
Abstract
Many economic problems can be formulated as dynamic games in which strategically interacting agents choose actions that determine the current and future levels of a single capital stock. We study necessary as well as sufficient conditions that allow us to characterise Markov perfect Nash equilibria for these games. These conditions can be translated into an auxiliary system of ordinary differential equations that helps us to explore stability, continuity and differentiability of these equilibria. The techniques are used to derive detailed properties of Markov perfect Nash equilibria for several games including voluntary investment in a public capital stock, the inter-temporal consumption of a reproductive asset and the pollution of a shallow lake.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Many economic problems can be formulated as dynamic games in which strategically interacting agents choose actions based on an inter-temporal objective that determine the current and future levels of a single capital stock. When formulated in continuous time, these games are differential games with a single state variable.Footnote 1
In this paper, we formulate a class of differential games in which \(n\) players either exploit or accumulate a single capital stock by choosing Markov strategies, where they select their current actions by fixing a policy function that relates the current state of the system (the single capital stock) to current actions. State-dependent Markov (or feedback) strategies can be contrasted to strategies that are set as simple time paths at the beginning of the game with the need for every player to pre-commitment to the announced time profile throughout the entire duration of the game. From an economics modelling point of view, pre-commitment is a very strong assumption for a dynamic game and largely unattractive.Footnote 2 On the contrary, Markov equilibrium strategies exhibit several desirable properties such as subgame perfectness, in case they are derived using backward induction, and no commitment, allowing rival players to immediately react to unexpected changes in the state of the system.
Finding subgame Markov perfect Nash equilibrium strategies of a differential game, even if the game is of the linear–quadratic type, is a formidable analytical problem. For instance, to find a Markov perfect Nash equilibrium in the general case of \(n\) players and \(m\) state variables requires to solve a system of \(n\) coupled nonlinear implicit \(m\)-dimensional partial differential equations (PDE). In case the underlying economic system can be described by a single state variable (a single capital stock), the system of PDEs collapses to a system of ordinary differential equations in the value functions that is much easier to deal with. Because of this tractability, the paper focuses on the least complex situation \(m=1\).
This system of ordinary differential equations in the value functions can be solved explicitly, and the Markov perfect Nash equilibrium (MPNE) can be derived analytically only for a restricted class of specific functional forms of the primitives of the model. Starting with the pioneering work of Case (1979), differential game theorists have modified this approach. Instead of working with the ordinary differential equations in the value functions, they derive a system of differential equations in shadow prices, that is, in the first derivatives of the value functions. Structurally, this system is much simpler to work with, in particular when symmetric equilibrium strategies are analysed. The shadow price system reduces then to a single quasi-linearFootnote 3 differential equation, explicitly dependent on the state variable, which for specific functional forms of the state equation and the objective functionals can be solved explicitly.
Using the shadow price system approach, Tsutsui and Mino (1990) derived nonlinear Markov equilibria for a linear quadratic differential game. The same approach was used by Dockner and Long (1994) in a model of transboundary pollution control and by Wirl (1996) in a public goods investment problem.
For a differential game with \(m\) state variables and \(n\) players, Rincón-Zapatero et al. (1998)Footnote 4 show that the approach introduced by Case (1979) can be made systematic when two assumptions are satisfied. The game must have an equal number of state and control variables and equilibria must be restricted to interior MPNE. Rincón-Zapatero et al. (1998) differentiate the Bellman equations to arrive at a system of quasi-linear partial differential equations in the shadow prices. Using the maximum condition, they are able to eliminate shadow prices and arrive at what can be referred to as a generalised Euler equation system (GEES) that is a system of partial differential equations in the state and control variables. By solving an example, they already point out that if the game is characterised by a single state variable, the GEES reduces to a linear system of ordinary differential equations.Footnote 5
The shadow price system and the GEES can be seen as two approaches to characterise MPNE, which are often mathematically equivalent. In this paper, we extend these two approaches substantially for \(n\)-player differential games with a single state variable and an infinite horizon. The \(n\)-dimensional system of ordinary quasi-linear non-autonomous differential equations in shadow prices is used to derive an auxiliary \((n+1)\)-dimensional system of ordinary autonomous differential equations whose solution trajectories trace out graphs of the equilibrium strategies. Our method is based on a well-known procedure used to analyse implicit ordinary differential equations. In the one-player situation, the auxiliary system reduces to the characteristic equations of the Hamilton–Jacobi equation; for the general non-symmetric \(n\)-player game, the system seems not to have been derived before.
The auxiliary system opens up the opportunity to geometrically analyse and study Markov perfect Nash equilibria for games with general functional forms. We introduce the terms of local and global Markov equilibria and point out how the auxiliary system can be used to identify these two types of equilibria. In addition, the auxiliary system can be used to gain important insights into the continuity and differentiability properties of MPNE. Points where the Markov strategies are continuous but not differentiable can conveniently be described by singularities of the auxiliary system. Moreover, using the auxiliary system, we are also able to find non-continuous Markov perfect Nash strategy equilibria. The derivation of the auxiliary system and its use to characterise non-continuous and non-differentiable Markov perfect Nash equilibria for differential games with a single state variable and general functional forms comprise, together with the analysis of several economic examples, the main contributions of this paper.
Dynamic games with a single capital stock can be applied in resource economics where \(n\) agents exploit a single renewable or exhaustible resource so as to maximise the present value of future consumption, see for example Levhari and Mirman (1980), Sundaram (1989), Benhabib and Radner (1992), Clemhout and Wan (1994), Dutta and Sundaram (1993), Dockner and Sorger (1996), Sorger (1998), Rincón-Zapatero et al. (1998), Marx and Matthews (2000), Benchekroun (2003), Akao (2008); see also Sorger (2008), Dutta and Radner (2012), Karp and Zhang (2012), Becker et al. (2013).
A game with \(n\) agents investing in a single public stock of capital also fits the class of differential games analysed in this paper, see Fershtman and Nitzan (1991), Wirl (1996) and Rowat (2007). Dynamic public bads games arise in case of transboundary pollution where the emissions of countries accumulate a single stock of pollution that incurs costs for each player. For more details on these kinds of game problems see Ploeg and Zeeuw (1992), Dockner and Long (1994) and Dockner et al. (1996). Finally, environmental economists have recently started to explore equilibria in the shallow lake problem. This problem is structurally similar to the exploitation of a single renewable resource stock but with a non-concave production function. Recent papers dealing with the shallow lake problem include Brock and Starrett (2003), Mäler et al. (2003), Wagener (2003), Kossioris et al. (2008), Kiseleva and Wagener (2010), Kossioris et al. (2011).
The article is organised as follows. Section 2 presents the general theory to derive MPNE for the class of differential games with a single state variable and includes a linear quadratic example. Section 3 makes use of the auxiliary system to study non-continuity and non-differentiability of MPNE. Section 4 applies the approach presented to two distinct examples from resource and environmental economics and Sect. 5 concludes.
2 General theory
In this section, we derive the auxiliary system for general feedback Nash equilibria in a dynamic game with a single state variable. In this game, \(n\) players choose Markov strategies, \(u_i(x)\), to maximise an inter-temporal objective function. The strategies determine the level of a single capital stock, \(x\), that is governed by the state dynamics. For this game, we characterise Markov perfect Nash equilibria that are either differentiable, or continuous, or have at most a finite number of jump points.
2.1 Definitions
We consider a game where \(n\) players can, at every point \(t\ge 0\) in time, choose actions from a given action set. These actions determine the evolution of an underlying state variable \(x(t)\) that takes values in a state space \(X\); we shall call \(x(t)\) the ‘state of the game at time \(t\)’. The initial value of the state will be denoted by \(x_0\):
We restrict attention to the case that \(X\) is a closed interval of the real line \({\mathbb R}\). For every \(x\in X\), the set \(U(x)\) of actions \(u\) available to one of the players is the closure of a convex open subset of \({\mathbb R}^q\), for some \(q>0\). We do not require the sets \(U(x)\) to be bounded. The union
is the action space of the player. We shall also assume that the action space is the closure of an open set.
Each player formulates his action choices in terms of a strategy, which specifies for each point in time which action to take. A Markov strategy is characterised by the requirement that the actions at each point in time are conditioned only on the state of the system. That is, a Markov strategy is a function \(u:X' \rightarrow {\mathbb R}^q\), where \(X'\) is a subinterval of \(X\) with \(x_0\in X'\), such that if \(x(t)\in X'\), the agent takes at time \(t\) the action \(u(x(t))\). Necessarily, we have that
for all \(x\in X'\); or, equivalently, the graph of \(u\) should be contained in the action space \(U\). If \(X'=X\), we call the Markov strategy globally defined or just global; if \(X'\subset X\), it is said to be locally defined or local.
Let \(i\) be an index, running from \(1\) to \(n\), which denotes the different players; player \(i\)’s strategy is then a real-valued function \(u_i\) defined on the interval \(X'_i\). Let
be the common domain of definition of all the strategies and introduce the strategy vector \( \mathbf{u} : X' \rightarrow ({\mathbb R}^q)^n\), given as
The elements of the strategy vector are the individual strategies. Also introduce the vector
of strategies other than the strategy of player \(i\). Given a strategy vector \(\mathbf{u}\), the state variable will evolve according to a state equation of the form
On the right-hand side of Eq. (1), the time argument of the function \(x\) is suppressed for readability; this will be done throughout the article.
It will be assumed that the vector field \(f\) satisfies the consistency requirement that for all available actions, it is ‘inward pointing’ on the boundary \(\partial X\) of the state space \(X\). In the present context, this means the following. For \(x\in \partial X\) let \(\nu (x)\) be an outward pointing unit ‘vector’: that is, \(\nu (x)=1\) if \(x\) is the upper endpoint of \(X\), and \(\nu (x)=-1\) if \(x\) is the lower endpoint. Let
be the set of available actions at \(x\), and let \(\mathbf{U}=\cup _x \{x\}\times \mathbf{U}(x)\). Then, \(f\) is inward pointing (with respect to \(\mathbf{U}\)), if for \(x\in \partial X\) the inequality
holds for all \(\mathbf{u}\in \mathbf{U}(x)\).
The pay-off of the players will depend on their strategies as well as on the state dynamics. In this article, we assume that the pay-off of the strategy choice \(u_i\) of player \(i\), given that the other players play \(\mathbf{u}_{-i}\), is of the general form
We shall assume the functions \(f\) and \(L_i\) to be smooth, which is meant to be ‘infinitely often differentiable’, but which could be read as ‘as often differentiable as is necessary’. But even with smooth data, the set of strategies that are available to the players has to be restricted in order for the dynamics and the pay-offs to be at least well defined. The specification of the available strategy set is an integral part of the specification of the game in question.
Attention will be restricted to Markov strategies that are piecewise continuously differentiable and bounded. That is, we assume that for every strategy \(u_i\), there are finitely many non-overlapping intervals that cover \(X'_i\) and which are such that \(u_i\) is continuously differentiable on the interior of each interval. The strategies are not required to be continuous.
The right-hand side of (1) is not necessarily Lipschitz continuous, and the theorem of existence and uniqueness of solutions to differential equations does not apply at those points where Lipschitz continuity fails to hold. By assumption, these points are a subset of the endpoints of the non-overlapping intervals covering \(X_i'\); in particular, there are only finitely many of them. We need to specify in what sense we interpret (1) at those points; this is done in Appendix 1.
We say that, given the strategies \(\mathbf{u}_{-i}\) of the other players, a strategy \(u_i\) is admissible or available to player i, if it is a bounded piecewise continuously differentiable function on \(X'\) such that its graph is contained in \(U_i\), and such that it satisfies the following consistency condition. Let \(F(x)=f(x,u_i(x);\mathbf{u}_{-i}(x))\), fix a point \(\hat{x}\) and denote by \(F_L\) and \(F_R\), respectively, the left and right limit of \(F(x)\) as \(x\) tends to \(\hat{x}\). The condition requires that if \(F_L>0>F_R\), then the value of \(u_i(\hat{x})\) satisfies
Such a value always exists as a consequence of the intermediate value theorem and the convexity of \(U_i(\hat{x})\). This mathematical condition may be interpreted as follows: by choosing the strategy \(u_i\) such that \(F_L>0\) and \(F_R<0\), player \(i\) intends to stabilise the system at \(x=\hat{x}\). To be consistent with this, at the point \(\hat{x}\) the action \(u_i(\hat{x})\) should be such that \(\dot{x} = f(\hat{x}, u_i(\hat{x}); \mathbf{u}_{-i}(\hat{x}))=0\).
The space of strategies available to player \(i\), given \(X\) and \(U_i\), is denoted by \(\fancyscript{A}_i\). The spaces \(X\) and \(\mathbf{U}\), together with the dynamics \(f\) and the instantaneous pay-offs \(L_i\) and the space of available strategies \(\fancyscript{A}_i\), for \(i=1,\ldots ,n\), define a differential game \(\fancyscript{G}\).
We recall the definition of a Markov perfect Nash equilibrium strategy of a game.
Definition 1
The strategy vector \(\mathbf{u}^*\) is a (global) Markov perfect Nash equilibrium of \(\fancyscript{G}\), if
for each \(i\); that is, if for each player his strategy is a best response to the strategies of the other players.
When investigating Markov equilibrium strategies for a differential game, the phenomenon is encountered that the Hamilton–Jacobi equation, which characterises these strategies, has many solutions that are not defined on the whole state space (see for instance Wirl 1996; Kossioris et al. 2008). In the context of the original game, these solutions are not admissible, as they do not specify the action of the players if the state leaves the domain of definition of one of the strategies. To address this, we introduce the concept of a local Markov perfect Nash equilibrium as follows.
Spaces \(X'\), \(U'_i\) and \(\fancyscript{A}'_i\) define a restriction \(\fancyscript{G}'\) of the game \(\fancyscript{G}\), if \(X'\subset X\), \(U'_i\subset U_i\), if \(f\) is inward pointing on \(\partial X'\) with respect to \(\mathbf{U}'\), and if \(\fancyscript{A}'_i\) is the set of strategies available to player \(i\), given \(X'\) and \(U'_i\).
Definition 2
The strategy vector \(\mathbf{u}^*\) is a local Markov perfect Nash equilibrium of \(\fancyscript{G}\), if it is a global Markov perfect Nash equilibrium for a suitable restriction \(\fancyscript{G}'\) of \(\fancyscript{G}\).
In economic terms, a local Markov perfect Nash equilibrium might arise if the players can commit cooperatively on restricting their action spaces and then proceed to play non-cooperatively with the restricted action spaces. See Rowat (2007) for a discussion of this ‘endogenising’ of the state space. Alternatively, the restriction of the action spaces could be imposed by a regulating agency. We shall see that in several examples, local Markov perfect Nash equilibria may improve on the global equilibria.
As a consequence, we obtain the notion of a state that can be stabilised, or is stabilisable, by a local Markov perfect Nash strategy.
Definition 3
A state \(x_*\in X\) can be stabilised by a local Markov perfect Nash equilibrium strategy \(\mathbf{u}^*\), if there is a restriction \(\fancyscript{G}'\) of the differential game such that
-
1.
\(\mathbf{u}^*\) is a Markov perfect Nash equilibrium for \(\fancyscript{G}'\);
-
2.
\(X'\) contains \(x_*\) in its interior;
-
3.
\(x^*\) is a stable steady state for the stock evolution dynamics
$$\begin{aligned} \dot{x} = f(x,\mathbf{u}^*(x)). \end{aligned}$$
Stabilisable steady states are those long-term steady states which can be obtained in a non-cooperative differential game if the players play a (local) Nash equilibrium.
2.2 The vector Hamilton–Jacobi equation
Given an \(n\)-person differential game \(\fancyscript{G}\), the present value Pontryagin functionFootnote 6 of player \(i\) reads as
here, \(p_i\) is the present value co-state of player \(i\) associated with the state \(x\). If this function is maximised, with respect to \(u_i\), at
the Hamilton function is defined as
The Hamilton–Jacobi equation for the value function of player \(i\) reads then as
Introduce the vector-valued function \(\mathbf{v}\) as
and the derivative of \(\mathbf{v}\) with respect to the actions \(\mathbf{u}_{-}\) of the other players as
In order to eliminate the functions \(u_i(x)\) from the problem, the system of equations
has to be solved for the \(u_i\); in vector notation, this system reads as
We assume that this system is solvable for \(\mathbf{u}\) and that the solution
is a continuously differentiable function of \(x\) and \(\mathbf{p}\). For instance, a sufficient condition for the solvability of the system is that the matrix
is invertible everywhere.
Consequently, it may be assumed that the game Hamilton functions \(G_i\), \(i=1,\cdots ,n\) of the players can be written as
and that the value functions solve the following vector Hamilton–Jacobi equation
where \(\mathbf{G}=(G_1,\ldots ,G_n)\). Taking derivatives with respect to \(x\) and substituting
yields
Note that \(\partial {\mathbf{G}}/\partial x\) is an \(n\)-dimensional vector, whereas \(\partial {\mathbf{G}}/\partial {\mathbf{p}}\) is an \(n\times n\) matrix. We obtain finally the equation
Equation (8) is referred to as the shadow price system. Due to the special structure of our class of games, the shadow price system is a system of quasi-linear ordinary differential equations in \({\mathbf{p}}(x)\). The differentiability assumptions on \({\hat{\mathbf{u}}}\) introduced during the above derivation imply that we restrict to interior strategies, that is, strategies where control constraints are not binding. This restriction is less serious than may appear at first glance, for our methods are local, tailored to dealing with the possible non-invertibility of \(\frac{\partial \mathbf{G}}{\partial \mathbf{p}}\), and they can be supplemented by other methods at points where the control constraints start to be binding.
As already pointed out, the shadow price system approach traces back to the analysis of Case (1979) who studied nonlinear Markov equilibria for the sticky price model, which was also analysed in detail by Tsutsui and Mino (1990). The shadow price system approach has subsequently been applied by Dockner and Long (1994) and by Wirl (1996) to derive nonlinear symmetric Markov perfect Nash equilibria.
If the relation (5) can be solved for \({\mathbf{p}}\), which is possible if \(\mathbf{u}\) is in the interior of the action space \(\mathbf{U}\), then we can rewrite Eq. (8) in terms of the actions \(\mathbf{u}\), which is more convenient in applications; we do this regularly in the examples given further below. Actually Rincón-Zapatero et al. (1998) analyse a version of Eq. (8) expressed in controls rather than co-states for state spaces of general dimension and demonstrate its applicability by considering specific examples. However, in problems where control constraints become active, or more generally when the relation between controls and co-states is not one-to-one, the analysis has to be done in terms of the shadow price vector \(\mathbf{p}\).
In the important symmetric special case that all players are equal and play the same strategies, the vector \({\mathbf{G}}\) of game Hamilton functions is invariant under permutations of the \(p_i\),
where \(\sigma \) is any permutation of \(n\) elements. If this is the case, the game is called symmetric.
Symmetric Markov perfect Nash equilibria then correspond to value functions
which are sought as solutions of the scalar Hamilton–Jacobi equation
which is the scalar analogon of the vector Eq. (6), where
with the sum taken over all permutations of \(n\) elements. Of course, the sum is just equal to \(G_1(x,p,\ldots ,p)\).
2.3 Sufficiency
In the following, we shall be interested, amongst other things, in finding geometric criteria that characterise possible jump points of Nash equilibrium strategies. As these are usually connected to points of non-differentiability of the value function, the question arises in what sense the Hamilton–Jacobi equation is satisfied in such points. Crandall and Lions (1983) have shown that the value function of an optimal control problem is usually the only viscosity solution of the Hamilton–Jacobi equation. Since then it has been widely accepted that this is the ‘right’ solution concept.
We recall the notion of viscosity solutions of scalar Hamilton–Jacobi equations of the form
For this, we give some preliminary definitions.
Definition 4
A vector \(p\) is a subdifferential of a function \(V\) at a point \(\hat{x}\), if there is a differentiable function \(v(x)\) such that \(\hat{x}\) is a local minimiser of the difference \(V(x)-v(x)\); then \(p = v'(x)\).
The set of all subdifferentials of \(V\) at \(\hat{x}\) is indicated as \(D\_\,\,V(\hat{x})\).
Superdifferentials are defined analogously.
The following definition of viscosity solutions, though not the most general, suffices for our purposes. It is adapted from chapter II of Fleming and Soner (2006).
Definition 5
Let \(V\) be a continuous function on \(X\).
-
1.
The function \(V\) is a viscosity supersolution of (11), if for all subdifferentials \(p\in D_-V(x)\) we have
$$\begin{aligned} H(x,p) - \rho V(x) \le 0. \end{aligned}$$(12) -
2.
The function \(V\) is a viscosity subsolution of (11), if for all superdifferentials \(p\in D_+V(x)\), we have
$$\begin{aligned} H(x,p) - \rho V(x) \ge 0. \end{aligned}$$(13) -
3.
Finally, \(V\) is a viscosity solution of (11), if it is both a viscosity subsolution and a viscosity supersolution.
If \(V\) is differentiable at \(x\), then \(D_+V(x)=D_-V(x)=\{V'(x)\}\), and equation (11) holds in the classical sense.
The following theorem states that solving equation (6) indeed gives us a Markov perfect Nash equilibrium.
Theorem 1
Let \(\mathbf{V}:X\rightarrow {\mathbb R}^n\) and \(\mathbf{u}^*:X\rightarrow {\mathbb R}^n\) be vector-valued functions satisfying the following conditions.
-
1.
The function \(\mathbf{V}=(V_1,\ldots ,V_n)\) is continuous and piecewise continuously differentiable.
-
2.
The strategy vector \(\mathbf{u}^*\) is admissible.
-
3.
For every \(i=1,\ldots ,n\), the \(i\)’th component \(V_i\) of \(V\) is a viscosity solution of
$$\begin{aligned} \rho V_i(x) = H_i(x,V_i'(x);\mathbf{u}^*_{-i}(x)). \end{aligned}$$(14) -
4.
For every admissible trajectory \(x\), we have that
$$\begin{aligned} \lim _{t\rightarrow \infty } \mathbf{V}(x(t)) \mathrm {e}^{-\rho t} = 0. \end{aligned}$$(15) -
5.
If \(\mathbf{V'}\) is differentiable at \(x\), then
$$\begin{aligned} \mathbf{u}^*(x) = {\hat{\mathbf{u}}}(x,\mathbf{V'}(x)). \end{aligned}$$ -
6.
If \(\mathbf{V'}\) is not differentiable at \(x\), then either
$$\begin{aligned} \mathbf{u}^*(\hat{x})=\lim _{x\uparrow \hat{x}} {\hat{\mathbf{u}}}(x,\mathbf{V'}(x)) \end{aligned}$$or
$$\begin{aligned} \mathbf{u}^*(\hat{x})=\lim _{x\downarrow \hat{x}} {\hat{\mathbf{u}}}(x,\mathbf{V'}(x)). \end{aligned}$$
Then, \(\mathbf{u}^*\) is a Markov perfect Nash equilibrium of the differential game.
For instance, condition (15) is satisfied if all admissible trajectories are bounded. The proof of theorem 1 is given in Appendix 2.
We shall call \(\mathbf{V}\) a viscosity solution of the equation
if for each \(i\) the function \(V_i\) is a viscosity solution of the associated Eq. (14).
2.4 Auxiliary system
Recall the definition of the adjoint matrix \(A^*\) of a given matrix \(A\): it is the matrix whose \((i,j)\)’th element is the cofactor of \(A\) that is obtained by deleting the \(j\)’th row and \(i\)’th column of \(A\) and taking the determinant of the remaining matrix. We have that \(A A^* = (\det A) I\), where \(I\) is the identity matrix; hence, \(A^{-1} =(\det A)^{-1} A^*\) if \(\det A\ne 0\). Multiplying an equation of the form
from the left with \(A^*\) yields
Multiplying the shadow price system (8) from the left with the cofactor matrix
yields therefore
The auxiliary system to Eq. (6) is now defined as
where \(s\in {\mathbb R}\) is some real parameter that has no immediate economic significance. In fact, we have the following result.
Theorem 2
Let the function \(\mathbf{V}(x)\) be continuous and piecewise continuously differentiable, and let it be a viscosity solution of
Set \(\mathbf{p}(x)=\mathbf{V}'(x)\) whenever the derivative is defined. Assume that \(x_0\) and \(\mathbf{p}_0\) are such that \(\mathbf{p}\) is defined and continuous at \(x_0\), such that \(\mathbf{p}_0 = \mathbf{p}(x_0)\), and such that
Then, \(\mathbf{p}\) is continuously differentiable in a neighbourhood of \(x_0\), and its graph is traced out by the curve
that satisfies (16) with initial conditions \((x(0),\mathbf{p}(0)) = (x_0,\mathbf{p}_0)\).
This theorem characterises solutions of the vector Hamilton–Jacobi Eq. (17) whenever they are differentiable, by relating the graph \(x\mapsto (x,\mathbf{V}'(x))\) to solution curves of the auxiliary system (16). This relation is general, and, in particular, it can be applied to find non-symmetric Markov perfect Nash equilibrium strategies.
When attention is restricted to symmetric Nash equilibria, the auxiliary system simplifies to
These equations are the characteristic equations of the Hamilton–Jacobi Eq. (6). However, in crucial contrast to the ‘one-player’ optimal control situation, the parameter \(s\) is different from the time parameter \(t\).
2.5 A linear–quadratic example
This subsection illustrates the theory by applying it to a standard economic problem, the analysis of private investment in a public capital stock.
This game was introduced by Fershtman and Nitzan (1991). They assumed that each agent derives quadratic utility from the consumption of the public capital stock. Investment in the stock is costly and results in quadratic adjustment costs. Fershtman and Nitzan solved both the open-loop game and the game with Markov strategies and found that the dynamic free rider problem is more severe when agents use linear Markov strategies. Wirl (1996) challenged these results and studied the identical linear quadratic game but solved it for nonlinear Markov equilibria. He found that if the discount rate is small enough nonlinear Markov strategies can support equilibrium outcomes that are close to the efficient provision of the public capital. Finally, Rowat (2007) derived explicit analytic expressions for the nonlinear Markov equilibria.
There are \(n\) players; player \(i\) voluntarily invests in the nonnegative public capital stock \(x\) at a rate \(u_i\ge 0\). The single public capital stock evolves according to
here \(\delta >0\) is the constant depreciation rate. Following Fershtman and Nitzan, we assume that player \(i\)’s utility functional is given by
where \(a,b>0\) are positive parameters. Note that compared to the formulation of Wirl (1996), one parameter has been scaled away. We see from this formulation that both \(X\) and \(U_i(x)\), for all \(i\) and all \(x\in X\), are equal to the interval \([0,\infty )\).
The corresponding present value Pontryagin function becomes
The function \(u_i\mapsto P_i(x,p_i,u_i;\mathbf{u}_{-i})\) is maximised at
The present value Hamilton function \(H_i\) of player \(i\) reads as
We now restrict our attention to the symmetric case, for which all players use the same strategy. The symmetric version of Eq. (6) reads as
Fershtman and Nitzan (1991) obtained a solution to this equation by the well-known method of substituting \(V(x) = c_0 + c_1 x + c_2 x^2\) and comparing coefficients of \(x\). Wirl (1996) pointed out that due to the fact that the Hamilton–Jacobi Eq. (21) has no initial conditions, there may be actually more solutions to this equation. He derived his conclusions from the shadow price system (8), which takes the form
Note that while Eq. (21) was an implicit nonlinear first-order ordinary differential equation in \(V\), Eq. (22) is easily rewritten as an explicit equation in \(p\) with non-constant coefficients. Rowat (2007) derives an explicit solution for this equation by carefully considering the singularity locus \((2n-1)p-\delta x=0\). We do not repeat his approach here but refer to his paper instead.
The auxiliary system associated with (22) takes for \(p\ge 0\) the form
while for \(p<0\), it reads as
Note that the derivatives are taken with respect to a parameter \(s\), which has no a priori economic interpretation; the point of the auxiliary system is that its solution trajectories
trace out graphs of solutions \(p=p(x)\) of Eq. (22). In the region \(p\ge 0\), this follows from the chain rule, which states that
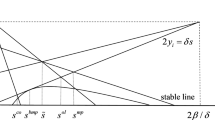
This is the same expression as in Eq. (22). Some trajectories of the auxiliary system are shown in Fig. 1. There, solutions of the auxiliary system are represented by drawn curves. They can, locally and for \(p>0\), be interpreted as the graphs of possible symmetric feedback strategies \(u(x) = p(x)\).

Solutions of the auxiliary system (23) in the region \(p \ge 0\), where \(u=p\), (drawn curves) as well as the line \(l_1\) of dynamic equilibria \(\mathrm {d}x/\mathrm {d}t=0\) (thickly dashed line) and the isocline \(l_2\) of the auxiliary system (thinly dashed line), where \(\mathrm {d}x/\mathrm {d}s=0\). The arrows indicate the direction of time evolution. Parameters: \(a=0.1\), \(b=0.1\), \(\delta =0.2\), \(\rho =0.1\)
This system has a single steady state
In Fig. 1, five generic strategies \(u_1, \ldots , u_5\) are highlighted. We shall show that none of these can correspond to Markov perfect Nash equilibrium strategies.
First consider \(u_1\) and \(u_2\). Both have the unstable eigenspace of the equilibrium \(P\) as its asymptotic limit as \(x\rightarrow \infty \). It is straightforward to show that the unstable eigenvector, corresponding to the unstable eigenvalue \(\lambda _u\), is of the form \((1,v)\) with
and \(\lambda _u>\delta \) for all \(\rho \ge 0\). It follows that \(v>\delta /n\). Consequently, for each strategy, like \(u_1\) and \(u_5\), that tends asymptotically towards the unstable eigenspace of \(P\), there is a state \(\bar{x}>0\) such that \(\mathrm {d}x /\mathrm {d}t>0\) for all \(x>\bar{x}\). But such a strategy cannot correspond to a Markov perfect Nash equilibrium, since for \(x\) sufficiently large the integrand of (20) is negative, and a strategy for which \(u(x)=0\) whenever \(x>\bar{x}\) is a deviation with a better pay-off.
Next we note that there is no interval \(X'\subset X\) such that \(f(x,u_3(x))\) is inward pointing into \(X'\); therefore, \(u_3\) cannot be even a local Markov perfect Nash equilibrium strategy.
Finally, we consider \(u_4\) and \(u_5\). Note that both are in the region that \(\dot{x} = n u - \delta x < 0\), and both satisfy \(u_j(x)=0\) if \(x\) is sufficiently small. Hence, \(x(t)\) tends to \(0\) as \(t\rightarrow \infty \). Since
if \(u_j(x)=0\), it follows that in this particular case \(s=t\). Moreover, from the auxiliary system, it follows that
with \(C<0\), where the term \(o(f)\) denotes a function that goes faster to zero as \(f\) if \(t\rightarrow -\infty \). Consequently, the transversality condition
is not satisfied for these strategies.
Having removed all strategies that cannot correspond to Markov Nash equilibria, we retain a single global Markov perfect Nash equilibrium and a family of local Markov perfect Nash equilibrium strategies; these are illustrated in Fig. 2.

Local (thin curves) and global (thick curve) Markov perfect Nash equilibrium strategies, together with the lines \(l_1\) and \(l_2\). Also indicated is the supremum \(x_{**}\) of the state values that can be stabilised by a local Markov perfect Nash equilibrium strategy. Parameters as in Fig. 1
Properties of equilibria
The feedback strategy that is formed by the upper two invariant manifolds of the steady state \(P\) of the auxiliary system is of the ‘kink’ type to be discussed below in Sect. 3.1. Also the globally defined strategy, thickly drawn in Fig. 2, has a kink: it is located at the point where the invariant manifold of \(P\) intersects the horizontal axis. This kink is however of a different kind, as it represents a control constraint that becomes active.
Consider the line \(l_1=\{(x,p)\,:\,f(x,p)=0\}\) of equilibria of the state dynamics (the broken thickly drawn line in the figure): the quantity \(\frac{\mathrm {d}x}{\mathrm {d}t}\) is positive above \(l_1\), and negative below. From the figure, it is readily apparent that points on \(l_1\) close to the origin (lower left-hand corner) are stable, while points on \(l_1\) in the upper right-hand corner are unstable. Hence, there is a point on \(l_1\) where equilibria change from stable to unstable; it is the unique point \((x_{**},p_{**})\) where a solution curve of the auxiliary system touches the line \(l_1\).
Let \(p(x)\) determine a local Markov perfect Nash equilibrium strategy. The stock then evolves according to
Let \(x_*\) be a steady-state equilibrium of this equation; then \(p_* = p(x_*) = (\delta /n) x_*\) and \((x_*,p_*)\in l_1\). This equilibrium is stable if
This stability condition holds, using (25), when
is satisfied. This condition can be simplified to read as
In other words, the value \(x_{**}\) is the supremum of the stock values that can be stabilised by a local Markov perfect Nash equilibrium strategy. In the present situation, we have that for every \(x_*<x_{**}\), there is an equilibrium strategy determined by \(p\) such that \(x_*\) is a stable steady state under the dynamics (27).
The maximal stream of utility derived from consuming the public good, that is, the maximum of \(a x - \frac{1}{2}b x^2\), is obtained at \(x_m=a/b\). Note that as the number \(n\) of players tends to infinity, the value \(x_{**}\), and with it the region of stock values that can be stabilised, increases towards \(x_m\). This is to be expected: as the adjustment costs are convex, it is better that average costs per player are distributed over more players.
From Fig. 1, we can also draw conclusions about which strategies maximise the pay-off for the players, if the initial state \(x_0=x(0)\) of the system is given; we obtain from Eq. (21) that
For fixed \(x\) the value of \(G\), and hence of \(V\), increases for increasing \(p\) if \(p\!>\!\delta x/(2n\!-\!1)\).
Consider first the case that \(x_0=0\). Then
and we see that the highest pay-off is attained if \(p\) is chosen as large as possible; from Fig. 2, we infer that this corresponds to the strategy that ends at the semi-stable steady state \(x=x_{**}\).
In general, for fixed \(x\), the function \(p\mapsto G(x,p)\) is convex, taking its minimum at \(p=\delta x /(2n-1)\). It follows that to maximise pay-offs for all players, the initial value of \(p\) has to be taken as large as is feasible for \(x\le x_P\). Beyond that point, the solutions with maximal \(p\) have to be compared with the globally defined strategy. For \(x\) sufficiently large, there is only a single candidate, which is necessarily optimal.
3 Structure of MPNE
In the preceding section, we derived the auxiliary system from the shadow price system and documented its use to derive qualitative insights into (symmetric) Markov perfect Nash equilibria for infinite horizon games. In this section, we will make use of the auxiliary system to gain insights into the general structure of Markov perfect Nash equilibria. In particular, we demonstrate that non-differentiability of equilibrium strategies corresponds to singularities of the auxiliary system and the number and values of discontinuities of Markov perfect Nash equilibrium strategies are related to solutions of the game Hamilton–Jacobi equation \(\rho \mathbf{V}(x) = \mathbf{G}(x,\mathbf{V^{\,\prime }}(x))\).
3.1 Kinks
Let \(\mathbf{p}:X\rightarrow {\mathbb R}^n\) be a given function. The graph of \(\mathbf{p}\) is said to have a kink point or kink at \((x_0,\mathbf{p}(x_0))\), if there is a neighbourhood \(U\) of \(x_0\) such that \(\mathbf{p}\) is continuous on \(U\), differentiable on \(U\backslash \{x_0\}\), and such that the left and right limits of \(\mathbf{p}'\) at \(x_0\) exist and satisfy
Theorem 2 already answers the question of when a continuous equilibrium Markov shadow price vector \(\mathbf{p}(x)\) may fail to be differentiable at certain (isolated) points \(x_0\): it is necessary that
at such points. This is therefore a necessary criterion for the occurrence of kinks in Markov perfect Nash equilibrium strategies. More generally, we have
Theorem 3
Let the same assumptions about \(\mathbf{V}\) as in Theorem 2 hold. Assume that \({\mathbf{p}}=\mathbf{V}'\) has a kink at \((x_0,\mathbf{p}(x_0))\). Then necessarily the following equations hold:
The proof of this result is immediate. For the symmetric case, we have the following corollary.
Corollary 1
Let the same assumptions as in Theorem 2 hold with respect to the function \(\mathbf{V}\). Assume moreover that the game is symmetric and that \(\mathbf{V}\) has the form
If \(p(x)=V'(x)\) has a kink at \((x_0,p(x_0))\), then this point is a steady state of the auxiliary system (18).
Summing up: if \(\mathbf{p}\) is continuous, we have the following two implications. If \(\mathbf{p}\) has a kink at \((x_0,\mathbf{p}(x_0))\), then condition (29) is satisfied; if (29) is not satisfied at the point \((x_0,\mathbf{p}(x_0))\), then \(\mathbf{p}\) is differentiable at \(x_0\).
3.2 Jump points
The function \(\mathbf{p}:X\rightarrow {\mathbb R}^n\) is said to have an isolated jump point at \(x_0\), or simply to jump at \(x_0\), if there is a neighbourhood \(U\) of \(x_0\) such that \(\mathbf{p}\) is continuous on \(U\backslash \{x_0\}\), and such that the left and right limits of \(\mathbf{p}\) at \(x_0\) exist and satisfy
Analogously to Theorem 3, the following result gives a necessary condition for the co-state function of an equilibrium strategy to have an isolated jump point.
Theorem 4
Let the function \(\mathbf{V}(x)\) be continuous, piecewise continuously differentiable, and let it solve the vector Hamilton–Jacobi Eq. (6). If \(\mathbf{p}(x)=\mathbf{V}'(x)\) has an isolated jump discontinuity at \(x=x_0\), then necessarily
Proof
This is a direct consequence of the vector Hamilton–Jacobi equation (6) together with the continuity of \(\mathbf{V}\).
We make a couple of remarks concerning this theorem. First, we note that it is possible to give a priory conditions that ensure the continuity of \(\mathbf{V}\). The relevant condition is that the system dynamics are locally controllable for every player at every point \(x\): that is, the set \(f(x,U_i(x);\mathbf{u}_{-i}(x))\) of possible state changes should contain \(0\) in its interior.
The theorem implies that starting from a point \((x_0,\mathbf{p}_0)\), the value of \(\mathbf{p}\) can jump only to the solutions of the system of equations
For the symmetric situation, we have the following result.
Theorem 5
Let the game be symmetric, and let the function
be continuous, piecewise continuously differentiable, and let it be a viscosity solution of the vector Hamilton–Jacobi equation (6), or, equivalently, let \(V(x)\) be a viscosity solution of the scalar Hamilton–Jacobi equation
Assume that \(G(x,p)\) is strictly convex in \(p\) and that \(p(x)=V'(x)\) has a jump discontinuity at \(x=\hat{x}\); that is, assume that the left and right limits \(p_L\) and \(p_R\) of \(p(x)\) exist as \(x\rightarrow \hat{x}\).
Then
The equality follows from the left and right continuity of \(G(x,V'(x))\) at \(x=\hat{x}\). The inequality is a consequence of Theorem 9 in the appendix.
4 Applications
The class of differential games introduced in the preceding sections is fairly general and allows us to study Markov equilibria for a variety of different examples. Here, we apply the techniques of the auxiliary system to two alternative models that have been dealt with in the literature: (i) the exploitation of a reproductive asset (Benhabib and Radner 1992; Dockner and Sorger 1996) and (ii) the shallow lake problem (Mäler et al. 2003; Brock and Starrett 2003; Wagener 2003; Kossioris et al. 2008; Kiseleva and Wagener 2010).
4.1 Exploitation of reproductive assets
Consider the problem where \(n\) agents strategically exploit a single reproductive asset, such as fish or other species (Dockner and Sorger 1996). The reproduction of the stock \(x\) occurs at rate \(h(x)\), whereas player \(i\) extracts the stock at rate \(u_i\). Hence, the state dynamics are given by
The instantaneous utility that agent \(i\) derives from the consumption of the stock is assumed to be of the constant elasticity type
with \(0<\sigma <1\), so that the utility functional of player \(i\) is
The function \(P_i\) becomes
From \(\partial P_i/\partial u_i\), we obtain \(p_i = u_i^{-\sigma }\) and \(u_i = p_i^{-1/\sigma }\), and the game Hamilton functions read as
In the symmetric case \(p_1=\cdots =p_n=p\), this simplifies to
and we obtain the auxiliary system
Using the relation \(u=p^{-1/\sigma }\), we find the form of the auxiliary system in state–control variables:
The situation \(\sigma =(1-1/n)\) is special, as then the factor \((n-1-n\sigma )/\sigma \) vanishes and the system can be integrated, yielding
Compare equation (4) of Dockner and Sorger (1996).
Stability of steady states
As in the linear–quadratic example given in Sect. 2.5, for a given symmetric Nash equilibrium strategy \(u(x)\), the state dynamics are given as \(f(x) = h(x) - n u(x)\). A state–control pair \((x,u)\), with \(u=u(x)\), corresponds to a steady state for these dynamics if \(f(x) = h(x) - n u = 0\), that is, if \(u =h(x)/n\). The state is locally attracting if \(f'(x)<0\). We compute, using the relation \(u=h(x)/n\):
It follows that \((x,u)\) corresponds to an attracting steady state if
and to an unstable state if the inequality sign is reversed. In particular, if \(h'(x)<0\), then \((x,h(x)/n)\) always corresponds to an unstable equilibrium for the state dynamics. Moreover, since the derivative \(h'(x)\) is bounded from above, if
then the state dynamics does not have stable equilibria in the interior of the state space.
Let us finally consider the “semi-stable” state \(\bar{x}\) that satisfies
this point is in the boundary of the set of all stabilisable states. Compare it to the optimal long-term steady state \(x_\mathrm{collusive}\) of the collusive outcome, for which
holds, the so-called golden rule. The strategic behaviour in the semi-stable state \(\bar{x}\) can be described as if each player ignores strategic interactions and acts as if he has a private stock that is reproduced at rate \(h(\bar{x})/n\).
Analysis of the auxiliary system
We shall assume that \(\rho \le h'(0)\). Then, there is a unique \(x_\rho \in [0,1)\) such that \(h'(x_\rho ) = \rho \). The auxiliary system has then fixed points
Note that the third equilibrium satisfies \(u>0\) only if \(n < 1/(1-\sigma )\).
Theorem 6
Assume that \(x_1\) is such that \(h\) is strictly decreasing for \(x>x_1\). Then, every \(n\)-player symmetric Markov perfect Nash equilibrium \(x\mapsto u(x)\) satisfies
for all \(x\ge x_1\).
Proof
Let \(\bar{u}\) be an \(n\)-player symmetric Markov perfect Nash equilibrium and assume that for \(x_0>x_1\), the inequality is violated, that is
If \(x(0)=x_0\), this implies that \(x(t) > x_0\) for all \(t>0\), and therefore, since all solutions of
are increasing, and since \(h\) is strictly decreasing for \(x>x_1\), that
for all \(t>0\). Consequently,
Now assume that player \(1\) deviates by playing the constant strategy
The system dynamics
has then \(x=x_0\) as steady state. From Eq. (33), it follows that
hence
We finally obtain that \(\bar{u}\) cannot be a Nash equilibrium strategy.
Using the theorem, we have plotted the symmetric Markov perfect Nash equilibria in Figs. 3 and 4. A characteristic feature of these strategy equilibria is that if the initial fish stock is higher than the semi-stable threshold value \(\bar{x}\) introduced above, it cannot be stabilised. Moreover, for these non-stabilisable initial stocks, we see that as the initial stock is larger, the eventually reached steady-state stock grows smaller.

Local (thin) and global (thick) Markov perfect Nash equilibria, obtained from the auxiliary system (32), together with the isocline \(\dot{x} = h(x)-nu = 0\) (dashed) in the symmetric two-player case of the fishery model with production function \(h(x)=x(1-x)\) and parameters \(\rho =0.2\) and \(\sigma =0.8\)

Local Markov perfect Nash equilibria in the symmetric two-player case of the fishery model with production function \(h(x)=x(1-x)\) and parameters \(\rho =0.2\) and \(\sigma =0.4\)
4.2 Shallow lake
Consider the following environmental problem. There are \(n\) players (countries, communes, farmers) sharing the use of a lake. Each player has revenues from farming, for which artificial fertiliser is used. The use of fertiliser has two opposing effects: more fertiliser means better harvests and hence higher revenues from farming. On the other hand, fertiliser is washed from the fields by rainfall and eventually accumulates a stock of phosphorus in the shallow lake. The higher the level of phosphorus the higher are the costs (for fresh water, decreased income from tourism) to the player. Since the level of the stock of phosphorus is the result of activities of all players sharing the lake, the resulting problem can best be described by a differential game. The shallow lake system has been investigated by Brock and Dechert (2008), Mäler et al. (2003), Wagener (2003), Kossioris et al. (2008), Kiseleva and Wagener (2010); we refer to these papers for background information. Particularly, Kossioris et al. (2008) found local Markov perfect Nash equilbria of the two-player game by analysing the shadow price equation expressed in controls numerically, but they failed to find the global equilibrium.
Let the stock variable \(x\) represent the amount of phosphorus in a shallow lake, and let \(u_i\) be the amount of fertiliser used by farmer \(i\). Assuming a concave technology to produce farming output and quadratic costs coming from the stock \(x\), player \(i\) maximises intertemporal utility
The level of phosphorus is assumed to evolve according to the following state equation:
Here, \(b\) is the constant rate of self-purification (sedimentation, outflow), and the nonlinear term \(x^2/(x^2+1)\) is the result of biological effects in the lake.
For this differential game, the function \(P_i\) is given by
Maximising over \(u_i\) yields that \(u_i = - 1/p_i\). Restricting again our attention to symmetric strategies, we find by setting \(p_j=p\) for all \(j=1,\ldots ,n\) that
The auxiliary system now reads as
or, in terms of controls, as
Solutions to the auxiliary system are presented in Fig. 5. The most important feature of the solution set is that there is a globally defined non-continuous Markov perfect Nash equilibrium strategy, indicated by a thick line in the figure. Indeed, it has been known for some time that the Hamilton–Jacobi equation of some economic optimal control problems may have jumps in the policy function, see Skiba (1978), and for the shallow lake model Mäler et al. (2003) and Wagener (2003). Since the game Hamilton–Jacobi equation for the case of two or more players is identical to that of the one player case, the same jump occurs. Note that the Nash strategies that are parametrised by parts of the stable and unstable manifolds of one of the saddle points of the auxiliary system are continuous, but not continuously differentiable everywhere.

Local (thin) and global (thick) Markov perfect Nash equilibrium strategies in the symmetric two-player case of the lake game, for parameter values \((b,c,\rho )=(0.65,0.5, 0.03)\). The global Nash equilibrium strategy is discontinuous at \(x_i\)
Finally, notice that the auxiliary system does not depend on the number of agents and therefore coincides with the state–control system of the shallow lake optimal control problem. In practical terms, this means that Fig. 5 can be used to analyse the situation for any number of players. The only difference exists in the symmetric time dynamics
Increasing the number of players \(n\) leads to a decrease in the isocline \(\dot{x} = 0\). In particular, though this will not be demonstrated here, for large values of \(n\), no states in the low-pollution region can be stabilised by a locally defined feedback Nash equilibrium strategy.
4.3 Strategies in near-symmetric games
We return to the linear–quadratic example of Sect. 2.5, but we drop the assumption that the players are fully symmetric. Instead, we assume that player \(i\)’s utility functional is given by
By rescaling time and the unit of measurement of \(J_i\), it can be achieved that \(a_1=a_2=\delta =1\). The present value Pontryagin functions then read as
The controls depend on the co-states as
where \(\chi (p)=\chi _{[0,\infty )}(p)\) equals \(1\) if \(p\ge 0\) and \(0\) if \(p<0\). Consequently, the game Hamilton functions take the form
We find that
and
with the understanding that the derivative \(\partial \mathbf{G}/\partial \mathbf{p}\) exists only for \(p_1\ne 0\) and \(p_2\ne 0\). The auxiliary system (16) then takes the form
First, we concentrate on the region \(p_1\ge 0\), \(p_2\ge 0\). There the auxiliary system takes the form
As we are interested in near-symmetrical Nash equilibrium feedback strategies, it is more convenient to work in coordinates \(v=p_1+p_2\) and \(w=p_2-p_1\); the graph of a symmetric feedback strategy will be contained in the plane \(w=0\).
Also, we introduce new parameters by setting \(b_1=b-\frac{1}{2}\varepsilon \) and \(b_2=b+\frac{1}{2}\varepsilon \): that is, if \(\varepsilon =0\), the fully symmetrical situation is retrieved. As we want to illustrate a principle, we choose particular values \(b=1\) and \(\rho =1\) for the remaining parameters.
After rearranging of terms, this results in
We shall show that the piecewise linear feedback strategy found in the symmetric analysis survives if a nearby non-symmetric configuration is considered; that is, we shall demonstrate the following result.
Theorem 7
For \(|\varepsilon |>0\) sufficiently small, there is a family \(u_\varepsilon (x)\) of feedback Nash equilibrium strategies of the near-symmetric game, depending continuously on \(\varepsilon \), such that for \(\varepsilon =0\), the fully symmetric strategy is obtained as \(u_0(x)\).
Proof
We shall show that there are two one-parameter families of equilibria of the symmetric auxiliary system, that is, the system with \(\varepsilon =0\). Moreover, their associated invariant manifolds are normally hyperbolic, intersect transversally and contain the equilibrium strategy in their intersection. Invoking the persistence of normally hyperbolic invariant manifolds under small perturbations (Hirsch et al. 1977), it follows that the perturbed invariant manifolds still intersect transversally. The intersection is finally shown to be a graph of a Nash feedback equilibrium of the perturbed game.
Our argument rests on the analysis of the three-dimensional auxiliary system of the symmetric situation, that is, for \(\varepsilon =0\). That system reads as
The plane \(w=0\), that is the plane \(p_1=p_2\), is invariant; this is of course a consequence of symmetry.
Equilibria
The equilibria of the auxiliary system are given as
and
Their position, as well as the position of the plane \(w=0\), is illustrated in Fig. 6. We turn to the eigenvalues of the linearisation of the auxiliary system at the equilibria, which are located on the graph of the symmetric feedback Nash equilibrium strategy. At each equilibrium, one of the eigenvalues is necessarily zero, as the equilibria are not isolated. Moreover, for equilibria in the plane \(w=0\), by invariance of the plane, two eigenvectors are contained in the plane, whereas the third is perpendicular to it. We denote these by, respectively, \(\lambda ^\parallel _{1,2}\) and \(\lambda ^\perp \).

Equilibria and invariant plane of the symmetric auxiliary system \((\varepsilon =0)\)
For the equilibria in \(E_1\), which are all contained in \(\{w=0\}\), the eigenvalues are given as
for the single equilbrium \(e_2\in E_2\cap \{w=0\}\), which is obtained for \(v=2/5\), they read as
Globally defined feedback solution
In the symmetric case \(\varepsilon =0\), a symmetric linear feedback strategy is contained in the plane \(w=0\). Its graph is an invariant line of the form
To find values for the coefficients \(c_0\) and \(c_1\), we take the derivative with respect to the parameter \(s\) to obtain the condition
substitute the derivatives from the auxiliary system and use (38) to eliminate \(v\). The left-hand side of the last expression is a quadratic polynomial in \(x\), all of whose coefficients should be zero. Solving these three equations yields three invariant lines in the half-plane \(w=0\), \(v\ge 0\):
Line \(L_1\) corresponds to the family of equilibria \(E_1\), \(L_u\) to the unstable invariant manifold of the equilibrium \(e_2\), and \(L_s\) to the stable invariant manifold of \(e_2\), which is also the graph of the feedback Nash equilibrium strategy found in Sect. 2.5.
Invariant manifolds
We proceed by defining two invariant manifolds \(M^0_1\) and \(M^0_2\) that contain \(L_s\) in their intersection.
To define \(M^0_1\), we introduce the intersection \(e_1\) of \(L_s\) and \(E_1\), given as
The eigenvalues of the equilibrium \(e_1\) are
In particular, \(\lambda _2^\parallel >0\) and \(\lambda ^\perp <0\). By continuity, there is a neighbourhood \(N_1\) of \(P_1\) on \(E_1\) such that all equilibria on \(N_1\) having their three eigenvalues \(\lambda _i\) satisfy \(\lambda _1<0=\lambda _2<\lambda _3\).
Define \(M^0_1\) as the union of the unstable manifolds of the equilibria in \(N_1\); that is, let \(M^0_1\) be the set of points \(z_0=(x_0,v_0,w_0)\) such that the trajectory
which passes for \(t=0\) through \(z_0\), tends towards an equilibrium in \(N_1\) as \(t\rightarrow -\infty \).
Likewise, let \(e_2\) be the intersection of \(L_s\) with \(E_2\), given as
The eigenspaces of \(e_2\) are \(L_0=\{x=3/5,\, v=2/5\}\) and \(L_s\) and \(L_u\) given above; the corresponding eigenvalues have been given in (37). Let \(N_2\) be a neighbourhood of \(e_2\) in \(E_2\), such that the eigenvalues \(\lambda _i\) of the equilibria in \(N_2\) satisfy \(\lambda _1<0=\lambda _2<\lambda _3\). Define \(M^0_2\) as the union of the stable manifolds of the equilibria in \(N_2\).
The manifolds \(M^0_1\) and \(M^0_2\) are smooth, that is, infinitely differentiable. Moreover, they are invariant under the flow of the auxiliary system, as they are both unions of invariant manifolds. As \(L_s\) passes through both \(e_1\) and \(e_2\), it is contained in the intersection of these manifolds. Moreover, as \(M^0_1\) is contained in \(w=0\), and \(M^0_2\) is transversal to \(w=0\), the intersection of \(M^0_1\) and \(M^0_2\) is transversal.
Normal hyperbolicity The next step consists in demonstrating that the manifolds \(M^0_1\) and \(M^0_2\), as well as their intersection, persist if the parameter \(\varepsilon \) is changed slightly from \(\varepsilon =0\).
For this, we note that these manifolds are normally hyperbolic. Rather than fully defining this notion, we note that the requested property is a direct consequence of the theorem in Sect. 2.1 of Takens and Vanderbauwhede (2010), which shows that \(M^0_1\) is infinitely normally attracting and \(M^0_2\) is infinitely normally expanding. We then invoke Theorem 4.1 from Hirsch et al. (1977), which shows that there is a compact neighbourhood \(C\) of \(L_s\) and a constant \(\varepsilon _0>0\) such that for every \(\varepsilon \in (-\varepsilon _0,\varepsilon _0)\), there are normally hyperbolic smooth manifolds \(M^\varepsilon _1\) and \(M^\varepsilon _2\) whose restrictions to \(C\) are close to \(M^0_1\) and \(M^2_1\) in the \(C^\infty \) topology.
In particular, the perturbed manifolds also intersect transversally in a curve \(L^\varepsilon \) which is \(C^\infty \)-close to \(L_s\).
Existence of globally defined strategies
It remains to prove that \(L^\varepsilon \) can be parametrised as a function of \(x\) for all \(x\). By the persistence of \(L_s\) under small perturbations, this is already guaranteed for a compact neighbourhood \(C\) of \(L_s\), which may be assumed to be large. As \(L_s\) intersects the plane \(x=0\) transversally at
the curve \(L^\varepsilon \) will do the same at a value of \(x\) close to \(x_1\). Likewise, as \(L_s\) restricted to the sufficiently large compact set \(C\) enters the region \(v,w<0\), corresponding to the region \(\{p_1<0,\,p_2<0\}\), \(L^\varepsilon \) will do the same.
In that region, the auxiliary system reads as
Since \(\mathrm {d}p_i/\mathrm {d}s<0\) if \(p_i=0\), the region \(\{p_1<0,\,p_2<0\}\) is invariant; hence, once the curve \(L^\varepsilon \) has entered this region, it cannot escape again. Moreover, as \(\mathrm {d}x /\mathrm {d}s>0\) for all \(x>0\), it follows that the trajectory will trace out the graph of a differentiable function of \(x\) also for large values of \(x\).
Concluding the proof
We have demonstrated that there is a continuous function \(x\mapsto \mathbf{p}^\varepsilon (x)=(p_1^\varepsilon (x),p_2^\varepsilon (x))\) that solves equation (7); this yields a continuously differentiable solution \(\mathbf{V}^\varepsilon (x)=\rho ^{-1}\mathbf{G}(x,\mathbf{p}(x))\) of the game Hamilton–Jacobi equation, and continuous policy functions \(u_i^\varepsilon =p_i^\varepsilon \chi (p_i^\varepsilon )\) for \(i=1,2\) by (36). Moreover, we have demonstrated that \(p_i^\varepsilon (x)<0\) for both \(i=1\) and \(i=2\) for large values of \(x\); but then the associated strategies satisfy \(\mathbf{u}^\varepsilon (x)=(u_1^\varepsilon (x),u_2^\varepsilon (x))=0\) if \(x\) is sufficiently large, and all trajectories \(x(t)\) remain bounded. It then follows from Theorem 1 that for all \(|\varepsilon |<\varepsilon _0\), the strategies \(\mathbf{u}^\varepsilon \) constitutes a Markov perfect Nash equilibrium of the asymmetric game.\(\square \)
5 Conclusions
In this article, a framework has been elaborated to find sufficient conditions as well as necessary conditions for Markov perfect Nash equilibrium strategies in differential games with a single state variable. The Nash equilibria have been characterised as solutions of a system of explicit first-order ordinary differential equations, usually nonlinear.
By analysing a series of classical examples, we have shown that this characterisation can be used to find both direct analytic information, by integration of the equations, and indirect qualitative information, by a geometric analysis of the solution curves of an auxiliary system in the phase space. Additionally, we have addressed the issues of continuity and differentiability of Markov strategies in this class of differential games.
In particular, in the shallow lake model, we have shown the existence of a global non-continuous Markov perfect Nash equilibrium. Our simple approach is capable enough to deliver interesting insights into a large class of capital accumulation games.
Notes
For a general introduction to the theory of differential games, we refer the reader to Dockner et al. (2000).
Pre-commitment strategies that are set as time functions only are also referred to as open-loop strategies and the corresponding dynamic game as an open-loop game.
A differential equation is called quasi-linear if it is linear in the highest derivatives of the unknown function.
Kossioris et al. (2008) apply the shadow price system approach to an environmental economics problem.
Also called Hamilton, pre-Hamilton or unmaximised Hamilton function.
References
Akao, K.-I.: Tax schemes in a class of differential games. Econ. Theory 35, 155–174 (2008). doi:10.1007/s00199-007-0232-9
Benchekroun, H.: Unilateral production restrictions in a dynamic duopoly. J. Econ. Theory 111, 214–239 (2003)
Benhabib, J., Radner, R.: The joint exploitation of a productive asset: A game theoretic approach. Econ. Theory 2, 155–190 (1992). doi:10.1007/BF01211438
Becker, R.A., Dubey, R.S., Mitra, T.: On Ramsey equilibrium: Capital ownership pattern and inefficiency. Econ. Theory doi:10.1007/s00199-013-0767-x
Brock, W.A., Dechert, W.D.: The polluted ecosystem game. Indian Growth Dev. Rev. 1, 7–31 (2008)
Brock, W., Starrett, D.: Nonconvexities in ecological management problems. Environ. Resource Econ. 26, 575–624 (2003)
Case, J.: Economics and the Competitive Process. New York University Press, New York (1979)
Clemhout, S., Wan, H.: Differential games—Economic applications. In: Aumann, R., Hart, S. (eds.) Handbook of Game Theory, pp. 801–825. North-Holland, Amsterdam (1994)
Crandall, M., Lions, P.-L.: Viscosity solutions of Hamilton–Jacobi equations. Trans. Am. Math. Soc. 277, 1–42 (1983)
Dockner, E., Long, N.V.: International pollution control: Cooperative versus non-cooperative strategies. J. Environ. Econ. Manag. 24, 13–29 (1994)
Dockner, E., Long, N.V., Jørgensen, S., Sorger, G.: Differential Games in Economics and Management Science. Cambridge University Press, Cambridge (2000)
Dockner, E., Long, N.V., Sorger, G.: Analysis of Nash equilibria in a class of capital accumulation games. J. Econ. Dyn. Control 20, 1209–1235 (1996)
Dockner, E., Sorger, G.: Existence and properties of equilibria for a dynamic game on productivity assets. J. Econ. Theory 71, 209–227 (1996)
Dutta, P., Radner, R.: Capital growth in a global warming model: Will China and India sign a climate treaty? Econ. Theory 49, 411–443 (2012). doi:10.1007/s00199-010-0590-6
Dutta, P., Sundaram, R.: How different can strategic models be? J. Econ. Theory 60, 413–426 (1993)
Fershtman, C., Nitzan, S.: Dynamic voluntary provision of public goods. Eur. Econ. Rev. 35, 1057–1067 (1991)
Fleming, W.H., Soner, H.M.: Controlled Markov Processes and Viscosity Solutions. Springer, Berlin (2006)
Hájek, O.: Discontinuous differential equations I. J. Differ. Equ. 32, 149–170 (1979)
Hirsch, M.W., Pugh, C.C., Shub, M.: Invariant Manifolds. Springer, Berlin (1977)
Josa-Fombellida, R., Rincón-Zapatero, J.P.: New approach to stochastic optimal control. J. Optim. Theory Appl. 135, 163–177 (2007)
Karp, L., Zhang, J.: Taxes versus quantities for a stock pollutant with endogenous abatement costs and asymmetric information. Econ. Theory 49, 371–409 (2012). doi:10.1007/s00199-010-0561-y
Kiseleva, T., Wagener, F.: Bifurcations of optimal vector fields in the shallow lake model. J. Econ. Dyn. Control 34, 825–843 (2010)
Kossioris, G., Plexousakis, M., Xepapadeas, A., de Zeeuw, A., Mäler, K.G.: Feedback Nash equilibria for non-linear differential games in pollution control. J. Econ. Dyn. Control 32, 1312–1331 (2008)
Kossioris, G., Plexousakis, M., Xepapadeas, A., de Zeeuw, A.: On the optimal taxation of common-pool resources. J. Econ. Dyn. Control 35, 1868–1879 (2011)
Levhari, D., Mirman, L.: The great fish war: An example using a dynamic Cournot Nash solution. Bell J. Econ. 11, 322–334 (1980)
Mäler, K.G., Xepapadeas, A., de Zeeuw, A.: The economics of shallow lakes. Environ. Resource Econ. 26, 105–126 (2003)
Marx, L., Matthews, S.: Dynamic voluntary contribution to a public project. Rev. Econ. Stud. 67, 327–358 (2000)
Peano, G.: Démonstration de l’intégrabilité des équations différentielles ordinaires. Mathematische Annalen 37, 182–228 (1890)
Rincón-Zapatero, J., Martínez, J., Martín-Herrán, G.: New method to characterize subgame perfect Nash equilibria in differential games. J. Optim. Theory Appl. 96, 377–395 (1998)
Rincón-Zapatero, J.P.: Characterization of Markovian equilibria in a class of differential games. J. Econ. Control 28, 1243–1266 (2004)
Rowat, C.: Non-linear strategies in a linearquadratic differential game. J. Econ. Dyn. Control 31, 3179–3202 (2007)
Skiba, A.: Optimal growth with a convex-concave production function. Econometrica 46, 527–539 (1978)
Sorger, G.: Markov-perfect Nash equilibria in a class of resource games. Econ. Theory 11, 79–100 (1998). doi:10.1007/s001990050179
Sorger, G.: Strategic saving decisions in the infinite-horizon model. Econ. Theory 36, 353–377 (2008). doi:10.1007/s00199-007-0273-0
Sundaram, R.: Perfect equilibria in non-randomized strategies in a class of symmetric games. J. Econ. Theory 47, 153–177 (1989)
Takens, F., Vanderbauwhede, A.: Local invariant manifolds and normal forms. In: Broer, H.W., Hasselblatt, B., Takens, F. (eds.) Handbook of Dynamical Systems 3, pp. 89–124. Elsevier, Amsterdam (2010)
Tsutsui, S., Mino, K.: Nonlinear strategies in dynamic duopolistic competition with sticky prices. J. Econ. Theory 52, 136–161 (1990)
van der Ploeg, R., de Zeeuw, A.: International aspects of pollution control. Environ. Resource Econ. 2, 117–139 (1992)
Wagener, F.: Skiba points and heteroclinic bifurcations, with applications to the shallow lake system. J. Econ. Dyn. Control 27, 1533–1561 (2003)
Wirl, F.: Dynamic voluntary provision of public goods: Extension to nonlinear strategies. Eur. J. Polit. Econ. 12, 555–560 (1996)
Acknowledgments
We would like to thank Christophe Deissenberg, Colin Rowat and Aart de Zeeuw, as well as two anonymous referees for helpful remarks and comments. The work of Florian Wagener has been supported under the CeNDEF Pionier grant and a MaGW-VIDI grant, both from the Netherlands Organisation for Science (NWO).
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Evolution near non-Lipschitz points
For continuous one-dimensional vector fields \(F:X\rightarrow {\mathbb R}\), where \(X\) is a closed interval of \({\mathbb R}\), Peano’s theorem (Peano 1890) guarantees the existence of a positive constant \(T>0\), possibly infinite, and a differentiable function \(x:[0,T]\rightarrow {\mathbb R}\) satisfying
for all \(t\in [0,T]\), and such that \(x(T)\in \partial X\).
At points \(\hat{x}\) where the right-hand side \(F\) of an ordinary differential equation has an isolated discontinuity, Peano’s theorem does not apply. For our purposes, it is sufficient to have the existence of continuous functions \(x(t)\) that satisfy (39) for all \(t\in [0,\infty )\backslash N\), where \(N\) is a discrete set, that is, a set without limit points. For the purpose of this appendix, we shall call these piecewise solutions in analogy to piecewise differentiable functions. Piecewise solutions are a special case of Carathéodory solutions, which are absolutely continuous functions \(x(t)\), satisfying (39) almost everywhere on \([0,\infty )\) (cf. Hájek 1979).
The theorem of this section gives a condition for one-dimensional vector fields with isolated jump discontinuities to have piecewise solutions.
Theorem 8
Let \(U\subset {\mathbb R}\) be an open interval including \(\hat{x}\), and let \(F\) restricted to \(U\backslash \{\hat{x}\}\) be continuous, non-zero and such that the right and left limits \(F_R\) and \(F_L\) of \(F(x)\) exist as \(x\) tends to \(\hat{x}\) from the right and from the left, respectively. Assume that
Then for all \(x_0\in U\), there exists a piecewise solution of (39) that satisfies \(x(0)=x_0\) and that is defined for all \(t\) such that \(x(t)\in U\).
Proof
In the proof, ‘trajectory’ will indicate a solution \(x\) of the differential equation, whose existence is guaranteed by Peano’s theorem, that is, as long as \(x(t)\ne \hat{x}\). A statement about a trajectory \(x\) that holds ‘for all \(t\)’ will always mean ‘for all \(t\) such that \(x(t)\in U\)’.
There are a number of different situations. Firstly, if \(F_L=F_R\), then \(F\) is continuous on \(U\), and Peano’s theorem yields the existence of a solution to the differential equation for all \(t\).
Secondly, \(F_L\) and \(F_R\) may be both nonnegative or both non-positive. Assume for definiteness that both are nonnegative. Then, a trajectory starting at \(x_0>\hat{x}\) does not decrease, never reaches \(\hat{x}\) and yields a piecewise solution for all \(t\), while a trajectory \(x_1\) starting at \(x_0\le \hat{x}\) reaches \(\hat{x}\) at some time \(T\ge 0\); if \(T=\infty \), then \(x_1\) is already a piecewise solution. Assume therefore that \(T\) is finite. Introduce
Let then \(x_2\) be a solution of \(\dot{x} = G(x)\) with initial condition \(x_2(T)=\hat{x}\), which exists as \(G\) is continuous. The trajectory that is equal to \(x_1(t)\) for \(0\le t < T\) and \(x_2(t)\) for \(t\ge T\) is a piecewise solution.
Thirdly, there is the possibility that \(F_L>0>F_R\). By assumption, we then have \(F(\hat{x}) = 0\). A trajectory \(x_1\) starting at \(x_0<\hat{x}\) will satisfy \(\lim _{t\uparrow T} x_1(T) = \hat{x}\) for some finite time \(T\). Concatenation with the constant trajectory \(x_2(t)=\hat{x}\) for \(t\ge T\) again yields a piecewise solution. The case \(x_0>\hat{x}\) is handled in the same manner.
Lastly, there is the situation that \(F_L<0<F_R\). As above, a trajectory with initial value \(x_0>\hat{x}\) is increasing, hence defined for all \(t\) and yields a piecewise solution; likewise, trajectories starting at \(x_0<\hat{x}\) are decreasing and are also defined for all \(t\ge 0\). If finally \(x_0=\hat{x}\), let \(G\) be defined as in (40), and let \(x\) be a solution of \(\dot{x} = G(x)\) with \(x(0)=x_0\). As \(G(x)>0\) for all \(x\), \(x(t)\) is increasing in \(t\) and satisfies therefore \(G(x(t))=F(x(t))\) for all \(t>0\). Hence, it is a piecewise solution as well. \(\square \)
Appendix 2: Proof of the sufficiency theorem
In this section, the Proof of theorem 1 is given. Before starting, we make a general remark on superdifferentials of viscosity solutions \(V:X\rightarrow {\mathbb R}\) to the Hamilton–Jacobi equation
where \(G:X\times {\mathbb R}\rightarrow {\mathbb R}\).
Theorem 9
Let \(G=G(x,p)\) be a continuous function that is strictly convex in \(p\), let \(\hat{x}\) be a point in \(X\), let \(U\) be an open neighbourhood of \(\hat{x}\) in \(X\), and let \(V\) be a viscosity solution of the Hamilton–Jacobi equation (11) that is continuously differentiable on \(U\backslash \{\hat{x}\}\). Then necessarily
and
Corollary 2
Let \(G\) and \(V\) be as in Theorem 9. Consider the state evolution equation
defined for all \(x\) where \(V'\) is differentiable in \(x\). If at a point \(\hat{x}\) the left and right limits \(F_L\) and \(F_R\) of \(F\) exist, then \(F_L\le F_R\).
Remark 1
It follows from theorem 8 that under the conditions of Theorem 9, the state evolution Eq. (41) has a piecewise solution.
Remark 2
Theorem 9 applies for instance to the global Markov perfect Nash equilibrium of the shallow lake model, discussed in Sect. 4.2.
Proof
(Of theorem 9). Let
and assume by contradiction that
Note that since \(V\) is \(C^1\) on \(U\backslash \{\hat{x}\}\), we have
Moreover, since \(p_L>p_R\)
Since \(G(\hat{x},p)\) is strictly convex in \(p\), it follows that for \(\bar{p} \in (p_R,p_L)\), we have
On the other hand, since \(V\) is a viscosity solution and \(\bar{p} \in D_+V(\hat{x})\), it follows that
This is impossible, hence \(p_L\le p_R\). \(\square \)
We now give the Proof of theorem 1.
Proof
We have to show the following. If the strategy vector of the players other than player \(i\) equals \(\mathbf{u}^*_{-i}\), then \(u^*_i\) is a best response of player \(i\); in other words, \(u_i(x)=u^*_i(x)\) solves the optimisation problem of player \(i\).
The proof consists of two parts, and it rests on the verification that \(V_i(x)\) is the value function of the optimisation problem of player \(i\). Let \(u_i(x)\) be any admissible strategy, set
and let \(\bar{x}\) be any piecewise solution of
whose existence is guaranteed by Theorem 8. The first part of the proof shows that then
that is, \(V_i(x_0)\) is an upper bound for the pay-off of player \(i\).
Then, for \(u_i=u_i^*(x)\), and \(x=x^*\) being any piecewise solution of
the second part of the proof demonstrates the opposite inequality
Together, these inequalities show that \(u_i^*\) is a best response of player \(i\).
Part one. As \({\bar{\mathbf{u}}}\) is piecewise differentiable, the set \(C\) of points where \(f(x, {\bar{\mathbf{u}}}(x))\) fails to be differentiable is a set of isolated points.
Let \(D\) be the set of states at which \(\mathbf{V}\) fails to be differentiable. By assumption this is a set of isolated points as well. Take \(\varepsilon \in (0,1)\) arbitrarily. Because of condition (15), there is a constant \(T>1/\varepsilon >0\) such that
Let \(\Sigma \subset [0,T]\) be such that
if and only if \(t\in \Sigma \). As \(\bar{x}\) is a piecewise solution, there are time points
such that the set \(\Sigma \) is the union of the finite set \(\Sigma _1=\{t_1,\ldots ,t_{k-1}\}\) and the interval \(\Sigma _2=[t_k,T]\), where it is understood that \(\Sigma _1\) may be empty and \(\Sigma _2\) may have zero length. Note that
if \(t\in \Sigma _2\).
Also set
From (46) it follows that
As \(V_i(x)\) is differentiable in the open intervals \((x_{j-1},x_j)\) as a function of \(x\) and \(\bar{x}\) is differentiable in \((t_{j-1},t_j)\) as a function of \(t\), the differentiations can be performed to yield
Here, the constant \(p_i\in D_-V_i(x_k)\) is an arbitrary subderivative of \(V_i\) at \(x_k\); as \(x_k\) is a steady state, we have that the inserted term
We compute
Note that for the second inequality, we used that \(H_i(x,p_i) = \max _{u_i} P_i(x,p_i,u_i)\). In the last inequality, we used that \(V_i\) is a viscosity supersolution of the Hamilton–Jacobi Eq. (14). Letting \(\varepsilon \rightarrow 0\) now yields inequality (43).
Part two. It remains to show the opposite inequality (45) if \(u_i(x) = u^*_i(x)\) for all \(x\), and \(x=x^*\) solving (44). Let \(C\) denote the isolated set of states where \(f(x,\mathbf{u}^*(x))\) fails to be differentiable, and let the set \(D\) be defined as above. Repeat the construction of \(T\), the \(t_i\), and the sets \(\Sigma _1\) and \(\Sigma _2\), but now with \(\bar{x}\) replaced by \(x^*\).
With an analogous reasoning as used to derive (48), we can show that
where \(p_i\in D_-V_i(x_k)\) is any subderivative of \(V_i\) at \(x_k\).
Again, if the interval \(\Sigma _2\) is nontrivial, the point \(x_k\) is a steady state of equation (42), with \({\bar{\mathbf{u}}}\) replaced by \(\mathbf{u}^*\). Introduce
By assumption, the strategy vector \(\mathbf{u}^*\), and consequently the function \(F\), is either left or right continuous at \(x_k\) – say it is left continuous, the other case being similar. Setting
it follows by continuity that
and hence that
Inequality (50) implies that
by definition of \(P_i\), and
by equation (51).
All the terms of the sum vanish, since
whenever \(x\in (x_{j-1},x_j)\). The final integral vanishes as well, as by continuity
Continuity of \(V_i\) then implies that
Taking the limit \(\varepsilon \rightarrow 0\) demonstrates inequality (45). \(\square \)
Rights and permissions
About this article
Cite this article
Dockner, E., Wagener, F. Markov perfect Nash equilibria in models with a single capital stock. Econ Theory 56, 585–625 (2014). https://doi.org/10.1007/s00199-014-0805-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00199-014-0805-3