
Abstract
An effective means to approximate an analytic, nonperiodic function on a bounded interval is by using a Fourier series on a larger domain. When constructed appropriately, this so-called Fourier extension is known to converge geometrically fast in the truncation parameter. Unfortunately, computing a Fourier extension requires solving an ill-conditioned linear system, and hence one might expect such rapid convergence to be destroyed when carrying out computations in finite precision. The purpose of this paper is to show that this is not the case. Specifically, we show that Fourier extensions are actually numerically stable when implemented in finite arithmetic, and achieve a convergence rate that is at least superalgebraic. Thus, in this instance, ill-conditioning of the linear system does not prohibit a good approximation.
In the second part of this paper we consider the issue of computing Fourier extensions from equispaced data. A result of Platte et al. (SIAM Rev. 53(2):308–318, 2011) states that no method for this problem can be both numerically stable and exponentially convergent. We explain how Fourier extensions relate to this theoretical barrier, and demonstrate that they are particularly well suited for this problem: namely, they obtain at least superalgebraic convergence in a numerically stable manner.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Let \(f : [-1,1] \rightarrow \mathbb {R}\) be an analytic function. When periodic, an extremely effective means to approximate f is via its truncated Fourier series. This approximation converges geometrically fast in the truncation parameter N, and can be computed efficiently via the Fast Fourier Transform (FFT). Moreover, Fourier series possess high resolution power. One requires an optimal two modes per wavelength to resolve oscillations, making Fourier methods well suited for (most notably) PDEs with oscillatory solutions [19].
For these reasons, Fourier series are extremely widely used in practice. However, the situation changes completely when f is nonperiodic. In this case, rather than geometric convergence, one witnesses the familiar Gibbs phenomenon near x=±1 and only linear pointwise convergence in (−1,1).
1.1 Fourier Extensions
For analytic and nonperiodic functions, one way to restore the good properties of a Fourier series expansion (in particular, geometric convergence and high resolution power) is to approximate f with a Fourier series on an extended domain [−T,T]. Here T>1 is a user-determined parameter. Thus we seek an approximation F N (f) to f from the set
Although there are many potential ways to define F N (f), in [5, 12, 22] it was proposed to compute F N (f) as the best approximation to f on [−1,1] in a least squares sense:
Here ∥⋅∥ is the standard norm on L2(−1,1)—the space of square-integrable functions on [−1,1]. Henceforth, we shall refer to F N (f) as the continuous Fourier extension (FE) of f.
In [1, 22] it was shown that the continuous FE F N (f) converges geometrically fast in N and has a resolution constant (number of degrees of freedom per wavelength required to resolve an oscillatory wave) that ranges between 2 and π depending on the choice of the parameter T, with T≈1 giving close to the optimal value 2 (see Sect. 2.4 for a discussion). Thus the continuous FE successfully retains the key properties of rapid convergence and high resolution power of a standard Fourier series in the case of nonperiodic functions.
We note that one does not usually compute the continuous FE (1.1) in practice. A more convenient approach [1, 22] is to replace (1.1) by the discrete least squares
for nodes {x n }|n|≤N ⊆[−1,1]. We refer to \(\tilde{F}_{N}(f)\) as the discrete Fourier extension of f. When chosen suitably—in particular, as in (2.11)—such nodes ensure that the difference in approximation properties between the extensions (1.1) and (1.2) is minimal (for details, see Sect. 2.2).
1.2 Numerical Convergence and Stability of Fourier Extensions
The approximation properties of the continuous and discrete FEs were analyzed in [1, 22]. Therein it was also observed numerically that the condition numbers of the matrices A and \(\tilde{A}\) of the least squares (1.1) and (1.2) are exponentially large in N. We shall confirm this observation later in the paper. Thus, if a=(a −N ,…,a N )⊤ is the vector of coefficients of the continuous or discrete FE, i.e. F N (f) or \(\tilde{F}_{N}(f)\) is given by ∑|n|≤N a n ϕ n , one expects small perturbations in f to lead to large errors in a. In other words, the computation of the coefficients of the continuous or discrete FE is ill-conditioned.
Because of this ill-conditioning, it is tempting to think that FEs will be useless in applications. At first sight it is reasonable to expect that the good approximation properties of exact FEs (i.e. those obtained in exact arithmetic) will be destroyed when computing numerical FEs in finite precision. However, previous numerical studies [1, 5, 12, 22, 24, 25] indicate otherwise. Despite very large condition numbers, one typically obtains an extremely good approximation with a numerical FE, even for poorly behaved functions and in the presence of noise.
The aim of this paper is to give a full explanation of this phenomenon. This explanation can be summarized as follows. In computations, one’s interest does not lie with the accuracy in computing the coefficient vector a, but rather the accuracy of the numerical FE approximation ∑|n|≤N a n ϕ n . As we show, although the mapping from a function to its coefficients is ill-conditioned, the mapping from f to its numerical FE is, in fact, well-conditioned. In other words, whilst the small singular values of A (or \(\tilde{A}\)) have a substantial effect on a, they have a much less significant, and completely quantifiable, effect on the FE itself.
Although this observation explains the apparent stability of numerical FEs, it does not address their approximation properties. In [1, 22] it was shown that the exact continuous and discrete FEs F N (f) and \(\tilde{F}_{N}(f)\) converge geometrically fast in N. However, the fact that there may be substantial differences between the coefficients of F N (f), \(\tilde {F}_{N}(f)\) and those of the numerical FEs, which henceforth we denote by G N (f) and \(\tilde{G}_{N}(f)\), suggests that geometric convergence may not be witnessed in finite arithmetic for large N. As we show later, for a large class of functions, geometric convergence of F N (f) (or \(\tilde{F}_{N}(f)\)) is typically accompanied by geometric growth of the norm ∥a∥ of the exact (infinite-precision) coefficient vector. Hence, whenever N is sufficiently large, one expects there to be a discrepancy between the exact coefficient vector and its numerically computed counterpart, meaning that the numerical extensions G N (f) and \(\tilde{G}_{N}(f)\) may not exhibit the same convergence behavior. In the first half of this paper, besides showing stability, we also give a complete analysis and description of the convergence of G N (f) and \(\tilde{G}_{N}(f)\), and discuss how this differs from that of F N (f) and \(\tilde{F}_{N}(f)\).
We now summarize the main conclusions of the first half of the paper. Concerning stability, we have:
-
1.
The condition numbers of the matrices A and \(\tilde{A}\) of the continuous and discrete FEs are exponentially large in N (see Sect. 3.1).
-
2.
The condition number κ(F N ) of the exact continuous FE mapping is exponentially large in N. The condition number of the exact discrete FE mapping satisfies \(\kappa(\tilde{F}_{N}) = 1\) for all N (see Sect. 3.4).
-
3.
The condition number of the numerical continuous and discrete FE mappings G N and \(\tilde{G}_{N}\) satisfy
$$ \kappa(G_N) \lesssim1/\sqrt{\epsilon},\qquad \kappa( \tilde{G}_N) \lesssim1,\quad\forall N \in \mathbb {N}, $$where ϵ=ϵ mach is the machine precision used (see Sect. 4.3).
To state our main conclusions regarding convergence, we first require some notation. Let \(\mathcal {D}(\rho)\), ρ≥1, be a particular one-parameter family of regions in the complex plane related to Bernstein ellipses (see (2.15) and Definition 2.10), and define the Fourier extension constant [1, 22] by
We now have the following:
-
1.
Suppose that f is analytic in \(\mathcal {D}(\rho^{*})\) and continuous on its boundary. Then the exact continuous and discrete FEs satisfy
$$ \bigl\| f - F_N(f) \bigr\| , \qquad \| f - \tilde{F}_{N} f \| \leq c_f \rho^{-N}, $$where ρ=min{ρ ∗,E(T)} and c f is proportional to \(\max_{x \in \mathcal {D}(\rho)} | f(x) |\) (see Sect. 2.3).
-
2.
For f as in 4. the errors of the numerical continuous and discrete FEs satisfy (see Sect. 4.2):
-
(i)
For N≤N 0 (continuous) or N≤N 1:=2N 0 (discrete), where N 0 is a function-independent breakpoint depending on ϵ and T only, both ∥f−G N (f)∥ and \(\| f - \tilde{G}_{N} f \|\) decay like ρ −N, where ρ is as in 4.
-
(ii)
When N=N 0 or N=N 1, the errors
$$ \bigl\| f - G_{N_0}(f) \bigr\| \approx c_f (\sqrt{\epsilon })^{d_f},\qquad\bigl\| f - \tilde{G}_{N_1}(f) \bigr\| \approx c_f \epsilon ^{d_f}, $$where c f is as in 4. and \(d_{f} = \frac{\log\rho}{\log E(T)} \in (0,1]\).
-
(iii)
When N>N 0 or N>N 1, the errors decay at least superalgebraically fast down to maximal achievable accuracies of order \(\sqrt{\epsilon}\) and ϵ, respectively. In other words,
$$ \limsup_{N \rightarrow\infty} \bigl\| f - G_{N}(f) \bigr\| \lesssim\sqrt{ \epsilon},\qquad\limsup_{N \rightarrow\infty} \bigl\| f - \tilde{G}_{N}(f) \bigr\| \lesssim\epsilon. $$
-
(i)
Remark 1.1
In this paper we refer to several different types of convergence of an approximation f N ≈f. We say that f N converges algebraically fast to f at rate k if \(\| f - f_{N} \| = \mathcal {O}( N^{-k} ) \) as N→∞. If ∥f−f N ∥ decays faster than any algebraic power of N −1 then f N is said to converge superalgebraically fast. We say that f N converges geometrically fast to f if there exists a ρ>1 such that \({\Vert f-f_{N}\Vert } = \mathcal {O}( \rho^{-N}) \). We shall also occasionally use the term root-exponential to describe convergence of the form \({\Vert f-f_{N}\Vert } = \mathcal {O}( \rho^{-\sqrt{N}} ) \).
As we explain in Sect. 4, the reason for the disparity between the exact and numerical FEs can be traced to the fact that the system of functions \(\{ \mathrm{e}^{{\mathrm{i}}\frac{n \pi}{T} \cdot} \}_{n \in \mathbb {Z}}\) forms a frame for L2(−1,1). The inherent redundancy of this frame, i.e. the fact that any function f has infinitely many expansions in this system, leads to both the ill-conditioning in the coefficients and the differing convergence between the exact and numerical approximations F N , \(\tilde{F}_{N}\), and G N , \(\tilde{G}_{N}\), respectively.
This aside, observe that conclusion 5. asserts that the numerical continuous FE G N (f) converges geometrically fast in the regime N<N 0 down to an error of order \((\sqrt{\epsilon})^{d_{f}}\), and then at least superalgebraically fast for N>N 0 down to a best achievable accuracy of order \(\sqrt{\epsilon}\). Note that d f =1 whenever f is analytic in \(\mathcal {D}(\rho)\) with ρ≥E(T). Thus G N approximates all sufficiently analytic functions possessing moderately small constants c f with geometric convergence down to order \(\sqrt {\epsilon}\), and this is achieved at N=N 0. For functions only analytic in regions \(\mathcal {D}(\rho)\) with ρ<E(T), or possessing large constants c f , this accuracy is obtained after a further regime of at least superalgebraic convergence. Note that c f is large typically when f is oscillatory or possessing boundary layers. Hence for such functions, even though they may well be entire, one usually still sees the second phase of superalgebraic convergence.
The limitation of \(\sqrt{\epsilon}\) accuracy for the numerical continuous FE is undesirable. Since ϵ=ϵ mach≈10−16 in practice, this means that one cannot expect to obtain more than 7 or 8 digits of accuracy in general. The condition number is also large—specifically, κ(G N )≈108 (see 3.)—and hence the continuous FE has limited practical value. This is in addition to G N (f) being difficult to compute in practice, since it requires calculation of 2N+1 Fourier integrals of f (see Sect. 2.2.1).
On the other hand, conclusion 3. shows that the discrete FE is completely stable when implemented numerically. Moreover, it possesses the same qualitative convergence behavior as the continuous FE, but with two key differences. First, the region of guaranteed geometric convergence is precisely twice as large, N 1=2N 0. Second, the maximal achievable accuracy is on the order of machine precision, as opposed to its square root (see 5.). Thus, an important conclusion of the first half of this paper is the following: it is possible to compute a numerically stable FE of any analytic function which converges at least superalgebraically fast in N (in particular, geometrically fast for all small N), and which attains close to machine accuracy for N sufficiently large.
Remark 1.2
This paper is about the discrepancy between theoretical properties of solutions to (1.1) and (1.2) and their numerical solutions when computed with standard solvers. Throughout we shall consistently use Mathematica’s LeastSquares routine in our computations, though we would like to stress that Matlab’s command ∖ gives similar results. Occasionally, to compare theoretical and numerical properties, we shall carry out computations in additional precision to eliminate the effect of round-off error. When done, this will be stated explicitly. Otherwise, it is to be assumed that all computations are carried out as described in standard precision.
1.3 Fourier Extensions from Equispaced Data
In many applications, one is faced with the problem of recovering an analytic function f to high accuracy from its values on an equispaced grid \(\{ f ( \frac{n}{M} ) : n=-M,\ldots,M \} \). This problem turns out to be quite challenging. For example, the famous Runge phenomenon states that the polynomial interpolant of this data will diverge geometrically fast as M→∞ unless f is analytic in a sufficiently large region.
Numerous approaches have been proposed to address this problem, and thereby ‘overcome’ the Runge phenomenon (see [8, 28] for a comprehensive list). Whilst many are quite effective in practice, ill-conditioning is often an issue. This was recently explained by Platte, Trefethen and Kuijlaars in [28] (see also Sect. 5.4), wherein it was shown that any exponentially convergent method for recovering analytic functions f from equispaced data must also be exponentially ill-conditioned. As was also proved, the best possible that can be achieved by a stable method is root-exponential convergence. This profound result, most likely the first of its kind for this type of problem, places an important theoretical benchmark against which all such methods must be measured.
As we show in the first half of this paper, the numerical discrete FE is well-conditioned and has good convergence properties. Yet it relies on particular interpolation points (2.11) which are not equispaced. In the second half of this paper we consider Fourier extensions based on equispaced data. In particular, if \(x_{n} = \frac{n}{M}\) we study the so-called equispaced Fourier extension
and its finite-precision counterpart G N,M (f).
Our primary interest shall lie with the case where M=γN for some γ≥1, i.e. where the number of points M scales linearly with N. In this case we refer to γ as the oversampling parameter. Observe that (1.4) results in an (2M+1)×(2N+1) least squares problem for the coefficients of F N,M (f). We shall denote the corresponding matrix by \(\bar{A}\).
Our main conclusions concerning the exact equispaced FE F N,M (f) are as follows (see Sect. 5.2):
-
6.
The condition number of \(\bar{A}\) is exponentially large as N,M→∞ with M≥N.
-
7.
The condition number of exact equispaced FE mapping κ(F N,γN ) is exponentially large in N whenever M=γN for γ≥1 fixed. Moreover, the approximation F N,γN (f) suffers from a Runge phenomenon for any fixed γ≥1. In particular, the error ∥f−F N,γN (f)∥ may diverge geometrically fast in N for certain analytic functions f.
-
8.
The scaling \(M = \mathcal {O}( N^{2} ) \) is required to overcome the ill-conditioning and the Runge phenomenon in F N,M . In this case, F N,M (f) converges at the same rate as the exact continuous FE F N (f), i.e. geometrically fast in N. Although the condition number of \(\bar{A}\) remains exponentially large, the condition number of the mapping κ(F N,M ) is \(\mathcal {O}( 1 ) \) for this scaling.
These results lead to the following conclusion. The exact (infinite-precision) equispaced FE F N,M with \(M = \mathcal {O}( N^{2} ) \) attains the stability barrier of Platte, Trefethen and Kuijlaars: namely, it is well-conditioned and converges root-exponentially fast in the parameter M.
However, since the matrix \(\bar{A}\) is always ill-conditioned, one expects there to be differences between the exact equispaced extension F N,M (f) and its numerical counterpart G N,M (f). In practice, one sees both differing stability and convergence behavior of G N,M (f), much like in the case of continuous and discrete FEs. Specifically, in Sect. 5.3 we show the following:
-
9.
The condition number κ(G N,γN ) satisfies
$$ \kappa(G_{N,\gamma N}) \lesssim\epsilon ^{-a(\gamma;T)},\quad\forall N \in \mathbb {N}, $$where ϵ=ϵ mach is the machine precision used, and 0<a(γ;T)≤1 is independent of N and satisfies a(γ;T)→0 as γ→∞ for fixed T (see (5.23) for the definition of a(γ;T)).
-
10.
The error ∥f−G N,γN (f)∥ behaves as follows:
-
(i)
If N<N 2, where N 2 is a function-independent breakpoint, ∥f−G N,γN (f)∥ converges or diverges exponentially fast at the same rate as ∥f − F N,γN (f)∥.
-
(ii)
If N 2≤N<N 1, where N 1 is as introduced previously in Sect. 1.2, then ∥f − G N,γN (f)∥ converges geometrically fast at the same rate as ∥f−F N (f)∥, where F N (f) is the exact continuous FE.
-
(iii)
When N=N 1 the error
$$ \bigl\| f - G_{N_1,\gamma N_1}(f) \bigr\| \approx c_f \epsilon ^{d_f-a(\gamma;T)}, $$where c f and d f are as in 5. of Sect. 1.2.
-
(iii)
If N>N 1 then ∥f−G N,γN (f)∥ decays at least superalgebraically fast in N down to a maximal achievable accuracy of order ϵ 1−a(γ;T).
-
(i)
These results show that the condition number of the numerical equispaced FE is bounded whenever M=γN, unlike for its exact analogue. Moreover, after a (function-independent) regime of possible divergence, we witness geometric convergence of G N,γN (f) down to a certain accuracy. As in the case of the continuous or discrete FEs, if the function f is sufficiently analytic with small constant c f then the convergence effectively stops at this point. If not, we witness a further regime of guaranteed superalgebraic convergence. But in both cases, the maximal achievable accuracy is of order ϵ 1−a(γ;T), which, since a(γ;T)→0 as γ→∞, can be made arbitrarily close to ϵ by increasing γ. Note that doing this both improves the condition number of the numerical equispaced FE and yields a less severe rate of exponential divergence in the region N<N 2. As we show via numerical computation of the relevant constants, double oversampling γ=2 with T=2 gives perfectly adequate results in most cases.
The main conclusion of this analysis is that numerical equispaced FEs, unlike their exact counterparts, are able to circumvent the stability barrier of Platte, Trefethen and Kuijlaars to an extent (see Sect. 5.4 for a more detailed discussion). Specifically, the numerical FE F N,γN has a bounded condition number, and for all sufficiently analytic functions—namely, those analytic in the region \(\mathcal {D}(E(T))\)—the convergence is geometric down to a finite accuracy of order c f ϵ 1−a(γ;T). This latter observation, namely the fact that the maximal accuracy is nonzero, is precisely the reason why the stability theorem, which requires geometric convergence for all N, does not apply. On the other hand, for all other analytic functions (or those possessing large constants c f ) the convergence is at least superalgebraic for N>N 1 down to roughly ϵ 1−a(γ;T); again not in contradiction with the theorem. Importantly, one never sees divergence of the numerical FE after the finite breakpoint N 2.
For this reason, we conclude that equispaced FEs are an attractive method for approximations from equispaced data. To further support this conclusion we also remark that although the primary concern of this paper is analytic functions, equispaced FEs are also applicable to functions of finite regularity. In this case, one witnesses algebraic convergence, with the precise order depending solely on the degree of smoothness (see Theorem 2.9).
1.4 Relation to Previous Work
One-dimensional FEs for overcoming the Gibbs and Runge phenomena were studied in [5] and [8], and applications to surface parametrizations considered in [12]. Analysis of the convergence of the exact continuous and discrete FEs was presented by Huybrechs in [22] and Adcock and Huybrechs in [1]. The issue of resolution power was also addressed in the latter. The content of the first half of this paper, namely analysis of exact/numerical FEs, follows on directly from this work.
A different approach to FEs, known as the FC–Gram method, was introduced in [26]. This approach forms a central part of an extremely effective method for solving PDEs in complex geometries [2, 11]. For previous work on using FEs for PDE problems (so-called Fourier embeddings) see [6, 27].
Equispaced FEs of the form studied in this paper were first independently considered by Boyd [5] and Bruno [10], and later by Bruno et al. [12]. In particular, Boyd [5] describes the use of truncated singular value decompositions (SVDs) to compute equispaced FEs, and gives extensive numerical experiments (see also [8]). Bruno focuses on the use of Fourier extensions (also called Fourier continuations in the above references) for the description of complicated smooth surfaces. He suggested in [10] a weighted least squares to obtain a smooth extension for this purpose, with numerical evidence supporting convergence results in [12]. Most recently Lyon has presented an analysis of equispaced FEs computed using truncated SVDs [24]. In particular, numerical stability and convergence (down to close to machine precision) were shown. In Sect. 5.3 we discuss this work in more detail (see, in particular, Remark 5.10), and give further insight into some of the questions raised in [24].
1.5 Outline of the Paper
The outline of the remainder of this paper is as follows. In Sect. 2 we recap properties of the continuous and discrete FEs from [1, 22], including convergence and how to choose the extension parameter T. Ill-conditioning of the coefficient map is proved in Sect. 3, and in Sect. 4 we consider the stability of the numerical extensions and their convergence. Finally, in Sect. 5 we consider the case of equispaced FEs.
A comprehensive list of symbols is given at the end of the paper.
2 Fourier Extensions
In this section we introduce FEs, and recap salient important aspects of [1, 22].
2.1 Two Interpretations of Fourier Extensions
There are two important interpretations of FEs which inform their approximation properties and their stability, respectively. These are described in the next two sections.
2.1.1 Fourier Extensions as Polynomial Approximations
The space \(\mathcal {G}_{N}\) can be decomposed as \(\mathcal {G}_{N} = \mathcal {C}_{N} \oplus \mathcal {S}_{N}\), where
consist of even and odd functions, respectively. Likewise, for f we have
and for any FE f N of f:
Throughout this paper we shall use the notation f N to denote an arbitrary FE of f when not wishing to specify its particular construction. From (2.1), it follows that the problem of approximating f via a FE f N decouples into two problems f e,N ≈f e and f o,N ≈f o in the subspaces \(\mathcal {C}_{N}\) and \(\mathcal {S}_{N}\), respectively, on the half-interval [0,1].
Let us define the mapping y=y(x):[0,1]→[c(T),1] by \(y = \cos \frac{\pi}{T} x\), where \(c(T) = \cos\frac{\pi}{T}\). The functions \(\cos\frac{n \pi }{T} x\) and \(\sin\frac{(n+1) \pi}{T} x / \sin\frac{\pi}{T} x\) are algebraic polynomials of degree n in y. Therefore \(\mathcal {C}_{N}\) and \(\mathcal {S}_{N}\) are (up to multiplication by \(\sin\frac{\pi}{T} x\) for the latter) the subspaces \(\mathbb {P}_{N}\) and \(\mathbb {P}_{N-1}\) of polynomials of degree N and N−1, respectively, in the transformed variable y. Letting
with \(g_{1,N}(y) \in \mathbb {P}_{N}\) and \(g_{2,N}(y) \in \mathbb {P}_{N-1}\), we conclude that the FE approximation f N in the variable x is completely equivalent to two polynomial approximations in the transformed variable y∈[c(T),1].
This fact is central to the analysis of FEs. It allows one to use the rich literature on polynomial approximations to determine the theoretical behavior of the continuous and discrete FEs (see Sect. 2.3).
Remark 2.1
The interpretation of f N in terms of polynomials is solely for the purposes of analysis. We always perform computations in the x-domain using the standard trigonometric basis for \(\mathcal {G}_{N}\) (see Sect. 2.2).
The interval [c(T),1]⊆(−1,1] is not standard. It is thus convenient to map it affinely to [−1,1]. Let
Observe that \(y = y(z) = c(T) + \frac{1-c(T)}{2}(z+1)\). Let m:[0,1]→[−1,1] be the mapping x↦z, i.e.
Note that \(x = m^{-1}(z) = \frac{T}{\pi} \arccos [ c(T) + \frac{1-c(T)}{2}(z+1) ]\). If we now define
then the FE f N is equivalent to the two polynomial approximations
of degree N and N−1 respectively in the new variable z∈[−1,1].
2.1.2 Fourier Extensions as Frame Approximations
Definition 2.2
Let H be a Hilbert space with inner product 〈⋅,⋅〉 and norm ∥⋅∥. A set \(\{ \phi_{n} \} ^{\infty}_{n =1} \subseteq \mathrm {H}\) is a frame for H if (i) \(\mathrm {span}\{ \phi_{n} \}^{\infty}_{n=1}\) is dense in H and (ii) there exist c 1,c 2>0 such that
If c 1=c 2 then \(\{ \phi_{n} \}^{\infty}_{n=1}\) is referred to as a tight frame.
Introduced by Duffin and Schaeffer [16], frames are vitally important in signal processing [14]. Note that all orthonormal, indeed Riesz, bases are frames, but a frame need not be a basis. In fact, frames are typically redundant: any element f∈H may well have infinitely many representations of the form \(f = \sum^{\infty}_{n=1} \alpha_{n} \phi_{n}\) with coefficients \(\{ \alpha_{n} \}^{\infty}_{n=1} \in l^{2}(\mathbb {N})\).
The relevance of frames to Fourier extensions is due to the following observation:
Lemma 2.3
[1]
The set \(\{ \frac{1}{\sqrt {2T}} \mathrm{e}^{{\mathrm{i}}\frac {n \pi}{T} x} \}_{n \in \mathbb {Z}}\) is a tight frame for L2(−1,1) with c 1=c 2=1.
Note that \(\{ \frac{1}{\sqrt{2T}} \mathrm{e}^{{\mathrm{i}}\frac{n \pi}{T} x} \}_{n \in \mathbb {Z}}\) is an orthonormal basis for L2(−T,T): it is precisely the standard Fourier basis on [−T,T]. However, it forms only a frame when considered as a subset of L2(−1,1). This fact means that ill-conditioning may well be an issue in numerical algorithms for computing FEs, due to the possibility of redundancies. As it happens, it is trivial to see that the set \(\{ \frac{1}{\sqrt{2T}} \mathrm{e}^{{\mathrm{i}}\frac {n \pi}{T} x} \}_{n \in \mathbb {Z}}\) is redundant:
Lemma 2.4
Let f∈L2(−1,1) be arbitrary, and suppose that \(\tilde{f} \in \mathrm {L}^{2}(-T,T)\) is such that \(f = \tilde{f}\) a.e. on [−1,1]. If \(\phi _{n}(x) = \frac{1}{\sqrt{2 T}} \mathrm{e}^{{\mathrm{i}}\frac{n \pi}{T} x}\) and \(\alpha_{n} = \langle\tilde{f}, \phi_{n} \rangle_{[-T,T]}\), then
In particular, there are infinitely many sequences \(\{ \alpha_{n} \}_{n \in \mathbb {Z}} \in l^{2}(\mathbb {Z})\) for which \(f = \sum_{n \in \mathbb {Z}} \alpha_{n} \phi_{n}\).
Proof
The sum \(\sum_{n \in \mathbb {Z}} \alpha_{n} \phi_{n}\) is the Fourier series of \(\tilde{f}\) on [−T,T]. Thus it coincides with \(\tilde{f}\) a.e. on [−T,T], and hence f when restricted to [−1,1]. Since there are infinitely many possible \(\tilde{f}\), each giving rise to a different sequence \(\{ \alpha_{n} \}_{n \in \mathbb {Z}}\), the result now follows. □
This lemma is valid for arbitrary f∈L2(−1,1). When f has higher regularity—say f∈Hk(−1,1), where Hk(−1,1) is the kth standard Sobolev space on (−1,1)—it is useful to note that there exist extensions \(\tilde{f}\) with the same regularity on the torus \(\mathbb {T}= [-T,T)\). This is the content of the next result. For convenience, given a domain I, we now write \({\Vert \cdot \Vert }_{\mathrm {H}^{k}(I)}\) for the standard norm on Hk(I):
Lemma 2.5
Let f∈Hk(−1,1) for some \(k \in \mathbb {N}\). Then there exists an extension \(\tilde{f} \in \mathrm {H}^{k}(\mathbb {T})\) of f satisfying \(\| \tilde{f}\| _{\mathrm {H}^{k}(\mathbb {T})} \leq c_{k}(T) \| f \|_{\mathrm {H}^{k}(-1,1)}\), where c k (T)>0 is independent of f. Moreover, \(f = \sum_{n \in \mathbb {Z}} \alpha_{n} \phi _{n}\), where \(\alpha_{n} = \langle\tilde{f}, \phi_{n} \rangle _{[-T,T]}\) satisfies \(\alpha_{n} = \mathcal {O}( n^{-k} ) \) as |n|→∞.
Proof
The first part of the lemma follows directly from the proof of Theorem 2.1 in [1]. The second follows from integrating by parts k times and using the fact that \(\tilde{f}\) is periodic. □
This lemma, which shall be important later when studying numerical FEs, states that there exist representations of f in the frame \(\{ \frac {1}{\sqrt{2T}} \mathrm{e}^{{\mathrm{i}}\frac{n \pi}{T} x} \}_{n \in \mathbb {Z}}\) that have nice (i.e. rapidly decaying) coefficients and which cannot grow large on the extended region [−T,T].
2.2 The Continuous and Discrete Fourier Extensions
We now describe the two types of FEs we consider in the first part of this paper.
2.2.1 The Continuous Fourier Extension
The continuous FE of f∈L2(−1,1), defined by (1.1), is the orthogonal projection onto \(\mathcal {G}_{N}\). Computation of this extension involves solving a linear system. Let us write \(F_{N}(f) = \sum^{N}_{n=-N} a_{n} \phi_{n}\) with unknowns \(\{ a_{n} \}^{N}_{n=-N}\). If a=(a −N ,…,a N )⊤ and b=(b −N ,…,b N )⊤, where
and \(A \in \mathbb {C}^{(2N+1) \times(2N+1)}\) is the matrix with (n,m)th entry
then a is the solution of the linear system Aa=b. We refer to the values \(\{ a_{n} \}^{N}_{n=-N}\) as the coefficients of the FE F N (f). Note that the matrix A is a Hermitian positive-definite, Toeplitz matrix with A n,m =A n−m , where \(A_{0} = \frac{1}{T}\) and \(A_{n} = \frac{\sin \frac{n \pi}{T}}{n \pi}\) otherwise. In fact, A coincides with the so-called prolate matrix [31, 33]. We shall discuss this connection further in Sect. 3.2.
For later use, we also note the following characterization of F N (f):
Proposition 2.6
Let F N (f) be the continuous FE (1.1) of a function f, and let h i (z) and h i,N (z) be given by (2.3) and (2.4), respectively (i.e. the symmetric and anti-symmetric parts of f and f N with the coordinate transformed from the trigonometric argument x to the polynomial argument z). Then h 1,N (z) and h 2,N (z) are the truncated expansions of h 1(z) and h 2(z), respectively, in polynomials orthogonal with respect to the weight functions
where \(m(T) = 1 - 2 \,\mathrm{cosec}^{2} ( \frac{\pi}{2T} ) < -1\). In other words, h i,N (z), i=1,2, is the orthogonal projection of h i (z) onto \(\mathbb {P}_{N+1-i}\) with respect to the weighted inner product \(\langle\cdot, \cdot \rangle _{w_{i}}\) with weight function w i .
2.2.2 The Discrete Fourier Extension
The discrete FE \(\tilde{F}_{N}(f)\) is defined by (1.2). To use this extension it is first necessary to choose nodes \(\{ x_{n} \}^{N}_{n=-N}\). This question was considered in [1], and a solution was obtained by exploiting the characterization of FEs as polynomial approximations in the transformed variable z.
A good system of nodes for polynomial interpolation is given by the Chebyshev nodes
Mapping these back to the x-variable and symmetrizing about x=0 leads to the so-called mapped symmetric Chebyshev nodes
This gives a set of 2N+2 nodes. Therefore, rather than (1.2), we define the discrete FE by
from now on, where \(\mathcal {G}'_{N} = \mathcal {C}_{N} \oplus \mathcal {S}_{N+1}\). Exploiting the relation between FEs and polynomial approximations once more, we now obtain the following:
Proposition 2.7
Let \(f_{N} = \tilde{F}_{N}(f) \in \mathcal {G}'_{N}\) be the discrete FE (2.12) based on the nodes (2.11), and let h i (z) and \(h_{i,N}(z) \in \mathbb {P}_{N}\) be given by (2.3) and (2.4), respectively. Then h i,N (z), i=1,2 is the Nth degree polynomial interpolant of h i (z) at the Chebyshev nodes (2.10).
Write \(\phi_{n}(x) = \cos\frac{n \pi}{T} x\), \(\phi_{-(n+1)}(x) = \sin \frac{n+1}{T} \pi x\), \(n \in \mathbb {N}\), and let \(\tilde{F}_{N}(f)(x) = \sum^{N}_{n=-N-1} a_{n} \phi_{n}(x)\). If a=(a −N−1,…,a N )−T and \(\tilde{A} \in \mathbb {R}^{(2N+2) \times(2N+2)}\) has (n,m)th entry
then we have \(\tilde{A} a =\tilde{b}\), where \(\tilde{b} = (\tilde{b}_{-N-1},\ldots,\tilde{b}_{N})^{\top}\) and \(\tilde{b}_{n} = \sqrt{\frac {\pi }{N+1}} f(x_{n})\).
The following lemma concerning the matrix \(\tilde{A}\) will prove useful in what follows:
Lemma 2.8
[1]
The matrix \(A_{W} = (\tilde{A})^{*} \tilde{A}\) has entries
where W is the positive, integrable weight function given by \(W(x) = \frac{\sqrt{2} \pi}{T} \frac{\cos\frac{\pi}{2T} x}{\sqrt{ \cos \frac{\pi}{T} x-\cos \frac{\pi}{T}}}\).
This lemma implies that the left-hand side of the normal equations of the discrete FE are the equations of a continuous FE based on the weighted least-squares minimization with weight function W.
2.3 Convergence of Exact Fourier Extensions
A detailed analysis of the convergence of the exact continuous FE, which we now recap, was carried out in [1, 22]. We commence with the following theorem:
Theorem 2.9
[1]
Suppose that f∈Hk(−1,1) for some \(k \in \mathbb {N}\) and that T>1. If F N (f) is the continuous FE of f defined by (1.1), then
where c k (T)>0 is independent of f and N.
This theorem confirms algebraic convergence of F N (f) whenever the approximated function f has finite degrees of smoothness, and superalgebraic convergence, i.e. faster than any fixed algebraic power of N −1, whenever f∈C∞[−1,1].
Suppose now that f is analytic. Although superalgebraic convergence is guaranteed by Theorem 2.9, it transpires that the convergence is actually geometric. This is a direct consequence of the interpretation of the F N (f) as the sum of two polynomial expansions in the transformed variable z (Proposition 2.6). To state the corresponding theorem, we first require the following definition:
Definition 2.10
The Bernstein ellipse \(\mathcal {B}(\rho) \subseteq \mathbb {C}\) of index ρ≥1 is given by
Given a compact region bounded by the Bernstein ellipse \(\mathcal {B}(\rho)\), we shall write
for its image in the complex x-plane under the mapping x=m −1(z), where m is as in (2.2).
Theorem 2.11
Suppose that f is analytic in \(\mathcal {D}(\rho^{*})\) and continuous on its boundary. Then ∥f−F N (f)∥∞≤c f ρ −N, where ρ=min{ρ ∗,E(T)}, c f >0 is proportional to \(\max_{x \in \mathcal {D}(\rho )}| f(x) |\), and E(T) is as in (1.3).
Proof
A full proof was given in [1, Theorem 2.3]. The expansion g N of an analytic function g in a system of orthogonal polynomials with respect to some integrable weight function satisfies ∥g−g N ∥∞≤c g ρ −N, where c g is proportional to \(\max_{z \in \mathcal {B}(\rho)} | g(z)|\) [30]. In view of Proposition 2.6, it remains only to determine the maximal parameter ρ of Bernstein ellipse \(\mathcal {B}(\rho)\) within which h 1(z) and h 2(z) are analytic.
The mapping z=m(x) introduces a square-root type singularity into the functions h i (z) at the point z=m(T)<−1. Hence the maximal possible value of the parameter ρ satisfies
Observe that if \(\psi(t) = t + \sqrt{t^{2}-1} \) then
Thus, since ρ>1, the solution to (2.16) is precisely ρ=E(T). Conversely, any singularity of f introduces a singularity of h i (z), which also limits this value. Hence we obtain the stated minimum. □
Theorem 2.11 shows that if f is analytic in a sufficiently large region (for example, if f is entire) then the rate of geometric convergence is precisely E(T). Recall that the parameter T can be chosen by the user. In the next section we consider the effect of different choices of T.
Remark 2.12
Although Theorems 2.9 and 2.11 are stated for F N (f), they also hold for the discrete FE \(\tilde {F}_{N}(f)\), since the latter is equivalent to a sum of Chebyshev interpolants (Proposition 2.7).
2.4 The Choice of T
Note that E(T)∼1+π(T−1) as T→1+ and \(E(T) \sim\frac{16}{\pi^{2}} T^{2}\) when T→∞. Thus, small T leads to a slower rate of geometric convergence, whereas large T gives a faster rate. As discussed in [1], however, a larger value of T leads to a worse resolution power, meaning that more degrees of freedom are required to resolve oscillatory behavior. On the other hand, setting T sufficiently close to 1 yields a resolution power that is arbitrarily close to optimal.
In [1] a number of fixed values of T were used in numerical experiments. These typically give good results, with small values of T being particularly well suited to oscillatory functions. Another approach for choosing T was also discussed. This involves letting
where ϵ tol≪1 is some fixed tolerance (note that this is very much related to the Kosloff Tal-Ezer map in spectral methods for PDEs [4, 23]—see [1] for a discussion). This choice of T, which now depends on N, is such that E(T)−N=ϵ tol. Although this limits the best achievable accuracy of the FE with this approach to \(\mathcal {O}( \epsilon_{\mathrm{tol}} ) \), setting ϵ tol=10−14 is normally sufficient in practice. Numerical experiments in [1] indicate that this works well, especially for oscillatory functions. In fact, since
this approach has formally optimal resolution power.
Remark 2.13
The strategy (2.18) is particularly good for oscillatory problems. However, if this is not a concern, a practical choice appears to be T=2. In this case, the FE has a particular symmetry that can be exploited to allow for its efficient computation in only \(\mathcal {O}( N (\log N)^{2} ) \) operations [25].
3 Condition Numbers of Exact Fourier Extensions
The redundancy of the frame \(\{ \frac{1}{\sqrt{2 T}} \mathrm{e}^{{\mathrm{i}}\frac {n \pi }{T} \cdot} \}_{n \in \mathbb {Z}}\) means that the matrices associated with the continuous and discrete FEs are ill-conditioned. We next derive bounds for the condition number of these matrices. The spectrum of A is considered further in Sect. 3.2, and the condition numbers of the FE mappings f↦F N (f) and \(f \mapsto\tilde{F}_{N}(f)\) are discussed in Sect. 3.4.
3.1 The Condition Numbers of the Continuous and Discrete FE Matrices
Theorem 3.1
Let A be the matrix (2.8) of the continuous FE. Then the condition number of A is \(\mathcal {O}( E(T)^{2N} ) \) for large N. Specifically, the maximal and minimal eigenvalues satisfy
where c 1(T) and c 2(T) are positive constants with \(c_{1}(T),c_{2}(T) = \mathcal {O}( 1 ) \) as T→1+.
Proof
It is a straightforward exercise to verify that
Using the fact that ∥ϕ∥≤∥ϕ∥[−T,T], we first notice that λ max(A)≤1. On the other hand, setting \(\phi=\frac{1}{\sqrt{2 T}}\), we find that λ max(A)≥T −1, which completes the result for λ max(A).
We now consider λ min(A). Recall that any \(\phi\in \mathcal {G}_{N}\) can be decomposed into even and odd parts ϕ e and ϕ o, with each function corresponding to a polynomial in the transformed variable z. Hence,
where w i , i=1,2, is given by (2.9). Since the weight function w i is integrable, we have
where \(C_{i}(T) = \int^{1}_{m(T)} \mathrm{d} w_{i}\), i=1,2. Moreover, by Remez’s inequality,
where \(T_{N} \in \mathbb {P}_{N}\) is the Nth Chebyshev polynomial. Since T N is monotonic outside [−1,1], we have ∥T N ∥∞,[m(T),1]=|T N (m(T))|. Moreover, due to the formula
an application of (2.17) gives
Next we note that w 1(z)≥D 1(T) and \(w_{2}(z) \geq D_{2}(T) \sqrt{1-z^{2}} \), ∀z∈[−1,1], for positive constants D 1(T) and D 2(T). Moreover, there exist constants d 1,d 2>0 independent of T such that
where \(v(z) = \sqrt{1-z^{2}}\) (this follows from expanding p in orthonormal polynomials \(\{ p_{n} \}_{n \in \mathbb {N}}\) on [−1,1] corresponding to the weight function w(z)=1, i.e. Legendre polynomials, or w(z)=v(z), i.e. Chebyshev polynomials of the second kind, and using the known estimate \(\| p_{n} \|_{\infty} = \mathcal {O}( n^{\frac{1}{2}} ) \) for the former and \(\| p_{n} \|_{\infty} = \mathcal {O}( n^{\frac{3}{2}} ) \) for the latter [3, Chapt. X]). Therefore
Substituting (3.4), (3.5) and (3.6) into (3.3) now gives
which gives the lower bound in (3.1).
For the upper bound, we set p 2=0 and p 1=T N in (3.3) to give
Using (3.5) we note that \(\| T_{N} \|_{\infty,[m(T),1]} \geq \frac{1}{2} E(T)^{N}\). Recall also that ∥p∥∞≤d 1 N∥p∥, \(\forall p \in \mathbb {P}_{N}\). Scaling this inequality to the interval [m(T),1] now gives
Note also that w 1(z)≥D 3(T), ∀z∈[m(T),1]. Therefore,
Substituting this into (3.7) now gives the result. □
We now consider the case of the discrete FE:
Theorem 3.2
Let \(\tilde{A}\) be the matrix (2.13) of the discrete FE. Then the condition number of \(\tilde{A}\) is \(\mathcal {O}( E(T)^{N} ) \) for large N. Specifically, the maximal and minimal singular values of \(\tilde{A}\) satisfy
where c 1(T),c 2(T),d 1(T),d 2(T) are positive constants that are \(\mathcal {O}( 1 ) \) as T→1+.
Proof
Using Lemma 2.8, the values \(\sigma ^{2}_{\min}(\tilde{A})\) and \(\sigma^{2}_{\max}(\tilde{A})\) may be expressed as in (3.2) (with ∥⋅∥ replaced by ∥⋅∥ W ). Note that \(W(0) \| \phi\|^{2} \leq\| \phi\|^{2}_{W} \leq\| \phi\|^{2}_{\infty} \int^{1}_{-1} \mathrm{d} W\). It is a straightforward exercise (using the bound (3.6) and the fact that ϕ can be expressed as the sum of two polynomials) to show that \(\| \phi\|_{\infty} \leq C_{1}(T) N^{\frac{3}{2}} \| \phi\|\), where \(C_{1}(T) = \mathcal {O}( 1 ) \) as T→1+. Thus we obtain
The result now follows immediately from the bounds (3.1). □
Theorems 3.1 and 3.2 demonstrate that the condition numbers of the continuous and discrete FE matrices grow exponentially in N. This establishes conclusion 1. of Sect. 1.
Remark 3.3
Although exponentially large, the matrix of the discrete FE is substantially less poorly conditioned than that of the continuous FE. In particular, the condition number is of order E(T)N as opposed to E(T)2N. This can be understood using Lemma 2.8. The normal form \(A_{W} = (\tilde{A})^{*} \tilde{A}\) of the discrete FE matrix is a continuous FE matrix with respect to the weight function A W . Hence \(\kappa(\tilde{A}) =\sqrt {\kappa(A_{W})} \approx\sqrt{\kappa(A)} \approx E(T)^{N}\). As we shall see later, this property also translates into superior performance of the numerical discrete FE over its continuous counterpart (see Sect. 4.2).
Since the constants in Theorems 3.1 and 3.2 are bounded as T→1+, this allows one also to determine the condition number in the case that T→1+ as N→∞ (see Sect. 2.4). In particular, if T is given by (2.18), then κ(A) and \(\kappa (\tilde{A})\) are (up to possible small algebraic factors in N) of order (ϵ tol)−2 and (ϵ tol)−1.
3.2 The Singular Value Decomposition of A
Although we have now determined the condition number of A, it is possible to give a rather detailed analysis of its spectrum. This follows from the identification of A with the well-known prolate matrix, which was analyzed in detail by Slepian [31, 33]. We now review some of this work.
Following Slepian [31], let \(P(N,W) \in \mathbb {C}^{N \times N}\) be the prolate matrix with entries
where \(0<W <\frac{1}{2}\) is fixed, and write 1>λ 0(N,W)>⋯>λ N−1(N,W)>0 for its eigenvalues. Note that
The following asymptotic results are found in [31]:
-
(i)
For fixed and small k,
$$ 1- \lambda_{k}(N,W) \sim\sqrt {\pi} (k!)^{-1} 2^{(14k+9)/4} \alpha^{(2k+1)/4} (2-\alpha )^{-(k+1/2)} N^{k+1/2} \beta^{-N}, $$(3.10)where α=1−cos2πW and \(\beta= \frac{\sqrt{2}+\sqrt{\alpha}}{\sqrt{2}-\sqrt{\alpha}} \).
-
(ii)
For large N and k with k=⌊2WN(1−ϵ)⌋ and 0<ϵ<1, \(1 - \lambda_{k}(N,W) \sim \mathrm{e}^{-c_{1} - c_{2} N}\) for explicitly known constants c 1,c 2 depending only on W and ϵ.
-
(iii)
For large N and k with k=⌊2WN+(b/π)logN⌋, \(\lambda_{k}(N,W) \sim\frac{1}{1+\mathrm{e}^{\pi b}}\).
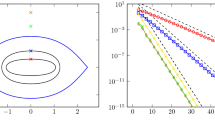
(Slepian also derives similar asymptotic results for the eigenvectors of P(N,W) [31].) From these results we conclude that the eigenvalues of the prolate matrix cluster exponentially near 0 and 1 and have a transition region of width \(\mathcal {O}( \log N ) \) around k=2WN. This is shown in Fig. 1.

The matrix A of the continuous FE is precisely the prolate matrix \(P(2N+1,\frac{1}{2T})\). In this case, the parameter β in (3.10) is given by
Applying Slepian’s analysis, we now see that the eigenvalues of A cluster exponentially at rate E(T)2 near zero and one (note that A corresponds to a prolate matrix of size 2N), and in particular, that the condition number is \(\mathcal {O}( E(T)^{2N} ) \). The latter estimate agrees with that given in Theorem 3.1. We remark, however, that Theorem 3.1 gives bounds for the minimal eigenvalue of A that hold for all N and T, unlike (3.10), which holds only for fixed T and sufficiently large N. Hence Theorem 3.1 remains valid when T is varied with N, an option which, as discussed in Sect. 2.4, can be advantageous in practice.
Since the matrix \(\tilde{A}\) of the discrete FE is related to A (see Lemma 2.8), we expect a similar structure for its singular values. This is illustrated in Fig. 1. As is evident, the only qualitative difference between \(\tilde{A}\) and A is found in the large singular values. The other features—the narrow transition region and the exponential clustering of singular values near 0—are much the same.
Remark 3.4
The choice T=2 (\(W = \frac{1}{4}\)) is special. As shown by (3.9), the eigenvalues λ k (N,W) are symmetric in this case, and the transition region occurs at \(k = \frac{1}{2} N\). This is unsurprising. When T=2, the frame \(\{ \mathrm{e}^{{\mathrm{i}}\frac{n \pi}{2} x} \}_{n \in \mathbb {Z}}\) decomposes into two orthogonal bases, related to the sine and cosine transforms. Using this decomposition and the associated discrete transforms for each basis, M. Lyon has introduced an \(\mathcal {O}( N (\log N)^{2} ) \) complexity algorithm for computing FEs [25].
3.3 Numerical Examples
We now consider several numerical examples of the continuous and discrete FEs. In Fig. 2 we plot the error ∥f−f N ∥∞ against N for various choices of f. Here the extension f N is the numerically computed continuous or discrete FE—i.e. the result of solving the corresponding linear system in standard precision (recall Remark 1.2). Henceforth, we use the notation G N (f) and \(\tilde{G}_{N}(f)\) for these numerical extensions, so as to distinguish them from their exact counterparts F N (f) and \(\tilde{F}_{N}(f)\). Note that the word ‘exact’ in this context refers to exact arithmetic. We do not mean exact in the sense that F N (f)=f for \(f \in \mathcal {G}_{N}\).

The error ∥f−f N ∥∞, where f N =G N (f) (squares and circles) or \(f_{N} = \tilde{G}_{N}(f)\) (crosses and diamonds) and T=2 (squares/crosses) or T=T(N;ϵ tol) (circles/diamonds) with ϵ tol=10−14
At first sight, Fig. 2 appears somewhat surprising: for all three functions we obtain good accuracy, and there is no drift or growth in the error, even in the case where f is nonsmooth or has a complex singularity near x=0. Evidently the ill-conditioning of the FE matrices established in Theorems 3.1 and 3.2 appears to have little effect on the numerical extensions G N (f) and \(\tilde{G}_{N}(f)\). The purpose of Sect. 4 is to offer an explanation of this phenomenon.
In Fig. 2 we also compare two choices of T: fixed T=2 and the N-dependent value (2.18) with ϵ tol=10−14. Note that the latter typically outperforms the fixed value T=2, especially for oscillatory functions. This is unsurprising in view of the discussion in Sect. 2.4.
Figure 2 also illustrates an important disadvantage of the continuous FE: namely, the approximation error levels off at around \(\sqrt{\epsilon_{\mathrm{mach}}}\), where ϵ mach≈10−16 is the machine precision used, as opposed to around ϵ mach for the discrete extension. Our analysis in Sect. 4 will confirm this phenomenon. Note that the differing behavior between the continuous and discrete extensions in this respect can be traced back to the observation made in Remark 3.3.
3.4 Condition Numbers of the Exact Continuous and Discrete FE Mappings
The exponential growth in the condition numbers of the continuous and discrete FE matrices imply extreme sensitivity in the FE coefficients to perturbations. However, the numerical results of Fig. 2 indicate that the FE approximations themselves are far more robust. Although we shall defer a full explanation of this difference to Sect. 4, it is possible to give a first insight by determining the condition numbers of the mappings F N and \(\tilde{F}_{N}\).
For vectors \(b \in \mathbb {C}^{2N+1}\) and \(\tilde{b} \in \mathbb {C}^{2N+2}\) let us write, with slight abuse of notation, F N (b) and \(\tilde{F}_{N}(\tilde{b})\) for the corresponding continuous and discrete Fourier extensions whose coefficient vectors are the solutions of the linear systems Aa=b and \(\tilde{A} a = \tilde{b}\), respectively. We now define the condition numbers
Here ∥⋅∥ denotes the usual l 2 vector norm, and W is the weight function of Lemma 2.8. Note that (3.11) gives the absolute condition numbers of F N and \(\tilde {F}_{N}\), as opposed to the more standard relative condition number [32]. The key results of this paper can easily be reformulated for the latter. However, we shall use (3.11) throughout, since it coincides with the definition given in [28] for linear mappings such as FEs. The work of [28] will be particularly relevant when considering equispaced FEs in Sect. 5.
We now have the following result:
Lemma 3.5
The condition numbers of the exact continuous and discrete FEs satisfy
Proof
Write \(F_{N}(b) = \sum^{N}_{n=-N} a_{n} \phi_{n}\), where Aa=b. We have ∥F N (b)∥2=a ∗ Aa=b ∗ A −1 b, and therefore \(\kappa(F_{N}) = 1/\sqrt{\lambda_{\min}(A)}\), as required. For the second result, we note that \(\| \tilde{F}_{N}(\tilde{b}) \|^{2} = a^{*} A_{W} a\), where \(A_{W} = (\tilde{A})^{*} \tilde{A}\) is the matrix of Lemma 2.8. Since \(\tilde{A} a = \tilde{b}\) the second result now follows. □
As with the FE matrices, this lemma shows that condition number of the discrete mapping \(\tilde{F}_{N}\), which is identically one, is much better than that of the continuous mapping F N . Similarly, the reason can be traced back to Remark 3.3. Note that this lemma establishes 2. of Sect. 1.
At first, it may seem that the fact that \(\kappa(\tilde{F}_{N}) =1 \) explains the observed numerical stability in Fig. 2. However, since λ min(A) is exponentially small (Theorem 3.1), the above lemma clearly does not explain the lack of drift in the numerical error in the case of the continuous FE. This is symptomatic of a larger issue: in general, the exact FEs F N (f) and \(\tilde{F}_{N}(f)\) differ substantially from their numerical counterparts G N (f) and \(\tilde{G}_{N}(f)\). As we show in the next section, there are important differences in both their stability and their convergence. In particular, any analysis based solely on F N and \(\tilde{F}_{N}\) is insufficient to describe the behavior of the numerical extensions G N and \(\tilde{G}_{N}\).
4 The Numerical Continuous and Discrete Fourier Extensions
We now analyze the numerical FEs G N and \(\tilde{G}_{N}\), and describe both when and how they differ from the exact extensions F N and \(\tilde{F}_{N}\).
4.1 The Norm of the Exact FE Coefficients
In short, the reason for this difference is as follows. Since the FE matrices A and \(\tilde{A}\) are so ill-conditioned, the coefficients of the exact FEs F N and \(\tilde{F}_{N}\) will not usually be obtained in finite precision computations. To explain exactly how this affects stability and convergence, we first need to determine when this will occur. We require the following theorem:
Theorem 4.1
Suppose that f is analytic in \(\mathcal {D}(\rho^{*})\) and continuous on its boundary. If \(a \in \mathbb {C}^{2N+1}\) is the vector of coefficients of the continuous FE F N (f) then
where c f is proportional to \(\max_{x \in \mathcal {D}(\rho)} | f(x) |\). If f∈L2(−1,1), then
for some c>0 independent of f and N.
Proof
Write F N (f)=f N =f e,N +f o,N , where f e,N and f o,N are the even and odd parts of f N , respectively. Since the set \(\{ \phi_{n} \}_{n \in \mathbb {Z}}\) is orthonormal over [−T,T] we find that
Recall from Sect. 2.1.1 that f e,N (x)=h 1,N (z) and \(f_{\mathrm{o},N}(x) =\sin ( \frac{\pi}{T} m^{-1}(z) ) h_{2,N}(z)\), where \(h_{i,N} \in \mathbb {P}_{N+1-i}\), i=1,2, is defined by (2.4). Thus, ∥a∥≤c(∥h 1,N ∥∞,[m(T),1]+∥h 2,N ∥∞,[m(T),1]) for some c>0. Consider h 1,N (z). This is precisely the expansion of the function h 1(z)=f 1(m −1(z)) in polynomials \(\{ p_{n} \}^{\infty }_{n=0}\) orthogonal with respect to the weight function w 1: i.e. \(h_{1,N} = \sum^{N}_{n=0} \langle h_{1}, p_{n} \rangle_{w_{1}} p_{n}\). Therefore
It is known that ∥p n ∥∞,[m(T),1]≤cE(T)n [22]. Also, since h 1 is analytic in \(\mathcal {B}(\rho ^{*})\) we have \(| \langle h_{1}, p_{n} \rangle_{w_{1}} | \leq c_{f} (\rho^{*})^{-n}\). Hence
which gives (4.1). For (4.2) we use the bound \(| \langle h_{1}, p_{n} \rangle_{w_{1}} | \leq\| h_{1} \|_{w_{1}} \leq c \| f \|\) instead. □
Corollary 4.2
Let f be as in Theorem 4.1. Then the vector of coefficients \(a \in \mathbb {C}^{2N+2}\) of the discrete Fourier extension \(\tilde{F}_{N}(f)\) of f satisfies the same bounds as those given in Theorem 4.1.
Proof
The functions h i,N , i=1,2 are the polynomial interpolants of h i at the nodes (2.10) (Proposition 2.7). Write \(h_{i,N}(z) = \sum^{N}_{n=0} \tilde{d}_{n} T_{n}(z)\), where T n (z) is the nth Chebyshev polynomial, and let \(\hat{d}_{n} = \langle h_{i}, T_{n} \rangle_{w}\) be the Chebyshev polynomial coefficient of h i . Note that \(| \hat{d}_{n} | \leq c_{f} (\rho ^{*})^{-n}\). Due to aliasing formula \(\tilde{d}_{n} = \hat{d}_{n} + \sum_{k \neq0} (\hat{d}_{2kN+n} + \hat{d}_{2kN-n})\) (see [13, Eq. (2.4.20)]) we obtain
The result now follows along the same lines as the proof of Theorem 4.1. □
To compute the continuous or discrete FE we need to solve the linear system Aa=b (respectively \(\tilde{A} a =\tilde{b}\)). When N is large, the columns of A (\(\tilde{A}\)) become near-linearly dependent, and, as shown in Sect. 3.2, the numerical rank of A is roughly 1/T times its dimension. Now suppose we solve Aa=b with a standard numerical solver. Loosely speaking, the solver will use the extra degrees of freedom to construct approximate solutions a′ with small norms. The previous theorem and corollary therefore suggest the following. In general, only in those cases where f is analytic with ρ ∗≥E(T) can we expect the theoretical coefficient vector a to be produced by the numerical solver for all N. Outside of this case, we may well have a′≠a for sufficiently large N, due to the potential for exponential growth of the latter. Hence, in this case, the numerical extension G N (f) will not coincide with the exact extension F N (f).
This raises the following question: if the numerical solver does not give the exact coefficients vector, then what does it yield? The following proposition confirms the existence of infinitely many approximate solutions of the equations Aa=b with small norm coefficient vectors:
Proposition 4.3
Suppose that f∈Hk(−1,1). Then there exist \(a^{[N]} \in \mathbb {C}^{2N+1}\), \(N \in \mathbb {N}\), satisfying
and
where c k (T) is the constant of Lemma 2.5. Moreover, if \(g_{N} = \sum_{|n| \leq N} a^{[N]}_{n} \phi_{n}\) then
Proof
Let \(\tilde{f} \in \mathrm {H}^{k}(\mathbb {T})\) be the extension guaranteed by Lemma 2.5, and write a [N] for the vector of its first 2N+1 Fourier coefficients on \(\mathbb {T}= [-T,T)\). By Bessel’s inequality, \(\| a^{[N]} \| \leq\| \tilde{f} \|_{[-T,T]} \leq c_{k}(T) \| f \|_{\mathrm {H}^{k}(-1,1)}\), which gives (4.3). For (4.4), we merely note that (Aa [N]−b) n =〈f−g N ,ϕ n 〉. Using the frame property (2.5) we obtain ∥Aa [N]−b∥≤∥f−g N ∥. Thus, (4.4) follows directly from (4.5), and the latter is a standard result of Fourier analysis (see [13, eq. (5.1.10)], for example). □
This proposition states that there exist vectors with norms bounded independently of N that solve the equations Aa=b up to an error of order N −k. Moreover, these vectors yield extensions which converge algebraically fast to f at rate k. Whilst it does not imply that these are the vectors produced by the numerical solver, it does indicate that, in the case where the exact extension F N (f) or \(\tilde{F}_{N}(f)\) has a large coefficient norm, geometric convergence of the numerical extension G N (f) or \(\tilde{G}_{N}(f)\) may be sacrificed for superalgebraic convergence so as to retain boundedness of the computed coefficients.
This hypothesis is verified numerically in Fig. 3 (all computations were carried out in Mathematica, with additional precision used to compute the exact FEs and standard precision used otherwise). Geometric convergence of the exact extension is replaced by slower, but still high-order convergence for sufficiently large N. Note that the ‘breakpoint’ occurs at roughly the same value of N regardless of the function being approximated. Moreover, the breakpoint occurs at a larger value of N for the discrete extension than for the continuous extension.

Comparison of the numerical continuous and discrete FEs G N (f) and \(\tilde{G}_{N}(f)\) (squares and circles) and their exact counterparts F N (f) and \(\tilde{F}_{N}(f)\) (crosses and diamonds) for T=2. Left: the uniform error ∥f−f N ∥∞ against N. Right: the norm ∥a∥ of the coefficient vector. Top row: \(f(x) = \frac {1}{1+16 x^{2}}\). Middle row: \(f(x) = \frac{1}{8-7 x}\). Bottom row: \(f(x) = 1+\frac{\cosh40 x}{\cosh40}\)
These observations will be established rigorously in the next section. However, we now make several further comments on Fig. 3. First, note that the breakdown of geometric convergence is far less severe for the classical Runge function \(f(x) = \frac{1}{1+16 x^{2}}\) than for the functions \(f(x) = \frac{1}{8-7 x}\) and \(f(x) = 1 + \frac{\cosh40 x}{\cosh 40}\). This can be explained by the behavior of these functions near x=±1. The Runge function \(f(x) = \frac{1}{1+16 x^{2}}\) is reasonably flat near x=±1. Hence it possesses extensions with high degrees of smoothness which do not grow large on the extended domain [−T,T]. Conversely, the other two functions have boundary layers near x=1 (also x=−1 for the latter). Therefore any smooth extension will be large on [−T,T], and by Parseval’s relation, the coefficient vectors corresponding to the Fourier series of this extension will also have large norm.
Second, although it is not apparent from Fig. 3 that the convergence rate beyond the breakpoint is truly superalgebraic, this is in fact the case. This is confirmed by Fig. 4. In the right-hand diagram we plot the error against N in log–log scale. The slight downward curve in the error indicates superalgebraic convergence. Had the convergence rate been algebraic of fixed order, then the error would have followed a straight line.

Comparison of the numerical continuous and discrete FEs G N (f) and \(\tilde{G}_{N}(f)\) (squares and circles) and their exact counterparts F N (f) and \(\tilde{F}_{N}(f)\) (crosses and diamonds) for T=2 and \(f(x) = \frac{1}{101-100 x}\). Left: the uniform error in log scale. Right: the uniform error in log–log scale
4.2 Analysis of the Numerical Continuous and Discrete FEs
We now wish to analyze the numerical extensions G N (f) and \(\tilde{G}_{N}(f)\). Since the numerical solvers used in environments such as Matlab or Mathematica are difficult to analyze directly, we shall look at the result of solving Aa=b (or \(\tilde{A} a =\tilde{b}\)) with a truncated singular value decomposition (SVD). This represents an idealization of the numerical solver. Indeed, neither Matlab’s ∖ or Mathematica’s LeastSquares actually performs a truncated SVD. However, in practice, this simplification appears reasonable: numerical experiments indicate that these standard solvers give roughly the same approximation errors as the truncated SVD with suitably small truncation parameter (typically ϵ=10−14). We shall also assume throughout that the truncated SVD is computed without error. However, this also seems fair: in experiments, we observe that the finite-precision SVD gives similar results to the numerical solver whenever the tolerance is sufficiently small.
Suppose that A (respectively \(\tilde{A}\)) has SVD USV ∗ with S being the diagonal matrix of singular values. Given a truncation parameter ϵ>0, we now consider the solution
where S † is the diagonal matrix with nth entry 1/σ n if σ n >ϵ and 0 otherwise. We write
for the corresponding FE. Suppose that \(v_{n} \in \mathbb {C}^{2N+1}\) is the right singular vector of A with singular value σ n , and let
be the Fourier series corresponding to v n . Note that the functions Φ n are orthonormal with respect to 〈⋅,⋅〉[−T,T] and span \(\mathcal {G}_{N}\). Also, if we define \(\mathcal {G}_{N,\epsilon} = \mathrm {span}\{ \varPhi_{n} : \sigma_{n} > \epsilon\} \subseteq \mathcal {G}_{N}\), then we have \(H_{N,\epsilon }(f) \in \mathcal {G}_{N,\epsilon}\).
We now consider the cases of the continuous and discrete FEs separately.
4.2.1 The Continuous Fourier Extension
In this case, since A is Hermitian and positive definite, the singular vectors v n are actually eigenvectors of A with Av n =σ n v n . By definition, we have 〈Φ n ,Φ m 〉=(v n )∗ Av m =σ n δ n,m , and therefore
Our main result is as follows:
Theorem 4.4
Let f∈L2(−1,1) and suppose that H N,ϵ (f) is given by (4.7). Then
and
Proof
The function H N,ϵ (f) is the orthogonal projection of f onto \(\mathcal {G}_{N,\epsilon}\) with respect to 〈⋅,⋅〉. Hence for any \(\phi\in \mathcal {G}_{N}\) we have ∥f−H N,ϵ (f)∥≤∥f−H N,ϵ (ϕ)∥≤∥f−ϕ∥+∥ϕ−H N,ϵ (ϕ)∥. Consider the latter term. Since \(\phi\in \mathcal {G}_{N}\), the observation that the functions Φ n are also orthonormal on [−T,T] gives
This yields (4.8). For (4.9) we first write ∥H N,ϵ (f)∥[−T,T]≤∥H N,ϵ (f−ϕ)∥[−T,T]+∥H N,ϵ (ϕ)∥[−T,T]. By orthogonality,
Since H N,ϵ is an orthogonal projection, we conclude that \(\| H_{N,\epsilon}(f-\phi) \|^{2}_{[-T,T]} \leq\frac{1}{\epsilon} \| f - \phi\|^{2}\), which gives the first term in (4.9). For the second, we notice that
since \(\phi\in \mathcal {G}_{N}\). □
This theorem allows us to explain the behavior of the numerical FE G N (f). Suppose that f is analytic in \(\mathcal {D}(\rho)\) and continuous on its boundary, where ρ<E(T) and \(\mathcal {D}(\rho)\) is as in Theorem 2.11. Set ϕ=F N (f) in (4.8), where F N (f) is the exact continuous FE. Then Theorems 2.11 and 4.1 give
For small N, the first term in the brackets dominates, and we see geometric convergence of H N,ϵ (f), and therefore also G N (f), at rate ρ. Convergence continues as such until the breakpoint
at which point the second term dominates and the bound begins to increase. On the other hand, Proposition 4.3 establishes the existence of functions \(\phi\in \mathcal {G}_{N}\) with bounded coefficients which approximate f to any given algebraic order. Substituting such a function ϕ into (4.8) gives
Therefore, once N>N 0(ϵ,T) we expect at least superalgebraic convergence of H N,ϵ (f) down to a maximal achievable accuracy of order \(\sqrt{\epsilon} \| f \|\). Note that at the breakpoint N=N 0, the error satisfies
If f is analytic in \(\mathcal {D}(E(T))\), and if \(c_{f} = \max_{x \in \mathcal {D}(\rho)} | f(x) |\) is not too large, then f is already approximated to order \(\sqrt{\epsilon}\) accuracy at this point. It is only in those cases where either ρ<E(T) or where c f is large (or both) that one sees the second phase of superalgebraic convergence.
Theorem 4.1 also explains the behavior of the coefficient norm ∥a ϵ ∥. Observe that breakpoint N 0(ϵ,T) is (up to a small constant) the largest N for which all singular values of A are included in its truncated SVD (see Theorem 3.1). Thus, when N<N 0(ϵ,T), we have H N,ϵ (f)=F N (f), and Theorem 4.1 indicates exponential growth of ∥a ϵ ∥. On the other hand, once N>N 0(ϵ,T), we use (4.9) to obtain
In particular, for N>N 0(ϵ,T), we expect decay of ∥a ϵ ∥ down from its maximal value at N=N 0(ϵ,T).
This analysis is corroborated in Fig. 5, where we plot the error and coefficient norm for the truncated SVD extension for various test functions. Note that the maximal achievable accuracy in all cases is order \(\sqrt{\epsilon}\), consistently with our analysis. Moreover, for the meromorphic functions \(f(x) = \frac{1}{1+16 x^{2}}\) and \(f(x) = \frac{1}{8-7 x}\) we see initial geometric convergence followed by slower convergence after N 0, again as our analysis predicts. The qualitative difference in convergence for these functions in the regime N>N 0 is due to the contrasting behavior of their derivatives (recall the discussion in Sect. 4.1). On the other hand, the convergence effectively stops at N 0 for f(x)=x, since this function has small constant c f and is therefore already resolved down to order \(\sqrt{\epsilon}\) when N=N 0.

Error (left) and coefficient norm (right) against N for the continuous FE with T=2, where \(f(x) = \frac{1}{1+16 x^{2}}\) (top row), \(f(x)= \frac{1}{8-7 x} \) (middle row) and f(x)=x (bottom row). Squares, circles, crosses and diamonds correspond to the truncated SVD extension H N,ϵ (f) with ϵ=10−6,10−12,10−18,10−24, respectively, and pluses correspond to the exact extension F N (f)
Since N 0(10−6,2)≈4, N 0(10−12,2)≈8, N 0(10−18,2)≈12, and N 0(10−24,2)≈16, Fig. 5 also confirms the expression (4.11) for the breakpoint in convergence. In particular, the breakpoint is independent of the function being approximated. This latter observation is unsurprising. As noted, N 0(ϵ,T) is the largest value of N for which H N,ϵ (f) coincides with F N (f). Beyond this point, H N,ϵ (f) will not typically agree with F N (f), and thus we cannot expect further geometric convergence in general. Note that our analysis does not rule out geometric convergence for N>N 0. There may well be certain functions for which this occurs. However, extensive numerical tests suggest that in most cases, one sees only superalgebraic convergence in this regime, and indeed, this is all that we have proved.
Remark 4.5
At first sight, it may appear counterintuitive that one can still obtain good accuracy when excluding all singular values below a certain tolerance. However, recall that we are not interested in the accuracy of computing a, but rather the accuracy of F N (f) on the domain [−1,1]. Since the nth singular value σ n is equal to \(\| \varPhi_{n} \|^{2} / \| \varPhi_{n} \| ^{2}_{[-T,T]}\), the functions Φ n excluded from H N,ϵ (f) are precisely those for which \(\| \varPhi_{n} \|^{2} < \epsilon\| \varPhi _{n} \|^{2}_{[-T,T]}\). In other words, they have little effect on F N (f) in [−1,1].
In Fig. 6 we plot the functions Φ n for several n. Note that these functions are precisely the discrete prolate spheroidal wavefunctions of Slepian [31]. As predicted, when n is small, the function Φ n is large in [−1,1] and small in [−T,T]∖[−1,1]. When n is in the transition region (n≈2N/T, see Sect. 3.2), the function Φ n is roughly of equal magnitude in both regions, and for n≈2N, Φ n is much smaller in [−1,1] than on [−T,T]. Note also that Φ n is increasingly oscillatory in [−1,1] as n increases, and decreasingly oscillatory in [−T,T]∖[−1,1]. This follows from the fact that Φ n has precisely n zeroes in [−1,1] and 2N−n zeroes in [−T,T]∖[−1,1] [31]. Such behavior also implies that any ‘nice’ function will eventually be well approximated by functions Φ n corresponding to ‘nice’ eigenvalues, as expected.

The SVD functions |Φ n (x)| for n=0, n=20 and n=40, where N=20 and T=2
4.2.2 The Discrete Fourier Extension
In this case, we have \(( \varPhi_{n} , \varPhi_{m})_{N} = \sigma^{2}_{n} \delta _{n,m}\), where
is the discrete inner product corresponding to the quadrature nodes \(\{x_{n} \}^{N}_{n=-N-1}\). Therefore
is the orthogonal projection of f onto \(\mathcal {G}'_{N,\epsilon}\) with respect to the discrete inner product (⋅,⋅) N .
Theorem 4.6
Let f∈L∞(−1,1) and \(\tilde {H}_{N,\epsilon}(f)\) be given by (4.14). Then
and
where Q(N;ϵ)=|{n:σ n >ϵ}|≤2(N+1) and W is the weight function of Lemma 2.8.
Proof
By the triangle inequality,
Consider the second term. Since \(\phi\in \mathcal {G}'_{N}\), and the quadrature is exact on \(\mathcal {G}'_{N}\), we have
For the third term, let g be arbitrary. Then \((\tilde{H}_{N,\epsilon}(g),\tilde{H}_{N,\epsilon}(g))_{N} = \sum_{n : \sigma_{n} > \epsilon} \frac{1}{\sigma^{2}_{n}} | (g, \varPhi_{n})_{N} |^{2}\). Hence
since \((\varPhi_{n},\varPhi_{n})_{N} = \sigma^{2}_{n}\). It is straightforward to show that \((g,g)_{N} \leq2 \pi\| g \|^{2}_{\infty}\). Setting g=f−ϕ now gives the corresponding term in (4.15), and completes its proof. For (4.16), we proceed as in the proof of Theorem 4.4. Note that
for any g∈L∞(−1,1). Also,
The result now follows by writing \(\| \tilde{H}_{N,\epsilon}(f) \| _{[-T,T]} \leq\| \tilde{H}_{N,\epsilon}(f-\phi) \|_{[-T,T]} +\| \tilde{H}_{N,\epsilon}(\phi) \|_{[-T,T]}\) and using (4.17)–(4.19). □
As with the continuous FE, this theorem allows us to analyze the numerical discrete extension \(\tilde{G}_{N}(f)\). Once more we deduce geometric convergence in N up to the function-independent breakpoint
with superalgebraic convergence beyond this point. These conclusions are confirmed in Fig. 7. Note, however, two key differences between the continuous and discrete FE. First, the bound (4.15) involves ϵ, as opposed to \(\sqrt{\epsilon}\), meaning that we expect convergence of \(\tilde{G}_{N}(f)\) down to close to machine precision. Second, the breakpoint N 1(T;ϵ) is precisely twice N 0(T;ϵ). Hence, the regime of geometric convergence of \(\tilde{G}_{N}(f)\) is exactly twice as large as that of the continuous FE. These observations are in close agreement with the behavior seen in the numerical examples in Sect. 4.1.

Error (left) and coefficient norm (right) against N for the discrete FE with T=2, where \(f(x) = \frac{1}{1+16 x^{2}}\) (top row), \(f(x) = \frac{1}{8-7 x}\) (middle row) and f(x)=x (bottom row). Squares, circles, crosses and diamonds correspond to the truncated SVD extension H N,ϵ (f) with ϵ=10−6,10−12,10−18,10−24, respectively, and pluses correspond to the exact extension F N (f)
4.3 The Condition Numbers of the Numerical Continuous and Discrete FEs
Having analyzed the convergence of the numerical FE—and in particular, established 5. of Sect. 1—we next address its condition number. Once more, we do this by considering the extensions H N,ϵ and \(\tilde{H}_{N,\epsilon}\):
Theorem 4.7
Let H N,ϵ be the continuous truncated SVD FE given by (4.7). Then
where c(T) is a positive constant independent of N. Conversely, if \(\tilde{H}_{N,\epsilon}\) is the discrete extension (4.14), then \(\kappa( \tilde{H}_{N,\epsilon})= 1\) for all \(N \in \mathbb {N}\) and ϵ>0.
Proof
The proof of the equalities is similar to that of Lemma 3.5 with A and \(\tilde{A}\) replaced by their truncated SVD versions. The upper bound for κ(H N,ϵ ) is a consequence of Theorem 3.1. □
This theorem, which establishes 3. of Sect. 1, has some interesting consequences. First, the discrete FE is perfectly stable. On the other hand, the numerical continuous FE is far from stable. The condition number grows exponentially fast at rate E(T) until it reaches \(1/\sqrt{\epsilon}\), where ϵ is the truncation parameter in the SVD. Thus, with the continuous FE, we may see perturbations being magnified by a factor of \(1/\sqrt{\epsilon _{\mathrm{mach}}} \approx10^{8}\) in practice.
Note that G N and \(\tilde{G}_{N}\) are both substantially better conditioned than the corresponding coefficient mappings. The explanation for this difference comes from Remark 4.5. A perturbation η in the input vector b gives large errors in the FE coefficients if η has a significant component in the direction of a singular vector v n associated with a small singular value σ n . However, since the corresponding function Φ n is small on [−1,1], this error is substantially reduced (in the case of the continuous FE) or canceled out altogether (for the discrete FE) in the resulting extension.
Another implication of Theorem 4.7 is the following: varying T has no substantial effect on stability. Although the condition number of the FE matrices depends on T (recall Theorems 3.1 and 3.2), as does the condition number of the exact continuous FE (see Lemma 3.5), the condition numbers of the numerical mappings \(\tilde{G}_{N}\) and, for all large N, G N are actually independent of this parameter.
It is important to confirm that the results of this theorem on the condition number of the truncated SVD extensions predict the behavior of the numerical extensions G N and \(\tilde{G}_{N}\). It is easiest to do this by computing upper bounds for κ(G N ) and \(\kappa (\tilde {G}_{N})\). Let \(\{ e_{n} \}^{2N+1}_{n=1}\) be the standard basis for \(\mathbb {C}^{2N+1}\). Then a simple argument gives
and therefore
We define the upper bound \(K(\tilde{G}_{N})\) in a similar manner:
In Table 1 we show K(G N ) and \(K(\tilde{G}_{N})\) for various choices of N. As we see, the discrete FE is extremely stable: not only is there no blowup in N, but the value of \(K(\tilde{G}_{N})\) is also close to one in magnitude. For the continuous extension, we see that \(K(G_{N}) \approx5 \times10^{6} =1/\sqrt{\epsilon}\), where ϵ=2.5×10−13. This behavior is in good agreement with Theorem 4.7.
The difference in stability between the continuous and discrete FEs is highlighted in Fig. 8. Here we perturbed the right-hand side b of the function f(x)=ex by noise of magnitude δ, and then computed its FE. As is evident, the discrete extension approximates f to an error of magnitude roughly δ, whereas for the continuous extension the error is of magnitude ≈106 δ, as predicted by Table 1.

The error |f(x)−f N (x)| against x, where f N =G N (f) (left) or \(f_{N} = \tilde{G}_{N}(f)\) (right), for N=30, T=2 and f(x)=ex, with noise at amplitudes δ=10−4,10−8,10−12,0
5 Fourier Extensions from Equispaced Data
We now turn our attention to the problem of computing FEs when only equispaced data is prescribed. As discussed in Sect. 1, a theorem of Platte, Trefethen and Kuijlaars [28] states that any exponentially convergent method for this problem must also be exponentially ill-conditioned (see Sect. 5.4 for the precise result). However, as we show in this section, FEs give rise to a method, the so-called equispaced Fourier extension, that allows this barrier to be circumvented to a substantial extent. Namely, it achieves rapid convergence in a numerically stable manner.
5.1 The Equispaced Fourier Extension
Let
be a set of 2M+1 equispaced points in [−1,1], where M≥N. We define the equispaced Fourier extension of a function f∈L∞[−1,1] by
If F N,M (f)=∑|n|≤N a n ϕ n , then the vector a=(a −N ,…,a N )⊤ is the least squares solution to \(\bar{A} a \approx\bar{b}\), where \(\bar{A} \in \mathbb {C}^{(2M+1) \times(2N+1)}\) has (n,m)th entry \(\frac{1}{\sqrt{M+1/2}} \phi_{m}(x_{n})\) and \(\bar{b}\) has nth entry \(\frac{1}{\sqrt{M+1/2}} f(x_{n})\).
Note that F N,M (f), as defined by (5.2), is (up to minor changes of parameters/notation) identical to the extensions considered in the previous papers [5, 8, 12, 24, 25] on equispaced FEs.
5.2 The Exact Equispaced Fourier Extension
Consider first the case M=N. Then F N,N (f) is equivalent to polynomial interpolation in z:
Proposition 5.1
Let \(F_{N,N}(f)= f_{N} = f_{\mathrm{e},N}+f_{\mathrm{o},N} \in \mathcal {G}_{N}\) be defined by (5.2) with N=M and let h i,N (z) be given by (2.4). Then h i,N (z), i=1,2 is the (N+1−i)th degree polynomial interpolant of h i (z) at the nodes \(\{ z_{n} \} ^{N}_{n=i-1} \subseteq[-1,1]\), where
This proposition allows us to analyze the theoretical convergence/divergence of F N,N (f) using standard results on polynomial interpolation. Recall that associated with a set of nodes \(\{ z_{n} \}^{N}_{n=0}\) is a node density function μ(z), i.e. a function such that (i) \(\int^{1}_{-1} \mu(z) \,\mathrm{d}z = 1\) and (ii) each small interval [z,z+h] contains a total of Nμ(z)h nodes for large N [18]. In the case of (5.3) we have
Lemma 5.2
The nodes (5.3) have node density function \(\mu (z) = T / (\pi \sqrt {(1-z)(z-m(T))})\).
Proof
Note first that \(\int^{1}_{-1} \mu(z) \,\mathrm{d}z = 1\). Now let I=[z,z+h]⊆[−1,1] be an interval. Then the node z n ∈I if and only if m −1(z+h)≤x n ≤m −1(z). Therefore, as N→∞, the proportion of nodes lying in I tends to m −1(z)−m −1(z+h). Now suppose that h→0. Then
Thus \(m^{-1}(z) - m^{-1}(z+h)= \mu(z) h + \mathcal {O}( h^{2} ) \), as required. □
It is useful to consider the behavior of μ(z). When z→1−, \(\mu(z) \sim T /(\pi\sqrt{1-z})\). On the other hand, μ is continuous at z=−1 with \(\mu(-1) = \frac{T}{2 \pi} \tan ( \frac{\pi}{2T} )\). Hence the nodes \(\{ z_{n} \}^{N}_{n=0}\) cluster quadratically near z=1 and are linearly distributed near z=−1. It is well known that to avoid the Runge phenomenon in a polynomial interpolation scheme, it is essentially necessary for the nodes to cluster quadratically near both endpoints (as is the case with Chebyshev nodes) [18]. If this is not the case, one expects the Runge phenomenon: that is, divergence (at a geometric rate) of the interpolant for any function having a singularity in a certain complex region containing [−1,1] (the Runge region for the interpolation scheme). Since the nodes (5.3) do not exhibit the correct clustering at the endpoint z=−1, we consequently expect this behavior in the equispaced FE F N,N (f).
As it transpires, the corresponding Runge region \(\mathcal {R}= \mathcal {R}(T)\) for F N,N can be defined in terms of the potential function \(\phi(t) = - \int^{1}_{-1} \mu(z) \log| t - z | \,\mathrm{d}z + c\). Here c is an arbitrary constant. Standard polynomial interpolation theory [18] then gives
(observe that this is a subset of the complex x-plane). We note also that the convergence/divergence of F N,N (f) at a point x will be exponential at a rate \(\mathrm{e}^{\phi(m(x_{0})) - \phi(m(x))}\), where x 0 is the limiting singularity of f. This follows from a general result on polynomial interpolation [18]. In particular, if f has a singularity in \(\mathcal {R}(T)\), then there will be some points x∈[−1,1] for which F N,N (f) diverges.
We next discuss two approaches for overcoming the Runge phenomenon in F N,N (f).
5.2.1 Overcoming the Runge Phenomenon I: Varying T
One way to attempt to overcome (or, at least, mitigate) the Runge phenomenon observed above is to vary the parameter T. Note that:
Lemma 5.3
The Runge region \(\mathcal {R}(T)\) satisfies \(\mathcal {R}(T) \rightarrow [-1,1]\) as T→1+, and \(\mathcal {R}(T) \rightarrow \mathcal {R}\) as T→∞, where \(\mathcal {R}\) is the Runge region for equispaced polynomial interpolation.
Proof
Suppose first that T→1+. Since m(T)∼−1, we have \(\mu(z) \sim\frac{1}{\pi\sqrt{1-z^{2}}}\). The right-hand side is the potential function for Chebyshev interpolation, and thus the first result follows.
For the second result, we first recall that \(\phi(m(x)) = - \int^{1}_{-1} \mu(z) \log| m(x) - z | \,\mathrm{d}z\). Define the change of variable z=m(s). Since m′(s)=−1/μ(m(s)) we have
Note that
Therefore
which is the potential function of equispaced polynomial interpolation, as required. □
This lemma comes as no surprise. As T→1+ for fixed N, the system \(\{ \mathrm{e}^{{\mathrm{i}}\frac{n \pi}{T} \cdot} \}_{|n| \leq N}\) tends to the standard Fourier basis on [−1,1]. The problem of equispaced interpolation with trigonometric polynomials is well-conditioned and convergent. On the other hand, when T→∞, the subspaces \(\mathcal {C}_{N}\) and \(\mathcal {S}_{N}\) both resemble spaces of algebraic polynomials in x. Thus, in the large T limit, F N,N (f) is an algebraic polynomial interpolant of f at equispaced nodes.
Since the Runge region \(\mathcal {R}(T)\) can be made arbitrarily small by letting T→1+, one way to overcome the Runge phenomenon is to vary T in the way described in Sect. 2.4 and set T=T(N;ϵ). One could also take T≈1 fixed. However, this will always lead to a nontrivial Runge region, and consequently divergence of F N,N for some nonempty class of analytic functions.
5.2.2 Overcoming the Runge Phenomenon II: Oversampling
An alternative means to overcome the Runge phenomenon in F N,M (f) is to allow M≥N. Oversampling is known to defeat the Runge phenomenon in equispaced polynomial interpolation [8, 9, 28], and the same is true in this context (see [5, 12] for previous discussions on oversampling for equispaced FEs).
It is now useful to introduce some notation. For nodes {x n }|n|≤M given by (5.1), let (⋅,⋅) M be the discrete bilinear form \((g,h)_{M} = \frac{1}{M+\frac{1}{2}} \sum_{|n| \leq M} g(x_{n}) \overline{h(x_{n})}\), and denote the corresponding discrete semi-norm by ∥⋅∥ M . Much as before, we define the condition number of F N,M by
We now have:
Theorem 5.4
Let F N,M (f) be given by (5.2), and suppose that
then
Moreover, the condition number κ(F N,M )=D(N,M).
Proof
For the sake of brevity, we omit the first part of the proof (a very similar argument is given in [9] for the case of polynomial interpolation). For the second part, we first notice that
Since F N,M (ϕ)=ϕ for \(\phi\in \mathcal {G}_{N}\) we have κ(F N,M )≥D(N,M). Conversely, since \(F_{N,M}(f) \in \mathcal {G}_{N}\), and since F N,M is an orthogonal projection with respect to the bilinear form (⋅,⋅) M , we have ∥F N,M (f)∥≤D(N,M)∥F N,M (f)∥ M ≤D(N,M)∥f∥ M . Hence κ(F N,M )≤D(N,M), and we get the result. □
This theorem implies that F N,M (f) will converge, regardless of the analyticity of f, provided M is chosen such that D(N,M) is bounded. Note that this is always possible: D(N,M)→1 as M→∞ for fixed N since ∥⋅∥ M is a Riemann sum approximation to ∥⋅∥ and \(\mathcal {G}_{N}\) is finite-dimensional. Up to small algebraic factors in M and N, the quantity D(N,M) is equivalent to
Note the meaning of \(\tilde{D}(N,M)\): it informs us how large a polynomial of degree N can be on [−1,1] if that polynomial is bounded at the M points z n . Unfortunately, numerical evidence suggests that
for constants β≥α>1. Thus one requires \(M = \mathcal {O}( N^{2} ) \) nodes for boundedness of D(N,M). This is clearly less than ideal: it means that we require many more samples of f to compute its N-term equispaced FE. In particular, the exact equispaced FE F N,M (f) of an analytic function f will converge only root-exponentially fast in the number M of equispaced grid values.
Had the nodes \(\{ z_{n} \}^{M}_{n=0}\) clustered quadratically near z=±1, then \(M = \mathcal {O}( N ) \) would be sufficient to ensure boundedness of \(\tilde{D}(N,M)\). Note that when N=M, \(\tilde{D}(N,M)\) is precisely the Lebesgue constant of polynomial interpolation. On the other hand, if \(\{ z_{n} \}^{M}_{n=0}\) were equispaced nodes on [−1,1] then (5.7) would coincide with a well-known result of Coppersmith and Rivlin [15]. The intuition for a bound of the form (5.7) for the nodes (5.3) comes from the fact that these nodes are linearly distributed near z=−1. Thus, at least near z=−1 they behave like equispaced nodes.
We remark that it is straightforward to show that the scaling \(M = \mathcal {O}( N^{2} ) \) is sufficient for boundedness of \(\tilde{D}(N,M)\). This is based on Markov’s inequality for polynomials. Necessity of this condition would follow directly from the lower bound in (5.7), provided (5.7) were shown to hold. It may be possible to adapt the proof of [15] to establish this result.
Since the scaling \(M = \mathcal {O}( N^{2} ) \) is undesirable, one can ask what happens when M=γN for some fixed oversampling parameter γ≥1. Using potential theory arguments, one can show that \(\tilde{D}(N, \gamma N)\) grows exponentially in N (with the constant of this growth becoming smaller as γ increases), as predicted by the conjectured bound (5.7). In other words,
for some c(γ;T)>1.Footnote 1 In view of this behavior, Theorem 5.4 guarantees convergence of the FE (5.2), provided ρ≥c(γ;T), where ρ is as in Theorem 2.11. In other words, f needs to be analytic in the region \(\mathcal {D}(c(\gamma;T))\) (recall \(\mathcal {D}\) from Theorem 2.11) to ensure convergence. Therefore, one expects a Runge phenomenon whenever f has a complex singularity lying in the corresponding Runge region \(\mathcal {R}(\gamma; T) = \mathcal {D}(c(\gamma;T))\). Naturally, a larger value of γ leads to a smaller (but still nontrivial) Runge region. However, regardless of the choice of γ, there will always be analytic functions for which one expects divergence of F N,γN (f) (see [9] for a related discussion in the case of equispaced polynomial interpolation). Moreover, the mapping f↦F N,γN will always be exponentially ill-conditioned for any fixed γ, since the condition number is precisely D(N,γN) (Theorem 5.4).
Primarily for later use, we now note that it is also possible to study the condition number of the equispaced FE matrix \(\bar{A}\) in a similar way. Straightforward arguments show that
Using the fact that \(1/\sigma_{\min}(A) = \sup \{ \| \phi\| _{[-T,T]} : \phi\in \mathcal {G}_{N}, \| \phi\|=1 \}\), where A is the matrix of the continuous FE, one can show that
(here we use ≲ to mean up to possible algebraic factors in N). Theorem 3.1 now shows that \(\bar{A}\) is always exponentially ill-conditioned in N, regardless of M≥N.
Much like the case of D(N,M) and \(\tilde{D}(N,M)\), one can show that the quantity B(N,M) is, up to algebraic factors, equivalent to
Potential theory can be used once more to determine the exact behavior of \(\tilde{B}(N,\gamma N)\). In particular,
for some constant d(γ;T)≥c(γ;T)>1.
5.2.3 Numerical Examples
In the previous section we established (up to the conjecture (5.7)) 6., 7. and 8. of Sect. 1. The main conclusion is as follows. In order to obtain a convergent FE in exact arithmetic using equispaced data one either needs to oversample quadratically (and thereby reduce the convergence rate to only root-exponential), or scale the extension parameter T suitably with N or both. However, recall from Sect. 4 that a FE obtained from a finite precision computation may differ quite dramatically from the corresponding infinite-precision extension. Is it therefore possible that the unpleasant effects described in the previous section may not be witnessed in finite precision? The answer transpires to be yes, and consequently FEs can safely be used for equispaced data, even in situations where divergence is expected in exact arithmetic.
To illustrate, consider the function \(f(x) = \frac{1}{1+100 x^{2}}\). When T=2, this function has a singularity lying in the Runge region \(\mathcal {R}(1;2)\). The predicted divergence of its exact (i.e. infinite-precision) equispaced FE is shown in Fig. 9. Note that double oversampling also gives divergence, whilst with quadruple oversampling the singularity of f no longer lies in \(\mathcal {R}(\gamma; T)\). We therefore witness geometric convergence, albeit at a very slow rate. This behavior is typical. Given a function f it is always possible to select the oversampling parameter γ in such a way that F N,γN (f) converges geometrically. However, such a γ depends on f in a nontrivial manner (i.e. the location of the nearest complex singularity of f) and therefore cannot in practice be determined from the given data. Note that this phenomenon—namely, the fact that careful tuning of a particular parameter in a function-dependent way allows geometric convergence to be restored—is also seen in other methods for approximating functions to high accuracy, such as the Gegenbauer reconstruction technique [20, 21] (see Boyd [7] for a description of the phenomenon) and polynomial least squares [9].

The error ∥f−f N ∥∞ against N for the equispaced FEs f N =F N,γN (f) (left) and f N =G N,γN (f) (right) of \(f(x) = \frac{1}{1+100 x^{2}}\) with oversampling factor γ=1,2,4 (squares, circles and crosses) and T=2
Fortunately, and unlike for these other methods, the situation changes completely for Fourier extensions when we carry out computations in finite precision. This is shown in Fig. 9. For all choices of γ used, the finite precision FE, which we denote G N,γN (f), converges geometrically fast, and there is no drift in the error once the best achievable accuracy is attained. Note that oversampling by a constant factor improves the approximation, but in all cases we still witness convergence. In particular, no careful selection of γ, such as that discussed above, appears to be necessary in finite precision.
5.3 The Numerical Equispaced Fourier Extension
We now explain these results by analyzing the numerical equispaced FE. Proceeding as in Sect. 4.2 we shall consider the truncated SVD approximation, which we denote H N,M,ϵ (f). Note that a similar analysis has also recently been presented in [24]; see Remark 5.10 for further details.
Let \(\varPhi_{n} \in \mathcal {G}_{N}\) be the function corresponding to the right singular vector v n of the matrix \(\bar{A}\). Write \(\mathcal {G}_{N,M,\epsilon } = \mathrm {span}\{ \varPhi_{n} : \sigma_{n} > \epsilon \}\) and \(\mathcal {G}^{\perp}_{N,M,\epsilon} = \mathrm {span}\{ \varPhi_{n} : \sigma_{n}\leq\epsilon\}\), and note that H N,M,ϵ is the orthogonal projection onto \(\mathcal {G}_{N,M,\epsilon}\) with respect to (⋅,⋅) M . Since \((\varPhi _{n},\varPhi_{m})_{M} = \sigma^{2}_{n} \delta_{n,m}\), we have
Our main result is as follows:
Theorem 5.5
Let f∈L∞(−1,1) and H N,M,ϵ (f) be given by (5.12). Then
and
where
Proof
Let \(\phi\in \mathcal {G}_{N}\). Then
Consider the second term. By definition of C 1(N,M;T,ϵ),
where the second inequality follows from the fact that H N,M,ϵ is an orthogonal projection with respect to (⋅,⋅) M . Noting that \(\| g \|,\| g \|_{M} \leq\sqrt{2} \| g \|_{\infty}\) for any function g∈L∞(−1,1) now gives the corresponding term in (5.13). The bound for the third term of (5.16) follows immediately from the definition of C 2(N,M;T,ϵ) and the inequality ∥ϕ−H N,M,ϵ (ϕ)∥[−T,T]≤∥ϕ∥[−T,T].
For (5.14), we first write ∥H N,M,ϵ (f)∥[−T,T]≤∥H N,M,ϵ (f−ϕ)∥[−T,T]+∥H N,M,ϵ (ϕ)∥[−T,T]. Observe that for any g∈L∞(−1,1) we have
Also, ∥H N,M,ϵ (ϕ)∥[−T,T]≤∥ϕ∥[−T,T] for \(\phi\in \mathcal {G}_{N}\). Setting g=f−ϕ and combining these two bounds now gives (5.14). □
Corollary 5.6
If f∈L∞(−1,1) then \(\| H_{N,M,\epsilon}(f) \| \leq\sqrt{2} / \epsilon\| f \|_{\infty}\), \(\forall N \in \mathbb {N}\), M≥N. Moreover, if f∈H1(−1,1), \(\mathbb {T}=[-T,T)\) is the T-torus and c 1(T)>0 is as in Lemma 2.5, then
Proof
By (5.14), we have
Setting ϕ=0 gives the first result. For the second, we let ϕ be the N-term Fourier series of \(\tilde{f}\) on \(\mathbb {T}\), so that ∥f−ϕ∥∞→0 as N→∞. The final inequality follows from Lemma 2.5. □
This corollary shows that the equispaced FE cannot suffer from a Runge phenomenon in finite precision, since it is bounded in N and M. This should come as no surprise. Divergence of H N,M,ϵ (f) would imply unboundedness of the coefficients a ϵ , a behavior which is prohibited by truncating the singular values of \(\bar {A}\) at level ϵ. Note that this corollary actually shows a much stronger result, namely that H N,M,ϵ (f) is bounded on the extended domain [−T,T], not just on [−1,1].
Although this corollary demonstrates lack of divergence of H N,M,ϵ (f), it says littles about its convergence besides the observation that ∥H N,M,ϵ (f)∥ is asymptotically bounded by \(\| f \|_{\mathrm {H}^{1}(-1,1)}\). To study convergence we shall use (5.13). For this we first need to understand the constants C i (N,M;T,ϵ).
5.3.1 Behavior of C i (N,M;T,ϵ)
Although Theorem 5.5 holds for arbitrary M≥N, we now focus on the case of linear oversampling, i.e. M=γN for some γ≥1.
Let N 2(γ,T,ϵ) be the largest N such that all the singular values of \(\bar{A}\) are at least ϵ in magnitude:
For N≤N 2(γ,T,ϵ) we have \(\mathcal {G}_{N, \gamma N,\epsilon} = \mathcal {G}_{N}\) and therefore C 1(N,γN;T,ϵ)=D(N,γN), where D(N,M) is given by (5.5). Thus we witness exponential divergence of C 1(N,γN;T,ϵ) at rate c(γ;T), where c(γ;T) is as in (5.8). This is shown numerically in Fig. 10.

The quantity C 1(N,γN;T,ϵ) against N for γ=1 (top row) or γ=2 (bottom row) and ϵ=10−6,10−12,10−18,10−24,10−30 (squares, circles, crosses, diamonds and dashes, respectively)
However, once N>N 2(γ,T,ϵ) the numerical results in Fig. 10 indicate a completely different behavior: namely, C 1(N,γN;T,ϵ) appears to be bounded. Although we have no proof of this fact, these results strongly suggest the following conjecture:
In other words, C 1(N,γN;T,ϵ) achieves its maximal value in N at N≈N 2. Recalling (5.9) and (5.11), we note that
Thus, substituting this into bound (5.18) results in the following conjecture:
In particular, C 1(N,γN;T,ϵ) is bounded for all N by some power of ϵ −1. Importantly, this power cannot be too large. Note that c(γ;T)≤d(γ;T), ∀T>1, since the maximum of a polynomial on [m(T),1] is at least as large as its maximum on the smaller interval [−1,1]—compare (5.10) to (5.6). Therefore the ratio \(\frac{\log c(\gamma;T)}{\log d(\gamma;T)}\) is at most one. Moreover, by varying either γ or T we may decrease this ratio to arbitrarily close to 1. We discuss this further in the next section.
The quantity C 2(N,M;T,ϵ) is harder to analyze, although clearly we have C 2(N,M;T,ϵ)=0 when N<N 2. Figure 11 demonstrates that C 2(N,γN,ϵ) is also bounded in N. Moreover, closer comparison with Fig. 10 suggests the existence of a bound of the form
Once more, we have no proof of this observation.

The quantity C 2(N,γN;T,ϵ) against N for γ=1 (top row) or γ=2 (bottom row) and ϵ=10−6,10−12,10−18,10−24,10−30 (squares, circles, crosses, diamonds and dashes, respectively)
Remark 5.7
The quantities C 1(N,M;T,ϵ) and C 2(N,M;T,ϵ) have the explicit expressions
where A is the continuous FE matrix, USV ∗ is the singular value decomposition of the equispaced FE matrix \(\bar{A}\), S ϵ is formed by replacing the nth column of S by the zero vector whenever σ n ≤ϵ, and V ϵ is formed by doing the same for columns of V corresponding to indices n with σ n >ϵ. These expressions were used to obtain the numerical results in Figs. 10 and 11. Computations were carried out with additional precision to avoid effects due to round-off.
5.3.2 Behavior of the Truncated SVD Fourier Extension
Combining the analysis of the previous section with Theorem 5.5, we now conjecture the bound
where C(γ,T,ϵ) is proportional to ϵ −a(γ;T) and a(γ;T) is given by
This estimate allows us to understand the behavior of the numerical equispaced FE G N,γN (f). When N<N 2 we have G N,γN (f)=F N,γN (f) and therefore G N,γN (f) will diverge geometrically fast in N whenever f has a singularity in the Runge region \(\mathcal {R}(\gamma;T)\) (see Sect. 5.2.1). However, once N exceeds N 2, one obtains convergence. Indeed, setting ϕ=F N (f) in (5.22), we find that the convergence is geometric up to the breakpoint N 1 (see (4.20)), and then, much as before, at least superalgebraic beyond that point. Note that the maximal achievable accuracy of order C(γ,T,ϵ)ϵ≈ϵ 1−a(γ;T).
In summary, we have now identified the following convergence behavior for H N,γN,ϵ (f):
-
(i)
\(N < N_{2}(\gamma,T,\epsilon) \approx- \frac{\log \epsilon }{\log d(\gamma;T)}\). Geometric divergence/convergence of H N,γN,ϵ (f) at a rate of, at worst, c(γ;T)/ρ, where ρ is as in Theorem 2.11 and c(γ;T) is given by (5.8).
-
(ii)
\(N_{2}(\gamma,T,\epsilon) \leq N < N_{1}(T,\epsilon) \approx- \frac{\log\epsilon}{\log E(T)}\). Geometric convergence at a rate of at least ρ.
-
(iii)
N=N 1(T,ϵ). The error
$$ \bigl\| f - H_{N,\gamma N,\epsilon}(f) \bigr\| \approx c_f \epsilon^{d_f-a(\gamma;T)}, $$where a(γ;T) is as in (5.23) and \(d_{f} = \frac{\log \rho }{\log E(T)} \in(0,1]\).
-
(iv)
N≥N 1(γ,T). Superalgebraic convergence of H N,γN,ϵ (f) down to a maximal achievable accuracy proportional to ϵ 1−a(γ;T).
(This establishes 10. of Sect. 1.) Much as in the case of the discrete FE, we see that if f is analytic in \(\mathcal {D}(E(T))\), and if c f is not too large, then convergence stops at N=N 1 with maximal accuracy of order c f ϵ 1−a(γ;T). Otherwise, we have a further regime of at least superalgebraic convergence before this accuracy is reached.
An important question is the role of the oversampling parameter γ in this convergence. We note:
Lemma 5.8
Let a(γ;T) be given by (5.23). Then a(γ;T) satisfies 0≤a(γ;T)≤1 for all γ and T. Moreover, a(γ;T)→0 as γ→∞ for fixed T, and a(γ;T)→0 as T→∞ for fixed γ.
Proof
Note that c(γ;T)≤d(γ;T). Also c(γ;T)→1 and d(γ;T)→E(T) as γ→∞ for fixed T, and d(γ;T)→∞ as T→∞ for fixed γ, whereas c(γ;T) is bounded. □
This lemma suggests that increasing γ will lead to a smaller constant C(γ,T,ϵ) in (5.22). In fact, numerical results (Figs. 10 and 11) indicate that using T=2 and γ=2 gives a bound of a little over 1 in magnitude for ϵ=10−14. Note that the effect of even just double oversampling is quite dramatic. Without oversampling (i.e. γ=1), the constant C(γ,T,ϵ) is approximately 104 in magnitude when ϵ=10−14 (see Figs. 10 and 11).
Let us make several further remarks. First, in practice the regime N<N 1 is typically very small—recall that N 1 is around 20 for T=2 (see Sect. 4.2.2)—and therefore one usually does not witness all three types of behavior in numerical examples. Second, as γ→∞, we have N 2→N 1 (recall that d(γ;T)→E(T) as γ→∞). Thus, with a sufficient amount of oversampling, the regime (ii) will be arbitrarily small. On the other hand, oversampling decreases c(γ;T), and therefore the rate of divergence in the regime (i) is also lessened by taking γ>1. Indeed, the numerical results in Fig. 12, as well as in Sect. 5.3.4 later, indicate that oversampling by a factor of 2 is typically sufficient in practice to mitigate the effects of divergence for most reasonable functions.

Error against N for H N,γN,ϵ (f), where \(f(x) = \frac{1}{1+16 x^{2}}\), T=2, γ=1 (left) or γ=2 (right) and ϵ=10−6,10−12,10−18 (squares, circles, crosses). Diamonds correspond to the exact equispaced FE F N,γN (f)
Figure 12 confirms these observations for the function \(f(x) = \frac{1}{1+16 x^{2}}\). For γ=1 the initial exponential divergence is quite noticeable. However, this effect largely vanishes when γ=2. Notice that a larger cutoff ϵ actually gives a smaller error initially, since there is a smaller regime of divergence. However, the maximal achievable accuracy is correspondingly lessened. We note also that maximal achievable accuracies for ϵ=10−6,10−12,10−18 are roughly 10−4, 10−8 and 10−12, respectively, when γ=1 and 10−7, 10−12 and 10−16 when γ=2. These are in close agreement with the corresponding numerical values of C 2(N,γN;T,ϵ) (see Fig. 11), as predicted by Theorem 5.5.
Remark 5.9
A central conclusion of this section is that one requires a lower asymptotic scaling of M with N for the numerical equispaced FE than for its exact counterpart. Since \(\mathcal {G}_{N,M,\epsilon}\) is a subset of \(\mathcal {G}_{N}\), we clearly have C 1(N,M;T,ϵ)≤D(N,M), where D(N,M) is given by (5.5). Hence quadratic scaling \(M = \mathcal {O}( N^{2} ) \) is sufficient (see Sect. 5.2.1) to ensure boundedness of C 1(N,M;T,ϵ), and one can make a similar argument for C 2(N,M;T,ϵ). However, Figs. 10 and 11 indicate that this condition is not necessary, and that one can get away with the much reduced scaling \(M=\mathcal {O}( N ) \) in practice.
This difference can be understood in terms of the singular values of \(\bar{A}\). Recall that small singular values correspond to functions \(\phi\in \mathcal {G}_{N}\) with ∥ϕ∥[−T,T]≫∥ϕ∥ M . Now consider an arbitrary \(\phi\in \mathcal {G}_{N}\). If the ratio ∥ϕ∥/∥ϕ∥ M is large, it suggests that ϕ lies approximately in the space \(\mathcal {G}^{\perp}_{N,M,\epsilon}\) corresponding to small singular values. Hence, ∥ϕ∥/∥ϕ∥ M cannot be too large over \(\phi\in \mathcal {G}_{N,M,\epsilon}\), and thus we see boundedness of C 1(N,M,ϵ), even when D(N,M)—the supremum of this ratio over the whole of \(\mathcal {G}_{N}\)—is unbounded.
Remark 5.10
A similar analysis of the equispaced FE, also based on truncated SVDs, was recently presented by M. Lyon in [24]. In particular, our expressions (5.13) and (5.22) are similar to equations (30) and (31) of [24]. Lyon also provides extensive numerical results for his analogues of the quantities C 1(N,M;T,ϵ) and C 2(N,M;T,ϵ), and describes a bound which is somewhat easier to use in computations. The main contributions of our analysis are the conjectured scaling of the constant C(γ,T,ϵ) in terms of ϵ, γ and T, the description and analysis of the breakpoints N 2 and N 1, and the differing convergence/divergence in the corresponding regions.
5.3.3 The Condition Number of the Numerical Equispaced FE
We now consider the condition number κ(G N,M ) (defined as in (5.4)) of the numerical equispaced extension. In Table 2 we plot K(G N,γN ) against N, where K(G N,M ) is an upper bound for κ(G N,M ) defined analogously to (4.22). The results indicate numerical stability, and, as we expect, improved stability with more oversampling.
Besides oversampling it is also possible to improve stability by varying the extension parameter T. In Fig. 13 we give a contour plot of K(G N,γN ) in the (γ,T)-plane. Evidently, increasing T improves stability. Recall, however, that a larger T corresponds to worse resolution power (see Sect. 2.4). Conversely, increasing γ also leads to worse resolution when measured in terms of the total number M=γN of equispaced function values required. Hence a balance must be struck between the two quantities. Figure 13 suggests that γ=T=2 is a reasonable choice in practice. Recall also that the choice T=2 allows for fast computation of the equispaced FE (Remark 3.4), and hence is desirable to use in computations.

Contour plot of the quantity K(G N,γN ) against 1≤γ≤4 and 1<T≤4 for N=200
The behavior of the condition number can be investigated with the following theorem (the proof is similar to that of Theorem 4.7 and hence omitted):
Theorem 5.11
The condition number κ(H N,M,ϵ ) of the truncated SVD equispaced FE H N,M,ϵ satisfies κ(H N,M,ϵ )=C 1(N,M;T,ϵ), where C 1(N,M;T,ϵ) is given by (5.15).
From the analysis of Sect. 5.3.1 we conclude that κ(H N,γN,ϵ )≲ϵ −a(γ;T), where a(γ;T) is as in (5.23). Lemma 5.8 therefore shows that κ(H N,γN,ϵ )≲1 as γ→∞ for fixed T, and κ(H N,γN,ϵ )≲1 as T→∞ for fixed γ. This confirms the behavior described above.
5.3.4 Numerical Examples
In Fig. 14 we consider the equispaced FE for four test functions. In all cases we use γ=2 and T=2. As is evident, all choices of T give good, stable numerical results, with the best achievable accuracy being at least 10−12. Robustness in the presence of noise is shown in Fig. 15. Observe that when γ=1, noise of amplitude δ is magnified by around 105, in a manner consistent with Theorem 5.11. Conversely, with double oversampling, this factor drops to less than 102, again in agreement with Theorem 5.11.

The error ∥f−G N,γN (f)∥∞, where γ=2 and T=2. Left: \(f(x) = \mathrm{e}^{25 \sqrt{5} \pi{ \mathrm{i}}x}\) (squares), f(x)=|x|7 (circles). Right: \(f(x) = \frac{1}{1+25 x^{2}}\) (squares), \(f(x) = \frac{1}{8-7 x}\) (circles)

The error |f(x)−G N,γN (f)(x)| against x, where γ=1 (left) or γ=2 (right), for N=30, T=2 and f(x)=ex, with noise at amplitudes δ=10−4,10−6,10−8,10−10,0
5.4 Relation to the Theorem of Platte, Trefethen and Kuijlaars
We are now in a position to explain how FEs relate to the impossibility theorem of Platte, Trefethen and Kuijlaars [28]. A restatement of this theorem (with minor modifications to notation) is as follows:
Theorem 5.12
[28]
Let F M , \(M \in \mathbb {N}\), be a sequence of approximations such that F M (f) depends only on the values of f on an equispaced grid of M points. Let \(\mathcal {E}\subseteq \mathbb {C}\) be compact and suppose that there exist C<∞, α>1 and \(\tau\in(\frac{1}{2},1]\) such that
for all \(M \in \mathbb {N}\) and all f that are continuous on \(\mathcal {E}\) and analytic in its interior. Then there exists a β>1 such that the condition numbers \(\kappa(F_{M}) \geq\beta^{M^{2 \tau-1}}\) for all sufficiently large M.
This theorem has two important consequences. First, any exponentially convergent method is also exponentially ill-conditioned. Second, the best possible convergence for a stable method is root-exponential in M. Note that the theorem is valid for all methods, both linear and nonlinear, that satisfy (5.24).
Consider now the exact equispaced Fourier extension F N,M . As shown in Sect. 5.2, when \(N = \mathcal {O}( \sqrt{M} ) \) this method is stable and root-exponentially convergent. Hence equispaced FEs in infinite precision attain the maximal possible convergence rate for stable methods satisfying the conditions of the theorem.
Now consider the numerical equispaced FE G ηM,M , where 0<η≤1 is the reciprocal of the oversampling parameter γ used in the previous sections. We have shown that this approximation is stable, so at least one condition in Theorem 5.12 must be violated. Suppose that we take \(\mathcal {E}= \mathcal {D}(E(T))\), for example. Then (5.22) shows that
The finite term ϵ in the brackets means that this approximation does not satisfy (5.24), and hence Theorem 5.12 does not apply. Recall that if c f is small then (5.25) describes the full convergence behavior for all M. On the other hand, if c f is large, or if \(f \in \mathcal {D}(\rho)\) with ρ<E(T), then the convergence is, after initial geometric convergence, at least superalgebraic down to the maximal achievable accuracy \(\epsilon ^{1-a(\eta^{-1};T)}\). This is also not in contradiction with the conditions of Theorem 5.12.
To summarize, equispaced FEs, when implemented in finite precision, possess both numerical stability and rapid convergence, and hence allow one to circumvent the impossibility theorem to an extent. In particular, for all functions \(f \in \mathcal {D}(E(T))\) possessing small constants c f , the approximations converge geometrically fast down to a maximal accuracy of order \(\epsilon^{1-a(\eta^{-1};T)}\). In all other cases, the convergence is at least superalgebraic down to the same accuracy.
6 Conclusions and Challenges
We conclude by making the following remark. Extensive numerical experiments [5, 8, 12, 24, 25] have shown the effectiveness of FEs in approximating even badly behaved functions to high accuracy in a stable fashion. The purpose of this paper has been to provide analysis to explain these results. In particular, we have shown numerical stability for all three types of extensions considered, and analyzed their convergence. The reason for this robustness, despite the presence of exponentially ill-conditioned matrices, is due to the fact that the FE is a frame approximation and that for all functions f, even those with oscillations or large derivatives, there eventually exist coefficient vectors with small norms which approximate f to high accuracy.
The main outstanding theoretical challenge is to understand the constants C i (N,M;T,ϵ) of the equispaced FE. In particular, we wish to show that linear scaling M=γN is sufficient to ensure boundedness of these constants in N, with a larger γ corresponding to a smaller bound. Note that the analysis of Sect. 5.2.1 implies the suboptimal result that \(M = \mathcal {O}( N^{2} ) \) is sufficient (Remark 5.9). It is also a relatively straightforward exercise to show that if M=cN/ϵ for suitable c>0, then C i (N,M;T,ϵ) is bounded. This is based on making rigorous the arguments given in Remark 5.9—we do not report it here for brevity’s sake. Unfortunately, although this estimate gives the correct scaling \(M = \mathcal {O}( N ) \), it is wildly pessimistic. It implies that M should scale like ≈1016 N, whereas the numerics in Sect. 5.3.1 indicate that M=γN is sufficient for any γ≥1.
One approach towards establishing a more satisfactory result is to perform a closer analysis of the singular values of the matrix \(\bar {A}\). Some preliminary insight into this problem was given in [17]. Therein it was proved that (whenever M=N and \(2T \in \mathbb {N}\)) the singular values cluster near zero and one, and the transition region is \(\mathcal {O}( \log N ) \) in width, much like for the prolate matrix A. Unfortunately, little is known outside of this result. There is no existing analysis for \(\bar{A}\) akin to that of Slepian’s for the prolate matrix—see [17] for a discussion. Note, however, that the normal form \(B = \bar{A}^{*}\bar{A}\) has entries \(B_{n,m} = \frac{\sin\frac{(n-m) \pi}{T}}{M T \sin\frac{(n-m) \pi}{M T}}\), and can therefore be viewed as a discretized version of the prolate matrix A. Indeed, B→A as M→∞ for fixed N. Given the similarities between the two matrices, there is potential for Slepian’s analysis to be extended to this case. However, this remains an open problem.
Another issue is that of understanding how to choose the parameters T and γ in the case of the equispaced extension. As discussed in Sect. 2.4, the choice of T is reasonably clear for the continuous and discrete FEs (where there is no γ). If resolution of oscillatory functions is a concern, one should choose a small value of T (in particular, (2.18)). Otherwise, a good choice appears to be T=2. However, for the equispaced FE, small T adversely affects stability (see Sect. 5.3.3). Hence it must be balanced by taking a larger value of the oversampling parameter γ, which has the effect of reducing the effective resolution power. In practice, however, a reasonable choice appears to be T=γ=2. Investigating whether or not this is optimal is a topic for further investigation.
Notes
The constant of growth was obtained in private communication with A. Kuijlaars. A closed expression (up to several integrals involving the potential function ϕ for the nodes z n ) can be found for c(γ;T). We omit the full argument as it is rather lengthy, but note that it is based on standard results in potential theory. A general reference is [29].
Abbreviations
- T :
-
Extension parameter
- N :
-
Truncation parameter
- M, γ :
-
Number of equispaced nodes of the equispaced FE, and the oversampling parameter γ=M/N
- ϕ n (x):
-
The exponential \(\frac{1}{\sqrt{2T}} \mathrm{e}^{{\mathrm{i}}\frac{n \pi}{T} x } \)
- \(\mathcal {G}_{N} \), \(\mathcal {S}_{N}\), \(\mathcal {C}_{N}\) :
-
Finite-dimensional spaces of exponentials, sines and cosines
- F N , \(\tilde{F}_{N}(f)\), F N,M (f):
-
Exact continuous, discrete and equispaced FEs
- G N , \(\tilde{G}_{N}(f)\), G N,M (f):
-
Numerical continuous, discrete and equispaced FEs
- a :
-
Vector of coefficients of an FE
- A, \(\tilde{A}\), \(\bar{A}\) :
-
Matrices of the continuous, discrete and equispaced FE’s
- b, \(\tilde{b}\), \(\bar{b}\) :
-
Data vectors for the continuous, discrete and equispaced FEs
- x, y, z :
-
Physical domain variable x∈[−1,1], and the mapped variables y∈[c(T),1] and z∈[−1,1]
- f e(x), f o(x):
-
Even and odd parts of the function f(x)
- g 1(y), g 2(y), g 1,N (y), g 2,N (y):
-
Images of f e(x) and \(f_{\mathrm{o}}(x) / \sin \frac{\pi}{T} x\) in the y-domain and their polynomial approximations
- h i (z), h i,N (z):
-
Images of g i and g i,N in the z-domain
- m(x):
-
The mapping x↦z
- c(T), E(T):
-
FE constants \(\cos \frac{\pi}{T}\) and \(\cot^{2} ( \frac{\pi}{4 T} )\).
- \(\mathcal {B}(\rho) \), \(\mathcal {D}(\rho)\) :
-
Bernstein ellipse in the z-domain and its image in the x-domain
- κ(F):
-
Condition number of a mapping F
- N 0, N 1, N 2 :
-
Breakpoints in convergence
- {u n ,σ n ,v n }:
-
Singular system of A, \(\tilde{A}\) or \(\bar{A}\)
- Φ n :
-
Fourier series corresponding to v n
- \(\mathcal {G}_{N,\epsilon} \), \(\mathcal {G}'_{N,\epsilon} \), \(\mathcal {G}_{N,M,\epsilon}\) :
-
The subspace span{Φ n :σ n >ϵ}
- H N,ϵ (f), \(\tilde{H}_{N,\epsilon}(f)\), H N,M,ϵ (f):
-
Truncated SVD FEs corresponding to the continuous, discrete and equispaced cases
- a(γ;T):
-
Quantity determining the maximal achievable accuracy of the equispaced FE
- L2(I), 〈⋅,⋅〉 I , ∥⋅∥ I :
-
Space of square-integral functions on a domain I and corresponding inner product and norm
- 〈⋅,⋅〉, ∥⋅∥:
-
Inner product and norm on L2(−1,1)
- \(\mathrm {L}^{2}_{w}(I)\), 〈⋅,⋅〉 w,I , ∥⋅∥ w,I :
-
Space of square integrable functions with respect to a weight function w and corresponding inner product and norm
- ∥⋅∥∞,I , ∥⋅∥∞ :
-
Uniform norms on an arbitrary domain I and the interval [−1,1] respectively
References
B. Adcock, D. Huybrechs, On the resolution power of Fourier extensions for oscillatory functions. Technical Report TW597, Dept. Computer Science, K.U. Leuven, 2011.
N. Albin, O.P. Bruno, A spectral FC solver for the compressible Navier–Stokes equations in general domains. I: Explicit time-stepping, J. Comput. Phys. 230(16), 6248–6270 (2011).
H. Bateman, Higher Transcendental Functions, vol. 2 (McGraw–Hill, New York, 1953).
J.P. Boyd, Chebyshev and Fourier Spectral Methods (Springer, Berlin, 1989).
J.P. Boyd, A comparison of numerical algorithms for Fourier extension of the first, second, and third kinds, J. Comput. Phys. 178, 118–160 (2002).
J. Boyd, Fourier embedded domain methods: extending a function defined on an irregular region to a rectangle so that the extension is spatially periodic and C ∞, Appl. Math. Comput. 161(2), 591–597 (2005).
J.P. Boyd, Trouble with Gegenbauer reconstruction for defeating Gibbs phenomenon: Runge phenomenon in the diagonal limit of Gegenbauer polynomial approximations, J. Comput. Phys. 204(1), 253–264 (2005).
J.P. Boyd, J.R. Ong, Exponentially-convergent strategies for defeating the Runge phenomenon for the approximation of non-periodic functions. I. Single-interval schemes, Commun. Comput. Phys. 5(2–4), 484–497 (2009).
J. Boyd, F. Xu, Divergence (Runge phenomenon) for least-squares polynomial approximation on an equispaced grid and Mock–Chebyshev subset interpolation, Appl. Math. Comput. 210(1), 158–168 (2009).
O.P. Bruno, Fast, high-order, high-frequency integral methods for computational acoustics and electromagnetics, in Topics in Computational Wave Propagation: Direct and Inverse Problems, ed. by M. Ainsworth et al. Lecture Notes in Computational Science and Engineering, vol. 31 (Springer, Berlin, 2003), pp. 43–82.
O. Bruno, M. Lyon, High-order unconditionally stable FC–AD solvers for general smooth domains. I. Basic elements, J. Comput. Phys. 229(6), 2009–2033 (2010).
O.P. Bruno, Y. Han, M.M. Pohlman, Accurate, high-order representation of complex three-dimensional surfaces via Fourier continuation analysis, J. Comput. Phys. 227(2), 1094–1125 (2007).
C. Canuto, M.Y. Hussaini, A. Quarteroni, T.A. Zang, Spectral Methods: Fundamentals in Single Domains (Springer, Berlin, 2006).
O. Christensen, An Introduction to Frames and Riesz Bases (Birkhauser, Basel, 2003).
D. Coppersmith, T. Rivlin, The growth of polynomials bounded at equally spaced points, SIAM J. Math. Anal. 23, 970–983 (1992).
R.J. Duffin, A.C. Schaeffer, A class of nonharmonic Fourier series, Trans. Am. Math. Soc. 72, 341–366 (1952).
A. Edelman, P. McCorquodale, S. Toledo, The future Fast Fourier Transform? SIAM J. Sci. Comput. 20(3), 1094–1114 (1999).
B. Fornberg, A Practical Guide to Pseudospectral Methods (Cambridge University Press, Cambridge, 1996).
D. Gottlieb, S.A. Orszag, Numerical Analysis of Spectral Methods: Theory and Applications, 1st edn. (SIAM, Philadelphia, 1977).
D. Gottlieb, C.-W. Shu, On the Gibbs’ phenomenon and its resolution, SIAM Rev. 39(4), 644–668 (1997).
D. Gottlieb, C.-W. Shu, A. Solomonoff, H. Vandeven, On the Gibbs phenomenon. I: Recovering exponential accuracy from the Fourier partial sum of a nonperiodic analytic function, J. Comput. Appl. Math. 43(1–2), 91–98 (1992).
D. Huybrechs, On the Fourier extension of non-periodic functions, SIAM J. Numer. Anal. 47(6), 4326–4355 (2010).
D. Kosloff, H. Tal-Ezer, A modified Chebyshev pseudospectral method with an \(\mathcal {O}(N^{-1})\) time step restriction, J. Comput. Phys. 104, 457–469 (1993).
M. Lyon, Approximation error in regularized SVD-based Fourier continuations, Appl. Numer. Math. 62, 1790–1803 (2012).
M. Lyon, A fast algorithm for Fourier continuation, SIAM J. Sci. Comput. 33(6), 3241–3260 (2012).
M. Lyon, O. Bruno, High-order unconditionally stable FC–AD solvers for general smooth domains. II. Elliptic, parabolic and hyperbolic PDEs; theoretical considerations, J. Comput. Phys. 229(9), 3358–3381 (2010).
R. Pasquetti, M. Elghaoui, A spectral embedding method applied to the advection–diffusion equation, J. Comput. Phys. 125, 464–476 (1996).
R. Platte, L.N. Trefethen, A. Kuijlaars, Impossibility of fast stable approximation of analytic functions from equispaced samples, SIAM Rev. 53(2), 308–318 (2011).
T. Ransford, Potential Theory in the Complex Plane (Cambridge Univ. Press, Cambridge, 1995).
T.J. Rivlin, Chebyshev Polynomials: From Approximation Theory to Algebra and Number Theory (Wiley, New York, 1990).
D. Slepian, Prolate spheroidal wave functions. Fourier analysis, and uncertainty. V: The discrete case, Bell Syst. Tech. J. 57, 1371–1430 (1978).
L.N. Trefethen, D. Bau, Numerical Linear Algebra (SIAM, Philadelphia, 1997).
J. Varah, The prolate matrix, Linear Algebra Appl. 187(1), 269–278 (1993).
Acknowledgements
The authors would like to thank John Boyd, Doug Cochran, Laurent Demanet, Anne Gelb, Anders Hansen, Arieh Iserles, Arno Kuijlaars, Mark Lyon, Nilima Nigam, Sheehan Olver, Rodrigo Platte, Jie Shen and Nick Trefethen for useful discussions and comments. They would also like to thank the anonymous referees for their constructive and helpful remarks.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Nira Dyn.
Rights and permissions
About this article

Cite this article
Adcock, B., Huybrechs, D. & Martín-Vaquero, J. On the Numerical Stability of Fourier Extensions. Found Comput Math 14, 635–687 (2014). https://doi.org/10.1007/s10208-013-9158-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10208-013-9158-8