
Abstract
Although improving the quality of habitat patches in fragmented landscapes is a main conservation target few studies have examined patch management in relation to the surrounding landscape. Tackling such an issue needs a cross-scale approach that takes the hierarchical nature of landscapes into account. Here I show the results of a cross-scale study focusing on the distribution patterns of ten forest vertebrate species (birds and mammals). The overarching goal of this study was to understand the strength of patch scale determinants of distribution, following the appropriate control for relevant landscape properties (e.g. habitat loss vs. habitat subdivision). I show how, after controlling for uncertainty in the detection of the species and for the role of landscape properties, patch scale variables still played an important role in determining occupancy patterns of forest vertebrates. For some species variation in the values of patch structure variables increased occurrence probability with only moderate levels of habitat loss, highlighting the fact that habitat management should be targeted towards precise landscape conditions. In other cases the effect of patch variables was strong therefore variation in their values always brought substantial increase/decrease of presence probability. Overall these results strongly suggest that habitat management should never be carried out irrespective of the properties of the surrounding landscape, rather, it should be carefully targeted towards specific landscape contexts (e.g. above a certain amount of habitat) where it is more likely to be effective.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The distribution of species in fragmented landscapes is determined by several processes that act at multiple scales: at one extreme there are landscape scale processes such as habitat loss and habitat fragmentation and at the other extreme there are patch scale processes, such as the decrease in quality of habitat (Fischer and Lindenmayer 2007). These processes are highly correlated, characterized by cross-scale interactions and often ambiguously defined by researchers (Fahrig 2003; Schooley and Branch 2007) making untangling their independent effects complicated.
The term “habitat fragmentation”, for instance, is often used ambiguously for several landscape scale processes including habitat loss, habitat fragmentation per se (the breaking apart of formerly contiguous habitat sensu Fahrig 2003), and disruption in structural connectivity (e.g. disruption in the network of hedgerows connecting patches Fischer and Lindenmayer 2007). Two landscapes with the same amount of habitat may have both different levels of habitat subdivision and different levels of structural connectivity (i.e. hedgerows in forested landscapes) (Fischer and Lindenmayer 2007; Radford and Bennett 2007). Their distinction is crucial for identifying the most appropriate conservation action (Fischer and Lindenmayer 2007) but understanding the consequences of landscape effects requires specifically designed landscape scale studies (Fahrig 2003; Bennett et al. 2006; Mortelliti et al. 2010a, b, c).
Most studies focusing on patch processes have been carried out at the patch scale or patch-landscape scale (sensu McGarigal and Cushman 2002; Bennett et al. 2006; Thornton et al. 2011).
Patch scale studies have been largely criticized because they do not consider the context where the patch is located (McGarigal and Cushman 2002; Fahrig 2003). Patch-landscape scale studies may also lead to biased results because the focus is on the neighborhood surrounding the patch rather than on landscape scale emerging properties such as habitat loss or habitat fragmentation. There are several studies that consider the whole landscape (Moore and Swihart 2005; Thornton et al. 2011) but these do not distinguish between correlated landscape processes.
Methodological issues have proven to be crucial in patch occupancy studies (Cushman and McGarigal 2004; Thornton et al. 2011) therefore separating correlated landscape processes and taking into account factors acting at multiple scales is important for obtaining an unbiased evaluation of the importance of patch processes and has strong implications for landscape management. Landscape management is often complicated by the fact that fragmented landscapes often occur in areas of high economical value in which an increase of habitat may not be possible, therefore improving the quality of habitat may be the only possible conservation action (Lindenmayer and Fischer 2006). Nevertheless, very little is known about the dependence of patch quality on landscape context (Chauvenet et al. 2010) whereas this kind of information may be crucial to help target actions towards those landscape contexts where they are most likely to be effective (e.g. habitat management may be carried out only in landscapes above a certain threshold of habitat amount or habitat fragmentation).
The overarching goal of this study is to evaluate whether the effect of patch quality depends on landscape structure. More specifically my aim was to evaluate under which landscape conditions a variation in patch quality (a proxy for habitat management) could increase the probability of occurrence of the target species.
In order to evaluate the relative strength of patch scale determinants of distribution with respect to landscape scale properties it was first necessary to design a landscape scale study that would allow me to separate the independent effects of landscape processes (habitat loss vs. habitat fragmentation per se vs. structural connectivity). Within each selected landscape I then selected a set of patches where to conduct a patch level occupancy analysis. Agricultural landscapes of central Italy fit the scope for three reasons: (a) they offered the required experimental conditions at the landscape level (contrasting levels of subdivision and connectivity for given levels of habitat amount) (b) the system is actively managed by periodical coppicing that alters the understory vegetation and thus the quality of patches (c) all landscapes were located within the same forest climax so it was possible to reduce background noise due to unknown environmental factors. Finally I identified a suite of forest dependent vertebrate species (7 birds and 3 mammals, listed in materials and methods) suited as model species for this study because they are known to respond to both patch and landscape factors (Cramp et al. 1992; Matthysen and Adriaensen 1998; Brichetti and Fracasso 2007; Pasinelli 2007; Mortelliti et al. 2009; Mortelliti et al. 2010a).
I predicted that both patch and landscape scale variables would contribute in explaining occupancy patterns, but with high variation amongst species (Mazerolle and Villard 1999; Holland and Bennett 2009; Mortelliti et al. 2010a, b, c; Thornton et al. 2011). As a consequence the efficacy of habitat management will depend on landscape context and thus its value as conservation measure will be not only species-specific but also context specific.
Methods
Study area
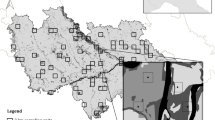
The study area was located in central Italy (Fig. 1) covering an area of 14,000 km² (42°31′N 11°51′E to 41°27′N 13°51′E). The experimental units were at two spatial scales: the first were 32 4 × 4 km “landscape” squares (hereafter landscape units): a size large enough to contain populations of the target species (Brichetti and Fracasso 2007; Amori et al. 2008), the second were 94 patches of forest habitat nested within the 32 landscape units. All the sampled forest patches were located within the climax of deciduous oak woodland (Quercus cerris and Quercus pubescens). Land use patterns varied across the area, with cereal cultivations dominating in plain and coastal areas, and orchards on the hills. The central, south-east and south western areas are characterized by large urban settlements.

Map of the study area; studied landscapes (4 × 4 km squares) were distributed throughout the Lazio region, central Italy. Grey represents forest areas, number correspond to individual landscape code
Landscape units were selected to represent: (1) a gradient in forest cover from <5 to ~80 %, (2) a gradient in the level of subdivision and aggregation of patches of forest, and (3) a gradient in the amount of hedgerows in the landscape and level of connectedness of forest patches in the landscape. For each of the following intervals of habitat amount (percentage of forest cover in the landscape: <5; 5–10; 10–15; 15–20; 20–40; 40–80 %). I chose two pairs of landscapes with contrasting configuration and contrasting levels of connectedness (see Radford et al. 2005; Radford and Bennett 2007; Haslem and Bennett 2008 for a similar design). A series of factors including the impossibility of finding reasonable replicates and logistical constraints resulted in a total sample of 32 landscapes (rather than the ideal combination of 48 landscapes resulting from six levels of habitat amount and all possible combinations of factors fragmentation and factor connectedness, including a replicate for each combination).
The number of forest patches sampled in each landscape unit increased with the number of patches present, ranging from one—in landscapes with one single patch (e.g. non fragmented landscapes)—to a maximum of six patches per landscape. A total of 94 individual patches were sampled (median number of sampled patches per landscape = 2.5): 79 patches for birds, 65 for the red squirrel (Sciurus vulgaris) and black rat (Rattus rattus), 73 for the hazel dormouse (Muscardinus avellanarius). The two largest patches in the landscape, where higher probability of presence was expected were always sampled; where applicable (e.g. if more than two patches were present in the landscape), the other sampled patches were selected in order to spread the sampling throughout the 4 × 4 km square and to obtain a range in the available sizes (e.g. two largest patches, two intermediate and two relatively small). A graphical synthesis of this approach is provided in Fig. S1, further details on sampled landscapes are provided in Table S1).
Explanatory variables (Table S2) were calculated with Arcview 3.3 using Corine Land Cover (resolution of 0.1 ha) and aerial photographs as main layers. Within each landscape a variable number of forest patches were selected (range 1–6; see later for more details; descriptive statistics in Table S2).
Target species
Target species for this study included: the green woodpecker Picus viridis, the great spotted woodpecker Dendrocopos major, the common chiffchaff Phylloscopus collybita, the firecrest Regulus ignicapilla, the long tailed tit Aegithalos caudatus, the Eurasian nuthatch Sitta europaea, the Eurasian jay Garrulus glandarius; amongst mammals were S. vulgaris, M. avellanarius and R. rattus. I selected these species for the following reasons: (a) they are habitat specialist forest dependent species (b) their range size is relatively small compared to the size of the landscape unit (c) they are relatively easy to detect (d) they are known to respond to fine scale habitat requirements (Brichetti and Fracasso 2007; Cramp et al. 1992; Mortelliti et al. 2010c, 2011; Spinozzi et al. 2012).
Site selection and sampling design
I followed MacKenzie and Royle (2005) and the sampling protocol developed by Mortelliti and Boitani (2008) to determine the number of sampling units (1 sampling unit = 1 nest-box, 1 hair-tube and 1 point count) to be used in the field sampling in order to estimate occupancy described in the next section. The procedure involved two steps: (A) first, detection probability and presence probability were estimated as a function of patch size by fitting occupancy models (MacKenzie et al. 2002) on capture history data gathered in previous studies (Mortelliti et al. 2009; Mortelliti and Boitani 2008) or detection history data of the first four landscapes sampled (in the case of birds). (B) total survey effort (total number of nest-boxes/hair-tubes/point counts required) was determined for each patch in the study area with a fixed number of three visits per patch and a desired standard error of 0.01 in the estimate of presence probability (obtained as a compromise of available material and logistical constraints).
Field surveys
The distribution of the S. vulgaris and R. rattus was studied by using hair-tubes (plastic tubes with adhesive material that capture mammal hairs; Mortelliti et al. 2011). In brief: a total of 434 hair-tubes were placed in the field for a total of 13,020 tube-days. The survey was carried out during spring-summer 2008; tubes were spaced at least 70 m apart and were inspected every 10 days, for 1 month (three visits). Four landscapes had to be excluded from the analysis since hair tubes were damaged by locals.
The presence of M. avellanarius was investigated using nest-boxes (Mortelliti et al. 2011): a total of 543 nest-boxes were placed in the field for a total of 16 months of activation. Nest-boxes were spaced at least 70 m apart and were inspected at regular intervals. The survey was carried out during spring 2008 to spring 2009; only detection history data of the second spring of activation (two visits) was used, in order not to violate closure assumptions (MacKenzie et al. 2002).
The target diurnal resident bird species are primarily associated with forest habitat for breeding and foraging activities (Mortelliti et al. 2010c). All selected patches were surveyed twice during a single reproductive season (in order not to violate population closure assumptions), between March and June 2009, avoiding rainy or windy days. In total 864 point counts (with unlimited radius) were performed lasting 10 min, between sunrise and 11:30 AM. Surveys were conducted by the same ornithologist to exclude between-observers variability.
Measurements of patch internal structure
Patch internal structure variables were measured in quadrat plots (100 m2; number of plots proportional to patch size); cover was estimated in the quadrat plots according to four cover classes (1 = 0–25 % of cover, 2 = 26–50 %, 3 = 51–75 %, 4 = 76–100 %). In addition to cover, the number of trees, tree height (in m) and mean circumference at breast height (dbh) were calculated in each quadrat plot (see Table S2 for a complete list).
In several cases the patch structure variables are directly related to the amount of resources for the target species, such as the abundance of shrubs for M. avellanarius which constitute its main diet, or the tree canopy for D. major and A. caudatus. In other cases (e.g. R. rattus), however, such variables could either be interpreted as proxies for resources or simple measurements that may be related with resources.
Statistical analyses
I carried out three series of principal components analysis (hereafter PCA): the first with variables related to the extent and configuration of forest habitat and the length of hedgerows in the landscape, the second with land-use variables related to the matrix (all land use types that were not classifiable as forest habitat), the third with patch scale variables (Tables 1, 2).
Landscape level components
The first component (HL, Table 1) was interpreted as a gradient in the amount of forest habitat, since it has a strong positive correlation with forest cover (0.887), the mean proximity index (0.927) and the sum of the proximity indices (0.961)—two measures of the amount of habitat within a threshold distance from the focal patch—and mean patch size (0.667). The second component (HF) was interpreted as a gradient in the subdivision and dispersion of forest habitat since it is positively correlated with the number of patches (0.888) and the mean edge-to-edge distances (0.883) and negatively correlated with mean patch size (−0.615).
The third component (SC) was interpreted as a gradient in structural connectivity since it is strongly correlated with mean number of hedges departing from a patch (0.992), with the km of hedgerows in the landscape (0.832) and with the total number of hedgerows (0.775). The principal components LU1, LU2 and LU3 are interpreted as geographical gradients in land use patterns (Table 1).
Patch scale components
The six patch scale components (Table 2) reflect the main variation in the geometrical and internal characteristics of habitat patches. The first component (SHB_STR, Table 2) was interpreted as a gradient in the amount of shrub abundance, since it has a strong positive correlation with the amount of shrubs at 1–8 m.
The second component (CONCT, Table 2) was interpreted as a gradient in connectivity provided by hedgerows since it is strongly correlated with total number of hedges departing from a patch (HDGxPCH: 0.910), number of hedgerows departing from a patch that are connected to another patch (HDG_CON: 0.950,) and number of patches connected to the focal patch (PCH_CON: 0.910).
The third component was interpreted as a gradient in the species richness and diversity of the shrub layer (SHB_DIV), since it is strongly correlated with total shrub cover (SHB_COV:0.839), shrub species richness (SHRB_RICH: 0.765) and diversity (SHRB_SIMP: 0.752).
The fourth component was interpreted as a gradient in the size and shape of the patch (GEOM), since it is strongly correlated with the size of the patch (AREA: 0.899) and its shape (perimeter/area, SHAPE: −0.888).
The fifth component was interpreted as a gradient in the size and height of canopy trees (MATURITY) since it is strongly correlated with canopy height (CAN_HEIGHT: 0.767) and mean circumference at breast height (MCBH: 0.836). The sixth component was interpreted as a gradient in the closure of the canopy (CANOPY) since it is strongly correlated with canopy cover (CAN_COV: 0.693) and mean number of trees (TREE: 0.889).
Cross-scale correlation coefficients between components are provided in Table S3 and S4. I opted for the PCA approach to tackle collinearity issues (Fahrig 2003) rather than regression of residuals (Villard et al. 1999) because the latter approach has been criticized (Koper et al. 2007); analyses were performed using R (R Development Core Team 2010).
Occupancy models
Detection history data (sequence of detection/non detection of the ten target species in a patch) were modelled as a function of explanatory variables using single season occupancy models implemented in the software PRESENCE (http://www.mbr-pwrc.usgov/software.html). In the case of hair-tube and nestbox surveys each visit to a patch corresponded to the inspection of all the tubes or nestboxes in the patch; in the case of bird surveys, each point count was considered as a visit of a patch.
Model selection
I followed the information-theoretic approach for model selection; models were ranked through AICc (Burnham and Anderson 2002). Model averaging was used to account for model selection uncertainty; in order to reduce estimation bias I rescaled weights to models in a confidence set within <4 ∆AICc (Burnham and Anderson 2002).
I evaluated accuracy of the occupancy models by using receiver operating characteristics (ROC) curves on the model averaged model. The ROC curves describe the false positive classification rate (1-specificity) and true-positive classification rate (sensitivity = 1-false negative rate) for predicted values. The area under the ROC curve varies between 0.5 and 1 (see Moore and Swihart 2005 for more details on the application of ROC curves to occupancy models).
I defined a set of a priori models (according to the hypotheses detailed below) with varying covariates that could explain the patterns of patch occupancy. I followed a three step hierarchical approach to inclusion of the variables in the models: Step (1) I began by fitting models with constant probability of presence (ψ) and detection probability (p) as a function of varying covariates [hence: ψ(.) p(covariate)models]. Step (2) Once I selected the relatively best “detectability” model I retained the relevant variables and started fitting landscape scale variables on ψ [hence: ψ(landscape level covariate) p(best covariates selected through step 1)]. Step (3) Once I selected the relatively best “landscape and detectability” model I started fitting patch level covariates [hence: ψ(patch level covariates + best landscape level covariates selected through step 2) p(best covariates selected through step 1)].
Detection probability (p) was modeled as a function of all patch-level covariates with the exception of the patch connectivity factor (CONCT) that was not suspected to influence the detectability of any of the target species. In the case of birds detection probability was also modeled as a function of the TIME covariate (minutes since sunrise) in order to take into account peaks in the calling activity that might influence detection; in the case of the arboreal rodents I modeled detection probability as a function of a survey specific covariate (SS) in order to take into account potential heterogeneity in detectability between the visits.
Probability of presence (ψ) was modeled as a function of all the PCA components listed in Tables 1 and 2. The rationale for such an approach is that all of the variables (amount and configuration of forest cover, matrix characteristics, geographic position, patch quality and structure) are known to potentially influence the distribution of mammals and birds in fragmented landscapes (Lindenmayer and Fischer 2006; Mazerolle and Villard 1999; Mortelliti et al. 2010b; Thornton et al. 2011).
Spatial autocorrelation and hierarchical generalized linear models (HGLM)
I tested for spatial autocorrelation on residuals using the Moran I test using 0.5 up to 10 km as distance lag. If a statistically significant autocorrelation was detected I accounted for it by including a spatial auto-covariate in the occupancy model. The auto-covariate should be considered an index of autocorrelation because it was calculated only from data at sampled sites (Moore and Swihart 2005).
Residuals were based on model averaged estimates and were calculated as the observed values at site i (detection = 1; non detection = 0) minus the probability of detecting the species at least once (D) (Moore and Swihart 2005):
where
where k is the number of “visits” to a patch; ψ is the presence probability; p is the detection probability.
One issue with analysing patch scale presence/absence data with several patches nested within the same landscape is that independence assumptions may be violated due to the fact that several patches present same values for landscape level independent variables (Moore and Swihart 2005), consequently, standard errors of parameter estimates may be biased (Raudenbush and Bryk 2002). The problem of nestedness is strictly linked to the issue of spatial autocorrelation, because both are due to the effects of proximity between sampling units. Controlling for spatial autocorrelation should solve the problems inherent in non-independence of data but this has to be evaluated analytically (Moore and Swihart 2005). I therefore fitted HGLM’s equivalent (=same ψ covariates) to the first ranked occupancy models in order to evaluate whether a unique effect imparted by each landscape was present and therefore if independence assumptions may have been violated [see Moore and Swihart (2005) for a similar application]. If each landscape is imparting a unique effect, the landscape level (level-2) variance component (parameter τ0) should be significantly different from zero (Raudenbush and Bryk 2002). When the parameter τ0 was significantly different from 0, I repeated the HGLM analysis including the spatial auto-covariate to test whether the unique landscape effect had been removed and thus sampling units could be considered independent [see Moore and Swihart (2005) for more details].
Modelling exercise
In order to explore whether variation in the vegetation structure of the patch or in the resource abundance (here considered as a proxy for habitat management) could overcome the landscape properties (quantified by the landscape scale variables), I carried out a modelling exercise with the model averaged parameter estimates for each species. After controlling for the relevant landscape properties (e.g. amount of habitat), I simulated variation in the patch-level variables (e.g. increasing amount of resources) and observed variation in presence probability. I controlled for landscape properties by keeping landscape-level variables constant (at fixed values) while varying patch-level variables. As an example the landscape-level variable HL (habitat loss) was kept constant at six different values ranging from the maximum of habitat loss to the minimum observed. Variation in the patch-level variables ranged from the minimum to the maximum value observed in the whole set of habitat patches. I focussed on the patch characteristics (represented by the PCA components SHB_STR, SHB_DIV, CANOPY, MATURITY, see Table 2) for two reasons: (a) the focus of this work is on habitat management, (b) in the real world modifications of the patch geometry (GEOM) and connectivity (CONCT) could also modify the value of landscape variables (HL, HF, SC).
When several landscape variables influenced the distribution of the target species, I chose the landscape scale variable with the lowest standard error in the parameter estimate and gave priority to the habitat loss variable (HL) which would provide the case of most general interest (e.g. rather than geographic position). This simplification was done in order to keep the overall number of simulations relatively low and to carry out the simulations only with the most reliable landscape variables. All simulations were carried out through R (R Development Core Team 2010).
Results
The most common bird at the landscape scale was A. caudatus (86.7 % of landscapes; N = 30), and the rarest was G. glandarius (50 % of landscapes); at the patch scale the commonest was P. viridis (57 % of patches), and the rarest was G. glandarius (30.4 % of patches). Amongst mammals M. avellanarius was found in 44 % of the patches (64 % of landscapes), S. vulgaris in 12 % of the patches (19 % of landscapes) and R. rattus in 41 % of the patches (53 % of landscapes).
Occupancy models
The number of models in the top set (ΔAICc < 4) was relatively small for most species (Table 3) with the exception of R. rattus and S. vulgaris where a certain degree of model selection uncertainty occurred. Overall the goodness of fit of models was relatively high as shown by the values of AUC (Table S5); ĉ (c-hat—overdispersion index) was <1.1 for all the species.
No significant spatial autocorrelation was found for the residuals of the global models for all the species (Moran I Test on residuals: p > 0.05, 999 permutations, lag distance 0.5–10 km) except P. viridis (significantly correlated lag distance: up to 1–2 km, p < 0.05), and A. caudatus (significantly correlated lag distance: up to 4–6 km, p < 0.05); consequently a spatial auto-covariate was introduced in the occupancy models of the two latter species. Model averaged parameter estimates are shown in Table S6.
Several covariates were found to influence detection probability, particularly GEOM included in the top model set of 5 species (Table 3), TIME (minutes from sunrise) for 3 bird species, and CANOPY and MATURITY for 6 and 7 species respectively. Detection probability increased in larger patches (with the exception of S. vulgaris), patches with larger trees and more closed canopy (Table 3).
The landscape scale variable HL (amount of habitat in the landscape) was included in the top model set (ΔAICc < 4) of 6 species (3 mammals and 3 birds; Table 3), the landscape variable reflecting structural connectivity (SC) was included in the top model set of 4 species (two mammals and two birds); HF (habitat subdivision) was included in the top set only for three bird species and one mammal. The principal component LU1 (reflecting a north-west south east geo-climatical gradient) was included in the top model set of three species (one mammal and two birds; Table 3); the PCA axis LU2 (reflecting a north–south gradient in cultivation patterns) was included only for two species and LU3 (reflecting main cultivation patterns of the plains- arable land- and hills-olive groves) was included only for two mammal species.
The PCA component GEOM describing patch size and shape was included in the top set of all the species with the exception of S. vulgaris, the component relative to the patch-level structural connectivity (CONCT) was included in the top set of 6 species (Table 3).
The PCA component describing the richness and diversity of shrubs (SHB_DIV) was included in the top model set of 6 species; the component describing the shrub layer structure (SHB_STR) was included in the top model set of 5 species. The PCA component describing the size of trees (MATURITY) was included in the top model set for 4 species (the three mammals and one bird); the component describing forest canopy (CANOPY) was included in the top model set of the 3 mammals and 4 bird species (Table 3).
Hierarchical generalised linear models
Results of the HGLM analyses are shown in Table 4. τ00 was found to be significantly different from 0 only in the case of P. viridis and A. caudatus; after introducing the auto-covariate in the model, however, τ00 was found to be non-significantly different from zero (Table 4) proving that the unique effect of each landscape has been removed.
Model Inference
I excluded S. vulgaris from the modelling exercise due to high uncertainty in model selection and poor model fit (Table 3, Table S5). I also excluded P. viridis from the modelling exercise since no patch structure variables occurred in the top model set.
Varying patch structure in landscapes with different levels of habitat loss
For four species (G. glandarius, D. major, S. europaea, M. avellanarius) I modelled probability of presence as a function of one or more variables describing the structure of the patch, such as shrub structure (SHB_STR) for G. glandarius, CANOPY and shrub layer diversity (SHB_DIV) for D. major, CANOPY for S. europaea, CANOPY and SHB_STR for M. avellanarius, while controlling for the amount of habitat at the landscape scale (HL; Fig 2a). Models predicted that modifying the structure of the patch would increase presence probability in landscapes with relatively high amount of habitat; however, for low levels of habitat amount, even extremely high values of the patch structure covariates were predicted to have little effect on probability of presence. The strength of this effect varied with the different species: in the case of D. major very high values of canopy cover were predicted to have a substantial effect whereas for intermediate values of canopy cover, high values of presence probability were reached only in landscape with high amounts of habitat.

a Results of the modeling exercise carried out with model averaged parameters for four of the target species (Sitta europaea, Dendrocopos major, Garrulus glandarius, Muscardinus avellanarius). Probability of presence is expressed as a function of patch level covariates (x axis) controlling for habitat amount (principal component HL). Each line represents a fixed value of the HL component (straight line = lowest amounts of habitat, dotted lines represent increasing habitat up to maximum observed in the sampled landscapes). The plus sign before the patch structure covariate indicates an increase on the x axis, whilst minus sign indicates a decrease. For the first two species a modification of the patch structure variable can increase the probability of presence in landscapes irrespectively of the landscape properties; in the case of Garrulus glandarius and Muscardinus avellanarius, a modification of the patch structure variable can increase the probability of presence in landscapes with moderate levels of habitat, but for low levels of habitat amount even high modifications will have little effect. b Results of the modeling exercise carried out with model averaged parameters for four of the target species (Aegithalos caudatus, Phylloscopus collybita, Regulus ignicapilla, Rattus rattus). Probability of presence of the target species is expressed as a function of patch level covariates (x axis) controlling for landscape variables. Each line represents a fixed value of the landscape variable indicated in the graph labels. The plus sign before the patch structure covariate indicates an increase on the x axis, whilst minus sign indicates a decrease
In the case of R. ignicapilla and P. collybita I modelled probability of presence as a function of CANOPY closure and the species richness diversity of the shrub layer (SHB_DIV, P. collybita), and the species richness diversity and abundance of the shrub layer (SHB_DIV and SHB_STR, R. ignicapilla), while controlling for the landscape variable LU1, mainly reflecting the geographic position of the landscape (Fig. 2b). For both species models predicted that modifying the structure of the patch would have a strong effect on the probability of presence; for low to intermediate values of patch structure variables, however, only the northernmost landscapes would have relatively high presence probability values.
In the case of A. caudatus, I modelled probability of presence as a function of CANOPY closure while controlling for the level of habitat subdivision (HS; Fig. 2b). Models predicted that modifying (decreasing) the values of CANOPY cover- would have a positive effect in fragmented and relatively continuous landscapes; nevertheless the effect was much stronger in relatively fragmented landscapes.
In the case of R. rattus I modelled probability of presence as a function of structure (SHB_STR) and shrub richness and diversity (SHB_DIV) while controlling for the landscape scale variable reflecting the north–south gradient in cultivation patterns (LU2 Fig. 2b). I did not use the variable HL due to excessively large values of standard errors of the parameter. Models predicted that modifying the structure of the shrub layer would always increase presence probability particularly in landscapes with higher values of the LU3 component.
Discussion
The results of this study show how, after taking into account the role of landscape properties, patch scale variables still played a relatively important role in determining occupancy patterns of forest vertebrates. The model inference showed how the strength and importance of patch structure variables varied from species to species; in some cases (e.g. S. europaea and G. glandarius) variation in the values of patch structure variables (e.g. shrub layer diversity) increased presence probability only with high habitat amount. This highlights the fact that habitat management should be carefully targeted towards precise landscape conditions (e.g. when there is enough habitat at the landscape scale). In other cases (e.g. D. major and R. ignicapilla), the effect of patch-structure variables was particularly strong therefore variation in the values of patch structure variables always brought substantial modification in the value of presence probability.
Biological interpretation of the outputs
Landscape level occupancy patterns (presence/absence of the species at the landscape scale) are discussed elsewhere (Mortelliti et al. 2010c, 2011). My focus here is on patch occupancy.
The size and shape of patches was found to influence the distribution of most bird species. As expected, increasing patch size increased the probability of occupancy in accordance with previous patch scale studies on Piciformes (van Dorp and Opdam 1987), A caudatus (van Dorp and Opdam 1987; Cramp et al. 1992; Bellamy et al. 2000) and S. europaea (van Dorp and Opdam 1987; Matthysen and Currie 1996; Bellamy et al. 1998). Similar results were obtained for mammals, with a patch connectivity effect on M. avellanarius, in accordance with previous studies (Bright and Morris 1996; Mortelliti et al. 2009). An interesting effect was found for R. rattus which had higher probability of occurrence in the largest patches of landscapes with less habitat, which could reflect niche availability for this alien species in contexts that are unsuitable (e.g. due to habitat loss) for indigeneous rodents such as M. avellanarius and S. vulgaris.
Three species (D. major, A. caudatus, S. europaea) were affected by the canopy layer reflecting nesting and foraging requirements, in accordance with previous knowledge (Cramp et al. 1992; Matthysen and Adriaensen 1998; Pasinelli 2007). The abundance, richness and diversity of shrubs, instead, was important both for birds (R. ignicapilla, P. collybita, G. glandarius) and mammals reflecting its key role for foraging and cover (Cramp et al. 1992; Amori et al. 2008).
Caveats with evaluating the role of patch scale variables and modelling inference
There has been an intensive debate on how important the quality of a patch is in fragmented landscapes (Thomas et al. 2001). Mortelliti et al. (2010a) showed how there is substantial empirical evidence that the quality of a patch plays a crucial role. However most studies, particularly on vertebrates, consider the structure of habitat patches, rather than quality itself, which should instead be measured either as the fitness of individuals or as the abundance of resources. Mortelliti et al. (2010a) showed how there is a clear difference between invertebrates and vertebrates: when studying the latter, resources are more difficult to measure directly.
I acknowledge that considering a variation in the amount of resources (or its indirect measurements), as a proxy for habitat management is an ambitious task and results should therefore be considered with great caution. At the same time I stress that the use of proxies rather than direct measurements is more than widespread in ecology, as an example most GIS based modeling are based on broadly defined habitat types. I suggest that this study provides a background for future research to invest sampling effort towards more direct measurements of resource availability.
Sampling all the patches in the landscape would have not been feasible (the proportion of sampled patches per landscape is provided in Table S1). As detailed in the methods, a variety of patches was sampled in order to ensure representativeness within the landscape. It is therefore likely that within-landscape sampling was sufficient to generalize about landscape effects on patch occupancy.
Implications for landscape and habitat management
The hierarchical approach I have followed has allowed me to explore the relative importance of patch scale variables in comparison to landscape scale variables. Patch scale variables were included in the final model set of all the species, therefore they retained a certain importance even after taking into account the main landscape effects. These results are in accordance with the general finding that local factors may be as important as landscape factors in fragmented landscapes (Moore and Swihart 2005; Pennington and Blair 2011; Thornton et al. 2011; but see Ritchie et al. 2009) and should therefore be incorporated in landscape management (Lee et al. 2002). Nevertheless the results of model inference show how translating this knowledge into clear-cut conservation targets is not straightforward since habitat management is not only species specific but also context specific. Models showed how the strength of the effect of patch scale variables may vary depending on the landscape characteristics and should thus be carefully targeted.
For three out of the four species sensitive to habitat loss at the landscape level (Fig. 2a, all species except D. major) models predicted that habitat management would be effective only for intermediate levels of habitat amount. For these species, investing resources in highly modified landscapes would be an ineffective conservation action. On the other hand in the case of the four species that were affected by other landscape variables (such as fragmentation or land use types) the modeling results show how investing resources in habitat management would always be effective since modifications in patch quality would always lead to a substantial increase of the probability of presence.
Such results confirm the importance of habitat loss in comparison to habitat fragmentation per se (Fahrig 2003), and suggest the possibility of landscape thresholds in habitat amount (as found elsewhere, Radford et al. 2005) beyond which habitat management may prove ineffective.
The general message of this study is that the efficacy of patch management in increasing occupancy probability will be species-specific but will also depend on landscape structure (such as the amount of remaining habitat). If the management of existing habitat is the conservation target for a given area, carrying out cross-scale studies such as the ones here presented will help to target and prioritize interventions.
References
Amori G, Contoli L, Nappi A (2008) Fauna d’Italia: mammalia II. Calderini, Bologna
Bellamy PE, Brown NJ, Enoksson B, Firbank LG, Fuller RJ, Hinsley SA, Schotman AGM (1998) The influences of habitat, landscape structure and climate on local distribution patterns of the nuthatch (Sitta europaea L.). Oecologia 115:127–136
Bellamy PE, Rothery P, Hinsley SA, Newton I (2000) Variation in the relationship between numbers of breeding pairs and woodland area for passerines in fragmented habitats. Ecography 23:130–138
Bennett AF, Radford JQ, Haslem A (2006) Properties of land mosaics: implications for nature conservation in agricultural environments. Biol Conserv 133:250–264
Brichetti P, Fracasso G (2007) Ornitologia Italiana vol 4—Apodidae—Prunellidae. Oasi Alberto perdisa Editore, Bologna
Bright PW, Morris PA (1996) Why are dormice rare? A case study in conservation biology. Mamm Rev 26:157–187
Burnham KP, Anderson DR (2002) Model selection and multimodel inference: a practical information-theoretic approach, 2nd edn. Springer, New York
Chauvenet AL, Baxter M, McDonald-Madden E, Possingham H (2010) Optimal allocation of conservation effort among subpopulations of a threatened species: how important is patch quality? Ecol Appl 20:780–787
Cramp S, Brooks DJ, Dunn E, Gillmor R, Hall-Craggs J, Hollom PAD, Nicholson EM, Ogilvie MA, Roselaar CS, Sellar PJ, Simmons KEL, Snow DW, Vincent D, Voous KH, Wallace DIM, Wilson MG (1992) The birds of the western palearctic, vol VI. Oxford University Press, Warblers
Cushman SA, McGarigal K (2004) Patterns in the species–environment relationship depend on both scale and choice of response variables. Oikos 105:117–124
Fahrig L (2003) Effects of habitat fragmentation on biodiversity. Annu Rev Ecol Evol Syst 34:487–515
Fischer J, Lindenmayer DB (2007) Landscape modification and habitat fragmentation: a synthesis. Glob Ecol Biogeogr 16:265–280
Haslem A, Bennett AF (2008) Birds in agricultural mosaics: the influence of landscape patterns and countryside heterogeneity. Ecol Appl 18:185–196
Holland GJ, Bennett AF (2009) Differing responses to landscape change: implications for small mammal assemblages in forest fragments. Biodivers Conserv 18:2997–3016
Koper N, Schmiegelow FKA, Merrill EH (2007) Residuals cannot distinguish between ecological effects of habitat amount and fragmentation: implications for the debate. Landsc Ecol 22:811–820
Lee M, Fahrig L, Freemark K, Currie DJ (2002) Importance of patch scale vs landscape scale on selected forest birds. Oikos 96:110–118
Lindenmayer DB, Fischer J (2006) Habitat fragmentation and landscape change: an ecological and conservation synthesis. Island Press, Washington
MacKenzie DI, Royle JA (2005) Designing occupancy studies: general advice and allocating survey effort. J Appl Ecol 42:1105–1114
MacKenzie DI, Nichols JD, Lachman GB, Droege S, Royle JA, Langtimm C (2002) Estimating site occupancy rates when detection probabilities are less than one. Ecology 83:2248–2255
Matthysen E, Adriaensen F (1998) Forest size and isolation have no effect on reproductive success of Eurasian Nuthatches (Sitta europaea). Auk 115:955–963
Matthysen E, Currie D (1996) Habitat fragmentation reduces disperser success in juvenile nuthatches Sitta europaea: evidence from patterns of territory establishment. Ecography 19:67–72
Mazerolle MJ, Villard M (1999) Patch characteristics and landscape context as predictors of species presence and abundance: a review. Ecoscience 6:117–124
McGarigal K, Cushman SA (2002) Comparative evaluation of experimental approaches to the study of habitat fragmentation effects. Ecol Appl 12:335–345
Moore JE, Swihart RK (2005) Modeling patch occupancy by forest rodents: incorporating detectability and spatial autocorrelation with hierarchically structured data. J Wildl Manag 69:933–949
Mortelliti A, Boitani L (2008) Inferring red squirrel (Sciurus vulgaris) absence with hair tubes surveys: a sampling protocol. Eur J Wildl Res 54:353–356
Mortelliti A, Santulli Sanzo G, Boitani L (2009) Species’ surrogacy for conservation planning: caveats from comparing the response of three arboreal rodents to habitat loss and fragmentation. Biodivers Conserv 18:1131–1145
Mortelliti A, Amori G, Boitani L (2010a) The role of habitat quality in fragmented landscapes: a conceptual overview and prospectus for future research. Oecologia 163:535–547
Mortelliti A, Amori G, Capizzi D, Rondinini C, Boitani L (2010b) Experimental design and taxonomic scope of fragmentation studies of European mammals: current status and future priorities. Mamm Rev 40:125–154
Mortelliti A, Fagiani S, Battisti C, Capizzi D, Boitani L (2010c) Independent effects of habitat loss, habitat fragmentation and structural connectivity on landscape occupancy of forest dependent birds. Divers Distrib 16:941–951
Mortelliti A, Amori G, Capizzi D, Cervone C, Fagiani S, Pollini B, Boitani L (2011) Independent effects of habitat loss, habitat fragmentation and landscape connectivity on the distribution of two arboreal rodents. J Appl Ecol 48:153–162
Pasinelli G (2007) Nest site selection in middle and great spotted woodpeckers Dendrocopos medius and D. major: implications for forest management and conservation. Biodivers Conserv 16:1283–1298
Pennington DN, Blair RB (2011) Habitat selection of breeding riparian birds within an urban environment: untangling the relative importance of biophysical elements and spatial scale. Divers Distrib 17:506–518
R Development Core Team (2010) R: A language and environment for statistical computing. R Foundation for Statistical Computing
Radford JQ, Bennett AF (2007) The relative importance of landscape properties for woodland birds in agricultural environments. J Appl Ecol 44:737–747
Radford JQ, Bennett AF, Cheers GJ (2005) Landscape-level thresholds of habitat cover for woodland-dependent birds. Biol Conserv 124:317–337
Raudenbush SW, Bryk AS (2002) Hierarchical linear models: applications and data analysis methods, 2nd edn. Sage, Thousand Oaks
Ritchie L, Betts M, Forbes G, Vernes K (2009) Effects of landscape composition and configuration on northern flying squirrels in a forest mosaic. Forest Ecol Manag 257:1920–1929
Schooley RL, Branch LC (2007) Spatial heterogeneity in habitat quality and cross-scale interactions in meta-populations. Ecosystems 10:846–853
Spinozzi F, Battisti C, Bologna MA (2012) Habitat fragmentation sensitivity in mammals: a target selection for landscape planning comparing two different approaches (bibliographic review and expert based). Rendiconti Lincei. doi:10.1007/s12210-012-0184-2
Thomas JA, Bourn NA, Clarke D, Stewart RT, Simcox KE, Pearman DJ, Curtis GS, Goodger B (2001) The quality and isolation of habitat patches both determine where butterflies persist in fragmented landscapes. Proc Biol Sci 268:1791–1796
Thornton DH, Branch LC, Sunquist ME (2011) The influence of landscape, patch, and within-patch factors on species presence and abundance: a review of focal patch studies. Landsc Ecol 26:7–18
van Dorp D, Opdam PFM (1987) Effects of patch size, isolation and regional abundance on forest bird communities. Landsc Ecol 1:59–73
Villard MA, Trzcinski M, Merriam G (1999) Fragmentation effects on forest birds: relative influence of woodland cover and configuration on landscape occupancy. Conserv Biol 13:774–783
Acknowledgments
Special thanks to Stefano Fagiani, Cristina Cervone, Barbara Pollini, Sergio Muratore and to the park wardens and naturalists of the Regione Lazio for help in the field surveys. Thanks to Joyce Keep for language revision.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article
Cite this article
Mortelliti, A. Targeting habitat management in fragmented landscapes: a case study with forest vertebrates. Biodivers Conserv 22, 187–207 (2013). https://doi.org/10.1007/s10531-012-0412-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10531-012-0412-1