
Abstract
Exoskeleton as a real-time interaction with the wearer’s intelligent robot, in recent years, becomes a hot topic mouth class research in the field of robotics. Wearable exoskeleton outside the body, combined with the organic body, plays a role in the protection and support. By wearing an exoskeleton robot, it is possible to expand the wearer’s athletic ability, increase muscle endurance, and enable the wearer to complete tasks that he or she cannot perform under natural conditions. Based on the above advantages, the exoskeleton robot in military medical care and rehabilitation has broad application prospects. This paper describes the multimodal model of machine learning research status and research significance of the text on the exoskeleton robot applications, and on the basis of a detailed study of gait. It mainly involves: analysis and planning and obtaining motion information processing, pattern recognition and analysis of gait and the gait conversion process, and the EEG and joint position, foot pressure, such as different modes of data as input to machine learning models to improve the timeliness, accuracy and safety of gait planning. Since the common movement process involves the transformation process of gait, this paper studies the gait transformation process including squatting, walking on the ground and standing.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Driven by electronic information technology [1], sensor technology [2] and computer technology [3] for more than half a century, robotics [4,5,6] is moving from traditional industrial manufacturing to educational entertainment, rescue exploration, military applications, family services, and even emerging fields such as medical care and inclusive finance have come to the forefront of robotics research and development. The development of network technology has also peaked in the past two decades. Similarly, the information technology revolution has reached an unprecedented climax under the global popularity of the Internet. Exoskeleton robot technology [7,8,9] is a comprehensive technology that integrates sensing, control, information, fusion, and mobile computing to provide a wearable mechanical mechanism for people who are operators, also known as “wearable robots.” The exoskeleton is a mechanical structure that is worn outside the operator’s body to provide power to assist the person’s movements and enhance the ability and speed of movement. In recent years, with the increasing use of lower extremity exoskeletons in military and medical prosthetics, how to achieve better coordination and fine control of this system is particularly important. Although the concept of exoskeleton has been around for decades in American science fiction movies, it has never been a practical concept given the limitations of basic technology. Energy supply is a major obstacle. The energy source of the human extracorporeal bone must be mobile and provide sufficient energy for the task assigned by the wearer. The energy source US military’s practical exoskeleton booster robot should not be attenuated during missions. Exercise is another issue. The human body can walk, run and bend freely forward and backward. These complex movements have proven to be difficult to simulate by machinery. The human in vitro skeletal assist robot originated from the vision and research and development of the 1982 Hardman power-assisted robot in the USA. Today, the whole is still in the research and development stage; the energy supply device and the control system and force transmission device meet the requirements of agile and accurate human body motion. There is a need to invest heavily in research and development and experimentation. Future exoskeleton boosters can be applied in many aspects including military [10], minerals [11], industry [12], medical [13], etc., because the future needs the human body’s function to continuously improve, even far beyond its limits. Exoskeleton booster equipment will be particularly important and will eventually become an essential product.
Although the exoskeleton robot is intelligent and it can adapt to a specific environment, there is still a certain deviation in the human motion recognition [14,15,16] and behavior pre-judgment [17], and the inevitable hysteresis is recognized in the pre-judgment. For exoskeleton robots, there are still many obstacles and problems in human–machine systems and artificial intelligence. However, in order to overcome the complexity and the harshness of the environment, more scholars have carried out motion recognition on this exoskeleton robot through research and practice, and behavioral pre-judgment to improve the synergy between the follow-up of the exoskeleton robot and the human movement and the stability of the exoskeleton system during design. The domestic exoskeleton robot [18,19,20,21] started relatively late and began in the early twentieth century. Among them are Zhejiang University, Harbin Engineering University, Hefei Intelligent Machinery Institute of Chinese Academy of Sciences and China University of Science and Technology. Zhejiang University developed a power-assisted robot for the medical rehabilitation field. The driver of the pith joint and the knee joint was designed as a circular cylinder, and the pressure sensor of the sole and the displacement signal of the cylinder were combined to judge the wearer’s intention of motion. Yang Canjun of Zhejiang University also proposed an adaptive neuro-fuzzy inference technique to learn and train the external bone marrow robots by collecting the motion information of the human gait training process.
Pattern recognition [22,23,24] is a technique that uses a computer to classify a series of physical objects on the basis of observations so that the recognition results are in good agreement with the objects. With this technology applied, much of the work can be performed by machines instead. For decades, robotics has grown rapidly as an emerging field. Applying pattern recognition to robot technology enables the robot to accurately identify various objects [25, 26], analyze and process the acquired information, so that the robot has more powerful recognition and processing functions. Humans provide more convenient services to meet demand. Intelligent robots equipped with pattern recognition technology have shown great development prospects. The human body’s movement pattern refers to different movement states according to different terrains, such as walking on the ground, uphill, and downhill. It is important that the movement mode of the exoskeleton robot can automatically and smoothly change. In daily research and practical application, it is necessary to accurately identify the movement mode of the exoskeleton robot so that the robot can better perform the corresponding action. The gait pattern recognition study can be distinguished by identifying different sources, such as classification based on EMG signals and classification based on joint kinematics/kinetic signals.
This paper designs a brain–computer interface system based on steady-state vision, collects EEG signals to identify the wearer’s motion intention, and then combines EEG signals and motion mechanics as input to the machine learning model to improve the overall gait planning. The real time, global and security of the system, the gait planning algorithm is improved, and the validity and accuracy of the multimodal machine learning model are verified by experiments.
2 Proposed method
2.1 Exoskeleton robot
The exoskeleton is a human–computer interaction intelligent mechanical device for human wear. It can protect and support the wearer by combining the intelligence of the human and the power of the robot. The movement of the exoskeleton robot can be controlled by human thinking and assist the human body in completing the movement, even completing tasks that humans cannot accomplish. As a branch of the biped robot, the exoskeleton robot not only has a complex dynamic system, but also involves the knowledge of many disciplines such as mechanism, gait control, information processing, human–computer interaction, communication network technology team and control theory. The primary function of the exoskeleton robot is to assist the wearer’s walking. After the human wears the exoskeleton, the corresponding path planning and gait control are performed according to the environment. Exoskeleton robots do not need to perform the complex gait planning required by ordinary biped robots and only need to combine the intelligence of the human body for simplified gait planning. After being able to coordinate with the human body, the main role of the exoskeleton robot is to provide power to the human body to help the human body to walk, improve the speed and endurance of walking, and at the same time reduce the weight of the human body through the robot’s own power system, so that the human body can cope with the long time. Walking with weights: These excellent characteristics of exoskeleton robots have broad application prospects. In order to assist the wearer to bear the heavier load, the exoskeleton robot can effectively enhance the individual combat capability of the military. Due to physical limitations, individual soldiers cannot carry too many weapons during the combat process, and they cannot perform long-term combat operations. After wearing the exoskeleton, they can not only provide the soldiers with the exoskeleton power system, the power of complex terrain walking can also replace the weapons of the soldiers, so that soldiers can carry more weapons and equipment than usual, reduce the fatigue of the soldiers, and effectively improve the time and efficiency of combat. In addition, in the event of a disaster such as an earthquake, many rescue equipments are often unable to arrive at the scene in the first time. Rescuers are required to walk on foot. This requires the rescue personnel to carry a variety of rescue equipment and may need to help rescuers heavy objects, carrying the injured. At the same time, work such as field surgery and geological exploration in complex and remote areas also requires exoskeleton robots to help researchers carry more research equipment for a broader and more in-depth research work.
In the military field, the exoskeleton is very attractive because it can effectively improve the individual combat capability. The US Army’s successful “Human General Weight Bearing Bracket” (HULC) is an exoskeleton robot that can greatly increase the soldier’s ability to carry weight, making it easy for soldiers to carry heavy loads of 90 kg. Putting on the fully charged UHLC, soldiers carrying a weight of 90 kg can march for 1 h at a speed of 4.8 km/h, with a maximum march speed of 16 km/h. In addition to military, exoskeleton robots can also be applied to various fields of social life, such as assisting disabled people to complete normal human body movements. Among them, the more famous one is the Hybird Assistive Leg series of lower extremity exoskeletons developed by cybemiesLab led by Prof. Shanhai Jiazhi of the University of Tsukuba in Japan. It is mainly used to assist patients with gait disorders to walk. HAL uses sensor devices such as angle sensors, EMG signal sensors and ground contact force sensors to obtain the state information of the exoskeleton and the operator. The operator’s motion intention is calculated by the computer, and finally the motor is driven to assist the human body motion. Although no soldiers have seen mechanical legs walking yet, military exoskeleton robots are gradually becoming a reality. Of course, due to some technical parameters, such as work continuity, size, weight, and reaction speed, it is far from “universal.” For the requirements of the soldiers, it takes a certain amount of time to make the exoskeleton robots really use for marching.
2.2 Motion pattern recognition
Motion recognition systems are widely used in medical, health care, sports, military, and entertainment. Therefore, data need to be processed, identified, and applied according to the needs of the system. The devices are mainly PCs or mobile phones. The main functions that need to be implemented are: it is necessary to receive and dynamically display data collected by the sensor terminal, as well as data query and storage, etc., in real time. However, depending on the occasion of its use, the research methods are also very different, and the application of its development is also different. Sports pattern recognition is a very interesting and challenging problem, which is widely used in sports, running, ball games and other fields. The usual implementation is a computer vision-based approach. The vision-based method captures the user’s motion through the camera and then recognizes different motion patterns through computer vision-related methods. At present, there are two main types of data that rely on the study of human gait: one is to use sensors to collect speed, displacement, bioelectrical signals and pressure signals, etc., and the other is based on computer vision. The gait is analyzed by collecting images or screens of the motion process. In the research of exoskeleton robots, considering the application of exoskeleton robots, most of them use sensor-based motion information acquisition. There are many mechanical sensors in the research, such as goniometers and sole pressure switches. Although such simple sensors cannot provide a large amount of data for gait analysis, they study key events in gait and some quantification. Analysis can play a certain role. Secondly, the measuring force sensors are the sole pressure sensor and the contact force sensor, etc.; because the foot is the only body part that is in contact with the ground during the movement, the sensor can detect the relationship between the pressure and the moment of the sole and the ground, and analyze the sole of the foot. The force situation provides a lot of useful information for gait analysis.
In recent years, with the rapid development of sensor technology, data signal processing technology and hardware circuit technology, many parameters of the human body can be expressed by collecting some sensor data. For example, the temperature of the human body can be represented by temperature sensor data information; the pulse of the human body can pass the pulse sensor which is used to indicate that some movements of the human body can be expressed by the acceleration sensor, the data information of the gyro sensor, and the like. The sensors currently used to collect human motion data information mainly include pressure sensors, acceleration sensors, and gyro sensors. Different researchers place sensor nodes at different locations to collect data information of different movements of the human body. Human motion gait is a complex process that involves multiple, multi-type data. It is difficult to accurately identify the movement gait and the movement intention of the exoskeleton wearer by relying on a single type of data, and relying on a single type of biosignal to make gait recognition; if it is affected by external uncertainties, it may cause erroneous recognition results, which may affect subsequent control. The use of two aspects of motion information, namely inertial data and MG data, is designed to provide high accuracy, reliability and versatility in the research results by relying on the motion information provided by the two types of data. The sensor module is mainly responsible for collecting data information of effective human motion.
2.3 Multimodal
The source or form of each type of information can be called a modality. For example, people have tactile, auditory, visual, and olfactory; media of information, voice, video, text, etc.; a variety of sensors, such as radar, infrared and accelerometers. Each of the above can be referred to as a modality. At the same time, the modality can also be defined very broadly. For example, two different languages can be regarded as two modalities, and even data sets collected in two different situations can be considered as two modalities. Multimodal representation there are two types: shows a combined characteristic map to different modalities of the same space, the representative methods neural network method, the method of FIG sequence model the model method. The coordination method features are still in the original space, but are coordinated by similarity or structural features. Multimodal feature translation is divided into sample-based and generative: sample-based method is to find the best translation from the feature dictionary. Sample-based methods are divided into search-based and merged methods. The generative method is to train a translation model through the sample and use the translation model to complete the transformation of the feature. The generative methods are grammar-based, encoder–decoder models, and continuous models. Multimodal feature alignment is the finding of the relationship between different modal features of the same instance. Explicit alignment methods include supervised models and unsupervised models. Unsupervised models are CCA and DTW (dynamic warping). Implicit alignment methods include graph models and neural networks. Characterized in multimodal fusion multimodal fusion wherein it means different from the modal features integrated together, together to complete a task, such as classification. Model-free fusion methods are divided into early models (based on features), late models (based on decision-making), and hybrid models with model fusion methods such as kernel methods, graph model methods, and neural network model methods.
In theory, due to the relationship between different modalities, the information contained in two or more modal data is larger than the information contained in any one of the modalities. Therefore, when processing data with multimodal information, if only one of the modal information is analyzed and utilized, it is equivalent to discarding the useful information contained in the remaining modalities, which is a waste of existing data. If the traditional data mining model is used to mine the data of each modality, it may not only cause repeated analysis of different modal data with common information, increase the amount of calculation, but also ignore different modal information. The relationship between the two is still difficult to avoid information waste. In order to fully utilize the information of the respective modalities of multimodal data and make full use of the inter-modal correlation information, academics and industry have been eager to obtain more effective multimodal learning algorithms to improve multimodality. The performance of tasks such as classification, retrieval, etc.
2.4 Machine learning model
The algorithms used in machine learning fall into three categories: supervised learning, unsupervised learning and reinforcement learning. Supervised learning provides feedback to indicate whether the prediction is correct or not, while unsupervised learning does not respond: the algorithm only attempts to classify the data based on the implicit structure of the data. Reinforcement learning is similar to supervised learning because it receives feedback, but feedback is not necessary for every input or state. People and animals perceive and learn through visual, listening, speaking, etc., and are essentially multimodal learning. In recent years, due to the development of deep learning, multimodal machine learning has become a research hotspot of artificial intelligence. People’s perceptions in life are diverse, including sight, hearing, touch, taste, smell and so on. Any lack of sensory ability can cause an abnormality in intelligence or ability. Based on this, multimodal machine learning provides multimodal data processing capabilities for machines. For example, look at the picture and watch the movie translation. The long-term goal of multimodal learning is to make the machine fully aware of the environment, such as perceiving human emotions, words, expressions, and interacting more intelligently with the environment. Multimodal machine learning, the full English name MultiModal Machine Learning (MMML), aims to realize the ability to process and understand multi-source modal information through machine learning. At present, the more popular research direction is multimodal learning between images, video, audio and semantics. Multimodal learning started in the 1970s and went through several stages of development. After 2010, it fully entered the deep learning phase. Single-modal representation learning is responsible for representing information as a numerical vector that a computer can process or further abstracting into a higher-level eigenvector, while multimodal representation learning refers to culling between modes by exploiting the complementarity between multimodalities. Redundancy to learn a better representation of features. It mainly includes two research directions: joint representations and coordinated representations. The joint representation maps multiple modal information together into a unified multimodal vector space; the cooperative representation is responsible for mapping each modality in the multimodality to its respective representation space, but the mapped vectors satisfy Certain correlation constraints (such as linear correlation).
At present, academically mature is multimodal learning between vision and semantics. For example, generate a text description for an image, or answer the corresponding text question for the content of a picture. Visual information is usually processed by CNN, and text information is processed smoothly using RNN. The way to align multi-dimensional data is the attention mechanism, for example, to see which object in the figure corresponds to the noun in the picture. Moreover, multimodal learning is superior to single-modal machine learning in many traditional machine learning tasks. For example, the text translation effect of assisting visual information is better than using only text information. Multimodal machine learning refers to the establishment of a model that allows the machine to learn the information of each modality from multimodality and to achieve the exchange and conversion of information of each modality. From early audio-visual speech recognition research to recent language and visual model research, multimodal machine learning enhances the machine’s cognitive ability to various modes, deepens the cognitive depth of the machine to each mode, and realizes information in the machine environment. Significant results have been achieved in terms of communication and interoperability. The multimodality gives the modal ability outside the machine learning database, that is, the modal generalization ability, and the multimodal representation and multimodal model learned on the existing modal can be generalized to the unmodality. Multimodal deep learning is an inevitable outcome of the development of multimodal machine learning to the present stage. Multimodal deep learning inherits the learning tasks and learning objectives of previous multimodal machine learning and promotes multimodal machines with deep learning methods. The progress and development of learning have made remarkable progress. Multimodal machine learning research originates from life and also serves life. Multimodal research is divided into four developmental periods, namely multimodality study of human behavior, multimodal computer processing research, multimodal interaction research and multimodal deep learning research.
3 Experiments
Taking into account the steady-state visually evoked potentials (steady-state visual evoked potential, SSVEP) having distinct cycle characteristics, the shorter the time required for stimulation, easily extracted feature data, the higher classification accuracy, etc., this thesis-based SSVEP’s EEG. Determine the appropriate stimulation frequency by dividing the refresh rate of the display.
where f represents the stimulation frequency, as shown in Table 1.
For a common LCD display, the 60 Hz corresponding time length is 1000 ms, so the stimulus time period t is:
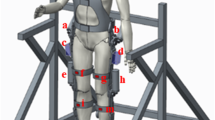
Therefore, the time periods corresponding to the two frequencies selected in this paper are 117 ms and 100 ms, respectively. The SSVEP-based brain–computer interface system designed in this paper is shown in Fig. 1. It mainly includes visual stimulator, ActiveTwo system, feature extraction and algorithm processing, and execution equipment. When the human brain receives the predetermined evoked source stimuli, the cerebral cortex will generate corresponding characteristic EEG signals, and the EEG signals will be collected by the ActiveTwo system, and the EEG data will be transmitted to the computer through conversion. The computer undergoes data preprocessing, data feature extraction, control conversion algorithm, and finally performs corresponding actions on the exoskeleton robot system.

Brain–computer interface system based on SSVEP
The experiments selected four average age of 25 years old in good health, after normal vision or corrected by the normal male volunteers participated in EEG acquisition experiments. Before the experiment, first explain the purpose and requirements of this experiment to each subject in detail, and let each subject do 2 min of preparatory stimulation before the official start, so that they can adapt to the experiment, try to stay relaxed and reduce ocular, myoelectric and other interference. Then, the subject wearing the electrode cap, and the conductive paste on the target injection electrode active plug electrode, the reference electrode is provided, the sampling frequency, amplitude scales and the like. Set the ActiveTwo system to a sampling frequency of 256 Hz and a total of 6 s of visual stimulation time per experiment.
4 Discussion
When the typical correlation analysis method is used to identify the motion intention corresponding to the EEG signal, the selected data length has an important influence on the recognition result. Therefore, this paper selects the EEG signals of different time lengths as input and calculates the recognition accuracy of CCA.
It can be seen from Fig. 2 that SSVEP signals of different time lengths have an important influence on the recognition result of CCA. When the time length is increased from 1 to 4 s, the recognition accuracy is higher and higher. However, considering that too long acquisition time will affect the performance of real-time experiments; this paper selects the acquisition data with a length of 3 s as input, which not only ensures better accuracy (more than 90%), but also shortens visual stimulation time, reduces visual fatigue in the subject and increases the speed at which the system resolves the intent of the movement.

The effect of time length on recognition accuracy
In this off-line experiment, each volunteer received 20 rounds of tasks, each round consisted of 5 experiments, so each volunteer produced a total of 100 visual stimulation experiments. The results are shown in Table 2.
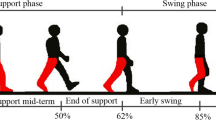
The off-line experiments of these four volunteers have a relatively high correct recognition rate, and the average accuracy rate is over 90%, which also shows that the frequency corresponding to the SSVEP signal can be well recognized by using CCA. At the same time, the recognition rates of different subjects are different, the smallest is 89%, and the largest is 95%, indicating that the “quality” of EEG signals of different subjects is different, and some can be well recognized. The possible features are not obvious, and the recognition rate is relatively low. To verify the effectiveness of the gait planning algorithm based on the multimode input machine learning model, we further conducted an online experiment, as shown in Fig. 3. The experimenter needs to complete three actions in sequence: squatting → walking → standing.

Squat station traveling operation Li
The experimenter has to accept a visual stimulus signal generating SSVEP. At this time, BCI system will carry out the current SSVEP signal analysis processing to identify the motion intent volunteers. Figures 4 and 5 show the experimental results of the experimenters 1 and 2, respectively.

Experimenter 1

Experimenter 2
It can be seen from the experimental results that the average correct rate of this experiment is more than 90%, and all the false positive rates are less than 5%, which again shows that CCA can effectively identify the SSVEP signal. Command and can reduce the error rate too, demonstrate the effectiveness of the proposed outer multimodal machine learning pattern recognition algorithms motion robot bone.
5 Conclusions
In today’s era, robotics has shown tremendous development potential in various fields and played an important role. It can be expected that with the development of the times, robotics will be applied more widely, reasonably and effectively, and further move toward intelligence and autonomy. At the moment of rapid development of deep learning, artificial intelligence has gradually embarked on the historical stage, and giving machines the ability to accept, synthesize, and process various external information and reflect the accepted information is the basic requirement for artificial intelligence. Multimodal deep learning is an effective means to achieve this basic requirement. As an important branch of biped robot, exoskeleton robot not only has broad application prospects in the military field, but also has important application value in disability, rehabilitation and other aspects. At the same time, exoskeleton robots are also a complex and multidisciplinary robotic system that has many problems to solve.
An important feature of the exoskeleton robot is the close interaction with the wearer. The exoskeleton needs to be able to understand the movement intention and movement state of the human body in real time, and realize the movement coordinated with the wearer through the control of the controller itself, thereby enabling the wearer to the role of support and protection. In order to understand the movement state of the human body, it is necessary to obtain specific information on human movement through certain methods. In this paper, the combination of motion mechanics and EEG signals is used as the input of machine learning model, comprehensive decision making, judgment of the wearer’s motion intention and execution of relevant instructions after analysis. The experimental results have high accuracy and demonstrate multimodal machine learning. The validity of the model.
References
Shore L, Power V, de Eyto A, O’Sullivan L (2018) Technology acceptance and user-centred design of assistive exoskeletons for older adults: a commentary. Robotics 7(1):3
Yang C, Huaiwei W, Li Z, He W, Wang N, Chun-Yi S (2018) Mind control of a robotic arm with visual fusion technology. IEEE Trans Ind Inform 14(9):3822–3830
Wright FD, Conte TM (2018) Standards: roadmapping computer technology trends enlightens industry. Computer 51(6):100–103
Faria C, Erlhagen W, Rito M et al (2015) Review of robotic technology for stereotactic neurosurgery. IEEE Rev Biomed Eng 8:125–137
Wiederhold BK (2017) Robotic technology remains a necessary part of healthcare’s future editorial. Cyberpsychol Behav Soc Netw 20(9):511–512
Suri RM, Dearani JA, Mihaljevic T et al (2016) Mitral valve repair using robotic technology: safe, effective, and durable. J Thorac Cardiovasc Surg 151(6):1450–1454
Kim YS, Lee J, Lee S et al (2005) A force reflected exoskeleton-type masterarm for human–robot interaction. IEEE Trans Syst Man Cybern A Syst Hum 35(2):198–212
Agarwal P, Deshpande AD (2019) A framework for adaptation of training task, assistance and feedback for optimizing motor (re)-learning with a robotic exoskeleton. IEEE Robot Autom Lett 4(2):808–815
Qiu S, Li Z, Wei H et al (2017) BrainźMachine interface and visual compressive sensing-based teleoperation control of an exoskeleton robot. IEEE Trans Fuzzy Syst 25(1):58–69
Huang B, Li Z, Wu X, Ajoudani A, Bicchi A, Liu J (2019) Coordination control of a dual-arm exoskeleton robot using human impedance transfer skills. IEEE Trans Syst Man Cybern: Syst 49(5):954–963
Karelis AD, Carvalho LP, Castillo MJ et al (2017) Effect on body composition and bone mineral density of walking with a robotic exoskeleton in adults with chronic spinal cord injury. J Rehabil Med 49(1):84
Gopura RARC, Kiguchi K (2008) Development of an exoskeleton robot for human wrist and forearm motion assist. In: International conference on industrial & information systems, pp 432–459
Gao B, Ma H, Guo S et al (2017) Design and evaluation of a 3-degree-of-freedom upper limb rehabilitation exoskeleton robot. In: IEEE international conference on mechatronics & automation, pp 345–374
Liu H, Ju Z, Ji X, et al. (2017) Human Motion Sensing and Recognition. A Fuzzy Qualitative Approach. Studies in Computational Intelligence. vol 675. Springer, Berlin, Heidelberg
Xu C, He J, Zhang X et al (2018) Recurrent transformation of prior knowledge based model for human motion recognition. Comput Intell Neurosci 2018(1):1–12
Vu C, Kim J (2018) Human motion recognition using E-textile sensor and adaptive neuro-fuzzy inference system. Fibers Polym 19(12):2657–2666
Lin CJ, Wu C, Chaovalitwongse WA (2017) Integrating Human behavior modeling and data mining techniques to predict human errors in numerical typing. IEEE Trans Hum-Mach Syst 45(1):39–50
Sale P, Franceschini M, Waldner A et al (2012) Use of the robot assisted gait therapy in rehabilitation of patients with stroke and spinal cord injury. Eur J Phys Rehabil Med 48(1):111
Cao J, Xie SQ, Das R et al (2014) Control strategies for effective robot assisted gait rehabilitation: the state of art and future prospects. Med Eng Phys 36(12):1555–1566
Jarrassé N, Proietti T, Crocher V et al (2014) Robotic exoskeletons: a perspective for the rehabilitation of arm coordination in stroke patients. Front Hum Neurosci 8(947):1845–1846
Taheri H, Rowe JB, Gardner D et al (2012) Robot-assisted Guitar Hero for finger rehabilitation after stroke. Conf Proc IEEE Eng Med Biol Soc 2012(4):3911–3917
Zerdoumi S, Sabri AQM, Kamsin A et al (2017) Image pattern recognition in big data: taxonomy and open challenges: survey. Multim Tools Appl 2:1–31
Nikonov DE, Csaba G, Porod W et al (2017) Coupled-oscillator associative memory array operation for pattern recognition. IEEE J Explor Solid-State Comput Devices Circuits 1:85–93
Nabet BY, Qiu Y, Shabason JE et al (2017) Exosome RNA unshielding couples stromal activation to pattern recognition receptor signaling in cancer. Cell 170(2):352–366
Lu Z, Chen X, Zhang X et al (2017) Real-Time control of an exoskeleton hand robot with myoelectric pattern recognition. Int J Neural Syst 27(5):1750009
Lu Z, Tong RK, Zhang X et al (2018) Myoelectric pattern recognition for controlling a robotic hand: a feasibility study in stroke. IEEE Trans Bio-Med Eng 99:1
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 51674155), the Key Research and Development Plan of Shandong Province (No. 2018GGX106001), and Shandong Provincial College Science and Technology Planning project (J18KA009).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflicts of interest to this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zheng, Y., Song, Q., Liu, J. et al. Research on motion pattern recognition of exoskeleton robot based on multimodal machine learning model. Neural Comput & Applic 32, 1869–1877 (2020). https://doi.org/10.1007/s00521-019-04567-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-019-04567-1