
Abstract
In this work, artificial neural networks (ANNs) were developed and applied in order to forecast the discomfort levels due to the combination of high temperature and air humidity, during the hot season of the year, in eight different regions within the Greater Athens area (GAA), Greece. For the selection of the best type and architecture of ANNs-forecasting models, the multiple criteria analysis (MCA) technique was applied. Three different types of ANNs were developed and tested with the MCA method. Concretely, the multilayer perceptron, the generalized feed forward networks (GFFN), and the time-lag recurrent networks were developed and tested. Results showed that the best ANNs type performance was achieved by using the GFFN model for the prediction of discomfort levels due to high temperature and air humidity within GAA. For the evaluation of the constructed ANNs, appropriate statistical indices were used. The analysis proved that the forecasting ability of the developed ANNs models is very satisfactory at a significant statistical level of p < 0.01.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
During the hot period of the year, the human body activates defense mechanisms such as perspiration in order to maintain its temperature at normal bearable levels. The cooling system of the human body may begin to fail in case of high levels of temperature and humidity in the environment along with low wind speed. This causes thermal discomfort, which, in extreme cases, may lead to heat stroke. In general, when the human body receives a higher heat load than what it can remove into the environment, a sense of thermal discomfort is established. In almost half of the different settings around the world, the risk of mortality increased by between 1 and 3 % per 1 °C change in high temperature (Hajat and Kosatky 2010). Díaz et al. (2002) found that very hot weather is associated with high mortality levels, especially regarding persons over 65 years old. Muthers et al. (2010) compared the heat-related mortality during the summer of the year 2003 with other years and analyzed whether 2003 summer was exceptional in Vienna (Austria). Results showed that mortality increases significantly with thermal stress, but this increase attenuated in the last decades. Nastos and Matzarakis (2011) investigated whether there is any association between the daily mortality for the wider region of Athens, Greece and the thermal conditions, for the 10-year period 1992–2001. The findings extracted by the applied generalized linear models showed that statistically significant relationships (p < 0.01) between air temperature, human thermal indices, and mortality exist on the same day. The feeling of thermal discomfort due to high values of relative humidity and air temperature varies from person to person, influenced by age, sex, weight, used clothing, shading, existence of wind, activity, etc. (Moustris et al. 2009). As high risk groups are considered elderly people with serious health problems, infants, and people working under conditions allowing for the onset of heatstroke; namely, people working outdoors and under the effect of strong solar radiation (Matzarakis et al. 1999; Becker et al. 2003; Conti et al. 2005).
In the last decades, many various indices have been proposed in order to calculate the human thermal perception levels, such as the physiologically equivalent temperature (PET; Matzarakis et al. 1999; Mayer and Höppe 1987; Höppe 1999; Nastos and Matzarakis 2006, 2008a, b; Matzarakis and Nastos 2010) and the Universal Thermal Climate Index (Jendritzky et al. 2002; Fiala et al. 2011). Additionally, more simplistic discomfort indices had been proposed, such as the Cooling Power index (Siple and Passel 1945; Besancenot 1978; Tzenkova et al. 2003) and the Thom’s discomfort index (DI; Thom 1959).
It is of great consensus among the scientific community that heat stress combined with air pollution, especially in urbanized areas, affects human health and activities. Matzarakis and Mayer (1991) studied the thermal and air quality components of the urban climate in Athens, Greece during the summer heat wave of year 1987. For this purpose, they calculated and analyzed the predictive mean vote, PET as well as the Thom’s DI, during year 1987 summer heat wave over Athens, Greece. Nastos and Matzarakis (2008a, b) examined the effects of the daily minimum air temperature (T min) and human biometeorological variables, as well as their day-to-day changes, on sleep disturbances (SD) in the inhabitants of Athens, Greece. The extracted results suggested that a considerable increase in SD existed in 1994 compared to 1989. This was due to the many consecutive days with heavy thermal load (PET > 35 °C and T min > 23 °C) in 1994 compared to the lack of such days in 1989. Cohen et al. (2012) examined the daily and seasonal climatic behavior of various urban parks with different vegetation cover and its impact on human thermal sensation in the summer and winter in Tel Aviv, Israel. The results showed that an urban park with a dense canopy of trees has maximum cooling effect during summer and winter in daytime.
The use of artificial neural networks (ANNs) based on predictive models to thermal control strategies produced in many cases better results than mathematical and statistical models. The thermal comfort conditions were improved and there were in some cases significant energy savings (Moon and Kim 2010).
Santamouris et al. (1999) developed an ANN in order to model the heat island effect in the greater Athens urban area, Greece. Mihalakakou et al. (2002) applied ANN to simulate the heat island effect over Athens, Greece, using synoptic types as a predictor. Kostopoulou et al. (2007) compared multilinear regression analysis, canonical correlation analysis, and ANNs in order to simulate the maximum and minimum temperature in different seasons and areas over Greece. Chronopoulos et al. (2008) developed an application of artificial neural network models to estimate air temperature data in Greek areas with sparse network of meteorological stations. Moustris et al. (2009) developed ANNs in order to forecast 24 h in advance the discomfort levels due to the combination of air temperature, air humidity, and wind speed during the hot period of the year at representative locations of Athens city, Greece. Moustris et al. (2010a) applied ANNs to forecast the discomfort levels for the next three consecutive days, as well as the number of consecutive discomfort hours during the day using air temperature, air humidity, and wind speed in the greater Athens area, Greece. Gobakis et al. (2011) developed a model for urban heat island prediction using ANN techniques. Finally, Chronopoulos et al. (2011) presented an ANN model-based approach to assess bioclimatic conditions in remote mountainous areas, in the mountainous area of Samaria Forest canyon, Greece, using a relatively limited number of microclimatic data from easily accessible meteorological stations.
The aim of this work is to investigate the ability of ANN models to predict the comfort–discomfort levels within the greater Athens area (GAA). For this reason, numerous ANN models were developed, and the multiple criteria analysis (MCA) technique was applied in order to choose the best ANN architecture.
2 Data and methodology
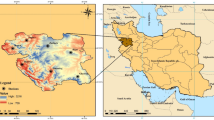
The GAA is located in a small peninsula at the southeast part of the mainland of Greece (Fig. 1). It covers an area of 450 km2 and is surrounded by mountains of moderate height (400–1,500 m) at the east, west, and north sides while the sea (Saronikos Gulf) lies at the south side. Small openings to the north, northwest, and northeast, connect the GAA with the Greek mainland (Paliatsos and Nastos 1999; Theoharatos et al. 2010). During the last decades, the expansion of the city of Athens established the so-called urban heat island (Philandras et al. 1999), which acts synergistically with the incidence of heat waves (Matzarakis and Nastos 2010), exacerbating the thermal perception of the inhabitants. Therefore, higher thermal conditions combined with the atmospheric pollution, has an explicit effect on people’s health and the quality of living (Moustris et al. 2010b). The issue of human thermal sensation in various outdoor areas of a city has drawn rather limited attention in the research field (McGregor et al. 2002; Spagnolo and de Dear 2003; Moustris et al. 2009). Most of the comfort–discomfort studies are conducted in indoor conditions such as vehicles, offices, and residential buildings (Shimizu and Jindo 1995; Atthajariyakul and Leephakpreeda 2005; Moon et al. 2009).

The map of Greece and the GAA (upper panel), and the location and the altitude of the hydrometeorological network stations within the GAA (lower panel)
In this work, for the investigation of comfort–discomfort levels, the Thom’s DI was used (Thom 1959). This is due to the fact that DI is a very simple discomfort index, as well as the availability of meteorological data covering the examined area (air temperature and relative humidity) and their low variability. The Thom’s DI refers to a human being indoors in a state of relaxation without having any vigorous physical activity and dressed in light clothing. In order to calculate DI, values of air temperature and relative humidity have to be used and this is the main reason why DI is one of the most frequently used discomfort indices worldwide. For these two meteorological parameters, there are available measurements from many places all over the world covering significant time series of data. The weaknesses of DI is that it does not take into account many other parameters, which have a great influence on the energy balance of the human body such as the short and long wave radiation, wind speed, metabolic rate, age and sex, activity of the person, etc.
The equation that is used for the calculation of the DI (Giles et al. 1990; Tzenkova et al. 2003) is :
or
where, T is the air temperature (degree Celcius), T w is the wet bulb temperature (degree Celcius), and RH is the relative humidity of the air (percentage). This is an easily used and calculable bioclimatic index. It can accurately describe only the thermal comfort–discomfort during the hot period of the year. The values of the DI and the sense of thermal comfort–discomfort of the population are depicted in Table 1.
The meteorological variables which were used in this work have been recorded by the Hydrological Observatory of Athens, operated by the National Technical University of Athens. It is an evolution from the hydro-meteorological network METEONET of the Laboratory of Hydrology and Water Resources Management of the National Technical University of Athens (METEONET 2011). The meteorological variables concern hourly values of air temperature (degree Celcius) and relative humidity (percentage) and cover the 5-year period 2006–2010.
These meteorological data were provided by eight fully automatic telemetric hydrometeorological stations installed within the GAA. Concretely, the eight regions are: Ano Liossia, Galatsi, Ilioupoli, Mandra, Menidi, Penteli, Pikermi, and Psittalia. These regions are depicted in Fig. 1 (lower panel).
Ιn order to predict the maximum daily value of the DI for the next 3 days along with the number of consecutive hours during the day where DI ≥ 24οC (over 50 % of the population feels discomfort due to hot) for each one of the eight examined stations areas, numerous ANN models were created.
At first, the appropriate number of input variables that were used for the training of the ANN models was defined. The trial-and-error approach was used in order to decide for the best ANNs architecture. The input parameters for the ANN models training are depicted in Table 2.
Afterwards, the appropriate number of the previous days that were used as input data to the ANN model was defined. This was done by using the trial-and-error technique. Moustris et al. (2010a) have used data of the six previous days to feed an ANN model in a similar model. Therefore, this is the number of days that this ANN model is initially tested. Adding and removing days and comparing the results provide the most accurate forecast. The results of these models are evaluated by the coefficient of determination. This statistical index is selected because it is the most widely used in the literature to evaluate similar models (Comrie 1997; Karul et al. 2000; Antonic et al. 2001; Yang and Kim 2004; Jiang 2008; Tseliou et al. 2010; Pelliccioni et al. 2010). Moreover, it is possible to compare models by using this statistical index among models that have the same or similar complexity (Dreyfus 2005). For this reason, only one parameter changes when a model is compared to another. This can be the number of neurons, hidden layers, epochs, etc.
Finally, MCA was used in order to select the most accurate ANN models with the aid of the coefficient of determination of each model. MCA is a useful tool for addressing some of these challenges involved in the evaluation of models that include many parameters. The ranking methodology was used. It is a simple method that involves assigning each decision element a rank that reflects its perceived degree of importance relative to the decision being made. The decision elements can then be ordered according to their rank (first, second, etc.). Ranks are assigned according to the following nine-point scale (Mendoza et al. 1999):
-
1
➜ Weakly important
-
3
➜ Less important
-
5
➜ Moderately important
-
7
➜ More important
-
9
➜ Extremely important
The ranking is then multiplied by the coefficient of determination (R 2) of each criterion, and the sum is the total score of each model (MCA score). Each model has six criteria to be evaluated. The first three are the value of the DI for the first, second, and the third day. The other three are the number of consecutive hours with high thermal discomfort levels during the day for the first, second, and the third day. The ranking given to these criteria is depicted in Table 3. The ranking was selected according to the above nine-point scale.
The initial ANN model was a multilayer perceptron (MLP) with one hidden unit consisting of 11 processing elements (PEs). Both hidden and output layer use momentum as learning rule with step size = 1.0, momentum = 0.7 and the activation function tanhaxon, which is given by the equation (Bishop 1995):
The number of epochs was set to 1,000, and the weights updated to batch. The steps that are followed to construct the final ANNs model are described below. It should be noted that the models with the highest MCA score proceed to the next step each time.
-
1.
Selection of the input variables used for the training of the ANN models. All and some of the variables are tested as inputs.
-
2.
Selection of the number of the previous days used for input data. Six days are initially tested. Then, the number of days decreases until a lower MCA score is achieved. Afterwards, the number of days increases until a lower MCA score is achieved.
-
3.
Selection of the number of hidden layers. One hidden layer is initially tested and then one more unit is added each time.
-
4.
Selection of the number of epochs. One thousand epochs are initially tested and then increase by 1,000 each time.
-
5.
Selection of the number of the PEs in the hidden layers. In this step, genetic algorithms (GA) are used in order to define the optimum number of PEs because manually testing would be much more time consuming (Ceravolo et al. 2009).
-
6.
Selection of the best type of neural networks. The MLP, generalized feed forward networks (GFFN), and time-lag recurrent networks (TLRN) type of neural networks were tested.
The result of the above steps was the selection of the best of the numerous ANNs developed models. These models were trained with data concerning the period 2006–2009 and then were tested on the data of year 2010. It should be noted that data of year 2010 are absolute unknown to the trained ANN model.
The predictions of the ANN models were compared to the real-observed ones and evaluated by using statistical methods and indices (Ma and Iqbal 1983; Elbir 2003; Shahi et al. 2009; Velten 2009). The accuracy of the models was evaluated by R 2, the Index of Agreement (IA), the mean bias error, the mean absolute bias error, and the root mean square error. The prediction of the exceedances (according to the DI thresholds), was evaluated by the true predicted rate (TPR), false-positive rate, false alarm rate, and success index (SI; Nunnari et al. 2004; Papanastasiou et al. 2007).
3 Results and discussion
At first, the number of the inputs that were used for the training of the ANN model was defined. The trial-and-error approach was used. The initial input and output data are those presented in Table 2.
The initial ANN model 1 was a MLP with one hidden layer consisting of 11 PEs or artificial neurons. The 20 % of the training data were used for the cross-validation method (Moustris et al. 2010a). Both hidden and output layer use the momentum as learning rule with step size = 1.0, momentum = 0.7, and the activation function is the tanhaxon. The number of epochs was set to 1,000 and the weight updated to batch. Data from the five previous days were used to train the network and produced results. In ANN model 1, all the input parameters have been used to train the network while in the ANN model 2, the station’s number and the month’s number have not been used (Table 2). The accuracy of each model was expressed by the R 2 and the results are depicted in Table 4. ANN model 2 achieves a higher MCA score and clearly outperforms the ANN model 1. Therefore, the input parameters station number and month number were not being used as input parameters.
Then, the number of the previous days that were used as input data to the ANN model was tested. The structure of ANN model 2 was used. The trial-and-error technique was applied. By adding one extra day each time to the training data of the ANN model, it is possible to find the number of days where the MCA score is maximized.
The following models were tested:
-
ANN model 2 (data from five previous days)
-
ANN model 3 (data from six previous days)
-
ANN model 4 (data from seven previous days)
The results are presented in Table 4. The ANN model 3 achieves the maximum MCA score; therefore, data from the six previous days were used in order to train the ANN model. The next step was to define the number of the hidden layers. The number of hidden layers is increased until the MCA score begins to fall. This is the criterion for selecting the number of hidden units. Two ANN models were tested:
-
ANN model 3 (one hidden layer)
-
ANN model 5 (two hidden layers)
The results are depicted in Table 4. The ANN model 3 achieves higher MCA score. Therefore, one hidden layer was used for the appropriate structure of the ANN model. This option is in agreement το the literature. The ANNs with one hidden layer seem to be more reliable forecasting models than those with two or more hidden layers.
Then, using the structure of the ANN model 3 the number of epochs was defined. The following models were developed and tested:
-
ANN model 3 (1,000 epochs)
-
ANN model 6 (2,000 epochs)
-
ANN model 7 (3,000 epochs)
The results are depicted in Table 4. The ANN model 6 achieves the highest MCA score. However, ANN model 3 is very close to it. Therefore, further testing of these two models was necessary in order to define the more accurate.
In order to find the optimal number of PEs in the hidden layer, GA was used. These algorithms test all the possible scenarios and select the number of PEs that provides the best accuracy. Two models are tested:
-
ANN model 8. The same as ANN model 3 but uses GA to identify the number of PEs.
-
ANN model 9. The same as ANN model 6 but uses GA to identify the number of PEs.
The results are presented in Table 4. ANN model 8 outperforms ANN model 9 and also ANNs models 3, 6 and 7 (Table 4). It is therefore selected as the model that will further proceed. Finally, two more ANN models were created to find the best type of ANN model:
-
ANN model 10. It has exactly the same structure as ANN model 8 but the type of neural network selected was the GFFN.
-
ANN model 11. It has exactly the same structure as ANN model 8 but the type of neural networks selected was the TLRN. Moreover, the type of this network includes short-term memory structures which have the following characteristics:
-
Memory: Focused
-
Activation function: Lagguare Axon
-
Sample depth: 1
-
Trajectory length: 30
-
The results are presented in Table 4. The best performance was achieved by ANN model 10. This is the final model which was selected and was further analyzed. In order to summarize, the structure of the ANN model 10 that was finally selected is presented below:
-
Type of neural networks: Generalized feed forward neural networks.
-
Input parameters: All except the station number and the month number. Detailed description of the parameters is in Table 3.
-
Input data of the six previous days.
-
Cross-validation: 20 % of training data.
-
One hidden layer.
-
Number of PEs: 6 (As was defined by the use of genetic algorithms)
-
Activation function: Tanhaxon
-
Learning rule: Momentum
-
Step size: 0.1
-
Momentum: 0.7
-
-
Output layer
-
Number of PEs: 6
-
Activation function: Tanhaxon
-
Learning rule: Momentum
-
Step size: 0.1
-
Momentum: 0.7
-
-
Maximum epochs: 1,000.
-
Weight update: Batch
A detailed analysis of the developed ANN model is presented by using various statistical indices. The accuracy of the created ANN model as well as the ability to predict the exceedances was evaluated.
As concerns the daily DI values, an excess day is when the daily value of DI is greater or equal to 24 °C (over 50 % of the population feels discomfort due to hot). As concerns the consecutive hours with DI ≥ 24 °C, an excess day is when the number of consecutive hours is greater or equal to 12 (at least the half of the day). Tables 5, 6, and 7 present the performance of the developed ANN forecasting model for a 24, 48, and 72-h prediction ahead, respectively.
According to Table 5, the predictive ability of the constructed ANN model 10 is very high. The values of the coefficient of determination, concerning the prediction of the next-day maximum daily value of DI, are ranging between 0.991 and 0.981. The same conclusion is clear based on the ΙΑ. The values of the IA are ranging between 0.993 and 0.997, showing a very high predictive ability. Similar conclusions are obtained for the predictive ability of the ANN model 10 in terms of the number of hours with strong thermal discomfort levels during the next 24 h.
Analogous results and conclusions obtained for the prediction of the exceedances, i.e., the days with DI ≥ 24 °C as well as the days with more than 12 consecutive hours with strong thermal discomfort levels, for the next day. The SI values are ranging between 98.0 and 99.4 % in terms of whether or not the next day is an exceedance day, showing a very good predictive ability.
According to Table 6, the prediction ability of ANN model 10, 2 days ahead, seems also to be very high. The values of the coefficient of determination, concerning the prediction of the maximum daily value of DI 2 days ahead, are ranging between 0.680 and 0.837. The same conclusion is clear based on the ΙΑ. The values of the IA are ranging between 0.902 and 0.948, showing a very high predictive ability. Similar conclusions are obtained for the predictive ability of the ANN model 10 in terms of the number of hours with strong thermal discomfort levels during the day and for 2 days ahead.
Analogous results and conclusions obtained for the prediction of the exceedances, i.e., the days with DI ≥ 24 °C as well as the days with more than 12 consecutive hours with strong thermal discomfort levels, 2 days ahead. The SI values are ranging between 86.9 and 90.9 % in terms of whether or not the next day is an exceedance day, showing a very good predictive ability.
According to Table 7, the prediction ability of ANN model 10, 3 days ahead, seems also to be enough satisfactory. The values of the coefficient of determination, concerning the prediction of the maximum daily value of DI 2 days ahead, are ranging between 0.423 and 0.687. The same conclusion is clear based on the ΙΑ. The values of the IA are ranging between 0.785 and 0.879, showing a very high predictive ability. Similar conclusions are obtained for the predictive ability of the ANN model 10 in terms of the number of hours with strong thermal discomfort levels during the day and for 2 days ahead.
Analogous results and conclusions obtained for the prediction of the exceedances, i.e., the days with DI ≥ 24 °C as well as the days with more than 12 consecutive hours with strong thermal discomfort levels, 2 days ahead. The SI values are ranging between 75.2and 83.2 % in terms of whether or not the next day is an exceedance day, showing a very good predictive ability.
The observed vs. the predicted values of the DI are depicted in Figs. 2, 3, and 4 for the 24, 48, and 72-h prediction ahead correspondingly. In each figure, the eight regions of the GAA are displayed separately. Figure 5 presents the differences between the predicted and observed values of DI for the best and the worst prediction respectively. In order to provide quantitative relations, the differences between the predicted and observed values of DI were calculated, for the best and the worst prediction respectively, by means of the coefficient of determination and the index of agreement for the forecasting cases of 24, 48, and 72 h ahead

Observed (blue line) vs. predicted (red line) maximum daily DI values using the ANN forecasting model 10 during the warm period of the year; 24 h prediction ahead, year 2010

Observed (blue line) vs. predicted (red line) maximum daily DI values using the ANN forecasting model 10 during the warm period of the year; 48 h prediction ahead, year 2010

Observed (blue line) vs. predicted (red line) daily DI values using the ANN forecasting model 10 during the warm period of the year; 72 h prediction ahead, year 2010

Differences between predicted and observed values of DI for the best (left panel) and the worst (right panel) prediction; 24 h ahead prediction (a), 48 h ahead prediction (b) and 72 h ahead prediction (c), year 2010
In the case of 24-h prediction ahead (Fig. 5a), the best prediction concerns the station Ano Liosia. The differences (predicted–observed values) range from −1.7 to +2.0 °C. The worst prediction concerns the station Menidi. The differences (predicted–observed values) range from −1.4 to +5.2 °C. In both cases, it seems that the highest differences between the predicted and the observed values are presented during the last 10 days of September. This may be due to the fact that during the last 10 days of September, the weather is, in general, changeable since autumn season begins.
In the case of 48-h prediction ahead (Fig. 5b), the best prediction concerns the station Ilioupoli. The differences (predicted–observed values) range from −2.5 to +5.6 °C. The worst prediction concerns the station Penteli. The differences (predicted–observed values) range from −3.4 to +5.2 °C.
Finally, in the case of 72-h prediction ahead (Fig. 5c), the best prediction concerns the station Ilioupoli. The differences (predicted–observed values) range from −3.1 to +6.4 °C. The worst prediction concerns the station Penteli. The differences (predicted–observed values) range from −3.7 to +5.6 °C.
4 Conclusions
The aim of this work was the prediction of the discomfort levels due to the combination of high temperature and air humidity during the hot period of the year for eight different regions within the greater Athens area. For this purpose, numerous artificial neural networks were developed and applied as forecasting models. For the choice of the best ANN model architecture, the technique of multiple criteria analysis was applied.
The analysis showed that the best type of ANN models for the discomfort levels prediction was the generalized feed forward neural networks. The prediction of the discomfort levels was done using an appropriate and simplistic index known as the Thom’s discomfort index.
The developed artificial neural network that was used for the prediction of Thom’s discomfort index daily value, performed very well for 3-day predictions ahead. More specifically, the accuracy of the created forecasting model for the first (0.98 < R 2 < 0.99, IA > 0.99), second (0.68 < R 2 < 0.84, IA > 0.90), and the third day (0.42 < R 2 < 0.69, IA > 0.79) was quite satisfactory. The predictions of the exceedances, in other words the days where at least 50 % of the population feel discomfort due to hot according to DI value, for the first (TPR > 95 %, SI > 97 %), second (TPR > 75 %, SI > 86 %), and the third day (TPR > 51 %, SI > 75 %) are very satisfactory.
It appears that the ANN models have the ability to predict the DI levels within an urban environment as well as the days exceeding hazardous levels of discomfort. The results of this study may be useful in many human activities such as the better distribution and savings of the electric energy in the GΑΑ according to the public needs, the protection of public health, knowing in advance the hazardous levels of the discomfort in different regions of the GΑΑ, and a better and more efficient operation of the government, the hospitals, the transportations, etc. A future work of the authors will be the application of ANN models to predict more complex thermal indices such as PET or UTCI.
References
Antonic O, Hatic D, Krian J, Bukocev D (2001) Modelling groundwater regime acceptable for the forest survival after the building of the hydro-electric power plant. Ecol Model 138:277–288
Atthajariyakul S, Leephakpreeda T (2005) Neural computing thermal comfort index for HVAC systems. Energ Convers Manage 46:2553–2565
Becker S, Potchter O, Yaakov Y (2003) Calculated and observed human thermal sensation in an extremely hot and dry climate. Energ Buildings 35:747–756
Besancenot JP (1978) Le bioclimat humain de Rio. In: Suchel JB, Altes E, Besancenot JP, Maheras P (eds) Recherches de Climatologie en Milieu Tropical et Mediterranean. Cahier No. 6 du Centre de Recherches de Climatologie. Universite de Dijon, Dijon
Bishop C (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
Ceravolo F, De Felice M, Pizzuti S (2009) Combining back-propagation and genetic algorithms to train neural networks for ambient temperature modelling in Italy. Appl EvolComput 5484:123–131. doi:10.1007/978-3-642-01129-0_16
Chronopoulos KI, Tsiros IX, Dimopoulos IF, Alvertos N (2008) An application of artificial neural network models to estimate air temperature data in areas with sparse network of meteorological stations. J Environ Sci Health A Tox Hazard Subst Environ Eng 43:1752–1757
Chronopoulos KI, Tsiros IX, Alvertos N (2011) Assessment of bioclimatic comfort using artificial neural network models—a preliminary study in a remote mountainous area of southern Greece. Acta Climatologica et Chorologica 44–45:65–71
Cohen P, Oded Potchter O, Matzarakis A (2012) Daily and seasonal climatic conditions of green urban open spaces in the Mediterranean climate and their impact on human comfort. Build Environ 51:285–295
Comrie AC (1997) Comparing neural networks and regression models for ozone forecasting. J Air Waste Manage 47:653–663
Conti S, Meli P, Menelli G, Solimini R, Toccaceli V, Vichi M, Beltrano C, Perini L (2005) Epidemiologic study of mortality during the summer 2003 heat wave in Italy. Environ Res 98:390–399
Díaz J, Garcia R, de Velazquez CF, Hernandez E, Lopez C, Otero A (2002) Effects of extremely hot days on people older than 65 years in Seville (Spain) from 1986 to 1997. Int J Biometeorol 46(3):145–149
Dreyfus G (2005) Neural networks: methodology and applications. Springer, Berlin
Elbir T (2003) Comparison of model predictions with the data of an urban air quality monitoring network in Izmir, Turkey. Atmos Environ 37:2149–2157
Fiala D, Havenith G, Bröde P, Kampmann B, Jendritzky G (2011) UTCI-Fiala multi-node model of human heat transfer and temperature regulation. Int J Biometeorol. doi:10.1007/s00484-011-0424-7
Giles BD, Balafoutis CH, Maheras P (1990) Too hot for comfort: the heatwaves in Greece in 1987 and 1988. Int J Biometeorol 34:98–104
Gobakis K, Kolokotsab D, Synnefac A, Saliari M, Giannopoulou K, Santamouris M (2011) Development of a model for urban heat island prediction using neural network techniques. Sustain Cities Soc 1:104–115
Hajat S, Kosatky T (2010) Heat-related mortality: a review and exploration of heterogeneity. J Epidemiol Community Health 64:753–760
Höppe PR (1999) The physiological equivalent temperature—a universal index for the biometeorological assessment of the thermal environment. Int J Biometeorol 43:71–75
Jendritzky G, Maarouf A, Fiala D, Staiger H (2002) An update on the development of a universal thermal climate index. 15th Conf. Biomet. Aerobiol. And 16th ICB02, 27 Oct–1 Nov 2002, Kansas City, AMS: 129–133
Jiang Y (2008) Prediction of monthly mean daily diffuse solar radiation using artificial neural networks and comparison with other empirical models. Energ Policy 36:3833–3837
Karul C, Soyupak S, Cilesiz AF, Akbay N, Germen E (2000) Case studies on the use of neural networks in eutrophication modeling. Ecol Model 134:145–152
Kostopoulou E, Giannakopoulos C, Anagnostopoulou C, Tolika K, Maheras P, Vafiadis M, Founda D (2007) Simulating maximum and minimum temperature over Greece: a comparison of three downscaling techniques. Theor Appl Climatol 90:65–82
Ma CCY, Iqbal M (1983) Statistical comparison of models for estimating solar radiation on inclined surgaces. Sol Energy 31:313–317
Matzarakis A, Mayer H (1991) The extreme heat wave in Athens in July 1987 from the point of view of human biometeorology. Atmos Environ 25(2):203–211
Matzarakis A, Nastos PT (2010) Human-biometeorological assessment of heat waves in Athens. Theor Appl Climatol 105(1):99–106
Matzarakis A, Mayer H, Iziomon M (1999) Applications of a universal thermal index: physiological equivalent temperature. Int J Biometeorol 43:76–84
Mayer H, Höppe P (1987) Thermal comfort of man in different urban environments. Theor Appl Climatol 38:3–49
McGregor GR, Markou MT, Bartzokas A, Katsoulis BD (2002) An evaluation of the nature and timing of summer human thermal discomfort in Athens, Greece. Clim Res 20:83–94
Mendoza GA, Macou P, Prahbu R, Sukadri D, Purnomo H and Hartanto H (1999) Guidelines for applying multi-criteria analysis to the assessment of criteria and indicators. Criteria & Indicators Toolbox series No. 9. Jakarta, Indonesia: CIFOR. Available at: http://www.cifor.cgiar.org/acm/methods/toolbox9.html
METEONET (2011) Hydrological Observatory of Athens. Available at: http://hoa.ntua.gr/info
Mihalakakou G, Flocas HA, Santamouris M, Helmis CG (2002) Application of neural networks to the simulation of the heat island over Athens, Greece, using synoptic types as a predictor. J Appl Meteorol 41(5):519–527
Moon JW, Kim JJ (2010) ANN-based thermal control models for residential buildings. Build Environ 45:1612–1625
Moon JW, Jung SK, Kim JJ (2009) Application of ANN (artificial-neural-network) in residential thermal control. In: Eleventh International IBPSA Conference. Building Simulation 2009. Glasgow, Scotland, 27–30 July, 2009. pp. 64–71
Moustris KP, Ziomas IC, Paliatsos AG (2009) 24 Hours in advance forecasting of thermal comfort–discomfort levels during the hot period of the year at representative locations of Athens city, Greece. Fresen Environ Bull 18(5):601–608
Moustris KP, Tsiros IX, Ziomas IC, Paliatsos AG (2010a) Artificial neural network models as a useful tool to forecast human thermal comfort using microclimatic and bioclimatic data in the great Athens area (Greece). J Environ Sci Heal A 45:447–453
Moustris KP, Ziomas IC, Paliatsos AG (2010b) 3-Day-ahead forecasting of regional pollution index for the pollutants NO2, CO, SO2, and O3 using artificial neural networks in Athens, Greece. Water Air Soil Poll 209:29–43
Muthers S, Matzarakis A, Koch E (2010) Summer climate and mortality in Vienna—a human biometeorological approach of heat-related mortality during the heat waves in 2003. Wien Klin Wochenschr 122:525–531
Nastos PT, Matzarakis Α (2006) Weather impacts on respiratory infections in Athens, Greece. Int J Biometeorol 50:358–369
Nastos PT, Matzarakis A (2008a) Human-biometeorological effects on sleep disturbances in Athens, Greece: a preliminary evaluation. Indoor Built Environ 17(6):535–542
Nastos PT, Matzarakis Α (2008b) Variability of tropical days over Greece within the second half of the twentieth century. Theor Appl Climatol 93:75–89
Nastos PT, Matzarakis A (2011) The effect of air temperature and human thermal indices on mortality in Athens, Greece. Theor Appl Climatol. doi:10.1007/s00704-011-0555-0
Nunnari G, Dorling S, Schlink U, Cawley C, Foxall R, Chatterton T (2004) Modelling SO2 concentration at a point with statistical approaches. Environ Modell Softw 19:887–905
Paliatsos AG, Nastos PT (1999) Relation between air pollution episodes and discomfort index in the greater Athens area, Greece. Global Nest J 1:91–97
Papanastasiou D, Melas D, Kioutsioukis I (2007) Development and assessment of neural network and multiple regression models in order to predict PM10 levels in a medium-sized Mediterranean city. Water Air Soil Poll 182:325–334
Pelliccioni A, Cotroneo R, Pungi F (2010) Optimization of neural net training using patterns selected by cluster analysis: a case-study of ozone prediction level. Eighth conference on Artificial Intelligence and its Applications to the Environmental Sciences, AMS 90th Annual Meeting, Atlanta, Georgia, 17–21 January, 2010. Available at: http://ams.confex.com/ams/90annual/techprogram/session_23974.htm
Philandras CM, Metaxas DA, Nastos PT, Repapis CC (1999) Climate variability and urbanization in Athens. Theor Appl Climatol 63:65–72
Santamouris M, Mihalakakou G, Papanikolaou N, Asimakopoulos DN (1999) A neural network approach for modeling the heat island phenomenon in urban areas during the summer period. Geophys Res Lett 26(3):337–340
Shahi A, Atan RB, Sulaiman MN (2009) Detecting effectiveness of outliers and noisy data on fuzzy system using FCM. Eur J Sci Res 36:627–638
Shimizu Y, Jindo T (1995) A fuzzy logic analysis method for evaluating human sensitivities. Int J Ind Ergonom 15:39–47
Siple PA, Passel CF (1945) Measurements of dry atmospheric cooling in subfreezing temperatures. Proc Am Philos Soc 89:177–199
Spagnolo J, de Dear R (2003) A field study of thermal comfort in outdoor and semi-outdoor environments in subtropical Sydney Australia. Build Environ 38:721–738
Theoharatos G, Pantavou K, Mavrakis A, Spanou A, Katavoutas G, Efstathiou P, Mpekas P, Asimakopoulos D (2010) Heat waves observed in 2007 in Athens, Greece: Synoptic conditions, bioclimatological assessment, air quality levels and health effects, Greece. Environ Res 110:152–161
Thom EC (1959) The discomfort index. Weatherwise 12:57–60
Tseliou A, Tsiros IX, Lykoudis S, Nikolopoulou M (2010) An evaluation of three biometeorological indices for human thermal comfort in urban outdoor areas under real climatic conditions. Build Environ 45:1346–1352
Tzenkova AS, Kandjov IM, Ivancheva JN (2003) Some biometeorological aspects of urban climate in Sofia. Proc of Fifth Int Conf Urban Climate, Lodz, Poland 2:103–106
Velten K (2009) Mathematical modeling and simulation: introduction for scientists and engineers. Wiley, Germany
Yang IH, Kim KW (2004) Prediction of the time of room air temperature descending for heating systems in buildings. Build Environ 39:19–29
Acknowledgments
This work was done with the assistance of the Postgraduate Program “MSc in Energy” which co-organized by the Department of Mechanical Engineering, TEI of Piraeus, Greece and the School of Engineering and Physical Sciences, Heriot-Watt University, UK.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Vouterakos, P.A., Moustris, K.P., Bartzokas, A. et al. Forecasting the discomfort levels within the greater Athens area, Greece using artificial neural networks and multiple criteria analysis. Theor Appl Climatol 110, 329–343 (2012). https://doi.org/10.1007/s00704-012-0626-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-012-0626-x