
Abstract
Semiparameric linear regression models are extensions of linear models to include a nonparametric function of some covariate. They have been found to be useful in data modelling. This paper provides local influence analysis to the Liu penalized least squares estimators that uses a smoothing spline as a solution to its nonparametric component. The diagnostics under the perturbations of constant variance, individual explanatory variables and assessing the influence on the selection of the Liu penalized least squares estimators parameter are derived. The diagnostics are applied to a real data set with informative results.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Diagnostic techniques for the parametric regression model have received a great deal of attention in statistical literature since the seminal work of Cook (1977) and others including Cook and Weisberg (1982), Belsley et al. (1989) and Walker and Brich (1988). In semiparametric regression models (SPRMs), diagnostic results are quite rare; among them Eubank (1985), Thomas and Cook (1989) and Kim (1996) studied the basic diagnostic building blocks such as residuals and leverages. Kim et al. (2001,2002) and Fung et al. (2002) proposed some type of Cook’s distances in SPRMs.
The existence of collinearity in the linear regression model can lead to a very sensitive least squares estimate, therefore mixed estimation and ridge regression are suggested to mitigate the effect of collinearity. However, as many authors noted, the influence of the observations on ridge regression is different from the corresponding least squares estimate, and collinearity can even disguise anomalous data (Belsley et al. 1989). Using case deletion method Walker and Brich (1988) and Jahufer and Chen (2009) studied the influence of observations in ordinary ridge regression (ORR) and modified ridge regression (MRR) respectively. They derived the dependence of several influence measures from case deletion on the estimates of ORR and MRR parameters. In SPRMs, Emami (2015) extended results from Walker and Brich (1988) and derived influence measures of ridge estimates using case deletion.
Instead of deleting cases one-by-one, the local influence approach considered in Cook (1986) assessed the influence by simultaneous perturbation of the assumed model, and the influence was measured by normal curvature of an influence graph based on likelihood displacement. This approach has received a lot of attention in the past. The local influence analysis does not involve recomputing the parameter estimates for every case deletion, so it is often computationally simpler. Furthermore, it permits perturbation of various aspects of the model to tell us more than what the case deletion approach is designed for. For example, it can help measure leverage of a design point and evaluate the impact of a small measurement error of x on our estimates. This approach has been extended to generalized models by Thomas and Cook (1989), to linear mixed models by Lesaffre and Verbeke (1998), to partial linear models by Zhu et al. (2003) and to linear measurement errors by Rasekh (2006). In multicollinearity problems, Shi and Wang (1999) and Jahufer and Chen (2012) studied the local influence of minor perturbations on the ridge estimate and Liu estimators in the ordinary regression, respectively. They derived the diagnostics under the perturbation of variance and explanatory variables.
In this paper we generalize the Shi and Wang (1999) results to the SPRMs and we assess the local influence of observations on the Liu estimates. We demonstrate that the local influence analysis of Cook (1986) can be extended to the Liu penalized least squares estimators (LPLSEs ) in SPRMs and provide some insight into the interplay between the linear and the nonparametric components in the context of influence diagnostics.
The paper is organized as follows. In the next section, SPRMs are introduced, the relevant notations and some inferential results are also given. Section 3 derives the local influence diagnostics of LPLSEs under the perturbation of constant variance and explanatory variables. Section 4 provides a diagnostic for detecting the local influential observations of selecting the LPLSEs parameter. In Sect. 5 the proposed methods are illustrated through a simulation study and a real data set. A discussion is given in the last section.
2 Model and inference
Consider the semiparametric regression model
where \(y_{i}\) is the scalar response, \(\beta \) is a p-vector of regression coefficients, \(x_{i}\) is a p-vector of explanatory variables, \(t_{i}\) is a scalar \((a\le t_{i},\ldots t_{n}\le b)\), and \(t_{i}'s\) are not all identical, g is a twice differentiable unknown smooth function on some finite interval and the errors \(\epsilon _{i}\) are uncorrelated with zero mean and unknown constant variance \(\sigma ^{2}\). This model is also called a partially linear model or a partial spline model. Model (1) has been used in discussion of many methods, e.g., penalized least square (see Fung et al. 2002; Chen and You 2005), smoothing spline (see Speckman 1988; Green and Silverman 1994). In this study we will focus our attentions on the local influence diagnostics for the penalized least square estimators as it is a well-studied method of estimation for such models.
2.1 Penalized least square estimators (PLSEs)
Let the ordered distinct values among \(t_{1},\ldots ,t_{n}\) be denoted by \(s_{1},\ldots ,s_{q}\). The connection between \(t_{1},\ldots ,t_{n}\) and \(s_{1},\ldots ,s_{q}\) is captured by means of \(n\times q\) incidence matrix \(\mathbf {N}\), with entries \(N_{ij}=1\) if \(t_{i}=s_{j}\) and 0 otherwise. Let g be the vector of value \(a_{i}=g(s_{i})\). For model (1) the penalized sum of squares is
where y is the vector of n response values and \(\mathbf {X}\) is \(n\times p\) design matrix. Minimizing (2) with respect to \(\beta \) and g, the PLSEs of \(\beta \) and g are
and
respectively, where \(\mathbf {I}\) is the identity matrix of size n, \(\mathbf {S}=\mathbf {N}(\mathbf {N}'\mathbf {N}+\lambda \mathbf {K})^{-1}\mathbf {N}'\) is a smoothing matrix, \(\lambda \) is a nonnegative tuning parameter and \(\mathbf {K}\) is a \(q\times q\) matrix whose entries only depend on the knots \(\{s_{j}\}\) (see Speckman 1988).
2.2 Liu penalized least squares estimators (LPLSEs)
The multicollinearity is a problem when the primary interest is in the estimation of the parameters in a regression model. In the case of multicollinearity we know that when the correlation matrix has one or more small eigenvalues, the estimates of the regression coefficients can be large in absolute value. The least squares estimator performs poorly in the presence of multicollinearity. Some biased estimators have been suggested as a means to improve the accuracy of the parameter estimate in the model when multicollinearity exists. There are a few studies that looked at overcoming the rank-deficient and ill-conditioned or multicollinearity problems in SPRMs (see Hu 2005; Tabakan and Akdeniz 2010; Roozbeh 2015; Roozbeh and Arashi 2015; Amini and Roozbeh 2015; Arashi and Valizadeh 2015). To overcome near multicollinearity, Liu (1993) combined the Stein (1956) estimator with ordinary ridge estimator to obtain the Liu estimator. This approach extended in semiparametric linear regression models (see Akdeniz and Akdeniz Duran (2010); Akdeniz et al. (2015)). Here, we use Liu estimators which can be obtained by minimizing the term
Following Green and Silverman (1994), minimization of (5) can be done in a two steps estimation process: first we minimize it subject to \(g(s_{j})=a_{j}, j=1,\ldots ,q\) and in the second step we minimize the result over the choice of g and \(\beta \). The problem of minimizing \(\int g''(t)^2 dt\) subject to g interpolating given points \(g(s_{j})=a_{j}\) is given by Green and Silverman (1994), and minimizing function g provides a cubic spline with knots \(\{s_{j}\}\). There exists a matrix \(\mathbf {K}\) only depending on the knots \(\{s_{j}\}\), such that the minimized value of \(\int g''(t)^2 dt\) is \(g'\mathbf {K}g\). The equation in (5) is therefore of the form
Minimizing (6) subject to \(\beta \) and g, the LPLSEs, say, \(\hat{\beta }_{d}\) and \(\hat{g}_{d}\), solve
where \(\mathbf {I}_{p}\) is the \(p\times p\) identity matrix. From (7) by simple calculation the LPLSEs are defined as
and
Using (8) and (9), the vector of fitted values is
where \(\mathbf {H}_{\beta }=\mathbf {X}\left( \mathbf {X}'\left[ \mathbf {I}-\mathbf {S}\right] \mathbf {X}+\mathbf {I}_{p}\right) ^{-1}( \mathbf {X}'\left[ \mathbf {I}-\mathbf {S}\right] \mathbf {X}+d\mathbf {I}_{p})\left( \mathbf {X}'\left[ \mathbf {I}-\mathbf {S}\right] \mathbf {X}\right) {\varvec{\tilde{\mathrm{X}}}}'\), \({\varvec{\tilde{\mathrm{X}}}}=(\mathbf {I}-\mathbf {S})\mathbf {X}\), \(\mathbf {H}_{g}=\mathbf {S}(\mathbf {I}-\mathbf {H}_{\beta })\) and \(\mathbf {H}_{d}\) is the hat matrix which in the expanded form is
The first part, \(\mathbf {S}\) is due to the nonparametric component of the model and the second part is due to the linear component of the model after adjusting for the former. The LPLSEs residual vector is evaluated as
The small value d is called the Liu estimator biasing parameter or the shrinkage parameter. A prediction criteria suggested by Liu (1993), to choose biasing parameter d by minimizing Mallows (1973) statistic and it is can be generalized for PLSEs by
where \({\textit{SSR}}_{d}\) is the sum of squares residuals, \(s^2=e_{d}'e_{d}/(n-p)\) is the estimator of \(\sigma ^2\) from LPLSEs in SPRM.
3 Local influence of LPLSEs
It is necessary to start by giving a brief sketch of the local influence approach suggested by Shi (1997) and Shi and Wang (1999) in which the generalized influence function and generalized Cook statistic are defined to assess the local change of small perturbation on some key issues. The generalized influence function of a concerned quantity \(\mathbf {T} \in {\mathbb {R}}^{n}\) is given by
where \(\omega =\omega _{0}+al \in {\mathbb {R}}^{n}\) represents a perturbation, \(\omega _{0}\) is an null perturbation which satisfies \(\mathbf {T}({\omega }_{0})=\mathbf {T}\) denotes an unit length vector. To assess the influence of the perturbations on \(\mathbf {T}\) , the generalized Cook’s statistic is defined as
where \(\mathbf {M}\) is a \(p \times p\) positive definite matrix, and c is a scalar. By maximizing the absolute value of \(GC(\mathbf {T} ; l)\) with respect to l, a direction \(l_{max}(\mathbf {T} )\) is obtained. This direction shows how to perturb the data to obtain the greatest local change in \(\mathbf {T}\) , and thus can be used as a main diagnostic. Maximum value \(GC_{max}(\mathbf {T} ) = GC(\mathbf {T} ; l_{max)})\) indicates the serious local influence. This method removes the need of likelihood. For a discussion on this method and its relationship with Cook (1986) approach, see Shi (1997).
3.1 Perturbing the variance
We first perturb the data by modifying the weight given to each case in the Liu penalized least squares criterion. This is equivalent to perturbing the variance of \(\epsilon _{i}\) in the model. Using the perturbation of constant error variance the term in (6) becomes
where \(\mathbf {W}=diag(\omega )\) is a diagonal matrix with diagonal elements of \(\omega =(\omega _{1},\ldots ,\omega _{n})\) and \(||.||^{2}_{\mathbf {W}}\) is weighted \(l^2\)-norm. Let \(\omega =\omega _{0}+al\), where \(\omega _{0}={1}\), the n vector of ones and \(l=(l_{1},\ldots ,l_{n}).\)
Theorem 1
Under the perturbation of variance the influence function of \(\hat{\beta }_{d}\) and \(\hat{g}_{d}\) are:
where \(\tilde{e}_{d}=\tilde{y}-\tilde{\mathbf {X}}\hat{\beta }_{d}\) and \(\tilde{{y}}=(\mathbf {I}-\mathbf {S}){y}\).
Proof
Minimizing (11), the perturbed version of the LPLSEs \({\hat{\beta }}_{d}\) and \(\hat{g}_{d}\) are
and
respectively.
Now, by differentiating and equating to the null matrix we obtain
and
Then using(12), (14) and (15) we have
Similary, from (13) and (16) we get
Therefore from (16) and (17) the proof is complete. Analogous to case deletion, two versions of the generalized Cook’s statistic of \(\beta \) can be constructed as
and
In (18) generalized Cook’s statistic is scaled by \(\mathbf {M}\) in the LS regression framework and in (19) generalized Cook’s statistic is scaled by \(\mathbf {M}\) in the Liu version of SPRM framework using the fact that
The generalized Cooks statistic of \(\hat{g}_{d}\) will be
Therefore associated diagnostics, denoted by \(l^{1}_{max}(\hat{\beta }_{d})\), \(l^{2}_{max}(\hat{\beta }_{d})\) and \(l_{max}(\hat{g}_{d})\) are the eigenvectors corresponding to the largest absolute eigenvalues of matrices \(\mathbf {A}_{\beta }\), \(\mathbf {B}_{\beta }\) and \(\mathbf {A}_{g}\) respectively. \(\square \)
3.2 Perturbing the explanatory variables
It is known that the minor perturbation of the explanatory variables can seriously influence the least squares results when collinearity is present (Cook 1986, p. 147). This section considers the influence that perturbation of explanatory variables has on the LPLSEs. We define the matrix \(\mathbf {X}=[x_{1},\ldots ,x_{p}]\) in which \(x_{i}, i=1,\ldots ,p\) vectors of explanatory variables and we refer to \(\mathbf {X}_{\omega }\) as the matrix \(\mathbf {X}\) after the perturbation of ith column. Therefore,
where \(\xi _{i}\) is a \(p\times 1\) vector with a 1 in the ith position and zeroes elsewhere. \(s_{i}\) denotes the scale factor and accounts for the different measurement units associated with the columns of \(\mathbf {X}\).
Theorem 2
Under the perturbation of explanatory variables the influence function of \(\hat{\beta }_{d}\) and \(\hat{g}_{d}\) are:
Proof
Under the perturbation of ith column in (6) the LPLSEs will be
and
Since
and \(\mathbf {X}'_{\omega }\left[ \mathbf {I}-\mathbf {S}\right] y=\mathbf {X}'\left[ \mathbf {I}-\mathbf {S}\right] y+as_{i}l\xi _{i}'\left[ \mathbf {I}-\mathbf {S}\right] y,\) then it is easy to obtain that
Hence, from (23) the (21) becomes
From (24) by similar calculations for (22) we have
Differentiating (24) and (25) with respect to a at \(a=0\) the proof will be complete. Analogous to the Sect. 3.1, the generalized Cook statistics can be written
and
The diagnostic direction \(l_{max}\) can be obtained by finding the eigenvector corresponding to the largest absolute eigenvalue of matrices in (26) and (27) respectively. \(\square \)
4 Assessing influence on the selection of Liu parameter d
In this section, using local influence analysis, a method is given to study the detection of the possible influential observations in the data which may have a serious influence on the estimation of d. The selection criterion we used is given in (10), and the perturbation scheme is (11). Let \(C_{d,\omega }\), \({\textit{SSR}}_{\omega ,d}\) and \(\mathbf {H}_{\omega }\) denote the perturbed versions of \(C_{d}\), \({\textit{SSR}}_{d}\) and \(\mathbf {H}_{d}\) respectively. Let \(d_{\omega }\) denote the estimator of d by minimizing
Then the \(l_{max}(\hat{d})\) which is the main diagnostic direction of local influence for \(\hat{d}\) has the form
Since \(C_{d,\omega }\) achieves a local minimum at \(\hat{d}_{\omega }\), we have
Differentiating both sides of (28) with respect to \(\omega \) and evaluating at \(\omega _{0}\), we obtain
We can get the following relation
where \(\Delta =\partial ^{2}C_{\omega ,d}/\partial d\partial \omega \mid _{\omega =\omega _{0},d=\hat{d}}\) and \(\ddot{C}_{d}=\partial ^{2}C_{\omega ,d}/\partial d^{2}\mid _{\omega =\omega _{0},d=\hat{d}}\). Under perturbation of variance, the sum of the squares of the residual \({\textit{SSR}}_{d,\omega }\) and the hat matrix \(\mathbf {H}_{d,\omega }\) in LPLSEs become \({\textit{SSR}}_{d,\omega }=(y-\mathbf {X}\hat{\beta }_{\omega }-\mathbf {N}\hat{g}_{\omega })'\mathbf {W}(y-\mathbf {X}\hat{\beta }_{\omega }-\mathbf {N}\hat{g}_{\omega })\) and
By the known matrix theory, we get
and
where \(\hat{\beta }\) is PLSE of \(\beta \).
A similar matrix partial differentiation for \(tr(\mathbf {H}_{d,\omega })\) gives that
where \(S_{i}'\) is ith row of \(\mathbf {S}\). Therefore, the ith element of \(l_{max}( \hat{d})\) is given by
5 Numerical illustration
5.1 Simulation study
A simulation study has been carried out in order to evaluate the performances of the proposed method in different situation. To achieve different degrees of collinearity, following McDonald and Galarneau (1975), the explanatory were generated using the following device:
where \(z_{ij}\) are independent standard normal pseudo-random numbers, and is specified so that the correlation between any two explanatory variables is given by \(\gamma ^2\). Three different sets of correlations corresponding to \(\gamma =\) 0.80, 0.90, and 0.99 are considered. Then, n observations for the dependent variable are determined by
with \(g(t_{i})=cos(2\pi t_{i})\), \(t_{i}\sim U(0,1)\) in which U(0, 1) denotes the uniform distribution in interval (0, 1). We vary the sample size with \(n=15, 30\) and \(n=50\). In ridge regression Newhouse and Oman (1971) stated that if the mean squared error is a function of \(\beta \), \(\sigma \), and ridge parameter and, if the explanatory variables are fixed, then the mean squared error is minimized when \(\beta \) is the normalized eigenvector corresponding to the largest eigenvalue of \(\mathbf {X}'\mathbf {X}\) matrix subject to constraint that \(\beta '\beta =1\). Here we can selected the coefficients \(\beta _{1}, \beta _{2}\) and \(\beta _{3}\) as normalized eigenvectors corresponding to the largest eigenvalues of \(\mathbf {X}'(\mathbf {I}-\mathbf {S})\mathbf {X}\) matrix so that \(\beta '\beta =1\). An outlier is created by adding \(\nu \) to the response \(y_{10}\), i.e., \(y_{10} = y_{10}+\nu \), where \(\nu \) corresponds to the standard deviation of response y. We calculate the diagnostic measures of \(l^{1}_{max}(\hat{\beta }_{d})\), \(l^{2}_{max}(\hat{\beta }_{d})\) and \(l_{max}(\hat{g}_{d})\) in different datasets. The results are shown in Table 1. It is easily seen from Table 1 that case 10 is the most influential observation. For example for \(n=15\) with \(\gamma =0.8\), the \(l^{1}_{max}(\hat{\beta }_{d})\), \(l^{2}_{max}(\hat{\beta }_{d})\) and \(l_{max}(\hat{g}_{d})\) have maximum values for case 10 compared to any other observation (which have values less than 0.104, 0.153 and 0.096 respectively). These results imply that our proposed diagnostic measures can identify the potential outlier.
5.2 Real data
The Longley (1967) data consisting of 7 economical variables, \(x_{1}=\) GNP implicit price deflator, \(x_{2}=\) Gross National Product, \(x_{3}=\) number of people in the armed forces, \(x_{4}=\) number of unemployed, \(x_{5}=\) Population, \(x_{6}=\) Year and \(y=\) number of people employed. This data has been used to explain the effect of extreme multicollinearity on the ordinary least squares estimators. The scaled condition number (see Walker and Brich 1988) of this data set is 43,275. This large value suggests the presence of an unusually high level of collinearity. Cook (1977) applied Cook’s distance to this data and found that cases 5, 16, 4, 10, and 15 (in this order) were the most influential observations in OLS. Walker and Brich (1988) analysed the same data to find anomalous observations in ORR using the method of case deletion influential measures. They found that cases 16, 10, 4, 15 and 5 (in this order) were the most influential observations in Cook’s and DFFITS measures. In local influence approach Shi and Wang (1999) find the cases 10, 4, 5 and 15 were the most influential observation for ridge estimation and Jahufer and Chen (2012) find the cases 4, 10, 1, 5 and 6 in this order were the five most influential observations for Liu estimator in ordinary regression. Recently, Emami (2015) used the same data to identify influential cases in ridge semiparametric regression model. By case deletion method he identified 12, 16, 2 and 5 were the most influential cases.
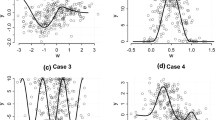
In this section, we use this data set to illustrate the method suggested in this article. The influence of observations on the LPLSEs of SPRM are studied based on small perturbations. Therefore, the influence of the different aspects of the model can be well approached. Here, we fit model (1) to the data, which \(\mathbf {X}=[x_{1},x_{2},x_{4},x_{5},x_{6}]'\) and \(g(t_{i})=g(x_{3})\). The parameter \(\lambda \) in this model is 0.007, which is obtained by minimizing GCV criterion. Estimate of nonparametric function for Longley data for \(d=0.985\) is shown in Fig. 1. First, we consider, the variance perturbation. The index plots of \(l^{1}_{max}(\hat{\beta }_{d})\) and \(l_{max}(\hat{g}_{d})\) are shown in Fig. 2, respectively (index plot of \(l^{2}_{max}(\hat{\beta }_{d})\) for \(d=0.985\) has a similar structure as \(l^{1}_{max}(\hat{\beta }_{d})\). In Fig. 2a, cases 16, 10, 15 and 5 are four most influential cases in \(\hat{\beta }_{d}\). However, the largest absolute component of \(l_{max}(\hat{g}_{d})\) in Fig. 2b directs attention to cases 10, 16, 2, and 12 in order for \(\hat{g}_{d}\). Therefore, local influential observations are slightly different from those in case deletion. This is partly due to the fact that local influence considers the joint influence instead of individual cases influence. Second, we considered the perturbation of individual explanatory variables. The maximum values of \(l^{1}_{max}(\hat{\beta }_{d})\) for separately perturbing explanatory variables \(x_{j}, (j=1,2,4,5\) and 6 ) are 10.28, 0.761 ,5.43 ,2.11 and 1.21 respectively, and also the maximum values of \(l_{max}(\hat{g}_{d})\) are 8.91, 0.44, 3.28, 0.87 and 0.96 respectively. Hence local change caused by perturbing \(x_{1}\) is the largest among the others and local changes by perturbing the other explanatory variables are almost the same. The index plots of \(l^{1}_{max}(\hat{\beta }_{d})\) and \(l_{max}(\hat{g}_{d})\) based on perturbation of \(x_{j}\), \(j=1,4,5 \) and 6 are listed in Figs. 3 and 4 respectively. Note that in these figures vertical scales have been chosen identically (except for the sign). From Fig. 3 it is obvious that the LPLSE \(\hat{\beta }_{d}\) is sensitive for the values of \(x_{1}, x_{4}\) and \(x_{5}\) at cases 1 and 11 and 16 and values of \(x_{5}\) at cases 5, 10 and 14. Also, from Fig. 4 LPLSE \(\hat{g}_{d}\) is sensitive for the values of \(x_{1}, x_{4}, x_{5}\) and \(x_{6}\) at cases 2, 6 and 12. Finally we estimated the \(l_{max}(\hat{d})\) values using (29). It is observed from the index plot of \(l_{max}(\hat{d})\) shown in Fig. 5, cases 2, 10, 5, 15 and 16 in this order are the five most influential observations on LPLSEs parameter.

Estimate of nonparametric function for Longley data with \(d=0.985\)

a (left panel) Index plot of \(l^{1}_{max}(\hat{\beta }_{d})\) with \(d = 0.985\). b (right panel) Index plot of \(l_{max}(\hat{g}_{d})\) with \(d = 0.985\)

Index plot of \(l_{max}(\hat{\beta }_{d})\) for separately perturbing \(x_{1}, x_{4}, x_{5}\) and \(x_{6}\)

Index plot of \(l_{max}(\hat{g}_{d})\) for separately perturbing \(x_{1}, x_{4}, x_{5}\) and \(x_{6}\)

Index plot of \(l_{max}(\hat{d})\) with \(d=0.985\)
6 Conclusion
Local influence diagnostics consider the joint influence of the data set, therefore it is useful to identify some influential patterns appearing in the data set. In this paper, we have studied several local influence diagnostic measures that seem practical and can play a considerable part in LPLSEs of SPRMs. Instead of using case deletion, we use the local influence method to study the detection of influential observations. By perturbing different aspects of the model, the influence compact of the data on the LPLSEs of SPRMs can be studied. The proposed techniques provide to the practitioner numerical and pictorial results that complement the analysis. We believe that the local influence diagnostics we derive here can be useful as part of any serious data analysis. All the proposed measures are the function of residuals, leverage points and LPLSEs. Furthermore, we study the influence of observations on selection of d, which is also important in Liu type regression models. Although no conventional cutoff points are introduced or developed for the Liu estimator local influence diagnostic quantities, it seems that index plot is an optimistic and conventional procedure to disclose influential cases.
References
Akdeniz F, Akdeniz Duran E (2010) Liu-type estimator in semiparametric segression models. J Stat Comput Simul 80:853–871
Akdeniz F, Akdeniz Duran E, Roozbeh M, Arashi M (2015) Effciency of the generalized difference-based Liu estimators in semiparametric segression models with correlated errors. J Stat Comput Simul 85:147–165
Amini M, Roozbeh M (2015) Optimal partial ridge estimation in restricted semiparametric regression models. J Multivar Anal 136:26–40
Arashi M, Valizadeh T (2015) Performance of Kibiria’s methods in partial linear ridge regression models. Stat Pap 56:231–246
Belsley DA, Kuh E, Welsch RE (1989) Regression diagnostics: identifying influential data and sources of collinearity. Wiley, New York
Chen G, You J (2005) An asymptotic theory for semiparametric generalized least squares estimation in partially linear regression models. Stat Pap 46:173–193
Cook RD (1977) Detection of influential observations in linear regression. Technometrics 19:15–18
Cook RD (1986) Assessment of local influence (with discussion). J R Stat Soc B 48:133–169
Cook RD, Weisberg S (1982) Residuals and influence in regression. Chapman & Hall, New York
Emami H (2015) Influence diagnostics in ridge semiparametric regression models. Stat Probab Lett 105:106–115
Eubank RL (1985) Diagnostics for smoothing splines. J R Stat Soc B47:332–341
Fung WK, Zhu ZY, Wei BC, He X (2002) Influence diagnostics and outlier tests for semiparametric mixed models. J R Stat Soc B 47:332–341
Green PJ, Silverman BW (1994) Nonparometric regression and generalized linear models. Chapman and Hall, London
Hu H (2005) Ridge estimation of a semiparametric regression model. J Comput Appl Math B 176:215–222
Jahufer A, Chen J (2009) Assessing global influential observations in modified ridge regression. Stat Probab Lett 79:513–518
Jahufer A, Chen J (2012) Identifying local influential observations in Liu estimator. Metrika 75:425–438
Kim C (1996) Cook’s distance in spline smoothing. Stat Probab Lett 31:139–144
Kim C, Lee Y, Park BU (2001) Cook’s distance in local polynomial regression. Stat Probab Lett 54:33–40
Kim C, Lee Y, Park BU (2002) Influence diagnostics in semiparametric regression models. Stat Probab Lett 60:49–58
Lesaffre E, Verbeke G (1998) Local influence in linear mixed models. Biometrics 54:570–582
Liu K (1993) A new class of biased estimate in linear regression. Commun Stat Theory 22:393–402
Longley JW (1967) An appraisal of least squares programs for electronic computer from the point of view of the user. J Am Stat Assoc 62:819–841
Mallows CL (1973) Some comments on Cp. Technometrics 15:661–675
McDonald GC, Galarneau DI (1975) A Monte Carlo evaluation of some ridge-type estimators. J Am Stat Assoc 70:407–416
Newhouse JP, Oman SD (1971) An evaluation of ridge estimators. http://www.rand.org/pubs/reports/2007/R716
Rasekh A (2006) Local influence in measurement error models with ridge estimate. Comput Stat Data Anal 50:2822–2834
Roozbeh M (2015) Shrinkage ridge estimators in semiparametric regression models. J Multivar Anal 136:56–74
Roozbeh M, Arashi M (2015) Feasible ridge estimator in partially linear models. J Multivar Anal 116:35–44
Shi L (1997) Local influence in principal component analysis. Biometrika 87:175–186
Shi L, Wang X (1999) Local influence in ridge regression. Comput Stat Data Anal 31:341–353
Speckman PE (1988) Regression analysis for partially linear models. J R Stat Soc B 50:413–436
Stein C (1956) Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In: Proceedings of the third Berkeley symposium on mathematical statistics and probability vol 1, pp 197–206
Tabakan G, Akdeniz F (2010) Difference-based ridge estimator of parameters in partial linear model. Stat Pap 51:357–368
Thomas W, Cook RD (1989) Assessing influence on regression coefficients in generalized linear models. Biometrika 76:741–749
Walker E, Birch JB (1988) Influence measures in ridge regression. Technometrics 30:221–227
Zhu Z, He X, Fung W (2003) Local influence analysis for penalized Gaussian likelihood estimators in partially linear models. Scan J Stat 30:767–780
Acknowledgments
The authors would like to thank two anonymous referees and the associate editor for their valuable comments and suggestions on an earlier version of this manuscript which resulted in this improved version.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Emami, H. Local influence for Liu estimators in semiparametric linear models. Stat Papers 59, 529–544 (2018). https://doi.org/10.1007/s00362-016-0775-6
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-016-0775-6