
Abstract
The failure probability function (FPF), aiming to decouple the nested-loop reliability-based design optimization solution into a single-loop optimization problem, has attracted a great deal of interest from designers and researchers. It is defined as a function of failure probability with respect to the design parameter. Among the estimation methods for the FPF, the Bayes theorem based on probability distribution function methods is competitive. It transforms the FPF as the estimation of the conditional joint probability density function (PDF) of design parameters on the failure event and the augmented failure probability. The augmented failure probability can be estimated by Monte Carlo simulation, while for the joint multi-dimensional PDF, the existing estimation methods are unavailable. To alleviate this issue, a novel FPF estimation method is proposed by Bayes theorem and copula. In the proposed method, the FPF is derived as a product of the conditional copula density and the augmented failure probability, in which the vine copula is employed to disassemble the multi-dimensional conditional copula density into several bivariate copula density functions, and they can be completed by the existing PDF estimation methods. In contrast to the existing Bayes theorem–based estimation methods for the FPF, the proposed method interprets the FPF as the dependence function between design parameters and the augmented failure probability in terms of copula, which involuntarily breaks the limitation of the multi-dimensional design parameters. In addition, the adaptive Kriging surrogate model is embedded in the proposed method to improve the efficiency of the proposed method. The presented examples demonstrate the efficiency and accuracy of the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A typical reliability-based design optimization (RBDO) solution is a nested-loop approach, i.e., the candidate optimal solutions are first acquired in the outer loop which is followed by the evaluation of reliability constraints in the inner loop. To decouple the nested loop for the RBDO, the failure probability function (FPF) PF(θ), defined as a function of failure probability varying with the design parameter vector θ = (θ1, θ2, ..., θm) (m is the dimension), has been proposed (Jensen 2005; Ching and Hsieh 2007a, b; Zou and Mahadevan 2006). If the function PF(θ) can be obtained beforehand, the inner reliability analysis is transformed into an ordinary constraint, so the nested-loop problem of the RBDO is decoupled into a single-loop optimization problem (Xiukai 2013).
Estimating the function PF(θ) is a challenging problem in real applications, and it has received great attention. Lots of estimation methods have been proposed to calculate the FPF. One strategy of these direct solutions is the interpolation method, i.e., after obtaining the numerous failure probabilities at the predefined interpolation points in the space of the design parameters, the FPF is approximated by the interpolation techniques. This solution is adopted by Jensen (2005), where a linear function of θ is used to calculate the function log[PF(θ)], and at least m reliability analyses are required to determine the corresponding coefficients of the linear function. Gasser and Schueller (1997) proposed to employ a quadratic function of θ to replace the linear function to locally approximate log[PF(θ)]. The minimum required number of reliability analyses is equal to m + m(m + 1)/2. Other competitive methods are based on the Bayes theorem. Au (2005) has proposed a novel augmenting the idea that only a single loop is needed to estimate the FPF PF(θ). The design parameter θ is regarded as a predefined random variable, and Bayes theorem is used to transform the function PF(θ) into a combination including the three parts, i.e., the joint probability density function (PDF) fθ(θ), the conditional joint PDF fθ(θ|F) on the failure event F, and the augmented failure probability P(F) of the failure event F. In these three parts, fθ(θ) is predefined and P(F) can be estimated by the classification of the Monte Carlo simulation (MCS) samples; thus, fθ(θ|F) is pivot for estimating the FPF PF(θ). There are several PDF estimation methods, such as the maximum entropy method (Ormoneit and While 1999; Zhang and Pandey 2013) and the kernel density estimation (KDE) (Botev et al. 2010; Resenblatt 1956). However, for the multi-dimensional (m > 2) design parameters, the maximum entropy method and KDE method are infeasible. There is a strong need to estimate the multi-dimensional conditional joint PDF which is the most critical part of the FPF PF(θ) based on Bayes theorem.
Recently, in the uncertainty analysis field, copula theory has been found widespread application for investigating the correlations of random variables. Copula function that fully defined the multivariate distribution of random variables links the joint distributions functions of random variables to their univariate marginal distributions (Nelsen 2006; Sklar 1959). A most remarkable feature of copula is that it retains all information of the dependence among the random variables (Montes and Heredia 2016). In recent years, the copula theory has been applied to reliability analysis widely. For example, Tang et al. (2013a, b) studied the impact of copula for modeling bivariate distributions on system reliability. Jiang et al. (2014) researched structural reliability analysis using copula-based evidence and used vine copula to process the multi-dimensional correlation for the structural reliability analysis (Jiang et al. 2015). In the engineering system with multiple failure modes, the correlations among the failure modes are investigated in Wu (2015) and He et al. (2018). Therefore, it is hopeful that a more universal reliability analysis strategy can be developed based on copula.
In this paper, FPF PF(θ) is firstly interpreted as a dependence function between the design parameters and the augmented failure probability in terms of copula. According to the transforming the joint PDF to the copula density function, PF(θ) is derived as a product of the conditional copula density function on the failure event and the augmented failure probability. Then, vine copula is used to disassemble the multi-dimensional conditional copula density functions into several bivariate copula density functions which can be obtained by the existing PDF estimations. Additionally, in order to improve the efficiency for classification of the conditional samples and estimating the augmented failure probability, the adaptive Kriging (AK) is embedded into the proposed method.
The rest of this paper is outlined as follows. In Section 2, we briefly review the formulations of the FPF and copula. Section 3 proposes a novel method based on Bayes theorem and copula, it derives the FPF as a product of the conditional copula density function and the augmented failure probability, and then, vine copula can be used to disassemble the multi-dimensional copula density functions into several bivariate copula density functions. Section 4 develops the solution for estimating the FPF by the proposed method, and the AK model is embedded to improve the efficiency of the proposed method. In Section 5, examples are given to illustrate the effectiveness of the proposed method. Section 6 draws some conclusions.
2 Review of basic definitions and formulations
2.1 Formulations of the FPF
Consider a performance function represented by Y = g(X) where X = (X1, X2, ..., Xn) denotes the n-dimensional random input vector, and there is m-dimensional design parameter vector θ = (θ1, θ2, ..., θm) of the m input variables. The FPF PF(θ) under the given θ is described as:
where the failure event F is defined by g(x) as F = {g(x) ≤ 0} and fX(x|θ) denotes the conditional PDF of the random input vector X on the given design parameter vector θ. IF(x) represents the indicator function of failure domain. If g(x) ≤ 0, IF(x) = 1; otherwise, IF(x) = 0.
Based on the Bayes theory and Au’s idea (Au 2005), the design parameters θ can be treated as the random variables, and the PDF fθ(θ) is assigned a prior PDF of θ subjectively. In this work, θ is assigned to be independent and follows the uniform distribution within the design space [θL, θU], where θU and θL represent the upper bound and lower bound, respectively. Hence, the FPF in (1) is derived as
In which, fθ(θ|F) represents the PDF of θ conditioned on the failure event F. The augmented failure probability P(F) of the failure event F is the probability the failure when both X and θ are considered to be random variables, and it is estimated as follows:
According to the expression of FPF in (2), the joint PDF fθ(θ) is usually assigned beforehand, so it can be evaluated without computational cost. The augmented failure probability P(F) can be obtained by the traditional MCS in which both X and θ are considered to be random variables. Thus, the estimating for the conditional PDF fθ(θ|F) is the key to the FPF. Among the existing PDF estimation methods, the maximum entropy method (Ormoneit and While 1999; Zhang and Pandey 2013) is only available for estimating one-dimensional PDF. The KDE method (Botev et al. 2010; Resenblatt 1956) is useable only for one-dimensional PDF or two-dimensional joint PDF estimation. Therefore, the existing methods based on Bayes theorem for estimating the FPF in (2) are limited for the solution to the multi-dimensional design parameters.
2.2 Definition of copula
It is well known that copula is a function that links the multivariate joint cumulative distribution function (CDF) with its one-dimensional marginal CDFs. By Sklar theory (Nelsen 2006; Sklar 1959), if two marginal CDFs \( {F}_{\theta_i}\left({\theta}_i\right) \) and \( {F}_{\theta_j}\left({\theta}_j\right) \) are continuous, and \( {F}_{\theta_i{\theta}_j}\left({\theta}_i,{\theta}_j\right) \) is the joint CDF of θi and θj, then there is only one unique copula \( C\left({F}_{\theta_i}\left({\theta}_i\right),{F}_{\theta_j}\left({\theta}_j\right)\right) \) to combine \( {F}_{\theta_i{\theta}_j}\left({\theta}_i,{\theta}_j\right) \) with marginal \( {F}_{\theta_i}\left({\theta}_i\right) \) and \( {F}_{\theta_j}\left({\theta}_j\right) \). It is defined as:
Let \( {u}_i={F}_{\theta_i}\left({\theta}_i\right) \) and \( {u}_j={F}_{\theta_j}\left({\theta}_j\right) \), \( {F}_{\theta_i}\left({\theta}_i\right) \) and \( {F}_{\theta_j}\left({\theta}_j\right) \) are the CDFs of the ith and the jth variables respectively, then the copula function C(ui, uj) of θi and θj is a joint CDF with uniform marginal distribution in [0, 1]2.
Accordingly, the copula density c(ui, uj) is given as:
Subsequently, joint probability density function of θi and θj is derived as
where \( {f}_{\theta_i}\left({\theta}_i\right)=\frac{d{u}_i}{d{\theta}_i} \) and \( {f}_{\theta_j}\left({\theta}_j\right)=\frac{d{u}_j}{d{\theta}_j} \) are marginal densities of θi and θj, respectively.
3 Bayes theorem–based and copula-based method for estimating the FPF
3.1 Expression of FPF based on Bayes theorem and copula
By use of the definition of copula in (4) and the copula density in (6), the conditional PDF fθ(θ|F) can be derived as:
where u = Fθ(θ) and v = FY(y), and for the special point y = 0 in the whole CDF of the model output, v∗ = FY(0) = P(Y ≤ 0) holds, i.e., the augmented failure probability P(F) = v∗.
Substituting (7) into (2), the FPF PF(θ) can be derived as follows:
Equation (8) indicates that the FPF PF(θ) equals the product of the conditional copula density cU(u|v ≤ v∗) and the augmented failure probability v∗. It also implies that PF(θ) can be regarded as the dependence function of u and v with respect to the copula. In contrast to the existing Bayes theorem–based estimation methods limited for the one- or two-dimensional design parameters, the novel expression of FPF in terms of copula can involuntarily break the limitation of the multi-dimensional design parameters by use of the vine copula.
3.2 Vine copula processing multi-dimensional design parameters
For multi-design parameters in (8), multi-dimensional conditional copula density estimation is the key to the FPF. Since the core of a vine copula is to disassemble the joint PDF of multi-dimensional random variables into several bivariate copula functions related to the margin PDF and their conditional CDFs, vine copula (Shemyakin and Kniazev 2017; Czado 2010; Frederik and Scherer 2014; Bedford and Cooke 2001) is employed to process the multivariate correlations.
For m ≥ 3 random variables θ1, θ2, ..., θm, with continuous marginal distribution functions F1(θ1), F2(θ2), ..., Fm(θm), this is a unique copula function C1, 2, ..., m expressed as
And copula density function c1, 2, ..., m is derived as
In order to illustrate the construction of vine copula, the construction of a 3-dimensional vine copula is explained. For the three-dimensional design parameter vector θ = (θ1, θ2, θ3), its joint PDF f(θ1, θ2, θ3) can be decomposed as outlined below:
where f2|1(θ2|θ1) and f3|1, 2(θ3|θ1, θ2) are the corresponding conditional PDF.
Based on the theory of vine copulas, in a case with three variables, the joint PDF f1, 2, 3(θ1, θ2, θ3) is disassembled by D-vine as follows:
i.e.,
where
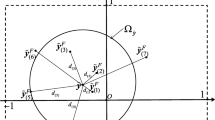
Figure 1 illustrates the principle of constructing a 3-dimensional vine copula by D-vine. It consists of (m − 1) = 2 trees Tj(j = 1, 2). In tree 1, three uniform distributed in [0,1] random variables F1(θ1),F2(θ2), and F3(θ3) are given and their pairwise dependences are represented by the bivariate copulas C12 and C23. In tree 2, there are two conditional CDFs F1|2 and F2|3 obtained by partial differentiation for the bivariate copulas C12 and C23 respectively, and the pairwise dependence between the two conditional CDFs is described by the conditional copula C13|2.

Construction of a 3-dimensional vine copula
In the case with three design variables θ = (θ1, θ2, θ3), let u|v ≤ v∗ = u∗, i.e., \( {u}^{\ast }=\left({u}_1^{\ast },{u}_2^{\ast },{u}_3^{\ast}\right) \). The FPF PF(θ) with three design variables is derived as
where \( {u}_{1\left|2\right.}^{\ast }={F}_{1\left|2\right.}\Big(\left({\theta}_1\left|F\Big)\right.\left|\Big({\theta}_2\left|F\Big)\right.\right.\right) \) and \( {u}_{3\left|2\right.}^{\ast }={F}_{3\left|2\right.}\Big(\left({\theta}_3\left|F\Big)\right.\left|\Big({\theta}_2\left|F\Big)\right.\right.\right) \).
Similarly, in the case with four design variables θ = (θ1, θ2, θ3, θ4), PF(θ) with four design variables is derived as
where \( {u}_{2\left|3\right.}^{\ast }={F}_{2\left|3\right.}\Big(\left({\theta}_2\left|F\Big)\right.\left|\Big({\theta}_3\left|F\Big)\right.\right.\right) \), \( {u}_{4\left|3\right.}^{\ast }={F}_{4\left|3\right.}\Big(\left({\theta}_4\left|F\Big)\right.\left|\Big({\theta}_3\left|F\Big)\right.\right.\right) \), \( {u}_{1\left|23\right.}^{\ast }={F}_{1\left|23\right.}\Big(\left({\theta}_1\left|F\Big)\right.\left|\Big({\theta}_2\left|F,\right.{\theta}_3\left|F\Big)\right.\right.\right) \), and\( {u}_{4\left|23\right.}^{\ast }={F}_{4\left|23\right.}\Big(\left({\theta}_4\left|F\Big)\right.\left|\Big({\theta}_2\left|F,\right.{\theta}_3\left|F\Big)\right.\right.\right) \).
Through the above analysis, it can be found that the FPF PF(θ) with multi-dimensional design parameters is fully determined by the augmented failure probability v∗ and several bivariate copula density functions disassembled from multivariate copula density. Therefore, based on the vine copula, the existing estimation methods based on Bayes theorem for the FPF PF(θ) can be extended to the multi-dimensional design parameters.
4 Solutions for estimating the FPF-based copula
Based on the novel expression of the FPF in terms of copula in (8), it implies that the FPF PF(θ) is fully determined by several bivariate copula density functions and the augmented failure probability v∗, which can be estimated by a group of MCS samples. For estimating these bivariate copula density functions, generally, there are two categories for this purpose: the parametric estimation and the nonparametric estimation. Comparing with the former, because it does not need to assume any specific family for copula function, the nonparametric estimation is more general and flexible (Bedford and Cooke 2002; Cherubini and Luciano 2004; Scaille and Fermanian 2002). Many nonparametric methods can be employed to estimate the bivariate copula density. In this paper, a widely used two-dimensional KDE method (Botev et al. 2010) is employed to evaluate these bivariate copula density functions.
4.1 Strategy of estimating the conditional CDFs
In the construction of the vine copula, it should be noted that the corresponding conditional CDFs are required for estimating the bivariate copula density functions. Although there are several nonparametric methods (Gijbels et al. 2011; Gijbels et al. 2012; Kauermann and Schellhase 2014; Nagler and Czado 2016) for estimating these CDFs, they require the complicated estimation of the weights, integral or other operators. In order to reduce the complexity of estimation, in this work based on Bayes theorem, a strategy of estimating the conditional CDFs proposed in Li et al. (2019) is employed, and the conditional CDFs are derived as
where FX(x) = U, FY(y) = V, and FZ(z) = W, cU is denoted as the copula density of U, fX, Y(x, y) is the joint PDF of X and Y, and fX, Y(x, y| Z ≤ z) and cUV(u, v| W ≤ w) are the conditional joint PDF of X and Y and conditional copula density on the event {Z ≤ z}, respectively.
In the vine copula, two kinds of conditional CDFs are needed, such as \( {u}_{1\left|2\right.}^{\ast }={F}_{1\left|2\right.}\Big(\left({\theta}_1\left|F\Big)\right.\left|\Big({\theta}_2\left|F\Big)\right.\right.\right) \) and \( {u}_{1\left|23\right.}^{\ast }={F}_{1\left|23\right.}\Big(\left({\theta}_1\left|F\Big)\right.\left|\Big({\theta}_2\left|F,\right.{\theta}_3\left|F\Big)\right.\right.\right) \). Based on (17) and (18) derived in Li et al. (2019), the two kinds of conditional CDFs can be derived as
where \( {\theta}_i^{\ast }={\theta}_i\mid F\ \left(i=1,2,...,m\right) \) denotes the design parameter falling into the failure domain.
According to (19) and (20), the conditional CDFs in vine copula can be obtained by the one- or two-dimensional KDE.
4.2 Estimation procedure of the proposed method
The FPF PF(θ) in (8) can be estimated by a group of MCS samples. The detailed steps of the proposed method are generalized as follows:
-
Step 1.
Generate N-samples of the margin CDF u of design parameters θ, N-samples of the design parameters θ and the corresponding input variables X. The detailed process is given as follows:
-
i.
Produce N-size sample set A = {u1, u2, ..., uN} of the m-dimensional random variables following the uniformly distributed in the interval [0, 1], where uj = (u1j, u2j, ...umj) (j = 1, 2, ..., N).
-
ii.
Obtain N-samples of the m-dimensional design parameters by \( {\boldsymbol{\theta}}_j={F}_{\theta_j}^{-1}\left({u}_j\right) \), where each of design parameters θ is assigned to be independent and follow uniform distribution with the upper bound θU and the lower bound θL, i.e., θ ∼ U(θL, θU).
-
iii.
For one sample point of design parameters θ, generate one corresponding input variable X. Thus, obtain N-size sample set S = {x1, x2, ..., xN} of the m-dimensional input variables by fX(X|θ), where xj = (x1j, x2j, ...xmj) (j = 1, 2, ..., N).
-
i.
-
Step 2.
Compute the model output for all the samples of input variables in S by (21), then obtain a vector of model output of dimension N × 1:
-
Step 3.
Screen the failure samples from A, and denote \( {\boldsymbol{A}}_F=\left\{{u}_1^{\ast },{u}_2^{\ast },...,{u}_{N_F}^{\ast}\right\} \) as the failure sample set, where NF is the number of the failure samples and \( {\boldsymbol{u}}_j^{\ast }=\left\{{u}_{1j}^{\ast },{u}_{2j}^{\ast },...,{u}_{mj}^{\ast}\right\}\ \left(j=1,2,...,{N}_F\right) \).
-
Step 4.
Estimate the augmented failure probability v∗ by
-
Step 5.
Use the D-vine construction of vine copula to disassemble the multi-dimensional copula density \( {c}_{U_1,{U}_2,...{U}_m}\left({u}_1^{\ast },{u}_2^{\ast },...,{u}_m^{\ast}\right) \) into a product of several bivariate copula density functions and marginal PDFs.
-
Step 6.
Estimate the conditional CDFs disassembled from vine copula by use of the strategy of estimating the conditional CDFs introduced in Section 4.1.
-
Step 7.
Estimate the bivariate copula density functions disassembled from vine copula by use of two-dimensional KDE method.
-
Step 8.
Estimate the FPF PF(θ) based on (8).
Apparently, for estimating the FPF PF(θ), a set of N samples of the design parameters and input variables is needed. Thus, the computational cost is free of the dimensionality of the design variables. However, the computational burden of the proposed method with N times of the actual performance function evaluations is still unacceptable for some complex engineering problems requiring time-consuming finite element analysis. In order to enhance its applicability of the proposed method, the AK surrogate model based on U-learning function (Echard et al. 2011) is embedded in the proposed method to improve the efficiency.
4.3 The implementation of combining the proposed method with the AK model for estimating FPF
Based on the estimation procedure of the proposed method in Section 4.2, it can be found that the computational cost for estimating FPF by the proposed method is mainly consumed in classifying the samples set into the safety sample set and the failure sample set to estimating the augmented failure probability v∗, while the copula density \( {c}_{U_1,{U}_2,...{U}_m}\left({u}^{\ast}\right) \) is the byproduct of estimating v∗. Therefore, the AK surrogate model can be employed to replace the actual performance function for classification of the samples based on U-learning function. The detailed introduction to the AK surrogate model (Echard et al. 2011) is given in the Appendix. And the detailed steps of the proposed method combining with the AK model are generalized as follows:
-
Step 1.
Generate N-size sample set A = {u1, u2, ..., uN} of the m-dimensional random variables following the uniformly distributed in the interval [0, 1], where uj = (u1j, u2j, ...umj) (j = 1, 2, ..., N).
-
Step 2.
Obtain N-samples of the m-dimensional design parameters by \( {\boldsymbol{\theta}}_j={F}_{\theta_j}^{-1}\left({u}_j\right) \), where each of design parameters θ is assigned to be independent and follow uniform distribution with the upper bound θU and the lower bound θL, i.e., θ ∼ U(θL, θU).
-
Step 3.
For one sample point of design parameters θ, generate one corresponding input variable X. Thus, obtain N-size sample set S = {x1, x2, ..., xN} of the m-dimensional input variables by fX(X|θ), where xj = (x1j, x2j, ...xmj) (j = 1, 2, ..., N).
-
Step 4.
Select N0-size initial sample points from S and calculate their outputs by the actual performance function, denoted as S0 and g0 respectively, and then collect them to the training sample set {S0, g0} to build the initial AK model gK(x).
-
Step 5.
Select the new training sample point xu by the following U-learning function:
where \( {\mu}_{g_K}\left({x}_j\right) \) and \( {\sigma}_{g_K}\left({x}_j\right) \) are respectively the prediction value and standard deviation of the current AK model gK(x) at xj ∈ S. And the new training sample point xu is obtained by
-
Step 6.
Judge the convergence of the current AK model:
-
i.
If U(xu) < 2, it indicates that the current gK(x) does not converge, the training sample set {S0, g0} should be updated as {S0 ∪ xu, g0 ∪ g(xu)}. Then, gK(x) should be updated by use of the updated training sample set and return to step 5.
-
ii.
If U(xu) ≥ 2, it indicates that the current gK(x) is convergent, and it can correctly distinguish the symbols of the outputs at the sample points in S with 1 − Φ(−2) = 97.7% probability, where Φ(⋅) denotes the calculative distribution function of a standard normal variable. Then, execute step 7.
-
i.
-
Step 7.
Screen the failure sample points from A by the convergent AK model gK(x), and collect the failure sample points to the failure sample set \( {\boldsymbol{A}}_F=\left\{{u}_1^{\ast },{u}_2^{\ast },...,{u}_{N_F}^{\ast}\right\} \), where NF is the number of the failure samples and \( {\boldsymbol{u}}_j^{\ast }=\left\{{u}_{1j}^{\ast },{u}_{2j}^{\ast },...,{u}_{mj}^{\ast}\right\}\ \left(j=1,2,...,{N}_F\right) \).
-
Step 8.
Estimate the augmented failure probability v∗ by
-
Step 9.
Use vine copula to disassemble the multi-dimensional copula density \( {c}_{U_1,{U}_2,...{U}_m}\left({u}_1^{\ast },{u}_2^{\ast },...,{u}_m^{\ast}\right) \) into a product of several bivariate copula density functions and marginal PDFs.
-
Step 10.
Estimate the conditional CDFs disassembled from vine copula by use of the strategy of estimating the conditional CDFs introduced in Section 4.1.
-
Step 11.
Estimate the bivariate copula density functions disassembled from vine copula by use of two-dimensional KDE method.
-
Step 12.
Estimate the FPF PF(θ) based on (8).
Based on the estimation steps above, in order to construct the convergent AK model, N0 + Nt times of model evaluations are acquired, where Nt is the size of the final new training sample points selected by (24). Generally, N0 + Nt < < N. Therefore, the efficiency of the proposed method combining with the AK is improved greatly. Since the convergent AK model can correctly distinguish the performance function g(X) signs of samples in S with 1 − Φ(−2) = 97.7% probability based on U-learning function defined by (23), the precision of the proposed method embedding AK model can keep almost same as that of the proposed method without AK model, while the computational cost can be greatly reduced.
Figure 2 demonstrates the procedure of the proposed method for estimating the FPF.

The flowchart of the proposed method for estimating the FPF
5 Illustrative examples
In this section, comparing with the traditional MCS with \( {N}_{\theta_1}\cdot {N}_{\theta_2}\cdot ...,\cdot {N}_{\theta_m}\cdot N \) times of the performance function evaluations (where \( {N}_{\theta_i}\ \left(i=1,2,...,m\right) \) denotes the number of the design parameter θi required at the predefined interpolation points, in this work, we discretize uniformly each design parameter space into 10 points, i.e., \( {N}_{\theta_i}=10 \), N is the number of performance function runs for estimating failure probability), three examples are analyzed to demonstrate the effectiveness of the proposed method by Bayes theorem and copula. The results obtained by the traditional MCS are regarded as the reference values.
5.1 Example 1: An automobile front axle
In the automobile engineering, the front axle supporting the weight of the front part of the vehicle is one of the most important structures, where the I-beam structure is general in the design of the front axle due to its high bend strength and light weight. As shown in Fig. 3, the dangerous location appears in cross section. And σ = M/Wx denotes the maximum normal stress and τ = T/Wρ represents the shear stress, where M, T, Wx, and Wρ are the bending moment, torque, section factor, and polar section factor, respectively. Wx and Wρ are evaluated as follows:

Automobile front axle structure
To check the strength of the front axle, the output of the model is expressed by (28)
where σs is the yield strength and σs = 460 MPa. The geometry variables of I-beam including a, B, C, and h shown in Fig. 3 and the load variables including M and T are mutually independent with normal distribution. The distribution parameters are listed in Table 1.
5.1.1 Case 1: One design parameter
Suppose the mean value of B be the single design parameter, i.e., θ = μB and μB ∈ [55, 75]. The interval of the design parameter μB is discretized uniformly into 10 points. The results of FPF PF(θ) estimated by the MCS, the proposed method based on the Bayes theorem and copula, and the proposed method combining with AK are shown in Fig. 4. In the MCS, for estimating failure probability at each sample point of the design parameter μB, 106 sample points of input random variable are needed, i.e., 107 times of the model evaluations are required for these 10 sample points of μB. For the sake of fairness, the samples of input variables for the proposed method are same to 106 at each sample point of the design parameter. However, Bayes theorem–based method is a single loop; 106 times of model runs are required for all of the 10 sample points of the design parameter by the proposed method. In the proposed method combining with the AK model, only 233 times of the model runs are required to construct the convergent AK model for classification of the conditional samples and estimating the augmented failure probability, which improves the efficiency dramatically. Because the convergent AK model can identify the symbols of the output in sample pool correctly, the accuracy of the proposed method combining with AK is same as that of the proposed method without embedding AK.

The estimates of FPF of case 1
As shown in Fig. 4, we can see that three curves plotted by the traditional MCS, the proposed method without embedding AK, and the proposed method combining with AK model are almost superposed, which indicates that the results estimated by the two proposed methods are consistent with those obtained by the traditional MCS.
In order to check the accuracy of the proposed method, the maximum relative error (MAXRE) is defined by
where Nθ is the number of design parameter θ required at the predefined interpolation points and PFj(θ) and \( {\hat{P}}_{Fj}\left(\boldsymbol{\theta} \right) \) represent the failure probability estimated by the proposed method and that obtained by the MCS, respectively. Figure 5 demonstrates the MAXRE curve of FPF obtained by the proposed method vs sample size. It can be found that the MAXRE of results gradually decreases with the increase of sample size.

The MAXREs estimated by the proposed method vs sample size in case 1
5.1.2 Case 2: Two design parameters
Suppose the mean value of a and B be the design parameters, i.e., θ = (μa, μB), and μa ∈ [10, 14] and μB ∈ [55, 75]. For each design parameters, we still discretize them into 10 points. Thus, 10 × 10 × 106 model evaluations are needed by the traditional MCS, where for each sample of 10 × 10 design points, 106 samples of input variables are employed for reliability analysis. While in the proposed method, as analyzed above in case 1, only a set of 106 samples are enough; thus, the computational cost of the proposed method is free of the dimensionality of the design parameters. In order to construct the AK model to identify the sample points falling into the failure domain in samples pool with 106 input variable samples, 100 initial samples and 149 training samples are needed. Therefore, the total number of model evaluating is only 249 in the proposed method combining with AK model.
The results of FPF in the diagonal of the whole design space are illustrated in Fig. 6. From Fig. 6, it can be seen that the curves obtained by the proposed method and that combining with AK model are in good agreement with that plotted by the traditional MCS. The MAXRE curve of results obtained by the proposed method and those estimated by MCS is plotted in Fig. 7. The MAXRE is generally smaller as the size of samples increasing, and when the sample size is 108, the MAXRE is smaller than 0.1.

The estimates of FPF of case 2

The MAXREs estimated by the proposed method vs sample size in case 2
5.1.3 Case 3: Three design parameters
Suppose the mean value of a, B, and h be the design parameters, i.e., θ = (μa, μB, μh), where μa ∈ [10, 14], μB ∈ [55, 75], and μh ∈ [75, 95]. The region of each design parameter is uniformly discretized into 10 points. Thus, in the whole space of design parameters, 10 × 10 × 10 × 106 model evaluations are required by the traditional MCS, where 106 sample points are employed to estimate the failure probability at each design point. For this problem with three design parameters, vine copula is needed to decompose the joint conditional PDF to several bivariate copula densities. Because of the Bayes theorem, only a single loop with a set of 106 samples is needed by the proposed method. While for the proposed method combining with AK model, 246 samples are enough for constructing the AK model to estimate the augmented failure probability. The efficiency of the methods for example 1 is listed in Table 2.
The results of FPF at the edges of the whole design space are plotted in Fig. 8. As demonstrated in Fig. 8, the curves obtained by the proposed two methods are consistent with each other. There is very small difference between the results evaluated by the proposed methods and those obtained by MCS. Figure 9 demonstrates the MAXRE of the results vs the sample size. It can be found that the bigger the sample size, the smaller the MAXRE, and it indicates that the proposed method is accurate for estimating FPF when the size of samples is big enough.

The estimates of FPF of case 3

The MAXREs estimated by the proposed method vs sample size in case 3
5.2 Example 2: An aero engine turbine disk
Turbine disk (Yun et al. 2018), which plays a big role in supporting, connecting, and transmitting torque and power, and meanwhile, undergoes the complex loads, is a very important part in engine turbine. Because of the complex structural shape, the stress concentration easily takes place in some parts during the working process, such as tongue, groove bottom, and pin hole. After working for a period of time, some cracks may appear. Figure 10 shows the crack of an aero engine turbine disk.

Crack of an aero engine turbine disk
The load applied on an aero engine turbine disk is F = Cω2/2π + 2ρω2J, in which ρ, C, ω, and J are the mass density, coefficient, rotation angular velocity, and moment of inertia, respectively. And ω = 2πn, n is the rotational frequency. The performance function of the structure is
where σs is the ultimate strength and A is the sectional area.
The distribution types and parameters of input variables are listed in Table 3.
Suppose the mean value of σs, ρ, C, and n be the design parameters, i.e., \( \boldsymbol{\theta} =\left({\mu}_{\sigma_s},{\mu}_{\rho },{\mu}_C,{\mu}_n\right) \), and \( {\mu}_{\sigma_s}\in \left[0.6\times {10}^9,1.6\times {10}^9\right] \), μρ ∈ [4000, 12000], μC ∈ [2.67, 8.67], and μn ∈ [150, 250]. With 10 points uniformly discretized for each design parameter in the design space, 10 × 10 × 10 × 10 × 106 times of model evaluations are needed by the traditional MCS, where 106 times of computational cost are used for each reliability analysis at each sample point of the design parameters. The computational burden of MCS with 1010 numbers of model runs is very heavy. In the proposed method, vine copula is employed to process four-dimensional design parameters by (16), and 106 times of model runs are enough for estimating the augmented failure probability. Combining with AK model with 100 initial samples and 106 training samples, the computational cost is only 206. Because the convergent AK model can recognize all symbols of outputs at all samples in the sample pool, the calculation accuracy of the proposed method combining with AK keeps as same as that of the proposed method without embedding AK, but the former efficiency is greatly higher. The efficiency of the methods for example 2 is listed in Table 4.
The curves of FPF at the edges of the design space are plotted in Fig. 11. As illustrated in Fig. 11, we can see that the curves of the FPF obtained by the proposed two methods are mostly in agreement with those estimated by the traditional MCS.

The estimates of FPF of the aero engine turbine disk with four design parameters
5.3 Example 3: A flap structure
In this example, a flap structure with four parts, including moveable wings, fixed wing, the control mechanism, and beams subjected to an aerodynamic load F, is investigated (Wei et al. 2013). One of the main failure modes is that the maximum displacement Δmax of the flap exceeds the threshold ΔD. Here, ΔD = 0.4 m. Based on the finite element analysis (the model is built by ANSYS 14 software in this work, as shown in Fig. 12), the performance function for the flap structure is:
where t1, t2, and t3 are the thickness of beams, respectively. E1 and E2 denote Young’s modulus of the skin and the frame, respectively. And G1 and G2 correspond to the shear modulus, respectively. These input variables are assumed to be independent and follow the normal distribution. Their distribution parameters are listed in Table 5.

Finite element model of the flap structure
In this example, five design parameters including the mean values of t1, t2, t3, G1, and G2 are considered design parameters, i.e., \( \theta =\left({\mu}_{t_1},{\mu}_{t_2},{\mu}_{t_3},{\mu}_{G_1},{\mu}_{G_2}\right) \), and \( {\mu}_{t_1}\in \left[1.9,2.1\right] \), \( {\mu}_{t_2}\in \left[1.9,2.1\right] \), \( {\mu}_{t_3}\in \left[3.8,4.2\right] \), \( {\mu}_{G_1}\in \left[2.5\times {10}^4,2.7\times {10}^4\right] \), and \( {\mu}_{G_2}\in \left[2.6\times {10}^4,2.8\times {10}^4\right] \). The region of each design parameter is uniformly discretized into 10 points. Thus, in the whole space of design parameters, 105 × 106 model evaluations are required by the traditional MCS, where 106 sample points are employed to estimate the failure probability at each design point. As mentioned by other examples, only a set of 106 samples is needed for the proposed method. While in the proposed method combining with AK model, 416 times of model runs are required to construct the convergent AK model for FPF, which improves the efficiency greatly. The efficiency of the methods for example 3 is listed in Table 6.
The results of FPF at the edges of the whole design space are plotted in Fig. 13. Figure 13 shows the curves obtained by proposed methods are almost consistent with those obtained by the MCS.

The estimates of FPF of example 3 with five design parameters
6 Conclusion
The FPF is defined as a failure probability function with respect to the design parameters of the random inputs, which can be used to decouple the nested-loop reliability-based design optimization solution into a single-loop optimization problem. In this paper, based on Bayes theorem and copula, a novel FPF estimation method is proposed. In the proposed method, FPF is derived as a product of the conditional copula density and the augmented failure probability, in which the vine copula can be used to disassemble the multi-dimensional conditional copula density into several bivariate copula density functions which can be estimated by the two-dimensional KDE method. Additionally, a novel strategy of estimating the conditional CDFs is used in vine copula. In contrast to the existing Bayes theorem–based methods for FPF, the novel method can be extended to multi-dimensionality. In order to further improve the efficiency for complex and time-consuming performance function to meet engineering requirements, the AK model based on U-learning function is embedded in the proposed method to estimate the augmented failure probability.
An automobile front axle, an aero engine turbine disk, and a planar 10-bar structure have been introduced for validating the proposed methods. Two main conclusions can be drawn. First, the proposed method can be used to estimate the FPF with multi-dimensional design parameters accurately. Second, the proposed method combining with AK model can dramatically reduce the computational burden to meet the requirement of the engineering application.
References
Au SK (2005) Reliability-based design sensitivity by efficient simulation. Comput Struct 83(14):1048–1061
Bedford T, Cooke RM (2001) Probability density decomposition for conditional dependent random variables modeled by vines. Ann Math Artif Intell 32:245–268
Bedford T, Cooke RM (2002) Vines-a new graphical model for dependent random variables. Ann Stat 30(4):1031–1068
Botev ZI, Grotowski JF, Kroese DP (2010) Kernel density estimation via diffusion. Ann Stat 38:2916–2957
Cherubini U, Luciano E, Vecchiato W. Copula methods in finance. John Wiley & Sons Ltd, 2004
Ching J, Hsieh YH (2007a) Approximate reliability-based optimization using a three step approach based on subset simulation. J Eng Mech 133(4):481–493
Ching J, Hsieh YH (2007b) Local estimation of failure probability function and its confidence interval with maximum entropy principle. Probabilistic Eng Mech 22(1):39–49
Czado C. Pair-copula constructions of multivariate copulas, Copula theory and its spplications. Springer Berlin Heidelberg, 2010, 93–109
Echard B, Cayton N, Lemaire M (2011) AK-MCS: an active learning reliability method combining Kriging and Monte Carlo simulation. Struct Saf 33(2):145–154
Frederik M, Scherer M. Pair copula constructions, Simulating copulas: stochastic models, sampling algorithms, and applications, 2014, 185–230
Gasser M, Schueller GI (1997) Reliability-based optimization of structural systems. Math Meth Oper Res 46(3):287–307
Gijbels I, Veraverbeke N, Omelka M (2011) Conditional copulas, association measures and their applications. Comput Stat Data An 55(5):1919–1932
Gijbels I, Omelka M, Veraverbeke N (2012) Multivariate and functional covariates and conditional copulas. Electron J Stat 6:1273–1306
He LL, Lu ZZ, Li XY (2018) Failure-mode importance measure in structure system with multiple failure modes and its estimation using copula. Reliability Engineering and Structural Safety 174:53–59
Hu J, Zhou Q, Jiang P et al (2017) An adaptive sampling method for variable-fidelity surrogate models using improved hierarchical Kriging. Eng Optim 5:1–19
Jensen HA (2005) Structural optimization of linear dynamical systems under stochastic excitation: a moving reliability database approach. Comput Methods Appl Mech Eng 194(12–16):1757–1778
Jiang C, Zhang W, Wang B et al (2014) Structural reliability analysis using a copula-function-based evidence theory model. Comput Struct 143:19–31
Jiang C, Zhang W, Han X (2015) A vine-copula-based reliability analysis method for structures with multidimensional correlation. J Mech Des 137:061405.1–13
Kauermann G, Schellhase C (2014) Flexible pair-copula estimation in D-vines with penalized splines. Stat Comput 24(6):1081–1100
Li XY, Zhang WH, He LL. A novel nonparametric estimation for conditional copula functions based on Bayes theorem, under review, 2019
Montes IR, Heredia ZE (2016) Reliability analysis of mooring lines using copulas to model statistical dependence of environmental variables. Appl Ocean Res 59:564–576
Nagler T, Czado C (2016) Evading the curse of dimensionality in nonparametric density estimation with simplified vine copulas. J Multivar Anal 151:69–89
Nelsen RB. An introduction to copulas, . Springer Series in Statistics, 2006
Ormoneit D, While H (1999) An efficient algorithm to compute maximum entropy densities. Econ Rev 18:127–140
Resenblatt M (1956) Remarks on some nonparametric estimates of a density function. Ann Math Stat 27(6):832–837
Scaille O, Fermanian, Jean D. Nonparametric estimation of copulas for time series. FAME Research paper No.57, 2002
Shemyakin A, Kniazev A. Introduction to Bayesian estimation and copula models of dependence. WILEY, 2017
Sklar M. Fonctions de Répartition à n-dimensions Marges. Universite Pairs,1959
Tang XS, Li DQ, Zhou CB et al (2013a) Bivariate distribution models using copulas for reliability analysis. Eng Mech 30(12):8–17
Tang XS, Li DQ, Zhou CB et al (2013b) Impact of copulas for modeling bivariate distributions on system reliability. Struct Saf 44:80–90
Wei PF, Lu ZZ, Song JW (2013) A new variance-based global sensitivity analysis technique. Comput Phys Commun 184:2540–2551
Wu XZ (2015) Assessing the correlated performance functions of an engineering system via probabilistic analysis. Struct Saf 52:10–19
Xiukai Y (2013) Local estimation of failure probability function by weighted approach. Probabilistic Eng Mech 34:1–11
Yun WY, Lu ZZ, Jiang X (2018) A modified importance sampling method for structural reliability and its global reliability sensitivity analysis. Struct Multidiscip Optim 57(4):1625–1641
Zhang XF, Pandey MD (2013) Structural reliability analysis based on the concepts of entropy, fractional moment and dimensional reduction method. Struct Saf 43:28–40
Zheng PJ, Wang CM, Zong ZH et al (2017) A new active learning method based on the learning function U of the AK-MCS reliability analysis method. Eng Struct 148:185–194
Zou T, Mahadevan S (2006) A direct decoupling approach for efficient reliability-based design optimization. Struct Multidiscip Optim 31(3):190–200
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
In behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Responsible Editor: Nam Ho Kim
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
To construct a Kriging surrogate model, the output of the model Y = g(X) can be considered a realization of stochastic process represented in Zheng et al. (2017) and Hu et al. (2017)
where β0 is the mean value and Z(X) represents a stationary Gaussian process with zero mean and a covariance between two samples x(i) and x(j), the covariance is defined by
where σ2 is the process variance of Z(⋅), R is the spatial correlation function, which is only dependent on the spatial distance between x(i) and x(j). In this paper, the widely used Gaussian correlation is employed.
Therefore, for the arbitrary sample x, the Kriging model gK(x) is a Gaussian random process, i.e., \( {g}_K(x)\sim N\left({\mu}_{g_K}(x),{\sigma}_{g_K}^2(x)\right) \), where \( {\mu}_{g_K}(x) \) and \( {\sigma}_{g_K}^2(x) \) are the Kriging prediction mean and variance respectively. More details can be obtained in Zheng et al. (2017) and Hu et al. (2017).
In order to construct a convergent adaptive Kriging (AK) model for the output of model and to identify the input samples falling into the failure domain, a sample pool and an active learning strategy are required. Firstly, a sample pool of input variables is built as S = {x1, x2, ..., xN}. Subsequently, N0 initial samples are selected to establish the initial Kriging model. Then, an active learning function is employed to select new training sample with the most contribution to the prediction quality to refine the initial Kriging model. For the failure problem, a widely used learning function, named as U-learning function (Echard et al. 2011), is adopted and it is denoted as
The U-learning function implies a reliability index of misjudging the sign of g(x) by gK(x), i.e.,
where Φ(⋅) denotes the calculative distribution function of a standard normal variable. Thus, the new training sample can be found in the sample pool by
When U(x) = 2, it indicates that there is Φ(−2) = 0.0228 probability to misjudge the sign of g(x). Then, the stop criterion of selecting the new training point in the sample pool S to update the current Kriging model is given as
The flowchart of the AK model based on U-learning function is shown in Fig. 14.

Flowchart of the AK model based on U-learning function
Replication of results
The original codes of examples in Section 5.1 including 3 folders are available in the Supplementary materials. The results can be replicated by running codes directly.
Rights and permissions
About this article

Cite this article
Li, X., Zhang, W. & He, L. Bayes theorem–based and copula-based estimation for failure probability function. Struct Multidisc Optim 62, 131–145 (2020). https://doi.org/10.1007/s00158-019-02474-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-019-02474-6