
Abstract
In this paper, we analyze the network properties of the Italian e-MID data based on overnight loans during the period 1999–2010. We show that the networks appear to be random at the daily level, but contain significant non-random structure for longer aggregation periods. In this sense, the daily networks cannot be considered as being representative for the underlying ‘latent’ network. Rather, the development of various network statistics under time aggregation points toward strong non-random determinants of link formation. We also identify the global financial crisis as a significant structural break for many network measures.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction and existing literature
Interbank markets are crucial for the functioning of the economy. The exchange of money on a very short-term basis allows banks to manage liquidity risks, cf. Allen and Gale (2000). However, as painfully illustrated by the global financial crisis (GFC) in 2007/2008, creating links at the micro-level may generate systemic risk at the macro-level.Footnote 1 Thus, the interbank network, based on connections in terms of credit relationships, is a complete representation of the liquidity management decisions of financial institutions. Clearly, the structure of such a network is important for its stability. The economy depends on stable interbank markets, since short-term money market rates affect those of longer maturities and thus the real economy. From this viewpoint, it appears quite surprising that the economics profession has not been concerned much with the functioning of interbank markets until recently. The usual focus is on the overnight segment of the interbank deposit market, since it tends to be the largest spot segment of money markets. In this paper, we analyze the network properties of the Italian e-MID (electronic market for interbank deposits) data based on overnight loans during the period 1999–2010.
Most existing studies on the structure of interbank markets have been conducted by physicists trying to get an idea of the topology of the linkages between financial institutions. Examples include Boss et al. (2004) for the Austrian interbank market, Inaoka et al. (2004) for the Japanese BOJ-Net, Soramäki et al. (2007) for the US Fedwire network, Bech and Atalay (2010) for the US Federal funds market, and De Masi et al. (2006) and Iori et al. (2008) for the Italian e-MID (electronic market for interbank deposits). The most important findings reported in this literature are: (1) most interbank networks are quite large (e.g. more than 5,000 banks in the Fedwire network), (2) interbank networks are sparse, meaning that only a small fraction of all possible links do actually exist, (3) degree distributions appear to be scale-free (with coefficients between 2 and 3), (4) transaction volumes appear to follow scale-free distributions as well, (5) clustering coefficients are usually quite small, (6) interbank networks are small worlds and (7) the networks show disassortative mixing with respect to the bank size, so small banks tend to trade mainly with large banks and vice versa.
In this paper we also analyze the Italian interbank market. We should stress that the e-MID data are the only interbank data which can be purchased freely without any restrictions. In contrast, getting access to similar datasets for other markets is usually far more complicated. Most relevant for our study are the two previous papers on the e-MID. The authors analyze daily networks from 1999–2002, finding intradaily and intramonthly seasonalities. The most important conclusion is that the networks appear to be random at the daily level, in the sense that preferential lending is limited and money flows directly from the lender to the borrower without intermediaries. This finding stands in stark contrast to the findings of preferential lending relationships in the Portuguese interbank market by Cocco et al. (2009). In the present paper, we are mostly concerned with matching these seemingly incompatible findings, by showing that the aggregation period has an effect on the informational value of the underlying networks. The main result is that networks constructed from daily data indeed feature a substantial amount of randomness and cannot be considered as being representative for the underlying ‘latent’ network of linkages between banks. This is illustrated on the basis of a number of network statistics, which are compared to those of random networks. Furthermore, we find a substantial amount of asymmetry in the network. Last but not least, we find that the GFC can be identified as a significant structural break for many network measures. While our findings do not solve the issue of what could be the ‘optimal’ structure of the interbank network (whatever optimal means in this context), the analysis of the dependence of reconstructed networks on the time horizon is a first important step in understanding the structure and dynamics of the banking system. Equipped with this knowledge, we can hope to build more realistic models in the future, which could be used to provide policy recommendations for the optimal management of interbank networks.
The remainder of this paper is structured as follows: Sect. 2 gives a brief introduction into (interbank) networks, Sect. 3 introduces the Italian e-MID trading system and gives an overview of the data set we have access to. Section 4 describes our findings and Sect. 5 discusses the relevance of our network analysis for the management of liquidity by banks, and how the financial crisis has distorted the normal mode of operation of the money market. Section 6 concludes and proposes avenues for future research.
2 Networks
A network consists of a set of \(N\) nodes that are connected by \(M\) edges (links). Taking each bank as a node and the interbank positions between them as links, the interbank network can be represented as a square matrix of dimension \(N\times N\) (data matrix, denoted \(\mathbf{D }\)).Footnote 2 An element \(d_{ij}\) of this matrix represents a gross interbank claim, the total value of credit extended by bank \(i\) to bank \(j\) within a certain period. The size of \(d_{ij}\) can thus be seen as a measure of link intensity. Row (column) \(i\) shows bank \(i\)’s interbank claims (liabilities) towards all other banks. The diagonal elements \(d_{ii}\) are zero, since a bank will not trade with itself.Footnote 3 Off-diagonal elements are positive in the presence of a link and zero otherwise.
Interbank data usually give rise to directed, sparse and valued networks.Footnote 4 However, much of the extant network research ignores the last aspect by focusing on binary adjacency matrices only. An adjacency matrix \(\mathbf A \) contains elements \(a_{ij}\) equal to 1, if there is a directed link from bank \(i\) to \(j\) and 0 otherwise. Since the network is directed, both \(\mathbf A \) and \(\mathbf D \) are asymmetric in general. In this paper, we also take into account valued information by using both the raw data matrix as well as a matrix containing the number of trades between banks, denoted as \(\mathbf T \). In some cases it is also useful to work with the undirected version of the adjacency matrices, \(\mathbf{A }^u\), where \(a_{ij}^u=\max (a_{ij},a_{ji})\).
As usual, some data aggregation is necessary to represent the system as a network. In this paper we compare different aggregation periods.
3 The Italian interbank market e-MID
The Italian electronic market for interbank deposits (e-MID) is a screen-based platform for trading of unsecured money-market deposits in Euros, US-Dollars, Pound Sterling, and Zloty operating in Milan through e-MID SpA.Footnote 5 The market is fully centralized and very liquid; in 2006 e-MID accounted for 17 % of total turnover in the unsecured money market in the Euro area. Average daily trading volumes were 24.2 bn Euro in 2006, 22.4 bn Euro in 2007 and only 14 bn Euro in 2008. We should mention that researchers from the European Central Bank have repeatedly stated that the e-MID data is representative for the interbank overnight activity, cf. Beaupain and Durré (2012).
Available maturities range from overnight up to one year. Most of the transactions are overnight. While the fraction was roughly 80 % of all trades in 1999, this figure has been continuously increasing over time with a value of more than 90 % in 2010.Footnote 6 As of August 2011, e-MID had 192 members from EU countries and the US. Members were 29 central banks acting as market observers, one ministry of finance, 101 domestic banks and 61 international banks. We will see below that the composition of the active market participants has been changing substantially over time. Trades are bilateral and are executed within the limits of the credit lines agreed upon directly between participants. Contracts are automatically settled through the TARGET2 system.
The trading mechanism follows a quote-driven market and is similar to a limit-order-book in a stock market, but without consolidation. The market is transparent in the sense that the quoting banks’ IDs are visible to all other banks. Quotes contain the market side (buy or sell money), the volume, the interest rate and the maturity. Trades are registered when a bank (aggressor) actively chooses a quoted order. The platform allows for credit line checking before a transaction will be carried out, so trades have to be confirmed by both counterparties. The market also allows direct bilateral trades between counterparties.
The minimum quote size is 1.5 million Euros, whereas the minimum trade size is only 50,000 Euros. Thus, aggressors do not have to trade the entire amount quoted.Footnote 7 Additional participant requirements, for example a certain amount of total assets, may pose an upward bias on the size of the participating banks. In any case, e-MID covers essentially the entire domestic overnight deposit market in Italy.Footnote 8
We have access to all registered trades in Euro in the period from January 1999 to December 2010. For each trade we know the two banks’ ID numbers (not the names), their relative position (aggressor and quoter), the maturity and the transaction type (buy or sell). As mentioned above, the majority of trades is conducted overnight and due to the GFC markets for longer maturities essentially dried up. We will focus on all overnight trades conducted on the platform, leaving a total number of 1,317,679 trades. The vast majority of trades (1,215,759 in total) involved two Italian counterparties. The large sample size of 12 years allows us to analyze the network evolution over time. For example, at the quarterly level we end up with 48 snapshots of the network.
4 Results
In this section, we look at the network structures formed by interbank lending over various horizons of time aggregation of the underlying data. We will see that comparing various network measures at different levels of time aggregation reveals interesting features suggestive of underlying behavioral regularities. Given that most studies focus on overnight data, it has become quite standard to focus on networks constructed from daily data. Here we find that, at least for the Italian interbank network, it may be more sensible to focus on longer aggregation periods, namely monthly or quarterly data. We also discuss in how far the network structure has changed (and, in how far it has remained intact) after the default of Lehman Brothers in September 2008.
4.1 General features
In total, 350 banks (255 Italian and 95 foreign) were active at least once during the sample period. However, the number of active banks changes substantially over time as can be seen from the left panel of Fig. 1.Footnote 9 We see a clear downward trend in the number of active Italian banks over time, whereas the additional large drop after the onset of the GFC is mainly due to the exit of foreign banks. The center panel shows that the decline of the number of active Italian banks went along with a relatively constant trading volume in this segment until 2008. This suggests that the decline of the number of active Italian banks was mainly due to mergers and acquisitions within the Italian banking sector. Given the anonymity of the data set, it is impossible to shed more light on this interesting issue. The overall upward trend of trading volumes was due to the increase of the number of active foreign banks until 2008, while their activities in this market virtually faded away after the onset of the crisis. Interestingly, the average volume per trade tends to increase over time, as can be seen from the strong negative trend in the total number of trades (right panel in Fig. 1), at least for the Italian banks.

Number of active banks (left), traded volume (center) and number of trades (right) over time (quarterly). We also split the traded volume into money lent by Italian and foreign banks, respectively. The same holds for the number of trades
An interesting question in this regard is, who trades with whom. Figure 2 illustrates this for the number of trades (top) and the transacted volume (bottom) by country. For example, the green lines show the total number of trades (traded volumes) of foreign banks lending money to Italian banks, relative to all outgoing trades of foreign banks. Similarly, the blue lines show the total number of trades (traded volumes) of money flowing between Italian banks, as a fraction of all outgoing trades of Italian banks. The general patterns are the same for both Figures: Italian banks lend most of the time to other Italian banks (99.3 % on average) and only a negligible amount to foreign banks (0.7 % on average). This pattern is remarkably stable over time. In contrast, at the beginning of the sample period, foreign banks mostly used the market in the absence of (many) other foreign counterparties to lend money to Italian banks. This has changed over time and foreign banks later on mostly used the platform to trade with other foreign banks. It is not quite clear why this is the case, the underlying trend seems to point towards structural changes altering the (foreign) banks’ behavior. For many research questions, one should therefore only use the subsample of Italian banks. In most of what follows, we stick to this choice.

Fraction of trades (top) and traded volume (bottom) between banks from different countries
This leads us to a first glance at the network structure. Figure 3 shows the banking network formed by the 119 active banks (89 Italian) in the last quarter of 2010.Footnote 10 The network mainly consists of two components: The very dense part formed by the Italian banks (circles) on the right-hand side and the far less interconnected foreign banks (triangles) on the left-hand side. The higher activity of the Italian banks does not come along with a similarly higher trading volume. We use total outgoing volume as a proxy for banks’ size and group the banks into four classes according to which percentile (30th, 60th, 90th or above) they belong to. This attribute is shown in the Figure as the size and the brightness of the nodes. We should note that 3 out of 12 banks of group 4 are foreign banks which is in line with their fraction of the total banks (30 out of 119). Hence, foreign banks trade less on average (both in terms of volume and number of trades), however, the volume per trade is higher.

The banking network in the 4th of quarter 2010: triangles are foreign banks. The size of the node as well as the brightness of the red color indicate the size in terms of volume lent
It is also interesting to highlight some specific features of the trading behavior of individual banks in this particular quarter, since not all banks use the market in the same way:Footnote 11 There are 14 banks with zero in-degree and 29 banks with zero out-degree.Footnote 12 Surprisingly these banks are quite heterogeneous and not, as one might expect, just small banks. As an example the highest overall transaction volume of 58.6 bn Euro for a single bank, and therefore roughly 9.3 % of the total trading volume, was traded by a German bank borrowing this sum in 90 trades from 8 counterparties. Another interesting case is an Italian bank trading only with one counterparty, lending this other bank 5.02 billion Euro in 76 trades, whereas borrowing just 0.03 billion in 3 trades. Even though these special relationships are quite interesting, the anonymity of the data set makes it impossible for us to say more on the particular relationships that might lead to these interesting outcomes.
As should be clear from the discussion above, we will mostly focus on the (sub)network formed by Italian banks only. Table 1 summarizes, for this subset, some basic descriptive statistics for the four different aggregation periods under investigation to get a first impression of the influence of the aggregation level.Footnote 13 Note that the number of active banks, trading volume, trades and links has to increase with the aggregation period. The difference is, however, that volume and trades are simply multiples of the daily values, whereas the number of links grows at a much lower rate. This already indicates that banks prefer to trade with specific counterparties. The trades per link show that even on the daily level on average every fourth link already represents two trades rather than only a single one. After this broad overview of the market and the ongoing interactions, we turn to the question of a sensible aggregation period for the network.
4.2 Density
The density \(\rho \) of a network is defined as the number of existing links \((M)\) relative to the maximum possible number of links. It can be calculated as
Figure 4 illustrates the evolution of the density for four different aggregation periods (day, month, quarter, year) restricting attention to interbank credit between Italian banks. Except for the daily networks the density is quite stable over time and slightly increases until the GFC, which constitutes a significant structural break for the monthly and quarterly networks. We should note that the breakpoint (quarter 39), coincides with the quarter during which Lehman Brothers collapsed. The daily density fluctuates much more strongly, but overall increases throughout the sample.Footnote 14

The density for yearly (blue), quarterly (red), monthly (green) and daily (black) aggregated networks. A Chow-test and an additional CUSUM-test indicate a structural break for quarter 39 (month 117) at the 1 % significance level, but not for the yearly or daily networks
We should stress that, compared to the findings for other interbank networks, the density of the Italian interbank network is quite high. For example, Bech and Atalay (2010) and Soramäki et al. (2007) report an average density of below 1 % in daily interbank networks, compared to an average density of roughly 3.1 % for the daily e-MID networks. The main reasons for the higher density are most likely the relatively small number of participating banks in the market and the transparent market structure which easily allows each bank to trade with any other bank in the market. For comparison, the Fedwire network investigated by Soramäki et al. (2007) contains 5,086 institutions.Footnote 15 The means of 20.8 % for quarterly aggregated networks (13.4 % for monthly networks) reveal much higher densities for longer aggregation levels. Obviously the network density is positively related to the aggregation period, but to our knowledge the structure of this relation has not been investigated for interbank networks so far.
For this reason, we compare the aggregation properties of the empirical networks with those of random networks. Here we use Erdös-Renyi networks, i.e. completely random networks, and random scale-free networks, where the out-degrees follow a power-law distribution with scaling parameter 2.3.Footnote 16 The experiments work as follows: For each year, we aggregate the daily networks and plot the resulting density in dependence on the aggregation period, from one day up to one year (roughly 250 days). For the random networks, we aggregate artificial Erdös-Renyi and scale-free networks for each day with the same number of active banks and density as the observed daily network. The results are the average values for 100 runs for the Erdös-Renyi and the scale-free networks.Footnote 17
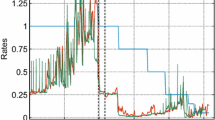
As an example, Fig. 5 illustrates the results for 1999, but we find very similar qualitative results for all 12 sample years. For all three networks, there appears to be a saturation level for the density, however at different levels. The Erdös-Renyi networks always show the highest density (up to 0.851), followed by the scale-free networks (up to 0.559) and the observed networks (only up to 0.280). Apparently, it is much more likely for the empirical data that the same link gets activated several times than for the randomized data of Erdös-Renyi and scale-free networks (although the overall number of links is the same by construction). This is supported by the fact that in the observed networks just 2,757 links are observed exactly once in this year, while for the scale-free and random networks these values are on average 5,040 and 5,746, respectively. Hence, these results indicate the existence of lasting (preferential) lending relationships in the actual banking network.

Data for 1999. Density for the aggregated Erdös-Reny (blue), Scale-Free (red) with \(\alpha =2.3\), and observed networks (green). Aggregation period in days. Note: we do not plot standard deviations, since these are negligible
4.3 What is a sensible aggregation period?
After showing that longer than daily aggregation tends to reveal non-random structures for the Italian banking network, we are concerned with determining the ‘correct’ aggregation period in more detail in this section. This question is crucial for extracting relevant information, since the banking network typically cannot be observed at a given point in time, but has to be approximated by aggregating trades over a certain period.Footnote 18 Most studies (including the present one) tend to analyze overnight loans only, in which case daily networks give an accurate picture of the actual linkages between financial institutions at a certain point in time. Most of the (apparently universal) properties of interbank networks, as mentioned in the literature overview, were derived based on such daily networks. From the perspective of a policymaker, real-time information on the structure of the interbank network is important as well, e.g. in order to assess the risk of systemic crises.
However, it should be clear that focusing on daily networks can also be potentially (dangerously) misleading, given that the low level of network connectivity suggests a negligible degree of systemic risk in general. Aggregating over a longer period is preferable, if it can reveal a non-random structure of the banking network. The existence of preferential relationships would imply that daily transactions are not determined myopically, but that a virtual network of longer lasting relationships exists. Daily transactions would then be akin to random draws from this underlying network with the realizations depending on current liquidity needs or liquidity overhang. Aggregation over a sufficiently long time horizon might reveal more and more of the hidden links, rather than adding up purely random draws from all possible links. Thus, for the purpose of identifying community structures and systemically important institutions, longer aggregation periods may be more sensible even if this comes at the cost of losing information.Footnote 19 Moreover, from an economic viewpoint, overnight loans can be seen as longer-term loans, where the lender can decide every day whether to prolong the loan or not. In this way, aggregating overnight credit relationships over longer frequencies could provide a more accurate picture of the interbank network.
In the following, we compare several statistical properties of the e-MID networks based on yearly, quarterly, monthly and daily aggregated networks. Table 1 briefly summarizes a number of summary statistics for the e-MID networks in dependence on the aggregation period. The use of a ‘sensible’ aggregation period should ensure that we extract stable features (if they exist) of the banking network rather than noisy trading patterns at different points in time. In this regard, it is important to investigate the stability of the link structure in order to assess whether subsequent occurrences of the network share many common links. In order to do this, we rely on the Jaccard Index (JI),Footnote 20 which can be used to quantify the similarity of two sample sets in general. Here it is defined as
where \(S_{xy}\) counts the number of relations having status \(a_{ij}=x\) at the first instance and \(a_{ij}=y\) at the second. The JI measures links which survive as a fraction of links which are established at any of the two points in time. Hence, it also takes into account those banks which are active in only one of the two periods.
Figure 6 shows that the JI is very stable over time for longer aggregation periods, but much less so for the daily level. As expected, the JI tends to be higher for longer aggregation intervals. The daily measures are much more unstable and increase substantially until the GFC. More problematic than the smaller average level are however the extreme outliers on the downside. An established rule-of-thumb in social network analysis is to consider networks with JI values above 0.3 as substantially stable.Footnote 21

Jaccard index for daily (black), monthly (green), quarterly (red) and yearly (blue) networks
Table 2 shows the mean, minimum, 10th percentile and standard deviation of the JIs for different aggregation periods. Again, the most evident observation is that the daily networks are rather special: the minimum and the 10th percentile of the JI are significantly smaller, indicating that we observe values below 0.2 in at least 10 % of the sample, which is not a rare event.Footnote 22 These results suggest a high degree of randomness in the daily networks.
Obviously, higher values of the JI are no guarantee that we are closer to the ‘real’ network per se. Note that in a network with randomly drawn connections, the index should be positively related to the length of the aggregation period. Thus, it is important to show that other network measures also take on values significantly different from random networks for longer aggregation periods. In the following, we will therefore have a closer look at the reciprocity of the network.
Reciprocity is a global concept for directed networks that measures how many of the existing links are mutual. It can be calculated by adding up all loops of length two, i.e. reciprocal links, and dividing them by the total number of links.
Table 3 shows higher levels of reciprocity for longer aggregation periods.Footnote 23 In the case of daily networks we observe very few mutual links. As Iori et al. (2008) stated this is a very plausible finding, since banks rarely borrow and lend money from the same bank within a particular day. However, the values for longer aggregation periods show that the banking network is not one-sided, supporting the evidence on the inability of daily networks to represent the ‘true’ underlying (directed) banking network. The left panel of Fig. 7 illustrates the results for 1999, where we perform a similar analysis as for the density above, by comparing the observed network reciprocity to those of Erdös-Renyi and scale-free random networks.Footnote 24 The actual values are, again, always the lowest. The right panel of Fig. 7 shows that the reciprocity (after 19 days for the real network) exceeds the density for all three networks. Note that for random networks one would expect the two measures to be almost identical. However, different banks are active at different days and if many banks are often simultaneously active the chance of forming a reciprocal link is higher (remember that we used the actually active banks of each day in the Monte-Carlo exercise). However, more important for our analysis is that for the real network the difference between reciprocity and density increases steadily and exceeds the difference between both measures for the random networks. Hence, using longer than daily aggregation is not only capable of taking mutual credit relationships into account, but even indicates a preference of banks to form them. Thus, the noise level of networks with longer aggregation periods is smaller and the directed version of the networks contains a substantial amount of information.

Data for 1999. Left reciprocity for the Erdös-Renyi (blue), scale-free (red) with \(\alpha =2.3\), and observed networks (green). Right difference between reciprocity and density for the respective networks. Aggregation period in days
On the base of the Jaccard index, monthly and quarterly networks appear most stable as they have a high index with a very low standard deviation, i.e., the highest degree of structural stability of lending relationships over time. Yearly aggregation levels, in contrast, have somewhat higher variation in their JI and might be problematic, because the banking network (in particular during unstable times) is likely to evolve much faster. Somewhat related is the change in the composition of banks, i.e. banks leaving and entering the market, since we consider a bank as active for the whole year even if it leaves the market after the first trading day.Footnote 25 Concerning the monthly level, Iori et al. (2008) discovered intradaily and -monthly seasonalities which may affect our results. In most of the following, we will therefore focus on the quarterly networks.
We should emphasize that providing general guidelines on the optimal aggregation period of interbank network data might be too demanding. Clearly, it depends on the research question at hand what the most sensible aggregation period is. Our findings for the Italian interbank network suggest that aggregation over a sufficiently long time horizon indeed reveals more and more of the hidden links, rather than adding up purely random draws from all possible links. The findings for the JI and the reciprocity, combined with the relatively fast saturation of the empirical density observed in Fig. 5, is consistent with this interpretation. However, for policymakers, who need to monitor the network and act on real-time data, monthly or quarterly aggregation periods may be too long. For other purposes, e.g. identifying community structure, longer aggregation is definitely necessary. Similar to our approach, we recommend checking the saturation of certain network statistics in order to quantify the structural stability of the network at hand.
4.4 Transitivity
Here we are interested in transitive relations between sets of three banks. The concept of transitivity states that a specific relationship \(\diamond \) is transitive if from \(i\diamond j\) and \(j\diamond k\) it follows that \(i\diamond k\) holds. Equality is a transitive relation, but inequality is not. From \(i=j=k\) follows \(i=k\), yet \(i\ne j\ne k\) does not imply \(i\ne k\).
The relation we are interested in is which other \(i\) has a link to \(j\) or \(a_{ij}=1\). The relationship is obviously not transitive, since \(i\) has a link to \(j\) and \(j\) has a link to \(k\) does not strictly imply that \(k\) also has a link to \(i\). However, it is interesting to investigate how many such closed triplets occur. More generally speaking, transitivity measures whether the existence of certain links depend both on the relation between the two counterparties and on the existence of links with a third party. The measure most prominently used for this purpose is the (directed) clustering coefficientFootnote 26, which, despite its name, has no relation to cluster identification whatsoever.Footnote 27 It measures the number of (directed) paths of length two in the network and takes the fraction of those that are closed.Footnote 28 Figure 8 illustrates two ways to close the triplet \(i,j,k\) in a directed network. First, the directed path may be closed into a loop as shown on the left hand side of the figure. The fraction of such closures is given by the coefficient \(CC^{1}\):
Second, the link from \(i\) to \(k\) may be reversed. The fraction of such closures is given by the coefficient:
An important distinction is that the nodes in the case of \(CC^{1}\), as apparent from Fig. 8, have each one in- and one outgoing link and therefore show no hierarchical ordering.

The two possibilities how the directed path of length two (solid lines) between \(i\) and \(k\) can be closed. On the left hand side the path is closed into a loop of length three (\(CC^{1}\)). On the right hand side the triplet is interconnected but not in the same single direction (\(CC^{2}\))
Figure 9 shows that the results for the two coefficients are very different. The mean for \(CC^{1}\) is 0.164 and 0.571 for \(CC^{2}\). This is further evidence for the non-random character of the banking network, since the probability of an ‘average’ link to exist is just equal to the density of 0.208. Hence, the existence of a path of length two between \(i\) and \(k\) via \(j\) makes it 2.75 times more likely that the link from \(i\) to \(k\) exists compared to a random linkFootnote 29, but reduces the probability that there is a link from \(k\) to \(i\) by 21 %. The huge difference indicates that the banking network has a hierarchical ordering on the triadic level.

The two clustering coefficients of quarterly networks: \(CC^{1}\) (green) is the fraction of path of length two which are closed into a loop by a third link. \(CC^{2}\) characterizes links in which the triangle is closed in a hierarchical way
Figure 10 illustrates that for the Erdös-Renyi networks the evolution of the clustering coefficients is almost identical (correlation above 0.999). The exact numbers of the clustering coefficients for the observed networks change with the aggregation, but \(CC^{1}\) is always much smaller than \(CC^{2}\) for all aggregation levels as shown by Fig. 10. \(CC^{2}\) is initially even higher for the observed network than for the random networks, but saturates after a steep increase relatively quickly on a much lower level (up to 0.624). \(CC^{1}\) on the other hand is almost zero for short horizons. Note that a loop of length three at a single day implies that each involved bank would get back some of its own lending via an intermediate bank, which appears very unlikely. However, \(CC^{1}\) increases (up to 0.386) for longer aggregation periods showing that such relations do exist, albeit to a much lower degree than in the simulated random and scale-free networks. Such closed triplets, therefore, appear to be a relatively rare phenomenon. Besides the tendency towards lasting credit relationships, our data aggregation exercise reveals a certain hierarchical structure of the interbank market (in the preference for the hierarchical \(CC^{2}\) triplets as opposed to the non-hierarchical \(CC^{1}\) structure).

Left \(CC^{1}\) for the Erdös-Renyi (blue), Scale-free (red) with \(\alpha =2.3\), and observed networks (green), aggregated on a daily basis up to the horizon of one year(1999). Right \(CC^{2}\)
4.5 Small-world property
Another very prominent measure in the network literature is the average shortest path length (ASPL). Interest in this measure stems from the remarkable finding that in many ‘real world’ networks the ASPL is quite small, also known as the small-world phenomenon.Footnote 30 Here we focus on the undirected version of the network.
Watts and Strogatz (1998) show that completely random networks already have a very small ASPL, but at the same time a relatively low (undirected) clustering coefficient (CC) equal to their density. On the other hand, a regular network, where all nodes have connections to their \(s\) nearest neighbours, has a high clustering coefficient and a very high ASPL. Interestingly, already the introduction of a few ‘random’ links reduces the ASPL significantly, because these ‘long range’ links connect different clusters of the network. The authors argue that the interesting ‘real world’ networks are neither purely regular nor random. Therefore, Watts and Strogatz (1998) define small-world networks by being characterized by a small ASPL together with a higher CC than random networks. Hence, to further investigate if the banking network exhibits the small-world property, we calculate these statistics and compare these values to those for random networks.
Let the (symmetric) matrix \(\mathbf G \) of dimension \(N \times N\) have elements \(g_{ij}\) equal to the geodesic distances between any two nodes, i.e. each element \(g_{ij}\) gives the length of the geodesic path between node \(i\) and \(j\). The ASPL is calculated by dividing the sum of all (existing) geodesic path lengths by the total number of (existing) geodesic paths.Footnote 31 The CC is calculated similar to the directed case (\(CC^{1}\) and \(CC^{2}\)), but ignores the direction of the links.
In this case a comparison of the networks aggregated day by day is not suitable, since the density of both random networks and scale-free networks becomes much higher than the density of the empirical network (cf. Fig. 5). Therefore, we simulate random and scale-free(undirected) networks corresponding to the aggregated quarterly networks with respect to their density (and their degree distribution for scale-free networks). Table 4 summarizes the results: the ASPL for all networks is small and almost identical. The CC for the Erdös-Renyi networks is by construction close to the density, since all links have exactly this probability to occur. The CC for the scale-free networks is higher (0.413), but is exceeded by the statistics of the observed network (0.542). This indicates higher regularity in the link structure. Hence, the banking network lies midway between regular and completely random graphs. As can be seen from the last column of Table 4, the ASPL does not provide much scope for distinguishing between the benchmark Erdös-Renyi and scale-free networks and the empirical ones. The reason might be that the relatively high density leads to relatively short path lengths anyway.Footnote 32
4.6 Effects of the global financial crisis
Finally, we take a closer look at the effects of the GFC on the banking network.Footnote 33 The start of the GFC is not easy to determine, but we have seen that the collapse of Lehman Brothers in quarter 39 (2008 Q4) was a major shock for the global financial markets in general and the Italian interbank market as well.Footnote 34 The effects of this event were twofold: first, the counterparties of Lehman Brothers realized huge loses. Second, the perception of risks changed, since Lehman had been considered to be ‘too-big-too-fail’ before. The resulting dramatic increase of perceived counterparty risk reduced the willingness of banks to lend to each other, which ultimately affected the real economy due to tighter lending restrictions. The monetary authorities and governments around the world injected substantial amounts of capital into the financial system to prevent interbank markets from freezing in the following weeks. We have seen, that important network measures such as density and reciprocity, were significantly affected by these events as well.
Here we investigate the change in banks’ behavior during and after the breakdown of Lehman Brothers in greater detail. To begin with, Table 5 contains several basic network statistics for ten quarters around the breakpoint (quarter 39). Interestingly, the number of active Italian banks remained relatively stable during this period, and in fact 86 banks were active in all of the ten quarters. The stability of this composition is important, since under these circumstances changes in the behavior of the banks on the aggregated or individual level should be mainly driven by their response to this exogenous shock.
We also see that the total trading volume, the number of trades and the number of links are all decreasing over this period, but the exact patterns are distinct. Surprisingly, the volume is quite stable until the 40th quarter, but drops by 39.3 % in the 41st quarter. In contrast, the number of trades starts to fall in the 39th quarter and decreases further until quarter 44. The total number of links already started to decrease in quarter 37, but overall tends to develop in a very similar way to the number of trades.Footnote 35 In the end, the most immediate reaction to the crisis had been that banks traded similar total volumes but in fewer trades and with a smaller number of counterparties in order to minimize their (perceived) counterparty risks.Footnote 36
Interestingly, the trades per link are the highest for the three quarters after the Lehman collapse. This indicates that the banks relied more heavily on their preferred counterparties. Preferred in this context might simply mean that the banks had more reliable information about these banks, which, however, should coincide with the existence of a previous trading relationship.
We conclude that the breakdown of Lehman Brothers significantly affected the behavior of individual banks and thus had a clear impact on the structure of the network in terms of its overall volume and activity. However, at the same time we find that the link structure of subsequent quarterly networks remained rather stable during this period, since no structural break had been detected for the Jaccard Index. Furthermore, despite the significant impact of the GFC, we do not find evidence for a complete drying up of the e-MID market, even at the daily level.Footnote 37
5 Discussion
What do we learn from this analysis of the network properties of the interbank market? Network analysis is one way to cope with the complexity of a huge system of dispersed activity and extract some hopefully important general characteristics from such a system. Without an attempt at such a condensation of information, the raw data of more than one million trades between financial institutions could hardly provide any useful insights. We have, however, demonstrated that different ways to approach these data (different aggregation levels) might reveal different pieces of information on the underlying structure, with more or less robust outcomes. If we think about the data revealing an underlying network structure through random sampling from this net of connections (as the activation of a link depends on the random realization of liquidity needs or liquidity overhangs), it might seem sensible to allow for a longer observation (aggregation) period to catch more of the existing but often dormant links. As it appears, practically all network statistics are more robust over longer horizons, while the daily horizon might just provide information on a small random part of the ‘true’ network. Under this perspective, daily data might not be a useful format for network inference at all—despite the fact that the underlying data are for daily maturities of interbank lending. This important distinction between the time horizon of the legal contract, and the appropriate time horizon for a meaningful network analysis seems to have been largely ignored in extant literature on interbank networks.
Besides this basic message, another interesting result is that the network is asymmetric in many respects. In particular, the two directed clustering coefficients are very different. The probability for a path of length two to be closed into a loop is less than one third of the probability for the alternative closure. Note that this speaks in favor of a hierarchical structure: if bank A receives credit from bank B and extends credit to bank C, it is much more likely that C also receives credit from B rather than being its creditor itself. The high level of asymmetry in the network indicates that different banks might play different roles in the network. Fricke (2012) and Fricke and Lux (2012) provide evidence that this is indeed the case. Moreover, for many measures the GFC could be identified as a structural break and also the decreasing number of volume, trades and links support that the GFC heavily affected the Italian interbank market. However, the link structure of the network remained surprisingly stable and despite the decrease of its volume (in the beginning of 2009) the e-MID market was never close to drying up completely.
In terms of managerial insights, our paper sheds light on the practical implementation of liquidity management at financial institutions. Indeed, while liquidity management is of outermost importance for the stability of both individual financial institutions and the financial system in its entiretyFootnote 38, relatively little is known about the empirical conduct of liquidity management. What we can infer from out present findings is that a purely neoclassical approach to liquidity management (as detailed, for example, in Brodt, 1978) would probably not provide a very accurate characterization of empirical practices. According to the neoclassical approach, individual banks (or rather their liquidity managers) would pursue an intertemporal linear programming strategy in order to maximize the profits under given constraints on reserve requirements and capital adequacy regulations. Thus, in such a world we would expect an atomistic market without any stable link formation between participants. Indeed, the very evidence of an interesting (i.e. not completely random) network structure speaks against a purely competitive market. While the present paper sheds light on the non-random structure of links and their stability over time on a purely phenomenological level, our model-based analyses in two companion papers underscore the non-random nature of link formation: Fricke and Lux (2012) show that participating banks in the e-MID platform can be very consistently categorized as either core or periphery banks. Typically, core banks borrow from a large pool of periphery banks, and lend to other core or periphery banks thus creating indirect links particularly between members of the ‘periphery’. Many of these links are very stable over time, as also demonstrated by Finger and Lux (2013) in a so-called ‘stochastic actor-oriented’ model of network formation (borrowed from sociology). Here it turns out that solely characteristics of the specific counterparty, most prominently past trades with the same counterparty, and not higher level relationsFootnote 39 are the strongest explanatory factors for link activation/termination in the interbank market. Surprisingly, interest rates have only a minor influence on the formation of links. Further evidence for the existence of stable long-run relationships in the interbank market is also provided by Cocco et al. (2009) for a different segment (Portuguese banks) with a different econometric methodology.
Overall, it seems that market participants focus strongly on lasting relationships rather than shopping for the best deals in terms of interest rates offered. It is particularly remarkable that these findings are based on data for an electronic platform that easily provides traders access to a long list of publicly quoted bids and asks. Obviously, trusted working relationships for liquidity adjustment are of value to the managers-in-charge who are often prepared to forego more advantageous offers from other market participants in favor of reliance on their existing relationships. Formation of stable links might also work as a way to reduce the complexity of the day-to-day task of balancing liquidity needs and excess liquidity (cf. Wilkinson and Young, 2002).Footnote 40 The overall non-random network is the ‘emergent’ macro structure from such dispersed behavioral strategies of individual market participants.
The importance of stable links also becomes apparent during the financial crisis: while we saw a dramatic decrease of overall activity in the network, no structural break in the Jaccard index was found. This means that the structure of link formation and continuation has remained very much intact, but trading activity has typically been concentrated on fewer counterparties than before. From this perspective, the non-random character of link formation might have prevented an even more detrimental collapse of network activity.Footnote 41 While the trigger for the crisis was an event outside the network under investigation (Lehman Brothers did not participate in the Euro denominated e-MID market we are investigating)Footnote 42, our analysis sheds some light on how a network of lasting business relationships reacts on such a disturbance (which might entail a loss of trust in some counterparties depending on experience and interaction or their exposure towards the source of the disruption). Both phenomenological and model-based analyses should, therefore, contribute essentially to understanding the vulnerability of the interbank network which is of crucial importance for the smooth functioning of the financial sector.
Knowledge of its intrinsic structure would also be instrumental in identifying feedback effects from the interbank market in liquidity stress tests for single financial institutions, or to design system-wide stress tests (cf. Elsinger et al. 2006, and Montagna and Lux 2013). In order to mitigate the danger of a collapse of the interbank market in times of distress, both knowledge about its network ‘topology’ as well as about the behavioral origins of this topology are indispensable. Effective and robust measures of macro-prudential regulation can only be designed on the base of thorough knowledge of the system (that until about 2008 was almost completely uncharted territory). Insofar, the mapping of the interbank market in the present paper and related research is just a preliminary step in our attempt to understand the intrinsic structure of the financial sector and enhance its robustness against shocks. The revealed topology of the interbank network should be instrumental in identifying relevant channels of contagion and implementing more realistic designs for system-wide stress tests.
6 Conclusions and outlook
In this paper, we have investigated the interbank lending activity as documented in the e-MID data from 1999 until the end of 2010 from a network perspective. Our main finding is that daily networks feature too much randomness to be considered a representative statistic of some underlying latent network. Various network measures exhibit strong variation over short horizons, but become much more stable for longer aggregation periods between monthly and quarterly time horizons. At such aggregation levels, the network appears structurally very stable so that one might argue that the underlying structure of link formation between banks is best studied on the base of appropriately aggregated data. However, the transition towards this more stable format under time aggregation also reveals interesting features. In particular, the tendency for the network’s density to increase much more slowly than (aggregated) random networks indicates the existence of preferred trading relations. In general the evolution of all global network measures for longer aggregation periods (month, quarter, year) is very similar in their deviation from the Erdös-Renyi and scale-free benchmarks. Moreover, the monthly and quarterly networks are characterized by a significantly higher than random clustering coefficient, and thus reveal some regularity in the link structure. The (almost) zero reciprocity and \(CC^{1}\) of daily networks proves the inability of this aggregation level to reveal information on such structural elements. Quarterly networks, in contrast, consistently exhibit a non-random structure and allow us to consider the mutuality of the relations and are therefore a preferable subject of study, especially if one is interested in the evolution of the network over time.
Essentially, these results show that it is far from trivial to map a given data structure into a ‘network’. While daily records of the interbank trading system can be arranged in an adjacency matrix and treated with all types of network statistics, they provide probably only a very small sample of realizations from a richer structure of relationships. Just like daily contacts of humans provide very incomplete information on networks of friendship and acquaintances, the daily interbank data might only provide a small selection of existing trading channels, while the majority of these probably remains dormant on any single day. Hence, inference based on such high-frequency data may be misleading while a higher level of time aggregation might provide a more complete view on the interbank market. What level of aggregation is sufficient for certain purposes is an empirical question depending on the research questions at hand. Saturation of certain measures may be a good indicator that most dormant links have been activated at least once over a certain time horizon. At the same time, such dependence of statistics on the time horizon serves to sort out a number of simple generating mechanisms (i.e. completely randomly determined networks in every period) and reveals interesting dynamic structure.
In the future, more attention should be given to the analysis of directed banking networks using longer aggregation periods to identify structural commonalities. While real-time information about the structure of the interbank network is important for policymakers having to take immediate action, regulators should also take stock of the information provided by longer network aggregates. Getting a better idea on the wider pool of counterparties of all credit institutions would allow the identification of possible behavioral changes among the set of active banks. Such changes might then serve as an indicator for funding problems of individual institutions, cf. Fricke and Lux (2012). In the end, it would be important to complement our phenomenological investigation of aggregate data by a behavioral analysis of the liquidity management practices at the micro level.
Notes
In the literature, the traditional approach is to focus on the optimal liquidity management of a particular financial institution, see e.g. Brodt (1978) and Ho and Saunders (1985). Recently, Brunnermeier and Pedersen (2009) introduced the distinction between funding liquidity and market liquidity in a theoretical model, showing that their relationship may give rise to systemic crises.
In the following, matrices will be written in bold, capital letters. Vectors and scalars will be written as lower-case letters.
This is true when we think of individual banks as consolidated entities.
Directed means that \(d_{i,j}\ne d_{j,i}\) in general. Sparse means that at any point in time the number of links is only a small fraction of the \(N(N-1)\) possible links. Valued means that interbank claims are reported in monetary values as opposed to 1 or 0 in the presence or absence of a claim, respectively.
The vast majority of trades (roughly 95 %) is conducted in Euro.
This development is driven by the fact that the market is unsecured. The recent financial crisis made unsecured loans in general less attractive, with stronger impact for longer maturities. It should be noted, that there is also a market for secured loans called e-MIDER.
The minimum quote size could pose an upward bias for participating banks. It would be interesting to check who are the quoting banks and who are the aggressors. Furthermore it would be interesting to look at quote data, as we only have access to actual trades.
More details can be found on the e-MID website, see http://www.e-mid.it/.
Similar developments are reported by Bech and Atalay (2010) for the federal funds market.
The Figure was produced using visone, http://www.visone.info/, by Brandes and Wagner (2004).
For a detailed analysis of the trading strategies in the e-MID, see Fricke (2012).
In a companion paper, we focus explicitly on fitting the degree distribution, see Fricke and Lux (2013). The main findings are: (1) the degree distributions are unlikely to follow power-laws, and (2) the in- and out-degrees do not follow the same distribution.
Note that mostly because of the shrinking number of active banks all statistics decrease over time, irrespective of the aggregation period.
The density for the total network, including the foreign banks, seems to steadily decline over the sample period. This illustrates the fact that the increasing fraction of foreign banks are less interconnected with the (smaller) Italian banks.
Additionally, the electronic nature of the trading platform simplifies the trading between any two counterparties, i.e. increases the probability of observing any link.
The power-law distribution with tail exponent 2.3 is a common finding in many interbank markets, see e.g. Boss et al. (2004). The resulting sequences of the out-degrees, i.e. the simulated quasi-daily networks, are attributed to the nodes by ranking those according to the observed out-degrees, considering only active banks during the particular day. Note that if we did not account for the ordering of the observed degree sequences, we would end up with very similar aggregation properties as in the Erdös-Renyi case. The in-degrees are distributed in a random uniform way, ruling out self-links and counting each link at most once.
Note that the density of aggregated Erdös-Renyi networks can be written as
$$\begin{aligned} \rho _{T}^{r}= 1 - \prod _{t=1}^{T} (1-\rho _{t}^{r}), \end{aligned}$$where \((1-\rho _{t}^{r})\) is the probability of observing no links in the network at time \(t\). Since we adjust the number of active banks on a daily basis these probabilities would not exactly coincide with the results of our simulations.
The literature on interbank networks is surprisingly silent about the choice of the aggregation period. We are aware of only one paper, namely Kyriakopoulos et al. 2009, investigating this issue.
The so-called graph correlation, see e.g. Butts and Carley (2001), shows qualitatively very similar results, but is not able to cope with banks entering or exiting the market. The correlation of both measures is always above \(.9\) irrespective of the aggregation period.
See Snijders et al. (2009).
We should note that, as apparent from Fig. 6, the reason for the 10th percentile to be below the 0.2 threshold is not the GFC.
A structural break (after the GFC) is detected by a Chow-test as well as an additional CUSUM test for the 10th year, the 39th quarter and the 117th month respectively, but not for daily networks. For the yearly networks only the Chow-test indicates a structural break. Note that the yearly analysis involves only 12 data points.
Again the results are qualitatively very similar for the other years as well.
This problem occurs for each aggregation period, but is likely to become more pronounced for longer frequencies.
For more detailed definitions of clustering coefficients see Zhou (2002).
Any connection along directed links between two nodes i and j is called a path and the length of the path is defined as the number of edges crossed. There are no restrictions on visiting a node or link more than once alongside a path.
The probability of random link is exactly the density of 0.208.
Small ASPLs have been detected for social, information, technological and biological networks. The first empirical finding dates back to the chain letter experiments conducted by Milgram (1967). His finding that on average only six acquaintances are needed to form a link between two random selected persons led to the famous phrase of ‘six degrees of separation’.
It is not necessary for two nodes to have a shortest path, since there might be no link leading from one to the other. In this case the two nodes lie in different components of the network and by convention the length of these non-existing geodesic paths are set to infinity. The undirected banking network consists always of only one connected component and the same is true for the simulated random networks, because of the high density.
The results are qualitatively the same for the directed version of the network. The ASPL for the quarterly networks is 1.912, while we obtain 1.776 for the scale-free and 1.802 for the Erdös-Renyi networks. The \(CC^{2}\) (0.571) is significantly higher than for the scale free with 0.342 and Erdös-Renyi networks with 0.208, whereas \(CC^{1}\) (0.164) is smaller. However, in this case the network consists not only of one giant component, but might contain separate clusters, which makes the interpretation of the ASPL more difficult.
See also Fricke and Lux (2012).
See Brunnermeier (2008).
The correlation between both is 0.963 for this period and 0.957 over the complete sample.
Fricke and Lux (2012) show that most of these changes were in fact driven by behavioral changes of core banks.
As noted above, this is not true for loans longer than overnight. These markets essentially collapsed completely, which is not surprising given that the loans are unsecured.
This means that banks do not consider the complete network, e.g. indirect relations, during the network formation process, although they could, in principle, infer such information from the e-MID platform.
With respect to the stability of relationships, the working of the interbank market seems not too different from that of the often-studied fish market. Here as well, stable links might underscore the importance of trust between buyer and seller as well as the element of complexity reduction in a day-to-day task where excessive shopping for good prices seems much less important than trust in the reliability of the counterpart, cf. Kirman and Vriend (2001), Gallegati et al. (2011).
Fricke and Lux (2012) show that mostly core banks reduced their lending activity but at the same time increased their borrowing from their counterparties in the periphery.
No bank from outside Europe traded in the Euro segment of the e-MID interbank market in the whole sample period.
References
Allen F, Gale D (2000) Financial contagion. J Political Econ 108(1):1–33
Basle Committee on Banking Supervision (2008) Principles for sound liquidity risk management and supervision. Framework publication, Bank of International Settlements, Basel
Beaupain R, Durré A (2012) Nonlinear liquidity adjustments in the Euro area overnight money market, Working Paper Series 1500, European Central Bank, Germany
Bech M, Atalay E (2010) The topology of the Federal funds market. Phy A 389(22):5223–5246
Boss M, Elsinger H, Summer M, Thurner S (2004) Network topology of the interbank market. Quant Finance 4(6):677–684
Brandes U, Wagner D (2004) Visone-analysis and visualization of social networks. In: Jünger M, Mutzel P (eds) Graph Drawing Software. Springer-Verlag, Berlin, pp 321–340
Brodt AI (1978) A dynamic balance sheet management model for a Canadian chartered bank. J Bank Finance 2(3):221–241
Brunnermeier MK (2008) Deciphering the liquidity and credit crunch 2007–08, Working Paper 14612, National Bureau of Economic Research, Cambridge
Brunnermeier MK, Pedersen LH (2009) Market liquidity and funding liquidity. Rev Financial Stud 22(6):2201–2238
Butts C, Carley K (2001) Multivariate methods for interstructural analysis. CASOS Working Paper. Carnegie Mellon University, Pittsburgh
Cocco JF, Gomes FJ, Martins NC (2009) Lending relationships in the Interbank market. J Financial Intermed 18(1):24–48
Craig B, von Peter G (2010) Interbank Tiering and Money Center Banks, Discussion Paper, Series 2: Banking and Financial Studies 12/2010, Deutsche Bundesbank
De Masi G, Iori G, Caldarelli G (2006) Fitness model for the Italian interbank money market. Phys Rev E 74(6):66112
Elsinger H, Lehar A, Summer M (2006) Using market information for banking system risk assessment. Intern J Cent Bank 2(1):1–29
Finger K, Lux T (2013) The evolution of the Banking network: an actor-oriented approach, unpublished manuscript
Fricke D (2012) Trading strategies in the overnight money market: correlations and clustering on the e-MID trading platform. Phy A 391:6528–6542
Fricke D, Lux T (2012) Core-periphery structure in the overnight money market: evidence from the e-MID trading platform, Kiel Working Paper 1759, Kiel Institute for the World Economy, Germany
Fricke D, Lux T (2013) On the distribution of links in the Interbank network: evidence from the e-MID overnight money market, Kiel Working Paper 1819, Kiel Institute for the World Economy, Germany
Gallegati M, Giulioni G, Kirman A, Palestrini A (2011) What’s that got to do with the price of fish? Buyers behavior on the Ancona fish market. J Econ Behav Organ 80(1):20–33
Ho TSY, Saunders A (1985) A micro model of the Federal funds market. J Finance 40(3):977–988
IIF Special Committee on Liquidity Risk (2007) Principles of liquidity risk management. Framework publication, Institute of International Finance, Finance
Inaoka H, Ninomyia T, Taniguchi K, Shimizu T, Takayasu H (2004) Fractal network derived from banking transaction: an analysis of network structures formed by financial institutions. Bank of Japan Working Papers
Iori G, De Masi G, Precup OV, Gabbi G, Caldarelli G (2008) A network analysis of the Italian overnight money market. J Econ Dyn Cont 32(1):259–278
Kirman AP, Vriend NJ (2001) Evolving market structure: an ACE model of price dispersion and loyalty. J Econ Dyn Cont 25(3–4):459–502
Kyriakopoulos F, Thurner S, Puhr C, Schmitz SW (2009) Network and eigenvalue analysis of financial transaction networks. Europ Phy J B 71(4):523–531
Milgram S (1967) The small-world problem. Psychol Today 2:60–67
Montagna M, Lux T (2013) Hubs and resilience: towards more realistic models of the Interbank markets, Kiel Working Paper 1826, Kiel Institute for the World Economy, Germany
Préfontaine J, Desrochers J, Godbout L (2010) The analysis of comments received by the BIS on “Principles for sound liquidity risk management and supervision”. Intern Bus Econ Res J 9(7):65–72
Snijders TAB, van de Bunt GG, Steglich CEG (2009) Introduction to stochastic actor-based models for network dynamics. Soc Netw 32(1):44–60
Soramaki K, Bech ML, Arnold J, Glass RJ, Beyeler W (2007) The topology of interbank payment flows. Phy A 379:317–333
Watts DJ, Strogatz SH (1998) Collective dynamics of small-world networks. Nature 393(6684):440–442
Wilkinson I, Young L (2002) On cooperating: firms, relations and networks. J Bus Res 55(2):123–132
Zhou H (2002) Scaling exponents and clustering coefficients of a growing random network. Phys Rev E 66:016125
Author information
Authors and Affiliations
Corresponding author
Additional information
The article is part of a research initiative launched by the Leibniz Community. We are grateful to Christian Freund and Mattia Montagna for intense discussion on the analysis of interbank networks, and to two anonymous referees for their helpful comments and suggestions.
Rights and permissions
About this article
Cite this article
Finger, K., Fricke, D. & Lux, T. Network analysis of the e-MID overnight money market: the informational value of different aggregation levels for intrinsic dynamic processes. Comput Manag Sci 10, 187–211 (2013). https://doi.org/10.1007/s10287-013-0171-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-013-0171-9