
Abstract
Since the work of Robert May in 1972, the local asymptotic stability of large ecological systems has been a focus of theoretical ecology. Here we review May’s work in the light of random matrix theory, the field of mathematics devoted to the study of large matrices whose coefficients are randomly sampled from distributions with given characteristics. We show how May’s celebrated “stability criterion” can be derived using random matrix theory, and how extensions of the so-called circular law for the limiting distribution of the eigenvalues of large random matrix can further our understanding of ecological systems. Our goal is to present the more technical material in an accessible way, and to provide pointers to the primary mathematical literature on this subject. We conclude by enumerating a number of challenges, whose solution is going to greatly improve our ability to predict the stability of large ecological networks.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
More than 40 years ago, Robert May, working on a problem posed by Gardner and Ashby (1970), showed that a sufficiently large ecological network resting at a feasible equilibrium point would invariably be unstable: arbitrarily small perturbations of the population densities would drive the system away from equilibrium (May 1972). May’s article and subsequent book (May 2001) had an immense influence on ecological theory, leading to hundreds of published works investigating which particular features of natural systems would violate May’s simple assumptions—and how these violations would translate into stabilizing or destabilizing mechanisms (Roberts 1974; Pimm 1984; Pimm et al. 1991; McCann et al. 1998; Moore and Hunt 1988; Kondoh 2003; Neutel et al. 2007; Allesina and Pascual 2008).
Until recently, however, May’s work had never been extended to more complex cases than the simple random matrix he proposed. We did so (Allesina and Tang 2012; Tang et al. 2014) by introducing to ecology some basic tools of Random Matrix Theory (RMT) (Bai and Silverstein 2009; Anderson et al. 2010). The idea of RMT is to study the properties of large matrices whose coefficients are sampled from specific random distributions. The birth of modern RMT is due to the work of Eugene Wigner in physics (Wigner 1958). Since the fifties, the field has come a long way, and is now one of the fastest growing areas of mathematics (Bai and Silverstein 2009). This is excellent news for biology, as biological systems are typically very large, and inherently “random”: the basic parameters regulating the growth and decay of cells, individuals, populations, and ecosystems, are all influenced by environmental and demographic stochasticity, and present variation across space and time. Therefore, RMT is ideally suited to study the fundamental behavior of large biological systems with network structure.
The goal of this work is to review May’s contribution and subsequent extensions in the light of RMT, and to outline a research program that will lead to a better understanding of the behavior of large ecological systems. Our hope is that most of the extensions and refinements we outline here will be completed by the time May’s paper turns 50.
Throughout the article, we keep the presentation of the material very informal, to make it accessible to a wide audience of ecologists interested in the theory of local asymptotic stability. We provide references to the primary mathematical literature for a formal treatment of these ideas.
Local asymptotic stability
We start with some preliminaries on local asymptotic stability (henceforth, stability). We model an ecological community composed of \(S\) populations as a continuous-time dynamical system, described by a set of \(S\) autonomous (i.e., which do not explicitly contain the time variable) ordinary differential equations, where each equation describes the growth rate of a population:
Here, \(X_i(t)\) represents the density of population \(i\) at time \(t\), the vector \({{\mathbf {X}}}(t)\) is the vector of all population densities, and \(f_i\) is a function relating the growth rate of population \(i\) to the density of the \(S\) populations. We say that the system is at an equilibrium point \(\mathbf {X^*}\) whenever
for all \(i\). Hence, if it is not perturbed, the system will remain at the equilibrium point indefinitely. In ecology, we are interested in feasible equilibria, for which \({\mathbf {X^*}} > {\mathbf {0}}\).
Stability analysis assesses whether infinitesimal perturbations of the equilibrium can be buffered by the system. The equilibrium is said to be locally stable if all infinitesimal perturbations die out eventually, and locally unstable if there exists an infinitesimal perturbation after which the system never goes back to the equilibrium. The analysis is carried out by linearization of the system at the equilibrium point. First, one builds the Jacobian matrix \(\mathbf {J}\), whose elements \(J_{ij}\) are defined as:
Therefore, the coefficients of the Jacobian matrix are functions of the densities of the populations (\({\mathbf {X}}\)). Then, one can substitute into the Jacobian (which is uniquely defined for each system), the equilibrium point whose stability one wants to evaluate (there could be many feasible equilibria). This produces the so-called “community-matrix” \({\mathbf {M}}\) (Levins 1968), defined as:
Each equilibrium corresponds to a community matrix (note that infinitely many systems at equilibrium can yield exactly the same community matrix). The coefficient \(M_{ij}\) measures the effect of a slight increase in the population \(j\) on the growth rate of population \(i\). The eigenvalues of \({\mathbf {M}}\), which have units of time\(^{-1}\) and therefore measure rates, determine the stability of the underlying equilibrium point: if all eigenvalues have negative real parts, then the equilibrium is stable, while if any eigenvalue has positive real part, the equilibrium is unstable, as there is at least one direction in which infinitesimal perturbations would drive the system away from the equilibrium.
Local asymptotic stability is limited in scope because it is based on linearization. First, the results hold only locally, and in the simple case outlined here, can be applied only to equilibria. Thus, local stability analysis has limited bearing for populations operating out-of-equilibrium. Second, instability does not necessarily imply lack of persistence: populations could coexist thanks to limit cycles or chaotic attractors, which typically originate from unstable equilibrium points. Third, the basin of attraction of a stable equilibrium point is difficult to measure analytically, so that local stability holds with certainty only for infinitesimal perturbations.
Given that the community matrix of an ecological system is composed of real numbers, its eigenvalues are either real (of the form \(\lambda = a\)), or complex forming conjugate pairs (of the form \(\lambda = a \pm i b\), where \(a\) and \(b\) are real numbers, and \(i\) is \(\sqrt{-1}\)). Thus, if we plot the eigenvalues on a complex plane where the horizontal axis is to the real axis, and the vertical the imaginary axis, the eigenvalues are always symmetric about the real axis. The stability of the equilibrium is exclusively determined by the real part of the “rightmost” eigenvalue(s). We order the eigenvalues according to their real part, and we denote the rightmost eigenvalue by \(\lambda _1\) and its corresponding real part by \({\mathfrak R}(\lambda _1)\), so that the equilibrium is stable whenever \({\mathfrak R}(\lambda _1) <0\). Note that the rightmost eigenvalue could in fact be several eigenvalues with the same real part.
Will a large complex system be stable?
To evaluate the stability of an equilibrium, we need to calculate \({\mathfrak R}(\lambda _1)\), which in turn requires knowledge of the community matrix. Then, we would need to know the exact form of the functions \(f_i({\mathbf {X}}(t))\) as well as to calculate precisely the equilibrium \(\mathbf {X^*}\), both of which are required to construct \({\mathbf {M}}\). This means that any different set of equations, and each equilibrium of the same set of equations, would lead to a different community matrix.
May’s insight (May 1972) was to skip the Jacobian matrix altogether, to consider directly the community matrix, modeled as a large random matrix, and to attempt estimating \({\mathfrak R}(\lambda _1)\) based on the characteristics of the random matrix. Here we briefly review the construction of such random matrices, and state May’s stability criterion. In the next section, we will show how May’s result can be derived using RMT.
For a species to be self-regulating, we need \(M_{ii} < 0\). This self-regulation is equivalent to setting a carrying capacity (or other similar density-dependent mechanism) for the population. May set all the diagonal elements \(M_{ii} = -1\). He then set the off-diagonal elements to \(0\) with probability \(1-C\), and with probability \(C\), he drew them independently from a distribution with mean \(0\) and variance \(\sigma ^2\). Note that, although in the subsequent literature this distribution is often assumed to be normal, May did not specify a shape for the distribution (May 1972). In the next section, we will see that this was an excellent idea, as the actual details of the distribution do not matter in the limit of \(S\) large (Tao et al. 2010). The only important quantities in this case are the mean and the variance of the distribution.
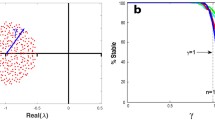
For such matrices, May claimed that the eigenvalues all have negative real parts with very high probability whenever:
and therefore, the equilibrium is very likely to be stable whenever the inequality is met. On the other hand, when the inequality is not met, then the equilibrium is unstable with high probability (Fig. 1). The \(1\) on the right-hand side of the inequality descends from having \(-1\) on the diagonal. For matrices with \(-d < 0\) on the diagonal, the inequality has \(d\) on the righ-hand side.

Probability of stability (\(y\)-axis) as a function of \(\sigma\) (\(x\)-axis) for random \(S \times S\) matrices whose off-diagonal coefficients are sampled independently from the uniform distribution \(\mathcal U[-\sqrt{3}\sigma , \sqrt{3}\sigma ]\) with probability \(C = 0.5\) and are set to \(0\) otherwise. The diagonal elements are set to \(-\sqrt{SC}\), so that in this case the stability criterion reduces to \(\sigma < 1\), i.e., the transition from stability to instability should happen at \(\sigma \approx 1\). We varied \(\sigma\) from \(0.8\) to \(1.2\) in steps of \(0.01\) (points). The point shapes indicate the size of the random matrices, with \(S=100\) for circles, 250 for triangles, and 500 for squares. The solid lines are the best-fitting logistic curves. The probability of stability is estimated using 200 randomizations for each combination of \(\sigma\) and \(S\). When \(S\) increases, the transition becomes sharper, and for \(S\) very large it would approach a step function
This inequality set into motion the so-called “stability–complexity” debate (McCann 2000) (also known as “May’s paradox”), given that in order to satisfy the inequality Eq. 5 a system cannot be too large (\(S\) large), too connected (large \(C\)), or with a large variance of the interactions (large \(\sigma\)).
Circular law and stability
May was inspired by Wigner’s work (Wigner 1958) on symmetric matrices (for which all eigenvalues are real), even though the matrices he studied are not symmetric. In his article, May (1972) signaled that he was aware of the contemporary work on the non-Hermitian (non-symmetric) case: he stated in a footnote that the work of Metha (1967) and Ginibre (1965) were “indirectly relevant”.
The analog of Wigner’s “semicircle law” in the case of non-symmetric matrices is known as the “circular law”. The circular law has a long and complicated history. It was possibly first put forward by Ginibre (1965), studied extensively by Girko (1985), proved by Metha (1967) for the normal case, extended considerably by Bai (1997), and finally proved in the most general case by Tao et al. (2010). In its latest and more general incarnation, the circular law can be stated as follows. Take an \(S \times S\) matrix \({\mathbf {M}}\), whose entries are independent and identically distributed (i.i.d.) random variables with mean zero and variance one. Then, the empirical spectral distribution (i.e., the distribution putting \(1/S\) probability mass on each eigenvalue) of \({\mathbf M}/\sqrt{S}\) converges to the uniform distribution on the unit disk as \(S \rightarrow \infty\) (Theorem 1.10 of Tao et al. 2010).
Note that the statement does not contain any specifics on the distribution of the coefficients: as long as the mean is zero and the variance is one, the empirical spectral distribution of the rescaled matrix \({\mathbf M}/\sqrt{S}\) is expected to converge to the uniform distribution on the unit disk as \(S\) gets sufficiently large. This property is known as “universality” (Tao et al. 2010). To demonstrate this point numerically, in Fig. 2 we show the eigenvalue distribution of a 1000 \(\times\) 1000 matrix whose entries are sampled from a normal distribution \(\mathcal N(0,1)\) (Fig. 2a) and from a uniform distribution \(\mathcal U[-\sqrt{3}, \sqrt{3}]\) (Fig. 2b), so that both distributions have mean zero and variance 1. We plot the eigenvalues of \({\mathbf M} / \sqrt{S}\), and show that in both cases the eigenvalues are about uniformly distributed on the unit disk of the complex plane.

Circular law. a Eigenvalues of the matrix \({\mathbf M}/\sqrt{S}\), with \(S\) = 1000. The \(x\)-axis represents the real part, and the \(y\)-axis the imaginary part of the eigenvalues (points). The coefficients of \({\mathbf M}\) are sampled independently from a normal distribution \(\mathcal N(0,1)\). The eigenvalues are approximately uniformly distributed in a disk of radius 1. b As a, but with entries sampled from the uniform distribution \(\mathcal U[-\sqrt{3}, \sqrt{3}]\) (which has variance 1). c Eigenvalues of the matrix \({\mathbf M}/\sqrt{SC}\), where the entries are sampled as in a with probability \(C = 0.25\), and are set to 0 otherwise. Normalizing the matrix using \(\sqrt{SC}\) yields eigenvalues falling in the unit disk. d As c, but with non-zero coefficients sampled with probability \(C = 0.15\) from the uniform distribution \(\mathcal U[-\sqrt{3}, \sqrt{3}]\). e Eigenvalues of \({\mathbf {M}}\), where the matrix is constructed as in c, but all the diagonal elements are set to \(-d = -10\). When the matrix is not normalized and has a non-zero diagonal, the eigenvalues are approximately uniform in a disk centered at \(-d\), and with radius \(\sigma \sqrt{SC}\). f) As e, but with non-zero coefficients sampled from the uniform distribution \(\mathcal U[-\sqrt{3}, \sqrt{3}]\), and diagonal entries set to \(-5\)
One subtle point to consider is that the circular law only describes the behavior of the “bulk” of the eigenvalues of the rescaled matrix \({\mathbf M} / \sqrt{S}\) in the limit \(S \rightarrow \infty\). As such, given that in the empirical spectral distribution each eigenvalue only contributes \(1/S\) to the density—which becomes negligible as \(S \rightarrow \infty\)—, the fact that the bulk converges to the unit disk does not necessarily mean that all eigenvalues are contained in the disk. This could greatly limit our ability to predict the position of any single eigenvalue, including \(\lambda _1\). Fortunately, it has been shown (Bai and Silverstein 2009) that if the distribution of the coefficients of \({\mathbf {M}}\) has mean zero, variance one, and bounded (i.e., not infinite) fourth moment, then all the eigenvalues, as \(S \rightarrow \infty\), are contained in the disk. Because in biology we are always confronted with distributions with finite moments, then we can confidently assume that all the eigenvalues, for \(S\) sufficiently large, are contained in the disk.
Hence, for sufficiently large \(S\), all the eigenvalues of \({\mathbf {M}}\) are approximately uniformly distributed in the disk in the complex plane centered at \((0,0)\) and with radius \(r_x = \sqrt{S}\), so that \({\mathfrak R}(\lambda _1) \approx \sqrt{S}\). Next, we relax the assumptions of the circular law to derive May’s result. We start by analyzing the case in which the variance of the entries of \({\mathbf {M}}\) is not one.
When the variance of the i.i.d. entries is \(\sigma ^{2} > 0\), not necessarily one, we can rescale the matrix to achieve a unit variance by simply dividing each entry by \(\sigma\). Combining this fact with the circular law, we estimate \({\mathfrak R}(\lambda _{1})\approx \sigma \sqrt{S}\) when \(S\) is sufficiently large. Generally speaking, the variance of the entries, denoted by \(V = Var (M_{ij})\), acts as a scaling factor for the radius of the disk formed by the eigenvalues of \({\mathbf {M}}\): the radius is multiplied by an additional factor of \(\sqrt{V}\), compared to the unit variance case.
Ecological systems are typically only sparsely connected: most of the coefficients in the community matrix are zero, and only few are non-zero. In this case, the universality of the circular law turns out to be key: we can think of sampling the coefficients from a “zero-inflated” distribution, such that the coefficients are zero with probability \(1-C\), and with probability \(C\) are taken from a given distribution with mean zero and variance \(\sigma ^2\). While the mean of \(M_{ij}\) sampled from such “zero-inflated” distribution is still zero, the variance is reduced to \(C\sigma ^{2}\). Consequently, the entries of \({{\mathbf {M}}}/\sqrt{C\sigma ^{2}}\) have unit variance, and thus \({\mathfrak R}(\lambda _{1}) \approx \sigma \sqrt{SC}\), as shown in Fig. 2c–f. This intuitive argument based on universality is confirmed by the rigorous study of sparse matrices (Wood 2012), where it is shown that the circular law holds if there exists some \(\alpha \in (0, 1]\) such that \(C\) is “behaving like” a constant multiplication of \(S^{-1+\alpha }\).
We next want to consider the effect of the diagonal entries of \({\mathbf {M}}\) on its eigenvalue distribution. As we stated above, the diagonal elements of the community matrix \({\mathbf {M}}\) model self-effects, and in the case of negative diagonal coefficients, we typically refer to “self-regulation”. Most models for consumer–resource interactions would predict the diagonal elements of the community matrix to be non-positive. The diagonal of a matrix determines the mean of the eigenvalues, due to the relation \(Tr ({{\mathbf {M}}}) = \sum _{i=1}^{S}M_{ii} = \sum _{i=1}^{S} \lambda _{i}\). Hence, the eigenvalues have the same mean as that of the diagonal elements, which we denote by \(-d\). In May’s case, we have \(d=1\), whereas for the circular law, since the diagonal entries of \({\mathbf {M}}\) are also assumed to be drawn from the same distribution as the off-diagonal entries, the mean of the diagonal is zero.
The fact that subtracting a constant from the diagonal elements shifts the distribution of the eigenvalue can be easily proved by the following argument. Take a matrix \(\mathbf {A}\): its eigenvalues can be obtained setting \(\text {Det}(\lambda {\mathbf {I}} - {\mathbf {A}}) = 0\), where \(\mathbf {I}\) is the identity matrix, and \(\text {Det}(\cdot )\) is the determinant. Denote the eigenvalues of \(\mathbf {A}\) as \(\lambda _{i}^{({\mathbf {A}})}\). Now take \({\mathbf {B}} = {\mathbf {A}} - d{\mathbf {I}}\), i.e., a matrix that is identical to \(\mathbf {A}\), but with diagonal elements \(B_{ii} = A_{ii}-d\). The eigenvalues of \(\mathbf {B}\) can be found setting to zero \(\text {Det}(\lambda {\mathbf {I}} - {\mathbf {B}}) = \text {Det}(\lambda {\mathbf {I}} - {\mathbf {A}} + d{\mathbf {I}}) = \text {Det}((\lambda + d) {\mathbf {I}} - {\mathbf {A}})\). As such \(\lambda _{i}^{({\mathbf {A}})} = \lambda _{i}^{({\mathbf {B}})}+d\), and thus \(\lambda _{i}^{({\mathbf {B}})} = \lambda _{i}^{({\mathbf {A}})} - d\): all the eigenvalues of \(\mathbf {B}\) are equal to those of \(\mathbf {A}\) shifted by \(-d\). The shape of the eigenvalue distribution is completely unaffected, but its position is shifted horizontally.
The circular law has been studied for the case in which all the entries (including the diagonal ones) are sampled from the same distribution. However, numerical simulations show that sampling all the off-diagonal elements from one distribution, and all the diagonal entries from some other distribution with mean zero and variance \(\sigma _{d}^{2} < \infty\) does not qualitatively alter the results: the circular law still holds in the \(S\rightarrow \infty\) limit. For finite \(S\), we recover the same result as long as the variance of the diagonal coefficients \(\sigma _{d}\) is relatively small. When diagonal coefficients have very large variance, we have to assess the matrices numerically, as the result depends on the exact arrangement of the coefficients along the diagonal (Tang et al. 2014). For simplicity, we may set the diagonal entries of \({\mathbf {M}}\) to be identically zero (in which case \(\sigma _{d}=0\)), and the eigenvalue distribution does not deviate appreciably from the circular law, when \(S\) is sufficiently large.
These considerations are sufficient to recover May’s result. The off-diagonal coefficients are zero with probability \(1-C\), and are sampled independently from a distribution with mean \(0\) and variance \(\sigma ^2\) with probability \(C\). The diagonal coefficients are all set to \(-d\). Then, for \(S\) large, the eigenvalues are about uniformly distributed in a disk centered at \(-d\), and with radius \(\sigma \sqrt{S C}\). For stability, we need the rightmost eigenvalue to have negative real part, \({\mathfrak R}(\lambda _1) < 0\). Substituting the approximation from the circular law, we obtain \({\mathfrak R}(\lambda _1) \approx \sqrt{S C \sigma ^2} -d < 0\), which becomes \(\sigma \sqrt{S C} <d\).
Having considered the effects stemming from the variance of the off-diagonal entries, and from the distribution of the diagonal entries, we want to assess the effect of having a nonzero mean for the off-diagonal entries on the eigenvalue distribution of \(\mathbf M\). This case is especially important, since in natural systems we do not expect the positive effects of resources on consumers to exactly offset the negatives of consumers on resources. The setting is as follows: with probability \(C\), the off-diagonal coefficients are sampled independently from a distribution of mean \(\mu\) and variance \(\sigma ^{2}\), and they are set to zero otherwise. Therefore, we have \(E = \mathbb E [M_{ij}] = C \mu\). The diagonal entries are all \(-d\).
Note that any matrix with constant row sum has \(\mathbf 1\) as its eigenvector and the row sum as the corresponding eigenvalue. When \({\mathbf {M}}\) is randomly constructed with i.i.d. off-diagonal entries and identical diagonal entries, although the row sum is not a constant, they have the same expectation, i.e.,
for any row \(i\). When \({\mathbf {M}}\) is large, its row averages are approximately the same due to the law of large numbers. Thus, for sufficiently large \(S\), one of the eigenvalues of \({\mathbf {M}}\) will be close to the expectation of the row sum given in Eq. 6, as confirmed by numerical simulations. Regarding the other \((S-1)\) eigenvalues, numerical simulations also show that they are still closely approximated by a uniform distribution on a disk. However, the disk has slightly shifted to account for the fact that the mean of all eigenvalues must still be \(-d\). The center of the shifted disk is given by the mean of the \(S-1\) values, and it can be computed subtracting \(-d + (S-1)E\) from the sum of all the eigenvalues \(-dS\) and dividing by \(S-1\). We also need to recompute the variance of the off-diagonal elements of \({\mathbf {M}}\), which becomes \(V = {\text {Var}}[M_{ij}] = {\mathbb E}[M_{ij}^{2}] - E^{2} = C(\sigma ^{2}+(1-C)\mu ^{2})\). This means that the rightmost eigenvalue on the disk is located approximately at \(-(d+E)+\sqrt{SV}\), where \(-(d+E)\) is the center of the disk and \(\sqrt{SV}\) estimates its radius.
We then estimate \({\mathfrak R}(\lambda _{1})\) for the nonzero mean case, when \(S\) is sufficiently large. If \(\mu\) is negative (thus \(E <0\)), then \(-d + (S-1)E < 0\). The rightmost eigenvalue of \({\mathbf {M}}\) corresponds to the rightmost point of the disk (Fig. 3a), and in this case, we estimate \({\mathfrak R}(\lambda _{1}) \approx -d -E+\sqrt{SV}\). If \(\mu\) is positive, on the other hand, we can have two situations: either the row sum is large enough to send an eigenvalue to the right of the disk (Fig. 3b), or it is weak enough such that the corresponding eigenvalue falls inside the disk (Fig. 3c). In the first case, \({\mathfrak R}(\lambda _{1})\approx -d +(S-1)E\), whereas in the second case \({\mathfrak R}(\lambda _{1}) \approx -d-E+\sqrt{SV}\). To consider all three scenarios, one can write a criterion for stability that takes into account both the eigenvalue corresponding to the row sum and the rightmost eigenvalue on the disk.
which, when writing the mean \(E\) and the variance \(V\) in terms of \(C\), \(\mu\), and \(\sigma\) becomes

a The eigenvalue distribution of a \(1000 \times 1000\) matrix \({\mathbf {M}}\) whose off-diagonal coefficients are \(0\) with probability \(1-C\), and with probability \(C\) are sampled from a normal distribution of mean \(\mu\) and variance \(\sigma ^2\). The diagonal elements are all set to \(-d\). In this case, \(C = 0.75\), \(d = 0\), \(\sigma ^2 ={1}/{2}\), and \(\mu = -0.1\). The negative mean results in a slight shift of the disk towards the right, and the appearance of an eigenvalue on the left of the disk, in correspondence of the expected row sum (small circle). The disk centered at \(-d + C \mu\) and with radius \(\sqrt{S C (\sigma ^2 + (1 - C) \mu ^2)}\), containing all other eigenvalues, is also drawn. b As a, but with \(\mu = 0.1\). In this plot, the eigenvalue determining stability is the one on the right of the disk. c As a, but with \(\mu = 0.01\). In this case, the eigenvalue corresponding to the expected row sum is contained in the disk
Elliptic law and stability
In the matrices above, the coefficients \(M_{ij}\) and \(M_{ji}\)—expressing the effects of species \(i\) on \(j\), and that of \(j\) on \(i\)—are i.i.d. In ecological networks, we often want to model pairwise interactions such as consumer–resource, mutualism, and competition, in which cases \(M_{ij}\) is not independent from \(M_{ji}\). Take consumer–resource interactions: then, for any \(M_{ij} < 0\), representing the negative effect of the consumer \(j\) on the resource \(i\), we would expect a \(M_{ji} > 0\), measuring the positive effect of the resource on the consumer. For this reason, we would like to sample directly the coefficients in pairs, rather than each coefficient separately. Doing so leads to the “elliptic law”.
The elliptic law is a generalization of the circular law to the case in which the pairs of coefficients \((M_{ij}, M_{ji})\) are sampled from a bivariate distribution. A simplified statement of this law is as follows. Take an \(S \times S\) matrix \({\mathbf {M}}\), whose off-diagonal coefficients are independently sampled in pairs from a bivariate distribution with zero marginal means, unit marginal variances, and correlation \(\rho\) (i.e., \(\rho = \mathbb E[M_{ij} M_{ji}]\)). Then, as \(S \rightarrow \infty\), the eigenvalue distribution of \({{\mathbf {M}}} / \sqrt{S}\) converges to the uniform distribution on an ellipse centered at \((0,0)\) with horizontal semi-axis of length \(1 + \rho\) and vertical semi-axis of length \(1 -\rho\).
Similar to the circular law, the elliptic law has a long history. Again, this law was conjectured early on and was investigated by Girko (1986). This phenomenon was also independently discovered in the physics literature (Sommers et al. 1988). Recently (Naumov 2012; Nguyen and O’Rourke 2012), proofs of the universality of the elliptic law started appearing in the mathematical literature. The elliptic law is illustrated in Fig. 4a.

Elliptic law. a Top eigenvalues of \({\mathbf {M}}\), a \(1000 \times 1000\) matrix with zero on the diagonal and off-diagonal coefficients \((M_{ij}, M_{ji})\) are sampled in pairs from the bivariate normal distribution illustrated below, so that the marginals have mean zero, variance one and correlation \(\rho = -2 / \pi\). b As (a), but, for each pair, sampling one of the coefficients from the half-normal distribution \(|\mathcal N(0,1)|\), and the other from a negative half-normal. Because this leads to the same covariance matrix found in case (a), the eigenvalues have approximately the same distribution (top), even though the coefficients have very different distributions (bottom, lighter shade for higher density). c As (a–b), where, however for each pair \((M_{ij}, M_{ji})\), we sample one coefficient from the uniform distribution \(\mathcal U[0, 2x]\), and the other from \(\mathcal U[-y-x, y-x]\). Setting \(x = \sqrt{2 / \pi }\) and \(y = \sqrt{6 - 14 / \pi }\), we obtain a covariance matrix identical to cases a–b, and thus the same ellipse
Just as for the circular law, the elliptic law can be extended to more general cases accounting for (1) partially connected matrices, (2) diagonal elements different from zero, (3) off-diagonal coefficients sampled from a bivariate distribution with non-zero marginal means, and (4) matrices with diagonal \(-d\). Suppose we are setting the off-diagonal pair \((M_{ij}, M_{ji})\) to \((0,0)\) with probability \(1-C\), and with probability \(C\) we are sampling the pair from a bivariate distribution of mean \(\varvec{\mu }\) and covariance matrix \(\mathbf {\Sigma }\):
The diagonal elements are set to \(-d\). As before, we need to track two eigenvalues: the one corresponding to the row sum, and the rightmost eigenvalue on the ellipse.
To this end, we compute the relevant statistics for the off-diagonal coefficients. The mean of the off-diagonal coefficients is \(E = \mathbb E[M_{ij}] = C \mu\), their variance is \(V = {\text {Var}}[M_{ij}] = C (\sigma ^2 + (1 - C) \mu ^2)\), and, finally, the correlation between the pairs of coefficients is
Since each off-diagonal coefficient is equally likely to come from either component of the bivariate distribution, the expected row sum is \(-d + (S-1) E\) (as for the circular case). Again, using the same strategy illustrated above, we find that the ellipse is centered at \(-d-E\), and has horizontal semi-axis \(\sqrt{S V}(1 + \rho )\). Using this notation, the criterion for stability becomes (Tang et al. 2014):
In the first application of the elliptic law to the stability of ecological networks (Allesina and Tang 2012), we showed that when we model a food web in which the elements of the non-zero pairs have opposite signs [\((+,-)\)], then this necessarily yields a negative correlation \(\rho\), which in turn is highly stabilizing. For example, in Fig. 4b we show the spectrum of a matrix in which, for each non-zero pair, one coefficient is taken from the half-normal distribution \(|\mathcal N(0,1)|\), and the other is taken from the negative half-normal \(-|\mathcal N(0,1)|\). As such, \(E = 0\), \(V = 1\) and \(\rho = -2 / \pi\): the sign-pairing produces a negative correlation, which in turn is stabilizing. Moreover, thanks to the universality property, any bivariate distribution with the same covariance matrix would lead to identical results, as shown in Fig. 4.
A research program
Having reviewed the contribution of May in the light of the circular law, and having shown how his results can be extended to the case of correlated pairs of interaction strengths, we now turn to the work that needs to be done in order to considerably extend the reach of these methods.
We present several semi-independent problems, which we hope will all be solved by the time May’s article turns 50. Our goal is to circumscribe precisely enough each problem, in order to make it “solvable”: too often in ecology we are confronted with very vague questions, whose answer is invariably “it depends”.
Non-equilibrium dynamics
The methods above rely heavily on the linearization around a feasible equilibrium point. However, natural systems are believed to operate out-of-equilibrium, with persistence of populations being achieved through more complex dynamics, such as limit cycles or chaotic attractors (McCann et al. 1998).
The stability criteria provide a natural bound for the complexity that can be achieved by a system resting at an equilibrium before reaching a bifurcation point. The question is then whether the same guidelines would apply to the persistence of species when it is governed by out-of-equilibrium dynamics. This is for example what found by Sinha and Sinha (2005) when using the exponential map to model the interaction between species.
Ultimately, this is a question about the nature of bifurcations in ecological systems. Much of the controversy about “May’s paradox” descends from viewing instability as being followed by a catastrophic change in species composition. When an equilibrium point becomes unstable, however, the system could respond in different manners: it could start cycling, move towards another attractor, lose a few species through a transcritical bifurcation, or experience more dramatic changes—such as in the case of a “fold” bifurcation. May’s results would be more of a paradox if bifurcations were invariably to lead to large effects on biodiversity. On the other hand, if most bifurcations were to have small effects on the number of species, we could have systems persisting at the stability/instability boundary, as hypothesized by Solé et al. (2002). The immigration of new species would trigger limited extinctions, setting the system again close to the bifurcation. In this scenario, the stability criteria would accurately predict the number of extant species.
The first challenge, could then be formulated as “Can we predict the out-of-equilibrium persistence of large ecological systems using the methods developed for local stability? Under which conditions?”
Clearly, a positive answer to these questions would have strong impact on our understanding of what makes ecosystems persistent, and on the nature of critical points in ecological systems. Moreover, much of the work on complex dynamics such as chaotic attractors and limit cycles is largely based on numerical simulations of small- to medium-sized systems, while a positive outcome of this challenge would open the door for analytic methods.
Effect of species-abundance distribution
Many authors (e.g., Kondoh 2003) considered this simple generalized Lotka–Volterra system of equations:
where the \(r_i\) is the intrinsic growth (death) rate of population \(i\), the term \(\alpha _{ii} < 0\) provides self-regulation, and \(\alpha _{ij}\) models the effect of \(j\) on the growth rate of \(i\) (including attack rates, efficiency, etc.). This system yields a particularly simple community matrix: \(M_{ii} = \alpha _{ii} X_i^*\), and \(M_{ij} = \alpha _{ij} X_i^*\). Moreover, we can choose any feasible \(\mathbf {X^*}\) and interaction matrix \(\mathbf {A}\), and then solve for the \(r_i\) which would make the system be at equilibrium (\(r_i = -\alpha _{ii} X_i^* - \sum \alpha _{ij} X_j^*\)).
This community matrix \({\mathbf {M}}\) has a particular feature: each element in the row \(i\) is obtained by multiplying the corresponding element in \(\mathbf {A}\) by \(X_i^*\). Using matrix notation, we have \({\mathbf {M}} = \text {diag}({\mathbf {X^*}}) \times \mathbf {A}\).
Thus, this is by far the simplest case in which one can probe the effect of species-abundance distribution on stability. The distribution of species abundances, typically showing a large number of rare species (Magurran 2003), remains an important problem in ecology, and this generalized Lotka–Volterra model shows that the particular shape of the distribution is going to affect the stability of the ecological community.
Suppose that \(\mathbf {A}\) is a random matrix, and that the elements of \(\mathbf {X^*}\) are sampled independently from a distribution. What is the spectrum of \({\mathbf {M}}\)? In Fig. 5, we sample the pairs in \(\mathbf {A}\) from a bivariate normal distribution, and then test the effect of sampling \(\mathbf {X^*}\) from a uniform, log-normal, or log-series distribution. In all cases, the eigenvalues of \({\mathbf {M}}\) are a “distorted” version of those of \(\mathbf {A}\). The distortion is more marked in the log-normal and log-series cases, but the general shapes of the spectra are quite similar. In these cases, the elliptic law fails to predict the location of the leading eigenvalue.
This leads to the formulation of the second challenge: “Can the eigenvalue distribution of \({\mathbf {M}} = \text {diag}({\mathbf {X^*}}) \times \mathbf {A}\) be studied analytically? What is the effect of the distribution of \(\mathbf {X^*}\) on stability?”
Solving this challenge would directly connect two ecological problems that are now quite separate, and could even illuminate a causal relationship between abundance distributions and stability.
Probably, the best tool to address this problem is represented by free probability (Hiai and Petz 2000). This mathematical theory is concerned with non-commutative random variables (e.g., random matrices): “free independence” is the analogue of independence in classical random variables, and many results have been derived for the sum and product of random matrices, or the product of a deterministic matrix and a random matrix.

a Eigenvalue distribution of \(\mathbf {A}\), a random \(1000 \times 1000\) matrix with connectance \(C = 0.25\) and non-zero pairs sampled from a bivariate normal distribution with means zero, \(\sigma = 0.5\) and \(\rho = -0.5\). The eigenvalue distribution of \({{\mathbf {M}}} = \text {diag}({\mathbf {X^*}}) \times \mathbf {A}\), where the elements of \(\mathbf {X^*}\) are sampled from different distributions, all having mean \(1/\log (2)\) for ease of comparison. b \(\mathbf {X^*}\) sampled from uniform \(\mathcal U[0,2/\log (2)]\). c Log-normal \(\ln \mathcal N(0, \sqrt{-\log (\log (2))})\). d Log-series (or logarithmic series distribution) with parameter \(p = 1/2\). In all cases, the spectrum is obtained by a “distortion” of the spectrum of \(\mathbf {A}\). The eigenvalues are not uniformly distributed over a shape, and the elliptic law grossly overestimates the value of \({\mathfrak R}(\lambda _1)\)
Network structure
For the circular (elliptic) law to hold, the matrices must represent a random network (i.e., if we were to connect any two species for which \(M_{ij} \ne 0\), we would obtain an Erdős-Rényi random directed graph). To put it bluntly, the lion is as likely to eat the gazelle as the gazelle is to eat the lion. This is not what we observe in natural systems, which are believed to be quite different from random graphs. First, in random graphs we find that the number of connections per species has a very concentrated distribution around the mean, while in empirical food webs, this is not the case (Dunne et al. 2002). Second, empirical food webs are almost acyclic and almost interval (Williams and Martinez 2000; Stouffer et al. 2006), two features that are not typical in random graphs. Third, we expect natural food webs to display modules (i.e., the species can be divided into subsets such that within-subset connections are much more frequent than between-subset connections—confusingly, these subsets are called “communities” in the complex-network literature) (Stouffer and Bascompte 2011), and groups of similar species (Allesina and Pascual 2009). Finally, it would be natural to conjecture that species cannot interact with an infinite number of other species (the connectance of an hypothetical “world-wide food web” would be much lower than that measured in local ecosystems). However, for the circular law to hold (Wood 2012), we need that \(SC \rightarrow \infty\) as \(S \rightarrow \infty\), but what if there was a cap on the maximum number of interactions, such that \(SC \rightarrow k\) as \(S \rightarrow \infty\)?
We start by illustrating this latter point. Take a small number of interactions per species (e.g., \(k = 7\)), and \(S\) large (e.g., \(S = 1000\)). Then, distribute the connections to each species in different ways. For example, in Fig. 6a, b we build a matrix in which each species has exactly the same number of connections (regular graph), or a very broad degree distribution (in which few species have many interactors, while many have few, such as in a power-law distribution). In both cases, the circular law would fail to describe the shape of the eigenvalue distribution. In the regular graph case, the distribution is still approximately uniform, but over a shape that looks like an astroid. In the power-law case, although an astroid-like pattern is still visible, the distribution is far from being uniform. These simple simulations show that there has to be a way to generalize the circular/elliptical law even further. Doing so will lead to better approximations of matrices possessing a structure similar to that of food webs.

Effect of network structure on eigenvalue distribution. Top eigenvalue distribution for a \(1000 \times 1000\) matrix. Bottom the network structure is illustrated by plotting the \(50 \times 50\) adjacency matrix (where a black square denotes interaction) built in the same way as in the corresponding top panel. a Regular graph structure. The interactions are assigned such that each column and row contains exactly \(k = 7\) interactions. The non-zero coefficients are sampled in pairs from a bivariate normal distribution with means zero, variances \(1/4\) and correlation \(0\). b As a), but with the adjacency matrix generated such that the degree distribution follows a power-law (in which few species have many interactions, and many have few). c A matrix in which the species are partitioned into two modules, and interactions are more frequent within module than between modules. The non-zero coefficients are sampled from a bivariate normal distribution with means \(0.1\), variances \(1/4\) and correlation \(0\). d Matrix constructed according to the niche model. For each non-zero element \(K_{ij}\) of the adjacency matrix, the coefficients \((M_{ij}, M_{ji})\) are sampled from the bivariate normal distribution with means \((-0.2, 0.1)\), variances \(1/4\) and correlation \(-0.5\)
If species live in different habitats, we expect the species in the same habitat to preferentially interact with those located in the same habitat, giving rise to “modules” (sometimes called “compartments”). The presence of modules must leave a mark in the eigenvalue distribution. For example, in Fig. 6c, we plot the eigenvalue distribution of a matrix in which there are two modules of \(500\) species each. The species in the first module have a probability \(0.5\) of interacting with the species in their module, while interactions with species in the other module are rare (with probability \(0.05\)). Similarly, the species in the second module have probability \(0.3\) of interacting within-module and \(0.05\) between-module. When two species interact, the pair of interaction strengths is sampled from a bivariate normal with \({\varvec{\mu}} = [0.1, 0.1]^T\), variance \({1}/{4}\) and correlation \(0\). Instead of having a single eigenvalue on the right of the ellipse, we find two, one at about the expected row mean for the first module, and the other at the row mean of the second module (Fig. 6c). The other eigenvalues are about uniform in an ellipse.
Finally, several models for food web structure have been developed (Williams and Martinez 2000; Stouffer et al. 2006; Allesina et al. 2008; Allesina and Pascual 2009). For example, the niche model (Williams and Martinez 2000) produces networks that are almost acyclic and interval (i.e., species can be arranged such that each predator consumes adjacent prey). The niche model can reproduce most of the characteristics observed in natural food webs. In Fig. 6d we plot the eigenvalues of a consumer–resource matrix whose network structure is generated by the niche model. In this case, we observe a few complex roots with large modulus and negative real part coming out of the ellipse predicted by the elliptic law.
Summarizing, we can divide this third challenge in three parts. First, “Can the circular/elliptic law be extended to the case of very sparse matrices, for which, as \(S \rightarrow \infty\), \(SC \rightarrow k\)?” This is going to be mathematically much challenging, especially because the “universality” property, which holds for the circular law and the elliptic law, is not going to be fulfilled in this case. However, results can probably be obtained for particular distributions of the coefficients, and for particular network structures.
Solving this challenge would have consequences extending well beyond biology. Take for example Facebook\(^\circledR\): in 2008 there were 56 million users, and the average number of friends was about 76, while in 2011 the number of users increased tenfold, while the average number of friends grew merely to 169 (Backstrom et al. 2012): if all people in the world were to join the social network, what would be the average number of friends? In this case, extending the elliptic law to the case of very sparse and structured matrices could for example be used to model the spread of rumors (or malicious software) on the social network (Wang et al. 2003).
The second part of the challenge deals with groups of similar species (species groups) or spatial/temporal clusters of species (modules): “What is the effect of modules and groups on stability?” The supposedly stabilizing effect of modules was put forward early on (Pimm 1979), but it is now time to revisit it exploiting the new tools provided by RMT.
The third and last part of the challenge deals directly with models for food web structure: “Can we write stability criteria for consumer–resource matrices (i.e., where if \(M_{ij} >0\), then \(M_{ji} < 0\)) whose network structure (i.e., the position of the negative/positive coefficients) is determined by a popular model for food web structure?” This third part, although mathematically quite challenging, would have the most direct application to food web theory.
Beyond stability
RMT could have many other applications in ecology.
For example, recently ecologists recognized the important role of the transient dynamics displayed by ecological communities after disturbance (Hastings 2001). Neubert and Caswell (1997) showed that stable equilibria could be classified as reactive or nonreactive depending on whether small perturbations can (reactive) or cannot (non reactive) be amplified before decaying. Interestingly, while stability (will perturbations eventually subside?) is determined by the eigenvalues of \({\mathbf {M}}\), reactivity (are perturbations initially amplified?) is controlled by that of the “Hermitian (symmetric) part” of the community matrix \({\mathbf {M}}\), defined as \({\mathbf H} = ({\mathbf M} + {\mathbf M}^T) / 2\). Because also \(\mathbf {H}\) is a random matrix, it is a matter of simple algebra to derive “reactivity criteria” (Tang and Allesina 2014). Transient dynamics can be described by other quantities related to matrices derived from \({\mathbf {M}}\). For example, the maximum amplification of perturbations is controlled by the matrix exponential \(e^{{\mathbf M}} = \sum _0^\infty {\mathbf M}^k / k!\) (Neubert and Caswell 1997), which could also be attacked using RMT.
Besides transient dynamics of ecological communities, random matrices could play an important role in providing null models for other ecological disciplines. For example, take metacommunities. We have a landscape, and habitable patches are scattered in the landscape. These patches are connected by dispersal, forming a dispersal matrix, whose coefficients are typically functions of the distance between patches. Hanski and Ovaskainen (2000) have shown that the relationship between the leading eigenvalue of the dispersal matrix (dubbed the “metapopulation capacity”) and the extinction rate for the population determine persistence. As such, one could use RMT to generate the expected persistence of the metapopulation when patches are randomly scattered in the landscape.
These “occupancy models” for metapopulations, in which the quantity being modeled is the presence/absence of a species in a patch, share many similarities with susceptible-infective-susceptible (SIS) models for infectious diseases. Take an SIS model unfolding on a network: individuals are connected by infection rates (\(\beta _{ij}\)), forming a “contact matrix”: again, the ratio between the leading eigenvalue of the contact matrix and the recovery rate strongly influence the occurrence and the size of epidemics (Van Mieghem and Cator 2012). Also in this case, RMT could help understanding which are the drivers of epidemics occurring on networks.
Conclusions
After more than 40 years, two of the main intuitions of May’s original article are still highly relevant for theoretical biology. First, biological systems are large: the gene-regulatory network of yeast is composed of about 6,000 genes, the richest ecosystems contain more than 10,000 species, and the contact network for the spread of influenza in the Chicago area would count millions of nodes. Second, the interactions between the genes/organisms/populations vary in time and space, and are highly dependent on environmental conditions. As such, there is not “a network” we can measure, but rather a statistical ensemble of networks sharing similar characteristics.
RMT is ideally suited to deal with this problem. We can introduce relevant rules for the construction of the random matrix and analytically probe the consequences of each constraint. Clearly, there are a number of important limitations that need to be overcome in order to make this approach more biologically relevant, and we have listed the more pressing issues in the preceding sections. For each obstacle we can overcome, we can incorporate into our matrices more and more biological realism, and thus construct better and more cogent null-models.
References
Allesina S, Pascual M (2008) Network structure, predator–prey modules, and stability in large food webs. Theor Ecol 1:55–64
Allesina S, Pascual M (2009) Food web models: a plea for groups. Ecol Lett 12:652–662
Allesina S, Tang S (2012) Stability criteria for complex ecosystems. Nature 483:205–208
Allesina S, Alonso D, Pascual M (2008) A general model for food web structure. Science 320:658–661
Anderson GW, Guionnet A, Zeitouni O (2010) An introduction to random matrices. Cambridge University Press, Cambridge
Backstrom L, Boldi P, Rosa M, Ugander J, Vigna S (2012) Four degrees of separation. In: Proceedings of the 3rd annual ACM web science conference. ACM, New York, pp 33–42
Bai Z (1997) Circular law. Ann Probab 25:494–529
Bai Z, Silverstein JW (2009) Spectral analysis of large dimensional random matrices. Springer, New York
Dunne JA, Williams RJ, Martinez ND (2002) Food-web structure and network theory: the role of connectance and size. Proc Natl Acad Sci USA 99:12917–12922
Gardner MR, Ashby WR (1970) Connectance of large dynamic (cybernetic) systems: critical values for stability. Nature 228:784
Ginibre J (1965) Statistical ensembles of complex, quaternion, and real matrices. J Math Phys 6:440–449
Girko VL (1985) Circular law. Theor Probab Appl 29(4):694–706
Girko VL (1986) Elliptic law. Theor Probab Appl 30(4):677–690
Hanski I, Ovaskainen O (2000) The metapopulation capacity of a fragmented landscape. Nature 404:755–758
Hastings A (2001) Transient dynamics and persistence of ecological systems. Ecol Lett 4:215–220
Hiai F, Petz D (2000) The semicircle law, free random variables and entropy, vol 77. American Mathematical Society, Providence
Kondoh M (2003) Foraging adaptation and the relationship between food-web complexity and stability. Science 299:1388–1391
Levins R (1968) Evolution in changing environments: some theoretical explorations. Princeton University Press, Princeton
Magurran AE, Henderson PA (2003) Explaining the excess of rare species in natural species abundance distributions. Nature 422:714–716
May RM (1972) Will a large complex system be stable? Nature 238:413–414
May RM (2001) Stability and complexity in model ecosystems. Princeton University Press, Princeton
McCann KS (2000) The diversity–stability debate. Nature 405:228–233
McCann KS, Hastings A, Huxel GR (1998) Weak trophic interactions and the balance of nature. Nature 395:794–798
Metha M (1967) Random matrices and the statistical theory of energy levels. Academic, New York
Moore JC, Hunt HW (1988) Resource compartmentation and the stability of real ecosystems. Nature 333:261–263
Naumov A (2012) Elliptic law for real random matrices. arXiv:1201.1639
Neubert MG, Caswell H (1997) Alternatives to resilience for measuring the responses of ecological systems to perturbations. Ecology 78:653–665
Neutel AM, Heesterbeek JA, van de Koppel J, Hoenderboom G, Vos A, Kaldeway C, Berendse F, de Ruiter PC (2007) Reconciling complexity with stability in naturally assembling food webs. Nature 449:599–602
Nguyen H, O’Rourke S (2012) The elliptic law. arXiv:1208.5883
Pimm SL (1979) The structure of food webs. Theor Popul Biol 16:144–158
Pimm SL (1984) The complexity and stability of ecosystems. Nature 307:321–326
Pimm SL, Lawton JH, Cohen JE (1991) Food web patterns and their consequences. Nature 350:669–674
Roberts A (1974) The stability of a feasible random ecosystem. Nature 251:607–608
Sinha S, Sinha S (2005) Evidence of universality for the May–Wigner stability theorem for random networks with local dynamics. Phys Rev E 71(020):902
Solé RV, Alonso D, McKane A (2002) Self-organized instability in complex ecosystems. Philos Trans R Soc B-Biol Sci 357:667–681
Sommers H, Crisanti A, Sompolinsky H, Stein Y (1988) Spectrum of large random asymmetric matrices. Phys Rev Lett 60:1895
Stouffer DB, Bascompte J (2011) Compartmentalization increases food-web persistence. Proc Natl Acad Sci USA 108:3648–3652
Stouffer DB, Camacho J, Amaral LAN (2006) A robust measure of food web intervality. Proc Natl Acad Sci USA 103:19015–19020
Tang S, Allesina S (2014) Reactivity and stability of large ecosystems. Front Ecol Evol 2:21
Tang S, Pawar S, Allesina S (2014) Correlation between interaction strengths drives stability in large ecological networks. Ecol Lett 17:1094–1100
Tao T, Vu V, Krishnapur M (2010) Random matrices: universality of ESDs and the circular law. Ann Probab 38:2023–2065
Van Mieghem P, Cator E (2012) Epidemics in networks with nodal self-infection and the epidemic threshold. Phys Rev E 86(016):116
Wang Y, Chakrabarti D, Wang C, Faloutsos C (2003) Epidemic spreading in real networks: an eigenvalue viewpoint. In: Proceedings of 22nd international symposium on reliable distributed systems. IEEE, New York, pp 25–34
Wigner EP (1958) On the distribution of the roots of certain symmetric matrices. Ann Math 67:325–327
Williams RJ, Martinez ND (2000) Simple rules yield complex food webs. Nature 404:180–183
Wood PM (2012) Universality and the circular law for sparse random matrices. Ann Appl Probab 22:1266–1300
Acknowledgments
SA and ST funded by NSF #1148867. Thanks to G. Barabás for comments. D. Gravel and an anonymous reviewer provided valuable suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
This manuscript was submitted for the special feature based on a symposium in Osaka, Japan, held on 12 October 2013.
Rights and permissions
About this article

Cite this article
Allesina, S., Tang, S. The stability–complexity relationship at age 40: a random matrix perspective. Popul Ecol 57, 63–75 (2015). https://doi.org/10.1007/s10144-014-0471-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10144-014-0471-0