
Abstract
Drought is a complex natural phenomenon, so, precise prediction of drought is an effective mitigation tool for measuring the negative consequences on agriculture, ecosystems, hydrology, and water resources. The purpose of this research was to explore the potential capability of support vector regression (SVR) integrated with two meta-heuristic algorithms i.e., Grey Wolf Optimizer (GWO), and Spotted Hyena Optimizer (SHO), for meteorological drought (MD) prediction by utilizing EDI (effective drought index). For this objective, the two-hybrid SVR–GWO, and SVR–SHO models were constructed at Kumaon and Garhwal regions of Uttarakhand State (India). The EDI was computed in both study regions by using monthly rainfall data series to calibrate and validate the advanced hybrid SVR models. The autocorrelation function (ACF) and partial-ACF (PACF) were utilized to determine the optimal inputs (antecedent EDI) for EDI prediction. The results produced by the hybrid SVR models were compared with the calculated (observed) values by employing the statistical indicators and through graphical inspection. A comparison of results demonstrates that the hybrid SVR–GWO model outperformed to the SVR–SHO models for all study stations located in Kumaon and Garhwal regions. Also, the results highlighted the better suitability, supremacy, and convergence behavior of meta-heuristic algorithms (i.e., GWO and SHO) for meteorological drought prediction in the study regions.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Drought is the most frequent natural disasters adversely affecting most parts of the world (Wilhite and Glantz 1985; Lin et al. 2017). Conceptually, drought is characterized through the prolonged and abnormal state of water deficit or remarkable shortfall in precipitation, consequently, it affects the water resources (Wilhite et al. 2014). In general, drought can be grouped in four broader categories including hydrological, meteorological, agricultural, and socio-economic droughts (Mishra et al. 2007; Mishra and Singh 2010). A variety of drought indices (DI) has been derived for monitoring and defining the drought parameters like duration, severity, intensity, and areal extent (Mishra and Singh 2011). Some of the widely used DI for meteorological drought quantification and forecasting include the Standardized Precipitation Index (SPI) (McKee et al. 1993), Effective Drought Index (EDI) (Byun and Wilhite 1999), Standardized Precipitation Evapotranspiration Index (SPEI) (Vicente-Serrano et al. 2010). The computation of the EDI assigns different weights to recent and historical precipitation (Byun and Wilhite, 1999), which is advantageous over the other DI (Kim et al. 2009; Byun and Kim 2010). In related contrast, several studies have reported the robustness and effectiveness of the EDI over the many DI (Morid et al. 2006; Jain et al. 2015b; Deo et al. 2017a). Therefore, scientists have drawn attention to the drought forecasting for several purposes such as planning and management of freshwater resources, policymaking, drought preparedness, risk management, and mitigation (Wilhite 1986; Mishra and Singh 2011; Kisi et al. 2019).
The spatio-temporal analysis of droughts helps to recognize the overall impact of drought on a regional scale with different thresholds (Mishra and Singh 2009). The information obtained from regional drought analysis is vital for short and long-term planning and management of water resources systems. Also, the frequency distribution of drought occurrence is utilized to construct the drought severity–area–frequency (SAF), severity–duration–frequency (SDF), and severity–area–duration (SAD) curves. These curves are beneficial for evaluating the droughts in a region. Various studies have been conducted by the researchers on spatial and temporal patterns of drought at a regional scale by employing the SAF, SDF, and SAD curves (Kim et al. 2002; Mishra and Desai 2005b; Vicente-Serrano 2006; Mishra and Singh 2009; Jasim and Awchi 2020). Presently, the spatio-temporal patterns of drought have been analyzed through the application of remote sensing and geographical information system using various DI (Akhtari et al. 2009; Jain et al. 2015a; Patel and Yadav 2015; Manikandan and Tamilmani 2015; Thomas et al. 2015; Rahman and Lateh 2016; Zarei et al. 2016; Mitra and Srivastava 2017).
However, the accurate forecasting of the drought is a critical subject in recent times, and the extensive work has been conducted on modeling numerous characteristics of drought, but the major challenge is to implement suitable methods for forecasting the onsets and terminations points of the droughts. Over the last 30 years, regression models (Kumar and Panu 1997; Leilah and Al-Khateeb 2005), stochastic models (Mishra and Desai 2005a; Fernández et al. 2009; Durdu 2010; Bahrami et al. 2019), probability models (Cancelliere et al. 2007) and neural network models (Mishra and Desai 2006; Morid et al. 2007; Mishra et al. 2007; Bacanli et al. 2009; Özger et al. 2012) have been applied for this purpose. Zhang et al. (2017a, b) applied Autoregressive Integrated Moving Average (ARIMA), Artificial Neural Network (ANN), and Wavelet-ANN (W-ANN) models to forecast the SPI-6 and SPI-12 in the north of Haihe River basin, China. They found that the WANN performed superior to the alternatives in forecasting the multi-scalar SPI in the study basin. Rafiei-Sardooi et al. (2018) forecasted SPI-3 and SPI-12 in the Jiroft Plain of south Kerman Province (Iran) using Neuro-Fuzzy (NF) and ARIMA models. They found that the NF model significantly outperformed the ARIMA model for both time scales in the study region. Soh et al. (2018) examined the potential of Wavelet-ARIMA-ANN and Wavelet-Adaptive Neuro-Fuzzy Inference System (W-ANFIS) to predict the SPEI-1, SPEI-3, and SPEI-6 in the Langat River basin, Malaysia. They found that the prediction accuracy of both models was improved with the length of time scale (wavelet-ARIMA-ANN for SPEI-3 and SPEI-6, and W-ANFIS for SPEI-1) in the study basin.
In recent times, the extensive and successful application of simple and hybrid meta-heuristic or artificial intelligence (AI) models such as Support Vector Regression (SVR), ANN, W-ANN, ANFIS, Multilayer Perceptron Neural Network (MLPNN), Genetic Algorithm (GA), Gene Expression Programming (GEP), Extreme Learning Machine (ELM), Co-Active Neuro-Fuzzy Inference System (CANFIS), Support Vector Machine (SVM), Adaptive Neuro-Fuzzy Inference System (ANFIS), W-SVM, and k-Nearest Neighbor (KNN) have been found in meteorological drought prediction on regional and global scales (Barua et al. 2012; Bari Abarghouei et al. 2013; Belayneh et al. 2014; Jalalkamali et al. 2015; Maca and Pech 2016; Djerbouai and Souag-Gamane 2016; Ali et al. 2017; Mokhtarzad et al. 2017; Zhang et al. 2017b; Ibrahimi and Baali 2018; Komasi et al. 2018; Bahrami et al. 2019; Khan et al. 2020). Memarian et al. (2016) examined the potential of CANFIS for meteorological drought forecasting in Birjand (Iran) through SPI and climatic parameters. They found better predictability of the CANFIS model over the study area. Achour et al. (2020) analyzed and forecasted drought using the multi-scalar SPI (i.e., 3, 6, 9, and 12 months) by the MLPNN model in Algeria. They found that the MLPNN model with the Levenberg–Marquardt algorithm provides suitable results over the study region. Zhang et al. (2020) applied ARIMA, W-ANN, and SVM techniques to forecast drought in the Sanjiang Plain of China using 12-month scale SPEI. Results showed that the ARIMA model outperformed the other two models in the study region. However, the performance of AI-based models could be improved by tuning its parameters to achieve robust accuracy.
Recently, the new bio-inspired algorithms, i.e. Grey Wolf Optimizer (GWO), Spotted Hyena Optimizer (SHO), Particle Swarm Optimization (PSO), Genetic Algorithm (GA), Ant Colony Optimization (ACO) have more attention to solve optimization problems and improve the AI models. Improving the AI model could increase the prediction accuracy even in the drought prediction field. Aghelpour et al. (2020) utilized three indices; Palmer Drought Severity Index (PDSI), SPI, and multivariate-SPI (MSPI) to forecast the agricultural drought by employing the ANFIS, ANFIS-ACO, ANFIS-GA, and ANFIS-PSO at 31 synoptic stations positioned in Iran. Results revealed the better suitability of ANFIS-ACO and ANFIS-GA models over the study stations, and the bio-inspired algorithms improve the accuracy of the ANFIS model. The GWO (Mirjalili et al. 2014) is one of the modern nature-inspired algorithms widely used for improving AI models, even in the field of hydrology. Dehghani et al. (2019) proposed the ANFIS-GWO model for immediate-short-term to long-term influent flow prediction from a wastewater treatment plant located in Isfahan city, Iran. The results obtained support the superiority of hybrid GWO models. Tikhamarine et al. (2020b) applied the GWO algorithm to improve AI model accuracy for monthly streamflow prediction. In this work, the GWO algorithm was combined with ANN, SVM, and MLR models to predict the monthly streamflow of the Nile River at the Aswan High Dam, Egypt, and the results obtained support the ability of hybrid GWO models. Moreover, Maroufpoor et al. (2020) used the GWO algorithm to improve the ANN model for estimating the daily reference evapotranspiration and their results were very promising.
According to the reported literature and author knowledge, only limited work has been conducted on the prediction of meteorological drought (MD) by employing the hybrid meta-heuristic approaches. Moreover, the benefits of the GWO algorithm get attention to use it for meteorological drought prediction and compared with another new algorithm (i.e. Spotted Hyena Optimizer: SHO). The novelty of the current work is to investigate the potential capability of support vector regression (SVR) embedded with novel bio-inspired algorithms (i.e. Grey Wolf Optimizer and Spotted Hyena Optimizer) for meteorological drought prediction in Kumaon (six stations) and Garhwal (seven stations) regions with effective drought index. These methods were not previously implemented for this issue. For validation purposes, the performance of these models was evaluated by using five statistical indicators and through graphical interpretation.
2 Study location and data collection
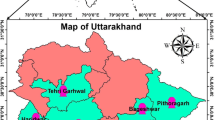
The Uttarakhand State is divided into (i) Kumaon region including six districts namely Almora, Bageshwar, Champawat, Nainital, Pithoragarh and Udham Singh Nagar (Pantnagar), and (ii) Garhwal region including seven districts namely Chamoli, Dehradun, Haridwar, Pauri Garhwal, Rudraprayag, Tehri Garhwal, and Uttarkashi (Fig. 1). The geographical co-ordinate of Uttarakhand State lies between 28°43′ N and 31°28′ N latitudes, and 77°34′ E and 81°03′ E longitudes with varying elevation from 145 to 7796 m above MSL and comprises 53,812.47 km2 area. The region of Uttarakhand with high altitude (> 4572 m) is cold throughout the year and unreachable due to heavy snowfall (Nandargi et al. 2016). The annual rainfall ranges from 260 to 3955 mm, mostly received (60–85%) in monsoon season (June–September month) over the State (Basistha et al. 2008; Nandargi et al. 2016; Malik et al. 2019b, 2020; Malik and Kumar 2020). The heavy rainfall is received in the eastern edges of the Himalayan ranges and comparatively dry in the western region. The temperature varies between sub-zero -43 °C, and during the winter season ranges from 0 to 15 °C in the Uttarakhand State (Nandargi et al. 2016; Malik et al. 2019b, 2020; Malik and Kumar 2020). Over the state, the summer season extends from April to June, while the winter season covers from October to February months. Table 1 explores the information on geographical coordinates and rainfall data availability year (month) for Kumaon and Garhwal regions. The monthly rainfall data for study stations were obtained from CRC (Crop Research Centre) observatory set at G.B. Pant University of Agriculture and Technology, Pantnagar, and IMD (Indian Meteorological Department), Pune.

Study location map of Kumaon and Garhwal regions (Uttarakhand)
3 Methodology
3.1 Effective drought index
EDI is a globally accepted standard metric for meteorological drought quantification, introduced by Byun and Wilhite (1999). The computation of EDI includes the effective precipitation (EP), which is the precipitation amount with a time-dependent reduction function, and precipitation required for return to normal (PRN) conditions. EDI was first developed for monitoring drought duration and severity on the daily time scale (Byun and Wilhite 1999; Kim et al. 2009; Roudier and Mahe 2010). Nowadays, its principles are prolonged on monthly time scales to investigate the drought duration, drought severity, and drought intensity (Smakhtin and Hughes 2007; Morid et al. 2007; Dogan et al. 2012; Jain et al. 2015b; Deo et al. 2017a). The EDI is computed using the Eqs. (1–4):
where P = monthly rainfall, EP = effective precipitation for the ith duration of summation (DS).
The deviation of EP (DEP) form the mean of EP (MEP) is computed using Eq. (2):
The precipitation needed for a return to normal \({(PRN}_{j})\) for the jth DS is determined using Eq. (3):
Finally, EDI is calculated as (Byun and Wilhite 1999):
where \(SD(PRN)\) indicates the standard deviation of PRN for the jth month in the record time.
3.2 Support vector regression (SVR)
The SVR is the extended version of SVM (support vector machine) created on regression functions. The SVM is an intelligent model dependent on the structural risk minimization (SRM) principle developed by Vapnik (1995). Smola (1996) added regression functions to the original version of the SVM model and created a new version of SVM to solve regression and prediction problems called SVR. The relationship among the input and output parameters is recognized (Su et al. 2018; Tikhamarine et al. 2019) using Eq. (5):
where \(y\) is the output variable, \(x\) is the input variable, \(f\) is the regression function, ϕ is the mapping function, \(w\) and \(b\) are the weight and the bias, and both defined using Eqs. (6–7) (Su et al. 2018):
where C is the penalty parameter, \({\xi }_{i}\) and \({\xi }_{i}^{*}\) are corresponding the slack variables and ε is the boundary value.
Employing the Lagrangian multipliers, the optimization problem largely converts to quadratic programming and a nonlinear regression function solution can be defined as below:
where \(K\left(x,{x}_{i}\right)\) is the Kernel function and \({\alpha }_{i}\), and \({\alpha }_{i}^{*}\) are the dual variables.
There are several kernel functions such as linear, radial basis function (RBF), polynomial, and sigmoid (Ansari and Gholami 2015; Zhang et al. 2017a; Tikhamarine et al. 2020a). In this study, the RBF kernel function was used to optimized the SVR model, and written as:
In which, \(\gamma\) denotes the kernel parameter.
3.3 Meta-heuristic algorithms
3.3.1 Grey Wolf Optimizer (GWO)
Mirjalili et al. (2014) developed the GWO algorithm based on the hunting mechanisms of grey wolves and their strict hierarchy to search and hunt for prey. The grey wolf hierarchy includes four groups: alpha (α), beta (ß), delta (δ), and omega (ω). The leader is the alpha wolf and first in charge of decision-making in the pack and followed by beta, delta, and omega wolves, respectively. The mechanisms of wolves’ hunting are: tracking, encircling, and attacking the prey (Fig. 2). For more information about the GWO algorithm, readers can refer to Mirjalili et al. (2014).

source: Mirjalili et al. 2014)
Hunting behavior of grey wolves: a chasing, approaching, and tracking prey; b–d pursuit, harassing, and encircling; e stationary situation and attack (
3.3.2 Spotted Hyena Optimizer (SHO)
Spotted Hyena Optimizer (SHO) is a new optimization algorithm suggested by Dhiman and Kumar (2017). The SHO algorithm mimics the hunting behavior of the Spotted Hyenas in nature. In this algorithm, the optimal solution is found based on four steps of prey hunting; encircling, hunting, attacking prey (exploitation), and search for prey (exploration). Figure 3 illustrates the most important steps of the aforementioned approach. Readers can refer to Dhiman and Kumar (2017) for detailed information about the working functions of the SHO algorithm.

source: Dhiman and Kumar 2017)
Hunting algorithm performed in the algorithm of Spotted Hyena Optimizer (SHO): a the feasible next places of the members along with position vectors, and b attacking the prey (
In this paper, SVR was selected and developed as an artificial intelligence model for meteorological drought prediction. Two meta-heuristic algorithms (i.e. GWO and SHO) were selected and compared to each other to find optimal SVR parameters to increase model performance. In fact, the performance of the SVR usually depends on the correct identification of its parameters. Consequently, the optimal parameters could increase the accuracy of SVR to achieve robust performance. Furthermore, a high optimization algorithm is needed to solve this optimization problem. To build the SVR–GWO hybrid model, the GWO algorithm was combined with the SVR model to find ideal SVR parameters, while the SHO was combined with the SVR to build the SVR–SHO model. The steps and construction processes for SVR–GWO (Mirjalili et al. 2014) and SVR–SHO (Dhiman and Kumar 2017) are concise in Fig. 4. The steps involved in Fig. 4 are outlined below:

Flowchart of the proposed hybrid a SVR–GWO, and b SVR–SHO models
Step 1: Initialize the population of spotted hyenas and position of grey wolves.
Step 2: Select the initial parameters of SHO and GWO, and describe the maximum number of iterations.
Step 3: Calculate the fitness value of each search agent for SHO and GWO.
Step 4: Explore the best search agent in the given search space.
Step 5: Outline the cluster of optimal solutions until the acceptable results are found.
Step 6: Update the positions of the search agents in SHO (Dhiman and Kumar 2017) and GWO (Mirjalili et al. 2014).
Step 7: Check the search agent that is bypassing the search space and then modify it.
Step 8: Calculate the update search agent fitness value and update the vector if there is a better solution than the previous optimal solution.
Step 9: Update the group of spotted hyenas and grey wolves to updated search agent fitness values.
Step 10: Stop the SHO and GWO algorithm, if the stopping criteria are satisfied, otherwise back to step 5.
Step 11: Return the best optimal solution, after stopping criteria is satisfied, which is obtained so far.
3.4 Optimal input parameter nomination
After the computation of EDI at the study stations, the prediction of the meteorological drought was proceeded by using hybrid SVR–GWO, and SVR–SHO models. The optimal inputs were nominated by employing autocorrelation function (ACF) and partial-ACF (PACF) on EDI time-series of each study station at 5% level of significance (Tiwari and Adamowski 2013; Deo et al. 2017b; Malik et al. 2019c). The ACF and PACF were computed using Eqs. (10 and 11):
where k displays the lag through the sequence \({Y}_{t}\), \(\stackrel{-}{Y}\) shows the average of the entire EDI data series, and N is the number of data points in the EDI series.
The PACF values for kth lags were tested at 5% level of significance by constructing the upper and lower critical limits (UCL and LCL) (Anderson 1942; Ljung and Box 1978) using Eq. (12):
The final nomination of input (lags) for output (target) prediction was done based on the significant value of PACF at 5% confidence interval (cross the UCL and LCL) for all the study stations located in both regions. In statistical hypothesis testing, at 5% confidence interval (critical limit = ± 1.96) given by Fisher (1925), and widely employed in numerous fields of water resources engineering (Sudheer et al. 2002; Landeras et al. 2009; Narasimha Murthy et al. 2019; Malik and Kumar 2020; Akar and Aksoy 2020; Malik et al. 2020). Table 2 explores the details of input variables (lags) used for output (EDI) prediction by constructing the SVR–GWO and SVR–SHO models at study stations. Figure 5a–f demonstrates the PACF results on EDI data series for Almora, Bageshwar, Champawat, Nainital, Pithoragarh, and Pantnagar stations of the Kumaon region, which indicates the significant (optimal) lags 1, 2, 5, and 6 for Almora Station (Fig. 5a), the lags 1, 2, and 6 for Bageshwar Station (Fig. 5b), the lags 1, 2, 5 and 6 for Champawat Station (Fig. 5c), the lags 1, 2, 4, 5, and 11 for Nainital Station (Fig. 5d), lags 1, and 9 for Pithoragarh (Fig. 5e), and the lags 1, and 2 for Pantnagar Station (Fig. 5f). Similarly, Fig. 6a–g illustrates the PACF results on EDI data series for Chamoli, Dehradun, Haridwar, Pauri Garhwal, Rudraprayag, Tehri Garhwal, and Uttarkashi stations of Garhwal region, which indicates the significant (optimal) lags 1, 7, and 9 for Chamoli Station (Fig. 6a), the lag 1 for Dehradun and Rudraprayag stations (Fig. 6b, e), the lags 1, and 2 for Haridwar and Tehri Garhwal stations (Fig. 6c, f), the lags 1, 2, 5, and 10 for Pauri Garhwal Station (Fig. 6d), and lags 1, and 7 for Uttarkashi Station (Fig. 6g). Table 3 summarises the details of training (70%) and testing (30%) EDI data percentages utilized for one month ahead meteorological drought prediction over the study regions.

PACF analysis of EDI at a Almora, b Bageshwar, c Champawat, d Nainital, e Pithoragarh, and f Pantnagar stations in Kumaon region

PACF analysis of EDI at a Chamoli, b Dehradun, c Haridwar, d Pauri Garhwal, e Rudraprayag, f Tehri Garhwal, and g Uttarkashi stations in Garhwal region
3.5 Statistical indicators
The formulated hybrid SVR–GWO and SVR–SHO models in Kumaon and Garhwal regions for EDI prediction were evaluated by utilizing statistical indicators (mean absolute error: MAE, root mean square error: RMSE, Nash–Sutcliffe efficiency: NSE, coefficient of correlation: COC, and Willmott Index: WI), and through graphical inspection (time variation graph, and scatter-plot). The mathematical expression of MAE, RMSE, NSE, COC, and WI are as follows:
-
1
Mean absolute error (Legates and McCabe 1999; Willmott and Matsuura 2005)
$$MAE=\frac{1}{N}\sum_{i=1}^{N}|{EDI}_{pre,i}-{EDI}_{cal,i}| \left(0 <{ MAE }<{ \infty }\right)$$(13) -
2
Root mean square error (Legates and McCabe 1999; Willmott and Matsuura 2005)
$$RMSE=\sqrt{\frac{1}{N} \sum_{i=1}^{N}({EDI}_{cal, i }- {EDI}_{pre,i}{)}^{2}} \left(0 <\mathrm{ RMSE }<{ \infty }\right)$$(14) -
3
Nash–Sutcliffe efficiency (Nash and Sutcliffe 1970)
$$NSE=1-\left[\frac{\sum_{i=1}^{N}({EDI}_{cal,i }- {EDI}_{pre,i}{)}^{2}}{\sum_{i=1}^{N}({{EDI}_{cal,i }- \stackrel{-}{{EDI}_{cal }})}^{2}}\right] \left(-\infty <\mathrm{ NSE }< 1\right)$$(15) -
4
Coefficient of correlation (Taylor 2001; Moriasi et al. 2015)
$$COC=\frac{\sum_{\mathrm{i}=1}^{\mathrm{N}}\left({EDI}_{cal,i }- \stackrel{-}{{EDI}_{cal }}\right) \left({EDI}_{pre,i} - \stackrel{-}{{EDI}_{pre}}\right) }{\sqrt{\sum_{\mathrm{i}=1}^{\mathrm{N}}({{EDI}_{cal,i }- \stackrel{-}{{EDI}_{cal }})}^{2} \sum_{\mathrm{i}=1}^{\mathrm{N}}({{EDI}_{pre,i} - \stackrel{-}{{EDI}_{pre}})}^{2} } } \left(-1 <\mathrm{ COC }< 1\right)$$(16) -
5
Willmott index (Willmott 1981)
$$\mathrm{WI}=1-\left[\frac{\sum_{i=1}^{N}({EDI}_{pre,i} - {EDI}_{cal, i}{)}^{2}}{\sum_{i=1}^{N}({\left|{EDI}_{pre,i} - \stackrel{-}{{EDI}_{cal }}\right|+\left|{EDI}_{cal,i }- \stackrel{-}{{EDI}_{cal }}\right|)}^{2}}\right]\left(0 <\mathrm{ WI }\le 1\right),$$(17)
where \({EDI}_{cal}\), \({EDI}_{pre}\), \(\stackrel{-}{{EDI}_{cal}}\), and \(\stackrel{-}{{EDI}_{pre}}\) represents the calculated, predicted, mean of calculated, and mean of predicted EDI values for N observations in the ith dataset. A model with lower MAE and RMSE, and higher NSE, COC, and WI were considered relatively better for MD prediction at study stations.
4 Results and discussion
4.1 Drought prediction using hybrid SVR models
After the selection of significant lags/inputs for both regions as listed in Table 2 were utilized for 1 month ahead EDI prediction by employing the hybrid SVR–GWO and SVR–SHO models. These hybrid SVR models were calibrated and validated using 70% and 30% of EDI time-series data and evaluated through statistical indicators (MAE, RMSE, NSE, COC, and WI) and by visual inspection (time variation graph, and scatter-plot). Table 4 summarizes the validation results of SVR–GWO and SVR–SHO models at Almora, Bageshwar, Champawat, Nainital, Pithoragarh, and Udham Pantnagar stations. The MAE, RMSE, NSE, COC and WI of the SVR–GWO, respectively, ranges 0.363 to 0.622, 0.538 to 0.964, 0.575 to 0.860, 0.763 to 0.930 and 0.865 to 0.958 while those of the SVR–SHO varies from 0.379 to 0.623, 0.567 to 0.965, 0.553 to 0.765, 0.745 to 0.931, and 0.847 to 0.931, respectively. The ranges clearly reveal that the SVR–GWO is superior to the SVR–SHO in drought prediction based on EDI. It is observed from Table 4 that the SVR–GWO model ranked first at Almora, Bageshwar, Champawat, Nainital, Pithoragarh and Pantnagar stations with minimum MAE (RMSE) = 0.418, 0.445, 0.420, 0.379, 0.363, 0.622 (0.603, 0.652, 0.659, 0.565, 0.538, 0.965) and higher NSE/COC (WI) = 0.575, 0.721, 0.646, 0.697, 0.860, 0.660/ 0.763, 0.850, 0.817, 0.835, 0.930, 0.819 (0.865, 0.916, 0.891, 0.906, 0.958, 0.895), respectively. The hybrid SVR–GWO model is closely followed by the SVR–SHO model. The comparison of two methods and all six stations in Table 4 exposed the best prediction of EDI at Pithoragarh station.
Similarly, Table 4 outlines the prediction results of SVR–GWO, and SVR–SHO models during the validation period for Chamoli, Dehradun, Haridwar, Pauri Garhwal, Rudraprayag, Tehri Garhwal, and Uttarkashi stations. The MAE, RMSE, NSE, COC and WI of the SVR–GWO vary from 0.253 to 0.402, from 0.363 to 0.658, from 0.558 to 0.805, from 0.754 to 0.899 and from 0.854 to 0.943 while the ranges of the SVR–SHO are 0.269 to 0.417, 0.379 to 0.667, 0.546 to 0.730, 0.755 to 0.893 and 0.854 to 0.923, respectively. In overall, the SVR–GWO has lower arrays of MAE and RMSE, and higher ranges of NSE, COC, and WI compared to SVR–SHO. As clearly seen from Table 4, the SVR–GWO model had the lowest MAE and RMSE and highest NSE, COC, and WI indicators at seven study stations located in the Garhwal region. Furthermore, a comparison across all two methods and seven stations in Table 4 shows that the SVR–GWO model (MAE = 0.253, RMSE = 0.363, NSE = 0.753, COC = 0.870, and WI = 0.929) yielded best prediction of EDI at Uttarkashi station.
The goodness-of-fit of two EDI predictive models was further assessed by plotting the time variation graphs and scatter plots of calculated vs predicted EDI values during the validation phase for six stations situated in the Kumaon region (Fig. 7a–f). These figures confirm the results presented in Table 4, illustrating the better performance of the SVR–GWO model with a coefficient of determination (R2) = 0.583, 0.723, 0.668, 0.698, 0.865, and 0.671 for Almora, Bageshwar, Champawat, Nainital, Pithoragarh, and Pantnagar stations compared to SVR–SHO, respectively. Also, the less degree of scattering was visible between predicted and calculated EDI observations for SVR–GWO models at six stations as illustrated in Fig. 7a–f. Based on the coefficient of determination of the regression line and degree of scattering, the SVR–GWO model appeared to have a better accuracy compared to the SVR–SHO model. Moreover, the SVR–GWO model with designated lags (Table 4) could be cast for prediction of MD based on EDI at six study stations of the Kumaon region.


Comparison of calculated and predicted EDI values by hybrid SVR models for validation period at a Almora, b Bageshwar, c Champawat, d Nainital, e Pithoragarh, and f Pantnagar stations in Kumaon region
Figure 8a–g demonstrates the time variation graphs and scatter plots between calculated and predicted EDI values by SVR–GWO, and SVR–SHO models during the validation period at seven stations positioned in the Garhwal region. It is noticed from these figures that the regression line has R2 = 0.717, 0.569, 0.577, 0.807, 0.666, 0.647, and 0.757 for the SVR–GWO model at Chamoli, Dehradun, Haridwar, Pauri Garhwal, Rudraprayag, Tehri Garhwal, and Uttarkashi stations which are higher than those of the SVR–SHO, respectively. Likewise, the degree of scattering was less between predicted and calculated EDI observations for the SVR–GWO model in the Garhwal region. Also, these figures clearly expose the SVR–GWO model with elected lags that could be utilized for MD prediction through EDI at seven stations of the Garhwal region.


Comparison of calculated and predicted EDI values by hybrid SVR models for validation period at a Chamoli, b Dehradun, c Haridwar, d Pauri Garhwal, e Rudraprayag, f Tehri Garhwal, and g Uttarkashi stations in Garhwal region
4.2 Discussion
To address the negative consequences of droughts on the ecosystem, the researchers must formulate the versatile models for better prediction or forecasting of drought, exclusively in the nations/ regions that are sensitive to climate change. In this study, two-hybrid SVR models have been used to predict the EDI in Kumaon (six stations) (and Garhwal seven stations) regions of Uttarakhand State utilizing data for the period of 1901–2015 (115-year), 1961–2016 (56-year), 1955–2015 (61 years), and 1951–2015 (65 years). Two types of meta-heuristic algorithms, i.e., Grey Wolf Optimizer and Spotted Hyena Optimizer were examined with the SVR technique. The results of the appraisal are evident in the better feasibility and predictability of the hybrid SVR–GWO model in Kumaon and Garhwal regions. Furthermore, with respect to the MAE (RMSE) of SVR–GWO model the prediction accuracy of SVR–SHO model was enhanced by 3.9% (2.6%) for Almora, 5.7% (3.0%) for Bageshwar, 6.3% (2.7%) for Champawat, 0.3% (0.4%) for Nainital, 28.3% (22.7%) for Pithoragarh, and 0.2% (0.1%) for Pantnagar stations placed in Kumaon region. Similarly, the prediction accuracy of SVR–SHO model was enhanced by 2.5% (1.0%) for Chamoli, 0.3% (0.4%) for Dehradun, 1.0% (1.3%) for Haridwar, 10.6% (8.3%) for Pauri Garhwal, 1.2% (0.9%) for Rudraprayag, 0.3% (0.2%) for Tehri Garhwal, and 5.9% (4.2%) for Uttarkashi stations in Garhwal region with respect to the MAE (RMSE) of SVR–GWO model. This analysis also confirms the superiority of the SVR–GWO model over the SVR–SHO model in both study regions.
The findings of the current research were compared with the other studies, conducted on meteorological drought (MD) prediction by employing the numerous hybrid meta-heuristic models (Minimax Probability Machine Regression: MPMR, Ensemble-ANFIS: E-ANFIS, M5T, Weighted Wavelet_Fuzzy_SVR: WW_F_SVR, Wavelet_Boosting_SVR: W_B_SVR, Multi-Input_Wavelet_Fuzzy_SVR: MI_W_F_SVR, and ANFIS coupled with Butterfly Optimization Algorithm: BOA, Ant Colony Optimizer: ACO, Genetic Algorithm: GA, and Particle Swarm Optimization: PSO) formulated based on several standardized drought indices are summarized in Table 5.
Overall, the results suggested that the applied methods, especially the SVR–GWO model, for regional drought prediction and proactive development strategies to combat drought disasters in the study region. Moreover, the forecasting of drought is a complex process, and endeavoring these forecasts blind is not advisable. The rewards of diverse methods depend on the basic properties or skills of models/ algorithms and the data series. So, it may be more practical and conclusive to select a suitable approach rendering to the characteristics of the data in the different study regions.
5 Conclusion
In the current research, the efficacy of two-hybrid methods; support vector regression with Grey Wolf Optimizer, and Spotted Hyena Optimizer was assessed to predict the meteorological drought by consuming EDI in Kumaon, and Garhwal regions of Uttarakhand State, India. The following conclusions were obtained from their comparison:
-
i.
The hybrid SVR–GWO model outperformed the SVR–SHO for meteorological drought prediction at all stations in both study regions, according to various statistical indicators (i.e., MAE, RMSE, NSE, COC, and WI), and through graphical scrutiny (i.e., time variation graph, and scatter-plot).
-
ii.
Comparison of two-hybrid SVR models at six stations of the Kumaon region and seven stations of the Garhwal region demonstrated that the SVR–GWO model produced the best prediction of EDI at Pithoragarh and Uttarkashi stations.
-
iii.
The obtained results from this research would support the hydrologists, agriculturalists, and water resources managers to formulate the drought mitigation strategy for sustainable development and management of water resources in the study region.
References
Abbasi A, Khalili K, Behmanesh J, Shirzad A (2019) Drought monitoring and prediction using SPEI index and gene expression programming model in the west of Urmia Lake. Theor Appl Climatol 138:553–567. https://doi.org/10.1007/s00704-019-02825-9
Achour K, Meddi M, Zeroual A et al (2020) Spatio-temporal analysis and forecasting of drought in the plains of northwestern Algeria using the standardized precipitation index. J Earth Syst Sci 129:42. https://doi.org/10.1007/s12040-019-1306-3
Aghelpour P, Bahrami-Pichaghchi H, Kisi O (2020) Comparison of three different bio-inspired algorithms to improve ability of neuro fuzzy approach in prediction of agricultural drought, based on three different indexes. Comput Electron Agric 170:105279. https://doi.org/10.1016/j.compag.2020.105279
Akar T, Aksoy H (2020) Stochastic and analytical approaches for sediment accumulation in river reservoirs. Hydrol Sci J 65:984–994. https://doi.org/10.1080/02626667.2020.1728474
Akhtari R, Morid S, Mahdian MH, Smakhtin V (2009) Assessment of areal interpolation methods for spatial analysis of SPI and EDI drought indices. Int J Climatol 29:135–145. https://doi.org/10.1002/joc.1691
Ali Z, Hussain I, Faisal M et al (2017) Forecasting drought using multilayer perceptron artificial neural network model. Adv Meteorol 2017:1–9. https://doi.org/10.1155/2017/5681308
Ali M, Deo RC, Downs NJ, Maraseni T (2018) An ensemble-ANFIS based uncertainty assessment model for forecasting multi-scalar standardized precipitation index. Atmos Res 207:155–180. https://doi.org/10.1016/j.atmosres.2018.02.024
Anderson R (1942) Distribution of the Serial Correlation Coefficient. Ann Math Stat 13:1–13. https://doi.org/10.1214/aoms/1177731638
Ansari HR, Gholami A (2015) An improved support vector regression model for estimation of saturation pressure of crude oils. Fluid Phase Equilib 402:124–132. https://doi.org/10.1016/j.fluid.2015.05.037
Bacanli UG, Firat M, Dikbas F (2009) Adaptive Neuro-Fuzzy Inference System for drought forecasting. Stoch Environ Res Risk Assess 23:1143–1154. https://doi.org/10.1007/s00477-008-0288-5
Bahrami M, Bazrkar S, Zarei AR (2019) Modeling, prediction and trend assessment of drought in Iran using standardized precipitation index. J Water Clim Change 10:181–196. https://doi.org/10.2166/wcc.2018.174
Bari Abarghouei H, Kousari MR, Asadi Zarch MA (2013) Prediction of drought in dry lands through feedforward artificial neural network abilities. Arab J Geosci 6:1417–1433. https://doi.org/10.1007/s12517-011-0445-x
Barua S, Ng AWM, Perera BJC (2012) Artificial neural network-based drought forecasting using a nonlinear aggregated drought index. J Hydrol Eng 17:1408–1413. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000574
Basistha A, Arya DS, Goel NK (2008) Spatial distribution of rainfall in Indian Himalayas—a case study of Uttarakhand region. Water Resour Manag 22:1325–1346. https://doi.org/10.1007/s11269-007-9228-2
Belayneh A, Adamowski J, Khalil B, Ozga-Zielinski B (2014) Long-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet neural network and wavelet support vector regression models. J Hydrol 508:418–429. https://doi.org/10.1016/j.jhydrol.2013.10.052
Byun HR, Kim DW (2010) Comparing the Effective Drought Index and the Standardized Precipitation Index. Options Méditerranéennes Séries A Mediterr Semin 85–89
Byun H-R, Wilhite DA (1999) Objective quantification of drought severity and duration. J Clim 12:2747–2756. https://doi.org/10.1175/1520-0442(1999)012%3c2747:OQODSA%3e2.0.CO;2
Cancelliere A, Di MG, Bonaccorso B, Rossi G (2007) Drought forecasting using the standardized precipitation index. Water Resour Manag 21:801–819. https://doi.org/10.1007/s11269-006-9062-y
Dehghani M, Seifi A, Riahi-Madvar H (2019) Novel forecasting models for immediate-short-term to long-term influent flow prediction by combining ANFIS and grey wolf optimization. J Hydrol 576:698–725. https://doi.org/10.1016/j.jhydrol.2019.06.065
Deo RC, Byun H-R, Adamowski JF, Begum K (2017a) Application of effective drought index for quantification of meteorological drought events: a case study in Australia. Theor Appl Climatol 128:359–379. https://doi.org/10.1007/s00704-015-1706-5
Deo RC, Tiwari MK, Adamowski JF, Quilty JM (2017b) Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model. Stoch Environ Res Risk Assess 31:1211–1240. https://doi.org/10.1007/s00477-016-1265-z
Dhiman G, Kumar V (2017) Spotted hyena optimizer: a novel bio-inspired based metaheuristic technique for engineering applications. Adv Eng Softw 114:48–70. https://doi.org/10.1016/j.advengsoft.2017.05.014
Djerbouai S, Souag-Gamane D (2016) Drought forecasting using neural networks, wavelet neural networks, and stochastic models: case of the Algerois Basin in North Algeria. Water Resour Manag 30:2445–2464. https://doi.org/10.1007/s11269-016-1298-6
Dogan S, Berktay A, Singh VP (2012) Comparison of multi-monthly rainfall-based drought severity indices, with application to semi-arid Konya closed basin, Turkey. J Hydrol 470–471:255–268. https://doi.org/10.1016/j.jhydrol.2012.09.003
Durdu ÖF (2010) Application of linear stochastic models for drought forecasting in the Büyük Menderes river basin, western Turkey. Stoch Environ Res Risk Assess 24:1145–1162. https://doi.org/10.1007/s00477-010-0366-3
Fernández C, Vega JA, Fonturbel T, Jiménez E (2009) Streamflow drought time series forecasting: a case study in a small watershed in North West Spain. Stoch Environ Res Risk Assess 23:1063–1070. https://doi.org/10.1007/s00477-008-0277-8
Fisher RA (1925) Statistical methods for research workers. Edinburgh, UK Oliver Boyd, p 43
Fung KF, Huang YF, Koo CH (2019) Coupling fuzzy–SVR and boosting–SVR models with wavelet decomposition for meteorological drought prediction. Environ Earth Sci 78:693. https://doi.org/10.1007/s12665-019-8700-7
Ibrahimi A, Baali A (2018) Application of Several Artificial Intelligence Models for Forecasting Meteorological Drought Using the Standardized Precipitation Index in the Saïss Plain (Northern Morocco). Int J Intell Eng Syst 11:267–275. https://doi.org/10.22266/ijies2018.0228.28
Jain VK, Pandey RP, Jain MK (2015a) Spatio-temporal assessment of vulnerability to drought. Nat Hazards 76:443–469. https://doi.org/10.1007/s11069-014-1502-z
Jain VK, Pandey RP, Jain MK, Byun H-R (2015b) Comparison of drought indices for appraisal of drought characteristics in the Ken River Basin. Weather Clim Extrem 8:1–11. https://doi.org/10.1016/j.wace.2015.05.002
Jalalkamali A, Moradi M, Moradi N (2015) Application of several artificial intelligence models and ARIMAX model for forecasting drought using the Standardized Precipitation Index. Int J Environ Sci Technol 12:1201–1210. https://doi.org/10.1007/s13762-014-0717-6
Jasim AI, Awchi TA (2020) Regional meteorological drought assessment in Iraq. Arab J Geosci 13:284. https://doi.org/10.1007/s12517-020-5234-y
Khan N, Sachindra DA, Shahid S et al (2020) Prediction of droughts over Pakistan using machine learning algorithms. Adv Water Resour 139:103562. https://doi.org/10.1016/j.advwatres.2020.103562
Kim T-W, Valdés JB, Aparicio J (2002) Frequency and Spatial Characteristics of Droughts in the Conchos River Basin, Mexico. Water Int 27:420–430. https://doi.org/10.1080/02508060208687021
Kim D-W, Byun H-R, Choi K-S (2009) Evaluation, modification, and application of the Effective Drought Index to 200-Year drought climatology of Seoul, Korea. J Hydrol 378:1–12. https://doi.org/10.1016/j.jhydrol.2009.08.021
Kisi O, Docheshmeh Gorgij A, Zounemat-Kermani M et al (2019) Drought forecasting using novel heuristic methods in a semi-arid environment. J Hydrol 578:124053. https://doi.org/10.1016/j.jhydrol.2019.124053
Komasi M, Sharghi S, Safavi HR (2018) Wavelet and cuckoo search-support vector machine conjugation for drought forecasting using Standardized Precipitation Index (case study: Urmia Lake, Iran). J Hydroinform 20:975–988. https://doi.org/10.2166/hydro.2018.115
Kumar V, Panu U (1997) Predictive assessment of severity of agricultural droughts based on agro-climatic factors. J Am Water Resour Assoc 33:1255–1264. https://doi.org/10.1111/j.1752-1688.1997.tb03550.x
Landeras G, Ortiz-Barredo A, López JJ (2009) Forecasting weekly evapotranspiration with ARIMA and artificial neural network models. J Irrig Drain Eng 135:323–334. https://doi.org/10.1061/(ASCE)IR.1943-4774.0000008
Legates DR, McCabe GJ (1999) Evaluating the use of “goodness-of-fit” Measures in hydrologic and hydroclimatic model validation. Water Resour Res 35:233–241. https://doi.org/10.1029/1998WR900018
Leilah AA, Al-Khateeb S (2005) Statistical analysis of wheat yield under drought conditions. J Arid Environ 61:483–496. https://doi.org/10.1016/j.jaridenv.2004.10.011
Lin Q, Wu Z, Singh VP et al (2017) Correlation between hydrological drought, climatic factors, reservoir operation, and vegetation cover in the Xijiang Basin, South China. J Hydrol 549:512–524. https://doi.org/10.1016/j.jhydrol.2017.04.020
Ljung GM, Box GEP (1978) On a measure of lack of fit in time series models. Biometrika 65:297–303. https://doi.org/10.1093/biomet/65.2.297
Maca P, Pech P (2016) Forecasting SPEI and SPI drought indices using the integrated artificial neural networks. Comput Intell Neurosci 2016:1–17. https://doi.org/10.1155/2016/3868519
Malik A, Kumar A (2020) Spatio-temporal trend analysis of rainfall using parametric and non-parametric tests: case study in Uttarakhand, India. Theor Appl Climatol 140:183–207. https://doi.org/10.1007/s00704-019-03080-8
Malik A, Kumar A, Ghorbani MA et al (2019a) The viability of co-active fuzzy inference system model for monthly reference evapotranspiration estimation: case study of Uttarakhand State. Hydrol Res 50:1623–1644. https://doi.org/10.2166/nh.2019.059
Malik A, Kumar A, Guhathakurta P, Kisi O (2019b) Spatial-temporal trend analysis of seasonal and annual rainfall (1966–2015) using innovative trend analysis method with significance test. Arab J Geosci 12:328. https://doi.org/10.1007/s12517-019-4454-5
Malik A, Kumar A, Singh RP (2019c) Application of heuristic approaches for prediction of hydrological drought using multi-scalar streamflow drought index. Water Resour Manage 33:3985–4006. https://doi.org/10.1007/s11269-019-02350-4
Malik A, Kumar A, Salih SQ et al (2020) Drought index prediction using advanced fuzzy logic model: regional case study over Kumaon in India. PLoS ONE 15:e0233280. https://doi.org/10.1371/journal.pone.0233280
Manikandan M, Tamilmani D (2015) Spatial and temporal variation of meteorological drought in the Parambikulam-Aliyar Basin, Tamil Nadu. J Inst Eng Ser A 96:177–184. https://doi.org/10.1007/s40030-015-0121-3
Maroufpoor S, Bozorg-Haddad O, Maroufpoor E (2020) Reference evapotranspiration estimating based on optimal input combination and hybrid artificial intelligent model: Hybridization of artificial neural network with grey wolf optimizer algorithm. J Hydrol 588:125060. https://doi.org/10.1016/j.jhydrol.2020.125060
McKee TB, Doesken NJ, Kleist J (1993) The relationship of drought frequency and duration to time scales. In: Eighth Conference on Applied Climatology, 17–22 January 1993, Anaheim, California
Memarian H, Pourreza Bilondi M, Rezaei M (2016) Drought prediction using co-active neuro-fuzzy inference system, validation, and uncertainty analysis (case study: Birjand, Iran). Theor Appl Climatol 125:541–554. https://doi.org/10.1007/s00704-015-1532-9
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey Wolf Optimizer. Adv Eng Softw 69:46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007
Mishra AK, Desai VR (2005a) Drought forecasting using stochastic models. Stoch Environ Res Risk Assess 19:326–339. https://doi.org/10.1007/s00477-005-0238-4
Mishra AK, Desai VR (2005b) Spatial and temporal drought analysis in the Kansabati river basin, India. Int J River Basin Manage 3:31–41. https://doi.org/10.1080/15715124.2005.9635243
Mishra AK, Desai VR (2006) Drought forecasting using feed-forward recursive neural network. Ecol Modell 198:127–138. https://doi.org/10.1016/j.ecolmodel.2006.04.017
Mishra AK, Singh VP (2009) Analysis of drought severity-area-frequency curves using a general circulation model and scenario uncertainty. J Geophys Res 114:D06120. https://doi.org/10.1029/2008JD010986
Mishra AK, Singh VP (2010) A review of drought concepts. J Hydrol 391:202–216. https://doi.org/10.1016/j.jhydrol.2010.07.012
Mishra AK, Singh VP (2011) Drought modeling – A review. J Hydrol 403:157–175. https://doi.org/10.1016/j.jhydrol.2011.03.049
Mishra AK, Desai VR, Singh VP (2007) Drought forecasting using a hybrid stochastic and neural network model. J Hydrol Eng 12:626–638. https://doi.org/10.1061/(ASCE)1084-0699(2007)12:6(626)
Mitra S, Srivastava P (2017) Spatiotemporal variability of meteorological droughts in southeastern USA. Nat Hazards 86:1007–1038. https://doi.org/10.1007/s11069-016-2728-8
Mokhtarzad M, Eskandari F, Jamshidi Vanjani N, Arabasadi A (2017) Drought forecasting by ANN, ANFIS, and SVM and comparison of the models. Environ Earth Sci 76:729. https://doi.org/10.1007/s12665-017-7064-0
Moriasi DN, Gitau MW, Pai N, Daggupati P (2015) Hydrologic and Water Quality Models: Performance Measures and Evaluation Criteria. Trans ASABE 58:1763–1785. https://doi.org/10.13031/trans.58.10715
Morid S, Smakhtin V, Moghaddasi M (2006) Comparison of seven meteorological indices for drought monitoring in Iran. Int J Climatol 26:971–985. https://doi.org/10.1002/joc.1264
Morid S, Smakhtin V, Bagherzadeh K (2007) Drought forecasting using artificial neural networks and time series of drought indices. Int J Climatol 27:2103–2111. https://doi.org/10.1002/joc.1498
Nandargi S, Gaur A, Mulye SS (2016) Hydrological analysis of extreme rainfall events and severe rainstorms over Uttarakhand, India. Hydrol Sci J 61:2145–2163. https://doi.org/10.1080/02626667.2015.1085990
Narasimha Murthy KV, Saravana R, Vijaya Kumar K (2019) Stochastic modelling of the monthly average maximum and minimum temperature patterns in India 1981–2015. Meteorol Atmos Phys. https://doi.org/10.1007/s00703-018-0606-5
Nash JE, Sutcliffe JV (1970) River flow forecasting through conceptual models part I—a discussion of principles. J Hydrol 10:282–290. https://doi.org/10.1016/0022-1694(70)90255-6
Özger M, Mishra AK, Singh VP (2012) Long lead time drought forecasting using a wavelet and fuzzy logic combination model: a case study in Texas. J Hydrometeorol 13:284–297. https://doi.org/10.1175/JHM-D-10-05007.1
Patel NR, Yadav K (2015) Monitoring spatio-temporal pattern of drought stress using integrated drought index over Bundelkhand region, India. Nat Hazards 77:663–677. https://doi.org/10.1007/s11069-015-1614-0
Rafiei-Sardooi E, Mohseni-Saravi M, Barkhori S et al (2018) Drought modeling: a comparative study between time series and neuro-fuzzy approaches. Arab J Geosci 11:487. https://doi.org/10.1007/s12517-018-3835-5
Rahman MR, Lateh H (2016) Meteorological drought in Bangladesh: assessing, analysing and hazard mapping using SPI, GIS and monthly rainfall data. Environ Earth Sci 75:1026. https://doi.org/10.1007/s12665-016-5829-5
Roudier P, Mahe G (2010) Study of water stress and droughts with indicators using daily data on the Bani river (Niger basin, Mali). Int J Climatol 30:1689–1705. https://doi.org/10.1002/joc.2013
Smakhtin V, Hughes D (2007) Automated estimation and analyses of meteorological drought characteristics from monthly rainfall data. Environ Model Softw 22:880–890. https://doi.org/10.1016/j.envsoft.2006.05.013
Smola A (1996) Regression estimation with support vector learning machines. Master’s thesis, Tech Univ M unchen
Soh YW, Koo CH, Huang YF, Fung KF (2018) Application of artificial intelligence models for the prediction of standardized precipitation evapotranspiration index (SPEI) at Langat River Basin, Malaysia. Comput Electron Agric 144:164–173. https://doi.org/10.1016/j.compag.2017.12.002
Su H, Li X, Yang B, Wen Z (2018) Wavelet support vector machine-based prediction model of dam deformation. Mech Syst Signal Process 110:412–427. https://doi.org/10.1016/j.ymssp.2018.03.022
Sudheer KP, Gosain AK, Ramasastri KS (2002) A data-driven algorithm for constructing artificial neural network rainfall-runoff models. Hydrol Process 16:1325–1330. https://doi.org/10.1002/hyp.554
Taylor KE (2001) Summarizing multiple aspects of model performance in a single diagram. J Geophys Res Atmos 106:7183–7192. https://doi.org/10.1029/2000JD900719
Thomas T, Nayak PC, Ghosh NC (2015) Spatiotemporal analysis of drought characteristics in the Bundelkhand region of central india using the standardized precipitation index. J Hydrol Eng 20:05015004. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001189
Tikhamarine Y, Souag-Gamane D, Kisi O (2019) A new intelligent method for monthly streamflow prediction: hybrid wavelet support vector regression based on grey wolf optimizer (WSVR–GWO). Arab J Geosci 12:540. https://doi.org/10.1007/s12517-019-4697-1
Tikhamarine Y, Malik A, Souag-Gamane D, Kisi O (2020a) Artificial intelligence models versus empirical equations for modeling monthly reference evapotranspiration. Environ Sci Pollut Res 27:30001–30019. https://doi.org/10.1007/s11356-020-08792-3
Tikhamarine Y, Souag-Gamane D, Najah Ahmed A et al (2020b) Improving artificial intelligence models accuracy for monthly streamflow forecasting using grey Wolf optimization (GWO) algorithm. J Hydrol 582:124435. https://doi.org/10.1016/j.jhydrol.2019.124435
Tiwari MK, Adamowski J (2013) Urban water demand forecasting and uncertainty assessment using ensemble wavelet-bootstrap-neural network models. Water Resour Res 49:6486–6507. https://doi.org/10.1002/wrcr.20517
Vapnik VN (1995) The nature of statistical learning theory. Springer, New York, p 314
Vicente-Serrano SM (2006) Differences in spatial patterns of drought on different time scales: an analysis of the Iberian Peninsula. Water Resour Manage 20:37–60. https://doi.org/10.1007/s11269-006-2974-8
Vicente-Serrano SM, Beguería S, López-Moreno JI (2010) A multiscalar drought index sensitive to global warming: the standardized precipitation evapotranspiration index. J Clim 23:1696–1718. https://doi.org/10.1175/2009JCLI2909.1
Wilhite DA (1986) Drought policy in the U.S. and Australia: a comparative analysis. J Am Water Resour Assoc 22:425–438. https://doi.org/10.1111/j.1752-1688.1986.tb01897.x
Wilhite DA, Glantz MH (1985) Understanding the drought phenomenon: the role of definitions. Water Int 10:111–120
Wilhite DA, Sivakumar MVK, Pulwarty R (2014) Managing drought risk in a changing climate: the role of national drought policy. Weather Clim Extrem 3:4–13. https://doi.org/10.1016/j.wace.2014.01.002
Willmott CJ (1981) On the validation of models. Phys Geogr 2:184–194. https://doi.org/10.1080/02723646.1981.10642213
Willmott C, Matsuura K (2005) Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim Res 30:79–82. https://doi.org/10.3354/cr030079
Zarei AR, Moghimi MM, Mahmoudi MR (2016) Analysis of changes in spatial pattern of drought using RDI index in south of Iran. Water Resour Manage 30:3723–3743. https://doi.org/10.1007/s11269-016-1380-0
Zhang X, Wang J, Zhang K (2017a) Short-term electric load forecasting based on singular spectrum analysis and support vector machine optimized by Cuckoo search algorithm. Electr Power Syst Res 146:270–285. https://doi.org/10.1016/j.epsr.2017.01.035
Zhang Y, Li W, Chen Q et al (2017b) Multi-models for SPI drought forecasting in the north of Haihe River Basin, China. Stoch Environ Res Risk Assess 31:2471–2481. https://doi.org/10.1007/s00477-017-1437-5
Zhang Y, Yang H, Cui H, Chen Q (2020) Comparison of the ability of ARIMA, WNN and SVM models for drought forecasting in the Sanjiang Plain, China. Nat Resour Res 29:1447–1464. https://doi.org/10.1007/s11053-019-09512-6
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Responsible Editor: A P Dimri.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Malik, A., Tikhamarine, Y., Souag-Gamane, D. et al. Support vector regression integrated with novel meta-heuristic algorithms for meteorological drought prediction. Meteorol Atmos Phys 133, 891–909 (2021). https://doi.org/10.1007/s00703-021-00787-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00703-021-00787-0