
Abstract
Two new tests for exponentiality, of integral- and Kolmogorov-type, are proposed. They are based on a recent characterization and formed using appropriate V-statistics. Their asymptotic properties are examined and their local Bahadur efficiencies against some common alternatives are found. A class of locally optimal alternatives for each test is obtained. The powers of these tests, for some small sample sizes, are compared with different exponentiality tests.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The exponential distribution is probably one of the most applicable distributions in reliability theory, survival analysis, and many other fields. Therefore, ensuring that the data come from the exponential family of distributions is of great importance. Goodness of fit testing for exponentiality has been popular for decades, and in recent times tests based on characterizations have become one of the primary directions. Many interesting characterizations of the exponential distribution can be found in Ahsanullah and Hamedani (2010), Arnold et al. (2008), Balakrishnan and Rao (1998) and Galambos and Kotz (1978). Goodness of fit tests based on characterizations of the exponential distribution are studied in Ahmad and Alwasel (1999), Angus (1982), Koul (1977, (1978), among others. In particular, the Bahadur efficiency of such tests has been considered in, e.g., Nikitin (1996), Nikitin and Volkova (2010), Volkova (2010).
Recently Obradović (2015) proved three new characterizations of the exponential distribution based on order statistics in small samples. In this paper we propose two new goodness of fit tests based on one of those characterizations:
Let \(X_0,X_1,X_2,X_3\) be independent and identically distributed (i.i.d.) non-negative random variables from a distribution that has a density f whose Maclaurin’s expansion converges for \(x>0\). Let \(X_{(2;3)}\) and \(X_{(3;3)}\) be the median and maximum of \(\{X_1, X_2, X_3\}\), respectively. If
then \(f(x)=\lambda e^{-\lambda x} \) for some \(\lambda >0\).
Let \(X_1,X_2,\ldots ,X_n\) be i.i.d. observations having a continuous distribution function F. We test the composite hypothesis \(H_0\) that F belongs to the family of exponential distributions \( {\mathcal {E}}(\lambda )\), where \(\lambda >0\) is an unknown parameter.
We shall consider the following integral and Kolmogorov-type test statistics which are invariant with respect to the scale parameter \(\lambda \):
where
In order to determine the quality of our tests that reject \(H_0\) for large values of \(I_n\) or \(K_n\), and to compare them with some other tests we shall use local Bahadur efficiency. We choose this type of asymptotic efficiency since it is applicable to non-normally distributed test statistics such as the Kolmogorov statistic. For asymptotically normally distributed test statistics the local Bahadur efficiency and the classical Pitman efficiency coincide (see Wieand 1976).
The paper is organized as follows. In Sect. 2 we study the integral statistic \(I_n\). We find its asymptotic distribution, large deviations and calculate its asymptotic efficiency against some common alternatives. We also present a class of locally optimal alternatives. In Sect. 3 we do the analogous study for Kolmogorov-type statistics. In Sects. 4 and 5 we compare our tests with some existing tests for exponentiality and give a real data example.
2 Integral-type statistic \(I_n\)
The statistic \(I_n\) is asymptotically equivalent to the V-statistic with symmetric kernel (Korolyuk and Borovskikh 1994)
where \(\pi (1:m)\) is the set of all permutations \(\{\pi _1,\pi _2,...,\pi _m\}\).
Its projection on \(X_1\) under \(H_0\) is
After some calculations we get
The expected value of this projection is equal to zero, while its variance is
Hence this kernel is non-degenerate. and therefore we can consider instead of V-statistic \(I_n\) the corresponding U-statistic with the same kernel which has almost identical asymptotic properties. Applying Hoeffding’s theorem (Hoeffding 1948) for non-degenerate U-statistics the asymptotic distribution of \(\sqrt{n}I_n\) is normal \(\mathcal {N}(0,\frac{29}{1680})\).
2.1 Local Bahadur efficiency
One way of measuring the quality of the tests is calculating their Bahadur asymptotic efficiency. This quantity can be expressed as the ratio of the Bahadur exact slope, a function describing the rate of exponential decrease for the attained level under the alternative, and the double Kullback–Leibler distance between the null and the alternative distribution. More about theory on this topic can be found in Bahadur (1971), Nikitin (1995).
According to Bahadur’s theory the exact slopes are defined in the following way. Suppose that, under an alternative indexed by a parameter \(\theta \), the sequence \(\{T_n\}\) of test statistics converges in probability to some finite function \(b(\theta )\). Suppose also that the large deviations limit
exists for any t in an open interval I, on which f is continuous and \(\{b(\theta ), \, \theta > 0\}\subset I\). Then the Bahadur exact slope is
The exact slopes always satisfy the inequality
where \(K(\theta )\) is the Kullback–Leibler distance between the alternative \(H_1\) and the null hypothesis \(H_0.\)
Given (3), the local Bahadur efficiency of the sequence of statistics \({T_n}\) is defined as
Let \(G(\cdot ,\theta ), \theta \ge 0\), be a family of distribution functions with densities \(g(\cdot ,\theta )\), such that \(G(\cdot ,0)\in \mathcal {E}(\lambda )\) and the regularity conditions from [Nikitin (1995), Chapter 6], including differentiation along \(\theta \) in all appearing integrals, hold. Let \(h(x)=g'_{\theta }(x,0)\). It is obvious that \(\int _{0}^{\infty }h(x)dx=0\).
We now calculate the Bahadur exact slope for the test statistic \(I_n\).
Lemma 1
For the stati stic \(I_n\) the function \(f_{I}\) from (1) is analytic for sufficiently small \(\varepsilon >0\), and we have
Proof
The kernel \(\varPsi \) is bounded, centered and non-degenerate. Therefore we can apply the theorem of large deviations for non-degenerate U-statistics (Nikitin and Ponikarov 2001) and get the statement of the lemma. \(\square \)
Lemma 2
For a given alternative density \(g(x;\theta )\) whose distribution belongs to \({\mathcal {G}}\), we have
The proof follows from the general result in Nikitin and Peaucelle (2004).
The Kullback–Leibler distance from the alternative density \(g(x,\theta )\) from \({\mathcal {G}}\) to the class of exponential densities \(\{\lambda e^{-\lambda x}, \quad x\ge 0 \}\), is
It can be shown (Nikitin and Tchirina 1996) that for small \(\theta \) Eq. (5) can be expressed as
This quantity can be easily calculated as \(\theta \rightarrow 0\) for particular alternatives.
In what follows we shall calculate the local Bahadur efficiency of our test for some alternatives. These alternatives are:
-
a Weibull distribution with density
$$\begin{aligned} g(x,\theta )=e^{-x^{1 + \theta }} (1 + \theta ) x^{\theta },\;\theta > 0,\; x\ge 0; \end{aligned}$$(7) -
a Makeham distribution with density
$$\begin{aligned} g(x,\theta )=(1+\theta (1-e^{-x}))\exp (-x-\theta ( e^{-x}-1+x)),\;\theta > 0, \;x\ge 0; \end{aligned}$$(8) -
an exponential mixture with negative weights (EMNW(\(\beta \))) (Jevremović 1991) with density
$$\begin{aligned} g(x,\theta )=(1+\theta )e^{-x}-\beta \theta e^{\beta x},\; \theta \in \left( 0,\frac{1}{\beta -1}\right] ,\; x\ge 0; \end{aligned}$$(9) -
a generalized exponential distribution (GED) (Nadarajah and Haghighi 2010) with density
$$\begin{aligned} g(x,\theta )=e^{1 - (1 + x)^{1 + \theta }} (1 + \theta ) (1 + x)^{\theta }\;\theta > 0, x\ge 0; \end{aligned}$$(10) -
an extended exponential distribution (EE) (Gomez et al. 2014) with density
$$\begin{aligned} g(x,\theta )=\frac{1 + \theta x}{1 + \theta }e^{-x},\; \theta > 0,\; x\ge 0. \end{aligned}$$(11)
In the following two examples we shall present the calculations of the local Bahadur efficiency.
Example 1
Let the alternative hypothesis be a Weibull distribution with density function (7). The first derivative along \(\theta \) of its density at \(\theta = 0\) is
Using (6) the Kullback–Leibler distance is \(K(\theta )=\frac{\pi ^2}{6}\theta ^2+o(\theta ^2),\;\;\theta \rightarrow 0.\) Applying Lemma 2 we have
According to Lemma 1 and (4) the local Bahadur efficiency is \(e_B(I)=0.746\).
The reasoning for alternatives (8–10) is analogous. Their efficiencies are given in Table 1. The exception is the alternative (11) where Lemma 2 and (6) cannot be applied. We present it in the following example.
Example 2
Consider the alternative (EE) with density function (11). Its first derivative along \(\theta \) at \(\theta = 0\) is
The expressions \(\int _{0}^{\infty } h(x)\psi (x)dx\) and \(\int _{0}^{\infty }h^2(x)e^xdx-\Big (\int _{0}^{\infty }xh(x)dx\Big )^2\) are equal to zero, hence we need to expand the series for \(b_{I}(\theta )\) and \(2K(\theta )\) to the first non-zero term. The limit in probability \(b_I(\theta )\) is equal to
The double Kullback–Leibler distance (5) from (11) to the family of exponential distributions is
where \(Ei(z)=\int _{-z}^{\infty }u^{-1}e^{-u}du\) is the exponential integral. According to Lemma 1 and (4) the local Bahadur efficiency is \(e_B(I)=0.481\).
We can notice from Table 1 that all efficiencies are reasonably high except for case (11), the example which was included to show the exception in calculation.
2.2 Locally optimal alternatives
In this section we determine some of those alternatives for which the statistic \(I_n\) is locally asymptotically optimal in the Bahadur sense. More on this topic can be found in Nikitin (1995) and Nikitin (1984). We shall determine some of those alternatives in the following theorem.
Theorem 1
Let \(g(x;\theta )\) be a density from \({\mathcal {G}}\) that satisfies the condition
Then, for small \(\theta \), the alternative densities
are locally asymptotically optimal for the test based on \(I_n\).
Proof
Put
It is easy to show that this function satisfies the following equalities:
The local asymptotic efficiency is
From the Cauchy–Schwarz inequality we have that \( e^{B}_I=1\) if and only if \(h_0(x)=C\psi (x) e^{-x}\). Inserting this expression in (13) we obtain h(x). The densities from the statement of the theorem have the same h(x), hence the proof is completed. \(\square \)
3 Kolmogorov-type statistic \(K_n\)
For a fixed \(t>0\) the expression \(H_n(t)-G_n(t)\) is a V-statistic with kernel:
The projection of this family of kernels on \(X_1\) under \(H_0\) is
After some calculations we get
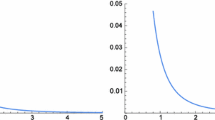
The variances of these projections \(\sigma _K^2(t)\) under \(H_{0}\) are
The plot of this function is shown in Fig. 1.

Plot of the function \(\sigma _K^2(t)\)
We find that
The supremum is attained for \(t_0=1.892\). Therefore, our family of kernels \(\varXi (X_1,X_2,X_3,X_4,t)\) is non-degenerate as defined in Nikitin (2010). It can be shown (see Silverman 1983) that the U-empirical process
converges weakly in \(D(0,\infty )\) as \(n \rightarrow \infty \) to a centered Gaussian process \(\nu (t)\) with calculable covariance. Thus, the sequence of statistics \(\sqrt{n}K_n\) converges in distribution to the random variable \(\sup _{t\ge 0} |\nu (t)|\) but its distribution is unknown.
Critical values for the statistic \(K_n\) for different sample sizes and levels of significance are shown in the Table 2. They are calculated using Monte Carlo methods based on 10,000 replications.
3.1 Local Bahadur efficiency
The family of kernels \(\{\varXi _4 (X_1,X_2,X_3,X_4,t),\;t\ge 0\}\) is centered and bounded in the sense described in Nikitin (2010). Applying the large deviation theorem for the supremum of the family of non-degenerate U- and V-statistics from Nikitin (2010), we find the function f from (1).
Lemma 3
For the statistic \(K_n\) the function \(f_{K}\) from (1) is analytic for sufficiently small \(\varepsilon >0\), and
Lemma 4
For a given alternative density \(g(x;\theta )\) whose distribution belongs to \({\mathcal {G}}\) we have
Using the Glivenko–Cantelli theorem for V-statistics (Helmers et al. 1988) we have
Put
After differentiating under the integral sign and some more calculations we get
Expanding \(a(t,\theta )\) in a Maclaurin series and inserting the result into (15) we obtain the statement of the lemma.
Now we calculate the local Bahadur efficiencies in the same manner as we did for the integral-type statistic. For the alternatives (7) and (11) the process of calculations is presented in following two examples, while for the others the values of efficiencies are presented in Table 3.
Example 3
Let the alternative hypothesis be a Weibull distribution with density function (7). Using Lemma 4 we have
The plot of the function \(a_{\theta }'(t,0)\), is shown in Fig. 2. The supremum of \(a(t,\theta )\) is attained at \(t_1=1.761\), thus \(b_K(\theta )=0.34\theta +o(\theta ), \quad \theta \rightarrow 0\).
Using Lemma 3 and Eqs. (2) and (4) we get that the local Bahadur efficiency in case of the statistic \(K_n\) is 0.258.

Plot of the function \(a_{\theta }'(t,0)\)
Example 4
Let the alternative density function be (11). The function \(a(t,\theta )\) from (16) is
The plot of the function \(a_2(t)\), the coefficient next to \(\theta ^2\), in the expression above is given in Fig. 3. Thus we have
The value of the double Kullback–Leibler distance is given in (12). Using Lemma 3 and Eqs. (2) and (4), the local Bahadur efficiency is seen to be 0.213.

Plot of the function \(a_2(t)\)
We can see that, as expected, the efficiencies are lower than in case of the integral-type test. However the efficiencies are not that bad compared to some other Kolmogorov-type tests based on characterizations (e. g. Volkova 2010).
3.2 Locally optimal alternatives
In this section we derive one class of alternatives that are locally optimal for the test based on statistic \(K_n\).
Theorem 2
Let \(g(x;\theta )\) be the density from \({\mathcal {G}}\) that satisfies the condition
Then, for small \(\theta \), alternative densities
where \(t_0=1.892\), are locally asymptotically optimal for the test based on \(K_n\).
Proof
We use the function \(h_0\) defined in (13). It can be shown that the function \(h_0\) satisfies condition (14), and we have
The local asymptotic efficiency is
From the Cauchy–Schwarz inequality we have \( e_{K}=1\) if, and only if, \(h_0(x)=C\xi (x,t_0) e^{-x}\). Inserting that in (13) we obtain h(x). The densities from the statement of the theorem have the same h(x), hence the proof is completed. \(\square \)
4 Power comparison
For purpose of comparison we calculated the powers for sample sizes \(n=20\) and \(n=50\) for some common distributions and compare the results with some other tests for exponentiality which can be found in Henze and Meintanis (2005). The powers are shown in Tables 4 and 5. The labels used are identical to the ones in Henze and Meintanis (2005). Bolded numbers represent cases where our test(s) have the higher or equal power than the competing tests. It can be noticed that in the majority of cases the statistic \(I_n\) is the most powerful. Also, the statistic \(K_n\) performs better in most cases than the other tests for \(n=20\), while it is reasonably competitive for \(n=50\). However, there are few cases where the powers of both our tests are unsatisfactory.
5 Application to real data
This data set represents inter-occurrence times of fatal accidents to British registered passenger aircraft, 1946–1963, measured in number of days and listed in the order of their occurrence in time (see Pyke 1965):
20 | 106 | 14 | 78 | 94 | 20 | 21 | 136 | 56 | 232 | 89 | 33 | 181 | 424 | 14 | |
430 | 155 | 205 | 117 | 253 | 86 | 260 | 213 | 58 | 276 | 263 | 246 | 341 | 1105 | 50 | 136. |
Applying our tests to these data, we get the following values of the test statistics \(I_n\) and \(K_n\), as well as the corresponding p values:
Statistic | \(I_n\) | \(K_n \) |
|---|---|---|
Value | 0.04 | 0.21 |
p value | 0.32 | 0.24 |
so we conclude that the tests do not reject exponentiality.
6 Conclusion
In this paper, we studied two goodness of fit tests for exponentiality based on a characterization. The major advantage of our tests is that they are free of the scale parameter \(\lambda \). We calculated the local Bahadur efficiencies for some alternatives and the results are more than satisfactory. We determined a locally optimal class of alternatives for each test. Finally, we compared these tests with some other goodness-of-fit tests and noticed that in most cases our tests were more powerful.
References
Ahmad I, Alwasel I (1999) A goodness-of-fit test for exponentiality based on the memoryless property. J R Stat Soc Ser B Stat Methodol 61(3):681–689
Ahsanullah M, Hamedani GG (2010) Exponential distribution: theory and methods. NOVA Science, New York
Angus JE (1982) Goodness-of-fit tests for exponentiality based on a loss-of-memory type functional equation. J Stat Plan Inference 6(3):241–251
Arnold BC, Balakrishnan N, Nagaraja HN (2008) A first course in order statistics. SIAM, Philadelphia
Bahadur RR (1971) Some limit theorems in statistics. SIAM, Philadelphia
Balakrishnan N, Rao CR (1998) Order statistics, theory and methods. Elsevier, Amsterdam
Galambos J, Kotz S (1978) Characterizations of probability distributions. Springer, Berlin
Gomez YM, Bolfarine H, Gomez HW (2014) A new extension of the exponential distribution. Rev C Estad 37(1):25–34
Helmers R, Janssen P, Serfling R (1988) Glivenko–Cantelli properties of some generalized empirical DF’s and strong convergence of generalized L-statistics. Probab Theory Rel Fields 79(1):75–93
Henze N, Meintanis SG (2005) Recent and clasicical tests for exponentiality: a partial review with comparisons. Metrika 61(1):29–45
Hoeffding W (1948) A class of statistics with asymptotically normal distribution. Ann Math Stat 19:293–325
Jevremović V (1991) A note on mixed exponential distribution with negative weights. Stat Probab Lett 11(3):259–265
Korolyuk VS, Borovskikh YV (1994) Theory of \(U\)-statistics. Kluwer, Dordrecht
Koul HL (1977) A test for new better than used. Commun Stat Theory Method 6(6):563–574
Koul HL (1978) Testing for new is better than used in expectation. Commun Stat Theory Method 7(7):685–701
Nadarajah S, Haghighi F (2010) An extension of the exponential distribution. Statistics 45(6):543–558
Nikitin Y (1995) Asymptotic efficiency of nonparametric tests. Cambridge University Press, New York
Nikitin YY (1996) Bahadur efficiency of a test of exponentiality based on a loss of memory type functional equation. J Nonparametr Stat 6(1):13–26
Nikitin Y, Peaucelle I (2004) Efficiency and local optimality of distribution-free tests based on U- and V-statistics. Metron 62(2):185–200
Nikitin YY (2010) Large deviations of \(U\)-empirical Kolmogorov-Smirnov tests, and their efficiency. J Nonparametr Stat 22(5):649–668
Nikitin YY (1984) Local asymptotic bahadur optimality and characterization problems. Theory Probab Appl 29:79–92
Nikitin YY, Ponikarov EV (1999) Rough large deviation asymptotics of Chernoff type for von Mises functionals and \(U\)-statistics. In: Proceedings of the St. Petersburg mathematical society 7:124–167. English translation in AMS Translations ser.2 203, 2001, 107–146
Nikitin YY, Tchirina AV (1996) Bahadur efficiency and local optimality of a test for the exponential distribution based on the Gini statistic. Stat. Methodol Appl 5(1):163–175
Nikitin YY, Volkova KY (2010) Asymptotic efficiency of exponentiality tests based on order statistics characterization. Georgian Math J 17(4):749–763
Obradović M (2015) Three characterizations involving median of sample of size three. J Stat Theory Appl. arXiv:1412.2563v1
Pyke R (1965) Spacings. J R Stat Soc Ser B Stat Methodol 27(3):395–449
Silverman BW (1983) Convergence of a class of empirical distribution functions of dependent random variables. Ann Probab 11:745–751
Volkova KY (2010) On asymptotic efficiency of exponentiality tests based on Rossbergs characterization. J Math Sci (NY) 167(4):486–494
Wieand HS (1976) A condition under which the Pitman and Bahadur approaches to efficiency coincide. Ann Stat 4:1003–1011
Acknowledgments
We would like to thank the Editor and the Referee for their very useful remarks.
Author information
Authors and Affiliations
Corresponding author
Additional information
Research was supported by Ministry of Science of the Republic of Serbia, Grant No. 174012.
Rights and permissions
About this article

Cite this article
Milošević, B. Asymptotic efficiency of new exponentiality tests based on a characterization. Metrika 79, 221–236 (2016). https://doi.org/10.1007/s00184-015-0552-x
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00184-015-0552-x