
Abstract
Many large-scale GNSS CORS networks have been deployed around the world to support various commercial and scientific applications. To make use of these networks for real-time kinematic positioning services, one of the major challenges is the ambiguity resolution (AR) over long inter-station baselines in the presence of considerable atmosphere biases. Usually, the widelane ambiguities are fixed first, followed by the procedure of determination of the narrowlane ambiguity integers based on the ionosphere-free model in which the widelane integers are introduced as known quantities. This paper seeks to improve the AR performance over long baseline through efficient procedures for improved float solutions and ambiguity fixing. The contribution is threefold: (1) instead of using the ionosphere-free measurements, the absolute and/or relative ionospheric constraints are introduced in the ionosphere-constrained model to enhance the model strength, thus resulting in the better float solutions; (2) the realistic widelane ambiguity precision is estimated by capturing the multipath effects due to the observation complexity, leading to improvement of reliability of widelane AR; (3) for the narrowlane AR, the partial AR for a subset of ambiguities selected according to the successively increased elevation is applied. For fixing the scalar ambiguity, an error probability controllable rounding method is proposed. The established ionosphere-constrained model can be efficiently solved based on the sequential Kalman filter. It can be either reduced to some special models simply by adjusting the variances of ionospheric constraints, or extended with more parameters and constraints. The presented methodology is tested over seven baselines of around 100 km from USA CORS network. The results show that the new widelane AR scheme can obtain the 99.4 % successful fixing rate with 0.6 % failure rate; while the new rounding method of narrowlane AR can obtain the fix rate of 89 % with failure rate of 0.8 %. In summary, the AR reliability can be efficiently improved with rigorous controllable probability of incorrectly fixed ambiguities.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Since 1990s, the CORS networks have been extensively established around the world to support high-precision positioning applications, such as precise farming, machine guidance, crustal deformation monitoring and other geoscience applications (Bock and Shimada 1989; Chen 1994; Han and Rizos 1996; Chen et al. 2000; Snay and Soler 2008; Liu 2011).
In current network RTK implementations, the inter-station distance is typically restricted to around 50 km or shorter in the lower latitude area mainly due to strong ionospheric disturbance (Chen et al. 2001; Wielgosz et al. 2005; Grejner-Brzezinska et al. 2007). If such density coverage was extended to the whole China, it would need thousands of reference stations, representing huge costs for hardware, software and on-going operations. Therefore, many researchers seek to develop new data processing strategies to expand the network density for the station separation of 100 km or beyond (Li et al. 2010a; Tang et al. 2010). In most recent years, an innovative PPP-RTK technology has been extensively studying with carrying forward the successful PPP applications based on the undifference data processing strategies (Wabbena et al. 2005; Laurichesse et al. 2008; Mervart et al. 2008; Collins et al. 2008; Li et al. 2010b, 2013c; Teunissen and Odijk 2010; Geng et al. 2011), which has demonstrated the high-precision positioning results in large-scale networks. Contrary to the extensive studies on PPP-RTK, the traditional double-difference-based network RTK research seems cooling down, which is somehow unfair, since both undifference and double-difference (DD) data processing are essentially the different implementation (utilization) of the network data. The high precision positioning gained both from fixing DD integer ambiguities. Therefore, it is worth to further address the traditional network RTK, after all it has been running in most of network systems. The following challenges are faced in the research for long baseline network RTK systems.
Network ambiguity resolution The long inter-station separation will reduce the spatial correlation of atmospheric biases such that their DD residuals are still considerable. These residuals usually have to be further captured by introducing more parameters. As a consequence, the formulated model will be very weak, thus hindering the precision of float ambiguity solutions and then the ambiguity fixing efficiency and reliability. Moreover, the complexity of residual DD atmospheric effects, especially for the low-elevation satellites, would likely bias the float solutions if they are not adequately treated (Chen et al. 2004; Dai et al. 2003; Li et al. 2013c). To reverse such a situation, more research efforts are needed to resolve the ambiguities fast and reliably.
Atmosphere correction generation After AR over all baselines of the network, the next step is to compute the high-precision atmospheric corrections in both spatial and temporal high resolutions. Besides, the good modeling strategies are needed to establish the high-precision model of atmospheric corrections over the network (Fortes et al. 2003; Zhang and Lachapelle 2001). The interpolated corrections can then adequately represent the real atmospheric biases and satisfy the requirement of high-precision RTK users.
Atmosphere correction application The corrections generated from the network are usually treated as deterministic quantities without any consideration of their uncertainties in the user receiver processing. This is obviously questionable since the corrections computed from network data are noisy and correlated with each other. Without taking into account these stochastic characteristics of the corrections, the rover solutions will be too optimistic.
Of three challenges aforementioned, the reliable AR would be the most crucial one since the incorrect network AR would result in the incorrect solutions for all users. The extensive research efforts have been made to improve the network AR in the past years (Odijk 2000; Hu et al. 2003; Li and Teunissen 2011; Odijk et al. 2012). Usually, the widelane ambiguities are fixed first, with which as known quantities, followed by the procedure of determination of the narrowlane ambiguity integers based on the ionosphere-free model.
In the network RTK processing, the new ambiguities are introduced from time to time and the unknown ambiguities have the different cumulative observation time, elevations and precisions. It is, therefore, impossible to always fix all ambiguities simultaneously. It is common that the so-called bootstrapping procedure is employed to successively fix the ambiguities (Dong and Bock 1989; Blewitt 1989; Dach et al. 2007). In the bootstrapping processing, a subset of ambiguities is selected and fixed with high confidence. In fact, after initialization, the full ambiguity vector or the selected ambiguity subset consists of only few or even mostly one ambiguity. In this case, the rounding method is employed by checking the ambiguity fraction from its nearest integer and its variance. If both fraction and variance are smaller than the user-defined thresholds, it is assumed that this ambiguity can be fixed with a sufficient confidence. However, in most of the existing studies, these two thresholds are, to a great extent, empirically given and invariant in the whole AR processing. The problem is that when the thresholds are too large, the fixed ambiguity will be doubtful; when the thresholds are too small, the efficiency of ambiguity fixing becomes lower, i.e., the ambiguity that can be confidently fixed is left unfixed.
This paper dedicates to improve the network AR by strengthening the float solutions and increasing the reliability of ambiguity fixing. It starts with the widelane AR using the Melbourne–Wübbena model (Melbourne 1985; Wübbena 1985), whose uncertainty is dominated by the pseudoranges. In this paper, a new strategy is introduced to capture the influence of observation complexity on the precision estimation of widelane ambiguity. With the fixed widelane ambiguities as known quantities, an ionosphere-constrained model is introduced to solve the narrowlane ambiguities instead of the ionosphere-free model. As a consequence, the absolute and/or relative constraints can be imposed on the ionospheric biases to enhance the AR model strength, thus improving the float solutions. For the narrowlane AR with the bootstrapping procedure, the partial AR for a subset of ambiguities selected according to the successively increasing elevations is performed. For scalar ambiguity fixing, we control the error probability of incorrect fixing by downscaling the rounding region adaptively in terms of its precision. As a result, the probability of successful ambiguity fixing is significantly increased.
The paper is organized as follows. In Sect. 2, the fundamental DD observation equations are outlined, followed by adaptive variance estimation in widelane AR. In Sect. 3, the ionosphere-constrained model is formulated and the sequential formulae are derived for the efficient computations. Moreover, several special models deduced from the ionosphere-constrained model are discussed. We discuss the narrowlane AR in Sect. 4, including the partial AR with ambiguity subset selected against the successively increased elevations and a new rounding strategy for improving the reliability of scalar ambiguity fixing. The real GPS data from USA CORS network (Snay and Soler 2008) are processed in Sect. 5 to demonstrate the performance of the presented methodology. Finally, some concluding remarks are given in Sect. 6.
2 Geometry-free and ionosphere-free model for widelane AR
Considering the ionospheric and tropospheric biases, the DD phase and code observation equations on frequency \(j\) read
where the subscripts \(j\) and \(k\) denote the frequency \(f_j\) and epoch number, while the superscripts \(u\) and \(v\) a pair of satellites. \(\phi \) and \(p\) are the DD phase and code observations in unit of meter. \(\varrho \) is the DD receiver-to-satellite distance computed using the known receiver and satellite coordinates. \(\tau \) is the residual DD tropospheric delay after correcting by using a standard troposphere model, for instance, UNB3 model (Collins and Langley 1997; Kim et al. 2004) along with Niell’s mapping function (Niell 1996). \(\iota \) is the DD ionospheric bias on frequency \(f_1\) with \(\mu _j=f_1^2/f_j^2\); \(\lambda _j\) is the phase wavelength and \(a\) its associated DD integer ambiguity; \(\epsilon \) is the random noise of normal distribution with zero mean.
2.1 Widelane AR with adaptive variance estimation
Resolution of the so-called widelane ambiguities using special linear combination of the L1 and L2 carrier and code observations has become standard (Mervart et al. 1994). Many AR strategies resolve firstly the widelane ambiguity, and the Melbourne–Wübbena model (MW) combination is extensively applied, proposed independently by Melbourne (1985) and Wübbena (1985). The float widelane ambiguity is computed at epoch \(k\) as
with widelane wavelength \(\lambda _{w}=c/(f_1-f_2)\approx 86~\mathrm{cm}\). The MW model can be understood as a both geometry-free and ionosphere-free model since the geometry and ionosphere-related biases are totally cancelled and the code noise is minimized (Mervart et al. 1994). Therefore, it is expected to fix the widelane ambiguity by rounding its averaged value over \(m\) epochs,
where \(\left[ \bullet \right] \) denotes the operator of integer rounding. \({\bar{a}}_w^{uv}\) is the averaged float widelane ambiguity over \(m\) epochs and \(\check{a}_w^{uv}\) is its fixed integer. It is assumed that the precisions of phase and code observations are unique for both frequencies, respectively, i.e., \(\sigma _{\phi }^2\equiv \sigma _{\phi _1}^2=\sigma _{\phi _2}^2\) and \(\sigma _p^2\equiv \sigma _{p_1}^2=\sigma _{p_2}^2\). Then the formal standard deviation of single-epoch widelane estimate is
Considering \(\sigma _{\phi }\ll \sigma _p\), it follows that \(\sigma _{{\hat{a}}_w^{uv}}\approx 0.7\sigma _p\) for dual-frequency GPS. The standard deviation of averaged widelane estimate \({\bar{a}}_w^{uv}\) over \(m\) epochs is
Denoting the distance of \({\bar{a}}_w^{uv}\) to its nearest integer as \(b_w^{uv}=|{\bar{a}}_w^{uv}-\check{a}_w^{uv}|\), the widelane ambiguity fixing is conducted by checking both \(b_w^{uv}\) and \(\sigma _{{\bar{a}}_w^{uv}}\). Given the thresholds \(b_\mathrm{m}\) and \(\sigma _\mathrm{m}\), one can fix \({\bar{a}}_w^{uv}\) to its nearest integer \(\check{a}_w^{uv}\) if
From the derivations above, it is clear that \(\sigma _{{\bar{a}}_w^{uv}}\) is dominated by \(\sigma _p\) that varies significantly for the different types of receivers and the different observation environments, like multipath (Li et al. 2008, 2011; Geng et al. 2012). This behavior is also recognized in Ge et al. (2005) by post-fitting the residuals. Therefore, to capture the influence of observation complexity on the widelane ambiguity precision, we immediately estimate the empirical standard deviation using the residuals of widelane ambiguities themselves over \(m\) epochs. Assuming that the widelane ambiguity is correctly fixed over \(m\) epochs, the empirical standard deviation of the single-epoch float widelane ambiguity is estimated as
Notice that here the use of numerator \(m\) is based on the assumption that the fixed solution \(\check{a_w^{uv}}\) is deemed as a deterministic quantity, which is practically true when its corresponding success rate sufficiently close to 1. Recall that the purpose of adaptive estimation of \(\hat{\sigma }_{{\hat{a}}_w^{uv}}\) is to reliably fix \(\check{a}_w^{uv}\). However, it seems contradictory that \(\check{a}_w^{uv}\) is involved in the estimation (6). Bear this in mind and continue further analysis. If \(\check{a}_w^{uv}\) is indeed the correct integer, (6) obviously holds true. If \(\check{a}_w^{uv}\) is not the correct integer, the integer that should be used in (6) has an integer bias from \(\check{a}_w^{uv}\). In such case, the estimate \(\hat{\sigma }_{a_w^{uv}}\) has already absorbed the effect of this integer bias and is, of course, larger than the realistic precision. As a result, this enlarged estimate will be, to a certain extent, helpful for rejecting the incorrect integer.
The parameters \(b_\mathrm{m}\) and \(\sigma _\mathrm{m}\) also play an important role in widelane ambiguity fixing. The large thresholds would derive the high probability of incorrect fixing, whereas the small values would increase the rejection of correct integers. In practice, one may conservatively prefer the small values of \(b_\mathrm{m}\) and \(\sigma _\mathrm{m}\) to control AR reliability, after all the widelane AR is easy and important for latter narrowlane AR.
3 Ionosphere-constrained model for solving the narrowlane float solution
3.1 Ionosphere-constrained model
For long baselines, the residual tropospheric biases (after corrected with a standard model) are usually modeled using so-called relative zenith troposphere delay (RZTD) parameter with mapping function as (Zhang and Lachapelle 2001; Hu et al. 2003; Dai et al. 2003),
where \(\theta _k^u\) and \(\theta _k^v\) are the average elevation angles of the two stations for satellites \(u\) and \(v\) at epoch \(k\), respectively. \(\xi _k\) is the RZTD parameter. Inserting (7) into (1) and parameterizing the DD ionospheric biases, the single-epoch observation equations read
where \(\varvec{\phi }_{1,k},~\varvec{\phi }_{2,k},~\varvec{p}_{1,k},~\varvec{p}_{2,k}\) are dual-frequency DD phase and code observation vectors corrected by the known receiver-to-satellite distances, of which \(\varvec{\phi }_{2,k}\) has been corrected with the formerly fixed widelane ambiguities. \(\varvec{c}_k\) is the coefficient vector to RZTD for all DD satellites. \(\varvec{\iota }_k\) is \((m\times 1)\) DD ionosphere parameter vector; \(\varvec{a}\) denotes the \((m\times 1)\) L1 DD ambiguity vector. \(\varvec{I}_m\) is the \((m\times m)\) identity matrix.
Let us now work out some constraints to enhance the model strength. Usually, RZTD is assumed to be a first-order Gauss–Markov process. The corresponding state translation equation between two consecutive epochs is
where \(\Delta t\) is time interval between two consecutive epochs; \(\tau _{\xi }\) and \(q_{\xi }\) are the correlation time and the spectrum density, respectively. \(w_{\xi _k}\) is the process white noise with variance \(\sigma _{w_{\xi _k}}^2\). In network RTK, because the sampling interval is very small relative to \(\tau _{\xi }\) (in this study we take \(\Delta t=5\) s), (9) can be approximated to a random walk process
Similar to the tropospheric delay, the state translation equation can also be set up for ionospheric parameters
In addition, the absolute (DD) ionospheric constraints may be achievable from a deterministic ionospheric model. The prior ionospheric biases, \(\varvec{\iota }_k^0\) with covariance matrix \(\varvec{Q}_{\iota _k^0}\), can be applied by a set of pseudo observation equations
where \(\varvec{D}_m^\mathrm{T}=[-\varvec{e}_m,~\varvec{I}_m]\) is the between-satellite single difference operator with the first satellite as reference. \(\varvec{e}_m\) is the \(m\)-column vector with all elements of 1. In many cases, one can simply take \(\varvec{\iota }_k^0\!=\!\varvec{0}\) with baseline length up to 500 km (Dach et al. 2007). Therefore, at this stage, it is rather crucial to specify the value of \(\sigma _{\iota ^0}\). If \(\sigma _{\iota ^0}\) is too small, the model strength can, of course, be enhanced significantly, which however may result in the biased float solution; whereas if it is too large, the contribution of constraints to enhancing the model strength is downscaled, which could not be helpful to improving AR. Although a small bias is theoretically allowed for successful AR (Li et al. 2013), it gives difficulty for controlling the AR reliability latter. Hence, in practice, one may conservatively prefer the large value of \(\sigma _{\iota ^0}\) to improve the float solution but without introducing bias.
Note that the relative and absolute ionospheric constraints will be invalid if the ionosphere-free model is used.
3.2 Sequential solutions of Kalman filter type
To speed up the computations, the sequential solutions of Kalman filter type will be derived based on the least squares criterion. To ease programming, the ambiguity parameter is incorporated in the filter state as well with an extremely small variance, for instance, \(\sigma _{w_{a_k}}=\mathrm{e}^{-16}\), to characterize its constant property, namely,
Collecting the observation equations (8), the state translation equations (10), (11) and (13) of \(\xi _k,\,\varvec{\iota }_k\) and \(\varvec{a}\), and the pseudo ionospheric equations (12) yileds
where \(\varvec{y}_k=\begin{bmatrix}\varvec{\phi }_{1,k}^\mathrm{T},&\varvec{\phi }_{2,k}^\mathrm{T},&\varvec{p}_{1,k}^\mathrm{T},&\varvec{p}_{2,k}^\mathrm{T}\end{bmatrix}^\mathrm{T},\,\varvec{x}_k=\begin{bmatrix}\xi _k,&\varvec{\iota }_k^\mathrm{T},&\varvec{a}^\mathrm{T}\end{bmatrix}^\mathrm{T}\). \(\varvec{A}_k\) is the corresponding design matrix taken from (8). \(\varvec{\epsilon }_k=\begin{bmatrix} \varvec{\epsilon }_{\varvec{\phi }_{1,k}}^\mathrm{T},&\varvec{\epsilon }_{\varvec{\phi }_{2,k}}^\mathrm{T},&\varvec{\epsilon }_{\varvec{p}_{1,k}}^\mathrm{T},&\varvec{\epsilon }_{\varvec{p}_{2,k}}^\mathrm{T}\end{bmatrix}^\mathrm{T}\) is observation noise vector and its covariance matrix is \(\varvec{Q}_{y_k}.\, \varvec{\Phi }_{k,k-1}\) is the state translation matrix and the identity matrix in this case. \(\varvec{w}_k=\begin{bmatrix}w_{\xi _k},&\varvec{w}_{\iota _k}^\mathrm{T},&\varvec{w}_{a_k}^\mathrm{T}\end{bmatrix}^\mathrm{T}\) is the state translation noise vector and \(\varvec{Q}_{w_k}=\text{ diag }(\sigma _{w_{\xi _k}}^2,~\varvec{Q}_{w_{\iota _k}},~\sigma _{w_{a_k}}^2\varvec{I}_m)\) is its covariance matrix.
The Kalman filter procedure to this equation system can be divided into two parts. One is a standard Kalman filter procedure. The other, as an additional step, is to update the solution from the standard Kalman filter by applying the absolute ionospheric constraints if available. The sequential solutions start with the standard Kalman filter (Yang et al. 2001; Yang and Xu 2003)
where \(\tilde{\varvec{x}}\) denotes the predicted values of unknowns and \(\varvec{Q}_{\varvec{\tilde{x}}_k}\) is its respective covariance matrix. If the ionospheric constraints are available, the additional step is carried out to update the filter solutions from the standard Kalman filter
where \(\varvec{Q}_{\hat{x}_k\hat{\iota }_k}=\left[ \varvec{Q}_{\hat{\iota }_k\hat{\xi }_k}^\mathrm{T},~\varvec{Q}_{\hat{\iota }_k}^\mathrm{T},~ \varvec{Q}_{\hat{\iota }_k{\hat{a}}_k}^\mathrm{T}\right] ^\mathrm{T}\). We denote the updated solutions using the same symbols as for standard Kalman filter solutions.
3.3 Special models reduced from ionosphere-constrained model
Relative to the ionosphere-free model, the advantage of ionosphere-constrained model is that the constraints can be now imposed on the ionospheric parameters. Thus the model strength can, to a certain extent, be enhanced by assigning \(\sigma _{\iota ^0}\) and \(\sigma _{w_{\iota _k}}\) appropriately. We discuss two extreme situations specified by a different \(\sigma _{\iota ^0}\):
-
If the absolute (DD) ionospheric constraints are not available, i.e., \(\sigma _{\iota ^0}\rightarrow \infty \), then \((\varvec{Q}_{\hat{\iota }_k}+\varvec{Q}_{\iota _k^0})^{-1}\rightarrow 0\). Hence it does not need to implement (16a) and (16b) anymore, and only the standard Kalman filter procedure (15a–15e) is implemented, which is similar to the special case of ionosphere-free solution in Schaffrin and Bock (1988).
-
If the absolute ionospheric constraints are so strong that they can be deemed as deterministic constraints, i.e., \(\sigma _{\iota ^0}\rightarrow 0\), then (16a) and (16b) become, see e.g., Yang et al. (2010)
$$\begin{aligned} \varvec{\hat{x}}_k:=\varvec{\hat{x}}_k+\varvec{Q}_{\hat{x}_k\hat{\iota }_k}\varvec{Q}_{\hat{\iota }_k}^{-1} (\varvec{\iota }_k^0-\varvec{\hat{\iota }}_k)\end{aligned}$$(17a)$$\begin{aligned} \varvec{Q}_{\hat{x}_k}:=\varvec{Q}_{\hat{x}_k} - \varvec{Q}_{\hat{x}_k\hat{\iota }_k} \varvec{Q}_{\hat{\iota }_k}^{-1}\varvec{Q}_{\hat{\iota }_k\hat{x}_k} \end{aligned}$$(17b)In this case, the ionospheric parameters are actually fixed to their prior values, namely
$$\begin{aligned} \varvec{\hat{\iota }}_k:=\varvec{\iota }_k^0,~~\varvec{Q}_{\hat{\iota }_k}:=\varvec{0} \end{aligned}$$
We further discuss two other special cases for our presented ionosphere-constrained model:
-
The ionosphere-free model is formed in terms of the equivalent theory (Xu et al. 2007; Shen et al. 2009; Li et al. 2010a) by multiplying a transformation matrix
$$\begin{aligned} \varvec{R} = \begin{bmatrix} \displaystyle \frac{-\mu _2}{\mu _1-\mu _2}&\displaystyle \frac{\mu _1}{\mu _1-\mu _2}&0&0\\ 0&\displaystyle \frac{\mu _1}{\mu _1+\mu _2}&\displaystyle \frac{\mu _2}{\mu _1+\mu _2}&0\\ 0&0&\displaystyle \frac{-\mu _2}{\mu _1-\mu _2}&\displaystyle \frac{\mu _1}{\mu _1-\mu _2} \end{bmatrix}\otimes \varvec{I}_m \end{aligned}$$left to both sides of observation equations (8) without any influence on the remaining parameter estimation. It is equivalent to the ionosphere-constrained model with the extremely large variances for both absolute and relative constraints. In other words, one can implement only the standard Kalman filter procedure (15a–15e) with an extremely large variance of relative ionospheric constraints, say, \(\sigma _{w_{\iota }}=\mathrm{e}^{16}\). This model is also known as ionosphere-float model (Odijk 2003).
-
The ionosphere-constrained model can be easily extended to include more parameters and constraints. For instance, the multipath parameters can be set up and their constraints can be imposed using their solutions on the past sidereal days.
4 Reliable narrowlane AR with controllable incorrectness
In the network RTK processing, the new ambiguities will be frequently introduced from time to time such that some ambiguities in the unknown ambiguity vector have been tracked for a long time but some just few seconds. It is, therefore, generally impossible to fix all ambiguities simultaneously. Commonly a bootstrapping procedure is employed to successively fix ambiguities (Dong and Bock 1989; Blewitt 1989; Dach et al. 2007). In this section, a partial AR strategy with ambiguity subset selected based on the successively increased elevations will be introduced. Moreover, concerning the fact that after initialization, the selected ambiguity subset consists of only few or even mostly one ambiguity, an incorrectness controllable rounding strategy will be developed to improve the rounding reliability.
4.1 Partial AR for ambiguity subset selected with the successively increased elevations
Let the float ambiguity solution \(\hat{\varvec{a}}\) with covariance matrix \(\varvec{Q}_{\hat{\varvec{a}}\hat{\varvec{a}}}\) computed from the Kalman filter system have the following partitions
where the ambiguity vector \(\hat{\varvec{a}}_1\) is assumed to be the subset that can be reliably fixed. One can then employ the LAMBDA method (Teunissen 1995) to efficiently work out its optimal integer solution \(\check{\varvec{a}}_1\). Following the bootstrapped AR procedure, the remaining ambiguity \(\hat{\varvec{a}}_2\) is corrected by virtue of its correlation with \(\hat{\varvec{a}}_1\) as
In practice, since the low-elevation ambiguities are more probably affected by the observation abnormality (inadequately modeled systematic errors), the ambiguity subset \(\hat{\varvec{a}}_1\) is selected based on the successively increased elevations. The procedure is as follows. We start with checking full AR with both ratio test and success rate as criteria, namely the computed ratio and success rate are both satisfied with the user-defined thresholds. If the full AR is possible, we fix all ambiguities immediately; otherwise turn to use partial AR. Let the elevations \(\theta _1<\cdots <\theta _j\), we first use the lowest elevation \(\theta _1\) to choose the ambiguity subset, denote \(\hat{\varvec{a}}_1(\theta _1)\), such that the ambiguities whose elevations lower than \(\theta _1\) are excluded. We then check whether \(\hat{\varvec{a}}_1(\theta _1)\) can be fixed based on the same criteria, i.e., both ratio test and success rate. If yes, we fix it and update the remaining ambiguities with (19a) and (19b). If not, we further exclude the ambiguities whose elevations lower than \(\theta _2\). The newly selected ambiguity subset \(\hat{\varvec{a}}_1(\theta _2)\) is again checked for fixing. Repeat this procedure with successively increased elevations until the selected ambiguity subset can be successfully fixed or the ambiguity subset is empty. For the ratio test and success rate involved in this processing, one can refer to the new version LAMBDA and Ps-LAMBDA softwares (Verhagen and Li 2012; Verhagen et al. 2013).
4.2 Incorrectness controllable integer rounding
After initialization of network AR, only one ambiguity is, at most time, involved in the selected ambiguity subset. In this case, the rounding method is applied for AR. Traditionally, we round the float ambiguity to its nearest integer if both its fraction and variance are satisfied with the pre-defined thresholds, \(b_\mathrm{m}\) and \(\sigma _\mathrm{m}\), which is referred to as the fixed-fraction-and-variance (FFV) strategy. In FFV strategy, the thresholds are, to a great extent, empirically given and kept invariant in the whole processing (Eueler and Goad 1991; Goad and Yang 1997; Chen et al. 2001; Dach et al. 2007). The problem is that if the thresholds are too large, the fixed solution will be doubtful; whereas if they are too small, it will affect the AR efficiency. To overcome this awkward situation, a new rounding strategy is proposed to control the probability of incorrect fixing by adaptively adjusting the rounding interval in terms of the quality of float ambiguity itself. Moreover, the two extreme situations (i.e., small variance with too large fraction or too large variance with small fraction) will be specially taken into account. As a result, the large probability of successful fixing can be achieved with small incorrectness rate.
Let the normally distributed scalar ambiguity \({\hat{a}}\) has the true integer \(a\) and variance \(\sigma _{{\hat{a}}}^2\). In terms of integer translation invariant property of integer admissible estimation (Teunissen 1999), the integer-removed ambiguity \({\hat{a}}-a\), here we still use \({\hat{a}}\) without any confusion, has normal distribution \({\hat{a}}\sim {N}(0,\sigma _{{\hat{a}}}^2)\) and its probability density function is
Now, the correct integer solution is 0 and all the other integers are wrong solutions. Therefore, for the standard rounding method, the success rate is
and the probability of incorrect fixing (fail rate) is
where
If \(P_{f}\) is sufficiently small, \({\hat{a}}\) can be fixed to 0. It is observed from (21) that both the variance \(\sigma _{{\hat{a}}}^2\) and the integral interval affect the fail rate \(P_{f}\). In the standard rounding, the integral interval is fixed to \([-0.5,~0.5]\), which means that \(P_{f}\) is dominated only by the variance of float ambiguity. Once the variance is given, the fail rate is fixed no matter what value the float ambiguity is.
In terms of the integer aperture estimation (Teunissen 2005), we downscale the integral interval to decrease the fail rate. Let the downscaled interval as \([-r,~r]~(0\le r\le 0.5)\), then the success rate is
and the fail rate is
Obviously, both \(P_s\) and \(P_{f}\) become smaller for smaller \(r\). Although the infinite non-zero integers are involved in computing \(P_{f}\), it is adequate to consider only several integers around 0 since the integrals of those integers far from 0 are so small to be ignored. Let the integers from \(-i_0\) to \(i_0\) be considered, we refer to Appendix for what value \(i_0\) should be taken as a function of float ambiguity precision \(\sigma _{{\hat{a}}}\) with very small errors. Obviously, only very few integers are necessary with very small error, see Fig. 8 in Appendix. With the integer \(i_0\), the fail rate (23) can be computed as (Li et al. 2012)
The fail rate \(P_{f}\) is a function of the rounding radius \(r\) and precision \(\sigma _{{\hat{a}}}\) of float ambiguity. With float ambiguity in hand, one can now control \(P_{f}\) by changing \(r\). In the network AR, one prefers to control \(P_{f}\) critically, for instance 0.01 % in this study, since the incorrect AR will result in the wrong positioning for all users.
As shown in Fig. 1, the solid line depicts the relation between \(r\) and \(\sigma _{{\hat{a}}}\) for which the fail rate \(P_{f}=0.01\) %. In principle, any float ambiguity below this line can be rounded to its integer with fail rate smaller than 0.01 %. However, we must be aware of two extreme situations:
-
(i)
The first situation is that \(\sigma _{{\hat{a}}}\) is very small but \({\hat{a}}\) is close to 0.5 cycle. In practice, the most plausible explanation for such scenario is some unmodeled error source. For example, the remaining tropospheric errors after modeling with RZTD and mapping functions could be still considerable, especially for lower-elevation satellites.
-
(ii)
The second situation is that \({\hat{a}}\) is very close to an integer but \(\sigma _{{\hat{a}}}\) is large. In practice, the large error could be due to the poor geometry, data outages, high ionospheric activity, etc. Being close to an integer in this case is just a coincidence.

The rounding regions with different criteria. The FFV strategy with the thresholds \((r_{\mathrm{m}}=0.4, \sigma _{\mathrm{m}}=0.2)\) or \((r_{\mathrm{m}}=0.2, \sigma _{\mathrm{m}}=0.1)\); Thresholds \(r_{\mathrm{m}}=0.4, \sigma _{\mathrm{m}}=0.3)\) with the decision function \(g>10^4\); The solid line with \(P_{f}=0.01\) % denotes that the float ambiguities are below this line can be fixed with fail rate smaller than 0.01 %
These two extreme situations are actually the curses for reliable AR, and the wise choice is to leave the ambiguity float. To avoid the wrong ambiguity fixing in these awkward situations, Dong and Bock (1989) introduced a so-called ‘taper’ function \(T\), see also Blewitt (1989). In this study, the taper function is generalized as
where \(r_\mathrm{m}\le 0.5\) and \(\sigma _\mathrm{m}\) are two thresholds applied to exclude the two extreme situations above. It is obvious that \(0 \le T<1\). Besides controlling the fail rate with excluding two extreme situations, it is expected in practice to maximize the success rate. Therefore, a decision function \(g\) is defined
Once the thresholds, \(r_\mathrm{m}\) and \(\sigma _\mathrm{m}\) used for excluding two extreme situations, are specified, \(g\) will be a function of \(r\) and \(\sigma _{{\hat{a}}}\). One can now determine a rounding region (precisely speaking it is not rounding anymore) by specifying a threshold for \(g\). For instance, \(r_\mathrm{m}=0.4,\,\sigma _\mathrm{m}=0.3\) and \(g=10^4\) are taken in this study based on the extensive experiments, where \(g=10^4\) is related to the failure rate of 0.01 %. The corresponding rounding region is shown in Fig. 1. It is clear from Fig. 1 that this region is a subset of the region with \(P_{f}=0.01~\%\). In other words, the float ambiguity in this region can be reliably fixed with fail rate smaller than 0.01 % and also abnormality excluded.
Denoting \(b_{{\hat{a}}}\) as the fraction of float ambiguity from its nearest integer, we describe the implementation of above procedure. The rounding interval \(r\) is first determined by (26) with \(g=10^4\) and \(\sigma _{{\hat{a}}}\) of float ambiguity. If \(b_{{\hat{a}}}<r\), we accept its rounding solution. However, the determination of \(r\) is complicated and takes time since the Eq. (26) is nonlinear. As an alternative, we can conduct this implementation as follows. One can first simply take \(r=b_{{\hat{a}}}\) and compute the success rate and fail rate with (22) and (24), respectively. Here the integer \(i_0\) is taken from Fig. 8. Then the decision function is computed by (25) and (26). If the value of decision function is larger than \(g=10^4\), the integer rounding solution can be accepted.
5 Experiment and analysis
5.1 Experiment setup
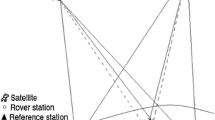
Eight daily dual-frequency GPS datasets with sample interval of 5 s were downloaded from USA CORS network (Snay and Soler 2008). The layout of eight stations is shown in Fig. 2. From these eight stations, seven independent baselines are formed with the baseline length of around 100 km, as presented in Table 1. The observation types include C1, P2, L1 and L2. The proposed methodology was implemented in “TJNRTK” software that is a self-developed software in Tongji University for the network RTK processing and its relevant engineering and scientific applications.

The layout of eight stations from USA CORS network used for the experiment
In the data processing, the cut-off elevation is set to \(7^\circ \) and the elevation-dependent stochastic model
is applied for the undifferenced measurements with \(a_0=2\, \hbox {mm}\), \(a_1=4\,\hbox {mm}\) for phase and \(a_0=20~\hbox {cm}\), \(a_1=40~\hbox {cm}\) for code. These parameters are obtained based on the evaluation of GPS stochastic characteristics in terms of Li et al. (2008). In the Kalman filter, we take \(q_{\xi }=3~\mathrm{cm}^2/\hbox {h}, \,q_{\iota }=5~\mathrm{cm}^2/\)h and \(\sigma _{\iota ^0}=15\) cm with \(\iota ^0=0\). (Tralli and Lichten 1990; Dodson et al. 1996; Liu and Lachapelle 2002; Odijk 2000; Schaffrin and Bock 1988). Although the data is post-processed, the processing is completely analogous to the real-time processing, namely, the data loading and all computations are implemented epoch by epoch.
5.2 Result of widelane AR
First of all, we demonstrate the proposed widelane AR with adaptive variance estimation. The minimal elevation for widelane AR is set to \(10^\circ \). In other words, we execute the widelane ambiguity fixing when its corresponding elevation is higher than \(10^\circ \). The convergence procedure of widelane ambiguity fixing is illustrated in Fig. 3. At beginning with very few epoch, the estimated precision with (6) is very poor and instable. With more data cumulated, the precision estimate becomes more and more stable and tight to bound the float widelane ambiguity. If the thresholds are taken as \(\sigma _\mathrm{m}=0.1\) and \(b_\mathrm{m}=0.2\), one can then fix widelane ambiguity once it touches the red line. Note that the satellite elevations in this example are around \(10^\circ \). That could be a reason why a slow convergence is received in this example.

Convergence procedure of widelane ambiguity fixing with adaptive variance estimation (the satellite elevations in this period are around \(10^\circ \)). The blue solid line indicates the computed float widelane ambiguity while the other two green dash lines indicate its upper and lower bounds, i.e., the float widelane ambiguity plus and minus its precision estimate. All of them are the functions of number of epochs
The fast widelane AR is examined for the different elevations with different thresholds. With correctly fixed widelane ambiguities based on all data as references, we reinitialize the processing every 10 min. In each reinitialization computation, we implement our widelane AR. Compared with the reference widelane ambiguities, the empirical successful fixing rate and unfix rate are defined as
and
The successful fixing rate \(P_\mathrm{sf}\) was defined in Teunissen and Verhagen (2007) to show the benefit of integer aperture estimation. With \(P_\mathrm{sf}\) and \(P_\mathrm{u}\), one can computed the empirical success rate \(P_\mathrm{s}\) and failure rate \(P_\mathrm{f}\) as
Here the non-italic subscripts used for variables to emphasize that their empirical (not theoretical) values. All of these statistics can be as indicators to show the AR performance. The successful fixing rates, unfix rates and failure rates of widelane AR are shown in Table 2 for the different elevation intervals. The result reveals that: (1) The successful fixing rate becomes larger while the unfix rate and failure rate smaller when the elevation increases. (2) With more critical (smaller) thresholds, the more ambiguities will be rejected without fixing, thus resulting in the larger unfix rate; But as a trade-off once the ambiguities satisfied with these smaller thresholds, they can be fixed more reliably with higher successful fixing rate and smaller failure rate. (3) The AR of low elevations is more sensitive to the varied thresholds than that of high elevations. The reason is that the high-elevation ambiguities can be solved very well with a few epochs such that they can be already satisfied with the most critical thresholds. This result suggests that one should use the conservative (critical) thresholds for widelane AR since the critical thresholds can hardly affect the high-elevation AR but efficiently control the reliability of low-elevation AR.
The time-to-first-fix (TTFF), defined as the number of epochs needed for successful AR, is further examined for widelane AR in different elevation intervals. The result is shown in Fig. 4. In general, the smaller TTFFs are assigned to the larger elevations and thresholds. However the TTFF difference is very marginal when the elevation is higher than \(30^\circ \).

TTFFs of widelane AR as a function of elevation intervals
Some comments are given before completing this section. First, we emphasize that the FFV rounding strategy was applied for widelane AR with different thresholds. Although, the AR results are shown here for different thresholds, we recommend using the critical thresholds, \(\sigma _\mathrm{m}=0.1\) and \(b_\mathrm{m}=0.2\), to improve the AR reliability because the widelane AR is easier. Of course one can easily apply the new rounding strategy to further improve the widelane AR, especially for lower-elevation ambiguities, which is, however, not shown in this paper.
5.3 Result of narrowlane AR
In TJNRTK software, after widelane ambiguities solved, the float solutions of narrowlane ambiguities are computed in a multi-baseline mode, while the ambiguity fixing processing is in a baseline-by-baseline mode. We first study the performance of presented partial AR with the ambiguity subset selected by successively increasing elevations, see Sect. 4.1. In this study, the elevations for ambiguity subset selection are from \(15^\circ \) to \(60^\circ \) every \(5^\circ \). The partial AR starts with checking the fixing possibility of the ambiguity subset with all ambiguity elevations higher than \(15^\circ \). If this ambiguity subset cannot be fixed, we go to the next iteration for checking the fixing possibility of a reduced ambiguity subset where all ambiguity elevations are higher than \(20^\circ \). Continue this procedure until the selected ambiguity subset is successfully fixed or empty.
The ratio values and the corresponding number of fixed ambiguities are shown in Fig. 5 for all partial AR computations except the cases of only scalar ambiguity, for which see the latter performance of improved rounding method. Both the success rate and ratio test are applied for validating the AR correctness. The bootstrapped success rate, the best lower bound of integer least squares success rate (Verhagen et al. 2013), is computed and compared with the user-defined threshold \(P_0=99.99\) %. The fixed-failure-rate ratio test (FF-RT) is applied by employing the new version of the LAMBDA software (Li et al. 2013a). Different from the ratio defined as the squared norm of the best integer solution divided by the squared norm of the second best one in the new version of LAMBDA software, its reciprocal is used in this paper such that all ratio results are larger than 1.

The ratio values (top) and the corresponding number of fixed ambiguities (bottom) for all partial AR computations. For each partial AR computation, its total number of ambiguities is shown as well
In general, the critical value of FF-RT is smaller for the float solution with the larger success rate and/or higher dimension. Since we first apply the success rate threshold \(P_0=99.99\) %, the float solutions that need the further ratio test always have the critical values of almost 1. Furthermore such critical values hold true only for the assumption that the underlying model indeed captures all systematic errors completely, i.e., no any bias exists in the float solution (Verhagen and Teunissen 2013). This ideal assumption is practically impossible. To practically improve the AR reliability, we take the critical ratio values conservatively with respect to different ambiguity dimensions as 2 for 2-dimension, 1.5 for 3/4-dimension, 1.3 for 5 to 7-dimension and 1.2 for higher than 7-dimension. Hence the ratio values of partial AR are all larger than at least 1.2 as shown on the top of Fig. 5. Most of them are within 10, but some are even several tens to hundred. The number of fixed ambiguities together with the corresponding total number of ambiguities, as shown in the bottom of Fig. 5, are very fluctuant adaptively to the underlying AR model strength. In other words, the partial AR can flexibly fix the subset of ambiguities that can be reliably fixed. As a consequence, the AR efficiency and then the RTK availability are improved.
Figure 6 shows the TTFFs of narrowlane AR for all baselines. Intuitively, the TTFF results are quite similar for all baselines because of the similar observation environment at the same time. With all TTFFs, we statistically work out its histogram and cumulative function. The result shows that 80 % ambiguities can be fixed within 80 epochs and further improved to 90 % within 110 epochs. All ambiguities can be fixed within 160 epochs.

TTFFs of narrowlane AR as a function of time (top) for all seven baselines and its corresponding histogram (bottom-left) and cumulative distribution function (bottom-right)
As aforementioned, the rounding method will be applied for fixing a scalar ambiguity. Four rounding schemes are designed and compared, of which two schemes are the widely-used FFV strategies with the thresholds (\(b_\mathrm{m}=0.2,~\sigma _\mathrm{m}=0.1\)) and (\(b_\mathrm{m}=0.4,~\sigma _\mathrm{m}=0.2\)); one is the rounding with purely controlled fail rate \(P_{f}=0.01\) %; and the other one is the proposed incorrectness controllable rounding. Their corresponding rounding regions are shown in Fig. 1. As theoretically analyzed before, the disadvantage of the FFV strategy is the difficulty of choosing thresholds. Too larger thresholds will derive the large fix rate but large failure rate as well, whereas too small thresholds can indeed control the fail rate, but will derive the small fix rate thus hindering the fixing efficiency. This theoretical analysis is indeed observed from Fig. 7 where the empirical fix rate is defined as the ratio of the number of fixed ambiguities divided by the total ambiguities, while the empirical failure rate as the ratio of the number of wrongly fixed ambiguities divided by number of fixed ambiguities.

The empirical fix rate (left) and failure rate (right) of all baselines for different rounding schemes
For FFV with (\(b_\mathrm{m}=0.2,~\sigma _\mathrm{m}=0.1\)), the fail-rate is even 0, but the fix rate is too low around 30 %, which is of course unacceptable in real applications. However the FFV with (\(b_\mathrm{m}=0.4,~\sigma _\mathrm{m}=0.2\)) can achieve as large as 93 % fix rate but its failure rate is as large as 1.6 %. This is not acceptable either for network AR, since the wrong AR will lead to the wrong solutions for all users. For the rounding with \(P_{f}=0.01\) %, the fix rate is largest (97 %) but its failure rate is largest as well (2.6 %). In principle, the computed failure rate should be consistent with \(P_{f}=0.01\) %. This discrepancy would be due to the inadequately modeled systematic errors, mostly corresponding to the two extreme situations aforementioned. That is the motivation of developing the new rounding strategy. For the new rounding method, the fix rate is slightly reduced to 89 % but the fail-rate is reduced to 0.8 %. The discrepancy of this fail-rate with the theoretical one would be attributed to the misspecification of stochastic model. Therefore, the new rounding method is promising with jointly considering the fixing efficiency and reliability.
Finally, combing the results of partial AR and rounding, the overall fix rate of narrowlane AR is shown in Table 3 for all baselines. In general, the high fix rate of narrowlane AR is obtained from the presented AR strategies. The fix rate is 88 % for fixing the ambiguities with elevations larger than \(15^\circ \), which can be improved to about 96.5 % for fixing the ambiguities with elevations larger than \(20^\circ \). One may notice in some of existing literatures, for instance, Tang et al. (2010); Chen et al. (2004), that the higher fix rate results would be obtained either for short/medium baselines or for long baselines with loosely controllable failure rate (lower reliability).
6 Concluding remarks
This paper contributed to improve the long baseline network RTK ambiguity resolution through the efficient procedures for improved float solutions and ambiguity fixing.
The ionosphere-constrained model was introduced instead of the traditional ionosphere-free model, such that the additional ionospheric constraints can be imposed to enhance the model strength and then improve the float solutions. The presented ionosphere-constrained model is flexible and can be easily either reduced to special models or extended with more parameters and constraints.
An adaptive variance estimation procedure was proposed to capture the influence of observation complexity on the reliable widelane AR. For the narrowlane AR, we advised to first apply the partial AR with ambiguity subset selected according to the successively increasing elevations. Moreover an incorrectness-controllable rounding method was introduced for the scalar ambiguity fixing.
The experiment results revealed that the new methodology generally works very well and the ambiguity fix rate is high. The presented partial AR is very flexible. It can start AR immediately once a subset of ambiguities can be reliably fixed, consequently improving the AR efficiency and RTK availability. The new rounding method is promising since it can control the failure rate rigorously. Comparing with the purely failure rate controllable rounding, the new rounding can reduce the failure rate significantly with very slight fix rate decrease.
References
Blewitt G (1989) Carrier phase ambiguity resolution for the global positioning system applied to geodetic baselines up to 2000 km. J Geophys Res 94:135–151
Bock Y, Shimada S (1989) Continuously monitoring GPS networks for deformation measurements. IAG Symp 102:40–56
Chen H, Rizos C, Han S (2004) An instantaneous ambiguity resolution procedure suitable for medium-scale GPS reference station networks. Surv Rev 37(291):396–410
Chen W, Hu C, Chen Y, Ding X (2001) Rapid static and kinematic positioning with Hong Kong GPS active network. In: ION GPS 2001, Salt Lake City, UT, pp 346–352
Chen X (1994) Analysis of continuous GPS data from the western Canada deformation array. In: ION GPS 94, pp 1339–1348
Chen X, Han S, Rizos C, Goh P (2000) Improving real time positioning efficiency using the Singapore integrated multiple reference station network (SIMRSN). In: ION GPS 2000, Salt Lake City, UT, pp 9–16
Collins J, Langley B (1997) A tropospheric delay model for the user of the wide area augmentation system. Tech. rep. no. 187, Department of Geodesy and Geomatics Engineering, University of New Brunswick
Collins P, Lahaye F, Héroux P, Bisnath S (2008) Precise point positioning with ambiguity resolution using the decoupled clock model. In: ION GNSS 2008, Fairfax, USA, pp 1315–13222
Dach R, Hugentobler U, Fridez P, Meindl M (2007) Bernese GPS software: version 5.0. Astronomical Institute, University of Bern
Dai L, Wang J, Rizos C, Han S (2003) Predicting atmospheric biases for real-time ambiguity resolution in GPS/GLONASS reference station networks. J Geod 76:617–628
Dodson AH, Shardlow PJ, Hubbard LCM, Elgered G, Jarlemark POJ (1996) Wet tropospheric effects on precise relative GPS height determination. J Geod 70:188–202
Dong D, Bock Y (1989) Global positioning system network analysis with phase ambiguity resolution applied to crustal deformation studies in California. J Geophys Res 94(B4):3949–3966
Eueler HJ, Goad CC (1991) On optimal filtering of GPS dual frequency observations without using orbit information. Bull Géod 65:130–143
Fortes LP, Cannon ME, Lachapelle G, Skone S (2003) Optimizing a network-based RTK method for OTF positioning. GPS Solut 7:61–73
Ge M, Gendt G, Dick G, Zhang F (2005) Improving carrier-phase ambiguity resolution in global GPS network solutions. J Geod 79:103–110
Geng J, Teferle FN, Meng X, Dodson AH (2011) Towards PPP-RTK: ambiguity resolution in real-time precise point positioning. Adv Space Res 47(10):1664–1673
Geng J, Shi C, Ge M, Dodson AH, Lou L, Zhao Q, Liu J (2012) Improving the estimation of fractional-cycle biases for ambiguity resolution in precise point positioning. J Geod 86(8):579–589
Goad CC, Yang M (1997) A new approach to precision airborne GPS positioning for photogrammetry. Photogramm Eng Remote Sens 63(9):1067–1077
Grejner-Brzezinska D, Kashani I, Wielgosz P, Smith D, Spencer P, Robertson D, Mader G (2007) Efficiency and reliability of ambiguity resolution in network-based real-time kinematic GPS. J Surv Eng 133(2):56–65
Han S, Rizos C (1996) GPS network design and error mitigation for real-time continuous array monitoring systems. In: ION GPS 96, Kansas City, MO, pp 1827–1836
Hu G, Khoo H, Goh P, Law C (2003) Development and assessment of GPS virtual reference stations for RTK positioning. J Geod 77:292–302
Kim D, Bisnath S, Langley R, Dare P (2004) Performance of long-baseline real-time kinematic applications by improving tropospheric delay modeling. In: ION GNSS 17th int. tech. meeting of the satellite division, Long Beach, CA, pp 1414–1422
Laurichesse D, Mercier F, Berthias JP, Bijac J (2008) Real time zero-difference ambiguities fixing and absolute RTK. In: ION national technical meeting, Fairfax, USA, pp 747–755
Li B, Teunissen PJG (2011) Array-aided CORS network ambiguity resolution. In: IAG symp, vol 139. doi:10.1007/978-3-642-37222-3_79
Li B, Shen Y, Xu P (2008) Assessment of stochastic models for GPS measurements with different types of receivers. Chin Sci Bull 53:3219–3225
Li B, Feng Y, Shen Y, Wang C (2010a) Geometry-specified troposphere decorrelation for subcentimeter real-time kinematic solutions over long baselines. J Geophys Res 115:B11,404. doi:10.1029/2010JB007549
Li B, Shen Y, Lou L (2011) Efficient estimation of variance and covariance components: a case study for GPS stochastic model evaluation. IEEE Trans Geosci Remote Sens 49(1):203–210
Li B, Shen Y, Zhang X (2012) Error probability controllable integer rounding method and its application to RTK ambiguity resolution. Acta Geod et Cat Sin 41(4):483–489 (in Chinese with English abstract)
Li B, Verhagen S, Teunissen PJG (2013a) GNSS integer ambiguity estimation and evaluation: LAMBDA and Ps-LAMBDA. In: China satellite navigation conference (CSNC) 2013 proceedings, lecture notes in electrical engineering, vol 24, Wuhan, pp 291–301
Li B, Verhagen S, Teunissen PJG (2013b) Robustness of GNSS integer ambiguity resolution in the presence of atmospheric biases. GPS Solut. doi:10.1007/s10291-013-0329-5
Li X, Zhang X, Ge M (2010b) Regional reference network augmented precise point positioning for instantaneous ambiguity resolution. J Geod 85:151–158
Li X, Ge M, Zhang H, Wickert J (2013c) A method for improving uncalibrated phase delay estimation and ambiguity-fixing in real-time precise point positioning. J Geod 87:405–416
Liu GC, Lachapelle G (2002) Ionosphere weighted GPS cycle ambiguity resolution. ION national technical meeting, San Diego, CA, pp 1–5
Liu J (2011) Next-step development of GNSS-based Continuously Operating Reference Stations (CORS) network: geoinfo-sensor-web. Geomatics Inf Sci Wuhan Univ 36(3):253–256 (in Chinese with English abstract)
Melbourne W (1985) The case for ranging in GPS-based geodetic systems. In: First international symposium on precise positioning with the global positioning system, Rockville, pp 373–386
Mervart L, Beutler G, Rothacher M, Wild U (1994) Ambiguity resolution strategies using the results of the International GPS Geodynamics Service (IGS). J Geod 68:29–38
Mervart L, Lukes Z, Rocken C, Iwabuchi T (2008) Precise point positioning with ambiguity resolution in real-time. ION GNSS 2008, Fairfax, USA, pp 397–405
Niell A (1996) Global mapping functions for the atmosphere delay at radio wavelengths. J Geophys Res 101(B2):3227–3246
Odijk D (2000) Weighting ionospheric corrections to improve fast GPS positioning over medium distances. In: ION GPS 2000, Salt Lake City, UT, pp 1113–1123
Odijk D (2003) Ionosphere-free phase combinations for modernized GPS. J Surv Eng 129(4):165–173
Odijk D, Verhagen S, Teunissen PJG (2012) Medium-distance GPS ambiguity resolution with controlled failure rate. In: IAG symp, vol 136, pp 745–751
Schaffrin B, Bock Y (1988) A unified scheme for processing GPS phase observations. Bull Géod 62:142–160
Shen Y, Li B, Xu G (2009) Simplified equivalent multiple baseline solutions with elevation-dependent weights. GPS Solut 13:165–171
Snay R, Soler T (2008) Continuously operating reference station (CORS): history, applications, and future enhancements. J Surv Eng 134(1):95–104
Tang W, Meng X, Shi C, Liu J (2010) Performance assessment of a long range reference station ambiguity resolution algorithm for network rtk GPS positioning. Surv Rev 42(316):132–146
Teunissen PJG (1995) The least-squares ambiguity decorrelation adjustment: a method for fast GPS integer ambiguity estimation. J Geod 70:65–82
Teunissen PJG (1999) An optimality property of the integer least-squares estimator. J Geod 73:587–593
Teunissen PJG (2005) Integer aperture bootstrapping: a new GNSS ambiguity estimator with controllable fail-rate. J Geod 79:389–397
Teunissen PJG, Verhagen S (2007) On GNSS ambiguity acceptance tests. In: Proc. IGNSS symp, Sydney, pp 1–13
Teunissen PJG, Odijk D, Zhang B (2010) PPP-RTK: results of CORS network-based PPP with integer ambiguity resolution. J Aeronaut Astronaut Aviat Ser A 42(4):223–230
Tralli DM, Lichten SM (1990) Stochastic estimation of tropospheric path delays in global positioning system geodetic measurements. Bull Géod 64:127–159
Verhagen S, Li B (2012) LAMBDA software package: Matlab implementation, version 3.0, Delft University of Technology and Curtin University, Perth, Australia
Verhagen S, Teunissen PJG (2013) The ratio test for future GNSS ambiguity resolution. GPS Solut 17(4):535–548
Verhagen S, Li B, Teunissen PJG (2013) Ps-LAMBDA: ambiguity success rate evaluation software for interferometric applications. Comput Geosci 54:361–376
Wabbena G, Schmitz M, Bagge A (2005) PPP-RTK: precise point positioning using state-space representation in RTK networks. In: ION GNSS 2005, Long Beach, CA, pp 2584–2594
Wielgosz P, Kashani I, Grejner-Brzezinska D (2005) Analysis of long-range network RTK during severe ionospheric storm. J Geod 79(9):524531
Wübbena G (1985) Software developments for geodetic positioning with GPS using TI-4100 code and carrier measurements. In: First international symposium on precise positioning with the global positioning system, Rockville, pp 403–412
Xu G, Yang Y, Sun H, Shen Y, Zhang Q, Guo J, Yeh TK (2007) Equivalence principle of GPS algorithms and and independent parameterisation method. In: ION GNSS 2007, Fort Worth, TX, pp 796–807
Yang Y, Xu T (2003) An adaptive kalman filter based on sage windowing weights and variance components. J Navigat 56:231–240
Yang Y, He H, Xu G (2001) Adaptively robust filtering for kinematic geodetic positioning. J Geod 75:109–116
Yang Y, Gao W, Zhang X (2010) Robust kalman filtering with constraints: a case study for integrated navigation. J Geod 84:373–381
Zhang J, Lachapelle G (2001) Precise estimation of residual tropospheric delays using a regional GPS network for real-time kinematic applications. J Geod 75:255–266
Acknowledgments
This work is supported by the National Natural Science Funds of China (41374031; 41274035; 41304024) and the State Key Laboratory of Geo-information Engineering (SKLGIE2013-M-2-2). WG is also supported by the Foundation for the Author of National Excellent Doctoral Dissertation of China (201162). The GPS datasets collected from USA CORS network were used in this study, which is acknowledged. The responsible Editor Prof. Pascal Willis and three anonymous reviewers are appreciated for their comments and suggestions.
Author information
Authors and Affiliations
Corresponding authors
Appendix
Appendix
The infinite sum over all non-zero integers is involved for computing \(P_{f}\), c.f., (23). It is, therefore, required to disregard the integers that give ignorable contribution to \(P_{f}\). Due to the symmetry of \(f_{{\hat{a}}}(x)\) with respect to 0, the analysis is based on only the positive integers. Obvious we have the inequality
for any integers \(i<j\). It is reasonable to ignore the probabilities of the integers larger than \(i_0\) if
where \(\mu \) is an extremely small value. Figure 8 shows the solved \(i_0\) as a function of \(\sigma _{{\hat{a}}}\) for different \(\mu \). It generally needs to take several integers into accounts.

The number of integers taken into account for computing the fail rate \(P_{f}\) as a function of the float ambiguity precision \(\sigma _{{\hat{a}}}\) with different errors \(\mu \)
Rights and permissions
About this article
Cite this article
Li, B., Shen, Y., Feng, Y. et al. GNSS ambiguity resolution with controllable failure rate for long baseline network RTK. J Geod 88, 99–112 (2014). https://doi.org/10.1007/s00190-013-0670-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00190-013-0670-z