
Abstract
Plant classification based on the leaf images is an important and tough task. For leaf classification problem, in this paper, a new weight measure is presented, and then a dimensional reduction algorithm, named semi-supervised orthogonal discriminant projection (SSODP), is proposed. SSODP makes full use of both the labeled and unlabeled data to construct the weight by incorporating the reliability information, the local neighborhood structure and the class information of the data. The experimental results on the two public plant leaf databases demonstrate that SSODP is more effective in terms of plant leaf classification rate.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Plant classification based on the leaf images is very important and necessary with respect to agricultural information, ecological protection and plant automatic classification systems. It is well known that how to validly extract classification features is central to the plant recognition based on leaf images. Currently, the widely used features for plant recognition based on leaf image can be divided into color, shape, and texture features [1–13]. However, these techniques have not fully considered the following characteristics of plant leaf image data. (1) Diversity: plant leaf images differ from each other in a thousand ways. On the one hand, the same kind of plant leaves appear in many different colors, shapes and sizes (as shown in Fig. 1a); on the other hand, different plants sometimes have a similar shape (as shown in Fig. 1b). (2) Nonlinearity: plant leaves vary with period, location, and illumination conditions, and make them distributed under some nonlinear manifold. These properties lead to the existing plant classifying methods difficult to achieve satisfactory recognition results.

Sample images of plant leaves. a Large within-class difference, b large between-class similarity
In plant leaf recognition and classification tasks, a key process is to reduce the dimensionality of these high-dimensionality unorganized leaf image data. Effective dimensional reduction algorithm can help to avoid the “curse of dimensionality” problem in making decisions and analyzing data efficiently. Over the past several decades, many dimensional reduction methods have been proposed. These methods could be divided into three categories according to whether utilizing the class information of the input samples: unsupervised, supervised and semi-supervised. Supervised methods have been proven to be more suitable for classification tasks than those unsupervised ones. In classification problems, the label information can be used to guide the procedure of dimensionality reduction. Among the existing methods, LDA [14] is one of the most commonly used linear supervised methods and has been widely applied to many high-dimensional classification problems. It encodes discriminant information by finding directions that maximize the ratio of between-class scatter to within-class scatter. However, there are two major drawbacks with LDA: the small-sample-size (SSS) problem and the Gaussian distribution assumption. Marginal fisher analysis (MFA) [15] is a supervised manifold learning-based method, which without the prior information on data distributions, the inter-class margin can better characterize the separability of different classes than the inter-class variance as in LDA. However, a disadvantage of MFA is that there are many parameters to be set empirically. In contrast to MFA, only one K-nearest-neighbor criterion is introduced to define the neighborhood graph in locality sensitive discriminant analysis (LSDA) [16]. Orthogonal discriminant projection (ODP) is another supervised manifold learning method [17]. ODP follows the supervised techniques and the label information is taken to model the manifold. In ODP, the weight between any two points is defined by using both local information and non-local information to explore the intrinsic structure of original data and to enhance the recognition ability.
It is well known that it is much easier to collect the unlabeled data than the labeled samples. Recently, semi-supervised learning has emerged as a hot topic in pattern recognition area. The semi-supervised learning algorithms effectively utilize a limited number of labeled samples and a large amount of unlabeled samples for real-world applications. Cai et al. [18] proposed a semi-supervised discriminant analysis (SDA), in which the labeled data points are used to maximize the discriminating ability, while the unlabeled data points are used to maximize the locality preserving power. Based on LSDA, Zhao et al. [19] proposed a locality sensitive semi-supervised (LSSS) feature selection method. Like LSDA, LSSS does not effectively consider the global information of the data. Zhang et al. [20] proposed a semi-supervised locally discriminant projection (SSLDP). SSLDP is sensitive to noise points. In our paper, like many manifold learning-based dimensionality reduction methods, the noise points are the leaves with poor quality, which may be caused by period, location, illumination, or other factors. Figure 2 illustrates some samples from the cherry blossoms leaves, where the first and second are normal, the others are noise points, which are very different from the normal samples.

Two normal and four noisy samples of cherry blossom leaves
All the above-mentioned methods are summarized in the following Table 1.
Inspired by semi-supervised learning and ODP, we proposed a semi-supervised orthogonal discriminant projection (SSODP) method for plant leaf classification problem. In contrast to the original ODP algorithm, SSODP has the following desirable properties: (1) SSODP definitely utilizes the unlabeled sample information; (2) SSODP improves the weight construction by incorporating the reliability information.
The rest of the paper is organized as follows: ODP is briefly introduced in Sect. 2. SSODP is proposed in Sect. 3. Section 4 reports some experimental results based on two real plant leaf databases to demonstrate the effectiveness of the proposed method. Finally, conclusions and future work are drawn in the last section.
2 Orthogonal discriminant projection (ODP)
Assume there are n D-dimensional data points \( X_{1} ,X_{2} , \ldots X_{n} \), it is desirable to project these points into a linear subspace where the points with the same label are clustered closer and the points belonging to different classes are located farther. Let \( Y_{1} ,Y_{2} , \ldots ,Y_{n} \) denote the projections of \( X_{1} ,X_{2} , \ldots ,X_{n} \) in d-dimensional subspace, thus the projection can be expressed by \( Y_{i} = A^{T} X_{i} \), where A is a linear transformation matrix. ODP seeks to find the linear transformation through the following steps.
Firstly, an adjacency graph \( G = \left( {V,E,H} \right) \) is constructed using k nearest neighbor criterion, where G denotes the graph, V is the node set and E is the edge set. H is an adjacency matrix, whose elements are defined based on their both local information and class information:
where \( E(X_{i} ,X_{j} ) = \exp \left[ { - d^{2} (X_{i} ,X_{j} )/\beta^{2} } \right] \), \( d(X_{i} ,X_{j} ) \) denotes the Euclidean distance between points \( X_{i} \) and \( X_{j} \), \( N (X_{i} ) \) is the k nearest neighborhoods of \( X_{i} \), \( C_{i} \) is the label of \( X_{i} \), and \( \beta \) is a parameter which is used as a regulator.
By introducing the weight matrix \( H = \{ H_{ij} \} \), the local scatter can be expressed to:
where \( S_{L} = \frac{1}{2}\frac{1}{n}\frac{1}{n}\sum\nolimits_{i = 1}^{n} {\sum\nolimits_{j = 1}^{n} {H_{ij} \left( {X_{i} - X_{j} } \right)\left( {X_{i} - X_{j} } \right)^{T} } } \).
After characterizing the local scatter, the non-local scatter can be characterized by the following expression,
where \( S_{T} = \frac{1}{2}\frac{1}{n}\frac{1}{n}\sum\nolimits_{i = 1}^{n} {\sum\nolimits_{j = 1}^{n} {\left( {X_{i} - X_{j} } \right)\left( {X_{i} - X_{j} } \right)^{T} } } \).
After the local scatter and the non-local scatter have been constructed, an optimization objective function is devised to maximize the difference between them with the constraint of \( A^{T} A = I \). The objective function can be expressed as follows:
where \( \alpha \) is an adjustable parameter.
The projecting matrix A is composed of the d eigenvectors associated with the d top eigenvalues of the following eigenvalue equation,
Thus, the optimal linear features \( Y \) can be obtained by the following linear transformation:
3 Semi-supervised orthogonal discriminant projection (SSODP)
Motivated by Eq. (1), we present a new weight between any two points as follows:
where \( D_{i} = \frac{1}{k}\sum\nolimits_{{X_{j} \in N(X_{i} )}} {E(X_{i} ,X_{j} )} \) is the reliability of \( X_{i} \) (\( i = 1,2, \ldots ,n \)), \( {\text{Max}}_{i} (D_{i} ) \) and \( {\text{Min}}_{i} (D_{i} ) \) is the maximum and minimum of \( D_{i} \)(i = 1,2,…,n), respectively. \( {\text{Mean}}_{{X_{j} \in N(X_{i} )\;{\text{or}}\;X_{i} \in N(X_{j} )}} E(X_{i} ,X_{j} ) = \frac{1}{2k}\sum\nolimits_{{X_{j} \in N(X_{i} )\;{\text{or}}\;X_{i} \in N(X_{j} )}} {E(X_{i} ,X_{j} )} \) is the weight mean of \( X_{j} \) in \( N (X_{i} ) \) or \( X_{i} \) in \( N (X_{j} ) \), and make W ii = 0 to avoid the self-similarity of data points.
Figure 3 shows the typical plot of W ij as a function of \( d^{2} (X_{i} ,X_{j} )/\beta^{2} \), where supposing \( D_{i} \) = 1(i = 1, 2,…,n), so \( {\text{Max}}_{i} (D_{i} ) = {\text{Min}}_{i} (D_{i} ) = {\text{Mean}}(D_{i} ) = 1 \).

Typical plot of W ij as a function of \( d^{2} (X_{i} ,X_{j} )/\beta^{2} \)
In Fig. 3, the curve A1 denotes X j is among the k nearest neighborhoods of X i or X i is among the k nearest neighborhoods of X j and they belong to the same class. The curve A2 denotes X j is among the k nearest neighborhoods of X i or X i is among the k nearest neighborhoods of X j and they do not belong to the same class. The curve A3 denotes X j is among the k nearest neighborhoods of X i or X i is among the k nearest neighborhoods of X j and X i or X j is unlabeled. The curve A4 denotes the other cases, including W ij = 0 to avoid self-loops.
According to the Eq. (7), W ij indicates that the neighboring points have more impact on the weight than the far-apart points. W ij reflects not only the class information and reliability information of the data, but also the basic neighborhood relation between two points. This property demonstrates the discriminant similarity of the data. Since the Euclidean distance \( d(X_{i} ,X_{j} ) \) is in the exponent, the parameter β is used to prevent \( d^{2} (X_{i} ,X_{j} ) \) from increasing too fast when \( d^{2} (X_{i} ,X_{j} ) \) is relatively large. The properties of W ij can be summarized as follows:
-
1.
By using the same neighborhood size for all points in a data set the neighborhood is just large enough to include at least two neighbors in each neighborhood The justification for using local neighborhoods is based on the argument that the weights should depend on the local geometry rather than the global structure of the whole data set.
-
2.
In Eq. (7), \( D_{i} \) expresses the reliability information; \( E(X_{i} ,X_{j} ) \) expresses local neighbor information; \( 1 + E(X_{i} ,X_{j} ) \) and \( 1 - E(X_{i} ,X_{j} ) \) express the discriminant information.
-
3.
\( D_{i} \) of \( X_{i} \) is large if its k nearest neighbors are all closer to its vicinity, and small if they are far from its vicinity.
-
4.
Since \( 1 < 1 + E(X_{i} ,X_{j} ) < 2 \) and \( 0 < 1 - E(X_{i} ,X_{j} ) < 1 \), when the Euclidean distance is equal, the within-class weight is larger than the between-class weight. This characteristic provides a certain chance to the points in the same class to have the larger weight than those in different classes, which is preferred for classification tasks.
-
5.
With the decrease of the Euclidean distance, the between-class weight decreases toward 0. It means for the closer points from different classes that the larger \( E(X_{i} ,X_{j} ) \), the smaller \( 1 - E(X_{i} ,X_{j} ) \) and the smaller value of weight.
With the new definition of the weight W ij , the new semi-supervised dimensionality reduction algorithm is proposed as follows:
Due to the above properties of W ij , we apply W = [W ij ] to the original ODP for improving the discriminant ability of the dimensionality reduction methods. Given n D-dimensional data points \( X = (X_{1} ,X_{2} , \ldots ,X_{n} ) \), each column vector X i represents a sample, we can construct an undirected full connected graph \( G = \left( {V,E,W} \right) \), where each vertex represents a sample in X and the element W ij defined as Eq. (7) in matrix W is the weight of edge between node X i and X j . W ij can reflect the similarity between X i and X j . Considering a linear projection \( A \in R^{n \times d} \) that maps each point \( X_{i} \) in the original space to a lower dimensionality vector \( Y_{i} \in R^{d} ,Y_{i} = A^{T} X_{i} \), the local scatter \( J_{L}^{{\prime }} \) and non-local scatter \( J_{N}^{{\prime }} \) can be defined as follows:
By simple algebraic formulation, Eq. (8) can be formulated as:
where \( S_{L}^{{\prime }} = D - W \) is the graph Laplacian of the within-class graph and \( W = \{ W_{ij} \} \), D is a diagonal matrix with entries \( D_{ii} = \sum\nolimits_{j} {W_{ij} } \).
Similarly, Eq. (9) can be formulated as:
where \( S_{N}^{'} = E - F \) is the graph Laplacian of the between-class graph and, \( F = \{ 1 - W_{ij} \} \), E is a diagonal matrix with entries \( E = \sum\nolimits_{j} {(1 - W_{ij} )} \).
After the local scatter \( J_{L}^{{\prime }} \) and the non-local scatter \( J_{N}^{{\prime }} \) have been constructed, the objective function is written as:
The Lagrangian function of the problem Eq. (10) is
In order to get the \( d \)th orthogonal basis vector, we maximize the following objective function:
with the constraints \( a_{d}^{T} a_{1} = a_{d}^{T} a_{2} = \cdots = a_{d}^{T} a_{d - 1} = 0 \), where d is the output reduction dimensionality.
To solve the above optimization problem, we use the Lagrangian multiplier:
where \( \delta \) is a number to be determined.Set the partial derivative of \( f \) with respect to \( a_{d} \) to zero and obtain
Multiplying the left side of Eq. (14) by \( a_{d}^{T} \), we obtain
According to the paper [21, 22], the orthogonal iterative algorithm of solving the orthogonal vectors of SSODP is summarized as follows:
-
1.
Initialize A as an arbitrary column-orthogonal matrix.
-
2.
Compute the trace ratio value \( \delta = \frac{{tr\left( {A^{T} XS_{N}^{{\prime }} X^{T} A} \right)}}{{tr\left( {A^{T} XS_{L}^{{\prime }} X^{T} A} \right)}} \).
-
3.
Form the trace difference problem as \( A^{\prime } = \max_{{A^{T} A = I}} tr(A^{T} (XS_{N}^{\prime } X^{T} - \delta XS_{L}^{\prime } X^{T} )A) \).
-
4.
Establish \( A^{{\prime }} \) by the d eigenvectors of \( XS_{N}^{{\prime }} X^{T} - \delta XS_{L}^{{\prime }} X^{T} \) corresponding to the d largest eigenvalues.
-
5.
Update A by \( A^{{\prime }} \).
-
6.
Iteratively perform steps (2)–(5) until convergence.
-
7.
Output the final linear transformation matrix.
From the above iterative processes, we obtain the mapping matrix \( A = (a_{1} ,a_{2} , \ldots ,a_{d} ) \). The low-dimensional representation in the SSODP subspace is defined as follows:
4 Experiments
In this section, we apply the proposed method to plant leaf classification in two public leaf databases. One is ICL-Plant Leaf database (http://www.intelengine.cn/source.htm), which contains more than 30,000 leaf images of 362 plant species. All leaf images were captured in different seasons, and at different locations and natural illuminations. Another is Swedish leaf dataset. The Swedish leaf dataset [23] contains 1125 images of leaves uniformly distributed in 15 species. The Swedish leaf dataset is very challenging because of its high inter-species similarity.
In the two databases, the original leaf images contain footstalks or petioles, which are not suitable for robust leaf recognition, since the length and orientation of those footstalks may heavily depend on the collection process. So we crop and normalize (in scale and orientation) and resize them to 32 × 32 pixels by histogram equilibrium with 255 gray levels per pixel and with the white background. All leaf images are represented as points in vector space. A typical image of size 32 × 32 describes a point in 1024-dimensional vector space.
In the two databases, although all leaf images are provided with class labels, for each experiment, we randomly draw several samples from every database as a training set, among them, a random subset is used with labels as the labeled subset, and the remained are used as the unlabeled subset.
To verify the effectiveness of the proposed method, we compared it with RLDA [24], ODP [17], SDA [18], and SSLDP [20]. ODP only makes use of the labeled data points. However, SDA, SSDR and our proposed method make use of both labeled and unlabeled data points. The training set is used to learn the low-dimensional subspace with the projection matrix. The testing set is used to obtain the final recognition rate. In every experiment, firstly, we randomly select an amount of images from all selected images as training set and the rest as testing set; secondly, we execute the dimensionality reduction method on the training dataset and obtain the mapping matrix; then the testing set is projected into the low-dimensional feature subspace; finally, the plant leaf images of the testing set are recognized by a suitable classifier. The parameters k and β are determined empirically. In the following experiments, the 1-nearest-neighbor (1-NN) classifier with Euclidean distance is adopted to classify plant leaf images. In these methods, PCA is used for data preprocessing (dimension reduction) in order to avoid the singular matrix problem and improve the computational efficiency.
4.1 Experiments on ICL-plant leaf database
In experiments, we select 500 leaf images from 20 kinds of plants and each plant has 25 leaf images. Figure 4 shows 20 representative leaf images of 20 plant species.

The representative leaf images of 20 plant species
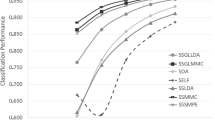
The classifying experiments are conducted to evaluate the effectiveness of the proposed method and to examine the effectiveness of the training number and the number of labeled points in training set on the performance. After all images preprocessed, from each kind of plant, we randomly select m leaf images as the training set, the rest (25 − m) is regarded as the test set, among them, l(l = 1, 2, 3, 4, 5, 6) labeled leaf images and m − l unlabeled leaf images. For each given m and l, a trial is independently performed 50 times. The maximal average result of every experiment is recorded. The average recognition rate means the performance of the classifier with the best set of fitted parameters. The final result is the average correct recognition rate and standard derivation over 50 random splits. We find that the proposed method is not sensitive to β when it is enough large, so we set β = 200. The other parameters k and d are decided by the maximal correct recognition results. Table 2 shows the performance of RLDA, ODP, SDA, SSLDP, and the proposed algorithm. As can be seen, our algorithm achieved 97.12 % recognition rate when six leaf labeled images per class were used for training, which is the best out of the six algorithms. We test the influence of selecting different dimensions in the reduced subspace on the recognition rate, as shown in Fig. 5, where m = 10 and l = 4. In general, the performance of all these methods varies with the number of dimensions. At the beginning, the recognition rates increase greatly as d increases. However, more dimensions do not lead to higher recognition rate after these methods attain the best results.

Plant leaf recognition rates versus the reduction dimensionality, where m = 10 and l = 4
4.2 Experiments on Swedish leaf database
The Swedish leaf data set comes from a leaf classification project at Linköping University and the Swedish Museum of Natural History [23]. The data set contains the isolated leaves from 15 different Swedish tree species, with 75 leaves per species. Figure 6 shows the representative leaf images of 15 different Swedish trees.

The representative images of 15 different species in Swedish leaf database, one image per species. Note that some species are quite similar, e.g., the first, third, and ninth images
The experimental design is the same as before. In every experiment, this procedure is also repeated 50 times and we obtain 50 maximal results for the proposed algorithm and each of the compared methods. The average recognition rates and standard derivations are recorded, as seen in Table 3. From Table 3, we can see three main points. First, OLDSE-ISSODP outperforms the other algorithms among all the cases. For example, when the ten leaf images per species are used for training, SSODP leads RLDA, ODP, SDA, and SSLDP up to 1.12, 4.05, 3.11, and 0.69 %, respectively. Second, SDA, SSLDP, and SSODP perform better than RLDA and ODP. The reason is that the semi-supervised methods make use of all the training images (including labeled and unlabeled images).
5 Discussion
From Tables 2, 3 and Fig. 5, we can see that the semi-supervised methods outperform ODP. The reason is that the semi-supervised methods make use of all the training images (including labeled and unlabeled images), while ODP only use the labeled data points. It is worth pointing out that the recognition rates in the optimizing procedure mainly depend on the ways of splitting the given training data set and the number of the labeled points. From Tables 2 and 3, as more leaf images and the labeled data points split from the given data set are used for training, the recognition rates increase for all the compared algorithms. This demonstrates that all the algorithms are capable of learning from these data points. Particularly, when l = 1, the recognition rates of SSLDP and SSODP are more than 70 %, so the intrinsic image manifold can still be estimated even with a single labeled leaf image per class.
From Tables 2, 3 and Fig. 5, we can see our method outperforms the other methods. A possible explanation is that our method is more robust. In fact, there are some irregular-shaped leaf images in the two plant leaf databases, which were taken from the same tree or from the same leaf in different sessions, so the similarity (or weight) of intra-leaf may be smaller than that of inter-leaf, as seen Fig. 1. As a result, nearest neighborhood points may belong to the different classes. Moreover, the leaf images were taken during two different sessions, so that the appearance of the same leaf image may look different, resulting in different distributions of the data points in the two sessions. The nearest neighbors of a point are more likely to belong to different classes. If points within the same nearest neighborhood are treated from the same class as ODP or SDA does, the recognition accuracy may be seriously affected. In our proposed method, we use \( {\text{Max}}_{i} (D_{i} ) \), \( {\text{Min}}_{i} (D_{i} ) \), and \( {\text{Mean}}_{{X_{j} \in N(X_{i} )\;{\text{or}}\;X_{i} \in N(X_{j} )}} \) to weaken the impact of the irregular-shaped or distorted leaves. In order to explain this conclusion, the experiments include several irregular-shaped leaf images in the training set and test set. To test whether our method is sensitive to such irregular-shaped leaf images, we remove them from the training set and conduct the experiments. The results indicate that the recognition rates are slightly affected by this kind of phenomenon. The reason might lie in the robust path-based similarity measurement [25]. In [25], the similarity expression \( \alpha_{i} = \sum\nolimits_{{X_{j} \in N(X_{i} )}} {E(X_{i} ,X_{j} )} \) is adopted to improve the robustness of the algorithm to noise points.
6 Conclusions and future works
Semi-supervised manifold learning-based methods have aroused a great deal of interest in dimensionality reduction. In this paper, a semi-supervised dimensionality reduction algorithm named semi-supervised orthogonal discriminant projection (SSODP) was proposed and applied successfully to leaf classification. SSODP utilizes all labeled and unlabeled samples to construct the weight between any pairwise points. The experiment results on leaf images demonstrated that SSODP is effective and feasible for leaf classification.
In SSODP, the common assumption is that we only have a limited number of labeled training samples. Developing an adaptive algorithm to automatically adjust the parameters k and β is our future work. In addition, in this paper, we focus on developing a semi-supervised manifold learning technique for leaf classification but do not systematically analyze the stability and robustness of the SSODP. This is a problem deserving further investigation.
References
Venters CC, Cooper DM (2000) A review of content-based image retrieval systems. Technical report, Manchester Visualization Centre, Manchester Computing, University of Manchester, Manchester, UK
Smeulders AWM, Worring M, Santini S et al (2000) Content-based image retrieval at the end of the early years. IEEE Trans Pattern Anal Mach Intell 22:1349–1380
Tico M, Haverinen T, Kuosmanen P (2000) A method of color histogram creation for image retrieval. In: Proceedings of the nordic signal processing symposium (NORSIG’2000), Kolmarden, Sweden, pp 157–160
El-ghazal A, Basir OA, Belkasim S (2007) Shape-based image retrieval using pair-wise candidate co-ranking. Lect Notes Comput Sci 4633:650–661
Park JS, Kim T-Y (2004) Shape-based image retrieval using invariant features. Advances in multimedia information processing-PCM, Berlin/Heidelberg. Lect Notes Comput Sci 2004:146–153
Abbasi S, Mokhtarian F, Kittler J (1999) Curvature scale space image in shape similarity retrieval. Multimed Syst 7:467–476
Ma W, Manjunath B (1996) Texture features and learning similarity. In: Proceedings of the conference on computer vision and pattern recognition (CVPR), pp 425–430
Han J, Ma K-K (2007) Rotation-invariant and scale-invariant gabor features for texture image retrieval. Image Vis Comput 25:1474–1481
Zhang D, Aylwin Wong MI, Lu G (2000) Content based image retrieval using gabor texture features. In: Proceedings of 1st IEEE Pacific Rim Conference on Multimedia (PCM00), pp 392–395
Manjunath B, Ma W (1996) Texture features for browsing and retrieval of image data. IEEE Trans Pattern Anal Mach Intell 18:837–842
Liu C, Wechsler H (2001) A Gabor feature classifier for face recognition. ICCV 2:270–275
Agarwal G, Belhumeur P, Feiner S et al (2006) First steps toward an electronic field guide for plants. Taxon 55(3):597–610
Kumar N, Belhumeur PN, Biswas A et al (2012) Leafsnap: a computer vision system for automatic plant species identification. Proc ECCV 2012:502–516
Belhumeour PN, Hespanha JP, Kriegman DJ (1997) Eigenfaces vs. fisherfaces: recognition using class specific linear projection. IEEE Trans Pattern Anal Mach Intell 19(7):711–720
Yan SC, Xu D, Zhao BY et al (2007) Graph embedding and extensions: a general framework for dimensionality reduction. IEEE Trans Pattern Anal Mach Intell 29(1):40–51
Cai D, He X, Zhou K, Han J, Bao H (2007) Locality sensitive discriminant analysis. IJCAI’07. In: Proceedings of the 20th international joint conference on Artificial intelligence, pp 708–713
Li B, Wang C, Huang DS (2009) Supervised feature extraction based on orthogonal discriminant projection. Neurocomputing 73:191–196
Cai D, He X, Han JW (2000) Semi-supervised discriminant analysis. IEEE 11th international conference on computer vision, pp 1–7
Zhao J, Lu K, He X (2008) Locality sensitive semi-supervised feature selection. Neurocomputing 71:1842–1849
Zhang SW, Lei YK, Wu YH (2011) Semi-supervised locally discriminant projection for classification and recognition. Knowl Based Syst 24:341–346
Zhu L, Zhu S (2007) Face recognition based on orthogonal discriminant locality preserving projections. Neurocomputing 70:1543–1546
Hu HF (2008) Orthogonal neighborhood preserving discriminant analysis for face recognition. Pattern Recogn 41:2045–2054
Söderkvist, O (2001) Computer vision classification of leaves from Swedish Trees. Master Thesis, Linköping Univ., Linköping
Friedman JH (1989) Regularized discriminant analysis. J Am Statist Assoc 84:165–175
Chang H, Yeung DY (2008) Robust path-based spectral clustering. Pattern Recogn 41:191–203
Acknowledgments
This work is supported by the grants of the National Science Foundation of China (61473237 & 61272333 & 61171170), the Anhui Provincial Natural Science Foundation (1308085QF99 & 1408085MF129), Shaanxi provincial education department Foundation (2013JK1145), and the higher education development special fund of Shaanxi Private (XJ13ZD01).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, S., Lei, Y., Zhang, C. et al. Semi-supervised orthogonal discriminant projection for plant leaf classification. Pattern Anal Applic 19, 953–961 (2016). https://doi.org/10.1007/s10044-015-0488-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-015-0488-9