
Abstract
Since state-rich formalism

is a combination of Z, CSP, refinement calculus and Dijkstra’s guarded commands, its model checking is intrinsically more complicated and difficult than that of individual state-based languages or process algebras. Current solutions translate executable constructs of

programs to Java with JCSP, or translate them to CSP processes. Data aspects of

programs are expressed in the Java programming language or as CSP processes. Both of them have disadvantages. This work presents a new approach to model-checking

by linking it to \(CSP \parallel B\); then we utilise ProB to model-check and animate the \(CSP \parallel B\) program. The most significant advantage of this approach is the direct mapping of the state part in

to Z and finally to B, which maintains the high-level abstraction of data specification. In addition, introduction of deadlock, invariant violation checking, LTL formula checking and animation is another key advantage. We present our approach, a link definition for a subset of

constructs, as well as a popular case study (reactive buffer) to show the practical usability of our work. We conclude with a discussion of related work, advantages and potential limitations of our approach and future work.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
In the past two decades, the advent of model checking [14], a technique used for the verification of a finite-state system by automatically and exhaustively checking whether the model meets a given specification, has been getting ever increasing interest from both industry and academia. Verification of systems specified using formal methods by model checking is one among these. Comparing to theorem proving, another technique for formal verification, the advantages of model checking, including an automated checking procedure, counterexamples for debugging and the capability of temporal logic properties checking, make it very important for a formalism to support both model checking and theorem proving in a complementary way.
Traditional research in formal methods often focuses on two schools: state-based, model-oriented specification languages such as Z [47], B [5] and VDM [26]; and behaviour-oriented process algebras such as CSP [25, 43], CCS [32] and ACP [8]. But in recent decades, there is an increasing research interest in specification languages that integrate both state and behavioural aspects. Early solutions aim to combine them together, such as CSP-OZ [18], ZCCS [23], Z and CSP [34, 44], and \(CSP \parallel B\) [46]. Fischer gave a summary of combination solutions of Z and process algebras [19]. However, state-rich formalism

[49] is not a simple combination of Z and CSP. It is a combination of Z, CSP, refinement calculus [33] and Dijkstra’s guarded commands [16]. Therefore, its model checking is intrinsically more complicated and difficult than that of individual Z and CSP. The complexity of model checking

is increased due to two main factors. The first one is state space explosion challenge. Basically, the state of a system specified by

is the state of its processes. However, for each process it may contain state and behaviour, and consequently its state is a combination of both variable state and action state. In addition, the process’s variable and action states are dynamically constructed and destroyed along with invocation and destroy of the process. It possibly has infinite number of distinct states as well. Because of this hierarchical structure of

and possible infinite states, how to represent and search its state space including infinite state space and infinite data type efficiently is really a challenge. Another factor is

’s very rich notations from Z, CSP and guarded commands. Along with its powerful expressiveness and high-level abstraction, all make the development of its model checker—to parse and typecheck

programs, check deadlock and livelock, check refinement in terms of

action refinement and data refinement and CSP failure-divergence refinement—difficult. In addition, the relationship between state and behaviour in early solutions is always orthogonal during development. Therefore, they can use the existing tools for each school separately. However, for

its syntax is a free mixture of CSP and Z. As a result it cannot use current Z and CSP tools directly.
Our proposed approach to model-check

in this paper is to link

to \(CSP \parallel B\) that integrates state and behaviour through synchronisation of operations. On the one hand, the state part in

is transformed to the B machine. On the other hand, the behavioural part is converted to CSP. The resultant CSP and B specifications maintain high-level abstraction of the initial

specification because they are specification languages rather than programming languages. Accordingly, it is more direct and powerful to specify the state part in B than in CSP. Furthermore, the final \(CSP \parallel B\) can be model-checked by ProB [3], a model checker and animator for multiple languages. Apart from these, with ProB we introduce LTL and CTL [14] property checking, automatic and manual animations and refinement checking into

specification.
Our contribution is to define a formal link from

to \(CSP \parallel B\). With this link, we take the model checking into

by model-checking \(CSP \parallel B\) using ProB. Additionally, to establish the link between them, we studied the transformation from Z in ISO Standard [4] dialect to Z in ZRM [47] and finally to B, and the transformation of

expressions from ISO Standard Z to CSP as well. The soundness of the link from

to the intermediate CSP and Z in ZRM is proved based on their semantics in Hoare and He’s Unifying Theories of Programming (UTP) [24]. We also studied the correctness of the link from Z in ZRM to B though it relies on the implementation of ProB. Furthermore, because of the expressiveness and high-level abstraction of

, it is impossible to define an inverse link from \(CSP \parallel B\) to

and achieve exactly the same

constructs as the original constructs. Hence, our link is one direction only from

to \(CSP \parallel B\) and can not form Galois connections [24].
The rest of the paper is structured as follows. We give a brief introduction of

and \(CSP \parallel B\) in Sect. 2. Then in Sect. 3, the link function, its decomposition and overall strategies are described. Afterwards, Sect. 4 presents a subset of rules for each link function. A case study of a buffer is undertaken in Sect. 5 to illustrate how our approach works. Finally, in Sect. 6, we discuss related work, our work’s pros and cons and future work.
2 Background
2.1


The BNF syntax of

is shown in Fig. 1. A

program consists of a sequence of paragraphs: Z paragraph, channel declaration, channel set definition or a process definition. A category, that is decorated with an additional star, such as \(\mathbf{CircusPar}^*\), denotes a possibly empty list of \(\mathbf{CircusPar}\), while a category decorated with an additional plus, such as \(\mathbf N ^+\), denotes a non-empty list of Z identifiers \(\mathbf N \). Par, SchemaExp, Exp, Pred and Decl represent Z paragraphs, schema expressions, expressions, predicates and declarations defined in the reference manual [47], respectively.

Syntax of Circus
A

paragraph can be a Z paragraph, a channel declaration, a channel set declaration, or a process declaration. A channel declaration is very similar to that in CSP except a schema channel declaration which merely groups the channel declarations into the schema. And a channel set declaration relates a name to a set of channels. Additionally, a process can be defined in the process declaration as a parametrised process ( ), an indexed process , an explicitly defined process (
), an indexed process , an explicitly defined process (
 ), or a compound process which is defined in terms of CSP operators or the indexed operator (
), or a compound process which is defined in terms of CSP operators or the indexed operator ( ). In particular, the indexed process (
). In particular, the indexed process ( ) is new to
) is new to

. For its instantiation  , it behaves like P, but for each channel c in P, it is changed to \(c\_i.e\). In addition, a process renaming operator (\(P[~ c_{old} := c_{new} ~]\)) substitutes the channels in \(c_{new}\) for the channels in \(c_{old}\) in the process P.
, it behaves like P, but for each channel c in P, it is changed to \(c\_i.e\). In addition, a process renaming operator (\(P[~ c_{old} := c_{new} ~]\)) substitutes the channels in \(c_{new}\) for the channels in \(c_{old}\) in the process P.
An explicitly defined process is composed of a state schema, which declares a set of state components in the process, multiple schemas and action declarations (possibly none of them), a main action, which defines the behaviour of this process. An action can be a schema expression ( ), a command, an action defined in terms of CSP. And a command can be an assignment (\(:=\)), an alternation (
), a command, an action defined in terms of CSP. And a command can be an assignment (\(:=\)), an alternation ( ), a guarded command (
), a guarded command ( ), a variable block (
), a variable block ( ), a parametrisation by value (
), a parametrisation by value ( ), by result (
), by result ( ) and by value-result (
) and by value-result ( ), a specification statement (
), a specification statement ( ), an assumption (\(\{\}\)), or a coercion ([ ]). Particularly, for CSP actions, the parallel composition (
), an assumption (\(\{\}\)), or a coercion ([ ]). Particularly, for CSP actions, the parallel composition ( where \(ns_1\) and \(ns_2\) are the state partitions of the actions \(A_1\) and \(A_2\) separately) and the interleaving (
where \(ns_1\) and \(ns_2\) are the state partitions of the actions \(A_1\) and \(A_2\) separately) and the interleaving ( ) in
) in

are slightly different. Both \(A_1\) and \(A_2\) have a copy of all variables in scope and may change the value of these variables. But only the changes made to the variables in \(ns_1\) and \(ns_2\) have an effect in the final state of the parallel composition and the interleaving. Furthermore, state components and local variables in an action can be renamed by a renaming operator (\(A[~v_{old} := v_{new}~]\)).
A simple buffer [12] specification in

is illustrated in Fig. 2. The size of the buffer is bounded by maxbuff, a global constant declared in the axiomatic paragraph. Afterwards, two typed channels input and output are declared to allow only natural number on their communications. Then an explicitly defined process, named Buffer, is defined. This process has two state variables buff and size. And the initial state of the process is an empty buffer where buff is an empty sequence and size is equal to 0. In addition to the state schema and the initial schema, there are two schemas InputCmd and OutputCmd defined as well. They are invoked by their corresponding schema expressions  and
and  in the actions Input and Output, respectively. The behaviour of Buffer is specified by its main action: it is initialised to the initial state; after that, it provides input (in case the buffer is not full) and output (in case the buffer is not empty) events to its environment continuously. Accordingly, it buffers the input message in its end and increases its size by one, or outputs its head and decreases its size by one.
in the actions Input and Output, respectively. The behaviour of Buffer is specified by its main action: it is initialised to the initial state; after that, it provides input (in case the buffer is not full) and output (in case the buffer is not empty) events to its environment continuously. Accordingly, it buffers the input message in its end and increases its size by one, or outputs its head and decreases its size by one.

The specification of buffer
Additionally, since

is a combination of several different languages that have different semantics, there arises an issue about how to unify its semantics into one. For example, CSP-OZ introduces the failures-divergences model [43] into Object-Z [11] classes and then integrates CSP processes with Object-Z classes based on the same failures-divergences semantics. But \(CSP \parallel B\) treats a B machine as a CSP process, and gives CSP traces, stable failures and failures-divergences semantics to B machines [46].

needs to combine not only Z and CSP, but also the guarded command language and the refinement calculus.

formalises its model in UTP because UTP is a common framework for the unification of programs from different paradigms. Denotational semantics [38, 39, 49] and operational semantics [21, 51, 52] of

have been given.
2.2 Unifying theories of programming
UTP is a unified framework to form theoretical basis for describing and specifying computer languages across different paradigms such as imperative, functional, declarative, nondeterministic, concurrent, reactive and high-order. A theory in UTP is described from three parts: alphabet, a set of variable names for the theory to be studied; signature, rules of primitive statements of the theory and how to combine them together to get more complex program; and healthiness conditions, a set of mathematically provable laws or equations to characterise the theory.
The alphabetised relational calculus [13] is the most basic theory in UTP. A relation is defined as a predicate with undecorated variables (v) and decorated variables (\(v'\)) as its alphabet. v denotes the observation made initially and \(v'\) denotes the observation made at the intermediate or final state. The behaviour of a design is described from initial observation and final observation by relating precondition P to postcondition Q as \((P \vdash Q)\) [24, 50]. It is defined as ( ) where okay records the program has started and \(okay'\) that it has terminated.
) where okay records the program has started and \(okay'\) that it has terminated.
But a reactive process cannot be characterised from the final observation alone because it interacts with its environments (other programs and users). It must take intermediate states into account. Therefore, three extra variables and their dashed counterparts are introduced: tr and \(tr'\), the sequences of the events occurred; ref and \(ref'\), the sets of events that may be refused; wait and \(wait'\), the boolean variables that denote whether the process has terminated (true) or is in an intermediate state (false). Cavalcanti and Woodcock [13] lift the theory of reactive processes to CSP processes. “CSP processes are reactive; moreover they are R-image of designs” [13, Fig. 1, p. 257]. The reactive processes are expressed as the reactive design (\(\mathbf R (P \vdash Q)\)).
2.3 Combination of CSP and B
\(CSP \parallel B\) [9] is a combination of CSP and B aiming to introduce behavioural specification into state-based B machines. The B method characterises abstract state, operations with respect to their enabling conditions and their effect on the abstract state, while CSP specifies overall system behaviour. But different from

, the CSP specification and B machine in \(CSP \parallel B\) are always orthogonal. They are individually complete specifications and can be checked separately.
Semantically the combination of CSP and B works in terms of CSP. The B machine, which has operations Ops (\(\{Op_1, \dots , Op_n\}\)) and variables Vars (\(\{v_1, \dots , v_m\}\)), is regarded as a process \(B_{proc}\) (1). The operation \(Op_i\) is enabled if its precondition holds or \(enabled(Op_i)\) is true. CSP may have all or part of events from the events Ops (\({\{Op_1, \dots , Op_n\}}\)) that have the same name as operations Ops in B. CSP and B processes are composed together by a generalised parallel composition in CSP, as shown in (2). B and CSP synchronise on events Ops in CSP and operations Ops in B. If an event \({Op_i}\) in Ops is allowed by the CSP specification and at the same time the operation \(Op_i\) in B is enabled as well, then they can make progress. After that, the state Vars of the B machine, which are specified in the predicate of operation \(Op_i\), are updated. Otherwise, if \({Op_i}\) is not allowed at the same time as \(Op_i\) is enabled, neither of them can make progress. In addition, for events only in CSP and not having corresponding operations in B, they engage independently. Conversely, for operations only specified in B and not in CSP, they are prevented from executing. If none of operations required by CSP specification are enabled or the CSP process is blocked, then the \(CSP \parallel B\) program is deadlocked. Consequently no state can be changed and no event can be engaged.


2.4 ProB
ProB is a model checker and animator developed by the University of Düsseldorf originally for the B language. It has been extended to support a variety of formal specification languages, such as Z, CSP, Event-B [6], TLA+ [27], Promela and \(CSP \parallel B\). Particularly, the dialect of Z supported is ZRM [47] and the syntax of CSP is written in

[45]. The main functions of ProB include temporal logic and refinement model checking, deadlock and invariant violation checking with counterexamples available, automatic and manual animations, visualisation of state spaces and test-case generation. Its kernel is written in SICStus Prolog [10]. Most importantly, its source code is open and licensed under EPL v1.0 [17].
3 Link definitions
3.1 Overall link function
A function \(\varUpsilon \) (pronounced “upsilon”) is defined to map a

program to a \(CSP \parallel B\) program.

The overall strategies of \(\varUpsilon \) are defined.
-
Fundamentally, the state part of

is linked to a B machine and the behavioural part to a CSP specification. Some constructs such as command actions, which specify both state and behaviour, are mapped to constructs in both B and CSP.
-
The definitions, such as type definitions, abbreviation and axiomatic definitions, are mapped to the counterparts in B and possibly in CSP if they are referred to in the behavioural part of

.
-
State components in

are mapped to variables in B. However, since state components are encapsulated in explicitly defined processes, they are merged to form variables in B when mapped.
-
Operational schemas within an explicitly defined process, which includes the state schema in its declaration and is not included by other schemas, are mapped to operations in B. However, these operations are restricted to manipulate variables that are mapped from state components of the same processes in

and never change variables that are mapped from state components of different processes.
-
Channel declarations are mapped to channel declarations in CSP.
-
The main action of an explicitly defined process is mapped to a same name process in CSP.
-
Compound processes are linked to the same name processes in CSP.




3.2 \(\varUpsilon \) function decomposition
Because a

program is linked to a \(CSP \parallel B\) program with a complete B machine and a CSP specification, we decompose the \(\varUpsilon \) function into two functions: \(\varOmega \) (pronounced “omega”) function and \(\varPhi \) (pronounced “phi”) function. The \(\varOmega \) function is responsible for the translation of the state part in

to B, while the \(\varPhi \) function is for that of the behavioural part to CSP.
However,

itself is not a simple combination of the CSP and Z languages but a free mixture of CSP and Z with additional guarded commands. An exact example is the assignment command that may specify both state and behaviour. For instance, this action (3) inputs a value x over c channel; then the assignment command updates the state variable s to x plus the local variable l. In this action, state and behaviour are mixed together. As a result, \(\varOmega \) and \(\varPhi \) functions cannot apply to the original

program directly.

Thus, another function, named \(R_{wrt}\), is defined. It aims to rewrite a

program to separate the state and behavioural parts into Z and CSP. The action (3) is rewritten to an action and a schema (4) according to the \(R_{wrt}\) Rule 7 which is defined latter. Finally, \(\varOmega \) and \(\varPhi \) can be easily applied to this rewritten

program.

where \(AssOp == [~ \varDelta P\_StPar; l?:T_{l?}; x?: T_c | s' = x? + l? ~]\)

Translation function (\(\varUpsilon \)) decomposition
The relation of \(\varUpsilon \) function decomposition is displayed in Fig. 3. In a rewritten

program, state and behaviour are separate. No construct will specify both state and behaviour at the same time. The interaction between them highly depends on schema expressions. The original schemas and schema expressions in Z and behaviour, respectively, are still kept in the rewritten program. In addition, it is worth noting that additional operational schemas are added in Z, and any direct state components accessed and updated in

actions will rely on schema expressions. Furthermore, for other constructs such as commands, they are rewritten to additional schemas and their schema expressions as well. Finally, we state that the rewritten

program has the same structure as the original program, which means state components of each process are still encapsulated in its own process.
3.2.1 \(\varOmega \) function decomposition
For the \(\varOmega \) function, our strategy is to reuse the currently available solution [41] in ProB to translate Z in ZRM to B. Considering this strategy, we map the state part of the

program to ISO Standard Z first because

itself is written in ISO Standard Z, then to Z in ZRM and finally from ZRM to B by ProB. Accordingly, the \(\varOmega \) function is decomposed as well: the \(\varOmega _1\) function translates the state part in Z in a rewritten

specification to a complete specification in ISO Standard Z by merging all state components and schemas from all processes; the \(\varOmega _2\) function syntactically transforms Z in ISO Standard Z to that in ZRM; the \(\varOmega _3\) function, translation function from ZRM to B, is implemented in ProB and stated in Daniel Plagge et al.’s work [41].
3.3 Link strategies
In addition to the overall strategies and link functions, some other strategies are defined:
-
Every rule defined for \(\varUpsilon \) is sound unless stated otherwise. The soundness of the map is based on UTP semantics. If the corresponding linked constructs in \(CSP \parallel B\) have the same semantics as the original constructs in

, then the link is sound.
-
From the design perspective, a design \(P_1 \vdash Q_1\) is equal to another design \(P_2 \vdash Q_2\) if, and only if,
 . If both designs have the same alphabets (ok, v, and their dashed counterparts), the same preconditions that imply the equal postcondition, we say they are semantically equal.
. If both designs have the same alphabets (ok, v, and their dashed counterparts), the same preconditions that imply the equal postcondition, we say they are semantically equal. -
From the reactive process (\(\mathbf R (P \vdash Q)\)) perspective, if both reactive processes have the same alphabets (ok, wait, tr, ref, v, and their dashed counterparts), the same preconditions that imply the equal postcondition and the same other observation variables, we say two reactive processes are semantically equal.
-
For state-based specification languages such as Z and B, their semantics are specified in the designs of UTP. But for CSP and the behavioural part of

, their semantics are specified in the reactive theory of UTP.
-
-
State components of

are maintained in a Z specification and finally a B machine. Thus we require they are updated only in the B machine but can be accessed in both B and CSP programs. The CSP specification will not maintain states. If a process in the CSP specification needs to get the value of variables in B, it shall retrieve them through a communication between CSP and B.

 . If both designs have the same alphabets (ok, v, and their dashed counterparts), the same preconditions that imply the equal postcondition, we say they are semantically equal.
. If both designs have the same alphabets (ok, v, and their dashed counterparts), the same preconditions that imply the equal postcondition, we say they are semantically equal.

4 Link rules
4.1 Identifiers
In ISO Z Standard, an identifier is a DECORWORD that is composed of WORD and STROKE [4, 8.4]. Stokes (’, ! and ?) are very important part in Z specification. They may denote dashed variables, input variables and output variables within a schema. In addition, they may form the schema decoration and binding construction expressions as well. A word can be a keyword, operator or name. In addition to letter, digital and underscore (_), a name may have other special symbols such as subscript and superscript.
However, the pattern of an identifier or name in

and B, [a-zA-Z][a-zA-Z0-9_] [15, 20], is limited. It begins with an alphabetic character ([a-zA-Z]) and is followed by any number of alphanumeric characters or underscores. Particularly, for

, it can be optionally followed by prime characters (’).
Therefore, we restrict the pattern used in

for a name the same as that in

and B. But for strokes, they are necessary and specially treated when translating to

and B.
4.2
 rewriting function—\(R_{wrt}\)
rewriting function—\(R_{wrt}\)
 rewriting function—
rewriting function—The \(R_{wrt}\) function is defined to rewrite

constructs to facilitate the application of the \(\varPhi \) function and the \(\varOmega \) function in the later stage.
\(R_{wrt}\) Rule 1 (Parametrised process) For the parametrised process, it is expanded to a number of explicitly defined processes, provided that T in (5) is finite and has n elements: \(x_1\), \(\ldots \), \(x_n\). The number of explicitly defined processes is equal to the cardinality of T.

where the substitution notation \(P[x_1/x]\) denotes the expression \(x_1\) consistently substituted for free occurrences of the variable x in P.
\(R_{wrt}\) Rule 2 (Indexed process) An indexed process (6) is rewritten to a parametrised process with all its channels renamed at first; then it is expanded to a number of explicitly defined processes by the parametrised process rule (5).

where
 denotes the renaming of each channel
c
in
P
to
\(c\_i.i\).
denotes the renaming of each channel
c
in
P
to
\(c\_i.i\).
\(R_{wrt}\) Rule 3 (Renaming operator) The renaming operator  renames the channel \(c_{old}\) in P to the channel \(c_{new}\).
renames the channel \(c_{old}\) in P to the channel \(c_{new}\).

where
 is a renaming function that replaces occurrences of the term
x
in
P
to the term
y.
is a renaming function that replaces occurrences of the term
x
in
P
to the term
y.
\(R_{wrt}\) Rule 4 (Indexed process with renaming) In

, the indexed process notation is commonly used with the renaming operator together to define more expressive processes. Therefore,

For explicitly defined processes, the \(R_{wrt}\) function is to separate the state part and the behavioural part as well as renaming of state components, schema paragraphs and action paragraphs. Consequently, all interactions between state and behaviour are through schema expressions only.
\(R_{wrt}\) Rule 5 (Additional state components retrieve schemas) The rule for state components retrieve schemas is shown in Fig. 4, where B function denotes the body of the action. For each state component in an explicitly defined process, one schema is added to retrieve the value of this state component. The name of the output variable in this schema is composed of the state component name and !. And its type is the same as the type of the state component.

Additional schemas for state components retrieve

Renaming
\(R_{wrt}\) Rule 6 (Renaming of state components, schemas, actions and their references) The rule for renaming is shown in Fig. 5. State components, schema paragraphs, action paragraphs and each reference to them within an explicitly defined process are renamed by prefixing the process’s name. The only exception is that the reference to state components in action is not changed.
\(R_{wrt}\) Rule 7 (Action rewriting) The rule for action rewriting is illustrated in Fig. 6, where \(P\_assOp\) (8) is a schema added in the process of this assignment. The definitions of \(R_{pre}\) and \(R_{post}\) functions are given in Definition 1. To rewrite the external choice, a \(R_{mrg}\) function is provided to merge the rewriting prefixes of both actions and it is defined in Definition 2. Note that it is not syntactically correct in

because schema expression actions cannot be a channel event in communication. But when schema expression actions are translated to events in CSP, it is valid in the final \(CSP \parallel B\).

Definition 1
(\(R_{pre}\)
and
\(R_{post}\)) Rewriting an action to get the value of state components in its first construct, \(R_{wrt}(A)\), is composed of \(R_{pre}(A)\) and \(R_{post}(A)\) which denotes the prefix (state components retrieve schema expressions) and the remaining, respectively:  . For example,
. For example,

provided the condition g evaluates state components \(s_i\),\(\dots \),\(s_j\) and \(OP\_s_i\) is the schema name for state component \(s_i\).

Action rewriting
Definition 2
(\(R_{mrg}\)) A \(R_{mrg}\left( R_{pre}(A_1),R_{pre}(A_2)\right) \) function is defined to merge the rewriting prefixes of \(A_1\) and \(A_2\) into one final prefix. Basically, it is equal to  if each state component retrieve schema expression in \(R_{pre}(A_2)\),
if each state component retrieve schema expression in \(R_{pre}(A_2)\),  , is different from any in \(R_{pre}(A_1)\). However, for any state component retrieve schema expression in \(R_{pre}(A_2)\), if it is the same as that in \(R_{pre}(A_1)\), it is removed from \(R_{pre}(A_2)\) before combination. For example,
, is different from any in \(R_{pre}(A_1)\). However, for any state component retrieve schema expression in \(R_{pre}(A_2)\), if it is the same as that in \(R_{pre}(A_1)\), it is removed from \(R_{pre}(A_2)\) before combination. For example,

4.3
 state part to B—\(\varOmega \)
state part to B—\(\varOmega \)
 state part to B—
state part to B—4.3.1
 state part to ISO standard Z—\(\varOmega _1\)
state part to ISO standard Z—\(\varOmega _1\)
 state part to ISO standard Z—
state part to ISO standard Z—The function \(\varOmega _1\) translates the state part in a rewritten

program to a Z specification in ISO Standard Z. Because the state part of

is also written in ISO Standard Z, for most constructs they are just a direct map without changes. However, a rewritten

program still has the same structure as the original program—all state components and schemas are encapsulated within the processes—but the state and schemas in a ISO Standard Z specification are flat. Therefore, we need to merge all state components and schemas into one global and flat specification in ISO Standard Z.
\(\varOmega _1\) Rule 1 (States and schemas merge) If there are more than one explicitly defined process, their states and operations are merged in the resultant Z specification. Assume there are n explicitly defined processes, named \(P_1, P_2, \ldots , P_n\), in a

specification. Their states and schemas are merged as shown in Fig. 7. The state schema is a conjunction of state schemas from all processes, as well as the Init schema. All other schemas from each process will be translated to corresponding schemas with their own declaration and predicate. Additionally they shall keep state components from other processes unchanged by including \(\varXi \) of all other state paragraphs into their declaration.

\(\varOmega _1\) function
4.3.2 ISO standard Z to ZRM—\(\varOmega _2\)
The function \(\varOmega _2\) takes the constructs in ISO Standard Z as input and outputs the corresponding constructs in ZRM. It is only syntactical transformation. Only the transformation rules used in this paper are shown.
\(\varOmega _2\) Rule 1 (Schema decoration)
\(\varOmega _2\) Rule 2 (Horizontal schema) In ISO standard Z, \(==\) is used for horizontal schema but  in ZRM. Thus,
in ZRM. Thus,

4.3.3 ZRM to B machine—\(\varOmega _3\)
Our \(\varOmega _3\) function, which translates from Z in ZRM to B machine, uses the implementation of ProZ [41] in ProB. Since ProB is the model checking tool for \(CSP \parallel B\) specification, our solution is to translate

to Z in ZRM and CSP specifications and then supply them to ProB. Eventually, ProB translates Z to B by ProZ and model-checks it as \(CSP \parallel B\) specification.
Furthermore, because only a considerable subset of Z is implemented in ProB and others [41] shown below are not supported, our solution is accordingly restricted.
-
Generic definitions cannot be supported. Therefore, genericity in

is not supported.
-
Reflexive-transitive closure construct is not supported.

4.4
 behaviour to CSP and Z—\(\varPhi \)
behaviour to CSP and Z—\(\varPhi \)
 behaviour to CSP and Z—
behaviour to CSP and Z—The function \(\varPhi \) transforms the behavioural part of a

specification to CSP and possibly Z.
\(\varPhi \) Rule 1 (Types, expressions and operators) The translation rules for only a very small number of types and expressions are shown below.
-
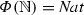 where
\({Nat = \{0..MAXINT\}}\)
and
MAXINT
is a constant declared in the beginning of CSP specification.
where
\({Nat = \{0..MAXINT\}}\)
and
MAXINT
is a constant declared in the beginning of CSP specification. -
 .
. -
 if Cartesian product is used in the channel expression.
if Cartesian product is used in the channel expression. -
 if Cartesian product is used in other places.
if Cartesian product is used in other places. -
 because
Seq
function in
because
Seq
function in

is an infinite set of finite sequence, it cannot be the type of channel in CSP of ProB. Otherwise, it results in the infinite enumeration error. Our solution is to treat
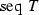 as a partial function
as a partial function
 but with extra restriction of maximum number of elements in its domain. Therefore, fseq function is defined in Fig. 8. MAXINS
denotes the maximum number of instances for model checking and it is put in the beginning of CSP specification like
MAXINT.
but with extra restriction of maximum number of elements in its domain. Therefore, fseq function is defined in Fig. 8. MAXINS
denotes the maximum number of instances for model checking and it is put in the beginning of CSP specification like
MAXINT.-
*
The cardinality of fseq(s) is equal to
$$\begin{aligned} \sum _{n=0}^{MAXINS} (card(s))^n \end{aligned}$$and if the size of s is 4 and MAXINS is 5, then the size of fseq(s) is 1365.
-
*
MAXINS is set by users but what is its optimum value highly depends on the programs to be checked and the computer that ProB runs on. On a powerful computer, it can be set to a higher value but still maintain reasonable model checking resources (memory, CPU and time) consumption.
-
*
-
Abbreviation definition \((AbbrDef == Expr)\) is linked to \(\left( {{nametype}\,AbbrDef = }\varPhi (Expr)\right) \) in CSP.
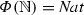 where
where
 .
. if Cartesian product is used in the channel expression.
if Cartesian product is used in the channel expression. if Cartesian product is used in other places.
if Cartesian product is used in other places. because
Seq
function in
because
Seq
function in

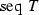 as a partial function
as a partial function
 but with extra restriction of maximum number of elements in its domain. Therefore, fseq function is defined in Fig.
but with extra restriction of maximum number of elements in its domain. Therefore, fseq function is defined in Fig. 
fseq function
\(\varPhi \) Rule 2 (Axiomatic definition) An axiomatic definition

is translated to x = c, where c is an instance from the set \(\{\texttt {x} | \texttt {x}<\texttt {-T, p}\}\) and shall be assigned manually before model checking. Notes: c shall match the value of constant x in Z.
\(\varPhi \) Rule 3 (Channel declaration) The link of the channel declaration in

to that in CSP is direct and straightforward.

\(\varPhi \) Rule 4 (Channel set)

\(\varPhi \) Rule 5 (Channel set declaration)

4.4.1 Actions
The rules for a subset of

actions are shown below.
\(\varPhi \) Rule 6 (Basic actions) The link of the basic actions in

to those in CSP is direct and straightforward.

\(\varPhi \) Rule 7 (Prefixing) The link of the prefixing in

to that in CSP is direct and straightforward.

\(\varPhi \) Rule 8 (Schema expression as action) A schema expression as action  is linked to an external choice of the same name event SExp with input and output variables and another event \({SExp\_f}\) which precondition is the negation of precondition of SExp. Therefore, if the precondition of SExp holds, it engages SExp event; otherwise, it engages \({SExp\_f}\) event and consequently diverges as \(\mathbf{div}\). Finally, these events are hidden from communication by adding both events to \({HIDE\_CSPB}\). That makes it semantically equal to schema expression as action in
is linked to an external choice of the same name event SExp with input and output variables and another event \({SExp\_f}\) which precondition is the negation of precondition of SExp. Therefore, if the precondition of SExp holds, it engages SExp event; otherwise, it engages \({SExp\_f}\) event and consequently diverges as \(\mathbf{div}\). Finally, these events are hidden from communication by adding both events to \({HIDE\_CSPB}\). That makes it semantically equal to schema expression as action in

.

provided SExp is a schema in Z with input variables ins? and output variables outs!; \(SExp\_f\) is an additional schema in Z; particularly, its predicate is the negation of the precondition of SExp.
\(\varPhi \) Rule 9 (Simplified schema expression as action) If the precondition of SExp always holds such as state component retrieve schema expressions and assignments, the rule 8 is simplified because it is not possible to make its precondition be evaluated to false.

\(\varPhi \) Rule 10 (Miscellaneous actions)

\(\varPhi \) Rule 11 (External choice) External choice of actions in

is only resolved by external events of the process or termination. Internal events of the process, such as schema expression as action and assignment, would not resolve it. Thus we restrict the actions that can occur in external choice construct to AA.

where AA can be one of actions below.
-
Basic actions:
 ,
,  , or
, or

-
Prefixed actions:

-
Guarded commands:

 ,
,  , or
, or



Furthermore, provided both actions are guarded commands and their conditions (\(g_1\) and \(g_2\)) are mutually exclusive, that is, \(g_1 = \lnot g_2\), then their guarded actions are not restricted.

\(\varPhi \) Rule 12 (Iterated operator)

\(\varPhi \) Rule 13 (Parallel composition and interleaving) Variables in parallel composition are partitioned to \(ns_1\) and \(ns_2\). Both actions can access the initial value of all variables from \(ns_1\) and \(ns_2\), but they can only modify variables in their own partition \(ns_1\) and \(ns_2\), respectively. Our solution is to declare temporary variables \(tpv_1\) and \(tpv_2\) which are initialised to the initial value of all variables in scope \(pv_1\) and \(pv_2\) for \(A_1\) and \(A_2\). Instead of updating \(pv_1\) and \(pv_2\), we update \(tpv_1\) and \(tpv_2\). Eventually, only variables in \(ns_1\) and \(ns_2\) are updated to the value of corresponding variables in \(tpv_1\) and \(tpv_2\), and others are discarded.

\(\varPhi \) Rule 14 (Parallel composition and interleaving (disjoint variables in scope))

provided
where scpV is a function to get a set of all variables in scope in an action.
\(\varPhi \) Rule 15 (Variable block) A variable block is linked to replicated internal choice in CSP which declares a set of local variables x and their initial value is arbitrary chosen. We use the memory model [35] (Definition 5) in CSP to maintain local variables. The linked process in CSP is put in parallel with replicated parallel of a set of memory cell processes. For each variable in x, there is a unique memory cell (MemCell process) that is distinguished by i.

Definition 3
(MemCell Process) A MemCell process defined below is the mechanism in CSP to store the value of a local variable. For each local variable, it shall have a MemCell process. Therefore, the process is distinguished by number i which is a unique number for each variable. MemCell process is initialised by \(set_i\) at first, and after that it will continuously provide update and retrieve of the variable by \(set_i\) and \(get_i\) channels, respectively. Additionally, it is capable of terminating successfully through end event.

Definition 4
(\(F_{Var}\) function) \(F_{Var}(P, v)\) function makes every access to each local variable l from the set v in CSP process P by \(get_i?l\), and every update to l by \(set_i!l\). For example,

Definition 5
(\(F_{Mem}\)) The function \(F_{Mem}\) gives a memory model for CSP process P to store and retrieve local variables, which are shown in a set v with m elements: \(l_1, \ldots , l_m\).

where 
\(\varPhi \) Rule 16 (Action renaming) The variable \(v_{old}\) is renamed to the \(v_{new}\) by the action renaming.

\(\varPhi \) Rule 17 (Action invocation) An action reference is the body of the action.

\(\varPhi \) Rule 18 (Parametrised action) A parametrised action invocation is the body of the parametrised action with the parameters x substituted by the expressions e.

4.4.2 Processes
\(\varPhi \) Rule 19 (Explicitly defined process) For an explicitly defined process, its main action is linked to a CSP process. Its state schema and operational schemas are linked to Z and finally B by the \(\varOmega \) function in Sect. 4.3.

\(\varPhi \) Rule 20 (Process invocation) A process invocation is the process itself.
\(\varPhi \) Rule 21 (Compound process) For a compound process defined in terms of CSP operators, it is simply an operator expansion.

\(\varPhi \) Rule 22 (Iterated process) For a process defined in terms of an iterated operator in CSP, it is simply an operator expansion.

\(\varPhi \) Rule 23 (Parametrised process invocation) For the parametrised process invocation, it is simply linked to its corresponding explicitly defined process after rewriting.

where const denotes a constant.
\(\varPhi \) Rule 24 (Indexed process invocation) For the indexed process invocation, it is simply linked to its corresponding explicitly defined process after rewriting.

5 Case study: reactive buffer
This section shows how the specification of a buffer and its implementation, a distributed reactive buffer, from the paper [12] can be linked to \(CSP \parallel B\) by the links defined. Eventually, we model-check them by ProB. Particularly, the implementation is checked to be both a trace refinement and a failure refinement of the specification.
5.1 Buffer specification
The specification of BufferSpec in

is shown in Fig. 2.
5.1.1 Rewriting by \(R_{wrt}\)
According to our link definitions in Sect. 3, a

program such as BufferSpec is linked to a \(CSP \parallel B\) program by the function \(\varUpsilon \).
First, it is transformed by the \(R_{wrt}\) function to get a rewritten program RewrittenBufferSpec. We add two schemas, named \(Op\_buff\) and \(Op\_size\), to retrieve state components buff and size, respectively, by the \(R_{wrt}\) Rule 5. Then we rename state components, schemas, actions and their references by prefixing \(Buffer\_\) by the \(R_{wrt}\) Rule 6. The only exception is the references to state components size and buff in the action. Finally, we rewrite the main action of the process Buffer by the \(R_{wrt}\) Rule 7. After that, we get the rewritten program as shown in Fig. 9.

Rewritten specification of buffer
5.1.2 The behavioural part
Then the behavioural part of the rewritten program is translated by the \(\varPhi \) function (\(\varPhi \left( RewrittenBufferSpec\right) \)) to get a CSP specification illustrated in Fig. 10. The rules of the \(\varPhi \) function that are applied sequentially are the channel declaration \(\varPhi \) Rule 3, the explicitly defined process \(\varPhi \) Rule 19, the type and expression \(\varPhi \) Rule 1, the sequential composition \(\varPhi \) Rule 10, the simplified schema expression as action \(\varPhi \) Rule 9, the basic action \(\varPhi \) Rule 3, the prefixing \(\varPhi \) Rule 7, the external choice \(\varPhi \) Rule 11, the guarded command \(\varPhi \) Rule 10 and the schema expression as action \(\varPhi \) Rule 8.

The behavioural part translation
5.1.3 The state part
Note that the behavioural translation of the schema expressions \(Buffer\_InputCmd\) and \(Buffer\_OutputCmd\) in Fig. 10 produces two additional schemas— and
and  —according to the schema expression as action \(\varPhi \) Rule 8, and they are added in the rewritten program RewrittenBufferSpec before the translation of the state part to get RewrittenBufferSpec1.
—according to the schema expression as action \(\varPhi \) Rule 8, and they are added in the rewritten program RewrittenBufferSpec before the translation of the state part to get RewrittenBufferSpec1.
Eventually, the state part of RewrittenBufferSpec1 is linked by \(\varOmega \) function to get a Z specification in Fig. 11, where the \(\varOmega _3\) function is applied in the later stage within ProB.

The state part translation
5.2 Distributed reactive buffer
The distributed cached-head ring buffer [12], an implementation of the buffer in Sect. 5.2, is a result of final development of refinement strategies. It is composed of the process Controller [12, Fig. 4], the process RingCell [12, Sect. 7.6], the indexed ring cell process IRCell [12, Sect. 7.6] and the process Ring [12, Sect. 7.6]. Finally, the process Buffer [12, Sect. 7.4] is a parallel composition of the process Ring and the process Controller. Obviously, this program shall have the definition of maxbuff and maxring and the declaration of channels. In addition, we name this distributed cached-head ring buffer as DisBuffer and define additional abbreviation RingIndex. These definitions and declarations are shown in Fig. 12. Note that the original RingCell has no initialisation schema and we explicitly add a schema named Init, that has the predicate true. The Init is the first event in the main action of the RingCell.
5.2.1 Rewriting by \(R_{wrt}\)
First, the process IRCell is rewritten by the \(R_{wrt}\) Rule. Particularly, the set RingIndex shall be determined before rewriting the IRCell. We assume maxring is equal to 3 and thus  .
.

The IRCell is expanded to three explicitly defined processes \(IRCell\_1\), \(IRCell\_2\) and \(IRCell\_3\). They are similar to the RingCell except that the channels rd and wrt in the RingCell are renamed.
Along with the Controller and RingCell, now we have five explicitly defined processes. According to the \(R_{wrt}\) rule in Fig. 4, five additional schemas for the Controller and one for the RingCell are added within them to access each state component. For \(IRCell\_1\), \(IRCell\_2\) and \(IRCell\_3\), they are similar. That is shown in Fig. 13.

The preamble of DisBufferSpec

Additional schemas for state retrieve
Then we rename state components, schemas, actions and their references of the Contoller and RingCell by prefixing \(Controller\_\) and \(RingCell\_\), respectively, by the \(R_{wrt}\) Rule in Fig. 5. The renamed Controller and RingCell are shown in Fig. 14 and Fig. 15 separately. It is also the similar case for \(IRCell\_1\), \(IRCell\_2\) and \(IRCell\_3\).

Renaming of Controller


Renaming of RingCell
In the end, the main action of the Controller and the RingCell is rewritten by the \(R_{wrt}\) Rule in Fig. 6. To begin with, the main action of the Controller is rewritten.

Among them, the action \(Controller\_InputController\) is rewritten to

where

and

Analogous to the rewriting of \(Controller\_InputController\), \(Controller\_OutputController\) is rewritten to

In addition, it is the similar case for the rewriting of the main action of the RingCell, \(IRCell\_1\), \(IRCell\_2\) and \(IRCell\_3\) as well. Eventually, their main actions after rewriting are illustrated in Fig. 16.

Rewrite of the main actions
5.2.2 The behavioural part
The behavioural part of the rewritten program is translated by the \(\varPhi \) function to get a CSP specification.
First of all, the axiomatic definition of the maxbuff and the maxring is translated to

by the \(\varPhi \) Rule 2, where c is a constant that is manually assigned before the model checking. For example, \(c = 3\).
The abbreviation definition RingIndex is transformed to

by the \(\varPhi \) Rule 1.
The channel declarations are transformed to

by the \(\varPhi \) Rule 3 and their expressions are transformed by the \(\varPhi \) Rule 1.
The behaviour of the Controller process is specified by its main action ma(Controller) in Fig. 16.

Then its main action is translated. Here, the additional channel declarations and events added in \({\hbox {HIDE}\_\hbox {CSPB}}\) are omitted. In addition, when a schema expression is linked by \(\varPhi \) Rule 8, an additional schema is added in the state part. For example,  generates the schema \(Controller\_CacheInput\_f\). This is omitted here as well.
generates the schema \(Controller\_CacheInput\_f\). This is omitted here as well.

The behaviour of the RingCell process is given by its main action ma(RingCell) in Fig. 16. Its translation is similar to that of the Controller process.

The behaviour of \(IRCell\_1\), \(IRCell\_2\) and \(IRCell\_3\) is their main actions as well. Only the translation of \(IRCell\_1\) is displayed below.

The Ring process is the interleaving of the indexed IRCell processes. It is link to

The Buffer process is translated to the Buffer process in CSP below.

The Buffer process is the main process of the DisBufferSpec program. Thus when translated to CSP, the MAIN process is the Buffer.

5.2.3 The state part
After the rewriting in Sect. 5.2.1 and the behaviour translation in Sect. 5.2.2, we have five explicitly defined processes: Controller, RingCell, \(IRCell\_1\), \(IRCell\_2\) and \(IRCell\_3\).
For the Controller, additional schemas are added by the schema expression as action \(\varPhi \) Rule 8 during the link of the behaviour to CSP.
-
\(Controller\_CacheInput\_f\)
-
\(Controller\_StoreInputController\_f\)
-
\(Controller\_NoNewCache\_f\)
-
\(Controller\_StoreNewCacheController\_f \)
For the RingCell, \(IRCell\_1\), \(IRCell\_2\) and \(IRCell\_3\), one additional schema is added for each process. They are  ,
,  ,
,  and
and  separately.
separately.
The state part of the program is linked to a B machine by the \(\varOmega \) function that is composed of the \(\varOmega _1\), the \(\varOmega _2\) and the \(\varOmega _3\). The \(\varOmega _3\) is applied within ProB and so it is skipped here.
To begin with, the axiomatic definition and the abbreviation RingIndex are moved to the Z program directly.
Then the states and schemas from five explicitly defined processes are merged by the \(\varOmega _1\) Rule 1. After that, the \(\varOmega _2\) function is simply applied. Finally, the state part is linked to a Z program.
The state schemas are merged as shown.

The initialisation schemas are merged.

All other schemas are merged as well. However, for a schema from one process, it shall include the state schemas from other processes in its declaration part by \(\varXi \) notation to make sure no change is made to the state components from others. For example, the \(Controller\_Op\_size\) schema from the Controller becomes

\(Controller\_CacheInput\) becomes

and \(Controller\_CacheInput\_f\) is transformed to

The translation of other schemas are very similar and thus skipped.
5.3 Model checking by ProB
Now we have got the final CSP program (Fig. 10) and the Z program (Fig. 11) for the buffer specification, and the CSP program (Sect. 5.2.2) and the Z program (Sect. 5.2.3) for the distributed buffer. Both of them can be model-checked by ProB. But before performing model checking, the value of the constants MAXINT, MAXINS and maxbuff shall be considered at first.
5.3.1 Maximum instances MAXINS and maximum size of buffer maxbuff
For the buffer specification, the type of buffer is  . When linked to \(CSP \parallel B\), we use fseq (Fig. 8) that introduces the bound constant MAXINS. Finally, the size of the set of finite sequences by fseq highly relies on the value of MAXINS as well as the data set s. The defined fseq computes the result relied on several intermediate functions (squash, pfun, rel and cross) which are defined in the functional language as well. The consumption of resources during resolution is still high. If the size of s is big and MAXINT is large, ProB will take longer time to compute all possible finite sequences. For an instance, on the system having 2GB RAM and 2.5 GHz CPU, and running Ubuntu 12.04, it takes approximately thirty minutes for ProB to load the CSP program when the size of s is 4 (MAXINT is set to 3) and MAXINS is 5. However, if the size of s is reduced to 2, we can increase MAXINS to 9 to make ProB load the CSP program still in a shorter time. Alternatively, instead of using the functional language to resolve fseq, we can compute all finite sequences in advance by another language, let us say Perl, then include them explicitly into a set and replace fseq in CSP programs by this set. For example, if s is
. When linked to \(CSP \parallel B\), we use fseq (Fig. 8) that introduces the bound constant MAXINS. Finally, the size of the set of finite sequences by fseq highly relies on the value of MAXINS as well as the data set s. The defined fseq computes the result relied on several intermediate functions (squash, pfun, rel and cross) which are defined in the functional language as well. The consumption of resources during resolution is still high. If the size of s is big and MAXINT is large, ProB will take longer time to compute all possible finite sequences. For an instance, on the system having 2GB RAM and 2.5 GHz CPU, and running Ubuntu 12.04, it takes approximately thirty minutes for ProB to load the CSP program when the size of s is 4 (MAXINT is set to 3) and MAXINS is 5. However, if the size of s is reduced to 2, we can increase MAXINS to 9 to make ProB load the CSP program still in a shorter time. Alternatively, instead of using the functional language to resolve fseq, we can compute all finite sequences in advance by another language, let us say Perl, then include them explicitly into a set and replace fseq in CSP programs by this set. For example, if s is  and MAXINT is 2, then we can get this set as
and MAXINT is 2, then we can get this set as  . By this way, it can reduce the program load time tremendously. But the loss of flexibility is a side effect because we have to compute this set in advance and externally (out of ProB).
. By this way, it can reduce the program load time tremendously. But the loss of flexibility is a side effect because we have to compute this set in advance and externally (out of ProB).
For the buffer specification the value of maxbuff shall be less than or equal to MAXINS.
5.3.2 Data independence and MAXINT
The type of data (T) in both the buffer specification and the buffer implementation is  . According to the definition of data independence [28, Sect. 2.7] and [43, Sect. 15.3.2], both the linked buffer programs in \(CSP \parallel B\) are data-independent because they input values of
. According to the definition of data independence [28, Sect. 2.7] and [43, Sect. 15.3.2], both the linked buffer programs in \(CSP \parallel B\) are data-independent because they input values of  along their input channels, store them in a sequence or a set of ring cells and then output values in order along their output channels without any computations. And they do not perform any explicit and implicit equality tests over T; therefore, they satisfy NoEqT [28, 42]. In addition, the Buffer process in the linked buffer specification (Fig. 10) satisfies Norm [28, 42]. According to Theorem 17.2 [42], the threshold of the size of T such that the implementation is a refinement of the specification in terms of traces, failures and failures-divergences is 2. There is a similar conclusion in the book [42, p.397] that the threshold of an N-bounded buffer for any N is 2. So for the refinement check, we can set MAXINT to 1 as there are two elements
along their input channels, store them in a sequence or a set of ring cells and then output values in order along their output channels without any computations. And they do not perform any explicit and implicit equality tests over T; therefore, they satisfy NoEqT [28, 42]. In addition, the Buffer process in the linked buffer specification (Fig. 10) satisfies Norm [28, 42]. According to Theorem 17.2 [42], the threshold of the size of T such that the implementation is a refinement of the specification in terms of traces, failures and failures-divergences is 2. There is a similar conclusion in the book [42, p.397] that the threshold of an N-bounded buffer for any N is 2. So for the refinement check, we can set MAXINT to 1 as there are two elements  and set maxbuff to 3. Actually, we also checked the refinement when MAXINT is increased to 3.
and set maxbuff to 3. Actually, we also checked the refinement when MAXINT is increased to 3.
5.3.3 Model checking of buffer specification
When model-checking this case by ProB, we notice ProB kernel treats  as set( couple (integer, T)) in Z and B. But it fails to match the sequence type in CSP. Therefore, it generates an incompatible type error. We change the implementation of predicate type_ok and is_csp_set_type in specfile.pl of ProB kernel source code to make
as set( couple (integer, T)) in Z and B. But it fails to match the sequence type in CSP. Therefore, it generates an incompatible type error. We change the implementation of predicate type_ok and is_csp_set_type in specfile.pl of ProB kernel source code to make  match the sequence type in CSP.
match the sequence type in CSP.
Additionally, \(\mathbf{div}\), the most divergent process, is not available in

as well as ProB. We define a process DIV as  , where div is a special event, in CSP for \(\mathbf{div}\). Though DIV is not a divergent process, we can check deadlock of combination of CSP and Z specifications to achieve divergence checking. We use the deadlock checking to find this kind of divergence because it is a more direct checking in ProB. In case that a deadlock is found, we check the counterexample to see if the last event is div or not. If the last event is div, it means the original
, where div is a special event, in CSP for \(\mathbf{div}\). Though DIV is not a divergent process, we can check deadlock of combination of CSP and Z specifications to achieve divergence checking. We use the deadlock checking to find this kind of divergence because it is a more direct checking in ProB. In case that a deadlock is found, we check the counterexample to see if the last event is div or not. If the last event is div, it means the original

specification can lead to divergence. Alternatively, LTL formula checking can be used to check deadlock as well. For example, the LTL formula (not F e(div)), which denotes the statement that finally div event is enabled, is not true. When it comes to this case, if we remove guarded conditions in Input or Output action in Fig. 2, the specification diverges because the precondition of InputCmd and OutputCmd may not hold. In the final CSP specification in Fig. 10, the corresponding boolean guard is removed as well. Using ProB, we can easily find the deadlock and the last event is div; therefore, it finds divergence.
Deadlock and Invariant Violation Checking Finally, we can model-check the combination of CSP and Z specifications and there is no deadlock found. A comparison of the model checking performance for different configuration of constants is shown in Table 1. This experiment was undertaken on ProB Linux version, which is modified based on ProB 1.5.0-Beta, on Ubuntu.
Deadlock and Divergence Checking by CSP Assertions ProB is capable of deadlock and divergence checking through CSP assertions as well. By adding the following three asserts to the CSP program (Fig. 10), we checked the deadlock free and divergence free of the Buffer process with the combination of constants in Table 1 successfully.

5.3.4 Model checking of distributed reactive buffer
One issue we found is about the well-definedness of the modulo operation in Z when it is translated to the counterpart in B. In Z, the modulo operation is defined on the integer dividend and the non-zero integer divisor [47]. However, it is defined on the natural number dividend and the non-zero natural number divisor in B machine. Therefore, when model-checking this case by ProB that translates the modulo to the modulo operation in B, it triggers an error about the well-definedness of the modulo because the dividend of the modulo in Z is possibly less than 0. Thus, we modified the implementation of the modulo operation in ProB to use the modulo operation mod in SICStus Prolog. Because the modulo operation in Z uses truncation towards minus infinity [47] and in Prolog it is the integer remainder after floored division [2], they use the same definition of modulo—floored division [29]. Hence, the well-definedness of mod in Z is retained.
In addition, ProB uses the built-in command \(\text{ time }\) in Tcl to measure the elapsed time for the model checking task. It can count up to 4,294,967,295 microseconds, approximately 72 minutes, for a task in a 32-bit machine; otherwise, it will cause the overflow. For the model checking of this case with the maxbuff larger than 3, it requires longer time and causes the overflow. Therefore, the output result about the time is not useful. We record the timestamp before the task execution and the timestamp after the completion of the task by \(\texttt {clock}\, \texttt {milliseconds}\) in Tcl and then calculate the difference between two timestamps. This is the model checking time.
Deadlock and invariant violation checking There is no deadlock or divergence found. A comparison of the model checking performance is shown in Table 2. Note that due to the state space exploration and resource limitation, we are not able to model check this case if maxbuff is larger than 3 and MAXINT is 3 because ProB runs out of memory on Linux with 3 GB memory. We can set the MAXINT to 1 to reduce the state space. The result is shown in the third row. Further methods like more specific initialisation can be used to tremendously decrease the size of the state space. For an instance, if we substitute (13) by the initialisation schema (14), the model checking result is displayed in the fourth row.

Deadlock and divergence checking by CSP assertions By adding the following three asserts to the CSP program (Sect. 5.2.2), we checked the deadlock free and divergence free of the Buffer process with the combination of constants in Table 2 successfully.

5.3.5 Refinement checking
In addition, ProB can check if an implementation in \(CSP \parallel B\) is a trace refinement of a specification in \(CSP \parallel B\) [30]. When checking the trace refinement, an issue we got in ProB for our case, after inspecting source code, is that ProB refinement checker compares the traces of both the specification and the implementation according to their transitions in the same state space. That works for the refinement of two processes in the same CSP program for the CSP model or the refinement of two processes in the same CSP program for the \(CSP \parallel B\) model. But for our case, the specification and the implementation have the different Z programs and it is impossible to put their CSP programs into one CSP file. Thus we modified the refinement_checker.pl of ProB to search the traces by the transitions from their own separate state space. After model-checking the buffer specification, we save its state space for later refinement check to a file. Then we load the buffer implementation to ProB, select “trace refinement check” function and open the saved state space file for the specification. Finally, ProB will show the result: the implementation is a trace refinement of the specification; or if not a trace refinement, a counter example is provided.
We checked the trace refinement between the buffer specification and the buffer implementation and finally got the result the distributed reactive buffer is a trace refinement of the buffer specification for MAXINT and maxbuff equal to 3 and 3 separately. Furthermore, ProB has an option to check failures. We checked the failure refinement between the specification and the implementation as well and finally found the distributed reactive buffer is also a failure refinement of the buffer specification with the same constants. The refinement checking performance is shown in Table 3. According to Sect. 5.3.2, we can conclude the buffer implementation is a failure refinement of the buffer specification.
However, if maxbuff between the specification and the implementation is not equal, ProB gives an error with a counterexample provided.
6 Conclusions and future work
Related work Model checking and animation are regarded as a very important tool support for the application of formalisms in both academia and industry. There are three existing solutions for implementing or model-checking

programs. The first solution is JCircus [22, 36, 37] which translates a concrete

program to a Java program with JCSP [48]. After that, linking

to CSP [7] aims to translate

to

and then use FDR2 [1] to model-check CSP specification. The last one is mapping

processes and refinement to CSP processes and refinement [31, 40] that transforms stateful

to stateless

first by introducing the memory model and then converts stateless

to CSP. The first is not a model checking solution but implementation instead, and it is restricted to executable

programs because Java is an imperative programming language and not a high-level specification language. Therefore, before supplying the

program to JCircus, it has to be refined to a concrete program. For the second solution, it is not clear how to connect the data part to the behavioural part of a

program. The third solution transforms both state and behavioural parts to CSP specification, which means all states are maintained in CSP. It is restricted to divergence-free

. Furthermore, it is not convenient and capable in CSP to maintain very complex states and rather difficult to understand the final CSP specification if it contains a lot of state operations.
Our work Comparatively, our work links

to \(CSP \parallel B\) to express the behavioural and state parts, which maintains the high-level abstraction. And using B to specify the state part is more straightforward and easier than using CSP. The capability of linking most of constructs in

to \(CSP \parallel B\) is another advantage because

itself consists of a large amount of syntactic constructs. Additionally, the capabilities of deadlock checking, LTL formula checking, refinement checking, automatic and manual animations are very important as well. Last but not least, we achieve the divergence checking of original

program by deadlock checking of \(CSP \parallel B\).
However, this work has some limitations as well. Generics in

are not supported; for \(CSP \parallel B\), its state is composed of the state from B and the state of the process from CSP and is expressed as a pair [9]; thus its state space is more complex for exploration; limited actions can occur in both sides of external choice (\(\varPhi \) Rule 11) due to the semantics of external choice [38]; the rule of parallel composition of actions (\(\varPhi \) Rule 13) achieves semantical equality, but is difficult to implement because we need to keep a copy of temporary variables in CSP for both state variables in B and local variables, which makes the state maintained in CSP temporarily before merge and is against our strategy that state and behaviour are separated in B and CSP; how to trace \(CSP \parallel B\) back to

is an issue.
Future work By now, we have defined the translation rules for a large subset of constructs in

, given the soundness, and developed a simple translator which can deal with very limited rules. We will continue to study a more complicated case, extend the translator to support approximately all rules defined. Most significantly, we need to minimize the limitations. For instance, we may modify the operational semantics of \(CSP \parallel B\) in ProB to make external choice resolved only by external events and termination but not communication between CSP and B, which makes all actions can occur in external choice. In addition, for link of axiomatic definition to CSP (\(\varPhi \) Rule 2), we will modify the implementation of ProB to make it instantiated to the same value as in Z.
References
FDR2: a refinement checker for establishing properties of models expressed in CSP. www.fsel.com/software.html
SICStus prolog manual (arithmetic expressions). https://sicstus.sics.se/sicstus/docs/latest4/html/sicstus.html/ref_002dari_002daex.html#ref_002dari_002daex
The ProB animator and model checker. http://www.stups.uni-duesseldorf.de/ProB/index.php5/Main_Page
ISO/IEC: Information technology-Z formal specification notation-syntax, type system and semantics (2002). http://standards.iso.org/ittf/PubliclyAvailableStandards/c021573_ISO_IEC_13568_2002(E).zip
Abrial, J.R.: The B-book: Assigning Programs to Meanings. Cambridge University Press, Cambridge (2005)
Abrial, J.R.: Modeling in Event-B: System and Software Engineering. Cambridge University Press, Cambridge (2010)
Beg, A., Butterfield, A.: Linking a state-rich process algebra to a state-free algebra to verify software/hardware implementation. In: Proceedings of the 8th International Conference on Frontiers of Information Technology (FIT ’10), pp. 47:1–47:5. ACM, New York (2010)
Bergstra, J.A., Klop, J.W.: Process algebra for synchronous communication. Inf. Control 60(1–3), 109–137 (1984)
Butler, M., Leuschel, M.: Combining CSP and B for specification and property verification. In: Fitzgerald, J., Hayes, I.J., Tarlecki, A. (eds.) FM 2005: Formal Methods. Lecture Notes in Computer Science, vol. 3582, pp. 221–236. Springer, Berlin, Heidelberg (2005)
Carlsson, M.: Sicstus PROLOG user’s manual 4. Swedish Institute of Computer Science (2015). ISBN: 9783735737441. https://sicstus.sics.se/sicstus/docs/latest4/pdf/sicstus.pdf
Carrington, D.A., Duke, D.J., Duke, R., King, P., Rose, G.A., Smith, G.: Object-Z: an object-oriented extension to Z. In: Formal Description Techniques for Distributed Systems and Communication Protocols (FORTE ’89), pp. 281–296. North-Holland Publishing Co., Amsterdam (1990)
Cavalcanti, A., Sampaio, A., Woodcock, J.: A refinement strategy for Circus. Form. Asp. Comput. 15(2–3), 146–181 (2003)
Cavalcanti, A., Woodcock, J.: A tutorial introduction to CSP in unifying theories of programming. In: Cavalcanti, A., Sampaio, A., Woodcock, J. (eds.) Refinement Techniques in Software Engineering. Lecture Notes in Computer Science, vol. 3167, pp. 220–268. Springer, Berlin, Heidelberg (2006)
Clarke Jr, E.M., Grumberg, O., Peled, D.A.: Model Checking. MIT Press, Cambridge (1999)
Clearsy: B language reference manual (version 1.8.6). http://www.atelierb.eu/ressources/manrefb1.8.6.uk.pdf
Dijkstra, E.W.: A Discipline of Programming. Prentice-Hall, Englewood Cliffs (1976)
Eclipse: Eclipse public license–v 1.0. http://www.eclipse.org/org/documents/epl-v10.html
Fischer, C.: CSP-OZ: a combination of object-Z and CSP (1997)
Fischer, C.: How to combine Z with process algebra. In: ZUM, pp. 5-23 (1998)
Formal systems (Europe) Ltd: FDR2 user manual, fdr 2.94 edn (2012)
Freitas, L.: Model checking Circus. Ph.D. thesis (2005)
Freitas, A., Cavalcanti, A.: Automatic translation from Circus to Java. In: Misra, J., Nipkow, T., Sekerinski, E. (eds.) FM 2006: Formal Methods. Lecture Notes in Computer Science, vol. 4085, pp. 115–130. Springer, Berlin, Heidelberg (2006)
Galloway, A., Stoddart, B.: An operational semantics for ZCCS. In: Proceedings of the 1st International Conference on Formal Engineering Methods (ICFEM ’97). IEEE Computer Society, Washington, DC (1997). ISBN: 0-8186-8002-4
Hoare, C., He, J.: Unifying Theories of Programming, vol. 14. Prentice Hall, Englewood Cliffs (1998)
Hoare, C.A.R.: Communicating Sequential Processes. Prentice-Hall, Englewood Cliffs (1985)
Jones, C.B.: Systematic Software Development using VDM, 2nd edn. Prentice Hall, Englewood Cliffs. Prentice Hall International Series in Computer Science (1991)
Lamport, L.: Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers. Addison-Wesley, Boston (2002)
Lazic, R.: A semantic study of data independence with application to model checking. Ph.D. thesis (1999). http://www.dcs.warwick.ac.uk/~lazic/thes_corr.ps.gz
Leijen, D.: Division and modulus for computer scientists (2001). http://research.microsoft.com/pubs/151917/divmodnote.pdf
Leuschel, M., Butler, M.J.: Automatic refinement checking for B. In: ICFEM, pp. 345-359 (2005)
Marcel Oliveira Augusto Sampaio, P.A.R.R.A.C.J.W.: Compositional analysis and design of CML models. COMPASS deliverable D24.1 (2013)
Milner, R.: A Calculus of Communicating Systems. Lecture Notes in Computer Science, vol. 92. Springer, Berlin (1980)
Morgan, C.C.: Programming from Specifications. Prentice Hall International Series in Computer Science 2nd edn. Prentice Hall, Englewood Cliffs (1994)
Mota, A., Sampaio, A.: Model-Checking CSP-Z. In: FASE, pp. 205–220 (1998)
Nogueira, S., Sampaio, A., Mota, A.: Test generation from state based use case models. Form. Asp. Comput. 1-50 (2012). doi:10.1007/s00165-012-0258-z
Oliveira, M.V.: Formal derivation of state-rich reactive programs using Circus. Ph.D. thesis, University of York (2005)
Oliveira, M., Cavalcanti, A., Woodcock, J.: Formal development of industrial-scale systems in Circus. ISSE 1(2), 125–146 (2005)
Oliveira, M., Cavalcanti, A., Woodcock, J.: A denotational semantics for Circus. Electr. Notes Theor. Comput. Sci. 187, 107–123 (2007)
Oliveira, M., Cavalcanti, A., Woodcock, J.: A UTP semantics for Circus. Form. Asp. Comput. 21(1–2), 3–32 (2009)
Oliveira, M., Sampaio, A., Conserva Filho, M.: Model-checking Circus state-rich specifications. In: E. Albert, E. Sekerinski (eds.) Integrated Formal Methods, Lecture Notes in Computer Science, pp. 39-54. Springer International Publishing, Berlin (2014). doi:10.1007/978-3-319-10181-1_3
Plagge, D., Leuschel, M.: Validating Z specifications using the ProB animator and model checker. In: J. Davies, J. Gibbons (eds.) Integrated Formal Methods, Lecture Notes in Computer Science, vol. 4591, pp. 480-500. Springer, Berlin (2007). doi:10.1007/978-3-540-73210-5_25
Roscoe, A.: Understanding Concurrent Systems, 1st edn. Springer, New York (2010)
Roscoe, A.W., Hoare, C.A.R., Bird, R.: The Theory and Practice of Concurrency. Prentice Hall PTR, Upper Saddle River, NJ, USA (1997)
Roscoe, A.W., Woodcock, J., Wulf, L.: Non-interference through determinism. J. Comput. Secur. 4(1), 27–54 (1996)
Scattergood, B.: The semantics and implementation of machine-readable CSP. Ph.D. thesis, University of Oxford (1998)
Schneider, S., Treharne, H.: CSP theorems for communicating B machines. Form. Asp. Comput. 17(4), 390–422 (2005)
Spivey, J.M.: Z Notation: A Reference Manual: Prentice Hall International Series in Computer Science, 2nd edn. Prentice Hall, Englewood Cliffs (1992)
Welch, P.H.: Process oriented design for Java: concurrency for all. In: PDPTA, vol. 1, pp. 51–57. CSREA Press (2000)
Woodcock, J., Cavalcanti, A.: The semantics of Circus. In: Bert, D., Bowen, J.P., Henson, M.C., Robinson, K. (eds.) ZB 2002: Formal Specification and Development in Z and B. Lecture Notes in Computer Science, vol. 2272, pp. 184–203. Springer, Berlin, Heidelberg (2002)
Woodcock, J., Cavalcanti, A.: A tutorial introduction to designs in unifying theories of programming. In: Boiten, E.A., Derrick, J., Smith, G. (eds.) Integrated Formal Methods. Lecture Notes in Computer Science, vol. 2999, pp. 40–66. Springer, Berlin, Heidelberg (2004)
Woodcock, J., Cavalcanti, A., Freitas, L.: Operational semantics for model checking Circus. In: Fitzgerald, J., Hayes, I.J., Tarlecki, A. (eds.) FM 2005: Formal Methods. Lecture Notes in Computer Science, vol. 3582, pp. 237–252. Springer, Berlin, Heidelberg (2005)
Woodcock, J., Cavalcanti, A., Gaudel, M.C., Freitas, L.: Operational semantics for Circus. Formal aspects of computing (2007). https://www.cs.york.ac.uk/ftpdir/pub/leo/utp/journal-pub/circus-operational-semantics.pdf
Acknowledgments
We thank Leo Freitas and Andrew Butterfield for discussions about the link approach, CZT as well as the insights of difficulties.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ye, K., Woodcock, J. Model checking of state-rich formalism  by linking to \(CSP\,\Vert \,B\)
.
Int J Softw Tools Technol Transfer 19, 73–96 (2017). https://doi.org/10.1007/s10009-015-0402-1
by linking to \(CSP\,\Vert \,B\)
.
Int J Softw Tools Technol Transfer 19, 73–96 (2017). https://doi.org/10.1007/s10009-015-0402-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10009-015-0402-1
