
Abstract
Prediction of rockburst in underground engineering is of significance as it is close to the safety of support structures, personnel, and working environments. To improve the accuracy of rockburst classification, this paper proposed an ensemble classifier RF-FA model in which the random forest classifier (RF) and firefly algorithm (FA) were combined to achieve the optimum performance on rockburst prediction. Five key parameters of surrounding rock, i.e., the depth H, the maximum tangential stress σθ, the uniaxial compressive strength σc, the tensile strength σt, and the elastic energy index Wet, are selected as input variables while the rockburst intensity including none, light, moderate, and strong classes was chosen as output. A total of 279 cases worldwide were collected and used for train and test the proposed RF-FA model. The results showed that the FA can optimize the hyperparameters of RF efficiently and the optimum model exhibited a high performance on rockburst data from the independent test set and new engineering projects. The feature importance obtained by the ensemble RF-FA model indicated that the elastic energy index plays the most important role in rockburst. Besides, the proposed model showed much better accuracy on rockburst classification compared with previously existing RF models and empirical criteria, which means it is a useful and robust tool for rockburst prediction.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Rockburst is a dynamic and uncontrolled nature hazard in mining and civil engineering, which is associated with high stress conditions, and brittle rock (Kaiser et al. 1996; Ortlepp 2005). Normally, due to the sudden release of elastic strain energy, rockburst causes unfavorable phenomena such as bursting, spalling, ejecting, and slabbing in a short time with high velocity, considerably jeopardizing the safety of personnel and directly destroying field equipment and established structures (Kie 1988; Cai 2013). Many cases and accidents associated with rockburst have been widely reported in a lot of countries such as China, America, Australia, Canada, South Africa, and Japan, during underground operations (i.e., tunneling and mining) (Dehghan et al. 2013; He et al. 2018; Zhou et al. 2018). For example, when constructing the Jinping II hydropower station in China (Zhang et al. 2012), many intense rockburst events occurred in tunnels as the overburden depth of the station is over 2525 m (the different rockburst intensity shown in Fig. 1). The rockburst hazard is a worldwide issue, and therefore, its prediction and control technique has a significant role in safety production.

The examples of rockburst in Jinping hydropower station, China. a The moderate rockburst, b the intensive rockburst case 1, c the intensive rockburst case 2, and d the extremely intense rockburst (modified after Zhang et al. 2012)
In recent decades, numerous research works related to the mechanisms, types, and hazard control methods of rockburst have been proposed according to field studies, laboratory tests, and theoretical analysis (Li et al. 2017c; Wu et al. 2019; Xibing et al. 2019). Moreover, several advanced monitoring approaches such as microseismic monitoring system, microgravity, and geological radar have been utilized (Lu et al. 2012). In some cases, they can record and predict before the occurrence of rockburst. However, predicting rockburst accurately is still a difficult task as it is affected by many factors such as stress levels, energy accumulation, rock properties, and geological conditions (Zhang et al. 2017). The long-term prediction of rockburst intensity was normally used in initial stages of construction in many underground activities, for which several models and methods have been presented such as theoretical prediction models normally associated with strength theory and energy theory, empirical knowledge methods, simulation approaches, and artificial intelligence (AI) methods (Peng et al. 2010; Zhou et al. 2019, 2020b, a; Farhadian 2021; Wang et al. 2021).
Among the above methods, AI methods partially known as machining learning-based models have been successfully applied in the prediction and classification of rockburst (Feng and Wang 1994; He et al. 2015). For example, there are various artificial intelligence methods for predicting long-term rockburst hazards such as support vector machines, cloud models, fuzzy comprehensive evaluation methods, artificial neural networks, Bayesian networks, and decision trees. The relevant studies were summarized in Table 1 containing accuracy and the number of data. It should be pointed out that although the adopted machine learning methods in the previous studies are available to predict rockburst, they still have some disadvantages such as long training time, the random selection of hyperparameters in algorithms, and low accuracy performance with larger number data (Huang et al. 2020b, a, 2021; Sun et al. 2020, 2021; Zhang et al. 2020; Wu et al. 2021). Therefore, with a large dataset, it is necessary to develop a high-efficiency and high-accuracy model for the prediction of rockburst.
In recent years, random forest (RF) is one of the most popular machine learning approaches for regression and classification and is has been widely employed in various areas such as civil engineering, mining engineering, and material science (Qi et al. 2018; Sun et al. 2019a; Zhang et al. 2019). RF is a robust and simple classifier and therefore the researchers and readers could utilize it for predicting rockburst easily in practice (Breiman 2001). It is reported that few studies used the RF model to classify the rockburst (Dong et al. 2013; Zhou et al. 2016a; Lin et al. 2018), and however, the accuracy is poor with large datasets because of lacking an efficient method to tune its structure intelligently (Sun et al. 2019b, c, 2020). To achieve the best structure, key parameters are known as hyperparameters in RF (the number of the trees, and the minimum leaf node) need to be optimized. The firefly algorithm (FA) is a global optimization algorithm, which shows better performance on both global optima and local optima, compared to the widely used random search method and particle swarm optimization (PSO) (Yang and He 2013). Therefore, FA can be used for searching the optimum parameters in RF, and then the ensemble method RF-FA is presented. To the authors’ knowledge, only a few research used the ensemble approach for rockburst classification and no relevant reports about the RF-FA model in this area.
To fill the above gap in rockburst prediction by machining learning-based model, this paper presents and assesses an ensemble model by the combination of RF and FA to classify rockburst in underground engineering. A large dataset was collected in previous studies representing the rockburst events worldwide. A five-fold cross-validation method and FA were used for selecting the optimum hyperparameters of RF. Then the combined RF-FA ensemble classifier was validated by the testing dataset. Compared with the conventional empirical criteria and existing RF models, the proposed ensemble classifier performed better on the accuracy. Therefore, the RF-FA was successfully applied to several new rockburst events in engineering projects, indicating that it is a robust method for rockburst evaluation in underground projects.
Dataset description
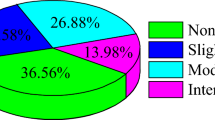
A total of 279 cases of rockburst reported in the previous literature were collected to evaluate the rockburst intensity (Jingyu 2010; Zhou et al. 2012, 2016a; Li et al. 2017b; Afraei et al. 2019; Ghasemi et al. 2020). The data was first updated and supplemented, as some data are different from the original literature. The data includes five influencing variables for input parameters and one output parameter, namely, rockburst intensity. Specifically, the input variables contain the buried depth of opening (H), maximum tangential stress of the excavation boundary (σθ), uniaxial compressive strength of rock (\({\sigma }_{c})\), the tensile strength of rock (\({\sigma }_{t}\)), and elastic energy index (Wet). These input variables are normally used in rockburst classification and can reflect the basic information of the occurrence of rockburst in underground conditions. The output only contains one parameter (i.e., rockburst intensity) but it has four classes according to the failure properties, i.e., none, light, moderate, and strong. The detailed definition of above-mentioned input and output parameters are summarized in Table 2. According to the dataset, the cumulative distribution and frequency of each input variable are shown in Fig. 2. The statistics of input and output are given in Table 3 and the pie chart (Fig. 3), respectively.

The histograms of rockburst under various influencing variables

Statistics of rockburst classes
Methodology
The collected dataset was divided into two sets (i.e., training dataset and testing set). The training set was applied for training the classification model and selecting the ideal hyperparameters of the classifier. The testing set was utilized for testing the generalization of the classifier. In this study, the rockburst prediction, as a typical classification problem, can be classified by an intelligent classifier. As the mentioned dataset, the training set contains 195 cases (70%) and the testing set contains 84 cases (30%). The following contents introduced the machine learning model (random forest), global optimization method (firefly algorithms), performance measures, and the procedures of hyperparameter tuning.
Random forest classifier (RF)
Random forest can train and predict samples by multiple trees and its output category is calculated by individual tree(Pal 2005). It has special advantages such as dealing different variables and fast learning speed. The typical structure of the RF classifier is shown in Fig. 4. Now it is well used for constructing a classifier, which can classify different issues accurately.
Firefly algorithm (FA)
FA is inspired by the firefly flicker especially relating its behavior (Yang 2008, 2010). The flow chart of FA is illustrated in Fig. 5. The function applied in updating two fireflies xi and xj is given as follows:
where β means the attractiveness, rij means the distance in xi and xj, γ denotes the light absorption coefficient, αt represents a parameter relating to step size, and εt means a number from Gaussian function.

structure of random forest classifier
Performance evaluation methods
The objective of this work is to present an intelligent model for predicting rockburst accurately. Thus, the method of evaluating the performance is of significance. The error matrix, namely, confusion matrix, can visualize model performance in which the row means prediction class, while the column denotes a real class. In this study, rockburst classification can be divided into 1, 2, 3, and 4 presenting none, light, moderate, and strong, respectively. Therefore, the classification of rockburst including correct and incorrect combinations can be summarized in Table 4.
According to the cases in Table 4, some evaluation formulas can be defined such as accuracy, precision, and recall (Zhou et al. 2015).
where n represents the total number of samples.
Besides, two typical methods for a classification model evaluation are the receiver operating characteristic (ROC) curve and AUC curve (the area under the ROC). The horizontal axis and vertical axis can be represented by the false positive rate (FPR) and the true positive rate (TPR) in ROC curve. Rockburst hazard determination is a fourfold classification issue, and therefore, the ROC and AUC are necessary for evaluating rockburst correctly. Assume C is the set of the n classes with ci as the positive class Pi and the other classes are treated as the negative class Ni, i.e.,
Each Ni consists of n − 1 classes, and the ROC curve of ci can be improved with improving prevalence within these classes. For AUC, the AUCs can be weighted by the prevalence of the reference class as follows:
where \(\mathrm{AUC}({c}_{i})\) denotes the area under the class reference ROC for ci and \(p({c}_{i})\) is the prevalence of ci.
Model development
In this study, the k-fold cross-validation (CV) method was utilized when the hyperparameters were tuned. The k was chosen as five, which means the dataset was split into five-folds, and the RF model was trained by four-folds while the other one fold is used for testing. The mentioned process would be repeated five times. The hyperparameters in RF such as tree_num and min_sample_leaf were adjusted by five-fold CV and FA. Specifically, during the tuning process, the AUC values can be regarded as the light intensity of fireflies, and these values can reach the largest state when the fireflies showed the brightest light. The initial setting of FA was summarized in Table 5. After tuning, the optimum RF classifier (RF-FA, combination of RF and FA) can be used for further performance evaluation on the testing dataset. Then the proposed ensemble model was compared with the baseline model such as multiple linear regression (MLR) and conventional RF model. Also, the influencing variables were further conducted by the ensemble model. The whole procedure of such an ensemble intelligent classifier RF-FA and its performance evaluation were illustrated in Fig. 6.

Flow chart of firefly algorithm
Results and validation
Results of hyperparameter tuning
Different from the binary classification problem, the rockburst classification is a multiclass classification problem. Thus, a one-vs.-rest method was introduced to address this problem. The main idea of one-vs.-rest method is to train a single classifier in each class with positive samples, whereas the remaining samples are treated as negatives. Specifically, four RF binary classifiers were trained and each RF is for a specific class. During this process, AUC is set as objective function, and the hyperparameters in RF were tuned by FA to construct a combination model RF-FA. Then four RF-FA models are used for unknown samples.
To show the effect of FA on tuning hyperparameters, the AUC values were obtained under each iteration (shown in Fig. 7). The AUC values and convergence shoed different patterns with different classes. With the increase of iteration, the average AUC values in the rockburst dataset (weak, moderate, and strong classes) became stable after 10 iterations, which means the influence of hyperparameters on the performance RF model is obvious. Compared with the strong class, the AUC convergence rate is slower than the moderate and weak class. It is noted that the performance of RF on none class was influenced by hyperparameters significantly, as the AUC value increased sharply at the first iteration and after that, the average AUC value increased slowly until 40 iterations, meaning that the model can predict the larger dataset accurately. The above analysis showed that the hyperparameters of RF were tuned effectively by FA.

The procedures of RF-FA classifier ensemble for rockburst prediction
As can be seen that the optimum AUC values in the weak class achieve 0.98, demonstrating that the RF-FA model has an excellent performance on the training dataset. The final AUC values in the moderate and strong class are 0.87 and 0.85, respectively, which shows that RF-FA also can be regarded as an outstanding classification model. It should be noted that though the average AUC value in the weak class exhibited a relatively low AUC value (0.81) probably because of the small dataset in this class, the model still has a good performance on training weak rockburst dataset. When the best AUC values were obtained, the hyperparameters in RF were correspondingly determined. Then the optimum ensemble RF-FA model can be evaluated by testing the rockburst dataset. The hyperparameters of RF were given in Table 6.
The validation of the proposed RF-FA model on the test set
As the development of the model, the training dataset was used to train the model and selecting the optimum hyperparameters, while the remaining dataset, i.e., testing set, was applied to test the RF-FA model. The confusion matrix on the test set is given in Table 7. It is clear that the accuracy is over 0.90 and fewer data are misclassification, showing that the proposed RF-FA has excellent performance on rockburst prediction and therefore the developed model has been validated.
Relative importance
To determine the feature importance of the rockburst, the Fourier amplitude sensitivity test (FAST) with the classifier ensemble as the objective function was applied. FAST can express the sensitivity of different variables, and therefore, the importance score of each input variables could be calculated. It is a qualitative global sensitivity analysis, which can sort the input parameters qualitatively according to the sensitivity with less computation. By this method, the influence between input and output can be given by
where \({V}_{xi}\) means the variance-based first-order influence for input \(xi\) and \(V(Y)\) is the total variance of the output.
Figure 8 shows the importance score of each variable in classes. The Wet plays the most important role in the rockburst intensity, followed by \({\sigma }_{\theta }\), H, and \({\sigma }_{c}\), while \({\sigma }_{t}\) is not important as above variables. Specifically, the score of the relative importance of Wet is 39.8%, and that value of \({\sigma }_{\theta }\), H is 30.4% and 24.2, respectively. Parameters \({\sigma }_{c}\) and \({\sigma }_{t}\) have relatively small scores (3.5% and 2.1, respectively). By analyzing the above scores, more attentions should pay to Wet, \({\sigma }_{\theta }\), and H in the field, but it does not mean that the other variables are not important as the results are obtained by comparing all influencing factors together.

The evolution of AUC values with different dataset classes by FA tuning
Discussion
Comparison of the ensemble RF-FA model with other models
The prediction performance of the proposed ensemble RF-FA model and other baseline classification, i.e., RF (random forest) and MLR (multiple linear regression), is given in Table 8. It is clear that the RF-FA model performed better (training set 0.95 and test set 0.91). Compared with individual classifier RF and MLR in training set, the accuracy of the proposed RF-FA ensemble classifier increased by 20.2% and 58.3%, respectively. Also, the model RF-FA exhibits the optimum performance on other indicators on the testing set (precision = 0.82, recall = 0.81), while the MLR model achieved the poorest performance on that (precision = 0.48, recall = 0.40).
Furthermore, the ROC and AUC values calculated by the three models are shown in Fig. 9. The ensemble classifier RF-FA performed the best compared with the other two models. Specifically, the RF-FA model achieved an AUC value of 0.95, followed by RF (0.83) and MLR (0.71). It is interesting that we found the proposed RF-FA model is the best one in all cases, though the threshold setting is low (below 0.05) or high (above 0.95), which means the RF-FA ensemble classifier exhibits a good ability of generalization and can be used in the prediction of rockburst engineering.

The relative importance of variables

ROC curve of the proposed ensemble RF-FA and individual RF, MLR model
Compared with the existing RF models in previous studies
As described above, few studies applied the conventional RF model on the rockburst assessment. In this section, the proposed ensemble classifier RF-FA was also compared with the previous studies (given in Table 9). The accuracy performance of the proposed model (0.91) is relatively higher than the previous studies (0.73 or 0.61). Interestingly, compared with the previous literature (in total of 246 cases with 6 or 7 input variables), the RF-FA model can achieve higher performance with more cases (279) and fewer input variables (5), which means the proposed model in this study is a robust and efficient method for rockburst prediction.
Comparison between RF-FA and empirical criteria
It is noted that there are some typical criteria of the prediction of rockburst such as rock brittleness coefficient criterion, burst proneness index, and Russenes criterion. In this study, a detailed comparison between the proposed models and empirical criteria was performed. The results are summarized in Table 10. The accuracy of the RF-FA model is much better than the empirical criteria, which means that the conventional models are limited by the single index and a small amount of data. Normally the empirical criteria are conservative and not suitable for all engineering, while the established prediction model in this paper exhibited high accuracy and applicability.
Application in new engineering projects
The developed RF-FA model was used for predicting eight rockburst events in four different engineering projects in deep tunnels and mines. Specifically, the field data are from Cangling tunnel, Dongguashan mine (Jia et al. 2013), Duoxiongla tunnel (Tang and Xu 2020), and Daxiangling tunnel (Jingyu 2010). The results are shown in Table 11. All cases are predicted correctly, which means that the RF-FA model can be used for rockburst prediction in advance and guide the engineering in practice.
Conclusion
This study proposed a novel ensemble classifier RF-FA combining random forest (RF) and firefly algorithm (FA) to classify the rockburst intensity in underground projects. The conclusion can be summarized as follows:
FA algorithm can tune the hyperparameters of random forest model (individual classifier) effectively, which means that the RF-FA model can be used for further application.
The proposed ensemble classifier performed better accuracy (0.91), in which that figure increased by 19.7% and 121.9% compared with the individual classifier RF and MLR, respectively.
The relative importance results demonstrate that Wet is the most important variable in rockburst classification.
Compared with the empirical criteria, existing RF models, the proposed performed much better on prediction accuracy. Besides, the proposed model was successfully used for predicting rockburst events in new projects.
It is noted that the accuracy and generalization of the machine learning models are influenced by the dataset. In this study, we used 70% of the data to train the proposed model and the remaining 30% of the dataset to validate the model. Normally, the generalization can be improved if we applied all data to train the model to some extent.
References
Adoko AC, Gokceoglu C, Wu L, Zuo QJ (2013) Knowledge-based and data-driven fuzzy modeling for rockburst prediction. Int J Rock Mech Min Sci 61:86–95
Afraei S, Shahriar K, Madani SH (2018) Statistical assessment of rock burst potential and contributions of considered predictor variables in the task. Tunn Undergr Sp Technol 72:250–271
Afraei S, Shahriar K, Madani SH (2019) Developing intelligent classification models for rock burst prediction after recognizing significant predictor variables, section 2: designing classifiers. Tunn Undergr Sp Technol 84:522–537
Breiman L (2001) Random forests. Mach Learn 45:5–32
Cai M (2013) Principles of rock support in burst-prone ground. Tunn Undergr Sp Technol 36:46–56
ChenHaijun L, NieDexin S (2003) Prediction of rockburst by artificial neural network. Chinese J Rock Mech Eng 22:762
Dehghan S, Shahriar K, Maarefvand P, Goshtasbi K (2013) 3-D modeling of rock burst in pillar No. 19 of Fetr6 chromite mine. Int J Min Sci Technol 23:231–236
Dong L, Li X, Kang P (2013) Prediction of rockburst classification using Random Forest. Trans Nonferrous Met Soc China 23:472–477
Faradonbeh RS, Taheri A (2019) Long-term prediction of rockburst hazard in deep underground openings using three robust data mining techniques. Eng Comput 35:659–675
Farhadian H (2021) A new empirical chart for rockburst analysis in tunnelling: tunnel rockburst classification (TRC). Int J Min Sci Technol
Feng X-T, Wang LN (1994) Rockburst prediction based on neural networks. Trans Nonferrous Met Soc China 4:7–14
Ghasemi E, Gholizadeh H, Adoko AC (2020) Evaluation of rockburst occurrence and intensity in underground structures using decision tree approach. Eng Comput 36:213–225
He M, e Sousa LR, Miranda T, Zhu G, (2015) Rockburst laboratory tests database—application of data mining techniques. Eng Geol 185:116–130
He M, Ren F, Liu D (2018) Rockburst mechanism research and its control. Int J Min Sci Technol 28:829–837
Hong-Bo Z (2005) Classification of rockburst using support vector machine. Rock Soil Mech 26:642–644
Huang J, Asteris PG, Pasha SMK, et al (2020a) A new auto-tuning model for predicting the rock fragmentation: a cat swarm optimization algorithm. Eng Comput 1–12
Huang J, Koopialipoor M, Armaghani DJ (2020b) A combination of fuzzy Delphi method and hybrid ANN-based systems to forecast ground vibration resulting from blasting. Sci Rep 10:1–21
Huang J, Sun Y, Zhang J (2021) Reduction of computational error by optimizing SVR kernel coefficients to simulate concrete compressive strength through the use of a human learning optimization algorithm. Eng Comput 1–18
Jia Y, Lv Q, Shang Y (2013) Rockburst prediction using particle swarm optimization algorithm and general regression neural network. Chinese J Rock Mech Eng 32:343–348
Jingyu LLC (2010) Fuzzy comprehensive assessment method adopted to predict rock burst in Daxiangling tunnel. Mod Tunn Technol 5
Kaiser PK, McCreath DR, Tannant DD (1996) Rockburst support handbook. Laurentian Univ Canada, Geomech Res Centre
Kidybiński A (1981) Bursting liability indices of coal. In: International Journal of Rock Mechanics and Mining Sciences & Geomechanics Abstracts. Elsevier, pp 295–304
Kie TT (1988) Rockbursts, case records, theory and control. In: Proceedings of the international symposium on engineering in complex rock formations. Elsevier, pp 32–47
Li N, Feng X, Jimenez R (2017a) Predicting rock burst hazard with incomplete data using Bayesian networks. Tunn Undergr Sp Technol 61:61–70
Li N, Jimenez R (2018) A logistic regression classifier for long-term probabilistic prediction of rock burst hazard. Nat Hazards 90:197–215
Li N, Jimenez R, Feng X (2017b) The influence of Bayesian networks structure on rock burst hazard prediction with incomplete data. Procedia Eng 191:206–214
Li X, Gong F, Tao M et al (2017c) Failure mechanism and coupled static-dynamic loading theory in deep hard rock mining: a review. J Rock Mech Geotech Eng 9:767–782
Lin Y, Zhou K, Li J (2018) Application of cloud model in rock burst prediction and performance comparison with three machine learning algorithms. IEEE Access 6:30958–30968
Liu Z, Shao J, Xu W, Meng Y (2013) Prediction of rock burst classification using the technique of cloud models with attribution weight. Nat Hazards 68:549–568
Lu C-P, Dou L-M, Liu B et al (2012) Microseismic low-frequency precursor effect of bursting failure of coal and rock. J Appl Geophys 79:55–63
Ortlepp WD (2005) RaSiM comes of age—a review of the contribution to the understanding and control of mine rockbursts. In: Proceedings of the Sixth International Symposium on Rockburst and Seismicity in Mines, Perth, Western Australia. pp 9–11
Pal M (2005) Random forest classifier for remote sensing classification. Int J Remote Sens 26:217–222
Peng Q, Qian AG, Xiao Y (2010) Research on prediction system for rockburst based on artificial intelligence application methods. J Sichuan Univ Eng Sci Ed 42:18–24
Pu Y, Apel DB, Lingga B (2018) Rockburst prediction in kimberlite using decision tree with incomplete data. J Sustain Min 17:158–165
Qi C, Fourie A, Du X, Tang X (2018) Prediction of open stope hangingwall stability using random forests. Nat Hazards 92:1179–1197
Russenes BF (1974) Analysis of rock spalling for tunnels in steep valley sides. Nor Inst Technol
Singh SP (1989) Classification of mine workings according to their rockburst proneness. Min Sci Technol 8:253–262
Sun Y, Li G, Zhang J (2020) Investigation on jet grouting support strategy for controlling time-dependent deformation in the roadway. Energy Sci Eng 8:1–8. https://doi.org/10.1002/ese3.654
Sun Y, Li G, Zhang J, Qian D (2019a) Prediction of the strength of rubberized concrete by an evolved random forest model. Adv Civ Eng. https://doi.org/10.1155/2019/5198583
Sun Y, Li G, Zhang N et al (2021) Development of ensemble learning models to evaluate the strength of coal-grout materials. Int J Min Sci Technol 31:153–162
Sun Y, Zhang J, Li G et al (2019b) Optimized neural network using beetle antennae search for predicting the unconfined compressive strength of jet grouting coalcretes. Int J Numer Anal Methods Geomech 43:801–813. https://doi.org/10.1002/nag.2891
Sun Y, Zhang J, Li G et al (2019c) Determination of Young’s modulus of jet grouted coalcretes using an intelligent model. Eng Geol 252:43–53. https://doi.org/10.1016/j.enggeo.2019.02.021
Tang Z, Xu Q (2020) Rock burst prediction based on nine machine learning algorithms. Chinese J Rock Mech Eng 161
Wang S, Zhou J, Li C et al (2021) Rockburst prediction in hard rock mines developing bagging and boosting tree-based ensemble techniques. J Cent South Univ 28:527–542
Wang Y-H, Li WD, Li QG et al (1998) Method of fuzzy comprehensive evaluations for rockburst prediction. Chinese J Rock Mech Eng 17:493–501
Wu K, Shao Z, Sharifzadeh M et al (2021) Analytical computation of support characteristic curve for circumferential yielding lining in tunnel design. J Rock Mech Geotech Eng 13:1–13
Wu S, Wu Z, Zhang C (2019) Rock burst prediction probability model based on case analysis. Tunn Undergr Sp Technol 93:103069
Xiaoming GLLXY, Lianghui X (2005) Rock burst prediction methods based on BP network theory [J]. Ind Saf Dust Control 10:
Xibing LI, Fengqiang G, Shao-feng W et al (2019) Coupled static-dynamic loading mechanical mechanism and dynamic criterion of rockburst in deep hard rock mines. Chinese J Rock Mech Eng 38:708–723
Yang X-S (2008) Firefly Algorithm Nature-Inspired Metaheuristic Algorithms 20:79–90
Yang X-S (2010) Firefly algorithm, stochastic test functions and design optimisation. arXiv Prepr arXiv10031409
Yang X-S, He X (2013) Firefly algorithm: recent advances and applications. arXiv Prepr arXiv13083898
Zhang C, Feng X, Zhou H et al (2012) A top pilot tunnel preconditioning method for the prevention of extremely intense rockbursts in deep tunnels excavated by TBMs. Rock Mech Rock Eng 45:289–309
Zhang J, Jiang F, Yang J et al (2017) Rockburst mechanism in soft coal seam within deep coal mines. Int J Min Sci Technol 27:551–556
Zhang J, Ma G, Huang Y et al (2019) Modelling uniaxial compressive strength of lightweight self-compacting concrete using random forest regression. Constr Build Mater 210:713–719
Zhang J, Sun Y, Li G, et al (2020) Machine-learning-assisted shear strength prediction of reinforced concrete beams with and without stirrups. Eng Comput 1–15
Zhou J, Guo H, Koopialipoor M, et al (2020a) Investigating the effective parameters on the risk levels of rockburst phenomena by developing a hybrid heuristic algorithm. Eng Comput 1–16
Zhou J, Li C, Arslan CA, et al (2019) Performance evaluation of hybrid FFA-ANFIS and GA-ANFIS models to predict particle size distribution of a muck-pile after blasting. Eng Comput 1–10
Zhou J, Li X, Mitri HS (2018) Evaluation method of rockburst: state-of-the-art literature review. Tunn Undergr Sp Technol 81:632–659
Zhou J, Li X, Mitri HS (2016a) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civ Eng 30:4016003
Zhou J, Li X, Mitri HS (2015) Comparative performance of six supervised learning methods for the development of models of hard rock pillar stability prediction. Nat Hazards 79:291–316
Zhou J, Li X, Shi X (2012) Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf Sci 50:629–644
Zhou J, Nekouie A, Arslan CA et al (2020b) Novel approach for forecasting the blast-induced AOp using a hybrid fuzzy system and firefly algorithm. Eng Comput 36:703–712
Zhou K, Yun LIN, Deng H et al (2016b) Prediction of rock burst classification using cloud model with entropy weight. Trans Nonferrous Met Soc China 26:1995–2002
Zhu YH, Liu XR, Zhou JP (2008) Rockburst prediction analysis based on v-SVR algorithm. J China Coal Soc 33:277–281
Funding
This research was supported by the projects of “the Fundamental Research Funds for the Central Universities (2020ZDPY0221, 2021QN1003)”, “National Natural Science Foundation of China (52104106, 52174089)”, "Natural Science Foundation of Jiangsu Province" (BK20210513), Basic Research Program of Xuzhou (KC21017).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sun, Y., Li, G., Zhang, J. et al. Rockburst intensity evaluation by a novel systematic and evolved approach: machine learning booster and application. Bull Eng Geol Environ 80, 8385–8395 (2021). https://doi.org/10.1007/s10064-021-02460-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10064-021-02460-7