
Abstract
A scheme for meteorological drought analysis at various temporal and spatial scales based on a spatial Bayesian interpolation of drought severity derived from Standardized Precipitation Index (SPI) values at observed stations is presented and applied to the Huai River basin of China in this paper, using monthly precipitation record from 1961 to 2006 in 30 meteorological stations across the basin. After dividing the study area into regular grids, drought condition in gauged sites are classified into extreme, severe, moderate and non drought according to SPIs at month, seasonal and annual time scales respectively while that in ungauged grids are explained as risks of various drought severities instead of single state by a Bayesian interpolation. Subsequently, temporal and spatial patterns of drought risks are investigated statistically. Main conclusions of the research are as follows: (1) drought at seasonal scale was more threatening than the other two time scales with a larger number of observed drought events and more notable variation; (2) results of the Mann–Kendall test revealed an upward trend of drought risk in April and September; (3) there were larger risks of extreme and severe drought in southern and northwestern parts of the basin while the northeastern areas tended to face larger risks of moderate drought. The case study in Huai River basin suggests that the proposed approach is a viable and flexible tool for monitoring meteorological drought at multiple scales with a more specific insight into drought characteristics at each severity level.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The evaluation and quantification of drought condition in a particular area has been an important aspect in water resources planning and management in order to mitigate the negative impacts of future occurrences. Various drought indices have been developed to identify the intensity of drought from several perspectives covering meteorological, agricultural, hydrological and socio-economic (Wilhite and Glantz 1985). Univariate indices are usually used to identify a drought when the variable exceeds a certain threshold value, such as precipitation (Blenkinsop and Fowler 2007; Sylla et al. 2010), runoff (Wang et al. 2011) and soil moisture (Wang 2005). At the same time water balance acts as the principal basis of multivariate indices with respect to two or more variables, such as PDSI (Dai et al. 2004; Strzepek et al. 2010) and Surface Moist Index (H) (Ma and Fu 2007). In terms of meteorological drought, which is often expressed as a function of precipitation at different scales, the Standardized Precipitation Index (SPI) has been widely used since McKee et al. (1993) first proposed it (Wu et al. 2007; Akhtari et al. 2009; Subash and Ram Mohan 2011) for its several advantages, including low requirement for data and good statistical consistency in both space and time (Guttman 1998; Hayes et al. 1999).
Observed data from meteorological stations are undoubtedly essential in a drought assessment process based on precipitation measurements. However, it should be kept in mind that available coverage and representing capability of observed sites are constantly limited. Although SPI has showed good performance monitoring drought at a point scale with consistent climate data of single station, appropriate interpolation techniques may be needed for estimation of drought severity at ungauged locations, which can provide more detailed information for analysis on spatial variability (Loukas and Vasiliades 2004; Smakhtin and Hughes 2007). In previous drought studies, several traditional methods such as Thiessen polygons, inverse distance, multiquadric, polynomial, and kriging have been widely used for interpolating monthly or annual precipitation data in a spatiotemporal analysis (Tase 1976; Chang 1991; Karamouz et al. 2007; Rhee et al. 2008). Akhtari et al. (2009) also attempted applying several geostatistical methods for interpolation of 1-month SPI at 43 climatic stations in the Tehran province of Iran, including kriging, co-kriging and thin plate smoothing splines with and without secondary variables, as well as Thiessen polygons and weighted moving average (WMA), which were then used to assess the derivation of maps of drought indices.
Nevertheless it should be noted that little attention has been paid to the treatment of uncertainty in any of these traditional methods. Since interpolation outcome is actually a best guess of point drought severity, a deterministic interpolation of SPI values from nearby stations can be quite unreliable when trying to identify the drought severity in ungauged areas. In this paper we extended the existing methodology of SPI with a Bayesian interpolation approach for meteorological drought assessment, aiming at providing a more specific insight into drought characteristics from identifying the probabilities of occurring drought on various severity degrees. Based on SPI values derived from observed data at gauged sites, a comprehensive description of drought risks covering different drought severities could be estimated to get a more reasonable cognition of drought condition in ungauged areas. Then the behaviors of drought risks in each severity category at multiple temporal and spatial scales can be extracted and analyzed respectively.
The paper is organized as follows. In Sect. 2 there is a description of the study area and data used for the study, then Sect. 3 provides information of the methodology adopted. Section 4 discusses some of the major results of the temporal and spatial variability of drought occurrence in the basin. A summary and conclusions are given in Sect. 5.
2 Study area and data
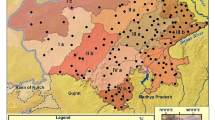
Huai River basin (30°55′–36°24′N, and 111°55′–121°25′E) is located in eastern China (Fig. 1) between the Yangtze River basin and the Yellow River basin. It flows through five provinces (Hubei, Henan, Anhui, Shandong and Jiangsu Province) of China covering an area of 270,000 km2. The population in the basin is around 170 million, and its population density is approximately four times higher than the nation’s average. The basin has a subtropical and warm temperate climate in south and north of the Huai River. Even though the mean annual precipitation reaches 883 mm, water resources per capita and per unit area is less than one-fifth of the national average. To make it worse, most of the annual precipitation (50–80 %) occurs between June and September. Uneven distribution of precipitation both temporally and spatially has been the main cause of high drought frequency in this area.

Location of Huai River Basin in China and the used meteorological stations
Monthly precipitation data of a total of 30 meteorological stations from 1961 to 2006 were collected from across the basin, provided by the China Meteorological Administration (Beijing, China). The distribution of stations (Fig. 1) is sufficient to cover the entire area and the records are generally consistent both spatially and temporally. Table 1 provides further details for all stations used in this study, including station name, code, geographic coordinates and length of record. Though records at most of the stations spanned all of the 46 years, the records in Linyi and Huaiyin needed to be extended to 2006. Multiple linear regression equations were used to extend the original records and interpolate several accidently missing months in this paper. First, correlation coefficients between the monthly precipitation observed at a given station and nearby stations with longer records were calculated. Then, the several sites with the highest correlation coefficients were selected as reference stations and missing monthly data at the station of interest were estimated by fitting multiple linear regression equations. In this case, Juxian and Rizhao turned out to be the best correlated stations with Linyi, with the correlation coefficient reaching 0.86 and 0.83 respectively, while measurements in Huaiyin was extended by Xuyi and Sheyang based on a correlation coefficient of 0.84 and 0.85 for each station.
3 Methodology
The overall procedure for drought analysis in this paper can be illustrated as three steps (Fig. 2): first, the entire area is divided into regular grids by the latitude and longitude lines, and drought conditions of gauged grids are classified based on the SPI values of different time scales. Second, the posterior probabilities of various drought severity degrees for ungauged grids are quantified by a Bayesian interpolation. Finally, drought risks of various severities and drought ranks for the entire area are evaluated, and the temporal and spatial patterns of meteorological drought in the basin then can be investigated statistically. A more detailed description is presented in subsequent subsections.

Overall procedure for drought analysis in this study
3.1 Computation and classification of SPI
The SPI is computed by fitting a probability density function of gamma distribution to the frequency distribution of precipitation summed over the time scale of interest (Mishra and Desai 2005). This is performed separately for each location in the basin at a particular time scale, with each probability density function transformed into a standardized normal distribution. The calculation procedure for the SPI series is carried out following the method described by McKee et al. (1993) and Edwards and McKee (1997).
The SPI values at different time scales are useful for monitoring various drought types. It is generally recognized that shorter time scales show a better relationship with agricultural drought while longer scales seem to be more suitable for water resources management purposes (Vicente-Serrano 2006; Raziei et al. 2009). The 1-month (SPI-1), 3-month (SPI-3) and 12-month (SPI-12) time scale are chosen for a further comparison of the inner and inter-annual variability in this study, which are intended to interpret drought characteristics monthly, seasonally and annually respectively. In terms of drought category, McKee et al. (1993) originally classified moderate, severe and extreme drought with SPI values between −1.00 and −1.49, −1.50 and −1.99, and less than −2.00. The threshold value of SPI for moderate drought (−1.00) corresponds to a probability of precipitation occurrence of 15.9 %. Several previous studies (Vermes 1998; Łabędzki 2007) have argued that this probability level is too low to detect possible dry events. Huai River basin is located in eastern China where monsoon climate plays the dominating role. Most of the rainfall occurs from April to September and drought may also occur during the same season. With a highly variable moisture condition both inner-annual and inter-annual, precipitation deficit less than the threshold value of SPI = −1.0 may also need attention. So we follow the classification with SPI ≤−0.5 taken as the threshold of drought (Łabędzki 2007), which is shown in Table 2.
3.2 Estimation of posterior probability at point scale
Along the latitude and longitude lines, we generally divide the rectangular area covering Huai River basin into 1,269 grids (0.2° × 0.2°), with each grid taken as a single point during assessment. The location of each grid can be determined by a two-dimensional vector, i.e., x = [m, n], \( m = 1,2, \ldots ,27 \) denotes the latitudinal location, and \( n = 1,2, \ldots ,47 \) denotes the longitudinal location.
First, drought severity of the grids covering observed stations are acquired by the classification of SPI values. It can also be described as a 4-dimension vector containing risks of four severity degrees
where C is the drought severity degrees, C 1, C 2, C 3 and C 4 are associated with extreme, severe, moderate and non drought severity respectively; t is the calculated time period, measured by month in this case; X is the location of gauged grid, considered as an aforementioned two dimensional vector.
Then the posterior probability of each drought severity at ungauged grid x is estimated based on a Bayesian classifier (Le et al. 1997; Shin and Salas 2000) as follows
where \( P(C^{j} \left| {x,t} \right.) \) is the posterior probability of the jth drought severity degree at unagauged grid x during t, valuing between 0 and 1; N j denotes the number of observations around x which has been classified as the jth drought severity degree by Eq. (1); X i is the ith gauged grid around x, \( i = 1,2, \ldots ,N^{j} \); GKF(X i ) is Gaussian kernel function given by
where \( D(X_{i} ,x) \) is the Euclidean distance between grid x = [m, n] and X i , \( D^{2} (X_{i} ,x) \) equals \( \left\| {x - X_{i} } \right\| \); \( \sigma (X_{i} ) \) is the width of the Gaussian kernel function, which controls the radial influence sphere of the function as a scaling factor. In interpolation issues, results obtained for every grid will become identical as \( \sigma (X_{i} ) \to \infty \), and vary dramatically as \( \sigma (X_{i} ) \to 0 \). Taking the non-uniform distribution of stations into account, the width parameter is often estimated separately for each data centre. The r-nearest neighbors heuristic method suggested by Moody and Darken (1989) is applied in this case
where X j are the r-nearest neighbors of station X i .
3.3 Estimation of regional drought risks and regional drought ranks at basin scale
Based on the posterior probabilities calculated at a point scale, we may also need to assess drought condition at larger spatial scales, which will be useful in making public decisions or issuing warning notices. Regional drought risks at a basin scale or in any interested area of the basin can be obtained by averaging point values as
where \( PB(C^{j} \left| t \right.) \) is the regional drought risks of jth drought severity during time t; Ng and Nu are the numbers of gauged and ungauged grids in the basin.
The PB index reflects not only the average risks of each drought severity, but also the spatial pattern of drought in the basin. Since in a particular time period, the sum of \( PB(C^{1} \left| t \right.) \), \( PB(C^{2} \left| t \right.) \), \( PB(C^{3} \left| t \right.) \) and \( PB(C^{4} \left| t \right.) \) reaches 1 regularly, a higher value of PB with the dominating drought severity expresses a more significant coherence of spatial distribution, which implies the drought may exert its influence in a larger area. On the other hand, a lower value of PB with the dominating drought severity expresses smaller differences between drought risks of each severity, which may imply a more noticeable spatial variability.
Then the regional drought rank (RDR) is further identified for a macroscopic comprehension of drought condition across the basin, which is calculated as
where RDR(t) is the rank of regional drought severity during time t. RDR(t) = 3, RDR(t) = 2 and RDR(t) = 1 respectively represent drought severity levels of extreme, severe and moderate. To make sure the ranking process is taken in a sequential order, \( PB(C^{1} \left| t \right.) \) is added to \( PB(C^{2} \left| t \right.) \) when identifying severe drought and \( PB(C^{1} \left| t \right.) + PB(C^{2} \left| t \right.) \) is added to \( PB(C^{3} \left| t \right.) \) when identifying moderate drought.
3.4 Detection of temporal and spatial patterns
Trends of the regional drought risks at different time scales are investigated with the Mann–Kendall (MK) statistical test (Mann 1945; Kendall 1975), which has been widely used for its superior applicability for non-normally distributed data as a rank-based non-parametric method (Yue et al. 2002). Time series of the regional drought risks are successively treated as follows
where S performs as the main test statistic in the method, n is the length of the sequential data set of PB, and
Mann (1945) and Kendall (1975) have documented that when n ≥ 8, the statistic S is approximately normally distributed with the mean 0 and the variance as follows
where t i denotes the number of ties of extent i. The standardized test statistic is computed by
Using a significant level of 5 %, a significant trend will be found if \( \left| Z \right| > 1.96 \). Positive and negative values of Z indicate upward and downward trends respectively.
In addition, drought severity maps are constructed by displaying the spatial distribution of mean point drought risks in four degrees in the basin, which can be calculated as
where T is the length of the research time period.
4 Results and discussion
4.1 Cross validation of the Bayesian interpolation method
In order to evaluate the validity of the proposed Bayesian interpolation method, cross validation technique was applied and drought condition of 1997–2006 at the 30 gauged grids were assessed by the Bayesian method, WMA (Akhtari et al. 2009) and ordinary kriging method (Goovaerts 1997) respectively. The interpolated SPI values were obtained by WMA and kriging method while the posterior probabilities of each drought degree were obtained by the Bayesian method. Then, drought ranks were classified and compared with the observed values. Rank value of 0, 1, 2 and 3 represent non, moderate, severe and extreme drought respectively. For WMA and kriging method, it was classified according to Table 2, and for the Bayesian method it was identified with the calculation procedure of RDR as mentioned before. Performance of the interpolation methods were evaluated by the frequency of differences in drought ranks at all gauged stations during the 10 years.
As shown in Table 3, the difference of zero means the drought rank is captured accurately and 1–3 means the level of error in interpolated drought rank. No dramatic difference was found among the results of the three methods and interpolation accuracy over 80 % can be gained in most cases. At both monthly and seasonal time scale, the frequencies of zero difference suggest that the Bayesian method can achieve better accuracy than WMA but slightly worse than kriging method. Very similar results were observed from SPI-12 series between the Bayesian method and WMA except that more 2-class differences were presented by WMA. Although kriging acquired lower total numbers of difference at all the three time scales, it should be noted that much more three-class differences have been observed from kriging method while none has been found from the Bayesian method. It suggests that kriging method performed worst in capturing extreme droughts. Generally speaking, the results indicate that the Bayesian method was slightly better, or at least no less skillful, than WMA and kriging method in this case.
4.2 Temporal characteristics of regional drought risks
After the calculation of SPI and posterior probabilities, regional drought risks in the study area were estimated covering the period from January 1962 to December 2006. Behaviors of drought risks for each severity including “Extreme”, “Severe”, “Moderate” and “Non” derived from SPI-1, SPI-3 and SPI-12 series (PB-1, PB-3 and PB-12) are separately shown in Figs. 3, 4 and 5. Several statistical indices of each time series including the max value, the mean value, the variability coefficient Cv and the skewness Cs were also calculated for a further comparison (Table 4). The maximum value of “Extreme” risk was 0.8242 in PB-3 series which occurred in January 1974 as the most significant extreme drought in the basin, while the peaks in PB-1 and PB-12 reached only 0.5512 and 0.4552. The maximum values of “Severe” and “Moderate” risk based at inner-annual scale SPIs were also much higher than that of annual values. Although the average values of both “Extreme” and “Severe” risks in PB-3 series were smaller than PB-12, it is quite noticeable that Cv values of those were much larger than series of PB-1 and PB-12, which reflected a more remarkable variation. A similar behavior can be observed in Cs values. Time series of “Extreme” and “Severe” risks at all the three time scales were positively skewed since the existence of a few extraordinary large values when drought occurred, and the larger Cs values of PB-3 may imply a more threatening situation than drought at other two time scales. Mean values of “Non” risk, which could indicate the overall probability of various drought events, showed that PB-3 series also had a lowest value of “Non” drought risks. Judging from the max values and distributing patterns, the PB-3 series that reflected the characteristics of seasonal precipitation displayed a most acute drought condition in the study period. More specific information about drought events in recent decades are discussed in the section below when assessing drought ranks.

Time behaviors of regional drought risks based on SPI-1 values for each severity in Huai River basin from Jan 1962 to Dec 2006

Time behaviors of regional drought risks based on SPI-3 values for each severity in Huai River basin from January 1962 to December 2006

Time behaviors of regional drought risks based on SPI-12 values for each severity in Huai River basin from January 1962 to December 2006
In order to investigate the long-term trends of drought risks, MK test was applied on PB series over two timeframes using a 5 % significance level: (1) all records of each PB series from January 1962 to December 2006; (2) records of each month extracted separately from each PB series from 1962 to 2006. Results of the trend tests are presented in Table 5 and the Z values larger than 1.96 or smaller than −1.96 are bolded as significant trends. We found little evidence of significant trends in the tests of complete PB records except a downward trend of “Extreme” risks in PB-3. Otherwise, series of PB-1 and PB-12 also showed downward trends but failed to exceed the threshold value −1.96. More significant trends had been detected after separating records to 12 months, including three upward trends and four downward trends. Both series of January PB-3 and July PB-12 revealed a noticeable downward trend of “Severe” risks, as well as “Moderate” risks of Jun PB-1 series. However, the series PB-3 showed a upward trend of “Moderate” risks and a downward trend of “Non” risks in April, while the series PB-1 and PB-12 showed a upward trend of “Moderate” risks and “Severe” risks respectively in September.
4.3 Assessment of regional drought ranks
Figure 6 further displays the time series of RDR based on SPI-1, SPI-3 and SPI-12 (RDR-1, RDR-3 and RDR-12), which have been subsequently obtained from drought risks of “Extreme”, “Extreme + Severe”, “Extreme + Severe + Moderate”. The number of drought events for each RDR and the corresponding percentages are listed in Table 6. Consistent with time behaviors of the three PB series, more drought events were observed in RDR-3 series spreading over every severity degree, with five extreme droughts, 21 severe droughts and 151 moderate droughts. The total number of drought events detected from seasonal time scale was 6.67 and 9.08 % more than that at monthly and annual scales. There were five time periods involved with extreme drought (Dr = 3) including February 1968, January 1970, January 1974, February 1977 and February 1984 in the RDR-1 series, as well as 4 months including January 1963, December 1987, November 1995 and December 1999 in the RDR-12 series. The one occurred in January 1974 was most serious with risks of extreme drought and severe drought reaching 0.8242 and 0.1758 respectively.

Time behaviors of regional drought rank based on SPI-1 (RDR-1), SPI-3 (RDR-3) and SPI-12 (RDR-12) in Huai River basin from January 1962 to December 2006. Rank values of 3, 2 and 1 indicate extreme, severe and moderate drought respectively
The RDR-12 series tended to mirror the drought condition from a long-term perspective. Although more droughts were detected at inner-annual time scales because of the huge variation of monthly precipitation in a hydrologic year, RDR-12 series showed stronger persistence. There were six drought periods longer than 10 months, namely August 1966–August 1967, October 1976–August 1977, July 1978–June 1979, June 1981–June 1982, August 1988–May 1989 and July 1999–May 2000, with three of them longer than a year. The most serious drought event occurred in August 1966–August 1967, during which time the basin suffered from severe drought (Dr = 2) in 9 of the 13 months.
4.4 Spatial patterns of mean point drought risks
As mentioned above, the PB index implies the general spatial distributing pattern in the basin. The time series of the drought risks for “Extreme” shows that the regional extreme risk value never reached 1 (Figs. 3, 4, 5), which means that an extreme drought covering the entire basin had never happened during the study period. However, the risk of “Extreme + Severe” at monthly scale (PB-1) reached one twice on January 1963 and December 1987, when the whole basin suffered from either extreme or severe drought. At the seasonal scale (PB-3), severe or worse droughts influencing the whole basin also occurred three times including February 1968, January 1974 and February 1977. In addition, behaviors of “Extreme + Severe + Moderate” risk have shown different patterns at different time scales, reaching one for 52, 86 and 6 times in PB-1, PB-3 and PB-12 series respectively. “Non” risk decreased to zero when those droughts influencing the entire basin with spatially various severity occurred.
Spatial patterns of drought condition were further depicted by geographical distribution of mean point drought risks. Mean values of extreme, severe and moderate drought risks in each grid based at the three time scales are illustrated separately in Figs. 7, 8 and 9 as drought severity maps. Among the three “Extreme” charts, Figs. 7a and 9a obviously display an upward trend of “Extreme” risk from north to south of the basin, while Fig. 8a suggests a more significant increasing trend from southeast to northwest. The spatial variability of “Severe” risk at monthly time scale (Fig. 7b) shows a similar pattern with Fig. 8a, reaching its maximum values in northwestern area. And Fig. 8b generally reveals an upward trend of “Severe” risk from north to south as “Extreme” charts Fig. 7a and 9a. Other than that, “Severe” risks at annual time scale (Fig. 9b) reveal two centers of high risk values—northwest corner and part of the central areas. From spatial distributions of the mean point drought risks of “Extreme” and “Severe” in study period, we can generally conclude that southern and northwestern parts of the basin tended to face a larger risk of extreme and severe drought events at the three time scales. However, very different distributions can be observed from “Moderate” maps. Figure 8c displays an upward trend of “Moderate” risk from southwest to northeast, and the highest risk values emerge in the eastern and northeastern parts respectively in Figs. 7c and 9c, which suggests that moderate drought was more likely to occur in these two parts of the basin.

Spatial distribution of mean point drought risks based on SPI-1. a Extreme, b severe, c moderate

Spatial distribution of mean point drought risks based on SPI-3. a Extreme, b severe, c moderate

Spatial distribution of mean point drought risks based on SPI-12. a Extreme, b severe, c moderate
5 Conclusions and discussion
The main objective of this research was to develop a scheme for analyzing meteorological drought condition at multiple temporal and spatial scales based on a spatial interpolation of the SPIs of observed station data in the study basin. The results of cross validation suggest that the proposed Bayesian interpolation method is an effective approach for identifying drought severity at ungauged grids. Besides the satisfying accuracy, the main merit of the method is the probabilistic interpretation of outcome. Compared with other deterministic approaches, the probabilistic results of drought risk on various severity degrees can provide a more insightful view for the reliability of the quantification and ranking of drought characteristics, which is inevitably limited by data quality and interpolation accuracy. For point drought evaluation, a higher risk value of the dominating drought degree suggests a higher reliability of drought ranking. At regional scale, the spatially averaged drought risks also reflect the spatial coherence of drought severity.
Temporal and spatial characteristics of drought risks at various temporal and spatial scales were evaluated in four severity categories including extreme, severe, moderate and non drought. Results of regional drought risks indicate that time behaviors of “Extreme” and “Severe” risks at seasonal scale (PB-3) have showed more notable variation than that at monthly and annual scales. The maximum value of “Extreme” risk (0.8242) in the basin was also observed in PB-3 series. The trend tests did not reveal many significant trends with a significance level of 5 %. The three PB series generally displayed a consistent result of decreasing “Extreme” risks and increasing “Moderate” risks, but failed to pass the significance test except a downward trend of “Extreme” risks in PB-3. However, more significant trends were found when we examined the records of each month separately. The three upward trends of “Moderate” or “Severe” risk at various time scales and one downward trend of “Non” risks at seasonal scale suggested that more attention should be paid on drought management in April and September.
The results of RDR assessment further demonstrate that drought at seasonal scale played a more threatening role than the other two time scales in study period, with five extreme droughts, 21 severe droughts and 151 moderate droughts. In terms of annual scale, dry events clearly exhibited stronger persistence though fewest droughts were detected without any of them reaching “extreme” severity. Six dry periods altogether were detected from RDR-12, in which the basin suffering from drought durations longer than 10 months.
As far as the influencing range of drought was concerned, behaviors of PB series indicate that an extreme drought spanning the entire basin never occurred during the study period, but meanwhile droughts influencing the entire basin with spatially various severities have occurred in 52, 86 and 6 months derived from monthly, seasonal and annual time scales respectively. The results of mean point drought risks have also revealed a variable spatial distribution of drought risks during the analyzed period. Generally, there were larger risks of extreme and severe drought in southern and northwestern parts of the basin while northeastern areas tended to face larger risks of moderate drought.
The case study in Huai River basin suggests that the proposed approach is a viable and flexible tool for assessing and monitoring meteorological drought at various temporal and spatial scales. Drought condition explained by risks of various severity degrees instead of single state can serve as a helpful reference for regional drought management and water resources planning. Nevertheless, it should be kept in mind that drought evaluation is vitally relied on the integrity and validity of observed data and results can be highly diverse up to the subjective definition of drought severity, which requires cautious treatment in applications.
References
Akhtari R, Morid S, Mahdian MH, Smakhtin V (2009) Assessment of areal interpolation methods for spatial analysis of SPI and EDI drought indices. Int J Climatol 29:135–145. doi:10.1002/joc.1691
Blenkinsop S, Fowler HJ (2007) Changes in drought frequency, severity and duration for the British Isles projected by the PRUDENCE regional climate models. J Hydrol 342:50–71
Chang TJ (1991) Investigation of precipitation droughts by use of kriging method. J Irrig Drain E 117(6):935–943
Dai A, Trenberth KE, Qian T (2004) A global data set of Palmer Drought Severity Index for 1870–2002: relationship with soil moisture and effects of surface warming. J Hydrometeorol 5:1117–1130
Edwards DC, McKee TB (1997) Characteristics of 20th century drought in the United States at multiple timescales. Colorado State University Fort Collins, Climatology Report No. 97-2
Goovaerts P (1997) Geostatistics for natural resources evaluation. Oxford University Press, New York
Guttman NB (1998) Comparing the palmer drought severity index and the standardized precipitation index. J Am Water Resour Assoc 34(1):113–121
Hayes MJ, Svoboda M, Wilhite DA, Vanyarkho O (1999) Monitoring the 1996 drought using the SPI. Bull Am Meteorol Soc 80:429–438
Karamouz M, Torabi S, Araghinejad S (2007) Case study of monthly regional rainfall evaluation by spatiotemporal geostatistical method. J Hydrol Eng 12(1):97–108
Kendall MG (1975) Rank correlation methods. Griffin, London
Łabędzki L (2007) Estimation of local drought frequency in central Poland using the standardized precipitation index SPI. Irrig Drain 56:67–77
Le ND, Sun W, Zidek JV (1997) Bayesian multivariate spatial interpolation with data missing by design. J R Stat Soc B 59(2):501–510
Loukas A, Vasiliades L (2004) Probabilistic analysis of drought spatiotemporal characteristics in Thessaly region, Greece. Nat Hazard Earth Syst 4:719–731
Ma Z, Fu Z (2007) The global drying fact in latter half century of 20th and its relationship with large-scale background. Sci China Ser D 37(2):222–233
Mann HB (1945) Nonparametric tests against trend. Econometrica 13(3):245–259
McKee TB, Doesken J, Kleist J (1993) The relationship of drought frequency and duration to time scales. In: Proceedings of the 8th conferrence on applied climatology, vol 17. American Meteorological Society, Boston, pp 179–184
Mishra AK, Desai VR (2005) Drought forecasting using stochastic models. Stoch Environ Res Risk Assess 19:326–339
Moody J, Darken C (1989) Fast learning in networks of locally tuned processing units. Neural Comput 1(2):281–294
Raziei T, Saghafian B, Paulo AA, Pereira LS, Bordi I (2009) Spatial patterns and temporal variability of drought in western Iran. Water Resour Manag 23:439–455
Rhee J, Carbone GJ, Hussey J (2008) Drought index mapping at different spatial units. J Hydrometeorol 9(6):1523–1534
Shin HS, Salas JD (2000) Regional drought analysis based on neural networks. J Hydrol Eng 5(2):145–155
Smakhtin VU, Hughes DA (2007) Automated estimation and analyses of meteorological drought characteristics from monthly rainfall data. Environ Model Softw 22:880–890
Strzepek K, Yohe G, Neumann J, Boehlert B (2010) Characterizing changes in drought risk for the United States from climate change. Environ Res Lett. doi:10.1088/1748-9326/5/4/044012
Subash N, Ram Mohan HS (2011) Trend detection in rainfall and evaluation of standardized precipitation index as a drought assessment index for rice–wheat productivity over IGR in India. Int J Climatol 31:1694–1709. doi:10.1002/joc.2188
Sylla MB, Gaye AT, Jenkins GS, Pal JS, Giorgi F (2010) Consistency of projected drought over the Sahel with changes in the monsoon circulation and extremes in a regional climate model projections. J Geophys Res. doi:10.1029/2009JD012983
Tase N (1976) Area-deficit-intensity characteristics of drought. Dissertation, Colorado State University
Vermes L (1998) How to work out a drought mitigation strategy. ICID Guide, 309/1998, Bonn
Vicente-Serrano SM (2006) Differences in spatial patterns of drought on different time scales—an analysis of the Iberian peninsula. Water Resour Manag 20:37–60
Wang G (2005) Agricultural drought in a future climate: results from 15 global climate models participating in the IPCC 4th assessment. Clim Dyn 25:739–753
Wang D, Hejazi M, Cai X, Valocchi AJ (2011) Climate change impact on meteorological, agricultural, and hydrological drought in central Illinois. Water Resour Res. doi:10.1029/2010WR009845
Wilhite DA, Glantz MH (1985) Understanding the drought phenomenon: the role of definitions. Water Int 10:111–120
Wu H, Svoboda MD, Hayes MJ, Wilhite DA, Wen F (2007) Appropriate application of the standardized precipitation index in arid locations and dry seasons. Int J Climatol 27:65–79. doi:10.1002/joc.1371
Yue S, Pilon P, Cavadias G (2002) Power of the Mann–Kendall and Spearman’s rho tests for detecting monotonic trends in hydrological series. J Hydrol 259:254–271
Acknowledgments
This work was jointly supported by the Major Program of National Natural Science Foundation of China (51239004), the National Basic Research Program of China (2010CB951102) and the National Natural Science Foundation of China (51009150). The authors are grateful to Doctor David Emanuel from University of California Davis and three anonymous reviewers for their helpful comments that substantially improved the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Duan, K., Xiao, W., Mei, Y. et al. Multi-scale analysis of meteorological drought risks based on a Bayesian interpolation approach in Huai River basin, China. Stoch Environ Res Risk Assess 28, 1985–1998 (2014). https://doi.org/10.1007/s00477-014-0877-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-014-0877-4