
Abstract
Previous studies in our lab have described kinematic difference between grasp-to-eat and grasp-to-place movements, whereby participants produce smaller maximum grip apertures (MGAs) when grasping to bring the item to the mouth than when grasping to bring the item to a container near the mouth. This task difference is limited to right-handed movements, regardless of handedness; it has, therefore, been interpreted as evidence of left-hemisphere lateralization of the grasp-to-eat and other hand-to-mouth grasping movements. However, the difference in end-goal aperture may have accounted for both the kinematic signature (smaller MGAs) and their lateralized expression. Specifically, if the right hand is more sensitive to the precision requirements of secondary movements, it may have produced more precise MGAs for actions whose ultimate goal is the small-aperture mouth rather than a comparatively large aperture container. The current study addresses this question by replacing the previously-used bib with a small drinking glass whose aperture more closely resembles that of the mouth. 25 adult participants reached-to-grasp small cereal items to either (a) eat them, or (b) place them into a small-aperture glass hanging beneath their chin. Results once more showed a lateralised kinematic signature in the form of smaller MGAs for the eat action, demonstrating that the signature is not a result of lateralized sensitivity to a movement’s secondary precision requirements. We discuss these results in terms of their impact on predominant theories regarding visual guidance of grasping movements.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Approximately 90% of the global population identifies as right-handed–that is, nine out of every ten people worldwide prefer to use their right hand for simple day-to-day actions (Annett 1967). Many of these people will not only believe that they are better, more skilled, and more dexterous when using their (dominant) right hand, but may imagine that they are clumsy or maladept in comparison when using their (non-dominant) left hand (Maruff et al. 1999). In contrast, many studies investigating the kinematics of reach-to-grasp actions find only minor, if any, kinematic differences between left- and right-handed movements (Begliomini et al. 2008; Flindall et al. 2014; Grosskopf and Kuhtz-Buschbeck 2006; Tretriluxana et al. 2008). Why then do we feel that our dominant hands are more suited to dexterous tasks, like the reach-to-grasp movement? Why then is right-hand dominance so prevalent?
Recent studies in our lab have discovered kinematic asymmetries in a movement with ecological relevance that may shed some light on these questions. When participants grasp an object (in this case, a small cereal item) with the intent to place it into a container, they perform this movement with identical kinematics regardless of whether they use their right or left hand. However, if instead they grasp the object with the intent to eat the item (or even just place it in their mouth), their right-hand maximum grip aperture (MGA) more closely approximates the size of the target during the pre-contact phase of the movement than does their left hand (Flindall and Gonzalez 2013, 2014). This right-hand kinematic signatureFootnote 1 (smaller MGAs for hand-to-mouth grasps) is not dependent on handedness, as it presents in the non-dominant right hand among left-handers more often than it does in the dominant hand (Flindall et al. 2015). This suggests that hand-to-mouth actions, a subset of actions in which the evolutionarily significant grasp-to-eat action is included, are not only distinct from other grasp-to-place actions, but are left-hemisphere lateralized in the majority of humans. We have argued that this lateralization may have, over millennia, resulted in the pattern of right-hand dominance we see today among the global population.
Kinematic differences between mechanistically similar reach-to-grasp actions that differ in terms of end-goal have been well described in the literature. In addition to differences between grasp-to-place and grasp-to-eat actions discussed above [see also Ferri, Campione, Dalla Volta, Gianelli, and Gentilucci (2010)], researchers have shown that participants spend more time decelerating toward a disc when they grasp-to-fit it into a slot than when they grasp-to-throw it away (Marteniuk et al. 1987). In another study, researchers found that MGAs are larger, and deceleration phase is shorter when participants must throw a parallelipiped rather than place it or simply lift it (Armbrüster and Spijkers 2006). When one grasps a bottle with intent to pour it, rather than place it, movement times are extended (Sartori et al. 2011). In all of these examples, the kinematic differences suggest that reach-to-grasp movements are completed with greater care when those movements precede secondary actions that require a high degree of precision, even when the to-be-grasped object’s size, shape, and location are unchanged. With respect to MGA, we observe smaller MGAs when the participant has full visual feedback of the limb and target (Flindall et al. 2014; Hu et al. 1999; Hu and Goodale 2000), and as grasp kinematics mature (Kuhtz-Buschbeck et al. 1998; Olivier et al. 2007); conditions which, it could be argued, act to increase the participant’s confidence in performing the reach-to-grasp action. These findings are in agreement with Fitts’ Law, which predicts that movements will slow as precision requirements (or movement difficulty) increase (Fitts 1954).
In a similar manner, requirements of precision embedded within the secondary phase of the grasp-to-eat movement may account for the kinematic signature we have described. In other words, task-dependent kinematic differences can be explained in terms of the visual system accounting for the greater precision requirements of the subsequent hand-to-mouth transport movement in a purely bottom-up fashion. In our previous studies, participants would either place the grasped food item into their mouths, or place it into a bib hanging beneath their chin. We originally conceived of these movements as functionally distinct (i.e., ‘eat’ vs. ‘place’); however, one may argue that the two movements may, in fact, be considered identical with respect to goal (i.e., placement), differing only in the aperture of that goal (the bib being several times larger than the mouth). If we accept this premise, then it is possible that the right-hand signature for hand-to-mouth movements may result not from a left-hemisphere lateralization of a “grasp-to-eat” engram as posited, but rather a right-hand sensitivity to the higher precision requirements of this hand-to-mouth placement. In other words, the hand-to-mouth movement may not be distinct due to any particular ecological relevance, but simply because the mouth represents a smaller aperture for placement relative to the bib, therefore, representing a goal with greater precision requirements.
To test whether the size of the aperture into which the item was placed was responsible for task-dependent MGA asymmetries, we conducted an experiment wherein participants were asked to grasp small cereal items (Cheerios™, average diameter 11 mm, and Froot Loops™, average diameter 15 mm) to either eat them, or place them into a small-mouthed shot glass (diameter 28 mm) hanging below their chin. Participants completed these grasp-to-eat and grasp-to-place tasks with both their left and right hands, in counter-balanced order. The kinematics of these movements were analyzed in a 2 (Hand; left and right) ×2 (Task; eat and place) ×2 (Target Size; small and large) ANOVA, the results of which are reported below.
Methods
Materials
The methods followed as closely as possible those of previous studies from our lab (Flindall and Gonzalez 2013; Flindall et al. 2015). Briefly, three infra-red light-emitting diodes (IREDs) were placed on the participant’s hand; two on the distal phalanges of thumb and index finger, slightly proximal with respect to the nails, and one on the wrist at the medial aspect of the styloid process of the radius. An Optotrak Certus camera bar [Northern Digital, Waterloo, ON, Canada] recorded IRED position during each trial at 200 Hz for 5 s. Vision was restricted between trials using Plato Liquid–crystal glasses (Translucent Technologies, Toronto, ON, Canada) worn by the participant for the duration of the experiment. Motion capture and audio equipment were controlled using Superlab 4.5 (Cedrus Corporation, San Pedro, CA, USA) and NDI First Principles (Northern Digital, Waterloo, ON, Canada).
Participants
28 young adults (16 females, mean age 22.3 years) volunteered to participate in the experiment in exchange for course credit. All participants gave written informed consent upon admission to the study, in accordance with the principles expressed in the Declaration of Helsinki and with the approval of the University of Lethbridge Human Subjects Research Committee (protocol #2011-022). All participants identified as right-handed via self-report, which was confirmed through a modified Edinburgh/Waterloo Handedness questionnaire (Cavill and Bryden 2003; Oldfield 1971; Stone et al. 2013), given to each participant following data collection. Participants were excluded from analysis if they had suffered neurological damage or recent mechanical injury affecting the dominant limb, if they had received specific training encouraging non-dominant hand use for 1 month or more, or if they failed to scale their grip aperture to target size with one or both hands (i.e., if they exhibited unrealistic, unnatural grasping behaviour). Left-handed participants were not explicitly excluded; however, our blind recruitment yielded no left-handed volunteers. Data from three participants were removed, because they failed to naturally scale their grip aperture for targets of different sizes, leaving data from 25 young adults (15 females, mean age 22.3 years) available for statistical analyses. All participants were naïve to the purpose of the experiment prior to commencement.
Participants were seated before a self-standing height-adjustable triangular pedestal. The distance to the pedestal was normalized to each participant’s reach distance (100% of length from shoulder to index finger with elbow at full 180° extension), such that they could reach the target comfortably at maximum reach distance without leaning forward. The height of the pedestal was adjusted for each participant, such that the target was approximately level with the base of the sternum of the seated participant, but also such that the edge of the pedestal did not act as a direct obstacle during the reach-to-grasp movement (Flindall and Gonzalez 2013; Whishaw et al. 2002).
Procedure
Each trial began with the participant seated behind the pedestal with her hand (thumb and index finger together) placed comfortably on her lap (“rest position”). The liquid–crystal occlusion goggles worn by the participant remained in an opaque state between trials, meaning that the participant was naïve to the size and precise location of the target until the beginning of the trial. While the participant’s vision was thus occluded, the researcher placed large and small targets on the pedestal, one per trial, in a pseudo-random order in an effort to prevent the participant from pre-planning her movements. Trials began when the occlusion goggles transitioned to a transparent state, allowing the participant an initial view of the target. An auditory tone sounded 1000 ms later; this indicated to the participant that she was to reach out and grasp the target, and depending on block condition either (a) eat it, or (b) place it in a small glass hanging beneath her chin. The glass used was a cylindrical shot glass, with a mouth diameter of 28 mm, attached either to a bib (the same one used in the previous experiments, n = 13; Fig. 1a), or hanging freely (in case participants considered the bib a “safety net” during the precise placement task, n = 12; Fig. 1b). Participants were instructed to perform each grasp at a comfortable, natural pace, with an emphasis on accuracy over speed of movement.

Target for the place condition. Participants in the first group (n = 13) placed the target into a shot glass attached to the front of the bib used in the previous experiments (Flindall and Gonzalez 2013). The bib was removed for participants in the second group (n = 12). The same shot glass was used as a target container for both groups
Participants were presented with target items individually in four blocks of twenty trials each. Blocks were defined by a 2 (hand; left, right) ×2 (task; eat, place) factorial design. Large and small targets (ten of each) were pseudo-randomly presented in each block. Block order was counter-balanced between participants; however, both eat and place tasks were always completed for the first hand before markers were shifted to the opposite hand; eat and place blocks were then completed in the same order for the second hand.
Data analysis
Data were collected via NDI First Principles, with kinematic calculations performed on unfiltered data using Microsoft Excel 2010. MGA was measured as the peak resultant distance between the thumb and index finger prior to the time of target contact. This value was obtained by averaging the resultant at rest (when fingertips were touching) across all of a participant’s trials and subtracting that constant from the peak resultant between IREDs for each trial (Flindall and Gonzalez 2013, 2014). Note that statistical tests were simultaneously run on uncorrected MGA values and that results of these tests were consistent between both data sets.
Variability of maximum grip aperture (vMGA; the standard deviation of MGAs within each condition, reported here in mm) has been used previously as a measure of consistency and surety, with increased variability associated with an increase in grasp difficulty and/or a decrease in actor confidence [e.g., via diminished visual feedback availability (Chieffi and Gentilucci 1993; Flindall 2012)]. Movement time (MT; reported here in ms) describes the speed at which a participant completes the required action. MT is measured as the time between reaction time and grasp onset. Reaction time is defined as the time at which the instantaneous velocity of the wrist marker exceeds 5% of the outgoing peak velocity (PV). Grasp onset was determined to have occurred when (1) instantaneous wrist velocity reached a local minimum immediately prior to the beginning of the return-transport phase of the action, and (2) grip aperture approached a plateau, signifying the closing of the grip around the target. Time of peak velocity (PVt) is reported as a percentage of total MT. Time of MGA (MGAt) typically occurs after PVt, and is also reported as a percentage of total movement time. Earlier relative PVt (i.e., more relative time spent decelerating toward the target) and earlier MGAt have been associated with decreased actor confidence, and more online corrections in the grasping movement (Chieffi and Gentilucci 1993; Flindall 2012). Note that all kinematic variables are limited to the outward phase of the reach-to-grasp movement; the return (i.e., placement, or hand-to-mouth) phase of each trial was not analyzed, as Optotrak/IRED line-of-sight limitations within our data collection area prohibit the consistent collection of both outward and inward phases.
Results
A three-way repeated-measures ANOVA with within-subjects factors of Hand (left, right), Task (eat, place), and Size (small, large) and the presence (n = 13) or absence (n = 12) of the bib as a between-subjects factor. The between-subjects factor was not found to be significant in any main effects or interactions; therefore, data were collapsed across groups and a three-way repeated-measures ANOVA with factors Hand, Task, and Size was run on the resulting set. Means and standard errors for variables in each condition can be found in Table 1. Main effects and interactions may be found in Table 1, and are reported in detail.
MGA
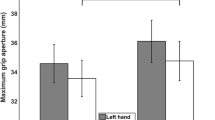
A main effect of task was observed, F(1, 24) = 8.766, p = 0.007, η p 2=0.268, wherein participants produced smaller MGAs when grasping to eat (23.82 ± 0.7 mm) than when grasping to place (25.07 ± 0.7 mm). A main effect of size was observed, F(1, 24) = 295.277, p < 0.001, η p 2=0.925, where participants produced smaller MGAs for small targets (22.13 ± 0.6 mm) than they did for large targets (26.76 ± 0.7 mm). Finally, a Hand × Task interaction was observed, F(1, 24) = 12.645, p = 0.002, η p 2=0.345. Post-hoc paired-sample t tests revealed that this effect was due to significantly smaller MGAs being produced in the right-handed eat task (22.66 ± 0.7 mm) than the left-handed eat task (24.98 ± 0.7 mm; t(24) = 3.431, p = 0.002) and the right-handed place task (24.98 ± 0.8 mm; t(24) = 4.580, p < 0.001) (Fig. 2). No other main effects or interactions were observed.

Hand × task interaction on MGA. Values shown are means + standard errors. Right-handed eat movements produced significantly smaller MGAs when compared to right-handed place movements or left-handed eat movements. Left-handed movements were not significantly affected by task
vMGA
No main effects or interactions were observed.
MT
A main effect of size was observed, F(1, 24) = 47.241, p < 0.001, η p 2=0.663, wherein participants spent significantly more time moving toward small targets (947 ± 36 ms) than they did toward large ones (882 ± 30 ms). No other main effects or interactions were observed.
PV
An interaction between hand and size was observed, F(1, 24) = 15.017, p < 0.001, ηp 2=0.385. Post-hoc paired-sample t tests revealed that this effect was due to the direction of difference between PVs for small and large items in either hand. During left-handed movements, slightly higher (though not significantly so, t(24) = 1.833, p = 0.079) PVs were reached when grasping large items (1.69 ± 0.05 m/s) than when grasping small items (1.68 ± 0.06 m/s). The reverse was true during right-handed movements: slightly higher (again, not significantly so, t(24) = 2.013, p = 0.055) PVs were reached when grasping small items (1.64 ± 0.05 m/s) than when grasping large items (1.63 ± 0.05 m/s). No other post-hoc tests were significant (all p > 0.07). No other main effects or interactions were observed.
PVt
A main effect of size was observed, F(1, 24) = 62.624, p < 0.001, η p 2=0.723, wherein PVt occurred significantly earlier when grasping small items (28.2 ± 0.7%MT) than when grasping large items (29.8 ± 0.7). A Hand × Task interaction was also observed, F(1, 24) = 6.288, p = 0.019, η p 2=0.208. Post-hoc paired-sample t tests revealed that this interaction was due to PVt occurring relatively later in the right-hand place condition (29.9 ± 0.8%MT) than in the right-hand eat condition (28.6 ± 0.6%MT), though this difference was not significant following Bonferroni correction (i.e., p > 0.0125), t(24) = 2.6, p = 0.016. No other post-hoc tests were significant (all p > 0.06). No other main effects or interactions were observed.
MGAt
A main effect of size was observed, F(1, 24) = 22.480, p < 0.001, η p 2=0.484, wherein MGAt occurred significantly earlier during grasps directed toward small items (54.0 ± 1.7%MT) than it did during grasps toward large items (58.6 ± 1.7%MT). No other main effects or interactions were observed.
Discussion
Recent studies in our lab have identified a right-hand kinematic signature for “grasp-to-eat” and other hand-to-mouth movements (Flindall and Gonzalez 2013, 2014, 2015, 2016; Flindall et al. 2015). We have shown that hand-to-mouth actions employ smaller MGAs than grasp-to-place actions (in which the same object is placed into a container near the mouth), as long as these movements are performed with the right hand. However, a limitation of these studies has been that the hand-to-mouth and grasp-to-place tasks employed have differed in terms of the size of the aperture into which the target was ultimately placed. Thus, while the ‘eat’ and ‘place’ actions shared identical mechanical requirements for the outward movement, the transport component of the grasps differed in terms of end-goal precision requirements. To determine whether this difference in precision requirements within the secondary phase of each movement could account for the reported MGA asymmetries in the initial outward action, we asked participants to grasp small food items and either eat them (i.e., a hand-to-mouth action), or place them into a small-aperture shot glass near their mouth (i.e., a grasp-to-place task with comparatively high precision requirements). Results showed that the Hand × Task interaction observed in the previous studies was not affected using a small-aperture target for the grasp-to-place task; in other words, end-goal precision requirements are not responsible for the task-dependent kinematic asymmetries we have previously observed.
In the current study, we have endeavored to maintain the physical/mechanistic requirements as much as possible between our hand-to-mouth and grasp-to-place tasks. Both tasks maintained the same visual feedback availability, the same hand start position, the same targets, the same direction of transport, and similar apertures of the end-goal for placement; the only way in which the two tasks differed was with respect to ultimate intent. In our grasp-to-place task, participants placed the food into a shot glass, whereas in the hand-to-mouth task, participants placed the food into their mouths. This difference in intent led to kinematic differences between the two movements, including an asymmetry in maximum grip apertures that appears to favour the right hand. While only right-handed participants took part in the current study, data from the previous experiments within our lab lead us to believe that this right-hand signature is preserved in the left-handed population (Flindall and Gonzalez 2015; Flindall et al. 2015). The fact that kinematic differences exist between movements that differ only in terms of actor intent implies that there are high-level processes that influence the production of these simple movements. This is by no means revelatory; despite the unconscious nature of dorsal visual stream function, the vision-for-action system is not purported to be independent from the influence of conscious perception (Milner and Goodale 2008). Similarly, the fact that actor intent is a conscious concept does not rule out the dorsal stream as the source of the kinematic signature for hand-to-mouth movements; the posterior parietal cortex is associated with high-level functions such as numeracy and working memory as much as it is with the skilled production of movement (Goodale 2011). Instead, the significance of our results lies in the quantification of this influence; in other words, in addition to the effects of intrinsic target parameters and extrinsic environmental factors (location, presence of obstacles, etc.) on grasp kinematics that have been described to date, we may now gauge the small but significant influence of actor intent on the production of grasping kinematics. The effect’s lateralization provides a simple and fortuitous control for these measurements; because the end-goal seems to only affect right-handed movements, the interaction of high-level actor intent and low-level physical restrictions may be investigated in future studies using a within-participant design. Would the influence of high- and low-level constraints on reach-to-grasp kinematics overlap, or would they compound? The answer to this question may teach us a great deal about the organisation of output in the visuomotor system. Regardless, the possibility that any kinematic effects may be lateralized dictates that left-handed movements should no longer be ignored when designing behavioural or imaging studies of reach-to-grasp actions in humans.
We have postulated that the hand-to-mouth and grasp-to-place movements are generated from distinct engrams; that is, the hand-to-mouth and grasp-to-place grasping movements, which may be identical to each other in terms of mechanical requirements, are supported by distinct neural circuitry. This speculation is based on electrophysiological experiments in macaques showing that functionally specific grasping actions can be elicited by precise differential stimulation of regions within the motor and premotor cortices (Graziano 2006; Graziano et al. 2005, 2002). However, it may be more parsimonious to suppose that conscious intent simply represents another layer of input upon which reach-to-grasp actions are produced. To determine whether this layer is dependent on visual input, we must assess whether task-dependent differences are present in memory-guided movements. If differences between the hand-to-mouth and grasp-to-place movement remain in during open-loop delay conditions (see Hu et al. 1999; Hu and Goodale 2000), then we can say with some certainty that top-down processing is influencing the production of these movements. Alternatively, to test the contribution of the ventral stream to the grasp-to-eat action, one might introduce a delay of variable length between the outward grasp and inward transport of the hand-to-mouth movement. Multiple studies have shown that the dorsal stream retains visual information only for, at maximum, a few seconds (Hesse and Franz 2010; Hu and Goodale 2000). If a movement is planned, and vision of the scene is interrupted, the motor plan generated by the dorsal stream begins to degrade immediately; after as little as 2000 ms, the kinematics of a movement planned with full vision will be indistinguishable from those of movements generated entirely from memory (Franz et al. 2007; Hesse and Franz 2010; Hu et al. 1999). Knowing this, it should be possible to test whether high-level decisions are influencing dorsal stream-mediated movements by inserting a pause at the time of target contact, prior to the transport phase of the grasp-to-eat and grasp-to-place tasks. If the grasp-to-eat signature discussed here is present even in a movement temporally separated from the transport phase, then higher-level factors (i.e., actor intent) must be influencing dorsal stream-mediated output. Ongoing investigations in our lab aim to address this question.
The results of the current study provide additional evidence for a right-hand kinematic signature applying to hand-to-mouth grasping movements. These asymmetries, tied as they are to the specific end-goal of the action (i.e., the mouth), appear to be independent of the difficulty/precision requirements pertaining to the size of that end-goal. In this regard, reach-to-grasp actions seem to violate Fitts’ Law, which describes how changes in task difficulty will affect the speed at which we execute a reaching movement (Fitts 1954). One early study on reach-to-grasp kinematics and their adherence to Fitts’ Law found that kinematics during reaches that differ in terms of difficulty are identical up to peak deceleration, at which point time following peak deceleration increases with decreases in target size (Marteniuk et al. 1990). Our results support these findings, as we found significant effects of size on MT; significant effects on PVt and MGAt can also be explained by a prolonged deceleration phase, as earlier relative timing of these variables will only occur if the deceleration phase of the movement is prolonged, while length of the acceleration phase remains constant. With respect to MGA, however, the task difference we observe cannot be explained by Fitts’ Law, for two reasons. First, the difference in end-goal aperture was consistent between tasks; therefore, we argue that the two tasks shared an equivalent level of difficulty, and yet, kinematic differences remain. Second, and consistent with earlier studies, the task effect was limited to right-handed movements; while research on the applicability of Fitts Law on non-dominant reaching is limited, evidence suggests that it applies equally to pointing movements performed with either hand (Maruff et al. 1999). We conclude that the hand-to-mouth kinematic signature is not resultant from differences in task difficulty–in fact, and there is increasing evidence that Fitts’ Law may not apply to grasping movements at all. Although it has been shown that some grasping kinematics are weakly affected by task difficulty [e.g., grip aperture variability; see Flindall et al. (2014)], evidence suggests that reach-to-grasp kinematics are independent of even large manipulations to goal instability and overall difficulty (Cooper et al. 2005). If the reach-to-grasp movement does not adhere to Fitts’ Law, this throws into question the notion of the reach-to-grasp movement as a composite of reaching and grasping actions (Jeannerod 1984, 1986). It is possible that, rather than being a typical reach coupled with hand pre-shaping appropriate for the acquisition of a distal target, the reach-to-grasp movement is a product of entirely distinct motor planning circuits. That is, the reach-to-touch and reach-to-grasp movements, despite being similar in that they both require distal transport of the hand, may be the product of distinct and separate neural processes. After all, many animals are capable of reaching to touch or manipulate a distal target in simple fashion (e.g., a dog or cat may be able to reach for a ball with their paw or snout), but relatively few are capable of a true unimanual reach-to-grasp movement resulting in target acquisition and control. In addition, the presence of robust asymmetries in reaching movements, and their relative absence in grasping movements, further suggests a neural separation between the two. This should be considered in functional imaging studies designed to investigate the neural origins of reaching and grasping movements.
Conclusion
The current study tested a previously described right-hand kinematic signature for hand-to-mouth actions [smaller MGAs versus grasp-to-place movements (Flindall and Gonzalez 2013, 2014)] using a grasp-to-place task with high precision requirements to determine whether differences in end-goal precision requirements could explain those task-dependent kinematic differences. Results suggest that the hand-to-mouth signature is not due to the precision requirements of the subsequent movement, as the right hand produces smaller MGAs even when precision requirements of the eat and place movement are closely matched. This finding demonstrates that high-level actor intent has the potential to subtly modify kinematics of a simple reach-to-grasp action, independent of changes relative to the environment in which the action is embedded.
Notes
In previous manuscripts, we have referred to this task-dependent effect as a kinematic advantage, as peak grip closing velocity, grip closing time, and metabolic energy requirements are reduced when MGA more closely matches absolute target size (Bootsma et al. 1994). However, larger maximum grip apertures may also represent a kinematic advantage; for example, larger MGAs result in an increased margin for error, and may improve the odds for successful target capture in cases of target uncertainty (Jakobson and Goodale 1991). In the absence of empirical data that would irrefutably support our use of the word advantage, we will instead use the broader expression of ‘kinematic signature’ to refer to the effect in question.
References
Annett M (1967) The binomial distribution of right, mixed and left handedness. Q J Exp Psychol 19(4):327–333
Armbrüster C, Spijkers W (2006) Movement planning in prehension: do intended actions influence the initial reach and grasp movement? Motor Control 10(4):311
Begliomini C, Nelini C, Caria A, Grodd W, Castiello U (2008) Cortical activations in humans grasp-related areas depend on hand used and handedness. PLoS One, 3(10), e3388. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2561002/pdf/pone.0003388.pdf
Bootsma RJ, Marteniuk RG, MacKenzie CL, Zaal F (1994) The speed-accuracy trade-off in manual prehension: effects of movement amplitude, object size, and object width on kinematic characteristics. Exp Brain Res 98:535–541
Cavill S, Bryden P (2003) Development of handedness: comparison of questionnaire and performance-based measures of preference. Brain Cogn 53(2):149–151
Chieffi S, Gentilucci M (1993) Coordination between the transport and the grasp components during prehension movements. Exp Brain Res 94(3):471–477
Cooper S, Doan J, Pellis S, Whishaw I, Brown L (2005) Reducing stability of support structure for a target does not alter reach kinematics among younger adults. Percept Mot Skills 100(3):831–838
Ferri F, Campione GC, Dalla Volta R, Gianelli C, Gentilucci M (2010) To me or to you? When the self is advantaged. Expl Brain Res 203(4):637–646. http://download.springer.com/static/pdf/44/art%253A10.1007%252Fs00221-010-2271-x.pdf?auth66=1380232878_62cfc7b7035886a80611d26558c83aac&ext=.pdf
Fitts PM (1954) The information capacity of the human motor system in controlling the amplitude of movement. J Exp Psychol 47:381–391
Flindall JW (2012) Manual asymmetries in the kinematics of reach-to-grasp actions. (Master of Science), University of Lethbridge, Lethbridge
Flindall JW, Gonzalez C (2013) On the evolution of handedness: evidence for feeding biases. PLoS One 8(11):e78967
Flindall JW, Gonzalez C (2014) Eating interrupted: the effect of intent on hand-to-mouth actions. J Neurophysiol 112(8):2019–2025
Flindall JW, Gonzalez C (2015) Children’s bilateral advantage for grasp-to-eat actions becomes unimanual by age 10 years. J Exp Child Psychol 133:57–71
Flindall JW, Gonzalez C (2016) The destination defines the journey: an examination of the kinematics of hand-to-mouth movements. J Neurophysiol 116(5):2105–2113
Flindall JW, Doan JB, Gonzalez C (2014) Manual asymmetries in the kinematics of a reach-to-grasp action. Later Asymmetries Body Brain Cognit 19(4):489–507
Flindall JW, Stone K, Gonzalez C (2015) Evidence for right-hand feeding biases in a left-handed population. Later Asymmetries Body Brain Cognit 20(3):287–305
Franz VH, Hesse C, Kollath S (2007) Grasping after a delay: more ventral than dorsal? J Vis 7(9):article #157
Goodale M (2011) Transforming vision into action. Vis Res 51(13):1567–1587
Graziano MS (2006) The organization of behavioral repertoire in motor cortex. Annu Rev Neurosci 29:105–134
Graziano MS, Taylor CS, Moore T (2002) Complex movements evoked by microstimulation of precentral cortex. Neuron 34(5):841–851. http://ac.els-cdn.com/S0896627302006980/1-s2.0-S0896627302006980-main.pdf?_tid=272b9d8c-2565-11e3-9f31-00000aacb35d&acdnat=1380060393_a319c3c1619b4bd55aebd0a7057b9208
Graziano MS, Aflalo TN, Cooke DF (2005) Arm movements evoked by electrical stimulation in the motor cortex of monkeys. J Neurophysiol 94(6):4209–4223. http://jn.physiology.org/content/94/6/4209.full.pdf
Grosskopf A, Kuhtz-Buschbeck JP (2006) Grasping with the left and right hand: a kinematic study. Exp Brain Res 168:230–240
Hesse C, Franz VH (2010) Grasping remembered objects: exponential decay of the visual memory. Vis Res 50(24):2642–2650
Hu Y, Goodale M (2000) Grasping after a delay shifts size-scaling from absolute to relative metrics. J Conitive Neurosci 12(5):856–868
Hu Y, Eagleson R, Goodale M (1999) The effects of delay on the kinematics of grasping. Exp Brain Res 126:109–116
Jakobson L, Goodale M (1991) Factors affecting higher-order movement planning: a kinematic analysis of human prehension. Exp Brain Res 86:199–208
Jeannerod M (1984) The timing of natural prehension movements. J Mot Behav 16(3):235–254
Jeannerod M (1986) The formation of finger grip during prehension. a cortically mediated visuomotor pattern. Behav Brain Res 19(2):99–116. http://www.ncbi.nlm.nih.gov/pubmed/3964409
Kuhtz-Buschbeck J, Stolze H, Jöhnk K, Boczek-Funcke A, Illert M (1998) Development of prehension movements in children: a kinematic study. Exp Brain Res 122(4):424–432
Marteniuk RG, MacKenzie CL, Jeannerod M, Athenes S, Dugas C (1987) Constraints on human arm movement trajectories. Can J Psychol Revue Canadienne de Psychologie 41(3):365. http://graphics.tx.ovid.com/ovftpdfs/FPDDNCGCOAIDPG00/fs046/ovft/live/gv023/00002784/00002784-198709000-00007.pdf
Marteniuk RG, Leavitt JL, MacKenzie CL, Athenes S (1990) Functional relationships between grasp and transport components in a prehension task. Hum Mov Sci 9(2):149–176
Maruff P, Wilson P, De Fazio J, Cerritelli B, Hedt A, Currie J (1999) Asymmetries between dominant and non-dominanthands in real and imagined motor task performance. Neuropsychologia 37(3):379–384
Milner A, Goodale M (2008) Two visual systems re-viewed. Neuropsychologia 46(3):774–785
Oldfield RC (1971) The assessment and analysis of handedness: the Edinburgh inventory. Neuropsychologia 9:97–113
Olivier I, Hay L, Bard C, Fleury M (2007) Age-related differences in the reaching and grasping coordination in children: unimanual and bimanual tasks. Exp Brain Res 179(1):17–27
Sartori L, Straulino E, Castiello U (2011) How objects are grasped: the interplay between affordances and end-goals. PLoS One 6(9):e25203. http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3182194/pdf/pone.0025203.pdf
Stone K, Bryant D, Gonzalez C (2013) Hand use for grasping in a bimanual task: evidence for different roles? Exp Brain Res 224(3):455–467. http://download.springer.com/static/pdf/829/art%253A10.1007%252Fs00221-012-3325-z.pdf?auth66=1395419957_da154861cf315bb4c78850b961d8607c&ext=.pdf
Tretriluxana J, Gordon J, Winstein CJ (2008) Manual asymmetries in grasp pre-shaping and transport-grasp coordination. Exp Brain Res 188:305–315
Whishaw IQ, Suchowersky O, Davis L, Sarna J, Metz GA, Pellis SM (2002) Impairment of pronation, supination, and body co-ordination in reach-to-grasp tasks in human Parkinson’s disease (PD) reveals homology to deficits in animal models. Behav Brain Res 133(2):165–176. http://ac.els-cdn.com/S016643280100479X/1-s2.0-S016643280100479X-main.pdf?_tid=8a631192-25ff-11e3-8adb-00000aab0f27&acdnat=1380126702_6e11baa1efb8f74322d9d9b531630ff1
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Flindall, J.W., Gonzalez, C.L.R. The inimitable mouth: task-dependent kinematic differences are independent of terminal precision. Exp Brain Res 235, 1945–1952 (2017). https://doi.org/10.1007/s00221-017-4943-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-017-4943-2