
Abstract
Operations in areas of importance to society are frequently modeled as mixed-integer linear programming (MILP) problems. While MILP problems suffer from combinatorial complexity, Lagrangian Relaxation has been a beacon of hope to resolve the associated difficulties through decomposition. Due to the non-smooth nature of Lagrangian dual functions, the coordination aspect of the method has posed serious challenges. This paper presents several significant historical milestones (beginning with Polyak’s pioneering work in 1967) toward improving Lagrangian Relaxation coordination through improved optimization of non-smooth functionals. Finally, this paper presents the most recent developments in Lagrangian Relaxation for fast resolution of MILP problems. The paper also briefly discusses the opportunities that Lagrangian Relaxation can provide at this point in time.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The aim of this paper is to review Lagrangian-Relaxation-based methods for mixed-integer linear programming (MILP) problems. Because of the integer variables, Lagrangian Relaxation leads to non-smooth optimization in the dual space. Accordingly, key non-smooth optimization methods will also be reviewed.
This paper focuses on the efficient resolution of separable Mixed-Integer Linear Programs (MILPs), which are formally defined as follows:
whereby I subsystems are coupled through the following constraints
The primal problem (1)–(2) is assumed to be feasible and the feasible region \({\mathcal {F}} \equiv \prod _{i=1}^I {\mathcal {F}}_i\) with \( {\mathcal {F}}_i \subset {\mathbb {Z}}^{n_i^x} \times {\mathbb {R}}^{n_i^y}\) is assumed to be bounded and finite.
1.1 Importance and difficulties of MILP problems
MILP has multiple applications in problems of importance to society: ambulance relocation (Lee et al., 2022), cost-sharing for ride-sharing (Hu et al., 2021), drop box location (Schmidt and Albert, 2023), efficient failure detection in large-scale distributed systems (Er-Rahmadi and Ma, 2022), home healthcare routing (Dastgoshade et al., 2020), home service routing and appointment scheduling (Tsang and Shehadeh, 2023), job-shop scheduling (Liu et al., 2021), facility location (Basciftci et al., 2021), flow-shop scheduling (Hong et al., 2019; Balogh et al., 2022; Öztop et al., 2022), freight transportation (Archetti et al., 2021), location and inventory prepositioning of disaster relief supplies (Shehadeh and Tucker, 2022), machine scheduling with sequence-dependent setup times (Yalaoui and Nguyen, 2021), maritime inventory routing (Gasse et al., 2022), multi-agent path finding with conflict-based search (Huang et al., 2021), multi-depot electric bus scheduling (Gkiotsalitis et al., 2023), multi-echelon/multi-facility green reverse logistics network design (Reddy et al., 2022), optimal physician staffing (Prabhu et al., 2021), optimal search path with visibility (Morin et al., 2023), oral cholera vaccine distribution (Smalley et al., 2015), outpatient colonoscopy scheduling (Shehadeh et al., 2020), pharmaceutical distribution (Zhu and Ursavas, 2018), plant factory crop scheduling (Huang et al., 2020), post-disaster blood supply (Hamdan and Diabat, 2020; Kamyabniya et al., 2021), real assembly line balancing with human-robot collaboration (Nourmohammadi et al., 2022), reducing vulnerability to human trafficking (Kaya et al., 2022), restoration planning and crew routing (Morshedlou et al., 2021), ridepooling (Gaul et al., 2022), scheduling of unconventional oil field development (Soni et al., 2021), security-constrained optimal power flow (Velloso et al., 2021), semiconductor manufacturing (Chang and Dong, 2017), surgery scheduling (Kayvanfar et al., 2021), unit commitment (Kim et al., 2018; Chen et al., 2019; Li and Zhai, 2019; Chen et al., 2020; Li et al., 2020; van Ackooij et al., 2021), vehicle sharing and task allocation (Arias-Melia et al., 2022), workload apportionment (Gasse et al., 2022), and many others. However, MILP problems belong, in general, to the class of NP-hard problems because of the presence of integer variables x. MILP problems of practical sizes are generally difficult to solve due to their combinatorial complexity. As the problem size increases, the computational effort required to obtain an optimal solution increases superlinearly, e.g., exponentially; for a number of practical problems, the computational effort may be significant to obtain even a feasible solution. Almost all optimization algorithms thus have a superlinear running time given the NP-hard nature of these problems, which implies that there is no known polynomial-time algorithm to solve them optimally unless P=NP. Moreover, many problems of importance typically require short solving times (ranging from 20 min to a few seconds, depending on the application), as well as high-quality solutions.
With decreasing problem size, the NP-hardness has the property of reducing complexity exponentially. The dual decomposition and coordination Lagrangian Relaxation method is promising to exploit this reduction of complexity; the method essentially “reverses” combinatorial complexity upon decomposition, thereby drastically reducing the effort required to solve subproblems (each subproblem i corresponds to a subsystem i). Lagrangian Relaxation is also deeply rooted in economic theory, whereby the solutions obtained are rested upon the economic principle of “supply and demand.” When the “demand” exceeds the “supply,” Lagrangian multipliers (which can be viewed as “shadow prices”) increase (and vice versa) thereby discouraging subsystems from making less “economically viable” decisions. Notwithstanding the advantage of the decomposition aspect, the “price-based” coordination of the method (to appropriately coordinate the subproblems), however, has been the subject of intensive research for many decades because of the fundamental difficulties of the underlying non-smooth optimization of the associated dual functions caused by the presence of integer variables in the primal space. Accordingly, key non-smooth optimization methods will also be reviewed.
The purpose of this paper is to present a brief overview of the key milestones in the development of the Lagrangian Relaxation method for MILP problems as well as in the optimization of convex non-smooth functions. The rest of the paper is structured as follows:
-
1.
At the beginning of Sect. 2, the Lagrangian dual problem is presented and the difficulties of Lagrangian Relaxation on a pathway to solving MILP problems are explained. In subsequent subsections, the difficulties are resolved one by one;
-
2.
In Sect. 2.1, early research on non-smooth optimization (Polyak, 1967, 1969) is presented to lay the foundation for further developments; specifically, the Polyak formula (Polyak, 1969) depending on the optimal dual value \(q(\lambda ^*)\) to ensure geometric (also referred to as linear) convergence rate is presented;
-
3.
In Sect. 2.2, fundamental research as well as applications of Lagrangian duality that emerged in 1970’s to solve discrete optimization problems is discussed;
-
4.
In Sect. 2.3, the subgradient-level method (Goffin and Kiwiel, 1999) is presented to ensure convergence without the need to know \(q(\lambda ^*)\);
-
5.
In Sect. 2.4, the fundamental difficulties associated with subgradient methods (high computational effort and zigzagging of multipliers) are explained;
-
6.
In Sects. 2.5 and 2.6, two separate research thrusts: surrogate (Kaskavelis and Caramanis, 1998; Zhao et al., 1999) and incremental (Nedic and Bertsekas, 2001) to reduce computational effort as well to alleviate zigzagging of multipliers are reviewed; the former thrust still requires \(q(\lambda ^*)\) for convergence; the latter thrust avoids the need to know \(q(\lambda ^*)\) following the “subgradient-level” ideas presented in Sect. 2.3;
-
7.
In Sect. 2.7, Surrogate Lagrangian Relaxation (SLR) (Bragin et al., 2015) with convergence proven without \(q(\lambda ^*)\) by exploiting “contraction mapping” while inheriting convergence properties of the surrogate method of Sect. 2.5 is reviewed;
-
8.
In Sect. 2.8, further methodological advancements for SLR are presented; to accelerate the reduction of constraint violations while enabling the use of MILP solvers, “absolute-value” penalties have been introduced (Bragin et al., 2018); to efficiently coordinate distributed entities while avoiding the synchronization overhead, computationally distributed version of SLR has been developed to efficiently coordinate distributed subsystems in an asynchronous way (Bragin et al., 2020);
-
9.
In Sect. 2.9, Surrogate “Level-Based” Lagrangian Relaxation (Bragin and Tucker, 2022) is reviewed; this first-of-the-kind method exploits the linear-rate convergence potential intrinsic to the Polyak’s formula presented in Sect. 2.1 but without the knowledge \(q(\lambda ^*)\) and without heuristic adjustments of its estimates presented in Sect. 2.3. Rather, an estimate of \(q(\lambda ^*)\) (the “level value”) has been innovatively determined purely through a simple constraint satisfaction problem; the surrogate concept (Zhao et al., 1999; Bragin et al., 2015) ensures low computational requirements as well as the alleviated zigzagging; accelerated reduction of constraint violations is achieved through “absolute-value” penalties (Bragin et al., 2018) enabling the use of MILP solvers;
-
10.
In Sect. 3, a brief conclusion is provided with future directions delineated.
2 Lagrangian duality for discrete programs and non-smooth optimization
The Lagrangian dual problem that corresponds to the original MILP problem (1)–(2) is the following non-smooth optimization problem:
where the convex dual function is defined as follows:
Here \(L(x,y,\lambda ) \equiv \sum _{i=1}^I \big ((c_i^x)^T \cdot x_i + (c_i^y)^T \cdot y_i\big ) + \lambda ^T \cdot \big (\sum _{i=1}^I A_i^x \cdot x_i + \sum _{i=1}^I A_i^y \cdot y_i - b\big )\) is the Lagrangian function obtained by relaxing coupling constraints (2) by using Lagrangian multipliers \(\lambda \). The minimization of \(L(x,y,\lambda )\) within (4) with respect to \(\{x,y\}\) is referred to as the relaxed problem, which is separable into subproblems due to the additivity of \(L(x,y,\lambda )\). This feature will be exploited starting from Sect. 2.5.
Even though the original primal problem (1) is non-convex, \(q(\lambda )\) is always continuous and concave with the feasible set \(\Omega \) being always convex. Due to integer variables x in the primal space, \(q(\lambda )\) is non-smooth with facets (each representing a particular solution to (4)) intersecting at ridges where derivatives of \(q(\lambda )\) exhibit discontinuities; in particular, \(q(\lambda )\) is non-differentiable at \(\lambda ^{*}\).
For further discussion, the following definitions will be helpful:
Definition 2.1
A vector \(g(\lambda ^k) \in {\mathbb {R}}^m\) is a subgradient of \(q: {\mathbb {R}}^m \rightarrow {\mathbb {R}}\) at \(\lambda ^k \in \Omega \) if for all \(\lambda \in \Omega \), the following holds: \(q(\lambda ) \le q(\lambda ^k) + \big (g(\lambda ^k)\big )^{T}\cdot (\lambda - \lambda ^k).\)
Note that a subgradient can exist even when q is not differentiable at \(\lambda ^k\). Moreover, there can be more than one subgradient of a function q at a point \(\lambda ^k\). A way to understand the significance of the subgradient is that \(q(\lambda ^k) + \big (g(\lambda ^k)\big )^{T}\cdot (\lambda - \lambda ^k)\) is a global overestimator of \(q(\lambda )\).
Definition 2.2
The set of subgradients of q at \(\lambda ^k\) is referred to as the subdifferential of q at \(\lambda ^k\), and is denoted as \(\partial q(\lambda ^k)\).
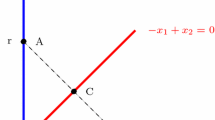
While the gradient gives a direction along which a function increases the most rapidly, as discussed above, subgradients are not unique and do not necessarily provide a direction along which a non-differentiable function increases (see a subgradient direction at point A in Fig. 1). Moreover, subgradients may almost be perpendicular to the directions toward optimal multipliers \(\lambda ^*\) thereby leading to zigzagging of \(\lambda \) across ridges of the dual function (see a corresponding subgradient direction at point B in Fig. 1 for illustrations).

An example of a dual function that illustrates the difficulties associated with subgradient methods. Solid lines denote the level curves, dash-dotted lines denote the ridges of the dual function whereby the gradients are not defined (possible subgradient directions at points A and B are shown by solid arrows), and dashed lines denote the subgradient direction from point B toward optimal multipliers. This figure is taken from (Bragin and Tucker, 2022) with permission
While Lagrangian multipliers \(\lambda \) are generally fixed parameters within (4), \(\lambda \) are “dual” decision variables with respect to the dual problem (3). Traditionally, (3) is maximized by iteratively updating \(\lambda \) by making a series of steps \(s^k\) along subgradients \(g(x^k,y^k)\) as:
where \(\{x^k,y^k\}\) is a concise way to denote an optimal solution \(\{x^*(\lambda ^k),y^*(\lambda ^k)\}\) to the relaxed problem (4) with multipliers equal to \(\lambda ^k.\) Within Lagrangian Relaxation, subgradients are defined as levels of constraint violations \(g(x^k,y^k) \equiv \sum _{i=1}^I A_i^x \cdot x_i^k + \sum _{i=1}^I A_i^y \cdot y_i^k - b\). Technically, since \(\{x^k,y^k\}\) is a function \(\lambda ^k\) as discussed above, the following notation is appropriate \(g(x^k,y^k) = g(\lambda ^k)\). Both notations can be used interchangeably and will be denoted simply as \(g^k\) for compactness as appropriate.
To see why \(g^k\) is indeed a subgradient, consider the following:
which is true in view of (4). Adding and subtracting \(\left( g^k\right) ^T \cdot (\lambda ^k)\) leads to
Since the above inequality holds for all feasible x and y, then it also holds for specific feasible values such as \(x^k\) and \(y^k.\) Therefore,
By definition (4) and due to \(\{x^k,y^k\}:= \{x^*(\lambda ^k),y^*(\lambda ^k)\}\),
Therefore,
This concludes the proof.
If inequality constraints \(\sum _{i=1}^I A_i^x \cdot x_i +\sum _{i=1}^I A_i^y \cdot y_i \le b\) are present, they are generally converted into equality constraints by introducing non-negative real-valued slack variables z such that \(\sum _{i=1}^I A_i^x \cdot x_i + \sum _{i=1}^I A_i^y \cdot y_i + z = b.\) Multipliers are then updated per (5) with subsequent projection onto the positive orthant \(\{\lambda : \lambda \ge 0\}\).
Because the dual problem results from the relaxation of coupling constraints, dual values are generally less than primal values \(q(\lambda ^k) < f(x^k,y^k),\)Footnote 1 i.e., there is a duality gap - the relative difference between \(q(\lambda ^k)\) and \(f(x^k,y^k)\).Footnote 2 Because of the discrete nature of the primal problem (1)–(2), even at optimality, the duality gap is generally non-zero, that is \(q(\lambda ^*) < f(x^*,y^*).\) Consequently, maximization of the dual function does not lead to an optimal primal solution \((x^*,y^*)\) or even a feasible solution. To obtain solutions feasible with respect to the original problem (1)–(2), solutions to the relaxed problem \(\{x^k_i,y^k_i\}\) are typically perturbed heuristically.Footnote 3 Generally, the closer the multipliers are to their optimal values \(\lambda ^*\), the smaller the levels of constraint violations (owing to the concavity of the dual function), and, therefore, the easier the search for feasible solutions.
In short summary, the roadblocks on the way of Lagrangian Relaxation to efficiently solve MILP problems are the following:
-
1.
Non-differentiability of the dual function;
-
(a)
Subgradient directions are non-ascending;
-
(b)
Necessary and sufficient conditions for extrema are inapplicable;
-
(a)
-
2.
High computational effort is required to compute subgradient directions if the number of subsystems is large;
-
3.
Zigzagging of multipliers across ridges of the dual function leads to many iterations required for convergence; this difficulty follows from the non-differentiability of the dual function, but this difficulty deserves a separate resolution;
-
4.
Solutions \(\{x^k_i,y^k_i\}\) to the relaxed problem, when put together, do not satisfy constraints (2). Moreover,
-
5.
Even at \(\lambda ^*\), levels of constraint violations may be large, and the heuristic effort to “repair” the relaxed problem solution \(\{x^k_i,y^k_i\}\) may still be significant.
In order to resolve difficulty 1(b), stepsizes need to approach zero (yet, this condition alone is not sufficient), as will be discussed in the subsection that follows. This requirement puts a restriction on the methods that will be reviewed.
Scope By examining the above-mentioned difficulties (which will also be referred to as D1(a), D1(b), D2, D3, D4, and D5), several stages in the development of Lagrangian Relaxation and its applications to optimizing non-smooth dual functions and solving MILP problems will be chronologically reviewed, along with specific features of the methods that address the above difficulties. In view of the above difficulties such as D1(b) and D2, several research directions, though having their own merit, will be excluded, for example:
-
1.
The Method of Multipliers The Alternate Direction Method of Multipliers (ADMM), which is derived from Augmented Lagrangian Relaxation (ALR) (the “Method of Multipliers”), introduces quadratic penalties to penalize violations of relaxed constraints, improving the convergence of Lagrangian Relaxation. The two methods (ADMM and ALR), however, only converge when solving continuous primal problems. Without stepsizes approaching zero, neither method converges [in the dual space] when solving discrete primal problems and does not resolve D1(b). Nevertheless, the penalization idea underlying ALR led to the development of other LR-based methods with improved convergence as described in Sect. 2.8.
-
2.
The Bundle Method The Bundle Method’s idea is to obtain the so-called \(\varepsilon -\)ascent direction to update multipliers (Zhao and Luh, 2002). Considering that the non-differentiability of dual functions may generally result in non-ascending subgradient directions, the Bundle method resolves D1(a). Since the relaxed problems need to be solved several times (Zhao and Luh, 2002), however, the effort required to obtain multiplier-updating directions exceeds that required in subgradient methods, thus the method does not resolve D2.
2.1 1960’s: minimization of “unsmooth functionals”
Optimization of non-smooth convex functions, a direction that stems from the seminal work of Polyak (1967), is a broader subject than the optimization of \(q(\lambda )\) within Lagrangian Relaxation. To present the underlying principles that support Lagrangian Relaxation to efficiently solve MILP problems, the work of Polyak (1967) is discussed next.
Subgradient Method with “Non-Summable” Stepsize While subgradients are generally non-descending (non-ascending) for minimization (maximization) problems (Polyak, 1967, p. 33), convergence to the optimal solution optimizing a non-smooth function (e.g., to \(\lambda ^*\) maximizing \(q(\lambda )\)) was proven under the following (frequently dubbed as non-summable) stepsizing formula satisfying the following conditions:
Subgradient Method with Polyak Stepsize As Polyak noted in his later work (Polyak, 1969, p. 15), non-summable stepsizes lead to very slow convergence. Intending to achieve linearFootnote 4 rate of convergence so that \(\Vert \lambda ^k - \lambda ^*\Vert \) is monotonically decreasing, Polyak developed a stepsizing formula, which can be presented in the following way:
Assuming that the function \(q(\lambda )\) is strongly convex (\(q(\lambda ^*) - q(\lambda ^k) \ge m \cdot \Vert \lambda ^* -\lambda ^k\Vert ^2\)) and satisfies the Lipshitz condition (\(g^k \le M \cdot \Vert \lambda ^k - \lambda ^*\Vert \)) [both conditions are stated in Polyak (1969, p. 17)], a rendition of Polyak’s result can be presented as follows. First, consider a binomial expansion of \(\Vert \lambda ^*-\lambda ^{k+1}\Vert ^2\) as
Owing to the concavity of the dual function,
Therefore, (13) becomes:
Given the Polyak stepsize formula (12), Eq. (15) becomes:
The strong convexity condition \(q(\lambda ^*) - q(\lambda ^k) \ge m \cdot \Vert \lambda ^* - \lambda ^k\Vert ^2\) implies that \(-\left( q(\lambda ^*) - q(\lambda ^k)\right) ^2 \le - m ^2 \cdot \Vert \lambda ^* - \lambda ^k\Vert ^4\), therefore, given that \((2 \cdot \gamma - \gamma ^2) >0\) for \(0 < \varepsilon _1 \le \gamma \le 2 - \varepsilon _2\) Eq. (16) becomes
Given that the Lipchitz condition is \(g^k \le M \cdot \Vert \lambda ^k -\lambda ^*\Vert \), Eq. (17) becomes
Therefore
Within (12)–(19) and thereafter in the paper, the standard Euclidean norm will be used (unless specified otherwise).
The Polyak stepsize (12) can be regarded as a creative workaround of D1(a) in the sense that a more computationally difficult problem of obtaining ascending directions at every iteration (as in the Bundle method) to ensure convergence is replaced with a provably easier problem of reducing \(\Vert \lambda ^*-\lambda ^{k}\Vert \) at every step to guarantee convergence.
Throughout the decades following 1969, research on the two distinct stepsize directions, i.e., “non-summable” (11) and “Polyak” (12), has continued, with various research groups focusing on one or the other. Both directions guarantee convergence to \(\lambda ^*\) that maximizes the dual function \(q(\lambda )\) (thereby resolving D1(b)), although, up to this stage in the discussion, convergence by using Polyak stepsize is purely theoretical, since optimal dual value \(q(\lambda ^*)\) required within (12) is unknown.
Before we delve into the resolution of the above difficulties, it is essential to reflect upon the foundational research that has shaped our understanding of Lagrangian Relaxation for discrete programming problems. Without this understanding of seminal research that significantly influenced the trajectory of research in discrete programming, our historical exploration of the subject would remain incomplete. Even though the optimal dual value \(q(\lambda ^{*})\) had not been known, both the geometric convergence potential offered by the formula (12) and the exponential reduction of complexity upon decomposition within Lagrangian Relaxation were extensively exploited and gave rise to the resolution of MILP problems as will be discussed next.
2.2 1970’s and 1980’s: application of LR and non-smooth optimization to mathematical programming and operations research problems
The decades of the 1970’s and 1980’s were characterized by an expansive wave of both foundational research and practical applications within the domain of Lagrangian Relaxation. The fundamental research, exemplified by the works such as Shapiro (1971), Geoffrion (1974) and Fisher and Shapiro (1974), laid the groundwork for the future development of the field. Concurrently, the field also witnessed a significant surge in the exploration and application of non-smooth optimization techniques. Notably, the Polyak method, as per Eq. (12), emerged as a widely employed technique for solving a broad spectrum of discrete optimization problems, encompassing both pure integer and mixed-integer problems. Since the optimal dual value \(q(\lambda ^{*})\) within (12) of the associated dual value is generally unknown, to compute stepsizes, \(q(\lambda ^{*})\) was estimated, for example, through a “target” value \(\overline{q}\) (e.g., Held and Karp (1971)) or by using a feasible cost of the primal problem (e.g., Fisher (1976)). Notable applications of the method are the traveling salesman problems (Held and Karp, 1970, 1971), scheduling problems (Fisher, 1973, 1976; Muckstadt and Koenig, 1977; Shepardson and Marsten, 1980), location problems (Cornuejols et al., 1977; Erlenkotter, 1978) and many others. Excellent summaries of early applications of Lagrangian relaxation for discrete programming problems can be found at Fisher (1981) and Fisher (1985). Through the retrospective examination of the above research, understanding the foundational principles, insights, and techniques that have shaped the development of Lagrangian Relaxation methods in discrete programming offers us valuable perspectives as we delve deeper into the advanced methodologies and innovative applications discussed later in our survey.
Transitioning into the 1990’s, a transformative approach—the Subgradient-Level Method—was introduced to tackle the practical convergence issues often encountered with the Polyak method.
2.3 The 1990’s: the subgradient-level method
The Subgradient-Level Method (Goffin and Kiwiel, 1999) addressed difficulties associated with the unavailability of optimal [dual] value, which is needed to compute Polyak stepsize (12) through adaptively adjusting a level estimate based on the detection of sufficient descent and oscillations of the [dual] solutions.
In terms of the problem (3), the procedure of the method is explained as follows: the “level” estimate \(q^{k}_{lev} =q^{k_j}_{rec} + \delta _j\) is used in place of the optimal dual value \(q(\lambda ^{*})\), where \(q^{k}_{rec}\) is the best (highest) dual value (“record objective value”) obtained up to an iteration k, and \(\delta _j\) is an adjustable parameter with j denoting the \(j^{th}\) update of \(q^{k}_{lev}.\) The main premise behind this is when \(\delta _j\) is “too large,” then multipliers will exhibit oscillations while traveling significant (predefined) distance R without improving the “record” value. In this case, the parameter \(\delta _j\) is updated as \(\delta _{j+1} = \beta \cdot \delta _j\) with \(\beta = \frac{1}{2}.\) On the other hand, if \(\delta _j\) is such that the dual value is sufficiently increased: \(q(\lambda ^k) \ge q^{k}_{lev} + \tau \cdot \delta _j,\) with \(\tau = \frac{1}{2},\) then the parameter \(\delta _j\) is unchanged and the distance traveled by multipliers is reset to 0 to avoid premature reduction of \(\delta _j\) by \(\beta \) in future iterations.
This method ushered in a new era of “level-based” optimization for non-smooth functions, which will be discussed to ultimately enhance the efficiency of the resolution of MILP problems. This advancement laid a robust foundation that has continued to resonate in subsequent methodologies and will reverberate throughout the later sections of this survey.
Followed by an examination of resolutions of D2 and D3, further discussions of the implementation of Polyak stepsize to resolve D1 will be deferred to future subsections.
2.4 Fundamental difficulties of subgradient methods
High Computational Effort (D2) In the methods reviewed thus far, non-smooth functions are assumed to be given. However, a dual function \(q(\lambda )\) cannot be obtained computationally efficiently. In fact, even for a given value of multipliers \(\lambda ^k\), minimization within (4) to obtain a dual value \(q(\lambda ^k)\) and the corresponding subgradient is time-consuming. Even then, only one possible value of the subgradient can generally be obtained; a complete description of the subgradient is generally non-attainable (Goffin, 1977).
Zigzagging of Multipliers (D3) As hypothesized by (Goffin, 1977), the slow convergence of subgradient methods is due to ill-conditioning. The condition number \(\mu \) is formally defined as (Goffin, 1977): \(\mu =\inf \{\mu (\lambda ): \lambda \in {\mathbb {R}}^m/P\},\) where \(P=\{\lambda \in {\mathbb {R}}^m: q(\lambda ) = q(\lambda ^{*})\}\) (the set of optimal solutions) and \(\mu (\lambda ) = \min _u {\frac{u^T \cdot (\lambda ^{*}-\lambda )}{\Vert u^T\Vert \cdot \Vert \lambda ^{*}-\lambda \Vert }}\) (the cosine of the angle that subgradient form with directions toward the optimal multipliers).Footnote 5 It was then confirmed experimentally when solving, for example, scheduling (Czerwinski & Luh, 1994, Fig. 3(b), p. 104) as well as power systems problems (Guan et al., 1995, Fig. 4, p. 774) that the ill-conditioning leads to the zigzagging of multipliers across the ridges of the dual function.
To address these two difficulties, the notions of “surrogate,” “interleaved” and “incremental” subgradients, which do not require relaxed problems to be fully optimized to speed up convergence, emerged in the late 1990 s, and early 2000 s as reviewed next.
2.5 The late 1990’s: interleaved- and surrogate-subgradient methods
Within the Interleaved Subgradient method proposed by (Kaskavelis and Caramanis, 1998), multipliers are updated after solving one subproblem at a time
rather than after solving all the subproblems as in subgradient methods. This significantly reduces computational effort, especially for problems with a large number of subsystems.
The more general Surrogate Subgradient method with proven convergence was then developed by Zhao et al. (1999) whereby the exact optimality of the relaxed problem (or even subproblems) is not required. As long as the following “surrogate optimality condition”
is satisfied, the multipliers are updated as
by using the following formula
The convergence to \(\lambda ^{*}\) is guaranteed (Zhao et al., 1999). Unlike that in the original Polyak formula (12), parameter \(\gamma \) is less than 1 to guarantee that \(q(\lambda ^{*}) > L(\tilde{x}^k,\tilde{y}^k,\lambda ^k)\) so that the stepsize formula (23) is well-defined in the first place, as proven in Zhao et al. (1999, Proposition 3.1, p. 703). Here, “tilde” indicates that the corresponding solutions do not need to be necessarily subproblem-optimal. Solutions \(\{\tilde{x}^k,\tilde{y}^k\}\) form a set \({\mathcal {S}}(\tilde{x}^{k-1},\tilde{y}^{k-1},\lambda ^k) \equiv \{(x,y): L(x,y,\lambda ^k) < L(\tilde{x}^{k-1},\tilde{y}^{k-1},\lambda ^k)\}\). Once a member \(\{\tilde{x}^k,\tilde{y}^k\} \in {\mathcal {S}}(\tilde{x}^{k-1},\tilde{y}^{k-1},\lambda ^k)\) is found, i.e., the surrogate optimality condition (21) is satisfied, the optimization of the relaxed problem stops and multipliers are updated per (22). A case when \({\mathcal {S}}(\tilde{x}^{k-1},\tilde{y}^{k-1},\lambda ^k) = \emptyset \) indicates that for given \(\lambda ^k\) no solution better than \(\{\tilde{x}^{k-1},\tilde{y}^{k-1}\}\) can be found indicating that \((\tilde{x}^{k-1},\tilde{y}^{k-1}) =(x^*(\lambda ^k),y^*(\lambda ^k))\) is subproblem-optimal for given value \(\lambda ^k\), and the multipliers are updated by using a subgradient direction.
The convergence proof is quite similar to that presented in (13)–(19). The only caveat is that \(L(\tilde{x}^k,\tilde{y}^k,\lambda ^k)\) is strictly speaking not a function; unlike the dual function \(q(\lambda ^k)\), \(L(\tilde{x}^k,\tilde{y}^k,\lambda ^k)\) can take multiple values for given \(\lambda ^k\). Therefore, the analogue of (14) cannot follow from concavity of \(L(\tilde{x}^k,\tilde{y}^k,\lambda ^k)\). It follows from the fact that the surrogate dual value is obtained without solving all the subproblems, hence
Adding and subtracting \(g(\tilde{x}^k,\tilde{y}^k)^T \cdot \lambda ^k\) from the previous inequality leads to
The procedure described in (15)–(19) follows analogously.
In addition to the reduction of computational effort, a concomitant reduction of multiplier zigzagging has been also observed. Indeed, with an exception of the aforementioned situation whereby \({\mathcal {S}}(\tilde{x}^{k-1},\tilde{y}^{k-1},\lambda ^k) = \emptyset \), a solution to one subproblem (20) is sufficient to satisfy (21). In this case, only one term within each summation of surrogate subgradient \(\sum _{i=1}^I A_i^x \cdot x_i + \sum _{i=1}^I A_i^y \cdot y_i - b\) will be updated thereby preventing surrogate subgradients from changing drastically, and from zigzagging of multipliers as the result.
2.6 The early 2000’s: incremental subgradient methods
In the incremental subgradient method, a subproblem i is solved before multipliers are updated (similar to the interleaved method). However, as opposed to updating all multipliers at once, the incremental subgradient method updates multipliers incrementally. After the ith subgradient component is calculated, multipliers are updated as
Here \(\beta _i\) are the vectors such that \(\sum _{i=1}^I \beta _i = b\), for example, \(\beta _i = \frac{b}{I}.\) Only after all i subproblems are solved, are the multipliers “fully” updated as
Convergence results of the subgradient-level method (Goffin and Kiwiel, 1999) have been extended for the subgradient method. Variations of the method were proposed with \(\beta \) and \(\tau \) belonging to an interval [0, 1] rather than being equal to \(\frac{1}{2}.\) Moreover, to improve convergence, rather than using constant R, a sequence of \(R_l\) was proposed such that \(\sum _{l=1}^{\infty } R_l = \infty .\)
2.7 2010’s: the surrogate lagrangian relaxation method
Based on contraction mapping, Surrogate Lagrangian Relaxation (SLR) (Bragin et al., 2015) overcomes the difficulty associated with the lack of knowledge about the optimal dual value. At consecutive iterations, the distance between multipliers must decrease, i.e.,
Based on (22) and (28), the stepsize formula has been derived:
Moreover, a specific formula to set \(\alpha _k\) has been developed to guarantee convergence:
Since \(\alpha _k \rightarrow 1,\) stepsizes within SLR are “non-summable.” Linear convergence can only be guaranteed outside of a neighborhood of \(\lambda ^*\) (Bragin et al., 2015, Proposition 2.5, p. 187).
When multipliers approach their optimal values,Footnote 6 surrogate subgradients become closer to actual subgradients, leading to reduced constraint violations due to the concavity of dual functions. This indicates that subproblems are well-coordinated, and relaxed problem solutions are near feasible ones. As a result, only a few subproblems cause infeasibility. This drastically helps with the resolution of Difficulty D4 (“solutions to the relaxed problem, when put together may not constitute a feasible solution to the original problem”): an “automatic” procedure to identify and “repair” a few subproblem solutions that cause the infeasibility of the original problem has been developed by Bragin et al. (2018).
2.8 The late 2010’s–early 2020’s: further methodological advancements
Surrogate Absolute-Value Lagrangian Relaxation (Bragin et al., 2018) The Surrogate Absolute-Value Lagrangian Relaxation (SAVLR) method is designed to guarantee convergence and to speed up the reduction of constraint violations while avoiding nonlinearity and nonconvexity that would have occurred if traditional quadratic terms had been used. In the SAVLR method, the following dual problem is considered:
where
The above minimization involves the exactly-linearizable piecewise linear penalties, which penalize constraint violations thereby ultimately reducing the number of subproblems that cause infeasibility mentioned in Sect. 2.7 and consequently reducing the effort required by heuristics to find primal solutions. This resolves Difficulty D5.Footnote 7
Distributed and Asynchronous Surrogate Lagrangian Relaxation (DA-SLR) (Bragin et al., 2020) With the emergence of technologies that enhance distributed computation, coupled with the networking infrastructure, computational tasks can be accomplished much more efficiently by using distributed computing resources than by using a single computer. With the assumption of a single coordinator, the DA-SLR methodology has been developed to efficiently coordinate distributed subsystems in an asynchronous manner while avoiding the overhead of synchronization. Compared to the sequential Surrogate Lagrangian Relaxation (Bragin et al., 2015), numerical testing shows a faster convergence (12 times speed-up to achieve a gap of 0.03% for one instance of the generalized assignment problem).
A short summary is in order here. While in theory, the Polyak formula offers a linear rate of convergence, the convergence rate of the Subgradient-Level Method, however, is not discussed either in the original paper by Goffin and Kiwiel (1999), or in subsequent applications of the subgradient “level-based” ideas (e.g., by Nedic and Bertsekas (2001)). Likely, because of the requirements that the multipliers need to travel, either explicitly or implicitly, an infinite distance, the linear rate of convergence cannot be achieved. While SLR-based methods avoid estimating the optimal dual value, the requirement (30) to avoid premature termination results in the [stepsize] non-summability. Ideally, the goal is to avoid multiplier zigzagging, reduce the computational effort required to obtain multiplier-updating directions and achieve linear convergence. The first step in this direction is explained in the following subsection.
2.9 Early 2020’s: surrogate level-based Lagrangian relaxation
To exploit the linear convergence potential inherent to the Polyak stepsize formula, the Surrogate “Level-Based” Lagrangian Relaxation (SLBLR) method has been recently developed (Bragin and Tucker, 2022). It was proven that once the following “multiplier divergence detection” feasibility problem
admits no feasible solution with respect to \(\lambda \) (which are the decision variables in the problem above) for some \(k_j\) and \(n_j\), then the “level value” equals to
where
In subsequent iterations, the Polyak stepsize formula is used
In essence, the above formula is used until the above feasibility problem admits no solution again, at which point the level value is reset from \(\overline{q}_{j}\) to \(\overline{q}_{j+1}\) and the multiplier-updating process continues. It is worth noting that the optimization problem (3) is the maximization problem and the quality of its solutions (Lagrangian multipliers) can be quantified through the upper bound provided by \(\{\overline{q}_{j}\}\).
The assumption here is that the above feasibility problem (33) becomes infeasible “periodically” and “infinitely often” thereby triggering recalculations of “level” values \(\overline{q}_{j}\), which will decrease and approach \(q(\lambda ^*)\) from above. The assumption is realistic since the only sure-fire way to ensure that (33) is always feasible is to know the optimal dual value.
Given the above and with the addition of “absolute-value” penalties to facilitate the feasible solution search, the SLBLR method addresses all the difficulties D1-D5. The method inherits features from Polyak’s formula (12), reduction of computational effort as well as the alleviation of zigzagging from surrogate methods (Zhao et al., 1999; Bragin et al., 2015) and the acceleration of reduction of the constraint violation from (Bragin et al., 2018). The decisive advantage of SLBLR is provided by the practically operationalizable use of the Polyak formula (12) though the efficient decision-based procedure described above to determine “level” values without the need for estimation or heuristic adjustment of estimates of the optimal dual value. Results reported in (Bragin and Tucker, 2022) indicate that the SLBLR method solves a wider range of generalized assignment problems (GAPs) to optimality as compared to other methods. With other things being equal, the “level-based” stepsizing of the SLBLR method (Bragin and Tucker, 2022) is more advantageous as compared to the “non-summable” stepsizing of the SAVLR method (Bragin et al., 2018). Additionally, SLBLR successfully solves other problems such as stochastic job-shop scheduling and pharmaceutical scheduling outperforming commercial solvers by at least two orders of magnitude.
The SLBLR method (Bragin and Tucker, 2022) is not restricted to MILP problems since linearity is not required for the above-mentioned determination of level values. The method is modular and has the potential to support plug-and-play capabilities. For example, while applications to pharmaceutical scheduling have been tested by using fixed data (Bragin and Tucker, 2022), the method is also suitable to handle urgent requests to manufacture new pharmaceutical products since such products can be introduced into the relaxed problem “on the fly” and the corresponding subproblems can keep being coordinated through Lagrangian multipliers without the major intervention of the scheduler and without disrupting the overall production schedule.
3 Conclusions and future directions
This paper intends to summarize key difficulties encountered on a path to efficiently solve MILP problems as well as to provide a brief summary of important milestones of a more than half-a-century-long research journey to address these difficulties by using Lagrangian Relaxation. Moreover, the most recent SLBLR method is (1) general having the potential to handle general MIP problems since linearity is not required to exploit the linear rate of convergence; (2) flexible and modular having the potential to support plug-and-play capabilities with real-time response to unpredictable and/or disruptive events such as natural hazards, operational faults, and cyber-physical events, including generator outages in power systems, receiving an urgent order in manufacturing or encountering a traffic jam in transportation. With communication and distributed computing capabilities, these events can be handled by a continuous update of Lagrangian multipliers, improving system resilience; the method is thus also suitable for fast re-optimization; (3) compatible with other optimization methods such as quantum-computing as well as machine-learning methods, which can potentially be used to further improve subproblem solving thereby contributing to drastically reducing the CPU time supported by the fast coordination aspect of the method.
Notes
In this particular case, \(f(x^k,y^k) \equiv \sum _{i=1}^I \left( (c_i^{x})^T \cdot x_i^k +(c_i^{y})^T \cdot y_i^k \right) \) such that \(\{x^k,y^k\}\) satisfy constraints (2).
Dual values can be used to quantify the quality of the solution \(\{x^k,y^k\}\).
To solve MILP problems, Lagrangian Relaxation is often regarded as a heuristic. However, in dual space, the Lagrangian relaxation method is exact; the method is also capable of helping to improve solutions through the multipliers update, unlike many other heuristic methods.
Upon visual examination of the dual function illustrated in Fig. 1, the condition number is likely 0 since the subgradient emanating from point B appears to form a right angle with the direction toward optimal multipliers.
A quality measure to quantify the quality of multipliers (i.e., how close the multipliers are to their optimal values) will be discussed in Sect. 2.9
The parameter \(\rho \) is increased as \(\rho ^{k+1}=\beta \cdot \rho ^k,\beta >1\) until surrogate optimality condition (21) is no longer satisfied, which signifies that proper “surrogate” subgradient directions can no longer be obtained. Moreover, with heavily penalized constraint violations, the feasibility is overemphasized and subproblem solutions may get stuck at a suboptimal solution. In these situations, \(\rho \) is no longer increased, rather, violations of surrogate optimality conditions prompt the reduction of penalty coefficients \(\rho ^{k+1}=\rho ^k/\beta ,\beta >1\).
References
Archetti, C., Peirano, L., & Speranza, M. G. (2021). Optimization in multimodal freight transportation problems: A survey. European Journal of Operational Research, 299(1), 1–20.
Arias-Melia, P., Liu, J., & Mandania, R. (2022). The vehicle sharing and task allocation problem: MILP formulation and a heuristic solution approach. Computers and Operations Research, 147, 105929.
Balogh, A., Garraffa, M., O’Sullivan, B., & Salassa, F. (2022). Milp-based local search procedures for minimizing total tardiness in the no-idle permutation flowshop problem. Computers and Operations Research, 146, 105862.
Basciftci, B., Ahmed, S., & Shen, S. (2021). Distributionally robust facility location problem under decision-dependent stochastic demand. European Journal of Operational Research, 292(2), 548–561.
Bragin, M. A., Luh, P. B., Yan, B., & Sun, X. (2018). A scalable solution methodology for mixed-integer linear programming problems arising in automation. IEEE Transactions on Automation Science and Engineering, 16(2), 531–541.
Bragin, M. A., Luh, P. B., Yan, J. H., Yu, N., & Stern, G. A. (2015). Convergence of the surrogate Lagrangian relaxation method. Journal of Optimization Theory and Applications, 164(1), 173–201.
Bragin, M. A., & Tucker, E. L. (2022). Surrogate level-based Lagrangian relaxation for mixed-integer linear programming. Scientific Reports, 22(1), 1–12.
Bragin, M. A., Yan, B., & Luh, P. B. (2020). Distributed and asynchronous coordination of a mixed-integer linear system via surrogate Lagrangian relaxation. IEEE Transactions on Automation Science and Engineering, 18(3), 1191–1205.
Chang, X., & Dong, M. (2017). Stochastic programming for qualification management of parallel machines in semiconductor manufacturing. Computers and Operations Research, 79, 49–59.
Charisopoulos, V., & Davis, D. (2022). A superlinearly convergent subgradient method for sharp semismooth problems. arXiv preprint arXiv:2201.04611
Chen, Y., Pan, F., Holzer, J., Rothberg, E., Ma, Y., & Veeramany, A. (2020). A high performance computing based market economics driven neighborhood search and polishing algorithm for security constrained unit commitment. IEEE Transactions on Power Systems, 36(1), 292–302.
Chen, Y., Wang, F., Ma, Y., & Yao, Y. (2019). A distributed framework for solving and benchmarking security constrained unit commitment with warm start. IEEE Transactions on Power Systems, 35(1), 711–720.
Cornuejols, G., Fisher, M. L., & Nemhauser, G. L. (1977). Exceptional paper—location of bank accounts to optimize float: An analytic study of exact and approximate algorithms. Management Science, 23(8), 789–810.
Czerwinski, C. S., & Luh, P. B. (1994). Scheduling products with bills of materials using an improved Lagrangian relaxation technique. IEEE Transactions on Robotics and Automation, 10(2), 99–111.
Dastgoshade, S., Abraham, A., & Fozooni, N. (2020). The Lagrangian relaxation approach for home health care problems. In International conference on soft computing and pattern recognition (pp. 333–344). Springer.
Erlenkotter, D. (1978). A dual-based procedure for uncapacitated facility location. Operations Research, 26(6), 992–1009.
Er-Rahmadi, B., & Ma, T. (2022). Data-driven mixed-integer linear programming-based optimisation for efficient failure detection in large-scale distributed systems. European Journal of Operational Research, 303(1), 337–353.
Fisher, M. L. (1973). Optimal solution of scheduling problems using Lagrange multipliers: Part I. Operations Research, 21(5), 1114–1127.
Fisher, M. L. (1976). A dual algorithm for the one-machine scheduling problem. Mathematical Programming, 11(1), 229–251.
Fisher, M. L. (1981). The Lagrangian relaxation method for solving integer programming problems. Management Science, 27(1), 1–18.
Fisher, M. L. (1985). An applications oriented guide to Lagrangian relaxation. Interfaces, 15(2), 10–21.
Fisher, M. L., & Shapiro, J. F. (1974). Constructive duality in integer programming. SIAM Journal on Applied Mathematics, 27(1), 31–52.
Gasse, M., Bowly, S., Cappart, Q., Charfreitag, J., Charlin, L., Chételat, D., Chmiela, A., Dumouchelle, J., Gleixner, A., Kazachkov, A. M., et al. (2022). The machine learning for combinatorial optimization competition (ML4CO): Results and insights. In NeurIPS 2021 competitions and demonstrations track (pp. 220–231). PMLR.
Gaul, D., Klamroth, K., & Stiglmayr, M. (2022). Event-based MILP models for ridepooling applications. European Journal of Operational Research, 301(3), 1048–1063.
Geoffrion, A. (1974). Lagrangian relaxation for integer programming. Mathematical Programming Study, 2, 82–114.
Gkiotsalitis, K., Iliopoulou, C., & Kepaptsoglou, K. (2023). An exact approach for the multi-depot electric bus scheduling problem with time windows. European Journal of Operational Research, 306(1), 189–206.
Goffin, J.-L. (1977). On convergence rates of subgradient optimization methods. Mathematical Programming, 13(1), 329–347.
Goffin, J.-L., & Kiwiel, K. C. (1999). Convergence of a simple subgradient level method. Mathematical Programming, 85(1), 207–211.
Guan, X., Luh, P. B., & Zhang, L. (1995). Nonlinear approximation method in Lagrangian relaxation-based algorithms for hydrothermal scheduling. IEEE Transactions on Power Systems, 10(2), 772–778.
Hamdan, B., & Diabat, A. (2020). Robust design of blood supply chains under risk of disruptions using Lagrangian relaxation. Transportation Research Part E: Logistics and Transportation Review, 134, 101764.
Held, M., & Karp, R. M. (1970). The traveling-salesman problem and minimum spanning trees. Operations Research, 18(6), 1138–1162.
Held, M., & Karp, R. M. (1971). The traveling-salesman problem and minimum spanning trees: Part II. Mathematical Programming, 1(1), 6–25.
Hong, I.-H., Chou, C.-C., & Lee, P.-K. (2019). Admission control in queue-time loop production-mixed integer programming with Lagrangian relaxation (MIPLAR). Computers and Industrial Engineering, 129, 417–425.
Huang, T., Koenig, S., & Dilkina, B. (2021). Learning to resolve conflicts for multi-agent path finding with conflict-based search. Proceedings of the AAAI Conference on Artificial Intelligence, 35(13), 11246–11253.
Huang, K.-L., Yang, C.-L., & Kuo, C.-M. (2020). Plant factory crop scheduling considering volume, yield changes and multi-period harvests using Lagrangian relaxation. Biosystems Engineering, 200, 328–337.
Hu, S., Dessouky, M. M., Uhan, N. A., & Vayanos, P. (2021). Cost-sharing mechanism design for ride-sharing. Transportation Research Part B: Methodological, 150, 410–434.
Kamyabniya, A., Noormohammadzadeh, Z., Sauré, A., & Patrick, J. (2021). A robust integrated logistics model for age-based multi-group platelets in disaster relief operations. Transportation Research Part E: Logistics and Transportation Review, 152, 102371.
Kaskavelis, C. A., & Caramanis, M. C. (1998). Efficient Lagrangian relaxation algorithms for industry size job-shop scheduling problems. IIE Transactions, 30(11), 1085–1097.
Kaya, Y. B., Maass, K. L., Dimas, G. L., Konrad, R., Trapp, A. C., & Dank, M. (2022). Improving access to housing and supportive services for runaway and homeless youth: Reducing vulnerability to human trafficking in New York City. IISE Transactions, 1–15.
Kayvanfar, V., Akbari Jokar, M. R., Rafiee, M., Sheikh, S., & Iranzad, R. (2021). A new model for operating room scheduling with elective patient strategy. INFOR: Information Systems and Operational Research, 59(2), 309–332.
Kim, K., Botterud, A., & Qiu, F. (2018). Temporal decomposition for improved unit commitment in power system production cost modeling. IEEE Transactions on Power Systems, 33(5), 5276–5287.
Lee, Y.-C., Chen, Y.-S., & Chen, A. Y. (2022). Lagrangian dual decomposition for the ambulance relocation and routing considering stochastic demand with the truncated poisson. Transportation Research Part B: Methodological, 157, 1–23.
Liu, A., Luh, P. B., Yan, B., & Bragin, M. A. (2021). A novel integer linear programming formulation for job-shop scheduling problems. IEEE Robotics and Automation Letters, 6(3), 5937–5944.
Li, X., & Zhai, Q. (2019). Multi-stage robust transmission constrained unit commitment: A decomposition framework with implicit decision rules. International Journal of Electrical Power and Energy Systems, 108, 372–381.
Li, X., Zhai, Q., & Guan, X. (2020). Robust transmission constrained unit commitment: A column merging method. IET Generation, Transmission and Distribution, 14(15), 2968–2975.
Morin, M., Abi-Zeid, I., & Quimper, C.-G. (2023). Ant colony optimization for path planning in search and rescue operations. European Journal of Operational Research, 305(1), 53–63.
Morshedlou, N., Barker, K., González, A. D., & Ermagun, A. (2021). A heuristic approach to an interdependent restoration planning and crew routing problem. Computers and Industrial Engineering, 161, 107626.
Muckstadt, J. A., & Koenig, S. A. (1977). An application of Lagrangian relaxation to scheduling in power-generation systems. Operations Research, 25(3), 387–403.
Nedic, A., & Bertsekas, D. P. (2001). Incremental subgradient methods for nondifferentiable optimization. SIAM Journal on Optimization, 12(1), 109–138.
Nourmohammadi, A., Fathi, M., & Ng, A. H. (2022). Balancing and scheduling assembly lines with human-robot collaboration tasks. Computers and Operations Research, 140, 105674.
Öztop, H., Tasgetiren, M. F., Kandiller, L., & Pan, Q.-K. (2022). Metaheuristics with restart and learning mechanisms for the no-idle flowshop scheduling problem with makespan criterion. Computers and Operations Research, 138, 105616.
Polyak, B. T. (1967). A general method for solving extremal problems. Doklady Akademii Nauk, 174(1), 33–36.
Polyak, B. T. (1969). Minimization of unsmooth functionals. USSR Computational Mathematics and Mathematical Physics, 9(3), 14–29.
Prabhu, V. G., Taaffe, K., Pirrallo, R., Jackson, W., & Ramsay, M. (2021). Physician shift scheduling to improve patient safety and patient flow in the emergency department. In 2021 Winter simulation conference (WSC) (pp. 1–12). IEEE.
Reddy, K. N., Kumar, A., Choudhary, A., & Cheng, T. E. (2022). Multi-period green reverse logistics network design: An improved benders-decomposition-based heuristic approach. European Journal of Operational Research, 303(2), 735–752.
Schmidt, A., & Albert, L. A. (2023). The drop box location problem. IISE Transactions, 1–24 (just-accepted).
Shapiro, J. F. (1971). Generalized Lagrange multipliers in integer programming. Operations Research, 19(1), 68–76.
Shehadeh, K. S., Cohn, A. E., & Jiang, R. (2020). A distributionally robust optimization approach for outpatient colonoscopy scheduling. European Journal of Operational Research, 283(2), 549–561.
Shehadeh, K. S., & Tucker, E. L. (2022). Stochastic optimization models for location and inventory prepositioning of disaster relief supplies. Transportation Research Part C: Emerging Technologies, 144, 103871.
Shepardson, F., & Marsten, R. E. (1980). A Lagrangean relaxation algorithm for the two duty period scheduling problem. Management Science, 26(3), 274–281.
Smalley, H. K., Keskinocak, P., Swann, J., & Hinman, A. (2015). Optimized oral cholera vaccine distribution strategies to minimize disease incidence: A mixed integer programming model and analysis of a Bangladesh scenario. Vaccine, 33(46), 6218–6223.
Soni, A., Linderoth, J., Luedtke, J., & Rigterink, F. (2021). Mixed-integer linear programming for scheduling unconventional oil field development. Optimization and Engineering, 22(3), 1459–1489.
Tsang, M. Y., & Shehadeh, K. S. (2023). Stochastic optimization models for a home service routing and appointment scheduling problem with random travel and service times. European Journal of Operational Research, 307(1), 48–63.
van Ackooij, W., d’Ambrosio, C., Thomopulos, D., & Trindade, R. S. (2021). Decomposition and shortest path problem formulation for solving the hydro unit commitment and scheduling in a hydro valley. European Journal of Operational Research, 291(3), 935–943.
Velloso, A., Van Hentenryck, P., & Johnson, E. S. (2021). An exact and scalable problem decomposition for security-constrained optimal power flow. Electric Power Systems Research, 195, 106677.
Yalaoui, F., & Nguyen, N. Q. (2021). Identical machine scheduling problem with sequence-dependent setup times: MILP formulations computational study. American Journal of Operations Research, 11(1), 15–34.
Zhao, X., & Luh, P. (2002). New bundle methods for solving Lagrangian relaxation dual problems. Journal of Optimization Theory and Applications, 113(2), 373–397.
Zhao, X., Luh, P. B., & Wang, J. (1999). Surrogate gradient algorithm for Lagrangian relaxation. Journal of Optimization Theory and Applications, 100(3), 699–712.
Zhu, S. X., & Ursavas, E. (2018). Design and analysis of a satellite network with direct delivery in the pharmaceutical industry. Transportation Research Part E: Logistics and Transportation Review, 116, 190–207.
Acknowledgements
This work was supported in part by the U.S. National Science Foundation under Grant ECCS-1810108.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bragin, M.A. Survey on Lagrangian relaxation for MILP: importance, challenges, historical review, recent advancements, and opportunities. Ann Oper Res 333, 29–45 (2024). https://doi.org/10.1007/s10479-023-05499-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-023-05499-9