
Abstract
We propose a method to construct a reduced order model with machine learning for unsteady flows. The present machine-learned reduced order model (ML-ROM) is constructed by combining a convolutional neural network autoencoder (CNN-AE) and a long short-term memory (LSTM), which are trained in a sequential manner. First, the CNN-AE is trained using direct numerical simulation (DNS) data so as to map the high-dimensional flow data into low-dimensional latent space. Then, the LSTM is utilized to establish a temporal prediction system for the low-dimensionalized vectors obtained by CNN-AE. As a test case, we consider flows around a bluff body whose shape is defined using a combination of trigonometric functions with random amplitudes. The present ML-ROMs are trained on a set of 80 bluff body shapes and tested on a different set of 20 bluff body shapes not used for training, with both training and test shapes chosen from the same random distribution. The flow fields are confirmed to be well reproduced by the present ML-ROM in terms of various statistics. We also focus on the influence of two main parameters: (1) the latent vector size in the CNN-AE, and (2) the time step size between the mapped vectors used for the LSTM. The present results show that the ML-ROM works well even for unseen shapes of bluff bodies when these parameters are properly chosen, which implies great potential for the present type of ML-ROM to be applied to more complex flows.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, a huge amount of detailed flow field information has been accumulated as fluid big data thanks to high-resolution numerical simulations and image-based measurements. Understanding essential phenomena and controlling flows based on such big data—as they are—are difficult due to their complexity. Therefore, reduced order models (ROMs) have been utilized as one way to tackle such problems. One of the beauties of ROMs is that they can map a flow field with high dimensions into a low-dimensional space [1]. Lumley [2] introduced the proper orthogonal decomposition (POD), which can express a flow field with several principal modes and the corresponding eigenvalues. Schmid [3] proposed the dynamic mode decomposition (DMD) that extracts the information from flow fields by focusing on a specific frequency. These ROMs are considered to have deepened our understanding [4] and enabled us to control flow phenomena at low computational costs [5]. Despite the great advantages of these linear methods, an annoying problem may be that the number of modes required to represent a flow often becomes too large to handle because nonlinear phenomena must be approximated by a linear superposition of orthogonal modes. Even for a turbulent channel flow at a low Reynolds number, for instance, 7260 POD modes are required to reconstruct 95% of its total energy [6]. In order to reduce the number of modes, use of the novel nonlinear dimension reduction technique that brought innovation to image recognition [7], i.e., machine learning, can be considered as a good candidate.
In recent years, machine learning techniques, which can automatically extract key features from tremendous amount of data, have achieved noteworthy results in various fields including fluid dynamics owing to the advances in the algorithms centering on deep learning [8,9,10,11,12,13], which has been enabled by the recent development of computational power. For instance, Ling et al. [14] proposed a tensor basis neural network to predict the Reynolds stress anisotropy tensor for Reynolds-averaged Navier–Stokes simulations. The proposed method was applied to the duct and wavy flows, and it showed substantial merits over the conventional eddy viscosity models. Fukami et al. [15] utilized convolutional neural networks (CNN) [16] for a super-resolution reconstruction of two-dimensional turbulence and reported that the customized CNN model can recover the maximum wavenumbers of energy spectrum from grossly coarse low-resolution flow data. A machine learning method was also applied to the flow around a circular cylinder so as to predict the flow fields at various Reynolds numbers from the pressure drag coefficient distribution [17]. Moreover, Viquerat and Hachem [18] have proposed a CNN-based method to predict drag coefficients in a two-dimensional low Reynolds number flow around various random shapes generated by Bézier curves. In this way, capability of machine learning has been demonstrated for different kinds of fluid dynamics problems, although it should be noted that the literature on this topic is vast and many other applications exist despite the references provided here.
Of particular interest concerning the machine learning for fluid dynamics is its applications to nonlinear reduced-order modeling. San and Maulik [19] proposed an ROM for quasistationary geophysical turbulent flows based on the extreme learning machine. Srinivasan et al. [20] proposed a machine learning model based on a multilayer perceptron and a long short-term memory (LSTM) [22] to successfully predict temporal behaviors of the coefficients in the nine-equation turbulent flow model. More recently, Murata et al. [21] have proposed nonlinear mode decomposition via CNN autoencoder (CNN-AE) and reported its great advantage over POD for the flow around a circular cylinder and its transient process in terms of the feature extraction of flow fields in lower dimensions.
The objective of the present study is to propose a method of reduced-order modeling using CNN-AE and LSTM, which have been separately shown to have great potentials as introduced above. The machine-learned reduced order model (ML-ROM) proposed here is constructed by combining a CNN-AE and an LSTM, which are trained in a sequential manner. The CNN-AE part is trained first to map the high-dimensional flow field obtained by direct numerical simulation (DNS) into a low-dimensional latent space. Then, the LSTM part is trained to predict the temporal evolution of the low-dimensionalized vectors obtained by the CNN-AE. As a test case, we consider two-dimensional unsteady flows around a bluff body. We randomly define the shapes of bluff bodies in order to assess the performance of the present ML-ROM for unseen data. Moreover, the effects of the two key parameters are examined to unveil their influence on the model performance.
The remainder of the paper is organized as follows. Section 2 introduces the details of the training data and the theory of the machine learning models. The results and case studies on the prediction of flows around bluff bodies of various shapes are presented and discussed in Sect. 3. Finally, the concluding remarks are provided in Sect. 4.
2 Methods
2.1 Training data
Two-dimensional direct numerical simulation (DNS) of flows around various bluff bodies, whose shapes are defined randomly, is performed to obtain the flow fields used for training, validation, and assessment of the ML-ROM. The governing equations are the incompressible continuity and Navier–Stokes equations, i.e.,
where \({{\varvec{u}}}{=[u, v]^T}\), p, and t denote the velocity, pressure, and time, respectively. All variables are made dimensionless by the fluid density \(\rho ^*\) , the uniform velocity \(U_\infty ^*\), and the frontal length \(D^*\) of the body, where the superscript \(*\) represents dimensional variables. The Reynolds number is set to \(\text {Re}_D=U_\infty ^*D^*/\nu ^*=100\), where \(\nu ^*\) is the kinematic viscosity.
The computational domain is shown in the left part of Fig. 1. The center of the bluff body is located 9D from the inflow boundary. The uniform velocity \(U_\infty =1\) is given at the inflow boundary, the convective boundary condition is used at the outflow boundary, and the free-slip condition is imposed on the top and bottom boundaries.
The present DNS code is basically the same as that used by Anzai et al. [23] for flows around a square cylinder, except that a ghost-cell method [24] is used to satisfy the no-slip boundary condition on the bluff body surface. The spatial discretization is done by using the energy-conservative second-order finite difference method on a staggered grid system [25], which is uniform in both streamwise (x) and transverse (y) directions with the grid size \(\varDelta x = \varDelta y = 0.025\). The number of computational cells is \((N_x, N_y)=(1024, 800)\). The time integration is done using the low-storage third-order Runge–Kutta/Crank–Nicolson (RK3/CN) scheme [26] with a velocity–pressure coupling similar to the simplified marker and cell (SMAC) method [25]. The time step is set to \(\varDelta t=2.5\times 10^{-3}\). The pressure Poisson equation is solved by means of the fast Fourier transform (FFT) in x direction with the mirroring technique [27] and the tridiagonal matrix algorithm (TDMA) in (y) direction. We have verified for some selected cases that the present grid resolution is sufficiently fine, and we have validated that the time-averaged drag and rms lift coefficients as well as the Strouhal number computed for a circular cylinder (for which references are available) are in good agreement with the references.

As mentioned above, the flows around bluff bodies with various shapes are considered in order to examine whether we can construct a single ML-ROM approximating the function \(\mathcal{F}\) corresponding to the time-discretized Navier–Stokes equation \({{\varvec{q}}}^{(n+1)\varDelta t} = \mathcal{F}({{\varvec{q}}}^{n\varDelta t})\) (where \({{\varvec{q}}}=[u,v,p]^T\) and the superscript denotes time), which is valid even for unseen shapes. The shape of a single bluff body is defined as
where r is the distance between the center and the surface, \(\theta \) represents the angle from the inflow (i.e., x) direction, and \(a_n\) denotes random numbers normalized to satisfy equation (4). The bluff body shapes generated using equations (3) and (4) are rescaled so that the frontal length becomes unity and \(\mathrm{Re}_D=100\) in all cases. Fifty different shapes are defined, and the flows around them are produced using the DNS. Moreover, the flow fields are rotated around the x-axis symmetry to increase the amount of training data. In this way, hundred kinds of flows are prepared as the data sets. Note in passing that the achievable range of shapes generated using equations (3) and (4) is limited, and the use of this formulation is intended to be a proof of concept.

An example of the velocity and pressure fields around the randomly defined bluff body
In order to focus on the flow around the bluff body, the velocities and pressure (u, v, p) in the region enclosed by the red line in Fig. 1 are extracted to use for machine learning. The size of the instantaneous field data used for ML-ROM construction is \((\hat{N_x}, \hat{N_y}, N_{\phi }) = (384, 192, 3)\), where \(\phi \) represents the considered physical quantities. An example of the flow fields is shown in Fig. 2. In this study, we do not apply any data preprocessing such as normalization or standardization since the order of magnitude is unity for all the quantities thanks to the nondimensionalization, and the bluff body shapes are adjusted to have the equal frontal length (i.e., unity) as mentioned above.
2.2 Machine learning
2.2.1 Convolutional neural network autoencoder (CNN-AE)
The convolutional neural network (CNN) [16] has been widely used in the field of image recognition, and it has also been applied to fluid dynamics in recent years [15, 17, 28] due to its ability to deal with spatially coherent information. The CNN is formed by connecting two kinds of layers: convolution layers and sampling layers.

Operations in the convolutional layer and the sampling layer: a convolutional operation using a weighted filter W; b the computation in the convolution layer with \(M=3\); c max pooling operation; d upsampling operation
The convolutional operation performed in the convolution layer can be expressed as
where \(z_{ijk}\) is the input value at point (i, j, k), \(W_{pqkm}\) denotes the weight at point (p, q, k) in the m-th filter, \(b_m\) represents the bias of the m-th filter, and \(s_{ijm}\) is the output of the convolution layer. The schematics of the convolutional operation and a convolution layer without bias are shown in Fig. 3a and b, respectively. The input is a three-dimensional matrix with the size of \(L_1\times L_2\times K\), where \(L_1\), \(L_2\), and K are the height, the width, and the number of channels (e.g., \(K=3\) for RGB images), respectively. There are M filters with the length H and the K channels. After passing the convolution layer, an activation function \(f(\cdot )\) is applied to \(s_{ijm}\), i.e.,
Usually, nonlinear monotonic functions are used as the activation function \(f(\cdot )\). The sampling layer performs compression or extension procedures with respect to the input data. Here, we use a max pooling operation for the pooling layer, as summarized in Fig. 3c. Through the max pooling operation, the machine learning model is able to obtain the robustness against rotation or translation of the images. In contrast, in the convolutional neural network autoencoder [29] (CNN-AE) explained below, the upsampling layer in the decoder part copies the values of the low-dimensional images into a high-dimensional field, i.e., the nearest neighbor interpolation, as shown in Fig. 3d.
The CNN-AE is composed of a CNN encoder \(\mathcal{F}_e\), which maps high-dimensional data into a low-dimensional space, and a CNN decoder \(\mathcal{F}_d\), which extends the data low-dimensionalized by the encoder part. If a CNN-AE \(\mathcal{F}_c\) having a smaller latent vector \(\tilde{{{\varvec{q}}}}\) than the input \({{\varvec{q}}}\) can generate the output identical to the input, it means that the dimension can be successfully reduced while retaining the original information. Summarizing above, the procedures of the CNN-AE are expressed as
where \({{\varvec{q}}}_{\text {deco}}\) denotes the decoder output.

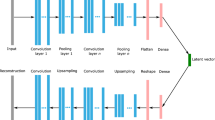
Schematic of the MS-CNN-AE. The layers represented by cubes in the encoder part include the convolutional layer, the batch normalization layer, the ReLU layer, and the max pooling layer in order. As for the decoder part, the cubes include the convolutional layer, the batch normalization layer, the ReLU layer, and the upsampling layer in order
In the present study, a multi-scale CNN-AE model (MS-CNN-AE) shown in Fig. 4 is proposed to reduce the spatial dimension of flow field data. The MS-CNN-AE is inspired by the multi-scale CNN [30] developed for image-based super-resolution analysis to capture multi-scale sense of images. The size of three scales of filters is \(3\times 3\), \(5\times 5\), and \(9\times 9\), respectively. As an example, the structure of the part to map the flow fields into the latent vector \(\tilde{{{\varvec{q}}}}\in {\mathbb R}^{6\times 3\times 4}\) (viz., the size of encoded values is \(n_z=72\)) is summarized in Table 1. There are batch normalization [31] layers between the convolution layer and the activation layer (ReLU) [32] to avoid the overfitting. The batch normalization, which normalizes the output of each unit based on the mean and variance in each training minibatch, is known to accelerate learning by suppressing so-called internal covariate shift. The left and right parts of Fig. 4 are the encoder and the decoder, respectively. The flow fields fed as the input are mapped by these three scales of filters, and then, three encoded values \(\in {\mathbb R}^{6\times 3\times 4}\) are obtained. These three encoded values are added in the add layer shown in Table 1 and fed into 7th Conv. layer to obtain the encoded values representing the flow field in the low-dimensional space. Then, the decoder reconstructs the flow fields in the physical space from the encoded values using upsampling layers.
Usually, the objective of regression tasks with supervised machine learning is to obtain optimized weights \({{\varvec{W}}}\) by minimizing the predefined error function \(\varepsilon \) such that \({{{\varvec{W}}}}=\mathrm{argmin}_{{{\varvec{W}}}}||\varepsilon ||_{\gamma }\), where \(\gamma \) is the parameter of the norm. Here, we use a combination of the mean squared error \(\varepsilon _m\) and the gradient difference loss \(\varepsilon _g\) [33] as the loss function \(\varepsilon \), i.e.,
where the subscripts represent the data indices. The gradient differential loss directly penalizes the gradient among grid points of the flow field data, and this feature enables the model to avoid blurry prediction [34]. Note that tuning of the weight between the mean squared error \(\varepsilon _m\) and the gradient differential loss \(\varepsilon _g\) is required, and its optimal weight varies depending on the problem. In this study, the weight is set to \(\varepsilon _m:\varepsilon _g=1:1\) following our preliminary test.
The Adam algorithm [35] is applied as the optimizer for weight updating, and a fourfold cross-validation is applied to train the models and avoid overfitting [36].

An example of learning curve for the CNN-AE part
The minibatch size is set at 100—changing the minibatch size had no significant influence in our preliminary test. The number of epochs is fixed at 200 (i.e., no early stopping). Figure 5 shows an example of the learning curve, which presents the relation between the number of epochs and the loss value. The curve shows good convergence, and no overfitting is observed. In the model evaluation, we use the best model which provides the lowest validation loss.

Internal procedures of an LSTM
2.2.2 Long Short-Term Memory (LSTM)
The long short-term memory (LSTM) [22] is a machine learning algorithm suited to handle time-series problems, e.g., speech recognition [38]. The LSTM layer is composed of a cell, an input gate, an output gate, and a forget gate, as illustrated in Fig. 6. The input gate is represented by d, output gate by o, and forget gate by g. The cell state is C and the cell output is given by \(h_t\), while the cell input is denoted as \(x_t\), where the subscripts represent a time step. In sum, the internal procedures of the LSTM are formulated as
where W represents the weights for each gates and \(\beta \) is the bias; the subscripts to C, e, and h represent the time indices, and \(\sigma \) is the sigmoid function. Although readers are referred to literature [22] for further details, this structure enables the LSTM layer to deal with the time-series problem by keeping the previous input information in the cell state.

Schematic of the prediction using the LSTM model. The encoded values in black letters are the initial fields generated by applying the CNN-AE to the DNS data. The encoded values indicate the predicted fields by the LSTM from the previous outputs of the LSTM or the initial fields. The number of the initial fields is \(\alpha +1\) in this figure

Schematics of the LSTM model. DO and FC in this figure represent dropout layers and fully connected layers, respectively. The values above the arrows indicate the number of input/output of those layers, and \(n_e\) represents the number of encoded values. Note that each LSTM layer has 128 units; viz., the output size of these layers is 128
In this study, an LSTM model is employed to predict the temporal evolution of low-dimensionalized flow fields generated by the CNN-AE as illustrated in Fig. 7. In the diagram, \(\tilde{{{\varvec{q}}}}\) denotes the low-dimensional field, and the superscript represents time indices. The arbitrary number of the flow fields are fed into the LSTM model as the initial encoded fields. Next, the field predicted from these initial fields is recursively incorporated as the input data to the LSTM model keeping the cell state. The details of the present LSTM model are summarized in Fig. 8. A dropout (DO) [39] is applied in order to avoid overfitting. A flag map of the bluff body (i.e., 1 for the bluff body region, 0 for the fluid region) is provided to the LSTM model as the information including the shape and boundary condition. Our preliminary test has shown that the model with the shape information outperforms the machine learning model without that information.
The mean squared error is used as the loss function \(\tilde{\varepsilon }\) to train the LSTM model, i.e., \(\tilde{\varepsilon }=\overline{(\tilde{{{\varvec{q}}}}_\mathrm{{true}}-\tilde{{{\varvec{q}}}}_\mathrm{{pred}})^2}\), where \(\tilde{{{\varvec{q}}}}_\mathrm{{true}}\) is the true encoded field, \(\tilde{{{\varvec{q}}}}_\mathrm{{pred}}\) is the field predicted by the LSTM model, and the overbar represents the average similar to equation (9). The solution data set is prepared from the output of the CNN-AE, and the LSTM model is trained using teacher forcing [40]. Following our preliminary test, the number of time sequences used for the training process is set to 20. Hence, the training for the LSTM model is equivalent to optimizing the weights in the LSTM model \({{{\varvec{w}}}}_L\) such that
where the subscript of “true” is omitted for brevity. Similarly to the CNN-AE above, the Adam algorithm [35] is applied as the optimizer, a fourfold cross-validation is used, and the best model which provides the lowest validation loss in the learning process is used for the model evaluation. Both the minibatch size and the number of epochs are set to 100. An example of learning curve for the LSTM part is presented in Fig. 9, which shows good convergence and no overfitting.
For the model evaluation, the number of time steps used for the input to the LSTM \(\mathcal{F}_L\) is set to 1 such that \({\tilde{{{\varvec{q}}}}}^{(n+1)\varDelta t}=\mathcal{F}_L({\tilde{{{\varvec{q}}}}}^{n\varDelta t})\) except for the first iteration. For the first iteration, the latent vector at the next time step is obtained from the solution data of the 5 initial time steps (i.e., \(\alpha =4\) in Fig. 7). In sum, the temporal evolution of the mapped vector in the LSTM is formulated as
Note that our preliminary test has shown that the results are not sensitive to the number of time steps used for the first iteration.

An example of learning curve for the LSTM part

Schematic of the ML-ROM with the latent space size of \(6\times 3\times 4\). The number of time steps of the initial field is set to 1 for illustration purpose. The compressed vector obtained by using the CNN encoder evolves temporally using LSTM. The temporal evolution of the flow field is recovered by using the CNN decoder
2.2.3 Machine-learning-based reduced order model (ML-ROM)
As illustrated in Fig. 10, the proposed machine-learning-based reduced order model (ML-ROM) is a combination of the MS-CNN-AE model and the LSTM model introduced above. The initial flow fields generated by DNS are fed into the trained CNN encoder to map those into the latent space. By feeding the obtained latent vectors to the trained LSTM model, it predicts the latent vector at the next time step. The LSTM model recursively predicts the temporal evolution of the encoded fields by using the previous output as the input. The temporal evolution of the flow field in the physical space can be recovered by using the trained CNN decoder. Note that the number of initial flow fields in this figure is set to 1 for simplicity of illustration.

The bluff body shapes of the test data set used to evaluate the machine learning models. The number shown above each shape represents the shape number

Instantaneous flow fields for various bluff bodies. Flow fields computed by the DNS and those reconstructed by the MS-CNN-AE model are compared
3 Results and discussion
3.1 Assessment of ML-ROM for wakes behind various random shapes
As a proof of concept to establish an ML-ROM for unseen data, we use the data sets of bluff bodies with various random shapes, as explained in Sect. 2. In this subsection, the MS-CNN-AE is developed first to map the high-dimensional flow \({\mathbb R}^{\in 384\times 192\times 3}\) into a latent space \({\mathbb R}^{\in 6\times 3\times 4}\). Then, the LSTM part is trained to learn the temporal evolution of the obtained latent vectors. Note that the dependence on the latent vector size will be examined in the next subsection.
The MS-CNN-AE is trained by using the data set which consists of flow data for 80 different bluff bodies with the 500 instantaneous time-series fields prepared for each bluff body shape. This model is evaluated by the test data set, which are different from those used for training. The test data set includes flows around bluff bodies for 20 different shapes shown in Fig. 11.

Time-averaged local squared error fields of MS-CNN-AE for shape number 1
The flow fields computed by the DNS and those reconstructed by the MS-CNN-AE are summarized in Fig. 12. In this figure, the flows with shape numbers of 1, 3, 5, 7, 9, 11, 13 and 15 are shown as the examples. The reconstructed flow fields show good agreement with the reference DNS fields. Although not shown here, the results with other bluff body shapes have similar trends to Fig. 12. Time-averaged local squared error fields for shape number 1 are shown in Fig. 13. Although the error is concentrated near the bluff body, the error is sufficiently small in the wake region.

Assessments of the MS-CNN-AE model for flows around various bluff bodies at \(\mathrm{Re}_D=100\): a mean streamwise velocities on the centerline for shape numbers 1, 3, 5, 7, 9, 11, 13 and 15; b mean squared errors against the reference DNS data; c time-averaged drag coefficient; d time-averaged lift coefficient
The mean streamwise velocities on the centerline of the wake are presented in Fig. 14a. The reconstructed centerline velocities are in excellent agreement with the reference DNS data. The mean squared errors, the time-averaged drag and lift coefficients are also summarized in Fig. 14b, c and d, which indicate that the mean squared errors are sufficiently small and the averaged force coefficients of the reconstructed fields reasonably match the DNS values.

Instantaneous flow fields with various bluff bodies at \(t=25\). The DNS and reconstructed flow fields by the ML-ROM are summarized

Assessments of ML-ROM with various shapes wake at \(\mathrm{Re}_D=100\): a mean streamwise velocity on the centerline for shape numbers 1, 3, 5, 7, 9, 11, 13 and 15; b drag coefficient; c lift coefficient; d Strouhal number
The LSTM is trained by using the time step of \(\varDelta t=0.25\) to learn the temporal evolution of the low-dimensionalized fields for the 80 different bluff bodies obtained by the MS-CNN-AE to construct the ML-ROM, as illustrated in Fig. 10. The amount of the training and validation data is 40000, which consist of 500 time-series data for each bluff body. Five instantaneous flows are prepared for each shape as the initial fields of the predictions, as mentioned above. Some instantaneous fields predicted by the ML-ROM after 100 recursive iterations corresponding to \(t=25\) are compared to the DNS data in Fig. 15. Both flows are observed to be similar for all attributes.
The statistical assessments of the prediction by the ML-ROM are summarized in Fig. 16. The predicted results are again in good agreement with the reference DNS data in terms of the mean centerline velocity and the force coefficients, which suggests that the present ML-ROM can successfully capture the feature of the unsteady wake. As shown in Fig. 16d, the Strouhal number \(\mathrm St\) is also well predicted, which confirms that the temporal structure is also well reproduced by the LSTM part even for the flows not used for the training (note again that shapes 1–20 are not used in the training process).

Time-averaged local squared error fields of ML-ROM for shape number 1

Time trace of mean squared error of ML-ROM for shape number 1
We also present in Fig. 17 the time-averaged local squared error computed using 1000 recursive inputs. Because of the recursive input, the time-averaged error is concentrated in the wake region, especially where the fluctuations are large. The time trace of the mean squared error is also shown in Fig. 18. The error varies periodically in time due to the small difference in the Strouhal number (Fig. 16d), but it does not grow. Summarizing above, the present ML-ROM is confirmed to have the ability to predict the flows around various bluff bodies.
3.2 Influence of the parameters
In the aforementioned discussion, we have set the size of the latent vector in the MS-CNN-AE to be \(n_z=72~(=6\times 3\times 4)\) and the time steps in between the mapped vectors for the LSTM to be \(\varDelta t=0.25\). In this subsection, we discuss the influence of these parameters.

Dependence on the latent vector size in the MS-CNN-AE: a mean streamwise velocity on the centerline; b mean squared error; c time-averaged drag coefficient; d time-averaged lift coefficient. Here, fourfold cross-validation is arranged
3.2.1 Dependence on the latent vector size in the MS-CNN-AE
The dependence on the latent vector size \(n_z\) in the MS-CNN-AE is investigated and summarized in Fig. 19. Here, we examine \(n_z=2\), 36, 72 (baseline), and 4608. Since the temporal evolution of the mapped vector is obtained by the LSTM, which has a fully connected structure between layers, a smaller latent vector allows us to establish an ML-ROM at a lower computational cost.
As shown in Fig. 19a, the mean centerline velocity looks reasonably well reproduced in all cases. However, the mean velocities for some shapes, i.e., shapes 1, 5, and 7, are underestimated with \(n_z=2\) and 36. Similar trends can also be seen in the assessment of the force coefficients as summarized in Fig. 19c and d. It suggests that \(n_z=72\) is the minimum size required to reconstruct the present flow fields with an appropriate fidelity. It is also surprising that the error \(\varepsilon \) with \(n_z=72\) is smaller than that with \(n_z=4608\), as shown in Fig. 19b. This is likely due to the structure of the CNN-AE, which has more pooling operations for \(n_z=72\) case. It is widely known that incorporating the pooling operation in CNN structures enables the models to retain the robustness against the rotation or translation of the images because the sensitivity is decreased [16]. It indicates that the model with \(n_z=72\) is better than that with \(n_z=4608\) in terms of generality for unknown wakes thanks to the aforementioned robustness, especially in the present case where the wakes behind random shapes are considered.
Summarizing above, over-compression of the input and output flow data has a risk to lack the spatially coherent information of the flow field because of the pooling operation; however, the appropriate number of the pooling operation allows us to keep the robustness for unseen data.

Dependence on the time step size in the LSTM: a mean streamwise velocity on the centerline; b relationship between time step and the \(L_2\) error; c time-averaged drag coefficient; d time-averaged lift coefficient; e Strouhal number. Here, fourfold cross-validation is arranged
3.2.2 Dependence on the time step size in the LSTM
For high-fidelity simulations such as DNS and large eddy simulation, the time step size is always limited by numerical constraints. Thus, it would be attractive if the present ML-ROM can be used with substantially wider time step sizes.
Let us examine the dependence on the time step size in the LSTM, as summarized in Fig. 20. Here, we consider 11 cases: \(\varDelta t= 0.25\) (baseline)–5.25 with an increment of 0.50 in dimensionless time, although only the cases with \(\varDelta t=0.25\), 1.25, 2.75, 3.75, and 5.25 are shown in Fig. 20a, c, d, and e. Recall that the time step used in the DNS was \(\varDelta t=2.5\times 10^{-3}\); namely the baseline time step of \(\varDelta t= 0.25\) used for the LSTM is already 100 times wider than that. As shown here, the basic trend observed for the all assessments is that the error increases with the time step size, especially for \(\varDelta t=2.75\) and 3.75.
It is worth noting that the mean centerline velocity profile and the force coefficients are in reasonable agreement even with \(\varDelta t =5.25\). However, in this case, the ML-ROM is considered to learn a typical aliasing signal because the sampling interval \(\varDelta t =5.25\) is close to one period of the actual flow \(T\simeq 6\). The Strouhal number predicted with \(\varDelta t = 5.25\) are around \(\mathrm{St}\simeq 0.02\) for all Reynolds numbers as shown in Fig. 20e, which is also consistent with the value for the \(-1\) aliasing at this sampling rate (i.e., \(|1/T - 1/\varDelta t|\simeq 0.02\)). A similar argument holds for the cases of \(\varDelta t =3.75\) or 2.75 where the sampling interval is longer than or just around the interval corresponding to the Nyquist frequency of the present periodic signal.
We note in passing that the results of the present ML-ROM also depends on the number of time steps used for the input of LSTM to predict the field of the next time step. We used 20 time steps for the training process of LSTM, but significant dependence was not observed in our preliminary test as far as more than 5 time steps were used. This is likely due to the periodic nature of this specific flow. Otherwise, the number of input time steps used for the training process is also a crucial factor, and it should be chosen depending on user’s requirements.
4 Conclusions
We presented machine-learning-based reduced-order modeling for unsteady flows. A convolutional neural network-based autoencoder (CNN-AE) was employed to map a high-dimensional flow field into a low-dimensional latent space, and a long short-term memory (LSTM) was utilized to deal with the temporal evolution of the low-dimensionalized vectors obtained by the CNN-AE. As a test case, flows around bluff bodies with various shapes were considered. The flows predicted by the machine-learned reduced order model (ML-ROM) showed statistically good agreement with the reference DNS data also for unseen bluff body shapes not used in the training process, which suggests that the present ML-ROM learns not just the flow fields used for training but the physics governed by the Navier–Stokes equation under different geometrical configurations.
Moreover, some case studies were conducted to investigate the dependence on the parameters used for the ML-ROM. The size of the latent vector of the CNN-AE model has relatively small influence on the reconstruction ability, but this might be specific to the present problem with temporal periodicity. We also found that the structure of the CNN-AE allows us to keep the robustness for unseen flow data. Concerning the dependence on the time step size used in the LSTM, the error increased with the time step size between the mapped vectors. The value of \(\varDelta t=0.25\), which corresponds to about 20 subdivisions of one period of vortex shedding, can be recommended from the present study to reproduce the Strouhal number accurately.
The present study was a proof of concept to establish an ML-ROM for more general fluid dynamics. It should be stressed again, however, that the present proof of concept was performed with a limited range of shapes, and that more variability will be required in practice. Although laminar periodic flows are considered as the problem setting in the present study, the proposed idea can be further extended to more complex phenomena, e.g., three dimensional flows at high Reynolds numbers. Concerning the possibility of applying LSTM to turbulent flows, Srinivasan et al. [20] have recently demonstrated that the chaotic temporal evolution of the nine-equation turbulent shear flow model can be well captured by utilizing the LSTM, as mentioned in the introduction. Therefore, the key issue for the present type of ML-ROM to be applied to more complex flows should be the development of a more efficient—and preferably interpretable—low-dimensionalization method, as is tackled by different research groups [21, 41].
References
Taira, K., Brunton, S.L., Dawson, S., Rowley, C.W., Colonius, T., McKeon, B.J., Schmidt, O.T., Gordeyev, S., Theofilis, V., Ukeiley, L.S.: Modal analysis of fluid flows: an overview. AIAA J. 55(12), 4013–4041 (2017)
Lumley, J.L.: The structure of inhomogeneous turbulent flows. In: Yaglom, A.M., Tatarski, V.I. (eds.) Atmospheric Turbulence and Wave Propagation, pp. 166–178. Nauka, Moscow (1967)
Schmid, P.: Dynamic mode decomposition of numerical and experimental data. J. Fluid Mech. 656, 5–28 (2010)
Bakewell, H.P., Lumley, J.L.: Viscous sublayer and adjacent wall region in turbulent pipe flow. Phys. Fluids 10, 1880 (1967)
Gómez, F., Blackburn, H.M.: Data-driven approach to design of passive flow control strategies. Phys. Rev. Fluids 2, 021901 (2017)
Alfonsi, G., Primavera, L.: The structure of turbulent boundary layers in the wall region of plane channel flow. Proc. R. Soc. A 463(2078), 593–612 (2007)
Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Nature 313, 504–507 (2006)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521, 436–444 (2015)
Kutz, N.: Deep learning in fluid dynamics. J. Fluid Mech. 814, 1–4 (2017)
Brunton, S.L., Noack, B.R., Koumoutsakos, P.: Machine learning for fluid mechanics. Annu. Rev. Fluid Mech. 52, 477–508 (2019)
Taira, K., Hemati, M.S., Brunton, S.L., Sun, Y., Duraisamy, K., Bagheri, S., Dawson, S.T.M., Yeh, C.-A.: Modal analysis of fluid flows: applications and outlook. AIAA J. 58(3), 998–1022 (2020)
Brenner, M.P., Eldredge, J.D., Freund, J.B.: Perspective on machine learning for advancing fluid mechanics. Phys. Rev. Fluids 4, 100501 (2019)
Fukami, K., Fukagata, K., Taira, K.: Assessment of supervised machine learning methods for fluid flows. Theor. Comput. Fluid Dyn. (2020). https://doi.org/10.1007/s00162-020-00518-y
Ling, J., Kurzawski, A., Templeton, J.: Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. J. Fluid Mech. 807, 155–166 (2016)
Fukami, K., Fukagata, K., Taira, K.: Super-resolution reconstruction of turbulent flows with machine learning. J. Fluid Mech. 870, 106–120 (2019)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Xiaowei, J., Peng, C., Wen-Li, C., Hui, L.: Prediction model of velocity field around circular cylinder over various Reynolds numbers by fusion convolutional neural networks based on pressure on the cylinder. Phys. Fluids 30, 047105 (2018)
Viquerata, J., Hachema, E.: A supervised neural network for drag prediction of arbitrary 2D shapes in low Reynolds number flows, arXiv preprint, arXiv:1907.05090 [physics.comp-ph] (2019)
San, O., Maulik, R.: Extreme learning machine for reduced order modeling of turbulent geophysical flows. Phys. Rev. E 97, 04322 (2018)
Srinivasan, P.A., Guastoni, L., Azizpour, H., Schlatter, P., Vinuesa, R.: Predictions of turbulent shear flows using deep neural networks. Phys. Rev. Fluids 4, 054603 (2019)
Murata, T., Fukami, K., Fukagata, K.: Nonlinear mode decomposition with convolutional neural networks for fluid dynamics. J. Fluid Mech. 882, A13 (2020)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9, 1735–1780 (1997)
Anzai, Y., Fukagata, K., Meliga, P., Boujo, E., Gallaire, F.: Numerical simulation and sensitivity analysis of a low-Reynolds-number flow around a square cylinder controlled using plasma actuators. Phys. Rev. Fluids 2, 043901 (2017)
Kor, H., Ghomizad, M.B., Fukagata, K.: A unified interpolation stencil for ghost-cell immersed boundary method for flow around complex geometries. J. Fluid. Sci. Technol. 12, JFST0011 (2017)
Amsden, A.A., Harlow, F.H.: The SMAC method, Los Alamos Scientific Lab. Report., No. LA-4370 (1970)
Spalart, P.R., Moser, R.D., Rogers, M.M.: Spectral methods for the Navier–Stokes equations with one infinite and two periodic directions. J. Comput. Phys. 96, 297–324 (1991)
Mitsuishi, A., Fukagata, K., Kasagi, N.: Near-field development of large-scale vortical structures in a controlled confined coaxial jet. J. Turbul. 8(23), 1–27 (2007)
Fukami, K., Nabae, Y., Kawai, K., Fukagata, K.: Synthetic turbulent inflow generator using machine learning. Phys. Rev. Fluids 4, 064603 (2019)
Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Science 313, 504–507 (2006)
Du, X., Qu, X., He, Y., Guo, D.: Single image super-resolution based on multi-scale competitive convolutional neural network. Sensors 18(789), 1–17 (2018)
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: The 32nd International Conference on Machine Learning. Lille, France (2015)
Nair, V., Hinton, G.E.: Rectified linear units improve restricted Boltzmann machines, In: Proc. 27th International Conference on Machine Learning (2010)
Mathieu, M., Couprie, C., LeCun, Y.: Deep multi-scale video prediction beyond mean square error, arXiv preprint, arXiv:1511.05440v6 [cs.LG] (2016)
Lee, S., You, D.: Data-driven prediction of unsteady flow over a circular cylinder using deep learning. J. Fluid Mech. 879, 217–254 (2019)
Kingma, D., Ba, J.: A method for stochastic optimization, arXiv preprint, arXiv:1412.6980 [cs.LG] (2014)
Brunton, S.L., Kutz, J.N.: Data-driven Science and Engineering: Machine Learning, Dynamical Systems, and Control. Cambridge University Press, Cambridge (2019)
Prechelt, L.: Automatic early stopping using cross validation: quantifying the criteria. Neural Netw 11(4), 761–767 (1998)
Graves, A., Jaitly, N., Mohamed, A.: Hybrid speech recognition with deep bidirectional LSTM, 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech, Dec. 8-12 (2013)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014)
Williams, R.J., Zipser, D.: A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1, 270–280 (1989)
Ehlert, A., Nayeri, C.N., Morzynski, M., Noack, B.R.: Locally linear embedding for transient cylinder wakes, arXiv preprint, arXiv:1906.07822 [physics.flu-dyn] (2019)
Acknowledgements
Authors are grateful to Dr. S. Obi, Dr. K. Ando, Mr. M. Morimoto, and Mr. T. Nakamura (Keio University) for fruitful discussions. This work was supported through JSPS KAKENHI Grant Number 18H03758 by Japan Society for the Promotion of Science.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Kunihiko Taira.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hasegawa, K., Fukami, K., Murata, T. et al. Machine-learning-based reduced-order modeling for unsteady flows around bluff bodies of various shapes. Theor. Comput. Fluid Dyn. 34, 367–383 (2020). https://doi.org/10.1007/s00162-020-00528-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00162-020-00528-w