Uddin, M. S., Abedin, M. Z., et al. (2019). Hybrid model for credit risk prediction: An application of neural network approaches. International Journal of Artificial Intelligence Tools, 28(5), 33.
Cy, A., Ml, B., Wei, L. C., et al. (2020). Improved adaptive genetic algorithm for the vehicle Insurance Fraud Identification Model based on a BP Neural Network. Theoretical Computer Science, 817, 12–23.
Filippetto, A. S., Lima, R., & Barbosa, J. (2021). A risk prediction model for software project management based on similarity analysis of context histories. Information and Software Technology, 131(1), 106497.
Ghosh, K., Stuke, A., Todorovi, M., et al. (2019). Machine learning: Deep learning spectroscopy: Neural networks for molecular excitation spectra. Advanced Science, 6(9), 1410.
Gu, N. (2021). Digital financial inclusion risk prevention based on machine learning and neural network algorithms. Journal of Intelligent and Fuzzy Systems, 2, 1–16.
Huang, X., Zhang, C. Z., & Yuan, J. (2020). Predicting extreme financial risks on imbalanced dataset: A combined kernel FCM and kernel SMOTE based SVM classifier. Computational Economics, 6, 1–30.
Karar, M. E., Alsunaydi, F., Albusaymi, S., et al. (2021). A new mobile application of agricultural pests recognition using deep learning in cloud computing system. AEJ-Alexandria Engineering Journal, 60(5), 4423–4432.
Li, W., Ding, S., Chen, Y., et al. (2019). Transfer learning-based default prediction model for consumer credit in China. Journal of Supercomputing, 75(2), 862–884.
Lin, Y. W., Zhou, Y., Faghri, F., et al. (2019). Analysis and prediction of unplanned intensive care unit readmission using recurrent neural networks with long short-term memory. PLoS ONE, 14(7), e0218942.
Liu, Y. (2019). Novel volatility forecasting using deep learning–long short term memory recurrent neural networks. Expert Systems with Applications, 132, 99–109.
Lu, M. (2020). A monetary policy prediction model based on deep learning. Neural Computing and Applications, 32(10), 5649–5668.
Mis, A., Jian, P., Mak, B., et al. (2020). Active deep neural network features selection for segmentation and recognition of brain tumors using MRI images. Pattern Recognition Letters, 129, 181–189.
Nayoga, B. P., Adipradana, R., Suryadi, R., et al. (2021). Hoax analyzer for indonesian news using deep learning models. Procedia Computer Science, 179(2), 704–712.
Pawiak, P., Abdar, M., Pawiak, J., et al. (2020). DGHNL: A new deep genetic hierarchical network of learners for prediction of credit scoring. Information Sciences, 516, 401–418.
Pu, B., Zhu, N., Li, K., & Li, S. (2020). Fetal cardiac cycle detection in multi-resource echocardiograms using hybrid classification framework. Future Generation Computer Systems, 115, 825–836.
Qin, Y., Li, K., Liang, Z., et al. (2019). Hybrid forecasting model based on long short term memory network and deep learning neural network for wind signal. Applied Energy, 236, 262–272.
Qiu, W. (2021). Enterprise financial risk management platform based on 5 G mobile communication and embedded system. Microprocessors and Microsystems, 80(4), 103594.
Song, Y., & Peng, Y. (2019). A MCDM-based evaluation approach for imbalanced classification methods in financial risk prediction. IEEE Access, 12(99), 1–1.
Song, Y., Zhang, F., & Liu, C. (2019). The risk of block chain financial market based on particle swarm optimization. Journal of Computational and Applied Mathematics, 370, 112667.
Su, Z., & Jiang, J. (2020). Hierarchical gated recurrent unit with semantic attention for event prediction. Future Internet, 12(2), 39.
Wang, C., & Wei, Y. (2020). Simulation of financial risk spillover effect based on ARMA-GARCH and fuzzy calculation model. Journal of Intelligent and Fuzzy Systems, 2, 1–12.
Wang, D., Wang, P., Yuan, Y., et al. (2020). A fast conformal predictive system with regularized extreme learning machine. Neural Networks, 126, 347–361.
Wang, H., Liu, R., Zhao, Y., et al. (2021). Prediction and application of computer simulation in time-lagged financial risk systems. Complexity, 12(1), 1–10.
Weng, Y., Wang, X., Hua, J., et al. (2019). Forecasting horticultural products price using ARIMA model and neural network based on a large-scale data set collected by web crawler. IEEE Transactions on Computational Social Systems, 6(3), 547–553.
Wu, S., & Wu, T. (2020). Risk prediction of financial insurance based on FPGA and neural network. Microprocessors and Microsystems, 3, 103406.
Xie, C., Zhang, P., & Yan, Z. (2021). Correlation analysis of aeroengine operation monitoring using deep learning. Soft Computing, 25(3), 1–12.
Zhang, D., & Lou, S. (2021). The application research of neural network and BP algorithm in stock price pattern classification and prediction. Future Generation Computer Systems, 115, 872–879.
Zhao, W. D., Chen, D. W., Zhuo, Y. Q., et al. (2020). Deep neural fuzzy system algorithm and its regression application. Zidonghua Xuebao/acta Automatica Sinica, 46(11), 2350–2358.
Zhou, H., Sun, G., Fu, S., et al. (2019). A big data mining approach of PSO based BP neural network for financial risk management with IoT. IEEE Access, 99, 1–1.
Zhu, Z., & Liu, N. (2021). Early warning of financial risk based on K-means clustering algorithm. Complexity, 2021(24), 1–12.
Acknowledgements
The Study on Reform of International Financial Public Goods Supply under the Perspective of International Monetary Power Transitions and Financial Technology Development (Grant No. 18CGJ002), Financial support from the National Social Science Fund of China.
Author information
Authors and Affiliations
Contributions
ZL: writing—original draft preparation; formal analysis, data curation; Conceptualization, methodology; GD: writing—review and editing, visualization, supervision. SZ: formal analysis, data curation; HL: formal analysis, data curation; HJ: visualization, supervision. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Human and Animal Rights
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised due to authors affiliation corrections.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, Z., Du, G., Zhou, S. et al. Analysis of Internet Financial Risks Based on Deep Learning and BP Neural Network. Comput Econ 59, 1481–1499 (2022). https://doi.org/10.1007/s10614-021-10229-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10614-021-10229-z