
Abstract
Cough is the most common symptom of several respiratory diseases. It is a defense mechanism of the body to clear the respiratory tract from foreign materials inhaled accidentally or produced internally by infections. The identification of wet and dry cough is an important clinical finding, aiding in the differential diagnosis especially in children. Wet coughs are more likely to be associated with lower respiratory track bacterial infections. At present during a typical consultation session, the wet/dry decision is based on the subjective judgment of a physician. It is not available for the non-trained person, long term monitoring or in the assessment of treatment efficacy. In this paper we address these issues and develop an automated technology to classify cough into ‘wet’ and ‘dry’ categories. We propose novel features and a Logistic regression model (LRM) for the classification of coughs into wet/dry classes. The performance of the method was evaluated on a clinical database of pediatric coughs (C = 536) recorded using a bed-side non-contact microphone from N = 78 patients. Results of the automatic classification were compared against two expert human scorers. The sensitivity and specificity of the LRM in picking wet coughs were between 87 and 88% with 95% confidence interval on training/validation dataset (310 cough events from 60 patients) and 84 and 76% respectively on prospective dataset (117 cough events from 18 patients). The kappa agreement with two expert human scorers on prospective dataset was 0.51. These results indicate the potential of the method as a useful clinical tool for cough monitoring, especially at home settings.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Cough is a common and one of the earliest symptoms in a range of respiratory diseases such as bronchitis, pneumonia, asthma and pertussis. It is a natural protective mechanism that helps clearing the secretions from the respiratory tract and prevents entering of noxious particles into the respiratory system. It is generally defined as the sudden expulsion of air accompanied with a “typical sound.”10 The prevalence of cough in communities in Europe and USA varies between 9–33%6 and likely higher in the developing world. Even though cough is common in respiratory diseases and considered an importance clinical symptom, there is no objective gold standard to assess cough quality. Subjective assessment of dry and wetness of the cough sounds is the reference method used by clinicians around the globe.3,19 Cough carries vital information on the state of the airway,17 but the field of cough analysis is in its infancy.
Based on the perception of presence of sounds related to secretions in the airways, cough is classified into the two categories ‘wet cough’ and ‘dry cough.’ Depending on its acoustic quality cough is characterized as wet when the sounds carry features indicative of mucus; in the absence of perceivable wetness they are called dry. This is essentially a subjective process. Medically there are different reasons for the wet and dry coughs and their identification aids in the differential diagnosis of diseases such as bronchiectasis, asthma, chronic bronchitis and bronchiolitis.3 Often, the dry-wet classification is used in epidemiological studies21,22 and clinical research.3,26 In children, wet cough is generally associated with lower respiratory tract infections.26 Diseases such as asthma and post-infections can cause dry cough. In some conditions the presence of dry cough as perceived by a clinician indicates early stage of the disease, which may later become wet cough with the progression of the disease leading to more secretions in airway.
In the current clinical practice cough quality is generally evaluated by asking the patients or patients’ caregivers during a clinical assessment. In cases when medical condition of patient allow, clinicians assess cough quality by listening while patient cough voluntarily. However while doing so significant temporal information about the frequency of coughs and variation in wetness of the cough is lost, which may be useful both for making a differential diagnosis and assessing the efficacy of the treatment. In addition to this, the manual evaluation of wetness of a cough is a subjective process and the outcome depends on the experience of clinicians.9,19 The process also suffers from the difficulties for humans to discern, via coughs, low-levels of mucus in airways; even trained clinicians underscore wet coughs as confirmed by bronchoscopic findings.3
Researchers have rarely attempted to develop technology for the automated, objective classification of cough into dry-wet categories. To the best of our knowledge, only two prior works exist in this area.5,14 Murata et al. 14 argued that cough sound frequencies can be used to discriminate between wet and dry coughs. Chatrzarrin et al. 5 proposed peaks of the energy envelop and spectral features of the cough sounds for the same purpose. These studies opened up a new branch of research in respiratory sound analysis. However they have been limited to a descriptive study of some characteristic features of coughs. No definitive classification algorithm or results were presented for wet/dry differentiation. The amount of data analyzed was fairly limited, 30 cough samples from 10 subjects (5 healthy and 5 bronchitis patients) in Murata et al. 14 and a total of 16 coughs in Chatrzarrin et al.,5 making the interpretation of the results difficult.
All existing work used cough sounds from adult subjects only and techniques used duration, magnitude and frequency features to characterize cough into dry/wet categories. Cough in adults are different in many ways; while wet cough is the term used in children, that used in adult is productive cough as adults are able to expectorate airway secretions. Further the same amount of secretions in a large airway (i.e., in adults) would biologically produce a different sound in a small airway (i.e., in children). Further production of cough sound is a complex physiological process involving several anatomical structures in the lower and upper respiratory system. Its acoustic properties vary significantly17 with the individual differences, age, gender and also depends heavily on the state of the airways.10 In diseases cough sound characteristics may change, making it necessary to develop robust methods to identify dryness/wetness. Intensity and duration dependent methods will not be sufficient to capture the rich information hidden in cough sounds.
Cough can be a symptom of serious diseases such as childhood pneumonia which kills over 1 million23 children in the world. The clinical community recognizes the important of cough in assessing the health of children. However, researchers have rarely attempted to develop objective, automated cough analysis systems for children. In particular, no prior work exists in the area of wet/dry classification. Cough assessment technology developed for adults cannot be extrapolated for children.2 There is an urgent need for developing automated objective cough assessment method for children.
In this paper we addresses these issues and propose an automated objective classification model to categorize cough sounds into wet and dry class. Method uses 1st, 2nd and 3rd order statistical features (e.g., formant frequencies, mel-cepstrum, non-Gaussianity, and bispectrum etc.) of the cough sounds. Model is trained and tested on a comprehensive database of 536 coughs from 78 subjects (41 male, 37 female) with age range of 1 month to 15 years. The subjects included in the study have a range of respiratory illnesses such as asthma, pneumonia, bronchitis and rhino-pharyngitis etc.
Materials and Methods
Figure 1 shows the block diagram of the automated cough classification algorithm proposed in this paper. It is divided into four stages, (A) data acquisition process (B) creating a cough sound database and classification into wet/dry classes by expert scorer (C) designing of automatic classifier (D) testing of classifier on prospective cough sound dataset. In section “Data acquisition” to section “Testing of selected LRM ℜ” we describe details of the method.

Block diagram for the proposed method for the wet/dry cough sound classification
Data Acquisition
The clinical data acquisition environment for this work is Respiratory Medicine Unit of the Sardjito Hospital, Gadjah Mada University, Indonesia. Table 1 lists the inclusion and exclusion criteria of subjects. All patients fulfilling the inclusion criteria were approached. An informed consent was made using form approved by the human ethics committees of Gadjah Mada University and The University of Queensland. Patients were recruited within the first 12 h of their admission. After the initial medical assessment sound recordings were made for next 4–6 h in the natural environment of the respiratory ward.
Sound recordings were made using two systems,
-
(i)
Computerized data acquisition system: A high fidelity system with a professional quality pre-amplifier and A/D converter unit (Model Mobile-Pre USB, M-Audio, California, USA) and a matched pair of low-noise microphones having a hypercardiod beam pattern (Model NT3, RODE, Sydney, Australia). Adobe audition software version 2 was used to record the sound data on to the laptop computer.
-
(ii)
Portable recording system: A high-end, light-weight portable, 2-AA battery powered audio recorder (Olympus LS-11) with two precision condenser microphones.
In both sound recording systems we used a sampling rate of 44.1 kHz with a 16 bit resolution (CD-quality recording). The nominal distance from the microphone to the mouth of the patient was 50 cm, but could vary from 40 to 70 cm due to patient movements. For each patient, we also received the final diagnosis as well as all the laboratory and clinical examination results.
Cough Sound Dataset and Classification into Wet or Dry by Expert Human Scorers
Let N be the number of patients whose sound recording is used in this paper and C be total number of cough events from N patients. These C cough events were manually segmented after screening though 6–8 h of the sound data of each patient. There is no accepted method for automatic marking of start and end of a cough event. Manual marking is still considered the gold standard. After careful listening start and end of all cough events were manually marked.
We divided N patients with C cough events into two datasets, (i) DS1 (model design dataset) and (ii) DS2 (prospective study dataset). The patients were divided into DS1 and DS2 based on the order of presentation to the respiratory clinic of the hospital. Patients in datasets DS1 and DS2 were mutually exclusive.
-
(i)
DS1—consisted of C1 cough events from N1 patients. Cough events from this dataset were used to design the optimal model.
-
(ii)
DS2—consisted of C2 cough events from N2 patients. Cough events from this dataset were used to test the designed model. Cough events from DS2 were blind to the process of model design.
Two expert scorers having experience of 15–20 years in pediatric respiratory diseases then scored cough events from two datasets into two classes, wet or dry. Scorers were blinded to the subject’s history and diagnosis. This manual classification is considered as the reference standard against which results of automatic classification are compared.
Design of Cough Sound Classifier
To design a system for automatic classification of cough sounds we used cough events from DS1. Let DS11 be the subset of DS1 containing those cough events on which both scorers agreed on the class of cough sounds. We had C11 cough events in DS11. Use cough events in DS11 to design automatic classifier model. This is a three step process.
[Step 1] Cough Event Feature Matrix Computation
In this step, feature vector containing ‘F’ mathematical features is computed from each of C11 cough events and a cough event feature matrix ‘MDS11’ of size, C11 × F was formed. To compute ‘F’ features from a cough event use below steps.
-
(i)
Let x denotes a discrete time sound signal from a cough event.
-
(ii)
Normalize x by dividing it by absolute maximum value.
-
(iii)
Segment x into ‘n’ equal size non-overlapping sub-segments. Let x i represents the ith sub-segment of x, where i = 1, 2, 3,…, n.
-
(iv)
Compute following features for each sub-segment and form feature vector containing F features: Bispectrum Score (BGS), Non-gaussianity score (NGS), formant frequencies (FF), Pitch (P), log energy (LogE), zero crossing (ZCR), kurtosis (Kurt), and twelve mel-frequency cepstral coefficients (MFCC). Please see “Appendix 1” for a detailed explanation of these features.
-
(v)
Repeat steps (i)–(iii) for all C11 cough events and form cough event feature matrix MDS11 of size C11 × F.
[Step 2] Automatic Classifier Design
In this paper we used a Logistic-regression model (LRM) as the pattern classifier. LRM is a generalized linear model, which uses several independent predictors to estimate the probability of a categorical event (dependent variable). In this work, the dependent variable Y is assumed to be equal to “one” (Y = 1) for wet cough and “zero” (Y = 0) for dry cough. A model is derived using regression function to estimate the probability Y = 1 (i.e., cough event belong to category of ‘wet cough’) given the independent variables (i.e., F features) as follows:
In Eqs. (1) and (2) f 1, f 2,…f F are the elements of feature vector (independent variables), β 0 is called the intercept and β 1, β 2 and so on are called the regression coefficient of independent variables. To select the optimal decision threshold λ from Y (that the cough is wet if Y is above λ otherwise dry) we used the Receiver-Operating Curve (ROC) analysis.
Use data in matrix MDS11 (C11 observations from F independent variables) and adopt leave-1-out cross validation (LOV) technique for LRM design. As the name suggests, LOV technique involves using data from all cough events except one to train the model and one cough event to validate the model. This process was systematically repeated C11 times such that each cough event in DS11 was used as the validation data once. This resulted in L C11 number of LRMs.
To evaluate the performance of the designed L C11, performance measures such as Sensitivity, Specificity, Accuracy, Positive Predicted Value (PPV), Negative Predicted Value (NPV), Cohen’s Kappa (K) statistic were computed. Please see “Appendix 2” on how to interpret K values.
Design logistic regression model (LRM) for
-
(i)
Feature Selection: Feature selection is a technique of selecting a sub-set of relevant features for building a robust learning model. Theoretically, optimal feature selection requires exhaustive search of all possible subsets of features. However, to do so for large number of features it will be computationally intensive and impractical. Therefore we searched for satisfactory set of features using p value. In LRM design a p value is computed for each feature and it indicates how significantly that feature contributed in development of the model. Important features have low p value. We used this property of LRM to select a reasonable combination of features (independent variables with low p value) that facilitate the classification, in the model during the training phase. Compute mean p value for ‘F’ features over L C11 LRMs. Select the features with mean p value less than p ths. Let F s be the sub-set of selected features from F.
-
(ii)
Robust LRM design Create a matrix: M′DS11 of size C11 × F s from MDS11. Matrix M′DS11 is a cough event feature matrix with only selected features F s from C11 cough events in DS11. Using M′DS11 and adopting LOV, retrain C11 LRMs.
[Step 3] Selecting a Good Model from L C11 LRMs
From L C11 LRMs we selected one model as the best, using the k-mean clustering algorithm8 to test on prospective study dataset DS2. In the k-mean clustering algorithm, target is to divide q data points in d-dimensional space into k clusters, so that within the cluster sum of squared distance from the centroid is minimized.
Problem in our hand is to select a good model from the L C11 models available to us. To do so we divided L C11 models in d-dimensional space into k = 2 clusters, i.e., high performance model cluster and low-performance model cluster. We set space dimension d equal to model parameters plus three performance measures (sensitivity, specificity and kappa). Then from the cluster of the high performance models, we selected that model which had the lowest mean square error value with respect to the centroid. Let ℜ represent the selected LRM and λ ℜ is the corresponding probability decision threshold (value determined using ROC curves such that the classifier performance is maximized). Once ℜ is chosen, we fix all the parameters of the model and use it for classifying cough sounds in the prospective dataset DS2.
Testing of Selected LRM ℜ
Following the procedure described in section “Design of cough sound classifier” [Step 1] and using the cough events from dataset DS2, compute the cough event feature matrix MDS2 of size C2 × F. C2 is total cough events in DS2 and ‘F’ is feature vector. Form M′DS2 from MDS2 by selecting only robust F s features. Use selected LRM ℜ to classify data in M′DS2 into classes wet or dry. Decision process of wet/dry class from the output of ℜ is as follows:
Let the output of the ℜ to a given cough input is Y ℜ. Then, the cough is classified as wet if Y ℜ ≥ λ ℜ and dry otherwise.
Compare the results of automatic classification by ℜ with that of expert scorers and compute the performance measures described in section “Design of cough sound classifier” [Step 2]. All the algorithms were developed using software programming language MATLAB version 7.14.0.739 (R2012a).
Results
Cough Sound Datasets and Agreement Between Expert Scorers
In this paper we used sound recording data from N = 78 patients (41 were male and 37 were female). The mean age of the subjects was 2 years and 11 month. The age range of the subjects varied from 1 month to 15 years and having diseases such as asthma, pneumonia, bronchitis and rhinopharyngitis. Table 2 gives the demographic and clinical details of the patients.
From N = 78 patients a total of C = 536 cough events were analyzed. On the average 7 cough events per patients were analyzed (minimum = 2 and maximum = 13). Dataset DS1 has C1 = 385 cough events from N1 = 60 patients and dataset DS2 has C2 = 151 cough events from N2 = 18 patients.
Table 3 shows the contingency table between two scorers in classifying cough sounds from DS1 and DS2, into two classes wet and dry. In DS1 out of 385 cough events, scorers agreed C11 = 310 times (80.5%) on the classes of cough events which were used to form subset DS11. In dataset DS2 they agreed 117 times out of 151 (77.5%). The kappa agreement between Scorer 1 and Scorer 2 is 0.55 for DS1 and 0.54 for DS2. Of the 310 cough events in DS11, 82 belonged to wet class and 228 belonged to dry class. The DS11 cough events were then used to design LRM models described in section “Design of cough sound classifier”.
Cough Sound Characteristics in Our Databases
The mean duration of dry cough in DS11 was 260 ± 77 ms (computed using 228 dry coughs) and that of wet cough was 238 ± 54 ms (computed using 82 wet coughs). Figure 2 shows a typical example of dry cough waveform and wet cough waveform from two patients, ids #35 & #38 respectively. The cough sound waveforms were generally clean with high signal-to-noise-ratio (SNR). The mean signal to noise ratio for the DS11 was 15.2 ± 5.5 db (maximum = 28.65 db and minimum = 2.9 db) and that for DS2 was 18.6 ± 4.5 db (maximum = 27.8 db and minimum = 11.1 db). Figure 3 shows the histogram of SNR for the cough sound in DS11 and DS2.

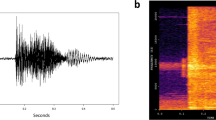
Typical example of dry cough waveform and wet cough waveform from two patients, ids #35 & #38 respectively in DS1. Start and end of each coughs were manually marked after listening by a single person, 1st author of the paper. We used n = 3 to divide each cough segment into 3 sub-segments

Histogram of signal-to-noise-ratio (SNR) for the cough sound in DS11 and DS2. The mean SNR for the cough sounds in DS11 was 15.2 ± 5.5 db (maximum = 28.65 db and minimum = 2.9 db) and that for DS2 was 18.6 ± 4.5 db (maximum = 27.8 db and minimum = 11.1 db)
Start and end of each coughs were carefully marked after listening to cough sounds as shown in the Fig. 2. All the markings were done by a single person, 1st author of the paper. Following the method given in section “Design of cough sound classifier” [Step 1] we computed feature matrix MDS11. We used n = 3 to divide each cough segment into 3 sub-segments. In the literature, clinicians and scientist alike have described cough sounds consisting of 3 phases, (i) initial opening burst, (ii) followed by noisy airflow and last Eq. (3) glottal closure.24,25 It has been shown that these phases carry different significant information specific to quality of cough, wet or dry. On this basis we divided each cough segments into 3 sub-segments. Setting n = 3 led to a feature vector F of length 66 consisting of following features (n × 12 MFCC) + (n × 4 FF) + (n × [BGS, NGS, P, LogE, Zcr, Kurt]). From C11 = 310 cough events and F = 66 features, cough event feature matrix MDS11 was created.
Automatic Classification using LRM
Feature Matrix and LRM Performance During Training Stage
Following LOV technique, L C11 = 310 LRMs were designed. The mean training sensitivity and specificity for the 310 LRMs were 92 ± 1% and 93 ± 0.5% respectively. Validation sensitivity and specificity for these models were 62 and 84% respectively. Table 4(A) gives the detailed classification results when all the F = 66 features were used to train the LRMs.
Following the process described in section "Design of cough sound classifier" [Step 2] and using p ths = 0.06, we selected F s = 31 features. Figure 4 shows the mean ‘p value’ associated with F = 66 features computed over C11 = 310 LRMs. All the features which have mean ‘p value’ less than p ths = 0.06 were selected. The selected features were 1 each from Bispectrum score, kurtosis, and number of zero-crossing, 2 each from non-gaussianity score and log-energy, 5 from formant frequencies, and 19 from mel-frequency cepstral coefficients. Table 5 gives details of the feature selected for designing the final LRM. According to this table MFCC based features were most dominant. Out of 31 selected features, 19 features were contributed from different MFCC components. After MFCC formant frequencies made second most dominant contribution with 5 features. Moreover except for 4th formant frequency and pitch based features, which were completely omitted, all other features contributed with features from at-least one sub-segment towards building of final LRM model.

Mean ‘p value’ and standard deviation as error bar, associated with F = 66 features computed over 310 trained LRMs. ‘p value’ indicates associated significance level of a feature in developing the model
When only selected features F s were used to re-train LRMs, mean training sensitivity and specificity were recorded as 87 ± 1% and 88 ± 0.5% respectively and validation sensitivity and specificity were 81 and 83%. The validation kappa agreement between the LRM and scorers was 0.46 when all the features were used to train LRM and it increased to 0.58 when only selected features were used. Table 4(B) gives the detailed training and validation results after feature selection.
Selection of LRM (ℜ)
From L C11 = 310 designed LRMs using data from DS11, optimal model ℜ was selected using k-mean clustering method as discussed in section “Design of cough sound classifier” [Step 3]. Models were clustered into two groups, high performance model and low performance models based on model parameters and performance measures. Of 310 models, 202 were clustered in high performance model group and 108 into low performance model group. LRM model #26 has the lowest mean square error value with respect to centroid of the high performance models. This model ℜ was chosen and all its parameters were fixed for future use. ℜ was tested on prospective dataset DS2.
Performance of ℜ on Prospective Dataset DS2
Table 6 gives the classification results of ℜ against expert scorers. When Scorer 1, wet/dry classification was used as reference standard, ℜ has the sensitivity of 77.5%, specificity of 76% and kappa agreement of 0.47. For the Scorer 2, results were sensitivity 75%, specificity 64% and kappa 0.31. When model ℜ was tested on only those events, in which Scorer 1 and Scorer 2 agreed on classification (117 cough events), sensitivity jumped to 84% and kappa value to 0.51. Table 7 shows the contingency table.
LRM Results When Matched for Age and Gender
Table 8 shows the performance of the LRM on DS11 and DS2 when matched for age and gender. Due to limited availability of data we considered only 4 divisions; (i) male with age ≤60 months, (ii) female with age ≤60 months, (iii) male with age >60 months and (iv) female with age >60 months. According to this table during the model designing stage, generally no significance difference was seen in the model validation performance across four divisions in comparison to when no division was considered, Tables 4 and 8(A). Similar to this on the prospective dataset DS2, selected model ℜ performed well across all division (Tables 6, 8(B)), except in the 3rd division (male with age >60) where performance were very poor.
Discussion
In this paper we proposed an automated, objective method to classify cough sounds into wet and dry categories. As far as we know, this is the first attempt to develop objective technology for the dry/wet classification of pediatric cough sounds, espcially in diseases such as pneumonia. Our work is also unique for the reason that we proposed and validated methods to classify a given cough event into dry/wet groups in contrast to existing work,5,14 which are limited to qualitaively describing chracteristics of cough events pre-classified by a human observer. The results presented in this paper are based on 536 cough events from 78 subjects, compared to existing work which use no more than 30 coughs in their descriptive analyses. For these reasons we do not have any other work to directly compare our results against.
The reference method used for the assessment of our technology is the subjective classification of cough sounds into wet/dry classes by two pediatric respiratory physicians from different countries. These scorers were blinded to the actual clinical diagnosis of the subjects. In an event-by-event cough classification, the two experts agreed with each other at a Moderate Level (kappa value of κ = 0.54). In Chang et al.,3 inter-clinician agreement for wet/dry cough is reported as κ = 0.88. However it should be noted that, in Chang et al. 3 clinicians assessed wetness of cough at the patient level but not at individual cough level. When we computed the agreement between scorers at the patient level, the kappa value increased to κ = 0.66 (Substantial Agreement). These numbers further illustrate the subjective nature of dry/wet classification.
Our classifier technology was trained on coughs from the training set (set DS1) using only events where both scorers reached consensus. As the output of the training process we identified a good Logistic Regression Model (ℜ) and fixed its parameters. The model was then tested on the Prospective Set (Set DS2) in several different ways. The highest sensitivity and specificity (84 and 76%) of classification were achieved when we tested ℜ against consensus events within DS2. It is interesting to note that these numbers were consistently higher than what we got by testing against individual classification outcomes of each scorer.
Another salient feature of our method is that it has a high negative predictive value (NPV = 93%), when scorer consensus data is used as the ground truth. This means that if the model classifies a cough as non-wet (dry), it is most likely that the two expert scorers would independently reach the same conclusion. However, the positive predictive value of our method compared to human scorers is lower (PPV = 55%). Thus, a sizable fraction of coughs classified by the model as wet ends up being consensus-classified as dry by human scorers. This phenomenon appears to be explained by the results presented by Chang et al. 3 which found that expert human scorers underscore wet coughs. In Chang et al. 3 they systematically compared subjective dry/wet classifications of expert clinicians with bronchoscopic indications of airway mucus. They reported that clinician’s classification of dry cough do not necessarily indicate the absence of secretions. Certain situations in airways, for instance small amounts of secretions, may not be reflected in cough sounds at a sufficient magnitude to be detected by a human observer. One of the possible reasons for a lower PPV value found in our method can be this weakness in the gold standard, human scorers, used to generate our performance statistics. This hypothesis needs to be carefully validated against bronchoscopic findings in the future.
The ability to correctly detect airway mucus can be particularly important in the management of suppurative lung diseases.3,4 Cough is an early symptom of diseases such as pneumonia, bronchitis and bronchiolitis. The accurate assessment of this symptom is a crucial factor in diagnosing acute diseases or the monitoring of chronic symptoms and treatment efficacy. It is known that in children, wet coughs are more likely to be associated with lower respiratory tract infections.4 The subjective classification of wet coughs has low sensitivity as a method of detecting airway mucus, even in the hands of expert clinicians. Accurate, objective technology for the classification of dry/wet coughs is currently unavailable either at the commercial or research levels. To the best of our knowledge, this work is the first attempt in the world to develop such technology.
We present the first ever approach to automate dry-wet classification of coughs. The results presented in this paper can be improved by syetematically optimizing the parameters and fine tuning the training processes of our classifier. Our heuristic model selection process makes the reported results pessimistic estimates. We also believe that the feature set can be improved and the classification accuracy of the method can be further increased. However before an optimization attempt, issue we need to resolve is to improve the ‘gold standard’ used in the clinical diagnosis. A carefully controlled bronchoscopy study will be best suited as the gold standard. We recognize that the optimization work is needed before taking the technology to the clinical practice, but we consider this out of the scope of this paper due to reasons explained above.
Another possible limiting factor to this study is the biasedness of the cough sound database towards dry coughs; almost 70% cough sounds are dry as perceived by expert human scorers. However, with all these factors, our method can currently classify wet and dry coughs with high sensitivity (84%) and specificity (76%) and with a good agreement (κ = 0.51) with the expert human scorers.
The results presented in this paper used manual identification of cough segments from long sound recordings. Once the sounds were identified, the dry/wet classification was fully automated. We currently developing automated cough identification technique and the results will be published elsewhere.
Conclusion
Proposed method in this paper can classify the cough sounds into dry and wet classes with high accuracy and good agreement with pediatricians. This is the first known method for wet/dry classification, presented with complete training and testing results on significantly large cough samples. It is also the first effort to automate the wet/dry classification in pediatric population with range of respiratory infectious diseases. It carries the potential to develop as a useful clinical tool for long term cough monitoring and in the assessment of treatment efficacy or in characterizing the lower respiratory tract infections. It will be essentially useful in clinical or research studies where temporal patterns of cough quality (wet/dry) from hour to hour basis are needed.
The methods proposed in this paper should be available for simultaneous implementation with other potential technologies such as microwave imaging and ultrasound imaging that may be capable of detecting consolidations and mucus in lungs.
References
Abeyratne, U. R. Blind reconstruction of non-minimum-phase systems from 1-D oblique slices of bispectrum. In: IEE Proceedings of Vision, Image and Signal Processing. IET, 1999.
Chang, A. B. Pediatric cough: children are not miniature adults. Lung 188:33–40, 2010.
Chang, A. B., J. T. Gaffney, M. M. Eastburn, J. Faoagali, N. C. Cox, and I. B. Masters. Cough quality in children: a comparison of subjective versus bronchoscopic findings. Respir. Res. 6, 2005.
Chang, A., G. Redding, and M. Everard. Chronic wet cough: protracted bronchitis, chronic suppurative lung disease and bronchiectasis. Pediatr. Pulmonol. 43:519–531, 2008.
Chatrzarrin, H., A. Arcelus, R. Goubran, and F. Knoefel. Feature extraction for the differentiation of dry and wet cough sounds. In: IEEE International Workshop on Medical Measurements and Applications Proceedings (MeMeA), IEEE, 2011, pp. 162–166.
Chung, K. F., and I. D. Pavord. Prevalence, pathogenesis, and causes of chronic cough. Lancet 371:1364–1374, 2008.
Ghaemmaghami, H., U. Abeyratne, and C. Hukins. Normal probability testing of snore signals for diagnosis of obstructive sleep apnea. In: Engineering in Medicine and Biology Society, 2009. EMBC 2009. Annual International Conference of the IEEE, IEEE, 2009.
Hartigan, J. A., and M. A. Wong. Algorithm AS 136: a k-means clustering algorithm. Appl. Stat. 100–108, 1979.
Ishikawa, S., R. Kasparian, J. Blanco, D. Sotherland, R. Clubb, L. Kenny, J. Workowicz, and K. MacDonell. Observer variability in interpretation of voluntary cough of ‘bronchitics’ and ‘asthmatics’. In: ILSA Proceedings Paris, vol. 10, 1987.
Korpá, J., J. Sadloová, and M. Vrabec. Analysis of the cough sound: an overview. Pulm. Pharmacol. 9:261–268, 1996.
Lee, T., U. Abeyratne, K. Puvanendran, and K. Goh. Formant-structure and phase-coupling analysis of human snoring sounds for detection of obstructive sleep apnea. Comput. Methods Biomech. Biomed. Eng. 3, 2000.
Logan, B. Mel frequency cepstral coefficients for music modeling. In: International Symposium on Music Information Retrieval, 2000.
Mendel, J. M. Tutorial on higher-order statistics (spectra) in signal processing and system theory: theoretical results and some applications. Proc. IEEE 79:278–305, 1991.
Murata, A., Y. Taniguchi, Y. Hashimoto, K. Y., Y. Takasaki, and S. Kudoh. Discrimination of productive and non-productive cough by sound analysis. Intern. Med. 37:732–735, 1998.
Ng, A. K., T. S. Koh, E. Baey, T. H. Lee, U. R. Abeyratne, and K. Puvanendran. Could formant frequencies of snore signals be an alternative means for the diagnosis of obstructive sleep apnea? Sleep Med. 9:894–898, 2008.
Oppenheim, A. V., R. W. Schafer, and J. R. Buck. Discrete-Time Signal Processing, Vol. 1999. Englewood Cliffs, NJ: Prentice hall, 1989.
Piirilä, P., and A. Sovijärvi. Differences in acoustic and dynamic characteristics of spontaneous cough in pulmonary diseases. Chest 96:46–53, 1989.
Quatieri, T. F. Discrete-Time Speech Signal Processing: Principles and Practice. Pearson Education India, 2002.
Smith, J. A., H. L. Ashurst, S. Jack, A. A. Woodcock, and J. E. Earis. The description of cough sounds by healthcare professionals. Cough 2:1, 2006.
Sondhi, M. New methods of pitch extraction. IEEE Trans. Audio Electroacoust. 16:262–266, 1968.
Soto Quiros, M. E., M. Soto Martinez, and L. Å. Hanson. Epidemiological studies of the very high prevalence of asthma and related symptoms among school children in Costa Rica from 1989 to 1998. Pediatr. Allergy immunol. 13:342–349, 2002.
Spengler, J. D., J. J. K. Jaakkola, H. Parise, B. A. Katsnelson, L. I. Privalova, and A. A. Kosheleva. Housing characteristics and children’s respiratory health in the Russian Federation. J. Inf. 94, 2004.
The Global Burden of Disease 2004 Update. World Health Organization, 2008.
Thorpe, C., L. Toop, and K. Dawson. Towards a quantitative description of asthmatic cough sounds. Eur. Respir. J. 5:685–692, 1992.
Thorpe, W., M. Kurver, G. King, and C. Salome. Acoustic analysis of cough. In: Intelligent Information Systems Conference, the Seventh Australian and New Zealand 2001, IEEE, 2001.
Zgherea, D., S. Pagala, M. Mendiratta, M. G. Marcus, S. P. Shelov, and M. Kazachkov. Bronchoscopic findings in children with chronic wet cough. Pediatrics 129:e364–e369, 2012.
Zheng, F., G. Zhang, and Z. Song. Comparison of different implementations of MFCC. J. Comput. Sci. Technol. 16:582–589, 2001.
Author information
Authors and Affiliations
Corresponding author
Additional information
Associate Editor Zahra Moussavi oversaw the review of this article.
Appendices
Appendix 1: Computed Features
For each sub-segment x i following features computed.
-
a)
Bispectrum Score (BGS): The 3rd order spectrum of the signal is known as the bispectrum. Unlike the power spectrum (2nd order statistics) based on the autocorrelation, bispectrum preserves Fourier phase information. The bispectrum can be estimated via estimating the 3rd order cumulant and then taking a 2D-Fourier transform. The 3rd order cumulant C(τ 1,τ 2) was estimated using Eq. (3) as defined in Abeyratne.1 By applying a bispectrum window function (minimum bispectrum-bias supremum window described in Mendel13) to the cumulant estimate, windowed cumulant function \( C_{\text{w}}^{i} (\tau_{ 1} ,\tau_{ 2} ) \) was obtained.
In Eq. (3) Q is the length of the 3rd order correlation lags considered. We used Q as 5% of the length of cough sub-segment. The bispectrum B i(ω 1,ω 2) of the segment x i was estimated using Eq. (4). We used FFT length of 512 points.
In the frequency domain, a quantity P i(ω;ϕ,ρ) can be defined for the data segment x i such that
describing a one-dimensional slice inclined to the ω 1-axis at an angle tan−1 ϕ and shifted from the origin along the ω 2-axis by the amount ρ (−π < ρ < π).2 For this work we set ϕ = 1 and ρ = 0 so that the slice of the bispectrum considered is inclined to the ω 1-axis by 45° and passes through the origin. Then Bispectrum Score (BSG) is computed using Eq. (6). In Eq. (6) we used ω 1 = 90 Hz, ω 2 = 5 kHz, ω 3 = 6 kHz and ω 4 = 10.5 kHz.
-
b)
Non-Gaussianity Score (NGS):7 NGS gives the measure of non-gaussianity of a given segment of data. The normal probability plot can be utilized to obtain a visual measure of the gaussianity of a set of data. The NGS of the data segment x i can be calculated using Eq. (7). Note that in Eq. (7), p and q represents the normal probability plot of the reference normal data and the analyzed data, respectively, with j ranging from the values 1 − N.
-
c)
Formants frequencies: In human voice analysis formants frequencies (FF) are referred as the resonance of the human vocal tract. In cough analysis, it is reasonable to expect that the resonances of the overall airway that contribute to the generation of a cough sound will be represented in the formant structure; mucus can change acoustic properties of airways. We included 1st four FF (F1, F2, F3, F4) in our feature set. Past studies in the speech and acoustic analysis have shown that F1–F4 corresponds to various acoustic features of airway.11,15 We computed F1–F4 by peak picking the Linear Predictive Coding (LPC) spectrum of cough sounds. For this work we used 14th order LPC model with the parameters determined via the Levinson-Durbin recursive procedure.16
-
d)
Pitch: In speech analysis, pitch is defined as the fundamental frequency of the vocal cord.18 Several algorithms have been proposed in the literature to estimate the pitch of a voiced acoustic signal. In this paper we used classical method of ‘autocorrelation with center clipping’20 to compute the pitch of an cough sub-segment.
-
e)
Log Energy(LogE): The log energy for every sub-segment was computed using Eq. (8)
In Eq. (8) ε in (%) is and arbitrarily small positive constant added to prevent any inadvertent computation of the logarithm of 0.
-
f)
Zero crossing (Zcr): The number of zero crossings were counted for each x i sub-segments.
-
g)
Kurtosis (Kurt): The kurtosis is a measure of the peakedness associated with a probability distribution of segment x i, computed using Eq. (9). μ and σ is the mean and stand deviation of the segment x i respectively.
-
h)
Mel-frequency cepstral coefficients (MFCC): MFCCs are commonly used in the music and speech audio signal analysis.12,27 They represent the short term power spectrum of an acoustic signal based on a cosine transform of a log power spectrum on a non-linear mel-scale of frequency. We included the 12 MFCC coefficients in our feature set.
Appendix 2
Kappa statistic is widely used in situations where the agreement between two techniques should be compared. Below are the guidelines for interpreting the Kappa values.
Kappa | Interpretation |
|---|---|
<0 | Less than chance agreement |
0.01–0.20 | Slight agreement |
0.21–0.40 | Fair agreement |
0.41–0.60 | Moderate agreement |
0.61–0.80 | Substantial agreement |
0.81–1 | Almost perfect agreement |
Appendix 3
Definition of the statistical measures used to evaluate the performance of the LRM.
True Positive (TP)—Wet cough correctly identified as ‘WET’ by LRM.
False Positive (FP)—Dry cough incorrectly identified as ‘WET’ by LRM.
True Negative (TN)—Dry cough correctly identified as ‘DRY’ by LRM.
False Negative (FN)—Wet cough incorrectly identified as ‘DRY’ by LRM.
Rights and permissions
About this article
Cite this article
Swarnkar, V., Abeyratne, U.R., Chang, A.B. et al. Automatic Identification of Wet and Dry Cough in Pediatric Patients with Respiratory Diseases. Ann Biomed Eng 41, 1016–1028 (2013). https://doi.org/10.1007/s10439-013-0741-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10439-013-0741-6