
Abstract
In this paper, we investigate the skewness of order statistics stemming from multiple-outlier proportional hazard rates samples in the sense of several variability orderings such as the star order, Lorenz order and dispersive order. It is shown that the more heterogeneity among the multiple-outlier components will lead to a more skewed lifetime of a k-out-of-n system consisting of these components. The results established here generalize the corresponding ones in Kochar and Xu (J Appl Probab 48:271–284, 2011, Ann Oper Res 212:127–138, 2014). Some numerical examples are also provided to illustrate the theoretical results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Order statistics play an important role in many areas such as reliability, data analysis, goodness-of-fit tests, outliers, robustness and quality control. Let \(X_1,\ldots ,X_n\) be independent random variables having possibly different distributions. Denote by \(X_{1:n}\le \cdots \le X_{n:n}\) the order statistics arising from \(X_i\)’s, \(i=1,\ldots ,n\). In the reliability context, it is well known that \(X_{k:n}\) denotes the lifetime of a \((n-k+1)\)-out-of-n system, and \(X_{n:n}\) and \(X_{1:n}\), respectively, denote the lifetimes of two particular systems called parallel and series systems. For the applications of order statistics in reliability, one may refer to Barlow and Proschan (1981) and Balakrishnan and Balakrishnan and Rao (1998a, b).
Because of the nice mathematical form and the unique memoryless property, the exponential distribution has widely been used in many fields including reliability analysis. One may refer to Balakrishnan and Basu (1995), for an encyclopedic treatment to developments on the exponential distribution. Pledger and Proschan (1971), for the first time, studied the ordering properties of the order statistics arising from two sets of heterogeneous exponential samples. After that, many researchers devoted themselves to conducting the comparisons on the order statistics from different aspects. For more details, the readers are referred to Proschan and Sethuraman (1976), Kochar (1996), Khaledi and Kochar (2000), Lillo et al. (2001), Pǎltǎnea (2008), Zhao et al. (2009), Balakrishnan and Zhao (2013), Torrado and Lillo (2013) and the references therein.
In addition to measuring the length of lifetimes of k-out-of-n system in the sense of magnitude stochastic orders, it would be also great interest of evaluating the degree of variation of lifetimes. For instance, the star and Lorenz orders (formal definitions of various stochastic orders will be given in Sect. 2), which have also been widely used in insurance, reliability theory and economics, serves as very useful tools for comparing variability between two distributions. Let \(X_i\)’s be independent exponential random variables with hazard rates \(\lambda _{1}\) for \(i=1,\ldots ,p\), and \(\lambda _{2}\) for \(i=p+1,\ldots ,n\), respectively, and let \(X_i^{*}\)’s be independent exponential random variables with hazard rates \(\lambda _{1}^{*}\) for \(i=1,\ldots ,p\), and \(\lambda _{2}^{*}\) for \(i=p+1,\ldots ,n\), respectively. Kochar and Xu (2011) showed that
where ‘\(\ge _{\star }\)’ denotes the star order, \(\lambda _{(1)}=\min \{\lambda _{1},\lambda _{2}\}\) and \(\lambda _{(2)}=\max \{\lambda _{1},\lambda _{2}\}\). In this regard, Da et al. (2014) proved that, without any restriction on the parameters, the variability of order statistics from heterogeneous exponential samples is always larger than that from homogeneous exponential samples in the sense of the Lorenz order.
Independent random variables \(X_1,\ldots , X_n\) are said to follow proportional hazard rates (PHR) model if, for \(i = 1,\ldots ,n\), the survival function of \(X_i\) can be written as \( {\overline{F}}_i(x)=[ {\overline{F}}(x)]^{\lambda _{i}}\), where \( {\overline{F}}(x)\) is the survival function of some underlying random variable X. Let \({r(\cdot )}\) be the hazard rate function of the baseline distribution F. Then, the survival function of \(X_i\) can be written as
for \(i = 1,\ldots ,n\), where \(R(x) =\int _{0}^{x}r(t)\mathrm {d}t\) is the cumulative hazard rate function of X. Many well-known models are special cases of the PHR model such as exponential, Weibull, Pareto, and Lomax et al. In many situations, the results established for exponential case can be generalized to the PHR model. However, the result in (1) cannot be extended to the PHR case directly due to the fact that the scale invariant property of the star order fails to be used for the PHR model. Motivated by this, we would like to find some sufficient conditions for the star order to hold under the PHR framework. It is worth mentioning here that Kochar and Xu (2014) showed that, under some mild conditions, the largest order statistics from heterogeneous PHR samples is larger than that from the homogeneous PHR samples according to the star order. Besides, they also obtained a general result stating that the k-th order statistics from multiple-outlier PHR samples is more skewed than that from the homogeneous PHR samples in the sense of the star order under the assumption that the common hazard rate for the homogeneous sample is greater than the geometric mean of the hazard rates in the multiple-outlier PHR samples.
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q) \), where \(p\ge 1, p+q=n\ge 2\) and the entries of both \(\mathbf{1}_p\) and \(\mathbf{1}_q\) are all ones. Let \(X_1^*,\ldots ,X_n^*\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\). Denote by \(X_{k:n}(p,q)\) and \(X_{k:n}^*(p,q)\) the corresponding k-th order statistics arising from the two sets of multiple-outlier PHR models, respectively. In this paper, we prove that, under a mild condition on the baseline distribution function,
and
Besides, a weaker condition is also given for comparing the largest order statistics by means of the star order, that is
We also present an interesting result for the k-th order statistics in terms of the dispersive order
The remainder of the paper is organized as follows. Section 2 introduces some pertinent definitions of stochastic orders and majorization orders. The main results are given in Sect. 3. Section 4 presents some discussions concluding this paper.
2 Preliminaries
Throughout this paper, increasing and decreasing mean nondecreasing and nonincreasing, respectively, and let \(\mathfrak {R}=(-\infty ,+\infty )\) and \(\mathfrak {R}^{+}=[0,+\infty )\). Before proceeding to the main results, we will review some notions used in the sequel.
Definition 2.1
Let X and Y be two absolute continuous random variables with distribution functions F and G; survival functions \(\overline{F}\) and \(\overline{G}\); and density functions f and g; respectively.
-
X is said to be larger than Y in the usual stochastic order (denoted by \(X\ge _{st} Y\)) if \(\overline{F}(x) \ge \overline{G}(x)\) for all x.
-
X is said to be larger than Y in the dispersive order (denoted by \(X\ge _{disp} Y\)) if
$$\begin{aligned} F^{-1}(v)-F^{-1}(u)\ge G^{-1}(v)-G^{-1}(u), \end{aligned}$$for \(0\le u\le v\le 1\), where \(F^{-1}\) and \(G^{-1}\) are the right continuous inverses of the distribution functions F and G of X and Y, respectively.
-
X is said to be larger than Y in the star order (denoted by \(X\ge _{\star }Y\)) if \(F^{-1}[G(x)]\) is star-shaped in the sense that \(F^{-1}[G(x)]/x\) is increasing in x on the support of X, where \(F^{-1}\) is the right continuous inverse of the distribution function F of X.
-
X is said to be larger than Y in the Lorenz order (denoted by \(X\ge _\mathrm{Lorenz}Y\)) if \(L_X(p)\le L_Y(p)\) for all \(p\in [0,1]\), where the Lorenz curve \(L_X\), corresponding to X, is defined as
$$\begin{aligned} L_X(p)=\frac{\int _0^{p}F^{-1}(u)\mathrm {d}u}{\mu _X}, \end{aligned}$$and \(\mu _X\) is the mean of X.
The star order is also called the more IFRA (increasing failure rate in average) in reliability theory and is one of the partial orders which are scale invariant. The Lorenz order can be used in economics to measure the inequality of incomes. It is known that
where \(CV(X)=\sqrt{Var(X)}/E(X)\) denotes the coefficient of variation of X. For more details, one may refer to Shaked and Shanthikumar (2007).
One of the useful tools in deriving various inequalities in statistics and probability is the notion of majorization.
Definition 2.2
Let \(x_{(1)}\le \cdots \le x_{(n)}\) be an increasing arrangement of the components of the vector \(\mathbf{{x}}=(x_1,\ldots ,x_n)\).
-
A vector \(\mathbf{{x}}\) in \(\mathcal {R}^{n}\) is said to be majorize the vector \(\mathbf{{y}}\) also in \(\mathcal {R}^{n}\) (written \(\mathbf{{x}}\mathop {\succeq }\limits ^\mathrm{m} \mathbf{{y}}\)) if \(\sum _{i=1}^jx_{(i)}\le \sum _{i=1}^j y_{(i)}\) for \(j=1,\ldots ,n-1\) and \(\sum _{i=1}^nx_{(i)}= \sum _{i=1}^n y_{(i)}\).
-
A vector \(\mathbf{{x}}\in \mathcal {R}^n\) is said to be weakly majorize another vector \(\mathbf{{y}}\) also in \(\mathcal {R}^{n}\) (written \(\mathbf{{x}}\mathop {\succeq }\limits ^\mathrm{w} \mathbf{{y}}\)) if \(\sum _{i=1}^jx_{(i)}\le \sum _{i=1}^j y_{(i)}\) for \(j=1,\ldots ,n\).
-
A vector \(\mathbf{{x}}\) in \(\mathcal {R}^{+n}\) is said to be p-larger than another vector \(\mathbf{{y}}\) also in \(\mathcal {R}^{+n}\) (written \(\mathbf{{x}}\mathop {\succeq }\limits ^\mathrm{p} \mathbf{{y}}\)) if \(\prod _{i=1}^j x_{(i)}\le \prod _{i=1}^j y_{(i)}\), for \(j=1,\ldots ,n\).
Khaledi and Kochar (2002) showed that \(\mathbf{{x}}\mathop {\succeq }\limits ^\mathrm{m} \mathbf{{y}}\) implies \(\mathbf{{x}}\mathop {\succeq }\limits ^\mathrm{p} \mathbf{{y}}\) for \(\mathbf{{x}}, \mathbf{{y}} \in \mathcal {R}^{+n}\). The converse is, however, not true. For example, \((0.2, 1, 5)\mathop {\succeq }\limits ^\mathrm{p} (1,2, 3)\), but clearly the majorization order does not hold. Also, \(\mathbf{{x}}\mathop {\succeq }\limits ^\mathrm{p} \mathbf{{y}}\) is equivalent to \({\log (\mathbf{{x}})\mathop {\succeq }\limits ^\mathrm{w} \log (\mathbf{{y}})}\) where \(\log (\mathbf{{x}})\) is the vector of logarithms of the coordinates of \(\mathbf{{x}}\). For any vectors \(\mathbf{{x}}\) and \(\mathbf{{y}}\) in \(\mathcal {R}^{+n}\), the following implications always hold
Details discussions on majorization, p-larger orders, Schur-convex(concave) functions and their applications may be found in Marshall et al. (2011), Bon and Pǎltǎnea (1999), and Khaledi and Kochar (2002).
3 Main results
In this section, we will present some comparison results on order statistics arising from multiple-outlier PHR models according to the star order, Lorenz order and dispersive order.
We firstly recall the definition of permanents and introduce some useful notation, which are the key tool to proving the main results of this section. It is useful to represent the joint density functions of order statistics by using the theory of permanents when the underlying random variables are not identical. If \(\mathbf{{A}}=\{a\}_{i,j}\) is an \(n\times n\) matrix, then the permanent of \(\mathbf{{A}}\) is defined as
where the summation is over all permutations \(\pi =(\pi (1),\ldots , \pi (n))\) of \(\{1,\ldots ,n\}\). We will denote the permanent of the \(n\times n\) matrix \(\begin{pmatrix} v_1,\ldots , v_n \end{pmatrix}\) by just \([v_1,\ldots , v_n]\). If \(\mathbf{{v}}_1,\mathbf{{v}}_2,\ldots \) are column random vectors on \(\mathcal {R}^n\), then the permanent
is obtained by taking \(r_1\) copies of \(\mathbf{{v}}_1, r_2\) copies of \(\mathbf{{v}}_1\) and so on. If \(r_i\) equals 1, then we omit it in the notation above. For more details on permanents, we refer the readers to Bapat and Beg (1989), and an excellent monograph by Balakrishnan (2007). Let us define for \(\underline{\lambda }=(\lambda , \lambda ^*)\) and for each pair (p, q),
and
where \(\overline{F}_{\lambda }(x)=e^{-\lambda R(x)}\) and \(\overline{F}_{\lambda ^*}(x)=e^{-\lambda ^* R(x)}\).
The following two lemmas are also needed in the proof of the main results.
Lemma 3.1
(Saunders and Moran 1978, p. 429) Let \(\{F_\lambda |\lambda \in R\}\) be a class of distribution functions, such that \(F_\lambda \) is supported on some interval \((a, b)\subseteq (0,\infty )\) and has a density \(f_\lambda \) which does not vanish on any subinterval of (a, b). Then,
if and only if
where \(F'_\lambda \) is the derivative of \(F_\lambda \) with respect to \(\lambda \).
Lemma 3.2
(Zhao and Zhang 2012) For all \(x\ge 0\), the function
-
(i)
\(\frac{x}{1-e^{-x}}\) is increasing in \(x\ge 0\);
-
(ii)
\(\frac{xe^{-x}}{1-e^{-x}}\) is decreasing in \(x\ge 0\).
We first present a preliminary result that will be helpful for proving the subsequent results.
Theorem 3.3
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda \mathbf{1}_q)\), and let \(X^*_1,\ldots ,X^*_n\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda \mathbf{1}_q)\), where \(p\ge 1\) and \(p+q=n\ge 2\). If \(\lambda _{1}\le \lambda _{1}^{*}\le \lambda \) and
then
Proof
Assume that \(b=\lambda -\lambda _{1}\) and \(b^{*}=\lambda -\lambda _{1}^{*}\). It can be seen that \(b\ge b^{*}\) due to \(\lambda _{1}\le \lambda _{1}^{*}\). Let \(f_{k,n,b}(x)\) be the density function of \(F_{k,n,b}(x)\), and \(F_{k,n,b}^{\prime }(x)\) be the partial derivative of \(F_{k,n,b}(x)\) with respect to b. Consequently, according to Lemma 3.1, it suffices to prove that
The distribution of \(X_{k:n}(p,q)\) can be written as
with its density function as
Note that, from the proof of Case 1 of Theorem 3.1 in Kochar and Xu (2011), we have
Thus, it follows that
and it is enough to show that the function
is increasing in \(x\in \mathfrak {R}^{+}\) for \(b\in [0,\lambda )\).
By Laplace expansion along the first \(k-1\) columns of the permanent, then
where
and
Then, it suffices to prove that
is \(RR_{2}\) in \((x,l)\in \mathfrak {R}^{+}\times \{0,1\}\). Firstly, we can observe that \(\phi (x,b)\) is increasing in \(x\in \mathfrak {R}^{+}\) for \(b\ge 0\), and hence \(\phi ^{i}(x,b)\) is \(TP_{2}\) in \((x,i)\in \mathfrak {R}^{+}\times \mathbb {I}\). Secondly, we can obtain that
is \(RR_{2}\) in \(i\times l\in \mathbb {I}\times \{0,1\}\). Thus, using the basic composition formula of Karlin (1968), the required result follows. This completes the proof. \(\square \)
It should be pointed out that, the condition of Theorem 3.1 in Kochar and Xu (2011) is quite general, which includes many special cases. The proof of following result is quite similar to that of Theorem 3.1 in Kochar and Xu (2011) and thus we omit it.
Theorem 3.4
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q)\) and let \(X^*_1,\ldots ,X^*_n\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\) where \(p\ge 1\) and \(p+q=n\ge 2\) . If
then
Upon using Theorems 3.3 and 3.4, we can get the following more general result. It means that for the multiple-outlier PHR model, more heterogeneity among the parameters leads to more skewed order statistics in the sense of the star order.
Theorem 3.5
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q)\) and let \(X^*_1,\ldots ,X^*_n\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\) where \(p\ge 1\) and \(p+q=n\ge 2\) . If \(\lambda _1\le \lambda _1^*\le \lambda _2^*\le \lambda _2\) and
then
Proof
From the definition of the weak majorization order, we have \(\lambda _{1}+\lambda _{2}\le \lambda _{1}^{*}+\lambda _{2}^{*}.\) The result for the case \(\lambda _{1}+\lambda _{2}=\lambda _{1}^{*}+\lambda _{2}^{*}\) follows from Theorem 3.4. For the case \(\lambda _{1}+\lambda _{2}<\lambda _{1}^{*}+\lambda _{2}^{*}\), we set \(\lambda _{1}^{\prime }=\lambda _{1}^{*}+\lambda _{2}^{*}-\lambda _{2}\). Therefore,
Now, suppose that \(Z_{1}\),...,\(Z_{p}\) are independent random variables with a common survival function \(\overline{F}^{\lambda ^{\prime }_{1}}(x)\), and \(Z_{p+1}\),...,\(Z_{n}\) are another set of independent random variables with a common survival function \(\overline{F}^{\lambda _{2}}(x)\). It follows from Theorem 3.4 that
Also, from Theorem 3.3 it follows that
Therefore, we obtain the desired result that
The proof is completed. \(\square \)
We now provide a counterexample to illustrate that the condition \(\lambda _1\le \lambda _1^*\le \lambda _2^*\le \lambda _2\) cannot be dropped out in Theorem 3.5.
Example 3.6
Set \(p=q=1, \lambda _{1}=0.2, \lambda _{2}=0.6, \lambda _{1}^{*}=0.3\) and \(\lambda _{2}^{*}=1.1\) in Theorem 3.5. Let \(R(x)=x\), which stands for the exponential case. It is easy to check that \((\lambda _{1},\lambda _{2})\mathop {\succeq }\limits ^\mathrm{w}(\lambda ^{*}_{1},\lambda ^{*}_{2})\) but \(\lambda _1\le \lambda _1^*\le \lambda _2\le \lambda _2^*\). Through some regular calculations, the coefficient of variation of \(X_{2:2}(1,1)\) is 0.88712, and the coefficient of variation of \(X_{2:2}^{*}(1,1)\) is 0.914357, which implies that \(X_{2:2}(1,1)\ngeq _{\star }X_{2:2}^{*}(1,1)\).
The following result follows from Theorem 3.5 for the Lorenz order.
Corollary 3.7
Under the setup of Theorem 3.5, it holds that
Next, we will give an example to illustrate the result established in Theorem 3.5. Let X be a random variable from Lomax distribution \(L(\lambda , b)\) with survival function
where \(b>0\) and \(\lambda >0\) are called the scale and shape parameters, respectively. It is known that \(\frac{R(x)}{xh(x)}=\frac{b+x}{x}\log (1+\frac{x}{b})\), for any \(b>0\), is increasing in x [cf. Kochar and Xu 2014, Sect. 4].

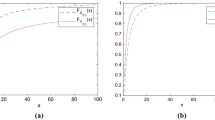
Density functions of \(X_{2:3}(1,2)\) and \(X^*_{2:3}(1,2)\)
Example 3.8
Let \((X_1,X_2,X_3)\) be independent random vector from Lomax distribution with shape parameters \((\lambda _1,\lambda _2,\lambda _2)=(3,6,6)\) and common scale parameter 1. Let \((X_1^*,X_2^*,X_3^*)\) be another set of independent Lomax random vector with shape parameters \((\lambda _1^*,\lambda _2^*,\lambda _2^*)=(4,5,5)\) and common scale parameter 1. It is easy to see that \((3,6)\mathop {\succeq }\limits ^\mathrm{w}(4,5)\) but \((3,6,6)\mathop {\nsucceq }\limits ^\mathrm{w}(4,5,5)\). Figure 1 plots the density functions of \(X_{2:3}(1,2)\) and \(X_{2:3}^{*}(1,2)\). Clearly, we can observe that \(X_{2:3}(1,2)\) is more skewed than \(X_{2:3}^{*}(1,2)\). By using Mathematica, the mean of \(X_{2:3}(1,2)\) can be computed that
The variance can be calculated as
Therefore the coefficient of variation \(X_{2:3}(1,2)\) is
Similarly, it is easy to check that the coefficient of variation \(X^*_{2:3}(1,2)\) is
which means that
Next, we will present another sufficient condition on the parameter vectors which ensures the star order to hold for the corresponding order statistics stemming from multiple-outlier PHR models.
Lemma 3.9
(Kochar and Xu 2014) Let \(\phi \) be a differentiable star-shaped function on \([0,\infty )\) such that \(\phi (x)\ge x\) for all \(x\ge 0\). Let \(\psi \) be an increasing differentiable function such that
Then, the function
Theorem 3.10
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q)\), and let \(X^*_1,\ldots ,X^*_n\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\), where \(p\ge 1\) and \(p+q=n\ge 2\). If
then
Proof
Since R(x) is increasing and \(R^{-1}(x)= {\overline{F}}^{-1}(e^{-x})\), we have, for \(x\ge 0, i=1,\ldots ,n\),
By making the transformation \(X'_{i}=R(X_{i}), i=1,\ldots ,n\), we know that \(X'_{i}\) is exponential with hazard rate \(\lambda _{1}\) for \(i=1,\ldots ,p\), and \(\lambda _{2}\) for \(i=p+1,\ldots ,n\). Similarly, let \(Y'_{i}=R(X_{i}^{*})\) be exponential with hazard rate \(\lambda _{1}^{*}\) for \(i=1,\ldots ,p\), and \(\lambda _{2}^{*}\) for \(i=p+1,\ldots ,n\). Observe that
it holds that
where \(G'_{k:n}(\cdot ), F'_{k:n}(\cdot )\) are distribution functions of \(Y'_{k:n}\) and \(X'_{k:n}\). By the definition of the star order, it suffices prove that
By Theorem 3.1 of Kochar and Xu (2011), \(F'^{-1}_{k:n}G'_{k:n}(x)\) is star-shaped on \([0,\infty )\). According to Pledger and Proschan (1971), it follows that \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q) \mathop {\succeq }\limits ^\mathrm{m} (\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\) implies
Based on Lemma 3.9, it is enough to show
which is equivalent to
Hence, the desired result follows immediately. \(\square \)
We also have the following more general result and we omit the proof here because it is quite similar to that of Theorem 3.5.
Theorem 3.11
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q)\) and let \(X^*_1,\ldots ,X^*_n\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\) where \(p\ge 1\) and \(p+q=n\ge 2\) . If \(\lambda _1\le \lambda _1^*\le \lambda _2^*\le \lambda _2\) and
then
Corollary 3.12
Under the same setup of Theorem 3.11, it follows that
Now, we will provide a numerical example to illustrate the result established in Theorem 3.11. Let X be a random variable from Pareto distribution \(Pa(\lambda , b)\) with survival function
where \(b>0\) and \(\lambda >0\) are called the scale and shape parameters, respectively. It is known that \(\frac{R(x)}{xh(x)}=\log (\frac{x}{b}), x\ge b>0\), is increasing in x [cf. Kochar and Xu (2014), Sect. 4].

Density functions of \(X_{4:5}(3,2)\) and \(X^*_{4:5}(3,2)\)
Example 3.13
Let \((X_1,X_2,X_3,X_4,X_5)\) be independent random vector from Pareto distribution with shape parameters \((\lambda _1,\lambda _1,\lambda _1,\lambda _2,\lambda _2)=(3,3,3,6.2,6.2)\) and common scale parameter 1. Let \((X_1^*,X_2^*,X_3^*,X_4^*,X_5^*)\) be another independent Pareto random vector with shape parameters \((\lambda _1^*,\lambda _1^*,\lambda _1^*,\lambda _2^*,\lambda _2^*) =(4,4,4,5,5)\) and common scale parameter 1. It is easy to see that \((3,3,3,6.2,6.2)\mathop {\succeq }\limits ^\mathrm{w}(4,4,4,5,5)\) but \((3,6.2)\mathop {\nsucceq }\limits ^\mathrm{w}(4,5)\). Figure 2 plots the density functions of \(X_{4:5}(3,2)\) and \(X_{4:5}^{*}(3,2)\). Clearly, we can observe that \(X_{4:5}(3,2)\) is more skewed than \(X_{4:5}^{*}(3,2)\). By using Mathematica, the mean of \(X_{4:5}(3,2)\) can be computed that
The variance can be calculated as
Therefore the coefficient of variation \(X_{4:5}(3,2)\) is
Similarly, it is easy to check that the coefficient of variation \(X^*_{4:5}(3,2)\) is given by
which means that
Next, a result for the dispersive order is presented when the parameter vectors majorize each other.
Theorem 3.14
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q)\), and let \(X^*_1,\ldots ,X^*_n\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\), where \(p\ge 1\) and \(p+q=n\ge 2\). If
then
Proof
From Pledger and Proschan (1971), it follows that \(X_{k:n}(p,q)\ge _\mathrm{st} X_{k:n}^*(p,q)\). On the other hand, for two continuous random X and Y, if \(X \le _{\star }Y\) , then \(X \le _\mathrm{st} Y \Rightarrow X \le _\mathrm{disp}Y\) (see Ahmed et al. 1986). We now can conclude that, \(X_{k:n}(p,q)\ge _\mathrm{disp} X_{k:n}^*(p,q)\). \(\square \)
In the next theorem, we partially improve the result in Theorem 3.11 for the case of \(k=n\).
Theorem 3.15
Let \(X_1,\ldots ,X_n\) be independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1\mathbf{1}_p,\lambda _2\mathbf{1}_q)\), and let \(X^*_1,\ldots ,X^*_n\) be another set of independent random variables following the multiple-outlier PHR model with parameters \((\lambda _1^*\mathbf{1}_p,\lambda _2^*\mathbf{1}_q)\), where \(p\ge 1\) and \(p+q=n\ge 2\). If \(\lambda _1\le \lambda _1^*\le \lambda _2^*\le \lambda _2\) and
then
Proof
The proof is proceeded by dividing into the following two cases.
Case 1 \({\lambda _1^p\lambda _2^q=(\lambda ^*_1)^p(\lambda ^*_2)^q}\). Denote \(t_1=\log \lambda _1, t_2=\log \lambda _2, t_1^*=\log \lambda _1^*\) and \(t_2^*=\log \lambda _2^*\). From the assumption, we observe that \(t_1\le t_1^*\le t_2^*\le t_2\). Then from these observations, it can be seen that \((t_1\mathbf{1}_p,t_2\mathbf{1}_q) \mathop {\succeq }\limits ^\mathrm{m}(t^*_1\mathbf{1}_p,t_2^*\mathbf{1}_q)\). Therefore, without loss of generality, let \(pt_1+qt_2=pt_1^*+qt_2^*=1\). Now, we set \(t_2=t\) and \(t_2^*=t^*\). Thus, it can be seen that \(t\ge t^*\) and \(t_1=\frac{1-qt}{p}\le t\). Let \(f_{t, n:n}(x)\) be the density function of \(F_{t, n:n}(x)\), and \(F_{t, n:n}^{\prime }(x)\) be the partial derivative of \(F_{t, n:n}(x)\) with respect to t. According to Lemma 3.1, it is enough to show that
The distribution function \(X_{n:n}(p,q)\) can be written as
where \(\xi (t)=e^{\frac{1-qt}{p}}\), and the density function \(X_{n:n}(p,q)\) also is given by
Taking the derivative of \(F_{t, n:n}(x)\) with respect to t leads to
By using the above observations, it follows that
Therefore, it is enough to show that the ratio function (2) is increasing in x. Note that, from Lemma 3.2 and the fact that \(\xi (t)\le e^t\), it can be seen that the second part of (2) is positive. Since \(\frac{R(x)}{xh(x)}\) is increasing in x, it is enough to prove that the positive function
is increasing in x, where \(\Lambda _2(x)=\frac{\xi (t)e^{-\xi (t) R(x)}}{1-e^{-\xi (t) R(x)}}[\frac{ e^te^{-e^t R(x)}}{1-e^{-e^t R(x)}}]^{-1}\). We observe that last equation is increasing in x if and only if \(\Lambda _2(x)\) is increasing in x. Taking derivative of \(\Lambda _2(x)\) with respect to x, we have

Now, assume that \(\xi (t)R(x)=y_1\) and \(e^t R(x)=y_2\). Since \(0\le \xi (t)\le e^t\), we have \(0\le y_1\le y_2\). So, it follows that
where the above inequality follows from Lemma 3.2. This completes the proof of the Case 1.
Case 2 \({\lambda _1^p\lambda _2^q<(\lambda ^*_1)^p(\lambda ^*_2)^q}\). In this case, there exists some \(\theta \) such that \(\lambda _1\le \theta \) and \(\theta ^p\lambda _2^q=(\lambda ^*_1)^p(\lambda ^*_2)^q\). Without loss of generality, assume \(\theta \le \lambda _2\) and \(\lambda _1^*\le \lambda _2^*\). As a result, we find that it is enough to prove the result under the following condition:
Now, let \(Z_1,\ldots ,Z_n\) be independent random variables from PHR model with \(Z_i, i=1,\ldots ,p\) having common parameters \((\theta _1\mathbf{1}_p)\) and \(Z_i, i=p+1,\ldots ,n\) having common parameters \((\lambda _2\mathbf{1}_q)\) where \(p\ge 1\) and \(p+q=n\ge 2\). By using the result of Case 1, it follows that
Next, from the assumption, we observe that \(\lambda _2\ge \theta \ge \lambda _1\), and it is enough to prove that \( X_{n:n}(p,q)\ge _{\star }Z_{n:n}(p,q)\). Using Theorem 3.3, we have
Combining (3) and (4) we reach the desired result that \(X_{n:n}(p,q)\ge _{\star }X^*_{n:n}(p,q)\). This completes the proof of the Case 2. \(\square \)
Remark 3.16
One may wonder that whether the result in Theorem 3.15 holds for the minimum order statistics. To answer this, we just imitate the proof of case 1 of Theorem 3.15. Let \(t_{1}=t\) and \(t_{1}^{*}=t^{*}\) in case 1. Then, we have \(t\le t^{*}\). Note that, for \(t\in (0,\frac{1}{p+q}]\),
is decreasing in \(x\in \mathfrak {R}^{+}\) for \(t\in (0,\frac{1}{p+q}]\). Thus, by Lemma 3.1, it can be concluded that, under the condition \((\log \lambda _1\mathbf{1}_p,\log \lambda _2\mathbf{1}_q)\mathop {\succeq }\limits ^\mathrm{m}(\log \lambda _1^*\mathbf{1}_p,\log \lambda _2^*\mathbf{1}_q)\) and other assumptions in Theorem 3.15, \(X_{1:n}(p,q)\le _{\star }X_{1:n}^{*}(p,q)\).
Since the star order implies the Lorenz order, we have the following result.
Corollary 3.17
Under the setup of Theorem 3.15, it holds that
Finally, we present an example where the lifetimes of parallel systems arising from two set of independent heterogeneous Weibull random variables are compared in the terms of the star order. Let X be a random variable from Weibull distribution \(W(\alpha , b)\) with survival function
where b and \(\alpha \) are called the scale and shape parameters, respectively. It is known that \(\frac{R(x)}{xh(x)}=\frac{1}{\alpha }\), is increasing in x (cf. Kochar and Xu 2014, Sect. 4).

Density functions of \(X_{3:3}(2,1)\) it and \(X^*_{3:3}(2,1)\)
Example 3.18
Let \((X_1,X_2,X_3)\) be independent Weibull random vector with scale parameters \((b_1,b_1,b_2)=(2,2,7)\) and common shape parameter 2. Let \((X_1^*,X_2^*,X_3^*)\) be another independent Weibull random vector with scale parameters \((b_1^*,b_1^*,b_2^*)=(3,3,5)\) and common shape parameter 2. Note that, \(\lambda _i=b_i^\alpha \). It is easy to see that, \((2^2,2^2,7^2)\mathop {\succeq }\limits ^\mathrm{p}(3^2,3^2,5^2)\) but \((2^2,7^2)\mathop {\nsucceq }\limits ^\mathrm{w}(3^2,5^2), (2^2,2^2,7^2)\mathop {\nsucceq }\limits ^\mathrm{w}(3^2,3^2,5^2)\). Figure 3 plots the density functions of \(X_{3:3}(2,1)\) and \(X^*_{3:3}(2,1)\). Therefore, it can be seen that the density function of \(X_{3:3}(2,1)\) is more skewed than that of \(X^*_{3:3}(2,1)\) which coincides with Theorem 3.15. Using Mathematica, the mean of \(X_{3:3}(2,1)\) can be computed that
The variance of the largest order statistics can be calculated as
Therefore the coefficien of variation \(X_{3:3}(2,1)\) is
Similarly, it is easy to check that the coefficient of variation \(X^*_{3:3}(2,1)\) is
which means that
4 Discussions
This work presents some new results for comparing the k-out-of-n systems consisting of multiple-outlier PHR components in the sense of the star, Lorenz and dispersive orders. It is demonstrated that the more heterogeneity among the multiple-outlier components will lead to a more skewed lifetime of the k-out-of-n system consisting of these components. Some explicit numerical examples are also provided to illustrate the established results.
Khaledi et al. (2011) have studied some ordering properties of parallel and series systems consisting of heterogeneous scale components. They provided some majorization-type sufficient conditions on the parameter vectors for the hazard rate and reversed hazard rate orders between the lifetimes of the series and parallel systems, respectively. Therefore, a generalization of the present work to the case of parallel and series systems with heterogeneous components under the scale model framework will be of interest. We are currently working on this problem and hope to report these findings in a future paper.
References
Ahmed AN, Alzaid A, Bartoszewicz J, Kochar SC (1986) Dispersive and superadditive ordering. Adv Appl Probab 18:1019–1022
Balakrishnan N (2007) Permanents, order statistics, outliers, and robustness. Rev Mat Complut 20:7–107
Balakrishnan N, Basu AP (1995) The exponential distribution: theory methods and applications. Gordon and Breach, NewYork, New Jersey
Balakrishnan N, Rao CR (1998a) Handbook of statistics. Order statistics: theory and methods, vol 16. Elsevier, Amsterdam
Balakrishnan N, Rao CR (1998b) Handbook of statistics. Order statistics: applications, vol 17. Elsevier, Amsterdam
Balakrishnan N, Zhao P (2013) Hazard rate comparison of parallel systems with heterogeneous gamma components. J Multivar Anal 113:153–160
Bapat RB, Beg MI (1989) Order statistics for nonidentically distributed variables and permanents. Sankhyā Indian J Stat Ser A 51:79–93
Barlow R, Proschan F (1981) Statistical theory of reliability and life testing, Silver Spring, MD:Madison
Bon JL, Pǎltǎnea E (1999) Ordering properties of convolutions of exponential random variables. Lifetime Data Anal 5:185–192
Da G, Xu M, Balakrishnan N (2014) On the Lorenz ordering of order statistics from exponential populations and some applications. J Multivar Anal 127:88–97
Karlin S (1968) Total positivity, vol I. Stanford University Press, Stanford, CA
Khaledi BE, Farsinezhad S, Kochar SC (2011) Stochastic comparisons of order statistics in the scale model. J Stat Plan Inference 141:276–286
Khaledi BE, Kochar SC (2000) Some new results on stochastic comparisons of parallel systems. J Appl Probab 37:283–291
Khaledi BE, Kochar SC (2002) Stochastic orderings among order statistics and sample spacings. In: Misra JC (ed) Uncertainty and optimality: probability, statistics and operations research. World Scientific Publications, Singapore, pp 167–203
Kochar SC (1996) Dispersive ordering of order statistics. Stat Probab Lett 27:271–274
Kochar SC, Xu M (2011) On the skewness of order statistics in the multiple-outlier models. J Appl Probab 48:271–284
Kochar SC, Xu M (2014) On the skewness of order statistics with applications. Ann Oper Res 212:127–138
Lillo RE, Nanda AK, Shaked M (2001) Preservation of some likelihood ratio stochastic orders by order statistics. Stat Probab Lett 51:111–119
Marshall AW, Olkin I, Arnold BC (2011) Inequalities: theory of majorization and its applications, 2nd edn. Springer, New York
Pǎltǎnea E (2008) On the comparison in hazard rate ordering of fail-safe systems. J Stat Plan Inference 138:1993–1997
Pledger P, Proschan F (1971) Comparisons of order statistics and of spacings from heterogeneous distributions. In: Rustagi JS (ed) Optim Methods Stat. Academic Press, New York, NY, pp 89–113
Proschan F, Sethuraman J (1976) Stochastic comparisons of order statistics from heterogeneous populations, with applications in reliability. J Multivar Anal 6:608–616
Saunders IW, Moran PA (1978) On the quantiles of the gamma and F distributions. J Appl Probab 15:426–432
Shaked M, Shanthikumar JG (2007) Stochastic orders. Springer, New York
Torrado N, Lillo RE (2013) Likelihood ratio order of spacings from two heterogeneous samples. J Multivar Anal 114:338–348
Zhao P, Li X, Balakrishnan N (2009) Likelihood ratio order of the second order statistic from independent heterogeneous exponential random variables. J Multivar Anal 100:952–962
Zhao P, Zhang Y (2012) On sample ranges in multiple-outlier models. J Multivar Anal 111:335–349
Acknowledgments
The authors would like to thank two anonymous reviewers for their valuable comments and suggestions on an earlier version of this manuscript which resulted in the present improved version.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by National Natural Science Foundation of China (11422109), Natural Science Foundation of Jiangsu Province (BK20141145), Qing Lan Project and A Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions.
Rights and permissions
About this article

Cite this article
Amini-Seresht, E., Qiao, J., Zhang, Y. et al. On the skewness of order statistics in multiple-outlier PHR models. Metrika 79, 817–836 (2016). https://doi.org/10.1007/s00184-016-0579-7
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00184-016-0579-7