
Abstract
Due to the disastrous socio-economic impacts of flood hazards and estimated rise of its occurrences in the near future, there has been an increase in the importance of flood prediction worldwide. Artificial intelligence (AI) models have contributed significantly by giving cost-effective solutions for simulating physical processes of flood events and improving accuracy in prediction over the last few decades. This paper presents a novel conjoint model to forecast river flood discharge (QFD) considering data from four gauging stations of River Brahmani, Odisha India. The developed hybridised metaheuristic algorithm, i.e. ANFIS-PSOSMA, improves exploration capability of Slime mould algorithm (SMA) by integrating it with particle swarm optimisation (PSO). Performance of novel hybrid model is assessed by utilising quantitative statistical measures like the coefficient of correlation (R2), Nash–Sutcliffe Model Efficiency (NSE), root mean square error (RMSE), and mean absolute error (MAE). The proposed hybrid ANFIS model using optimisation algorithm provided the best performance values with NSE of 0.9952, R2 of 0.9946, RMSE of 0.0485, and MAE of 0.0265 during training and NSE of 0.9736, R2 of 0.9731, RMSE of 8.4236, and MAE of 4.3197 during testing at Jenapur gauging station, indicating the prospective of utilising the developed models in forecasting flood discharge. The present study’s importance lies in integrating several input parameters, and AI algorithms have been utilised for developing flood prediction model. In addition, the attained results indicated that combining the optimisation algorithms with ANFIS enhanced its performance in modelling monthly flood discharge time series.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The pressure of population growth, industrialisation, upgraded living standards, and urbanisation has led to increased water requirements and consumption (Zhou et al. 2002). Accurate and reliable flood forecasts are vital, predominantly in flood-affected regions. Unlike any other natural disaster, floods affect countless lives, property, infrastructure, and cause limitless destruction. An accurate flood forecast with proper lead time can provide forward-thoughtful attentiveness to an impending flood event early enough to minimise flood damage significantly. It is not possible to have complete protection from flooding; however, countless lives and vast amounts of money can be avoided by timely and precise predictions of the crests, magnitude, and duration of the flood. The control of floods is essential to halting climate change. In order to adjust to a changing environment and climate, flood management innovation is vital. Ineffective flood management has serious repercussions. Each year, flooding causes up to tens of billions of dollars worth of economic damage and hundreds of fatalities worldwide. Because of machine learning (ML) algorithm’s strong authority in unravelling non-linear relationships, they have been broadly employed for solving environmental and hydrological problems (Fan et al. 2019; Xiao et al. 2019; Yaseen et al. 2019; Deo et al. 2016). Data-driven models (DDM) work on the basis of functional connections between input (e.g. independent) and target (e.g. dependent) variables (Liang et al. 2019; Kim et al. 2019). In hydrological studies, DDM, using ML algorithms, has been extensively utilised and has revealed better prediction performances with lesser constraints compared to physical-based models (Mosavi et al. 2018; Zia et al. 2015; Samantaray et al. 2022f). Classic DDM for hydrological investigations comprises artificial neural networks (ANN; McCulloch and Pitts 1943), support vector machines (SVM; Vapnik 1995), random forest (RF; Breiman 2001), and ANFIS (Jang 1993). ANN has been utilised in several hydrological processes, including river engineering, water resources management, and hydrology. In terms of accuracy and application, several ANN-based studies have demonstrated an effective method for flow forecast, precipitation prediction, and water quality prediction (Fan et al. 2019; Huang et al. 2019; Samantaray et al. 2022a; Ghose and Samantaray 2019; Samantaray and Ghose 2019; Samantaray et al. 2022b). Several studies have reported application of ANN-based flood prediction models using different meteorological parameters of the study region (Mandal et al. 2005; Han et al. 2007; Dawson et al. 2006; Do Hoai et al. 2011; Elsafi 2014; Mitra et al. 2016; Tsakiri et al. 2018; Sahoo et al. 2022a, b). Singh (2012) applied wavelet-based ANN model for predicting flood events and compared it with existing statistical models. They found that WANN model predicted better flood values than statistical models. In another study, Dhunny et al. (2020) studied the use of ANN model for flood prediction using 20,000 climatic datasets (minimum temperature, maximum temperature, rainfall, and humidity) that were gathered over the course of 2 years for Mauritius. They found ANN to be a good predictor for the specified study region.
Although the ANN method is widely used, it may not produce extremely accurate results, which leads to instability. The inability of ANNs to accurately forecast changes in hydrological variables led to the development of ANFIS that can operate with non-linear relationships. Data pre-processing techniques are required to boost ANN performance. ANFIS is said to be a good amalgamation of ANN and FL. Even though ANN and ANFIS have a lot in common in their modelling stages, reports recommend that ANFIS usually has superior performance than ANN (Sahoo et al. 2022b; Samantaray et al. 2022c; Akrami et al. 2013; El-Shafie et al. 2011); hence, it appears to be a reasonable indication for focusing on ANFIS. It is known to be one of the most beneficial and has a satisfactory performance in modelling many hydrological and environmental phenomena (Kheradpisheh et al. 2015; Mekanik et al. 2016).
Nayak et al. (2005) explored the potential of ANFIS for forecasting flood flow of Kolar river basin, India. In another study, Ullah and Choudhury (2010) explored the usability of ANFIS in flood discharge forecasting of Barak river basin. Both the studies concluded that ANFIS provided better results compared to the ANN model. Nguyen and Chua (2012) implemented ANFIS for daily water level forecasting of Lower Mekong River using water levels of 1 to 5 days ahead. Ghalkhani et al. (2013) used ANN and ANFIS, for flood routing based on different lag times in Madarsoo river basin, Iran. Applied models generated good results at the study location. Anusree and Varghese (2016) applied multiple nonlinear regression (MNLR), ANN, and ANFIS to predict daily flow with different input combinations at exit of Karuvannur river basin. The outcomes indicated that ANFIS predicted river flow more precisely than MNLR and ANN models. Tabbussum and Dar (2021) applied ANN, ANFIS, and fuzzy logic techniques based on different training algorithms to forecast QFD inflowing Srinagar city at Padshahi Bagh station of Jhelum River. They found that ANFIS model utilising hybrid training algorithm generated best prediction outcomes.
While classic AI techniques are utilised to model different phenomena, they generally suffer from certain shortcomings, such as utilising local search techniques, getting trapped in local optima, high computing, and over-fitting (Kisi et al. 2018; Peyghami and Khanduzi 2013). ANN and ANFIS are two well-known methods utilised for stimulating different hydrological phenomena. Often, they produce satisfactory performance in modelling the events mentioned above; however, they sometimes face problems estimating flood discharge. It may be because the non-linear and non-stationary condition of flow makes its modelling difficult. Hence, it appears to be a good indication to develop modelling quality by diminishing the complications of classical models. But, even though ANFIS has several benefits, its training approaches undergo a few flaws resulting in the incompetence of the models in some circumstances (Kisi et al. 2017). Finding an appropriate structure and its constraints in a neuro-fuzzy (NF) system is essential and also, the system’s success depends on its training algorithm’s accuracy and efficiency.
Several researches have been published on the successful use of genetic algorithm (GA) in combination with ANN and ANFIS models in predicting river flow discharge (Mukerji et al. 2009; Chau et al. 2005; Wu and Chau 2006). In a similar manner, hybrid ANFIS model with different evolutionary algorithms (Firefly Algorithm (FA); ant colony optimisation (ACO); Whale Optimisation algorithm (WOA); Gray Wolf Optimisation (GWO); Salp Swarm algorithm (SSA); Harris Hawks Optimization (HHO); Butterfly Optimization Algorithm (BOA); Black Widow Optimization Algorithm (BWOA)) have been successfully applied for modelling several hydrological variables like precipitation, temperature, solar radiation, evapotranspiration, runoff, drought, water table depth, and humidity (Tao et al. 2018; Yaseen et al. 2018; Dehghani et al. 2019; Seifi et al. 2020; Penghui et al. 2020; Samantaray et al. 2022d, e; Panahi et al. 2021; Emami and Emami 2021; Mirboluki et al. 2022, Fadaee et al. 2022). Azad et al. (2018) utilised ACO, GA, and PSO, to train ANFIS for estimating the river flow of Zayandehrood river basin, Iran. Among all considered models, ANFIS-PSO performed best and classical ANFIS performed worst. Yaseen et al. (2019) investigated the potential of GA, PSO, and differential evolution (DE) in tuning membership function (MF) of ANFIS for improving accuracy of streamflow forecasting in River Pahang, Peninsular Malaysia. Analysis of performance indicated that PSO improved the proficiency of ANFIS more than DE and GA algorithms. Inyang et al. (2020) applied k-means, self-organising maps (SOM), ANFIS-GA, and ANFIS-PSO models for predicting flood severity levels. ANFIS-PSO model with lowest error established to be superior compared to other applied models. Arya Azar et al. (2021) evaluated ANFIS, least-squares support vector machine (LS-SVM), and ANFIS-HHO models for predicting evaporation utilising data related to Doroudzan dam located in central Iran. They reported that ANFIS-HHO model gave superior performance to LS-SVR and ANFIS models. Mohammadi et al. (2021) investigated performance of single Non-Recorded Catchment Areas (NRECA), Hydrologiska Byråns Vattenbalansavdelning (HBV), SVM, ANFIS, GMDH (group method of data handling) models, and hybridised NRECA and HBV with ANFIS, SVM, and GMDH models in streamflow prediction considering precipitation and streamflow data of four stations in Indonesia. The results revealed that hybrid models performed better than single models, with hybrid GMDH model performing best among all. Haznedar and Kilinc (2022) developed a hybrid ANFIS-GA model to predict river flow from data collected from Zamanti and Körkün stations of River Seyhan, Turkey, and compared its results with traditional ANN and LSTM models. Their outcomes showed that projected ANFIS-GA technique was successful in predicting river flow more accurately. Malik et al. (2022) applied three machine learning models namely MLP, SVM, and ANFIS and their optimisation with PSO, SMA, and spotted hyena optimiser (SHO) algorithms to predict soil temperature at different depths for a semi-arid zone of Punjab, India. They found that SMA algorithm best optimised the ML models and can be applied for other regions across India.
The developed technique, called ANFIS-PSOSMA, works by constructing a group of solutions, each of which refers to arrangement from ANFIS model’s parameters. The training set, representing 70% of total samples, is used to evaluate each solution. The solution with the smallest fitness value is the best, which is found by calculating the RMSE. After that, PSO’s operators are utilised for enhancing the existing population. This procedure is trailed by utilising SMA’s operators to improve solutions till they attain the final condition. The preeminent arrangement of ANFIS, i.e. the preeminent solution, is assessed utilising a testing set representing 30% of the entire samples. To the best of the authors’ understanding, this is the first application of PSOSMA to improve prediction capability of ANFIS and implemented in a real dataset (i.e. flood discharge dataset of Brahmani River). Study flow chart with methodology is given in Fig. 1.

Study flow chart with methodology
Study area
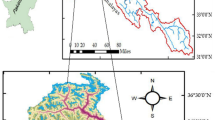
River Bramhani is the second longest river in Odisha and a major seasonal river in eastern India. The Brahmani is a significant seasonal river in the eastern Indian state of Odisha (Fig. 2). The Sankh and South Koel rivers meet to form the Brahmani, which flows through the Sundargarh, Deogarh, Angul, Dhenkanal, Cuttack, Jajapur, and Kendrapara districts. The basin is located on the right by Mahanadi basin and on the left by Baitarani basin. It forms a sizable delta with the river Baitarani before draining into the Bay of Bengal at Dhamra. It is situated amid 20°30′10′′ and 23°36′42′′N latitudes and 83°52′55′′ and 87°00′38′′E longitudes. About 80% of the water of river Bramhani is used in irrigation. In the summer, the temperature may get as high as 47° C, while in the winter, it can get as low as 4 °C. In the state of Odisha, the basin is the primary source of water supplies for several towns and businesses as well as for agriculture. Having a total 39,313.50 km2 catchment area, it spreads over Chhattisgarh (3.5% of basin area), Jharkhand (39.2% of basin area), and Odisha (57.3% of basin area) states. Flood is a common aspect in Baitarani basin.

Study area depicting four selected gauge stations
Materials and methods
ANN
ANNs have been increasingly utilised in hydrological modelling, like streamflow modelling, rainfall-runoff modelling, and reservoir modelling (Othman and Naseri 2011). ANNs are parallelly dispersed processing systems having tendency of storing experiential information (Latt and Wittenberg 2014). ANN descend connotation from historical dataset, as opposed to physical aspects of a watershed (Cai et al. 2009). MLP is a broadly utilised ANN comprising of neurons called perceptron (Mukerji et al. 2009). In mathematical terms, MLP can be expressed by Eq. (1):
where \(y\)—output; \({x}_{z}\)—input vector \((z = 1\dots n\)); \(f\)—transfer function; \({m}_{z}\)—weight vector; \(b\)—bias. Basic architecture of ANN is shown in Fig. 3.

Architecture of ANN
ANFIS
A NF system combines ideas of ANNs and fuzzy logic. Depending on training data, they change the types of membership fuzzy functions and inference fuzzy rules using an artificial neural network’s learning capability (Das et al. 2019; Sarkar et al. 2021). Learning and logical inference benefits are therefore incorporated into a single system. ANFIS is one of the most widely utilised NF systems (Samantaray et al. 2022g). A multilayer neural network called ANFIS produces output variable’s specific value for identified inputs depending on datasets (input–output vector) used during training.
The ability of ANFIS to accurately simulate non-linear links between input and output is a key characteristic. The implementation of an error propagation backward technique, either separately or in conjunction with approach of least squared error, is the foundation of ANFIS training. For describing ANFIS’s structure, the system comprises two inputs (\(x\) and \(y\)), two Sugeno’s type fuzzy if–then rules, and a single output \((y)\):
where \({C}_{i}\) and \({D}_{i}\)—fuzzy sets, \(q\), \(p\), \(r\)—subsequent model parameters assessed during training phase. Five layers of the ANFIS structure are seen in Fig. 4.

Architecture of ANFIS
The 1st layer comprises fuzzy MFs having output function for every node as shown in Eqs. (2) and (3):
where \(\mu\)—generalised Gaussian MF.
The 2nd layer calculates firing power of a rule utilising multiplication operator using Eq. (4):
The 3rd layer normalises firing power of each rule, utilising ratio between firing power of \(i\) th node and addition of firing powers from all nodes (Eq. (5)). Non-adaptive nodes are present in the 3rd layer.
\({w}_{i}-i\mathrm{th}\) output from layer 2
The 4th layer utilises a nodal function for calculating the impact of \(i\) th rule concerning the output of the model (Eq. (6)):
where \({p}_{i}\), \({q}_{i}\), and \({r}_{i}\)—parameter sets of node and \({w}_{i}\)—normalised firing power of 3rd layer.
The 5th layer consists of a solitary non-adaptive node that computes ANFIS model’s overall output utilising a summation system (Eq. (7)):
PSO
Kennedy and Eberhart (1995) proposed a population-based meta-heuristic algorithm known as PSO algorithm for solving optimisation problems. The societal behaviour of cluster of “birds” (particles) inspired the two scientists for developing this optimisation technique. The behaviour of birds known as flocking is based on finding certain foodstuff for themselves. At first, population (particle) is initialised by some arbitrarily produced location values. The preeminent position of every particle (\(pbest\)) is uninterruptedly stored locally in conjunction with the knowledge about global best particle (\(gbest\)). The position and velocity of all population are updated utilising Eq. 8 and Eq. 9 respectively.
where \({x}_{i,n}^{j}\) and \({v}_{i,n}^{j}\)—position and velocity of \({i}^{th}\) particle respectively, \(w\)—inertial weight of current particle utilised for modifying subsequent group of particles, \({p}_{i,n}^{j}\)—personal preeminent location having fitness cost (value) of \(i\) th particle usually termed \(pbest\), \({p}_{g,n}^{j}\)—global preeminent particle position usually termed \(gbest\), \({c}_{1}\) and \({c}_{2}\)—coefficient of acceleration utilised for handling exploration and exploitation ability respectively, \({r}_{1}\) and \({r}_{2}\)—equally dispersed arbitrary number between [0, 1]. All elements work together with one another to search for a best solution with their optimal fitness function. Basic architecture of PSO is shown in the following algorithm.

PSO algorithm
SMA
Because metaheuristic algorithms perform better than deterministic algorithms and use less processing power and time, they have gained popularity in several practical fields in recent years. In addition, certain deterministic algorithms are affected by local optima because they lack unpredictability in their latter stages. In contrast, random elements in MAs might cause the algorithm to search for all optimal solutions in the search space, successfully avoiding local optimum. Li et al. (2020) developed a technique for creating wireless sensor networks that use two different slime mould tubular networks corresponding to two different regional routing algorithms.
Approach food
For replicating the contraction technique in this approach, following model equations are expressed (Eq. (10)):
where \(\overrightarrow{vb}\)—constraint utilised in \([-a, a]\), \(\overrightarrow{vc}\)—constraint values that vary from 1 to 0. \(t-{t}_{th}\) iteration,\(\overrightarrow{{Y}_{b}}\)—discrete location of present best,\(\overrightarrow{Y}\)—position of present solution, \(\overrightarrow{{Y}_{A}}\) and \(\overrightarrow{{Y}_{B}}\)—two randomly selected solutions, and \(\overrightarrow{W}\)—weight of current solution. \(p\) value is determined as follows (Eq. (11)):
where\(i \in 1, 2, 3, . ... , n\), \(S\left(i\right)\)—fitness function of present solution and \(\overrightarrow{vb}\) is found using the following expression Eq. (12):
The \(\overrightarrow{W}\) is obtained based on subsequent Eq. (13):
where \(r\)—arbitrary value between [0, 1], \(bF\)—best-attained fitness values, \(wF\)—worst-attained fitness values, and \(SmellIndex\)—organised fitness values.
Wrap food
When food item is satisfied to extend to a location where the quantity of food is fragile, then the importance of that area diminishes, initiating investigators to move their observation towards other areas of food accessibility which are not as important as the food item. To update the locations, the following mathematical expression is used as depicted:
where \(UB\) and \(LB\)—upper and lower boundaries, \(rand\) and \(r\)—arbitrary values between \([\mathrm{0,1}]\), and \(z\) is a value of parameter between \([0, 0.1]\).
Grabble food
\(\overrightarrow{vb}\)—zone of arbitrary numbers between \([-a, a]\), \(\overrightarrow{vc}\) lies between \([-1, 1]\). Even though slime mould obtained an enhanced feed source, it still would extend organic material to seek other sites for a superior-class food source instead of investing all of it in a solitary region for discovering a more consistent nutrition source. The mechanism of SMA algorithm is represented in the following algorithm.

Pseudo-code of SMA
Proposed ANFIS-PSOSMA model
The applied algorithm intends at improving the capability of ANFIS model for predicting QFD by finding its optimal constraints. This is obtained by utilising a novel metaheuristic algorithm called SMA. SMA is dependent on utilising PSO for generating initial population (first generation) as it has the biggest impact on conjunction of solutions concerning optimum solution. The developed model namely ANFIS-PSOSMA, as shown in Algorithm 3, starts by constructing the network that comprises five layers like the conventional ANFIS. After that, the input data is divided into two groups; first set (70% of total data) is utilised for training the network and finding optimal constraints and second set (30% of total data) is utilised for assessing superlative network built utilising PSOSMA. The subsequent procedure is to generate a group of arbitrary solutions and assess superiority of each one for determining best solution in accordance to training set.
Subsequently, solutions are updated utilising PSO operators, and updated population is delivered to SMA algorithm, which means until they reach at end conditions, operators of SMA will be utilised for updating solutions. The best solution of the preeminent ANFIS network is reverted from learning phase. After that, the testing set is utilised for evaluating performance of the best ANFIS model. Steps of ANFIS-PSOSMA model is demonstrated in Fig. 5.

Steps of ANFIS-PSOSMA

Pseudo-code of ANFIS-PSOSMA
Evaluating standards
R2 (Sridharam et al. 2021; Chaudhury et al. 2022; Samantaray and Ghose 2022), MAE (Singh et al. 2022; Jamei et al. 2022), and RMSE (Wang et al. 2022; Ehteram et al. 2019) are standard assessment measures for determining the preeminent prediction model (Eq. (15), Eq. (16), and Eq. (17)). Furthermore, the NSE (Patel et al. 2022; Samani et al. 2022) is also utilised to assess the power of the ANFIS-PSOSMA model (Eq. (18)). For the selection of the best model in this research, the criteria is MAE and RMSE are to be minimum and NSE, R2 must be maximum.
where
- P i :
-
predicted value.
- O i :
-
observed value.
- \(\overline{P }\) :
-
mean predicted value
- \(\overline{O }\) :
-
mean observed value
The applied models based on different input combinations of meteorological components (precipitation (Pt), temperature (Tt), humidity (Ht), infiltration (It), evapotranspiration (ETt)) are presented in Table 1. The observed rainfall (Pt), average temperature (Tt), mean humidity (Ht), and mean evapotranspiration loss (Et) data are collected from IMD (Indian Meteorological Department), Pune. Infiltration data is obtained from Soil Water Infiltration Global Database.
Statistical analysis (minimum, maximum, mean, standard deviation, and kurtosis) of considered hydrological parameters (precipitation, humidity, temperature, evapotranspiration loss, and infiltration), for all datasets (training and testing) of all four stations, is conducted in Tables 2, 3, 4, and 5. The obtained results are presented in Table 6. After monitoring the data quality, datasets were divided into training (70% of complete data) and testing (30% of complete data). The period from January 1990 to December 2010 was utilised to train the models, and from January 2011 to December 2019 to test them.
Results
The performance of three models were tested for predicting monthly QFD in both training and testing phases utilising different statistical assessment measures (Tables 6, 7, 8, 9, and 10). Based on the applied evaluation measures, it was witnessed that all applied models had good prediction capability (R2 > 0.7). The results of R2 revealed that applied models are satisfactory; however, ANFIS-PSOSMA model generated the best QFD values, with the highest value of R2 (0.9946), followed by ANFIS-SMA (0.9813), ANFIS-PSO (0.9748), ANFIS (0.9657), and ANN (0.9507) models in the training phase and in the testing phase, R2 values of 0.9731, 0.9517, 0.9436, 0.9314, and 0.9176 in Jenapur station. Considering RMSE values, ANFIS-PSOSMA model had the lowest RMSE (0.0485) proving its best predictive power, followed by ANFIS-SMA (2.2532), ANFIS-PSO (6.8964), ANFIS (13.8749), and ANN (30.9957) models. Moreover, NSE criteria were categorised from highest prediction power to lowest providing similar to R2, as follows: ANFIS-PSOSMA (0.9952) > ANFIS-SMA (0.9818) > ANFIS-PSO (0.9755) > ANFIS (0.9662) > ANN (0.9513).
The statistical indices discussed above have very well evaluated the prediction capability of projected models. In addition to that, scatter plots and time-series plots are very much useful in assessing the efficiency of forecasting data against the observed data.
It is observed from the scatterplots (Fig. 6) that all models achieved reasonable outcomes in terms of low and high QFD values. However, the values of R2 (Fig. 6) showed that ANFIS-PSOSMA performed superiorly compared to other hybrid and conventional models. As shown in Fig. 6d, the outcomes attained from the five models in the Jenapur station are more closely to 45° reference line than those of Jaraikela, Gomlai, and Tilga stations. Also, ANFIS-PSOSMA generated the best R2 value (0.99468), which inferred superior prediction than other models. The scatter plots of Tilga, Jaraikela, and Gomlai stations are shown in Fig. 6a–c.




Scatter plots of actual vs. predicted flood discharge using ANN, ANFIS, ANFIS-PSO, ANFIS-SMA, and ANFIS-PSOSMA models for a Tilga, b Jaraikela, c Gomlai, and d Jenapur stations
Performance of ANN, ANFIS, and ANFIS-SMA are further demonstrated in a more instinctive manner by plotting observed versus predicted QFD in the form of hydrographs, as presented in Fig. 6. Monthly forecasting time series data for all models are illustrated in Fig. 6 using data from 1 January 1990 to 31 December 2010 during training, whereas during the testing period uses data from 1 January 2011 to 31 December 2019. For all the stations considered in this study, ANFIS-PSOSMA model performed best for QFD forecasting, as estimated QFD values were closer to corresponding actual values and followed similar trend in all sketches, as displayed in Fig. 6. The time-series plots of Tilga, Jaraikela, Gomlai, and Jenapur stations are presented in Fig. 6a–d. Different from predictions from Jaraikela, Gomlai, and Tilga stations, predictions from Jenapur station can better forecast higher and lower flows. Among all the four stations considering the five applied models, the prediction accuracy of Jaraikela station is poor with the least R2 value in both the training and testing stages.
Linear scale plot of actual vs. estimated QFD for applied models are demonstrated in Fig. 7. The figures demonstrate that predicted peak QFD are 459.179M3/s, 454.666M3/s, 444.198M3/s, 433.496M3/s, 414.187M3/s for ANFIS-PSOSMA, ANFIS-SMA, ANFIS-PSO, ANFIS, and ANN in contrast to actual peak of 465.274M3/s for Tilga station. The approximated peak discharges are 3736.342M3/s, 3705.635M3/s, 3624.51M3/s, 3541.109M3/s, and 3344.36M3/s for ANFIS-PSOSMA, ANFIS-SMA, ANFIS-PSO, ANFIS, and ANN against actual peak 3790.931M3/s for Jaraikela division. For Gomlai gauging station, actual QFD is 2859.61M3/s aligned with predicted QFD 2822.149M3/s, 2804.991M3/s, 2736.075M3/s, 2667.444M3/s, and 2547.626M3/s for ANFIS-PSOSMA, ANFIS-SMA, ANFIS-PSO, ANFIS, and ANN correspondingly. Similarly, for Jenapur, observed peak discharge is 4432.095M3/s with respect to predicted QFD 4371.819M3/s, 4326.168M3/s, 4242.401M3/s, 4143.566M3/s, and 3871.435M3/s, for ANFIS-PSOSMA, ANFIS-SMA, ANFIS-PSO, ANFIS, and ANN respectively.




Observed and computed stream flow for a Tilga, b Jaraikela, c Gomlai, and d Jenapur stations
The results of boxplot are shown in Fig. 8. The boxplot of ANFIS-PSOSMA model for QFD prediction was nearly close to the actual boxplot compared to other two hybrid models (ANFIS-SMA and ANFIS-PSO), whereas conventional ANFIS, and ANN underestimated QFD. In terms of quartile, minimum and median values of all considered models were capable of predicting QFD values closer to actual values with a substantial degree of precision, even though ANFIS-PSOSMA model performed best among all models.

Boxplot representation for proposed models for a Tilga, b Jaraikela, c Gomlai, and d Jenapur stations
Correspondingly, frequency analysis is done through a histogram plot (Fig. 9) of actual and predicted data set. The x-axis presents QFD values, and the number of events was determined by the bin ranges of the histograms. From the above analysis, it is clearly found that ANFIS-SMA is more suitable than ANFIS and ANN approach. It can be concluded that after incorporating SMA to ANFIS models, there is a noticeable decrease in forecasting uncertainty resulting in the assessment of the prediction model.

Histogram plots showing frequency of actual and predicted data a Tilga, b Jaraikela, c Gomlai, and d Jenapur
Discussion
The applied models realise flood discharge prediction with a forecasting horizon. The performance criteria of hybrid ANFIS-PSOSMA is satisfactory (NSE = 0.9952, RMSE = 0.0485 R2 = 0.9946, MAE = 0.0265). The coefficient of determination (Fig. 6) illustrates that the developed model has adequately acquired the aspects of time series (QFD) of training data series. The predicted and observed QFD by ANFIS-PSOSMA model are nearly similar (Fig. 7). The same situation is observed with the NSE (0.9952). A small deviation is observed in terms of the RMSE (0.0485) between the forecasted flood discharge against the actual discharge. Hence, the proposed hybrid ANFIS-PSOSMA model has appropriately adjusted with variations in the input dataset (meteorological components) during the training period. The evaluation of generalisation capability, i.e. absence of overfitting or underfitting, is conducted with the testing dataset which has not been utilised in the training period. For each occurrence, testing results showed a good generalisation capability of the selected model. This reveals that there was neither overfitting nor underfitting during training. Also, it specifies perfect forecasts of flood peaks. There was a slight deviation between predicted and observed flood peaks, and hence, we can conclude that ANFIS-PSOSMA model has a better forecasting or prediction ability for flood peaks. The major advantage of the developed holistic approach is automatic determination of ANFIS variables and arrangement of key standardisation samples for overcoming limitations of conventional ML in modelling real-world problems when series of sample values is huge. The PSO is utilised for modifying search operators of SMA for avoiding its limitations in determining preeminent solution because of its fragile exploitation capability. As a result, integration of PSO and SMA, i.e. PSOSMA, utilises benefits of both SMA and PSO, and it shows higher performance outcomes compared to original SMA and PSO.
The key drawback of this research is the assessment of five applied ML approaches utilising data from a particular area. The proposed techniques can further be verified by utilising additional data from other climatic conditions. Also, the prospective of hybridisation of PSOSMA technique with stochastic models, mainly models with exogenous input, necessities to be evaluated. In future works, integrating ANFIS-PSOSMA with ensemble modelling techniques (like Bayesian model averaging) or preprocessing methods (e.g. EEMD or EMD) may be considered for improving models' effectiveness.
Conclusion
This research investigates the possibilities of modelling flood extremes utilising the newly developed AI approaches for improving early flood warning systems to mitigate the effect of flood hazards in the future. The present study was conducted for improving the appropriateness of ANFIS model integrated with PSOSMA for estimating flood discharge. Analysis of outcomes revealed that ANFIS in combination with meta-heuristic algorithms has great potential in estimating QFD with high accurateness and can enhance performance of standalone ANFIS by evading from the possibility of being stuck in local optima. It also decreases the dependency on conditions of the specified problem and improves search technique and capability of optimising complex problems. A good agreement was achieved amid observed and predicted values for simulated QFD in Bramhani River.
-
Among all employed AI models, ANFIS-PSOSMA model provided superior accurateness compared to other models namely ANFIS-SMA, ANFIS-PSO, ANFIS, and ANN. Novel ANFIS-PSOSMA model gave best value of R2 = 0.9946 than ANFIS-SMA (0.9813), ANFIS-PSO (0.9748), ANFIS (0.9657), and ANN (0.9507) models.
-
Addition of evapotranspiration as input to models showed substantial enhancement; hence for building an excellent QFD prediction model, rainfall data should be taken into consideration. In terms of accuracy in predicting QFD, it appears that the employed hybrid models performed very well.
-
Therefore, the hybrid ANFIS algorithm without the need for an innovative mathematical model is excellent for mimicking the non-linear restraints of obtained data and could be useful as a QFD estimation tool. To forecast QFD, identical algorithms with related model architectures could be taken and verified worldwide.
-
Provided that usage of better-quality datasets in ANN models will give more consistent results, however, accessibility of these high-quality hydro-climatic data series is one of the major limitations of these types of approaches. For future studies, efforts should be made for applying other appropriate EA and investigating their capability by comparing the models recommended in this work. Also, proposed EA techniques can be applied in other popular AI models that might face certain problems during training phase.
Data availability
The data for the current study are available on reasonable request from the corresponding author.
References
Akrami SA, El-Shafie A, Jaafar O (2013) Improving rainfall forecasting efficiency using modified adaptive neuro-fuzzy inference system (MANFIS). Water Resour Manag 27(9):3507–3523
Anusree K, Varghese KO (2016) Streamflow prediction of Karuvannur River Basin using ANFIS, ANN and MNLR models. Procedia Technol 24:101–108. https://doi.org/10.1016/j.protcy.2016.05.015
Arya Azar N, Ghordoyee Milan S, Kayhomayoon Z (2021) Predicting monthly evaporation from dam reservoirs using LS-SVR and ANFIS optimized by Harris hawks optimization algorithm. Environ Monit Assess 193(11):1–14. https://doi.org/10.1007/s10661-021-09495-z
Azad A, Farzin S, Kashi H, Sanikhani H, Karami H, Kisi O (2018) Prediction of river flow using hybrid neuro-fuzzy models. Arab J Geosci 11(22):1–14. https://doi.org/10.1007/s12517-018-4079-0
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Cai M, Yin Y, Xie M (2009) Prediction of hourly air pollutant concentrations near urban arterials using artificial neural network approach. Transp Res Part D: Transp Environ 14(1):32–41
Chau KW, Wu CL, Li YS (2005) Comparison of several flood forecasting models in Yangtze River”. J Hydrol Eng 10(6):485–491. https://doi.org/10.1061/(ASCE)1084-0699(2005)10:6(485)
Chaudhury S, Samantaray S, Sahoo A, Bhagat B, Biswakalyani C, Satapathy DP (2022) “Hybrid ANFIS-PSO Model for Monthly Precipitation Forecasting.” In Evolution in Computational Intelligence (pp. 349–359). Springer, Singapore. https://doi.org/10.1007/978-981-16-6616-2_33
Das UK, Samantaray S, Ghose DK, Roy P (2019) Estimation of aquifer potential using BPNN, RBFN, RNN, and ANFIS. In: Smart intelligent computing and applications: proceedings of the Second International Conference on SCI 2018, vol 2. Springer Singapore, pp 569–576
Dawson CW, Abrahart RJ, Shamseldin AY, Wilby RL (2006) Flood estimation at ungauged sites using artificial neural networks. J Hydrol 319(1–4):391–409. https://doi.org/10.1016/j.jhydrol.2005.07.032
Dehghani M, Seifi A, Riahi-Madvar H (2019) Novel forecasting models for immediate-short-term to long-term influent flow prediction by combining ANFIS and grey wolf optimization. J Hydrol 576:698–725. https://doi.org/10.1016/j.jhydrol.2019.06.065
Deo RC, Wen X, Qi F (2016) A wavelet-coupled support vector machine model for forecasting global incident solar radiation using limited meteorological dataset. Appl Energy 168:568–593
Dhunny AZ, Seebocus RH, Allam Z, Chuttur MY, Eltahan M, Mehta H (2020) Flood prediction using artificial neural networks: empirical evidence from Mauritius as a case study. Knowl Eng Data Sci 3(1):1–10
Do Hoai N, Udo K, Mano A (2011) Downscaling global weather forecast outputs using ANN for flood prediction. J Appl Math. https://doi.org/10.1155/2011/246286
Ehteram M, Afan HA, Dianatikhah M, Ahmed AN, Ming Fai C, Hossain MS, Allawi MF, Elshafie A (2019) Assessing the predictability of an improved ANFIS model for monthly streamflow using lagged climate indices as predictors. Water 11(6):1130. https://doi.org/10.3390/w11061130
El-Shafie A, Jaafer O, Akrami SA (2011) Adaptive neuro-fuzzy inference system based model for rainfall forecasting in Klang River, Malaysia. Int J Phys Sci 6(12):2875–2888
Elsafi SH (2014) Artificial neural networks (ANNs) for flood forecasting at Dongola Station in the River Nile, Sudan. Alex Eng J 53(3):655–662. https://doi.org/10.1016/j.aej.2014.06.010
Emami H, Emami S (2021) Application of Whale Optimization Algorithm Combined with Adaptive Neuro-Fuzzy Inference System for Estimating Suspended Sediment Load. J Soft Comput Civ Eng 5(3):1–14. https://doi.org/10.22115/SCCE.2021.281972.1300
Fadaee M, Mahdavi-Meymand A, Zounemat-Kermani M (2022) Suspended sediment prediction using integrative soft computing models: on the analogy between the butterfly optimization and genetic algorithms. Geocarto Int 37(4):961–977. https://doi.org/10.1080/10106049.2020.1753821
Fan C, Sun Y, Zhao Y, Song M, Wang J (2019) Deep learning-based feature engineering methods for improved building energy prediction. Appl Energy 240:35–45
Ghalkhani H, Golian S, Saghafian B, Farokhnia A, Shamseldin A (2013) Application of surrogate artificial intelligent models for real-time flood routing. Water Environ J 27(4):535–548. https://doi.org/10.1111/j.1747-6593.2012.00344.x
Ghose DK, Samantaray S (2019) Estimating runoff using feed-forward neural networks in scarce rainfall region. In: Smart intelligent computing and applications: proceedings of the Second International Conference on SCI 2018, vol 1. Springer Singapore, pp 53–64
Han D, Kwong T, Li S (2007) Uncertainties in real-time flood forecasting with neural networks. Hydrol Process: Int J 21(2):223–228. https://doi.org/10.1002/hyp.6184
Haznedar B, Kilinc HC (2022) A Hybrid ANFIS-GA Approach for Estimation of Hydrological Time Series. Water Resour Manage 36(12):4819–4842. https://doi.org/10.1007/s11269-022-03280-4
Huang Y, Liu Y, Liu Y, Li H, Knievel JC (2019) Mechanisms for a record-breaking rainfall in the coastal metropolitan city of Guangzhou, China: observation analysis and nested very large eddy simulation with the WRF model. J Geophys Res Atmos 124(3):1370–1391
Inyang UG, Akpan EE, Akinyokun OC (2020) A hybrid machine learning approach for flood risk assessment and classification. Int J Comput Intell Appl 19(02):2050012. https://doi.org/10.1007/s11069-016-2220-5
Jamei M, Ali M, Malik A, Prasad R, Abdulla S, Yaseen ZM (2022) Forecasting Daily Flood Water Level Using Hybrid Advanced Machine Learning Based Time-Varying Filtered Empirical Mode Decomposition Approach. Water Resour Manage 36(12):4637–4676. https://doi.org/10.1007/s11269-022-03270-6
Jang JS (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man, and Cybernetics 23(3):665–685
Kennedy J, Eberhart R (1995) Particle swarm optimization. Proceedings of ICNN'95 - International Conference on Neural Networks, vol.4. Perth, WA, Australia, pp. 1942-1948. https://doi.org/10.1109/ICNN.1995.488968
Kim J, Han H, Johnson LE, Lim S, Cifelli R (2019) Hybrid machine learning framework for hydrological assessment. J Hydrol 577:123913
Kisi O, Sanikhani H, Cobaner M (2017) Soil temperature modeling at different depths using neuro-fuzzy, neural network, and genetic programming techniques. Theor Appl Climatol 129:833–848
Kisi O, Shiri J, Karimi S, Adnan RM (2018) Three different adaptive neuro fuzzy computing techniques for forecasting long-period daily streamflows. Big data in engineering applications. pp 303–321
Kheradpisheh Z, Talebi A, Rafati L, Ghaneian MT, Ehrampoush MH (2015) Groundwater quality assessment using artificial neural network: a case study of Bahabad plain, Yazd, Iran. Desert 20(1):65–71
Latt ZZ, Wittenberg H (2014) Improving flood forecasting in a developing country: a comparative study of stepwise multiple linear regression and artificial neural network. Water Resour Manag 28:2109–2128
Li S, Chen H, Wang M, Heidari AA, Mirjalili S (2020) Slime mould algorithm: a new method for stochastic optimization. Futur Gener Comput Syst 111:300–323
Liang J, Li W, Bradford SA, Šimůnek J (2019) Physics-informed data-driven models to predict surface runoff water quantity and quality in agricultural fields. Water 11(2):200
Malik A, Tikhamarine Y, Sihag P, Shahid S, Jamei M, Karbasi M (2022) Predicting daily soil temperature at multiple depths using hybrid machine learning models for a semi-arid region in Punjab, India. Environ Sci Pollut Res 29(47):71270–71289
Mandal S, Saha D, Banerjee T (2005) A neural network based prediction model for flood in a disaster management system with sensor networks. In Proceedings of 2005 International Conference on Intelligent Sensing and Information Processing, 2005. (pp. 78–82). IEEE. https://doi.org/10.1109/ICISIP.2005.1529424
Mekanik F, Imteaz MA, Talei A (2016) Seasonal rainfall forecasting by adaptive network-based fuzzy inference system (ANFIS) using large scale climate signals. Clim Dyn 46:3097–3111
McCulloch WS, Pitts W (1943) A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics 5:115–133
Mirboluki A, Mehraein M, Kisi O (2022) Improving accuracy of neuro fuzzy and support vector regression for drought modelling using grey wolf optimization. Hydrol Sci J 67(10):1582–1597. https://doi.org/10.1080/02626667.2022.2082877
Mitra P, Ray R, Chatterjee R, Basu R, Saha P, Raha S, Barman R, Patra S, Biswas SS, Saha S (2016) Flood forecasting using Internet of things and artificial neural networks. In 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON) (pp. 1–5). IEEE. https://doi.org/10.1109/IEMCON.2016.7746363
Mohammadi B, Moazenzadeh R, Christian K, Duan Z (2021) Improving streamflow simulation by combining hydrological process-driven and artificial intelligence-based models. Environ Sci Pollut Res 28(46):65752–65768. https://doi.org/10.1007/s11356-021-15563-1
Mosavi A, Ozturk P, Chau KW (2018) Flood prediction using machine learning models: literature review. Water 10(11):1536
Mukerji A, Chatterjee C, Raghuwanshi NS (2009) Flood forecasting using ANN, neuro-fuzzy, and neuro-GA models. J Hydrol Eng 14(6):647–652
Nayak PC, Sudheer KP, Rangan DM, Ramasastri KS, (2005) Short-term flood forecasting with a neurofuzzy model. Water Resour Res 41(4). https://doi.org/10.1029/2004WR003562
Nguyen PK-T, Chua LH-C (2012) The data-driven approach as an operational real-time flood forecasting model. Hydrol Process 26(19):2878–2893. https://doi.org/10.1002/hyp.8347
Othman F, Naseri M (2011) Reservoir inflow forecasting using artificial neural network. Int J Phys Sci 6(3):434–440
Panahi F, Ehteram M, Emami M (2021) Suspended sediment load prediction based on soft computing models and Black Widow Optimization Algorithm using an enhanced gamma test. Environ Sci Pollut Res 28(35):48253–48273. https://doi.org/10.1007/s11356-021-14065-4
Patel N, Bhoi AK, Paika DK, Sahoo A, Mohanta NR, Samantaray S (2022) Water Table Depth Forecasting Based on Hybrid Wavelet Neural Network Model. In Evolution in Computational Intelligence (pp. 233–242). Springer, Singapore. https://doi.org/10.1007/978-981-16-6616-2_22
Penghui L, Ewees AA, Beyaztas BH, Qi C, Salih SQ, Al-Ansari N, Bhagat SK, Yaseen ZM, Singh VP (2020) Metaheuristic optimization algorithms hybridized with artificial intelligence model for soil temperature prediction: Novel model. IEEE Access 8:51884–51904. https://doi.org/10.1109/ACCESS.2020.2979822
Peyghami MR, Khanduzi R (2013) Novel MLP neural network with hybrid tabu search algorithm. Neural Network World 23(3):255
Sahoo A, Samantaray S, Ghose DK (2022a) Multilayer perceptron and support vector machine trained with grey wolf optimiser for predicting floods in Barak river, India. J Earth Syst Sci 131(2):1–23. https://doi.org/10.1007/s12040-022-01815-2
Sahoo A, Mohanta NR, Samantaray S, Satapathy DP (2022b) Application of Hybrid ANFIS-CSA Model in Suspended Sediment Load Prediction. In Advanced Computing and Intelligent Technologies (pp. 295–305). Springer, Singapore. https://doi.org/10.1007/978-981-19-2980-9_24
Samani S, Vadiati M, Nejatijahromi Z, Etebari B, Kisi O (2022) Groundwater level response identification by hybrid wavelet–machine learning conjunction models using meteorological data. Environ Sci Pollut Res 1–22. https://doi.org/10.1007/s11356-022-23686-2
Samantaray S, Ghose DK (2019) Dynamic modelling of runoff in a watershed using artificial neural network. In: Smart intelligent computing and applications: proceedings of the Second International Conference on SCI 2018, vol 2. Springer, Singapore, pp 561–568
Samantaray S, Ghose DK (2022) Prediction of S12-MKII rainfall simulator experimental runoff data sets using hybrid PSR-SVM-FFA approaches. Journal of Water and Climate Change 13(2):707–734
Samantaray S, Sahoo A, Satapathy DP, Mishra SS (2022a) Prophecy of groundwater fluctuation through SVM-FFA hybrid approaches in arid watershed, India. In Current Directions in Water Scarcity Research, Elsevier, pp 341–365 https://doi.org/10.1016/B978-0-323-91910-4.00020-0
Samantaray S, Sahoo A, Sathpathy DP (2022b) Temperature Prediction Using Hybrid MLP-GOA Algorithm in Keonjhar, Odisha: A Case Study. In Smart Intelligent Computing and Applications, (pp. 319–330). Singapore: Springer Nature Singapore. https://doi.org/10.1007/978-981-16-9669-5_29
Samantaray S, Sahoo A, Mishra SS (2022c) Flood forecasting using novel ANFIS-WOA approach in Mahanadi river basin, India. In Current Directions in Water Scarcity Research. Elsevier, pp 663–682. https://doi.org/10.1016/B978-0-323-91910-4.00037-6
Samantaray S, Sahoo A, Satapathy DP (2022d) Prediction of groundwater-level using novel SVM-ALO, SVM-FOA, and SVM-FFA algorithms at Purba-Medinipur, India. Arab J Geosci 15(8):1–22. https://doi.org/10.1007/s12517-022-09900-y
Samantaray S, Sah MK, Chalan MM, Sahoo A, Mohanta NR (2022e) Runoff Prediction Using Hybrid SVM-PSO Approach. In Data Engineering and Intelligent Computing (pp. 281–290). Springer, Singapore. https://doi.org/10.1007/978-981-19-1559-8_29
Samantaray S, Sahoo A, Paul S, Ghose DK (2022f) Prediction of Bed-Load Sediment Using Newly Developed Support-Vector Machine Techniques. J Irrig Drain Eng 148(10):04022034. https://doi.org/10.1061/(ASCE)IR.1943-4774.0001689
Samantaray S, Biswakalyani C, Singh DK, Sahoo A, Prakash Satapathy D (2022g) Prediction of groundwater fluctuation based on hybrid ANFIS-GWO approach in arid Watershed, India. Soft Computing 26(11):5251–5273. https://doi.org/10.1007/s00500-022-07097-6
Sarkar BN, Samantaray S, Kumar U, Ghose DK (2021) Runoff is a key constraint toward water table fluctuation using neural networks: a case study. Communication software and networks: proceedings of INDIA 2019. Springer Singapore, pp 737–745
Seifi A, Ehteram M, Singh VP, Mosavi A (2020) Modeling and uncertainty analysis of groundwater level using six evolutionary optimization algorithms hybridized with ANFIS, SVM, and ANN. Sustainability 12(10):4023
Singh RM (2012) Wavelet-ANN model for flood events. In Proceedings of the International Conference on Soft Computing for Problem Solving (SocProS 2011) (pp. 165–175). Springer, New Delhi. https://doi.org/10.1007/978-81-322-0491-6_16
Singh UK, Kumar B, Gantayet NK, Sahoo A, Samantaray S,Mohanta, NR (2022) A Hybrid SVM–ABC Model for Monthly Stream Flow Forecasting. In Advances in Micro-Electronics, Embedded Systems and IoT (pp. 315–324). Springer, Singapore. https://doi.org/10.1007/978-981-16-8550-7_30
Sridharam S, Sahoo A, Samantaray S, Ghose DK (2021) Assessment of flow discharge in a river basin through CFBPNN, LRNN and CANFIS. In Communication software and networks (pp. 765–773). Springer, Singapore. https://doi.org/10.1007/978-981-15-5397-4_78
Tabbussum R, Dar AQ (2021) Performance evaluation of artificial intelligence paradigms—artificial neural networks, fuzzy logic, and adaptive neuro-fuzzy inference system for flood prediction. Environ Sci Pollut Res 28(20):25265–25282
Tao H, Diop L, Bodian A, Djaman K, Ndiaye PM, Yaseen ZM (2018) Reference evapotranspiration prediction using hybridized fuzzy model with firefly algorithm: Regional case study in Burkina Faso. Agric Water Manag 208:140–151. https://doi.org/10.1016/j.agwat.2018.06.018
Tsakiri K, Marsellos A, Kapetanakis S (2018) Artificial neural network and multiple linear regression for flood prediction in Mohawk River, New York. Water 10(9):1158. https://doi.org/10.3390/w10091158
Ullah N, Choudhury P (2010) Flood forecasting in river system using ANFIS. In AIP Conference Proceedings. Am Inst Phys 1298(1):694–699 https://doi.org/10.1063/1.3516407
Vapnik V (1995) The nature of statistical learning theory. Springer, New York, NY, USA
Wang J, Cui Q, He M (2022) Hybrid intelligent framework for carbon price prediction using improved variational mode decomposition and optimal extreme learning machine. Chaos Solitons Fractals. 156:111783. https://doi.org/10.1016/j.chaos.2021.111783
Wu CL, Chau KW (2006) A flood forecasting neural network model with genetic algorithm. Int J Environ Pollut 28(3–4):261–273
Xiao K, Li G, Li H, Zhang Y, Wang X, Hu W, Zhang C (2019) Combining hydrological investigations and radium isotopes to understand the environmental effect of groundwater discharge to a typical urbanized estuary in China. Sci Total Environ 695:133872
Yaseen ZM, Ghareb MI, Ebtehaj I, Bonakdari H, Siddique R, Heddam S, Yusif DR (2018) Rainfall pattern forecasting using novel hybrid intelligent model based ANFIS-FFA. Water Resour Manage 32(1):105–122. https://doi.org/10.1007/s11269-017-1797-0
Yaseen ZM, Mohtar WHMW, Ameen AMS, Ebtehaj I, Razali SFM, Bonakdari H, Salih SQ, Al-Ansari N, Shahid S (2019) Implementation of univariate paradigm for streamflow simulation using hybrid data-driven model: Case study in tropical region. IEEE Access 7:74471–74481. https://doi.org/10.1109/ACCESS.2019.2920916
Zia H, Harris N, Merrett G, Rivers M (2015) Predicting discharge using a low complexity machine learning model. Comput Electron Agric 118:350–360
Zhou SL, McMahon TA, Walton A, Lewis J (2002) Forecasting operational demand for an urban water supply zone. J Hydrol 259:189–202
Author information
Authors and Affiliations
Contributions
Sandeep Samantaray: conceptualisation, analysis, writing-original draft. Abinash Sahoo: formulation, analysis, validation, review, and editing. Pratik Sahoo: methodology, review, and editing. Deba Prakash Satapathy: supervision and validation.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Responsible Editor: Marcus Schulz
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Samantaray, S., Sahoo, P., Sahoo, A. et al. Flood discharge prediction using improved ANFIS model combined with hybrid particle swarm optimisation and slime mould algorithm. Environ Sci Pollut Res 30, 83845–83872 (2023). https://doi.org/10.1007/s11356-023-27844-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-023-27844-y