
Abstract
In order to improve the detection accuracy of the network, it proposes multi-scale feature fusion and attention mechanism net (MFANet) based on deep learning, which integrates pyramid module and channel attention mechanism effectively. Pyramid module is designed for feature fusion in the channel and space dimensions. Channel attention mechanism obtains feature maps in different receptive fields, which divides each feature map into two groups and uses different convolutions to obtain weights. Experimental results show that our strategy boosts state-of-the-arts by 1–2% box AP on object detection benchmarks. Among them, the accuracy of MFANet reaches 34.2% in box AP on COCO dataset. Compared with the current typical algorithms, the proposed method achieves significant performance in detection accuracy.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Object detection refers to a type of computer vision technology that can classify and locate objects. It is widely used in many fields, such as face recognition [1], gait recognition [2], tracking [3], and crowd counting [4,5,6]. Traditional object detection [7, 8] requires manual feature extraction, which is difficult to obtain robust characteristics and very sensitive to external environmental noise.
With the development of deep learning and the progress of hardware, object detection algorithms based on convolutional neural networks (CNN) develop rapidly. They are mainly divided into two-stage and single-stage algorithms. The two-stage detection algorithm first generates a region proposal, then classifies and calibrates the candidate regions, and obtains the final detection result. Gkioxari [9] proposed RCNN in 2015, which finds the boxes that may contain objects according to the region proposal. Then, the method predicts the bounding box offset and classifies each region. In 2017, Faster-RCNN [10] introduced a Region Proposal Network (RPN) that shares features with the detection network. And it realizes nearly cost-free region proposals. Cai et al. [11] proposed Cascade-RCNN in 2018, which uses different IoU thresholds to divide positive and negative samples, and makes the detector of each stage focus on detecting the proposal of the IoU in a certain range.D2Det [12] introduced a dense local regression that predicts multiple dense box offsets for an object proposal in 2020. Sun et al. [13] proposed Sparse R-CNN in 2021, which uses a fixed number of learnable boxes to replace anchors. These two-stage algorithms have higher detection accuracy. But they have slower detection speed than the single-stage algorithm.
The single-stage detection algorithm directly gives the final detection result without generating candidate boxes. In 2016, YOLO [14] was proposed to frame the object detection as a regression problem. It uses the image as input to directly implement object location regression and classification. SSD [15] was introduced to output a set of default boxes with different aspect ratios at each feature map location. In 2019, Tian et al. [16] proposed FCOS. And the algorithm completely avoids the complex calculations related to the anchors by eliminating the pre-defined anchors. RepPoints [17] learns the offset of deformable convolutions through direct supervision of localization and classification and generates pseudo-boxes by sampling points. LIN et al. [18] designed RetinaNet based on FocalLoss in 2020, which can address the class imbalance. PAA [19] proposes a probabilistic model for assigning labels to anchors in view of the assignment of anchor labels in the current anchor-based model. In 2021, VFNet [20] proposed IoU-aware classification score (IACS) to classify detection, and it combines varifcoal loss, star-shaped bounding box and bounding box refinement to improve detection accuracy. Chen et al. [21] proposed YOLOF, which uses an expansion encoder and unifies matching to narrow the performance gap between SISO and MIMO encoder. The single-stage object detection algorithm does not have a region proposal process. It only needs to be sent to the network once to predict all bounding boxes. The speed is relatively fast, and the number of parameters is small, but the accuracy is lower than the two-stage algorithm.
The ATSS [22] is a one-stage object detection algorithm. The network consists of three parts: backbone, neck and heads. Backbone uses a classification network that removes the fully connected layer to extract image features. Neck is used for feature fusion to achieve multi-scale detection of objects, which adopts the feature pyramid network (FPN) to fuses deep feature maps with low-level feature maps through upsampling to obtain rich semantic information. In order to better calculate the classification and regression loss, heads adopt an adaptive sample selection method to realize the classification and regression of objects.
We believe that FPN only performs feature fusion in the spatial dimension, and this fusion method will lead to the loss of semantic information. Therefore, the paper proposes multi-feature fusion network with attention mechanism (MFANet)-based ATSS. It proposes feature fusion to obtain rich semantic features and adopts a channel attention mechanism to strengthen important features and suppress non-important features. The major contributions of this study can be summarized as follows:
(1) Multi-scale feature fusion uses upsampling and compression operations in the two dimensions of space and channel to fuse feature maps of different sizes. Finally, feature maps of different dimensions are added to obtain rich semantic features.
(2) The attention mechanism obtains feature maps of different receptive fields to get rich contextual information. It divides each feature map into two groups, and realizes channel attention learning of local cross-channel interaction without dimensionality reduction by one-dimensional convolution.
(3) It has achieved remarkable results on the Ms CoCo2017 dataset and PASCAL VOC Datasets.
2 Related work
2.1 Multi-scale feature fusion
To solve the problem of predicting objects of different sizes, Lin et al. [23] proposed the famous feature pyramid network (FPN). And the basic idea is to combine the fine-grained spatial information of the shallow feature map and the semantic information of the deep feature map to detect multi-scale objects. On this basis, many researchers have proposed improved FPN structures. Liu et al. [24] proposed PANet, which first uses up-sampling to fuse feature maps of different sizes and then performs down-sampling feature fusion. NAS-FPN [25] is a combination of top-down and bottom-up connections, which can be integrated across a range. AugFPN [26] uses consistent supervision, residual feature augmentation and soft RoI selection modules for FPN defects. BiFPN [27] performs weight fusion of features to learn the importance of different input features. Qiao et al. [28] proposed Recursive-FPN, which inputs the output of traditional FPN to backbone for a second cycle.
These modules only effectively integrate features in the spatial dimension. The information between different channels may be correlated or redundant. Therefore, we propose the multi-dimensional feature pyramid network (MFPN), which adds a branch to fuse feature in the channel dimension. The branch compresses all channel information together and performs semantic fusion and finally obtains rich semantic spatial information.

Illustration of the proposed MFANet

The proposed MFPN module
2.2 Attention mechanism
The attention mechanism originates from the study of human vision. And it was first applied in the field of natural language to realize the efficient allocation of information processing resources. In recent years, the attention mechanism has been rapidly developed in the field of computer vision. In 2018, Hu et al. [29] proposed SENet, which implements the channel attention mechanism through three parts: squeeze, incentive, and scale. In 2018, non-local neural networks were proposed [30] to compute the response at the current area as a weighted sum of the global area. DANet [31] was proposed to use a dual attention network to adaptively integrate local features and global dependencies in 2019. And two types of attention modules are added to the traditional expanded FCN to simulate the semantic interdependence in space and channel dimensions, respectively. In 2020, ASNet [32] introduced a density attention network, and it can provide ASNet with attention masks of different density levels. In 2021,Hou et al. [33] proposed coordinate attention. It captures not only cross-channel information, but also direction-aware and position-sensitive information, which enables the model to more accurately locate and identify the target area.
To show the correlation between different channels, it should strengthen important features and suppress non-important features. This paper proposes multi-receptive field attention mechanism (MFA). It uses 4 parallel branches of different receptive fields. Each branch is divided into two groups, which uses different convolution kernels to obtain channel weights.
3 Our approach
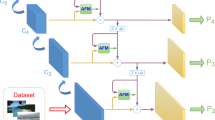
MFANet consists of three parts: backbone, neck and heads. The backbone uses resnet50, which is used to extract the features of the image. Neck is used to connect backbone and heads. And it is used to fuse features of different sizes. Heads are used for object detection to achieve object classification and regression. The loss function is divided into classification loss, regression loss and center loss. The classification loss function adopts FocalLoss, the regression loss adopts GIoULoss, and the center loss adopts CrossEntropyLoss. The network structure is shown in Fig. 1.

The proposed MFA module

The structure of extract module
3.1 MFPN
The MFPN module is shown in Fig. 2. \( [c_{3},c_{4},c_{5}],c\in R^{(B,C,H,W)} \) denotes the input feature map. The sizes are \([[B,C_{3},H_{3},W_{3}],[B,C_{4},H_{4},W_{4}],[B,C_{5},H_{5},W_{5}]] \), where B, C, H, W indicate the batch size, channel size, spatial height, and width. The size of C, H, W is expressed by Equation 1.
It uses 1*1 convolution to change their channel to the same size C.
The branch1 is to conduct feature fusion in the channel dimension. First, it uses the unfold operation to change the shape of the feature maps. After that, the shape of the feature maps is \( [B,C^{'},L] \). The size of \( C^{'} \) is \( C^{'}=C*K*K \). And L is expressed by Eq. 2.
where K is the size of the convolution kernel, and \( C^{'} \) represents the size of the sliding window. The padding is the padding size, stride is the step size, and L is the number of sliding windows. Then the output is expressed by Eq. 3.
where \( W_{a} \) indicates the \( 1*1 \) convolution layer and \( F_{UF} \) is an unfold operator. Finally, the output of branch1 is expressed by Eq. 4.
where \( F_{RS} \) is a reshape operator.
The branch 2 operation is to conduct feature fusion in the spatial dimension of the feature map. \( [c^{''}3,c^{''}4,c^{''}5] \) is obtained by \( 1*1 \) convolution. The output of branch2 is expressed by Eq. 5.
where \( F_{US} \) is an upsample operator.
Finally, the feature maps of the two branches are fused to get [p3, p4, p5] , and [P3, P4, P5, P6, P7] are obtained after ablation and down-sampling.
3.2 MFA
The MFA is shown in Fig. 3. Let X denote the input feature map, its size is [B, C, H, W] , where B, C, H, W indicate the batch size, channel size, spatial height, and width, respectively.
It uses \( 1*1, 3*3, 5*5, 7*7 \) convolutions to conduct convolution on X and obtain four tensors \( [X_{1},X_{2},X_{3},X_{4}] \) with different receptive fields. The sizes are all [B, C, H, W] , then \( [X_{1},X_{2},X_{3},X_{4}] \) are added to obtain \( X_{5} \) .
It divides each tensor into two groups in the channel dimension. And the size of each group is [B, C//2, H, W] . And it uses two extract modules with different convolution kernel sizes to obtain the channel weights of each group. The convolution kernel sizes are [3,5], respectively. Then it concatenates the two groups in the channel dimension to obtain the weighs of each tensor.
The structure of the extract module is shown in Fig. 4. Let \(X_{CH}\) denote the input feature map, its size is [B, C, H, W], where B, C, H, W indicate the batch size, channel size, spatial height, and width, respectively. It obtains \(X_{a},X_{a}\in R^{(B,C,1,1)} \) by global average pooling operation. To avoid the model being too complicated, it squeezes and permutes \( X_{a} \) , then obtains \( X_{s},X_{s}\in R^{(B,1,C)} \). After that, we use convolution kernel of k*k to realize the local cross-channel interaction to get \( X_{c},X_{c}\in R^{(B,1,C)} \). \(X_{sg},X_{sg}\in R^{(B,1,C)} \) is obtained by sigmoid activation function. Finally, it unsqueezes and permutes \( X_{sg} \) and then obtains \( X_{weight},X_{weight}\in R^{(B,C,1,1)} \) .
The extract module is expressed by Eq. 6.
where \( F_{a} \) is an adaptive avg-pool operator, \( F_{sg} \) is a sigmoid operator, \( W_{1d} \)is a k*k convolution layer, \( F_{s} \) is a compression and swap operator, and \( F_{un} \) is a decompression and swap operator. The output of weigh5 is expressed by Eq. 7.
where \( F_{SP} \) is a group operator and concat is a splice operator. Finally, we fuse all channel weights and then multiply the weight by X. And it gets the output after channel shuffle. The output of MFA is expressed by Eq. 8.
where \( F_{cs} \) is channel shuffle operator and \( \odot \) is a multiplication operator.
Channel shuffle operator is to integrate channels without increasing the amount of calculation. It is to expand \( X,X\in R^{(B,C,H,W)} \) into \( X_{cs},X_{cs}\in R^{(B,G,C//G,H,W)} \) and then reshapes \( X_{cs} \) to get \( X_{sc},X_{sc}\in R^{(B,C//G,G,H,W)} \). Finally, it is restored to \( X,X\in R^{(B,C,H,W)} \) to achieve global channel information interaction.
4 Experiments
4.1 PASCAL VOC datasets
The PASCAL VOC 2007 and 2012 datasets are divided into four major categories: vehicle, household, animal, and person, and a total of 20 sub-categories (21 categories with background), respectively. PASCAL VOC 2007 object detection consists of 2501 training images, 2510 verification images, 5011 trainval images and 4952 test images. PASCAL VOC 2012 object detection consists of 5717 training images, 5823 verification images, 11540 trainval images and 11540 test images.
4.2 Ms CoCo2017 dataset
The Ms CoCo2017 dataset contains a total of 80 categories for detection. It is a large and rich object detection, segmentation and captioning dataset, which contains four files: annotations, test2017, train2017, and val2017. Among them, train2017 contains 118287 images, val2017 contains 5000 images, and test2017 contains 28660 images. Annotations are a collection of annotation types: object instances , object keypoints and image captions , which are stored in json files.
4.3 Experimental environment
CPU: Intel Xeon E5-2683 V3@2.00GHz; RAM: 32 GB; Graphics card: Nvidia GTX 1080Ti; Hard disk: 500GB.
It built a Python compilation environment with PyTorch1.6.0, torchvision = 0.7.0, CUDA10.0, and CUDNN7.4 as the deep learning framework, and implemented it on the platform mmdetection2.6.
4.4 Experimental strategy
It adjusts the size of all images to \(512 \times 512\) for multi-scale training and uses data enhancement to perform various operations on the image dataset. Limited by experimental equipment, all algorithms use resnet50 as the backbone network. The SGD optimizer is adopted, the learning rate is 0.001, the momentum is 0.9, the weight decay is 0.0001, the learning rate adopts a step adjustment strategy, and the iteration period is 12 epochs.
For PASCAL VOC datasets, the evaluation standard of the experiment adopts mAP. For Ms CoCo2017 dataset, the evaluation standard of the experiment adopts average precision (Average-Precision, AP),\( AP_{50} \), \( AP_{75} \), \( AP_{S} \), \( AP_{M} \), \( AP_{L} \) as the main evaluation standards.
4.5 Ablation study
ATSS [22] points out that the essential difference between one-stage anchor-based and center-based anchor-free detectors is actually the definition of positive and negative training samples. However, whether the fusion of image features is sufficient or not directly affects the detection accuracy.
The neck of ATSS [22] adopts the feature pyramid network (FPN), which fuses deep feature maps to low-level feature maps through upsampling to obtain rich semantic features. We believe that the FPN structure is difficult to adequately fuse features in spatial, so it proposes MFPN. In order to reduce redundancy and enhance salient features, it proposes MFA. In this section, ablation experiments will be performed for the proposed method on the PASCAL VOC datasets and Ms CoCo2017 dataset. The 4.5.1 and 4.5.2 test the influence of MFPN and MFA on different networks.
4.5.1 MFPN experiments
In order to verify the effectiveness of the MFPN structure, we conduct ablation comparison experiments on 4 different networks. The experimental results are shown in Tables 1 and 2. Considering our experimental equipment and detection accuracy, resnet50 is finally used. Resnet101 can better extract features. But it has more complex network and longer training time. And the performance requirements for GPU are also higher.
As Table 1 shows, the AP of ATSS has increased from 32.7% to 34%, \( AP_{50} \) and \( AP_{L} \) have even increased by 2%. The AP of FCOS has increased by 0.9% from 29.1%, and its other indicators can also be increased by more than 1%. Vfnet’s AP increases by only 0.4% from 34.1%, but \( AP_{L} \) increases from 50.5 to 52.8%. The MFPN has the most obvious improvement in Foveabox. And its AP increases by 2.4%, and \( AP_{L} \) increases from 43.8 to 47.8%. FPN only fuses features of different sizes in space, and MFPN has more feature fusion in the channel dimension. So, the MFPN can obtain richer semantic features. And the accuracy of object detection will be higher.
MFPN has different effects on different networks. It has an AP increase of 0.4% on VFNet, and an \( AP_{L} \) increase of 2.4% on Foveabox. VFNet’s original network AP is as high as 34.1%, while Foveabox’s AP is only 28.5%. Four different networks use the same backbone, neck and different heads. The detection accuracy of ATSS network is lower than that of VFNet, indicating that the detection accuracy of ATSS heads is lower than that of VFNet heads. MFPN has limited improvement for small object, but it has a significant improvement in the detection of medium-sized object and large object. In the field of object detection, in order to improve the detection accuracy of small objects, a larger size feature map is required.
For PASCAL VOC datasets, as Table 2 shows, ATSS has increased from 78 to 78.9% in the mAP. Foveabox has increased by 2.1% from 75. FCOS has increased from 74.4 to 76.5%. It has mAP increase of 0.9% on VFNet. The MFPN can greatly improve the detection accuracy of most categories on different networks. There are some categories, such as: “cat,” “chair,” “dog,” “horse.” Their accuracy has declined. That is because these categories are relatively few in training and are taken as part of pictures rather than as a whole.
4.5.2 MFA experiment
In order to further study the impact of MFA on detection accuracy. We perform MFA ablation comparison experiments on 4 different networks. The experimental results are shown in Tables 3 and 4.
As Table 3 shows, the AP of ATSS increases by 1%, \( AP_{S} \) increases from 13.5 to 14.3%, and \( AP_{L} \) increases by 2.2%. All indicators of FCOS have increased by an average of 1%. VFNet increases by 0.4% AP, but \( AP_{L} \) increases by 2.5%. MFA has the most obvious effect on Foveabox. And its AP increases from 28.5 to 31.1%, and \( AP_{L} \) increases from 43.8 to 47.3%.
It can be seen from Table 3 that MFA improves \( AP_{50} \) more significantly than AP. MFA improves \( AP_{S} \) by an average of nearly 1–2 %, and \( AP_{L} \) can increase by more than 2%. The feature maps of different receptive fields have different effects on object detection of different sizes. The MFA structure integrates the feature maps of 4 different receptive fields, so it can effectively balance object of different sizes. And its extraction of different channel weights can also enhance important features and reduce redundancy, which shows that it is effective for MFA to use feature maps of different receptive fields.

Visualization on Ms CoCo2017 dataset
As Table 4 shows, The mAP of ATSS has increased from 78 to 78.5%. Foveabox has increased by 2.2% from 75%. FCOS has increased from 74.4 to 76.4%. It has a mAP increase of 0.6% on VFNet. The MFA can greatly improve the detection accuracy of most categories on different networks. Although there are also some categories that have declined, such as: “cat,” “cow,” “diningtable” and so on. But it is not obvious, it can even be considered as experimental error.
Feature visualization operations are also performed on Ms CoCo2017 dataset. In Fig. 5, Column (a) is the input image. Columns (b) and (d) are the heat maps of the original network and network with MFA, respectively. Columns (c) and (e) are the superimposed effect diagrams of the heat map and the input.
From the column(b) and column(d), it is obvious that without the MFA, the network’s attention to pictures is scattered. The feature weights of the objects extracted from the original backbone network are not high. When adding the MFA, the network’s attention is focused on the object. The context information in the feature extraction will be aggregated, and important information will be given higher weight (such as the bright spot in Fig. 5). And it is not difficult to find that the attention algorithm can make the framework pay more attention to the area of interest.

visual comparison of different networks. All images have the confidence threshold set to 0.3
4.6 Compare with classic networks
For sub-modules, their outputs are different, but they all perform better than baseline ATSS (Resnet50). From Table 5, it can be seen that the baseline output is only 32.7% AP. There is an increase of 1.0% AP in MFA module and 1.3% AP in MFPN module. After feature fusion, the superposition of the two modules, that is, the output of our model can reach 34.2% AP. Although the \( AP_{L} \) has decreased, the \( AP_{S} \) has increased by up to 2%.
We compare the proposed network with other classic networks. From Table 6, the proposed network is the highest of AP, \( AP_{50} \) and \( AP_{S} \). \( AP_{75} \) is 36.6%, second only to 37% in all networks. \( AP_{M} \) is 38.2%, which is only 0.1% lower than the highest 38.3%. Although \( AP_{L} \) is 50.3%, \( AP_{S} \) has improved significantly. And it can effectively balance the detection effect of the network on objects of different sizes.
It compares the detection effect with classic networks. As can be seen from Fig. 6, the loss of SSD information is obvious. In the first image, it does not detect the puppy, and in the fourth image it does not detect the cup. Although Faster-RCNN can detect objects, its false detection is very high. In the first image, the tie is falsely detected many times. In the third image, the front wheel of the motorcycle is falsely detected as a car. In the fourth image, the laptop is falsely detected as tv. The detection effect of ATSS on the second, third and fourth images is ok, but the detection of the first image obviously misses the dog and tie. Although PAA has high detection accuracy, its detection frame redundancy is also high. The proposed method can not only accurately detect objects in images, but also has low missed detection and redundancy rates.

Qualitative results of MFANet. This model achieves 34.2% in AP. All images have the confidence threshold set to 0.3
It tests the detection effect of the proposed method. As can be seen from Fig. 7, only a dog in the picture, the network can accurately detect the object. When multiple objects in the picture, it can also separate different objects well, such as a person riding a horse. In road traffic scenes, it can detect dense vehicles and traffic lights. In dimly lit scenes, it can also detect cup. In an incomplete picture, it can detect a motorcycle based on a wheel. It is not difficult to see that the proposed method has completed the task of accurate object detection and has an excellent identification effect at the edge.
5 Conclusion
In this paper, we propose the MFANet. The core modules of the network are as follows: multi-scale feature fusion and attention mechanism modules. The feature maps of different sizes are effectively fused in the two dimensions of space and channel. And it realizes channel attention learning of local cross-channel interaction without dimensionality reduction.
Based on the same configuration and platform, it verifies the excellent performance of the proposed algorithm. Under the premise of the same configuration, our algorithm improves 1.5% AP, 2.9%\( AP_{50} \), 1.8%\( AP_{75} \) , 2.6%\( AP_{S} \), 1.4%\( AP_{M} \) and 0.5%\( AP_{L} \), respectively. In future work, we will investigate how feature fusion differs in channel dimension and spatial dimension. We will also explore their respective effects on the detection accuracy of objects of different sizes.
References
Sugiura, M., Miyauchi, C. M., Kotozaki, Y.: Neural mechanism for mirrored self-face recognition. Cereb. Cortex 25(9), 2806–14 (2015)
Boulgourisa, N.V., Plataniotis, K., Hatzinakos, D.: Gait recognition using linear time normalization. Pattern Recogn. 39(5), 969–979 (2006)
Mei, J., Zhou, D., Cao, J., et al.: HDINet: hierarchical dual-sensor interaction Network for RGBT tracking. IEEE Sens. J. 21(15), 16915–16926 (2021). https://doi.org/10.1109/JSEN.2021.3078455
Chaudhry, H., Rahim, M. S. M., Saba, T.: Crowd detection and counting using a static and dynamic platform: state of the art. Int. J. Comput. Vis. Robot. 9(3), 228–59 (2009)
Cerezo, E., Pérez, F., Pueyo, X.: A survey on participating media rendering techniques. Vis. Comput. 21(5), 303–328 (2005)
Wang, G., Zhai, Q.: Feature fusion network based on strip pooling. Sci. Rep. 11(1), 1–8 (2021)
Verschae, R., Ruiz-del-Solar, J.: Object detection: current and future directions. Front. Robot. AI 2, 29 (2005)
Xiao, Y., Tian, Z., Yu, J.: A review of object detection based on deep learning. Multimed. Tools Appl. 79(33/34), 23729–91 (2020)
Gkioxari, G., Girshick, R., Malik, J.: Contextual action recognition with r* cnn. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1080–1088 (2015)
Ren, S., He, K., Girshick, R.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–49 (2017)
Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6154–6162 (2018)
Cao, J., Cholakkal, H., Anwer, R.M., Khan, F.S., Pang, Y., Shao, L.: D2det: towards high quality object detection and instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11485–11494 (2020)
Sun, P., Zhang, R., Jiang, Y., Kong, T., Xu, C., Zhan, W., Luo, P.: Sparse r-cnn: End-to-end object detection with learnable proposals. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14454–14463 (2021)
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788 (2016)
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: SSD: Single shot multibox detector. In: European Conference on Computer Vision, pp. 21–37. Springer, Cham (2016)
Tian, Z., Shen, C., Chen, H., He, T.: Fcos: Fully convolutional one-stage object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9627–9636 (2019)
Yang, Z., Liu, S., Hu, H., Wang, L., Lin, S.: Reppoints: Point set representation for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9657–9666 (2019)
Lin, T.-Y., Goyal, P., Girshick, R.: Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42(2), 318–27 (2020)
Kim, K., Lee, H.S.: Probabilistic anchor assignment with IOU prediction for object detection. In: European Conference on Computer Vision, pp. 355–371. Springer, Cham (2020)
Zhang, H., Wang, Y., Dayoub, F., Sunderhauf, N.: Varifocalnet: An IOU-aware dense object detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8514–8523 (2021)
Chen, Q., Wang, Y., Yang, T., Zhang, X., Cheng, J., Sun, J.: You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13039–13048 (2021)
Zhang, S., Chi, C., Yao, Y., Lei, Z., Li, S.Z.: Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9759–9768 (2020)
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2117–2125(2017)
Liu, S., Qi, L., Qin, H., Shi, J., Jia, J.: Path aggregation network for instance segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8759–8768 (2018)
Ghiasi, G., Lin, T.Y., Le, Q.V.: Nas-fpn: Learning scalable feature pyramid architecture for object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7036–7045(2019)
Guo, C., Fan, B., Zhang, Q., Xiang, S., Pan, C.: Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12595–12604 (2020)
Tan, M., Pang, R., Le, Q.V.: EfficientDet: Scalable and efficient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10781–10790 (2020)
Qiao, S., Chen, L.C., Yuille, A.: Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition pp. 10213–10224 (2021)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141 (2018)
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7794–7803 (2018)
Fu, J., Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z., Lu, H.: Dual attention network for scene segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3146–3154 (2019)
Jiang, X., Zhang, L., Xu, M., Zhang, T., Lv, P., Zhou, B., Pang, Y.: Attention scaling for crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4706–4715 (2020)
Hou, Q., Zhou, D., Feng, J.: Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13713–13722 (2021)
Kong, T., Sun, F., Liu, H.: FoveaBox: beyound anchor-based object detection. IEEE Trans. Image Process. 29, 7389–98 (2020)
Li, D., Huang, C., Liu, Y.: YOLOv3 target detection algorithm based on channel attention mechanism. In: 2021 3rd International Conference on Natural Language Processing (ICNLP), pp. 179–183. IEEE (2021)
Funding
This work is supported in part by the National Key R &D Program of China under Grant 2017YFB1302400.
Author information
Authors and Affiliations
Contributions
Gaihua Wang, Xin Gan, Qing Caocheng and Qianyu Zhai conceived the experiments. Xin Gan and Qingcheng Cao conducted the experiments. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
This article has no conflict of interest with any individual or organization.
Code or data availability
Code and data are available.
Ethics approval
The experiments in this article are all realized through program operation, which will not cause harm to humans and animals and will not cause moral and ethical problems.
Consent to participate
Welcome readers to communicate.
Consent for publication
Completed at Hubei University of Technology on December 14, 2021.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, G., Gan, X., Cao, Q. et al. MFANet: Multi-scale feature fusion network with attention mechanism. Vis Comput 39, 2969–2980 (2023). https://doi.org/10.1007/s00371-022-02503-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-022-02503-4