
Abstract
Designing an engineering system that is both environmentally and economically sustainable is a challenging task. Designers need to cope with socio-technical uncertainties and design systems to provide high performance during long lifecycles. Flexibility in engineering design provides ways to address such challenges by making engineering systems changeable in the face of uncertainty. It is difficult, however, to identify suitable system elements for designing flexibility, especially when subjected to multiple sources of uncertainty and complex interdependency between socio-technical and systems elements. This paper considers embedding flexibility into the engineering design as a mechanism to ensure better sustainability and to improve economic performance in long-term lifecycles. The main contribution is a novel methodology to identify valuable opportunities to embed flexibility as a way to deal pro-actively with uncertainty in market and environment. The proposed methodology integrates Bayesian network into engineering system design to effectively model complex change propagation in the flexibility identification process. It helps structure concept generation activities by identifying candidate areas to embed flexibility in the system. It compares favorably to other concept generation methods (e.g., prompting, brainstorming) that require modeling and evaluation of a large number of concepts generated in order to identify the ones offering better performance. It differs from other flexibility enabler identification methods by considering indirect as well as direct dependencies, in addition to the probabilistic nature and risk resulting from possible changes. Another contribution is the demonstration application of the proposed methodology through the analysis of a waste-to-energy technology in Singapore based on anaerobic digestion. Results show that the expected net present value of the flexible design concepts provides more than 10 % improvement over a fixed benchmark design in terms of economic lifecycle performance. This design is conducive of better economic sustainability via additional power generation and better use of resources. Results also indicate that the flexible design can reduce downside risks and capitalize on upside opportunities significantly.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Complex engineering systems, such as urban infrastructure systems for communication, transportation, waste-to-energy (WTE) or power generation and supply, are developed and operated in complex and changing environments. They inevitably face uncertainties during their long lifecycles in terms of markets, environment, regulations and technology. These uncertainties play a significant role in their success and failure. For instance, a WTE system may be designed to convert wet and dry organic wastes into electric power that can be redistributed to the grid. Uncertainties such as changes in waste generation patterns, demographics, recycling rate, waste composition and quality, energy price and material cost may significantly impact the economic lifecycle performance of such system. Currently, how to make complex engineering systems such as WTE systems more flexible and resilient to uncertainty becomes a challenging but necessary task for designers, city planners, government agencies and researchers.
In the literature, flexibility in engineering design is a promising way to deal with uncertainty. Flexibility enables engineering systems to change easily in the face of uncertainty (Fricke and Schulz 2005), while contributing in making a system’s performance more sustainable in their operating environments and over time. One example of flexibility in commercial real estate is the ability to expand a building vertically if needed (Guma et al. 2009). This flexible strategy reduces the impact of downside uncertainties since less capital is required upfront to build a small building in the initial development phase (e.g., acting like an insurance policy). In addition, it helps capitalizing on upside opportunities since additional profit can be generated under favorable market conditions by expanding the capacity if demand for retail or office space is higher than expected (e.g., acting like a call option on a stock—limiting downsides, improving upsides). This example illustrates that flexibility can help manage uncertainties and make a system adaptable to changing conditions, with the net effect of improving overall lifecycle performance. Furthermore, embedding flexibility in engineering systems can make better use of resources later in the operational phase and provide opportunities for sustainable development in the future by making better use of such resources, reducing costs and improving systems performance (i.e., economic or other). Motivated by the fact that flexibility can help address the challenges of sustainable development, this work aims to consider embedding flexibility as a mechanism to ensure better resilience and sustainability in the face of changing markets, technology, regulatory and environmental contexts.
When embedding flexibility in engineering systems, many factors need to be considered. Usually, engineering systems have a large number of system elements with complex dependent relationships. In addition, the system may face many uncertainty sources—see (de Weck et al. 2007) for a classification of different uncertainty sources and processes to analyze uncertainty. Therefore, it may not be clear to designers and researchers which is the better flexible strategy, when is the right time to exercise flexibility, and where to focus design efforts in embedding flexibility in the system. A good flexible systems design concept should comprise a flexible design strategy and a set of design enablers (Cardin 2014). The flexible design strategies, such as deferring capital investment and expanding capacity, are akin to real options and offer different ways to change and adapt the system in the face of uncertainty (Trigeorgis 1996). The flexible design enablers are potential areas to embed the flexibility into the design, so the strategies can be exercised in operations. For example, expanding capacity by adding more levels is a flexible strategy, and strengthening the footings and infrastructure is a mechanism to enable such flexible strategy concretely in the early design.
In an attempt to support flexible systems design concept generation, different approaches and procedures have been suggested in the literature. Some procedures focus on the issue of generating flexible strategies (e.g., Trigeorgis 1996) or identifying flexible enablers (e.g., Suh et al. 2007). Some procedures consider both issues (e.g., Mikaelian et al. 2012). Although much efforts have been devoted to support flexible concept generation (e.g., Cardin et al. 2013), many challenges still remain. It is not clear how to model the indirect dependent relationships between elements within a complex system in the enabler identification phase. Modeling these indirect dependent relationships could help measure the effect of change and avoid risk to the whole system in the initial design phase. Given there are many uncertainty sources, design variables and design principles to consider, it is not easy to quantitatively select and rank suitable components for flexibility. Ranking information could be used to reduce the space of feasible flexible design concepts to analyze and save computational resources.
This study is motivated by the challenges above and focuses on the issue of identifying enablers as a way to stimulate flexible systems design concept generation. A novel methodology is proposed to identify the crucial and valuable design areas to embed flexibility in complex systems. It aims to extend existing enabler identification methods by considering direct as well as indirect dependencies. In addition, the proposed methodology attempts to select and rank suitable system elements for embedding flexibility before the concept evaluation phase, embodiment and more detailed design phases. Application of the proposed methodology is demonstrated through an analysis of WTE system in Singapore.
The remainder of this paper is organized as follows. The related work is presented in Sect. 2. The proposed methodology is presented in Sect. 3. The case study of the WTE system is explained in Sect. 4. Finally, the contributions, the validity of the results and directions for future work are discussed and summarized in Sect. 5.
2 Related work
Background information about flexibility and real options analysis is introduced in Sect. 2.1. The objective is to provide an overview of the field, provide the motivation for generating flexibility in complex systems and explain how concept generation contrasts and compares to the evaluation process. Next, the state-of-the-art research for generating flexibility is summarized in Sect. 2.2. The challenges and important issues for generating flexibility are identified. In Sect. 2.3, latest research efforts on change propagation management are reviewed. Existing work on modeling direct/indirect dependencies and assessing the effects of change propagation is summarized. The need to account for the effects of change propagation in the flexibility generation process is also discussed. In Sect. 2.4, an overview of existing work on WTE systems is provided. The last section compares existing approaches and summarizes the research gaps addressed in this paper.
2.1 Flexibility and real options
Flexibility is an important system attribute that can enable better economic sustainability. It provides the “right, but not the obligation, to change a system as uncertainty unfolds” (Trigeorgis 1996). Flexibility has been shown to improve lifecycle performance by 10–30 % compared to standard design and evaluation approaches (de Neufville and Scholtes 2011). Two ways of embedding flexibility in engineering systems design are proposed in the literature, namely real options “on” projects and real options “in” projects (Wang 2005). A real option “on” project treats the whole system as a “black box” and focuses on managerial flexibility, specifically providing decision-makers with the option to make strategic decisions at a later stage, such as deferring capital investment until favorable market conditions, expanding capacity and switching inputs and/or outputs to accommodate different markets. A real option “in” project refers to flexibility within the system and focuses on how system elements can be adapted easily to suit a changing environment.
Currently, much research on flexible engineering design focuses on constructing an appraisal mechanism to evaluate flexibility. The aim is to quantify the benefits of flexibility and compare to the additional costs required to enable flexibility. The work done in the real option analysis (ROA) community enables a quantitative evaluation of flexibility in engineering design (Trigeorgis 1996). Most studies, however, are based on the assumption that the flexible concepts are known a priori and already embedded in the system. In practice, it may not be clear to designers where to focus the design effort for flexibility, especially since a large number of design variables, complex interdependencies and various uncertainty scenarios have to be considered. Nowadays, many researchers realize that where/how to generate flexibility in engineering systems is an important and challenging task. Therefore, it has become an attractive research topic in engineering design. Hence, this paper focuses on the question of how to generate flexibility in complex systems design and management. It aims to provide a practical methodology for identifying potential elements in a system where valuable flexibility can be embedded.
2.2 Flexible design concept generation for engineering design
Embedding flexibility in engineering design usually involves five phases: (1) standard/baseline design, (2) uncertainty recognition, (3) concept generation, (4) design space exploration and (5) process management (Cardin 2014). Various design theories and methodologies have been proposed to support design activities in each phase. For example, axiomatic design (Suh 1990) and the architecture generation method (Moullec et al. 2013) are used to generating baseline designs in phase 1. Binomial lattices (Cox et al. 1979) are used in phase 2 to characterize and model uncertainty scenarios. In phase 3, a procedure based on explicit training and prompting (Cardin et al. 2013) can be used to support flexible systems design concept generation. Multi-attribute tradespace exploration (Ross 2006) can be used in phase 4 to explore the design space once early concepts are generated. Serious and simulation games (Mayer 2009; Ligtvoet and Herder 2012; Cardin et al. 2015) can be used in phase 5 to study the complete process management and understand the conditions more conducive of productive analysis and management.
This paper aims to improve the methodologies available in Phase 3. Usually, flexible concept generation involves two main steps: (1) generating strategies in response to major uncertainty drivers, with the goal of improving lifecycle performance and (2) identifying enablers to embed flexibility in engineering design. Various procedures have been proposed to generate flexible strategies or generate complete flexible ideas including both strategies and enablers. Trigeorgis (1996) suggested a number of generic flexibility strategies, such as deferring investment until favorable market conditions and abandoning failed projects. Mikaelian et al. (2011) proposed a holistic approach, based on the characterization of real options as a mechanism and type, as part of the integrated real options framework (IRF). Mikaelian et al. (2012) extended the IRF framework and proposed a logical multiple domain matrix (Logical-MDM) to effectively represent and identify mechanisms and types of real options across multiple domains. Cardin et al. (2013) investigated and evaluated the effects of two educational training procedures and two ideation procedures in order to systematically guide decision-makers to create concepts for flexibility.
Enabler identification methods rely mostly on design structure matrix (DSM)—see thorough survey of DSM literature by Browning (2001). Fricke and Schulz (2005) suggested the design principles of changeability to generate new concepts (e.g., ideality, simplicity and modularity). Suh et al. (2007) proposed change propagation analysis (CPA) to identify multipliers as opportunities to embed flexibility. Kalligeros (2006) proposed sensitivity design structure matrix (sDSM) to look for the design variables that are most sensitive to changes in other design variables and functional requirements. Bartolomei et al. (2012) extended CPA and sDSM by considering multiple sources of uncertainty from technical, human and social-technical domains and suggested the engineering system matrix (ESM) to select “hot spots” or good opportunities to embed flexibility. Hu et al. (2013) extended the ESM methodology and identified valuable opportunities to embed flexibility in engineering systems.
Although existing methodologies are applicable and effective in different circumstances, several challenging and important issues remain unaddressed. The procedure based on prompting and explicit training (Cardin et al. 2013) stimulate creativity and systematically guides decision-makers to generate flexibility. However, the resulting performance of a large number of feasible concepts needs to be evaluated before selection and implementation (i.e., the approach imposes no limit on the number of concepts generated). The IRF framework clearly characterizes the real option and shows the mapping between the types of flexibility and the sources of flexibility. The Logical-MDM extends the framework and identifies the flexible strategies as well as the enablers to generate complete flexible design concepts. It analyzes the problem based on all the possible ways to achieve an objective. This approach, however, does not consider the efforts that should be paid to change from one state to the objective state (i.e., cost of change). This issue is important since decision-makers may not want to pay more in the initial design phase to enable flexibility if the system with standard design components can change easily in the future (i.e., low cost of changing the standard design). Enabler identification techniques, such as ESM and sDSM, only consider direct dependent relationships between elements, although changes may not only impact the elements with direct connection, but also propagate to other elements with indirect secondary connections (Eckert et al. 2004). Only considering direct dependent relationships between elements may not fully capture such indirect dependencies and ignore valuable opportunities to embed flexibility.
2.3 Change propagation management
Jarratt et al. (2011) provided a comprehensive review of the research on change propagation management. They summarized existing work from different perspectives, such as the nature of the change propagation process (e.g., Eckert et al. 2004), the tools and methods to support decisions in the change propagation process (e.g., Pasqual and de Weck 2012) and the strategies to cope with change impacts (e.g., Martin and Ishii 2002). Clarkson et al. (2004) proposed a change prediction method (CPM) to predict the risk of change propagation in terms of likelihood and impact of change. This methodology extends the change propagation analysis beyond direct dependencies. It helps capture more fully the complex relationships between elements and also better assess change propagation effects. To date, the CPM method has been used and extended (e.g., Giffin et al. 2009; Koh et al. 2013). Attempts to expand change propagation analysis from one design domain (i.e., component domain) to many different design domains have also been made (e.g., Koh et al. 2012).
Besides the CPM method and its extensions, Bayesian networks (BN) is another technique that can be used to predict change effects. Tang et al. (2007) applied BN to build an architecture rational and element linkage model to assess how changing the requirements and design decisions will affect a system. Mirarab et al. (2007) used BN theory to predict change propagation phenomena in a software system. Zhou et al. (2008) proposed a BN-based approach to predicting change behavior between source code entities in software systems.
Existing methodologies are mainly applied in the redesign phase, and their objective is to avoid undesired change propagation when engineers aim to improve a complete design. Little research, however, takes into account the potential impact of change propagation during the design concept generation phase. Embedding flexibility early on will have most impact on system changeability and enable the system to adapt to new environmental conditions. On the other hand, if the change triggers a significant cost to the whole system, the flexible option may not be worthy of investment in the initial design phase. Therefore, there is a need to differentiate between the elements that are suitable for a more fixed and/or robust design and the ones that are suitable for flexible design in the initial stage by considering and predicting the potential effects of change propagation. This paper aims to address these issues by adapting existing procedures for change propagation management, such as the CPM method and BN theory, to support flexible design concept generation activities.
2.4 Previous work in waste-to-energy systems
This section provides an overview of existing work in WTE infrastructure system technology development. Chang et al. (2011) performed a comprehensive review of systems analysis techniques in waste management practice. They indicated that systems engineering tools such as cost-benefit analysis (e.g., Tin et al. 1995), optimization (e.g., Xu et al. 2009), forecasting and simulation (e.g., Liu et al. 2006) are widely used. Other systems assessment tools are also used to evaluate WTE system performance (e.g., Feo and Malvano 2009).
Research efforts on WTE systems so far have been devoted mostly to system optimization and evaluation. Yet, little work has focused on the problem of interdependency representation between the system elements. Existing methodologies analyze WTE systems from environmental, social and technological standpoints and aim to achieve sustainable solutions. To these authors’ knowledge, however, few studies have analyzed sustainable WTE systems from the perspective of enabling flexibility in the engineering design, specifically as a mechanism to ensure better sustainability and improve lifecycle performance in the face of an uncertain future. This paper aims to address the issue of how to generate flexible design concepts for WTE systems and generate better design solutions for real-world implementation. The methodology proposed in this paper is explained first and then applied to select valuable system elements to insert flexibility as a way to deal with uncertainty and provide a better lifecycle performance. Indeed, it is argued that explicit considerations of uncertainty and flexibility in the early design phases will result in better use of resources later in the operational phase by planning for careful adaptation to changing conditions (e.g., waste usage and generation patterns, demographics, technology, emissions regulations). This will help reduce the cost of change (i.e., the cost associated with exercising flexibility, which changes the system from one state to another) often associated with adaptive mitigation strategies that are more reactive in nature. Overall, this analysis contributes to create a system that is more sustainable, both in terms of economic performance and also in terms of waste recycling and eco-friendly power generation.
2.5 Research gaps
Table 1 compares the methods focusing on flexible concept generation and change propagation management. The methods are evaluated based on whether they consider multiple uncertainties and indirect change propagation in the analysis process and whether they have the capability to deal with uncertainty, analyze multiple domain information and help generate flexible systems design concepts.
As shown in Table 1, only Koh et al. (2012, 2013) have considered the factors of multiple uncertainties and indirect change propagation at the same time. Their work, however, focuses on managing change propagation as opposed to generating flexible systems design concepts. Existing work supporting flexible concept generation, such as Cardin et al. (2013) and Bartolomei et al. (2012), has analyzed multiple domain information and dealt with uncertainty. Indirect change propagation, on the other hand, has not been examined. This discussion shows that further research is required to consider all five factors in Table 1, with the goal of generating better flexible systems design concepts, which is the focus of this paper.
3 Methodology
This paper addresses the issues of considering simultaneously the costs of change in the flexibility generation process as well as both direct and indirect dependencies to fully capture flexible design opportunities. It proposes a novel methodology to identify flexible design enablers, which extends and merges recently developed techniques from the fields of engineering design and Bayesian network analysis. It addresses the following research question: “How do we model indirect change propagation and predict its potential effects in the initial design phase, with the goal of selecting suitable system elements for designing flexibility and creating a better performing, more sustainable system?” The proposed methodology extends the ESM method to capture complex dependent relationships between system elements from multiple domains. It further integrates Bayesian network model and the CPM method to effectively model complex change propagation and predict the effects when certain elements in the system need to be changed.
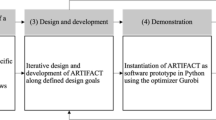
An overview of the proposed methodology is shown in Fig. 1. It begins by analyzing a specific design problem and developing a quantitative performance model (Sect. 3.1). The objective is to select a benchmark design under deterministic analysis. Next, the complex dependent relationships between socio-technical elements and major uncertainty drivers for the design problem are identified in Step 2 (Sect. 3.2). Here, the ESM method is extended to analyze the system from multiple domains standpoint. In addition, multiple uncertainties that affect system performance are modeled. Using the identified information, such as system-level dependencies and the cost of changing from one state of design to another, the potential flexibility in design opportunities are then selected in Step 3 (Sect. 3.3). Step 3 is a core element in the proposed methodology. It integrates the Bayesian network model into engineering system designs to model indirect change propagation and measures the risk susceptibility of each system element. Based on the risk susceptibility index, flexible design opportunities are recommended and flexible design concepts are generated accordingly to deal with uncertainty. In the final step, the value of exercising flexibility in operations is analyzed using real option analysis (Sect. 3.4). The selected benchmark design (i.e., generated in Step 1) and the recommended flexible designs (i.e., recommended in Step 3) are evaluated and compared under uncertainties (i.e., the uncertainties identified and modeled in Step 2). The objective of the final step is to analyze whether the flexible designs suggested by the proposed methodology are worthy of investment. The design details of the four steps will be described in the following subsections.

Summary of proposed methodology to generate flexibility in engineering systems design
3.1 Step 1: Initial design
The first step focuses on identifying a baseline design concept and analyzing the design problem by constructing a performance model. The baseline design can be generated using existing techniques such as axiomatic design, Pahl & Beitz, etc. Tomiyama et al. (2009) provide an overview of such procedures. As explained by Cardin (2014), it is recommended to start the process for flexibility from an existing design and further improve the baseline by consideration of uncertainty and flexibility in subsequent phases. This is because starting a design from scratch for flexibility may render the design space very large, with many possibly moving parts, and the task may become easily intractable. Starting from an existing solution and trying to improve it by means of flexibility determine the initial size of the design space. It also allows designers to start from an instance that they already know and have expertise with. Here, designers may start from the design of an existing WTE plant and improve its performance following the process suggested below.
Once a baseline design is identified, various modeling techniques can be used to analyze its performance, such as discounted cash flow (DCF) analysis, discrete event simulation and computer-aided design. Take DCF analysis for example: It is constructed after understanding the main cost and revenue components of the design problem. The DCF model is analyzed based on a set of deterministic point forecasts of uncertainty factors, such as customer demands and requirements. Using this model, the net present value (NPV) lifecycle performance of each candidate design concept is calculated. The best design concept with better lifecycle performance is selected. The selected design concept serves as a benchmark design. It is further compared with the flexible design concepts to determine the value of flexibility (VOF) in Step 4.
3.2 Step 2: Dependency and uncertainty analysis
The second step focuses on modeling and representing a complex engineering system at a systems level. It is recommended to identify and model the major sources of uncertainties in this phase. There are many uncertainty sources (i.e., exogenous and endogenous sources) for complex systems, and it is impossible to model and analyze them all. Identifying the main uncertainty drivers after creating a baseline design can help designers identify uncertainties that are most relevant and make the uncertainty space more specific to the system of interest. This phase relies heavily on the designer’s expertise with the system to identify the main uncertainty drivers most relevant and impactful for its future lifecycle performance. One can use a method inspired from the prompting process described by Cardin et al. (2013) to identify uncertainty drivers based on such expertise. In phase 1, the variables capturing such uncertainty may exist in the performance model, but variability is not yet introduced (i.e., a deterministic analysis is conducted). For example in the WTE case, quantity of waste disposed of is clearly stochastic. This phase recognizes such variability in the modeling and in the system-level representation described next.
After the most influential uncertainty drivers are identified, the ESM methodology is used to characterize them along with their interdependencies with the system elements. ESM models the engineering system using an adjacency matrix and represents the direct dependent relationships between the neighboring system elements from multiple domains (i.e., function domain and stakeholder domain) (Bartolomei et al. 2012).
Here, the ESM methodology is extended by considering the likelihood of one element changing due to a change in a neighboring element. Specifically, the extended ESM not only models dependency relationships, it also examines the degree of likelihood of such dependency. The relation and the degree of dependency are represented using a conditional probability, which is defined as the probability that a change in one element will lead to a change in a neighboring element. In addition, the prior probability—showing the likelihood of an uncertain scenario occurring in the future—and the cost of change—representing the cost of system elements related to the change—are analyzed. All of the domain information for constructing the system-level representation is extracted based on expert knowledge and historical data. The likelihood of change can be determined using expert elicitation techniques (Morgan and Henrion 1990).
Besides identifying dependent relationships and constructing the ESM, modeling major uncertainties is another important task. This is because major uncertainties play a significant role in a system’s success or failure. Modeling the uncertainties in the initial design phase can help designers consider a wide range of possible scenarios rather than an expected scenario. The lifecycle performance of a system can be improved by pro-actively dealing with the distribution of possible outcomes (de Neufville and Scholtes 2011). Currently, various methods exist to model uncertainties, such as lattice, diffusion models and scenario planning (de Weck et al. 2007). Based on the modeled uncertain scenarios, flexible concepts are generated to deal with the uncertainties (see Sect. 3.3). In addition, the flexible concepts can be evaluated under uncertainty and the best concepts can be selected for the detailed design and implementation phases (see Sect. 3.4).
3.3 Step 3: Flexible design opportunities identification
The third step supports flexible systems design concept generation. It involves: 1) developing a Bayesian network model, 2) predicting the risk susceptibility of each system element and 3) recommending suitable system elements. As shown in Fig. 2, the inputs of Step 3 are an ESM matrix and the costs of change for system elements. The ESM matrix indicates the dependent relationships for the system elements as well as the degree of dependencies. It provides the prior information for constructing the Bayesian network model. After the Bayesian network is developed, the probability of change in a particular system element can be easily inferred if another system element is changed. The inferred probabilities of change, together with the costs of change, are used to measure risk susceptibilities for system elements. Based on the risk susceptibility index, different design strategies are recommended and flexible design opportunities can be selected.

Main procedures for flexible design opportunities identification
3.3.1 Bayesian network model development
A Bayesian network is used to model complex interdependencies between system elements. Changes in the system elements and their impacts on other system elements are considered, while also considering indirect connections. A single change may ultimately transform and propagate across a large portion of the system and thus cause significant impact. This complex change mechanism is measured quantitatively by a posterior conditional probability, and it is used to represent the change in probability of one element given the change in other elements with either direct or indirect dependent relationships. This posterior conditional probability predicts how likely one element might be affected if other elements are changed.
The Bayesian network is a probabilistic graphical model that represents a set of random variables and their joint probability distributions. It is a directed acyclic graph in which nodes represent variables and edges represent conditional dependencies. The main use of Bayesian networks is for inference: It updates the probability distribution of the unobserved variables in the network, knowing the value of some observed variables. The posterior conditional probability of each element can be inferred based on the network representation of the system. The system elements analyzed in the ESM matrix are represented as nodes. Each node has only two states: (1) changed in light of a change from dependent elements or (2) unchanged in that it is insensitive to changes in other elements. The direct relationships between elements in the ESM are modeled as edges in the Bayesian network. The prior probability and the conditional probability elicited from experts or historical data are used to construct the Bayesian network. The conditional probability, however, only reflects how a node is dependent on each of its direct parents. To construct the network, one should also identify the distribution of a node conditioned on all parents (i.e., the probability of change when several changes occur and affect the particular node). To solve this problem, a “Noisy-Or” assumption (Pearl 1988) is used. This means that the direct dependencies from each parent node(s) to each child node(s) are considered separately to construct the CPT for the Bayesian network. Suppose y 1, y 2, …, y n are the parent nodes for x. Given conditional probabilities \(p\left( {x|y_{n} } \right), n = 1,2, \ldots , N\) (i.e., numbers from the ESM matrix), the effect of all parents considering all direct and indirect dependencies can be calculated using Eq. (1):
Once the Bayesian network is constructed, the posterior conditional probability of each element can be quickly inferred. A number of efficient inference algorithms can be used for performing the probabilistic updating, thus providing a powerful function for predictions and reasoning (Pearl 2000). In addition, the designers can easily set values to model the changes. For example, the major uncertainty factors (e.g., customer requirement) can be set with 100 % probability of change. This information may affect some direct elements (e.g., increase the probability of demolishing old equipment and buying new one). The impact (i.e., the increased probability of change) propagates through the network (e.g., increases the probability of other elements to replace a connecting infrastructure or change a setting). The customer requirements change will produce a new probability distribution over the remaining elements in the network. It shows the what-if scenarios of the impact of the change. The characteristics of each system element that shows the sensitivity to the uncertain scenarios can then be identified.
3.3.2 Risk susceptibility prediction and measurement
This subsection focuses on predicting the risk susceptibility of each system element if a change is triggered and propagated within the system. Risk susceptibility is measured by the posterior conditional probability, which is inferred using the Bayesian network, and the cost of change, which is extracted from Step 2. In the risk susceptibility prediction process, the costs of change are normalized with respect to the maximum cost of change for each system element. The risk measurement methodology used here is adapted from risk management theory and the change prediction method (Clarkson et al. 2004).
First, one measures the risk received by each system element when a change is triggered by external uncertainties (e.g., change in design requirement, market conditions). This risk is denoted as \(R_{{s_{i} }}^{\text{Received}}\) and is calculated as:
Variable s i represents the ith system element, \(U\) is the set of uncertainties, u j is one of the uncertainties in U, and \(C_{{s_{i} }}\) is the cost of change for system element \(s_{i}\). The term \(P_{{s_{i} |\forall u_{j} \in U}}\) represents the probability that system element s i will change due to all of the uncertainty factors, via both direct and indirect links. This kind of probability is a posterior conditional probability inferred using the Bayesian network model. For example, \(P_{{s_{i} |\forall u_{j} \in U}}\) could be the probability that critical equipment will be demolished and replaced by new equipment to adapt to new requirements, given a change in customer requirements. It shows how sensitive the critical equipment is to changes in the uncertainty factor. Variable \(C_{{s_{i} }}\) would be the cost of demolishing the old equipment and buying new equipment. Thus, \(R_{{s_{i} }}^{\text{Received}}\) indicates the degree of risk received by system element s i due to the impact of possible changes upstream.
The second measurement predicts the risk caused by system element \(s_{i}\) if it is changed. Let us assume that a system element \(s_{i}\) is changed (e.g., critical equipment has been demolished and replaced by advanced equipment to adapt to new requirements). This change becomes a “source of uncertainty” to other child nodes in the system and generates a risk of change to child nodes. For example, it may require other equipment to change settings to connect to the new equipment. If there are a large number of elements needing to change their settings and the cost of changing the settings is very high, it may propagate risk to the whole system. The problem is how to measure the risk to these child nodes downstream due to a change in system element \(s_{i}\) upstream and finally avoid this risk in the initial design phase. The risk generated by system element s i can be calculated as:
Here, s j represents a child node of system element s i , s i ≠ s j , \(D_{{s_{i} }}\) is a set of system elements that contains all of the child nodes of system element \(s_{i}\), \(P_{{s_{j} |s_{i} ,\forall u_{j} \in U}}\) is the posterior conditional probability of a change in system element s j given a change in system element \(s_{i} ,\) and \(P_{{s_{j|} \forall u_{j} \in U}}\) is the posterior conditional probability of a change in system element s j only subject to the external uncertainties. The subtraction here represents the increased probability of child node (s j ) changing due to the effect of changing the parent node \(s_{i}\). A large difference between the probabilities means that given the new information from parent node \(s_{i}\) (e.g., the parent node \(s_{i}\) will be changed with 100 % probability), the probability for changing the child node s j has been significantly increased and the child node s j becomes more likely to change. Variable \(R_{{s_{i} }}^{\text{Generated}}\) indicates the degree of risk generated by a change in system element s i under uncertainty \(U\).
3.3.3 Recommendations
A risk susceptibility index (RSI) is proposed to recommend different strategies for different elements. The RSI is inspired from the change propagation index (CPI) methodology by Suh et al. (2007) and calculated below:
For ease of visualization, the risk susceptibility of the system elements can be plotted in a chart, as shown in Fig. 3. The chart can be subdivided into four regions based on the value obtained by \(R_{{s_{i} }}^{\text{Received}}\) and \(R_{{s_{i} }}^{\text{Generated}}\). The recommendations are explained using a graph, as shown in Fig. 4. The nodes in Fig. 4 represent exogenous uncertainties or system elements, while the arcs represent the dependent relationships between them.

Risk susceptibility of system element

Change propagation for a general system
The risk susceptibility of each system element in Fig. 4 is estimated based on Eqs. (2) and (3). The system elements that fall on the upper part of the chart in Fig. 3 have high \(R^{\text{Received}}\). The meaning of high \(R^{\text{Received}}\) can be explained using the automotive system example from Suh et al. (2007). For instance, suppose node A in Fig. 4 represents customer requirement for an engine that changes from V6 to V8 in the future. Node B represents a system element that is used to fit engine requirements. Suppose node B is a fixed design for V6 engine initially (e.g., \(B_{{V6 }}\)). Given node \(A\) changes, node B has a high probability to change to accommodate a V8 engine (e.g., \(B_{{V6 }}\) changes to \(B_{{V8 }}\)). If the cost of change for node B (i.e., cost for changing \(B_{{V6 }}\) to \(B_{{V8 }}\)) is also high, this means node B has high \(R^{\text{Received}}\). It motivates designers to consider an advanced design (e.g., flexibility or robustness) for node B in the initial stage, with the goal of reducing cost of change in the future. To further determine whether node B is suitable for flexibility or robustness, risk susceptibility \(R^{\text{Generated}}\) should be analyzed and node B is considered as an internal source of uncertainty.
-
1.
If changing node B (e.g., \(B_{{V6 }}\) changes to \(B_{{V8 }}\)) will not cause significant impacts to downstream nodes (i.e., node \(C\)), node B has low \(R^{\text{Generated}}\) (i.e., node B falls on the upper left of the chart). Specifically, the probability or cost of changing node C is low given node B changes. Low R Generated of node B can guarantee that less cost is required to accommodate the change of node \(B\). Therefore, node B can be made easier to change in the initial stage to save the cost of change in the future. This can be accomplished by embedding flexibility. For instance, one could design a flexible option in \(B_{{V6 }}\) to make it easier to change to \(B_{{V8 }}\) when a future situation requires implementation of the V8 engine configuration. This flexible option can reduce the cost for changing node \(B\), and exercising the flexibility will not impact other nodes significantly.
-
2.
If changing node B will cause significant impacts to node \(C\), it means high \(R^{\text{Generated}}\) for node \(B\) (i.e., node \(B\) falls on the upper right of the chart). High R Generated indicates changing the element may further amplify changes and generate more risk to downstream elements. Therefore, this element is recommended as an area to embed robustness in design, which handles uncertainties without the need to change the architecture of the system (Jugulum and Frey 2007). Robust design elements reduce the likelihood of change by reducing change propagation to other downstream elements. For instance, node B could be designed to fit both V6 and V8 engine, even though it may only require to fit a V6 engine initially. The robust design can avoid unwanted change propagation since node B can handle the uncertainty without changing its architecture in the future.
The strategies for the system elements that fall on the lower part of the chart in Fig. 3 are different. This is because these system elements have relatively low \(R^{\text{Received}}\). They are unlikely to change in the future in response to major uncertainties, or a small cost is needed for changing them. For instance, suppose node D in Fig. 4 represents the wheelbase of the automotive system. Suppose a dependent relationship exists between nodes A and \(D\), but this dependence is not strong. This dependence may exist because customers who require advanced V8 engine may also require vehicle roominess that will affect the design of the wheelbase. This impact, however, depends on customers’ preference. Therefore, given node A changes, the probability for changing node D is low. Suppose the cost for changing node D is also low, node D has thus low \(R^{\text{Received}}\). This means that node D is insensitive to the uncertainty and little effort is required for changing node D as uncertainty unfolds. Even though the probability for changing node D is low, it still requires special attention. Risk susceptibility R Generated should also be analyzed if node D changes.
-
1.
If changing node D will not cause significant impacts to downstream nodes (i.e., node \(E\)), node D has low \(R^{Generated}\) (i.e., it falls on the lower left of the chart). This indicates that node D is unlikely to change in the future. Even if it is required to change, only a small cost is needed for changing it. In addition, only a small influence on the other system elements is incurred. Hence, this element can be considered as part of a fixed design.
-
2.
If changing node D will cause significant impacts to node E, node D has high R Generated (i.e., it falls on the lower right of the chart). It indicates that significant risk will be generated to the whole system if node D changes. It is similar to those elements that fall on the upper right of the chart. Designers may consider robust design to reduce the likelihood of change for node \(D\), to avoid further unwanted change for the whole system in the future.
Elements that have the widest numerical difference between the \(R_{{s_{i} }}^{\text{Received}}\) and \(R_{{s_{i} }}^{\text{Generated}}\)—i.e., in the upper left with high risk received and low risk generated—are considered suitable candidates to embed flexibility. In other words, the higher \({\text{RSI}}_{{s_{i} }}\) is, the more suitable the corresponding system element is for embedding flexibility.
3.4 Step 4: Flexibility valuation
The fourth step focuses on embedding flexibility in the system design and quantifying the benefits of flexibility on lifecycle performance. This analysis helps designers determine whether flexibility is worth the additional cost and design effort. An approach to real options analysis based on Monte Carlo simulations is used to generate stochastic scenarios, run a wide range of scenarios and lead to a distribution of possible performance outcomes. The expected NPV lifecycle performance of the flexible design and the benchmark design is calculated based on the simulated future scenarios. The difference between the expected NPVs is the VOF, which indicates the benefits of considering flexibility and uncertainty in the design. A positive VOF quantifies the accrued benefit to the system performance stemming from flexibility. Generally, decision-makers should not be willing to pay more than the VOF to embed flexibility in the system design.
4 Application
This section uses a WTE plant relying on anaerobic digestion (AD) technology as an example to demonstrate how the method described in Sect. 3 can be used to identify flexible design opportunities. The proposed methodology selects flexible design opportunities among the physical system elements of an AD plant. It analyzes the system in the Singapore context and aims to identify the best flexible systems design concepts for deploying AD technology in the near future.
Figure 5 shows a general digestion process for an AD plant design based on publicly available information as well as communications with local experts. It shows that waste collectors deliver food waste to the plant. The collected wastes are first fed into pre-processing equipment, such as bag breaker to shred plastic bags and a screener to separate plastics and non-organics from the food wastes. The impurity portion is then sent to incineration plants. The separated wastes are mixed with circulate material from digesters, which are then pumped into the digesters. During the digestion process, bio-gas is produced and stored in gasholders. The biogas can be continuously fed into gas engines for generating electricity. The generated power is pumped to the grid and sold in the wholesale electricity market. The digested material left in the digesters is then further treated, such as screwing and dewatering. After all the processing, the residues are finally sent to incineration plants for further treatment. Based on the general functions, the AD plant is later divided into several system elements (e.g., Fig. 6).

General process flow for anaerobic digestion plants

ESM representation with triggering probability for an AD plant
To gather real data and better understand the AD technology, a comprehensive review was done to include recent efforts in the design of AD plants, the technical details of AD plants and commercialized applications in Europe and Singapore (e.g., IUT Global Pte Ltd 2006; De Baere 2010; Allen Kani 2001). Keywords such as “anaerobic digestion” and “waste to energy” or different combinations thereof were used in e-index search engines such as Web of Science and Google Scholar. Besides the literature survey, communication with experts in the research area of biochemistry and bioenergy was pursued. Experts were research fellows at the National University of Singapore with many years of experience in AD technology research. They explained the technical details of AD plants described here. In addition, they answered questions such as “what are the main physical components for AD plants?” and “how feedstock impacts the performance of AD plants?” Their answers were useful to construct the ESM and for developing the performance model described below.
4.1 Step 1: Initial design
Based on the procedure described in Sect. 3, a model is developed in the first step to quantify the lifecycle performance of a WTE system design. The design configuration (i.e., combination of design variables) producing the best performance is then selected and referred as the benchmark design. In this case study, a discounted cash flow (DCF) performance model for AD plants in Singapore is developed. The DCF model is as follows:
Variable CF t is the cash flow at year \(t\); R t D represents the revenue for disposing of the wastes at year \(t\); R t E represents the revenue for selling recovered electricity at year \(t\); \(C_{\text{init}}\) is the initial capital cost of developing the WTE system; C t OM represents the operation and maintenance cost at year \(t\); \(C_{\text{SC}}^{t}\) is the cost of change at year \(t\); i is the discount rate, which is assumed to be 5 %, and T is the study period, assumed to be 30 years. The revenue for disposing of wastes is calculated using the following equation:
where Q t Tot is the total amount of organic wastes disposed of by the AD plant at year \(t\), P to is the tipping fee for the organic wastes that are charged at the AD plant, Q t is the total amount of organic wastes generated at year t, Re t is the recycling rate for organic wastes at year t and z is the capacity of the AD plant. The profit for electricity recovery is determined as follows:
where Q t e is the total amount of electricity (KWh) available for sale at year \(t\); P e is the sales price of electricity; R Gbio is the biogas generation rate; V en is the energy value of the biogas; R Ce is the electricity conversion rate; R a is the engine availability rate and R nea is the net energy available rate. The operation and maintenance cost includes the cost from four parts, namely the staff requirement, regular maintenance, operational cost for digesting wastes and disposal fee for residue, calculated as follows:
where N t is the total number of staff in year \(t\); W is the average annual wage for each staff; M t c is the maintenance cost for buildings and equipment at year \(t\); C ope is the average operational cost for digesting one ton of wastes; Q t r is the total amount of residue at year \(t\); ∂ is the residue rate of the AD plant and C dis is the unit residue disposal fee. C t SC is determined by the capital cost for each system element, which is fully discussed in Sect. 4.3. The main assumptions used to develop the model are listed in Table 2. Full reference to each source is available in the reference section.
Table 3 summarizes the capital cost for two AD plants with a capacity of 275 tons per day (tpd) and 550 tpd, respectively. Considering the economies of scale, the basic cost estimation function is as follows:
where a 1 is the economies of scale factor and a 0 is the coefficient parameter. Based on the available data in Table 3, a 0 is determined as 272,283 and a 1 is equal to 0.83. Therefore, C init can be estimated for different capacities. The benchmark design has a capacity of 800 tpd without considerations of possible expansion in the future. This benchmark design is justified by providing the highest net present value (NPV) [i.e., NPV is calculated using Eqs. (5)–(13)] among several designs with different capacities, based on deterministic market projections.
4.2 Step 2: Dependency and uncertainty analysis
In step 2, the ESM methodology is used to analyze the conditional dependencies of system elements. To construct an ESM for AD systems, principles described in Eppinger and Browning (2012) have been followed. Figure 6 shows the ESM representation of the AD plant and summarizes the dependent relationships of the elements from five system domains. All of the information shown in Fig. 6 is estimated and analyzed based on expert communications and publicly available information (e.g., Rogoff and Screve 2011). The prior conditional probabilities are categorized during the expert elicitation process into three levels to represent weak, moderate and strong dependent relationships.Footnote 1 The numbers in Fig. 6 represent the likelihood and dependent relationships: the higher the number, the stronger the dependence between the system elements. For example, the government (T 1) strongly controls the strategy for the AD company (T 3) by issuing new policies and regulations. Therefore, the triggering probability \(p_{T3|T1}\), which represents the probability that element T 3 will change triggered by a change in government’s strategy \(T_{1}\), is assigned a value of 0.9. On the other hand, the operation and management of the AD company—i.e., the amount of wastes digested annually, the amount of residue disposed to landfill and the electricity generated by digesting the wastes—may only have limited impact on government agency (T 1). Therefore, the corresponding triggering probability is \(p_{T1|T3}\) = 0.3. An empty cell shows that no explicit dependence is expected between the two system elements, such that a change in one element does not trigger any more changes.
In this case, the major sources of uncertainty come from the system drivers domain. The total amount of organic wastes generated, Q t, is modeled using geometric Brownian motion (GBM):
The parameter \(\mu\) represents the mean percentage drift around the total waste amount and \(\sigma\) represents the volatility. Here, \(\mu\) is assumed to be 2.6 %, volatility is 3.29 % and Q 0 is 2.56 million tons. The assumptions are generated based on historical data about Singapore (e.g., National Environment Agency 2011). dt is a small time increment of one period, which is assumed to be 1 year. The random variable dW t captures the standard Wiener variable modeling of stochastic error at time \(t\). It is sampled from a standard normal distribution ∼N(0, 1). Based on these assumptions, 2000 scenarios consisting of an annual amount of organic waste for 30 years are generated. Five out of 2000 runs and the deterministic projection are shown in Fig. 7. The recycling rate of organic waste and the waste moisture content are modeled in a similar fashion.

GBM simulation of future generated organic wastes (5 out of 2000 runs)
4.3 Step 3: Flexible design opportunity identification
After the AD plant has been analyzed at a systems level, a Bayesian network is constructed to capture the system interdependencies. Figure 8 shows an example of how to use the numbers in Fig. 6 to construct the Bayesian network. Figure 8a shows the dependent relationships between the system components and the conditional probabilities from the direct parents. Based on the “Noisy-Or” assumptions, a conditional probability table for constructing the Bayesian network is calculated using Eq. (1), as shown in Fig. 8b. T represents the corresponding system component that has been changed (e.g., the capacity has been expanded) and F represents the components that do not change. Take the probabilities in the fourth row in Fig. 8b for example. They are calculated as follows:

a Dependent relationship between system components, b the conditional probability table for constructing the Bayesian network
The objective of the Bayesian network model is to infer the posterior conditional probability of each system element given the available information. Many algorithms have been proposed in the literature to perform such inferences (Pearl 2000). In this paper, a tool called Netica, which applies a classical algorithm that can clearly provide exact results, is used.
Figure 9 is a screenshot from software NeticaFootnote 2 showing a prototype network model. Visualization of the network includes the name of each node and the state name for each node. Here, each node has only two states: One state shows whether the system element has to change in light of a change in dependent elements, while the other shows whether the system element does not change and is insensitive to other elements. For example, the state “larger than expectation” for amount of organic wastes (top left corner) means that the amount of wastes generated in Singapore has been increasing rapidly and that it significantly deviates from deterministic projections. On the other hand, the state “within current range” means that the amount of wastes generated is similar to the deterministic projection, and the situation is still under control without affecting other variables. The numbers here show the probabilities of these two states (scenarios) occurring. The dependencies between nodes are shown as edges.

Bayesian network model of AD plant with uncertainties occur
The probability of each state of a node can be updated when other variables are known. This inference is an application of Bayes’ theorem:
Figure 9 shows the updated probability distributions of all remaining nodes, assuming that the three sources of uncertainty—amount of organic wastes, recycling rate and waste moisture content—are changed simultaneously with a probability of 100 %. It can be inferred, for instance, that the pre-process equipment will be changed with a posterior conditional probability of 98.2 %. This indicates that the pre-process equipment is the most sensitive physical component in the objects domain when the quantity and quality of waste are changed. The cost of change for each system element is determined based on the small design with a capacity of 275 tpd. The cost of change is assumed to be 80 % of the initial cost for each system element. Take the tipping floor and new buildings for example. The cost of change means the cost for developing additional tipping floors and buildings (i.e., expanding by 200 tpd). Here, the cost of change is normalized with respect to the maximum value of each system element, which is shown in Table 4. The normalized cost is used in the risk measurement process. It should be noted that the cost of exercising flexibility is assumed to be 70 % of the cost of change. This is because the flexibility can make the element change easily and require less cost to change in the future. To enable flexibility, however, an additional 10 % of the initial cost should be added at the beginning. Another issue is that the initial cost of general site works is the same with different capacities (see Table 3) and no explicit dependent relationships exist between the general site works and other elements (see Fig. 6). Therefore, the element of general site works may not change in the future, and no switching cost is shown in Table 4.
The system elements from the objects domain in the ESM model are referred to as system components. The focus is to identify valuable system components for flexibility in this domain. The posterior conditional probability of each system component is inferred from the Bayesian network (Fig. 9). Together with the information about the cost shown in Table 4, the system components can be quantitatively ranked using their RSI value. Taking the system component of pre-process equipment as an example, the posterior conditional probability is 98.2 % and the normalized cost is 0.34 (see Table 4). Based on Eq. (2), the R Received for pre-process equipment is calculated as 0.33. Since changing pre-process equipment does not impact other system components (no dependent relationships as seen in Fig. 6), the corresponding \(R^{\text{Generated}}\) is 0 according to Eq. (3). Therefore, the RSI value for pre-process equipment is 0.33 based on Eq. (4). Table 5 summarizes the ranking information for each system component. It suggests that the system components of tip floor and equipment building, main equipment and major tankage have the top three RSI values and are therefore selected as valuable opportunities for embedding flexibility. The residue compactor and flaring and odor control are suggested for standard platform components. To demonstrate that embedding flexibility in the selected components can improve the lifecycle performance as compared to the benchmark design, the value of flexibility is evaluated next as demonstration for the top three components.
4.4 Step 4: Flexible design concepts and evaluation
The top three system elements from step 3 are selected as candidate components for embedding flexibility. In this section, suitable flexible systems design concepts are generated based on the selected elements. In addition, the value of flexibility is evaluated using simulation-based ROA, and different flexible systems design concepts are compared.
4.4.1 Flexible design concept generation
To generate valuable flexible systems design concepts, suitable flexible strategies need to be selected based on the selected system components. In this study, the flexible strategies by Trigeorgis (1996) are considered one by one. They are mapped to each selected component and selected if they can help create valuable concepts, which is similar to the approach proposed by Mikaelian et al. (2011). Two types of flexible strategies—expanding capacity and switching technology—are selected to address the three major sources of uncertainty. The suggestions are made to enable these flexibilities in the selected system components.
The first source of flexibility is an expansion option enabled in the tipping floor and equipment building component. This source of flexibility enables capacity expansion for the tipping floor building to add more equipment and quickly deliver the feedstock to any of the pre-processing equipment when the amount of wastes and the recycling rate increase significantly. This strategy reduces exposure to losses because less capital cost is needed in the initial phase (i.e., start from smaller and more affordable capacity). In addition, the strategy helps system operators to capitalize on the opportunity to receive and dispose of more feedstock by expanding the capacity in the future as needed. This strategy further reduces the cost of change in the operation process. This is because the tipping floor equipment requires higher capital cost than other system components (see Table 3), which indicates that the cost of changing the tipping floor from one state to another state is very high. Adding flexibility makes this system component change more easily and reduces the cost if change is needed in the future. To enable flexibility, a stronger structure is constructed for the buildings so that additional floors can be added and the capacity of the tipping floor can be expanded. In addition, more land is reserved so that the downstream equipment such as post-processing equipment could expand capacity accordingly to deal with more feedstock. The cost of enabling the flexibility can be compared to the additional VOF calculated below to determine economic viability and worthiness. The second source of flexibility in major tankage (i.e., expansion option) is designed and developed in a similar way. The only difference is to make the major tankage easily changeable in the future, rather than the tipping floor.
The third source of flexibility is a switching option enabled in the main equipment. This source of flexibility switches the dry process (i.e., yield high biogas only when the total solid content of feedstock is 20–40 %) to an advanced technology that can adapt to different water content during operation. This switching option allows the AD plant to exploit the benefits of both “wet” and “dry” processes, such as insensitivity to variance in feedstock composition and high biogas yield. One example is the anaerobic digestion of organic slurry (ADOS) process, which has been applied in IUT Singapore (IUT Global Pte Ltd 2006). The heart of the ADOS process is a specially designed “wet-mill”, the so-called ADOS mill, which can reduce particle size, treat the input material to slurry and maximize the quality of the material going to the digesters. Designing modular main equipment is a mechanism that enables the real option to upgrade to the dry process and switch to the advanced process when the waste moisture content changes significantly.
The flexible design with expansion options starts from 400 tpd and the corresponding decision rule is to expand the capacity if the available organic wastes are larger than the designed capacity in the previous year. This rule expands the capacity by 200 tons each time and until the maximum capacity of the benchmark design is reached (i.e., 800 tpd). As for the flexible design with the switching option, the initial capacity is the same as the benchmark design. However, it is designed with a dry process in the initial design phase. The switching option is exercised when the moisture rateFootnote 3 is higher than 80 %.
Combining these three sources of flexibility gives rise to different design concepts, as summarized in Table 6. The three sources of flexibility correspond to three factors. Each factor has two levels: Y represents flexibility turned on and N represents flexibility turned off. The flexible design concepts 1–3 represent only one source of flexibility embedded in the AD plant, while the design concepts 4–7 show different combinations. The seven flexible strategies and one benchmark strategy are analyzed in Sect. 4.4.2.
4.4.2 Flexible design concept evaluation
The quantity of food waste Q t and the capacity of design concept z will affect economic profits [e.g., according to Eqs. (7) and (8)] and costs [e.g., according Eqs. (11) and (13)]. Each design concept (i.e., with different capacities) will generate one NPV under one simulated sample scenario. The anticipated lifecycle performance is measured using the expected (or average) NPV (ENPV) [i.e., calculated using Eqs. (5)–(13)] by taking 2000 samples for the simulated quantity of food waste described by Eq. (14). Figure 10 shows the cumulative NPV distributions and ENPVs for flexible design concepts 1–7 and the benchmark design. The results show that all flexible concepts perform better than the benchmark design, with the overall effect of improving the system’s ENPV compared to the fixed, rigid initial design. The ENPVs of flexible concepts 1–7 are larger than those of the benchmark design, showing clear improvement over the benchmark design. There is a 5 % chance—the value at gain (VAG) or percentile 95 value (P95)—that the NPV values generated by flexible design concept 7 will be greater than S$206 million, which is also significantly larger than those for the benchmark design. From the perspective of value at risk (VAR)—a measure of possible downside conditions—the benchmark has a 5 % chance of generating NPV values less than S$92 million. This is less than the P5 values for the flexible concepts (except concept 3, which is relatively close), indicating the latter strategies are also good at alleviating the impact of downside scenarios. The results support the view that the selected system components are valuable choices for embedding flexibility.

Cumulative probability of NPV for flexible strategies and benchmark designs
Table 7 summarizes the key statistics for all eight concepts.
The results show that all flexible concepts perform better than the benchmark design, with the overall effect of improving the system’s ENPV compared to the fixed, rigid initial design. The ENPVs of flexible concepts 1–7 are larger than those of the benchmark design, showing clear improvement over the benchmark design. For instance, there is a 5 % chance—the value at gain (VAG) or percentile 95 value (P95)—that the NPV values generated by flexible design concept 7 will be greater than S$206 million, which is also significantly larger than that for the benchmark design. From the perspective of value at risk (VAR)—a measure of possible downside conditions—the benchmark has a 5 % chance of generating NPV values less than S$92 million. This is less than the P5 values for the flexible concepts (except concept 3, which is relatively close), indicating the latter strategies are also good at alleviating the impact of downside scenarios. The results support the view that the selected system components are valuable choices for embedding flexibility.
Figure 11 shows the trade-off between ENPV and standard deviation of NPV for the eight design concepts. It portrays the design concepts in a manner analogous to how different investment portfolios are represented in modern portfolio theory in finance. It captures graphically the risk versus return trade-offs, where standard deviation of outcomes is used as a proxy for the level of volatility, and risk.

ENPV versus standard deviation plot for the eight design concepts
As illustrated in Fig. 11, the eight design concepts can be grouped into three clusters. Cluster 1 includes “low-return and high-risk” design concepts (i.e., design concept 3 and the benchmark design). These two design concepts are designed without expansion flexibility in the initial stage. Compared with the benchmark design, design concept 3 has a slightly lower risk and a higher return. This indicates that only enabling the switching option to deal with the uncertainty of waste quality could result in improvement, but the improvement is small. Cluster 2 includes “mid-range-return and low-risk” design concepts (i.e., design concepts 1 and 2). These concepts show improved ENPV since the uncertainty of waste quantity is mitigated by only enabling expansion flexibility. Compared with design concept 3 with only switching, design concepts 1 and 2 achieve a better return and lower risk. This suggests that design concepts 1 and 2 with expansion flexibility are the first choices when the decision-makers have limited resources and can invest only in one source of flexibility. Cluster 3 includes “high-return and low-risk” design concepts (i.e., design concepts 4, 5, 6 and 7). They represent the best strategies among the eight design concepts. This is because the ENPVs are improved by combining multiple flexibilities to pro-actively deal with uncertainty. In addition, the standard deviations are less than those of the benchmark design. More capital investment is needed, however, to enable expansion and switching flexibility with the goal of making multiple system components change more easily in the future. Thus, this group of concepts is recommended when decision-makers have sufficient resources in the initial phase.
4.4.3 Sensitivity studies
4.4.3.1 Comparison with change propagation analysis
Change propagation analysis (CPA) proposed by Suh et al. (2007) is an alternative method to identify flexible design enablers. The method calculates the change propagation index (CPI) for each component i using Eq. (18):
CPI i expresses the difference between the numbers of changes propagating “in” component i from components that are directly connected upstream (i.e., \(\Delta E_{\text{in}}\)) and the numbers of changes propagating “out” to other downstream components (i.e., \(\Delta E_{\text{out}}\)). Depending on the CPI value, elements can be further classified. A positive CPI indicates that the element is a multiplier; a zero CPI indicates the element is a carrier, and a negative number indicates the element is an absorber. The multipliers that propagate more changes than they received are suggested as candidates to embed flexibility.
The AD system is also analyzed using the CPA method for comparison. \(\Delta E_{\text{in}}\) and \(\Delta E_{\text{out}}\) for each system component are calculated based on the information shown in the objects domain in Fig. 6. The change propagation between two elements will occur if there is a probability in the matrix—essentially replacing the probability by “1”, since CPA does not account for probabilistic changes and only account for whether a change is propagating or not in a direct manner. The CPI values and class information are displayed in Table 8 (i.e., M is multiplier, A is absorber and C is carrier). Based on the CPA method, the tipping floor and major tankage are suitable elements to enable flexibility, which confirms the findings from the proposed Bayesian approach. Although the calculations for the CPA method and the proposed method are different [i.e., the CPA method is calculated in the format of (\(\Delta E_{\text{out}} -\Delta E_{\text{in}}\)) and the proposed method is calculated in the format of (\(R_{{s_{i} }}^{\text{Received}} / {\text{in}} - R_{{s_{i} }}^{\text{Generated}} / {\text{out}}\))], both methods can identify similar solutions. The reason is that the mechanism behind risk “in” and risk “out” for these two methods is different: (1) \(R_{{s_{i} }}^{\text{Received}}\) estimates risk susceptibility from exogenous uncertainties, which is quite different from \(\Delta E_{\text{in}}\) that only considers endogenous uncertainty; and (2) risk susceptibility in the proposed method is estimated based on a probability of change and cost of change, while risk in the CPA method only counts incoming and outgoing arcs for a particular element. The proposed method identifies one more candidate for flexibility, main equipment, which is not identified as a change multiplier by the CPA method. Above, main equipment has been shown to improve economic performance via real options analysis. This comparison shows that (a) the proposed framework can identify similar opportunities as existing approaches relying on direct change propagation (i.e., the validation) and (b) that it enables identifying more opportunities when considering both direct and indirect relationships, the likelihood of change, and the risk resulting from changes (i.e., the improvement).
4.4.3.2 Sensitivity analysis
To illustrate the overall system performance, a single-factor sensitivity analysis is conducted. The ENPV of flexible design concept 7 and the benchmark design is calculated when the discount rate changes from 5 to 20 % with a 1 % increment. Figure 12 depicts the ENPVs of the design concepts for different discount rates. For each discount rate, the VOF is derived as shown in the filled area. It shows that the VOF value increases when the discount rate increases. This is because a flexible design making use of capacity expansion flexibility benefits from the time-value of money (i.e., the ability to defer investments in additional capacity to later, or avoid unnecessary capacity deployment under low generated waste scenarios). The higher the discount rate i, the more incentive there is to delay expansion, hence the higher VOF. The VOF value is also calculated for volatility \(\sigma\) = 1 % and \(\sigma\) = 30 % under the same number of simulation samples (i.e., 10 runs of 2000 scenarios). Figure 13 shows the sensitivity of VOF with respect to uncertainty, and Table 9 summarizes the key inputs/outputs. Each bar shows how VOF changes as each volatility parameter assumption changes from 1 to 30 %. The analysis shows that the volatilities for amount of organic wastes and recycling rate are the most sensitive parameters. They have a larger effect on VOF than the volatility for waste moisture content. In addition, the results indicate that the higher the volatility, the higher the VOF. This observation confirms the intuition that the value of flexibility increases as uncertainty increases, which is a classical result in financial and real options analysis.

Value of flexibility for different discount rate \(\varvec{i}\)

Value of flexibility for different uncertain factors
5 Discussion and conclusion
5.1 Objectives and contributions
The first objective of this paper is to propose a novel methodology to identify valuable opportunities to embed flexibility in complex engineering system design. The contribution is a procedure that integrates a Bayesian network methodology into engineering system design and effectively models complex change propagation within multiple domains. It builds upon and improves existing methodologies that only consider direct neighboring relationships in the generation of flexible design concepts. The proposed methodology selects and ranks a set of system elements by predicting and analyzing the risk of change propagation. In contrast to other concept generation methods such as prompting proposed by Cardin et al. (2013) that require analyzing a large amount of feasible design concepts before detailed analysis and implementation, the proposed method provides ranking information of system elements and limits the number of flexible design concepts to analyze in the early conceptual stage. It does so by determining the engineering system boundary through the ESM generation mechanism. The approach saves a significant amount of analytical resources in concept generation and evaluation activities. The ranking information provides guidance to designers and decision-makers, especially when resources are limited.
The second objective is to demonstrate application of the proposed tool in the analysis of a WTE infrastructure system in Singapore. An expansion option and a switching option are embedded in three system components: tipping floor and equipment building, major tankage and main equipment. The results show more than 10 % ENPV improvement compared with a fixed, rigid system when flexibility is embedded in the selected system component. This analysis supports the view that the system components selected are valuable choices for embedding flexibility, and represent the second main contribution of the work. In addition, the results indicate that embedding the expansion option in a WTE system can generate larger ENPV values than embedding the switching option given uncertainties for waste quantity and quality.
5.2 Results validity and limitations
One threat to internal validity of the results is whether the Singapore case study is a valid example and represents reality well. If the evaluation case itself is unreasonable, the results cannot be used to validate the proposed methodology and provide a useful tool to support better design decision-making. Many factors could affect the internal validity of the evaluation case. For example, the dependency between the system components may not completely capture all the complexities of the different relationships between socio-technical and system components since based on subjective expert elicitation inputs, and publicly available information. The expansion and switching options were not the only flexible solutions available to designers.
Many strategies were explored to alleviate the impact of these factors and enhance internal validity. The cost data used in the evaluation case were collected based on successful applications in European countries. It represents the best available data since only one AD plant has been built in Singapore and limited information about the Singapore market is publicly available. The probabilistic dependencies between the system components were classified into three levels based on expert knowledge and historical data. This is a reasonable approach to showing the degree of relationships to a certain extent, given the difficulty of acquiring exact values. Under the same set of assumptions, decision rules and sample size, the relationship of the ENPV values for different flexible concepts remained the same across different simulation runs. The same stochastic parameter assumptions were used to evaluate all flexible strategies to ensure that they could be compared on an equivalent basis. Therefore, the evaluation case study represents some of the realities of practice.
In terms of external validity, one threat is whether the proposed methodology is a valid design procedure to help generate flexible systems design concepts in other engineering systems. Here, the proposed methodology identified concepts in a WTE system, which mainly focused on the flexible options at the plant level. The WTE system is an example of engineering system, since it fulfills important functions for society (ESD 2011), has a long lifecycle, is operated under an uncertain environment and is comprised of complex socio-technical interdependencies between system elements. Although those are all important properties of engineering systems, the conclusions of the case study are only valid for the system analyzed. Fully validating the process would require more applications and analyses of different engineering systems. To this end, Hu (2012) already demonstrated application of the proposed method to the analysis of a high-speed rail system, which is another example of engineering system. This shows that the methodology can be used to analyze other engineering systems sharing similar system-level and socio-technical properties.
Another limitation of the proposed method is that it is difficult to address the cyclic dependency using Bayesian network model since a directed acyclic graph is typically assumed. Therefore, the proposed method can only be used for a particular snapshot of the system at a particular time. A more detailed analysis can be done by modeling the complex dependency using a dynamic Bayesian network. Such network adds the temporal dimension into the standard Bayesian network model, similar to the idea proposed by Bartolomei et al. (2012) that the evolution of an ESM framework should be studied over time. The change in the system can be modeled as a series of time slices and every time slice of a model corresponds to one particular state of the system. The advantage of using the dynamic Bayesian network is that the cyclic dependency can be fully analyzed in the modeling process and no loops may occur in any one time slice if the time interval is sufficiently small (i.e., assuming a change does not propagate immediately to another component).
5.3 Future work
Many opportunities for future research exist by addressing the limitations of this work. Ongoing work is conducted to optimize the flexible decision rules using optimization techniques, as reported by Xie et al. (2014). The ranking information could be validated further by conducting analysis in collaboration with academics and industry leaders in the real-world design and implementation. Modeling and simulation showed that system performance can be improved by embedding flexibility in the selected top three components based on RSI values. Thus, it shows that ranking can be a meaningful way to improve the expected lifecycle performance of the system under uncertainty, while requiring a reasonable amount of time and analytical resources. This analysis, however, does not consider how many concepts should be considered, the optimal combination of concepts or the cutoff point for selecting the top components. Those remain as valuable opportunities for future work. Potential flexible design opportunities could be considered on a network of WTE plants in an urban environment, providing more opportunities for operational-, tactical- and strategic-level flexibility. A follow-up study could improve the proposed methodology by modeling the dependencies among system components using a dynamic Bayesian network to holistically analyze the complex relationships and their potential impact over time. Also, the proposed methodology could be compared with other flexible concept generation methodologies, such as prompting and explicit training by Cardin et al. (2013) or the IRF by Mikaelian et al. (2011), to determine which is the most effective, depending on the context and analytical resources available.
Notes
Example survey questions are provided in “Appendix”.
More information is available on Netica’s website: http://www.norsys.com/.
Moisture (%) = 100 − total solid (%).
Abbreviations
- AD:
-
Anaerobic digestion
- ADOS:
-
Anaerobic digestion of organic slurry
- BN:
-
Bayesian network
- CPA:
-
Change propagation analysis
- CPI:
-
Change propagation index
- CPM:
-
Change prediction method
- DCF:
-
Discounted cash flow
- DSM:
-
Design structure matrix
- ENPV:
-
Expected net present value
- ESM:
-
Engineering system matrix
- GBM:
-
Geometric Brownian motion
- IRF:
-
Integrated real options framework
- Logical-MDM:
-
Logical multiple domain matrix
- NPV:
-
Net present value
- ROA:
-
Real option analysis
- RSI:
-
Risk susceptibility index
- TPD:
-
Ton per day
- VOF:
-
Value of flexibility
- WTE:
-
Waste-to-energy
References
Bartolomei JE, Hastings DE, de Neufville R, Rhodes DH (2012) Engineering systems multiple-domain matrix: an organizing framework for modeling large-scale complex systems. Syst Eng 15:41–61
Browning TR (2001) Applying the design structure matrix to system decomposition and integration problems: a review and new directions. IEEE Trans Eng Manag 48(3):292–306
Cardin M-A (2014) Enabling flexibility in engineering systems: a taxonomy of procedures and a design framework. J Mech Des 136(1):011005–011005. doi:10.1115/1.4025704
Cardin M-A, Kolfschoten GL, Frey DD, de Neufville R, de Weck OL, Geltner DM (2013) Empirical evaluation of procedures to generate flexibility in engineering systems and improve lifecycle performance. Res Eng Des 24(3):277–295
Cardin M-A, Jiang Y, Yue HKH, Fu H (2015) Training design and management of flexible engineering systems: an empirical study using simulation games. IEEE Transactions on Systems, Man, and Cybernetics: Systems. doi:10.1109/TSMC.2015.2392072
Chang NB, Pires A, Martinho G (2011) Empowering systems analysis for solid waste management: challenges, trends, and perspectives. Crit Rev Environ Sci Technol 41(16):1449–1530
Clarkson PJ, Simons C, Eckert C (2004) Predicting change propagation in complex design. J Mech Des 126:788–797
Cox JC, Ross SA, Rubinstein M (1979) Option pricing: a simplified approach. J Financ Econ 7(3):229–263
De Baere L (2010) The Dranco technology: a unique digestion technology for solid organic waste. Organic Waste Systems (OWS) Pub Brussels, Beligium
de Neufville R, Scholtes S (2011) Flexibility in engineering design. MIT Press, Cambridge
de Weck OL, Eckert C, Clarkson PJ (2007) A classification of uncertainty for early product and system design. In: International conference on engineering design
Eckert C, Clarkson PJ, Zanker W (2004) Change and customisation in complex engineering domains. Res Eng Des 15(1):1–21
Eppinger SD, Browning TR (2012) Design structure matrix methods and applications. MIT Press, Cambridge
ESD (2011) Engineering systems division strategic report. Massachusetts Institute of Technology, Cambridge
Feo GD, Malvano C (2009) The use of LCA in selecting the best MSW management system. Waste Manag 29(6):1901–1915
Fricke E, Schulz AP (2005) Design for changeability (DfC): principles to enable changes in systems throughout their entire lifecycle. Syst Eng 8(4):342–359
Giffin M, de Weck OL, Bounova G, Keller R, Eckert C, Clarkson PJ (2009) Change propagation analysis in complex technical systems. J Mech Des 131:081001
Guma A, Pearson J, Wittels K, de Neufville R, Geltner D (2009) Vertical phasing as a corporate real estate strategy and development option. J Corp Real Estate 11(3):144–157
Hu J (2012) Flexible engineering system design with multiple exogenous uncertainties and change propagation. Doctoral Dissertation in Industrial and Systems Engineering, National University of Singapore, Singapore
Hu J, Cardin M-A, Poh KL, Chia ES (2013) An approach to generate flexibility in engineering design of sustainable waste-to-energy systems. Paper presented at the International Conference on Engineering Design, Seoul, Korea
Jarratt TAW, Eckert C, Caldwell NHM, Clarkson P (2011) Engineering change: an overview and perspective on the literature. Res Eng Des 22(2):103–124
Jugulum R, Frey DD (2007) Toward a taxonomy of concept designs for improved robustness. J Eng Des 18(2):139–156
Kalligeros K (2006) Platforms and real options in large-scale engineering systems. Doctoral Dissertation in Engineering Systems, Massachusetts Institute of Technology, Cambridge, MA, USA
Allen Kani (2001) WDO study: implications of different waste feed streams (source-separated organics and mixed waste) on collection options and anaerobic digestion processing facility design, equipment and costs. Ontario Waste Diversion Organization
Koh ECY, Caldwell NHM, Clarkson PJ (2012) A method to assess the effects of engineering change propagation. Res Eng Des 23(4):329–351. doi:10.1007/s00163-012-0131-3
Koh ECY, Caldwell NHM, Clarkson PJ (2013) A technique to assess the changeability of complex engineering systems. J Eng Des 24(7):477–498
Ligtvoet A, Herder PM (2012) Simulation and gaming for understanding the complexity of cooperation in industrial networks. In: Hammami O, Krob D, Voirin J-L (eds) 2nd international conference on complex systems design and management. Springer, Berlin
Liu X, Tanaka M, Matsui Y (2006) Generation amount prediction and material flow analysis of electronic waste: a case study in Beijing, China. Waste Manag Res 24(5):434–445
IUT Global Pte Ltd (2006) 9.5 MW food waste based grid connected power project implemented by IUT Singapore Pte Ltd. Clean Development Mechanism
Martin MV, Ishii K (2002) Design for variety: developing standardized and modularized product platform architectures. Res Eng Des 13(4):213–235
Mayer IS (2009) The gaming of policy and the politics of gaming: a review. Simul Gaming 40(6):825–862
Mikaelian T, Rhodes DH, Hastings DE (2011) Real options in enterprise architecture: a holistic mapping of mechanisms and types for uncertainty management. IEEE Trans Eng Manag 58(3):457–470
Mikaelian T, Rhodes DH, Nightingale DJ, Hastings DE (2012) A logical approach to real options identification with application to UAV systems. IEEE Trans Syst Man Cybern Part A Syst Hum 42(1):32–47
Mirarab S, Hassouna A, Tahvildari L (2007) Using bayesian belief networks to predict change propagation in software systems. In: 15th IEEE international conference on program comprehension (ICPC), 2007. pp 177–188
Morgan MG, Henrion M (1990) Uncertainty: a guide to dealing with uncertainty in quantitative risk and policy analysis. Cambridge University Press, Cambridge
Moullec M-L, Bouissou M, Jankovic M, Bocquet J-C, Requillard F, Maas O, Forgeot O (2013) Towards system architecture generation and performances assessment under uncertainty using bayesian networks. J Mech Des 135(4). doi:10.1115/1.4023514
National Environment Agency (2011) Environmental Protection Division Report
National Environmental Agency (2013) Solid waste management. http://app2.nea.gov.sg/energy-waste/waste-management/refuse-disposal-facility
Ng RLAK (2011) Recycling firm IUT Global being wound up. The Business Times
Pasqual MC, de Weck OL (2012) Multilayer network model for analysis and management of change propagation. Res Eng Des 23(4):305–328
Pearl J (1988) Probabilistic reasoning in intelligent systems: networks of plausible inference. Morgan Kaufmann, Los Altos
Pearl J (2000) Causality: models, reasoning and inference, vol 29. Cambridge University Press, Cambridge
RIS international Ltd (2005) Feasibility of generating green power through anaerobic digestion of garden refuse from the sacramento area. MacViro Consultants
Rogoff MJ, Screve F (2011) Waste-to-energy: technologies and project implementation. William Andrew, Norwich
Ross AM (2006) Managing Unarticulated Value: changeability in multi-attribute tradespace exploration. Doctoral Dissertation in Engineering Systems, Massachusetts Institute of Technology, Cambridge, MA, USA
Singapore Power (2013) Electricity tariff rate. http://www.singaporepower.com.sg/irj/portal?NavigationTarget=navurl://41c8e6a3faf48bb168af2c222faa8ee4&windowId=WID1366188757420
Statistics Singapore (2012) Household income from work. http://www.singstat.gov.sg/statistics/browse-by-theme/household-income-and-expenditure
Suh NP (1990) The principles of design, vol 7. Oxford University Press, New York
Suh ES, de Weck OL, Chang D (2007) Flexible product platforms: framework and case study. Res Eng Des 18(2):67–89
Tang A, Nicholson A, Jin Y, Han J (2007) Using Bayesian belief networks for change impact analysis in architecture design. J Syst Softw 80(1):127–148
Tin AM, Wise DL, Su WH, Reutergardh L, Lee SK (1995) Cost–benefit analysis of the municipal solid waste collection system in Yangon, Myanmar. Resour Conserv Recycl 14(2):103–131
Tomiyama T, Gu P, Jin Y, Lutters D, Kind C, Kimura F (2009) Design methodologies: industrial and educational applications. CIRP Ann Manuf Technol 58:543–565
Trigeorgis L (1996) Real options: managerial flexibility and strategy in resource allocation. MIT Press, Cambridge
Wang T (2005) Real options ‘in’ projects and systems design—identification of options and solutions for path dependency. Doctoral Dissertation in Engineering Systems, Massachusetts Institute of Technology, Cambridge, MA, USA
Xie Q, Cardin M-A, Ng TS, Wang S, Hu J (2014) Analyzing Flexibility in Design of Waste-to-Energy Systems. Paper presented at the IIE Conference and Expo, Montréal, Québec, Canada
Xu Y, Huang G, Qin X, Huang Y (2009) SRFILP: a stochastic robust fuzzy interval linear programming model for municipal solid waste management under uncertainty. J Environ Inf 14(2):72–82
Zhou Y, Wursch M, Giger E, Gall H, Lu J (2008) A bayesian network based approach for change coupling prediction. In: 15th working conference on reverse engineering (WCRE), 2008. pp 27–36
Acknowledgments
We are thankful for the financial support provided by the National Research Foundation Singapore under its Campus for Research Excellence and Technological Enterprise (CREATE), which is administered by the National University of Singapore and Shanghai Jiao Tong University. We are also grateful to Poh Kim Leng for his valuable inputs.
Author information
Authors and Affiliations
Corresponding author
Appendix: Example survey questions
Appendix: Example survey questions
Thank you very much for your participation. You are involved in a research project on how to identify flexible design enablers in an anaerobic digestion (AD) system. The goal is ultimately to improve the anticipated future performance of the AD system by considering flexibility in planning, deployment and management. This survey investigates the dependent relationships between system elements within the AD system. Your suggestions will help us better understand the AD system. It also can help construct an engineering system matrix (ESM) representation of the complex system, which is a valuable tool for our research.
-
1.
What are the major sources of uncertainty affecting the future performance of AD systems?
-
2.
Does the quantity of wastes significantly affect the design of AD systems?
-
3.
Which physical components are significantly affected by the change of waste quantity?
-
4.
What are the main stakeholders for AD systems?
-
5.
What are the main objectives for AD systems?
-
6.
What are the main functions provided by AD systems?
-
7.
What are the main physical components for AD systems?
-
8.
How to breakdown the physical components of AD systems?
-
9.
Does dependent relationship exist between element A (e.g., the total amount of organic wastes) and element B (e.g., the design of tipping floor)?
-
10.
What should be a good assignment for strong, moderate, and weak probability of change?
-
11.
How likely is it that element B will change due to a change in element A? Please consider either a strong, moderate or weak assignment.
-
12.
Are you satisfied with the way to investigate the dependencies?
-
13.
Are you happy with the results we achieved?
Rights and permissions
About this article

Cite this article
Hu, J., Cardin, MA. Generating flexibility in the design of engineering systems to enable better sustainability and lifecycle performance. Res Eng Design 26, 121–143 (2015). https://doi.org/10.1007/s00163-015-0189-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00163-015-0189-9