
Abstract
Daily and sub-daily weather data are often required for hydrological and environmental modeling. Various weather generator programs have been used to generate synthetic climate data where observed climate data are limited. In this study, a weather data generator, ClimGen, was evaluated for generating information on daily precipitation, temperature, and wind speed at four tropical watersheds located in Hawai‘i, USA. We also evaluated different daily to sub-daily weather data disaggregation methods for precipitation, air temperature, dew point temperature, and wind speed at Mākaha watershed. The hydrologic significance values of the different disaggregation methods were evaluated using Distributed Hydrology Soil Vegetation Model. MuDRain and diurnal method performed well over uniform distribution in disaggregating daily precipitation. However, the diurnal method is more consistent if accurate estimates of hourly precipitation intensities are desired. All of the air temperature disaggregation methods performed reasonably well, but goodness-of-fit statistics were slightly better for sine curve model with 2 h lag. Cosine model performed better than random model in disaggregating daily wind speed. The largest differences in annual water balance were related to wind speed followed by precipitation and dew point temperature. Simulated hourly streamflow, evapotranspiration, and groundwater recharge were less sensitive to the method of disaggregating daily air temperature. ClimGen performed well in generating the minimum and maximum temperature and wind speed. However, for precipitation, it clearly underestimated the number of extreme rainfall events with an intensity of >100 mm/day in all four locations. ClimGen was unable to replicate the distribution of observed precipitation at three locations (Honolulu, Kahului, and Hilo). ClimGen was able to reproduce the distributions of observed minimum temperature at Kahului and wind speed at Kahului and Hilo. Although the weather data generation and disaggregation methods were concentrated in a few Hawaiian watersheds, the results presented can be used to similar mountainous location settings, as well as any specific locations aimed at furthering the site-specific performance evaluation of these tested models.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Hydrological and environmental models have become important tools for natural resource and environmental management. However, these models require different input data (i.e., solar radiation, wind speed, maximum and minimum temperature, precipitation, soil water content, streamflow, and sediment concentration) at variable time intervals (e.g. daily, hourly) which are often limited. Daily temperature and precipitation are readily available climate forcing data in mountainous watersheds (Waichler and Wigmosta 2003). Solar radiation, relative humidity, and wind speed are often not available at the sites of interest. Many climate monitoring stations have very short periods of record and often carry missing data in the time series. Therefore, hydrological models often require generating synthetic climate data derived from short-term observations using different statistical distributions. Weather generators, e.g., ClimGen (Stockle et al. 1999), CLIGEN (Nicks and Gander 1994), USCLIMATE (Johnson et al. 1996), CLIMAK (Danuso and Della 1997), and WGEN (Richardson and Wright 1984), have automated the synthetic data generation process with the help of computers. These weather generators use statistical properties of existing short-term historical weather datasets to generate long-term synthetic daily weather data. Previous studies (McKague et al. 2005; Stockle et al. 1998) have shown that ClimGen allows greater flexibility in location-specific statistical parameterization and produces reasonable daily weather data. Castellvi and Stockle (2002) reported that WGEN generates better monthly weather data means, whereas ClimGen was better in reproducing daily variability. The performance of ClimGen has been evaluated under different environments (Acutis et al. 1999; Castellvi and Stockle 2002; Stockle et al. 1998); however, it has not been evaluated under mountainous tropical watershed conditions
Weather data at a finer time scale (i.e., sub-daily) are vital for making hydrologic predictions, especially in mountainous tropical watersheds such as Hawaiian watersheds where there is strong spatial and temporal variability. As a result of short-duration but intense rainfall events, streamflow in Hawai‘i can change by a factor of 60 in only 15 min, thus producing dangerous flash floods (Sahoo et al. 2006). Many distributed hydrological models (e.g., DHSVM, HSPF) are designed to perform better with sub-daily weather input parameters (e.g., rainfall, temperature, etc.).
Several studies have focused on generating (Debele et al. 2007; Running et al. 1987) and/or disaggregating (Debele et al. 2007; Waichler and Wigmosta 2003) daily weather data into sub-daily data for use with hydrological models. The distribution of daily available weather data to sub-daily data, assuming uniform distribution, is the most common approach (Gutierrez-Magness and McCuen 2004), which can be far from the accurate representation of reality. Efforts have been made in molding the diurnal patter of weather data using daily observations. Sub-daily weather data have been generated from daily data using several disaggregation utilities (e.g., MuDRain, Hyetos) (Debele et al. 2007; Socolofsky et al. 2001), generalized linear model (Segond et al. 2006), and using gauge information and artificial neural networks (Burian et al. 2000; Zhang et al. 2008). Sine, cosine, and linear air temperature models have been developed and used in many parts of the world (Bilbao et al. 2002; de Wit 1978; Ephrath et al. 1996; Parton and Logan 1981; Waichler and Wigmosta 2003). Daily wind speed has been disaggregated using cosine and random functions (Debele et al. 2007). The performance of the above models varied spatially depending on the diurnal distribution of weather data. For example, Debele et al. (2007) found MuDRain model to perform better than Hyetos and the uniform method in disaggregating daily precipitation in Cedar Creek watershed, TX, USA. For air temperature, cosine model performed better in Cedar Creek watersheds, whereas in the Mediterranean Belt climate Erbs model (Erbs 1984) outperformed cosine model (Bilbao et al. 2002).
There are numerous techniques that can be used to generate long-term synthetic data and also disaggregate daily weather data into sub-daily time scale. However, a site-specific evaluation of different alternatives can help narrow down the choice of an appropriate model. This study aimed to evaluate the few selected models on the basis of model complexity, necessary input variables, and diurnal pattern in Hawaiian weather data. The specific objectives of this paper were to evaluate the performance of the (1) long-term weather generator ClimGen and (2) daily weather data disaggregation techniques under tropical watershed conditions in Hawai‘i.
2 Materials and methods
2.1 Study area and data
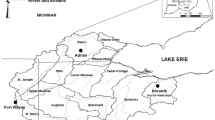
An evaluation of ClimGen model was performed using measured weather data from four stations with the most comprehensive records operated by National Climatic Data Center (NCDC, http://www.ncdc.noaa.gov) in the state of Hawai‘i. These stations are located at Honolulu, Lihue, Kahului, and Hilo airports on the island of O’ahu, Kauai, Maui, and Hawai‘i, respectively (Fig. 1). For the evaluation of the disaggregation techniques, hourly weather data were collected from six different weather stations operated mainly by NCDC, United States Geological Survey, and University of Hawai‘i, located in the west part of O’ahu with elevation ranging from 82 to 1,227 m. A summary of data sources, types, their geographic location, and duration of records are presented in Table 1.

Study area showing the Mākaha watershed and locations of weather data disaggregation and ClimGen evaluation sites
2.2 Description of ClimGen
ClimGen generates daily data for precipitation, maximum and minimum temperature, solar radiation, relative humidity, and wind speed and can be parameterized for each station. ClimGen uses the Weibull distribution (Weibull 1951) to represent daily precipitation and its spline approach is an improvement over the one-term Fourier series used by many other weather generators (e.g., CLIGEM) to simulate seasonal variation in climate data. Two-state Markov chain model (Richardson and Nicks 1990) is used to generate the number and distribution of events. The combination of conditional probabilities for a two-state (α, wet day following a dry day, and β: dry day following a wet day) Markov chain is calculated for each station individually on a monthly basis using historical observed data as follows (Nicks et al. 1990):
where
- P(W|D) :
-
is the probability of a wet day given a previous dry day.
- P(D|D) :
-
is the probability of a dry day given a previous dry day.
- P(D|W) :
-
is the probability of a dry day given a previous wet day.
- P(W|W) :
-
is the probability of a wet day given a previous wet day.
ClimGen uses a two-parameter Weibull distribution to calculate the magnitude of wet day precipitation. Weibull distribution has proven to be superior to other probability distribution functions in representing daily precipitation (Selker and Haith 1990). The cumulative probability distribution of the precipitation amount can be given by:
where F(P) is cumulative probability distribution, κ >0 and λ > 0 are the shape and scale parameters calculated from observed precipitation data on monthly basis. Precipitation magnitudes (P) are sampled from the inverse cumulative distribution and using uniform random variable between 0 and 1(X) as follows:
Quadratic spline functions are used for the daily interpolation of monthly values of Weibull distribution shape (κ) and scale (λ) parameters as well as Markov chain conditional probabilities of a wet day given a previous wet day and a wet day given a previous dry day. ClimGen also uses the method of Arnold and Williams (1989) to generate the peak 30-min storm intensity and duration. However, this approach requires the parameterization of storm intensity at each station using historical storm records.
Similar to wet day precipitation, ClimGen uses the two-parameter Weibull distribution in computing the daily wind speed after calculating the shape and scale parameter of the distribution from observed wind data. Daily maximum and minimum air temperature details are generated using an approach similar to WGEN, considering temperature as a continuous multivariate process with the daily mean and standard deviation conditioned by the precipitation status (Stockle et al. 1999). ClimGen, however, uses a spline-fitting procedure to adjust for variations in season means and standard deviations compared to Fourier series used in WGEN and CLIGEN.
2.3 Disaggregation techniques
2.3.1 Precipitation
Daily precipitation was disaggregated into hourly values based on a uniform distribution, a combination of normal ratio and diurnal distribution, and a multivariate-based distribution technique. For uniform distribution, daily precipitation values were uniformly distributed over the day. Diurnal distribution was performed in two steps: first, the daily precipitation amounts at 842.1 were disaggregated into hourly amounts based on the diurnal precipitation patterns at 800.3, 844, and 847 using the following equation:
where P is the precipitation amount (mm), and superscripts m and n represent the stations with daily and hourly precipitation, respectively; subscripts d and h represent day and hour, respectively. The selection of hourly stations were based on the correlation coefficient values derived from their daily precipitation data at corresponding stations and at 842.1; and second, for the days where no other station recorded rain except 842.1, daily precipitation values were disaggregated based on the probability of precipitation occurrence during each hour of the day. The probability of precipitation occurrence during each hour of the day was calculated from 844, 847, and 800.3 on monthly basis to maintain seasonality.
The multivariate disaggregation method was based on Multivariate Disaggregation of Rainfall (MuDRain) model. MuDRain disaggregates daily rainfall at a single site or at multiple sites based on the temporal and spatial relationships between available daily and hourly rainfall data at two or more sites. A detailed description of MuDRain model can be found in Koutsoyiannis et al. (2003). Model input parameters were prepared based on the following steps as described by Debele et al. (2007):
-
1.
Cross-correlations between hourly rainfall (r ij,h ) data at 844, 847, and 800.3 were established on a month-to-month basis to maintain seasonality.
-
2.
Hourly data from 844, 847, and 800.3 were aggregated into daily values (r ij,h ) and cross-correlations were re-calculated using daily rainfall values on a monthly basis.
-
3.
The cross-correlation values determined in steps one and two were fitted into the equation \( {r_{{ij,h}}} = {({r_{{ij,d}}})^m} \) (Koutsoyiannis et al. 2003) and values of m were determined for each month separately. Subscripts i and j represent the two stations i and j between which a cross-correlation was established. Alternatively, if hourly rainfall data are not available for the study area, coefficient m, which explains the relationship between daily and hourly cross-correlation coefficients between two stations, can be approximated in the range of 2–3 (Fytilas 2002).
-
4.
A cross-correlation was determined between daily rainfall data at 842.1 and at 844, 847, and 800.3.
-
5.
The cross-correlation values calculated in step 4 using daily data were converted into hourly cross-correlations between all four stations based on the value of m as determined in step 3.
2.3.2 Temperature
Daily average temperature values were disaggregated into hourly values using four different models. The models were selected based on the diurnal analysis of measured data which show sinusoidal patterns, especially the daytime temperature, and their performance as reported in the literature. Following is a brief description of these models and their input data requirements:
-
1.
Modified sine curve model (Waichler and Wigmosta 2003)
This method is a modified form of the model proposed by Running et al. (1987) and Parton and Logan (1981) and uses daily minimum (T min) and maximum (T max) temperature data. Hourly air temperature was modeled based on three quadrant sine wave (−π/2 to π) with minimum values at sunrise, maximum values at solar noon (π/2), and mean values at sunset (π). Daytime temperature was fitted to a sinusoidal function and nighttime temperature was linearly interpolated between midnight and sunrise, and midnight and sunset. Sunrise and sunset times were calculated using the method described by Burman and Pochap (1994). The modified sine curve model is expressed as follows:
$$ \begin{gathered} {T_t} = ({T_{{\max }}} - {T_{{\min }}})\sin \left( {\frac{{\pi (t - (12 - \frac{Y}{2} - b))}}{{Y + 2a}}} \right){\text{ sunrise }} \leqslant { }t{ } \leqslant {\text{ sunset}} \hfill \\ {T_t} = {T_{\text{start}}} + 0.5{ }t{ }{\Delta_{\text{am}}}{ 24 } \leqslant { }t{\text{ < sunrise}} \hfill \\ {T_t} = {T_{\text{ave}}} + 0.5{ }t{ }{\Delta_{\text{pm}}}{\text{ sunset < }}t{ < 24 } \hfill \\ \end{gathered} $$(5)where T t is the temperature (°C) at time t (h); Y is the day light hour (h); T max, T min, and T ave are the maximum, minimum, and average daily temperature (°C), respectively. T start is the temperature at the start of the day (j) which is calculated as: \( T_{\text{start}}^j = (T_{\text{ave}}^{{j - 1}} + T_{{\min }}^j)/2 \). \( {\Delta_{\text{am}}} \) and \( {\Delta_{\text{pm}}} \) are the rate by which temperature increases and decreases from midnight to sunrise and sunrise to sunset, respectively. Constants a and b are the time lags in maximum temperature after noon and in minimum temperature after sunrise, respectively. The values of a and b were calculated by comparing observed and simulated hourly air temperature. The optimized values of a and b were 1 and −2 h, respectively.
-
2.
Cosine model (de Wit 1978)
Diurnal variation in daily mean air temperature was fitted using the daily maximum and minimum temperature dataset. Debele et al. (2007) evaluated this model with data from Cedar Creek watershed, TX, USA, and have shown prominent results in explaining the diurnal variation using daily surface air temperature data. The cosine function has the following form:
$$ {T_t} = \frac{{{T_{{\max }}} - {T_{{\min }}}}}{2}\cos \left( {\frac{{\pi (t - a)}}{{12}}} \right) + \frac{{{T_{{\max }}} + {T_{{\min }}}}}{2} $$(6)where T t is the temperature (°C) at time t (h); T max and T min are the maximum and minimum daily air temperatures (°C), respectively; a is a coefficient that was fitted using least squares optimization in Microsoft Excel (Microsoft Office 2007). The optimized value of a was 14 as compared to 13 which was reported by Debele et al. (2007).
-
3.
Double cosine model (ESRA 2000)
The double cosine model uses three sinusoidal segments determined based on the occurrence time of daily minimum and maximum temperature as follows:
$$ \begin{gathered} {T_t} = \left\{ \begin{gathered} \frac{{{T_{{\max }}} + {T_{{\min }}}}}{2} - \cos \left[ {\frac{{\pi ({t_{{{T_{{\min }}}}}} - t)}}{{24 + {t_{{{T_{{\min }}}}}} - {t_{{{T_{{\max }}}}}}}}} \right]\frac{{{A_{\text{T}}}}}{2}{ 0 < }t{ } \leqslant { }{t_{{{T_{{\min }}}}}} \hfill \\ \frac{{{T_{{\max }}} + {T_{{\min }}}}}{2} + \cos \left[ {\frac{{\pi ({t_{{{T_{{\max }}}}}} - t)}}{{{t_{{{T_{{\max }}}}}} - {t_{{{T_{{\min }}}}}}}}} \right]\frac{{{A_{\text{T}}}}}{2}{ }{t_{{{T_{{\min }}}}}} < t \leqslant {t_{{{T_{{\max }}}}}} \hfill \\ \frac{{{T_{{\max }}} + {T_{{\min }}}}}{2} - \cos \left[ {\frac{{\pi (24 + {t_{{{T_{{\min }}}}}} - t)}}{{24 + {t_{{{T_{{\min }}}}}} - {t_{{{T_{{\max }}}}}}}}} \right]\frac{{{A_{\text{T}}}}}{2}{ }{t_{{{T_{{\max }}}}}} < t \leqslant 24 \hfill \\ \end{gathered} \right. \hfill \\ \hfill \\ \end{gathered} $$(7)where T t is the temperature (°C) at time t (h); T max and T min are the maximum and minimum daily air temperatures (°C), respectively; t Tmax and t Tmin are the times of day at which daily maximum and minimum temperatures occur; and A T is the daily thermal amplitude (°C) calculated as the difference between minimum and maximum air temperatures.
-
4.
Erbs model (Erbs 1984)
Location- and month-independent Erbs model was used to explain the diurnal variation in daily temperature data. Erbs model uses the following expressions:
$$ {T_t} = {T_{\text{m}}} + {A_{\text{Tm}}}\left[ \begin{gathered} 0.4632\cos (\alpha - 3.805) + 0.0984\cos (2\alpha - 0.36) + \hfill \\ 0.0168\cos (3\alpha - 0.822) + 0.0138\cos (4\alpha - 3.513) \hfill \\ \end{gathered} \right] $$(8)\( {\text{wher}}{\text{e}}\alpha = 2\pi (t - 1)/24 \); T t is the temperature (°C) at time t (h); T m and A Tm are the monthly mean daily air temperature and the thermal amplitude (°C), respectively. In this study, daily average temperature and thermal amplitude were used instead of their corresponding monthly values since they were available.
2.3.3 Wind speed
Hourly wind speed data collected at stations 1 and 6 were fitted using two different models (sinusoidal and random function). The sinusoidal form of the model uses the daily average wind speed data to generate hourly values considering that maximum wind speed occurs around noon. The model is expressed as follows:
where W t is the wind speed (ms−1) at hour t (h); W day is the daily average wind speed (ms−1); and a and b are the empirical constants.
Optionally, we can also distribute the daily average wind speed (W day) into hourly (W t ) using the random function. Many of the existing hydrologic models with disaggregation method, i.e., Soil and Water Assessment Tool, use this method to generate hourly wind speed. These sinusoidal and random function models have been proven to produce reasonable results (Debele et al. 2007). The hourly values of wind speed using the random function (rnd) are computed as follows:
2.3.4 Relative humidity
In this study, inverse estimation of dew point temperature was performed using observed relative humidity. Hourly values of actual (e a) and saturated (e s) vapor pressure were calculated using a dry bulb (average daily air temperature, T ave) and a corresponding wet bulb temperature (T dp), respectively. Relative humidity at any given time (t) is calculated as follows:
Daily dew point temperature (\( T_{\text{dp}}^j \)) was disaggregated following the method of Meteotest (2003) assuming that it varies linearly between consecutive days and its daily average value occurs right before sunrise. The hourly value of dew point temperature (\( T_{\text{dp}}^i \)) is given by:
where i is the hour of day (1–24) and j is the day count; \( T_{{\Delta {\text{dp}}}}^i \)is the hourly fluctuation in dew point temperature within a day, which is determined as follows:
where k r is a constant that depends on the monthly average solar radiation. If the monthly average solar radiation is higher than 8.64 MJ m−2 day−1, then k r = 6; else, k r = 12 (Debele et al. 2007). We used k r = 6 since the average monthly solar radiation for all 12 months was higher than the threshold value of 8.64 MJ m−2 day−1.
2.4 Model accuracy assessment
The coefficient of determination or Pearson’s correlation coefficient, which only quantifies the dispersion, is one of the most commonly used measures for model performance assessment. For accurate mode assessment, it is often recommended to use a combination of graphical techniques, dimensionless and error index statistics (Moriasi et al. 2007), and different efficiency criteria complemented by the assessment of the absolute or relative volume error (Krause et al. 2005). Gutierrez-Magness and McCuen (2004) reported that the disaggregated time series does not perform well when compared to the measured data on an hourly basis because of the uncertainty in identifying the actual hour in the disaggregated time series at which storm is supposed to begin. Socolofsky et al. (2001) identified four important measures for evaluating the model performance that should be matched by the disaggregated time series: conservation of mass, probability of zero rainfall, variance of hourly rainfall, and lag 1-h serial correlation coefficient. In this study, the accuracy of model performance was evaluated by comparing the statistical measures, scatter plots, and frequency distribution of measured and generated/disaggregated data. The proportion of dryness, cross-correlation, and lag −1 autocorrelation were also computed and compared between the measured and hourly disaggregated precipitation. In addition to the mean and standard deviation of observed and simulated variables, goodness-of-fit statistics (Gutierrez-Magness and McCuen 2004; McCuen 2003) were used to assess model accuracy. These statistics include mean absolute error (MAE), bias (ē), standard error of the estimate (S e), relative bias (R b), relative standard error (R s), relative difference between observed and predicted standard deviations (ΔS), and significance of difference test. Correlation coefficient (R), S e, R s, ē, and R b are some of the important indicators used to evaluate model reliability and are commonly computed as part of model development (McCuen 2003). A detailed description of some model performance statistics is given in the “Appendix” section.
A further test of the model applicability was performed using the nonparametric Wilcoxon rank-sum test. Wilcoxon rank-sum test has been used for checking the significant difference between two independent random samples. If probability, p, is less than 0.05, then the test rejects the null hypothesis of independent, identical continuous distributions with equal medians.
2.5 Significance to hydrologic modeling
The hydrologic significance of different weather data disaggregation methods was evaluated using distributed hydrology soil vegetation model (DHSVM) (Wigmosta et al. 1994) in the setting of Mākaha watershed (Fig. 1). The performance of the model in simulating streamflow was also evaluated at the study domain and DHSVM reproduced the daily streamflow reasonably well (Safeeq 2010). The Nash–Sutcliffe efficiency was 0.68 during calibration and 0.54 during the validation period. A detailed description on the model parameterization and evaluation can be found in Safeeq (2010).
All of the simulations in this study were performed for water years (WY) 2006 and 2007 at 30-m spatial resolution and 1-h time step. DHSVM input data were prepared and used by Safeeq (2010); for the purpose of this study, we only changed the required climate forcing. In an effort to reduce the simulation time, we also increased the spatial resolution from 10 to 30 m. Since only hourly measured precipitation was available at 842.1, we used the hourly temperature, wind speed, and relative humidity from station 1 (Fig. 1). The daily observed and simulated streamflow for WY 2006 and 2007 were compared to confirm that there was no significant change in model performance after the above changes in the model input. A set of 11 meteorological scenarios (Table 7) was generated based on different disaggregation methods. Simulated hourly streamflow, evapotranspiration (ET), and groundwater recharge under different meteorological scenarios (S1–S10) were compared with those obtained from observed hourly climate data (B).
3 Results and discussion
3.1 Disaggregation
3.1.1 Precipitation
Station 844 has the highest total frequency of precipitation events (n = 30,298), followed by 847 (n = 12,844) and 800.3 (n = 9,963), between May 1965 and December 2008 (Fig. 2). Data of the three stations showed similar patterns with two distinct minima and maxima; however, the percent contribution of precipitation for each hour to the total rainfall varied spatially. Chen and Nash (1994) attributed the early morning maximum to the katabatic winds converging near the surface with trade winds on windward slopes, while the afternoon maximum is related to the daytime heating of the land and onshore anabatic sea breezes that cause near-surface convergence. Mair and Fares (2010) reported a similar bimodal diurnal pattern with one maximum in the predawn period around 0400 h, a minimum at 1000 h, a primary maximum at 1600 h, and a second minimum at 2200 h from a relatively small sample of data (2006–2008). Roy and Balling (2004) reported similar patterns for precipitation in Hawaiian watersheds using data from 133 weather stations across the state between 1965 and 1998. The diurnal precipitation distribution in this study clearly shows that the precipitation in Hawai‘i is not concentrated during a certain period of the day but instead is almost equally distributed over the 24 h of a day.

Diurnal rainfall patterns at 844, 847, and 800.3
After fitting the monthly cross-correlation coefficients, values of m were estimated for each month (Table 2). The values of the coefficient m in this study range between 5.32 in February and 1.75 in September. Debele et al. (2007) reported m values in a range of 2–6 which is in agreement with our findings, whereas Koutsoyiannis et al. (2003) reported m values between 2 and 3. The cross-correlations between daily and hourly precipitation for January, a wet month, were almost similar for the four stations (Table 3). The highest correlation was between 847 and 800.3, which could be attributed to their similar elevations. Cross-correlations between stations were low during summer months compared to those during winter months. This can be attributed to pronounced orographic summer precipitations on windward slopes of mountains (Chu and Chen 2005), which exerts strong spatial variability in summer compared to that in winter precipitation.
The monthly distribution of percent wet hours from each disaggregation method and values of m at 800.3 are presented in Table 2. The uniform distribution of daily precipitation clearly over-predicted the actual number of wet hours. This is because of the fact that the daily total precipitation, which could have resulted from short-duration storm that occurred only in a few hours of the day, was distributed equally over 24 h. The number of wet hours predicted by the diurnal and MuDRain methods were comparable to the observed data. MuDRain method slightly over-predicted the actual number of wet hours during wet months and under-predicted it during dry months, whereas the diurnal method consistently over-predicted the actual number of wet hours throughout the year. Two-sample, paired t-test result showed no significant difference (95% confidence) in percent wet hours between the measured and calculated values with the diurnal and MuDRain methods.
The hourly precipitation frequencies of the observed data and the three disaggregation methods for 800.3 and 842.1 are presented in Fig. 3. A uniform precipitation distribution had no hourly precipitation rate higher than 15 mm. The diurnal method data best fitted the actual data at 842.1, whereas the MuDRain method data best fitted the actual data at 800.3. This could be due to the cross-correlation between these datasets since actual hourly precipitation data at 800.3 were used as input for MuDRain model. A similar pattern was also observed with the percent wet hours at 842.1. MuDRain model significantly over-predicted the actual percent wet hours (result not shown), indicating that MuDRain performs better when hourly data from nearby station were used as input for the model. For low-intensity precipitation events, a uniform distribution produces better results at both locations (Fig. 3). The diurnal patterns of monthly precipitation clearly indicate that the diurnal method performed relatively better than the other two methods (Fig. 4). However, there was a lag between observed and generated data using the diurnal distribution.

Frequency distribution of hourly observed and generated precipitation data using different disaggregation methods (diurnal, MuDRain, and uniform) at 842.1 (a) and 800.3 (b)

Total measured and disaggregated hourly precipitation by month during each hour of the day at location 842.1 for the period 1993–2007
MuDRain and diurnal methods outperformed the uniform distribution method at 842.1 (Table 4). MuDRain fitted better the observed data than the diurnal method based on the correlation coefficients and S e. However, the diurnal method has a slightly lower MAE and index of agreements (d 2 and d 1) as compared to the uniform and MuDRain methods. A standard deviation for diurnal method data was close to that of the measured data (ΔS =0.095), indicating that the diurnal model was good in explaining the variance in observed precipitation, which can also be confirmed from Fig. 3. The results of the F-test show a significant difference in variance of observed and disaggregated data using MuDRain and uniform methods. Lag-1 autocorrelation coefficient is often used to assess the degree of non-randomness in time series data. All of the weather parameters have high values of lag-1 autocorrelation (minimum for precipitation and highest for dew point temperature), indicating that adjacent values separated by 1 h are strongly correlated. Among the three disaggregation methods, the diurnal method was good in explaining the non-randomness of precipitation data.
3.1.2 Temperature
All of the four temperature disaggregation methods tested in this study performed reasonably well in reproducing the hourly temperature data at both locations (1 and 6) (Table 4). The sine curve model showed a 2-h lag; thus, a 2-h early shift yielded the best fit. At station 1, the sine curve model had higher S e values, under-predicted temperature, and showed a large scattering in higher temperatures. A similar scattering was observed at a lower temperature range (Fig. 5) with the other two models. At station 6, the sine curve model had better results than the cosine and Erbs model (Table 4). A scattered data plot for station 6 clearly showed that the cosine model and Erbs model slightly over-predicted the high temperature values and showed a larger scattering in the low temperature range as compared to the sine curve model (Fig. 6).

Correlation between observed and calculated (using different disaggregation methods) hourly air temperature at station 1

Correlation between observed and calculated (using different disaggregation methods) hourly air temperature at station 6
The cumulative frequency distribution of the sine curve model was similar to that of the measured data at stations 1 and 6 (Fig. 7a, b). The sine curve model with a 2-h lag performed better than the cosine and Erbs models; thus, it can be used as a dependable temperature disaggregation model. It also has low values of ē, MAE, and R s, and there was a statistically non-significant difference (test <1.0) between observed and model-generated data at both locations.

a Cumulative probability distributions for measured and estimated hourly temperature data at station 1. b Cumulative probability distributions for measured and estimated hourly temperature data at station 6
3.1.3 Wind speed
The cosine and random function models produced reasonable hourly wind speed data compared with the observed data (Table 4); however, the former model relatively outperformed the latter as it is shown by their correlation coefficients and low MAE, ē, and R s. Data generated by the cosine model have a higher correlation as compared to the random model at both locations. There was no statistically significant difference (test <1.0) between observed values and data generated by the cosine model at both locations. As expected, disaggregated wind speed using the random function model was the least autocorrelated (lag-1). In addition, although the cosine model performed consistently well, it clearly failed to reproduce high wind speed data (Fig. 8), which can cause significant errors in calculating ET using wind speed-based models (e.g., Penman–Monteith).

Cumulative probability distributions for measured and disaggregated hourly wind speed from the cosine and random function models at station 1 and station 6
3.1.4 Relative humidity
Hourly dew point temperatures were calculated from measured relative humidity at stations 1 and 6 using the established procedure described by Allen et al. (1994). Calculated hourly dew point temperature was compared with disaggregated data using the method of Meteotest (2003). A high value of correlation coefficients (Fig. 9) and low values of MAE, R b, R s, and ē (Table 4) confirm that the model-generated dew point temperatures closely match the measured data. However, under-prediction of hourly dew point temperature was observed during daytime.

Cumulative probability distributions for measured and disaggregated hourly dew point temperature from the cosine model at station 1 and station 6
3.1.5 Hydrologic significance
Simulated streamflow using DHSVM was slightly lower (R b = 2%) compared to the observed streamflow using current climate input from 842.1 and station 1 and at 30-m spatial resolution. The Nash–Sutcliffe efficiency for WY 2006 and 2007 was optimal (0.66). These results indicate that the increase in spatial resolution and using temperature, wind speed, and relative humidity from station 1 did not have any significant impact on model performance during WY 2006 and 2007.
The hydrologic results from different meteorological scenarios were different compared to the baseline scenario (Fig. 10). Streamflow was the most sensitive compared to ET and groundwater recharge across the different meteorological inputs. Among the precipitation disaggregation scenarios, S2 resulted in the smallest error in streamflow compared to S1 and S3. Disaggregating daily precipitation using uniform and MuDRain methods resulted in a decrease in streamflow. Although the diurnal precipitation disaggregation was based on the observed hourly precipitation at locations close to 842.1, there was a decline in streamflow by an average of 7%, with a slight increase in groundwater recharge. The main reason for higher ET and lower streamflow as well as groundwater recharge under S1 and S3 was the under-prediction of the frequency of high rainfall intensities during these disaggregation methods (Fig. 3a).

Comparison of streamflow (a), evapotranspiration (b), and groundwater recharge (c) across different meteorological scenarios. Corresponding biases relative to baseline scenarios are presented in d–f
Air temperature-based disaggregation scenarios had the least influence on streamflow, ET, and groundwater recharge. Meteorological input S5–S7 showed a similar response on water balance, causing a slight increase in ET and a decrease in streamflow and groundwater recharge. Scenario S4 had no influence on streamflow but resulted in a noticeable increase in groundwater recharge and a decrease in ET. All of the four disaggregation methods were able to capture the diurnal pattern and showed very little hydrologic sensitivity. The relative bias in average annual streamflow was 19.5% with S8 and 20% with S9, caused by a much lower ET. Both the cosine and random models resulted in a decline of ET by nearly 8% and can be attributed to the under-prediction of high wind speed values. Additionally, the average diurnal pattern of observed and disaggregated wind speed showed that both the cosine and random models under-predicted the daytime wind speed. Hourly humidity input generated using hourly dew point temperature from S10 resulted to an increase in ET by 5%. Although the hourly observed and disaggregated dew point temperatures were in close agreement (Fig. 9), the average hourly RH values calculated using the disaggregated dew point temperatures were significantly lower during the day compared to the observed RH. In Hawai’i, RH is inversely related to air temperature at lower elevation and increases at higher elevation due to the upslope moist air flow (Giambelluca and Nullet 1991). This lowering of low-elevation RH during the daytime was rapid and greater in the disaggregated data compared to the observed RH.
3.2 Performance of ClimGen
3.2.1 Precipitation
The mean monthly and daily observed and simulated precipitations and goodness-of-fit statistics at Lihue, Kahului, Hilo, and Honolulu were compared using the data for the period 1961–2008. Similarly, observed and simulated monthly proportions of wet days were also compared for the period 1961–2008. Relative frequency distributions of precipitation amounts were plotted with the following intervals: 0–0.1, 0.1–0.5, 0.5–1, 1–2, 2–5, 5–10, 10–15, 15–30, 30–50, 50–100, 100–150, and >150 mm. Daily means and standard deviations for each station were compared at 5% level of significance using paired t-test.
The observed daily precipitation was in good agreement with that generated by ClimGen. The maximum differences between observed and ClimGen generated precipitations were 0.66, 0.38, −1.08, and 0.51 mm at Lihue, Kahului, Hilo, and Honolulu, respectively (Table 5). ClimGen underestimated the precipitation at Hilo (slope > 1.0) and overestimated it at Lihue, Kahului, and Honolulu (slope < 1.0). There was no significant difference between the observed and simulated mean daily precipitation at Lihue and Honolulu based on a paired t-test. However, the differences in mean daily observed and simulated precipitation were significant for Kahului and Hilo. Model performance varied by location and the maximum differences in SD of observed and simulated precipitation were 7.46, 2.8, 5.53, and 3.63 mm at Lihue, Kahului, Hilo, and Honolulu, respectively. Irrespective of the location and the month, the standard deviation of simulated precipitation was lower than that of the observed precipitation (Table 5), indicating that ClimGen did not fully reproduce the variability of the observed data. This was confirmed by the results of the paired t-test (p < 0.001) which showed a highly significant difference between the standard deviation of the observed and simulated precipitation at all locations. Abraha and Savage (2006) reported similar results and recommended that extra care is needed while interpreting the climate change impact assessment results obtained from using such weather data due to uncertainties pertaining to the above statistics.
There was no significant correlation between observed and simulated precipitation (Table 6). Lag-1 autocorrelation between observed daily precipitations varied from 0.23, at Lihue, to 0.39, at Hilo, indicating a higher probability of having a wet day if the previous day was wet. However, lag-1 autocorrelations between simulated daily precipitations were weak (highest 0.09) for all the locations, which indicates that ClimGen will most likely predict a dry day following a wet day. The mean absolute error, ΔS, ē, and R b values were relatively low at all four locations. The first-order index of agreement d 1 was highest at Kahului (0.45) and lowest at Hilo (0.35). The second-order index of agreement d 2 was highest at Hilo (0.25) and lowest at Honolulu (0.12). As expected, the value of d 1 was lower than d 2 for all stations. Stockle et al. (1998) suggested that a model performance can be considered acceptable if d 2 is in the range of 0.90–0.95. However, on a daily time step, values of the index of agreement were outside the range of 0.90–0.95. The indexes of agreements d 1 and d 2 on a monthly basis range between 0.48–0.67 and 0.41–0.57, respectively. The Wilcoxon rank-sum test of identical distribution was rejected (p < 0.05), except for Honolulu station.
The correlation coefficients between mean monthly observed and simulated precipitation for the period 1961–2008 were 0.98, 0.99, 0.96, and 0.98 at Lihue, Kahului, Hilo, and Honolulu stations, respectively (Fig. 11). There was a significant difference between the monthly mean observed and simulated precipitation at Lihue and Honolulu stations. The proportions of wet days generated by ClimGen were in good agreement with those of the observed data (Fig. 12). The Q–Q plots of daily precipitation at the four locations (Fig. 13) showed that ClimGen underestimates the precipitation at a higher percentile. The difference in Q–Q plot is more prominent at Hilo due to a high frequency of extreme events along the eastern slopes of Mauna Kea Mountain (Chu et al. 2009). ClimGen may not be useful under these conditions if high-intensity daily precipitation data are required (i.e., flood modeling). At Honolulu station, which is located in the drier side of the island associated with less frequent extreme events, Q–Q plot showed a good agreement with the observed data.

Simulated and measured monthly mean precipitations at Lihue, Kahului, Hilo, and Honolulu (HNL) for the period 1961–2008

Proportion of wet days in each month from measured and simulated data at Lihue, Kahului, Hilo, and Honolulu (HNL) for the period 1961–2008

Q–Q plot of the daily precipitation for the period 1961–2008 at Lihue, Kahului, Hilo, and Honolulu
The generated relative frequency distributions of precipitation amounts generally matched the observed data well, but at all four weather stations the model underestimated the frequency of precipitation of >100 mm (Fig. 14). Chu et al. (2009) described the extreme rainfall in Hawaiian Islands using a three-parameter generalized extreme value distribution with the shape parameter close to zero (−0.1 to 0.1) and suggested that a simple Gumbel distribution is a reasonable choice for explaining the extreme rainfall events. We fitted the two-parameter Weibull distribution to the daily precipitation amount >0 mm using maximum likelihood optimization. The shape parameter varied from 0.61 to 0.74 and the scale parameter ranged from 3.11 to 9.43 with the lowest value at Honolulu and the highest at Hilo. The scale parameter at Hilo was three times higher than the rest of the stations, exhibiting a much different precipitation regime. Extra care is needed while using ClimGen for climate change scenarios as extremes are more likely to occur under a changing climate (Katz and Brown 1994).

Comparison of measured and simulated relative frequencies of precipitation at Lihue, Kahului, Hilo, and Honolulu for the period 1961–2008
3.2.2 Temperature
There was no significant difference (p > 0.05) between the observed and simulated mean minimum and maximum temperatures and their corresponding standard deviations (Table 5). The maximum temperature was slightly over-predicted at Lihue and Hilo. The minimum temperature was over-predicted at Lihue only. The percentage of days for which ClimGen over-predicted the temperature by at least 2°C than the observed air temperature varied between 13% and 22% for T max and between 16% and 26% for T min for all of the four locations. This indicates that, at least 74% of the time, the difference between the observed and simulated temperatures was less than 2°C. On a monthly scale, the difference between observed and simulated temperature was less than 0.5°C at all stations. The average amplitude for the observed (7.8°C) and simulated (7.6°C) air temperatures were within those reported by Safeeq (2010) for the island of O’ahu. Values of Pearson’s correlation between observed and simulated T max and T min were higher as compared to those for precipitation (Table 6). Lag-1 autocorrelation, mean, and standard deviation of simulated temperature were similar to those of the observed data. ClimGen generates a reasonable daily T max and T min as compared to the observed data given the high values of d 1 and d 2 and low values of MAE, ΔS, ē, R b, and the statistically non-significant differences (test < 0.001). The cumulative probability of measured and simulated temperature showed a good agreement (result not shown). However, the Wilcoxon rank-sum test results indicate a statistically significant difference between the distribution of observed and simulated air temperature data at all four locations.
3.2.3 Wind speed
The daily simulated and observed wind speeds were in good agreement at all four locations (Table 6). The daily observed and simulated mean wind speed and their corresponding standard deviations were very similar. In addition, there was no significant difference between their monthly means and standard deviations (Table 5). However, ClimGen slightly over-predicted the monthly standard deviation at all locations. The Wilcoxon rank-sum test results for Kahului and Hilo indicate identical continuous distributions of wind speed with equal medians at the 5% significance level. The simulated data show an almost non-significant lag-1 autocorrelation because ClimGen generates wind speed using randomly generated real numbers between 0 and 1. This indicates that the magnitude of ClimGen-generated wind speed between two subsequent days is highly likely different.
4 Summary and conclusions
The daily and sub-daily meteorological data are vital inputs for hydrological and environmental modeling. The lack of meteorological data at a finer time scale often limits the full use of these models. In the current study, we evaluated the applicability of one stochastic weather generator, ClimGen, and the various approaches of disaggregating daily weather data into an hourly data. Two of the three tested disaggregation methods for daily precipitation are MuDRain and diurnal methods, which performed reasonably well compared to the observed data. The third method based on a 24-h uniform distribution failed to reproduce most of the statistical parameters computed from observed hourly data. MuDRain produced better results for wet hours as compared with the other two models. However, the diurnal method performed well over the other two models in reproducing the observed variance in hourly precipitation. Among the temperature disaggregation models, the sine curve model with a 2-h lag performed better than the cosine or Erbs model. The cosine model relatively outperformed the random function model in disaggregating the daily wind speed into an hourly data.
The diurnal method showed the least error in simulating streamflow as compared to MuDrain and uniform methods. There was a little difference in hydrologic sensitivities between the uniform and MuDRain methods. Disaggregating daily precipitation had a significant hydrologic impact on water balance in this mountainous watershed. The largest differences in annual water balance were related to wind speed followed by precipitation and relative humidity. Under-prediction of hourly wind speed and dew point during the daytime caused a decrease and an increase in ET, respectively. Simulated hourly streamflow, evapotranspiration, and groundwater recharge were less sensitive to the method of disaggregating daily air temperature.
The performance of ClimGen weather generator model varied by location and by weather parameter (i.e., rain, wind speed, temperature). Out of the four locations, ClimGen was only able to reproduce the observed precipitation distribution at Honolulu. We found that ClimGen failed to reproduce the precipitation extremes at two of the tested locations and it underestimated precipitation at higher percentiles. However, it performed reasonably well in generating the daily minimum and maximum temperatures and wind speed. ClimGen was able to reproduce the distribution of minimum temperature at Kahului. The distributions of simulated wind speed at Kahului and Hilo were similar to those of measured wind speed. On a monthly basis, the ClimGen-generated precipitations were in agreement with the observed precipitations at all four locations tested. Similar results were found for the number of monthly wet days at all locations. This study indicates that location-specific evaluation and parameterization of the ClimGen are needed before using it in generating long-term weather data, especially for the smaller time intervals (i.e., daily).
References
Abraha MG, Savage MJ (2006) Potential impacts of climate change on the grain yield of maize for the midlands of KwaZulu-Natal, South Africa. Agric Ecosyst Environ 115:150–160
Acutis M, Donatelli M, Stockle, CO (1999) Performance of two weather generators as a function of the number of available years of measured climatic data. Proceedings First International Symposium Modelling Cropping Systems, Lleida, Spain, 21–23 June, pp 129–130
Allen RG, Smith M, Pereira LS, Perrier A (1994) An update for the calculation of reference evapotranspiration. ICID Bull 43:35–92
Arnold JG, Williams JR (1989) Stochastic generation of internal storm structure at a point. Transactions of the ASAE 32(1):161–167
Bilbao J, Miguel A, Kambezidis HD (2002) Air temperature model evaluation in the north Mediterranean Belt area. J Appl Meteorol 41:872–884
Burian SJ, Durrans SR, Tomic S, Pimmel RL, Wai CN (2000) Rainfall disaggregation using artificial neural networks. J Hydrol Eng 5(3):299–307
Burman RD, Pochop LO (1994) Evaporation, evapotranspiration and climatic data. Developments in atmospheric science. Elsevier, Amsterdam
Castellvi F, Stockle, CO (2001) Comparing the performance of WGEN and ClimGen in the generation of temperature and solar radiation. Trans of ASAE 44:1683–1687
Chen YL, Nash AJ (1994) Diurnal variation of surface airflow and rainfall frequencies on the island of Hawai‘i. Mon Weather Rev 122:34–56
Chu PS, Chen H (2005) Interannual and interdecadal rainfall variations in the Hawaiian Islands. J Climate 18:4796–4813
Chu PS, Zhao X, Ruan Y, Grubbs M (2009) Extreme rainfall events in the Hawaiian Islands. J Appl Meteor Climatol 48:502–516
Danuso F, Della MV (1997) CLIMAK reference manual. DPVTA, University of Udine, Italy
de Wit CT (1978) Simulation of assimilation, respiration and transpiration of crops. Wageningen, Pudoc, p 148
Debele B, Srinivasan R, Parlange JY (2007) Accuracy evaluation of weather data generation and disaggregation methods at finer timescales. Adv Water Resour 30:1286–1300
Ephrath JE, Goudriaan J, Marani A (1996) Modelling diurnal patterns of air temperature, radiation wind speed and relative humidity by equations from daily characteristics. Agric Syst 51(4):377–393
Erbs DG (1984) Models and applications for weather statistics related to building heating and cooling loads. Ph.D. thesis, Mechanical Engineering Department, University of Wisconsin-Madison, Wisconsin, Madison, 336 pp
ESRA (2000) European solar radiation atlas (ESRA). In: Scharmer K, Greif J (eds) Database and exploitation software, vol. 2. Commission of the European Communities, Ecole des Mines de Paris, France
Fytilas P (2002) Multivariate rainfall disaggregation at a fine time scale (diploma thesis). University of Rome, La Sapienza
Giambelluca TW, Nullet D (1991) Influence of the trade-wind inversion on the climate of a leeward mountain slope in Hawaii. Clim Res 1:207–216
Gutierrez-Magness AL, McCuen RH (2004) Accuracy evaluation of rainfall disaggregation methods. J Hydrol Eng 9(2):71–78
Johnson GL, Hanson CL, Hardegree SP, Ballard EB (1996) Stochastic weather simulation: overview and analysis of two commonly used models. J Appl Meteorol 35:1878–1896
Katz RW, Brown BG (1994) Sensitivity of extreme events to climate change: the case of autocorrelated time series. Environmetrics 5:451–462
Koutsoyiannis D, Onof C, Wheater H (2003) Multivariate rainfall disaggregation at a fine time scale. Water Resour Res 39(7):1–18
Krause P, Boyle DP, Base F (2005) Comparison of different efficiency criteria for hydrological model assessment. Adv Geosci 5:89–97
Legates DR, McCabe GJ (1999) Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour Res 35(1):233–241
Mair A, Fares A (2010) Throughfall characteristics in three non-native Hawaiian forest stands. Agric For Meteorol 150:1453–1466
McCuen RH (2003) Modeling hydrologic change. CRC, Boca Raton
McKague K, Rudra R, Ogilvie J, Ahmed I, Gharabaghi B (2005) Evaluation of weather generator ClimGen for Southern Ontario. Can Water Resour J 30(4):315–330
Meteotest (2003) Meteonorm version 5.0. The global meteorological data base for engineers, planners and education. Software and data on CD-ROM. James and James, London
Moriasi BN, Arnold JG, Van Liew MW, Bingner RL, Harmel RD, Veith TL (2007) Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans ASABE 50(3):885–900
Nicks AD, Gander GA (1994) CLIGEN: a weather generator for climate inputs to water resource and other models. In: Watson DG, Zazueta FS, Harrison TV (eds) Proceedings of the Fifth International Conference on Computer in Agriculture, 1994. ASAE, St Joseph, pp 903–909
Nicks AD, Richardson CW, Williams JR (1990) Evaluation of the EPIC model weather generator. In: Sharpley AN, Williams JR (eds) EPIC—erosion/productivity impact calculator, 1. Model documentation. USDA Technical Bulletin No. 1768, Government Printing Office, Washington, DC, pp 105–124
Parton WJ, Logan JA (1981) A model for diurnal variation in soil heat flux and net radiation. Agric Meteorol 23:205–216
Richardson CW, Nicks AD (1990) Weather generation description. In: Sharpley AN, Williams JR (eds) EPIC—Erosion/Productivity Impact Calculator, 1. Models documentation, USDA Technical Bulletin No. 1768. GPO, Washington, DC, pp 93–104
Richardson CW, Wright DA (1984) WGEN: a model for generating daily weather variables. USDA, Agricultural Research Services, Bulletin No. ARS-8. Government Printing Office, Washington, DC
Roy SS, Balling RC Jr (2004) Analysis of Hawaiian diurnal rainfall patterns. Theor Appl Climatol 79:209–214
Running S, Nemani R, Hungerford R (1987) Extrapolation of synoptic meteorological data in mountainous terrain and its use for simulating forest evapotranspiration and photosynthesis. Can J For Res 17:472–483
Safeeq M (2010) The response of different hydrologic processes under changing land use/land cover and climate in Mākaha watershed, O’ahu. Ph.D. thesis, University of Hawaii at Manoa, HI, USA
Sahoo GB, Ray C, Carlo EHD (2006) Calibration and validation of a physically distributed hydrological model, MIKE SHE, to predict streamflow at high frequency in a flashy mountainous Hawaii stream. J Hydrol 327:94–109
Segond ML, Onof C, Wheater HS (2006) Spatial–temporal disaggregation of daily rainfall from a generalized linear model. J Hydrol 331(3–4):674–689
Selker JS, Haith DA (1990) Development and testing of single-parameter precipitation distribution. Water Resour Res 26(11):2733–2740
Socolofsky SA, Adams EE, Entekhabi D (2001) Disaggregation of daily rainfall for continuous watershed modeling. J Hydrol Eng 6(4):300–309
Stockle CO, Bellocchi G, Nelson R (1998) Evaluation of the weather generator ClimGen for several world locations. Seventh International Congress for Computer Technology in Agriculture, Italy
Stockle CO, Campbell GS, Nelson R (1999) ClimGen manual. Biological Systems Engineering Department, Washington State University, Pullman
Waichler SR, Wigmosta MS (2003) Development of hourly meteorological values from daily data and significance to hydrological modeling at H. J. Andrews Experimental Forest. J Hydrometeor 4:251–263
Weibull W (1951) A statistical distribution function of wide applicability. J Appl Mech-Trans ASME 18(3):293–297
Wigmosta MS, Lettenmaier DP, Vail LW (1994) A distributed hydrology–vegetation model for complex terrain. Water Resour Res 30(6):1665–1679
Willmott CJ (1981) On the validation of models. Phys Geogr 2:184–194
Willmott CJ (1982) Some comments on evaluation of model performance. Bull Am Meteorol Soc 63(11):1309–1313
Zhang J, Murch RR, Ross MA, Ganguly AR, Nachabe M (2008) Evaluation of statistical rainfall disaggregation methods using rain-gauge information for West-Central Florida. J Hydrol Eng 13(12):1158–1169
Acknowledgements
We thank Alan Mair for his assistance in establishing the climate monitoring network. The authors wish to thank Roger Nelson at Washington State University for assisting with ClimGen and providing technical supports. The authors also wish to thank the Honolulu Board of Water Supply and members of Mohala I Ka Wai for their assistance and cooperation. Finally, the authors would like to thank two reviewers for their constructive comments.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Model bias (ē) and standard error (S e) were calculated as follows:
where P i and O i are the predicted and observed data at any given time i, and N is the total number of data points.
If the model is reliable, then S e will be significantly smaller than the standard deviation of measured data (S o). Thus, the ratio S e/S o ,which is known as relative standard error R s, is a dimensionless measure of the improvement in the accuracy of prediction (McCuen 2003). When R s is near zero, the model significantly improves the accuracy of prediction over the mean; however, when R s is near 1.0, the model provides no improvement in prediction compared to the mean. Other dimensionless indices such as relative bias (R b), relative standard error (R s), relative difference between observed and predicted standard deviations (ΔS), and significance of difference test (Test) were calculated as follows:
where \( \bar{O} \) and \( \bar{P} \) are the mean of observed and predicted weather data, respectively, and S p is the standard deviation of predicted weather data. The closer the values of R b, R s, and ΔS to zero, the better the models are. The significant difference test was evaluated based on a two tailed z-test at 95% significance level. If the test values are greater than 1.0, then the difference between observed and predicted data is significant.
The index of agreement (d 2) proposed by Willmott (1981, 1982) represents the ratio between mean square error and the potential error. The d 2 can detect additive and proportional differences in the observed and simulated means and variances. However, d 2 is often criticized for its over-sensitivity to extreme values due to squared differences. Legates and McCabe (1999) suggested a modified version of index of agreement (d 1) that is less sensitive to extreme values. The index of agreement ranges between 0 and 1, where a value of 1 indicates a perfect agreement and a value of 0 indicates no agreement at all. The index of agreement (d 2) and its modified form (d 1) were estimated as follows:
and
Rights and permissions
About this article
Cite this article
Safeeq, M., Fares, A. Accuracy evaluation of ClimGen weather generator and daily to hourly disaggregation methods in tropical conditions. Theor Appl Climatol 106, 321–341 (2011). https://doi.org/10.1007/s00704-011-0438-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-011-0438-4