
Abstract
Feature selection plays a critical role in many applications that are relevant to machine learning, image processing and gene expression analysis. Traditional feature selection methods intend to maximize feature dependency while minimizing feature redundancy. In previous information-theoretical-based feature selection methods, feature redundancy term is measured by the mutual information between a candidate feature and each already-selected feature or the interaction information among a candidate feature, each already-selected feature and the class. However, the larger values of the traditional feature redundancy term do not indicate the worse a candidate feature because a candidate feature can obtain large redundant information, meanwhile offering large new classification information. To address this issue, we design a new feature redundancy term that considers the relevancy between a candidate feature and the class given each already-selected feature, and a novel feature selection method named min-redundancy and max-dependency (MRMD) is proposed. To verify the effectiveness of our method, MRMD is compared to eight competitive methods on an artificial example and fifteen real-world data sets respectively. The experimental results show that our method achieves the best classification performance with respect to multiple evaluation criteria.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Feature selection is widely used in data preprocessing [13, 20] and intends to select the most informative feature subset from an original feature set [10, 19, 30]. Feature selection methods can reduce the computational cost of data analysis and improve the classification performance [11, 26]. Therefore, feature selection methods have received increasing attention.
According to different selection strategies, feature selection methods can be divided into three models [5, 8, 27]: filter models, wrapper models, and embedded models. Filter models are independent of any classifier and they evaluate a feature based on a specific criterion. Wrapper models are dependent on classifiers and embedded models select the feature subset during the learning stage. Compared to wrapper models and embedded models, filter models have lower computational cost [12, 24]. In this study, we focus on filter models.
There are many techniques that are applied during the feature selection process, such as similarity learning, sparse learning, statistics and information theory [15]. Information-theoretical-based feature selection methods are the focus in the area of data preprocessing [4, 28].
To capture a compact feature subset from an original feature set, traditional feature selection methods focus on minimizing the feature redundancy while maximizing the feature dependency. However, a critical issue is that the larger values of the traditional feature redundancy term do not indicate the worse a candidate feature because a candidate feature can obtain large redundant information, meanwhile offering large new classification information.
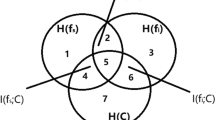
As described in Fig. 1, Xk1 and Xk2 are two candidate features, Xj is an already-selected feature and Y is the class. One of the traditional feature redundancy term is the mutual information between the candidate feature and the already-selected feature, and the feature redundancy term can be represented as the union areas of 1 and 3 and the union areas of 5 and 6 in the Fig. 1. Another one of the traditional feature redundancy term is the interaction information among the candidate feature, the already-selected feature and the class, and the feature redundancy term can be represented as the area 3 and the area 6. Obviously, the area 3 is larger than the area 6 and the union areas of 1 and 3 are larger than the union areas of 5 and 6. That is, the redundancy of feature Xk1 is larger than the feature Xk2. However, we can discover that the area 2 is larger than the area 7, that is, Xk1 offers more new classification information than that of Xk2 with respect to the class Y. In fact, the candidate feature Xk1 is more important than the feature Xk2.

Venn diagram illustrates the relation between the feature and the class
To address this issue, we propose a novel feature redundancy term and we select the most informative features by minimizing the new feature redundancy term while maximizing the feature dependency term.
The main contributions in this paper are as follows:
- (1)
In this paper, we design a new feature redundancy term that considers the relevancy between a candidate feature and the class given each already-selected feature.
- (2)
We discuss the case that the candidate feature is independent of the already-selected feature, in other words, the candidate feature does not contain any redundant information when the candidate feature is independent of each already-selected feature.
- (3)
We propose a new feature selection method that maximizes feature dependency while minimizing the new feature redundancy term named min-redundancy and max-dependency (MRMD).
- (4)
We execute MRMD method and eight compared methods on an artificial example to show the feature selection process of different feature selection methods.
- (5)
Finally, MRMD method is compared to eight feature selection methods on fifteen real-world benchmark data sets that are from different research areas to verify the effectiveness of our method.
We organize this paper as follows: Section 2 states theoretical background for this work. In Section 3, we review previous related work. Section 4 proposes a novel feature selection method. In Section 5, we describe and discuss the experimental results on an artificial example and fifteen real-world data sets respectively. Finally, Section 6 concludes this work and gives a plan for future research.
2 Information theory
In this section, we introduce some basic concepts of information theory. There are many metrics in information theory, such as mutual information, conditional mutual information and joint mutual information. Let X, Y and Z be three random variables. Mutual information is defined as follows [7]:
where H(Y ) is entropy, entropy is used to measure the uncertainty of a random variable, and H(Y |X) represents the conditional entropy that describes the amount of uncertainty left in Y when another random variable X is given. Therefore, mutual information measures the uncertainty reduced when another variable is given.
Conditional mutual information measures the mutual information between two random variables when another variable is introduced, and it is described by Formula (2):
where H(X, Y |Z) is also a conditional entropy, which measures the amount of uncertainty left in (X, Y ) when the variable Z is given.
Another important concept is joint mutual information which is defined as follows:
Joint mutual information measures the mutual information between (Y, Z) and X.
Interaction information measures the mutual information among three random variables, and it is defined as follows:
3 Related work
In this section, we review the information-theoretical-based feature selection methods. Feature selection intends to select a feature subset from an original feature set, and maximizes the mutual information between feature subset and the class I(S;Y ), where S represents the feature subset. However, due to the amount of calculations and the limited number of observations available for the calculation of the high-dimensional probability density function, the accurate calculation of I(S;Y ) is impractical [2]. Cumulative summation of already-selected features is used in many feature selection methods [8, 18, 23].
Mutual Information Maximization (MIM) [14] method evaluates the significance of each candidate feature according to the value of mutual information between the candidate feature and the class. The MIM method does not consider the redundancy among features.
Considering feature dependency and feature redundancy, Mutual Information Feature Selection (MIFS) [1] maximizes the feature dependency while minimizing the feature redundancy:
where Xk indicates a candidate feature, Xj represents an already-selected feature, and S is the already-selected feature subset. J(Xk) represents a “scoring” criterion that measures how potentially useful a candidate feature Xk may be. The mutual information I(Xj;Xk) evaluates the feature redundancy. The parameter β varies between zero and one, and β is set to be one according to the suggestion of the authors in our experiment.
With the increase of the number of already-selected feature, it becomes more difficult to remove the redundant features than before [2]. Therefore, the parameter β is set to be the inverse of the number of already-selected feature in minimal-redundancy-maximal-relevance criterion (mRMR) [23], the criterion of mRMR is expressed as follows:
Conditional Infomax Feature Extraction (CIFE) [18] is proposed to obtain the most informative features. The evaluation criterion is defined as follows:
According to the Formula (4), Formula (7) can be rewritten as follows:
Different from MIFS method and mRMR method, the interaction information I(Xj;Xk;Y ) is considered as the feature redundancy term in the CIFE method.
The criterion of Joint Mutual Information (JMI) [31] employs cumulative summation of joint mutual information to evaluate the significance of the candidate feature. The criterion of JMI is expressed as Formula (9):
Xj is an already-selected feature. As a result, \({\sum }_{X_{j} \in S}I(X_{j};Y)\) can be viewed as a constant in the feature selection process. According to the Formula (4), Formula (9) can be rewritten as follows:
Similar to CIFE method, the JMI method also considers the interaction information as the measurement of the feature redundancy term. The difference is that the JMI method employs the inverse of the number of already-selected feature \(\frac 1{|S|}\) to balance feature relevance term and feature redundancy term.
Gao et al. propose a feature selection method named Dynamic Change of Selected Feature with the class (DCSF) [8] that designs a new term that calculates dynamic change of selected features with the class. The criterion of DCSF is presented as follows:
additionally, Gao et al. propose a new feature selection named Composition of Feature Relevancy (CFR) that analyses the composition of feature relevancy [9]. The criterion of CFR is defined by:
Wang et al. [29] propose a new feature selection method named Max-Relevance and Max-Independence (MRI). MRI is defined as follows:
MRI is rewritten as follows:
additionally, Interaction Weight based Feature Selection (IWFS) takes feature interdependency into accounts. First, IWFS [32] defines interaction weight factor as follows:
then, the criterion of IWFS is proposed as follows:
where \(SU(X_{k},X_{j})= \frac {2I(X_{k};X_{j})}{H(X_{k})+H(X_{j})}\), it is a normalized measure of mutual information.
We summarize these feature selection methods mentioned above in Table 1. MIM does not consider the redundancy among features. MIFS, mRMR and DCSF employ the mutual information I(Xj;Xk) to measure the feature redundancy. CIFE, JMI, CFR and MRI use the interaction information I(Xj;Xk;Y ) to measure the feature redundancy. Since IWFS is a nonlinear method, it does not define explicitly the feature redundancy term. As shown in Table 1, a critical issue is that these methods do not consider the relevancy between a candidate feature and the class given each already-selected feature when the feature redundancy term is calculated. In addition, Appice et al. design an effective method for eliminating redundant Boolean features for multi-class classification tasks, in which a feature is viewed as a redundant feature when it separates the classes worse than another feature or feature set. The critical idea of the method is that: a set of examples with the same class where the number of different features between examples is small. In this paper, we propose a new feature redundancy term where the feature relevancy is considered. Finally, a novel feature selection method named min-redundancy and max-dependency (MRMD) is proposed.
4 The proposed method for feature selection
As we know, feature selection aims to select a compact feature subset that has the maximal dependency with respect to the class [3, 25]. Many feature selection methods use information theory to measure the dependency between a candidate feature and the class, they intend to retain the dependent features and eliminate the redundant features.
The feature redundancy term in traditional feature selection methods is measured by the mutual information between a candidate feature and each already-selected feature or the interaction information among a candidate feture, each already-selected feature and the class. However, the larger values of the traditional feature redundancy term do not indicate the worse a candidate feature because a candidate feature can obtain large redundant information, meanwhile offering large new classification information as analysed in Fig. 1. The new classification information is the relevancy between a candidate feature and the class given the already-selected feature subset S. To address this issue, we design a new feature redundancy term that considers the relevancy between a candidate feature and the class under the condition of the already-selected feature subset S. It is defined as follows:
where I(S;Xk) is traditional feature redundancy term and I(Xk;Y |S) is the new classification information. Suppose that the value of traditional feature redundancy term is large, meanwhile the value of new classification information is large, in such case, I(S;Xk) is overestimated due to the large new classification information. Employing Formula (17) can reduce the negative impact of redundant information I(S;Xk). Because of the impractical calculations for already-selected feature subset, we replace the already-selected feature subset with each already-selected feature [2]. The specific definition is as follows:
\(\frac 1{|S|}\) is the inverse of the number of already-selected features |S|, which is used to balance the feature dependency term and the feature redundancy term. The criterion combining the new feature redundancy term with the feature dependency term is named min-redundancy and max-dependency (MRMD):
According to the Formula (19), I(Xk;Y ) is the feature dependency term, and \(\frac 1{|S|}{\sum }_{X_{j} \in S}\{I(X_{j};X_{k})-I(X_{k};Y|X_{j})\}\) is the feature redundancy term, additionally, we consider the case that the candidate feature is independent of the already-selected feature. According to the information theory [7], it means that I(Xj;Xk) = 0 and I(Xk;Y |Xj) = I(Xk;Y ), and the Formula (19) can be reduced to the following Formula:
In this case, MRMD is equal to the method MIM [14].
The steps of MRMD are described as follows:
- 1)
(Initialization) Set \(F \leftarrow \) “Original feature set”, \(S \leftarrow \) “empty set”.
- 2)
(Calculate the mutual information between the class and each candidate feature) For each feature Xk ∈ F, calculate I(Xk;Y ).
- 3)
(Select the first feature) Find the feature Xk that with the maximal I(Xk;Y ), \(F\leftarrow F \setminus \{X_{k}\}\); \(S\leftarrow \{X_{k}\}\).
- 4)
(Greedy selection) Repeat until |S| = K
- (a)
(Calculate the new feature redundancy term) For all pairs of features Xk and Xj that Xk ∈ F and Xj ∈ S, calculate I(Xj;Xk) and I(Xk;Y |Xj).
- (b)
(Select the next feature) Choose the feature Xk that maximizes Formula (19). \(F\leftarrow F \setminus \{X_{k}\}\); \(S\leftarrow \{X_{k}\}\).
- (a)
- 5)
Output the feature set S including the already-selected features.
First, MRMD chooses the maximum of the mutual information between each candidate feature and the class. Then, the new feature redundancy term is calculated to select the feature that maximizes the Formula (19). The procedure is ended until |S| = K.
Complexity analysis: suppose that K is the number of features to be selected, M is the number of instances in the data set, and N is the total number of features. The time complexity of mutual information and conditional mutual information is O(M) because all instances need to be examined for probability estimation. In MRMD method, each iteration involves the calculation of the information terms on all features, that is, the time complexity is O(MN), and the total iteration is K times, therefore the time complexity of MRMD is O(KMN). The calculation process of other feature selection methods (CIFE, MIFS, mRMR, IWFS, MRI, DCSF and CFR) are similar to that of MRMD, the time complexity of these methods is O(KMN). The MIM method does not involve the selected features. It only needs to calculate the mutual information between all features and the class one time in the process of feature selection, and then the K top-ranked features on the values of mutual information are the feature subset, that is, the time complexity of MIM is O(MN).
When the candidate features are independent of the already-selected features, that is, I(fk;fj) = 0. MRMD is equal to the MIM, that is, both the two methods select the same features. The difference is that the MIM does not take into account the selected features, while the MRMD includes the process of calculating the mutual information. The time complexity of MIM is O(MN) and the time complexity of MRMD is O(KMN). Therefore, MRMD is more time consuming than MIM. However, when the candidate features are correlation with the already-selected features with respect to the class, MRMD is more effective than MIM.
5 Experimental results and analysis
In this section, we evaluate the effectiveness of MRMD on an artificial example and fifteen real-world data sets respectively. All the experiments are executed on an Intel Core i7 with a 3.40 GHZ processing speed and 16 GB main memory. The programming language is Python, and compared methods CIFE, MIFS, MIM and mRMR come from the scikit-feature feature selection repository [16]. IWFS, MRI, DCSF and CFR methods are achieved by ourselves. Additionally, all the classification algorithms are from scikit-learn repository [22].
5.1 Experiments on an artificial data set
To verify the effectiveness of our method, an artificial example D = (O, F, Y ) is presented in Table 2. O represents the instance set, F is the feature set and Y represents the class, where O = {o1, o2,..., o10}, F = {X1, X2,..., X8}. CIFE, MIFS, MIM, mRMR, IWFS, MRI, DCSF, CFR and MRMD are executed on this artificial example. We detail the feature selection process of MRMD. Jr(.) represents the value of current feature redundancy term, i.e., Formula (18), and J(.) is the final result of Formula (19). By MRMD, we have
- 1.
The mutual information between Xi and Y is calculated. I(X1;Y ) = 0.0058, I(X2;Y ) = 0.02, I(X3;Y ) = 0.0464I(X4;Y ) = 0.0913, I(X5;Y ) = 0.02, I(X6;Y ) = 0.0464I(X7;Y ) = 0.2564, I(X8;Y ) = 0.02; J(X1) = 0.0058, J(X2) = 0.02, J(X3) = 0.0464J(X4) = 0.0913, J(X5) = 0.02, J(X6) = 0.0464J(X7) = 0.2564, J(X8) = 0.02. The maximum value J(Xi) of every Xi is compared, and X7 is selected. Then, the candidate feature set is {X1, X2, X3, X4, X5, X6, X8}.
- 2.
When the number of already-selected features is equal to one, Jr(X1) = − 0.1087, Jr(X2) = − 0.17, Jr(X3) = − 0.1171Jr(X4) = 0.5078, Jr(X5) = − 0.17, Jr(X6) = − 0.3926Jr(X8) = 0.1784;
J(X1) = 0.1145, J(X2) = 0.19, J(X3) = 0.1635J(X4) = − 0.4165, J(X5) = 0.19, J(X6) = 0.439J(X8) = − 0.1584.
The maximum value J(Xi) of every Xi is compared, and X6 is selected. Then, the candidate feature set is {X1, X2, X3, X4, X5, X8}.
- 3.
When the number of already-selected features is equal to two, Jr(X1) = 0.0618, Jr(X2) = 0.125, Jr(X3) = − 0.1108Jr(X4) = 0.0945, Jr(X5) = 0.125, Jr(X8) = − 0.1008;
J(X1) = − 0.056, J(X2) = − 0.105, J(X3) = 0.1573J(X4) = − 0.003, J(X5) = − 0.105, J(X8) = 0.1208 The maximum value J(Xi) of every Xi is compared, and X3 is selected. Then, the candidate feature set is {X1, X2, X4, X5, X8}.
For the artificial example, MRMD selects the feature subset {X7, X6, X3}, which is the optimal feature subset. The optimal subset can classify all the instances correctly. However, CIFE, IWFS, MRI, DCSF and CFR select {X7, X6, X8}, mRMR and MIFS select {X7, X1, X3}, MIM selects select {X7, X4, X3}. These feature selection methods do not choose the optimal feature subset.
Observing the artificial example above, we discover that the nine feature selection methods choose the same feature X7 at first. Second, CIFE, MRI, DCSF, CFR and our method choose the feature X6 and the other two methods, mRMR and MIFS, choose the feature X1 due to the different feature redundancy terms. Next, MRMD chooses the feature X3 as the third feature, as a result, MRMD finds the optimal feature subset by only three features. However, CIFE, mRMR, MIM, MIFS, MRI, DCSF and CFR do not choose the optimal feature subset. IWFS does not obtain optimal feature subset when it selects only three features.
5.2 Experimental results on the real-world data sets
In this section, our method is compared to CIFE [18], MIFS [1], MIM [14], mRMR [23], IWFS [32], MRI [29], DCSF [8] and CFR [9] on fifteen real-world data sets that are from different area. Ten-fold cross-validation is used in this experiment. The fifteen data sets come from UCI database [17] and the literature [15] , and the specific descriptions of the data sets are shown in Table 3. These fifteen data sets include binary and multiclass problems, continuous features and discrete features. For the sake of fairness, continuous features are discretized into five bins using equal-width discretization. Additionally, we select these fifteen data sets that come from different research areas, such as physical data, image data and biological data, etc. As a result, the experimental results are convincing. The experimental framework is illustrated in Fig. 2.

Experimental framework
We employ five different classifiers, the Naïve-Bayes (NB) classifier, the Support Vector Machine (SVM) classifier, the LogisticRegression classifier (LR), the Random Forest classifier (RF) and the Multi-Layer Perception classifier (MLP), to evaluate the average classification accuracy. The average classification accuracy is obtained across 30 groups of feature subsets on each classifier. The results of the classification performance are recorded in Tables 4, 5, 6, 7 and 8. MRMD implements a paired two-tailed t-test with other compared methods. “+”, “-” and “=” indicate that our method performs “better than”, “worse than” and “equal to” the corresponding method at a statistical significance level of 5%. The bold fonts indicate the maximal value of the corresponding row. “W/T/L” indicates the number of the data set that our method has higher/equal/lower accuracy than the compared methods.
In Table 4, MRMD method obtains the highest values of the average accuracy on 11 data sets, the average accuracies of MRMD are 66.24%, 92.8%, 91.23%, 57.43%, 95.01%, 93.08%, 90.86%, 85.71%, 70.21%, 55.79%, 76.85%, 73.47%, 52.64%, 83.51% and 64.5% respectively. DCSF achieves the best classification performance on the data set Breast, mRMR obtains the highest values of the average accuracy on the data set ALLAML, MRI outperforms the other feature selection methods on the data set PCMAC and CIFE obtains the highest values of the average accuracy on the data set Lung_cancer. Similarly, MRMD method obtains the highest values of the average accuracy on 10 data sets, 10 data sets, 11 data sets, 12 data sets in Tables 5-8 respectively. Additionally, the average accuracy of MRMD method is equivalent to the MIM method in some data sets on different classifiers. For example, the average accuracy of MRMD method is equivalent to the MIM method on five data sets using NB classifier and four data sets using SVM classifier, respectively. In the whole, we can conclude that MRMD outperforms the other compared methods in terms of average classification accuracy.
We show the statistical results of “W/T/L” in the Tables 4-8 using Figs. 3, 4, 5, 6 and 7. The X-axis represents the ratio of “W/T/L” that obtained using the classifiers and the Y-axis represents the data sets. As shown in Figs. 3-7, MRMD achieves better or equal performance than compared methods on most data sets.

MRMD performs “better/equally-well/worse” than the compared methods on NB classifier

MRMD performs “better/equally-well/worse” than the compared methods on SVM classifier

MRMD performs “better/equally-well/worse” than the compared methods on LR classifier

MRMD performs “better/equally-well/worse” than the compared methods on RF classifier

MRMD performs “better/equally-well/worse” than the compared methods on MLP classifier
Furthermore, we show the highest value of the average accuracies attained by five classifiers on each data set using the features selected by each feature selection method in Table 9. Table 9 indicates that MRMD obtains the highest value of the highest accuracies on 8 data sets. CFR obtains the highest accuracy on the data sets Leukemia, mRMR achieves the highest accuracies on four data sets, MIM obtains the highest accuracy on data set Colon, and MRI achieves the highest accuracy on the data set Lung_cancer. As a result, MRMD method achieves the best classification performance in terms of the highest accuracies among the 9 feature selection methods.
To show the classification performance clearly, Fig. 8 illustrates the classification accuracies against the number of features on the data sets Musk1 and ORL; The number K on horizontal axis indicates the first K features with an already-selected order. The vertical axis is the average accuracies of the five classifiers at the first K features. Classification accuracy does not increase with the number of selected features, and we set the number of selected feature K from 1 to 30, it is also used in other literature [32]. Different colors and shapes represent different feature selection methods. As shown in Fig. 8, MRMD method outperforms the other compared methods significantly.

Average classification accuracy achieved with Musk1 and ORL
Furthermore, the Areas Under ROC Curves (AUCs) and F1 score of the five classifiers for the nine methods are shown by the boxes in Fig. 9, 10, 11, 12 and 13. The AUC represents the area under the ROC curve and is an effective metric to evaluate classification performance. F1 score is another metric of a test’s accuracy, where the F1 score reaches its best value at 1 and worst at 0.

The AUCs and F1 score across all of the benchmark data sets on NB classifier

The AUCs and F1 score across all of the benchmark data sets on SVM classifier

The AUCs and F1 score across all of the benchmark data sets on LR classifier

The AUCs and F1 score across all of the benchmark data sets on RF classifier

The AUCs and F1 score across all of the benchmark data sets on MLP classifier
As shown in Figs. 9-13, MRMD outperforms the other eight methods in terms of AUCs and F1 score. The classification performance of feature selection methods are dependent on the characteristics of classifiers. The same opinion is illustrated in the literature [6, 21]. Additionally, it is worthy to notice that, for some data sets that include missing values, we replace all missing values with the means of the values of features [32].
Finally, we show the running time of MRMD and other eight compared methods (CIFE, MIFS, MIM, mRMR, IWFS, MRI, DCSF and CFR) on fifteen data sets in Table 10. Compared to the methods IWFS, MRI and DCSF, our method is more computationally efficient. The running time of CIFE, MIFS and mRMR is close to our method MRMD. Although MIM has the less running time than other compared methods, the classification performance of MIM is not as good as its running time, which has been demonstrated in Section 5.1. As a result, the time complexity and the running time of MRMD is acceptable.
6 Conclusion and future work
In this work, we propose a new feature redundancy term that not only involves the redundancy between a candidate feature and each already-selected feature, but also considers the relevancy between a candidate feature and the class given each already-selected feature. The proposed method maximizes feature dependency while minimizing the new feature redundancy. To evaluate the effectiveness of our method, the proposed method is compared to eight competitive methods on an artificial example and fifteen real-world data sets respectively. Multiple evaluation criteria including average classification accuracy, the highest accuracy, AUCs and F1 score demonstrate that our method achieves the best classification performance among the nine feature selection methods.
In the future, we plan to explore the correlations between feature dependency and feature redundancy and test the effectiveness of methods on more real-world data sets. Additionally, we will furthermore explore the classification performance of over-dimensioned data sets that are from different areas for feature selection.
References
Battiti R (1994) Using mutual information for selecting features in supervised neural net learning. IEEE Trans Neural Netw 5(4):537–550
Bennasar M, Hicks Y, Setchi R (2015) Feature selection using joint mutual information maximisation. Expert Syst Appl 42(22):8520–8532
Bennasar M, Setchi R, Hicks Y (2013) Feature interaction maximisation. Pattern Recogn Lett 34 (14):1630–1635
Bolón-Canedo V, Sánchez-Marono N, Alonso-Betanzos A, Benítez JM, Herrera F (2014) A review of microarray datasets and applied feature selection methods. Inf Sci 282:111–135
Chen R, Sun N, Chen X, Yang M, Wu Q (2018) Supervised feature selection with a stratified feature weighting method. IEEE Access 6:15,087–15,098
Chen S, Ni D, Qin J, Lei B, Wang T, Cheng JZ (2016) Bridging computational features toward multiple semantic features with multi-task regression: a study of ct pulmonary nodules. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 53–60
Cover TM, Thomas JA (2012) Elements of information theory. Wiley, New York
Gao W, Hu L, Zhang P (2018) Class-specific mutual information variation for feature selection. Pattern Recogn 79:328–339
Gao W, Hu L, Zhang P, He J (2018) Feature selection considering the composition of feature relevancy. Pattern Recogn Lett 112:70–74
Gui J, Sun Z, Ji S, Tao D, Tan T (2017) Feature selection based on structured sparsity: a comprehensive study. IEEE Trans Neural Netw Learn Syst 28(7):1490–1507
Hancer E, Xue B, Zhang M, Karaboga D, Akay B (2018) Pareto front feature selection based on artificial bee colony optimization. Inf Sci 422:462–479
Huda S, Yearwood J, Jelinek HF, Hassan MM, Fortino G, Buckland M (2016) A hybrid feature selection with ensemble classification for imbalanced healthcare data: a case study for brain tumor diagnosis. IEEE Access 4:9145–9154
Lee S, Park YT, dAuriol BJ, et al. (2012) A novel feature selection method based on normalized mutual information. Appl Intell 37(1):100–120
Lewis DD (1992) Feature selection and feature extraction for text categorization. In: Proceedings of the workshop on Speech and Natural Language. Association for Computational Linguistics, pp 212–217
Li J, Cheng K, Wang S, Morstatter F, Trevino RP, Tang J, Liu H (2016) Feature selection: A data perspective. arXiv:1601.07996
Li J, Cheng K, Wang S, Morstatter F, Trevino RP, Tang J, Liu H (2018) Feature selection: a data perspective. ACM Comput Surv (CSUR) 50(6):94
Lichman M (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml
Lin D, Tang X (2006) Conditional infomax learning: an integrated framework for feature extraction and fusion. In: European conference on computer vision. Springer, pp 68–82
Liu M, Xu C, Luo Y, Xu C, Wen Y, Tao D (2018) Cost-sensitive feature selection by optimizing f-measures. IEEE Trans Image Process 27(3):1323–1335
Mafarja M, Aljarah I, Heidari AA, Hammouri AI, Faris H, AlaM AZ, Mirjalili S (2018) Evolutionary population dynamics and grasshopper optimization approaches for feature selection problems. Knowl-Based Syst 145:25–45
Obozinski G, Taskar B, Jordan M (2006) Multi-task feature selection. Statistics Department, UC Berkeley, Technical Report 2(2.2)
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit-learn: Machine learning in Python. J Mach Learn Res 12:2825–2830
Peng H, Long F, Ding C (2005) Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell 27(8):1226–1238
Sayed GI, Hassanien AE, Azar AT (2019) Feature selection via a novel chaotic crow search algorithm[J]. Neural Comput Appl 31(1):171–188
Senawi A, Wei HL, Billings SA (2017) A new maximum relevance-minimum multicollinearity (mrmmc) method for feature selection and ranking. Pattern Recogn 67:47–61
Sheikhpour R, Sarram MA, Gharaghani S, Chahooki MAZ (2017) A survey on semi-supervised feature selection methods. Pattern Recogn 64:141–158
Singh D, Singh B (2019) Hybridization of feature selection and feature weighting for high dimensional data[J]. Appl Intell 49(4):1580–1596
Vergara JR, Estévez PA (2014) A review of feature selection methods based on mutual information. Neural Comput Appl 24(1):175–186
Wang J, Wei JM, Yang Z, Wang SQ (2017) Feature selection by maximizing independent classification information. IEEE Trans Knowl Data Eng 29(4):828–841
Wang Y, Feng L, Zhu J (2018) Novel artificial bee colony based feature selection method for filtering redundant information. Appl Intell 48(4):868–885
Yang HH, Moody J (2000) Data visualization and feature selection: New algorithms for nongaussian data. In: Advances in neural information processing systems, pp 687–693
Zeng Z, Zhang H, Zhang R, Yin C (2015) A novel feature selection method considering feature interaction. Pattern Recogn 48(8):2656–2666
Acknowledgments
This work is funded by: Postdoctoral Innovative Talents Support Program under Grant No. BX20190137, and National Key R&D Plan of China under Grant No. 2017YFA0604500, National Sci-Tech Support Plan of China under Grant No. 2014BAH02F00, and by National Natural Science Foundation of China under Grant No. 61701190, and by Youth Science Foundation of Jilin Province of China under Grant No. 20160520011JH and 20180520021JH , and by Youth Sci-Tech Innovation Leader and Team Project of Jilin Province of China under Grant No. 20170519017JH, and by Key Technology Innovation Cooperation Project of Government and University for the whole Industry Demonstration under Grant No. SXGJSF2017-4, and Key scientific and technological R&D Plan of Jilin Province of China under Grant No. 20180201103GX, and China Postdoctoral Science Foundation under Grant No. 2018M631873.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Gao, W., Hu, L. & Zhang, P. Feature redundancy term variation for mutual information-based feature selection. Appl Intell 50, 1272–1288 (2020). https://doi.org/10.1007/s10489-019-01597-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-019-01597-z