
Abstract
Roof fall is one of the most important problems connected with underground coal mines because it plays a significant role in financial and human losses. Hence, it is essential to accurately predict the roof fall rate for the purpose of controlling, reducing, and/or even eliminating the risk of the involved problems. On the other hand, there are many different parameters that make a considerable impact on the occurring roof rate. Most of these factors are not completely known or measurable. Therefore, the problem of predicting roof fall is vague, sophisticated, and complex. Adaptive neuro-fuzzy inference system (ANFIS) is a powerful and robust tool for modeling linear and non-linear patterns in science and engineering problems. In this paper, the ANFIS system is applied to model the roof fall rate in coal mines. The constructed model uses the subtractive clustering method to generate fuzzy rules based on 109 data of roof performance from US coal mines. The results demonstrate that prediction of roof fall rate by the ANFIS model is satisfactory.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Roof fall is a crucial component in underground mine safety because it has a great impact on the cost and production of a mine. It accounted for 18.18 % of all fatal accidents in coal mines, contributing to about 35.29 % of all fatal accidents in below-ground operations in 2005 [1]. For this reason, various studies are conducted to find the relationship between the roof falls and different parameters that have a significant effect on events of falling roofs in coal mines. Table 1 lists several studies that formulate the relationship between the roof fall and other effective factors.
However, the aforementioned models are not capable of simultaneously handling both complexity and inherent uncertainty connected with the roof fall problem. Hence, with respect to importance of the roof fall problem, applying a proper technique can help designers to analyze the problem more accurately and precisely. Adaptive neuro-fuzzy inference system (ANFIS) has been a powerful tool for formulating complex problems over the last decade and has demonstrated its capabilities and effectiveness as a problem-solving tool in modeling different aspects of engineering and management problems [16–30]. Some applications of ANFIS in geotechnical engineering can be found in [31]. This method is found to be a viable contender in competition with various conventional models [18, 22, 25].
The unique features of ANFIS can be on account of the existing advantages in the two methods, artificial neural network (ANN) and fuzzy inference system (FIS), that form the ANFIS structure. However, ANN is capable of modeling all types of the existing complexity and non-linearity in the structure of the data under consideration. Likewise, FIS is successful in the face of uncertain data and can take into account the human knowledge in modeling.
The main aim of the study is to develop an ANFIS model for predicting the roof fall rate in order to obtain a more accurate, precise, and sure equation. To show the capability and effectiveness of the constructed model, the results are compared with multivariate regression (MVR) based on three indices, including coefficient of determination (R 2), mean absolute error (MAE), and root mean square error (RMSE).
The rest of this paper is organized as follows: multivariate regression is briefly illustrated in the next section. The basic concepts of adaptive neuro-fuzzy inference system (ANFIS) are presented in Sect. 3. Section 4 explains the indices employed for evaluating model performance. Dataset is described in Sect. 5. In Sect. 6, development of the ANFIS model is implemented to formulate the roof fall rate and its performance is investigated in comparison with the MVR model. In Sect. 7, results and discussion are discussed. Section 8 includes the conclusions of the study.
2 Multivariate regression analysis
Regression analysis is widely used for modeling relationship between inputs and output variables. Based on basic concepts of multivariate regression (MVR), the relationship between input variables and the output variable is generally explored by the function that is fitted to a dataset. The standard form of the MVR model in statistical analysis can be defined as
where y is the dependent variable, x n (n = 1, 2, …, n) is independent variable, b 1, b 2, …, b n are the regression coefficients, which represent the amount the dependent variable changes when the corresponding independent variables change 1 unit. c is the constant term, which represents the amount the dependent variable will be when all the independent variables are 0.
The major conceptual limitation of all regression techniques is that one can only ascertain relationships, but never be sure about the underlying causal mechanism [25].
3 ANFIS modeling
A fuzzy inference system applied in the form of a neuro-fuzzy system with crisp functions in consequents is the Takagi–Sugeno-type fuzzy system, well known as ANFIS. ANFIS was first introduced by Jang [32]. The ANFIS can be trained to tune its parameters and learn the existing structures in the dataset. The relationships between input and output variables are represented by means of fuzzy if–then rules with unclear predicates. The ANFIS model is established by adapting the antecedent parameters and consequent parameters so that a specified objective function (usually a difference between the model output and the actual output) is minimized [33]. Several methods are developed for learning rules [32, 34]. In this paper, the hybrid learning algorithm developed by Jang [32], that is a combination of least square estimation and back-propagation algorithms, is applied.
Suppose that the rule base contains of the following two Sugeno-type fuzzy if-then rules:
-
Rule 1 : If x is A 1 and y is B 1, then \( f_{1} = p_{1} x + q_{1} y + r_{1} \)
-
Rule 2 : If x is A 2 and y is B 2, then \( f_{2} = p_{2} x + q_{2} y + r_{2} \)
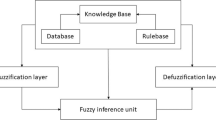
where x and y are two inputs; A i and B i are the terms which are represented by fuzzy sets. f i is the output variable within the fuzzy region specified by the fuzzy rule the membership function parameters of which are premise parameters. p i , q i , and r i are designing parameters which are obtained during the learning process [35]. The ANFIS architecture with two rules is depicted in Fig. 1. The output of each node in every layer is indicated by O l i (ith node output in lth layer). The performance of each layer can be described as follows:

ANFIS architecture with two rules
The first layer is the fuzzifying layer in which A i and B i are the linguistic terms. The output of the layer is the membership functions of these linguistic terms are given as
In the second layer, the rules’ firing strengths are calculated by multiplying each node with each other as presented in the following equation:
where \( \mu_{{A_{i} }} \) and \( \mu_{{B_{i} }} \) are the membership functions of the input variables x and y, respectively.
In the third layer, the firing strengths obtained in the previous layer of the nodes are normalized. Every node in the layer computes the ratio of the ith rule’s firing strength to the sum of all rules’ firing strengths by using Eq. (4):
In the fourth layer, every node calculates a linear function where the function coefficients are adapted using the back-propagation algorithm of the artificial neural networks [36]. The output of this layer is derived from multiplication of normalized firing strength obtained in the third layer by the first order of the Sugeno fuzzy rule.
In the fifth layer, the overall output is calculated as a summation of all the incoming signals through Eq. (6):
The first and fourth layers in ANFIS structure are adaptive layers. The consequent coefficients (p i , q i , and r i ) are continuously adjusted using fuzzy membership functions in order to minimize the errors between the model outputs and the observations [36].
4 Model performance
Since there are no unique and more appropriate unbiased estimators applied to see how far the model is able to forecast the values of roof fall, several measures of accuracy are employed. For this reason, the models are evaluated by three estimators containing the coefficient of determination (R 2), the root mean square error (RMSE), and the mean absolute error (MAE).
The above-mentioned estimators are obtained by
where P i is the predicted value, A i is the observed value, \( \bar{A}_{i} \) is the average of observed set, and N is the number of datasets.
R 2 shows how much of the variability in the dependent variable can be explained by independent variable(s). R 2 is a positive number that can only take values between zero and one. A value for R 2 close to one shows a good fit of the forecasting model and a value close to zero presents a poor fit.
MAE would reflect if the results suffer from a bias between the actual and modeled datasets [37]. RMSE is a used measure in order to calculate the differences between values predicted by a model and the values observed from the thing being modeled. RMSE and MAE are non-negative numbers that for an ideal model can be zero and have no upper bound.
5 Dataset
The dataset involved in this study includes 109 observations of the roof fall rate against its affecting parameters [38]. In order to construct ANFIS model for the roof fall rate, the existing dataset is separated into training and test sets. For achieving the aim, 82 observations (75 %) are randomly selected to formulate the model and the rest of the observations (25 %) are used to reflect the performance of the different constructed models. Based on the MVR model, the affecting parameters on the roof fall rate are extracted as described in the following part.
One of the most important steps in developing a successful predicting model is the selection of the input variables, which determine the architecture of the model. Based on the literature, five input parameters for predicting the roof fall rate (RFR) are identified, including CMRR (i.e., the quality of roof rock plays a significant role in the rate of roof fall [38]), PRSUP (i.e., roof fall rate is influenced by roof bolt density [15]), IS (i.e., most of the falls in the total database occur in intersections, so that they are much more likely to fall than entry or crosscut segments between intersections [38]), DOF (i.e., increasing depth leads to increase in virgin stress levels in the rock mass [15]), and MH (i.e., mining height influences the rate of roof fall [39]). Basic descriptive statistics on the dataset involved in modeling are presented in Table 2.
6 Prediction model
Based on classical assumptions of the linear model, the best forecast of Y (variable Y regressed on X) is \( \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{Y} \) can be calculated by Eq. (10):
here, Y is RFR and X = [1, CMRR, PRSUP, IS, DOF, MH] is the set of independent variables defined, respectively, as the constant term, Coal Mine Roof Rating, Primary roof support, Intersection diagonal span, Depth of cover, and Mining height, so that the model is results in the following:
The performance measures of the MVR model for the dataset are listed in Table 3. From the last row of Table 3, it can be seen that the MVR model is not satisfactory. Therefore, the ANFIS model is implemented in the following part.
According to the basic concepts of ANFIS design and using productive algorithm in MATLAB 7.11 package software, the development of the ANFIS model is implemented. In order to obtain the optimum network architecture, several network architectures are established to select the best-fitted ANFIS model. The established model is schematically depicted in Fig. 2.

Structure of fuzzy model
Before constructing the ANFIS model, all variables are normalized to the interval of 0 and 1 using Eq. (11):
There are different methods to generate the fuzzy rules. Two of the most popular methods are Grid partition [32] and subtractive clustering [40]. The subtractive clustering method is more used when there are many input variables. For instance, let it be assumed that there are 10 input variables and three MFs for each input variable; the rules will be 310 (59049 rules) that results in the computations being long and time-consuming. With this reason, the authors use a subtractive fuzzy clustering to generate the relationship between the input and output variables. This method uses the given search radius to measure the density of data points in the feature space [40]. A small cluster radius will usually yield many small clusters in the data and lead to generating many rules, and a large cluster radius will usually result in a few large clusters in the data and cause fewer rules [41–44]. In this paper, the most appropriate value for the cluster radius is identified by a trial and error approach by changing the cluster radius value from 0.1 to 0.9 (in increments of 0.1). The results of testing data, as seen in Table 3, show that the optimum value for the cluster radius is 0.4 since it produces the highest R 2 of 0.856 with the lowest MAE and RMSE of 1.215 and 1.738, respectively (As highlighted in Table 3). The optimal number of rules for the best-fitting model is 71.
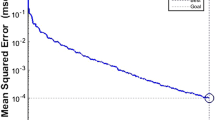
After forming the initial ANFIS structure, the training stage is accomplished. In order to train the ANFIS model, the number of iteration of the hybrid algorithm for correction of model parameters and objective error is taken into account as 30 and 10−9, respectively. Figure 3 shows the trend of errors when the number of epochs is increased. A sample of rules generated by the ANFIS model is presented in Fig. 4.

Trend of errors during epochs

A sample of rules generated for the ANFIS model
Then, the constructed model is checked by the testing dataset. For achieving the aim, the input vectors from the test dataset are presented to the trained network and the predicted outputs are compared with the actual ones for the performance measurement as shown in Table 4.
The interdependency of input and output parameters derived from the rules generated by subtractive clustering can be shown using the control surface as depicted in Fig. 5. As seen in the figure, Fig. 5a shows the interdependency of RFR on CMRR and PRSUP, Fig. 5b depicts the interdependency of RFR on CMRR and IS, Fig. 5c shows the interdependency of RFR on CMRR and DOF, and Fig. 5d depicts the interdependency of RFR on CMRR and MH.

Control surface of RFR on a CMRR and PRSUP; b CMRR and IS; c CMRR and DOF; and d CMRR and MH
7 Results and discussion
The performance measures of the ANFIS and MVR models for testing dataset are listed in the last three rows of Table 4. It can be seen that the R 2 value for the ANFIS model is 0.856, which is dramatically greater than that obtained in MVR, which is 0.039 (R 2 < 60 % is unacceptable).
The MAE value for the ANFIS model is 1.215, which is significantly smaller than that resulting from MVR, which is 2.834. The RMSE value for the ANFIS model is 1.738, which is smaller than that yielded by MVR, which is 4.034. According to the yield results, the capability and efficiency of the ANFIS model for predicting RFR is more accurate and precise than the MVR model. This is due to the fact that the problem of RFR is such a complex and vague problem that linear methods are not capable to model such behaviors.
8 Conclusion
Roof fall is an important and critical problem in underground coal mines, which has a significant impact on the activity continuity of mining and producing. Therefore, accurate prediction of the problem can help decision makers reduce or eliminate risks associated with the problem of roof fall. This problem is a vague and uncertain issue because there are a number of parameters that can affect the problem of roof fall and often these parameters are ill defined or immeasurable. Therefore, according to the sophisticated structure of the problem, imprecise data, less of information, and inherent uncertainty, the usage of the fuzzy sets can be useful. On the other hand, ANN is widely used for modeling different problems of science and engineering. Fuzzy logic is integrated with ANN, well known as ANFIS, to take into account advantages of the two methods for modeling complex problems under a fuzzy environment.
In this paper, using the ANFIS model based on the subtractive clustering method, a model is constructed to predict roof fall rate. The results of the established model demonstrate that the ANFIS is a more powerful and capable tool than the MVR to improve the safety of coal mines. The output of the model can be used for selecting the proper reaction strategy in order to reduce or eliminate the risk of roof fall.
References
Palei SK, Das SK (2008) Sensitivity analysis of support safety factor for predicting the effects of contributing parameters on roof falls in underground coal mines. Int J Coal Geol 75:241–247
Kidybinski A (1997) Roof rock stability tests and power support selection systems for longwalls, state-of-the-art report, USDI/CMI Joint Research Project No. 14 -01-0001-1450, Rep. No. 2
Unrug K, Szwilski A (1980) Influence of strata control parameters on longwall mining design. In: Proceedings of the 21st U.S. symposium on rock mechanics, Rolla, Mo, pp 720–728
Newman DA, Bieniawski ZT (1986) Modified version of the geomechanics classification for entry design in underground coal mines. T Soc Min Eng AIME 280:2134–2138
Molinda G, Mark C (1994) The coal mine roof rating (CMRR)—a practical rock mass classification for coal mines. USBM IC 9387, 83 pp
Mark C (1999) Application of the coal mine roof rating (CMRR) to extended cuts. Min Eng 51:52–56
Molinda GM, Mark C, Debasis D (2001) Using the coal mine roof rating (CMRR) to ssess roof stability in U.S. coal mines. J Min Met Fuel (India) 49(8–9):314–321
Mark C, Molinda GM, Barton TM (2002) New developments with the coal mine roof rating. In: Proceedings of the 21st international conference on ground control in mining. West Virginia University, Morgantoen, WV, pp 294–301
Deb D (2003) Analysis of coal mine roof fall rate using fuzzy reasoning techniques. Int J Rock Mech Min 40:251–257
Duzgun HSB, Einstein HH (2004) Assessment and management of roof fall risks in underground coal mines. Saf Sci 42:23–41
Duzgun HSB (2005) Analysis of roof fall hazards and risk assessment for Zonguldak coal basin underground mines. Int J Coal Geol 64:104–115
Torabi SR, Sereshki F, Zare M, Javanshir M (2008) An empirical approach in prediction of the roof rock strength in underground coal mines. Coal operators’ conference, The AusIMM Illawarra Branch, pp 132–136
Javanshir M, Ataei M, Torabi SR (2009) Modeling and classification of roof behavior in coal mines. Int J Ind Eng Prod Man 19(9):45–53
Palei SK, Das SK (2009) Logistic regression model for prediction of roof fall risks in bord and pillar workings in coal mines: an approach. Saf Sci 47:88–96
Ghasemi E, Ataei M (2012) Application of fuzzy logic for predicting roof fall rate in coal mines. Neural Comput Appl. doi:10.1007/s00521-012-0819-3
Esen H, Inalli M, Sengur A, Esen M (2008) Predicting performance of a ground-source heat pump system using fuzzy weighted pre-processing-based ANFIS. Build Environ 43(12):2178–2187
Riverol C, Sanctis CD (2009) A fuzzy filter for improving the quality of the signal in adaptive-network-based fuzzy inference systems (ANFIS). Appl Soft Comput 9(1):305–307
Sobhani J, Najimi M, Pourkhorshidi AR, Parhizkar T (2010) Prediction of the compressive strength of no-slump concrete: a comparative study of regression, neural network and ANFIS models. Constr Build Mater 24(5):709–718
Hayati M, Rezaei A, Seifi M, Naderi A (2010) Modeling and simulation of combinational CMOS logic circuits by ANFIS. Microelectron J 41(7):381–387
Ekici BB, Aksoy UT (2011) Prediction of building energy needs in early stage of design by using ANFIS. Expert Syst Appl 38(5):5352–5358
Bilgehan M (2011) Comparison of ANFIS and NN models—with a study in critical buckling load estimation. Appl Soft Comput 11(4):3779–3791
Khorami MT, Chelgani SCh, Hower JC, Jorjani E (2011) Studies of relationships between free swelling index (FSI) and coal quality by regression and adaptive neuro fuzzy inference system. Int J Coal Geol 85(1):65–71
Mohandes M, Rehman S, Rahman SM (2011) Estimation of wind speed profile using adaptive neuro-fuzzy inference system (ANFIS). Appl Energy 88(11):4024–4032
Pousinho HMI, Mendes VMF, Catalã JPS (2012) Short-term electricity prices forecasting in a competitive market by a hybrid PSO–ANFIS approach. Int J Electer Power 39(1):29–35
Yilmaz I, Kaynar O (2011) Multiple regression, ANN (RBF, MLP) and ANFIS models for prediction of swell potential of clayey soils. Expert Syst Appl 38:5958–5966
Sepúlveda C, Llera JCD, Jacobsen A (2012) An empirical model for preliminary seismic response estimation of free-plan nominally symmetric buildings using ANFIS. Eng Struct 37:36–49
Patil PP, Sharma SC, Jain SC (2012) Performance evaluation of a copper omega type Coriolis mass flow sensor with an aid of ANFIS tool. Expert Syst Appl 39(5):5019–5024
Azamathulla HM, Ghani AA, Fei SY (2012) ANFIS-based approach for predicting sediment transport in clean sewer. Appl Soft Comput 12(3):1227–1230
Rezaei E, Karami A, Yousefi T, Mahmoudinezhad S (2012) Modeling the free convection heat transfer in a partitioned cavity using ANFIS. Int Commun Heat Mass 39(3):470–475
Singh R, Kainthola A, Singh TN (2012) Estimation of elastic constant of rocks using an ANFIS approach. Appl Soft Comput 12(1):40–45
Cabalar AF, Cevik A, Gokceoglu C (2012) Some applications of adaptive neuro-fuzzy inference system (ANFIS) in geotechnical engineering. Comput Geotech 40:14–33
Jang JSR (1993) ANFIS: adaptive-network-based fuzzy inference systems. IEEE T Syst Man Cy 23:665–685
Alizadeh M, Jolai F, Aminnayeri M, Rada R (2012) Comparison of different input selection algorithms in neuro-fuzzy modeling. Expert Syst Appl 39:1536–1544
Tang AM, Quek C, Ng GS (2005) GA-TSKfnn: parameters tuning of fuzzy neural network using genetic algorithms. Expert Syst Appl 29:769–781
Mehrabi M, Pesteei SM, Pashaee TG (2011) Modeling of heat transfer and fluid flow characteristics of helicoidal double-pipe heat exchangers using adaptive neuro-fuzzy inference system (ANFIS). Int Commun Heat Mass 38:525–532
Jeong H, Hwang W, Kim E, Han M (2012) Hybrid modeling approach to improve the forecasting capability for the gaseous radionuclide in a nuclear site. Ann Nucl Energy 42:30–34
Khatibi R, Ghorbani MA, Kashani MH, Kisi O (2011) Comparison of three artificial intelligence techniques for discharge routing. J Hydrol 403:201–212
Molinda GM, Mark C, Dolinar D (2000) Assessing coal mine roof stability through roof fall analysis. In: Proceedings of the new technology for coal mine roof support. US Department of Health and Human Services, Centers for Disease Control and Prevention, National Institute for Occupational Safety and Health, NIOSH Publication No. 9453, pp 53–72
Fotta B, Mallett LG (1997) Effects of mining height on injury rates in U.S. underground nonlongwall bituminous coal mines. NIOSH, IC 9447
Chiu SL (1994) Fuzzy model identification based on cluster estimation. J Intell Inf Syst 2:267–278
Tzamos S, Sofianos AI (2006) Extending the Q system’s prediction of support in tunnels employing fuzzy logic and extra parameters. Int J Rock Mech Min 43(6):938–949
Gentili PL (2007) Boolean and fuzzy logic implemented at the molecular level. Chem Phys 336:64–73
Jelleli TM, Alimi AM (2009) On the applicability of the minimal configured hierarchical fuzzy control and its relevance to function approximation. Appl Soft Comput 9(4):1273–1284
Gopalakrishnan K, Ceylan H, Attoh-Okine NO (2009) Intelligent and soft computing in infrastructure systems engineering: recent advances. Springer, Berlin, Heidelberg
Acknowledgments
The authors would like to acknowledge the financial support of the University of Tehran for this research.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Farid, M., HosseinAbadi, M.M., Yazdani-Chamzini, A. et al. Developing a new model based on neuro-fuzzy system for predicting roof fall in coal mines. Neural Comput & Applic 23 (Suppl 1), 129–137 (2013). https://doi.org/10.1007/s00521-012-1271-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-012-1271-0