
Abstract
This paper proposes a new blind watermarking algorithm, which embedding the binary watermark into the blue component of a RGB image in the spatial domain, to resolve the problem of protecting copyright. For embedding watermark, the generation principle and distribution features of direct current (DC) coefficient are used to directly modify the pixel values in the spatial domain, and then four different sub-watermarks are embedded into the different areas of the host image for four times, respectively. When watermark extraction, the sub-watermark is extracted with blind manner according to DC coefficients of watermarked image and the key-based quantization step, and then the statistical rule and the method of “first to select, second to combine” are proposed to form the final watermark. Hence, the proposed algorithm is executed in the spatial domain rather than in discrete cosine transform (DCT) domain, which not only has simple and quick performance of the spatial domain but also has high robustness feature of DCT domain. The experimental results show that the proposed watermarking algorithm can obtain better invisibility of watermark and stronger robustness for common attacks, e.g., JPEG compression, cropping, and adding noise. Comparison results also show the advantages of the proposed method.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development of Internet and networked multimedia, illegal copying, tampering, and modifying of digital copyright have been becoming one more and more urgent problem and many techniques about information safety have been proposed to process these issues (Li et al. 2015; Zheng et al. 2015; Su et al. 2014; Ma et al. 2015; Xia et al. 2014; Fu et al. 2016; Guo et al. 2014). Digital watermarking emerged as a tool for protecting the multimedia data from copyright infringement. The feature of digital watermarking is to allow for imperceptibly embedding watermark information in the original multimedia data (Seitz 2005; Cox et al. 2007). For a digital watermark to be effective, it should at least exhibit the following characteristics:
-
(1)
Imperceptibility. The watermark should be invisible in a watermarked image/video or inaudible in watermarked digital music. Embedding this extra data must not degrade human perception about the object. Evaluation of imperceptibility is usually based on an objective measure of quality, called peak signal-to-noise ratio (PSNR) or a subjective test with specified procedures.
-
(2)
Robustness. The embedded watermarks should not be removed or eliminated by unauthorized distributors using common processing techniques, including compression, filtering, cropping, and quantization.
-
(3)
Security. The watermarking procedure should rely on secret keys to ensure security, so that pirates cannot detect or remove watermarks by statistical analysis from a set of images or multimedia files. An unauthorized user, who may even know the exact watermarking algorithm, cannot detect the presence of hidden data, unless he/she has access to the secret keys that control this data embedding procedure.
-
(4)
Real-time processing. Watermarks should be rapidly embedded into the host signals without much delay.
Along with the rapid development of computer technique, digital watermarking has recently received an increasing attention in many application fields such as image, video, audio, text, and software. By embedding information into digital signals, digital watermarking can attain higher imperceptibility and robustness. Since the inception of digital watermarking around the early 1990s, there have been a variety of methods proposed in the literature, and there are many ways to classify them. For example, they can be classified according to the application, source type (image watermarks, video watermarks, audio watermarks, text watermarks), human perception, and technique used. As watermarks can be applied in the spatial or frequency domain, different concepts, such as discrete Fourier (DFT), discrete cosine (DCT), and wavelet transformation, or additionally, manipulations in the color domain and noise adding can be mentioned. Furthermore, digital watermarks can be subdivided on the basis of human perception. Digital watermarks can be invisible or visible. We see visible watermarks every day watching television, that is, TV station logos. They can be subdivided into blind and non-blind detection techniques, which are strongly related to the decoding process. At least, digital watermarks can be robust against operations or even fragile for use in copy control or authenticity applications (Seitz 2005). In which, robust watermarking techniques are developed to resist any kind of attack, modification or tampering of the cover data by an adversary. Robust watermarking algorithms are designed to achieve the maximum possible robustness against any intentional or unintentional modification of the watermarked data. On the contrary, fragile watermarking is mainly used for content authentication of multimedia data. In fragile watermarking algorithms, the watermark is generally a secure keyed hash of the entire cover signal. Even a minimal modification of the cover multimedia data (e.g., a single bit in the extreme case) by an adversary destroys a fragile watermark, and consequently causes authentication failure at the receiver side. In other words, a fragile watermark is desirably destroyed and is rendered undetectable, even in the case of minimal modification of the watermarked cover data (Cox et al. 2007).
According to the processing domain of the host image, these existing techniques of image watermarking may be divided into two categories: spatial domain watermarking (Nasir et al. 2010; Arcangelo et al. 2015; Coltuc and Chassery 2007; Pizzolante et al. 2014; Rigoni et al. 2016) and frequency domain watermarking (Zheng and Feng 2008; de Queiroz and Braun 2006; Su et al. 2013; Das et al. 2014; Zeng and Qiu 2008; Kalra et al. 2015).
The main feature of the spatial domain watermarking is to embed the watermark into the host image by directly modifying a selected set of pixel values in the host image. Usually, the watermark is embedded into the least significant bit planes of the original image to obtain the resultant watermarked image. Any change in watermarked image will change bits of least significant bit (LSB) of watermarked image. In Nasir et al. (2010), a novel digital watermarking technique for the copyright protection of digital color images was proposed, in which four similar watermarks were directly combined after extracting the sub-watermarks, then the final watermark was selected from four similar watermarks according to correlation coefficient (CC), that is, the original watermark was required. Thus, method of Nasir et al. (2010) was a non-blind watermarking scheme. Seriously, the true state of extracted sub-watermark was not reflected by its final watermark since using the method that “first to combine sub-watermark to 4 whole watermarks, then select the optimum final watermark from the whole watermarks.” One of the contributions of Arcangelo et al. (2015) is an engine for lossless dynamic and adaptive compression of 3D medical images, which also allows the embedding of security watermarks within them was proposed, and the compression engine is based on a predictive technique for what concerns the 3D image compression part and on the LSB technique for that relating the digital watermarking. A spatial domain reversible watermarking scheme that achieves high-capacity data embedding without any additional data compression stage was proposed in Coltuc and Chassery (2007). Pizzolante et al. (2014) proposed a novel scheme which is able to embed two watermarks into a confocal 3-D microscopy image. Rigoni et al. (2016) presented a framework for detecting tampered information in digital audiovisual content, in which the proposed framework uses a combination of temporal and spatial watermarks that do not decrease the quality of host videos, and a modified version of the quantization index modulation (QIM) algorithm is used to embed watermarks. The fragility of the QIM watermarking algorithm makes it possible to detect local, global, and temporal tampering attacks with pixel granularity (Rigoni et al. 2016; Chen and Wornell 2001).
For increasing the robustness of spatial domain-based watermarking techniques, various methods have been proposed in recent years (Zheng and Feng 2008; de Queiroz and Braun 2006; Su et al. 2013; Das et al. 2014; Zeng and Qiu 2008; Kalra et al. 2015). Frequency domain watermarking is nonlinear and confidently deals with the frequency components of the image. At present, some watermarking based on discrete cosine transform (DCT), discrete Fourier transform (DFT), and discrete wavelet transform (DWT) are well-known transform domain watermarking. The frequency domain watermarking has strong robustness and can resist many geometric attacks such as rotation, scaling, and cropping attack. For example, in Zheng and Feng (2008), a multi-channel DWT domain image watermarking was proposed to against geometric attacks and experimental results show that the proposed method is fairly resistant against the lossy compression attack and has a good trade-off between robustness and computational complexity. In de Queiroz and Braun (2006), a reversible method to convert color graphics and pictures to gray images based on watermarking that using one level of the DWT, which provides a high-capacity embedding watermarking scheme and better invisibility.
Das et al. (2014) presented a novel blind watermarking algorithm in DCT domain using the correlation between two DCT coefficients of adjacent blocks in the same position. Zeng and Qiu (2008) considered direct current (DC) coefficient to trade-off the robustness and the invisibility and proposed a blind watermarking scheme with quantization index modulation (QIM) technology, in which the DC coefficient was obtained after the 2-DCT was performed independently for every block of the image. Kalra et al. (2015) proposed an adaptive digital image watermarking for color images in frequency domain which utilizes the advantages of DCT, DWT, Arnold transform, Chaos and Hamming as ECC. In the methods of Das et al. (2014), Zeng and Qiu (2008), Kalra et al. (2015), 2-DCT was performed independently for every block of the image and inverse 2-DCT was applied to the modified DCT coefficients of each embedding block to rebuild the watermarked image when embedding the watermark. Moreover, 2-DCT was also performed independently for every block of the watermarked image when extracting the watermark. Although more information for embedding and better robustness against the common attacks can be achieved through frequency domain method, the computational cost is higher than that of spatial domain. Embedding the watermark into the component of the original image in spatial domain is a straightforward method which has the advantages of low computational complexity (Su et al. 2013).
Motivated by the above-mentioned discussions, combining these advantages of the frequency domain and spatial domain, a blind watermarking algorithm is proposed in this paper, which using the DC coefficient that directly obtained in spatial domain instead of DCT transform to extract the embedded watermark in the spatial domain based on the statistical rule and the method that “first to select the optimum sub-watermark from 4 sub-watermarks, then combine the optimum sub-watermarks to the final watermark,” i.e., “first to select, second to combine,” which is different from the method of Nasir et al. (2010). Experimental results prove that the proposed method not only can resolve the non-blind extraction problem, but also can embed and extract watermark in the spatial domain instead of the DCT domain.
The rest of this paper is organized as follows. Section 2 introduces the technique of modifying DC coefficients in spatial domain. Section 3 gives the procedures of the watermark embedding and extraction. The experimental results prove the performance of the proposed method in Sect. 4. Finally, Sect. 5 concludes this paper.
2 The technique of modifying DC coefficients in spatial domain
2.1 The important feature of DC coefficient
DCT is a kind of transform domain methods in the field of real number, whose transform kernel is the cosine function. An image can be transformed from the spatial domain to DCT domain by 2-D DCT, and the image can also be restored from DCT domain to the spatial domain via 2-D inverse DCT.
For a \(M\times N\) image \(f(x,y)\,(x=0,1,2,\ldots ,M-1, y=0,1,2,\ldots ,N-1)\), 2-D DCT is given as follows:
where M and N are the row and the column size of f(x, y), u and v are the horizontal and the vertical frequency \((u=0, 1, 2, \ldots , M-1, v=0, 1, 2,\ldots , N-1)\), and C(u, v) is DCT coefficient of image f(x, y).
DCT coefficients of an image include one DC coefficient and some alternating current (AC) coefficients with different frequencies. From Eq. (1), DC coefficient can be obtained by
As can be seen from Eq. (3), DC coefficient can be directly obtained in spatial domain without DCT transform.
2.2 Modifying DC coefficients in the spatial domain rather than in DCT domain
As is mentioned above, DC coefficient can be directly obtained in the spatial domain. When DC coefficient of the image block has been changed in the DCT domain, the value of each pixel in the spatial domain will be changed after inverse DCT, that is, the modified quantity of each pixel of the image block is decided by the changed quantity of DC coefficient. Now, the key problem is how to determine the modified quantity of each pixel in the spatial domain according to the changed quantity of DC coefficient in DCT domain.
According to DCT principle, the inverse DCT of the image f(x, y) is described as following.
The inverse DCT in Eq. (4) can be rewritten by
where \(\hbox {AC}(x,y)\) is the reconstructed image from the set of AC coefficients.
Suppose the host image is represented by
where M, N are the row and the column size of the host image, the host image is divided into \(i\times j\) non-overlapped blocks with \(b\times b\) pixels. The indexes of each block are represented by (i, j), and (m, n) is the pixel position in each block.
When embedding watermark W into DC coefficient of the (i, j)-th block, the modified quantity of DC coefficient is denoted as \(\Delta M_{i,j}\). According to Eq. (3), the traditional process of embedding the watermark into DC coefficient of the (i, j)-th non-overlapped \(b\times b\) block is given by
where \(\hbox {DC}_{i,j} \) is DC coefficient of the (i, j)-th block, \(\hbox {DC}_{i,j}^{\prime } \) is the modified DC coefficient with increment \(\Delta M_{i,j} \).
According to Eq. (5), the recovered image block \(f_{i,j}^{\prime } (m,n)\) can be described as follows.
Using Eqs. (6) and (7), (8) can be rewritten as
where \(\hbox {PM}_{i,j} \) denotes the modified quantity of each pixel in the spatial domain, and it is defined by
In Eq. (9), it is shown that for the host image f(x, y), the procedure of embedding watermark into DC coefficients in DCT domain can also be performed directly in the spatial domain rather than in DCT domain.
3 The proposed watermarking scheme
In this paper, a new blind digital image watermarking algorithm is proposed by combining spatial domain with frequency domain. Firstly, the original binary watermark is divided into four sub-watermarks, and the blue component of the color host image is also divided into 16 sub-images. When embedding the watermark, the distribution features and quantization table of DC coefficients are used and the pixel values are directly modified in the spatial domain, which means DC coefficients in DCT domain are modified indirectly. All of the four sub-watermarks can be repeatedly embedded into the 16 sub-images for 4 times based on the security key Key1, which can effectively improve the security and robustness of watermark. Moreover, the key-based quantization step will be utilized to extract the watermark with blind manner.
3.1 Watermark preprocessing
The preprocessing of watermark is one of the key steps in the watermarking algorithm, and it will directly influence the robustness and security of watermark, which includes the following two steps.
Firstly, the \(32\times 32\) original watermark is divided into four sub-watermarks \(W_{i}\) with size \(32\times 8 (1\le i\le 4)\), which will decrease the probability of whole watermark be attacked and enhance the robustness of watermark.
Secondly, the key-based Hash pseudo-random permutation algorithm based on MD5 is utilized to permute the sub-watermarks with different keys \(\hbox {K}_{i}\, (1\le i\le 4)\).
It should be pointed out that, in the proposed method, MD5 is applied to the specific Hash function (Rivest April 1992), which makes it difficult for the third party to extract the watermark integrally without the keys. Hence, this proposed algorithm is of higher security. The permuting process of the original binary watermark W is shown in Fig. 1.

The permuting process of original watermark: (a) original watermark, (b) sub-watermark blocks and (c) permuted sub-watermark blocks
3.2 Watermark embedding scheme
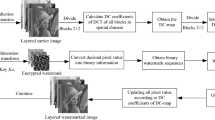
Because, the sensors in the human eye are called as cones which are responsible for color vision. The cones could be separated into three major sensing categories as red, green and blue. Nearly 65% of the cones are sensitive to red color, 33% are sensitive to green color and just 2% are sensitive to blue color (Vaishnavi and Subashini 2015). That is, the human visual system is much less sensitive to blue colors than to others (Kutter and Winkler 2002). Hence, the permuted watermark is embedded into the blue component of the host image in this paper. Firstly, the blue component of the host image is firstly divided into many sub-images and each host sub-image is further divided into sub-blocks with \(8\times 8\) pixels, and DC coefficient of each sub-block is calculated. Then, the modified quantity of DC coefficient is decided according to the watermark information and DC coefficient of the present sub-block. Finally, one watermark bit is embedded into one pixel block by modifying the pixel value via Eq. (9). The proposed embedding watermark process is shown in Fig. 2, and the detail steps of embedding watermark are given as follows.

The diagram of embedding watermark process
Step 1 Obtain sub-image of the blue component.
In order to improve the robustness of watermarking, the \(512\times 512\) blue component of the original host image I is divided into 16 sub-images \(I_{s }(1\le s\le 16)\) with size \(128\times 128\) pixels based on the security key Key1
Step 2 Obtain embedding block.
Each sub-image is divided into 256 non-overlapped embedding blocks with \(8\times 8\) pixels. Thus, the whole host image can be divided into 4096 non-overlapped embedding blocks.
Step 3 Obtain DC coefficients in the spatial domain.
The DC coefficient of embedding block is further calculated according to Eq. (3).
Step 4 Create the quantization table \(\hbox {QA}(k)\) and \(\hbox {QB}(k)\), which are created by the quantification step \(\Delta \) based on the secret key Key2.
where \(1\le k\le \hbox {round} ((\hbox {max}(C_{i,j}(0,0))+2\Delta )/(2\Delta ))-\hbox {round}((\hbox {min}(C_{i,j}(0,0))-2\Delta )/(2\Delta )))\), \(\hbox {min}(.)\) and \(\hbox {max}(.)\) denote the minimum and the maximum of the DC coefficient of all embedding non-overlapped blocks with \(8\times 8\) pixels in the host image, respectively, \(i (1\le i\le 64)\) is the horizontal position of non-overlapped embedding block in the host image, \(j (1\le j\le 64)\) is the vertical position of non-overlapped embedding block in the host image, and \(\hbox {round}(.)\) is the integral function.
Step 5 Calculate the modified DC coefficient \(\hbox {DC}_{i,j}^{\prime }\).
The modified value \(\hbox {DC}_{i,j}^{\prime }\) of the DC coefficient is calculated by
where \(\hbox {abs}(.)\) is the absolution function.
Step 6 Calculate the modified quantity of each DC coefficient.
The modified quantity \(\Delta M_{i,j}\) of each DC coefficient can be calculated by Eq. (14).
Step 7 Embedding watermark.
By using Eqs. (9) and (10), the pixel value can be modified by \(\Delta M_{i,j}\) in the spatial domain rather than in DCT domain, that is, one binary watermark bit is embedded into one embedding block. In this procedure, the modified quantity is between 0 and 2.5, which will enhance the invisibility of watermark.
By repeating the procedures of Steps 3–7, each sub-watermark \(W_{i }(1\le i\le 4)\) can be embedded into four different positions according to the order number in Fig. 3. Thus, each sub-watermark is embedded into the host image for four times and the watermarked image \(I^{{\prime }}\).

The embedded positions of sub-watermarks
3.3 Watermark extraction scheme
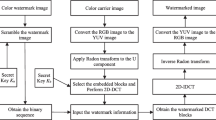
When extracting the watermark, the quantization step is used to directly extract watermark from DC coefficients without the original host image and original watermark. Firstly, the four sub-watermarks of each sub-image are extracted. Then, the optimum sub-watermark is obtained by the statistics-based optimum. Finally, these optimum sub-watermarks are combined to attain the whole watermark. The proposed embedding watermark process is shown in Fig. 4, the detailed steps are listed as follows.

The diagram of extracting watermark process
Step 1 Obtaining DC coefficients in the spatial domain.
The watermarked image is processed by using the similar operation of Steps 1–2 in Sect. 3.2, and DC coefficient \(\hbox {DC}_{i,j}^{\prime }\) of each embedded block is obtained by Eq. (3).

Original host images: a Lena, b Baboon, c Avion, and d Peppers
Step 2 Extracting the sub-watermarks.
According to Eq. (15), the quantization step \(\Delta \) based on key Key2 is used to extract the watermark \(W_{i,j}^{\prime }\) in \(\hbox {DC}_{i,j}^{\prime } \), until all sub-watermarks are extracted.
where \(W_{i,j}^{\prime }\) presents the extracted watermark from the (i, j)-th embedding block, and \(\hbox {mod}(.)\) is modulo operation.
Step 3 Getting the optimum sub-watermark.
Because each sub-watermark is repeatedly embedded for 4 times, 4 similar or identical watermarks of the same sub-watermark can be extraction. Hence, the optimum sub-watermark \(W*(m, n)\,(1\le m\le 32, 1\le n\le 8)\) of each sub-watermark can be statistically computed by Eq. (16).
where W(m, n) is the watermark bit in the coordinate (m, n) of four sub-watermarks, and \(\hbox {sum}(.)\) is the sum function.
Step 4 Obtaining the final watermark.
By using the secret key \(\hbox {K}_{i }(1\le i\le 4)\), Hash inverse permutation is performed on the 4 optimum sub-watermarks, respectively. Then, these permuted sub-watermarks are combined to obtain the whole extracted watermark image \(W^{\prime }\).
In summary, the proposed method firstly selects the optimum sub-watermark of each part via the statistic feature of the extracted 4 sub-watermarks, and then combines the selected optimum sub-watermarks to form the final watermark. Hence, this proposed method, i.e., “first to select the optimum sub-watermark from 4 sub-watermarks, then combine the optimum sub-watermarks to the final watermark,” not only extract the optimum watermark to improve the watermark robustness, but also can achieve the purpose of blind extraction.
4 Experimental results and discussion
In this paper, the binary image of size \(32\times 32\) is used as original watermark, as shown in Fig. 1a, and all 24-bit \(512\times 512\) color images in the CVG-UGR image database are used as the host images (University of Granada 2012). For limitation space of the paper, only four 24-bits color images, as shown in Fig. 5, are taken for example. By considering the trade-off between the robustness and the invisibility of the watermark, let quantization step \(\Delta =20\).
For evaluating the performance of the proposed method, the original color image I is re-arranged to two-dimensional host image H by the order of R, G and B component, and the watermarked image \(I^{{\prime }}\) is also re-arranged to two-dimensional watermarked image \(H^{{\prime }}\) by the order of R, G and B component. The peak signal-to-noise ratio (PSNR) in Eq. (17) is utilized to measure the similarity degree between the two-dimensional image H and the watermarked two-dimensional image \(H^{{\prime }}\)
where H(x, y), \(H^{\prime } (x,y)\) present the value of pixel (x, y) in the two-dimensional host image and the watermarked one, and M, N denote its width and height, respectively.
Moreover, structural similarity (SSIM) index measurement developed by Wang et al. (2004) was considered to be correlated with the quality perception of the human visual system (HVS). The SSIM is designed by modeling image distortion that combines three factors: loss of correlation, luminance distortion and contrast distortion, and it is defined as:
where
The first term in Eq. (19) measures the closeness of the two images’ mean luminance \((\mu _H \) and \(\mu _{H^{{\prime }}})\). The second term measures the closeness of the contrast of the two images, and the contrast is measured by the standard deviation \(\sigma _H\) and \(\sigma _{H^{{\prime }}}\). The third term is the structure comparison function which measures the correlation coefficient between the two images H and \(H^{{\prime }}\). Note that \(\sigma _{{ HH}^{{\prime }}} \) is the covariance between H and \(H^{{\prime }}\). The positive constants \(C_1\), \(C_2\) and \(C_3\) are used to avoid a null denominator. The positive values of the SSIM index are in [0, 1].
In addition, in order to measure the robustness of the watermark, we use the normalized correlation (NC) between the original watermark W and the extracted watermark \(W^{{\prime }}\), which is shown as follows.
where P and Q denote the row and the column size of the original watermark image, and (x, y) is the pixel position of watermark image.
4.1 Testing the watermark invisibility
Generally, a larger PSNR or SSIM indicates that the watermarked image resembles the original host image more closely, which means that the watermarking method makes the watermark more imperceptible. A higher NC reveals that the extracted watermark resembles the original watermark more closely. If a method has a higher NC value, it is more robust.
Table 1 shows the comparison results of watermark invisibility between the proposed method, methods of Das et al. (2014) and Kalra et al. (2015). It can be seen from Table 1, all embedded watermarks can be completely extracted from the watermarked images without any attacks (all NC values are 1), and the proposed algorithm has better invisibility (its PSNR values are more than 45 db and SSIM values are bigger than other methods). This is because the modified quantity of each pixel ranges from 0 to 2.5 according to the watermark bit and DC coefficient. Less modified amplitude will get a better invisibility and obtain bigger PSNR or SSIM values. Hence, the proposed method can obtain higher watermark invisibility than other methods.
4.2 Testing the watermark robustness
In practice, the watermarked image will be subjected to a variety of distortions before reaching the detector. Watermarks designed to survive legitimate and everyday usage of image, e.g., JPEG compression, adding noise and filtering, are referred to as robust watermark. To verify the watermark robustness of the proposed method, all watermarked images are attacked by common image processing operations (such as JPEG compression, adding Salt-and-Pepper noise, adding Gaussian noise, median filtering, and mosaic piecing attack) and geometrical distortions (such as scaling, rotation, affine transform, and cropping). At the same time, the proposed method is compared with methods of Das et al. (2014) and Kalra et al. (2015) in term of NC.
Lossy compression techniques are commonly used to encode color image for efficient storage and communication. The watermark robustness against the attack of lossy compression is an important performance to be evaluated. In this simulation, JPEG compression is employed to attack the watermarked image. It is shown in Table 2 that the original watermark can be extracted from all attacked images when compression factor is 70 by all compared method, which because the NC value is more than 0.75. Relatively, the method of Kalra et al. (2015) is the best method to resist the compression attack. The proposed method has better robust than method of Das et al. (2014) in most cases.
The watermarked image is easily and inevitably attacked by adding noise in the image transmission. Hence, adding noise is a classical attack and can affect the embedded watermark. Table 3 shows the results of the extracted watermark from the image attacked by adding Salt-and-Pepper noise with different noise intensities. It can be seen from it that the watermark still can be extracted normally when the noise intensity is 0.012 in the proposed method and method of Kalra et al. (2015), but the watermark can hardly be extracted when noise intensity is below 0.006 with method of Das et al. (2014). Relatively, the proposed algorithm has stronger robustness (NC value is bigger than 0.75) to resist noise adding attack than other methods of Das et al. (2014) and Kalra et al. (2015). Moreover, adding Gaussian noise is performed on the watermarked image. The watermarked images were tested against Gaussian noise with \(\hbox {mean}=0\) and different variance values from 0 to 0.15. Table 4 shows the comparison results of extracted watermark by different methods. Relatively, the proposed method and method of Kalra et al. (2015) have better robust than the method of Das et al. (2014).
Filtering attack is one of the classical attacks. Since the embedded watermark can be removed by the filter with different sizes, the median filtering and Butterworth low-pass filtering are used to attack the watermarked image. Table 5 gives the comparison results of extracted watermark from the watermarked image attacked by median filtering with different sizes. It is obvious that when the filter template size is odd, the watermark robustness is superior to that with the even size. In addition, Table 6 shows the comparison results of the extracted watermark from the watermarked image attacked by Butterworth low-pass filtering with cut-off frequency 50 Hz and different fuzzy radii N, which illustrates that the watermark can be extracted in the whole test range. However, it is difficult for method of Das et al. (2014) to extract the watermark information in the Baboon image (because NC value is smaller than 0.75). Hence, the algorithm in this paper has stronger robustness to resist median-filtering attack and Butterworth low-pass filtering attack than other methods of Das et al. (2014) and Kalra et al. (2015).
In the image processing, the image rotation is one of the geometric operation, which will lead to the change of image size and image pixel values. Hence, the embedded watermark will be affected by rotation operation. The watermarked image is rotated by \(30^{\circ }\), \(60^{\circ }\), \(90^{\circ }\), \(120^{\circ }\), \(180^{\circ }\) and \(270^{\circ }\) in clockwise direction, respectively, and the watermark is extracted by re-rotating the image in counter-clockwise direction. In the rotation process, the size of the watermarked image will be changed. For extracting watermark, the cropping and the scaling operations are also needed to make the size of the watermarked image be \(512\times 512\), that is, the combined attacks, e.g., rotation+cropping+scaling, are performed on the watermarked image. Table 7 gives the comparison result of the extracted watermark from the watermarked image attacked by rotation, and shows the robustness of the proposed algorithm is superior to other methods of Das et al. (2014) and Kalra et al. (2015).
The mosaic processing has very simple principle and can directly change the pixel values in the pixel template by average operation. Table 8 lists the comparison results of the extracted watermark from the watermarked image attacked by mosaic processing with different sizes, which shows the robustness that measured by NC value is decreasing with increasing the size of mosaic and the robustness in the proposed method is superior to those of Das et al. (2014) and Kalra et al. (2015).

The comparison of extracted watermark by different methods after cropping attacks: a cropped watermarked image, b extracted watermark from (a) by method of Das et al. (2014) (NC), c extracted watermark from (a) by method of Kalra et al. (2015) (NC), and d extracted watermark from (a) by the proposed method (NC)
The scaling operation includes scaling up and scaling down, in which the pixel values are modified by interpolation computing. Table 9 shows the comparison results of the extracted watermark from the watermarked image attacked by scaling with different ratios, which shows the robustness that measured by NC value is weaker when scaling down the watermarked image. Relatively, the proposed method has higher robust than those of Das et al. (2014) and Kalra et al. (2015). The reason can be explained as follows: in the scaling test, the watermarked image of size \(512\times 512\) is scaled up or down by the scaling ratio, and then resize the scaled image to the original size \(512\times 512\) for extracting watermark. When scaled up is performed, the interpolation is involved, and the watermarked image has little influence when resize to the original size. Hence, the robustness of scaling with ratio more than 1 is good, but it is bad when the scaling ratio is less than 1.
Obviously, the cropping attack can cut part of image pixel, which directly decides the quality of the extracted watermark. Figure 6 is the results of the extracted watermark from the watermarked Lena image attacked by cropping with different sizes in different positions, in which Fig. 6a is the cropped watermarked image, Fig. 6b–d shows the extracted watermarks and NC values by methods Das et al. (2014), Kalra et al. (2015) and the proposed one, respectively. By comparison, it is found the proposed method has strong robustness to resist cropping attack because of each sub-watermark is embedded for 4 times in different positions of the original host image.
In addition, various affine transform geometric attacks are performed on the watermarked image. Table 10 shows the results obtained by different methods, where Attack 1 denotes Resize 0.8 times at X direction, Attack 2 denotes Resize 1.2 times at X direction, Attack 3 denotes Resize 0.8 times at Y direction, Attack 4 denotes Resize 1.2 times at Y direction, Attack 5 denotes Line transform [1.013, 0.008; 0.011, 1.008], Attack 6 denotes Line transform [1.007, 0.010; 0.010, 1.012], Attack 7 denotes Removing row 17 column 5, and Attack 8 denotes Removing row 5 column 17. Because the proposed method selects the optimum sub-watermark from 4 sub-watermarks and combine the sub-watermarks to the final watermark, the final watermark will better than other methods.
It can be seen from the above comparison results that the proposed method has better robustness than other methods in most cases. The main feature in the proposed method is based on the idea “first to select the optimum sub-watermark from 4 sub-watermarks, then combine the sub-watermarks to the final watermark”, which is different with Nasir et al. (2010), i.e., “first to combine sub-watermark to 4 whole watermarks, then select the optimum final watermark from the whole watermarks.”

The extracted watermark with different wrong keys
4.3 The execution time comparison
In our experiments, a laptop computer with a duo Intel CPU at 2.007 GHZ, 4.00 GB RAM, Win 7, MATLAB 7.10.0 (R2010a) is used as the computing platform. As can be seen from the Table 11, the whole execution time of the proposed method is 5.9972 s with standard variation 0.0871 when the DC coefficient is directly obtained in the spatial domain, but the whole execution time is 6.9478 s with standard variation 0.0507 in Das et al. (2014), and 7.0928 s with standard variation 0.0661 in Kalra et al. (2015) which performed in DCT and DWT domain. Since 2-DCT and inverse 2-DCT were applied to the modified DCT coefficients of each embedding block to rebuild the watermarked image when embedding the watermark in Das et al. (2014), Kalra et al. (2015), and 2-DCT was also performed independently for every block of the watermarked image when extracting the watermark in Das et al. (2014), Kalra et al. (2015), which need more time than in the spatial domain. Moreover, 2-DWT is also used in Kalra et al. (2015). Hence, the proposed method has higher efficiency than (Das et al. 2014; Kalra et al. 2015).
4.4 The security analysis
In the proposed method, the security key Key1 is used to select the embedding position, the probability of locating all blocks is \(1/(16\times 4!)\); since the Hash pseudo-random algorithm based on MD5 with keys \(K_{i}\, (1\le i\le 4)\) is used to permute the sub-watermarks, and the key space of MD5 is 128 bits, the probability of restoring right state is \(1/2^{128}\times 1/2^{128}\times 1/2^{128}\times 1/2^{128}\); the key Key2 is used as the quantization step to determine the strength of embedding watermark and extracting watermark and its value is integer or float number between 0 and 255. When key Key2 is integer number, its probability of determining right number is \(1/255\approx 1/256\), the security of our algorithm only relies on the right private key Key1, Key2 and \(K_{i}\, (1\le i\le 4)\). Thus there requires a tremendous number of colluding attackers \((24\times 2^{524})\), and this implies the probability of extracting right watermark is very lower. When key Key2 is float number, the value of Key2 cannot be determined, the probability of extracting right watermark is near to 0.
As can be seen from Fig. 7, the right watermark cannot be extracted when either the secret Key1 is wrong, or the secret Key2 is wrong or the secret \(\hbox {K}i\) is wrong. If and only if all the three secret keys are right, the right watermark can be extracted and combined. Hence, the attacker can hardly extract the legal watermark image without any right keys, which enhance the security of watermarking.
4.5 The capacity analysis
In this paper, the capacity of watermark is also analyzed by the embedding rate. The embedding rate represented in bit per pixel (bpp) is the pure payload (i.e., the total amount of embedded bits minus that of all overhead information) (Wu and Huang 2012). Since the embedded watermark is \(32\times 32\) binary image and the host image is \(512\times 512\) color image in this paper, the capacity is \((32\times 32)/(512 \times 512 \times 3)=0.0013\hbox {(bpp)}\). The capacity of method of Das et al. (2014) is \((64\times 63) /(512\times 512)=0.0154\hbox {(bpp)}\), and the capacity of method of Kalra et al. (2015) is \((64\times 64) /(512\times 512)=0.0156\hbox {(bpp)}\). It is obviously that the proposed method has the lowest capacity, which because the \(8\times 8\) image block is only embedded one watermark information and all watermark information is repeat embedded into the host image for four times. Hence, we will consider how to improve the capacity of watermark when keeping the robustness and the invisibility.
In summary, the proposed method not only has higher watermark invisibility, but also has stronger robustness against the common image processing attacks and part of the geometric attacks. Moreover, the experimental results have proved the proposed method has higher efficiency and better security.
5 Conclusion
In this paper, we have proposed a blind watermarking based on DC coefficients in the spatial domain. When embedding watermark, the principle of DC coefficient modification in DCT domain is used to repeatedly embed watermark in the spatial domain for four times, which can improve the invisibility and the robustness of watermark. Moreover, in this method the sub-watermark is extracted by the extraction rules without the original host image or the original watermark. Moreover, the statistical rule and the idea of “first to select the optimum sub-watermark from four sub-watermarks, then combine the optimum sub-watermarks to the final watermark” are proposed to combine the sub-watermarks. Experimental results have shown that the proposed algorithm has strong robustness against common image processing and geometric attacks. In the further work, the color image will be viewed as original watermark.
References
Arcangelo Castiglione, Pizzolante R, De Santis A, Carpentieri B, Aniello Castiglione, Francesco Palmieri (2015) Cloud-based adaptive compression and secure management services for 3D healthcare data. Future Gener Comput Syst 43:120–134
Chen B, Wornell GW (2001) Quantization index modulation: a class of provably good methods for digital watermarking and information embedding. IEEE Trans Inf Theory 47(4):1423–1443
Coltuc D, Chassery JM (2007) Very fast watermarking by reversible contrast mapping. IEEE Signal Process Lett 14(4):255–258
Cox IJ, Miller ML, Bloom JA, Fridrich J, Kalker T (2007) Digital watermarking and steganography. Morgan Kaufmann, Los Altos
Das C, Panigrahi S, Sharma VK, Mahapatra KK (2014) A novel blind robust image watermarking in DCT domain using inter-block coefficient correlation. AEU-Int J Electron Commun 68(3):244–253
de Queiroz RL, Braun KM (2006) Color to gray and back: color embedding into textured gray images. IEEE Trans Image Process 15(6):1464–1470
Fu Z, Wu X, Guan C, Sun X, Ren K (2016) Towards efficient multi-keyword fuzzy search over encrypted outsourced data with accuracy improvement. IEEE Trans Inf Forensics Secur. doi:10.1109/TIFS.2016.2596138
Guo P, Wang J, Geng XH, Kim CS, Kim JU (2014) A variable threshold-value authentication architecture for wireless mesh networks. J Internet Technol 15(6):929–935
Kalra GS, Talwar R, Sadawarti H (2015) Adaptive digital image watermarking for color images in frequency domain. Multimed Tools Appl 74(17):6849–6869
Kutter M, Winkler S (2002) A vision-based masking model for spread-spectrum image watermarking. IEEE Trans Image Process 11(1):16–25
Li J, Li X, Yang B, Sun X (2015) Segmentation-based image copy-move forgery detection scheme. IEEE Trans Inf Forensics Secur 10(3):507–518
Ma T, Zhou J, Tang M, Tian Y, Abdullah AD, Mznah AR, Sungyoung L (2015) Social network and tag sources based augmenting collaborative recommender system. IEICE Trans Inf Syst 98(4):902–910
Nasir I, Weng Y, Jiang J, Ipson S (2010) Multiple spatial watermarking technique in color images. Signal Image Video Process 4(2):145–154
Pizzolante R, Castiglione A, Carpentieri B, De Santis A, Castiglione A (2014) Protection of microscopy images through digital watermarking techniques[C]. In: Intelligent Networking and Collaborative Systems (INCoS), 2014 International Conference on. IEEE, pp 65–72. doi:10.1109/INCoS.2014.116
Rigoni R, Freitas PG, Farias MCQ (2016) Detecting tampering in audio-visual content using QIM watermarking. Inf Sci 328:127–143
Rivest RL (1992) The MD5 message-digest algorithm. Request for comments (RFC) 1321, Internet activities board, Internet privacy task force. https://www.ietf.org/rfc/rfc1321.txt
Seitz J (2005) Digital watermarking for digital media. IGI Global, Information Science Publishing, USA, pp 25–27
Su Q, Niu Y, Zhao Y, Pang S, Liu X (2013) A dual color images watermarking scheme based on the optimized compensation of singular value decomposition. AEU-Int J Electron Commun 67(8):652–664
Su Q, Niu Y, Wang G, Jia S, Yue J (2014) Color watermark image embedded in color host image via QR decomposition. Signal Process 94:219–235
University of Granada (2012) Computer vision group. CVG-UGR Image Database. [2012-10-22]. http://decsai.ugr.es/cvg/dbimagenes/c512.php
Vaishnavi D, Subashini TS (2015) Robust and invisible image watermarking in RGB color space using SVD. Procedia Comput Sci 46:1770–1777
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Wu HT, Huang J (2012) Reversible image watermarking on prediction errors by efficient histogram modification. Signal Process 92(12):3000–3009
Xia Z, Wang X, Sun X, Wang B (2014) Steganalysis of least significant bit matching using multi-order differences. Secur Commun Netw 7(8):1283–1291
Zeng G, Qiu Z (2008) Image watermarking based on DC component in DCT. In: Intelligent Information Technology Application Workshops, 2008. IITAW ’08. International Symposium on, pp 573–576
Zheng JB, Feng S (2008) A color image multi-channel DWT domain watermarking algorithm for resisting geometric attacks. In: 2008 International Conference on Machine Learning and Cybernetics, vol 2. IEEE pp 1046–1051
Zheng Y, Jeon B, Xu D, Wu QMJ, Zhang H (2015) Image segmentation by generalized hierarchical fuzzy C-means algorithm. J Intell Fuzzy Syst 28(2):961–973
Acknowledgements
The research was partially supported by the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD), Jiangsu Collaborative Innovation Center on Atmospheric Environment and Equipment Technology (CICAEET), Natural Science Foundation of China (61202111, 61572258), Natural Science Foundation of Shandong Province (ZR2014FM005), Key Science and Technology Plan Projects of Yantai City (2016ZH057), Department of Science and Technology of Shandong Province (2013GGB01231) and Shandong Province Important Research Plan Projects (2015GSF116001). The authors would like to thank anonymous referees for their valuable comments and suggestions which lead to substantial improvements of this paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Communicated by V. Loia.
Rights and permissions
About this article

Cite this article
Su, Q., Chen, B. Robust color image watermarking technique in the spatial domain. Soft Comput 22, 91–106 (2018). https://doi.org/10.1007/s00500-017-2489-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-017-2489-7