
Abstract
The uniaxial compressive strength (UCS) and elasticity modulus (E) are two of the most quoted rock strength parameters in engineering application. Due to approved technical difficulties indirect measurements, the tendency for determining these parameters through predictive models using simpler and cheaper tests in practical oriented applications have widely been highlighted. In this paper, a new hybridized multi-objective support vector regression (MSVR) model integrated with the firefly metaheuristic algorithm (FMA) was developed to touch upon a computational method in rock engineering purposes. The optimum internal parameters were adjusted through parametric investigation using 222 physical and mechanical rock properties corresponding to a variety of quarried stones from all over Iran. The accuracy and robustness of models were evaluated using different error indices, the area under curve for receiver operation characteristics (AUCROC) and F1-score criteria. Comparing to MSVR, the predictability level of UCS and E showed 8.35% and 5.47% improvement in hybrid MSVR-FMA. The superior and more promising results imply that hybrid MSVR-FMA as a flexible alternative can be applied for rock strength prediction in designing of construction projects. Using tow sensitivity analyses, the point load index and P-wave velocity were distinguished as the main effective factors on predicted UCS and E.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The natural stones as one of the efficient but oldest recognized materials provide many possibilities in different civil and construction applications (e.g., building industry, road base, paving, concrete, and asphalt). However, due to heterogeneity of these materials plethora and quite variable engineering characteristics can be observed.
Strength properties, durability, attractiveness (appearance and color), cost, economy and quarrying susceptibility are the primary common criteria in selecting the appropriate building stones. In specific applications, some other properties such as hardness, toughness, specific gravity, porosity and water absorption, dressing, seasoning, workability, fire, and chemical resistance also may need to be considered. Using laboratory tests suitability of stones for building purposes can be evaluated. However, many scholars indicated that laboratory tests for determining uniaxial compressive strength (UCS) and elasticity modulus (E) as two of the most important rock mechanical characteristics is a challenging task (e.g., [2, 11, 42]). Thereby, in practice prediction of UCS and E using statistical regression of simple, inexpensive and non-destructive tests are preferred and notified (e.g., [1, 2, 36, 42, 43, 45, 53]). However, such correlations due to inconsistency of various rock types have shown different degrees of success. Furthermore, the regression analyses among the variables do not imply causality [50], and the strong relationship between variables can be the result of the influence of other unmeasured parameters [46]. Therefore, to interpret predictive statistical model different incompetence (e.g. assumptions, subjective judgment of unobserved data, effect of auxiliary factors, uncertainty of experimental tests, inaccurate prediction in wide expanded range of data) should be considered [2, 4, 27, 29].
The demerits of statistical techniques in producing more efficient and accurate predictive models can be covered using different subcategories of soft computing approaches. The literature reviews highlighted that soft computing techniques such as artificial neural networks (e.g. [5, 35, 36]), support vector machine [6], random forest [38], genetic programming [7, 14], ANFIS [53, 57], Gene expression programming [15] and hybrid systems [11, 31] are able to predict more promising results for the UCS and E than the conventional statistical methods.
The support vector regression (SVR) [24] is a developed novel kind of supervised-learning support vector machine (SVM) for both classification and regression purposes that can map the inputs to an n-dimensional feature space. This model using nonlinear kernel functions simultaneously can maximize predictive accuracy and avoids overfitting [58]. Similar to SVM, the main idea in SVR is always minimizing the error and individualizing the hyperplane which maximizes the margin. However, using small subset of training points in SVR gives enormous computational advantages than SVM which does not depend on the dimensionality of the input space and thus provides excellent generalization capability, with high prediction accuracy [13]. This implies that the possible poor performance of ANNs (e.g. few labeled data points, trapping into local minimal, overfitting) can be treated using SVR to achieve more precise results [49].
In the recent years, different metaheuristic algorithms have been used for possible enhancement in the performance and predictability level of intelligence models (e.g. [8, 11, 61, 65]). Designing supervised learning systems generally is a multi-objective optimization problem [55] which aims to find appropriate trade-offs between several objectives in complex models. However, in practice it is advised to make the number of function evaluations as few as possible in finding an optimal solution [65]. Moreover, the value of design variables (objectives) are obtained by real or computational experiments, where the form of objective functions is not given explicitly in terms of objectives [66]. However, the time dependent (dynamic) multi-objective optimization due to relying on different moments is a very difficult task [40]. Therefore, in the current paper a hybridized multi-objective support vector regression (MSVR) incorporated to firefly metaheuristic algorithm (FMA) for prediction of UCS and E was developed.
The population based stochastic FMA is a swarm intelligence method inspired by the flashing behavior of fireflies [61]. This trial and error procedure efficiently and simultaneously can be applied for solving the hardest optimization problems to find both global and local optima [64]. The performance of hybrid MSVR-FMA was examined by different error criteria and then compared with MSVR. The models were run using 222 datasets of different building stones including rock class, density (γ), porosity (n), P-wave velocity (Vp), water absorption (w) and point load index (Is) from almost all over quarry locations of Iran. It was demonstrated that by applying the FMA, the success of correct classification rate for UCS and E from 81.2% and 79.5% were progressed to 88.6% and 84.1%, respectively. The comparison of different error criteria showed that MSVR-FMA as an accurate enough model can efficiently be applied to estimate the UCS and E. The main effective factors on predicted values were then recognized using different sensitivity analyses.
2 Mathematical configuration of MSVR
In classification, SVR is characterized by the use of kernels, sparse solution and control of the margin, and the number of support vectors. Hence, the output of SVR is found from the mapped support vectors through feature space and calculated weights using Lagrange multipliers and assigned biases (Fig. 1). As the output of SVR is a real number, thus in regression purposes a tolerance margin (ε) known as ε-insensitive loss function is set in the approximation [58]. This provides a symmetrically flexible tube of minimal radius around the estimated function in which the absolute values of errors less than a certain threshold are ignored both above and below the estimate. Consequently, the points outside the tube are penalized, but those within the tube, either above or below the function receive no penalty.

Processing procedure in MSVR structure using support vector algorithm
Considering to dimensionality of input and output spaces (d and Q), the output vector (yi ∈ RQ) subjected to a given set of training input data {(xi, yi)}i=1, 2,…n (xi ∈ Rd) is derived from minimizing of:
where; Lp(W, b) is the Lagrangian optimization function. wj (W ∈ RQ×d) represents an m × m weighted matrix corresponds the model parameter and thus each wi ∈ Rd is the predictor for yi. The bj (b ∈ RQ; j = {1,…, Q}) and ek ∈ R denote the bias matrix term and error variables. The w and b can be obtained using the iterative reweighted trial error least squares procedure (IRWLS) to lead a matrix for each component that to be estimated [47, 48]. The term structure risk (regularization term) is used to control the smoothness or complexity of the function. The user specified constant C > 0 determines the trade-off between the empirical error and the amount up to deviations larger than ε [16]. The parameter ε should be tuned and is equivalent to the approximation accuracy in the training process and shows that the datasets in the range of [+ ε, − ε] do not contribute to the empirical error [13]. ϕ(·) is the feature space factor to provide nonlinear transformation to a higher dimension. The term L(ui) as the loss function using Taylor expansion is defined as:
On kth iteration (Wk and bk), optimizing problem and constructing the quadratic approximation is expressed by:
where \(C\tau\) as a sum of constant term is independent either on W or b. Applying W = Wk and b = bk, provide theame value and gradient for LP (W, b) and L′P (W, b). Thereby, \(\nabla L_{{\text{P}}}^{\prime } \left( {{\varvec{W}}^{k} ,{\varvec{b}}^{k} } \right) = \nabla L_{{\text{P}}} \left( {{\varvec{W}}^{k} , {\varvec{b}}^{k} } \right) \cdot L_{{\text{P}}}^{\prime } \left( {{\varvec{W}}^{k} ,{\varvec{b}}^{k} } \right)\) is a lower bound of LP (W, b) where LP (W, b) > L′P (W, b). The \(a_{i}\), \(u_{i}^{k}\) and \((e_{i}^{k} )^{T}\) then can be calculated using:
Linear combination of the training datasets can provide the best solution for optimizing the learning problem within the inner product of feature space kernel [56]:
Where 1 = [1, 1, …, 1]T is an n dimensional column vector and a = [a1,…, an]T shows an identity matrix. (K)ij = k (xi, xj) is the kernel matrix of two vectors xi and xj that can be easily evaluated [23]. The ||·|| correspond the Euclidean norm for vectors and γ denotes the variance of the radial basis function (RBF) kernel which controls the sensitivity of the kernel function. βj is the parameter which should be computed by searching algorithm and depends on Lagrange multipliers. Hereby, the training datasets via the kernel function are moved into a higher dimension space where various kernel functions may produce different support vectors (Fig. 1). Therefore, the jth output of each new incoming vector x can be expressed as:
where yj = [y1j, …, ynj]T is the outputs. Consequently, the final output (y) is computed by:
where ϕ (xi) and ϕ (xj) are the projection of the xi and xj in feature space. The number of support vectors and biases are noted by n and bj respectively. Kx is a vector that contains the kernel of the input vector x and the training datasets. RBF kernel (Eq. 10) has shown more promising results compared than other proposed kernels [33].
3 Firefly metaheuristic algorithm (FMA)
The FMA as a swarm intelligence population-based algorithm inspired by flashing behavior of fireflies [61] effectively can be applied to solve the hardest global and local optimization problems [64]. During the recent years the applicability of this algorithm has been modified. Gao et al. [25] improved this algorithm using particle filter and presented a powerful tool in solving visual tracking problems. Sayadi et al. [52] developed a powerful version of discrete FMA to deal with non-deterministic polynomial-time scheduling problems. An efficient binary coded FMA to investigate the network reliability was proposed by Chandrasekaran and Simon [17]. Coelho et al. [21] proposed a chaotic FMA that outperformed other algorithms [22]. The studies of Yang [62] on this version of FMA showed that under different ranges of parameter, an enhanced performance using tuning can be achieved. The Lagrangian FMA is another proposed variant [51] for solving the unit commitment problem for a power system. An interesting multi-objective discrete FMA version or the economic emission load dispatch problem was proposed by Apostolopoulos and Vlacho [9]. Meanwhile, Arsuaga-Rios and Vega-Rodriguez [10] independently proposed another multi-objective FMA tool for minimizing energy consumption in grid computing. This version further was developed to solve multi-objective production scheduling systems [34]. Furthermore, a discrete variant of FMA for the multi-objective hybrid problems [37], an extended FMA for converting the single objective to multi-objective optimization in continuous design problems [63], and an enhanced multi-objective FMA in complex networks [8] were also presented.
As presented in Fig. 2, the primary concept for a firefly's flash is based on signal system to attract other fireflies which can be figured out using brightness (I), attractiveness (β) of fireflies i and j in the adjacent distance (rij), absorption coefficient (γ) and tradeoff constant to determine the random behavior of movement (α). The fireflies in this system subjected to trial–error procedure tend to move towards the brighter one and aim to find a new solution using the updated distance between two considered fireflies.

The configuration of FMA and corresponding applied parameters
The I of each firefly represents the solution, s, as a proportion of the objective function [I(s) ∝ f(s)]. The β is also proportional to the intensity of visible light for adjacent fireflies in each distance coordinate, I(r), as:
The distance between any two si and sj or i and j fireflies in an n-dimensional problem is expressed as the Euclidean or the Cartesian distance by:
where I0 denotes the light intensity of the source. γ is the absorption coefficient with a decisive impact on the convergence speed that can theoretically capture any value from interval γ ∈ [0, ∞) but in most optimizing problems typically varies within [0.1–10]. β0 is the attractiveness at rij = 0.
In each iteration of FMA, the fitness function (FT) of the optimal solution of each firefly will own its brightness. Therefore, searching for better FT corresponding to higher brightness level produces new solutions. This embedded iterative process will renew several times comparing to previous results, and only one new solution based on FT is kept. This iterative process can be expressed as:
where αt denotes the tradeoff constant to determine the random behavior of movement and varies in [0, 1] interval. The rand function as a random number of solutions I and β0 at zero distance is normally set to 1. sj is a solution with lower FT than si and (sj − si) represents the updated step size.
Considering to variation of γ within [0, ∞) interval, when γ → 0 then β0 = β that express the standard particle swarm optimization (PSO). In the situation that γ → ∞, the second term falls out from Eq. (16) which not only indicate random walk movement but also is essentially a parallel version of simulated annealing. Consequently, the FMA generally is controlled by three parameters γ, β, and α where in β0 = 0, the movement is a simple random walk.
Depending on compared FT, the new solution (one or more than one or no new solution) between firefly i and other fireflies in the current population is described with:
Therefore, if the considered solution i is also the global best solution, no new solution will be generated. If the best global solution in the population (n) belongs to firefly j, then only one new solution \(s_{{\text{i}}}^{{{\text{new}}}}\) is achieved, else, at least two better solutions than si in n − 1 is available where the lowest FT (FTbest) is retained and others are discarded.
4 Acquired database
A database including 222 sets of rock class, density (γ), porosity (n), P-wave velocity (Vp), water absorption (w) and point load index (Is) from 49 different quarry locations in Iran was assembled (Tables 1 and 2). The statistically analyzed datasets as well as calculated 95% confidence intervals of mean and median of provided datasets are presented in Table 3 and Fig. 3. According to suggested classification by the International society of rock mechanics [30], the majority of compiled datasets fall in the medium to high strength categories (Table 4). The components of processed database due to different units were then normalized within the range of [0, 1] to produce dimensionless sets and improve the learning speed and model stability. These sets further were randomized into training (55%), testing (25%) and validation (20%). The rock classes including sedimentary, igneous, digenetic and metamorphic were coded from 1 to 4, respectively.

95% confidence intervals of mean and median for the employed variables
5 Hybridized MSVR and system results
The structure of MSVR is developed through the input, intermediate and output layers subjected to a series of training experiments. As presented in Fig. 4, the MSVR was trained using iterative reweighted trial error least squares procedure (IRWLS) [47, 48]. Weighting is based on the output of the true objective function and thus the reweighting scheme is considered as a feedback control. The accuracy of MSVR output depends on the appropriate regularized C, ε as well as γ and σ (Min and Lee [39], but no unified procedure for estimating these parameters are accepted. To tune the optimum C and γ, numerous combinations of these parameters with step sizes of 20.2 and 20.1 over log2 using the LIBSVM code in Matlab (Chang and Lin [18] were examined. The FT of optimum parameters in the training process then was evaluated using separate validation datasets or cross-validation technique [19, 32] using:
where RMSE expresses the root mean square error.

Flowchart of model construction and assessing the optimized structure
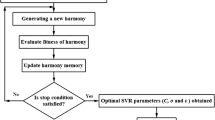
Due to ability of the FMA in control the parameters for effective balancing [20], it was applied to improve the quality of the initial population and optimizing the C and σ. Refer to Fig. 4, the main loop of FMA is controlled by the maximum number of generations (Max Gen). This loop using a gen-counter parameter (t), calculates the new values for the randomization parameter (α) through the functions Δ = 1–10−4/0.91/Max Gen and α(t+1) = 1 − Δ. α(t). Δ determines the step size of changing parameter α(t+1) and is descended with the increasing of t. Then, the new solution si(t) is evaluated based on a fitness function f(s(t)). With respect to the fitness function, f(si(t)) is ordered ascending the solutions si(t) for n populations, where si(t) = S(xi(t)) and thus the best solution s* = s0(t) is determined in the population P(t). The FMA parameters (n, α, β0, γ) were obtained considering variations in the weight results, meanwhile, one was tested the other one was fixed. The number of fireflies was obtained according to the convergence history of the iteration process. Tables 5 and 6 summarize the information about initial, final values and rate of variation in each parameter as well as a sample of series efforts in parametric analyzing. The number of iteration and corresponding fireflies were found through the convergence history of different populations (Fig. 5). The results showed that 1000, 30, 1, 0.2, 0.05, 0.2 and 0.5 corresponding to the number of iterations, number of fireflies, γ, β, Δ, α and β0 can be selected as the most appropriate tuned parameters in FMA.

Convergence history subjected to different firefly populations
In this study, for a stable learning process and reduce the computational effort the MSVR was managed using a quadratic loss function with the value of 0.1 and RBF kernel function subjected to tenfold cross-validation. In the cross-validation method (Fig. 6), the entire training dataset is randomly split into roughly equal subset folds. For K times, each of the folds can be chosen for test data and the remaining is used as training sets. The errors should be less than ε and any deviation larger than this is not accepted. As reflected in Table 7, the optimum values for C and γ were then selected from the lowest error and highest correlation coefficient (R2) in tenfold cross-validation. Accordingly, the performance of the hybridized MSVR-FMA using adjusted parameters comparing to measured values was checked and presented in Fig. 7.

K-fold cross-validation using split randomized dataset

Predictability level of optimum and hybridized MSVR in training stage for E (a, c) and UCS (b, d)
6 Validation and discussion
The correct classification rate (CCR) is a leading assessment metric in discriminant analysis. This criterion can be extracted from the confusion matrix [54] as an unambiguous table layout method to present the predictability of machine learning classifier. Referring to conducted confusion matrix (Table 8), the calculated correct classification rate (CCR) showed 10.27% and 5.47% improvement in predictability of UCS and E using hybrid MSVR-FMA (Table 9). These results reflect the significant influence of incorporated FMA on the accuracy progress of prediction process.
The area under the curve (AUC) of receiver operating characteristic (ROC) is one of the most important graphical metrics in performance and diagnostic ability of a classifier system. ROC is a probability curve that summarizes the trade-off between the true and false positive rates (TPR and FPR) for a predictive model at various threshold settings while AUC represents the degree of separability. Therefore, AUCROC expresses the capability and strength of the model in distinguishing classes (Fig. 8a). In machine learning, precision shows the capability of a classification model in identifying only the relevant data points, while recall monitors all the related cases within a dataset. An optimal combination of precision and recall can be interpreted using F1-score as:

Analyzed performance of MSVR and hybrid MSVR-FMA using AUCROC (a) and F1-score criteria (b)
This criterion expresses a harmonic mean that can be used instead of a simple average. It avoids extreme values and thus is used in imbalanced classes when the false negatives and false positives are crucial [28]. High precision and low recall express extremely accurate model, but it misses a significant number of instances that are difficult to classify. In optimal recall and precision values, the F1-score of a balanced classification model tends to be maximize. This situation reflects veracity (correctly classified data) and robustness (not miss significant instances) of the classifier. In optimizing of the classifier to increase one and disfavor the other, the harmonic mean shows quick decreasing when both precision and recall are equal (Fig. 8b).
The performance of the presented models and forecasted outputs were also pursued using statistical error indices as reflected in Table 10. The formulation of these indices can widely be found in statistical textbooks. The MAPE is one of the most popular indexes for description of accuracy and size of the forecasting error. The MAD reflects the size of error in the same units as the data, and reveals that high predicted values cause higher error rates. The generic IA [60] indicates the compatibility of modeled and observations. The VAF as an intrinsically connected index between predicted and actual values is a representative of model performance. Therefore, higher values of VAF, IA and R2 as well as smaller values of MAPE, MAD and RMSE are interoperated as better model performance (Table 10).
Sensitivity analyses cab express the influence of input parameters on predictability level and provide robust calibrated models in the presence of uncertainty [12]. This implies that removing the least effective inputs may lead to better results. The importance of input variables using the cosine amplitude (CAM) and partial derivative (PaD) [26] are calculated as:
where CAMij and PaDi express the importance (contribution) of ith variable. xi and xj denote elements of data pairs. Okp and xip are output and input values for pattern P, and SSDi is the sum of the squares of the partial derivatives respectively.
The results of CAM and PaD (Fig. 9) showed that Is, Vp and n are the main effective factors on predicted UCS and E, while the rock class and γ expressed the least influences.

Influence of input parameters on predicted UCS and E using different sensitivity analyses
7 Conclusion
Due to the heterogeneity of rocks and dependency of strength parameters (UCS and E) to different physical and mechanical properties, conducting reliable and accurate predictive models is great of interest. In this paper, a new MSVR using 222 datasets of rock class, density (γ), porosity (n), P-wave velocity (Vp), water absorption (w) and point load index (Is) for a wide variety of quarried rocks in Iran was developed. To enhance the progress and improve the efficiency, the MSVR successfully was hybridized with FMA. The results showed that by applying the FMA, the characterized internal properties of MSVR were optimized. Hybridizing procedure revealed that the CCR for UCS from 81.2% was promoted to 88.6% in MSVR-FMA. Similarly, for E this criterion was updated from 79.5 to 84.1%. These values indicate for 8.35% and 5.47% improvement in predictability level of UCS and E in MSVR-FMA. Investigating the robustness of models using AUCROC, F1-score exhibited superior performance in MSVR-FMA (85.1%) than MSVR (82.9%). The figured out accuracy performance of both classifiers using statistical error indices represented higher reliability in MSVR-FMA. According to evaluated criteria, 21.35% and 16.36% improvements in RMSE for UCS and E subjected to hybrid model was observed. Correspondingly, progress of 3.1% (UCS) and 4.16% (E) in MSVR-FMA was raised. Calculated IA showed that the MSVR-FMA with 5.54% and 6.82% progress for UCS and E is more compatible than MSVR. The implemented sensitivity analyses showed that Is, Vp and n are the most effective factors on both UCS and E. This ranking can be interpreted with previous empirical correlations which mostly have been established by these three factors. The accuracy level of predicted outputs approved that the hybrid MSVR-FMA can efficiently utilizes a promising and superior alternative for the purpose of rock strength predictions in designing of construction projects.
References
Abbaszadeh Shahri A, Gheirati A, Espersson M (2014) Prediction of rock mechanical parameters as a function of P-wave velocity. Int Res J Earth Sci 2(9):7–14
Abbaszadeh Shahri A, Larsson S, Johansson F (2016) Updated relations for the uniaxial compressive strength of marlstones based on P-wave velocity and point load index test. Innov Infrastruct Solut 1:17. https://doi.org/10.1007/s41062-016-0016-9
Abbaszadeh Shahri A (2016) Assessment and prediction of liquefaction potential using different artificial neural network models—a case study. Geotech Geol Eng 34(3):807–815. https://doi.org/10.1007/s10706-016-0004-z
Abbaszadeh Shahri A, Larsson S, Renkel C (2020) Artificial intelligence models to generate visualized bedrock level: a case study in Sweden. Model Earth Syst Environ. https://doi.org/10.1007/s40808-020-00767-0
Abdi Y, Garavand AT, Sahamieh RZ (2018) Prediction of strength parameters of sedimentary rocks using artificial neural networks and regression analysis. Arab J Geosci 11:587. https://doi.org/10.1007/s12517-018-3929-0
Aboutaleb Sh, Behnia M, Bagherpour R, Bluekian B (2018) Using non-destructive tests for estimating uniaxial compressive strength and static Young’s modulus of carbonate rocks via some modeling techniques. Bull Eng Geol Environ 77(4):1717–1728. https://doi.org/10.1007/s10064-017-1043-2
Alemdag S, Gurocak Z, Cevik A, Cabalar AF, Gokceoglu C (2016) Modeling deformation modulus of a stratified sedimentary rock mass using neural network, fuzzy inference and genetic programming. Eng Geol 203:70–82. https://doi.org/10.1016/j.enggeo.2015.12.002
Amiri B, Hossain L, Crawford JW, Wigand RT (2013) Community detection in complex networks: multi-objective enhanced firefly algorithm. Knowl Based Syst 46(1):1–11. https://doi.org/10.1016/j.knosys.2013.01.004
Apostolopoulos T, Vlachos A (2011) Application of the firefly algorithm for solving the economic emissions load dispatch problem. Int J Combin. https://doi.org/10.1155/2011/523806
Arsuaga-Rios M, Vega-Rodriguez MA (2012) Multi-objective firefly algorithm for energy optimization in grid environments. In: Dorigo M et al (eds) Swarm intelligence. ANTS 2012. Lecture notes in computer science, vol 7461. Springer, Berlin. https://doi.org/10.1007/978-3-642-32650-9_41
Asheghi R, Abbaszadeh Shahri A, Khorsand Zak M (2019) Prediction of strength index parameters of different rock types using hybrid multi output intelligence model. Arab J Sci Eng 44(10):8645–8659. https://doi.org/10.1007/s1336-019-04046-8
Asheghi R, Hosseini SA, Sanei M, Abbaszadeh Shahri A (2020) Updating the neural network sediment load models using different sensitivity analysis methods—a regional application. J Hydroinf. https://doi.org/10.2166/hydro.2020.098
Awad M, Khanna R (2015) Support vector regression. In: Efficient learning machines. Apress, Berkeley, pp 67–80. https://doi.org/10.1007/978-1-4302-5990-9_4
Beiki M, Majdi A, Givshad AD (2013) Application of genetic programming to predict the uniaxial compressive strength and elastic modulus of carbonate rocks. Int J Rock Mech Min Sci 63:159–169. https://doi.org/10.1016/j.ijrmms.2013.08.004
Behnia D, Behnia M, Shahriar K, Goshtasbi K (2017) A new predictive model for rock strength parameters utilizing GEP method. Procedia Eng 191:591–599. https://doi.org/10.1016/j.proeng.2017.05.222
Bennett KP, Mangasarian OL (1992) Robust linear programming discrimination of two linearly inseparable sets. Optim Methods Softw 1:23–34. https://doi.org/10.1080/10556789208805504
Chandrasekaran K, Simon SP (2012) Network and reliability constrained unit commitment problem using binary real coded firefly algorithm. Int J Electr Power Energy Syst 42(1):921–932. https://doi.org/10.1016/j.ijepes.2012.06.004
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol. https://doi.org/10.1145/1961189.1961199
Cherkassky V, Mulier F (1998) Learning from data: concepts, theory and methods. Wiley, New York
Coelho LDS, Mariani VC (2013) Improved firefly algorithm approach applied to chiller loading for energy conservation. Energy Build 59:273–278. https://doi.org/10.1016/j.enbuild.2012.11.030
Coelho LS, de Andrade Bernert DL, Mariani VC (2011) A chaotic firefly algorithm applied to reliability-redundancy optimization. In: 2011 IEEE Congress of Evolutionary Computation (CEC’11), 12117561, New Orleans, USA, pp 517–521. https://doi.org/10.1109/CEC.2011.5949662
Coelho LS, Mariani VC (2012) Firefly algorithm approach based on chaotic Tinkerbell map applied to multivariable PID controller tuning. Comput Math Appl 64(8):2371–2382. https://doi.org/10.1016/j.camwa.2012.05.007
Courant R, Hilbert D (1953) Methods of mathematical physics. Interscience, New York
Drucker H, Burges CJC, Kaufman L, Smola AJ, Vapnik VN (1997) Support vector regression machines. In: proceedings of NIPS'96, the 9th international conference on neural information processing systems, pp 155–161
Gao ML, Li LL, Sun XM, Yin LJ, Li HT, Luo DS (2015) Firefly algorithm based particle filter method for visual tracking. Optik 126:1705–1711
Gevrey M, Dimopoulos I, Lek S (2003) Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol Model 160(3):249–264. https://doi.org/10.1016/S0304-3800(02)00257-0
Ghaderi A, Abbaszadeh Shahri A, Larsson S (2019) An artificial neural network based model to predict spatial soil type distribution using piezocone penetration test data (CPTu). Bull Eng Geol Environ 78:4579–4588. https://doi.org/10.1007/s10064-018-1400-9
Hand D, Christen P (2018) A note on using the F-measure for evaluating record linkage algorithms. Stat Comput 28(3):539–547. https://doi.org/10.1007/s11222-017-9746-6
Imbens GW, Lemieux T (2008) Regression discontinuity designs: a guide to practice. J Econ 142(2):615–635
ISRM (1981) Rock characterization testing and monitoring. In: Brown ET (ed) ISRM suggested methods, International Society of Rock Mechanics. Pergamon Press, Oxford
Jahed Armaghani D, Mohamad ET, Momeni E, Monjezi M, Narayanasamy MS (2016) Prediction of the strength and elasticity modulus of granite through an expert artificial neural network. Arab J Geosci 9:48. https://doi.org/10.1007/s12517-015-2057-3
Kavousi-Fard A, Samet H, Marzbani F (2014) A new hybrid modified firefly algorithm and support vector regression model for accurate short term load forecasting. Expert Syst Appl 41(13):6047–6056
Li X, Chen X, Yan Y, Wei W, Wang J (2014) Classification of EEG signals using a multiple kernel learning support vector machine. Sensors 14(7):12784–12802. https://doi.org/10.3390/s140712784
Li HM, Ye CM (2012) Firefly algorithm on multi-objective optimization of production scheduling system. Adv Mech Eng Appl 3(1):258–262
Madhubabu N, Singh PK, Kainthola A, Mahanta B, Tripathy A, Singh TN (2016) Prediction of compressive strength and elastic modulus of carbonate rocks. Measurement 88:202–213. https://doi.org/10.1016/j.measurement.2016.03.050
Mahdiabadi N, Khanlari G (2019) Prediction of uniaxial compressive strength and modulus of elasticity in calcareous mudstones using neural networks, fuzzy systems, and regression analysis. Period Polytech Civil Eng 63(1):104–114. https://doi.org/10.3311/PPci.13035
Marichelvam MK, Prabaharan T, Yang XS (2013) A discrete firefly algorithm for the multi-objective hybrid flowshop scheduling problems. IEEE Trans Evol Comput 18(2):301–305. https://doi.org/10.1109/TEVC.2013.2240304
Matin SS, Farahzadi L, Makaremi S, Chelgani SC, Sattari GH (2018) Variable selection and prediction of uniaxial compressive strength and modulus of elasticity by random forest. Appl Soft ing 70:980–987. https://doi.org/10.1016/j.asoc.2017.06.030
Min J, Lee Y (2005) Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters. Expert Syst Appl 28(4):603–614. https://doi.org/10.1016/j.eswa.2004.12.008
Jiang M, Hu W, Qiu L, Shi M, Tan KC (2018) Solving dynamic multi-objective optimization problems via support vector machine. In: 2018 tenth international conference on advanced computational intelligence (ICACI). https://doi.org/10.1109/ICACI.2018.8377567
Momeni E, Jahed Armaghani D, Hajihassani M, For M, Amin M (2015) Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Measurement 60:50–63. https://doi.org/10.1016/j.measurement.2014.09.075
Moradian ZA, Behnia M (2009) Predicting the uniaxial compressive strength and static Young’s modulus of intact sedimentary rocks using the ultrasonic test. Int J Geomech 9(1):14–19. https://doi.org/10.1061/(ASCE)1532-3641(2009)9:1(14)
Najibi AR, Ghafoori M, Lashkaripour GR, Asef MR (2015) Empirical relations between strength and static and dynamic elastic properties of Asmari and Sarvak limestones, two main oil reservoirs of Iran. J Petol Sci Eng 126:78–82. https://doi.org/10.1016/j.petrol.2014.12.010
Nocedal J, Wright SJ (1999) Numerical optimization. Springer-Verlag, New York
Palchik V (2011) On the ratios between elastic modulus and uniaxial compressive strength of heterogeneous carbonate rocks. Rock Mech Rock Eng 44(1):121–128. https://doi.org/10.1007/s00603-010-0112-7
Pedhazur EJ (1997) Multiple regression in behavioral research, 3rd edn. Harcourt Brace College Publishers, Fort Worth
Pérez-Cruz F, Navia-Vázquez A, Alarcón-Diana PL, ArtésRodríguez A (2000a) An IRWLS procedure for SVR. In: Proc. EUSIPCO, Tampere, Finland
Pérez-Cruz F, Alarcón-Diana PF, Navia-Vázquez A, ArtésRodríguez A (2000) Fast training of support vector classifiers. In: Leen T, Dietterich T, Tresp V (eds) Neural information processing systems, vol 13. MIT Press, Cambridge, pp 734–740
Platt J (1999) Fast training of support vector machines using sequential minimal optimization, advances in Kernel methods support vector learning. MIT Press, Cambridge
Powers DA, Xie Y (2008) Statistical methods for categorical data analysis, 2nd edn. Emerald, Howard House
Rampriya B, Mahadevan K, Kannan S (2010) Unit commitment in deregulated power system using Lagrangian firefly algorithm. IEEE Int Conf Commun Control Comput Technol (ICCCCT2010) 11745352 Ramanathapuram India. https://doi.org/10.1109/ICCCCT.2010.5670583
Sayadi MK, Ramezanian R, Ghaffari-Nasab N (2010) A discrete firefly meta-heuristic with local search for makespan minimization in permutation flow shop scheduling problems. Int J Ind Eng Comput 1(1):1–10. https://doi.org/10.5267/j.ijiec.2010.01.001
Singh R, Rk U, Ahmad M, Ansari MK, Sharma LK, Singh TN (2017) Prediction of geomechanical parameters using soft computing and multiple regression approach. Measurement 99:108–119. https://doi.org/10.1016/j.measurement.2016.12.023
Stehman SV (1997) Selecting and interpreting measures of thematic classification accuracy. Remote Sens Environ 62(1):77–89. https://doi.org/10.1016/S0034-4257(97)00083-7
Suttorp T, Igel C (2006) Multi-objective optimization of support vector machines. In: Jin Y (eds) Multi-objective machine learning. Studies in computational intelligence, vol 16. Springer, Berlin, pp 199–220. https://doi.org/10.1007/3-540-33019-4_9
Tuia D, Verrelst J, Alonso L, Pérez-Cruz F, Camps-Valls G (2011) Multi output support vector regression for remote sensing biophysical parameter estimation. IEEE Geosci Remote Sens Lett 8(4):804–808. https://doi.org/10.1109/LGRS.2011.2109934
Umrao RK, Sharma LK, Singh R, Singh TN (2018) Determination of strength and modulus of elasticity of heterogenous sedimentary rocks: an ANFIS predictive technique. Measurement 126:194–201. https://doi.org/10.1016/j.measurement.2018.05.064
Vapnik VN (1995) The nature of statistical learning theory, 2nd edn. Springer-Verlag, New York
Wang H, Hu D (2005) Comparison of SVM and LS-SVM for regression. In: Proc. Int. Conf. on neural networks and brain. IEEE, New York, pp 279–283. https://doi.org/10.1109/ICNNB.2005.1614615
Willmott CJ (1984) On the evaluation of model performance in physical geography. Spatial Stat Models. https://doi.org/10.1007/978-94-017-3048-8_23
Yang XS (2008) Firefly algorithm. Luniver Press, Bristol
Yang XS (2012) Chaos-enhanced firefly algorithm with automatic parameter tuning. Int J Swarm Intell Res 2(4):125–136. https://doi.org/10.4018/jsir.2011100101
Yang XS (2013) Multi-objective firefly algorithm for continuous optimization. Eng Comput 29(2):175–184
Yang XS (2014) Nature-inspired optimization algorithms. Elsevier. https://doi.org/10.1016/C2013-0-01368-0
Yun Y, Yoon M, Nakayama H (2009) Multi-objective optimization based on meta-modeling by using support vector regression. Optim Eng 10:167–181. https://doi.org/10.1007/s11081-008-9063-1
Yun Y, Nakayama H, Arakawa M (2004) Using support vector machines in multi-objective optimization. In: 2004 IEEE international joint conference on neural networks (IEEE Cat. No. 04CH37541). https://doi.org/10.1109/IJCNN.2004.1379903
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Abbaszadeh Shahri, A., Maghsoudi Moud, F. & Mirfallah Lialestani, S. A hybrid computing model to predict rock strength index properties using support vector regression. Engineering with Computers 38, 579–594 (2022). https://doi.org/10.1007/s00366-020-01078-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-020-01078-9