
Abstract
The presence of fog degrades visibility in natural scene conditions. Computer vision applications like navigation, tracking, and surveillance need clear atmospheric images or videos as prerequisites for optimal performance. However, foggy atmosphere creates problems for computer vision applications due to reduced visibility. Different fog removal techniques are used to improve the visual quality of images and videos. The fog density depends on the depth information. Scene depth information estimation needs multiple images, which limits its real-life application. Hence, a single image fog removal requires some prior knowledge and/or assumptions to get the depth information. In this paper, the recent fog removal techniques are grouped into three broad categories: (1) filter-based methods, (2) color correction based methods, and (3) learning-based methods, for ease of understanding. The primary objective is to provide an introduction to this field and compare performance (both qualitative and quantitative) of representative techniques for each category. It is found that filter-based methods are doing overall better compared to other categories.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Fog and haze cause visibility reduction leading to accidents. According to the Federal Highway Administration in US,Footnote 1 in the year 2007–2016, an average of 8902 persons were injured, and 464 persons died in 451 crashes due to fog. Similarly, according to The Times of India,Footnote 2 in India, 9317 people died due to fog-related crashes in the year 2016. The death toll increased to 11,090 in 2017, which is a jump of almost 20%. Fog removal algorithms are needed to assist drivers in reducing fog-related risks. Outdoor scenes are usually degraded by the presence of dust particles and water droplets which cause atmospheric absorption and scattering of light. The bad weather can be due to fog, haze, mist, and/or rain.
Fog and haze are created by suspended water droplets of size 1–10 \(\upmu {\hbox {m}}\) and \(10^{-2}\)–1 \(\upmu {\hbox {m}}\), respectively. Fog and haze belong to the steady bad weather category. The presence of fog and haze attenuates the radiance of the objects received by the camera from the scene point. It causes a reduction in visibility, increasing travel time, and increasing the number of accidents. Different fog removal algorithms aim to recover color and details from a foggy image. Fog induces two types of attenuation in the foggy image: (a) Direct attenuation and (b) Air-light. In direct attenuation, the image’s intensity values are affected or degraded, reducing the contrast of the image. Air-light induces color degradation in the foggy image compared to the fog-free images. Foggy images cannot be used directly for different computer vision applications, as fog degrades the image quality. Hence, we need good fog removal techniques that can improve the contrast and recover the color of the images. Fog removal increases the contrast of the image by which the images are more suitable for different computer vision applications like tracking and navigation. In recent years, many articles on fog removal techniques have been proposed. Over time, the number of publications is increasing. So, it is difficult for a new researcher to follow all the updates. It is easier for researchers to find a direction for their work if they have a comprehensive view of recent techniques. Tripathi et al. [50] and Singh et al. [45] have done a review on previous fog removal techniques for both multiple images fog removal and single image fog removal up to the year 2012 and 2017, respectively.
In this article, we have focused on fog removal techniques from a single image proposed in 2012 and onwards. The main contributions of this paper are
-
We propose grouping the fog removal techniques into three different categories depending on the constituent building blocks for ease of understanding.
-
With the help of a few state-of-the-art techniques, each category is discussed to explain the evolution of the technology followed by qualitative and quantitative performance comparison. We have presented other important methods in Table 1 with a brief introduction.
-
Different techniques use different databases, metrics, and competing techniques for comparison, creating problems for a new researcher in this field. In this paper, we have tested the prominent techniques using the same databases (one natural and two synthetic foggy image databases) to compare their (both qualitative and quantitative) performance.
The structure of the paper is as follows. Section 2 describes the state-of-the-art single image fog removal techniques. In Sect. 3, different types of performance metrics and their merits are discussed. Simulation and results are discussed in Sect. 4. The paper is concluded in Sect. 5.
2 Literature survey
Initially, fog removal methods were grouped into enhancement-based methods and restoration-based methods. In the literature, early fog removal methods are enhancement-based techniques. Enhancement-based methods use contrast enhancement to remove fog from images; for example, histogram equalization is one such method. These methods work well for images with haze and very light fog. As the fog density increases, enhancement-based methods fail to remove the fog efficiently. The restoration-based techniques use a physical model to estimate the degree of fog degradation, and based on the estimation, it recovers the clear image. Based on Koschmieder’s law, the physical model for a foggy image is given by [50],
where \(I_{\mathrm{foggy}}(x)\) is the foggy image, \(I_{\mathrm{clear}}(x)\) is the fog-free image, \(A\) is the global atmospheric light, and \(t(x)\) is the transmission map. When the atmosphere is homogeneous, the transmission \(t\) can be represented by
where \(\beta \) is the atmosphere extinction coefficient, and d is the distance of the scene point from the camera. In Eq. (1), the first term \(I_{\mathrm{clear}}(x)t(x)\) is known as the direct attenuation, which causes the contrast reduction in the image and the second term \(A(1-t(x))\) is known as the air-light which causes the scene color shifting.
As fog concentration depends on the distance between the object and the camera, depth information is required for fog removal. Generally, for depth information, two or more images are required. From a practical point of view, it is more useful if the fog can be cleared independently for every image. Single image fog removal needs some prior knowledge and/or assumptions for the depth information. In the review paper [50], fog removal techniques up to the year 2012 have been discussed and compared. Techniques by Tan et al. [47], Fattal et al. [10], Tarel et al. [48], He et al. [14], and Tripathi et al. [49] have been compared, and among them, Tripathi et al. [49] is found to be best method in terms of quality. This article concentrates single image fog removal techniques from the year 2012 and onwards. Thus, Tripathi et al. [49] is chosen as a benchmark technique to represent the year 2012 and before. In the second review paper [45], different fog removal techniques from the year 2008 up to the year 2017 have been reviewed. Singh et al. [45] did a comprehensive review by grouping the fog removal algorithms into different categories and analyzed the fog removal techniques qualitatively in terms of their pros and cons. However, Singh et al. [45] did not make a quantitative comparison of the de-hazing techniques. Recently, several learning-based techniques have been proposed for fog removal. These methods may or may not use the physical model of fog for restoration. These methods can be classified as enhancement-based or restoration-based methods, depending on the use of the fog model for improvement.
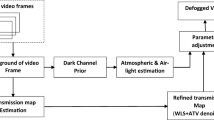
In this article, for ease of understanding, the single-image-based fog removal methods are categorized into three broad categories: (1) Filter-based methods, (2) Color correction-based methods, and (3) Learning-based methods. The learning-based methods can further be divided into (a) simple learning-based method and (b) deep learning-based method. The filter-based methods, color correction based methods, and the simple learning-based methods belong to the restoration-based method. The basic block diagram for the fog removal shown in Fig. 1 applies to restoration-based methods. In Table 1, new fog removal methods (the year 2017 and onwards) are grouped based on the building blocks and performance.
2.1 Filter-based methods
This category comprises of the methods which use filters for the transmission map refinement. Transmission map refinement is the last step in the Depth Map Information estimation in Fig. 1. Though this is the oldest among the three categories, it still attracts the attention of researchers [2, 6, 7, 13,14,15, 17, 20, 27, 28, 31, 41, 49, 52].

Fog removal framework for restoration based techniques
In the year 2011, He et al. [14] proposed a concept named dark channel prior (DCP), which gives a new direction for single image fog removal. DCP is based on the assumption that at least one color channel intensity in a local patch of an outdoor image is near zero. Thus for an image, dark channel prior is defined as
where \(I^c\) is a color channel of image I and \(\Omega (x), \) is a local patch centered at x. So, the transmission map was obtained by
The transmission map is refined using soft matting [24]. The refined transmission map is used to recover the fog-free image. But this method fails when there is a bright object in the image, and it produces halo and block artifacts in the fog-free image.
For dark channel (DC) estimation, Tripathi et al. [49] takes the minimum over the color channel and omits spatial filtering.
The proposed dark channel has better structural preservation than DCP. The anisotropic diffusion is applied over the dark channel to get the depth map. A depth map should be smooth for object except for the edges. Anisotropic diffusion does smoothing in the central region, not in edge regions. So, anisotropic diffusion helps in edge preservation. Tripathi et al. [49] proposed anisotropic diffusion filter to estimate the depth map. The refined depth map is called airlight map and using it the defogged image is recovered as
where \(A_{\mathrm{map}}(x)\) is the airlight map at pixel index x. Here, the value of the global atmospheric constant for channel c, \(A^c(x)\) is taken as 1. As the recovered images are low in contrast, post-processing is done by histogram stretching [11].
The concept of DCP by He et al. [14] produces artifacts at times. Hence, He et al. [15] proposed guided image filter (GIF) for refining DCP to remove artifacts. The assumption for GIF is, the GIF output is a linear transform of the guidance image, i.e., the filtered output is a scaled and translated version of the guidance image in a local window \(w_i\)
where x is the pixel location, \((a_i, b_i)\) are constant coefficients in \(w_i\), G is the guidance image, P is the filtered output and \(w_i\) is the patch centered at pixel i. In this method, the dark channel image [\(I_{\mathrm{DC}}\) from (5)] is taken as the guidance image, G. To determine the coefficients \((a_i, b_i)\), the output P is modeled as,
where Q is filtering input (DCP) and n is the unwanted components or the noise. A solution is needed to minimize the difference between P and Q and maintain the relation of Eq. (7). So, a cost function is calculated in the window \(w_i\) given by,
where \(\epsilon \) is a regularization parameter. Hence, we can get the values of \((a_i,b_i)\) by minimizing the cost function (E). After calculating the \((a_i,b_i)\), the optimal value for GIF output, P is calculated by,
where \((\bar{a_{i}},\bar{b_{i}})\) are the average value of \((a_i,b_i)\) in the window \(w_i\) (typically \(w_i=20\times 20\)). The output of GIF (P) is used to obtain the transmission map using Eq. (4) and the defogged image is recovered from Eq. (1).
In the end of year 2015, Li et al. [27] proposed a weighted guided image filter (WGIF) to remove the artifacts (e.g., halo artifact) produced by GIF. Li et al. [27] introduced an edge-aware weighting and incorporated it into the GIF to form WGIF [29]. The edge-aware weighting \(\varGamma \) measures the importance of a pixel concerning the whole guidance image by,
where \(\sigma _{G,\Omega }^2(x)\) is the variance of the window size \((2\Omega +1) \times (2\Omega +1)\) centered at pixel x in the guidance image G, M is the total number of pixels in the Guidance image. \( \epsilon =(0.001\times L)^2 \) is a small constant, where L is a dynamic range of the guidance image. The \(\varGamma \) value for the edge pixels is higher than the smoother region pixels. So, it preserves the edges and removes the halo artifacts which are created in the case of GIF. So, the cost function modified by inserting \(\varGamma \) in Eq. (9) is given by,
where \(\gamma \) is the regularization parameter. Again the dark channel image (DC) is taken as the guidance image, G, and DCP image as filter input, Q. The refined transmission map is obtained using the GIF output P. For atmospheric light estimation, Li et al. [27] have used hierarchical quad-tree subdivision. This method has good edge-preserving quality and no halo effects in restored images.
In the review by Singh et al. [45], WGIF [27] has been placed among the top two ranked methods based on its performance. Therefore, WGIF is chosen as a benchmark technique for further comparison.
2.2 Color correction-based methods
This category includes the methods which use color correction in the restoration of the defogged image. Sometimes, the presence of color cast in hazy images affects some or all color channels of the image. So, there is a need for color correction in those images for efficient defogging. Over time, this category is getting more attention from the researchers [18, 19, 22, 37, 46].
Huang et al. [18] proposed a method of combining DCP and median filter for obtaining the transmission map from a foggy image. The median filter technique is good at suppressing the noise components while preserving the edge information of the image. Here, an edge information is calculated by
where w is a constant, \(I_{\mathrm{min}}={\hbox {min}}_{c\in (r,g,b)}I^c\) and I is the foggy image. The refined transmission map \(t_r\) is measured by subtracting the edge information from the DCP transmission map [Eq. (4)] obtained as,
Thus, as a result, the transmission map has clear edge. Huang et al. [18] have used an adaptive Gamma correction method to enhance the transmission map which depends on the density of haze. The value of Gamma is calculated by
where \(I_{\mathrm{max}}\) is the maximum intensity of the input image, \(\hbox {th}\) is an intensity value when cumulative probability density (cdf ) is equal to 0.1. The threshold value \(\hbox {TH}\) is empirically set to 120. The enhanced transmission map \(t_e\) is given by
Using the gray world assumption, the color shift for each channel is calculated. The fog free image is derived from Eq. (1) as,
where \(d_{\mathrm{shift}}\) is the color shift for each channel measured by,
where \({\hbox {avg}}_c\) is the average intensity for channel c.
Peng et al. [37] proposed a fog removal method based on ambient light estimation using depth-dependent color change. The transmission map is estimated from the absolute difference between the observed intensity and the ambient light. Then, depending upon the different haze and visual conditions, the generalization of the DCP is performed to restore image. The transmission map for foggy image is obtained using Eq. (4). When there is a color cast, the color correction coefficient is calculated by,
where \(I_{\mathrm{avg}}^c=\max ({\mathrm{avg}}_x(I^c(x)),0.1)\). The color cast is measured in CIELab color space by \(D_\sigma =\frac{ \Vert \mu \Vert _2-\Vert \sigma \Vert _2}{\Vert \sigma \Vert _2}\) where \(\Vert \ \Vert _2\) is \(L^2\) norm, \(\mu =(\mu _a,\mu _b)^{\mathrm{T}}\) and \(\sigma =(\sigma _a,\sigma _b)^{\mathrm{T}}\) represents mean and standard deviation of chromatic components. If \(D_\sigma \) is large value, then the color cast is strong and if \(D_\sigma \) is zero, then there is no color cast. So, the ambient light (A) is corrected by \(A_\theta ^c=\frac{A^c}{\theta ^c}\). Using the corrected atmospheric light constant and from Eq. (1), the clear image is recovered.
2.3 Learning-based methods
Learning-based methods are those methods in which the model is trained to create a mapping function for the given input and output pair. During training the model, the parameters of the mapping function are estimated. So, fog-free ground-truth images and the corresponding foggy images (ground-truth + fog) are required for training the model. Such pairs can be generated faithfully by adding synthetic fog in a ground-truth image.
2.3.1 Simple learning-based methods
Zhu et al. [58] proposed a method based on color attenuation prior and guided filter. It works on the HSV plane. Color attenuation prior is based on the assumption that the scene depth at a point is a linear function of
where d is the scene depth, x is the pixel index, S, and V are the saturation and brightness in the HSV plane. \(k_{0}\), \(k_{1}\), and \(k_{2}\) are the parameters that need to be calculated, and e is the normally distributed error. Using 500 synthetic foggy images and supervised learning method, the model is trained and the final coefficients are obtained as \(k_{0}=0.121779\), \(k_{1}=-0.780245\), \(k_{2}=0.959710\) and the standard deviation (\(\sigma \)) for e is 0.041332. Once the depth map is obtained, it is refined using a guided filter [15] where the guidance image is the dark channel image, and the final fog-free image is restored using Eq. (1). As the fog degradation model is used to get the fog-free image, it can also be called a restoration-based technique. Recently, this subcategory is drawing more and more attention from the researchers [4, 16, 21, 30, 35, 38, 44].
2.3.2 Deep learning-based methods
Recently, deep-learning-based methods are playing significant roles in object classification and recognition tasks [5, 9, 23, 32,33,34, 39, 40, 51, 54,55,56,57].
Cai et al. [5] proposed a convolutional neural network (CNN) using a nonlinear activation function called bilateral rectified linear unit (BReLU). Cai et al. proposed DehazeNet for fog removal, which takes the foggy image as input, estimates the transmission map and restores the defogged image using Eq. (1). The refinement of the transmission map helps preserve the edges and reduces the artifacts in the restored image. Thus, this method is suboptimal as no refinement is done on the transmission map, and the time for de-hazing is also high. It is a restoration-based method.
Li et al. [25] proposed restoration-based de-hazing model called All-in-one Dehazing Network (AOD-Net) which is also based on the CNN. It does not need a separate estimation of the transmission map and atmospheric constant for defogging, instead used an end-to-end mapping to get defogged image directly from foggy image. Li et al. [25] minimized the recovered image error in the pixel level by merging the estimation of transmission map (t(x)) and global atmospheric constant(A) into one variable obtained by,
where \(I_{\mathrm{clear}}(x)\) is the fog-free image, \(I_{\mathrm{foggy}}(x)\) is the foggy image. K(x) is the variable which contains both transmission map (t(x)) and air-light (A) and b is a bias constant with value 1. From Eq. (22), the value of K(x) also depends on foggy input I(x). But, sometimes this method is unable to remove the fog completely from the images, i.e., the recovered images have some fog residues.
Goodfellow et al. [12] proposed a Generative Adversarial Network (GAN) framework based on adversarial learning to generate realistic-looking images from random noise. But GAN is hard to train, and also it often induces artifacts like color shifts and noise in the retrieved images. Li et al. [26] proposed an end-to-end de-hazing framework based on Conditional Generative Adversarial Network (cGAN) by incorporating pre-trained Visual Geometry Group (VGG) features and a \(L_1\)-regularized gradient prior into basic cGAN. It uses an encoder and decoder architecture for single image haze removal. Each layer of the encoding process includes convolution, batch normalization, and LeakyReLU, while each layer of the decoding process includes deconvolution, batch normalization, and ReLU. The architecture of cGAN contains the generator and the discriminator frameworks. The generator tries to generate a clear image from the foggy image, whereas the discriminator (CNN) tries to decide whether the clear image is real or fake. Both compete with each other in an adversarial two-player game.
3 Performance metrics
Although fog removal techniques can be compared visually from the defogged image, quantitative metrics are needed to get an unbiased opinion. Here, some of the standard performance metrics like contrast gain (\(C_{\mathrm{gain}}\)), percentage of the number of saturated pixels (\(\sigma \)), gradient norm (r), structural similarity index SSIM, Peak Signal to noise ratio PSNR, and the execution time (t) are used to compare the fog removal methods. Out of these metrics, SSIM and PSNR need reference or ground-truth.
3.1 Contrast gain
Contrast gain [50] is described as a mean contrast difference between defogged and foggy images. Since clear day images have higher contrast than foggy images, the contrast gain should be positive for restored images. A higher value of contrast gain indicates better performance of the fog removal algorithm. The \(C_{\mathrm{gain}}\) is measured by
where \(C_{\mathrm{defogged}}\) and \(C_{\mathrm{foggy}}\) are the mean contrast of the defogged and foggy image, respectively. Let an image of size \(M \times N\) is denoted by I. Then, mean contrast is expressed as
where C(x, y) is the contrast of pixel at (x, y), which is measured as
where m(x, y) and s(x, y) are calculated as
where \((2p+1)^2\) is the window size. Here, \(5\times 5\) window is taken for calculating mean contrast, i.e., the value of p is 2.
3.2 Percentage of saturated pixels (\(\sigma \))
Saturated pixels are those pixels which turn to either completely black or white in the image after the fog removal. The value of \(\sigma \) [18, 49, 50] is measured as,
where, n is the number of the pixels which are saturated after fog removal but were not before. The lower is the value of \(\sigma \), the better is the result.
3.3 Gradient norm (r)
Gradient norm [18] is the ratio between the average gradient of the image after fog removal and the foggy image. The gradient norm is given by
where \(|\nabla {I_{\mathrm{Defogged}}}|\) is magnitude of gradient of restored image and \(|\nabla {I_{\mathrm{Foggy}}|}\) is magnitude of gradient of foggy image. The gradient magnitude is calculated by the L2 norm between the horizontal and vertical gradients. The higher is the gradient norm, the better is the result.
3.4 Structural similarity index (SSIM)
SSIM [53] measures the similarity between reference fog free image and the restored image. The range of SSIM is [0,1]. The SSIM value is calculated by,
where I is the reference image or the ground-truth, J is the restored image, \(\mu _{I}\) and \(\mu _{J}\) are the average of I and J, respectively, \(\sigma _{I}^2\) and \(\sigma _{J}^2\) are the variances of I and J, respectively, \(\sigma _{IJ}\) is the covariance of I and J. \(c_{1}=(k_1L)^2\) and \(c_{2}=(k_2L)^2\) are the variables to stabilize the division and \(k_1=0.01\) and \(k_2=0.03\) are constants and L is the dynamic range of the pixel values. The higher the value of SSIM, the better is the result.

Images from O-Haze Database (a–d); Images from D-Hazy Database (e–h); Natural foggy images from LIVE Image Defogging Database (i–l)
3.5 Peak Signal to Noise Ratio (PSNR)
PSNR measures the peak signal-to-noise ratio, in decibels, between two images that is the reference fog-free image and the defogged image. The PSNR can be calculated as
where \(R=255\) and MSE is the mean-squared-error between fog-free image (I) and defogged image (J).
The MSE can be calculated as
where (m, n) are the pixel index and \({M\times N}\) is the image dimension. The higher the value of PSNR, the better is the result.
3.6 Execution time (t)
Execution time (t) is the time taken by algorithms to remove fog from an image. Here, the execution time per Mega-pixels is calculated for each image. A lower value of t means a faster algorithm.
4 Experiments and results
In this section, we present details of the databases used and the experimental setup as well as comparisons with various other competing methods.
4.1 Database
We have used publicly available O-Haze [3] dataset, D-Hazy [1], and LIVE Image Defogging Database [8] for comparison. As fog is a natural phenomenon, we need natural foggy images for testing the efficiency of the defogging methods. So, we have used all 100 natural foggy images without ground-truth from the 100-foggy-test-image of the LIVE Image Defogging Database. But for comparing fog removal methods using the metrics like SSIM and PSNR, we need ground-truth corresponding to the foggy images. Hence, we have used the O-Haze dataset and D-Hazy dataset, which are collections of foggy images with their respective ground-truths. The O-Haze dataset consists of 45 foggy outdoor images with their ground-truth images (clear outdoor image). These foggy images are generated using the haze generated by a professional haze machine that imitates with high fidelity real hazy conditions. The D-Hazy dataset consists of foggy indoor images with their ground-truth images (clear indoor image). From the D-Hazy database, 1159 images are used to train the deep learning-based methods (DehazeNet, AOD-Net, cGAN, GridDehazeNet), and the remaining 290 foggy images with their ground-truth are used for comparison (testing). In Fig. 2, some examples of the three databases are shown.
4.2 Simulation settings
The simulation is performed in MATLAB R2016b on Linux Intel(R) Core(TM) i7-7700 CPU @ 3.60 GHz and 32 Gb RAM with NVIDIA GEFORCE GTX 1080 Ti (11 Gbps GDDR5X memory and 11 GB frame buffer) GPU platform. Using the foggy images from the O-Haze database, the D-Hazy database, and 100 foggy images from the LIVE Image Defogging Database, the comparative analysis is performed. In Table 2, the values of the parameters for each bench-marked fog removal method are provided. The DehazeNet (Cai et al. [5]) method codes are taken from “https://github.com/zlinker/DehazeNet”. Cai et al. [5] have randomly collected 10,000 haze-free images from the internet and synthesized 1,00,000 hazy images from them. The DehazeNet is trained using these 1,00,000 synthesized foggy images. The AOD-Net (Li et al. [25]) method codes are taken from “https://github.com/Boyiliee/AOD-Net”. Li et al. [25] have used the ground-truth images from NYU2 Depth Database [36] to synthesize the foggy images using Eq. (1) for different atmospheric light (A) and \( \beta \) [from Eq. (2)]. The AOD-Net is trained using 27,256 synthesized indoor foggy images. The codes for cGAN (Li et al. [26]) are taken from “https://github.com/hong-ye/dehaze-cGAN”. Li et al. [26] have used the ground-truth (indoor) images from NYU2 Depth Database [36] and ground-truth (outdoor) images from Make3D dataset [42, 43] to synthesize the foggy images using Eq. (1). The cGAN model is trained using randomly chosen 2400 synthesized foggy images. The code of GridDehazeNet [34] is taken from “https://github.com/proteus1991/GridDehazeNet”. All the deep-learning-based techniques are trained using the synthetic foggy images from the D-Hazy database. The codes for technique by Kim et al. [22] are taken from “https://sites.google.com/view/ispl-pnu/software”. The DehazeNet, AOD-Net, cGAN, and Kim et al. [22] are implemented using Python language. In Tables 3 and 4, the quantitative comparison in terms of \(C_{\mathrm{gain}}\), r, SSIM, PSNR, and \(\sigma \) is shown for the O-Haze and D-Hazy database, respectively. In Table 5 the quantitative comparison in terms of \(C_{\mathrm{gain}}\), r, and \(\sigma \) is shown for the LIVE Image Defogging Database. In Table 6, the execution time (in seconds per Mega-pixels) for each fog removal techniques is given.

Defogging results of competing methods on Foggy Indoor Image No. 1221 of D-Hazy Database: a Foggy Input; output of same by, b Tripathi et al., c Huang et al., d Zhu et al., e WGIF, f DehazeNet, g AOD-Net, h cGAN, i Peng et al., j Salzar-colores et al., k Kim et al., l GridDehazeNet; and m Groundtruth; Full resolution images are given in link: http://tiny.cc/compare-image-restoration

Defogging results of competing methods on Foggy Outdoor Image No. 19 of O-Haze Database: a Foggy Input; output of same by, b Tripathi et al., c Huang et al., d Zhu et al., e WGIF, f DehazeNet, g AOD-Net, h cGAN, i Peng et al., j Salzar-colores et al., k Kim et al., b GridDehazeNet; and m Groundtruth; Full resolution images are given in link: http://tiny.cc/compare-image-restoration

Defogging results of competing methods on Foggy Outdoor Image No. 22 of O-Haze Database: a Foggy Input; output of same by, b Tripathi et al., c Huang et al., d Zhu et al., e WGIF, f DehazeNet, g AOD-Net, h cGAN, i Peng et al., j Salzar-colores et al., k Kim et al., l GridDehazeNet; and m Groundtruth; Full resolution images are given in link: http://tiny.cc/compare-image-restoration

Defogging results of competing methods on Natural Foggy Image of LIVE Image Defogging Database: a Foggy Input; output of same by, b Tripathi et al., c Huang et al., d Zhu et al., e WGIF, f DehazeNet, g AOD-Net, h cGAN, i Peng et al., j Salzar-colores et al., k Kim et al., l GridDehazeNet; Full resolution images are given in link: http://tiny.cc/compare-image-restoration

Enlarged version of Swan from Fig. 6; Full resolution images are given in link: http://tiny.cc/compare-image-restoration
4.3 Discussion
In Figs. 3, 4, 5 and 6, a qualitative comparison between different techniques are shown. In Fig. 3, it can be observed that techniques proposed by Tripathi et al. [49], Huang et al. [18], Zhu et al. [58], cGAN (Li et al. [26]), Salazar-Colores et al. [41] and GriDehazeNet [34] are doing a good job in removing the fog. The defogged image from techniques by DehazeNet [5] and AOD-Net [25] contains some residual fog in the background. The method by Kim et al. [22] can remove the fog but is unable to preserve color in the restored image. In Fig. 3, techniques by WGIF [27] and Peng et al. [37] are unable to remove the fog. In Fig. 4, all the methods are doing a great defogging work for the foreground, but are unable to properly defog the background. The defogged image restored by Salazar-Colores [41] method is underexposed.
In Fig. 5, defogged image from techniques by Zhu et al. [58] (Fig. 5k:left) and AOD-Net [25] is under-exposed and the defogged image from Peng et al. [37] has halo artifacts around the wooden structure (Fig. 5k:right). In Fig. 6, a standard natural foggy image having two white objects (swans) is shown. In fog removal, the presence of white objects (which are similar to atmospheric light) sometimes creates challenges as the color of the white objects may change due to the error in estimation of the dark channel. In Fig. 7, an enlarged region of interest containing a swan, for each technique, is analyzed. From Fig. 7, it can be noticed that Tripathi et al. [49] and Salazar-colores et al. [41] are handling the white object better than other techniques. In Fig. 7, Huang et al. [18] is successful in removing the fog, but failed to preserve the white objects. Kim et al. [22] is able to remove fog, but induces a color tint in the restored image. GridDehazeNet [34] is handing the white object better but is unable to remove the fog completely. Techniques by Zhu et al. [58], DehazeNet [5], WGIF [27] are removing the fog, but the images are becoming underexposed. The image restored by Peng et al. [37] method has undesired halo artifacts (Fig. 7h). Full resolution images are given in link: http://tiny.cc/compare-image-restoration.Footnote 3
From Tables 3, 4 and 5, it can be noted that contrast gain (\(C_{\mathrm{gain}}\)) for all techniques is positive, which implies that all the methods are successful in enhancing the contrast of the images. As fog removal techniques are grouped into four different categories, we should first investigate the best method in each category.
From filter-based category, three technologies that are Tripathi et al. [49], WGIF (by Li et al. [27]), and Salazar-Colores et al. [41] are benchmarked. For O-Haze database (Table 3), in terms of contrast gain (\(C_{\mathrm{gain}}\)), gradient norm (r) and percentage of number of saturated pixels (\(\sigma \)), Tripathi et al. [49] is performing better than WGIF (by Li et al. [27]) and Salazar-Colores et al. [41] whereas in terms of SSIM and PSNR, WGIF performs better. Similarly, for the D-Hazy database (Table 4), Tripathi et al. [49] perform superior than WGIF (by Li et al. [27]) and Salazar-Colores et al. [41] in terms of all the metrics except gradient norm (r). Similarly, Salazar-Colores et al. [41] is preferable in terms of gradient norm (r). If the mean and standard deviation values are close to each other for both the ground-truth image and the recovered image, then the SSIM value will be high. In Tripathi et al.’s method, there is contrast stretching (Post-processing) after the fog-free image is restored, and it changes the mean and standard deviation values, which lowers the SSIM index. In WGIF (by Li et al. [27]), the use of guidance image and the absence of post-enhancement after restoration causes similar mean and standard deviation values of a ground-truth image and the defogged image resulting in a higher SSIM value. From the above discussion, it can be deduced that Tripathi et al. [49] is an overall better method than WGIF [27] and Salazar-Colores et al. [41] in the filter-based category based on chosen metrics and databases.
From the color correction-based category, three methods, Huang et al. [18], Peng et al. [37] and Kim et al. [22], are taken for bench-marking. For O-Haze database (Table 3), in terms of \(C_{\mathrm{gain}}\), r, and SSIM, Peng et al. [37] is performing better than Huang et al. and Kim et al., but for D-Hazy database (Table 4) the technique by Huang et al. is performing superior to Peng et al. and Kim et al. in most of the metrics. From Tables 3 and 4, Peng et al. [37] is an overall better method than Huang et al. [18] and Kim et al. [22] in Color-Correction category, but it is also creating halo effects (Fig. 7) in restored images which is undesirable. From Tables 3 and 4, it can observed that for O-Haze databse, cGAN (by Li et al. [26]) is performing better in terms of all the metrics except contrast gain (\(C_{\mathrm{gain}}\)) where as for D-Hazy database, GridDehazeNet is performing better in terms of PSNR and SSIM. As deep-learning-based models are trained using foggy and corresponding ground-truth image pairs, they have better SSIM and PSNR values compared to techniques of other categories. Zhu et al. [58] is doing better contrast enhancement in the learning-based category, but it also has a high percentage of saturated pixels (\( \sigma \)), which is undesirable. Hence, for learning-based methods, cGAN [26] is more acceptable in fog removal compared to others.
From Table 3 for O-Haze database, we can notice that, in terms of \(C_{\mathrm{gain}}\), Tripathi et al. [49] has the highest value, followed by Salazar-Colores et al. [41] and Zhu et al. [58] which shows that Tripathi et al. [49] method is doing a better job at contrast enhancement. Concerning metric r, Tripathi et al. [49] has the highest value, followed by Peng et al., and Salazar-Colores et al. [41]. Concerning metric SSIM, cGAN [26] has the highest value, followed by WGIF [27] and Peng et al. [37]. As, SSIM shows the similarity of two images, cGAN [26] has better preservation of the structures in the restored images. Concerning metric PSNR, cGAN [26] has the highest value, followed by WGIF [27] and DehazeNet [5]. Similarly, for \(\sigma \), GridDehazeNet [34] has the lowest value, followed by cGAN [26] and Huang et al. [18].
From Table 4 for D-Hazy database, in terms of \(C_{\mathrm{gain}}\), Zhu et al. [58] has the highest value, followed by Tripathi et al. [49] and Salazar-Colores et al. [41]. Concerning metric r, Tripathi et al. [49] has the highest value, followed by Salazar-Colores et al. [41] and cGAN [26]. Similarly, concerning metric SSIM, GridDehazeNet [34] has the highest value, followed by cGAN [26] and DehazeNet [5]. As, the deep learning-based methods are trained using the D-Hazy database, they have better SSIM and PSNR. Concerning metric PSNR, GridDehazeNet [34] has the highest value, followed by cGAN [26] and Huang et al. [18]. Similarly, for \(\sigma \), Kim et al. [22] has the lowest value, followed by AOD-Net [25] and cGAN [26].
From Table 5, with respect to \(C_{\mathrm{gain}} \), Tripathi et al. [49] has the highest value, followed by Salazar-Colores et al. [41], followed by Zhu et al. [58] which shows that Tripathi et al. [49] method is doing a better work at contrast enhancement. Concerning metric r, Tripathi et al. [49] have the highest value, followed by Salazar-Colores et al. [41], followed by Peng et al. [37]. Similarly, for \(\sigma \), cGAN [26] has the lowest value, followed by GridDeHazeNet [34] and Kim et al. [22]. So, it can be noted that the technique by Tripathi et al. [49] is giving a better defogging result at high \(C_{\mathrm{gain}}\) and low \(\sigma \) and also have high gradient value.
For better performance, the defogged image should have high contrast gain with a low saturation percentage. cGAN [26] method has the lowest \(\sigma \) value, but with a low contrast gain. In Tripathi et al. [49]’s method, the defogged image has high contrast gain with a low saturation percentage. Hence, it can be deduced that Tripathi et al. [49] is giving an overall better result.
In Table 6, the execution time (in seconds per Mega-pixels) for each fog removal technique is observed. From the table, AOD-Net [25] is the fastest compared to other methods. However, AOD-Net [25] is executed using a high-end GPU; the execution time comparison is not fair. From the table, for all databases (O-Haze database, D-Hazy database, and Live Image Defogging Database), Tripathi et al. [49] have the lowest execution time, followed by Zhu et al. [58], and Huang et al. [18] for MATLAB implemented codes using only the CPU. So, Tripathi et al. [49] is the fastest method. As AOD-Net and cGAN have been tested using CPU and GPU, they are faster than the other techniques. For the Python-based codes (AOD-Net and cGAN and the method by Kim et al. [22]), AOD-Net [25] is faster.
From the above discussion, it can be analyzed that filter-based techniques are better for defogged image restoration than the other categories.
The filter-based techniques use a modified concept of DCP to remove the fog, but most of the filter-based methods have high execution time. However, as a category, filter-based techniques are better than other groups in terms of execution time. For the filter-based techniques, sometimes the artifacts associated with DCP are present in the output. The outputs lose their natural look, which causes low values of SSIM and PSNR of restored images. The future work in this category should be to get a fast filtering method which can reduce artifacts and give a natural look.
The color correction-based methods work well for foggy or hazy images with a color cast. However, they distort the color of the defogged image if no color cast is present in the input foggy images, which is undesirable. The future direction for the methods should be to find the color correction methods that can work nicely for hazy images with or without a color cast and preserve the color in either scenario.
All the deep learning-based methods need an extensive database of foggy images with their respective ground truth for training the models. These methods give good results for synthetic foggy images but fail to do the same for natural foggy images. The deep learning-based methods are faster as they use high-end GPU, which is not always feasible in real applications. So, the future direction for this category should be to make them more robust, which can give better results for synthetic and natural foggy images with low execution time with the use of only CPU or low-end GPU.
5 Conclusion
Over time, the methods for removing fog are becoming more and more sophisticated. In this paper, the recent fog removal techniques are analyzed. First, the new fog removal techniques are categorized based on their constituent blocks. From each category, the prominent methods are discussed comprehensively. The merits and demerits of the fog removal methods are analyzed. Then, the competing techniques are bench-marked based on their performance. The competing techniques are compared qualitatively and quantitatively using three databases (O-Haze, D-hazy, and Live Fog Database). The metrics like contrast gain \((C_{\mathrm{gain}})\), gradient norm (r), percentage of saturated pixels \((\sigma )\), SSIM, and PSNR are used for quantitative comparison. From the discussion, it can be deduced that filter-based techniques, though old, are performing better than other categories in fog removal from natural foggy images and O-Haze dataset (outdoor synthetic foggy images). For the D-Hazy dataset (synthetic indoor foggy images), the deep-learning-based techniques perform superior to other categories. As the deep-learning-based techniques are trained using the synthetic foggy images, they are doing better fog removal for similar synthetic foggy images. The deep-learning techniques are also fast as they use the help of a high-end GPU. However, they perform poorly for natural foggy images as they cannot be trained using natural foggy images. Recently, the use of deep learning techniques for defogging is increasing. Although the deep learning techniques are giving good results, the computational complexity of these techniques is very high, and they need prior knowledge of depth to train the model. So, at this moment, it is not easy to use these methods for a real-time application. However, in conventional techniques, there is no need for ground-truth (fog-free image). Using some assumptions and/or prior knowledge, they can get the scene depth. From the comparisons, it can be deduced that the conventional techniques are doing better than the deep learning-based techniques. From the qualitative and quantitative analysis, it can be noted that few filter-based techniques viz. Tripathi et al. [49], Salazar-Colores [41] are giving overall better results. From the deep learning-based techniques, cGAN [26] and GridDehazeNet [34] are performing better than the other. In the future, with more training data and GPU power, deep learning-based techniques may overcome these obstacles and exceed other performance techniques.
Each category of fog removal technique has its advantages as well as limitations. Hence, there is a scope of improvement for all fog removal techniques in each group. For the filter category, the methods can be faster without degrading the restored image (without the halo, block artifact) and retain the natural look. For the color correction category, the techniques should work for with or without color cast foggy images. Similarly, learning-based methods should also work efficiently for natural images using only CPU or low-end GPU. In the future, the techniques may overcome the research gap in each category to improve fog removal.
References
Ancuti, C., Ancuti, C.O., De Vleeschouwer, C.: D-hazy: A dataset to evaluate quantitatively dehazing algorithms. In: 2016 IEEE International Conference on Image Processing (ICIP), pp. 2226–2230. IEEE (2016)
Ancuti, C.O., Ancuti, C.: Single image dehazing by multi-scale fusion. IEEE Trans. Image Process. 22(8), 3271–3282 (2013)
Ancuti, C.O., Ancuti, C., Timofte, R., De Vleeschouwer, C.: O-haze: a dehazing benchmark with real hazy and haze-free outdoor images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 754–762 (2018)
Berman, D., Treibitz, T., Avidan, S.: Single image dehazing using haze-lines. IEEE Trans. Pattern Anal. Mach. Intell. (2018)
Cai, B., Xu, X., Jia, K., Qing, C., Tao, D.: Dehazenet: an end-to-end system for single image haze removal. IEEE Trans. Image Process. 25(11), 5187–5198 (2016)
Chen, B.H., Huang, S.C.: Edge collapse-based dehazing algorithm for visibility restoration in real scenes. J. Disp. Technol. 12(9), 964–970 (2016)
Chen, B.H., Huang, S.C., Cheng, F.C.: A high-efficiency and high-speed gain intervention refinement filter for haze removal. J. Disp. Technol. 12(7), 753–759 (2016)
Choi, L.K., You, J., Bovik, A.C.: Referenceless prediction of perceptual fog density and perceptual image defogging. IEEE Trans. Image Process. 24(11), 3888–3901 (2015)
Dudhane, A., Murala, S.: Ryf-net: deep fusion network for single image haze removal. IEEE Trans. Image Process. 29, 628–640 (2019)
Fattal, R.: Single image dehazing. ACM Trans. Graph. (TOG) 27(3), 72 (2008)
Gonzalez, R.C., Woods, R.E.: Digital Image Processing, vol. 2. Addison-Wesley, Boston (1992)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680 (2014)
Guo, J.M., Syue, J.Y., Radzicki, V., Lee, H.: An efficient fusion-based defogging. IEEE Trans. Image Process. (2017)
He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 33(12), 2341–2353 (2011)
He, K., Sun, J., Tang, X.: Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 35(6), 1397–1409 (2013)
He, L., Zhao, J., Zheng, N., Bi, D.: Haze removal using the difference-structure-preservation prior. IEEE Trans. Image Process. 26(3), 1063–1075 (2016)
Hu, H.M., Guo, Q., Zheng, J., Wang, H., Li, B.: Single image defogging based on illumination decomposition for visual maritime surveillance. IEEE Trans. Image Process. 28(6), 2882–2897 (2019)
Huang, S.C., Chen, B.H., Wang, W.J.: Visibility restoration of single hazy images captured in real-world weather conditions. IEEE Trans. Circuits Syst. Video Technol. 24(10), 1814–1824 (2014)
Huang, S.C., Ye, J.H., Chen, B.H.: An advanced single-image visibility restoration algorithm for real-world hazy scenes. IEEE Trans. Ind. Electron. 62(5), 2962–2972 (2014)
Jha, D.K., Gupta, B., Lamba, S.S.: l 2-norm-based prior for haze-removal from single image. IET Comput. Vis. 10(5), 331–341 (2016)
Ju, M., Ding, C., Guo, Y.J., Zhang, D.: Idgcp: image dehazing based on gamma correction prior. IEEE Trans. Image Process. 29, 3104–3118 (2019)
Kim, S.E., Park, T.H., Eom, I.K.: Fast single image dehazing using saturation based transmission map estimation. IEEE Trans. Image Process. 29, 1985–1998 (2019)
Kuanar, S., Rao, K., Mahapatra, D., Bilas, M.: Night time haze and glow removal using deep dilated convolutional network (2019). arXiv preprint arXiv:1902.00855
Levin, A., Lischinski, D., Weiss, Y.: A closed-form solution to natural image matting. IEEE Trans. Pattern Anal. Mach. Intell. 30(2), 228–242 (2007)
Li, B., Peng, X., Wang, Z., Xu, J., Feng, D.: Aod-net: all-in-one dehazing network. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4770–4778 (2017)
Li, R., Pan, J., Li, Z., Tang, J.: Single image dehazing via conditional generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8202–8211 (2018)
Li, Z., Zheng, J.: Edge-preserving decomposition-based single image haze removal. IEEE Trans. Image Process. 24(12), 5432–5441 (2015)
Li, Z., Zheng, J.: Single image de-hazing using globally guided image filtering. IEEE Trans. Image Process. 27(1), 442–450 (2018)
Li, Z., Zheng, J., Zhu, Z., Yao, W., Wu, S.: Weighted guided image filtering. IEEE Trans. Image Process. 24(1), 120–129 (2015)
Ling, Z., Gong, J., Fan, G., Lu, X.: Optimal transmission estimation via fog density perception for efficient single image defogging. IEEE Trans. Multimed. 20(7), 1699–1711 (2017)
Liu, P.J., Horng, S.J., Lin, J.S., Li, T.: Contrast in haze removal: configurable contrast enhancement model based on dark channel prior. IEEE Trans. Image Process. 28(5), 2212–2227 (2018)
Liu, R., Fan, X., Hou, M., Jiang, Z., Luo, Z., Zhang, L.: Learning aggregated transmission propagation networks for haze removal and beyond. IEEE Trans. Neural Netw. Learn. Syst. 30(10), 2973–2986 (2018)
Liu, W., Hou, X., Duan, J., Qiu, G.: End-to-end single image fog removal using enhanced cycle consistent adversarial networks. IEEE Trans. Image Process. 29, 7819–7833 (2020)
Liu, X., Ma, Y., Shi, Z., Chen, J.: Griddehazenet: attention-based multi-scale network for image dehazing. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 7314–7323 (2019)
Mandal, S., Rajagopalan, A.: Local proximity for enhanced visibility in haze. IEEE Trans. Image Process. (2019)
Silberman, N., Hoiem, D., Kohli, P. and Fergus, R.: Indoor segmentation and support inference from rgbd images. In: ECCV (2012)
Peng, Y.T., Cao, K., Cosman, P.C.: Generalization of the dark channel prior for single image restoration. IEEE Trans. Image Process. 27(6), 2856–2868 (2018)
Raikwar, S.C., Tapaswi, S.: Lower bound on transmission using non-linear bounding function in single image dehazing. IEEE Trans. Image Process. 29, 4832–4847 (2020)
Ren, W., Liu, S., Zhang, H., Pan, J., Cao, X., Yang, M.H.: Single image dehazing via multi-scale convolutional neural networks. In: European Conference on Computer Vision, pp. 154–169. Springer (2016)
Ren, W., Ma, L., Zhang, J., Pan, J., Cao, X., Liu, W., Yang, M.H.: Gated fusion network for single image dehazing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3253–3261 (2018)
Salazar-Colores, S., Cabal-Yepez, E., Ramos-Arreguin, J.M., Botella, G., Ledesma-Carrillo, L.M., Ledesma, S.: A fast image dehazing algorithm using morphological reconstruction. IEEE Trans. Image Process. 28(5), 2357–2366 (2018)
Saxena, A., Chung, S.H., Ng, A.Y.: Learning depth from single monocular images. In: Advances in Neural Information Processing Systems, pp. 1161–1168 (2006)
Saxena, A., Chung, S.H., Ng, A.Y.: 3-d depth reconstruction from a single still image. Int. J. Comput. Vis. 76(1), 53–69 (2008)
Shi, L.F., Chen, B.H., Huang, S.C., Larin, A.O., Seredin, O.S., Kopylov, A.V., Kuo, S.Y.: Removing haze particles from single image via exponential inference with support vector data description. IEEE Trans. Multimed. 20(9), 2503–2512 (2018)
Singh, D., Kumar, V.: Comprehensive survey on haze removal techniques. Multimed. Tools Appl. 77(8), 9595–9620 (2018)
Son, C.H., Zhang, X.P.: Near-infrared fusion via color regularization for haze and color distortion removals. IEEE Trans. Circuits Syst. Video Technol. 28(11), 3111–3126 (2017)
Tan, R.T.: Visibility in bad weather from a single image. In: 2008 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE (2008)
Tarel, J.P., Hautiere, N.: Fast visibility restoration from a single color or gray level image. In: 2009 IEEE 12th International Conference on Computer Vision, pp. 2201–2208. IEEE (2009)
Tripathi, A., Mukhopadhyay, S.: Single image fog removal using anisotropic diffusion. IET Image Process. 6(7), 966–975 (2012)
Tripathi, A.K., Mukhopadhyay, S.: Removal of fog from images: a review. IETE Tech. Rev. 29(2), 148–156 (2012)
Wang, A., Wang, W., Liu, J., Gu, N.: Aipnet: image-to-image single image dehazing with atmospheric illumination prior. IEEE Trans. Image Process. 28(1), 381–393 (2018)
Wang, W., Yuan, X., Wu, X., Liu, Y.: Fast image dehazing method based on linear transformation. IEEE Trans. Multimed. 19(6), 1142–1155 (2017)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P., et al.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Yang, X., Li, H., Fan, Y.L., Chen, R.: Single image haze removal via region detection network. IEEE Trans. Multimed. 21(10), 2545–2560 (2019)
Yeh, C.H., Huang, C.H., Kang, L.W.: Multi-scale deep residual learning-based single image haze removal via image decomposition. IEEE Trans. Image Process. (2019)
Zhang, H., Patel, V.M.: Densely connected pyramid dehazing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3194–3203 (2018)
Zhang, J., Tao, D.: Famed-net: a fast and accurate multi-scale end-to-end dehazing network. IEEE Trans. Image Process. 29, 72–84 (2019)
Zhu, Q., Mai, J., Shao, L.: A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 24(11), 3522–3533 (2015)
Acknowledgements
The authors would like to thank A.K. Tripathi, Zhengguo Li, Bolun Cai, Boyi Li, Runde Li, and Se-Eun Kim for sharing their fog removal codes.
Funding
The first and third authors are getting research scholar fellowship and salary under the employment of Indian Institute of Technology Kharagpur, India. The second author worked on this while at IIT Kharagpur and was not funded by any university or agency. This study is not funded by any other agency.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Das, B., Ebenezer, J.P. & Mukhopadhyay, S. A comparative study of single image fog removal methods. Vis Comput 38, 179–195 (2022). https://doi.org/10.1007/s00371-020-02010-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-020-02010-4