
Abstract
Multiple motor learning processes can be discriminated in visuomotor rotation paradigms. At least four processes have been proposed: Implicit adaptation updates an internal model based on prediction errors. Model-free reinforcement reinforces actions that achieve task success. Use-dependent learning favors repetition of prior movements, and strategic learning uses explicit knowledge about the task. The current experiment tested whether the processes involved in motor learning differ when visual feedback is altered. Specifically, we hypothesized that online and post-trial feedback would cause different amounts of implicit adaptation. Twenty subjects performed drawing movements to targets under a 45° counterclockwise visuomotor rotation while aiming at a clockwise adjacent target. Subjects received visual feedback via a cursor on a screen. One group saw the cursor throughout the movement (online feedback), while the other only saw the final position after movement execution (post-trial feedback). Both groups initially hit the target by applying the strategy. After 80 trials, subjects with online feedback had drifted in clockwise direction [mean direction error: 15.1° (SD 11.2°)], thus overcompensating the rotation. Subjects with post-trial feedback remained accurate [mean: 0.7° (SD 2.0°), TIME × GROUP: F = 3.926, p = 0.003]. We interpret this overcompensation to reflect implicit adaptation isolated from other mechanisms, because it is driven by prediction error rather than task success (model-free reinforcement) or repetition (use-dependent learning). The current findings extend previous work (e.g., Mazzoni and Krakauer in J Neurosci 26:3642–3645, 2006; Hinder et al. in Exp Brain Res 201:191–207, 2010) and suggest that online feedback promotes more implicit adaptation than does post-trial feedback.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Humans learn new and modify existing behavior throughout life. The underlying processes that enable us to learn are manifold and complex. The potential to influence their interplay through noninvasive interventions provides exciting opportunities for training and therapy that have only been partially explored. According to current theories, one major distinction lies between explicit and implicit processes of motor learning (Taylor and Ivry 2012). Explicit or strategic learning enables subjects to achieve task success by applying explicit knowledge about the nature of the task. Once the relevant explicit knowledge has been created, such strategies can be used relatively flexibly according to situational demands (Taylor and Ivry 2011; Zhu et al. 2012). Implicit adaptation on the other hand is mostly thought of as the updating of an internal model that relates sensory inputs to motor outputs and expected sensory consequences (Wolpert et al. 2011). This updating occurs when prediction errors, meaning discrepancies between the predicted and the actual sensory consequences of an action, arise (Taylor and Ivry 2012; Haith and Krakauer 2013). Both, explicit learning and implicit adaptation have been categorized as model-based learning, as they involve a model about the environment that movements occur in (Haith and Krakauer 2013). Recent theoretical and experimental developments suggest that there further exist at least two other processes that are characterized as non-model based or ‘model-free’: Use-dependent learning describes a bias to repeat prior movements (e.g., a tendency toward a specific finger/hand trajectory after several repetitions in a reach task) independent of their outcomes (Wolpert et al. 2011). Model-free reinforcement on the other hand is driven by task success and thus reinforces actions that are successful with respect to a task goal (Huang et al. 2011; Haith and Krakauer 2013).
The processes described have often been investigated in studies using visuomotor adaptation paradigms. In such paradigms, a mismatch between intended action and perceived sensory consequence is created. For example, in visuomotor rotation (VR), the mapping of hand position onto a cursor visible on a computer screen is rotated around the start point in a precision reach task, inducing a direction error that subjects can learn to compensate for with repeated practice (Krakauer et al. 2000). A typical VR experiment consists of baseline practice without the cursor rotation followed by a practice phase in which the rotation is introduced, resulting in initially large errors in cursor direction that subjects subsequently learn to reduce by moving their hand in a direction opposite to the rotation. This is often followed by a washout phase in which the rotation is turned off in order to test for ‘aftereffects.’ Aftereffects are errors in a direction opposite to the rotation that occur after removal of the rotation and can thus be regarded as carryover of behavior that was successful in the rotated environment. When the removal of the rotation is apparent to the subjects by instruction or visual feedback, explicit strategies from the rotated environment are presumably no longer applied. Aftereffects that occur under these conditions are therefore frequently used as a (quantitative) marker of implicit adaptation (Hinder et al. 2008).
Naturally, learning of VRs relies on visual feedback about hand position. Previous studies have documented that the way in which feedback was provided determined whether learning was dominantly implicit or explicit. Specifically, many visuomotor adaptation studies have focused on a comparison between online feedback, in which subjects see the cursor throughout their movement, and post-trial feedback, in which subjects do not see the cursor during their movement, but are presented with a static depiction of either end position or movement trajectory after movement execution (Bernier et al. 2005; Hinder et al. 2008, 2010; Shabbott and Sainburg 2010; Peled and Karniel 2012).
Several studies (Hinder et al. 2008, 2010; Shabbott and Sainburg 2010) found that online feedback caused significantly larger aftereffects than post-trial feedback. It was concluded that online visual feedback is critical for implicit adaptation to a visuomotor rotation (or ‘visuomotor remapping’).
However, with the more recent concepts of model-free processes like reinforcement and use-dependent learning, a reevaluation of the findings regarding the difference between online and post-trial feedback seems warranted. Aftereffects in the relevant previous studies (Hinder et al. 2008, 2010; Shabbott and Sainburg 2010) occurred in the direction that was repeated (use-dependent learning) and associated with task success (reinforcement learning) in the rotated environment. Further, as model-free reinforcement and use-dependent learning do not involve a strong cognitive component, it seems unlikely that behavior resulting from them is subject to quick changes based on cognitive decisions—as in the case of explicit strategies. Thus, aftereffect in these experiments could in principle also be a result of use-dependent learning and/or model-free reinforcement. The fact that some aftereffects remained (Hinder et al. 2008; Shabbott and Sainburg 2010) even with post-trial feedback may be indicative of such a multi-process principle (i.e., the feedback difference may only impair one out of several of learning processes, each of which contributes to aftereffects).
However, use-dependent learning is—by definition—feedback independent (Wolpert et al. 2011), and it is therefore unlikely that a change in feedback would alter the involvement of this process. In contrast, for model-free reinforcement, studies indicate that this mechanism is sensitive to feedback modalities (Shmuelof et al. 2012). Therefore, the differences in aftereffects found by earlier studies (Hinder et al. 2008, 2010; Shabbott and Sainburg 2010) could be a result of feedback-related changes in either implicit adaptation or model-free reinforcement, or both.
A possibility to further clarify this point lies in a design that was introduced by Mazzoni and Krakauer (2006) and that has the potential to show implicit adaptation isolated from other mechanisms. In a visuomotor rotation setup, these authors provided subjects with a strategy to counter a visuomotor rotation. Thus, a 45° counterclockwise (CCW) rotation was compensated by aiming the movement at an additional target located 45° clockwise (CW) from the visual target. Surprisingly, while subjects were initially able to use the strategy and successfully hit the target, they subsequently drifted in a CW direction and thus overcompensated for the rotation. As this overcompensation constitutes a decline in task success due to a drift toward a ‘new’ direction, it cannot logically result from model-free reinforcement (which maximizes task success), or use-dependent learning (which favors movements in prior directions rather than introducing new ones). As an explicit strategy is provided as experimental variable in this design, explicit learning is also unlikely to be the cause of overcompensation. More likely, overcompensation in this task reflects implicit adaptation driven by the prediction error that results from the discordance between hand and cursor position, regardless of task success (Mazzoni and Krakauer 2006; Haith and Krakauer 2013).
In the present study, we used the design from Mazzoni and Krakauer (2006) to clarify the difference between online and post-trial feedback in visuomotor adaptation by testing feedback effects on implicit adaptation isolated from other processes.
Methods
Tests were performed in accordance with the Declaration of Helsinki. Twenty subjects [10 males, 10 females, mean age: 23 (SD 3) years] gave informed consent and were assigned to an online or a post-trial feedback group in a pseudorandom fashion, yielding ten subjects per group. Two of the subjects (one per group) were self-declared left-handers. The test movements were performed with the right hand by all subjects.
Experimental setup
We used a standard visuomotor rotation setup with a digitizing tablet (Intuos 4, Wacom, Tokyo, Japan) and corresponding pen as input device. Subjects sat in a chair at a table with their head about 1 m in front of a vertically propped LCD-screen (MultiSync LCD3210, NEC, Tokyo, Japan), which was connected to a standard PC running on Windows XP (Microsoft, Redmont, WA, USA). The digitizing tablet was mounted flat on the table surface. Vision of the tablet and hand was covered by a cardboard screen. By moving the pen on the tablet, subjects controlled a custom cursor (red filled circle of 0.5 cm diameter) on the screen. The tablet surface was covered with tape, with a circle of 7 cm diameter left out at its center. The center of the circle was marked with a dot of tape. Each trial consisted of a discrete drawing movement from the center marker to the outer boundary of the circle. Subjects were instructed to make these movements fast and straight and then rest where they hit the boundary until the end of the trial without making further corrections to the position. The subjects were told to retain full movement speed till they hit the boundary, and the boundary was designed so that subjects could hit it without passing it. The trials were guided by three tones displayed in a constant rhythm. The first tone (440 Hz, 200 ms) indicated that subjects should be ready with the pen on the center marker. The second tone (600 Hz, 400 ms) marked the period during which subjects were required to perform the drawing movement. The third tone (350 Hz, 200 ms) marked the end of the trial, after which subjects were supposed to regain the starting position by lifting the pen from the tablet, finding the center marker with the index finger of the left hand and matching the pen to it. This way, subjects’ exposure to the rotated/intuitive environment (see below) was restricted to the target movements. A trial lasted 4.2 s with 1.4 s between the first and second tone and 2 s between the second and third tone. Between trials, there was a 2.8 s break for regaining the start position.
On the screen, a custom Labview-based (National Instruments, Austin, TX, USA) software (Touch Recorder, pfitec, Endingen, Germany) displayed a white background with the position corresponding to the center of the tablet marked by a start circle (empty black circle, 1 cm diameter) and eight targets (empty black lines, 0.5 cm width, 11 cm length) surrounding it. The targets were positioned with equal distance of 80 pixels to the start circle and equally spaced so that their longitudinal sides paralleled radial vectors from the center of the start circle to 22.5°, 67.5°, 112.5°, 157.5°, 202.5°, 247.5°, 292.5° and 337.5°, respectively (see Fig. 1). While the physical amplitude boundary ensured that the cursor would always reach about half the targets length, the particular target shape and alignment were intended to emphasize the greater relevance of angular error relative to amplitude. On each trial, one of the targets would be filled blue and this would be the cursor target for this trial, meaning that subjects should hit this target with the cursor (see Fig. 1). This cursor target would change in a pseudorandom fashion so that eight trials would cover each target once, making one cycle of trials.

The screen display with the target at −67.5° filled and thus marked as cursor target. 0° would be horizontally to the right in our convention. The hand target for this trial would be the one at −22.5°
Experimental protocol
To become familiar with the reaching task, each subject underwent a familiarization period, which consisted of 20 random direction movements with no target, and 16 trials to targets without the rotation. Thereafter, subjects performed six test phases (similar to the protocol of Taylor et al. 2010). During the first three phases, each consisting of three cycles, the mapping of the cursor to pen movements on the tablet would be in an intuitive fashion, i.e., no rotation of the cursor. These phases thus tested baseline performance, with the first and third phase testing subjects’ ability to hit the cursor target (baseline). In the second phase (‘baseline + strategy’), subjects were instructed to aim at the target that neighbored the cursor target for the respective trial in a CW direction (subsequently called hand target) and thus deliberately produce a 45° error with respect to the cursor target. This phase was meant to familiarize subjects with the procedure they would later use as a strategy (see below) and to make sure they correctly understood it (cf. Taylor et al. 2010). In the fourth and fifth phase, the mapping of hand direction to cursor direction would be changed so that cursor movement direction would be rotated around the start circle by 45° CCW relative to the hand movement. The fourth phase (‘rotation − strategy’) lasted only two trials and, since the rotation was not announced to the subjects in advance, all of them displayed a large error in the direction of the rotation. Thereafter, in the fifth phase, subjects were instructed that they should counter the rotation they had just experienced, by aiming at the neighboring target as previously practiced. Subsequently, subjects performed ten cycles (80 trials, ‘rotation + strategy’), in which they were supposed to strategically compensate the rotation. The sixth phase (ten cycles) was a ‘washout’ phase where the mapping of pen to cursor was set back to intuitive fashion and subjects were instructed that the rotation had been turned off, and they should stop using the strategy. This phase thus tested for aftereffects.
During all trials, subjects in the online group saw the cursor throughout the trial (online feedback), while subjects in the post-trial group only saw the cursor in the start position and in the final position for 1,600 ms while waiting for the third tone (post-trial feedback).
Data analysis
The final cursor position of each trial was recorded using a Labview-based (National Instruments, Austin, TX, USA) custom software (Imago Record, pfitec, Endingen, Germany). The angular error of each trial was calculated as the angle between the vector connecting the start circle to the final cursor position and the vector connecting the start circle to the respective cursor target. For further analysis, these angular errors were binned (i.e., the mean was taken) over each cycle of eight trials to average out potential offsets depending on the target direction, as these were of no particular interest for our research question. The two trials of the ‘rotation − strategy’ phase were also averaged to one bin. There were thus 30 bins in total (Fig. 2). Note that, while the two trials of this phase naturally did not cover all eight target directions in a single subject, randomization within cycles was still applied to prevent potential direction-dependent biases from influencing the analysis. To account for potential differences in baseline performance, the last bin of ‘baseline − strategy’ was subtracted from all bins of ‘rotation + strategy’ and ‘washout’ for statistical testing (cf. Taylor et al. 2014). Descriptive values are reported without this subtraction.

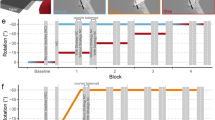
Each line represents one subject. The left-handed subject of each group is highlighted with a thicker, dashed line. Direction error (y axis) is averaged over bins of eight trials (x axis) so that each bin includes one movement to each of the targets. a Depicts subjects from the online, b from the post-trial group. Solid vertical lines divide baseline, rotation and washout. Dashed vertical lines enclose sub-phases with strategy
Statistical testing
Statistical tests were performed with SPSS Statistics 21 (IBM®, Armonk, NY, USA). In order to test our main hypothesis that different feedback would cause differences in overcompensation between groups, an analysis of variance (ANOVA) was performed with the ten bins of the ‘rotation + strategy’ phase as within-subject factor TIME and the between-groups factor GROUP. Additionally, we tested for differences in ‘washout,’ also using an ANOVA with the ten bins as within-subject factor TIME and between-groups factor GROUP. We report Greenhouse–Geisser corrected values for the ANOVAs.
We further performed an independent student’s t test between groups for the last bin of ‘baseline − strategy’ to see if there were any significant between group differences.
We had one left-handed subject per group, and this could have made a difference to our findings. We therefore also performed all tests with the respective subjects excluded to ensure that this would yield no different results. Data for these tests are not reported in detail.
Results
Angular errors are reported as group means (standard deviation). In the ‘rotation + strategy’ phase, both groups initially showed small angular errors [first bin: online: 4.5° (4.2°), post-trial: 0.6° (3.3°)]. The online group subsequently drifted in a CW direction [last bin: 15.1° (11.2°)], while the post-trial group stayed accurate [last bin: 0.7° (2.0°)]. The ANOVA indicated that this group difference in development across ‘rotation + strategy’ was significant and reasonably large (TIME × GROUP interaction: F = 3.926, p = 0.003, partial η 2: 0.179). In the ‘washout’ phase, the online group started out with a CW deviation [first bin 7.8° (4.4°)] that decayed with repetition [last bin: 0.7° (2.4°)], while the post-trial group displayed accurate performance throughout [first bin: −0.6° (3.1°), last bin: 0.4° (4.2°)]. Accordingly, the ANOVA also revealed a significant and large TIME × GROUP interaction for this phase (F = 4.279, p = 0.001, partial η 2: 0.201).
Subjects of both groups were accurate in their baseline performance and were able to correctly apply the ‘strategy’ in ‘baseline + strategy’ as indicated by an expected deviation of about 45° [last bin: online: 44.3° (2.5°), post-trial: 42.6° (5.0°)]. There were further no obvious dissimilarities between groups in the three baseline phases (Fig. 3). Accordingly, we did not find any significant differences between groups at the end of ‘baseline − strategy’ [online: −1.4° (2.0°), post-trial: −0.9° (2.9°), p = 0.688]. In the ‘rotation-strategy’ phase, all subjects produced a large error in CCW direction, as intended [online: −45.9° (9.3°), post-trial: −46.5° (4.4°)].

Average group values of direction error for consecutive trials. Solid, gray line and light gray area indicate mean error and SD for the post-trial group, dashed, black line and structured, dark gray area for the online group. Solid vertical lines divide baseline, rotation and washout. Dashed vertical lines enclose sub-phases with strategy
The two left-handed subjects (one in each group) did not behave in any special way (Fig. 2). Accordingly, the analyses excluding these subjects conformed to those for the whole group (data not shown).
Discussion
During the ‘rotation + strategy’ phase, the group receiving online feedback behaved similar to what has been described by Mazzoni and Krakauer (2006). Subjects drifted in the direction opposite to the rotation, indicating overcompensation. Subjects also displayed aftereffects. We therefore successfully replicated the effect seen by Mazzoni and Krakauer (2006). Additionally, the present study demonstrated that the post-trial group displayed significantly smaller overcompensation from the beginning to the end of ‘rotation + strategy,’ in addition to significantly smaller aftereffects. Thus, online feedback promoted implicit adaptation more strongly than post-trial feedback. This finding in principle confirms previous studies, which have already proposed greater implicit involvement with online feedback (Hinder et al. 2008, 2010; Shabbott and Sainburg 2010; Peled and Karniel 2012). However, these previous studies could not differentiate whether the feedback-related changes were the result of implicit adaptation and/or model-free reinforcement. Therefore, our study extends these previous findings by selectively assessing implicit adaptation (based on overcompensation, as reasoned in the introduction).
While the distinction between online and post-trial feedback drawn in our study is relevant, as such differences occur in applied training situations, it is not ideal for exploring functional relationships as it comprises at least two levels of change: the timing of feedback is changed so that feedback is delayed with respect to the execution, and the feedback content is changed as only a static representation of the movement is displayed in post-trial feedback while subjects see the cursor dynamically moving along the trajectory in online feedback. The study of Hinder et al. (2008) comprises two post-trial groups that differ with respect to feedback content. One group is presented with only endpoint position, while the other sees a static display of the movement’s trajectory after its execution. While the two groups are not compared explicitly, neither of them displays significant aftereffects (Hinder et al. 2008), which may indicate that these two types of feedback content do not differ greatly in their effect on learning processes. Interestingly, significant (albeit relatively small) overcompensation has previously been observed in experiments that provided their subjects with ‘endpoint feedback,’ meaning that upon the cursor’s passage of an invisible circle representing target amplitude, a stationary marker was presented at the intersection (Taylor et al. 2010; Taylor and Ivry 2011). A recent experiment that directly compared this type of endpoint feedback to online feedback also found aftereffects with endpoint feedback to be smaller, but still present (Taylor et al. 2014). The fact that significant overcompensation occurred with endpoint feedback clearly demonstrates that dynamic cursor movement is not a prerequisite for implicit adaptation, although it may facilitate it (Taylor et al. 2014). The absence of significant aftereffect/overcompensation with post-trial feedback in our and previous studies (Hinder et al. 2008, 2010; Shabbott and Sainburg 2010) is thus likely explained by delays between movement termination and feedback presentation that were not present in the studies with endpoint feedback. Indeed, it has been shown that a delay in cursor movement during movement execution causes a decrease in aftereffect size (Kitazawa et al. 1995; Honda et al. 2012a, b). It is reasonable to assume that this effect would persist or even increase when the delay is stretched beyond movement termination.
Taken together, a reasonable interpretation of previous and our findings is that the amount of implicit adaptation to a visuomotor rotation depends on the extent to which a part of our brain associates actions with specific sensory consequences and that the strength of this association may be influenced by task constrains like timing and possibly also content of feedback.
The cerebellum has repeatedly been suggested as a relevant neural structure for implicit adaptation (Smith and Shadmehr 2005; Tseng et al. 2007; Galea et al. 2011; Wolpert et al. 2011). Interestingly, behavior of cerebellar patients in a similar setup (Taylor et al. 2010) resembled that of subjects with post-trial feedback in the current study. Thus, it might be speculated that post-trial feedback does not activate the cerebellum in the same way as online feedback. Several researchers have proposed a critical role for signal timing in cerebellar processes (Ohyama et al. 2003; Miall et al. 2007; Carrillo et al. 2008; Honda et al. 2012a). The timing of feedback thus seems a likely cause for a possible difference in cerebellar activation with online and post-trial feedback.
Practical implications
Previous research has demonstrated that behavior learned via different processes (e.g., implicit adaptation, explicit learning and model-free reinforcement) may differ with respect to properties like generalization of the learned behavior, rate of acquisition and forgetting, or the stability under pressure (Huang et al. 2011; Zhu et al. 2012; Shmuelof et al. 2012). Our results as well as those of others provide knowledge on how feedback activates specific processes of motor learning. This knowledge may provide coaches and therapists with guidelines on how to achieve optimal training success by applying feedback appropriate for training goals (e.g., fast acquisition, stability against forgetting and pressure). With regard to the current results, it should, however, be noted that these were obtained in a highly specific task that involved learning of a visuomotor transformation rather than of a new skill. It therefore remains to be clarified to which extent our findings apply to other, more functional and also long-term learning scenarios.
Our study included two left-handed subjects who consequently performed the test with their non-dominant hand. We did not observe any deviant behavior in these subjects, and analyses with these subjects excluded led us to no different interpretation. However, due to the very small sample for left-handed subjects, our findings should be taken with care with respect to left-handed subjects and non-dominant performance. Further research is required to clarify this point.
References
Bernier P-M, Chua R, Franks IM (2005) Is proprioception calibrated during visually guided movements? Exp Brain Res 167:292–296. doi:10.1007/s00221-005-0063-5
Carrillo RR, Ros E, Boucheny C, Coenen OJ-MD (2008) A real-time spiking cerebellum model for learning robot control. Biosystems 94:18–27. doi:10.1016/j.biosystems.2008.05.008
Galea JM, Vazquez A, Pasricha N et al (2011) Dissociating the roles of the cerebellum and motor cortex during adaptive learning: the motor cortex retains what the cerebellum learns. Cereb Cortex 21:1761–1770. doi:10.1093/cercor/bhq246
Haith AM, Krakauer JW (2013) Model-based and model-free mechanisms of human motor learning. Adv Exp Med Biol 782:1–21. doi:10.1007/978-1-4614-5465-6
Hinder MR, Tresilian JR, Riek S, Carson RG (2008) The contribution of visual feedback to visuomotor adaptation—how much and when? Brain Res 1197:123–134. doi:10.1016/j.brainres.2007.12.067
Hinder MR, Riek S, Tresilian JR et al (2010) Real-time error detection but not error correction drives automatic visuomotor adaptation. Exp Brain Res 201:191–207. doi:10.1007/s00221-009-2025-9
Honda T, Hirashima M, Nozaki D (2012a) Adaptation to visual feedback delay influences visuomotor learning. PLoS one 7:e37900. doi:10.1371/journal.pone.0037900
Honda T, Hirashima M, Nozaki D (2012b) Habituation to feedback delay restores degraded visuomotor adaptation by altering both sensory prediction error and the sensitivity of adaptation to the error. Front Psychol 3:540. doi:10.3389/fpsyg.2012.00540
Huang VS, Haith AM, Mazzoni P, Krakauer JW (2011) Rethinking motor learning and savings in adaptation paradigms: model-free memory for successful actions combines with internal models. Neuron 70:787–801
Kitazawa S, Kohno T, Uka T (1995) Effects of delayed visual information on the rate and amount of prism adaptation in the human. J Neurosci 15:7644–7652
Krakauer JW, Pine MZ et al (2000) Learning of visuomotor transformations for vectorial planning of reaching trajectories. J Neurosci 20:8916–8924
Mazzoni P, Krakauer JW (2006) An implicit plan overrides an explicit strategy during visuomotor adaptation. J Neurosci 26:3642–3645
Miall RC, Christensen LOD, Cain O, Stanley J (2007) Disruption of state estimation in the human lateral cerebellum. PLoS Biol 5:e316. doi:10.1371/journal.pbio.0050316
Ohyama T, Nores WL, Murphy M, Mauk MD (2003) What the cerebellum computes. Trends Neurosci 26:222–227. doi:10.1016/S0166-2236(03)00054-7
Peled A, Karniel A (2012) Knowledge of performance is insufficient for implicit visuomotor rotation adaptation abstract. J Mot Behav 44:185–194. doi:10.1080/00222895.2012.672349
Shabbott BA, Sainburg RL (2010) Learning a visuomotor rotation—simultaneous visual and proprioceptive information is crucial for visuomotor remapping. Exp Brain Res 203:75–87. doi:10.1007/s00221-010-2209-3
Shmuelof L, Huang VS, Haith AM et al (2012) Overcoming motor “forgetting” through reinforcement of learned actions. J Neurosci 32:14617–14621. doi:10.1523/JNEUROSCI.2184-12.2012
Smith MA, Shadmehr R (2005) Intact ability to learn internal models of arm dynamics in Huntington’s disease but not cerebellar degeneration. J Neurophysiol 93:2809–2821. doi:10.1152/jn.00943.2004
Taylor JA, Ivry RB (2011) Flexible cognitive strategies during motor learning. PLoS Comput Biol 7:e1001096. doi:10.1371/journal.pcbi.1001096
Taylor JA, Ivry RB (2012) The role of strategies in motor learning. Ann N Y Acad Sci 1251:1–12. doi:10.1111/j.1749-6632.2011.06430.x
Taylor JA, Klemfuss NM, Ivry RB (2010) An explicit strategy prevails when the cerebellum fails to compute movement errors. Cerebellum 9:580–586
Taylor JA, Krakauer JW, Ivry RB (2014) Explicit and implicit contributions to learning in a sensorimotor adaptation task. J Neurosci 34:3023–3032. doi:10.1523/JNEUROSCI.3619-13.2014
Tseng Y, Diedrichsen J, Krakauer JW et al (2007) Sensory prediction errors drive cerebellum-dependent adaptation of reaching. J Neurophysiol 98:54–62. doi:10.1152/jn.00266.2007
Wolpert DM, Diedrichsen J, Flanagan JR (2011) Principles of sensorimotor learning. Nat Rev Neurosci Adv 739–51. doi: 10.1038/nrn3112
Zhu F, Poolton J, Masters R (2012) Neuroscientific aspects of implicit motor learning in sport. In: Gollhofer A, Taube W, Nielsen JB (eds) Routledge handbook of motor control and motor learning. Routledge, London, pp 155–174
Acknowledgments
We are grateful to Axel Scherle and Florian Pfister, who provided technical support for the study, and Alexander Kurz, who supported subject acquisition.
Conflict of interest
The authors declare that they have no conflict of interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Schween, R., Taube, W., Gollhofer, A. et al. Online and post-trial feedback differentially affect implicit adaptation to a visuomotor rotation. Exp Brain Res 232, 3007–3013 (2014). https://doi.org/10.1007/s00221-014-3992-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-014-3992-z