
Abstract
Weirs are hydraulic structures mostly used to measure the flow discharge and control the flow level in artificial or natural open channels. The ratio of the actual discharge to the theoretical discharge (discharge coefficient—Cd) must be known, in order to calculate the discharge of the channel having the weir. In this study, 91 experimental measurements are taken on seven trapezoidal broad-crested weirs with different upstream and downstream slopes. Experimentally measured flow properties are used to validate numerical models based on the computational fluid dynamics (CFD) methods. Two new weir geometries, not experimentally measured, are added in the numerical modeling, and 270 Cd values are calculated for nine weir geometries using numerical modeling. Theoretical Cd values are estimated using the artificial neural network (ANN), support vector machine (SVM), and M5Tree methods. In the models, the Froude number in the upstream region and dimensionless parameters of the flow are used as inputs. The performance of these methods has been examined to estimate the Cd values for eight cases. The performances of the methods are evaluated by the coefficient of determination (R2), root-mean-square error, mean absolute percentage error, and Nash–Sutcliffe model efficiency coefficient. The study results show that the Froude number significantly increases the performance of the models in estimating Cd values, and the ANN method is more successful in determining Cd than other methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Hydraulic structures such as dams and weirs are built to benefit the most efficiently from water resources. Weirs are the oldest structures in hydraulic engineering. They are commonly used to control and regulate the flow, increase the water level, and measure discharge in the open channels (artificial or natural). Weirs can be classified according to their geometric shapes, such as ogee, piano, broad-crested and sharp-edged. Broad-crested weirs are mostly preferred to calculate the flow discharge and to determine the amount of water used in agricultural activities. Although it is possible to determine the flow discharge theoretically, conditions caused by the interaction of the flow with the structure are not considered in the calculation. The physical characteristics of the weir structure and flow conditions can cause separations in the weir crest, upstream, and downstream regions. In addition, a new boundary layer development begins when the flow field changes from the weir structure. In this case, the curvilinear flow can occur in the crest and upstream region of the weir, and the pressure distribution deviates from the hydrostatic pressure. Due to these reasons, the theoretical discharge is calculated as greater than the actual one. The theoretical discharge must be multiplied by a coefficient (discharge coefficient—Cd) to determine the actual discharge.
There are many studies in the literature to calculate the Cd for different weir types with empirical formulas using flow properties the experimentally measured [1,2,3,4,5]. In these studies, empirical formulas are suggested to determine the Cd based on the experiments performed for various weir types. In addition to empirical approach, advanced machine learning methods are frequently preferred to estimate the Cd in recent years. In the estimation, the parameters affecting the Cd are nondimensionalized and evaluated as input parameters. For instance, Salmasi, Yıldırım, Masoodi, Parsamehr [6] determined Cd values of the compound broad-crested rectangular weir with 39 experimental measurements. The effect of crest length and weir height on the Cd was investigated. In the study, the experimentally obtained the Cd results were calculated by using multiple regression equations based on dimensional analysis. The results of the regression were compared with genetic programming (GP) and artificial neural network (ANN) method results. According to the coefficient of determination (R2) and root-mean-square error (RMSE) parameters, it was seen that the GP was slightly more successful than the ANN method in determining the discharge coefficient. Hoseini and Afshar [7] evaluated the Cd of the rectangular broad-crested weir with the rounded upstream face for different flow conditions. They determined that the discharge coefficient was related to the water depth over the weir crest (h) in the upstream region, weir crest length (L), and channel width (b). Equations calculating Cd values were obtained by applying the multiple regression method. As a result, it was seen that the compatibility between the theoretical Cd and the Cd calculated with the proposed equation was high. Roushangar et al. [8] estimated the Cd of stepped spillways using the gene expression programming (GEP) and support vector machine (SVM) methods. Dimensionless geometric and hydraulic parameters of the spillway were used as inputs. As a result of the study, it was suggested that the GEP method can be used to determine the discharge coefficient of the spillway. Salmasi, Sattari [9] estimated the flow coefficient of broad-crested weirs, which they measured experimentally, with the M5Tree method. As a result of the study, they reported that the correlation between the M5Tree method and the experimental data was 0.95, and the RMSE value was 0.036. Li et al. [4] used ANN, SVM, and extreme learning machine (ELM) methods to estimate the Cd of the rectangular sharp-edged weir. Four statistical criteria were used to evaluate the success of the models, and Cd value was tried to be estimated in three different input combinations. Comparing the results of the estimation methods shows that the SVM method performed better than the other methods. Besides these works, there are many studies that used machine learning methods successfully in estimating the discharge coefficient [10,11,12,13,14]. Most of these studies estimated the Cd with a limited number of data due to the limitations caused by the experimental equipment. In addition, when these studies were examined, it was seen that the M5Tree, SVM, and ANN methods were frequently used, but there was no study in which they were used together to determine the Cd. For this purpose, it will also be investigated the performance of these methods in the same experimental set.
Moreover, the Cd estimation models, made for a single weir geometry, can be quite limited in using different geometries. However, this study aims to determine the Cd for the trapezoidal broad-crested weir, which has nine different upstream and downstream geometries. For this purpose, 91 Cd values are experimentally obtained from 13 discharges for the seven different weir geometries. Since the number of experimental measurements is insufficient to predict the Cd with artificial intelligence methods, numerical modeling based on computational fluid dynamics (CFD) methods has been carried out to increase the dataset. Due to the developments in computer technology, the use of CFD in the design and analysis of water structures has become widespread. Numerical modeling has given successful results in studies about the different flow-structure interactions, including weir flows [15,16,17,18,19,20,21]. However, numerical models need to be validated with experimental models before analyzing water structures. The main reason is that turbulence is defined by different approaches when solving the basic equations governing the flow. The previous studies show that turbulence kinetic energy and turbulent kinetic energy dissipation rate-based turbulence models give successful results in numerical modeling broad-crested weir flow [22,23,24,25,26,27].
Furthermore, there are also studies in which the Cd is determined using numerical simulations in the literature. For example, Kulkarni, Hinge [21] investigated Cd of the compound broad-crested weir with experimental and numerical models. The numerical model results were validated using the experimental results. In numerical models, the volume of fluids (VOF) method was used to determine the water–air interface, and the renormalization group (RNG) model was preferred to define turbulence in the basic equations. It was determined that the Cd values obtained experimentally and numerically were quite compatible. Thus, it is possible to evaluate a wider range of flow properties by increasing the experimentally obtained Cd using numerical models.
For this purpose, 91 experimental Cd values with a limited range due to the restrictions of the laboratory conditions are reproduced using the CFD techniques. Then, it was investigated how to determine these Cd values in cases of limited knowledge with the help of machine learning methods. Thus, practitioners will be able to easily calculate Cd values and, accordingly, flow discharge values using the results we have given in this present study for different weir and flow types.
The main motivation of this study is to solve the problems caused by the determination of the Cd coefficient, which is used for flow measurement in open channels in the laboratory environment over wide ranges. For this purpose, numerical models are created using the RNG turbulence model validated with 91 experimental measurements taken. Then, using the numerical model, two new weir geometries are added, and the number of weir geometries is raised to nine. In total, 270 Cd values are calculated according to 30 different discharges of each weir geometry. Thus, enough data could be obtained to estimate the Cd for a wide range. Finally, Cd values of the trapezoidal broad-crested weir are estimated using the ANN, SVM, and M5Tree methods with different input combinations. The estimation methods employed in this study use input combinations of dimensionless parameters of the weir and the flow properties because they are easily obtained in practice. In addition, how to estimate Cd values in the case of a limited number of inputs is also investigated within the scope of this study.
2 Data collection
2.1 Physical experiments
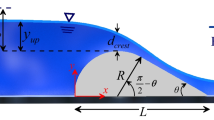
Experiments are carried out to determine the Cd for the trapezoidal broad-crested weir with different upstream and downstream slopes. These measurements are taken in the rectangular open channel, all surfaces of the channel are glass (Fig. 1). This open channel model has a length of 4 m, and width (b) and height of 0.35 m. The flow depth interacting with the trapezoidal broad-crested weir is measured with a 0.1 mm sensitivity digital limnimeter, and the flow discharge is obtained using an ultrasonic flow meter with a sensitivity of 0.01 m3/h. The trapezoidal broad-crested weir is placed in the open channel model at 1.40 m from the beginning of the model, and the measurements are taken when the open channel flow is ensured to be regular. The geometric properties of trapezoidal weirs with different slopes used in experimental and numerical modeling are given in Fig. 2. In the figure, L is the length of the weir crest, P is the weir height, α is the upstream slope, β is the downstream slope, and h is the water depth over the weir crest in the upstream region. The total weir head is defined as H0 = h + V2/2 g, where V is the average velocity in the upstream region and g is gravity acceleration. In the experiments, L, P, and b are taken constant as 0.3 m, 0.1 m, and 0.35 m, respectively.

Experimental setup

Geometric properties of trapezoidal broad-crested weir
2.2 Numerical modeling
Numerical models based on the CFD method have many advantages compared to physical model studies, such as being economical, having the ability to be repeated, and requiring fewer human resources. In addition, numerical modeling does not require special measurement systems and equipment to obtain details about the flow properties or structure in physical experiments. To the reliability of the results of numerical modeling studies, which have many advantages, they should be validated with the results of physical model studies [21]. After the validation, numerical modeling studies can be used as an alternative to the physical model.
In this study, the basic equations (continuity and momentum) governing the motion of the two-dimensional, steady, turbulent, and incompressible open channel flow interacting with the trapezoidal broad-crested weir are solved with the ANSYS-Fluent software, which provides solutions based on the finite volume method. The water–air interface is determined by the VOF method. Additionally, the RNG turbulence model [28], based on the Boussinesq approach, is used in turbulence modeling. In this model, the turbulence stresses are solved by using turbulent kinetic energy and turbulent kinetic energy dissipation rate equations. It is stated that the RNG model is successful in modeling the open channel flows where boundary layer separations and secondary flows present [28]. Many researchers have reported that turbulence models (standard, realizable, and RNG) based on the solution of turbulent kinetic energy and turbulent kinetic energy dissipation rate are also successful in the numerical modeling of broad-crested weir flow [23, 25, 29].
2.3 Calculation of discharge coefficient (C d)
The formulation of the discharge coefficient (Cd) is given in Eq. 1. Cd value is calculated by dividing the actual discharge by the theoretical [30].
In Eq. 1, Qactual is the experimentally measured discharge, b is the channel width, g is the gravitational acceleration, and Ho is the total weir head.
3 Artificial intelligence methods
3.1 Support vector machine (SVM)
The support vector machine (SVM) method is a machine learning model that can be used for both classification and regression [31, 32]. It is accepted as a successful method for solving different learning problems such as classification, regression, transformation, and novelty detection [33]. The SVM theory is originally developed for classification purposes. Then it has acquired the ability to estimate quantitative output based on input values [34]. The regression with the SVM method first maps the input data to a high-dimensional feature space defined by the kernel function and obtains the optimum hyperplane that separates the training data with the maximum margin [35]. On the other hand, the method determines coefficients to minimize the effect of outliers on the regression equations; however, only residuals in absolute value greater than some positive constant are considered in the loss function [34, 36]. The SVM method uses e, insensitive loss functions, as shown in Eq. 2(e ≥ 0) [37]. Thus, if the difference between the predicted and observed values given in Fig. 3 is less than e, the loss is zero, and only data points with an absolute difference greater than e are considered lost.

Model parameters of support vector machines method
For multidimensional data (x1, y1),.….,(xn, yn) (xi ∈ X ⊆ Rm, yi ∈ Y ⊆ R), n is the number of samples in the training process. The approached multivariate regression function can be written as Eq. 3 [38].
where ϕ(x) is the transformation from core to kernel space. The SVM method minimizes the e value while minimizing the difference between the predicted and desired outputs. The function approximation problem is transformed into an optimization problem shown in Eq. 4:
Here \(\xi_{i}\) and \(\xi_{i}^{*}\) are the resulting values to protect against outliers and smooth transition (\(\xi_{i} ,\xi_{i}^{*} \ge 0\)). C is a variable weight parameter that minimizes error. The quadratic optimization problem in Eq. 4 is solved with the Lagrangian equation shown in Eq. 5, where λ, λ*, α, and α* are positive real numbers.
For nonlinear regression, kernel functions k (…) are used to map the raw data to a higher-dimensional space to linearize it for higher accuracy (Eq. 6). The function approach is shown in Eq. 7.
Gaussian kernel function (Eq. 8) is used to define the kernel function term in Eq. 7 [39].
Kernel function parameters given in Eq. 8 are determined by the Bayesian optimization algorithm [40].
3.2 Artificial Neural Network (ANN)
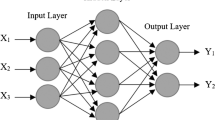
The artificial neural network (ANN) method is a conceptual technique widely used in different branches of science. Researchers frequently prefer the method because of its convenience in modeling problems without including analytical relationships [41,42,43]. The ANN models try to match the intrinsic nonlinear relationship between parameters to a complex problem. Figure 4 shows a typical ANN model with n neurons in the input layer (i), m neurons in the hidden layer (j), and one neuron in the output layer (k). The terms wij and Wjk given in Fig. 4 are the connection weights between the cell layers, and these values take random values during the model setup. However, they are constantly changed due to comparing the output values calculated during the training process with the desired output. Finally, the errors propagate backward until they converge to the link weight values, which will minimize the errors. In this study, the Levenberg–Marquardt algorithm is used to adjust the weights [44]. Levenberg–Marquardt (LM) algorithm requires less training time [45] and can converge even in highly complex optimization problems [46].

Structure of artificial neural network method
Connection weights are used to connect the neurons of each layer to the neurons of the next layer. The sum of the weighted inputs and deviation as net inputs to the activation function in the hidden layer and the output layer is calculated according to Eqs. 9 and 10.
where oj is the output of the hidden layer, Out is the output of the hidden layer, wji is the link weights between the input layer and the hidden layer, Wji is the link weights between the hidden layer and the input layer, βi and βj are the bias values in the output layer and the hidden layer, f is the activation function (Sigmoid). The sigmoid activation function is shown in Eq. 11. In this study, n values are determined using the trial–error method. For this purpose, n is changed from 1 to 10, and the root-mean-square error (RMSE) is computed in every calculation. Then, the n value, which gives the minimum RMSE, is selected as the hidden layer neurons number of the ANN model, and in every case, this procedure is repeated. Besides, the maximum number of epochs, performance goal, and minimum performance gradient in training are selected as 1000, 10–10, and 10–100, respectively.
3.3 M5Tree
The M5Tree model, proposed by Quinlan [47], is based on the tree classification approach to show the relationship between dependent and independent variables. The M5Tree model, unlike the decision tree model for categorical data, may be utilized for both categorical and quantitative data. Contrary to standard regression models, which use just one equation to represent all data, the M5Tree regression tree model divides the data into subregions before assigning leaf labels. A linear regression equation is used to identify the nodes in the M5 model, allowing it to expect or forecast continuous numerical data [47]. The structure of a decision tree is like a tree with roots, branches, nodes, and leaves. The root is at the top level as the first node and is a chain of branches and nodes extending to the leaves. Each node belongs to a predictor variable, and a split occurs in the node. A numerical range leaves a parent node to reach a child node in a branch. Two branches branch off from each parent node in the M5Tree method.
The decision tree model is generated in two phases. The model is created in the first stage by separating the open data definition. Then, the M5Tree model's division criterion is optimized for the decrease in the data substandard node's deviation. The primary node is not divided, and the final node or leaf is attained when the standard deviation cannot be further decreased [48]. The corresponding equations are shown in Eqs. 12 and 13.
where σr is the reduction of the standard deviation at the sub-node, t is the input dataset to the parent node, ti is a subset of the input data to the parent node, n is the number of datasets used, and σ is the standard deviation. Due to the division operation, the standard deviation at the sub-node is less than at the main node, leading to greater homogeneity [49].
3.4 Performance criteria
The coefficient of determination (R2), root-mean-square error (RMSE), mean absolute percentage error (MAPE), and Nash–Sutcliffe model efficiency coefficient (NSE) parameters are used to evaluate the performance of the models in estimating the Cd values. The equations of the R2, RMSE, MAPE, and NSE parameters are given in Eqs. 14, 15, 16, and 17, respectively.
In the equations, Ti is the theoretical Cd, \(\overline{{T_{i} }}\) is the mean theoretical Cd, Pi is the predicted Cd, \(\overline{{P_{i} }}\) is the mean of the predicted Cd, and n is the total data number. The convergence of R2 and NSE to 1 and RMSE and MAPE to 0 means that the forecasting model is successful.
4 Results
4.1 Experimental and numerical data collection
The determinate number of flow rates used in laboratory discharge coefficient studies also caused the obtained Cd values to be limited. The CFD methods mentioned in Sect. 2.2 were used to overcome this problem. This process was done in three stages. Firstly, seven different weir geometries (Models 1–7) and 13 Cd values for each weir geometry were measured in the laboratory. Upstream (α) and downstream (β) slopes of the weirs, water depth over the weir crest (h), total weir load (Ho), and ε (Ho/(Ho + L)) values obtained from the experimental are given in Table 1. Secondly, the numerical model is validated by means of all experimentally measured weir and flow conditions (13 discharges for each weir geometry). Flow conditions with the same characteristics as the experiments are modeled numerically, and the Cd values are determined depending on the numerical results. The mean absolute percentage error (MAPE) is used to determine the agreement between the experimental and numerical Cd values. The box plot of the MAPE values obtained in each weir geometry (called as model) is given in Fig. 5. The MAPE of Cd values calculated based on experimental and numerical model results are generally less than 10%. The mean MAPE values of each model are below 5%, except for Model 3. The fact that the mean MAPE values of the numerical and experimental Cd values are mostly less than 5% for different weir and discharge conditions means that the numerical model results are compatible with the experimental results.

MAPE values of experimental and numerical models
Finally, using CFD models validated with experimental data, 17 new analyses were carried out for each model, increasing the Cd number to 30. Moreover, a dataset was created by calculating 30 Cd values for two new weir geometries (Models 8 and 9), which could not be measured experimentally. Thus, the range of variation of the considered input parameters is quite wide. The calculated 270 Cd values for nine weir geometries with six upstream angles (α = 11.3°, 14.0°, 18.4°, 26.6°, 45°, and 90.0°) and five downstream angles (β = 11.3°, 14.0°, 18.4°, 26.6°, and 45°) vary between 0.35 and 0.43. Approximately 34% of the total 270 Cd values used in the study were obtained entirely from experiments, and the remaining part was obtained from the numerical models.
The variation of Cd value according to h/L, ε, and Fr values is given in Fig. 6. In the figure, the colors and shapes of the symbols represent the upstream slope (α) and the downstream slope (β) of the weir, respectively. The smallest Cd value is obtained in Model 4 (α = 90° and β = 18.4°), and the largest Cd value is obtained in Model 6 (α = 26.6° and β = 14.0°). As the h/L, Fr, and ε parameters increase, Cd value decreases in Models 3, 6, and 7, and increases in Models 1, 2, 4, 5, 8, and 9. In case the downstream slope remained the same, there is an increase in the Cd with the decrease in the upstream slope. In addition, Model 1 has larger Cd values when the h/L value, which increases with the rise of the discharge, varies between 0.3 and 0.35. A similar situation occurs when the Froude number varies between 0.20 and 0.25 and the ε value changes between 0.23 and 0.28. These results are consistent with those of Hager, Schwalt [30], Sargison, Percy [1], and Madadi, Hosseinzadeh Dalir, Farsadizadeh [50] are also compatible with the experimental results. These results reveal that numerically obtained Cd values can be evaluated like Cd values obtained by physical experiments. In this way, more discharge characteristics and different weir geometries can be also considered in numerical modeling. For this purpose, two new weir geometries are added to the seven weir geometries that are first physically measured. Moreover, the number of Cd, which is calculated experimentally, from 13 for each weir geometry has been increased to 30 with numerical modeling. Thus, after adding numerical experiments to the number of physical the number of Cd evaluated in the study becomes 270.

Variation of the discharge coefficient with (a) h/L, (b) ɛ, and (c) Fr
4.2 Estimating C d values
A dataset is created to estimate the Cd values from the physical and numerical data obtained for different weir models with the ANN, SVM, and M5Tree methods. Experimentally and numerically, a total of 270 Cd values are obtained for nine weir geometries. 70% of this dataset is in training, and 30% is used in the testing. The same number of data is randomly taken from each model for training and testing. Thus, the total data used in the training process are 189, 9 (Number of models)*21 (70% of each experimental set).
The distributions of the input (h/L, Fr, ε) and output (Cd) parameters used in the estimation models for training and testing are given in Fig. 7. Observations that are more than 1.5 interquartile range (IQR) below Q1 or more than 1.5 IQR above Q3 are considered outliers. The IQR describes the middle 50% of values when they are ranked from lowest to highest. As clearly shown in Fig. 7, although the distributions are different, there are no outliers in any input parameters. However, there are outliers in Cd values in both the training and testing processes. Cd values are generally within a specific range (0.380–0.390), but Cd values increase or decrease significantly, especially at very high and very low flow rates. Since this is hydraulically significant, these outliers have been preserved. In addition, the descriptive statistics values for the training and testing processes are given in Table 2. Here, Q1, Q2, and Q3 denote the 1st, 2nd, and 3rd quartiles, respectively. As the 2nd quartile gives the median value, the max values also represent the 4th quartile. As given in Table 2, statistics in training and testing are generally close to each other. Although the value ranges of the variables in training are similar to those in testing, the most important difference is the Cd values. The maximum Cd values in training were higher than in testing.

Amount of change of model parameters in the training and testing
The input and output data distributions are especially important to be close to each other when creating the training and testing data. For example, the mean of h/L, ε, Fr, and Cd parameters in the training are 0.239, 0.149, 0.189, and 0.384, respectively. The mean of the h/L, ε, Fr, and Cd parameters in the testing are obtained as 0.246, 0.153, 0.193, and 0.384, respectively. A similar situation exists for the median, maximum, and minimum values. Thus, it is seen that the h/L, Fr, ε, and Cd parameters show a homogeneous distribution in the training and testing process. The input and output parameters of the cases created to be used in estimation methods are given in Table 3. In all cases, the h/L parameter is used as input. In the models, besides the h/L parameter, the weir's upstream (α) and downstream slopes (β) are added to examine the effect of the geometric features. In the first four cases, different combinations of h/L, α, β, and ε are used as input. On the other hand, in the last four cases, along with the h/L, α, β, and ε, the Froude number in the upstream region of the weir is used as the input.
The R2, MAPE, RMSE, and NSE values obtained from ANN, SVM, and M5Tree methods for the training and testing of eight input combinations are given in Table 4. It is expected that the model success evaluated according to the performance criteria obtained in the training and testing processes will be consistent with each other, and the results will be supported according to all criteria. In addition, the success of the estimation methods is evaluated regarding these criteria obtained in the testing. The results presented in Table 4 show that Case 1 and Case 2 give low R2 and NSE values in all methods. It is meaning that these cases are not suitable to be used to estimate Cd values. Besides, Case 2 with the M5Tree method has the worst performance in predicting Cd. In Case 3, where the upstream slope is used as an input, the highest NSE and R2 values and the lowest RMSE and MAPE values are obtained with the ANN method. The SVM and M5Tree methods have similar results for Case 3. In Case 4, especially in the ANN and SVM methods, the R2 and NSE values are above 0.9 and the MAPE value is below 1%. The M5Tree method is worse compared to the other two methods in Case 4. The results of the estimation methods are remarkable when the cases in which the Fr number is included (Cases from 5 to 8). In all estimation methods, Case 5, where only Fr and h/L values are input, gives very good results compared to the first four cases (From Case 1 to 4) in which Fr is not as input. For Case 5, the highest NSE and R2 values are obtained as 0.9816 and 0.9811 with the ANN method, respectively. Although the SVM method gives slightly lower values, its results are similar to the ANN method. However, the NSE and R2 values are obtained as a result of the estimation modeling for Case 5 with the M5Tree method are below 0.9 (about 0.87). In Case 6, prepared by adding the ε as a new input parameter to h/L and Fr, the most successful method is the SVM. Although there is little difference between the ANN and SVM methods and the R2 and NSE values, they are very successful with a value of 0.999 in both training and testing. It is observed that the performance of the SVM method decreased, but the performance of the ANN and M5Tree methods increased in Case 7. It estimated the Cd values best among all models and cases with the ANN method in Case 8. The ANN method with Case 8 predicts almost perfectly the Cd values according to all performance criteria.
Figure 8 shows the distribution of the MAPE values calculated between the theoretical Cd values and the Cd values obtained with the ANN, SVM, and M5Tree methods for different cases in the testing. It is clearly seen that the MAPE values are high in all methods in cases not using the Fr number, but in cases using the Fr the mean MAPE values are low in ANN and SVM methods, and the distribution occurs in a very limited range. In particular, the maximum MAPE values are determined below 0.5% in Case 6 for the SVM method and in Case 7 and Case 8 for the ANN method.

Change of MAPE values obtained in the testing for the different cases
The Taylor diagram is a graphical representation that provides a comparative evaluation of different models according to a reference point. This diagram presents the predictive value and its statistical relationship to the reference value. Three different statistical parameters, correlation coefficient, standard deviation, and root mean difference error (RMDE), can be seen simultaneously in the diagram. The most successful predicted model is coinciding with or closest to the reference point. Figure 9 shows Taylor diagrams of Cd values obtained in the different cases by the ANN, SVM, and M5Tree methods. Figure 9a shows that Cd values estimated using Cases 6, 7, and 8 from the Taylor diagram of the ANN method are quite close to the theoretical Cd values, also Case 8 almost coincides with the reference values. From the results of the SVM method, Case 6 is estimated quite close to the theoretical Cd value compared to the other cases (Fig. 9b). Case 7 is determined as the most successful case with the M5Tree method (Fig. 9c).

Taylor diagrams of Cd values obtained with different cases and methods
The scatter plots of the theoretical and estimated Cd values of the testing for all cases are given for the ANN, SVM, and M5Tree methods in Figs. 10, 11, and 12, respectively. According to Fig. 10, the ANN method is insufficient to predict low Cd values (< 0.36) in Cases 1 and 2 and Cd values greater than 0.40 in Case 3. Although the ANN methods predict relatively better in Case 4 than the first three cases, it has been determined that the Cd values around 0.40 do not give very satisfactory results. In Case 5, it is seen that the estimated values converge to the theoretical Cd except for a few values, while in Cases 6, 7, and 8 almost all Cd values are estimated quite close. The SVM results given in Fig. 11 are generally similar to the ANN method results. Nevertheless, the SVM method, which predicted Cd values successfully, especially with Case 6, decreases estimation performance with Case 7. In Case 7, it is observed that the upstream slope (α) parameter added reduced the prediction success for the SVM method. The scatter plots obtained with M5Tree are in line with the performance criteria values in Table 4 and the Taylor diagram results. The M5Tree method with Case 7 is the most successful prediction among all cases. However, this method determined the Cd values are mostly above the theoretical Cd value. In general, it has been determined that using the upstream slope as an input in the estimation of Cd increases the model's success. Additionally, it is observed that the downstream slope does not contribute to the success of the model as much as the upstream slope.

Scatter plots of Cd values theoretical and estimated with the ANN method in the testing

Scatter plots of Cd values theoretical and estimated with the SVM method in the testing

Scatter plots of Cd values theoretical and estimated with the M5Tree method in the testing
The results of the estimation methods show that if it is not possible to calculate the Fr number, it would be more appropriate to use the ANN method with Case 4. If it is possible, the ANN method with Case 8 would be more appropriate to calculate Cd values. The ANN is a black-box method, but it can be applied if the weight and bias values are known. For this purpose, the weight and bias values of Case 4 and Case 8 for the ANN method are given in Tables 5 and 6, respectively. In the tables, j is the number of hidden layers, and the values of wij, Wji, and βij represent the terms in Eqs. 10 and 11.
5 Conclusions
In this study, the discharge coefficient of trapezoidal broad-crested weirs is investigated experimentally and numerically. The numerical model study is validated by using 91 experimental results in 13 different discharges in seven different weir geometries. Then, two new different weir geometries that do not investigate experimentally are added and 270 numerical models are carried out for nine different weir geometries. The Cd values obtained theoretically by using experimental and numerical model results are estimated with the ANN, SVM, and M5Tree methods with eight different input combinations. R2, RMSE, MAPE, and NSE performance criteria are preferred in determining the success of the methods. The following main results are obtained,
-
Among the models in which the Fr number is not used as an input, Case 4 (inputs: h/L, α, β, and ε) is the most successful in all methods according to all performance criteria.
-
The models that used the Fr number give better results according to the models without the Fr number. The ANN method with Case 8 (inputs: h/L, α, β, ε, and Fr), the SVM method with Case 6 (inputs: h/L, ε, and Fr), and the M5Tree method with Case 7 (inputs: h/L, α, ε, and Fr) are most successful.
-
Using the weir's upstream slope (α) as the input increases the success of the models more than using the downstream slope (β).
-
The ANN method is most successfully determined to estimate Cd values than the SVM and M5Tree methods according to the performance criteria.
As a result of the study, it has been determined that if the upstream Froude number cannot be obtained, h/L, β, and α can be used as input parameters. However, if the Froude number can be acquired, the Cd values can be calculated by using the Fr, h/L, β, α, and ε parameters as inputs in the ANN method.
With the study results, it is possible to determine the Cd values in limited or full data cases by using the model parameters given in this article for the broad-crested weir and different flow types with different geometric properties. However, since the success of the estimation results obtained with limited inputs (Cases 1–4) is significantly lower than that obtained with the addition of other hydraulic parameters, new studies are required to increase the success of Cd estimation. It is evaluated that increasing the number of weir geometry and the Cd range will improve the performance of the Cd prediction models that would be developed.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Sargison JE, Percy A (2009) Hydraulics of broad-crested weirs with varying side slopes. J Irrig Drain Eng 135(1):115–118. https://doi.org/10.1061/(ASCE)0733-9437(2009)135:1(115)
Emiroglu ME, Agaccioglu H, Kaya N (2011) Discharging capacity of rectangular side weirs in straight open channels. Flow Meas Instrum 22(4):319–330. https://doi.org/10.1016/j.flowmeasinst.2011.04.003
Mehboudi A, Attari J, Hosseini S (2016) Experimental study of discharge coefficient for trapezoidal piano key weirs. Flow Meas Instrum 50:65–72. https://doi.org/10.1016/j.flowmeasinst.2016.06.005
Li S, Yang J, Ansell A (2021) Discharge prediction for rectangular sharp-crested weirs by machine learning techniques. Flow Meas Instrum 79:1–9. https://doi.org/10.1016/j.flowmeasinst.2021.101931
Saffar S, Babarsad MS, Shooshtari MM, Riazi R (2021) Prediction of the discharge of side weir in the converge channels using artificial neural networks. Flow Meas Instrum 78:1–9. https://doi.org/10.1016/j.flowmeasinst.2021.101889
Salmasi F, Yıldırım G, Masoodi A, Parsamehr P (2013) Predicting discharge coefficient of compound broad-crested weir by using genetic programming (GP) and artificial neural network (ANN) techniques. Arab J Geosci 6(7):2709–2717. https://doi.org/10.1007/s12517-012-0540-7
Hoseini SH, Afshar H (2014) Flow over a broad-crested weir in subcritical flow conditions, physical study. J River Eng 2(1):1005–1012
Roushangar K, Akhgar S, Salmasi F (2018) Estimating discharge coefficient of stepped spillways under nappe and skimming flow regime using data driven approaches. Flow Meas Instrum 59:79–87. https://doi.org/10.1016/j.flowmeasinst.2017.12.006
Salmasi F, Sattari MT (2017) Predicting discharge coefficient of rectangular broad-crested gabion weir using M5 tree model. Iran J Sci Technol Trans Civ Eng 41(2):205–212. https://doi.org/10.1007/s40996-017-0052-5
Johnson MC (2000) Discharge coefficient analysis for flat-topped and sharp-crested weirs. Irrig Sci 19(3):133–137. https://doi.org/10.1007/s002719900009
Ameri M, Ahmadi A, Dehghani AA (2015) Discharge coefficient of compound triangular–rectangular sharp-crested side weirs in subcritical flow conditions. Flow Meas Instrum 45:170–175. https://doi.org/10.1016/j.flowmeasinst.2015.06.003
Parsaie A, Haghiabi AH (2017) Improving modelling of discharge coefficient of triangular labyrinth lateral weirs using SVM, GMDH and MARS techniques. Irrig Drain 66(4):636–654. https://doi.org/10.1002/ird.2125
Haghiabi AH, Parsaie A, Ememgholizadeh S (2018) Prediction of discharge coefficient of triangular labyrinth weirs using adaptive neuro fuzzy inference system. Alex Eng J 57(3):1773–1782. https://doi.org/10.1016/j.aej.2017.05.005
Roushangar K, Alami MT, Shiri J, Asl MM (2018) Determining discharge coefficient of labyrinth and arced labyrinth weirs using support vector machine. Hydrol Res 49(3):924–938. https://doi.org/10.2166/nh.2017.214
Kirkgoz MS, Akoz MS, Oner AA (2008) Experimental and theoretical analyses of two-dimensional flows upstream of broad-crested weirs. Can J Civ Eng 35(9):975–986. https://doi.org/10.1139/l08-036
Akoz MS, Gumus V, Kirkgoz MS (2014) Numerical simulation of flow over a semicylinder weir. J Irrig Drain Eng. https://doi.org/10.1061/(asce)ir.1943-4774.0000717
Haun S, Olsen NRB, Feurich R (2014) numerical modeling of flow over trapezoidal broad-crested weir. Eng Appl Comput Fluid Mech 5(3):397–405. https://doi.org/10.1080/19942060.2011.11015381
Aydin MC (2016) Investigation of a sill effect on rectangular side-weir flow by using CFD. J Irrig Drain Eng. https://doi.org/10.1061/(asce)ir.1943-4774.0000957
Bilhan O, Aydin MC, Emiroglu ME, Miller CJ (2018) Experimental and CFD analysis of circular labyrinth weirs. J Irrig Drain Eng. https://doi.org/10.1061/(asce)ir.1943-4774.0001301
Carrillo JM, Matos J, Lopes R (2019) Numerical modeling of free and submerged labyrinth weir flow for a large sidewall angle. Environ Fluid Mech 20(2):357–374. https://doi.org/10.1007/s10652-019-09701-0
Kulkarni KH, Hinge GA (2022) Comparative study of experimental and CFD analysis for predicting discharge coefficient of compound broad crested weir. Water Supply 22(3):3283–3296. https://doi.org/10.2166/ws.2021.403
Sarker MA, Rhodes DG (2004) Calculation of free-surface profile over a rectangular broad-crested weir. Flow Meas Instrum 15(4):215–219. https://doi.org/10.1016/j.flowmeasinst.2004.02.003
Simsek O, Akoz MS, Soydan NG (2016) Numerical validation of open channel flow over a curvilinear broad-crested weir. Prog Comput Fluid Dyn Int J 16(6):364–378. https://doi.org/10.1504/PCFD.2016.080055
Jiang L, Diao M, Sun H, Ren Y (2018) Numerical modeling of flow over a rectangular broad-crested weir with a sloped upstream face. Water 10(11):1663. https://doi.org/10.3390/w10111663
Soydan Oksal NG, Akoz MS, Simsek O (2020) Numerical modelling of trapezoidal weir flow with RANS, LES and DES models. Sādhanā. https://doi.org/10.1007/s12046-020-01332-2
Idrees AK, Al-Ameri R, Das S (2022) Using CFD modelling to study hydraulic flow over labyrinth weirs. Water Supply 22(3):3125–3142. https://doi.org/10.2166/ws.2021.424
Malekzadeh F, Salmasi F, Abraham J, Arvanaghi H (2022) Numerical investigation of the effect of geometric parameters on discharge coefficients for broad-crested weirs with sloped upstream and downstream faces. Appl Water Sci. https://doi.org/10.1007/s13201-022-01631-5
Yakhot V, Orszag SA (1986) Renormalization-group analysis of turbulence. Phys Rev Lett 57(14):1722–1724. https://doi.org/10.1103/PhysRevLett.57.1722
Ilkentapar M, Oner AA (2017) Genis Baslikli Savak Etrafindaki Akimin Incelenmesİ. Ömer Halisdemir Üniversitesi Mühendislik Bilimleri Dergisi 6(2):615–626. https://doi.org/10.28948/ngumuh.341819
Hager WH, Schwalt M (1994) Broad-crested weir. J Irrig Drain Eng 120(1):13–26. https://doi.org/10.1061/(ASCE)0733-9437(1994)120:1(13)
Smola AJ, Schölkopf B (2004) A tutorial on support vector regression. Stat Comput 14(3):199–222. https://doi.org/10.1023/B:STCO.0000035301.49549.88
Kabacoff R (2015) R in action: data analysis and graphics with R. Manning Publications Co., Shelter Island
Magoulès F, Zhao H (2016) Data mining and machine learning in building energy analysis. Wiley, Hoboken
James G, Witten D, Hastie T, Tibshirani R (2013) An introduction to statistical learning, vol 112. Springer, New York. https://doi.org/10.1007/978-1-0716-1418-1
Yu-Wei CDC (2015) Machine learning with R cookbook. Packt Publishing Ltd, Birmingham
Kuhn M, Johnson K (2013) Applied predictive modelling, vol. 26. Springer, New York. https://doi.org/10.1007/978-1-4614-6849-3
Vapnik V (2013) The nature of statistical learning theory. Springer, New York
Awad M, Khanna R (2015) Efficient learning machines: theories, concepts, and applications for engineers and system designers. Springer, Berlin
Karatzoglou A, Meyer D, Hornik K (2006) Support vector machines in R. J Stat Softw 15(9):1–28. https://doi.org/10.18637/jss.v015.i09
Taylor KE (2001) Summarizing multiple aspects of model performance in a single diagram. J Geophys Res: Atmos 106(D7):7183–7192. https://doi.org/10.1029/2000JD900719
Naseri M, Othman F (2012) Determination of the length of hydraulic jumps using artificial neural networks. Adv Eng Softw 48:27–31. https://doi.org/10.1016/j.advengsoft.2012.01.003
Norouzi R, Daneshfaraz R, Ghaderi A (2019) Investigation of discharge coefficient of trapezoidal labyrinth weirs using artificial neural networks and support vector machines. Appl Water Sci 9(7):20. https://doi.org/10.1007/s13201-019-1026-5
Salmasi F, Nahrain F, Abraham J, Taheri Aghdam A (2021) Prediction of discharge coefficients for broad-crested weirs using expert systems. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2021.1983477
Marquardt DW (1963) An algorithm for least-squares estimation of nonlinear parameters. J Soc Ind Appl Math 11(2):431–441. https://doi.org/10.1137/0111030
Sherwani F, Ibrahim BSKK, Asad MM (2021) Hybridized classification algorithms for data classification applications: a review. Egypt Inform J 22(2):185–192. https://doi.org/10.1016/j.eij.2020.07.004
Chong LW, Rengasamy D, Wong YW, Rajkumar RK (2017) Load prediction using support vector regression. Paper presented at the TENCON 2017 - 2017 IEEE Region 10 conference
Quinlan JR (1992) Learning with continuous classes. In: Proceedings of the fifth australian joint conference on artificial intelligence, Hobart, Australia, November 16–18
Pal M, Deswal S (2009) M5 model tree based modelling of reference evapotranspiration. Hydrol Process 23(10):1437–1443. https://doi.org/10.1002/hyp.7266
Sattari MT, Mirabbasi R, Sushab RS, Abraham J (2018) Prediction of groundwater level in ardebil plain using support vector regression and M5 tree model. Groundwater 56(4):636–646. https://doi.org/10.1111/gwat.12620
Madadi MR, Hosseinzadeh Dalir A, Farsadizadeh D (2014) Investigation of flow characteristics above trapezoidal broad-crested weirs. Flow Meas Instrum 38:139–148. https://doi.org/10.1016/j.flowmeasinst.2014.05.014
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that he has no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Simsek, O., Gumus, V. & Ozluk, A. Prediction of discharge coefficient of the trapezoidal broad-crested weir flow using soft computing techniques. Neural Comput & Applic 35, 17485–17499 (2023). https://doi.org/10.1007/s00521-023-08615-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08615-9