
Abstract
Case-based reasoning (CBR) is an artificial intelligent approach to learning and problem-solving, which solves a target problem by relating past similar solved problems. But it faces the challenge of weights assignment to features to measure similarity between cases. There are many methods to overcome this feature weighting problem of CBR. However, neural network’s pruning is one of the powerful and useful methods to overcome this feature weighting problem, which extracts feature weights from trained neural network without losing the generality of training set by four popular mechanisms: sensitivity, activity, saliency and relevance. It is habitually assumed that the training sets used for learning are balanced. However, this hypothesis is not always true in real-world applications, and hence, the tendency is to yield classification models that are biased toward the overrepresented class. Therefore, a hybrid CBR system is proposed in this paper to overcome this problem, which adopts a cost-sensitive back-propagation neural network (BPNN) in network pruning to find feature weights. These weights are used in CBR. A single cost parameter is used by the cost-sensitive BPNN to distinguish the importance of class errors. A balanced decision boundary is generated by the cost parameter using prior information. Thus, the class imbalance problem of network pruning is overcome to improve the accuracy of the hybrid CBR. From the empirical results, it is observed that the performance of the proposed hybrid CBR system is better than the hybrid CBR by standard neural network. The performance of the proposed hybrid system is validated with seven datasets.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
CBR is an intelligent technique to learning and problem-solving, which solves problems based on past experiences stored in case base and also captures new knowledge/experiences, making it immediately available for solving next problems. These experiences encode relevant features/attributes, courses of action that were taken and solutions that are ensued. This base of experience forms the memory for the CBR system. CBR is also a variety of reasoning by analogy (Aamodt and Plaza 1994; Leake 1996). Aamodt and Plaza (1994) have described CBR typically as a cyclical process comprising the four REs:
-
Retrieval retrieves one or more similar cases from case base that can be used to solve a new problem.
-
Reuse is responsible for proposing solution to the new problem from retrieved cases.
-
Revise is responsible to evaluate the proposed solution. If the proposed solution is fit for the new problem, then it is possible to learn about the success; otherwise, the solution is repaired/adapted using some problem domain-specific knowledge or any other ways.
-
Retain consists of a process of integrating the useful information about the new problem’s resolution in case base, if it is a case whose solution is not readily available in case base.
It is observed that the core of CBR methodology is the retrieval of similar cases stored in case base. Therefore, a similarity measure is required to calculate the similarity between the stored cases and a new case, and hence, similarity measure becomes the key element in obtaining a reliable solution for new situations (Nunez et al. 2004; Buta 1994). The task of defining similarity measures for real-world problems is one of the greatest challenges of research in this area as assessing the similarity between cases is a key aspect of CBR. The k-nearest neighbor (k-NN) is one of the most popular similarity measures in CBR, which uses a distance function to find similarity between cases. However, the biggest problem with k-NN is to determine the weight of features because several studies have shown that k-NN’s performance is highly sensitive to the definition of its distance function (Watson and Marir 1994; Wettschereck et al. 1997). Many k-NN variants have been proposed to reduce this sensitivity by parameterizing the distance function with feature weights (Wettschereck et al. 1997).
The k-NN considers that each query, q (new case) is represented by b features which are numeric or discrete. The similarity of q with each stored case, \({c} = \{{c}_{1}, {c}_{2}, {c}_{3}, {\ldots }, c_{b}, o_{c}\)} in a set C is calculated where \(c_{1}\) to \(c_{b}\) are attribute values or problem description of the case c and \(o_{c}\) is c’s class value. The k-NN then retrieves k most similar (least distance) cases and predicts their weighted majority class or majority class only as the class of q. The distance can be calculated by Eq. (1) given below.
where \(w_{{i}}\) is the parameterized weight value assigned to feature i and
The distance given in Eq. (1) is weighted Euclidean distance but can also be weighted absolute or city block distanceFootnote 1. City block distance examines the absolute differences between co-ordinates of a pair of objects. The detail of Eqs. (1) and (2) could be found in Wettschereck et al. (1997). The concept of equal weights handicaps k-NN as it allows redundant and irrelevant features to have as much impact on distance computations as others. For the cases belonging to the same class, some features may often have the same value, while others vary their values in most of the cases in that class. Therefore, the features will always have different degrees of impact in similarity measure. Accordingly, different feature weights should be provided to avoid incorrectness in similarity measure. If all of the features are regarded as being equally important, i.e., all the features have the same weight value, then CBR allows redundant or irrelevant features to influence the final solution as well as similarity measure. Therefore, it is very important to solve the feature weighting problem of CBR to work properly where similarity measure is k-NN.
Many methods have been proposed to sort out the feature weighting problem. For example, Daelemans et al. (1994) and Wettschereck and Dietterich (1995) used mutual information to compute coefficients on numeric attributes. Many other feature weighting methods and their analysis could be found in Wettschereck et al. (1997).
Although many feature weighting methods for k-NN have been reported for classification or prediction task, feature weighting methods which can capture generality and domain-specific knowledge together are rare. Artificial neural network (ANN) is a method which captures generality and domain-intensive knowledge to estimate the relative importance of each feature. Therefore, many network pruning tasks are attempted and implemented (Shin and Park 1999; Shin et al. 2000; Im and Park 2007; Park et al. 2004; Ha 2008; Zeng and Martinez 2004; Yang and Jin 2010; Peng and Zhuang 2007; Sarwar et al. 2010; Park et al. 2006) to find feature weights. Sensitivity, activity saliency and relevance mechanisms are used in Shin and Park (1999), Shin et al. (2000), Im and Park (2007) and Park et al. (2004) to find symbolic feature weights from back-propagation neural network (BPNN). They have assumed that the training sets used for learning are balanced in those works. However, this hypothesis is not habitually true in real-world applications. Traditional learning algorithms applied to complex and highly imbalanced training sets do not give satisfactory results when distinguishing between examples of classes. The tendency is to yield classification model that is biased toward the overrepresented (majority) class (Braga and Castro 2013). This paper attempts to overcome the class imbalance problem for sensitivity, activity, saliency and relevance mechanisms, which improves the performance of these feature weighting mechanisms.
Many solutions are proposed to resolve the class imbalance problem both at the data and at the algorithmic levels. The common practice for dealing with imbalanced data at the data level includes different sampling techniques like oversampling the minority class, or under sampling the majority class, until the classes become balanced. However, while implementing these sampling techniques, some known drawbacks are associated with them. The implementation of under sampling tends to discard the potentially useful data (Ganganwar 2012). Oversampling the minority class leads to increase the number of training examples and hence-over fits the dataset and also increases the learning time as the dataset is rebalanced artificially by using sampling methods.
The solutions at the algorithmic level include various mechanisms. Adjusting the costs of various classes is one of the significant solutions at the algorithmic level to reduce the class imbalance. This is what the core concept of cost-sensitive learning approach (Ganganwar 2012). A cost-sensitive learning approach takes cost, such as misclassification cost, into consideration during model construction and supports to build a classifier that has the minimum cost (Nguyen et al. 2009). The cost-sensitive learning assumes higher misclassification cost with samples in the minority class and hence affords to minimize high cost errors (López et al. 2012). Consequently, this approach reduces the bias toward the majority class in an efficient way while keeping the original dataset size intact. Therefore, the paper proposes a hybrid CBR model, which overcomes the class imbalance problem for sensitivity, activity, saliency and relevance feature weighting mechanisms by cost-sensitive BPNN (Braga and Castro 2013).
The paper is organized as follows: Sect. 2 depicts cost-sensitive BPNN, while Sect. 3 describes weight learning mechanisms from trained neural network and outlines some previous works. Section 4 describes the framework of the proposed hybrid CBR system. Section 5 discusses the results of seven datasets, and finally some conclusions are drawn in Sect. 6.

A neural network
2 Cost-sensitive BPNN
The dataset, D, of the binary classification task can be written as \(D = \{D_{1}\cup D_{2}\}\), where \(D_{1} = \{(\mathbf{x}(p), {y}(p)) {\vert } p = 1, \ldots , {N}_{1}\}\); the vector \(\mathbf{{x}}(p)\) is the pth case of the positive class and \({y}(p) = +1, \forall \mathbf{{x}}(p)\in D_{1}\). The number of positive cases is represented by \({N}_{1}\). Analogous definitions hold for \(D_{2}\), for negative class. In order to achieve solutions that are sensitive to the importance of each class, a cost function for the parameter estimation of BPNN is used. The cost function is defined in Eq. (3) as the weighted sum of functionals \({J}_{1}\) and \({J}_{2}\) which correspond to the sum of squared errors for \(D_{1}\) and \(D_{2}\), respectively
where, \({J}_{1}\) and \({J}_{2}\) are described by the following equations:
The vector x(r) is the rth case of the negative class; e(p) and e(r) denote errors for pth and rth case of \(D_{1}\) and \(D_{2}\), respectively. \({N}={N}_{1}+{N}_{2}\) and the parameter, \(\lambda (0<\lambda <1)\) is used to weight the contribution of \({J}_{1}\) and \({J}_{2}\) in the composition of J. The parameter \(\lambda \) modifies the standard formulation of learning by assigning unequal costs to the errors of each class. \(\lambda \) influences the location of the decision boundary obtained from training, compensates the class imbalance and obtains a balanced decision boundary. Thus, if \({N}_{2}\) is greater than \({N}_{1}\), this parameter can be used to compensate the class imbalance problem (Braga and Castro 2013).
3 Weight learning by neural network
Neural networks are helpful in adjusting the connection weights among the nodes of the network due to their input–output mapping, robustness and adaptive capabilities. Therefore, ANN model can be used to resolve the problem of feature weighting. BPNN model can be used to process the case feature values by two stages: First is learning stage, which also means to build BPNN model and using this model, and samples are taught to get the desired result. Second is the exchanging weight stage, which transfers the nodes value into the desired result to the case feature values. Knowledge exploited by ANNs from the training dataset is stored as connected links of trained neural network nodes. Knowledge extraction from trained neural network is one of the main interests for a long time (Shin and Park 1999). Several methodologies have been attempted for using the connectionist approach (ANN) in CBR system design (Becker and Jazayeri, 1989; Thrift 1989). The work of hybrid CBR with ANN architecture is reinforced to solve complicated problem in Shin and Park (1999), which calculates a set of feature weights from a trained BPNN that plays the core role in finding the most similar cases from case base for prediction or classification.
The four feature weighting mechanisms are proposed: sensitivity, activity, saliency and relevance to obtain a vector of feature weights \(\{w_{1}, w_{2},{\ldots }, w_{d}\}\) from a trained BPNN in Shin and Park (1999), Shin et al. (2000), Im and Park (2007) and Park et al. (2004), where d is the number of input features. Each of the feature weighting mechanisms is briefly described below.
Consider a neural network given in Fig. 1 with a single hidden layer, which consists of d inputs \(({x}_{{i}}\), where \(i = 1, 2,\ldots ,d\)), m number of hidden neurons \(({z}_{{h}}\), where \(h= 1, 2, {\ldots }, m\)) and one output, \({y}_{{j}}\). Here \(w_{{hi}}\) denotes the weight connecting from \({x}_{{i}}\) to \({z}_{{h}}\) and \(w_{{jh}}\) is the connecting weight between \({z}_{{h}}\) to \({y}_{{j}}\).
-
(i)
Sensitivity The sensitivity of an input node is calculated by removing the input node from the trained neural network. Sensitivity measure of an input feature is the difference in prediction value between when the feature is removed and when it is left in place. The sensitivity, \({S}_{{i}}\), of an input feature, i, is defined by Eq. (6):
$$\begin{aligned} \quad {S}_{{i}} =\frac{\left[ \sum _{{L}} \frac{\left| {P}^{{o}}-{P}^{{i}} \right| }{{P}^{{{o}}}} \right] }{{n}} \end{aligned}$$(6)where \({P}^{{o}}\) is the normal prediction value for each training instance after training, \({P}^{{i}}\) is the modified prediction value when the input feature i is removed, L is the set of training data and n is the number of training data.
-
(ii)
Activity The activity of a node is measured by the variance of the activation level in training data. The activation of a hidden node, \({z}_{{h}}\), is defined by Eq. (7):
$$\begin{aligned} \quad {A}_{h} =\left[ {w_{{jh}}} \right] ^{2}\cdot \hbox {var}\left[ {{g}\left( {\sum \limits _{{i}=1}^{d} w_{{hi}} {x}_{{i}} } \right) } \right] \end{aligned}$$(7)where \(\hbox {var}\left( \right) \) is the variance function, \(w_{{jh}}\) is the weight between output node j and hidden node h, \(w_{{hi}} \) is the weight between hidden node h and input node i. The activity of an input node, \({x}_{{i}} \), is defined by Eq. (8):
$$\begin{aligned} \quad {A}_{{i}} =\mathop \sum \limits _{{h}=1}^{m} \left[ {\left( {w_{{hi}} } \right) ^{2}\cdot {A}_{h} } \right] \end{aligned}$$(8) -
(iii)
Saliency The saliency of a weight is measured by estimating the second derivative of the error with respect to the weight. The saliency of an input node, i, is defined by Eq. (9):
$$\begin{aligned} \quad \hbox {Saliency}_{{i}} =\mathop \sum \limits _{{h}=1}^{m} \left[ {\left( {w_{{hi}} } \right) ^{2}\cdot \left( {w_{{jh}} } \right) ^{2}} \right] \end{aligned}$$(9) -
(iv)
Relevance The variance of weights into a node is a good predictor of the node’s relevance, and the relevance of a node is a good predictor of the increase in error expected when the node’s largest weight is deleted. The relevance of a hidden node, \({z}_{h}\) is defined by Eq. (10):
$$\begin{aligned} \quad {R}_{h} =\left( {w_{{jh}}} \right) ^{2}\cdot \hbox {var}\left( {w_{{hi}} } \right) \end{aligned}$$(10)And the overall relevance of an input node, \({x}_{{i}} \), is defined by Eq. (11):
$$\begin{aligned} \quad {R}_{{i}} =\mathop \sum \limits _{{h}=1}^{m} \left( {w_{{hi}} } \right) ^{2}\cdot {R} \end{aligned}$$(11)Shin and Park (1999) have combined MBR and ANN by integrating the calculated feature weights. This hybrid method is also compared with some other machine learning methods. Shin et al. (2000) have used the same concept of weight extraction as Shin and Park (1999) and have built the same hybrid CBR system except decision-making process. The developed hybrid system is validated by high dimensional and dynamic systems like odd parity problem, decision making in sinusoidal task, Wisconsin diagnostic breast cancer (WDBC) problem, credit card application, classification of sonar signals and auto-mpg regression problem. Im and Park (2007) have also used the same concept of weight extraction and building of hybrid CBR system. They have added the concept of value difference metric (VDM) when feature attributes are non-numeric and the hybrid system is applied to build an expert system for personalization. Ha (2008) has used the same concept of hybrid CBR and also applied in same application as Im and Park (2007), but has reported changes in performance. Sensitivity, activity, saliency and relevance feature weighting mechanisms are used in all those works.

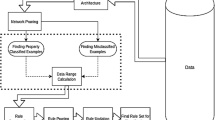
Framework of hybrid CBR
4 The proposed hybrid CBR model
The cost-sensitive BPNN Braga and Castro (2013) is integrated into CBR during the retrieval process that retrieves a set of k-nearest neighbors to a target case. The cost-sensitive BPNN is initially trained, which takes care about class imbalance problem and finds feature weights. The symbolic feature weights are calculated from the trained BPNN using sensitivity, activity, saliency, and relevance mechanisms. When a query (new/target) case is encountered in case retrieval module, k similar cases are retrieved from the case base using k-NN similarity measure where pre-calculated symbolic feature weights are used to measure similarity between cases. Then, case reuse and revision module are used to propose a solution, which is sent to the query (new/target) case that demands a solution. The framework of the proposed hybrid CBR model is shown in Fig. 2. The discussion of the stages of the hybrid CBR model is given below.
4.1 STAGE 1: case representation
A case is a piece of knowledge in a particular context that represents an experience. A case stored in case base consists of problem specification and known solution. Case representation is very important in CBR because proper case representation enhances the acceptance of proposed solution. Each case is defined by problem specification having assignment of values \({a} = ({a}_{1},{a}_{2},{a}_{3},\ldots ,{a}_{{g}})\) to a set of features \({f} = ({f}_{1},\ldots ,{f}_{g})\), and solution as one of s possible classes, \(o_{1},\ldots ,o_{s}\) to the class label o. In binary case classification tasks, the applicable classes to the class label are \(o_{1}=0\) and \(o_{2}=1\). The learning of a classifier is inherently determined by the feature values of the cases. In this paper, each case stored in the case base consists of the values of the feature vector representing the problem specification, together with its associated solution or class in the form of ‘1’ or ‘0’ representing either of two classes. Furthermore, a query (new/target) case refers to a problem requiring solution, which is obtained through prediction. Suppose t is the number of attributes that form the problem description of a case. Then, Q \((q_{1},q_{2,}{\ldots },q_{{t}})\) is the query case and \({C}(c_{1},c_{2},{\ldots },c_{{t}},c_{({t}+1)})\) is any stored case, where \(c_{({t}+1)}\) is solution description of the stored case.
4.2 STAGE 2: case selection/retrieval of k-NN
Retrieval of most similar cases is very critical to the success of a CBR system. The top most similar cases are selected by k-NN, which are presented in the system to measure the performance of the hybrid model. Selection of cases is done by performing the following steps:
-
RETRIEVE multi-attribute-based information of past cases by cost-sensitive BPNN in terms of symbolic weights.
-
MATCH past cases with the query (new) case by Eq. (1) where weights are calculated from the trained cost-sensitive BPNN by feature weighting mechanisms, i.e, sensitivity, activity, saliency and relevance.
-
COMPARE the past cases with each other by dissimilarity score.
-
SELECT the past cases having least values of dissimilarity score.
4.3 STAGE 3: case reuse and revision
Top k most retrieved similar cases are taken into consideration to produce the predicted result by observing the frequency of occurrence of similar solutions, i.e., based on the majority of voting of top most similar cases. The top most similar case is initially reused as the proposed solution for the query (new) case, and then, the performance of the model is measured. Subsequently, the measured performance is compared with the performances of the model when number of similar cases (k) is changed (\(k=2, 3, {\ldots }, 20\)). If k is too large, prediction result would taper off because of the inclusion of an increasing number of decreasingly similar cases. Therefore, the value of k is restricted up to 20. The value of k, which produces highest accuracy of the proposed hybrid CBR model, can be adopted as optimal k. Therefore, when a query (new) case arrives, the solution of the query (new) case is determined by majority of voting of the optimal k nearest neighbors.
4.4 STAGE 4: retention
Retention is not adopted based on the requirement of the proposed model but that can be adopted by setting a threshold value in similarity score. If the similarity score is less than the threshold value, then the query (new) case may be considered as totally a new case in the case base. The encountered new case with solution given by domain expert can be retained in the case base for future use.
5 Results and discussion
5.1 Dataset collection
The experimentation of the proposed model is done by MATLAB 7.12.0.635 (R2011a) in Windows environment. The following binary classification tasks which are obtained from the UCI machine learning repository are incorporated into the paper. In addition, Swine flu data are gathered from physicians in several hospitals and from the Internet. With the aid of internet and consulting local medical practitioners, the symptoms of Swine flu are categorized (indexed) and ranged, and accordingly the cases are generated and validated by medical institutions. All the experiments of the paper use three experimental setups to find out the accuracy of the proposed hybrid CBR model: (i) 80 % cases of a case base as training set and 20 % cases of the case base as test set, which is termed as 80:20 split, (ii) 70 % cases of a case base as training set and 30 % cases of the case base as test set, which is termed as 70:30 split, and (iii) five-folded validation as five independent runs are executed to validate the comparison results by using Wilcoxon rank-sum nonparametric statistical test. The concise description of the datasets is given below:
5.1.1 Blood transfusion
There are total 748 instances and 5 attributes. One of the 5 attributes is used as solution (decision). The classification task involves in determining whether someone has donated blood or not. 1 stands for donating blood and 0 stands for not donating blood. The attributes are given below with brief description:
-
Recency (R)—months since last donation
-
Frequency (F)—total number of donation
-
Monetary (M)—total blood donated in c.c.
-
Time (T)—months since first donation and
-
A binary variable representing whether he/she donated blood in March 2007.
5.1.2 Diabetes mellitus
The database contains 8 attributes and 768 cases. Prediction task involves in determining either presence or absence of diabetes. The attributes are given below:
-
Number of times pregnant
-
Plasma glucose concentration a 2 h in an oral glucose tolerance test
-
Diastolic blood pressure (mm Hg)
-
Triceps skin fold thickness (mm)
-
2-h serum insulin (mu U/ml)
-
Body mass index (weight in kg/(height in \(\hbox {m}^2\)))
-
Diabetes pedigree function
-
Age (years)
5.1.3 Heart disease
The database contains 13 attributes and 270 cases. Prediction task involves in determining either presence or absence of heart disease. The attributes are given below:
-
age
-
sex
-
chest pain type (4 values)
-
resting blood pressure
-
serum cholesterol in mg/dl
-
fasting blood sugar \(>{120}\) mg/dl
-
resting electrocardiographic results (values 0, 1, 2)
-
maximum heart rate achieved
-
exercise-induced angina
-
old peak \(=\) ST depression induced by exercise relative to rest
-
the slope of the peak exercise ST segment
-
number of major vessels (0–3) colored by fluoroscopy
-
thal: 3 \(=\) normal; 6 \(=\) fixed defect; 7 \(=\) reversible defect
5.1.4 Liver disorder
There are total 345 cases and 7 attributes. One of the attributes is used to determine the classification. The classification problem involves in determining either presence or absence of liver disorder. The attributes are given below:
-
mcv: mean corpuscular volume
-
alkphos: alkaline phosphatase
-
sgpt: alanine aminotransferase
-
sgot :aspartate aminotransferase
-
gammagt: gamma-glutamyl transpeptidase
-
drinks: number of half-pint equivalents of alcoholic beverages drunk per day
5.1.5 Swine flu
Swine flu prediction is a problem that involves in determining whether an individual has Swine flu or not. Ten prominent attributes are used as the problem description of a Swine flu case, and class of the case is a decision that is either yes (1) or no (0). This database contains 250 cases. Each attribute of a case is indexed, as given in Table 1 as per their ranges.
5.1.6 Sonar Signals
The database contains 60 attributes and 208 cases. Classification task involves in discriminating between sonar signals bounced off a metal cylinder at various angles and under various conditions as ‘Mine’ and those bounced off a roughly cylindrical rock under similar conditions as ‘Rock.’
5.1.7 Ionosphere
This database contains 34 attributes and 351 cases and describes about the radar returns from the ionosphere. The classification task involves in determining either good or bad where ‘good’ radar returns are those showing evidence of some type of structure in the ionosphere and ‘bad’ returns are those that do not; their signals pass through the ionosphere.
5.2 Results
Tables 2, 3, 4, 5, 6, 7 and 8 show the experimental results of heart, diabetes, blood transfusion, liver disorder, Swine flu, sonar and ionosphere datasets, respectively, for two splits of each dataset: 80:20 and 70:30. The experimental results of Tables 2, 3, 4, 5, 6, 7 and 8 show the performance of the hybrid CBR model with standard BPNN and with cost-sensitive BPNN for sensitivity, activity, saliency and relevance. The performance (accuracy) is shown in percentage in all the tables. The value of k represents the number of similar case(s) taken into consideration to find the performance of the hybrid model. The value of k out of 20, which produces the highest accuracy, is considered as optimal k and is indicated by boldface for each feature weighting mechanism in Tables 2, 3, 4, 5, 6, 7 and 8. The highest accuracy is assumed as system performance. It is observed that the performance of the hybrid CBR model with cost-sensitive BPNN is better than the hybrid CBR model with standard BPNN in all the datasets for both splits. The proposed model achieves 90.74 %, 87.03 %, 85.18 % and, 74.07 % accuracy for sensitivity, activity, saliency and relevance, respectively, in heart disease dataset for 80:20 split where the hybrid CBR with standard BPNN achieves 85.18 %, 83.33 %, 83.33 % and, 68.51 % accuracy for the same. It is observed from Tables 2, 3, 4, 5, 6, 7 and 8 that the similar comparison and improvement hold true in all datasets for both the splits. The performance of the hybrid CBR model is represented by red and black colors for 80:20 and 70:30 splits, respectively, in Tables 2, 3, 4, 5, 6, 7 and 8.

Solid line is for cost-sensitive and dotted line is for standard BPNN, red color is for 80:20 split and black color is for 70:30, a activity, b relevance, c saliency and d sensitivity for heart (color figure online)

Solid line is for cost-sensitive and dotted line is for standard BPNN, red color is for 80:20 split and black color is for 70:30, a activity, b relevance, c saliency and d sensitivity for diabetes (color figure online)

Solid line is for cost-sensitive and dotted line is for standard BPNN, red color is for 80:20 split and black color is for 70:30, a activity, b relevance, c saliency and d sensitivity for blood transfusion (color figure online)

Solid line is for cost-sensitive and dotted line is for standard BPNN, red color is for 80:20 split and black color is for 70:30, a activity, b relevance, c saliency and d sensitivity for liver disorder (color figure online)

Solid line is for cost-sensitive and dotted line is for standard BPNN, red color is for 80:20 split and black color is for 70:30, a activity, b relevance, c saliency and d sensitivity for Swine flu (color figure online)

Solid line is for cost-sensitive and dotted line is for standard BPNN, red color is for 80:20 split and black color is for 70:30, a activity, b relevance, c saliency and d sensitivity for sonar (color figure online)

Solid line is for cost-sensitive and dotted line is for standard BPNN, red color is for 80:20 split and black color is for 70:30, a activity, b relevance, c saliency and d sensitivity for ionosphere (color figure online)
Two statistical measures are also used: mean and mean absolute percentage error (MAPE) to show the improvement of the proposed model for both the splits. It is observed from Table 2 that mean performances for sensitivity, activity, saliency and relevance of the proposed model are 83.98 %, 83.15 %, 82.40 % and 69.26 %, respectively, in heart disease dataset for the 80:20 split, whereas mean performances for sensitivity, activity, saliency and relevance of the hybrid CBR with standard BPNN are 81.39 %, 81.39 %, 81.48 % and 57.87 %, respectively, for the same. Similar improvement is also observed for 70:30 split. For all other datasets, similar improvement by the proposed model is also observed as given in Tables 2, 3, 4, 5, 6, 7 and 8. It is also observed from Table 2 that MAPEs for sensitivity, activity, saliency and relevance of the proposed model are 19 %, 20 %, 21 % and, 45 %, respectively, in heart disease dataset for the 80:20 split, whereas MAPEs for sensitivity, activity, saliency and relevance of the hybrid CBR with standard BPNN are 23 %, 23 %, 23 % and, 76 %, respectively, for the same. Similar improvement is also observed for 70:30 split. For all other datasets, similar improvement by the proposed model is also observed as given in Tables 2, 3, 4, 5, 6, 7 and 8. Hence, the superiority of the proposed model statistically holds true in all the datasets for both the splits.
The performance graphs of the hybrid CBR with cost-sensitive BPNN and with standard BPNN of sensitivity, activity, saliency and relevance are shown in Figs. 3, 4, 5, 6, 7, 8 and 9 for heart, diabetes, blood transfusion, liver disorder, Swine flu, sonar and ionosphere datasets, respectively, for easy comparison between cost-sensitive BPNN and standard BPNN in imbalanced datasets for both the splits. The red lines and black lines represent the performance of the hybrid CBR models for 80:20 and 70:30 splits, respectively, in all the performance graphs. Dotted line represents standard BPNN, and solid line represents cost-sensitive BPNN. The X axis stands for the value of k from 1 to 20, and the Y axis stands for accuracy in percentage for each of the k values in Figs. 3, 4, 5, 6, 7, 8 and 9. Graphs for average performances (means) of cost-sensitive BPNN and standard BPNN are shown in Fig. 10. Solid fill is for cost-sensitive BPNN, and pattern fill is for standard BPNN, and brown color is for 80:20 split and green color is for 70:30 split. Performance graphs and tables are showing the same analysis of the results. Performance graphs are used to improve the clarity and easy understanding of the comparisons.
Table 9 shows the optimal BPNN architectures, and Tables 10 and 11 show the \(\lambda \) values of the corresponding datasets for 80:20 and 70:30 splits, respectively.
Five independent runs (five-folded validation) are executed to validate the comparison results by using Wilcoxon rank-sum nonparametric statistical test. The Wilcoxon rank sum is a nonparametric test which tests whether two independent samples come from identical continuous distributions with equal medians \((\mu _{1}=\mu _{2})\), against the alternatives, \((\mu _{1} > \mu _{2})\) or \((\mu _{1} < \mu _{2})\) or \((\mu _{1} != \mu _{2})\). \(\mu _{1}\) is the median for first sample and \(\mu _{2}\) is the median for second sample. This test is based on the ranks of all \({N} ({=}{n}_{1} +{n}_{2})\) observations after the two samples are combined, and the observations are ordered from smallest to largest. Table 12 shows the performance of the hybrid CBR model with cost-sensitive and with standard BPNN for five independent runs in Swine flu dataset by relevance mechanism. Combined performances and their rank are also shown in the table.
\({H}_{0}\): represents null hypothesis; \({H}_{1}\): represents alternative hypothesis

Comparison of mean values of 20 nearest neighbors for different datasets. Solid fill is for cost-sensitive and pattern fill is for standard BPNN, and brown color is for 80:20 split and green color is for 70:30. a Heart dataset, b diabetes dataset, c blood transfusion dataset, d liver disorder dataset, e Swine flu dataset, f sonar dataset and g ionosphere dataset (color figure online)
For a fixed level \(\alpha \) (0.95) test, the test rejects Ho (null hypothesis), where z-statistic \(=\) 1.671145,
Upper value \(({z}^{*}) = - 1.64485\) and P value (1-NORMSDIST (z)) \(=\) 0.047346.
The test result shows that at 95 % confidence level, z-statistic is greater than upper critical value as well as P value is <0.05.
Hence, \({H}_{1}\): case retrieval (performance) using cost-sensitive BPNN is better than standard BPNN (i.e., \(\mu _{1} \!>\! \mu _{2})\).
Table 13 shows the performance of the hybrid CBR model with cost-sensitive and with standard BPNN for five independent runs in ionosphere dataset by activity mechanism.
For ionosphere dataset at a fixed level \(\alpha \) (0.95), z-statistic \(=\) 1.775592, upper value \(({z}^{*}) = - 1.64485\) and P value (1-NORMSDIST (z)) = 0.0379. Z-statistic is greater than upper critical value as well as P value is <0.05. Hence, \(H_0\) (null hypothesis) is rejected and \({H}_{1}\) hypothesis (case retrieval (performance) using cost-sensitive BPNN is better than standard BPNN (i.e., \(\mu _{1} > \mu _{2}\))) is satisfied.
Similarly, for all the other datasets \({H}_{1}\) hypothesis is satisfied at 95 % confidence level.
5.3 Discussion
It is observed from Tables 2, 3, 4, 5, 6, 7 and 8 and graphs in Figs. 3, 4, 5, 6, 7, 8 and 9 that sensitivity, activity, saliency and relevance from the cost-sensitive BPNN have performed better in retrieving most similar cases than Shin and Park (1999), Shin et al. (2000) and Im and Park (2007) in all the cases. It has also enhanced the performance of the case retrieval mechanism as compared to the weights in Shin and Park (1999), Shin et al. (2000) and Im and Park (2007). It is because Shin and Park (1999), Shin et al. (2000) and Im and Park (2007) used standard BPNN and CBR to retrieve similar cases. Standard BPNN assumes that all the datasets (classes) are balanced and therefore has a tendency to get biased toward the majority class. As a result, the accuracy of the retrieved cases by Shin and Park (1999), Shin et al. (2000) and Im and Park (2007) gets affected. To cope with this problem, the proposed hybrid model uses a cost-sensitive BPNN, which uses a cost parameter to identify the importance of each class. Comparison of the proposed model is done only with Shin and Park (1999), Shin et al. (2000) and Im and Park (2007) as models in Shin and Park (1999), Shin et al. (2000) and Im and Park (2007) have been already compared with other methods of case-based reasoning, and they outperformed all other previously existing case-based reasoning methods. The highest accuracy achieved by the proposed hybrid CBR model is made boldface in Tables 2, 3, 4, 5, 6, 7 and 8 for all the datasets and both the splits. For example, the proposed model produces 90.74, 87.03, 85.18 and 74.07 % accuracy for sensitivity, activity, saliency and relevance, respectively, in heart disease dataset for 80:20 split. A good model desires higher mean and lower MAPE (mean absolute percentage error). Tables 2, 3, 4, 5, 6, 7 and 8 and Fig. 10 show that the proposed model produces better mean and MAPE than Shin and Park (1999), Shin et al. (2000) and Im and Park (2007) in most of the cases. For 70-30 split, it is observed from Tables 2, 3, 4, 5, 6, 7 and 8 and Fig. 10 that the average performance of the proposed model is better in all the cases except saliency of heart, diabetes, blood transfusion and Swine flu datasets, and activity of heart dataset. Similarly for 80–20 split, the average performance of the proposed model is better in all the cases except sensitivity, activity, saliency and relevance of diabetes dataset, and relevance of liver disorder dataset. From Tables 2, 3, 4, 5, 6, 7 and 8, it is also observed that for some datasets, the accuracy obtained is less (such as <60 %) and for some datasets accuracy obtained is more (such as more than 90 %). This is because of high or low nonlinearity of the datasets. The datasetsproducing less accuracy are highly nonlinear. By applying the proposed model with cost-sensitive BPNN, the accuracies for the highly nonlinear datasets are significantly increased. And those datasets producing better accuracy are less nonlinear but after applying the proposed model, significant improvement is also observed. So, it can be said that the proposed model retrieves k most similar cases more accurately. The revision of CBR cycle is implemented by frequency of occurrence of top most similar cases and the value of k, which produces highest accuracy, is only considered to measure the performance of the hybrid model. If more than one k produces highest accuracy, then the first k of them is taken as optimal k.
In order to obtain weights from trained neural network, it is essential to find out the optimal architecture of the network to be trained. A BPNN is used whose architecture is formed with one hidden layer because single hidden layer neural networks are superior to networks with more than one hidden layer with the same level of complexity mainly due to the fact that the later are more prone to fall into poor local minima (de Villiers , Barnard 1993). The gradient descent learning algorithm is used, and the learning rate taken is 0.01. The number of input nodes to the network architecture is equal to the number of features of a pattern in a dataset, and there is one output node. The number of hidden nodes in the hidden layer is varied between (\(i+1\)) to (2i) to determine the number of hidden nodes where i is the number of input nodes. Mean square error (MSE) is measured for each of the architectures, and the one which produces minimum MSE is selected for further experimentation and is called optimal architecture of the network. The network architectures that give the highest performance are given in Table 9 with respective datasets. The \(\lambda \) values that give the highest accuracy are given in Tables 10 and 11 with respective datasets. It should be noted that the value of \(\lambda \) is experimental.
6 Conclusions
Feature weighting mechanisms: sensitivity, activity, saliency and relevance, from a trained cost-sensitive BPNN are investigated in this paper. It is found that feature weighting mechanisms: sensitivity, activity, saliency and relevance, from a trained cost-sensitive BPNN perform better than feature weighting mechanisms: sensitivity, activity, saliency and relevance, from a trained standard BPNN. This is because the majority of machine learning techniques habitually assume that the training sets used for learning are balanced; however, this hypothesis is not always true in real-world applications. The tendency is to yield a classification model that is biased toward the overrepresented (majority) class.
The use of ANN to provide weights to k-NN module and identification of more exact nearest neighbors to a query case adds more intelligence to the hybrid CBR system. The efficiency of the proposed hybrid CBR model is reflected in obtaining proper retrieval of cases which produces better accuracy.
The proposed model can be used in any binary classification tasks such as diagnosis, prediction and many others. The feature weighting mechanisms with the cost-sensitive BPNN can be used to sort out feature weighting problem of CBR without any hitch. This work can be augmented by introducing the concept of local weighting mechanism. The proposed model is only for binary classification tasks but can also be augmented to multi-classification tasks.
Notes
The distance is always greater than or equal to zero. The measurement would be zero for identical points and high for points that show little similarity. It is also known as Manhattan distance or Boxcar distance or absolute value distance
References
Aamodt A, Plaza E (1994) Case-based reasoning: foundational issues, methodological variations, and system approaches. Artif Intell Commun 7(1):39–52
Becker L, Jazayeri K (1989) A connectionist approaches to case-based reasoning. In: Proceedings of case-based reasoning workshop pensacola beach. Morgan Kaufmann, San Mateo, pp 213–217
Braga AP, Castro CL (2013) Novel cost-sensitive approach to improve the multilayer perceptron performance on imbalanced data. IEEE Trans Neural Netw Learn Syst 24(6):888–899
Buta P (1994) Mining for financial knowledge with CBR. AI Expert 9(2):34–41
Daelemans W, Gillis S, Durieux G (1994) The acquisition of stress: a data oriented approach. Comput Linguist 20(3):421–451
de Villiers J, Barnard E (1993) Backpropagation neural nets with one and two hidden layers. IEEE Trans Neural Netw 4(1):136–141
Ganganwar V (2012) An overview of classification algorithms for imbalanced datasets. Int J Emerg Technol Adv Eng 2(4):42–47
Ha S (2008) A personalized counseling system using case-based reasoning with neural symbolic feature weighting (CANSY). Appl Intell 29(3):279–288
Im KH, Park SC (2007) Case-based reasoning and neural network based expert system for personalization. Expert Syst Appl 32(1):77–85
Leake DB (1996) Case-based reasoning: experiences, lessons and future directions. MIT Press, Cambridge
López V, Fernández A, Moreno-Torres JG, Herrera F (2012) Analysis of preprocessing vs. cost-sensitive learning for imbalanced classification. Open problems on intrinsic data characteristics. J Expert Syst Appl 39(7):6585–6608
Nguyen GH, Bouzerdoum A, Phung SL (2009) Learning pattern classification tasks with imbalanced data sets. In: Yin P (ed) Pattern recognition, chap 10. In-Tech, Vukovar, Croatia, pp 193–208
Nunez H, Sanchez-Marre M, Cortes U, Comas J, Martinez M, Rodriguez-Roda I, Poch M (2004) A comparative study on the use of similarity measures in case based reasoning to improve the classification of environmental system situations. Environ Model Softw 19(9):809–819
Park JH, Im KH, Shin CK, Park SC (2004) MBNR: case-based reasoning with local feature weighting by neural network. Appl Intell 21(3):265–276
Park SC, Kim JW, Im KH (2006) Feature-weighted CBR with neural network for symbolic features. ICIC, LNCS 4113, pp 1012–1020
Peng Y, Zhuang L (2007) A case-based reasoning with feature weights derived by BP network. In: Proceedings of workshop on intelligent information technology application. IEEE Computer Society, pp 26–29
Sarwar S, Ul-Qayyum Z, Malik OA (2010) CBR and neural networks based technique for predictive prefetching. MICAI, Part II, LNAI 6438, pp 221–232
Shin CK, Park SC (1999) Memory and neural network based expert system. Expert Syst Appl 16(2):145–155
Shin CK, Yun UT, Kim HK, Park SC (2000) A hybrid approach of neural network and memory-based learning to data mining. IEEE Trans Neural Netw 11(3):637–646
Thrift P (1989) A neural network model for case-based reasoning. In: Proceedings of case-based reasoning workshop, Pensacola Beach. Morgan Kaufmann, San Mateo, pp 334–337
Watson I, Marir F (1994) Case-based reasoning: a review. Knowl Eng Rev 9(4):327–354
Wettschereck D, Dietterich T (1995) An experimental comparison of the nearest-neighbor and nearest-hyper rectangle algorithms. Mach Learn 19(1):5–27
Wettschereck D, Aha DW, Mohri T (1997) A review and empirical evaluation of feature weighting methods for a class of lazy learning algorithms. Artif Intell Rev 11(1–5):273–314
Yang B, Jin X (2010) Method on determining feature weight in case-based reasoning system. In: E-Product E-Service and E-Entertainment (ICEEE) international conference on 7–9 Nov 2010, pp 1–4
Zeng X, Martinez TR (2004) Feature weighting using neural networks. In: IEEE international joint conference on neural networks, pp 1327–1330
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interests regarding the publication of this paper.
Additional information
Communicated by V. Loia.
Rights and permissions
About this article

Cite this article
Biswas, S.K., Chakraborty, M., Singh, H.R. et al. Hybrid case-based reasoning system by cost-sensitive neural network for classification. Soft Comput 21, 7579–7596 (2017). https://doi.org/10.1007/s00500-016-2312-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-016-2312-x