
Abstract
This work aims to minimize a continuously differentiable convex function with Lipschitz continuous gradient under linear equality constraints. The proposed inertial algorithm results from the discretization of the second-order primal-dual dynamical system with asymptotically vanishing damping term addressed by Boţ and Nguyen (J. Differential Equations 303:369–406, 2021), and it is formulated in terms of the Augmented Lagrangian associated with the minimization problem. The general setting we consider for the inertial parameters covers the three classical rules by Nesterov, Chambolle–Dossal and Attouch–Cabot used in the literature to formulate fast gradient methods. For these rules, we obtain in the convex regime convergence rates of order \({\mathcal {O}}\left( 1/k^{2} \right) \) for the primal-dual gap, the feasibility measure, and the objective function value. In addition, we prove that the generated sequence of primal-dual iterates converges to a primal-dual solution in a general setting that covers the two latter rules. This is the first result which provides the convergence of the sequence of iterates generated by a fast algorithm for linearly constrained convex optimization problems without additional assumptions such as strong convexity. We also emphasize that all convergence results of this paper are compatible with the ones obtained in Boţ and Nguyen (J. Differential Equations 303:369–406, 2021) in the continuous setting.
Similar content being viewed by others

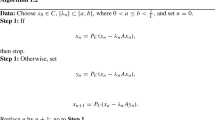
Avoid common mistakes on your manuscript.
1 Introduction
1.1 Problem formulation and motivation
Consider the optimization problem
where \({\mathcal {H}}, {\mathcal {G}}\) are real Hilbert spaces, \(f :{\mathcal {H}}\rightarrow {\mathbb {R}}\) is a convex and Fréchet differentiable function with \(L-\)Lipschitz continuous gradient, for \(L >0\), \(A :{\mathcal {H}}\rightarrow {\mathcal {G}}\) is a continuous linear operator and \(b \in {\mathcal {G}}\). We assume that the set \({\mathcal {S}}\) of primal-dual optimal solutions of (1.1) (see Sect. 1.2 for a precise definition) is nonempty.
Optimization problems of type (1.1) arise in many applications in areas like image recovery [13, 23, 26, 28], machine learning [9, 17], and network optimization [30].
Other than in the unconstrained case, for which fast continuous and discrete time approaches have been intensively investigated in the last years, the study of solution methods with fast convergence rates for linearly constrained convex optimization problems of the form (1.1) is in an incipient stage.
Zeng, Lei, and Chen (in [30]) and He, Hu, and Fang (in [16]) have investigated a dynamical system with asymptotic vanishing damping attached to (1.1), and have shown a convergence rate of order \({\mathcal {O}}\left( 1/t^{2} \right) \) for the primal-dual gap, while Attouch, Chbani, Fadili and Riahi have considered in [2] a more general dynamical system with time rescaling. More recently, for a primal-dual dynamical system formulated in the spirit of [2, 16, 30], Boţ and Nguyen have obtained in [8] fast convergence rates for the primal-dual gap, the feasibility measure and the objective function value along the generated trajectory, and, additionally, have proved asymptotic convergence guarantees for the primal-dual trajectory to a primal-dual optimal solution.
Fast numerical methods for solving (1.1) have been mainly considered in the literature under additional assumptions such as strong convexity, and in several cases the convergence rate results have been formulated in terms of ergodic sequences. In the merely convex regime no convergence result for the iterates has been provided so far for fast convergence algorithms. To the works addressing fast converging methods for linearly constrained convex optimization problems belong [11,12,13, 15, 19, 20, 23, 24, 26,27,28,29], at which we will take a closer look in Sect. 1.3.
The aim of this paper is to propose a numerical algorithm for solving (1.1), which results from the discretization of the dynamical system in [8], exhibits fast convergence rates for the primal-dual gap, the feasibility measure, and the objective function value as well as convergence of the sequence of iterates without additional assumptions such as strong convexity. Although there is an obvious interplay between continuous time dissipative dynamical systems and their discrete counterparts, one cannot directly and straightforwardly transfer asymptotic results from the continuous setting to numerical algorithms, thus, a separate analysis is needed for the latter. In this paper we will also comment on the similarities and the differences between the continuous and discrete time approaches.
1.2 Augmented Lagrangian formulation
Consider the saddle point problem associated to problem (1.1)
where \({\mathcal {L}}:{\mathcal {H}}\times {\mathcal {G}}\rightarrow {\mathbb {R}}\) denotes the Lagrangian function
Since f is a convex function, \({\mathcal {L}}\) is convex with respect to \(x \in {\mathcal {H}}\) and affine with respect to \(\lambda \in {\mathcal {G}}\). A pair \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {H}}\times {\mathcal {G}}\) is said to be a saddle point of the Lagrangian function \({\mathcal {L}}\) if for every \(\left( x , \lambda \right) \in {\mathcal {H}}\times {\mathcal {G}}\)
If \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {H}}\times {\mathcal {G}}\) is a saddle point of \({\mathcal {L}}\), then \(x_{*} \in {\mathcal {H}}\) is an optimal solution of (1.1) and \(\lambda _{*} \in {\mathcal {G}}\) is an optimal solution of its Lagrange dual problem. If \(x_{*} \in {\mathcal {H}}\) is an optimal solution of (1.1) and a suitable constraint qualification is fulfilled (see, for instance, [5, 7]), then there exists an optimal solution \(\lambda _{*} \in {\mathcal {G}}\) of the Lagrange dual problem of (1.1) such that \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {H}}\times {\mathcal {G}}\) is a saddle point of \({\mathcal {L}}\).
The set of saddle points of \({\mathcal {L}}\), called also set of primal-dual optimal solutions of (1.1), will be denoted by \({\mathcal {S}}\) and, as stated above, throughout this paper it will be assumed to be nonempty. The set of feasible points of (1.1) will be denoted by \({\mathcal {F}}:= \left\{ x \in {\mathcal {H}}:Ax = b \right\} \) and the optimal objective value of (1.1) by \(f_{*}\).
The system of primal-dual optimality conditions for (1.1) reads
where \(A^{*} : {\mathcal {G}}\rightarrow {\mathcal {H}}\) denotes the adjoint operator of A. This optimality system can be equivalently written as
where
is the maximally monotone operator associated to the convex-concave function \({\mathcal {L}}\). Indeed, it is immediate to verify that \({\mathcal {T}}_{{\mathcal {L}}}\) is monotone. Since it is also continuous, it is maximally monotone (see, for instance, [5, Corollary 20.28]). Therefore \({\mathcal {S}}\) can be interpreted as the set of zeros of the maximally monotone operator \({\mathcal {T}}_{{\mathcal {L}}}\), which means that it is a closed convex subset of \({\mathcal {H}}\times {\mathcal {G}}\) (see, for instance, [5, Proposition 23.39]).
For \(\beta \geqslant 0\), we also consider the augmented Lagrangian \({\mathcal {L}}_{\beta }:{\mathcal {H}}\times {\mathcal {G}}\rightarrow {\mathbb {R}}\) associated with (1.1)
For every \((x, \lambda ) \in {\mathcal {F}}\times {\mathcal {G}}\) it holds
If \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\), then for every \(\left( x , \lambda \right) \in {\mathcal {H}}\times {\mathcal {G}}\) we have
In addition,
1.3 Related works
In this section we will recall the most significant fast primal-dual numerical approaches for linearly constrained convex optimization problems and for convex optimization problems involving compositions with continuous linear operators.
In [11], Chambolle and Pock have studied in a finite-dimensional setting the convergence rates of their celebrated primal-dual algorithm for solving the minimax problem
which is naturally attached to the convex optimization problem
with \(f :{\mathcal {H}}\rightarrow {\mathbb {R}}\cup \left\{ + \infty \right\} \) and \(g :{\mathcal {G}}\rightarrow {\mathbb {R}}\cup \left\{ + \infty \right\} \) proper, convex and lower semicontinuous functions and \(g^{*} :{\mathcal {G}}\rightarrow {\mathbb {R}}\cup \left\{ + \infty \right\} \) the Fenchel conjugate of g. The problem (1.6) becomes (1.1) for g the indicator function of the set \(\{b\}\). For the primal-dual sequence of iterates \(\left\{ (x_{k} , \lambda _{k}) \right\} _{k \geqslant 0}\) the corresponding ergodic sequence \(\left\{ (\bar{x}_{k} , \bar{\lambda }_{k}) \right\} _{k \geqslant 0}\) is defined for every \(k \geqslant 0\) as
where \(\left\{ \sigma _{k} \right\} _{k \geqslant 0}\) is a sequence of properly chosen positive step sizes. The Chambolle-Pock primal-dual algorithm exhibits for the restricted primal-dual gap an ergodic convergence rate of
where \({\mathcal {X}}\subseteq {\mathcal {H}}\) and \({\mathcal {Y}}\subseteq {\mathcal {G}}\) are bounded sets. If f is strongly convex, then the accelerated variant of this primal-dual algorithm exhibits for the same restricted primal-dual gap an ergodic convergence rate of
whereas, if both f and \(g^*\) are strongly convex, then even linear convergence can be achieved.
In [12], Chen, Lan and Ouyang have considered the same minimax problem (1.5), but for \(f :{\mathcal {H}}\rightarrow {\mathbb {R}}\) a convex and Fréchet differentiable function with L-Lipschitz continuous gradient, for \(L>0\), and have proposed a primal-dual algorithm that exhibits for the restricted primal-dual gap an ergodic convergence rate of
A stochastic counterpart of the primal-dual algorithm along with corresponding convergence rate results and, for both the deterministic and the stochastic setting, convergence rates when either \({\mathcal {X}}\) or \({\mathcal {Y}}\) is unbounded have been also provided.
Later on, Ouyang, Chen, Lan and Pasiliao Jr. have developed in [23] an accelerated ADMM algorithm for the optimization problem (1.6) with f assumed to be Fréchet differentiable with L-Lipschitz continuous gradient, for \(L>0\), on its effective domain. In the case when f and \(g^*\) have bounded domains this method has been proved to exhibit an ergodic convergence rate for the objective function value of type (1.7), with the coefficient of \(1/{k^2}\) depending on L and the diameter of \(\mathrm {dom}f\) and the coefficient of 1/k depends on \(\Vert A\Vert \) and of the diameter of \(\mathrm {dom}g^*\). On the other hand, without assuming boundedness for the domains of f and \(g^*\), the accelerated ADMM algorithms has been proved to exhibit ergodic convergence rates for the feasibility measure and the objective function value of \({\mathcal {O}}\left( 1/k \right) \) as \(k \rightarrow +\infty \).
By using a smoothing approach, Tran-Dinh, Fercoq and Cevher have designed in [26] a primal-dual algorithm for solving (1.6) and its particular formulation (1.1) that exhibits last iterates convergence rates for the objective function value and the feasibility measure in the convex regime of \({\mathcal {O}}\left( 1/k \right) \), and in the strongly convex regime of \({\mathcal {O}}\left( 1/{k^2} \right) \) as \(k \rightarrow +\infty \).
Goldstein, O’Donoghue, Setzer and Baraniuk have studied in [13] the two-block separable optimization problem with linear constraints
where \({\mathcal {K}}\) is another real Hilbert space, \(f :{\mathcal {H}}\rightarrow {\mathbb {R}}\cup \left\{ + \infty \right\} \) and \(h :{\mathcal {K}}\rightarrow {\mathbb {R}}\cup \left\{ + \infty \right\} \) are proper, convex and lower semicontinuous functions, \(A :{\mathcal {H}}\rightarrow {\mathcal {G}}\) and \(B :{\mathcal {K}}\rightarrow {\mathcal {G}}\) are continuous linear operators and \(b \in {\mathcal {G}}\). It is obvious that (1.1) can be reformulated as (1.8) and vice versa. In [13] a numerical algorithm for solving (1.8) has been proposed that exhibits, when f and h are strongly convex, convergence rates for the dual objective function of \({\mathcal {O}}\left( 1/k^{2} \right) \) and for the feasibility measure of \({\mathcal {O}}\left( 1/k \right) \) as \(k \rightarrow +\infty \). For a fast version of the Alternating Minimization Algorithm (see [27]) a convergence rate for the dual objective function of \({\mathcal {O}}\left( 1/k^{2} \right) \) as \(k \rightarrow +\infty \) has been also proved.
Xu has proposed in [28] a linearized Augmented Lagrangian Method for the optimization problem (1.1) for which he has shown that it exhibits for constant step sizes ergodic convergence rates of \({\mathcal {O}}\left( 1/k \right) \) as \(k \rightarrow +\infty \) for the feasibility measure and the objective function value, whereas the sequence of primal-dual iterates has been shown to converge to a primal-dual solution. He has also proved that for appropriately chosen variable step sizes, in particular when allowing the dual step sizes to be unbounded, the convergence rates of the feasibility measure and the objective function value can be improved to \({\mathcal {O}}\left( 1/{k^2} \right) \) as \(k \rightarrow +\infty \), without saying anything about the convergence of the primal-dual iterates in this setting. In addition, a linearized Alternating Direction Method of Multipliers for (1.8) has been proposed in [28], for which similar statements as for the linearized Augmented Lagrangian Method have been proved, whereby the fast convergence rates have been obtained by assuming that one of the summands in the objective function is strongly convex.
In [14], He and Yuan have enhanced the Augmented Lagrangian Method for the linearly constrained convex optimization problem (1.1) with a Nesterov’s momentum update rule for the sequence of dual iterates. They have proved that the expression \({\mathcal {L}}(x_*,\lambda _*) - {\mathcal {L}}\left( x_{k} , \lambda _k \right) \) has an upper bound of order \(1/k^2\), where \(\left( x_{k} , \lambda _k \right) _{k \geqslant 0}\) denotes the generated sequence of primal-dual iterates and \((x_*,\lambda _*)\) is an arbitrary optimal solution of the Wolfe dual problem of (1.1).
In [29], Yan and He have proposed for optimization problems of type (1.1), with a proper, convex and lower semicontinuous objective function, a numerical algorithm which combines the Augmented Lagrangian Method with a Bregman proximal evaluation of the objective. When choosing the sequence of proximal parameter to fulfil \(\eta _{k} := \eta \left( k + 1 \right) ^{p}\) for every \(k \geqslant 0\), where \(\eta >0\) and \(p \geqslant 0\), ergodic convergence rates of
have been obtained.
In [24], Sabach and Teboulle have considered a unified algorithmic framework for proving faster convergence rates for various Lagrangian-based methods designed to solve optimization problems of type (1.1) with a proper, convex and lower semicontinuous objective function. In the convex regime these methods exhibit a non-ergodic rate of convergence of \({\mathcal {O}}\left( 1/k \right) \) as \(k \rightarrow +\infty \) for the feasibility measure and the objective function value, namely,
In the strongly convex regime the convergence rates can be improved to \({\mathcal {O}}\left( 1/k^{2} \right) \) as \(k \rightarrow +\infty \).
For the same class of optimization problems, He, Hu, and Fang have proposed in [15] an accelerated primal-dual Lagrangian-based method, with inertial parameters following the choice of Chambolle–Dossal, that achieves a convergence rate of \({\mathcal {O}}\left( 1/k^{2} \right) \) as \(k \rightarrow +\infty \) for the feasibility measure and the objective function value without any strong convexity assumption.
Recently, in [19], Lou have introduced in the same context an unifying algorithmic scheme which covers both the convex and the strongly convex setting. In the convex regime a convergence rate of \({\mathcal {O}}\left( 1/k \right) \) as \(k \rightarrow +\infty \) is obtained for the primal-dual gap, the feasibility measure, and the objective function value, while in the strongly convex regime these rates are improved to \({\mathcal {O}}\left( 1/k^{2} \right) \) as \(k \rightarrow +\infty \). These results have been extended to optimization problems of type (1.8) in [20], where it has been shown that, in order to achieve a convergence rate of \({\mathcal {O}}\left( 1/k^{2} \right) \) as \(k \rightarrow +\infty \), it is enough to assume that only one of the functions in the objective is strongly convex.
Noticeably none of theses works has addressed to convergence of the sequences of primal-dual iterates, with very few exceptions in the strongly convex regime. This phenomenon could be noticed for unconstrained convex optimization problems, too. The convergence of the sequences of iterates generated by fast numerical methods has been proved much later (by Chambolle and Dossal in [10] and by Attouch and Peypouquet in [3]) after the derivation of the convergence rates for Nesterov’s accelerated gradient method [21] and FISTA [6]. One explanation for this is that the analysis of the first is much more involved.
1.4 Our contributions
We consider as starting point a second-order dynamical system with asymptotic vanishing damping term associated with the optimization problem (1.1). This dynamical system is formulated in terms of the augmented Lagrangian and it has been studied in [8]. By an appropriate time discretization this system gives rise to an inertial primal-dual numerical algorithm, which allows a flexible choice of the inertial parameters. This choice covers the three classical inertial parameters rules by Nesterov [6, 21], Chambolle–Dossal [10] and Attouch–Cabot [1] used in the literature to formulate fast gradient methods. We show that for these rules the resulting algorithm exhibits in the convex regime convergence rates of order \({\mathcal {O}}\left( 1/k^{2} \right) \) for the primal-dual gap, the feasibility measure, and the objective function value. In addition, we prove that the generated sequence of primal-dual iterates converges weakly to a primal-dual solution of the underlying problem, which is nothing else than a saddle-point of the Lagrangian. The convergence of the iterates is stated in a general setting that covers the inertial parameters rules by Chambolle–Dossal and Attouch–Cabot. This is the first result which provides the convergence of the sequence of iterates generated by a fast algorithm for linearly constrained convex optimization problems without additional assumptions such as strong convexity. All convergence and convergence rate results of this paper are compatible with the ones obtained in [8] in the continuous setting.
The proposed Fast Augmented Lagrangian Method and all convergence results can be easily extended by using the product space approach to two-block separable linearly constrained optimization problems of the form (1.8) with f and h convex and Fréchet differentiable functions with Lipschitz continuous gradients.
1.5 Notations and preliminaries
We denote by \({\mathbb {B}}\left( x ; \varepsilon \right) := \left\{ y \in {\mathcal {H}}:\left\Vert x - y \right\Vert \leqslant \varepsilon \right\} \) the closed ball centered at \(x \in {\mathcal {H}}\) with radius \(\varepsilon > 0\).
Let \(x, y \in {\mathcal {H}}\). We have
For every \(s, t \in {\mathbb {R}}\) such that \(s+t=1\) it holds ( [5, Corollary 2.15])
From here one can easily deduce that for \(s, t \in {\mathbb {R}}\) such that \(s+t \ne 0\) it holds
We denote by \({\mathbb {S}}_{+} \left( {\mathcal {H}}\right) \) the family of self-adjoint and positive semidefinite continuous linear operators \({\mathcal {W}}:{\mathcal {H}}\rightarrow {\mathcal {H}}\). Every \({\mathcal {W}}\in {\mathbb {S}}_{+} \left( {\mathcal {H}}\right) \) induces on \({\mathcal {H}}\) a semi-norm defined by
The Loewner partial ordering on \({\mathbb {S}}_{+} \left( {\mathcal {H}}\right) \) is defined for \({\mathcal {W}}, {\mathcal {W}}' \in {\mathbb {S}}_{+} \left( {\mathcal {H}}\right) \) as
Thus \({\mathcal {W}}\in {\mathbb {S}}_{+} \left( {\mathcal {H}}\right) \) is nothing else than \({\mathcal {W}}\succcurlyeq 0\). If there exists \(\alpha > 0\) such that \({\mathcal {W}}\succcurlyeq \alpha \mathrm {Id}\) then the semi-norm \(\left\Vert \cdot \right\Vert _{{\mathcal {W}}}\) becomes a norm.
In the spirit of (1.9) and (1.11), respectively, for every \(x, y \in {\mathcal {H}}\) it holds
and for every real numbers s, t such that \(s+t \ne 0\)
Let \(f :{\mathcal {H}}\rightarrow {\mathbb {R}}\) be a continuously differentiable and convex function such that \(\nabla f\) is \(L-\)Lipschitz continuous, for \(L >0\). For every \(x, y \in {\mathcal {H}}\) it holds (see [22, Theorem 2.1.5] or [5, Theorem 18.15])
The second inequality is also known as the Descent Lemma.
The following result is a particular instance of [5, Lemma 5.31] and will be used several times in this paper.
Lemma 1.1
Let \(\left\{ a_{k} \right\} _{k \geqslant 1}\), \(\left\{ b_{k} \right\} _{k \geqslant 1}\) and \(\left\{ d_{k} \right\} _{k \geqslant 1}\) be sequences of real numbers. Assume that \(\left\{ a_{k} \right\} _{k \geqslant 1}\) is bounded from below, and \(\left\{ b_{k} \right\} _{k \geqslant 1}\) and \(\left\{ d_{k} \right\} _{k \geqslant 1}\) are nonnegative such that \(\sum _{k \geqslant 1} d_{k} < + \infty \). Suppose further that for every \(k \geqslant 1\) it holds
Then the following statements are true
-
(i)
the sequence \(\left\{ b_{k} \right\} _{k \geqslant 1}\) is summable, namely \(\sum _{k \geqslant 1} b_{k} < + \infty \);
-
(ii)
the sequence \(\left\{ a_{k} \right\} _{k \geqslant 1}\) is convergent.
In order to establish the weak convergence of the iterates, we will use Opial’s Lemma in discrete form (see, for instance, [5, Theorem 5.5]), which we recall as follows.
Lemma 1.2
Let \({{{\mathcal {C}}}}\) be a nonempty subset of \({{\mathcal {H}}}\) and \(\left\{ x_{k} \right\} _{k \geqslant 1}\) a sequence in \({\mathcal {H}}\). Assume that
-
(i)
for every \(x_{*} \in {{{\mathcal {C}}}}\), \(\lim \limits _{k \rightarrow + \infty } \left\Vert x_{k} - x_{*} \right\Vert \) exists;
-
(ii)
every weak sequential cluster point of \(\left\{ x_{k} \right\} _{k \geqslant 1}\) belongs to \({{{\mathcal {C}}}}\).
Then the sequence \(\left\{ x_{k} \right\} _{k \geqslant 1}\) converges weakly to an element in \({{{\mathcal {C}}}}\) as \(k \rightarrow + \infty \).
2 Continuous time approaches and their discrete counterparts
In this section we want to derive by time discretization a primal-dual numerical algorithm from the second-order dynamical system investigated in [8]. The employed discretization technique replicates the one used when relating fast gradient algorithms with the second-order dynamical system proposed by Su, Boyd and Candès in [25] in the unconstrained case.
2.1 The primal-dual dynamical approach with vanishing damping
The second-order primal-dual dynamical system with asymptotically vanishing damping term associated in [8] with the augmented Lagrangian formulation of (1.1) reads

where \(t_{0}>0, \alpha \geqslant 3, \beta \geqslant 0, \theta >0\) and \(\left( x_{0}, \lambda _{0} \right) , \left( {\dot{x}}_{0} , {\dot{\lambda }}_{0} \right) \in {\mathcal {H}}\times {\mathcal {G}}\).
Plugging the expressions of the partial gradients of \({\mathcal {L}}_{\beta }\) into the system leads to the following formulation for (\(\mathrm {PD}\)-\(\mathrm {AVD}\))
In [8] it has been shown that, supposing that
for a solution \(\left( x , \lambda \right) :\left[ t_{0} , + \infty \right) \rightarrow {\mathcal {H}}\times {\mathcal {G}}\) of (\(\mathrm {PD}\)-\(\mathrm {AVD}\)) and \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\) it holds for every \(t \geqslant t_0\)
and
where \({\widehat{C}} >0\).
If, in addition, \(\nabla f\) is \(L-\)Lipschitz continuous, \(\alpha >3\) and \(\dfrac{1}{2}> \theta > \dfrac{1}{\alpha - 1}\), then it holds
and, consequently,
whereas
By additionally requiring that \(\beta >0\), it has been also proved in [8] that the trajectory \(\left( x \left( t \right) , \lambda \left( t \right) \right) \) converges weakly to a primal-dual optimal solution of (1.1) as \(t \rightarrow + \infty \).
2.2 Fast gradient scheme: from continuous to discrete time
We recall in this section for reader’s convenience the connection between the second-order dynamical system by Su, Boyd and Candès [25] and the fast gradient numerical methods formulated in [1, 10] in the spirit of Nesterov’s accelerated gradient algorithm [21]. To this end we consider the unconstrained optimization problem
where \(f : {\mathcal {H}}\rightarrow {{\mathbb {R}}}\) is a convex and Fréchet differentiable function with L-Lipschitz continuous gradient, for \(L>0\).
The continuous time approach proposed in [25] in connection with this optimization problem reads
where \(t_{0} > 0\) and \(\alpha \geqslant 3\). One can easily notice that for \(A=0\) and \(b=0\) the optimization problem (1.1) becomes (2.3), while (\(\mathrm {PD}\)-\(\mathrm {AVD}\)) reduces to (AVD).
For every \(t \geqslant t_{0}\), we define
This leads to
and (AVD) can be written as a first-order ordinary differential equation
Let \(\sigma > 0\). For every \(k \geqslant 1\) we take as time step
and set \(\tau _{k} := \sqrt{\sigma _{k}} k = \sqrt{\sigma k \left( k + \alpha - 1 \right) } \approx \sqrt{\sigma } \left( k + 1 \right) \), \(x \left( \tau _{k} \right) \approx x_{k+1}\) and \(z \left( \tau _{k} \right) \approx z_{k+1}\). We “approximate” \(\tau _k\) with \(\sqrt{\sigma } \left( k + 1 \right) \) since it is closer to this value than to \(\sqrt{\sigma } k\). This also explains why we consider \(x \left( \tau _{k} \right) \approx x_{k+1}\) and \(z \left( \tau _{k} \right) \approx z_{k+1}\) instead of the seemingly more natural choices \(x \left( \tau _{k} \right) \approx x_{k}\) and \(z \left( \tau _{k} \right) \approx z_{k}\), respectively.
The implicit finite-difference scheme for (2.4) at time \(t := \tau _{k}\) gives
or, equivalently,
where the gradient \(\nabla f\) is evaluated at the point \(y_{k}\), which is to be determined as a suitable convex combination of \(x_{k}\) and \(z_{k}\) such that \(x_{k+1} - y_{k} \rightarrow 0\) as \(k \rightarrow + \infty \). Notice that, since \(\nabla f\) is \(L-\)Lipschitz continuous, this implies that \(\nabla f \left( x_{k+1} \right) - \nabla f \left( y_{k} \right) \rightarrow 0\) as \(k \rightarrow + \infty \).
The second equation in (2.5) is equivalent with
and consequently suggests the following choice for \(y_k\)
From the second equation in (2.5) we further obtain
In addition,
Consequently, (2.5) can be equivalently written as
This is nothing else than the algorithm considered by Chambolle and Dossal in [10] (see also [3]).
Furthermore, if we write for every \(k \geqslant 1\)
so that
then (2.7) becomes
Modifications of the sequence \(\left\{ t_{k} \right\} _{k \geqslant 1}\) which preserve its asymptotic behaviour lead to various acceleration schemes from the literature.
For instance, the classical Nesterov’s accelerated gradient method [21] is precisely (2.9), where the sequence \(\left\{ t_{k} \right\} _{k \geqslant 1}\) satisfies the recurrence rule
Another example is the algorithm proposed by Attouch and Cabot in [1] that corresponds to (2.9) with the choice
It can also be interpreted as a discretization of (2.4) with time step
and by setting \(\tau _{k} := \sqrt{\sigma _{k}} \left( k - \alpha + 1 \right) = \sqrt{\sigma k \left( k - \alpha + 1 \right) } \approx \sqrt{\sigma } \left( k + 1 \right) , x \left( \tau _{k} \right) \approx x_{k+1}\) and \(z \left( \tau _{k} \right) \approx z_{k+1}\).
2.3 The time discretization of (\(\mathrm {PD}\)-\(\mathrm {AVD}\))
In order to provide a useful time discretization of the dynamical system (\(\mathrm {PD}\)-\(\mathrm {AVD}\)) we follow the approach of the previous section and define for every \(t \geqslant t_{0}\)
Further, we set
The parameter \(\gamma \) will play an essential role in our analysis. For every \(t \geqslant t_0\) we define
Using these notations, the system (\(\mathrm {PD}\)-\(\mathrm {AVD}\)) (see also its equivalent formulation (2.1)) can be written as
Using that for every \(t \geqslant t_0\)
the first two lines in (2.15) can be equivalently written as
Let \(\sigma , \rho > 0\). For every \(k \geqslant 1\) we take for x and \(\lambda \) two different time steps
respectively, and set \(\tau _{k} := \sqrt{\sigma _{k}} k \approx \sqrt{\sigma } \left( k + 1 \right) , x \left( \tau _{k} \right) \approx x_{k+1},z \left( \tau _{k} \right) \approx z_{k+1}, z^{\gamma } \left( \tau _{k} \right) \approx z_{k+1}^{\gamma }\), and \(\tau _{k}' := \sqrt{\rho _{k}} k \approx \sqrt{\rho } \left( k + 1 \right) , \lambda \left( \tau _{k}' \right) \approx \lambda _{k+1}, \nu \left( \tau _{k}' \right) \approx \nu _{k+1}\) and \(\nu ^{\gamma } \left( \tau _{k}' \right) \approx \nu _{k+1}^{\gamma }\).
The implicit finite-difference scheme for (2.16) at time \(t := \tau _{k}\) for x and time \(t := \tau _{k}'\) for \(\lambda \) gives
where \(y_{k}\) and \({\widetilde{\nu }}_{k+1}\) will be chosen appropriately to obtain an easily implementable iterative scheme. Notice that \({\widetilde{\nu }}_{k+1}\) must be an approximation of \(\nu _{k+1}^{\gamma }\).
Once again we take as in the previous section (see (2.6))
which, by using the third equation in (2.17), gives
Following (2.6) we set also for the sequence of dual variables
which, by using the fifth equation in (2.17), gives
For these choices, and by taking into consideration the definition of \(\left\{ t_{k} \right\} _{k \geqslant 1}\) in (2.8) and (2.17) becomes
where \({\widetilde{\nu }}_{k+1}\) is still to be chosen such that \({\widetilde{\nu }}_{k+1} - \nu _{k+1}^{\gamma } \rightarrow 0\) as \(k \rightarrow + \infty \). We will not opt for \({\widetilde{\nu }}_{k+1} = \nu _{k+1}^{\gamma }\) in order to avoid an implicit iterative scheme, but choose instead (see also (2.18))
Such a choice is reasonable as long as \(\lambda _{k+1} - \lambda _{k} \rightarrow 0\) as \(k \rightarrow + \infty \), which will then imply that \({\widetilde{\nu }}_{k+1} - \nu _{k+1}^{\gamma } \rightarrow 0\) as \(k \rightarrow + \infty \). By setting
the second line in (2.19) becomes
or, equivalently,
After rearranging the order in which the sequences are updated, (2.19) leads to the fast Augmented Lagrangian Method which we propose in this paper, and also investigate from the point of view of its convergence properties.
3 Fast Augmented Lagrangian Method
In this section we will give a precise formulation of the Augmented Lagrangian Method for solving (1.1) and prove that it exhibits convergence rates of order \({\mathcal {O}}\left( 1/k^{2} \right) \) for the primal-dual gap, the feasibility measure, and the objective function value.
3.1 The algorithm

One can notice that Algorithm 1 can be written in a concise way only in terms of the sequences of primal-dual iterates \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\), however, this elaborated formulation using auxiliary sequences is more convenient for its analysis.
Even though the choice \(\gamma =1\) would give a simplified version of Algorithm 1, without affecting its fast convergence properties, we will see that in order to guarantee the convergence of \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) to a primal-dual optimal solution it will be crucial to choose \(\gamma \in (0,1)\). A similar phenomenon is known from the continuous and discrete schemes in the unconstrained case, where fast convergence rates have been obtained for \(\alpha \geqslant 3\), while the convergence of the sequence of iterates/trajectory could be shown only for \(\alpha >3\). In view of (2.13), in order to be allowed to choose \(\gamma \in (0,1)\), one must have \(\alpha >3\).
Example 3.1
(The case \(A=0\) and \(b=0\)) If \(A=0\) and \(b=0\), then (1.1) becomes the unconstrained optimization problems (2.3) and Algorithm 1 reduces to the well-known accelerated gradient scheme which, given \(0 < \sigma \leqslant \dfrac{1}{L}\), \(\{t_k\}_{k \geqslant 1}\) a nondecreasing sequence fulfilling (3.2) and \(x_{0} = x_{1} \in {\mathcal {H}}\), reads for every \(k \geqslant 1\)
as the dual sequence \(\left\{ \lambda _{k} \right\} _{k \geqslant 0}\) can be neglected.
Remark 3.2
By denoting for every \(k \geqslant 1\)
it yields
On the other hand, (3.4c) with index \(k+1\) reads
which is equivalent to
Subtracting (3.5) from (3.7), we obtain
Furthermore, by the definition of \(z_{k}^{\gamma }\) and \(z_{k}\) in (3.3g) and (3.4a), it holds
which leads to
By a similar argument, denoting for every \(k \geqslant 1\)
we can derive that
Example 3.3
(The choice \(\gamma =1\)) In case \(\gamma =1\) we denote \(z_k:=z_k^1\) and \(\nu _k:=\nu _k^1\) for every \(k \geqslant 1\), which is consistent with the notations in the remark above. Given \(0 < \sigma \leqslant \dfrac{1}{L + \beta \Vert A\Vert ^2}\), \(\{t_k\}_{k \geqslant 1}\) a nondecreasing sequence fulfilling (3.2) \(x_{0} = x_{1} \in {\mathcal {H}}\) and \(\lambda _{0} = \lambda _{1} \in {\mathcal {G}}\), Algorithm 1 simplifies for every \(k \geqslant 1\) to
The fact that this iterative scheme exhibits fast convergence rates for the primal-dual gap, the feasibility measure, and the objective function value will follow from the analysis we will do for Algorithm 1. However, nothing can be said about the convergence of the primal-dual iterates. To this end we will have to assume that \(\gamma \in (0,1)\), which will be a crucial assumption.
Remark 3.4
He, Hu and Fang have considered in [15] for \(\alpha > 3\), \(\sigma , \sigma ' > 0\) and
the following iterative scheme which reads for every \(k \geqslant 1\)
This algorithm differs from Algorithm 1 for the choice \(\gamma =1\) (as formulated in the above example) in the way the primal-dual iterates \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) are defined. The formulation of the first allows a more direct derivation of the fast convergence rates for the feasibility measure and the objective function value. The convergence of \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) has been not addressed in [15], and it is by far not clear whether this sequence converges.
The following lemma collects some properties of the sequence \(\{t_k\}_{k \geqslant 1}\) fulfilling (3.2).
Lemma 3.5
Let \(0 < m \leqslant 1\) and \(\left\{ t_{k} \right\} _{k \geqslant 1}\) a nondecreasing sequence fulfilling
Then for every \(k \geqslant 1\) it holds
Proof
Let \(k \geqslant 1\). From the assumption we have that
which further gives
We define the function \(\psi : [ 1 , + \infty ) \rightarrow {\mathbb {R}}\) as \(s \mapsto \dfrac{m + \sqrt{m^{2} + 4s^{2}}}{2} - s\). Since
\(\psi \) is nonincreasing, consequently
The statements in (3.13) follow from the fact that \(t_{k} \geqslant 1\) for every \(k \geqslant 1\) and \(\varphi _m \geqslant 0\) and by telescoping arguments, respectively. \(\square \)
3.2 Some important estimates and an energy function
In this section we will provide some important estimates which will be useful when proving that the sequence of values of a discrete energy function, which we will associate with Algorithm 1, takes at a saddle point is nonincreasing.
Lemma 3.6
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1. Then for every \(x \in {\mathcal {H}}\) and every \(k \geqslant 1\) the following inequality holds
Proof
Let \(x \in {\mathcal {H}}\) and \(k \geqslant 1\) be fixed. According to (3.3f) we have that
On the other hand, from (3.3c), (3.3e) and (3.3h) we have
where the last equation follows from (3.11). Hence, replacing (3.16) in (3.15) we have
The Descent Lemma inequality (1.14) provides
and
By summing up these relations it yields
which is nothing else than (3.14). \(\square \)
In the following we denote
Assumption (3.1) guarantees that \(\gamma {\mathcal {Q}}- L \mathrm {Id}\in {\mathbb {S}}_{+} \left( {\mathcal {H}}\right) \), as
Lemma 3.7
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1. Then for every \(\left( x , \lambda \right) \in {\mathcal {F}}\times {\mathcal {G}}\) and every \(k \geqslant 1\) the following two inequalities hold
and
Proof
Let \(x \in {\mathcal {F}}\), which means that \(Ax = b\), \(\lambda \in {\mathcal {G}}\), and \(k \geqslant 1\) be fixed. We deduce from Lemma 3.6 that
where, by using the definition of \({\mathcal {Q}}\), the last identity follows from
Recall that from (3.3h) we have
which yields further
Moreover, from (3.3d) and (3.3g) we have
therefore, by summing up (3.22) and (3.23) and after rearranging the terms, the estimate (3.20) follows.
Next we will prove the second estimate. By take \(x := x_{k}\) in inequality (3.14) we get
where, by using again the definition of \({\mathcal {Q}}\), the last identity follows from
The identity (1.9) gives us
hence, by recalling relation (1.3) and (3.24) can be equivalently written as
In addition, by taking \(\lambda := \lambda _{k}\) in (3.23) gives
Moreover, we have from (3.3d) and (3.3g)
therefore, by summing up (3.25) and (3.26) and after rearranging terms, the estimate (3.21) follows. \(\square \)
For \((x,\lambda ) \in {\mathcal {F}}\times {\mathcal {G}}\) and \(k \geqslant 1\) we introduce the following energy function associated with Algorithm 1
According to (1.4), for every \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\) and every \(k \geqslant 1\) it holds
The following estimate for the energy function will play a fundamental role in our analysis.
Proposition 3.8
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1. Then for every \(\left( x , \lambda \right) \in {\mathcal {F}}\times {\mathcal {G}}\) and every \(k \geqslant 1\) it holds
Proof
Let \(\left( x , \lambda \right) \in {\mathcal {F}}\times {\mathcal {G}}\) and \(k \geqslant 1\) be fixed. Multiplying (3.21) by \(t_{k+1} \left( t_{k+1} - 1 \right) \geqslant 0\) and (3.20) by \(\gamma t_{k+1}\), and adding the resulting inequalities, yields
According to (3.3b), (3.3g) and (3.3h) we have
where in the last inequality we use that \(\{t_k\}_{k \geqslant 1}\) is nondecreasing and that \(t_{k} \geqslant 1\) for every \(k \geqslant 1\).
On the other hand, (3.3g), (3.9a) and (1.12) give
From (1.13), (3.9b) and (3.8) we have
which we combine with (3.30) to obtain
By using the same technique, we can derive that
Plugging (3.29), (3.31) and (3.32) into (3.28), and taking into consideration the fact that \(\gamma \in \left( 0 , 1 \right] \), gives the desired statement. \(\square \)
Next we record some direct consequences of the above estimate.
Proposition 3.9
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 and \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). Then the sequence \(\left\{ {\mathcal {E}}_{k} \left( x_{*} , \lambda _{*} \right) \right\} _{k \geqslant 1}\) is nonincreasing and the following statements are true
Proof
Since \(\left\{ t_{k} \right\} _{k \geqslant 1}\) is an nondecreasing sequence that satisfies (3.2) and \(0 < m \leqslant \gamma \leqslant 1\), we have for every \(k \geqslant 1\)
Moreover, as \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\), we must have \(x_{*} \in {\mathcal {F}}\) and \({\mathcal {L}}_{\beta }\left( x_{k} , \lambda _{*} \right) - {\mathcal {L}}_{\beta }\left( x_{*} , \lambda _{k} \right) \geqslant 0\) for every \(k \geqslant 1\) due to (1.4). Combining these observations, we deduce from the inequality (3.27) applied to \((x,\lambda )=(x_*,\lambda _*)\) that for every \(k \geqslant 1\)
By applying Lemma 1.1 we obtain all conclusions. \(\square \)
Remark 3.10
Since the sequence \(\left\{ {\mathcal {E}}_{k} \left( x_{*} , \lambda _{*} \right) \right\} _{k \geqslant 1}\) is nonincreasing and for every \(k \geqslant 1\)
we deduce that
Consequently, for every \(k \geqslant 1\) we have
Remark 3.11
Recall that from Proposition 3.9 we have
whenever \(\gamma < 1\). Taking into account the way \(\gamma \) has arisen in the context of the dynamical system (\(\mathrm {PD}\)-\(\mathrm {AVD}\)) (see (2.13)), this corresponds to
In the continuous case it has been proved (see [8, Theorem 3.2]) that, if \(\dfrac{1}{\alpha - 1} < \theta \), then
which can be seen as the continuous counterpart of (3.36). Both statements play a crucial role in the proof of the convergence of the sequence of iterates generated by Algorithm 1 and of the trajectory generated by (\(\mathrm {PD}\)-\(\mathrm {AVD}\)), respectively.
The following result, which complements the statements of Proposition 3.9, will also play a crucial role in the proof of the convergence of the sequence of iterates.
Proposition 3.12
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 with
and \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). Then the following statements are true
In addition, there exists \(C_{0}> 0\) such that for every \(k \geqslant 1\)
Proof
From (3.17), after rearranging some terms, we have for every \(k \geqslant 1\)
It follows from Proposition 3.9, by using (3.19) and the fact that \(t_k \geqslant 1\), that for every \(k \geqslant 1\)
According to (3.3d) we have for every \(k \geqslant 1\)
hence, by applying the identity (1.10), we get
On the other hand, it follows from condition (3.2) and the fact that \(\left\{ t_{k} \right\} _{k \geqslant 1}\) is nondecreasing that for every \(k \geqslant 1\)
Combining (3.38) and (3.39), it yields for every \(k \geqslant 1\)
We are in the setting of inequality (1.15) with
for every \(k \geqslant 1\). According to Lemma 1.1, (3.37a) and (3.37b) are fulfilled and the sequence \(\left\{ t_{k} \left( 1 + \dfrac{1}{\gamma } \left( t_{k} - 1 \right) \right) \left\Vert A^{*} \left( \lambda _{k} - \lambda _{*} \right) \right\Vert ^{2} \right\} _{k \geqslant 1}\) is convergent, therefore it is bounded. Consequently, there exists \(C_{0}> 0\) such that for every \(k \geqslant 1\)
which provides the conclusion. \(\square \)
3.3 On the boundedness of the sequences
In this section we will discuss the boundedness of the sequence of primal-dual iterates \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) and also of other related sequences which play a role in the convergence analysis.
To this end we define on \({\mathcal {H}}\times {\mathcal {G}}\) the inner product
where \({{\mathcal {Q}}}\) is the operator defined in (3.18) which we proved to be positive definite under assumption (3.1). The norm induced by this scalar product is
The condition on the sequence \(\left\{ t_k \right\} _{k \geqslant 1}\) which we will assume in the next proposition in order to guarantee boundedness for the sequences generated by Algorithm 1 has been proposed in [4]. Later we will see that it is satisfied by the three classical inertial parameters rules by Nesterov, Chambolle–Dossal and Attouch–Cabot.
Proposition 3.13
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1. Suppose that
Then the sequences \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\), \(\left\{ \left( z_{k}^{\gamma } , \nu _{k}^{\gamma } \right) \right\} _{k \geqslant 1}\) and \(\lbrace ( t_{k+1} ( x_{k+1} - x_{k} ) , t_{k+1} ( \lambda _{k+1} - \lambda _{k} ) ) \rbrace _{k \geqslant 0}\) are bounded. If, in addition \(\beta > 0\), then the sequence \(\lbrace t_{k+1} ( t_{k+1} - 1 ) ( Ax_{k+1} - Ax_{k} ) \rbrace _{k \geqslant 0}\) is also bounded.
Proof
Let \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\) be fixed. For brevity we will write
By applying (1.13), we have from (3.3g) that for every \(k \geqslant 1\)
By applying (1.11), we have from (3.3d) that for every \(k \geqslant 1\)
This means the energy function at \((x_*,\lambda _*)\) can be written for every \(k \geqslant 1\) as
According to Proposition 3.9, the sequence \(\left\{ {\mathcal {E}}_{k} \left( x_{*} , \lambda _{*} \right) \right\} _{k \geqslant 1}\) is nonincreasing, therefore for every \(k \geqslant 1\)
From here we conclude that the sequence \(\left\{ \left( z_{k}^{\gamma } , \nu _{k}^{\gamma } \right) \right\} _{k \geqslant 1}\) is bounded. In addition, for every \(k \geqslant 1\) it holds
where the last inequality is due to (3.12), with the convention \(t_{0} := 0\). After telescoping, we get
Then thanks to (3.40) we obtain
which means that \(\left\{ u_{k} := \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) is bounded. That \(\lbrace ( t_{k+1} ( x_{k+1} - x_{k} ) , t_{k+1} ( \lambda _{k+1} - \lambda _{k} ) ) \rbrace _{k \geqslant 0}\) is bounded follows from the fact that for all \(k \geqslant 1\)
Finally, recall that from (3.11), (3.3h) and (3.3g), we have for every \(k \geqslant 1\)
The last statement of the proposition follows from here and (3.35). \(\square \)
In the following, we will see that the two most prominent choices for the sequence \(\{t_k\}_{k \geqslant 1}\) from the literature, namely, the ones following the rules by Nesterov and by Chambolle–Dossal satisfy not only (3.2), but also (3.40).
Example 3.14
(Nesterov rule) The classical construction proposed Nesterov in [21] for \(\left\{ t_{k} \right\} _{k \geqslant 1}\) satisfies the following rule
The sequence \(\left\{ t_{k} \right\} _{k \geqslant 1}\) is strictly increasing and verifies relation (3.2) for \(m:=1\) with equality. In addition (see, for instance, [6, Lemma 4.3]), it holds \(t_{k} \geqslant \dfrac{k + 1}{2}\) for every \(k \geqslant 1\), which means that (3.40) is satisfied for \(\kappa \geqslant \dfrac{1}{2}\).
Example 3.15
(Chambolle–Dossal rule) The construction proposed by Chambolle and Dossal in [10] (see also [3]) for \(\left\{ t_{k} \right\} _{k \geqslant 1}\) satisfies for \(\alpha \geqslant 3\) the following rule
First we show that this sequence fulfills (3.2) with \(m := \dfrac{2}{\alpha - 1} \leqslant 1\). Indeed, for every \(k \geqslant 1\) we have
Furthermore, one can see that for every \(k \geqslant 1\) it holds
which proves that (3.40) is verified for \(\kappa =\dfrac{1}{\alpha - 1} \).
Finally, we observe that, by taking into consideration the choice of \(\gamma \) in (2.13) in the context of the dynamical system (\(\mathrm {PD}\)-\(\mathrm {AVD}\)) and assumption (3.1) in Algorithm 1, it holds
This connects the choice of the parameter m in Algorithm 1 with the one of the parameter \(\theta \) in (\(\mathrm {PD}\)-\(\mathrm {AVD}\)).
3.4 Fast convergence rates for the primal-dual gap, the feasibility measure and the objective function value
We have seen in Remark 3.10 that, for the general choice of the sequence \(\{t_k\}_{k \geqslant 1}\) in (3.2), the convergence rate of the primal-dual gap is of order \({\mathcal {O}}\left( 1 / t_{k}^{2} \right) \) as \(k \rightarrow +\infty \). In addition, if \(\beta >0\), then the convergence rate of the feasibility measure is of order \({\mathcal {O}}\left( 1 / t_{k} \right) \) as \(k \rightarrow +\infty \). In this section we will prove that convergence rates of the feasibility measure and of the objective function value are \({\mathcal {O}}\left( 1 / t_{k}^{2} \right) \) as \(k \rightarrow +\infty \) when the sequence \(\{t_k\}_{k \geqslant 1}\) is chosen by following the rules by Nesterov, Chambolle–Dossal and also Attouch–Cabot.
In view of (3.40), this will lead for the primal-dual sequence \(\{(x_k,\lambda _k)\}_{k \geqslant 0}\) generated by Algorithm 1 and a given primal-dual solution \((x_{*},\lambda _*)\) to the following fast convergence rates
We start with the following lemma which holds in the very general setting of Algorithm 1.
Lemma 3.16
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 and \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). Then the quantity
Proof
Let \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\) and \(\mu \in {\mathbb {B}}\left( \lambda _{*} ; 1 \right) \). The Cauchy-Schwarz inequality gives
On the other hand, as \(\nu _{1}^{\gamma } = \gamma \lambda _{1}\) and \(\mu \in {\mathbb {B}}\left( \lambda _{*} ; 1 \right) \), it holds
Combining these estimates, as \(z_{1}^{\gamma } = \gamma x_{1}\), we have
which proves the statement. \(\square \)
3.4.1 The Nesterov [21] rule
We have seen that by choosing \(\left\{ t_{k} \right\} _{k \geqslant 1}\) as in (3.42) and (3.2) is fulfilled as equality for \(m = 1\), which also yields \(\gamma = 1\) due to (3.1). Consequently, from Proposition 3.8 it follows that for every \(\left( x , \lambda \right) \in {\mathcal {F}}\times {\mathcal {G}}\) and every \(k \geqslant 1\) it holds
which means that the sequence \(\left\{ {\mathcal {E}}_{k} \left( x , \lambda \right) \right\} _{k \geqslant 1}\) is nonincreasing. This statement is stronger than the one in Proposition 3.9, where we have proved that the sequence of function values of the energy function taken at a primal-dual optimal solution is nonincreasing, and will play an important role in the following.
Theorem 3.17
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1, with the sequence \(\left\{ t_{k} \right\} _{k \geqslant 1}\) chosen to satisfy Nesterov rule (3.42), and \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). Then for every \(k \geqslant 1\) it holds
and
Proof
As mentioned earlier in (3.46), for every \(\left( x , \lambda \right) \in {\mathcal {F}}\times {\mathcal {G}}\) and every \(k \geqslant 1\) we have (take into account that \(\gamma =1\))
We fix \(n \geqslant 1\) and define
Then \(x_{*} \in {\mathcal {F}}\) and \(r_{n} \in {\mathbb {B}}\left( \lambda _{*} ; 1 \right) \). Hence, \(\left( x_{*} , r_{n} \right) \in {\mathcal {F}}\times {\mathbb {B}}\left( \lambda _{*} ; 1 \right) \), therefore, according to (3.49) and Lemma 3.16,
If \(Ax_{n} - b \ne 0\), then
On the other hand, if \(Ax_{n} - b = 0\), we have
thus, in both scenarios, (3.50) becomes
Since \(n \geqslant 1\) has been arbitrarily chosen, we obtain (3.47).
As \({\mathcal {L}}\left( x_{k} , \lambda _{*} \right) - {\mathcal {L}}\left( x_{*} , \lambda _{k} \right) \geqslant 0\), a direct consequent of (3.47) is that for every \(k \geqslant 1\)
From (3.47) and the Cauchy-Schwarz inequality, we deduce from here that for every \(k \geqslant 1\)
On the other hand, the convexity of f together with (1.2) guarantee that for every \(k \geqslant 1\)
By combining (3.51) and (3.52), we obtain (3.48). \(\square \)
3.4.2 The Chambolle–Dossal [10] rule
In this section we prove fast convergence rates for the primal-dual gap, the feasibility measure and the objective function value for the sequence of inertial parameters \(\left\{ t_{k} \right\} _{k \geqslant 1}\) following for \(\alpha \geqslant 3\) the Chambole-Dossal rule (3.43). We have seen in Example 3.15 that in this case \(\left\{ t_{k} \right\} _{k \geqslant 1}\) fulfills (3.2) for \(m:=\frac{2}{\alpha -1}\) and (3.40) for \(\kappa :=\frac{1}{\alpha -1}\).
For the beginning we observe that for \(\frac{2}{\alpha -1} = m \leqslant \gamma \leqslant 1\) and every \(k \geqslant 1\) it holds (see (3.44))
Next we are going to consider two separate cases depending on the relation between \(m:=\frac{2}{\alpha -1}\) and \(\gamma \). First we will assume that they are equal, which will then also cover the case \(\alpha =3\).
Theorem 3.18
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 with the sequence \(\left\{ t_{k} \right\} _{k \geqslant 1}\) chosen to satisfy Chambolle–Dossal rule (3.43), \(m:=\frac{2}{\alpha -1} = \gamma \leqslant 1\), \(\beta >0\), and \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). Then for every \(k \geqslant 2\) it holds
and
where
Proof
We fix \(n \geqslant 2\) and define
Then \(x_{*} \in {\mathcal {F}}\) and \(r_{n} \in {\mathbb {B}}\left( \lambda _{*} ; 1 \right) \). Since \(\gamma (\alpha -1) =2\), according to (3.53), we have for every \(k \geqslant 1\)
By taking \(\left( x , \lambda \right) := \left( x_{*} , r_{n} \right) \in {\mathcal {F}}\times {\mathbb {B}}\left( \lambda _{*} ; 1 \right) \) in (3.27), we obtain for every \(k \geqslant 1\)
where (3.56b) follows from (3.35) and(3.56c) is due to (3.40). By a telescoping sum argument and Lemma 3.16 we conclude that for every \(k \geqslant 1\)
where
By choosing \(k := n-1\), it yields
We have seen in the proof of Theorem 3.17 that
thus, by taking into account (3.40), we obtain
therefore, since \(2 + \log (n-1) \leqslant 2(n-1)^{1/2}\),
Taking into account also Lemma 3.16 and the definition of \(C_{4}\), we have that for every \(k \geqslant 1\)
Using this estimate in (3.56a), we obtain for every \(k \geqslant 1\)
By using once again a the telescoping sum argument, we conclude that for every \(k \geqslant 1\)
From here, (3.54) follows by choosing \(k:=n-1\), and by using that \(\gamma t_n^2 \leqslant t_n(t_n-1+\gamma )\) and (3.57). Statement (3.55) follows from (3.54) by repeating the arguments at the end of the proof of Theorem 3.17. \(\square \)
Now we come to the second case, namely, when \(m:=\frac{2}{\alpha -1} < \gamma \leqslant 1\), which implicitly requires that \(\alpha >3\). For the proof of the fast convergence rates we will make use of the following result which can be found in [18, Lemma 2] (see, also, [17, Lemma 3.18]).
Lemma 3.19
Let \(\left\{ \zeta _{k} \right\} _{k \geqslant 1} \subseteq {{{\mathcal {G}}}}\) be a sequence such that there exist \(\delta >1\) and \(M >0\) with the property that for every \(K \geqslant 1\)
Then for every \(K \geqslant 1\) it holds
Theorem 3.20
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 with the sequence \(\left\{ t_{k} \right\} _{k \geqslant 1}\) chosen to satisfy Chambolle–Dossal rule (3.43), \(m:=\frac{2}{\alpha -1} < \gamma \leqslant 1\), \(\beta >0\), and \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). Then for every \(k \geqslant 1\) it holds
and
where
with
Proof
Relation (3.58) follows from (3.35). We fix \(K \geqslant 1\). For every \(1 \leqslant k \leqslant K\), according to (3.3g), we have
Taking into consideration (3.11), (3.3h) and (3.53), by a telescoping argument it yields
We define
and
It holds
Furthermore, it follows from (3.40) and (3.35) that
Combining the relations (3.61), (3.62) and (3.63), we get via the triangle inequality
where we also recall that, due to Proposition 3.13, it holds \(\sup \nolimits _{k \geqslant 1} \left\Vert \nu _{k} \right\Vert < + \infty \).
Inequality (3.64) holds for every \(K \geqslant 1\) (notice that \(C_{7}\) is independent of K), consequently, we can apply Lemma 3.19 to conclude that \(\left\Vert \mathop {\sum }\nolimits _{k = 1}^{K} \zeta _{k} \right\Vert \leqslant C_{7}\) for every \(K \geqslant 1\). By using again the triangle inequality and (3.64), we obtain for every \(K \geqslant 1\) that
Using the inequality (3.13) in Lemma 3.5, we see that for every \(K \geqslant 1\) it holds
By combining (3.65) and (3.66), we obtain (3.59).
Statement (3.60) follows from (3.58) and (3.59) by repeating the arguments at the end of the proof of Theorem 3.17. \(\square \)
3.4.3 The Attouch–Cabot [1] rule
Another inertial parameter rule used in the literature in the context of fast numerical algorithms is the one proposed by Attouch and Cabot in [1], which reads for \(\alpha \geqslant 3\)
This sequence is monotonically increasing and it fulfills (3.2) with \(m := \dfrac{2}{\alpha - 1} \leqslant 1\) as, for every \(k \geqslant 1\), it holds
This shows that the sequence \(\left\{ t_{k} \right\} _{k \geqslant 1}\) has very much in common with the Chambolle–Dossal parameter rule. The only significant difference is that is starts at 0 and that \(t_k \geqslant 1\) holds only for \(k \geqslant k_1:=\lfloor \alpha \rfloor +1\). Consequently, the fast convergence rate results for the primal-dual gap, the feasibility measure and the objective function value are valid also for the Attouch–Cabot rule. This can be easily seen by slightly adapting the proofs made in the setting of the Chambolle–Dossal rule by taking into consideration that some of the estimates hold only for \(k \geqslant k_{1}\). This exercise is left to the reader.
4 Convergence of the iterates
In this section we will turn our attention to the convergence of the sequence of primal-dual iterates generated by Algorithm 1 to a primal-dual solution of (1.1). First, we will prove that the first assumption in the Opial Lemma is verified and to this end we will need the following technical lemma.
Lemma 4.1
Let \(\left\{ \theta _{k} \right\} _{k \geqslant 1},\left\{ a_{k} \right\} _{k \geqslant 1}, \left\{ t_{k} \right\} _{k \geqslant 1}\) be real sequences such that \(\left\{ a_{k} \right\} _{k \geqslant 1}\) is bounded from below and \(\left\{ t_{k} \right\} _{k \geqslant 1}\) is nondecreasing and bounded from below by 1, and \(\left\{ d_{k} \right\} _{k \geqslant 1}\) be a nonnegative sequence such that for every \(k \geqslant 1\)
If \(\sum _{k \geqslant 1} d_{k} < + \infty \), then the sequence \(\left\{ a_{k} \right\} _{k \geqslant 1}\) is convergent.
Proof
It follows from (4.1b) that for every \(k \geqslant 1\)
where \([\cdot ]_+\) denotes the positive part. Since the right-hand side of this inequality is nonnegative, it yields that for every \(k \geqslant 1\)
which, by telescoping cancellation, gives \(\sum _{k \geqslant 1} \left[ \theta _{k} \right] _{+} < + \infty \).
According to (4.1a), we have that for every \(k \geqslant 1\) it holds
By using Lemma 1.1 we obtain from here that the sequence \(\left\{ a_{k} \right\} _{k \geqslant 1}\) is convergent. \(\square \)
Proposition 4.2
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 with \(0< m< \gamma < 1\). Then for every \( \left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\) the limit \(\lim \nolimits _{k \rightarrow + \infty } \left\Vert \left( x_{k} , \lambda _{k} \right) - \left( x_{*} , \lambda _{*} \right) \right\Vert _{{\mathcal {W}}}\) exists.
Proof
Let \(\left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\) be fixed. For brevity we will write
It follows from (3.33) that \({\mathcal {E}}_{k+1} \left( x_{*} , \lambda _{*} \right) \leqslant {\mathcal {E}}_{k} \left( x_{*} , \lambda _{*} \right) \) for every \(k \geqslant 1\). In view of (3.41), after rearranging some terms, we get for every \(k \geqslant 1\)
Set \(a_{0}:= \dfrac{\gamma }{2} \left\Vert u_{0} - u_{*} \right\Vert _{{\mathcal {W}}}^{2} \geqslant 0\) and for every \(k \geqslant 1\)
We notice that for every \(k \geqslant 1\) the estimate (4.3) becomes (4.1b), while (4.1a) obviously holds. As \(0< m< \gamma < 1\), it follows from Proposition 3.9 that \(\sum _{k \geqslant 1} d_{k} < + \infty \).
Hence, we can apply Lemma 4.1 to conclude that \(\left\{ \left\Vert \left( x_{k} , \lambda _{k} \right) - \left( x_{*} , \lambda _{*} \right) \right\Vert _{{\mathcal {W}}} \right\} _{k \geqslant 1}\) is convergent. \(\square \)
The following result is the discrete counterpart of [8, Theorem 4.7] (see (2.2)). Its proof is a direct consequence of Proposition 3.9 and Proposition 3.12.
Theorem 4.3
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 with the sequence \(\{t_k\}_{k \geqslant 1}\) chosen to satisfy (3.40), \(0< m < \gamma \leqslant 1\), \(0< \sigma < \dfrac{\gamma }{L + \gamma \beta \Vert A\Vert ^2}\), \(\beta >0\), and \( \left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). Then it holds
consequently,
and
As seen in Sect. 3.4, if, in addition, \(\{t_k\}_{k \geqslant 1}\) is chosen to satisfy Chambolle–Dossal or Attouch–Cabot rule and \(m:= \frac{2}{\alpha -1}\), then
Now we can prove the main theorem of this section establishing the convergence of the sequence of iterates generated by Algorithm 1.
Theorem 4.4
Let \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) be the sequence generated by Algorithm 1 with the sequence \(\{t_k\}_{k \geqslant 1}\) chosen to satisfy (3.40), \(0< m< \gamma < 1\), \(0< \sigma < \dfrac{\gamma }{L + \gamma \beta \Vert A\Vert ^2}\) and \(\beta >0\). Then the sequence \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) converges weakly to a primal-dual optimal solution of (1.1).
Proof
From Proposition 4.2 it follows that the limit \(\lim \limits _{k \rightarrow + \infty } \left\Vert (x_k, \lambda _k) - (x_*,\lambda _*) \right\Vert \) exists for every \( \left( x_{*} , \lambda _{*} \right) \in {\mathcal {S}}\). This proves the first condition of Lemma 1.2.
In order to prove condition (ii), let \(\left( {\widetilde{x}}, {\widetilde{\lambda }}\right) \in {\mathcal {H}}\times {\mathcal {G}}\) be an arbitrary weak sequential cluster point of \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\). This means that there exists a subsequence \(\left\{ \left( x_{k_{n}} , \lambda _{k_{n}} \right) \right\} _{n \geqslant 0}\) which converges weakly to \(\left( {\widetilde{x}}, {\widetilde{\lambda }}\right) \) as \(n \rightarrow + \infty \). According to Theorem 4.3 we have \(\nabla f \left( x_{k} \right) + A^{*} \lambda _{k} \rightarrow 0\) and \(Ax_k - b \rightarrow 0\) as \(k \rightarrow + \infty \), hence,
Since the graph of the operator \({\mathcal {T}}_{{\mathcal {L}}}\) is sequentially closed in \(\left( {\mathcal {H}}\times {\mathcal {G}}\right) ^{\mathrm {weak}} \times \left( {\mathcal {H}}\times {\mathcal {G}}\right) ^{\mathrm {strong}}\) (cf. [5, Proposition 20.38]), it follows from here that
In other words, \(\left( {\widetilde{x}}, {\widetilde{\lambda }}\right) \in {\mathcal {S}}\) and the proof is complete. \(\square \)
Remark 4.5
If the sequence \(\{t_k\}_{k \geqslant 1}\) is chosen to satisfy the Chambolle–Dossal or the Attouch–Cabot rule with
then Theorem 4.4 guarantees that the sequence \(\left\{ \left( x_{k} , \lambda _{k} \right) \right\} _{k \geqslant 0}\) converges weakly to a primal-dual optimal solution of (1.1). This statement is in addition to the fast convergence rates of order \({\mathcal {O}}\left( 1/k^{2} \right) \) for the primal-dual gap, the feasibility measure, and the objective function value.
If the sequence \(\{t_k\}_{k \geqslant 1}\) is chosen to satisfy the Nesterov rule, then, as we have seen, the fast convergence rate results also hold, however, since in this setting \(m=\gamma =1\), one cannot apply Theorem 4.4 to obtain the convergence of the iterates. This is consistent with the unconstrained case for which it is also not known if the sequence of iterates generated by the fast gradient method with inertial parameters following the Nesterov rule converges.
References
Attouch, H., Cabot, A.: Convergence rates of inertial forward-backward algorithms. SIAM J. Optim. 28(1), 849–874 (2018)
Attouch, H., Chbani, Z., Fadili, J., Riahi, H.: Fast convergence of dynamical ADMM via time scaling of damped inertial dynamics. J. Optim. Theory Appl. 193, 704–736 (2022)
Attouch, H., Peypouquet, J.: The rate of convergence of Nesterov’s accelerated forward-backward method is actually faster than \(1/k^2\). SIAM J. Optim. 26(3), 1824–1834 (2016)
Bauschke, H.H., Bui, M.N., Wang, X.: Applying FISTA to optimization problems (with or) without minimizers. Math. Program. 184, 349–381 (2020)
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. CMS Books in Mathematics. Springer, New York (2017)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imag. Sci. 2(1), 183–202 (2009)
Boţ, R.I.: Conjugate Duality in Convex Optimization. Lecture Notes in Economics and Mathematical Systems, vol. 637. Springer, Berlin Heidelberg (2010)
Boţ, R.I., Nguyen, D.-K.: Improved convergence rates and trajectory convergence for primal-dual dynamical systems with vanishing damping. J. Differential Equations 303, 369–406 (2021)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning 3(1), 1–122 (2010)
Chambolle, A., Dossal, C.: On the convergence of the iterates of the “Fast Iterative Shrinkage/Thresholding Algorithm’’. J. Optim. Theory Appl. 166(3), 968–982 (2016)
Chambolle, A., Pock, T.: On the ergodic convergence rates of a first-order primal-dual algorithm. Math. Program. 159, 253–287 (2016)
Chen, Y., Lan, G., Ouyang, Y.: Optimal primal-dual methods for a class of saddle point problems. SIAM J. Optim. 24(4), 1779–1814 (2014)
Goldstein, T., O’Donoghue, B., Setzer, S., Baraniuk, R.: Fast alternating direction optimization methods. SIAM J. Imag. Sci. 7(3), 1588–1623 (2014)
He, B.S., Yuan, X.M.: On the acceleration of augmented Lagrangian method for linearly constrained optimization. Optimization Online http://www.optimization-online.org/DB_HTML/2010/10/2760.html
He, X., Hu, R., Fang, Y.-P.: Inertial accelerated primal-dual methods for linear equality constrained convex optimization problems. Numerical Algorithms https://doi.org/10.1007/s11075-021-01246-y
He, X., Hu, R., Fang, Y.-P.: Convergence rates of inertial primal-dual dynamical methods for separable convex optimization problems. SIAM J. Control. Optim. 59(5), 3278–3301 (2021)
Li, H., Lin, Z., Fang, C.: Accelerated Optimization for Machine Learning. Springer, Singapore (2019)
Li, H., Lin, Z.: Accelerated Alternating Direction Method of Multipliers: an optimal \(O(1/K)\) nonergodic analysis. J. Sci. Comput. 79, 671–699 (2019)
Lou, H.: Accelerated primal-dual methods for linearly constrained convex optimization problems. arXiv:2109.12604
Lou, H.: A unified differential equation solver approach for separable convex optimization: splitting, acceleration and nonergodic rate. arXiv:2109.13467
Nesterov, Y.: A method of solving a convex programming problem with convergence rate \({\cal{O} } \left(1 / k^{2} \right)\). Soviet Mathematics Doklady 27, 372–376 (1983)
Nesterov, Y.: Introductory Lectures on Convex Optimization. Springer, New York (2004)
Ouyang, Y., Chen, Y., Lan, G., Pasiliao, E., Jr.: An accelerated linearized Alternating Direction Method of Multipliers. SIAM J. Imag. Sci. 8(1), 644–681 (2015)
Sabach, S., Teboulle, M.: Faster Lagrangian-based methods in convex optimization. SIAM J. Optim. 32(1), 204–227 (2022)
Su, W., Boyd, S., Candès, E.: A differential equation for modeling Nesterov’s accelerated gradient method: theory and insights. J. Mach. Learn. Res. 17(153), 1–43 (2016)
Tran-Dinh, Q., Fercoq, O., Cevher, V.: A smooth primal-dual optimization framework for nonsmooth convex optimization. SIAM J. Optim. 28(1), 96–134 (2018)
Tseng, P.: Applications of splitting algorithm to decomposition in convex programming and variational inequalities. SIAM J. Control. Optim. 29(1), 119–138 (1991)
Xu, Y.: Accelerated first-order primal-dual proximal methods for linearly constrained composite convex programming. SIAM J. Optim. 27(3), 1459–1484 (2017)
Yan, S., He, N.: Bregman Augmented Lagrangian and its acceleration. arXiv:2002.06315
Zeng, X., Lei, J., Chen, J.: Dynamical primal-dual accelerated method with applications to network optimization. IEEE Transactions on Automatic Control, https://doi.org/10.1109/TAC.2022.3152720
Acknowledgements
The authors are thankful to the two anonymous reviewers for their remarks and suggestions which have improved the quality of the paper.
Funding
Open access funding provided by Austrian Science Fund (FWF).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
R. I. Boţ: Research partially supported by FWF (Austrian Science Fund), project W 1260. E. R. Csetnek: Research partially supported by FWF (Austrian Science Fund), project P 29809-N32. D.-K. Nguyen: Research supported by FWF (Austrian Science Fund), project P 29809-N32.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Boţ, R.I., Csetnek, E.R. & Nguyen, DK. Fast Augmented Lagrangian Method in the convex regime with convergence guarantees for the iterates. Math. Program. 200, 147–197 (2023). https://doi.org/10.1007/s10107-022-01879-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-022-01879-4
Keywords
- Augmented Lagrangian Method
- Primal-dual numerical algorithm
- Nesterov’s fast gradient method
- Convergence rates
- Iterates convergence