
Abstract
The provision of long-distance travel time information has been a major factor facilitating the intelligent transportation system to become more successful. Previous studies have pointed out that non-recurrent congestion is the major cause of freeway delay. The long travel distance complicates the characteristics of traffic flow. Hence, how to improve the prediction capability of long-distance travel time in the case of non-recurrent congestion is an important issue that must be overcome in the field of travel time prediction. This study constructs the travel time prediction model for a segment of 36.1 kms (including eight interchanges) in the National Freeway No. 1, Taiwan, by using the multilayer perceptron. To improve the prediction capability of the model in the case of non-recurrent congestion, this study collects data of average spot speed and heavy vehicle volume gathered by dual-loop vehicle detectors, in addition to rainfall and temporal feature. Furthermore, the historical travel time inferred from the original data of electronic toll collection (ETC) system is also used as the input variable, and the actual travel time inferred from ETC is used as the training target to establish a robust prediction model. As suggested by the results of 168 experimental combinations, the most appropriate prediction model established in this study is a highly accurate forecasting model with MAPE of 6.47 %.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The provision of travel time information has been one of the major factors facilitating the advanced traffic management system (ATMS) and advanced traveler information system (ATIS) to become more successful [1]. Furthermore, the establishment of ATMS and ATIS can improve the performance of existing transportation systems, make more efficient use of limited resources, and reduce pollution emissions to slow down the global warming ultimately. Hence, travel time prediction has been a research topic of concern and attention. The long-distance travel time prediction can effectively provide alternative freeway route information to facilitate ATMS and ATIS to be more successful. However, the longer section of freeway contains more interchanges, leading to more complex changes in the characteristics of traffic flow and thus higher difficulty of travel time prediction. Hence, the prediction of long-distance travel time becomes a major issue that must be overcome in the area of travel time prediction. Nevertheless, the development of continuous travel time prediction model will encounter the traffic condition of non-recurrent congestion as a result of incidents.
The study of Oak Ridge National Laboratory [2] pointed out that 55 % of the delays drivers encounter in American freeways are caused by non-recurrent events, 72 % of which are freeway accidents [3]. Therefore, improving the accident prediction capability [4, 5], finding the key accident-related variables [6], and estimating the impact [7–9] are all issues that should be addressed seriously by research institutions and management units. However, due to the gap between accident reporting time and the occurrence time, the important parameters to measure traffic performance such as the accident disposal time and number of closed lanes cannot be accurately measured at the first time. As a result, how to collect important variables and develop a robust prediction model when it is unable to acquire important accident-related variables in real time to improve the real-time continuous prediction capability in the case of non-recurrent congestion becomes an interesting issue that needs to be further addressed.
As far as prediction technology is concerned, since 1970, researchers have used the autoregressive integrated moving average (ARIMA), Kalman filtering [10, 11], locally weighted regression (LWR) [12], and exponential smoothing (ES) models [13–18] to perform travel time prediction or traffic flow prediction. Furthermore, many successful studies of travel time prediction or traffic flow prediction on freeway in the past also utilized the support vector regression [19], ARIMA-like time series [20], Markov Chains [21], neural networks [22–24], and so on. Regarding the travel time prediction of freeway, studies on topics such as short distance [23, 25], general vehicle flow status (excluding non-recurrent congestion) [19, 21, 24, 26], and peak hour [22] have achieved good results. Van Lint et al. [23] pointed out that the travel time would have a larger variance when congestion occurs. Furthermore, since the freeway delay is mainly caused by non-recurrent congestion events [2], improving the capability of the prediction model in the case of non-recurrent congestion is an important issue that needs to be addressed. Fei et al. [27] presented a Bayesian inference-based dynamic linear model to predict online short-term travel time on a freeway section under both recurrent and non-recurrent traffic conditions. In recent decades, the artificial neural network (ANN) has been widely applied in the areas of traffic flow prediction, speed prediction [28–31], and travel time prediction [32]. Additionally, ANN has been successfully applied in other areas such as water quality prediction [33] and automotive price forecasting [34]. From the results of Najah et al. [33], the radial basis function neural network outperforms the linear regression model and the multilayer perceptron (MLP). In [34], Reza Peyghami and Khanduzi proposed a hybrid learning approach based on the genetic algorithm and least square method to obtain the weights of neural networks. Previous research findings (e.g., [28–32]) showed that the MLP have relatively high degree of robustness and prediction capability in the case of complex, nonlinear, and hardly predictable issues. Therefore, this study attempts to employ the MLP network as the travel time prediction tool in the case of freeway with non-recurrent congestion.
This study collects the characteristics of traffic on freeway with non-recurrent congestion and develops a travel time prediction model of long distance on freeway by using MLP. The remainder of this paper is organized as follows. Section 2 elaborates on the variable selection process. Section 3 presents the travel time prediction model in the case of freeway with non-recurrent congestion. The data distribution is illustrated in Sect. 4. Thereafter, the experimental process and results are presented in Sect. 5. Finally, conclusions of this study are drawn in Sect. 6.
2 Variable selection
The study of travel time can be done by simulation or estimation. In terms of travel time prediction by estimation, selecting the significant variables to reflect the characteristics of traffic flow is the key in improving the prediction and estimation capability of models. Chang [4] pointed out that factors affecting the characteristics of traffic flow can be divided into three categories including geometric variables, traffic characteristics, and environmental factors. The geometric variables include variables such as the degree of horizontal curve and vertical grade. The traffic characteristics include variables such as average daily traffic (ADT) per lane, trucks percentage, bus percentage, and peak hour factor (PHF). The environmental factors mainly include the number of days with precipitation. The research findings in Chang [4] indicated that rainfall and bus percentage are important variables to explain accidents. Wei et al. [8] utilized the traffic, time, space, and geometric attributes to analyze the accident lasting time and achieve good results. In Wei et al. [8], the traffic data including the speed and traffic flow were collected by dual-loop vehicle detectors (VDs). As this study predicts the travel time at every 5 min and the important variables in analyzing traffic flow characteristics such as geometric and space attributes do not vary significantly in the short-term continuous prediction model, this study collects data regarding traffic characteristics, time, and environmental factors.
Data collection methods can be divided into the spot and spatial collection methods. The main techniques of spot data collection method include the inductance loop detectors, microwave, infrared, and radar. Traffic variables such as the space-mean-speed, vehicle type, and traffic flow can be collected by the above methods. The data collection method of using inductance loop detectors is most widely employed in Taiwan. Yeon et al. [21] pointed out that using the traffic flow and average spot speed collected by dual-loop VDs to predict the travel time of general traffic status (congestion not due to weather, accidents, incidents, or work zones) can achieve good estimation results. Yuan et al. [35] indicated that variables of speed, occupancy, and volume are also the important factors to capture traffic characteristics. Additionally, Chang et al. [36] pointed out that bus percentage is an important variable for accident analysis, indicating that the flow of heavy vehicle is an important variable affecting the characteristics of traffic flow. As the freeway segment in this study is the main connection road of major economically developed areas including Hsinchu Science-Based Park, Jungli Industrial Park, Taoyuan International Airport, Songshan International Airport, Taipei Port, and Keelung Port, the characteristics of traffic flow are affected by complex economic activities. In addition to reflecting the economic activities, the larger volume of heavy vehicle has a greater impact on the moving efficiency of overall traffic flow due to different speed limits for heavy vehicles and small vehicles on the National Freeway No. 1, Taiwan, as well as the relatively poor climbing and lane-changing capability of heavy vehicles. In view of this, this study collects the heavy vehicles flow via the dual-loop VDs as the input variables of prediction model.
Furthermore, in terms of the spatial data collection methods, the travel time prediction of freeway with non-recurrent congestion can mainly be conducted by automatic vehicle identification (AVI) [37, 38] and probe vehicle technology [39]. The actual travel time of the freeway segment under study can be collected by AVI and probe systems such that the reliability of prediction model can be guaranteed. It is also because the AVI system does not need to overcome the problems such as the error resulted from positioning by using global positioning system (GPS) and time delay of data feedback in the data acquisition process, and the AVI system has advantages such as higher accuracy and timeliness as compared with the probe vehicle technology. Due to the higher establishment cost of AVI system, previous studies were limited in road segment under study and number of samples. In Taiwan, the ETC system was established in 2006; the ETC system covers the entire National Freeway No. 1. Up to the end of October 2009, the utilization rate has reached 36.48 %, and there are a total of 16,247,908 charge records in October 2009 with charge success rate being at 99.9984 %. Therefore, through the ETC system, the data of travel time can be collected on a long-road segment and the number of samples can also considerably increase to ensure the representativeness of the samples. In this study, the original data are collected and the actual travel time is calculated as the training target through the ETC system. In addition, generally speaking, traffic characteristics vary in weekdays and weekends. Hence, the different encoding schemes for the day of the week are also the important variable in mastering the characteristics of traffic flow.
To summarize, in addition to integrating important variables affecting the characteristics of traffic flow such as rainfall, the day of the week, morning and afternoon, spot speed, and heavy vehicle volume, this study further integrates the historical travel time inferred from the original ETC data and utilizes the actual travel time as the training target to establish a robust travel time prediction model for the freeway with non-recurrent congestion.
3 Travel time prediction architecture
The procedure of travel time prediction in this study is illustrated in Fig. 1. In this study, the data including rainfall, speed and heavy vehicle volume collected by VDs, historical travel time and actual travel time transformed from ETC were used to build the model of travel time prediction. With the results of data collection, the relatively stable traffic parameters detected by the dual-loop VDs are selected as the input variables of VD to avoid the deviation of prediction results from the actual traffic flow due to the over-imputation of missing data. Missing data could be a problem in the process of collecting original data of various attributes. The suitable imputation approach could reflect the actual characteristics of traffic flow and improve the application of the continuous prediction model. In addition, this study calculates the historical travel time and actual travel time based on the original ETC data. The AVI algorithms proposed by the Southwest Research Institute [40] and Transmit [41] are used to identify the consecutive trips and compute the travel time. After the steps of data collection, summarization, and computation, various experimental combinations are designed to understand the impact of different variable combinations on travel time prediction. In order to build a robust prediction model, this study integrates data of various attributes by using MLP network to improve the capability of travel time prediction model in the case of the freeway with non-recurrent congestion.

Travel time prediction procedure
3.1 Data collection
National Freeway No. 1 is the main inter-city transportation corridor for the west coast of Taiwan. In a total length of 373 km, National Freeway No. 1 totally has 20 toll stations. In this study, data of VD, ETC, accident, and rainfall were collected from September 16 to October 16, 2009, between the Yangmei Toll Station and Taishan Toll Station of the freeway in northward direction. Figure 2 illustrates that the freeway segment in this study includes a total of six interchanges and two system interchanges with a total length of 36.1 km. Moreover, according to the statistics of September and October 2009 of the Taiwan Area National Freeway Bureau, MOTC, the ADT volumes of Yangmei Toll Station and Taishan Toll Station were, respectively, 111,938 and 224,957 vehicles, which approximately account for 23.5 % of the ADT volume of National Freeway No. 1. It thus can be seen that the freeway segment in this study covered the busiest freeway section of the National Freeway No. 1. In this study, speed and heavy vehicle volume were collected at a 5-minute interval by the dual-loop VDs (a total of 22 VDs) through the database of Traffic Control Center of Taiwan Area National Freeway Bureau, MOTC. The original toll charging time of ETC users was also collected. The rainfall data were collected from the database of Central Weather Bureau (data from three rainfall detectors). Moreover, accident data were collected from the accident database of National Freeway Police Bureau. The above databases are established by Taiwan’s governmental agencies to permanently collect the most complete and real-time data for information dissemination, management, and research use.

The freeway segment in this study
3.2 Data availability checking
Regarding the complex traffic environment, the more complete data for representing the traffic characteristics can better improve the prediction capability of nonlinear models. In light of this, this study collected data of all dual-loop VDs in a total number of 22 on the freeway segment in this study. However, data credibility is the most important and basic requirement for model building. Selection of VDs of high stability can further ensure data credibility and improve model applicability. Regarding the data collected by VDs in this study, the VDs with missing data for more than 2 h were regarded as unstable and were eliminated from the model building. In the end, 11 VDs of relatively high stability were selected for model building. The number of VDs for data collection and number of VDs applied in this study on various freeway sections in this study are illustrated in Fig. 3.

The number of VDs for data collection and the number of VDs applied at various freeway sections
3.3 Missing data processing
Although automatic data collection has advantages such as long time collection, wide range investigation, smaller error and consistency, routine maintenance, construction, cable theft, weather conditions and other force majeure events may result in system failure or poor stability, leading to the unavoidable problem of missing data. The missing data may be deleted or imputed. The data imputation can be processed in the following three ways. First, the imputation is performed by using the historical data of the same time on different dates in the original spot of data collection, and the data of closer dates or data with same characteristics have a higher priority for imputation. Second, in the same spot of data collection, the data of Time t is imputed based on the data of Time t – n by using the arithmetic mean method, simple weighting method, ES method, etc. Third, the imputation is performed by using the data collected in upstream and downstream spots, and the closer spot and the spot belonging to the same group have a higher priority.
The missing data of Taiwan’s ETC system may occur at a particular Time t due to the following reasons: (1) equipment maintenance; (2) judgment of non-continuous trips when the travel time at Time t deviates from that at Time t – 1 over 40 %; or (3) no trip recorded as a result of no ETC vehicle passing through the toll station, resulting in the lack of travel time samples. In this study, the ETC-based actual travel time is used as the target for model training, validation, and test, and the historical travel time is used as an input variable. To avoid inconsistency between the result of model training and the real-world situation as a result of data imputation error, the sample at Time t with missing data of actual travel time and historical travel time is deleted. Furthermore, the missing data in the VD data collection process can be categorized into three cases and are imputed accordingly. These three cases are described as follows. Case 1: vehicle detector j \( ({\text{VD}}_{j} ) \) has a single missing data at Time t, but there are data at Time t – 1. Case 2: vehicle detector j \( ({\text{VD}}_{j} ) \) causes multiple missing data, and there are no missing data in the upstream and downstream VDs of \( ({\text{VD}}_{j} ) \), that is, there are missing data at Times t and t – 1, and there are no missing data in the upstream and downstream VDs. Case 3: vehicle detector j \( ({\text{VD}}_{j} ) \) causes multiple missing data, and there are missing data in the upstream and downstream VDs of \( ({\text{VD}}_{j} ) \), that is, there are missing data at Times t and t – 1, and there are missing data in the upstream and downstream VDs. Notice that, for the imputation of missing data of heavy vehicles, the heavy vehicle volume at the time with the speed closest to that of Time t within the previous half hour is used to impute the missing heavy vehicle volume of Time t in \( ({\text{VD}}_{j} ) \). For example, if the speed at Time t – 1 is closest to that at Time t, the missing heavy vehicle volume at Time t is imputed by that at Time t – 1. This way, the impact of factors such as different VD detection quality at various observation spots and different traffic characteristics were taken into consideration. Hence, filling the missing data with on-time data of the same observation spot is an effective method to reflect the traffic characteristics of the observation spot. For Case 1, simple weighting method, that is, \( {\text{Speed}}_{j} (t) = {\text{Speed}}_{j} (t - 1) \) and \( {\text{HVV}}_{j} (t) = {\text{HVV}}_{j} (t - 1) \), is used to impute the missing data. For Cases 2 and 3, the third data imputation method presented in Sect. 3.3 is used. In summary, for the above-mentioned three cases, the procedure of data imputation is described as follows.
-
Step 1: If the missing data in the data collection process of VD conform to Case 1, go to Step 2. Otherwise, go to Step 4.
-
Step 2: Find the speed and heavy vehicle volume of \( ({\text{VD}}_{j} ) \) at Time t – 1 from database, and they are recorded as \( {\text{Speed}}_{j} (t - 1) \) and \( {\text{HVV}}_{j} (t - 1) \), respectively.
-
Step 3: Set \( {\text{Speed}}_{j} (t) = {\text{Speed}}_{j} (t - 1) \) and \( {\text{HVV}}_{j} (t) = {\text{HVV}}_{j} (t - 1) \), and go to Step 17.
-
Step 4: If the missing data in the data collection process of VD conform to Case 2, go to Step 5. Otherwise, go to Step 12.
-
Step 5: Record the data of \(\left\{{{\text{VD}}_{j} (t) > 0} \right\}\).
-
Step 6: According to the VDj grouping mark, find out the data \(\left\{{{\text{VD}}_{j}^{k}>0}\right\}\).
-
Step 7: The \( {\text{VD}}_{j} \) that is closer to \( {\text{VD}}_{m} \) (i.e., min distance \( ({\text{VD}}_{j} , {\text{VD}}_{m} ) \)) has the higher priority of data imputation.
-
Step 8: Impute the speed of \( {\text{VD}}_{j} \) at time t by using the LRM model and set \( {\text{speed}}_{j} (t) = a + b \times {\text{speed}}_{m} (t) \).
-
Step 9: Find the speed of \( {\text{VD}}_{j} \) within a half hour of Time t that is closest to \( {\text{speed}}_{j} (t) \) \( (\min \left\{ {\left| {{\text{speed}}_{j} (t) - {\text{speed}}{}_{j}(t - i)} \right|} \right\},\quad i = 1,2, \ldots ,6) \). Impute the heavy vehicle volume of Time t by setting \( {\text{HVV}}_{j} (t) = {\text{HVV}}_{j} (t - i) \).
-
Step 10: If the missing data in the data collection process of VD conform to Case 2, go to Step 11. Otherwise, go to Step 15.
-
Step 11: If the consecutive time of data imputation is more than 2 h, stop imputing the data and delete the following consecutive missing data. Otherwise, repeat Steps 5–9 until finishing the imputation of missing data and go to Step 17.
-
Step 12: Case 3. Record the data of \(\left\{{{\text{VD}}_{j} (t) > 0} \right\}\).
-
Step 13: Check whether \( {\text{VD}}_{j} \) of the same group K have data at Time t, \( {\text{VD}}_{j}^{k} \). If so, select the VD with data of the same group K as the object of data imputation, \(\left\{{{\text{VD}}_{j}^{k}>0}\right\}\). Otherwise, select \( {\text{VD}}_{j} \) with data of a different group η as the object of data imputation, \(\left\{{{\text{VD}}_{j}^{\eta} > 0} \right\},\quad \eta\ne K\).
-
Step 14: Repeat Steps 7–9.
-
Step 15: Check whether the missing data in all VDs at Time t have been imputed. If so, go to Step 16. Otherwise, impute the missing data of next VD and repeat Steps 13 and 14.
-
Step 16: If the consecutive time of data imputation is more than 2 hours, stop imputing the data and delete the following consecutive missing data. Otherwise, repeat Steps 12–13 until all missing data are imputed and go to Step 17.
-
Step 17: Check whether all missing data have been imputed. If so, stop the data imputation process. Otherwise, go to Step 1.
If the missing data of VD do not fit into any above-mentioned case, this sample is deleted. In addition, the sample is deleted if data at Time t are regarded as abnormal. The driving speed more than 120 km/h is regarded as abnormal since the speed limit on the freeway segment in this study is 120 km/h. Moreover, from the statistics of traffic volume in September 2009 reported by the Taiwan Area National Freeway Bureau, the percentage of heavy vehicle volume was between 10.0 and 17.1 %. Accordingly, it would be regarded as abnormal if the heavy vehicle volume is more than 150 at Time t. After the above data preprocessing, a total of 7,908 samples were acquired for model building.
3.4 Computation of historical travel time and actual travel time
The ETC system collects the times of a vehicle passing through the upstream point A and the downstream point B by identifying ID, and the AVI system collects the times by identifying the vehicle license plate. Although the technologies of vehicle identification and time collection adopted by ETC and AVI are different, the logic of travel time computation are applicable in both systems. Therefore, in this study, the ETC charging times of freeway users were collected to calculate the historical travel time and actual travel time by using the algorithms developed by Southwest Research Institute [40] and Transmit [41]. Regarding the computation of travel time by AVI system, Southwest Research Institute [40] developed the TransGuide and TranStar algorithms. Both algorithms employ the concept of rolling average algorithm to automatically calculate the travel time. Equation (1) expresses the set, \( {\text{Ctt}}_{ABt} \), for computing the travel time by using the SwRI algorithm.
Equation 1 is utilized to estimate the travel time of a vehicle passing through two AVI readers, which are the upstream point A, \( t_{Ai} \), and the downstream point B, \( t_{Bi} \). To avoid the data of abnormal travels (detour and parking) from affecting the estimation of travel time, if the travel time \( (t_{Bi} - t_{Ai} ) \) of vehicle i passing through points A and B of AVI readers is more than the link threshold parameter, \( l_{\text{th}} \), the data of this travel will be eliminated. The threshold, \( l_{th} \), in both TransGuide and TranStar is set to 0.2. That is, if the travel time of vehicle i is lower or more than 20 % of the previous average travel time,\( {\text{Btt}}_{ABt} \), this travel will be regarded as abnormal and will not be included in the travel time computation. Furthermore, regarding the observation window, \( t_{r} \), of travel time data set, \( {\text{Ctt}}_{ABt} \), the observation window is set to 2 min in the TransGuide algorithm, that is, the average travel time of all trips within 2 min is computed by using Eq. (2). It takes form as follows:
However, the TranStar algorithm differs from the TransGuide algorithm in fix window concept as it simultaneously renews the travel time data set and computes the average travel time if AVI readers obtain new travel time samples [37].
The computation logic of Transmit algorithm is very similar to those of TransGuide and TranStar. The main difference is that the Transmit algorithm does not use the concept of rolling average algorithm to calculate the travel time in line with the threshold, but it calculates the travel time within 15 min. In the Transmit algorithm, at each fix time interval, s, it collects the travel time samples of two AVI readers, ns, with an upper limit of 200 samples, and calculates the travel time, \( {\text{Ott}}_{ABS} \), by using Eq. (3) in the time interval [41]. Equation (3) takes form as follows [41]:
In addition, with the travel time database, in which the travel time is computed every 15 min, the actual travel time, \( {\text{Att}}_{ABS}^{\prime \prime } \), can be computed by using Eq. (4). It takes form as follows:
In Eq. (4), with the historical travel time in period S, \( {\text{Htt}}_{ABS} \), and the actual travel time in period \( S - 1 \), \( {\text{Att}}_{ABS - 1}^{\prime \prime } \), after being adjusted by the smoothing parameter α, the actual travel time in period S, \( {\text{Att}}_{ABS}^{\prime \prime } \), can be estimated. According to [37], in the case of no incident detected, smoothing parameter (α) is set to 0.1, whereas in the case of incident detected, smoothing parameter is set to 0. To prevent the characteristic of non-recurrent congestion due to accidents from affecting the normal traffic flow represented by the historical database, this database of travel time does not include the travel time data after accidents. Therefore, Transmit algorithm is limited to the case of stable traffic flow without accidents and to the area with a linear change in actual travel time and historical data. Although the historical travel time can reflect some conditions of traffic flow, the accidents occur randomly, and it is difficult to accurately present the characteristics of complex traffic conditions by using linear equations. Hence, in this study, the historical travel time and actual travel time in the ETC database are computed by using the AVI travel time algorithm. Moreover, the MLP network is used to develop a robust model to predict the freeway travel time in the case with complex and nonlinear traffic characteristics.
3.5 The MLP-based travel time prediction model
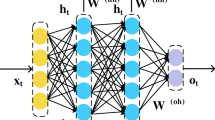
The neural network can build nonlinear models and furthermore exclude the disadvantage of setting up several assumptions when building models by the multiple linear regression method and Auto-regressive Integrated Moving Average Model (ARIMA) [42]. According to the survey from 1992 to 1998 by Vellido et al. [43], about 78 % of studies using neural networks to business-related area employed Back-Propagation Neural Network (BPN). The architecture of BPN is a multilayer feed-forward network with supervised learning, and thus it is also termed as MLP [44]. It inputs the training samples into the network while transmitting the outputs to allow the network to learn the mapping between the input and output variables. BPN is mainly composed of input layer, hidden layer, and output layer. In this study, the input layer is mainly used to receive the input variables, specifically, such as rainfall, speed and heavy vehicle volume collected by VDs, the day of the week, historical travel time collected by ETC, and time (AM or PM). Figure 4 illustrates the structure of BPN applied in this study.

The BPN architecture
This study employs the SAS Enterprise Miner, version 5.3, to build the prediction model of freeway travel time. The number of hidden nodes is an important parameter affecting the prediction performance of MLP. Hence, in the case of common parameter settings (see Table 1) for various experimental combinations, this study evaluates the prediction performance of different numbers of hidden nodes. The root mean square error (RMSE) is used to measure the prediction performance, and the lower RMSE value represents the better prediction performance. Finally, the number of hidden nodes with the lowest RMSE is used to develop the prediction model for each experimental combination, and the prediction results of all experimental combinations are compared in this study.
4 Data analysis
4.1 ETC
At present, Taiwan’s ETC system mainly charges at a fixed rate instead of a mileage-based rate. At the beginning, as the system only records the charging time and amount of vehicles at toll stations, it is unable to compute the travel time. The travel time is the important and valuable information to both road users and managers. Therefore, the ETC system at present time provides the vehicle an identity (ID) number at first charge at the toll station, and the travel time sampling logic is the same as the SwRI algorithm. If the travel time of the vehicle deviates from the average travel time of the last time interval on the freeway segment more than the threshold, it is judged as a non-continuous trip, and the vehicle will be given a new ID number. According to the judgment rule of non-continuous trips in Taiwan’s ETC system, the threshold is set to 40 %. This threshold is based on the result of long-term experiment by the Taiwan Area National Freeway Bureau, MOTC. That is to say, if the average travel time of the last time interval on the freeway segment is 20 min, a trip with the travel time of more than 28 min or less than 12 min will be regarded as non-continuous, and the vehicle will be given a new ID. If a vehicle of same ID passes through the upstream point A and the downstream point B, it is a continuous trip and can be a sample for computing the travel time.
In this study, through the ETC system, the charging times and ID numbers of northbound vehicles passing through the Yangmei Toll Station and Linkou Toll Station were collected. A total of 1,679,868 data points are collected, and the Transmit algorithm is employed to compute the historical travel time and actual travel time at 5-min intervals without the restriction of 200 samples. The computation of historical travel time \( ( {\text{HTT}}_{ABt} ) \) is expressed in Eq. (5).
With the time of vehicle i passing through point B, \( t_{Bi} \), as the judgment basis, data of vehicles passing through point B in an interval of 5 min are collected, and the completed trips between upstream point A and downstream point B are utilized as the samples to compute the average travel time as the historical travel time \( ({\text{HTT}}_{ABt} ) \). Although the historical travel time does not represent the actual travel time of vehicle i from upstream point A to freeway section AB \( ({\text{ATT}}_{ABt} ) \), it may imply the historical traffic characteristics of the freeway section. The historical travel time may impact the travel time prediction; therefore, it is taken as an input variable for model building.
The actual travel time \( ({\text{ATT}}_{ABt} ) \) is computed by using Eq. (6), and it can be expressed as
With the time of vehicle i passing through point A, \( t_{Ai} \), as the judgment basis, data of vehicles passing through point A in an interval of 5 min are collected, and the average travel time of vehicles completing the freeway section AB is computed. This travel time represents the actual travel time of vehicle i after passing through point A to enter the freeway section AB. Through the ETC system, a large amount of original data is collected, and the actual travel time \( ({\text{ATT}}_{ABt} ) \) is computed as the target for model training to build a travel time prediction model of high credibility.
4.2 Rainfall
Konstantopoulos et al. [45] pointed out that rainfall can affect the drivers’ line of sight, increase the driving risk, and is an important variable of accident occurrence. The amount of rainfall affects driving behaviors and is an important factor affecting traffic characteristics. Hence, regarding the research of travel time, rainfall has been an important variable that must be considered in areas of a large number of rainy days and high rainfall. With an island-type climate, the number of rainy days and rainfall amount are high in Taiwan. The area in this study is located in northern Taiwan. According to the rainfall data of 55 major cities across the world from the Central Weather Bureau, there are on average 168 days of rainfall more than 0.1 mm each year in Taipei, only fewer than the 187 days in Jakarta, 174 days in Oslo, and 173 days in Stockholm. However, the annual rainfall of 2,325 mm ranks first in the 55 major cities across the world. In light of this, in this study, the data of rainfall detector of Yangmei, Taoyuan, and Linkou are collected as the variables for building the prediction model of travel time. As the basic time unit of current rainfall data is 10 min, to predict the 5-min travel time, this study converts the basic time unit of rainfall data into 5 min by using the arithmetic mean method for building the prediction model.
4.3 Accidents
Since accidents happen randomly, data of relevant important variables (e.g., the accident occurrence time, number of closed lanes, accident removal time, etc.) for estimating the accident impact on traffic flow cannot be obtained accurately and in real time due to report limitations. Hence, how to use relevant real-time information to develop a robust prediction model and ensure the prediction capability in line with the needs of managers and users is the key issue to overcome in this study. There were a total of 76 accidents in the time span of this research, and 176 vehicles were damaged with six people injured (see Table 2). The statistics show that 96.1 % accidents involved only vehicle damaged without personnel injured. In addition, it is noteworthy that although fewer accidents occurred in the freeway section between Taoyuan interchange and Linkou interchange than those in the freeway section between Jungli interchange and Neili interchange, more vehicles were damaged in accidents occurring in the freeway section between Taoyuan interchange and Linkou interchange than those in the freeway section between Jungli interchange and Neili interchange. It thus can be known that the impact of accidents on traffic flow is greater in the freeway section between Taoyuan interchange and Linkou interchange.
4.4 Current travel time analysis
Figure 5 illustrates the 5-min travel time distribution of the freeway segment in this study. Figure 5a–h shows that there are about 1–3 peak hours each day. The lasting time, start time, and end time of each peak hour as well as the travel time within each peak hour vary. Observing Fig. 5a, the morning peak hour is 7:00–10:00, noon peak 13:00–15:00, and afternoon peak 17:00–21:00. In addition, generally speaking, Saturday and Sunday are regarded as weekends, and Tuesday, Wednesday, and Thursday are regarded as weekdays. Meanwhile, the traffic flows of days of weekends or the traffic flows of days of weekdays have the similar characteristics. However, the morning hours shown in Fig. 5c–e indicate that there was no obvious peak hour on September 16 (Wednesday), while the morning peak hour of September 22 (Tuesday) was 7:20–11:00. Moreover, Fig. 5g–h illustrates that as far as the morning peak hour of weekends was concerned, there was no obvious peak hour in the morning of September 20 (Sunday), while the morning peak hour of September 26 (Saturday) fell on the time period of 11:00–13:30. Thus, regardless of weekends or weekdays, peak hours varied, and the number, length, start time, and end time of peak hours on different dates varied considerably. The above characteristics of peak hour are clearly shown from the wavy and distorted surfaces of travel time in Fig. 5.

Distributions of 5-min travel time. a Travel time of all days. b Travel time on Mondays. c Travel time on Tuesdays. d Travel time on Wednesdays. e Travel time on Thursdays. f Travel time on Fridays. g Travel time on Saturdays. h Travel time on Sundays
Areas of long freeway section, high traffic flow, many interchanges, and frequent rainfall will have relatively more complex traffic characteristics because more factors interfere with the smooth moving of traffic flow. Moreover, areas with more complex traffic characteristics are prone to accidents, and accident and rainfall are factors that are difficult to predict. Therefore, in such areas, the traffic characteristics vary considerably. Figure 6 illustrates the travel time, accident, and rainfall on Tuesdays. In the case where there was no rainfall and accident, from the distribution of travel time on October 13 shown in Fig. 6a, the morning peak hour of the freeway segment in this study was about 7:00–8:20. In the case of rainfall, the peak time always lengthened. Taking September 29 as an example, due to the intermittent shower during 5:25–6:40 (see Fig. 6b), the morning peak hour of this day became 7:20–8:50. Furthermore, the intermittent rainfall in 7:15–8:0 in the morning of October 6 resulted in the morning peak hour to be 7:00–9:30. The fifth generation car following model of General Motors (GM) reflects that when drivers change the behaviors of acceleration and deceleration due to the impact from the external driving environment, an impact on the following overall traffic is generated, and such impact will tend to be stable after a period of time. To understand the explanatory power of various cumulative rainfall variables (e.g., 5 min, 1 h, 2 h, etc.) on traffic characteristics, this study investigates it by experimentation.

Travel time, accident, and rainfall on Tuesdays. a Line graph of travel time. b Line graph of rainfall. c Distributions of number of accident vehicles and lasting time
In addition, as far as the traffic characteristics of this freeway segment in Tuesday afternoons are concerned, the afternoon peak would not be obvious if there was no accident. However, when there were accidents, the travel time on this freeway segment would increase significantly. Taking September 29 as an example, accidents consecutively occurred during 15:10–18:45 (see Fig. 6c), and there was a peak hour during 16:30–18:45 on this freeway segment accordingly (see Fig. 6a). Furthermore, there was an accident involving three vehicles during 10:40–11:27 in the morning on September 22, resulting in the morning peak hour lasting from 7:15 to 11:25. Hence, accident is an important variable affecting the travel time. As it is not easy to acquire accident-related data in real time, and it is not easy to master the accident occurring time and accident vanishing time, this study utilizes the time-mean-speed collected by VDs to represent real-time traffic characteristics.
5 Experiments
5.1 Experimental design
In this study, rainfall (seven types), speed, and heavy vehicle volume collected by VDs (three types), encoding scheme of the day of the week (two types), historical travel time collected by ETC (two types), and time (AM or PM) (two types) are used as input variables, and various types of variables are designed accordingly (see Table 3) to understand the impact of different variable combinations on the prediction performance. Totally, 168 experimental combinations are investigated in this study.
Furthermore, to build a robust prediction model, in the case of each experimental combination, the 7,990 samples are randomly split into training, validation, and test data sets by the percentages of 40, 30, and 30 %, respectively. Regarding each experimental combination, various numbers of hidden nodes are investigated to find the best structure (i.e., the optimal number of hidden nodes) of the combination, and root mean square error (RMSE) and mean absolute percentage error (MAPE) are employed as the performance measures to determine the best structure of each combination. The characteristics of various experimental combinations are analyzed according to the RMSE and MAPE values of test data set of the best structure in each experimental combination.
RMSE is a nonlinear criterion able to effectively calculate the average error of predicted value \( (\overline{x} (k)) \) and actual value \( (x(k)) \) at fixed time span t with M samples. RMSE has the concept of relative value, and it can be expressed as Eq. (7) [46]:
MAPE was proposed by Lewis in 1982 [47]. MAPE is not subject to the influence of the unit of actual value and predicted value. Hence, it can objectively obtain the relative difference between the actual value and predicted value. If MAPE < 10 %, it is a highly accurate forecasting; if 10 % < MAPE < 20 %, it is a good forecasting; if 20 % < MAPE < 50 %, it is a reasonable forecasting; if MAPE > 50 %, it is an inaccurate forecasting. MAPE can be expressed as Eq. (8) [47]:
From Eqs. (7) and (8), lower values of MAPE and RMSE indicate the better prediction performance
5.2 Analysis of results
5.2.1 Analysis of rainfall variable
Neural networks can deal with the multicollinearity issue better than the statistical methods [48]. In addition, rainfall has been an important factor affecting drivers’ behaviors. As a result, in Experiment 1, various variable combinations are designed based on the cumulative rainfall data collected by rainfall detectors (see Table 3), and the results are compared to investigate the impact of rainfall on travel time prediction. Experiment 1.1 includes one cumulative rainfall variable of 5-min cumulative rainfall. Experiment 1.2 additionally includes the 1-h cumulative rainfall as the input variable. Similarly, Experiment 1.7 includes seven cumulative rainfall variables of 5 min, 1 h, 2 h, 3 h, 4 h, 5 h, and 6 h (see Table 3). For investigating the prediction capabilities of seven types of rainfall variables (see Experiments 1.1–1.7), the performance of each type of rainfall variables is based on the average performance measures of 24 experimental combinations, which include three types of speed and heavy vehicle volume collected by VDs, two types of encoding scheme of the day of the week, two types of historical travel time collected by ETC, and two types of time variable. The prediction capabilities of other types of variables (Experiments 2–5) are investigated in the similar manner. From Table 4, the prediction model built in Experiment 1.1 is not the best experimental combination in terms of performance measures. Generally speaking, increasing the number of input variables in an MLP can improve the prediction capability. However, the test results of this study indicate that the model in Experiment 1.7 is not the one with the best prediction performance. To further understand whether the variance and mean of performance measures of various experimental combinations have significant differences, this study first employs the F test to analyze the significant differences in variance of various combinations. Then, the t test is used to analyze the significant differences in mean of various combinations. The results are summarized in Tables 5, 6, 7, 8. Although the two measures MAPE and MAPE > 20 % of seven experimental combinations regarding rainfall are not significantly different, RMSE and MAPE > 50 % are significantly different (see Tables 5, 6, 7, 8). These results illustrate that not only increasing the number of cumulative rainfall variables is unable to help improve the performance of travel prediction, but also the percentage of MAPE > 50 % increases. The increase in inaccurate forecasting may lower the road users’ acceptance of reporting the predicted travel time and considerably increase the resistance to implement the policy. Moreover, variable reduction can decrease the cost of prediction model building. From the above discussions, by considering the traffic characteristics of freeway segment in this study, taking only the 5-min cumulative rainfall as the input variable (Experiment 1.1) is the best combination in selecting the rainfall variables.
5.2.2 Analysis of speed and heavy vehicle volume collected by VDs
In Experiment 2, various variable combinations are designed based on the data of speed and heavy vehicle volume collected by VDs (see Table 3), and the prediction capabilities of various combinations are compared. In Experiment 2.1, the data of speed and heavy vehicle volume collected by 10 VDs are utilized as the input variables, while in Experiment 2.2, the data of speed collected by 10 VDs are employed as the input variables. In Experiment 2.3, the data of speed collected by 11 VDs are used as the input variables. For investigating the prediction capabilities of three types of speed and heavy vehicle volume collected by VDs (see Experiments 2.1–2.3), the performance of each type of speed and heavy vehicle volume collected by VDs is based on the average performance measures of 56 experimental combinations, which include seven types of rainfall variables, two types of encoding scheme of the day of the week, two types of historical travel time collected by ETC, and two types of time variable. From Table 9, in the case of taking the data of speed and heavy vehicle volume collected by 10 VDs as input variables (Experiment 2.1), the model performs worst in terms of all performance measures, and the standard deviations of performance measures are relatively high. However, interestingly, in the case of taking only the data of speed collected by 11 VDs as input variables, the prediction performance is improved. Furthermore, from the results of statistical tests shown in Table 10, all the performance measures of various experimental combinations based on the variables of speed and heavy vehicle volume collected by VDs are significantly different. From the experimental results, in the case of taking the data collected by 10 VDs as input variables, the model with only the speed variables outperforms the one with the variables of speed and heavy vehicle volume in terms of MAPE and RMSE. Moreover, the model with the data of speed variables collected by 11 VDs as input variables (Experiment 2.3) outperforms the one with the data of speed variables collected by 10 VDs as input variables (Experiment 2.2) in terms of MAPE and RMSE. Hence, the speed collected by VDs is an important variable to improve the prediction performance. In addition, taking data of heavy vehicle volume as input variables cannot improve the prediction performance. More importantly, to improve and ensure users’ trust in travel time information, the percentage of samples of reasonable forecasting or inaccurate forecasting should be reduced as many as possible. For this purpose, the percentage of samples of MAPE > 20 % is 3.67 % on average in Experiment 2.3, and it is lower than those of other two combinations. Therefore, the variables of speed collected by VDs are important variables for predicting the travel time.
5.2.3 Analysis of encoding scheme of the day of the week variable
To investigate whether the traffics of the freeway segment in this study on Tuesday, Wednesday, and Thursday and on weekends (Saturday and Sunday) are homogenous, Experiment 3 is designed to compare the prediction performance of different encoding schemes of the day of the week variable. In Experiment 3.1, Saturday and Sunday are encoded as 1; Monday and Friday are encoded as 2, and the rest days of the week are encoded as 3. In Experiment 3.2, the traffics of all the days in a week are regarded as heterogeneous, and thus the days of the week are encoded as 1–7 in order from Monday to Sunday. For investigating the prediction capabilities of two types of encoding scheme of the day of the week (see Experiments 3.1–3.2), the performance of each type of encoding scheme of the day of the week is based on the average performance measures of 84 experimental combinations, which include seven types of rainfall variables, three types of speed and heavy vehicle volume collected by VDs, two types of historical travel time collected by ETC, and two types of time variable. From the experimental results shown in Table 11, the model of Experiment 3.1 is worse than that of Experiment 3.2 in terms of all performance measures. In addition, the variance of MAPE of Experiment 3.1 is higher than that of Experiment 3.2. This indicates the model of Experiment 3.1 performs more unstable. However, from the results of statistical tests shown in Table 12, there exists no significant difference in the performance measures of two encoding schemes of the day of the week variable. Generally, as the freeway segment of long distance, high traffic flow, and dense interchange connects a number of economically developed regions and plays the role in major inter-city transportation, such a freeway segment has the more complex trip characteristic. Therefore, it is more difficult to distinguish the traffic characteristics by weekday or weekend. Although the prediction capabilities of two encoding schemes of the day of the week variable do not significantly different, the model of Experiment 3.2 performs better in terms of average values of performance measures. Hence, in this study, categorizing into weekday and weekend in the encoding scheme of the day of the week variable (i.e., Experiment 3.1) can improve less accuracy in travel time prediction.
5.2.4 Analysis of historical travel time collected by ETC
Experiment 4 compares the performance of using historical travel time collected by ETC as input variable (Experiment 4.1) with the performance of not using historical travel time collected by ETC as input variable (Experiment 4.2). For investigating the prediction capabilities of usage of historical travel time collected by ETC (see Experiments 4.1–4.2), the performance of usage of historical travel time collected by ETC is based on the average performance measures of 84 experimental combinations, which include seven types of rainfall variables, three types of speed and heavy vehicle volume collected by VDs, two types of encoding scheme of the day of the week, and two types of time variable. The experimental results shown in Table 13 indicate that the model with the historical travel time collected by ETC (Experiment 4.1) outperforms that without the historical travel time collected by ETC (Experiment 4.2) in terms of all performance measures. Moreover, the variances of performance measures of the model with the historical travel time collected by ETC are lower. Additionally, the results of t test of performance measures (see Table 14) show that, except MAPE > 50 %, RMSE, and MAPE, MAPE > 20 % are significantly different. Thus, employing the historical travel time collected by ETC as input variable can improve the capability of travel time prediction model and build a more robust model due to the lower variances of performance measures. More importantly, it can effectively reduce the percentage of samples of MAPE > 20 % and increase the road users’ acceptance of travel time prediction because the percentage of samples of MAPE > 20 % is an important measure for evaluating travel time prediction.
5.2.5 Analysis of time variable
Experiment 5 compares the performance of not using time (AM or PM) variable as the input variable (Experiment 5.1) with the performance of using time variable as the input variable (Experiment 5.2). For investigating the prediction capabilities of usage of time variable (see Experiments 5.1–5.2), the performance of usage of time variable is based on the average performance measures of 84 experimental combinations, which include seven types of rainfall variables, three types of speed and heavy vehicle volume collected by VDs, two types of encoding scheme of the day of the week, and two types of historical travel time collected by ETC. The average values of performance measures of Experiments 5.1 and 5.2 are summarized in Table 15. From this table, it can be seen the model of Experiment 5.1 performs worse than that of Experiment 5.2 in terms of all average values of performance measures and the model of Experiment 5.1 generates higher variances of performance measures. In addition, from the results of t test shown in Table 16, except RMSE, the performance measures of using the time variable and not using the time variable as the input variable are significantly different. Therefore, using the time variable as the input variable can improve the capability of travel time prediction by applying MLP.
5.3 Discussion
The experimental results indicate that the model including the historical travel time collected by ETC as the input variable has a better capability of travel time prediction. The traffic characteristic represented by the historical travel time collected by ETC is more comprehensive, which is different to the traffic characteristic of an individual point collected by VDs. Therefore, the historical travel time collected by ETC can help reflect the overall traffic on the freeway segment, and build a more stable prediction model of travel time.
Moreover, although the heavy vehicle volume is an important factor affecting the traffic characteristics, misjudgment of vehicle type is unavoidable by using inductance loop detectors. As vehicle flow is often in platoon, misjudgment of vehicle type has less impact on the computation of average vehicle speed. Due to the above reasons, the error of statistics of vehicle type is larger than that of speed. It results in the inability to improve the explanatory power of traffic characteristic when using the heavy vehicle volume as the input variable, and thus the capability of prediction model is reduced.
In general, the analysis of traffic characteristic is categorized into weekday and weekend since the traffic characteristics of weekday and weekend are regarded as homogeneous, respectively. Such categorization is not applicable in the freeway segment in this study. This freeway segment has the more complex distribution of trip purpose affected by the complicated economic factors. It is also the reason why the traffic characteristics of weekday and weekend are heterogeneous, respectively.
DeTienne et al. [48] and Karlaftis et al. [49] pointed out that neural networks can deal with the multicollinearity issue better than statistical methods. Furthermore, neural networks tend to select one of the variables with multicollinearity, and assign a larger weight to it in the learning process. Therefore, adding variables with multicollinearity as input variables of neural networks cannot improve the accuracy of travel time prediction. In addition, if increase in variables exceeds the learning capability of neural networks, the capability of prediction model will be reduced. The learning characteristic of neural networks is reflected by the results of seven experimental combinations based on the cumulative rainfall variables.
6 Conclusions
This study investigates the impact of variables including rainfall, speed and heavy vehicle volume collected by VDs, encoding scheme of the day of the week, historical travel time collected by ETC, and time (AM or PM) on the prediction model of travel time for the freeway with non-recurrent congestion. From the experimental results, selecting only the 5-min cumulative rainfall from rainfall variable as the input variable can reduce the number of input variables and percentage of samples of “inaccurate forecasting” (the percentage of MAPE > 50 %), while keeping lower MAPE and RMSE, and thus build a robust prediction model. As far as the input variables collected by VDs are concerned, using the heavy vehicle volume as the input variable cannot improve the capability of prediction model. Using only speed as the input variable can reduce RMSE and MAPE, and adding the speed of one more VD as the input variable, the percentages of samples of “reasonable forecasting” and “inaccurate forecasting,” and MAPE can be reduced. For the encoding scheme of the day of the week, if the traffic characteristics of all days of the week are regarded as heterogeneous, and they are encoded as 1–7, RMSE and MAPE are lower. Categorizing into weekday and weekend in the encoding scheme of the day of the week is not applicable in the freeway segment in this study. The prediction model with the historical travel time collected by ETC is stable and highly accurate. Finally, taking the time (AM or PM) as the input variable can improve the capability of prediction model. According to the above discussions, the prediction model of travel time for the freeway with non-recurrent congestion including input variables of historical travel time collected by ETC, speed variables collected by 11 VDs, the days of the week encoded as 1–7, 5-min. cumulative rainfall, and time encoded as AM or PM is a robust one. Its MAPE is 6.47 %, being a highly accurate forecasting model. The parameter setting of this result (i.e., MAPE = 6.47 %) is summarized in Table 1, and the number of hidden nodes is 2.
As mentioned in Sect. 3.3, the missing data of Taiwan’s ETC system may occur at a particular Time t due to three reasons. For the second reason, the non-continuous trips are identified when the travel time at Time t is higher than that at Time t – 1 over 40 %. In such a situation, there are no data sample at Time t. This situation describes the application scope of the proposed model. However, the probability of such a situation is very low.
As we know, the data imputation method is an important factor affecting the capability of prediction model. Although the data imputation method used in this study can generate accurate prediction results, the imputation methods of data of speed and heavy vehicle volume can be further developed in the future. Next, the distance of shock wave is an important measure to analyze the impact of events or road bottlenecks on traffic. Whether the explanatory power of queuing length calculated by shock wave theory for non-recurrent congestion can improve the performance of travel time prediction is an issue worth to be addressed in the future. Furthermore, as the accuracy of travel time prediction directly affects the feelings of road users, MAPE should be as low as possible. However, more importantly, to lower road users’ untrustworthiness on information of travel time prediction, future work can try to reduce percentages of samples of “inaccurate forecasting” and “reasonable forecasting” to enhance road users’ acceptance and trust on the travel time prediction.
References
Lam WHK, Chan KS, Tam ML, Shi JWZ (2005) Short-term travel time forecasts for transport information system in Hong Kong. J Adv Transp 39(3):289–306
Chin SM, Franzese O, Greene DL, Hwang HL, Gibson RC (2004) Temporary loss of freeway capacity and impacts on performance: phase 2. Report No. ORLNL/TM-2004/209, Oak Ridge National Laboratory
Skabardonis A, Varaiya P, Petty KF (2003) Measuring recurrent and nonrecurrent traffic congestion. Transp Res Record 1856:118–124
Chang LY (2005) Analysis of freeway accident frequencies: negative binomial regression versus artificial neural network. Saf Sci 43(8):541–557
Santosh TV, Srivastava A, Sanyasi Rao VVS, Ghosh AK, Kushwaha HS (2009) Diagnostic system for identification of accident scenarios in nuclear power plants using artificial neural networks. Reliab Eng Syst Saf 94(3):759–762
Gevrey M, Dimopoulos I, Lek S (2003) Review and comparison of methods to study the contribution of variables in Artificial Neural Network models. Ecol Model 160(3):249–264
Chung Y (2010) Development of an accident duration prediction model on the Korean Freeway Systems. Accid Anal Prev 42(1):282–289
Wei CH, Lee Y (2007) Sequential forecast of incident duration using Artificial Neural Network models. Accid Anal Prev 39(4):944–954
Hall RW (2002) Incident dispatching, clearance and delay. Transp Res Part A Policy Pract 36(1):1–16
Chien SIJ, Kuchipudi CM (2003) Dynamic travel time prediction with real-time and historic data. J Transp Eng 129(6):608–616
Stathopoulos A, Karlaftis MG (2003) A multivariate state space approach for urban traffic flow modeling and prediction. Transp Res Part C Emerg Technol 11(2):121–135
Zhong M, Sharma S, Lingras P (2005) Refining genetically designed models for improved traffic prediction on rural roads. Transp Plan Technol 28(3):213–236
Hamed MS, Cook AR (1979) Analysis of freeway traffic time-series data by using Box–Jenkins techniques. Transp Res Record 722:1–9
Hamed MM, Al-Masaeid HR, Said ZM (1995) Short-term prediction of traffic volume in urban arterials. J Transp Eng 121(3):249–254
Der Voort MV, Dougherty M, Watson S (1996) Combining Kohonen maps with ARIMA time series models to forecast traffic flow. Transp Res Part C Emerg Technol 4(5):307–318
Park B, Messer CJ, Urbanik TII (1998) Short-term traffic volume forecasting using radial basis function neural network. Transp Res Record 1651:39–47
Lee S, Fambro D (1999) Application of subset autoregressive integrated moving average model for short-term freeway traffic volume forecasting. Transp Res Record 1678:179–188
Castro-Neto M, Jeong Y-S, Jeong M-K, Han LD (2009) Online-SVR for short-term traffic flow prediction under typical and atypical traffic conditions. Expert Syst Appl 36(3, Part 2):6164–6173
Wu CH, Wei CC, Su DC, Chan MH, Ho JM (2004) Travel time prediction with support vector regression. IEEE Trans Intell Transp Syst 5(4):276–281
Nihan NL, Holmesland KO (1980) Use of the box and Jenkins time series technique in traffic forecasting. Transportation 9(2):125–143
Yeon J, Elefteriadou L, Lawphongpanich S (2008) Travel time estimation on a freeway using Discrete Time Markov Chains. Transp Res Part B Methodol 42(4):325–338
Park D, Rilett L, Han G (1999) Spectral basis neural networks for realtime travel time forecasting. J Transp Eng 125(6):515–523
Van Lint JWC, Hoogendoorn SP, Van Zuylen HJ (2005) Accurate freeway travel time prediction with state-space neural networks under missing data. Transp Res Part C Emerg Technol 13(5–6):347–369
Innamaa S (2005) Short-term prediction of travel time using neural networks on an interurban freeway. Transportation 32(6):649–669
Zhang X, Rice JA (2003) Short-term travel time prediction. Transp Res Part C Emerg Technol 11(3–4):187–210
Van Lint JWC (2008) Online learning solutions for freeway travel time prediction. Trans Intell Transp Syst 9(1):38–47
Fei X, Lu CC, Liu K (2011) A Bayesian dynamic linear model approach for real-time short term freeway travel time prediction. Transp Res Part C Emerg Technol 19(6):1306–1318
Ishak S, Kotha P, Alecsandru C (2003) Optimization of dynamic neural network performance for short-term traffic prediction. Transp Res Record 1836:45–56
Ishak S, Alecsandru C (2004) Optimizing traffic prediction performance of neural networks under various topological input, and traffic condition settings. J Transp Eng 130(4):452–465
Xiao H, Sun H, Ran B, Oh Y (2004) Special factor adjustment model using fuzzy-neural network in traffic prediction. Transp Res Record 1879:17–23
Vanajakshi L, Rilett LR (2004) A comparison of the performance of artificial neural networks and support vector machines for the prediction of traffic speed. 2004 IEEE Intell Veh Symp 194–199
Dia H (2001) An object-oriented neural network approach to short-term traffic forecasting. Eur J Oper Res 131(2):253–261
Najah A, El-Shafie A, Karim OA, El-Shafie AH (2012) Application of artificial neural networks for water quality prediction. Neural Comput Appl. doi:10.1007/s00521-012-0940-3
Reza Peyghami M, Khanduzi R (2012) Predictability and forecasting automotive price based on a hybrid train algorithm of MLP neural network. Neural Comput Appl 21(1):125–132
Yuan F, Cheu RL (2003) Incident detection using support vector machines. Transp Res Part C Emerg Technol 11(3–4):309–328
Chang LY, Chen WC (2005) Data mining of tree-based models to analyze freeway accident frequency. J Saf Res 36(4):365–375
Dion F, Rakha H (2006) Estimating dynamic roadway travel times using automatic vehicle identification data for low sampling rates. Transp Res Part B Methodol 40(9):745–766
Tam ML, Lam William HK (2010) Application of automatic vehicle identification technology for real-time journey time estimation. Information Fusion 12(1):11–19
Liu Henry X, Ma W (2009) A virtual vehicle probe model for time-dependent travel time estimation on signalized arterials. Transp Res Part C Emerg Technol 17(1):11–26
Sw R (1998) Automatic vehicle identification model deployment initiative—system design document. Report prepared for TransGuide. Texas Department of Transportation, Southwest Research Institute, San Antonio
Mouskos KC, Niver E, Pignataro LJ, Lee S (1998) Transmit system evaluation. Final Report. Institute for Transportation. New Jersey Institute of Technology, Newark, NJ
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning internal representation by error propagation. In: Rumelhart DE, McClelland JL, PDP Research Group (eds) Parallel distributed processing: explorations in the microstructure of cognition: foundations, vol 1. MIT Press, Cambridge, pp 318–362
Vellido A, Lisboa PJG, Vaughan J (1999) Neural networks in business a survey of applications (1992–1998). Expert Syst Appl 17(1):51–70
Kumar S (2005) Neural networks: a classroom approach. McGraw-Hill, New York
Konstantopoulos P, Chapman P, Crundall D (2010) Driver’s visual attention as a function of driving experience and visibility. Using a driving simulator to explore drivers’ eye movements in day, night and rain driving. Accid Anal Prev 42(3):827–834
Mazloumi E, Rose G, Currie G, Moridpour S (2011) Prediction intervals to account for uncertainties in neural network predictions: methodology and application in bus travel time prediction. Eng Appl Artif Intell 24(3):534–542
Lewis CD (1982) International and business forecasting methods. Butterworths, London
DeTienne KB, Detienne DH, Joshi SA (2003) Neural networks as statistical tools for business researchers. Organ Res Methods 6(2):236–265
Karlaftis MG, Vlahogianni EI (2011) Statistical methods versus neural networks in transportation research: differences, similarities and some insights. Transp Res Part C Emerg Technol 19(3):387–399
Acknowledgments
This work is partially supported by National Science Council, Taiwan, R.O.C. under grant NSC 100-2410-H-009-013-MY3.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Li, CS., Chen, MC. Identifying important variables for predicting travel time of freeway with non-recurrent congestion with neural networks. Neural Comput & Applic 23, 1611–1629 (2013). https://doi.org/10.1007/s00521-012-1114-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-012-1114-z