
Abstract
In this paper, human facial emotions are detected through normalized minimal feature vectors using semi-supervised Twin Support Vector Machine (TWSVM) learning. In this study, face detection and tracking are carried out using the Constrained Local Model (CLM), which has 66 entire feature vectors. Based on Facial Animation Parameter’s (FAPs) definition, entire feature vectors are those things that visibly affect human emotion. This paper proposes the 13 minimal feature vectors that have high variance among the entire feature vectors are sufficient to identify the six basic emotions. Using the Max & Min and Z-normalization technique, two types of normalized minimal feature vectors are formed. The novelty of this study is methodological in that the normalized data of minimal feature vectors fed as input to the semi-supervised multi-class TWSVM classifier to classify the human emotions is a new contribution. The macro facial expression datasets are used by a standard database and several real-time datasets. 10-fold and hold out cross-validation is applied with the cross-database (combining standard and real-time). In the experimental result, using ‘One vs One’ and ‘One vs All’ multi-class techniques with 3 kernel functions produce a 36 trained model of each emotion and their validation parameters are calculated. The overall accuracy achieved for 10-fold cross-validation is 93.42 ± 3.25% and hold out cross-validation is 92.05 ± 3.79%. The overall performance (Precision, Recall, F1-score, Error rate and Computation Time) of the proposed model was also calculated. The performance of the proposed model and existing methods were compared and results indicate them to be more reliable than existing models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
For the past three decades several researchers have displayed more interest in human emotion recognition for Human Computer Interaction (HCI), affecting computing, etc. In [1, 2] and [3] research determined the facial emotion analysis criteria using the still images that had a high recognition rate, but not in video sequences. The work carried out in [4] and [5] established the automatic facial emotion recognition system (FERs) from facial video sequences, which analyse facial emotion through detection and tracking of feature points. From a literature review in [6] and [7] it is suggested that facial emotion is defined by the maximum number of facial feature points with Action Units (AUs) [8]. A maximum feature point for facial emotion creates complex data in computation with less accuracy [6,7,8,9]. To overcome this problem, selecting the minimal feature points is essential. Paul Ekman [10] used the Facial Action Coding System (FACS), which defines only muscular movement of a facial feature. FACS also defines the basic six emotions on a human face. However, FACS uses a combination of additional facial features (i.e. the eyebrow, jaw and mouth region, etc.) to define human facial emotions. In FACS, the facial emotion recognition system has more data complexity and high computation time using 40 Action Units (AUs). In this case, Facial Animation Parameters (FAPs) define human facial emotions through the facial feature point movements. Facial Animation Parameters (FAPs) [11] defines facial emotion of action units within 10 groups using entire feature points. FAP also defines facial emotions with minimal facial actions. In line with FAPs, this paper concentrates only on minimal feature vectors of human emotion. In [12], the geometric deformable model (CLM) has specific face detection and tracking mechanisms when compared to different face modelling, which is considered state of the art.
From the literature survey [1,2,3] and [13,14,15,16,17,18,19,20,21] and [22] the FER system developed by various supervised learning systems achieved good accuracy. However, the robust and automatic facial emotion recognition system is not suitable above those FERs. Therefore, semi supervised learning was chosen for FERs because it is better than supervised learning of FERs. From the survey of [23,24,25] and [26] the semi-supervised Twin Support Vector Machines (TWSVMs) has a high performance compared to the other classifier models. From the [27, 28] and [29] other semi-supervised learning of facial emotion has less accuracy and moderate performance. In this study, multi-class TWSVMs was used to detect human motions.
The purpose of this study is to detect human emotions using semi-supervised learning with minimal facial feature vectors from videos. Four essential steps are involved in this emotion recognition system. First, Constrained Local Method (CLM) is used for face detection, tracking, and extracting the feature points. Second, the minimal feature vectors are formed based on FAPs of AUs. Third, using normalization, minimal feature vectors are obtained. Finally, the normalized minimal feature vectors are fed as input to the TWSVMs for facial emotion classification. Section 2 describes the methods involving facial emotion systems. Section 3 describes the experimental analysis and validation. Section 4 outlines the experimental results and discussion of the proposed system. Section 5 summarises the conclusion and recommendations for future studies.
2 Facial emotion recognition system
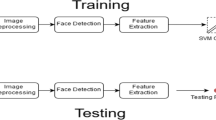
The architecture of the robust facial emotion recognition system is shown in Fig. 1 and contains the following five steps:

Facial emotion recognition system architecture
2.1 Facial detection and tracking
The non-rigid shape of the face is employed by the Point Distribution Model (PDM). In PDM, 2D vertex meshes is symbolized as dimensionality shaped vectors. PDM is applied through Principal Component Analysis (PCA) for acquiring aligned non-rigid face shapes. Before PCA, the Procrustes analysis is applied for removing the parameters s, R, tx, ty of aligned mesh shapes. The 2D PDM is linearly deformed by the variation of non-rigid shapes and is combined with the transformation, placing the shape in an image frame as shown in (1).
Where s, R, tx, ty denotes as scale, rotation, and translation respectively. Where xi denotes ith landmark of 2D PDM’s location, xi denotes as mean shape of 2D PDM and pose parameters of PDM represent as p = (s,R,t,q). In CLM fitting, applied Subspace Constrained Mean Shift (SCMS) [30] is applied to combine the good local (patch) search and optimised 2D PDM landmark fitting. In an exhaustive local search, using linear logistic regression [31] gives the response maps for the ith landmark position in image frame, which is given in (2).
Where li is a discrete random variable that denotes the ith number of iterations, it aligns to correct the PDM landmark value. I denotes the 2D location in local images (x). β is the regression coefficient and denotes as to correct the 2D landmark of local maps. Ci is the linear classifier of a local detector which is defined in (3) with \(\textbf {x}_{i=1}^{m}\)\( \in {\Omega }_{\textbf {x}_{i}}\) (image patch) and bi is shape vector parameters.
The optimized probabilistic function of local response image for each landmark detection is given in (4). Once the response maps of each landmark of local search have been found that the probabilistic function is maximized.
With respect to p. PDM parameters, xi is parametrized of response images. The active shape model is defined as a summation of weighted least square difference between the maximum response map and peak response of PDM coordinates, which is given in (5).
A first order Taylor expansion is applied in (4) for minimising the active shape model, which leads to convergence of the PDM landmark. This is defined in (6).
And solving the parameter update is defined in (7).
The current parameter is applied in p ← p + Δp to estimate the pose and shape. Here Jacobian is J = [J1; ⋯ ; Jn] and current shape parameter update is \(x = [{x_{1}^{c}}; \cdots ;{x_{n}^{c}}]\). For independent maximisation and non-parametric representation of the Kernel Density Estimate (KDE), [32] is applied for each PDM landmark location in the Mean-Shift Algorithm (MSA) [33]. This consists of a fixed point iteration and is defined in (8). Equation (8) is applied iteratively until it reaches convergence Δp
To convert the shape constrained to optimisation, which is defined in (9), MSA uses a two-step strategy: i) compute the mean-shift update for each 2D PDM landmark, ii) constrain the mean-shifted landmark to remain in the PDM parametrization using a least-square fit. The Gauss Newton update for least square PDM constraint is also defined in (9).
The image that has a high probabilistic function of local response obtained from (4) is given as an input to the EM algorithm to find the difference between the peak responses. The Q-function of M-step is defined in (10), and is formed using the linear shape model in (6).
Where J† denotes the pseudo-inverse of J and \(x_{i}^{(\tau +1)}\), it denotes the ith landmark of mean shift update parameters, which is given in (8). The kernel width relaxation and local optima is addressed in the subspace constrained mean shift (SCMS) [30].
2.2 Feature vectors displacement
The geometric deformable model (CLM) is carried out to perform face detection, tracking and extraction from video. The feature vectors displacement (di, j) is defined as the facial feature point movement between the consecutive frame by frame sequence. (di, j) is the difference between the grid node displacements of the first to ith node coordinates. The feature vectors displacement is given in (11).
i = 1, … , F, j = 1, … , N , where Δxi, j, Δyi, j are x, y axis coordinates of grid node displacement of the ith node in the jth frame, respectively. F is the number of grid node (F = 66 no. of nodes of CLM) and N is the number of extracted facial frames from video. The grid deformation feature vector displacement gj consists of feature vector displacement of the every geometric grid node di, j, gj which is given in (12).
2.3 Minimal feature vectors displacement
The pictorial representations of feature points that are affected by different emotions are shown in Fig. 2. The entire feature vectors and minimal feature vectors of the six basic emotions are shown in Fig. 2a and b, respectively.

Entire and minimal feature vectors of six facial emotions movements
In [11], [34] describe the groups, number of FAPs, and textual description of emotion, which are affected by the six basic emotions. Based on the definition of FAPs, which is illustrated in Tables 1 and 2, it provides the information regarding the number of feature points and group numbers that are affected by the six basic emotions. Table 1 provides information about the entire set of feature points involved in six emotions. Insight of any emotion is given as onset, where staring points of emotion, apex, where emotion reaches peak position, and offset, where emotion returns to the neutral state. The entire set of feature vectors of any emotion is the displacement between the onset and offset phase. From the literature [6, 9] and [35], the entire vectors displacement has a high data redundancy, less accuracy, and low data computation. To increase the accuracy and reduce computation time, the minimal feature vectors displacement is chosen. Any emotion that reaches the apex phase from onset phase is defined as the peak response. The minimal feature vectors displacements are chosen based on the high variance values among feature points during the peak response of an emotion. In Table 2, the high variance range of minimal feature is calculated and tabulated. The major feature movement for six facial emotions are eyebrow (ebw), outer lip (olp), eyelids (eld) and corner lip (clp). Table 2, shows the differences of variance range of the other than minimal feature points that are also tabulated.
Based on the definition of FAPs and the facts stated above, surprise emotion involves 45 entire feature points. In those 45 feature points, 5 feature points have a high variance compared to the remaining 40 feature points. Similarly, for all the emotions, the minimal feature vectors points are determined and are tabulated in Table 2. Table 2 provides details of the minimal feature points of six emotions that are affected. The minimal feature points from eyebrow, mouth, and eyelids are observed. To obtain effective performance and improve accuracy, less data redundancy and computation time are selected by the minimal feature points. From (11) and (12), the minimal feature vectors displacements are obtained.
2.4 Normalization of feature vectors displacement
For data scaling, normalization is applied on the minimal feature vectors displacement to increase the feature scaling. In this paper, Max & Min and Z-normalization are applied and compared to obtain the feature scaling as defined in (13). Using normalization, the normalized data of minimal feature vectors displacement is formed.
2.5 Facial emotion classifier-bilinear classifier
In this system, the TWSVM classifier is used to classify the basic six facial emotions. The normalized data of minimal feature vectors displacement is given as input to the two classes TWSVM [23, 25] and [26] to classify facial emotion. Using TWSVM, the two non-parallel hyperplanes for each class is constructed to solve the quadratic programming problem. In this case, let gj = {(xi, yi)}; i = 1, … , k; x ∈ ℜn; yi ∈ {− 1, + 1} is the training dataset of normalized minimal feature vectors displacement. The separating hyperplane of linear data is defined in (14). Separating the minimal feature vectors displacement gj = RL in the order of positive and negative class is formed by the Karush-Kuhn Tucker (K.K.T) conditions, which is provided in (14).
Where wT is the weight vector and b is a bias. The objective function of linear TWSVM is corresponding to one class and constraints to the other class are defined by (15).
Where c+, c− are a penalty parameter and are slack variables. e+, e− are vectors of suitable dimensions. Let \(\textit {H}=[\textit {X}^{T}_{+} \textit {e}^{T}_{+}]\) and \(\textit {G}=[\textit {X}^{T}_{-} \textit {e}^{T}_{-}]\). In (16), the Lagrangian and Wolf dual problem are formulated and they obtained from the equation of TWSVM.
Where Lagrangian multipliers are α and β. In (17) introduces a term δI(δ > 0) to avoid becoming singular and the ill-conditioning of HTG. Where I denotes a regularisation identity matrix. The function of non-parallel hyperplane of TWSVM from the α and β value is defined in (17).
Where \(\textit {u}_{i=1,2} =[\textit {w}^{T}_{\pm }\textit {b}_{\pm }]^{T}\). From (17), the weight vector and bias value of optimal hyperplane of linear TWSVM is obtained. For validation, a new data sample is assigned to class ‘i’ by the decision function, as given in (18). A decision surface classified in the new data depends upon whether its distance is closer to hyperplane (18).
For Non-Linear cases of TWSVM, the training data are examined with the Kernel Function such as Linear, Polynomial and Radial Base Function (RBF) [23,24,25] and [26]. The Multi class TWSVM [25, 26] and [36] has two approaches: ‘One vs One’ and ‘One vs All’. The ‘One vs One’ approach is a ‘divide and conquer’ approach, consisting of building one TWSVM class for each pair of subclasses. The ‘One vs All’ is a ‘single approach’ consisting of built TWSVM which is one class versus all other classes. This paper carried out both approaches of multi class TWSVM and it proved more effective in the ‘One vs All’ approach.
3 Experimental analysis and validation
3.1 Experimental settings
The FAPs [11], [34] ’s definition has a combination of AU, for emotion identification, with entire and minimal feature vectors. This is shown in Fig. 2. From the FAPS definition [34], the entire feature vectors displacement is in the form of the neutral to peak response then returning to the neutral state (i.e. expressive time episode = onset, apex and offset phase). In this system, the geometric deformable grid node (CLM) has L = 66*2 = 132 dimensions. The feature vectors displacement is employed for the set of six emotions (i.e. Surprise (SUR), Happy (HAP), Disgust (DIS), Fear (FEA), Angry (ANG) and Sad (SAD)) using TWSVM. In this proposed system, CLM and TWSVM are developed in C++ with open framework and Matlab2014b, which are implemented with an Intel i5 processor. In both training and testing phases, standard databases such as the MMI facial expression database [37], Oulu Database [38], CK [39], Extended CK + database [40] and Mahonb Laughter database [41] are used. A few real-time databases were also used [24] in which the video rate was 25 frames/sec. In training and testing phases, let gj be the feature vectors displacements of the extracted face image sequence from the standard database as i = 1, … , N, N = 6, emotions in face, which is shown in Fig. 2. The normalized data of minimal feature vectors is fed as input to the multi-class TWSVM to classify facial emotions.
3.2 Training and testing
The 10-fold and hold out cross-validation technique is applied in both training and testing phases. A new database is formed through the fusion of existing standard databases such as MMI, Oulu, CK, CK + , Mahnob and a few real-time datasets. The normalized minimal feature vectors of cross-databases are given to hold out validation. In cross- validation, 80% of normalized datasets are given to the training phase and the remaining 20% of datasets is used as a testing phase for validating the facial emotion classifier. In validation, the multi-class TWSVM of 3 kernel cases (Linear, Polynomial and RBF) with both normalization are evaluated. In hold out cross-validation, 3 kernel case of penalty and kernel parameters values such as c1, c2 and γ = 0.5 is applied. In 10-fold cross-validation, the grid search mechanism is formulated for attaining the optimal parameters such as Cost (c1 and c2) and Gamma (γ) value in the training phase. The range of Cost (c1and c2) is 10− 5, 10− 4.5, .... , 104.5, 105 and Gamma (γ) is 2− 5, 2− 4.5, .... , 24.5, 25 are applied in the training phase. From the training phase, the optimal value of Cost and Gamma value is formed by the optimal trained model and then testing the unknown data of six emotions. In cross-validation, the linear case is considered where Cost value and non-linear case (Poly, RBF), whereas Cost and Gamma value are considered. The Confusion Matrix of ‘One vs One’ and ‘One vs All’ is employed in both phases.
From the results of the Confusion Matrix, validation parameters such as True Positive (TP), True Negative (TN), False Positive (FP), False Negative (FN), Accuracy (Acc), Precision (Pre), Recall (Rec), F1-score (F1-sco), Error rate (Err.rte), and Computational Time (Comp. Time) are calculated. For each emotion, 18 models of multi-class (‘One vs One’ and ‘One vs All’ with 3 kernel) with one normalization method are calculated. A total of 36 models are calculated by Max & Min and Z-normalization through the multi class TWSVM classifier. The computation time of training and testing phase of all basic emotions are also calculated.
4 Experimental results and discussion
4.1 Experimental results
4.1.1 Hold out cross validation
Max-Min and Z-norm is applied on minimal feature vector displacement to produce the global normalized data which is fed as input to multi-class classifiers and validated with the hold out method for each kernel namely Linear, Polynomial (Poly) and RBF. In cases of ‘One vs One’ and ‘One vs All’, the validation parameter (accuracy, precision, recall, F1-score, error rate) of the six basic emotions are computed and shown in Tables 3, 4, 5, 6, 7, 8, 9, 10. From the Table 3–10, it is inferred that ‘One vs All’ multi classes have higher performance than the ‘One vs One’ multi classes. From the Table 3–10, the bar chart representation of validation parameter of proposed model (‘One vs All’) are plotted and shown in Figs. 3, 4, 5. In Figs. 3–5, relations between the validation parameters, Multi class and facial emotions. From Fig. 3a, it is inferred that the six emotions: Surprise (95.85%), Happy (95.6%), Disgust (88.26%), Fear (91.69%), Anger (91.89%) and Sad (88.6%) have high accuracy, which is achieved in RBF kernel of ‘One vs All’ using Z-norm. Similarly, the validation parameter such as Precision, Recall, Error rate, F1-score, Computation Time for training and testing phase are also shown in Table 3–10, is calculated. From Tables 3–10 and Figs. 3a, 4a and 5, it is inferred that RBF kernel of ‘One vs All’ using Z-norm has high Precision, high Recall, high F1-score, less Error rate and less computational time compared to other kernel (multi class) of normalization. The overall performance of the proposed model which was higher in RBF (‘One vs All’) and Z-norm are calculated and tabulated in Table 19. From Table 19, the overall validation parameter such as Accuracy is 92.05 ± 3.79%, Precision is 0.75 ± 0.18, Recall is 0.68 ± 0.25, Error rate is 0.32 ± 0.25, F1-score is 2.74 ± 0.98 and computation time 2.05 ± 0.43 sec of basic six emotions are achieved.

Bar chart representation of Accuracy of the proposed system (‘One vs All’) using both validation

Bar chart representation of Precision, Recall, Error.rate,F1-score of the proposed system (‘One vs All’) using both validation

Bar chart representation of Computation time of the proposed system (One vs All) using both validation
4.1.2 10-fold cross validation
The 10-fold cross-validation result of system shown in Tables 11, 12, 13, 14, 15, 16, 17, 18. Similarly, used Max & Min and Z-normalization with 3 kernel to attain the 36 optimal trained model of the FER system. Table 11–18 shows the 10 fold cross-validation of accuracy, cost, gamma, and validation parameter result of tested data. In Table 11, it is inferred that the RBF kernel of the ‘One vs All’ model achieved high performance using 10-fold validation of z-normalization data. From the result of the 10-fold RBF kernel model is the cost and gamma value for creating the optimal trained model for the surprise eyebrow feature. Then the tested data is given to the optimal trained model achieving high validation parameter when compared to other multi class models of surprise eyebrow. Similarly, in Tables 11–18, it is inferred that the RBF kernel of ‘One vs All’ model achieved high performance using 10-fold validation of z-normalization data. Somehow emotion has attained high accuracy in different optimal models but the performance is less than the RBF Trained model. From Fig. 3b, it is inferred the six emotions such as Surprise (96.6%), Happy (96%), Disgust(91.6%), Fear(90.15%), Anger(93.16%) and Sad(90.67%) has high accuracy is achieved in RBF kernel of ‘One vs All’ using Z-norm. From Table 11–18 and Figs. 3b, 4b and 5 this inference the RBF kernel model has high optimal performance for all six basic emotions when compared to the other model.
The overall performance of proposed model that is higher in RBF (‘One vs All’) and Z-norm are calculated and tabulated in Table 19. From Table 19, the overall validation parameter such as Accuracy is 93.42 ± 3.25% (10-fold) and 92.56 ± 3.02% (test), Precision is 0.76 ± 0.11, Recall is 0.73 ± 0.22, Error. Rate is 0.27 ± 0.22, F1-score is 20.76 ± 0.22 and computation time 15.08 ± 4.08 sec of basic six emotions are achieved. From the experiments, it is found that the minimal feature vector which is specified in Table 2 is good enough to classify the basic six emotions such as Surprise (eyebrow+outer lip), Happy (corner lip), Disgust (eyelids), Fear (eyebrow + outer lip), Anger (eyebrow) and Sad (corner lip+outer lip).
4.2 Discussion
From Table 20 the comparison of various classifier models for recognition of facial emotion shows supervised and semi-supervised models, databases, and accuracy of the model. From Table 20, Uddin [30] have supervised classifiers as LDP+HMM and LDP-PCA+HMM used for facial emotion recognition, which achieved accuracy are 82.91% and 87.50% respectively. Yu [14] has used SVM+PCA supervised classifier for facial emotion recognition achieved 75.50% accuracy. Saeed [15] has applied a supervised SVM classifier for facial emotion recognition that achieved 83% accuracy. Wan [16] applied a supervised SVM classifier for facial emotion recognition that achieved 80% accuracy. Mohammadian [17] used a supervised SVM classifier for facial emotion recognition which achieved 83.90% accuracy. Ren [18] applied the Fuzzy+SVM for facial emotion recognition that achieved an 81.4% accuracy. Jiang [19] used a SRC classifier for facial emotion recognition which achieved an 80% accuracy. Papachristou [20] applied an SSL classifier for facial emotion recognition with 71.14% (CK, CK + ) and 71.84% (BU) accuracy. Nikitidis [21] used a MMPP classifier for facial emotion recognition with 80.9% accuracy. Owusu [1] has used SVM of facial emotion system was attained 97.57% (JAFFE), 92.33% (Yale) accuracy. Patil [2] has developed Patch-LDSMTNN for Facial emotion system of accuracy are 98.33% (JAFFE), 99.27% (CMU-AMP), 98.14% (ORL), 98.44% (Yale), 98.49% (CK) was achieved. Siddiqi [3] has developed robust facial emotion system with help HMM 95% (You tube images) accuracy was achieved. Cohen [27] have a three semi supervised classifier for facial emotion that achieved accuracy are Navies Bayes (69.10 ± 1.44%), Tree-Augmented Naive Bayes classifier (69.30 ± 1.44%), and Stochastic search (74.80 ± 1.36%). Rifai [28] has semi-supervised classifier is CC-NET+CDA+SVM, which achieved 85% accuracy of facial emotion recognition. Jihang [29] achieved 82.68% and 87.71% accuracy using Transfer Learning Adaptive Boosting semi-supervised learning for facial emotions. From Table 20, [1], [2],[3], it is inferrred that it has a higher accuaracy than our proposed model, but the drawback is differences in types of datasets. Our proposed FERs model are used video datasets of facial emotions not in images. Most of the existing model are used images datasets and few model are used videos are highlited in Table 20. From Table 20, our proposed model has high accuracy and high performance than the state of arts of FER system. Our proposed model has attained the good performance for facial emotions using semi-supervised lerning from the video sequence compared to other existing model. In this work, compared to other models for a semi-supervised classifier for facial emotion, TWSVM achieved a higher accuracy and better performance than Cohen [27], Rifai [28] and Jihang [29].
In this work, the research produces an overall computation time of 2.05 ± 0.43 sec(hold out) and 15.08 ± 4.08 sec(10-fold) in training and testing phases of basic six emotion classification. However Dapgony’s [42] work shows the computation time of 11.75 ± 7.5 sec and Guo’s [43] work shows a computation time of 3.0 ± 0.25 sec for training and testing phase of emotional classifier. Patil’s [2] system shows the computation time of 4 sec. This shows the computational time is reduced in our model when compared to the other models are shown in the Table 21 . From the experiments result, the 10-fold cross validation found above 90% accuracy of all basic six facial emotions and the hold out cross validation found that Disgust and Sad has less than 90% accuracy when compared to other emotions (Surprise, Happy, Fear, and Anger). This may be improved by local normalized data with cross-validation applied in the minimal feature vector of TWSVM classifier. The optimal model can be achieved by validating the above experiment with (k-fold, leave-one-out and bootstrapping with grid search) minimal feature vectors of TWSVM classifier.
5 Conclusion
This paper proposes the classification of facial emotion with minimal facial features of geometric deformable nodes with a semi-supervised classifier. In this system, it is demonstrated that those minimal feature vectors with a semi supervised classifier has high accuracy and less computation time. In this paper, the hold-out validation and 10-fold cross validation of a fused global normalized minimal feature vector is applied in Multi TWSVM to determine the validation parameters of the proposed system. From the comparison of validation parameters, using RBF kernel (‘One vs All’) with Z-normalization have achieved high accuracy of all facial emotions compared to other kernels with normalization. From the proposed model, good performance and accuracy are achieved with the comparison of proposed and existing models, which achieves a better performance than the existing model. This work can be extended for micro and subtle expression as well. This work can go much deeper by applying different cross-validation, local normalized features and feature selection optimization. This work can go in real time application of Human Computer Interactions.
References
Owusu E, Zhan Y, Qi RM (2014) An svm-adaboost facial expression recognition system. Appl Intell 40(3):536–545
Patil H, Kothari A, Bhurchandi K (2016) Expression invariant face recognition using semidecimated dwt, patch-ldsmt, feature and score level fusion. Appl Intell 44(4):913–930
Siddiqi MH (2018) Accurate and robust facial expression recognition system using real-time youtube-based datasets. Appl Intell: 1–18
Suwa M, Sugie N, Fujimora K (1978) A preliminary note on pattern recognition of human emotional expression. In: International joint conference on pattern recognition, vol 1978, pp 408–410
Samal A, Iyengar PA (1992) Automatic recognition and analysis of human faces and facial expressions: a survey. Pattern Recogn 25(1):65–77
Zhang Z, Girard JM, Wu Y, Zhang X, Liu P, Ciftci U, Canavan S, Reale M, Horowitz A, Yang H, et al. (2016) Multimodal spontaneous emotion corpus for human behavior analysis. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3438–3446
Martins P, Batista J (2009) Identity and expression recognition on low dimensional manifolds. In: 2009 16Th IEEE international conference on image processing (ICIP). IEEE, pp 3341–3344
Tian Y-I, Kanade T, Cohn JF (2001) Recognizing action units for facial expression analysis. IEEE Trans Pattern Anal Mach Intell 23(2):97–115
Wu Y, Ji Q (2016) Constrained joint cascade regression framework for simultaneous facial action unit recognition and facial landmark detection. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR)
Ekman PE, Sorenson RE, Friesen WV (1969) Pan-cultural elements in facial displays of emotion. Science 164(3875):86–88
Pandzic IS, Forchheimer R (eds) (2003) MPEG-4 Facial animation: the standard, implementation and applications. Wiley, New York
Salam S (2013) Multi-Object modelling of the face. PhD thesis, Supélec
Uddin MZ (2014) An efficient local feature-based facial expression recognition system. Arab J Sci Eng 39(11):7885–7893
Yu K, Wang Z, Hagenbuchner M, Feng DD (2014) Spectral embedding based facial expression recognition with multiple features. Neurocomputing 129:136–145
Saeed A, Al-Hamadi A, Niese R, Elzobi M (2014) Frame-based facial expression recognition using geometrical features. Advances in Human-Computer Interaction 2014:4
Wan C, Tian Y, Liu S (2012) Facial expression recognition in video sequences. In: 2012 10th world congress on intelligent control and automation (WCICA). IEEE, pp 4766–4770
Mohammadian A, Aghaeinia H, Towhidkhah F (2015) Video-based facial expression recognition by removing the style variations. IET Image Process 9(7):596–603
Ren F, Huang Z (2015) Facial expression recognition based on aam–sift and adaptive regional weighting. IEEJ Trans Electr Electron Eng 10(6):713–722
Jiang X, Feng B, Jin L (2016) Facial expression recognition via sparse representation using positive and reverse templates. IET Image Process 10(8):616–623
Papachristou K, Tefas A, Pitas I (2014) Symmetric subspace learning for image analysis. IEEE Trans Image Process 23(12):5683–5697
Nikitidis S, Tefas A, Pitas I (2014) Maximum margin projection subspace learning for visual data analysis. IEEE Trans Image Process 23(10):4413–4425
Kumar MP, Rajagopal MK (2018) Detecting happiness in human face using minimal feature vectors. In: Computational signal processing and analysis. Springer, pp 1–10
Khemchandani R, Chandra S et al (2007) Twin support vector machines for pattern classification. IEEE Trans Pattern Anal Mach Intell 29(5):905–910
Kumar MP, Rajagopal MK (2018) Detecting happiness in human face using unsupervised twin-support vector machines. International Journal of Intelligent Systems and Applications 10(8):85
Tomar D, Agarwal S (2016) Multi-class twin support vector machine for pattern classification. In: Proceedings of 3rd international conference on advanced computing, networking and informatics. Springer, pp 97–110
Ding S, Zhao X, Zhang J, Zhang X, Xue Y (2017) A review on multi-class twsvm. Artif Intell Rev, pp 1–27
Cohen I, Sebe N, Cozman FG, Huang TS (2003) Semi-supervised learning for facial expression recognition. In: Proceedings of the 5th ACM SIGMM international workshop on Multimedia information retrieval. ACM, pp 17–22
Rifai S, Bengio Y, Courville A, Vincent P, Mirza M (2012) Disentangling factors of variation for facial expression recognition. In: Computer vision–ECCV 2012. Springer, pp 808–822
Jiang B, Jia K, Sun Z (2013) Research on the algorithm of semi-supervised robust facial expression recognition, pp 136–145. Cham
Saragih JM, Lucey S, Cohn JF (2011) Deformable model fitting by regularized landmark mean-shift. Int J Comput Vis 91(2):200–215
Wang Y, Lucey S, Cohn JF (2008) Enforcing convexity for improved alignment with constrained local models IEEE conference on computer vision and pattern recognition, 2008. CVPR 2008. IEEE, pp 1–8
Silverman BW (1986) Density estimation for statistics and data analysis, vol 26. CRC Press, Boca Raton
Cheng Y (1995) Mean shift, mode seeking, and clustering. IEEE Trans Pattern Anal Mach Intell 17(8):790–799
Tekalp AM, Ostermann J (2000) Face and 2-d mesh animation in mpeg-4. Signal Process Image Commun 15(4):387–421
Chen H, Li J, Zhang F, Li Y, Wang H (2015) 3d model-based continuous emotion recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1836–1845
Tomar D, Agarwal S (2015) An effective weighted multi-class least squares twin support vector machine for imbalanced data classification. International Journal of Computational Intelligence Systems 8(4):761–778
Valstar M, Pantic M (2010) Induced disgust, happiness and surprise: an addition to the mmi facial expression database. In: Proc 3rd intern workshop on EMOTION (satellite of LREC): Corpora for research on emotion and affect, p 65
Zhao G, Huang X, Taini M, Li SZ, Pietikäinen M (2011) Facial expression recognition from near-infrared videos. Image Vis Comput 29(9):607–619
Kanade T, Cohn JF, Tian Y (2000) Comprehensive database for facial expression analysis. In: Fourth IEEE international conference on automatic face and gesture recognition, 2000. Proceedings. IEEE, pp 46–53
Lucey P, Cohn JF, Kanade T, Saragih J, Ambadar Z, Matthews I (2010) The extended Cohn-Kanade dataset (ck+): a complete dataset for action unit and emotion-specified expression. In: 2010 IEEE Computer society conference on computer vision and pattern recognition-workshops. IEEE, pp 94–101
Petridis S, Martinez B, Pantic M (2013) The mahnob laughter database. Image Vis Comput 31(2):186–202. Affect analysis in continuous input
Dapogny A, Bailly K, Dubuisson S (2015) Pairwise conditional random forests for facial expression recognition. In: Proceedings of the IEEE international conference on computer vision, pp 3783–3791
Guo Y, Zhao G, Pietikäinen M (2012) Dynamic facial expression recognition using longitudinal facial expression atlases. In: Computer vision–ECCV 2012. Springer, pp 631–644
Acknowledgments
The authors would like to thank, Internet of Things (IOT) laboratory, SENSE and research colleague of Vellore Institute Technology, Chennai, India for real time dataset of facial emotion and execution of this research work.
Funding
No funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kumar, M.P., Rajagopal, M.K. Detecting facial emotions using normalized minimal feature vectors and semi-supervised twin support vector machines classifier. Appl Intell 49, 4150–4174 (2019). https://doi.org/10.1007/s10489-019-01500-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-019-01500-w