
Abstract
Modeling suspended sediment load is a critical element of water resources engineering. In this work, using the ANFIS method, everyday suspended sediment particles were estimated in different categories of the river in US Sediment big data, and various flow rates were utilized for testing and training. The artificial intelligent (AI) method called ANFIS is used to train actual data from the river and provide an AI model with artificial data points. This artificial data point can show the occurrence of disaster for a critical day with different flow rates. The changing parameter in the AI model enables us to make a correct decision about critical time for rivers. This study also concentrates on the sensitivity investigation of ANFIS setting parameters on the accurateness of numerical results in order to find the best ANFIS model for rapid oscillation in the data set. The best performance of the ANFIS method is achieved with the trimf membership function, the number of input membership function = 16, and the number of iteration = 1000. The results also showed that the ANFIS model can provide fast computational calculation, and adding more nodes for the prediction cannot change the overall time of calculation due to the meshless behavior of the model. In addition to this model, we used the ant colony method for training of data set, and we found that the ANFIS method is better in learning and prediction of the dataset.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The accurate estimating of the sediment’s volume carried by large channels or rivers is significantly essential in water engineering and optimization of channel structure because of its direct influence on planning, designing, managing, and operating the hydraulic structures. To date, various attempts have been made to discover the association between the flow features and quantity of suspended load in the river, including discharge, flow velocity, and the shear stress. Nevertheless, the universal degree was never attained for all applications [1, 2]. The physical driven models involve expensive computing Navier–Stokes or calculation of complicated nonlinear equations of sediment flux [2]. Karim and Kennedy [3] aimed at establishing associations among sediment discharge, flow velocity, friction factor, and bed form geometry of alluvial rivers. Lopes and Ffolliott [4] found that the association between the streamflow and sediment concentration is relatively complex, owing to the hysteresis impact.
Previously, researchers provided some sediment curves for determining the average association between suspended sediment load and discharge. Those models include components corresponding to physical procedures, and they are theoretically able to consider the spatial variation of uneven distribution of evapotranspiration and precipitation [2]. Nevertheless, using the physical-based models is relatively complex due to requiring detailed temporal and spatial environmental data that are not regularly accessible. Estimating the suspended sediment load is difficult at excellent resolution [5]. In general, the linear relations were assumed by time series methods between variables; however, these relationships cannot be easily used regarding real hydrological data; hence, the analysis may be improved by the novel artificial intelligence (AI) methods.
Several mathematical, numerical (computational fluid dynamics) and soft computing methods [6,7,8] have been used in predicting real data or modeling the physical/chemical phenomena. The artificial neural network (ANN) is favored over numerical and mathematical approximations because of numerous benefits, including non-requiring the data of internal system elements and fact calculation, the combination of neural cells and fuzzy structure system are able to calculate the complex association between output and input data [9,10,11,12]. Within this technique, extensive applications are found in biochemical and chemical industries [13, 14] for predicting various complex problems, particularly for failing conventional modeling approaches. Compared to other conventional mathematical models and prediction approaches (for instance, regression), it is greatly capable of identifying system, exclusive of previous knowledge for the procedure associations while providing further reliable outcomes.
The adaptive neuro-fuzzy inference system (ANFIS) or neuro-fuzzy network [15] is an advanced machine learning method with high ability in the prediction of different engineering problems, mainly in biochemical, chemical, and wastewater treatment procedures. It is possible to consider this technique as a hybrid intelligent system combining the representation of fuzzy logic and artificial neural networks (ANNs). A significant capability is represented by the ANFIS technique in learning and estimating indeterminate systems, finally providing a suitable calculating framework with consistent outcomes. Compared to other numerical and mathematical approaches, it can learn the process with the existing data point, and through the fuzzy structure, it can find out the connection between parameters [16,17,18]. Intelligent algorithms (soft computing methods) have been extensively used in many engineering problems to propose appropriate models to prevent complex mathematical modeling, long computational time, and high experimental cost. Recently these algorithms have been used for modeling different types of two-phase reactors [19, 20] in which CFD data was used for developing the ANFIS method to predict BCR hydrodynamics [20,21,22]. They developed the ANFIS method [23, 24] for prediction of BCR data, which had not been used in the training process. They reported that this method has a great ability to predict two-phase flow at different operational conditions. Furthermore, for their training process, they used a huge number of data to predict air fractions at various column heights [24]. Initially, proposed ANFIS technique was proposed with different rules arrangement in predicting fluid problems [19, 25]. This study specifically concentrates on the influence of ANFIS setting parameters in accurately predicting suspended sediment load as far as the load data have rapid oscillation in someday. The ANFIS method is required to select based on a sensitivity study of tuning parameters. For this matter, in this study, prior ANFIS methodology is used for advanced ANFIS development to predict the flow behavior in the river during critical days. We iteratively calculate accuracy of the model for different functions to define the best rule and function structure.
In previous works, different AI methods are extensively used to mimic physical behavior in chemical engineering or nano-fluid applications. Previous researchers have used their AI model to train (learn) computational fluid dynamics results, and they have represented AI results instead of numerical results. As an example, they predicted two-phase flow in reactors, or predicted Nano-fluid in the square shape domain [25,26,, 26]. However, in this study, we concentrated on the convergence of AI results based on the various number of iterations. More specifically, we examine the method with different membership functions (MFs), and evaluate the accuracy of each function based on the different number of iterations. In addition, for the prediction of AI method, we compare the current AI method with other existing numerical AI methods.
We particularly used suspended-sediment load data. For the prediction of our data 2 different methods were used, including ant colony and ANFIS. In the ant colony, we used a combination of ant colony optimization (ACO) method and fuzzy inference system (FIS) structure. We used two inputs, and for the best condition of AI, we used 16 number of input membership functions to have an intelligent system. The best type of MFs for the FIS system was timf, but different other types were used for the modeling, including gbell, gaussmf, gaussm2f, dsigmf, psigmf, and trimf. For training of the data, we used 80 percent of the data, and in testing and the final evaluation of the data, we used the total 100 percent of data. For the total data that the number was 4017 datasets, we used 200 spots in order to cover sediment data. The first input that we studied was the date of the month, which varies from 1 to 30. The second input was day continuous. The output was the amount of discharge. Also, we compare ANFIS and ACO to examine which data can provide us better conditions.
2 Experimental observation
2.1 Utilized data
Data gathering for this study is based on river stations, which were selected for several years. During several years, all behavior of the river is recorded, and we can make sure that there is no non-training point during the learning process. The river sediment load and daily water discharge information of the Cumberland River in the USA were used within 11 years of data gathering (1979 Oct 1st, 1990 Sept 29th) [27]. These data points are selected based on USGS web site. Data collection for discharge as a function of time in the Pineville station (Station ID: 03403000) [28] is shown in Fig. 1.

a Time series scheme of sediment load and river discharge for the Pineville station within the study course. b 3D-plot of time series of sediment load and river discharge for the Pineville station over the study period
3 Methodology
3.1 Adaptive neuro-fuzzy application
Artificial intelligence methods can build up the structure that is computationally smart. It alters linguistic perceptions to computational or mathematical formats for various complex issues. This technique can be very flexible to learn physics and approximate the behavior of numerous uncertain procedures. This technique initially finds system patterns via neural networks, and then fuzzy inference systems implement the decision. By merging these two procedures, they can make a new technique for recognizing and appropriately predicting a problem. This novel system possesses an excellent capability in learning chemical or physical systems for different boundary conditions [25, 26, 29, 30]. The great ability of this method in learning, and also prediction makes this method superior among all numerical AI methods. To show this ability, we also compare this method with the ant colony method.
3.2 ANFIS
To change linguistic concepts for computational and mathematical architecture, fuzzy logic systems can be used. However, they imprecisely find and learn physical procedures, altering boundary circumstances. The detection capability and learning procedure were improved by combining fuzzy logic and ANN methods. This combination is known as ANFIS, combining the natural language explanation of fuzzy systems and learning features of neural-networks. In this work, the time-series data set is used as input and outputs during the learning process. The prediction procedure is initiated by choosing the fuzzy framework for decision. Three fuzzy system frameworks include: Mamdani, Tsukamoto, and Sugeno. Mamdani structure uses two fuzzy frames as two controllers for generating input, and crisp values are extracted within defuzzifying procedure. The crisp functions are used by Sugeno fuzzy models as outputs. Generally, this mathematical structure is a polynomial in the input parameters, which can be zero-order polynomial or first-order polynomial. Owing to model transparency and less computational expenses, the Sugeno framework is a fuzzy structure in the combination of neural cells and fuzzy system models. This artificial model can predict the complex connection between input and output parameters. Originally, the first-order Sugeno fuzzy model is suggested as a superior group of fuzzy systems with extensive application in a fuzzy framework for predicting physical and chemical conditions. This AI model is greatly capable of learning and explaining the membership functions of the problem’s input data.
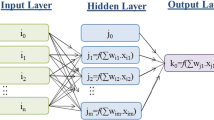
In this work, the first-order Sugeno fuzzy model, with two fuzzy if–then rules is utilized. Figure 2a represents the computing of Sugeno expression, and the equivalent ANFIS format is represented in Fig. 2b. Similar functions exist for nodes in the same layer.

ANFIS framework structure to predict river behavior in the Pineville station
Layer 1: signal point i in this first step represents an adaptive element with an artificial intelligent node calculation.
In this case, the membership function can be any appropriate parameterized membership function. The membership function entirely characterizes a fuzzy set. Various membership calculations exist, including triangular, Gaussian, trapezoidal, sigmoidal, and generalized bell. Trapezoidal and triangular functions contain the straight-line segment; they are not smooth at the parameters-specified corner points. Bell and Gaussian functions are the most common to specify the fuzzy sets as a result of their concise notations and smoothness. It contains one more freedom degree to regulate the steepness at the crossover artificial intelligence node. The generalized bell calculation is utilized as a result of the best capabilities in generalizing the nonlinear input and output parameters:
Layer 2: Each node in the 2nd layer shows a fixed node and its output denotes for all signals’ consequent, which is incoming:
Layer 3: Each element in the 3rd layer shows a constant node. The sum of the firing strength of all rules’:
Layer 4: Each node I in this 4th layer shows an adaptive node with a node function:
Layer 5: In the 5th layer, the whole output is determined by the fixed node as the sum of all arriving signals:
By the hybrid learning technique, the parameters in the ANFIS framework are identified. Functional signals in the forward pass of this technique, go forward until Layer 4. The least-square estimate recognizes the consequent variables.
4 Results
4.1 ANFIS model analysis
For the total data that the number was 4017 datasets, we used 200 spots to cover sediment data. Different membership functions (MFs), number of input membership functions and number of iteration (N.I) are used to find the best prediction results. First, the ANFIS framework is trained with measured data through the above-provided data. Second, the ANFIS network is verified with different mathematical equations to show the best performance of this method. Figures 3, 4, and 5 show the sensitivity study of the different number of input membership function (i.e., 2, 8, and 16) on the accuracy of ANFIS prediction outcomes. The best ANFIS result is achieved when the number of input membership functions reaches to 16. In this case, the coefficient of determination for testing and training data is more than 0.9 (see Fig. 5). In contrast, when the number of the input membership function is 2, the coefficient of determination for testing and training data is less than 0.5. The ANFIS method cannot predict real trends when the number of input membership functions = 2 (Fig. 3), while the method with the number of input membership functions = 16 can show all oscillations in the results with a slight difference. In this case, the method can fully recognize the pattern of data, and even some jumps in dataset for some days.

Prediction outcomes using generalized bell-shaped membership function (gbellmf) when number of input membership function is 2

Prediction outcomes using generalized bell-shaped membership function (gbellmf) when the number of input membership function is 8

Prediction results using generalized bell-shaped membership function (gbellmf) when number of input membership function is 16
By increasing the number of input membership functions up to 8, there is a great improvement in the accuracy of the method. The results show that in the case of increasing membership function up to 8, amount of R2 rises more than 0.9 (see Fig. 4). This improvement in accuracy of the method is more tangible when the number of input membership functions increases up to 16 (see Fig. 5).
Figure 6 represents the coefficient of determination between ANFIS and real data for different MFs. According to the figure, the best ANFIS method is achieved when the trimf function is used as a membership function in the algorithm. In this case, the coefficient of determination is more than 0.98 for both training and testing data. Among all other functions, dsigmf function contains low level of accuracy among all other AI methods. The R2 value in this method in testing evaluation level is less than 0.8. Other functions can also provide a minimum level of accuracy for prediction of the dataset (R2 > 0.9). Figure 7 provides the performance of all MFs on the prediction results. Figure 7 shows that the trimf function can better find the oscillations of real data. It should be mentioned that, in this section, the number of input membership functions and N.I are 16 and 1000, respectively. This function can fully find the trend of the dataset, and it can predict the flow for every day.


Coefficient of determination for different membership functions for training and testing evaluations


Comparison between prediction results and real data for different membership functions
The ANFIS method is also used for the prediction of data. According to Fig. 7, the ANFIS method with former setting parameters can also predict Pineville station data and its oscillation for different days. The negative values in prediction results show the normal behavior of the ANFIS method in predicting the process. Due to rapid oscillations in the results, the ANFIS method tries to fit the model based on rapid oscillations. This fitting process results in a negative value in some parts of the results. Reported that, multi-membership functions or flittering data can be used in order to resolve inaccurate prediction results.
4.2 Comparison between ANFIS and ant colony optimization method
In order to compare the AI method with other algorithms, we compare ANFIS with the ant colony (ACO) method. In general, the method of ANFIS with the ability of neural network training can learn all datasets, while the ACO method describes the learning mechanism with the ant optimization method. By consideration of two different learning schemes, we can assess the ANFIS method and its prediction capability and level of accuracy. To have similar training conditions, the number of inputs, iterations, and percentage of training data are 2, 1000, and 8%, respectively, for both the ANFIS and ACO methods (see Table 1).
First, for comparison of two methods, we consider the best ANFIS model based on function and number of input membership functions which represented earlier, and then we compare it with ant colony method. The main goal of this comparison is to show the ability of ANFIS and ACOFIS in learning this data set and prediction of the final pattern for every day.
In the ACO method, we used the FIS structure for the prediction, and the ant colony was used for the training. As shown in Fig. 8, we plotted the discharge as a function of time. As shown, the two methods can almost predict the discharge data for various days. But we see a peak for our data, which happens between the day 160 to day 180 that the ANFIS method can predict it very well compared to the ACO method. Both of the methods show some deviations in some days. But in general, the ACO method could have a good prediction for the system. On the other hand, as shown in the plot, we compared the regression of the two systems, and in our comparison, we found that the ANFIS method is suitably capable of the prediction in our study. According to the amount of R2, the ANFIS system reaches to 1 and 0.98 in training and testing, successively. For the ACO, R2 reaches to 0.95 in training, and in testing it reaches lower than 0.9; therefore, the ANFIS method that was used in this study has a high capability for the prediction (see Fig. 8).

Comparison between the best intelligence of ANFIS method and ant colony optimization-based fuzzy inference system (ACOFIS)
Figure 8 also shows that the ANFIS method can perfectly match to experimental datasets. However, the ACO method cannot track discharge as a function of times, and it can only predict the overall trend of discharge. Details of comparison between the accuracy of the ANFIS and ACO method are shown in Table 1. Table 1 shows that the ANFIS method contains a lower range of error compared with ACO. For instance, \(R\) and \(R^{2}\) for the ANFIS method are higher than 0.96 for the testing process. However, for the ACO these assessments are less than 0.91 that shows the low capability of prediction. Apart from the testing process, in the training stage, the ANFIS method is very powerful in training compared with ACO. The results show that in the ACO method \(R\) and \(R^{2}\) are 0.96. This evaluation shows that in general the ANFIS method contains a higher capability of prediction with a high level of accuracy.
5 Conclusions
This paper shows the ability of different ANFIS parameters in predicting suspended sediment load. To test the ability of the ANFIS method in predicting real data, different number of input membership functions (2, 8, and 16), type of membership functions, and the number of iteration are used in the MATLAB code. All prediction results are compared with real data with various mathematical criteria. The best performance of the ANFIS method is achieved with trimf function, the number of input membership function = 16, and NI = 1000. The determination coefficient for both testing and training data is more than 0.98, which shows the great agreement between ANFIS and real data. The development of artificial nodes for prediction of river behavior enables us to provide online monitoring, which is fully artificial and computationally inexpensive. Machine learning enables us to connect inputs and outputs dataset and provides a better understanding of the dataset. As a result of the training dataset, this model can give accurate mathematical equations that extensively explain the process. For a better understanding of the process, we also used an ant colony optimization-based fuzzy inference system (ACOFIS) to predict the process, and we compared this prediction process with the ANFIS method. We found that the ANFIS method is more accurate during the noise in the data set. This method can be a great option for suspended sediment load for everyday prediction. For future studies, deep learning can be an excellent option to train suspended sediment load, as they are highly dependent on time. The multi-membership function or filtering technique can be used for the prediction of rapid data when there is a lack of information for the modeling of suspended sediment load. On the other hand, combining other numerical methods, such as computational fluid dynamics with AI models enables us to predict the flow more accurately. For example, using the turbulence model can provide a better prediction of the flow in the river as a river contains turbulence behavior.
References
Vanoni V, Sediment discharge formulas. Sedimentation engineering. 1975: the American Society of Civil Engineers. pp 190–229.
Aytek A, Alp M (2008) An application of artificial intelligence for rainfall-runoff modeling. J Earth Syst Sci 117(2):145–155
Karim MF, Kennedy JF (1990) Menu of coupled velocity and sediment-discharge relations for rivers. J Hydraul Eng 116(8):978–996
Lopes VL, Ffolliott PF (1993) Sediment rating curves for a clearcut ponderosa pine watershed in northern Arizona 1. JAWRA J Am Water Resour Assoc 29(3):369–382
Sivakumar S, Diamente PR, van Veggel FC (2006) Silica-coated Ln3+-doped LaF3 nanoparticles as robust down-and upconverting biolabels. Chem—A Eur J 12(22):5878–5884
Pourtousi M et al (2015) Prediction of multiphase flow pattern inside a 3D bubble column reactor using a combination of CFD and ANFIS. RSC Adv 5(104):85652–85672
Varol Y et al (2007) Prediction of flow fields and temperature distributions due to natural convection in a triangular enclosure using adaptive-network-based fuzzy inference system (ANFIS) and artificial neural network (ANN). Int Commun Heat Mass Transf 34(7):887–896
Lei Y et al (2007) Fault diagnosis of rotating machinery based on multiple ANFIS combination with GAs. Mech Syst Signal Process 21(5):2280–2294
Yilmaz I, Kaynar O (2011) Multiple regression, ANN (RBF, MLP) and ANFIS models for prediction of swell potential of clayey soils. Expert Syst Appl 38(5):5958–5966
Panella, M. and A.S. Gallo (2005) An input-output clustering approach to the synthesis of ANFIS networks. IEEE Trans Fuzzy Syst 13(1):69–81
Schurter KC, Roschke PN (2000) Fuzzy modeling of a magnetorheological damper using ANFIS. In: Fuzzy systems, 2000. FUZZ IEEE 2000. The 9th IEEE international conference on. IEEE
Jang J-SR, Sun C-T, Mizutani E (1997) Neuro-fuzzy and soft computing; a computational approach to learning and machine intelligence. IEEE Trans Autom Control 42(10):1482–1484
Boyacioglu MA, Avci D (2010) An adaptive network-based fuzzy inference system (ANFIS) for the prediction of stock market return: the case of the Istanbul stock exchange. Expert Syst Appl 37(12):7908–7912
Avila G, Pacheco-Vega A (2009) Fuzzy-C-means-based classification of thermodynamic-property data: a critical assessment. Numer Heat Transf, Part A: Appl 56(11):880–896
Jang J-S (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst, Man, Cybern 23(3):665–685
Yun Z et al (2008) RBF neural network and ANFIS-based short-term load forecasting approach in real-time price environment. IEEE Trans Power Syst 23(3):853–858
Varol Y et al (2008) Analysis of adaptive-network-based fuzzy inference system (ANFIS) to estimate buoyancy-induced flow field in partially heated triangular enclosures. Expert Syst Appl 35(4):1989–1997
Ben-Nakhi A, Mahmoud MA, Mahmoud AM (2008) Inter-model comparison of CFD and neural network analysis of natural convection heat transfer in a partitioned enclosure. Appl Math Model 32(9):1834–1847
Xu P et al (2019) Flow visualization and analysis of thermal distribution for the nanofluid by the integration of fuzzy c-means clustering ANFIS structure and CFD methods. J Vis 23(1):1–14
Tian E et al (2019) Simulation of a bubble-column reactor by three-dimensional CFD: multidimension-and function-adaptive network-based fuzzy inference system. Int J Fuzzy Syst 2:411–490
Cao Y et al (2019) Prediction of fluid pattern in a shear flow on intelligent neural nodes using ANFIS and LBM. Neural Comput Appl 32(17):13313–13321
Shamshirband S et al (2020) Prediction of flow characteristics in the bubble column reactor by the artificial pheromone-based communication of biological ants. ArXiv preprint arXiv:2001.04276
Shamshirband S et al (2020) Prediction of flow characteristics in the bubble column reactor by the artificial pheromone-based communication of biological ants. Eng Appl Comput Fluid Mech 14(1):367–378
Babanezhad M et al (2019) Liquid-phase chemical reactors: Development of 3D hybrid model based on CFD-adaptive network-based fuzzy inference system. Can J Chem Eng 97:1676–1684
Nabipour N et al (2020) Prediction of nanofluid temperature inside the cavity by integration of grid partition clustering categorization of a learning structure with the fuzzy system. ACS Omega 5(7):3571–3578
Babanezhad M, Nakhjiri AT, Shirazian S (2020) Changes in the number of membership functions for predicting the gas volume fraction in two-phase flow using grid partition clustering of the ANFIS method. ACS Omega 5(26):16284–16291
Survey, U.S.G. USGS 03403000 Cumberland river near pineville, KY provisional data subject to revision. November 15, 2019. Available from https://waterdata.usgs.gov/nwis/dvreferred_module=sw&site_no=03403000
Cumberland River near Pineville, KY (USGS-03403000) site data in the water quality portal. November 15, 2019. https://www.waterqualitydata.us/provider/NWIS/USGS-KY/USGS-03403000/
Sremac S et al (2018) ANFIS model for determining the economic order quantity. Decis Mak: Appl Manag Eng 1(2):81–92
Stojčić M, Stjepanović A, Stjepanović Đ (2019) ANFIS model for the prediction of generated electricity of photovoltaic modules. Decis Mak: Appl Manag Eng 2(1):35–48
Acknowledgements
This work was supported by the Government of the Russian Federation (Act 211, contract 02.A03.21.0011) and by the Ministry of Science and Higher Education of Russia (grant FENU-2020-0019).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Babanezhad, M., Behroyan, I., Marjani, A. et al. Artificial intelligence simulation of suspended sediment load with different membership functions of ANFIS. Neural Comput & Applic 33, 6819–6833 (2021). https://doi.org/10.1007/s00521-020-05458-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-05458-6