
Abstract
We develop and test multistage portfolio selection models maximizing expected end-of-horizon wealth while minimizing one-sided deviation from a target wealth level. The trade-off between two objectives is controlled by means of a non-negative parameter as in Markowitz Mean-Variance portfolio theory. We use a piecewise-linear penalty function, leading to linear programming models and ensuring optimality of subsequent stage decisions. We adopt a simulated market model to randomly generate scenarios approximating the market stochasticity. We report results of rolling horizon simulation with two variants of the proposed models depending on the inclusion of transaction costs, and under different simulated stock market conditions. We compare our results with the usual stochastic programming models maximizing expected end-of-horizon portfolio value. The results indicate that the robust investment policies are indeed quite stable in the face of market risk while ensuring expected wealth levels quite similar to the competing expected value maximizing stochastic programming model at the expense of solving larger linear programs.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Multi-period investment problems taking into account the stochastic nature of the financial markets, are usually solved in practice by scenario approximations of stochastic programming models. These scenario-based stochastic programming models may ignore the risks associated with the portfolio positions resulting from their implementation. The purpose of this paper is to develop and test robust to market risk, multi-period (two- or three-period) portfolio selection models using scenario approximation of the market parameters. The models advocated in this paper are based on a trade-off objective function aiming to maximize expected end-of-horizon portfolio value while minimizing a downside risk measure, in the spirit of Markowitz portfolio theory (Markowitz 1952). The main contribution consists in establishing experimentally that the proposed models are indeed robust to market risk in the sense of reducing significantly the variance of the end-of-horizon wealth and the probability of a loss. Furthermore, the two-stage models have the property of retaining optimality of the second-stage (recourse) decisions. The optimization tool used in the paper is simply linear programming with off-the-shelf optimization software although admittedly the dimensions of the associated robust linear programs increase by a factor proportional to the number of scenarios in comparison to the risk-neutral stochastic linear programs. To the best of the author’s knowledge the aforementioned ideas had not been tested yet in a multi-period portfolio selection context. The present paper aims to fill this void.
The stochastic multi-period investment problem
For ease of exposition we begin with the two-period problem which goes as follows. Let us assume that we have m+1 assets of which the first m are risky stocks, whereas the (m+1)th is the riskless asset that we can assume to be cash. We will denote the portfolio decision vector at the beginning of period 1 as x 0 with components x 0[i] corresponding to the monetary value of asset i in the portfolio. A similar definition applies for the portfolio decision vector x 1 at the beginning of period 2. Let us denote by r 1 and r 2 the random vectors of net asset returns that are revealed to the investor only after periods 1 and 2 are elapsed. In other words, the investor does not know the realization of r 1 at the beginning of period 1, and commits to a portfolio vector x 0 (possibly paying some transaction fees) using a total budget of one unit of currency. He/she waits during period 1 to observe the realization of r 1 and with his/her total current wealth (r 1)T x 0 obtained as a result of the market movement during period 1, commits to a new portfolio position x 1 (again possibly paying some transaction fees). He/she holds this portfolio during period 2 at the end of which he/she realizes a gain or loss over his/her initial endowment at the beginning of period 1. We do not allow short positions.
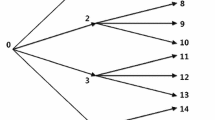
Throughout this paper we follow the general probabilistic setting of (King 2002) in that we approximate the behavior of the stock market by assuming that r 1 and r 2 are discrete random variables supported on a finite probability space (\(\Omega ,{\user1{\mathcal{F}}},P\)) whose atoms are sequences of real-valued vectors (asset returns) over the discrete time periods t=0, 1, 2. We further assume the market evolves as a discrete scenario tree in which the partition of probability atoms ω∈Ω generated by matching path histories up to time t corresponds one-to-one with nodes \(n \in {\user1{\mathcal{N}}}_{t} \) at level t in the tree. The root node n=0 corresponds to the trivial partition \({\user1{\mathcal{N}}}_{0} = \Omega \) consisting of the entire probability space, and the leaf nodes \(n \in {\user1{\mathcal{N}}}_{2} \) correspond one-to-one with the probability atoms ω∈Ω. In the scenario tree, every node \(n \in {\user1{\mathcal{N}}}_{t} \) for t=1, 2 has a unique parent denoted \(\pi {\left( n \right)} \in {\user1{\mathcal{N}}}_{{t - 1}} \), t=0,1 has a non-empty set of child nodes \({\user1{\mathcal{S}}}{\left( n \right)} \subset {\user1{\mathcal{N}}}_{{t + 1}} \). The probability distribution P is obtained by attaching weights p n to each leaf node \(n \in {\user1{\mathcal{N}}}_{2} \) so that \({\sum\nolimits_{n \in {\user1{\mathcal{N}}}_{2} } {p_{n} } } = 1\).
In our models, the random vectors r 1 and r 2 are measurable with respect to \({\user1{\mathcal{N}}}_{1} \) and \({\user1{\mathcal{N}}}_{2} \), respectively. For a discussion of a time-indexed collection of random variables measurable with respect to an information set, the reader is referred to Chapter 3 of Pliska (2000). Let r n 1 denote realizations of random vectors r 1 corresponding to node n at level 1 of the scenario tree. Likewise, let r n 2 denote realizations of random vectors r 2 corresponding to node n at level 2 of the scenario tree. Then the root node of the scenario tree corresponds to the beginning of period 1, and thus to the selection of x 0 while, with each node of level 1 is associated portfolio positions x n 1 for all \(n \in {\user1{\mathcal{N}}}_{1} \). Then the straightforward stochastic programming formulation of the two-stage portfolio selection model without transaction costs based on maximizing expected end-of-horizon portfolio value reads as follows:
where
Due to the separability of the recourse problems \(Q_{n} {\left( {x^{0} } \right)},n \in {\user1{\mathcal{N}}}_{2} \), the above optimization problem (1) is equivalent to
The robust models
The above formulation (3) assumed that the decision maker is risk-neutral, i.e., bases the portfolio decisions solely on expected end-of-horizon portfolio value. Mulvey, Vanderbei and Zenios (1995) proposed to incorporate robustness into two-stage stochastic programs by adding a risk term into the objective function controlled by a scalar parameter. They advocated the use of variance as the risk term à la Markowitz mean-variance portfolio theory (Markowitz 1952) and referred to the resulting models as “robust optimization”. Later, Malcolm and Zenios (1994) developed an application of this methodology to power capacity expansion planning. The Mulvey–Vanderbei–Zenios approach applied to (1) would lead to the following “robust model” in our context:
where Q n (x 0) is defined in (2), λ is a non-negative scalar, N represents the total number of nodes in the scenario tree, and \(f:{\user2{\mathbb{R}}}^{N} \mapsto {\user2{\mathbb{R}}}\) is a variability measure, usually the variance on the second period wealth. The value of λ serves as a knob to control the trade-off between a higher expected end-of-horizon wealth and an investment policy with smaller variability in final wealth. Instead of the above model where separability is no longer assured, Mulvey, Vanderbei and Zenios (1995) proposed their separable robust model which in our context would correspond to
with
In a more recent paper, Takriti and Ahmed (2004) showed that for an arbitrary variability measure f, the model (5) may give an optimal solution where the second-period portfolio decisions are not optimal for the recourse problem (2). In other words, we can no longer claim that models (4) and (5) are equivalent. A consequence of this fact is that the model (5) may have underestimated the risk associated with the investment policy it advocates. In their quest to find sufficient conditions to guarantee second-stage optimality, Takriti and Ahmed (Takriti and Ahmed 2004) defined a non-decreasing function f as follows. Given two vectors z 1 and z 2 in \({\user2{\mathbb{R}}}^{L} \), the notation z 1<z 2 means z l 1≤z l 2 for l=1, ..., L, and z l 1<z l 2 for some l. A function \(f:{\user2{\mathbb{R}}}^{L} \mapsto {\user2{\mathbb{R}}}\) is called non-decreasing if z 1<z 2 implies f(z 1)≤f(z 2). Takriti and Ahmed then show that if f is a non-decreasing function, and λ≥0, then (4) and (5) are equivalent. Therefore, the use of a non-decreasing variability measure resolves the issue of second-period optimality. Takriti and Ahmed (2004) use a piecewise-quadratic measure of variability defined as follows:
where R * is a target value (in our context, a target wealth level), (z)+ denotes max(0, z) for a real number z, and t is a discrete random variable with realizations \(t_{1} , \ldots ,t_{{{\left| {{\user1{\mathcal{N}}}_{2} } \right|}}} \), and \(\rho _{1} , \ldots ,\rho _{{{\left| {{\user1{\mathcal{N}}}_{2} } \right|}}} \) are the corresponding probabilities. To keep our computational effort at a minimum by solving only linear programming problems we adopt a piecewise-linear variability measure given by
which also fulfills the condition of being non-decreasing. Indeed, Ahmed in a later article (2005) also elaborates on the piecewise-linear variability measure. Therefore, our basic model of two-period portfolio selection in the present paper is the following:
where \({\user1{\mathcal{X}}}\) is as defined above. Now, using Proposition 3 of (Takriti and Ahmed 2004) we can state the following result that summarizes the discussion thus far.
Proposition 1
Let λ≥0. Then, model ( 4 ) with f as defined in ( 6 ) and model ( 7 ) are equivalent.
The natural extension of the above framework to three-period portfolio selection problem is as follows. Let r n 3 denote realizations of random vectors r 3 corresponding to node n at level 3 of the scenario tree. Then the root node of the scenario tree corresponds to the beginning of period 1, and thus to the selection of x 0 while, with each node of level 1 is associated portfolio position x n 1 for all \(n \in {\user1{\mathcal{N}}}_{1} \), and to each node n of level 2 corresponds portfolio position x n 2 for all \(n \in {\user1{\mathcal{N}}}_{2} \). Let the total number of variables in the problem be N=(m+1)N 1+(m+1)N 2+m+1, where N 1 is the number of nodes in the scenario tree at level one and N 2 is the number of nodes at level two. Define the set of equations governing the self-financing transaction dynamics as
Then, our robust model of three-period portfolio selection in the present paper is the following:
Clearly, setting λ=0 we recover the three-period version of the risk-neutral stochastic programming problem (3):
An approach related to the ideas of the present paper was developed in King (1993). We discuss this contribution briefly here. Motivated by the common sense reasoning that higher returns should be preferred to lower returns, King (1993) develops asymmetric risk measures starting from a second-order expansion to the utility function of an investor where he uses a linear quadratic penalty term instead of a purely quadratic term in the second-order part of the Taylor expansion. Then, using this linear-quadratic approximation to the utility function he proposes a tracking model which minimizes the deviation of the return of a portfolio from a target return (tracking error), the deviation being measured by the linear-quadratic approximate utility function. This approximation allows to retain the local quadratic feature of the Taylor expansion, but treats deviations larger than a user-defined tolerance by a linear term. However, a good choice for the user-defined tolerance is related to the first and second derivatives of the utility function. Hence, it is important to know the utility function of the investor. The tracking model in King (1993) which aims to minimize the tracking error under a budget constraint for assembling the portfolio, is proposed for a single-period portfolio selection problem under a finite probability space setting as in the present paper. Our model, developed in the paragraphs above, does not use a linear-quadratic approximation to utility functions and, hence does not assume knowledge of a utility function of the investor. Moreover, it is a multi-stage stochastic linear programming model with recourse that treats multi-period decisions, and as such addresses a potentially harder problem. The use of a piecewise-linear penalty function as a risk measure enables us to exploit the computationally faster linear programming technology.
The robust model with linear transaction costs
In this section we present a slightly different version of the robust model (7) allowing transaction costs for buying and selling assets, proportional to the amount sold and bought. We chose to develop this subject as an extension not to detract from the simplicity of the basic two-period investment models in the previous section.
We proceed as in Ben-Tal et al. (2000) (where the authors are in turn inspired by the model of Dantzig and Infanger 1993) and denote by y n 1 the (m+1)-vector of amount of assets bought at level 1 and node \(n \in {\user1{\mathcal{N}}}_{1} \), and by z n 1 the (m+1)-vector of amount of assets sold at level 1 and node \(n \in {\user1{\mathcal{N}}}_{1} \). We use μ i 1 to denote the transaction cost associated with buying one dollar worth of asset i in period 1, and by ν i 1 the transaction cost associated with selling one dollar worth of asset i in period 1. Since we do not allow short positions we do not need to define selling variables for the initial portfolio position. We denote by x n 1[i] the ith component of vector x n 1, and by x 0[i] the ith component of vector x 0, and similarly for y n 1 and z n 1. Now, the asset dynamics are stated as follows: for all i=1, ... , m (risky assets) and for all \(n \in {\user1{\mathcal{N}}}_{1} \) we have
whereas for the riskless asset (cash) we have for all \(n \in {\user1{\mathcal{N}}}_{1} \):
The initial budget equation is also modified as follows:
Now, define the feasible set \({\user1{\mathcal{T}}} = {\left\{ {{\left( {x^{0} ,x_{n} ^{1} ,y_{n} ^{1} ,z_{n} ^{1} ,\forall _{n} \in {\user1{\mathcal{N}}}_{1} } \right)} \geqslant 0:{\left( {10} \right)},{\left( {11} \right)},{\left( {12} \right)}\;{\text{hold}}} \right\}}\). The expected end-of-horizon portfolio value maximizing stochastic linear programming model is as follows:
Similarly to the previous section, we can state the robust two-period portfolio selection model with linear transaction costs:
We skip the three-period versions of the models with transaction costs as the basic three-period model are already quite demanding computationally, and the two-period models with transaction costs are sufficient to make our point in the section on numerical results.
The experimental financial market setup
We adopt the following stochastic model based on a simple factor model for the asset returns from Ben-Tal et al. (2000):
and
where {v 1, v 2} are independent k-dimensional Gaussian random vectors with zero mean and unit covariance matrix (equal to identity matrix), \(e = {\left( {1,...,1} \right)}^{T} \in {\user2{\mathbb{R}}}^{k} ,\;{\text{and}}\;\Omega _{i} \in {\user2{\mathbb{R}}}^{k}_{ + } \) are fixed vectors (not to be confused with the Ω and ω of the Introduction). The random vectors r 1 and r 2 are i.i.d, while the coordinates of every vector are interdependent. The returns of the riskless asset are simply deterministic and do not depend on the period. For simplicity, we also assumed the transaction costs to be deterministic, and independent of asset type and time period throughout the experiments, i.e., we take ν i 1=μ i 1=μ i 0=ν where ν is some positive constant. We define ω I =Ω i T e, as the sum of the elements of Ω i , for all i=1, ..., m.
In our simulations, we choose the parameters, Ω i , i=1, ..., m, κ, σ so as to satisfy the following requirements as in Ben-Tal et al. (2000):
-
Since the (m+1)th asset is the riskless (cash) asset, it is natural that the other assets should have an expected return higher than the riskless asset. Denote the expected value of a random variable by “mean” and its standard deviation by “std”. From the model (15)–(16) we have
$${\text{mean}}{\left( {r^{l} {\left[ i \right]}} \right)} = \exp {\left\{ {\omega _{i} \kappa + {\Omega ^{T}_{i} \Omega _{i} \sigma ^{2} } \mathord{\left/ {\vphantom {{\Omega ^{T}_{i} \Omega _{i} \sigma ^{2} } 2}} \right. \kern-\nulldelimiterspace} 2} \right\}},$$and
$${\text{std}}{\left( {r^{l} {\left[ i \right]}} \right)} = {\text{mean}}{\left( {r^{l} {\left[ i \right]}} \right)}{\sqrt {\exp {\left\{ {{\Omega ^{T}_{i} \Omega _{i} \sigma ^{2} } \mathord{\left/ {\vphantom {{\Omega ^{T}_{i} \Omega _{i} \sigma ^{2} } 2}} \right. \kern-\nulldelimiterspace} 2} \right\}} - 1} }.$$Observing that κ and σ are of the same order of magnitude, both being significantly less than one since the annual rate of growth of a national economy is a few percent, we see that if ω i is significantly less than 1, then mean(r l[i])<exp{κ}. Therefore, we should choose Ω i so as to make ω i greater than or equal to 1.
-
The higher the expected return of the riskless asset, the higher its risk should be. In the model of Ben-Tal et al. (2000), this is indeed (almost) the case since we have that the ratio std(r l[i])/mean(r l[i])=exp{σ 2Ω i T Ω i }−1, so that the risk (which is the left-hand ratio) grows with Ω i T Ω i while one would ideally like it to grow with ω i . Nonetheless, the aforementioned growth property is sufficient for our purposes.
-
One has to make sure that the most attractive assets in terms of expected return should carry a significant probability of a return inferior to the riskless asset return. In other words, we want the probability of the event ln r l[i]<κ, l=1, 2, to be significant. Without repeating the discussion of Ben-Tal et al. (2000), these requirements are fulfilled in Ben-Tal et al. (2000) by choosing three free parameters as follows:
$$\kappa \;{\text{ $>$ }}\;{\text{0,}}\gamma \in {\left[ {{\text{0}}{\text{.5,0}}{\text{.15}}} \right]},\;{\text{and}}\;\omega _{{max}} \in {\left[ {1.5,2} \right]},$$and then setting
$$\begin{array}{*{20}c} {{\sigma = \kappa \mathord{\left/ {\vphantom {\kappa \gamma }} \right. \kern-\nulldelimiterspace} \gamma ,}} \\ {{k = {\left\lfloor {{\left( {\frac{{\omega _{{max}} }}{{\omega _{{max}} - 1}}} \right)}^{2} } \right\rfloor },}} \\ {{k_{i} = \min {\left\{ {k,{\left\lfloor {\frac{{m - i}}{m}k + \frac{i}{m} + 1} \right\rfloor }} \right\}},}} \\ {{\omega _{i} = \frac{{m - i}}{m} + \frac{i}{m}\omega _{{max}} ,}} \\ \end{array} $$for i=1, ..., m. Furthermore, the number of non-zero entries in Ω i is k i , and the indices of these entries are picked at random in the set of integers {1, 2, ..., k}. Then, the k i -dimensional vector w i containing of non-zero entries of Ω i is assigned randomly in the simplex \({\left\{ {w \in {\user2{\mathbb{R}}}^{{k_{i} }}_{ + } \left| {{\sum\nolimits_j {w_{j} = \omega _{i} } }} \right.} \right\}}\). With these choices, the probability of the event ln r l[i]<κ, l=1, 2, is indeed significant (see Ben-Tal et al. 2000), for details.
Ben-Tal, Margalit and Nemirovski (2000) also characterize the market by the risk indices of the assets defined as Prob(r l[i]<1), and choosing the maximum among these probabilities to represent the market risk.
Having set the aforementioned parameters as described above, we generate a scenario tree to be used in the numerical experiments in accordance with the requirements of the models of the present paper. The scenario generation procedure is quite straightforward, and works as follows. We fix a positive integer S for the number of scenarios to be generated per period. I.e., we generate S random vectors r j 1, j=1, ..., S and another S random vectors r j 2, j=1, ..., S, for periods 1 and 2, respectively, as detailed below in (17)–(18). The random vectors r 1 1, ..., r S 1 constitute the level 1 nodes of the scenario tree. Then, with each node of the level 1 we associate S child nodes corresponding each to r 1 2, ..., r S 2, thereby obtaining a total of S 2 nodes at level 2 of the scenario tree. The jth scenario of the period l corresponding to asset i is obtained as
and
where τ j l is a Gaussian k-dimensional vector with zero mean and covariance matrix equal to the identity matrix. This process is carried out for l=1 generating τ j l, for l=1, ..., S, and setting the return vectors according to Equations (17)–(18) for each asset in {1, ..., m+1} and then independently generating τ j l for l=2 (and, for l=3 in the case of three-periods) and again setting the return vectors for each asset in {1, ..., m+1} according to Equations (17)–(18). Upon completion of this process, we have S 2 nodes corresponding to S 2 paths from the root to each leaf node, each having equal probability of occurrence 1/S 2. Therefore, we approximate the return process given by the factor model (15)–(16) by the discrete probability distribution generated according to Equations (17)–(18). With this setup, the model (7) without linear transaction costs has (S+1)(m+1)+S 2 non-negative variables and S 2+S+1 constraints when posed as a linear program after dealing with the piecewise-linear objective function in the usual way. The model (14) under the above setup has (3S+1)(m+1)+S 2 non-negative variables and S 2+S(m+1)+1 constraints when posed as a linear program. In contrast, the model (3) has (S+1)(m+1) non-negative variables with S+1 constraints while model (13) has (3S+1)(m+1) non-negative variables and S(m+1)+1 constraints. Obviously, in the three-period models we obtain S 3 scenario paths from the root to each leaf node with equal probability (1/S 3). Consequently, the number of constraints and variables of the linear program corresponding to the three-period robust problem (8) is given by S 3+S 2+S+1 and (m+1)(S 2+S+1)+S 3, respectively. Removing the term S 3 one arrives at the number of non-negative variables and constraints of the model (9).
Numerical results
In this section we compare the performance of the robust two-period and three-period investment policies with the performance of the expected end-of-horizon wealth based stochastic programming policy under different simulated market conditions. To keep the resulting linear programs at a reasonable size (in the order of a few thousand variables and constraints) since we will solve a large of number of these, we limit our experimentation to m=21 assets, the last one being the riskless asset, and to S=60 yielding 3,600 two-stage scenario paths in the two-period case. We also tried larger S, e.g., S=80 and S=100. Since the results essentially remained identical, we kept S=60 in the interest of shorter run times. For the three period case, we limit ourselves 10+1 assets with at most S=30, yielding 27,000 scenario paths.
Rolling horizon testing
We test all investment policies under the rolling horizon simulation mode of (Ben-Tal et al. 2000), which works as follows. In the two-period case we first build and solve the two-period model—be it the models (3), (7), (13) or (14)—and record the x 0 component of the optimal solution. Building the initial model entails setting the parameters ω max , τ, and γ, generating the return vector realizations according to Equations (17) and (18), as well as choosing λ, R *, ν and μ depending on whether we solve the expected value maximizing stochastic linear program or the robust stochastic linear program. Then, with the portfolio x 0 fixed for the moment, the asset returns are simulated according to Equations (17)–(18), and the value of x 0 updated using the simulated return vector. This portfolio value is used afterwards as the initial endowment for the solution of a one-period portfolio problem—of the same kind as the previous two-period one among again Equations (3), (7), (13) or (14)—that is set up and solved. The optimal solution of this problem is adopted as the final (end-of-horizon) portfolio that we use for “stress testing” against a suitable number K of randomly generated (according to Equations (17)–(18)) return scenarios. For the three-period case, the rolling horizon simulation mode is identical with the exception that we start by solving the full three-period problem, and go on by solving a two-period problem, and finally a single period problem, at which time we subject the final portfolio to stress testing as in the two-period case.
There are two major questions we wish to answer with these tests:
-
1.
Does the robust model indeed deserve the title “robust”? I.e., does it reduce significantly the variability of portfolio value at the end of the planning horizon in both two and three-period models? Does it reduce the risk of losses in the portfolio significantly even in adverse market conditions?
-
2.
Does the robust model preserve the ability to still realize a significant appreciation of the portfolio value while reducing risks?
To answer these questions, in the paragraphs below we report the results of 50 major simulations for each line in the tables as in Ben-Tal et al. (2000) (with the exception of Table 4; see explanation below), where a major simulation is a single rolling horizon test of an investment policy with K=100 end-of-horizon random tests. Therefore, each line in the Tables 1, 2, and 3 below corresponds to statistics obtained from the sample of 5,000 random realizations of the end-of-horizon portfolio value associated with that particular investment policy. We refer to the execution of the 50 major simulations as a “run”. We report the following statistics for a run:
-
the minimum portfolio value observed, denoted v min,
-
the maximum portfolio value observed, denoted v max,
-
the average portfolio value, denoted v avg,
-
the sample standard deviation of portfolio value, v std,
-
the empirical probability (frequency) of loss (a loss is defined as the value of the portfolio being less than 1) computed as the ratio of observed losses in the sample to the sample size, denoted P l,
-
the empirical probability (frequency) of a significant loss (a significant loss is defined as the portfolio value being inferior to 0.8) again computed as the ratio of the number of observed significant losses to the sample size, denoted P sl,
-
the empirical probability (frequency) of significant appreciation (a significant appreciation in the value of the portfolio is defined as the portfolio value being superior to the conservative policy of investing the initial endowment of one unit in the riskless asset and keeping this investment until the end of the two-period horizon; the associated portfolio value in our case is given by (exp τ)2 in the two-period environment, and by (exp τ)3 in the three-period one) computed again as the above frequencies, which we denote P sa.
All experiments are carried out on a personal computer with 2.8 GHz clock speed using the GAMS-IDE (General Algebraic Modeling System) interface with the CPLEX 8.1 linear programming solver. In this computing environment, a single run (i.e., 50 major simulations as detailed above) of models (3), (13), (7) or (14) takes between 20 min to 2 h of computing time. A major portion (almost 70%) of this running time is spent in translating the GAMS models into a form readable by CPLEX 8.1 optimizer, the robust models taking longer times to get treated by GAMS and solved by CPLEX. The three-period model runs take around three to 4 h to complete. This increased computational burden seems to be the price to pay to integrate robustness into the models.
After an exploratory phase of initial experimentation, we settled for the value of τ=0.05, and adopted four different values of depending on how risky we want the simulated market to be. These values are chosen as 0.33, 0.25, 0.216 and 0.2 as in Ben-Tal et al. (2000) which would correspond (with an associated τ=0.1 and ω max=1.2) to market risk ranging from 33% to about 40%; c.f., definition of risk indices of assets following discussion on the choice of these parameters in the previous section. We also choose ω max=1.2. Our empirical results reported below show that the market indeed becomes riskier as γ falls from 0.33 to 0.2. We use R *=1.11 in our experiments.
We report our results in Tables 1, 2, 3 and 4. We abbreviate the robust model results as ROB, and those with the expected end-of-horizon portfolio value maximizing stochastic programming models as STOCH. In the first three tables we have m=20 risky assets plus the riskless asset and 3,600 scenario paths. In Table 1, we summarize the results with the two-period models without transaction costs. In Table 2 and Table 3, we summarize our experimentation with two-period models with transaction costs of ν=μ=0.01 and ν=μ=0.001, respectively. Table 4 gives results for the three-period model without transaction costs where we used m=10 risky assets in addition to the riskless asset, and we have carried out 10 major simulations with K=300 as the models become too large and time-consuming. Therefore, in Table 4, our sample is size 3,000.
We can summarize our findings as follows:
-
It is clear that the robust models indeed diminish the variability of the final portfolio value significantly as the value of λ is increased. In fact, the decrease in the standard deviation of the portfolio value v std from the expected end-of-period portfolio value maximizing stochastic model to the robust model seems to be a linear function of λ at least until a certain value of λ around 10. The reduction in the loss frequency is even more pronounced, being almost always equal to zero in the significant loss case, while the risk-neutral optimal portfolio may result in heavy losses.
-
The robust portfolios of Table 1 display an empirical probability of a gain exceeding the riskless investment strategy comparable (in fact superior) in all cases to that of the risk-neutral investment strategy. Combined with the much reduced risk of losses (as well as the amount of loss at stake) the robust investment strategy appears to be preferable for most investors.
-
Pushing λ to larger values (we have reported results in Table 1 with λ=50 on two-period models) makes the robust portfolio almost mimic a riskless investment where the riskless asset constitutes more than 90% of the portfolio composition.
-
In Tables 2 and 3 we have reported results with different transaction costs. The results of Table 2 reveal that although the robust models still fulfill their function of diminishing variability in portfolio value and loss frequencies, the robust portfolios yield a relatively smaller chance of value appreciation beyond the riskless investment compared to the risk-neutral strategy; c.f. the final column of the tables. However, this result is to be expected under the relatively high level of transaction costs as in the Table 2 experiments under the increasingly riskier market conditions. In Table 3 we diminish the transaction costs tenfold, and obtain robust investment strategies with reduced variability as usual, and with a higher chance of value appreciation beyond the riskless return.
-
From Table 4 we notice that we can achieve significant reductions in the variability of portfolio value at the end of the three-period planning horizon while preserving a considerable chance of exceeding the riskless return.
Clearly, these observations serve to answer in the affirmative the two questions we posed above.
Finally, in Fig. 1 we plot the v avg versus the v std values for a typical problem with m=21, 3,600 scenario paths and γ=0.33, using λ values varying from 1 to 8. We refer to the resulting trade-off curve as the “Experimental portfolio value versus risk trade-off curve”. It is reassuring to be able to display—albeit only experimentally—a curve reminiscent of efficient mean-variance frontiers à la Markowitz.

Experimental trade-off curve
Conclusions
In this paper we developed and tested under simulated market conditions, robust multi-period (two- and three-stage) portfolio selection models based on penalizing a downside-risk term while maximizing the expected end-of-horizon portfolio value. Detailed testing of the robust investment policies under the rolling horizon simulation mode revealed that the proposed models are indeed robust even in adverse market conditions in the sense of reducing the variability of the final portfolio value and the loss probability significantly while maintaining the chance of a decent end-of-horizon return. The robust models correctly identify a risk-return trade-off, giving a chance to the individual investor to position her/himself on an “experimental” trade-off curve by the choice of the preference parameter λ.
References
Ahmed S (2005) Convexity and decomposition of mean-risk stochastic programs. Math Program (to appear)
Ben-Tal A, Margalit T, Nemirovski AS (2000) Robust modeling of multi-stage portfolio problems. In: Frenk HGB, Roos K, Terlaky T, Zhang, S. (eds) High performance optimization, Kluwer, 303–328
Dantzig GB, Infanger G (1993) Multi-stage stochastic linear programs for portfolio optimization. Ann Oper Res 45:59–76
King AJ (1993) Asymmetric risk measures and tracking models for portfolio optimization under uncertainty. Ann Oper Res 45:165–177
King AJ (2002) Duality and martingales: a stochastic programming perspective on contingent claims. Math Program Ser B 91:543–562
Malcolm S, Zenios SA (1994) Robust optimization of power capacity expansion planning. J Oper Res Soc 45:1040–1049
Markowitz HM (1952) Portfolio selection. J Finance 7:77–91
Mulvey JM, Vanderbei RJ, Zenios SA (1995) Robust optimization of large-scale systems. Oper Res 43:264–281
Pliska S (2000) Introduction to mathematical finance. Blackwell, Maldon, MA
Takriti S, Ahmed S (2004) On robust optimization of two-stage systems. Math Program 99:109–126
Dr. Oya E. Karaşan kindly helped with the initial programming of the scenario generation procedure. Her assistance is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Additional information
Dedicated to the memory of Søren S. Nielsen.
Rights and permissions
About this article
Cite this article
Pınar, M.Ç. Robust scenario optimization based on downside-risk measure for multi-period portfolio selection. OR Spectrum 29, 295–309 (2007). https://doi.org/10.1007/s00291-005-0023-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00291-005-0023-2