
Abstract
Facial expression recognition has been widely used in lots of fields such as health care and intelligent robot systems. However, recognizing facial expression in the wild is still very challenging due to variations, light intensity, occlusions and the ambiguity of human emotion. When training samples cannot include all these environments, the classification can easily lead to errors. Therefore, this paper proposes a new heuristic objective function based on the domain knowledge so as to better optimize deep neural networks for facial expression recognition. Moreover, we take the specific relationship between the facial expression and facial action units as the domain knowledge. By analyzing the mixing relationship between different expression categories and then enlarging the distance of easily confused categories, we define a new heuristic objective function which can guide deep neural network to learn better features and then improve the accuracy of facial expression recognition. The experimental results verify the effectiveness, universality and the superior performance of our methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Facial expression plays an essential role in human’s daily life. Facial Expression Recognition(FER) is crucial in real-world applications, such as service robots, driver fragile detection and human computer interaction[1]. Recently, with the large-scale databases (AffectNet [2], RAF-DB [3], SFEW [4], FER2013 [5], FER2013plus [6], EmotionNet [7], etc.), many deep learning approaches for FER [8,9,10,11,12] have been proposed and achieved promising performance. For example, recently proposed TransFER[60] obtains the nice performance which uses complex Transformer to learn different relation-aware local representation. However, their accuracies are greatly affected in the wild. For example, face images may be different from the age, race, gender, culture. Images from the same person still have changes in posture, occlusion, light intensity and other factors. On the other hand, the training samples have quality problems. For example, the data set collected from the Internet has the problem of the imbalanced categories and unconspicuous characteristics. That is because of the small difference between categories and difficult labeling, which leads to the low recognition efficiency of the model.
Facial expression is usually expressed in two ways: the basic expression classification (Anger, Disgust, Fear, Happy, Sad and Surprise), and the face action units (AUs) [13]. The former is common and easy to understand the expression of face behavior. The latter comes from Facial Action Coding System (FACS) [14], which is the domain knowledge resulted from human expert research. The facial action units could more subtly describe the action information of the local area of the face. It is not difficult to understand that the basic expression describes the facial behavior in a global way, while the facial action units describe the local changes of the facial muscle, which shows that the facial expression has a strong correlation and dependence with the facial action units. They are called domain knowledge. For example, as shown in Fig. 1, when action units with “Eyebrows together and down” and “Lips closed and down” are detected, it is most likely an “Angry”. Besides, the facial expression is more likely to be a “Surprise”, if “Eyebrows rose and wide-eyed” and “Mouth open without stretching” action units are detected. Therefore, modeling the relationship between facial action units and facial expressions is inevitably beneficial to improve the performance of facial expression recognition, especially for those expressions with highly uncertain or ambiguous.

Examples of the correlation between facial expression and action units
Thus, this paper uses the relationship between facial expression and facial action units to define new heuristic objective functions to guide neural network learning so as to complete facial expression recognition more robustly and accurately. Usually, the distance between samples with the same expression category should be closer. However, when the learned expression features are fuzzy, distance among some samples may be far, which may lead to classification errors. In such case, just using universal classification loss function (Cross-Entropy Loss) [15] to guide the neural network learning, the classification model may make mistakes when classifying these samples. Obviously, choosing a more appropriate objective function is very critical. Using the domain knowledge of facial expression, the objective function can be defined with the experience summarized by human beings so as to guide the model learning more reasonably and efficiently, and then improve the accuracy of facial expression recognition. The main contributions are summarized as follows:
-
1.
Based on the facial action coding system as the domain knowledge, relationships between expression categories and facial action units are established. Subsequently, the connection between expression and expression can be inferred and used. The neglect of this connection is one of the important reasons for the errors in the classification of current models.
-
2.
A new heuristic objective function based on the facial expression domain knowledge is proposed. Its aim is to guide the model to widen the distance among samples from different categories, which makes the model better classify samples.
-
3.
On the standard databases, we compare our method with existing deep learning models to verify the universality, effectiveness and superiority of the proposed method.
The remainder chapters are introduced as follows: Sect. 2 introduces the related works of domain knowledge FER. Section 3 represents the proposed method in detail. The experimental results and analysis are introduced in Sect. 4. Finally, the conclusions are given in Sect. 5.
2 Related work
In this section, we discuss details of the deep learning techniques for facial expressions recognition based on domain knowledge as well as the related loss functions.
2.1 FER based on domain knowledge
Domain knowledge is the knowledge related to current tasks that machine learning methods aim to solve[16]. Facial expression recognition tasks also have the domain knowledge that can be used to improve the accuracy of machine learning. For example, there is a certain connection between the facial action units. According to FACS, action units such as Brow Lowerer (AU4) and Lid Tightener (AU7) appear when “Anger” occurs. Check Raiser (AU6) and Outer Brow Raiser (AU12) usually appear with “Happy,” which are domain knowledge. In addition, the connection with the characteristics between expression and identity information in psychology [17,18,19], and in Micro Expression is established, while the correlation characteristics of expressions have been also built[20]. Currently, researches have used these domain knowledge for facial expression recognition in [21,22,23,24,25,26,27]. For example, Pu et al.[28] exploited AU and expressions to mine useful local AU information so as to enhance image feature learning. Zhang et al.[17] suggested that identity information can promote facial expression recognition, proposing an identity-expression two-branching network model for facial expression recognition. He et al.[29] proposed a method for facial expression and AUs recognition based on the graph convolutional network [30] by exploiting the dependence between expression and AU. Wen et al.[31] observed the mixing relationship among expression categories from the confusion matrix, proposed a domain information loss function and achieved dynamic objective learning. Different from the method proposed in [31], this paper deduces the connection with expression according to the relationship between expression categories and facial action units. Finally, we design the heuristic objective function of facial expression recognition based on domain knowledge to guide the model training.
2.2 Loss function
Deep neural networks require a loss function to guide model learning. At present, there are many loss functions, such as Cross-Entropy Loss [15], Contrast Loss [32], Center Loss [33], Triplet Loss [34], and so on. Recently, Softmax Loss [35] and Cross-Entropy Loss in facial expression recognition have commonly been applied. In addition, new loss functions for facial expression recognition tasks have been proposed for the moment. For instance, Large-Margin Softmax loss [36] clearly guides model learning, which makes the class more compact and more separable. As an auxiliary loss function, the Center Loss is usually used in combination with the Softmax Loss, which can further reduce the intra-class distance of the same class of expression features and at the same time, keep the different categories of characteristics distinguishable. To make the features learn the more separable angular features, SphereFace Loss [37] improves on Softmax Loss, which makes the weight normalization and the deviation is set to zero. CosFace Loss [38] considers the features which are placed as one for normalization. But if the value is too small, it will cause the training loss to be too large. Thus, the scaling factor and the punishment factors are introduced, which obtain more separable features. ArcFace Loss [39] places the penalty on the angle, and then constraints the classification boundary in the angular space directly. The domain information loss [31] considers the domain information from the perspective of the confusion matrix, making the model learning more targeted.
Our method differs from the above ones, which proposes a new loss function through redefined facial expression mix relationship domain knowledge. With the center of the same sample as a positive example and easy to mix recognition as a negative example, we choice these as a new defined loss input to enlarge the distance among the classification and close the distance among the expression of the same category.
3 Proposed method
Based on expression category and facial action units domain knowledge, we propose a new heuristic objective function, which makes each sample distance from the class center as small as possible and at the same time, away from its confused other expression class center distance. So learning features can make the mixed expression category distance of samples increase so as to improve the deep neural network model generalization ability and robustness.
3.1 Domain knowledge of expression and AUs
Expression is the overall effect of facial movements. It is generally believed that the six basic expressions can be described by AUs unrelated to age, race, and culture [40]. Take “happy” for example, Cheek Raiser (AU6) and Lip Comer Puller (AU12) appear simultaneously to produce happy expression, as shown in Fig. 2. According to FACS, Ekman gives a correspondence between AUs and basic expression categories as shown in Table 1 [41, 42]. It is not difficult to find that the relationship among categories of expression can be indirectly inferred through the relationship between expression and AUs. In fact, some emotions are easy to recognition such as happy and disgust whose AUs are not the same. However, another some emotions are difficult to be distinguished such as surprise and fear, which are also difficult even for humans. Meanwhile, their AUs have an intersection, which include AU1, AU2, and AU26. This indicates that the recognition error among expression categories easily occurs when they have AUs in common.

Relationship between facial expressions and facial action units
According to this intuition, the domain knowledge can be concluded from Table 1 that anger, fear and sad are easy to be confused, while fear, sad and surprise are also difficult to be distinguished. Moreover, it's a little hard to classify between disgust and sad. Consequently, we can obtain the easily confused relationship among five expression categories: Anger, Fear, Sad, Surprise and Disgust. The concrete mixing relationship is shown in the Expression-Expression Relationships of Fig. 3.

The heuristic objective function used for deep neural network to learn the better expression features
3.2 Heuristic objective function
With mixed relationships among expression categories as the heuristic domain knowledge, we define a new heuristic objective function that guides deep neural network learning to enlarge the distance among different expression categories and make the distance as small as possible among samples with the same expression category. The form of our loss function is similar to the triplet loss function but with different semantics. The core of Triplet Loss is sharing model with the anchor example, the positive example and the negative example[43], which the anchor sample is clustered with the positive sample, away from the negative example by model. Thus, this paper implements the heuristic objective function by improving the Triplet Loss.
In the deep neural network model, facial expression images \(x\) is mapped to the multi-dimensional Euclidean space \(f\left( x \right)\) by the constructed embedding. And our goal is mainly to optimize the feature map of facial expressions after embedding. For each training sample, heuristic objective function will get three different features through the network model, respectively, as: \(f\left( {x_{i} } \right)\)、\(f\left( {x_{i}^{s} } \right)\) and \(f\left( {x_{i}^{m} } \right)\), where \(f\left( {x_{i}^{s} } \right)\) represents the expression category center, \(f\left( {x_{i}^{m} } \right)\) corresponds to the expression category center which are easily confused (i.e., the center features of anger, fear, sad, surprise and disgust). The corresponding mixed classification is obtained from the above domain knowledge. The heuristic objective function which guides deep neural network learning aims to make the features of the training sample and the center of the same category closer and closer, while making the distance between the sample and the features of the mixed classification center as large as possible. The formula is as follows:
Heuristic objective function is defined as follows:
where \(E\left( {y_{i} } \right) \) indicates a set of labels easily mixed with \( y_{i}\) which can be easily constructed in advance according to the domain knowledge, \(B = \left\{ {x_{i} } \right\}\) is a mini-batch of training sample set, \(y_{i}\) is the category of the expression, ||.|| is the Euclidean distance, and \(\left[ {} \right]_{ + }\) represents the loss value when the value in the central bracket is greater than 0, and the loss value is 0 when the value in the central parenthesis is less than 0, \(\alpha\) is the margin parameter which is a minimum interval of the feature distances between \(x_{i}\) and \(x_{i}^{m}\) and the feature distances between \(x_{i}\) and \(x_{i}^{s}\). The role of parameter \(\alpha\) is that it widens the distances among anchor, positive picture pair and anchor, negative picture pair. Those fully conform to our motives that HO can enhance the generalization ability and robustness of the deep neural network.
In order to reach the clearer understanding of the semantics of the heuristic objective function, we present another example. In Fig. 4, anger, sad and disgust are mixed expression categories. After learning through the heuristic objective function, the spatial distribution of the samples changed. The distance of the sad samples becomes shorter, while the distance between the anger and sad samples becomes larger, making the classification more easy and increasing the generalization ability of the network model.

Example of easily mixed expressions
3.3 Application mode of the HO
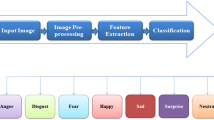
Deep neural networks used for expression recognition require loss functions to guide learning. At present, the main loss functions for FER are Softmax Loss and Cross-Entropy Loss. Clearly, more suitable loss functions would help guide deep neural networks to learn more discriminating expression features for FER. However, each loss function has its own special meaning and the solved problem, so that they have certain complementation. To validate the heuristic objective function and apply it to FER, we combine it with Cross-Entropy Loss to construct the most basic deep neural network. The basic structure is shown in Fig. 3. Because facial expression recognition is a multi-classification problem of images, the Cross-Entropy Loss objective function is usually used in the classification problems:
where \( t \) represents the number of categories, \(y_{ic}\) is a symbolic function, and \(p_{ic}\) represents the probability that the label of \(x_{i}\) is \(y_{i}\). And then the loss function of the entire neural network is the combination of Cross-Entropy Loss and heuristic objective functions as follows:
where \(\lambda\) is an adjustable nonnegative weight coefficient. Of course, not limited to Cross-Entropy Loss, there are lots of loss functions that can be combined with our heuristic objective function by various combination rules.
4 Experimental results
To evaluate the effectiveness of the proposed heuristic objective function, this paper performed extensive experiments on three famous facial expression databases. They demonstrate the universality and superiority of the proposed method by comparing with existing facial expression recognition methods.
4.1 Experimental data
RAF-DB [3] is a crowd sourced database which includes two distinct subsets, the basic one being single tagged and the compound one being double-tagged. In our experiment, a single-label subset with seven classes of basic emotions was used. The number of the training set and testing set is 12,271 images and 3068 images, respectively, and the expressions of them have near-identical distribution.
FER2013Plus[6] which is extended from FER2013[5], consists of 28,709 training facial expression images, 3589 validation images and 3589 testing images. It includes 8 classes in FER2013Plus, and contempt is introduced.
AffectNet [2] is the largest database of facial expression, with approximately 400 k manually annotated images. We choose 283,901 facial images as training set and 3500 images as testing set with the same seven basic expression as that in RAF-DB.
These datasets are illustrated in Table 2.
4.2 Implementation details
All experimental results are obtained by training the Python code on two NVIDIA GeForce RTX 3090 GPUs. We used ResNet34 as a feature extractor for facial expression images and pre-trained on ImageNet ILSVRC-2012 using Pytorch framework2. We use the stochastic gradient descent (SGD) optimizer with a momentum of 0.9 and a weight decay is set to 5e–4. Additionally, the initial learning rates of our proposed method are set to 0.01 and epoch to 100. The batch size is set as 64. The hyper-parameter \(\lambda\) is used to balance the loss function. By default, it is set as \(\lambda\) = 0.5.
4.3 Effects of the proposed loss
To validate effectiveness and universality of the proposed heuristic objective function, we apply it to lots of recent deep neural network models and then experiments are conducted on three datasets. The experimental results are shown in Table 3. The +HO represents adding the heuristic objective function to existing models. It can be seen that the overall accuracy rate has been improved in varying degrees. The average recognition accuracy on RAF-DB datasets can reach the second best result of 89.03%. The average recognition accuracy on the FER2013plus datasets and the AffectNet datasets also achieves the better performance than the baseline models.
To further analyze the effects of the heuristic objective function on different emotion categories, we present the confusion matrix of the baseline model (ResNet34) and the model with heuristic objective function, as shown in Fig. 5.

Confusion matrix analysis
It can be seen from the confusion matrix of RAF-DB datasets in Fig. 6a, b that accuracy of Anger increased from 79.33 to 87.84%, increased by 8.51%. For Fear and Sad categories, accuracy of fear increased from 28.75 to 49.38%, increased by 20.63%, and Sad from 83.26 to 84.10%, increased by 0.84%. The probability of classifying the samples of Disgust into Sad decreased from 12.16 to 10.81%. Surprise increased from 71.60 to 73.46%, increased by 1.86%. However, there are also accuracies of some categories improved and the corresponding mixed classification probabilities do not drop. On the other hand, we can find that the accuracy improvement of a single category can be as high as 20.63% (e.g., Fear), while the accuracy improvement of the total datasets is only 2.8%. The reason is the category imbalance of the datasets. As shown in Table 2, for RAF-DB datasets, the Fear has only 281 images, representing 2.29% of the total data. The confusion matrix on the FER2013plus datasets is shown by (c) and (d) in Fig. 6. The classification accuracy of the Anger was increased from 82.78 to 83.15%, up by 0.37%; The Fear class was increased from 46.99 to 53.01%, up by 6.02%. The Sad was increased from 73.96 to 74.48%, up by 0.52%. Disgust was increased from 27.78 to 33.33%, up by 5.63%. Surprise increased from 89.90 to 91.67%, up by 1.77%. A similar analysis can be performed for the confusion matrices of the AffectNet datasets as shown in Fig. 6e, f. Through these analyses, the effects of the heuristic objective function are obvious, demonstrating the effectiveness and universality of the proposed method.

The learned feature distribution of ResNet34. For a (b), 0: Anger; 1: Disgust; 2: Fear; 3: Happy; 4: Sad; 5: Surprise; 6: Neutral; for c (d), 0: Anger; 1:Contempt; 2: Disgust; 3: Fear; 4: Happy; 5: Sad; 6: Surprise; 7: Neutral
4.4 Comparison with state-of-the-art methods
In order to further validate the proposed loss function, we compare it with more state-of-the-art methods on the RAF-DB, FER2013Plus, and AffectNet. The experimental results are shown in Table 4. It can be seen from Table 4a that our proposed method can obtain the second best recognition rate (89.03%) on the superposition of the existing models. The recognition results on the FER2013Plus database are shown in Table 4b. There are eight expression categories in the FER2013Plus database. Therefore, we evaluated all methods with eight expression categories (i.e., seven basic expressions and contempt expressions). It can be seen that our proposed method achieves 89.25% recognition rate on the superposition of existing models and has the best performance on the FER2013Plus datasets. The recognition accuracy on the AffectNet is shown in Table 4c. It can be seen that our method achieved the highest recognition rate on AffectNet7 (64.02%). These results under different real-world facial expression data verify that our proposed method can obtain better facial expression recognition performance in the wild.
In addition, it can be seen from Table 5 that different base method costs different time. When HO loss is used, the time further increases but with the smaller margin. Although FDRL [49] achieves the better performance, but it costs too much time. This is why RUL [46] is selected to verify the effectiveness, universality, and the superior performance of the proposed method.
4.5 Visual analysis
To further analyze the effect of the heuristic objective function, we use the t-SNE [44] tool to visualize the samples distribution after extracting features of each image, where features are extracted, respectively, by the baseline model and model with the heuristic objective function. The aim is to prove the effectiveness of the heuristic objective function. As shown in Fig. 6, it is not difficult to find that after adding the heuristic objective function, the feature distribution of the same class of facial expressions is more compact, and the feature distribution boundary among different facial expressions is more obvious. This shows that the heuristic objective function can promote the compactness and widen the inter-class distance to some extent.
Meanwhile, we directly observe the effects of the heuristic objective function by analyzing the expression classification results of samples. We selected 12 images from RAF-DB and AffectNet datasets, as shown in Fig. 7, where labels of the first row is the true expression, labels of the second row is labels predicted by the baseline model, and labels of the third line is the predicted labels by the model with the heuristic objective function. It is not difficult to find that some of labels predicted by the baseline model are wrong, while the predicted labels are correct after adding the heuristic objective function. It indicated that the heuristic objective function has the ability to correct the easily mixed expression categories.

Visualize the results before and after the adjustment
5 Conclusion and future work
This paper proposes a new heuristic objective function based on the domain knowledge. It enlarges the distance among expression categories while narrowing the distance between expression samples of the same category. After using heuristic objective function, deep neural network can effectively alleviate the problem of inter-classification of expression recognition, which is conducive to improve the accuracy of facial expression recognition. On the other hand, the heuristic objective function is universal and can be used in most of deep neural networks for facial expression recognition. Furthermore, it can be combined with various existing loss functions in complementary way to achieve higher accuracy. However, although the experiments have proved the effectiveness of the proposed method, its effect can be further improved. The proposed heuristic objective function is based on the domain knowledge relevant to facial expression recognition. However, the domain knowledge can be obtained from diverse perspectives. In the future, the action relationship within and among expression classes will be deeply explored and then define the better heuristic objective function. Simultaneously, the connection between heuristic objective functions and existing loss functions should be exploited carefully, and then the best compositional pattern should be found for FER.
References
Sun, Y., Wen, G.: Cognitive facial expression recognition with constrained dimensionality reduction. Neurocomputing 230, 397–408 (2017)
Mollahosseini, A., Hasani, B., Mahoor, M.H.: AffectNet: a database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 10(1), 18–31 (2019)
Li, S., Deng, W., Du, J.: Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In: Proceedings of the IEEE conference on computer vision pattern recognition (CVPR), pp. 2852–2861 (2017)
Dhall, A., Goecke, R., Lucey, S., Gedeon, T.: Static facial expression analysis in tough conditions: data, evaluation protocol and benchmark. In: 2011 IEEE international conference on computer vision workshops (ICCVW) (2011)
Goodfellow, I.J., Erhan, D., Carrier, P.L., Courville, A., Mirza, M., Hamner, B., Cukierski, W., Tang, Y., Thaler, D., Lee, D.H., et al.: Challenges in representation learning: a report on three machine learning contests. In: Lee, M., Hirose, A., Hou, Z.G., Kil, R.M. (eds.) Neural information processing, pp. 117–124. Springer, Berlin (2013). https://doi.org/10.1007/978-3-642-42051-1_16
Barsoum, E., Zhang, C., Ferrer C.C., Zhang, Z.: Training deep networks for facial expression recognition with crowd-sourced label distribution. In: Proceedings of the 18th ACM international conference on multimodal interaction, pp. 279–283 (2016)
Fabian Benitez-Quiroz, C., Srinivasan, R., Martinez, A.M.: Emotionet: an accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) (2016)
Wen, G., Li, H., Huang, J., et al.: Random deep belief networks for recognizing emotions from speech signals. Comput. Intell. Neurosci. 2017, 1–9 (2017). https://doi.org/10.1155/2017/1945630
Chen, S., Wang, J., Chen, Y., Shi, Z., Geng, X., Rui, Y.: Label distribution learning on auxiliary label space graphs for facial expression recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) (2020)
Villanueva, M.G., Zavala, S.R.: Deep neural network architecture: application for facial expression recognition. IEEE Latin Am. Trans. 18(07), 1311–1319 (2020). https://doi.org/10.1109/TLA.2020.9099774
Joseph, J.L., Mathew, S.P.: Facial expression recognition for the blind using deep learning. In: 2021 IEEE 4th international conference on computing, power and communication technologies (GUCON), pp. 1–5 (2021). https://doi.org/10.1109/GUCON50781.2021.9574035.
Liu, C., Liu, X., Chen, C., Wang, Q.: Soft thresholding squeeze-and-excitation network for pose-invariant facial expression recognition. Visual Comput. (2022). https://doi.org/10.1007/s00371-022-02483-5
Jun Wang. Facial Expression and Action Unit Recognition Based on Prior Knowledge. University of Science and Technology of China, 2015.
Ekman, P., Rosenberg, E.L.: What the Face Reveals: Basic and Applied Studies of Spontaneous Expression using The Facial Action Coding System (FACS). Oxford University Press, USA (1997)
Nuanes, T., Elsey, M., Sankaranarayanan, A., Shen, J.: Soft cross entropy loss and bottleneck tri-cost volume for efficient stereo depth prediction. In: 2021 IEEE/CVF conference on computer vision and pattern recognition workshops (CVPRW), pp. 2840-2848 (2021). doi: https://doi.org/10.1109/CVPRW53098.2021.00319
Anderson, J.R., Michalski, R.S., Carbonell, J.G., et al.: Machine Learning: An Artificial Intelligence Approach. Morgan Kaufmann, Burlington (1986)
Zhang, H., Su, W., Yu, J., Wang, Z.: Identity–expression dual branch network for facial expression recognition. IEEE Trans. Cognitive Dev. Syst. 13(4), 898–911 (2021). https://doi.org/10.1109/TCDS.2020.3034807
Li, M., Hao, X., Huang, X., Song, Z., Liu, X., Li, X.: Facial expression recognition with identity and emotion joint learning. IEEE Trans. Affective Comput. 12(2), 544–550 (2021). https://doi.org/10.1109/TAFFC.2018.2880201
Chen, J., Guo, C., Xu, R., Zhang, K., Yang, Z., Liu, H.: Toward children’s empathy ability analysis: joint facial expression recognition and intensity estimation using label distribution learning. IEEE Trans. Industr. Inf. 18(1), 16–25 (2022). https://doi.org/10.1109/TII.2021.3075989
Zhang, T., et al.: Cross-database micro-expression recognition: a benchmark. IEEE Trans. Knowl. Data Eng. 34(2), 544–559 (2022). https://doi.org/10.1109/TKDE.2020.2985365
Wang, J., et al.: Capture expression-dependent AU relations for expression recognition. In: 2014 IEEE international conference on multimedia and expo workshops (ICMEW) IEEE (2014)
Wang, Z., Chen, T., Ren, J., Yu, W., Cheng, H., Lin, L.: Deep reasoning with knowledge graph for social relationship understanding. In Proceedings of the international joint conference on artificial intelligence, pp. 2021–2028 (2018)
Chen, T., Yu, W., Chen, R., Lin, L.: Knowledge-embedded routing network for scene graph generation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6163–6171 (2019)
Chen, T., Xu, M., Hui, X., Wu, H., Lin, L.: Learning semanticspecific graph representation for multi-label image recognition. In: Proceedings of the IEEE international conference on computer vision, pp. 522–531 (2019)
Xie, Y., Chen, T., Pu, T., Wu, H., Lin, L.: Adversarial graph representation adaptation for cross-domain facial expression recognition. In: Proceedings of the 28th ACM international conference on multimedia, pp. 1255–1264 (2020)
Chen, T., Pu, T., Xie, Y., Wu, H., Liu, L., Lin, L.: Cross-domain facial expression recognition: a unified evaluation benchmark and adversarial graph learning. IEEE Trans Pattern Anal. Mach. Intell. (2020). https://doi.org/10.1109/TPAMI.2021.3131222
Chen, T., Lin, L., Hui, X., Chen, R., Wu, H.: Knowledge-guided multi-label few-shot learning for general image recognition. IEEE Trans. Pattern Anal. Mach. Intell. (2020). https://doi.org/10.1109/TPAMI.2020.3025814
Pu, T., Chen, T., Xie, Y., Wu H., Lin, L.: AU-expression knowledge constrained representation learning for facial expression recognition. In: 2021 IEEE international conference on robotics and automation (ICRA), pp. 11154-11161 (2021). https://doi.org/10.1109/ICRA48506.2021.9561252.
He, J., Xiaocui, Y., Sun, B., Lejun, Y.: Facial expression and action unit recognition augmented by their dependencies on graph convolutional networks. J. Multimodal User Interfaces 15(4), 429–440 (2021). https://doi.org/10.1007/s12193-020-00363-7
Jin, X., Lai, Z., Jin, Z.: Learning dynamic relationships for facial expression recognition based on graph convolutional network. IEEE Trans. Image Process. 30, 7143–7155 (2021). https://doi.org/10.1109/TIP.2021.3101820
Wen, G., Chang, T., Li, H., Jiang, L.: Dynamic objectives learning for facial expression recognition. IEEE Trans. Multimedia 22(11), 2914–2925 (2020). https://doi.org/10.1109/TMM.2020.2966858
Pan, H., Han, H., Shan, S., Chen, X.: Mean-variance loss for deep age estimation from a face. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5285–5294 (2018)
Wen, Y., Zhang, K., Li, Y., Qiao, Y.: A discriminative feature learning approach for deep face recognition. In: Leibe, Bastian, Matas, Jiri, Sebe, Nicu, Welling, Max (eds.) Computer vision – ECCV 2016: 14th european conference, Amsterdam, The Netherlands, October 11–14, 2016, proceedings, Part VII, pp. 499–515. Springer International Publishing, Cham (2016). https://doi.org/10.1007/978-3-319-46478-7_31
Sandhya, M., Morampudi, M.K., Pruthweraaj, I., et al.: Multi-instance cancelable iris authentication system using triplet loss for deep learning models. Vis. Comput. (2022). https://doi.org/10.1007/s00371-022-02429-x
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp. 770–778 (2016)
Wang, F., Cheng, J., Liu, W., Liu, H.: Additive margin softmax for face verification. IEEE Signal Process. Lett. 25(7), 926–930 (2018)
Liu, W., Wen, Y., Yu, Z., et al.: Sphereface: deep hypersphere embedding for face recognition. In: Honolulu: IEEE conference on computer vision and pattern recognition (2017)
Wang, H., Wang, Y., Zhou, Z., et al.: Cosface: large margin cosine loss for deep face recognition. In: Salt Lake City: IEEE conference on computer vision and pattern recognition (2018)
Deng, J., Guo, J., Stefanos, Z.: Arcface: additive angular margin loss for deep face recognition. In: Seattle: IEEE/CVF conference on computer vision and pattern recognition (2019)
Shan, L., Deng, W.: Deep facial expression recognition: a survey. IEEE Trans. Affective Comput. (2018). https://doi.org/10.1109/TAFFC.2020.2981446
Ekman, P., Friesen, W.V.: Constants across cultures in the face and emotion[J]. J. Pers. Soc. Psychol. 17(2), 124–129 (1971)
Ekman, P., Friesen, W.V.: Facial Action Coding System (FACS)[M]. Consulting Psychologists Press (1978)
Zhu, D., Tian, G., Zhu, L., Wang, W., Wang, B., Li, C.: LKRNet: a dual-branch network based on local key regions for facial expression recognition. Signal Image Video Process. 15(2), 263–270 (2020). https://doi.org/10.1007/s11760-020-01753-w
Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. J. Mach. Learn. Res. 9(11), 2579–2605 (2008)
Wang, K., Peng, X., Yang, J., Lu, S., Qiao, Y.: Suppressing uncertainties for large-scale facial expression recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6897–6906 (2020)
Zhang, Y., Wang, C., Deng, W.: Relative uncertainty learning for facial expression recognition. NeurIPS 34, 17616–17627 (2021)
Zhao, Z., Liu, Q., Wang, S.: Learning deep global multi-scale and local attention features for facial expression recognition in the wild. IEEE Trans. Image Process. 30, 6544–6556 (2021). https://doi.org/10.1109/TIP.2021.3093397
Wang, K., Peng, X., Yang, J., Meng, D., Qiao, Yu.: Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 29, 4057–4069 (2020)
Ruan, D., Yan, Y., Lai, S., et al.: Feature decomposition and reconstruction learning for effective facial expression recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 7660–7669 (2021)
She, J., Hu, Y., Shi, H., Wang, J., Shen, Q., Mei, T.: Dive into ambiguity: latent distribution mining and pairwise uncertainty estimation for facial expression recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6248–6257 (2021)
Zhao, Z., Liu, Q., Zhou, F.: Robust lightweight facial expression recognition network with label distribution training. In: Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 4, pp. 3510–3519 (2021)
Ma, F., Sun, B., Li, S.: Facial expression recognition with visual transformers and attentional selective fusion. IEEE Trans. Affective Comput. (2021). https://doi.org/10.1109/TAFFC.2021.3122146
Albanie, S., Nagrani, A., Vedaldi, A., Zisserman, A.: Emotion recognition in speech using crossmodal transfer in the wild. In: Proceedings of the 26th ACM international conference on Multimedia, pp. 292–301 (2018)
Lian, Z., Li, Y., Tao, J., Huang, J., Niu, M.: Region based robust facial expression analysis. In: 2018 First Asian conference on affective computing and intelligent interaction (ACII Asia), pp. 1–5. IEEE (2018)
Li, M., Xu, H., Huang, X., Song, Z., Liu, X., Li, X.: Facial expression recognition with identity and emotion joint learning. IEEE Trans. Affect. Comput. 2, 71 (2018)
Chen, S., Wang, J., Chen, Y., Shi, Z., Geng, X., Rui, Y.: Label distribution learning on auxiliary label space graphs for facial expression recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13984–13993 (2020)
Vo, T.-H., Lee, G.-S., Yang, H.-J., Kim, S.-H.: Pyramid with super resolution for in-the-wild facial expression recognition. IEEE Access 8(131), 988–132001 (2020)
Darshan Gera, S., Balasubramanian, A.J.: CERN: compact facial expression recognition net. Pattern Recognit. Lett. 155, 9–18 (2022). https://doi.org/10.1016/j.patrec.2022.01.013
Chen, B., Guan, W., Li, P., Ikeda, N., Hirasawa, K., Huchuan, L.: Residual multi-task learning for facial landmark localization and expression recognition. Pattern Recognit 115, 107893 (2021). https://doi.org/10.1016/j.patcog.2021.107893
Xue, F., Wang, Q., Guo, G.: Transfer: learning relation-aware facial expression representations with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision (ICCV), pp. 3601–3610 (2021)
Acknowledgements
This study was supported by National Natural Science Foundation of China (Grant Nos. 62006049, 62176095, 62172113 and 62072123), Guangdong Province Key Area R&D Plan Project (Grant No. 2020B1111120001), Guangzhou Science and Technology Planning Project (Grant No. 201803010088), Ministry of Education Humanities and Social Science project (Grant No. 18JDGC012).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, H., Xiao, X., Liu, X. et al. Heuristic objective for facial expression recognition. Vis Comput 39, 4709–4720 (2023). https://doi.org/10.1007/s00371-022-02619-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-022-02619-7