
Abstract
Single-loop approach (SLA) exhibits higher efficiency than both double-loop and decoupled approaches for solving reliability-based design optimization (RBDO) problems. However, SLA sometimes suffers from the non-convergence difficulty during the most probable point (MPP) search process. In this paper, a hybrid self-adjusted single-loop approach (HS-SLA) with high stability and efficiency is proposed. Firstly, a new oscillating judgment criterion is firstly proposed to precisely detect the oscillation of iterative points in standard normal space. Then, a self-adjusted updating strategy is established to dynamically adjust the control factor of modified chaos control (MCC) method during the iterative process. Moreover, an adaptive modified chaos control (AMCC) method is developed to search for MPP efficiently by selecting MCC or advanced mean value method automatically based on the proposed oscillating judgment criterion. Finally, through integrating the developed AMCC into SLA, the hybrid self-adjusted single-loop approach is proposed to achieve stable convergence and enhance the computational efficiency of SLA for complex RBDO problems. The high efficiency of AMCC is demonstrated by five nonlinear performance functions for MPP search. Additionally, five representative RBDO examples indicate that the proposed HS-SLA can improve the efficiency, stability, and accuracy of SLA.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
There exist various kinds of uncertainties in practical engineering structures, such as material properties, geometric dimension, manufacturing process, and external loads. Reliability-based design optimization (RBDO) provides a powerful and systematic tool for optimum design of structures with considering these uncertainties, and the designs of RBDO are more reliable than those of traditional deterministic structural optimization. Generally, RBDO methods can be divided into three categories (Aoues and Chateauneuf 2010; Valdebenito and Schueller 2010): double-loop approaches, decoupled approaches, and single-loop approaches.
For double-loop approaches, two different ways can be applied to evaluate the probability constraints: reliability index approach (RIA) (Lee et al. 2002) and performance measure approach (PMA) (Tu et al. 1999). Actually, PMA always exhibits much higher efficiency and stability than RIA to solve RBDO problems (Lee et al. 2002; Youn and Choi 2004). For PMA, the inner reliability analysis loop aims to search for the most probable point (MPP). The advanced mean value (AMV) method (Wu et al. 1990) is popularly utilized to search for MPP owing to its simplicity and efficiency. However, AMV generates numerical instability such as divergence, periodic oscillation, bifurcation, and even chaos when locating the MPP for concave or highly nonlinear performance functions (Du et al. 2004; Youn et al. 2003). Later, several improved iterative algorithms were suggested to overcome the non-convergence of AMV when searching for MPP, such as conjugate mean value (CMV) method, hybrid mean value (HMV) method (Youn et al. 2003), enhanced hybrid mean value method (Youn et al. 2005b), conjugate gradient analysis method (Ezzati et al. 2015), and step length adjustment iterative algorithm (Yi and Zhu 2016). From the perspective of chaotic dynamics, Yang and Yi (2009) proposed the chaos control (CC) method to address the non-convergence issue of AMV based on stability transformation method (STM) (Pingel et al. 2004; Schmelcher and Diakonos 1997). To improve the efficiency of CC, modified chaos control (MCC) method (Meng et al. 2015) was developed by extending the iterative point to the target reliability surface in every iterative step. However, the chaos control factor has a great influence on the computational efficiency of MCC (Li et al. 2015; Meng et al. 2015; Meng et al. 2018), in which the control factor remains constant. Thereafter, some researches concentrate on the automatic determination of control factor during the iterative process of MPP search based on MCC. These methods include adaptive chaos control method (Li et al. 2015), relaxed mean value approach (Keshtegar and Lee 2016), enhanced chaos control method (Hao et al. 2017) which is related with the non-probabilistic RBDO (Meng et al. 2018; Meng and Zhou 2018; Meng et al. 2019), self-adaptive modified chaos control method (Keshtegar et al. 2017), hybrid self-adjusted mean value (HSMV) method (Keshtegar and Hao 2017), modified mean value method (Keshtegar 2017), hybrid descent mean value (HDMV) method (Keshtegar and Hao 2018c), enriched self-adjusted mean value (ESMV) method (Keshtegar and Hao 2018b), and dynamical accelerated chaos control (DCC) method (Keshtegar and Chakraborty 2018). Although these enhanced versions can enhance the efficiency of MPP search to a certain extent, the computational cost of double-loop approaches is still large for RBDO problems with highly nonlinear performance functions.
To improve the computational efficiency of double-loop approaches, decoupled approaches convert the original RBDO problem into a series of deterministic optimization problems by separating the inner reliability analysis loop from the external deterministic optimization loop. Representative decoupled approaches mainly include sequential optimization and reliability assessment (SORA) (Du and Chen 2004), sequential approximate programming approach (Cheng et al. 2006), and direct decoupling approach (Zou and Mahadevan 2006). Later, some improvements were also reported based on the concept of SORA, such as adaptive decoupling approach (Chen et al. 2013), approximate sequential optimization and reliability assessment (Yi et al. 2016), general RBDO decoupling approach (Torii et al. 2016), and probabilistic feasible region approach (Chen et al. 2018). The computational efficiency of SORA is also enhanced by using convex linearization (Cho and Lee 2011) and hybrid chaos control (HCC) method (Meng et al. 2015). In general, SORA is a widely utilized decoupled approach to solve RBDO problems (Aoues and Chateauneuf 2010), whereas its efficiency needs to be improved.
In single-loop approaches, the Karush-Kuhn-Tucker (KKT) optimality conditions of the inner reliability loops are employed to approximate probabilistic constraints with equivalent deterministic constraints, which can avoid the repeated MPP search process in reliability analysis. Hence, the efficiency of single-loop approaches is greatly improved than double-loop approaches for solving RBDO problems. Typically, the single-loop single vector (SLSV) method (Chen et al. 1997) firstly attempted to convert the double-loop RBDO problem to a true single-loop problem. Liang et al. (2008) proposed single-loop approach (SLA) to improve the efficiency of SLSV. A complete single-loop approach (Shan and Wang 2008) was developed on the basis of reliable design space to eliminate the reliability analysis process and achieve higher efficiency and accuracy. Jeong and Park (2017) introduced single-loop single vector method using the conjugate gradient to enhance the convergence capability and accuracy of SLSV. Although SLA is a promising strategy for linear and moderate nonlinear RBDO problems, it yields numerical instability and non-convergence solutions for highly nonlinear problems (Aoues and Chateauneuf 2010). To overcome this problem, Jiang et al. (2017) suggested the adaptive hybrid single-loop method to adaptively select the approximate MPP or accurate MPP which is located by the developed iterative control strategy. Keshtegar and Hao (2018a) developed the enhanced single-loop method based on single-loop approach and the hybrid enhanced chaos control method. Meng et al. (2018) proposed chaotic single-loop approach (CSLA) to realize convergence control of iterative algorithm of MPP search in SLA based on chaotic dynamics theory. Moreover, Zhou et al. (2018) suggested a two-phase approach which is an enhanced version of SLA based on sequential approximation. To improve the efficiency and stability of SLA, Meng and Keshtegar (2019) proposed adaptive conjugate single-loop approach based on the conjugate gradient vector with a dynamical conjugate scalar factor.
To combine two of these three different types of RBDO methods mentioned above is a new tendency to make full use of respective advantages of different RBDO methods in recent years. These hybrid methods contain adaptive-loop method (Youn 2007), adaptive hybrid approach (Li et al. 2015), semi-single-loop method (Lim and Lee 2016), etc. However, the numerical efficiency and stability of RBDO algorithms for large reliability index and highly nonlinear problems are still expected to enhance further.
In this paper, an adaptive modified chaos control (AMCC) method is firstly developed to search for MPP efficiently by selecting modified chaos control method or advanced mean value method automatically, based on the proposed oscillating judgment criterion of iterative point and self-adjusted control factor. Then, a hybrid self-adjusted single-loop approach (HS-SLA) is proposed by integrating the developed AMCC into SLA, in order to achieve stable convergence and enhance the computational efficiency of SLA for RBDO problems with highly nonlinear performance functions. Finally, five representative examples are tested and compared for RBDO algorithms to illustrate the high efficiency and stability of the proposed HS-SLA.
2 Reliability-based design optimization and methods of MPP search
2.1 Basic RBDO formulation
A typical RBDO problem is formulated as follows (Jiang et al. 2017; Youn et al. 2003; Youn et al. 2005b):
where d denotes deterministic design variable vector with lower bound dL and upper bound dU, X, and P represent random design variable vector and random parameter vector, respectively. μX and μP indicate the means of X and P, respectively. \( \kern0.2em {\boldsymbol{\upmu}}_{\mathbf{X}}^L\kern0.3em \) and \( {\boldsymbol{\upmu}}_{\mathbf{X}}^U\kern0.1em \) are the lower bound and upper bound of μX.f(d, μX, μP) means the objective function. The performance function gi(d, Xi, Pi) ≤ 0 represents the safe region. ng refers to the number of probabilistic constraints. The probabilistic constraint P(gi(d, X, P) ≤ 0) ≥ Ri represents that the probability of satisfying the i-th performance function should not be less than the target reliability \( {R}_i=\Phi \left({\beta}_i^{\mathrm{t}}\right) \), where \( {\beta}_i^{\mathrm{t}} \) indicates the target reliability index of the i-th constraint and Φ(·) is the standard normal cumulative distribution function.
2.2 Performance measure approach
In PMA (Tu et al. 1999; Youn et al. 2003), the performance measure function is employed to replace the RBDO probabilistic constraint in (1). The RBDO model based on PMA can be formulated as:
In the inverse reliability analysis of PMA, the random design variables are transformed from the original space (X-apace) into the standard normal space (U-space) through Rosenblatt transformation or Nataf transformation (U = T (X), U = T (P)). Then, the performance function is expressed as gi (d, X, P) = gi (T−1 (U)) = Gi (U), which can be calculated by the following optimization problem in U-space (Youn et al. 2003):
The optimal solution in (3) is defined as the most probable point on the target reliability surface.
2.2.1 Chaos control method
Owing to the simplicity and efficiency, the advanced mean value method (Wu et al. 1990) is popularly applied to search for the MPP by solving the optimization problem in (3) as follows:
where ∇Ug(uk) is the gradient vector of performance function at the k-th iterative point uk in U-space, and nk is the normalized steepest descent direction.
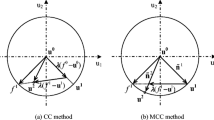
Although AMV is efficient for solving convex performance functions, it has difficulties in iterative convergence when the MPP is searched for concave or highly nonlinear performance functions (Du et al. 2004; Youn et al. 2003). As illustrated in Fig. 1a, AMV generates period-2 oscillation which constructs a diamond by the four points: the origin u0, two adjacent iterative points uk and uk + 1 at the round, and the intersecting point of the two negative gradient direction vectors nk and nk + 1. Introducing the chaotic dynamics theory, Yang and Yi (2009) proposed the chaos control method, shown in Fig. 1b, to control the non-convergence phenomenon of AMV based on stability transformation method (Pingel et al. 2004; Schmelcher and Diakonos 1997) with solid mathematical basis as follows:
where λ is the control factor ranging from 0 to 1 (i.e., λ∈(0,1)), and C is the n × n dimensional involutory matrix (namely, C2 = I, only one element in each row and each column in this matrix is 1 or − 1, and the others are 0).

MPP search for different methods. a Period-2 oscillation of AMV method. b CC method. c MCC method
2.2.2 Modified chaos control method
However, the efficiency of CC is limited due to excessively reducing every step size of the AMV method (Li et al. 2015; Meng et al. 2015). Accordingly, the modified chaos control method (Meng et al. 2015) indicated in Fig. 1c was proposed to enhance the convergence speed of CC by extending the iterative point to the target reliability surface in every iterative step. The iterative formula of MCC is written as:
As observed in references (Li et al. 2015; Meng et al. 2015; Meng et al. 2018), the control factor λ has a significant influence on the computational efficiency of both CC and MCC.
2.3 Single-loop approach
In SLA (Liang et al. 2008), the probabilistic optimization problem is converted into a deterministic optimization problem by using KKT optimality conditions, and it avoids the repeated MPP search process in reliability analysis. The standard SLA is expressed as:
In (7), \( {\beta}_i^{\mathrm{t}} \) indicates the target reliability index of the i-th constraint. d means the vector of deterministic design variables with lower bound dL and upper bound dU. \( {\mathbf{X}}_i^k \) and \( {\mathrm{P}}_i^k \) represent the k-th approximate MPPs of random design variable vector X and random parameter vector P in X-space for the i-th performance function, respectively. During the outer deterministic optimization process, the random design variable mean μX is updated while the random parameter mean μP keeps unchanged. \( {\alpha}_{\mathbf{X}i}^k \) and \( {\alpha}_{\mathbf{P}i}^k \) represent the normalized gradient vector of the i-th constraint gi(·) to X and P, respectively. For non-normally distributed random variables, Rosenblatt transformation or Nataf transformation can be applied to transform the original random space into the standard normal space. Despite the fact that SLA is highly efficient, it encounters difficulties in converging to accurate results for highly nonlinear performance functions.
3 Oscillating judgment criteria
Generally, correctly identifying the oscillation of iterative points during the iterative process exerts a remarkable influence on the efficiency of MPP search. Two common oscillating judgment criteria, i.e., criterion 1 and criterion 2, have been widely used to judge the oscillation of iterative points. However, both criterion 1 and criterion 2 cannot correctly and completely identify the oscillation of iterative points. In this section, a new oscillating judgment criterion 3 is developed to precisely detect the oscillation of the iterative points during the iterative process of MPP search.
3.1 Criterion 1
For hybrid mean value method (Youn et al. 2003), the type of performance function is defined by
In (8), ςk + 1is the index for identifying the performance function type at the k + 1th step, nk stands for the normalized steepest descent direction for a performance function at uk, and sign(·) is a symbolic function. Criterion 1 is actually an angle condition. The basic idea of HMV is to first identify the performance function type according to criterion 1 in (8), and then adaptively select advanced mean value method or conjugate mean value method to search for MPP: if the performance function is convex, AMV is used to update the next iterative point. Otherwise, CMV is adopted for concave performance function. HMV is suitable for convex and weakly nonlinear concave performance function. Nevertheless, it converges slowly or even fails to converge for highly nonlinear concave function.
To combine respective advantages of different MPP search methods, some researches (Li et al. 2015; Meng et al. 2015) adaptively selected appropriate methods to control oscillation by judging the oscillation of iterative points based on criterion 1. Figure 2a and b exhibit the relationship between performance function type and oscillation of iterative points based on criterion 1. For convex performance function, the corresponding iterative points gradually converge (Fig. 2a); the iterative points corresponding to concave performance function appear to oscillate (Fig. 2b). However, for the case of Fig. 2c, the criterion 1 is invalid: although the performance function is convex, the corresponding iterative points gradually diverge. Therefore, criterion 1 cannot correctly and completely judge the oscillation of iterative points.

Relationship between performance function type and oscillation of iterative points. a Convex type (convergence). b Concave type (oscillation). c Convex type (divergence)
3.2 Criterion 2
Based on the variation of oscillation amplitude of random variables in U-space, which is also considered as sufficient descent condition, criterion 2 in (9) is applied to judge the oscillation of iterative points, and then appropriate methods are adaptively chosen to search for MPP in references (Keshtegar and Hao 2018c; Yi and Zhu 2016):
If the oscillation amplitude of iterative points in U-space decreases, the iterative points gradually converge (Fig. 3a), and the original method is maintained to update the next iterative points. Otherwise, if the oscillation amplitude increases, divergence or oscillation occurs at the iterative points (Fig. 3b), and a certain strategy is adopted to control the non-convergence of the random variables in the iterative process. However, criterion 2 fails to determine the oscillation of iterative points in Fig. 3c. Although the oscillation amplitude decreases little by little, the corresponding iterative points oscillate rather than converge. Therefore, criterion 2 cannot completely judge the oscillation of iterative points.

Relationship between oscillation amplitude variation and oscillation of iterative points in U-space. a Decreases (convergence). b Increases (non-convergence). c Decreases (oscillation)
3.3 Criterion 3
To overcome the respective disadvantages of criterion 1 and criterion 2 described above, a new oscillating judgment criterion 3 is proposed to correctly detect oscillation of iterative points in U-space by combining criterion 1 and criterion 2:
Iterative points will gradually converge only if the two conditions of (10), i.e., angle condition and sufficient descent condition, are simultaneously satisfied (Fig. 4a). Otherwise, they fail to converge, and divergence or oscillation will occur (Fig. 4b–d). On the one hand, the criterion 3 proposed in this paper can detect the oscillation of iterative points. The convergence in Fig. 4a can be all detected by criterion 1, criterion 2, and criterion 3. For the case of Fig. 4b, all the above three oscillation criteria can judge the divergence of the iterative point. On the other hand, the proposed criterion 3 can overcome the drawbacks of both criterion 1 and criterion 2. For Fig. 4c, the iterative point is regarded as convergence with using criterion 1, while the iterative point is viewed as divergence via criterion 3, which is consistent with the fact that the iterative point diverges. For Fig. 4d, the iterative point is considered as convergence with using criterion 2. Nevertheless, the iterative point actually oscillates which is the same as the result judged by using criterion 3. Therefore, the proposed criterion 3 can precisely detect the oscillation of iterative points in U-space, and provide a better judgment criterion for selecting appropriate approaches to search for MPP. Consequently, the efficiency of MPP search is improved.

Relationship between the satisfaction of criterion 3 and oscillation of iterative points in U-space. a Satisfy (convergence). b Dissatisfy (divergence). c Dissatisfy (divergence). d Dissatisfy (oscillation)
4 Hybrid self-adjusted single-loop approach
4.1 Self-adjusted updating strategy for chaos control factor
Chaos control factor λk has a remarkable influence on the computational efficiency of CC and MCC when searching for MPP. Therefore, it is of great significance to propose a proper updating strategy for λk to improve the convergence rate of MPP search. In this work, a new self-adjusted updating strategy is proposed to dynamically adjust the control factor during the iterative process as follows:
where P is a parameter (0.10 ≤ P ≤ 1.00). Figure 5 shows the iterative histories of self-adjusted control factor for different P. It can be seen that P has a great influence on the change of λk during the iterative process, and thus affects the convergence rate of MPP search. In order to prevent the slow convergence rate caused by too small control factor, the minimum value of λk is taken as λmin = 0.25 and P is 0.40 for all the following RBDO numerical examples. Obviously, the iterative formula of proposed self-adjusted control factor is based on the previous iterative information and is simpler than those of methods such as HDMV, ESMV, DCC, and HSMV. Besides, the self-adjusted control factor is combined with the oscillating judgment criterion 3 in AMCC to achieve control of unstable solutions for highly nonlinear performance functions, and can improve the efficiency of MPP search with stable convergence.

Iterative histories of chaos control factor λk for different P
4.2 Adaptive modified chaos control method for MPP search
Although AMV is efficient to search for MPP for convex performance functions, it has convergence difficulties for both concave and highly nonlinear performance functions. MCC performs well for concave or highly nonlinear performance functions. Nevertheless, the computational efficiency of MCC is greatly influenced by the control factor. Based on the above developed oscillating judgment criterion 3 in (10) and self-adjusted updating strategy for control factor in (11), an adaptive modified chaos control method is proposed to search for MPP in U-space. The iterative formula of AMCC is written as:
The basic idea of AMCC is that modified chaos control method or advanced mean value method is automatically selected to control the iterative direction of the next MPP in the light of the oscillation of iterative points. If the current iterative point does not satisfy the oscillating judgment criterion 3, which means the current iterative point fails to converge, the control factor λk of MCC needs to be dynamically updated based on the proposed self-adjusted updating strategy in (11), and then MCC is adopted to control the iterative oscillation. Otherwise, if the iterative point in U-space satisfies the oscillating judgment criterion 3, which means the iterative point does not oscillate. In other words, the control factor λk needs not to be updated and remains unchanged, so AMV is used to update the next iterative point. The framework of proposed AMCC method to search for MPP is plotted in Fig. 6. The proposed AMCC method can provide stable results and achieve global convergence for MPP search. The corresponding proof for C = I is presented as follows:

Framework of AMCC to search for MPP
Firstly, it is assumed that the iterative points hold the angle condition and sufficient descent condition simultaneously at each iteration (Fig. 4a), i.e., the criterion 3 is satisfied as \( \left({\mathbf{n}}_{\mathrm{AMV}}^k-{\mathbf{n}}_{\mathrm{AMCC}}^{k-1}\right)\cdotp \left({\mathbf{n}}_{\mathrm{AMCC}}^{k-1}-{\mathbf{n}}_{\mathrm{AMCC}}^{k-2}\right)>0 \) and \( \left\Vert {\mathbf{u}}_{\mathrm{AMV}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right\Vert \le \left\Vert {\mathbf{u}}_{\mathrm{AMCC}}^k-{\mathbf{u}}_{\mathrm{AMCC}}^{k-1}\right\Vert \). Therefore, AMV is adopted to update the new iterative points as \( {\mathbf{u}}_{\mathrm{AMCC}}^{k+1}={\mathbf{u}}_{\mathrm{AMV}}^{k+1} \). Then, we have
It can be concluded that \( \underset{k\to \infty }{\lim}\prod \limits_{i=1}^k{t}_i\approx 0 \) and \( \underset{k\to \infty }{\lim}\left\Vert {\mathbf{u}}_{\mathrm{AMCC}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right\Vert \approx 0 \). Therefore, \( {\mathbf{u}}_{\mathrm{AMCC}}^{k+1}\approx {\mathbf{u}}_{\mathrm{AMCC}}^k \).
Secondly, if the iterative points only satisfy the sufficient descent condition but not angle condition (Fig. 4d), i.e., \( \left({\mathbf{n}}_{\mathrm{AMV}}^k-{\mathbf{n}}_{\mathrm{AMCC}}^{k-1}\right)\cdotp \left({\mathbf{n}}_{\mathrm{AMCC}}^{k-1}-{\mathbf{n}}_{\mathrm{AMCC}}^{k-2}\right)\le 0 \) and \( \left\Vert {\mathbf{u}}_{\mathrm{AMV}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right\Vert \le \left\Vert {\mathbf{u}}_{\mathrm{AMCC}}^k-{\mathbf{u}}_{\mathrm{AMCC}}^{k-1}\right\Vert \), MCC is applied to update the new iterative points. From (12), we have
Since 0 < λk < 1, then \( \left\Vert {\tilde{\mathbf{u}}}_{\mathrm{MCC}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right\Vert <\left\Vert {\mathbf{u}}_{\mathrm{AMV}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right\Vert \). Thus,
Clearly, \( \prod \limits_{i=1}^k{q}_i\to 0 \) is attained more quickly than \( \prod \limits_{i=1}^k{p}_i\to 0 \) for k → ∞, then, we have \( {\mathbf{u}}_{\mathrm{AMCC}}^{k+1}\approx {\mathbf{u}}_{\mathrm{AMCC}}^k \). Therefore, AMCC can converge more quickly than AMV used only in Fig. 4d by reducing the oscillating amplitude of iterative points.
Finally, if the iterative points do not satisfy the sufficient descent condition, the new iterative points are computed by MCC in (12) no matter whether the angle condition is satisfied or not (Fig. 4b, c). We can obtain \( {\tilde{\mathbf{u}}}_{\mathrm{MCC}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k={\lambda}^k\left({\mathbf{u}}_{\mathrm{AMV}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right) \). Since \( {\left({\tilde{\mathbf{u}}}_{\mathrm{MCC}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right)}^{\mathrm{T}}\left({\tilde{\mathbf{u}}}_{\mathrm{MCC}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right)={\lambda}^k{\left({\tilde{\mathbf{u}}}_{\mathrm{MCC}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right)}^{\mathrm{T}}\left({\mathbf{u}}_{\mathrm{AMV}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right) \), the following formulas are derived
The proposed control factor is λk ≈ 0 when k → ∞ as illustrated by Fig. 5 and (11), which means that \( \left\Vert {\tilde{\mathbf{u}}}_{\mathrm{MCC}}^{k+1}-{\mathbf{u}}_{\mathrm{AMCC}}^k\right\Vert \approx 0 \) when k → ∞. Thus, \( {\mathbf{u}}_{\mathrm{MCC}}^{k+1}\approx {\mathbf{u}}_{\mathrm{AMCC}}^k \). Consequently, a fixed point is captured as \( {\mathbf{u}}_{\mathrm{AMCC}}^{k+1}\approx {\mathbf{u}}_{\mathrm{AMCC}}^k \) for k → ∞. To sum up, AMCC can achieve stable iterative solutions and realize global convergence.
To verify the efficiency of AMCC, the oscillating judgment criterion 3 is replaced with criterion 1 and criterion 2 to obtain algorithms of AMCC1 and AMCC2, respectively. Four mathematical examples and a high dimensional engineering reliability problem (i.e., the velocity problem of the door in a vehicle side impact for Example 5) for reliability analysis are selected to demonstrate the efficiency of AMCC compared with AMV, HMV, CC, HCC, AMCC1, and AMCC2. For the CC and HCC, C = I and λ = 0.10 are adopted. The convergence criterion is set as || xk + 1 – xk || / || xk + 1 || ≤ 10−6 and the initial value is u0 = (0, 0) for all those methods.
Example 1 (Youn et al. 2003)
Example 2 (Yang and Yi 2009)
Example 3 (Yang and Yi 2009)
Example 4 (Yang and Yi 2009)
Example 5 (Yang and Yi 2009; Youn et al. 2005a)
The iterative results of performance function values at the MPP and required iterative numbers in the parentheses for different methods are listed in Table 1. It is observed that there is no oscillation for convex performance function G1(x) in the iterative process of MPP search. As a result, AMV, HMV, HCC, AMCC1, AMCC2, and AMCC only utilize the AMV to search for MPP, and same iterative numbers are obtained for all these methods, while the iterative number of CC is the most. Additionally, AMV fails to converge for the remaining four performance functions. The AMV iterations searching for MPP for G2(x) and G5(x) generate period-18 and period-2 solutions, respectively, while the iterative solutions for G3(x) and G4(x) are in chaos with intrinsic randomness. Although HMV and CC can control the non-convergence of G2(x), G4(x), and G5(x), they exhibit lower efficiency compared to AMCC. For concave and highly nonlinear performance functions G2(x) and G3(x) and the high dimensional performance function G5(x), AMCC1 based on criterion 1 has difficulty in converging to the corresponding MPPs. For concave performance function G4(x), AMCC2 based on criterion 2 needs more iterative numbers than AMCC1 and AMCC. However, AMCC converges more efficiently than both AMCC1 and AMCC2 for the four performance functions G2(x), G3(x), G4(x), and G5(x).
It should be pointed out that, for the adaptive modified chaos control method, other involutory matrices except C = I can also be taken to control the non-convergence of inverse reliability computation such as periodic solution and chaos. For example, the MPP of G2(x) is captured after 22 iterations by AMCC when C = C1 = [1 0; 0–1]. For G3(x), the MPP is obtained after 14 iterations by AMCC when C = C2 = [0–1; − 1 0] with the same results as C = I. For simplicity, however, the involutory matrix C is usually taken as identity matrix (i.e., C = I) for various modified MPP search methods based on chaos feedback control.
4.3 Flowchart and procedure of HS-SLA
Combine the developed adaptive modified chaos control method in subsection 4.2 with single-loop approach, an efficient hybrid self-adjusted single-loop approach is proposed to achieve stable convergence and enhance the computational efficiency of SLA for complex RBDO problems. The optimization formulation of HS-SLA is written as follows:
where \( {\mathbf{u}}_{\mathbf{X}i}^k \) and \( {\mathbf{u}}_{\mathbf{P}i}^k \) are the k-th approximate MPPs of random design variable vector X and random parameter vector P in U-space for the i-th performance function, respectively. The chaos control factor is updated by the self-adjusted updating strategy in (11) and the initial value is set as 0.50 for each performance function, i.e.,\( {\lambda}_i^0=0.5 \). The new self-adjusted updating strategy in (11) provides an appropriate control factor, and the iterative search direction vectors are dynamically adjusted based on the proposed oscillating judgment criterion 3 in AMCC for MPP search. These measures contribute to the proposed HS-SLA achieving high computational accuracy for solving RBDO problems.
Figure 7 shows the flowchart of HS-SLA, and its procedure is summarized as follows:
- (1)
Initialize \( {\mathbf{X}}_i^0=\kern0.3em {\boldsymbol{\upmu}}_{\mathbf{X}}^0 \) and \( {\mathbf{P}}_i^0=\kern0.3em {\boldsymbol{\upmu}}_{\mathbf{P}} \).
- (2)
Utilize AMCC to adaptively select AMV or MCC to update the next MPP: when the iterative point in U-space satisfies the oscillating judgment criterion 3 or k < 3, AMV is used to update the next iterative point (\( {\mathbf{u}}_{\mathbf{X}i}^{k+1} \),\( {\mathbf{u}}_{\mathbf{P}i}^{k+1} \)). Otherwise, if the current iterative point does not satisfy the oscillating judgment criterion 3 and k ≥ 3, the control factors are dynamically updated based on the proposed self-adjusted updating strategy in (11), and MCC is then adopted to control the oscillation and calculate the next MPP (\( {\mathbf{u}}_{\mathbf{X}i}^{k+1} \),\( {\mathbf{u}}_{\mathbf{P}i}^{k+1} \)).
- (3)
Perform the deterministic optimization to update the random design variable means \( {\boldsymbol{\upmu}}_{\mathbf{X}}^{k+1} \)using optimization algorithm such as the method of moving asymptotes.
- (4)
Check if the convergence criterion \( \left\Vert {\boldsymbol{\upmu}}_{\mathbf{X}}^{k+1}-{\boldsymbol{\upmu}}_{\mathbf{X}}^k\right\Vert /\left\Vert {\boldsymbol{\upmu}}_{\mathbf{X}}^{k+1}\right\Vert \le \varepsilon ={10}^{-4} \)is satisfied. If it is satisfied, then stop. Otherwise, set k = k + 1, and go to step (2) to continue iterative calculation until convergence.

Flowchart of the hybrid self-adjusted single-loop approach for RBDO problems
5 Numerical examples for RBDO problems
In this section, the efficiency and stability of the proposed HS-SLA are compared with the other approaches such as RIA, PMA, SORA, SLA, and CSLA by five nonlinear RBDO problems. The convergence criterion of these RBDO approaches is ||dk + 1 – dk||/||dk + 1|| ≤ ε = 10−4.
5.1 Weakly nonlinear mathematical Example 1
This RBDO problem (Cho and Lee 2011; Youn and Choi 2004) contains three weakly nonlinear performance functions and two random variables which obey the Gumbel distribution. The standard deviations of the two random variables are both 0.3, and their mean values are selected as design variables. The initial values of the design variables are d0 = [5.0, 5.0]. Two different target reliability indexes, i.e., βt = 3.0 and βt = 4.0, are considered to investigate their effect on the efficiency and stability of the proposed HS-SLA. This RBDO example is formulated as
The optimal results of different approaches are tabulated in Table 2 for βt = 3.0 and Table 3 for βt = 4.0. In these two Tables and the following Tables, Iters denote the number of outer optimal iterations, and F-evals represent the sum of the number of performance function and objective function evaluations and the number of their gradient function evaluations. F-evals are used to measure the computational efficiency of different RBDO approaches. The optimal results of RIA, PMA, SORA, SLA, and CSLA for βt = 3.0 and βt = 4.0 are extracted from the reference (Meng et al. 2018).
As presented in Table 2, all RBDO approaches except RIA can successfully converge, and the results are consistent with those of the reference (Aoues and Chateauneuf 2010) for βt = 3.0. The number of function evaluations of SORA is less than that of PMA in that SORA decouples the reliability analysis loop from the optimization loop. By converting the probabilistic optimization problem into a deterministic optimization problem, SLA exhibits much higher efficiency compared to PMA and SORA. CSLA improves the efficiency of SLA, because it can control the oscillation of iterative points in U-space and improve the iterative convergence by adopting the chaos control theory. Additionally, the proposed HS-SLA is capable of precisely judging the oscillation of iterative points in U-space through a more reasonable oscillating judgment criterion. As a result, less computational effort for HS-SLA is required to converge to the optimum compared to both SLA and CSLA.
The optimal results of different approaches for βt = 4.0 are summarized in Table 3. Similar results of RBDO approaches except SORA and SLA for βt = 4.0 can be obtained as those for βt = 3.0. RIA fails to converge for the two target reliability indexes. For large reliability index, more computational efforts of PMA and SORA are needed and a lack of accuracy for SORA is also simultaneously observed. Despite the high efficiency, SLA has difficulties in converging to the correct optimum for large target reliability index. However, large reliability index has less effect on CSLA and HS-SLA. Both CSLA and HS-SLA can converge to the correct optimum, and the number of function evaluations of HS-SLA is less than CSLA. Therefore, SLA exhibits some weakness in terms of stability, while the stability of HS-SLA remains unchanged with the increase of target reliability index. Moreover, HS-SLA can also improve the accuracy of SLA for both βt = 3.0 and βt = 4.0.
To test whether the target reliability of the probabilistic constraints is satisfied, Monte Carlo simulation (MCS) with ten million samples is applied to evaluate the reliability index of the probabilistic constraints at the optimum. In Table 2, \( {\beta}_j^{\mathrm{MCS}} \) stands for the reliability index of the j-th probabilistic constraint at the optimum. As shown in Table 2 for βt = 3.0, the first and second probabilistic constraints (g1 and g2) are active, while the third one (g3) is inactive and the corresponding reliability index is infinite. All the RBDO approaches can satisfy the target reliability index at the optimum.
For βt = 4.0, all the probabilistic constraints of RBDO approaches except SORA and SLA satisfy the target reliability at the optimum listed in Table 3. RIA cannot converge to the optimum. Although SORA can obtain an optimized design, the reliability index of the second probability constraint g2 is smaller than the target reliability index, which means g2 is violated. The reliability index of SLA for the second probability constraint g2 at the optimum is only 1.6003 which is much smaller than the target reliability index. Therefore, the optimized solution of SLA cannot satisfy the target reliability index of the second probability constraint.
5.2 Highly nonlinear mathematical Example 2
This mathematical problem (Meng et al. 2018; Youn et al. 2005b) contains three highly nonlinear performance functions. There are two random variables which are statistically independent and follow the normal distribution Xi ~ N (di, 0.32), i = 1, 2. The design variables are the means of the two random variables. Three different initial points, i.e., d0 = [1, 1], d0 = [5, 5], and d0 = [15, 15], are chosen to verify the stability of the proposed HS-SLA. The target reliability index is βt = 3.0. The RBDO example is formulated as
The RBDO results of three different initial points are listed in Tables 4, 5, and 6, respectively. All RBDO approaches can converge to the optimum except RIA and SLA, which are consistent with the reference (Meng et al. 2018). As observed in these tables, SORA is considerably more efficient than PMA for all the three different initial points. SLA generates period-2 solution during the iterative process due to the second highly nonlinear performance function g2. CSLA converges to the correct optimum by controlling the oscillation and the corresponding numbers of function evaluations are much less than those of SORA. Based on the developed reasonable oscillating judgment criterion 3 and self-adjusted control factor, the proposed HS-SLA can control the periodic oscillation of SLA. Consequently, HS-SLA improves the efficiency and stability of SLA. Furthermore, HS-SLA shows higher convergence rate than CSLA for all the three different initial points.
As illustrated in Tables 4, 5, and 6, PMA and SORA are sensitive to the initial point. PMA and SORA require less computational effort when the initial point lies in the vicinity of the optimum. In contrast, when the initial point is far from the optimum, the numbers of function evaluations required by PMA and SORA substantially increase. However, different initial points have less influence on the computational efficiency and stability of CSLA and HS-SLA, and thus less computational cost for CSLA and HS-SLA is needed.
In Tables 4, 5, and 6, the reliability indexes for three different initial points at the optimum are evaluated by MCS with ten million samples. Same conclusions can be drawn for all three different initial points. The first and second probability constraints (g1 and g2) are active, while the third one is inactive. The probabilistic constraints except RIA and SLA can meet the target reliability at the optimum. Moreover, iterative histories of objective function for CSLA and HS-SLA with three initial points for Example 2 are presented in Fig. 8. Overall, HS-SLA converges to the correct objective function more quickly than CSLA. Moreover, the iterative processes of MPPs and control factors of three performance functions by HS-SLA with d0 = [5, 5] are listed in Table 7. Only the iterative point in U-space cannot meet the oscillating judgment criterion 3 in (10) and presents non-convergence, the corresponding control factor λk is automatically updated by (11). As the iterative number increases, the oscillation amplitude of every iterative step decreases and the control factor gradually decreases.

Iterative histories of objective function for CSLA and HS-SLA with three different initial points for Example 2. a d0 = [1, 1]. b d0 = [5, 5]. c d0 = [15, 15]
To further verify the efficiency and stability of HS-SLA, ten initial values of design variables are randomly generated in the interval [0, 20], and the RBDO results of CSLA and HS-SLA are listed in Tables 8 and 9. It is indicated that both CSLA and HS-SLA can converge to the optimum when choosing the random initial points, and HS-SLA is more efficient and accurate than CSLA. Moreover, the MCS results of CSLA and HS-SLA are similar: the first and second probability constraints are active while the third one is inactive, and all the probability constraints of CSLA and HS-SLA satisfy the target reliability.
5.3 Welded beam structure
A welded beam structure (Lee and Lee 2005) in Fig. 9 is considered. There are four random design variables and five probability constraints. The objective of this RBDO problem is to minimize the welding cost with the target reliability index βt = 3.0. The design variables are depth and length of welding, and height and thickness of the beam. Each design variable follows a statistically independent normal distribution. The probabilistic constraints are related to shear stress, bending stress, bucking, and displacement behaviors. The system parameters are listed in Table 10. The RBDO model of the welded beam is expressed as:

A welded beam structure
The result of deterministic optimization is set as the initial design point, i.e., d0 = [6.208, 157.82, 210.62, 6.208]. The optimal results of different RBDO approaches for the welded beam structure are given in Table 11. As illustrated from Table 11, the optimized results of these RBDO approaches except RIA are in agreement with those in reference (Li et al. 2015). SLA improves the efficiency of PMA and SORA. HS-SLA is more efficient than SLA and CSLA. Table 12 gives the evaluation of probabilistic constraints for welded beam structure by MCS with ten million samples at the optimum. For all RBDO approaches except RIA, g1, g2, g3, and g5 are active constraints while g4 is inactive constraint. All the probability constraints of different RBDO approaches except RIA satisfy the target reliability at the optimum.
5.4 A speed reducer
Figure 10 is a speed reducer (Lee and Lee 2005; Meng et al. 2018) which is used to rotate the engine and propeller with efficient velocity in light plane. There are seven random variables and 11 probability constraints. To minimize the weight is the objective function of this RBDO problem. The probability constraints are related to bending and contact stress, longitudinal displacement, stress of the shaft, and geometry. Seven design variables are gear width (X1), teeth module (X2), number of teeth in the pinion (X3), distance between bearings (X4, X5), and axis diameter (X6, X7). All random design variables are statistically independent and obey lognormal distribution with a standard deviation of 0.005. The RBDO model of the speed reducer is formulated as follows:

A speed reducer
The optimal results of different approaches for the speed reducer are listed in Table 13. As observed in Table 13, all these RBDO approaches converge to the same optimum as shown in the literature (Meng et al. 2018). Compared to the double-loop approaches (i.e., RIA and PMA) and the decoupled approach (i.e., SORA), SLA, CSLA, and HS-SLA can improve the RBDO efficiency for this problem owing to the single-loop strategy. The proposed HS-SLA requires less computational effort than both SLA and CSLA for this example. Table 14 exhibits the reliability indexes of each probabilistic constraint calculated by MCS with ten million samples at the optimum. Same conclusions can be drawn for all different approaches. The four probability constraints of g5, g6, g8, and g11 are active, while the remaining seven are inactive. All the probabilistic constraints satisfy the target reliability at the optimum.
5.5 High dimensional RBDO problem
To verify the applicability of HS-SLA to high dimensional RBDO problem, the last mathematical example is the Hock and Schittkowski problem no.113 (Lee and Lee 2005), which has ten random design variables and eight probability constraints. All design variables follow independent normal distribution with a standard deviation of 0.02. The description of this example is formulated as follows:
The optimal result obtained from deterministic optimization (Lee and Lee 2005) is taken as the initial design point, i.e., d0 = [2.17, 2.36, 8.77, 5.10, 0.99, 1.43, 1.32, 9.83, 8.28, 8.38]. The optimal results of different RBDO approaches tabulated in Table 15 are close to those from the reference (Cho and Lee 2011). As seen in Table 15, the number of function evaluations of SLA is less than RIA, PMA, and SORA, and CSLA improves the efficiency of SLA. Furthermore, less computational effort for HS-SLA is required to converge to the optimum compared to both SLA and CSLA. Therefore, the computational efficiency of HS-SLA is the highest. The reliability indexes of each probabilistic constraint calculated by MCS with 10 million samples at the optimum are given in Table 16. Same conclusions can be made for all different approaches. Two probability constraints (g6 and g8) are inactive, while the remaining six are active. All the probabilistic constraints satisfy the target reliability at the optimum. HS-SLA is more efficient and stable for this high dimensional RBDO problem.
6 Conclusions
Despite the high efficiency of single-loop approach, SLA has difficulties to find the correct optimum for RBDO problem with large target reliability index and highly nonlinear performance functions. In this paper, a new oscillating judgment criterion of iterative point and self-adjusted updating strategy for control factor are investigated firstly. Then, an adaptive modified chaos control method is suggested to automatically select the MPP search formulas between MCC method and AMV method based on the oscillation of the iterative points. Moreover, an efficient hybrid self-adjusted single-loop approach is proposed by integrating the developed AMCC into SLA. Five mathematical examples for reliability analysis are presented to demonstrate the high efficiency of AMCC to search for MPP. Finally, five representative RBDO examples are tested to demonstrate the high efficiency and stability of the proposed HS-SLA. Some conclusions can be drawn as follows.
- (1)
For RBDO problems with large reliability index and highly nonlinear performance functions, SLA has difficulties in terms of iterative convergence. However, the stability of HS-SLA remains unchanged and HS-SLA are more efficient than other RBDO approaches.
- (2)
Both PMA and SORA are very sensitive to the initial point, while CSLA and HS-SLA are insensitive to the choice of initial point.
- (3)
HS-SLA is more efficient and stable for high dimensional RBDO problems. Consequently, HS-SLA can improve the efficiency, accuracy, and stability of SLA. Moreover, HS-SLA is more efficient and stable than other approaches for RBDO problems with highly nonlinear performance function. In the future, the research will focus on the application of the proposed HS-SLA for large-scale structural design.
7 Replication of results
Data will be made available on request.
References
Aoues Y, Chateauneuf A (2010) Benchmark study of numerical methods for reliability-based design optimization. Struct Multidiscip Optim 41(2):277–294
Chen XG, Hasselman TK, Neill DJ (1997) Reliability based structural design optimization for practical applications. In: Proceedings of the 38th AIAA/ASME/ASCE/AHS/ASC structures, structural dynamics and materials conference, Kissimmee, 7-10 April, Paper no: AIAA-97-1403
Chen ZZ, Qiu HB, Gao L, Su L, Li PG (2013) An adaptive decoupling approach for reliability-based design optimization. Comput Struct 117:58–66
Chen ZZ, Li X, Chen G, Gao L, Qiu HB, Wang S (2018) A probabilistic feasible region approach for reliability-based design optimization. Struct Multidiscip Optim 57(1):359–372
Cheng GD, Xu L, Jiang L (2006) A sequential approximate programming strategy for reliability-based structural optimization. Comput Struct 84(21):1353–1367
Cho TM, Lee BC (2011) Reliability-based design optimization using convex linearization and sequential optimization and reliability assessment method. Struct Saf 33(1):42–50
Du XP, Chen W (2004) Sequential optimization and reliability assessment method for efficient probabilistic design. J Mech Des 126(2):225–233
Du XP, Sudjianto A, Chen W (2004) An integrated framework for optimization under uncertainty using inverse reliability strategy. J Mech Des 126(4):562–570
Ezzati G, Mammadov M, Kulkarni S (2015) A new reliability analysis method based on the conjugate gradient direction. Struct Multidiscip Optim 51(1):89–98
Hao P, Wang YT, Liu C, Wang B, Wu H (2017) A novel non-probabilistic reliability-based design optimization algorithm using enhanced chaos control method. Comput Methods Appl Mech Eng 318:572–593
Jeong SB, Park GJ (2017) Single loop single vector approach using the conjugate gradient in reliability based design optimization. Struct Multidiscip Optim 55(4):1329–1344
Jiang C, Qiu HB, Gao L, Cai XW, Li PG (2017) An adaptive hybrid single-loop method for reliability-based design optimization using iterative control strategy. Struct Multidiscip Optim 56(6):1271–1286
Keshtegar B (2017) A modified mean value of performance measure approach for reliability-based design optimization. Arab J Sci Eng 42(3):1093–1101
Keshtegar B, Chakraborty S (2018) Dynamical accelerated performance measure approach for efficient reliability-based design optimization with highly nonlinear probabilistic constraints. Reliab Eng Syst Saf 178:69–83
Keshtegar B, Hao P (2017) A hybrid self-adjusted mean value method for reliability-based design optimization using sufficient descent condition. Appl Math Model 41:257–270
Keshtegar B, Hao P (2018a) Enhanced single-loop method for efficient reliability-based design optimization with complex constraints. Struct Multidiscip Optim 57(4):1731–1747
Keshtegar B, Hao P (2018b) Enriched self-adjusted performance measure approach for reliability-based design optimization of complex engineering problems. Appl Math Model 57:37–51
Keshtegar B, Hao P (2018c) A hybrid descent mean value for accurate and efficient performance measure approach of reliability-based design optimization. Comput Methods Appl Mech Eng 336:237–259
Keshtegar B, Lee I (2016) Relaxed performance measure approach for reliability-based design optimization. Struct Multidiscip Optim 54(6):1439–1454
Keshtegar B, Hao P, Meng Z (2017) A self-adaptive modified chaos control method for reliability-based design optimization. Struct Multidiscip Optim 55(1):63–75
Lee JJ, Lee BC (2005) Efficient evaluation of probabilistic constraints using an envelope function. Eng Optim 37(2):185–200
Lee JO, Yang YS, Ruy WS (2002) A comparative study on reliability-index and target-performance-based probabilistic structural design optimization. Comput Struct 80(3–4):257–269
Li G, Meng Z, Hu H (2015) An adaptive hybrid approach for reliability-based design optimization. Struct Multidiscip Optim 51(5):1051–1065
Liang JH, Mourelatos ZP, Tu J (2008) A single-loop method for reliability-based design optimisation. Int J Prod Dev 5(1–2):76–92
Lim J, Lee B (2016) A semi-single-loop method using approximation of most probable point for reliability-based design optimization. Struct Multidiscip Optim 53(4):745–757
Meng Z, Keshtegar B (2019) Adaptive conjugate single-loop method for efficient reliability-based design and topology optimization. Comput Methods Appl Mech Eng 344:95–119
Meng Z, Zhou HL (2018) New target performance approach for a super parametric convex model of non-probabilistic reliability-based design optimization. Comput Methods Appl Mech Eng 339:644–662
Meng Z, Li G, Wang BP, Hao P (2015) A hybrid chaos control approach of the performance measure functions for reliability-based design optimization. Comput Struct 146:32–43
Meng Z, Yang DX, Zhou HL, Wang BP (2018) Convergence control of single loop approach for reliability-based design optimization. Struct Multidiscip Optim 57(3):1079–1091
Meng Z, Zhang DQ, Li G, Yu B (2019) An importance learning method for non-probabilistic reliability analysis and optimization. Struct Multidiscip Optim. https://doi.org/10.1007/s00158-018-2128-7
Pingel D, Schmelcher P, Diakonos FK (2004) Stability transformation: a tool to solve nonlinear problems. Phys Rep 400(2):67–148
Schmelcher P, Diakonos FK (1997) Detecting unstable periodic orbits of chaotic dynamical systems. Phys Rev Lett 78(25):4733–4736
Shan SQ, Wang GG (2008) Reliable design space and complete single-loop reliability-based design optimization. Reliab Eng Syst Saf 93(8):1218–1230
Torii AJ, Lopez RH, Miguel LFF (2016) A general RBDO decoupling approach for different reliability analysis methods. Struct Multidiscip Optim 54(2):317–332
Tu J, Choi KK, Park YH (1999) A new study on reliability-based design optimization. J Mech Des 121(4):557–564
Valdebenito MA, Schueller GI (2010) A survey on approaches for reliability-based optimization. Struct Multidiscip Optim 42(5):645–663
Wu YT, Millwater HR, Cruse TA (1990) Advanced probabilistic structural analysis method for implicit performance functions. AIAA J 28(9):1663–1669
Yang DX, Yi P (2009) Chaos control of performance measure approach for evaluation of probabilistic constraints. Struct Multidiscip Optim 38(1):83–92
Yi P, Zhu Z (2016) Step length adjustment iterative algorithm for inverse reliability analysis. Struct Multidiscip Optim 54(4):999–1009
Yi P, Zhu Z, Gong JX (2016) An approximate sequential optimization and reliability assessment method for reliability-based design optimization. Struct Multidiscip Optim 54(6):1367–1378
Youn BD (2007) Adaptive-loop method for non-deterministic design optimization. Proc Inst Mech Eng Part O J Risk Reliab 221(2):107–119
Youn BD, Choi KK (2004) An investigation of nonlinearity of reliability-based design optimization approaches. J Mech Des 126(3):403–411
Youn BD, Choi KK, Park YH (2003) Hybrid analysis method for reliability-based design optimization. J Mech Des 125(2):221–232
Youn BD, Choi KK, Du L (2005a) Adaptive probability analysis using an enhanced hybrid mean value method. Struct Multidiscip Optim 29(2):134–148
Youn BD, Choi KK, Du L (2005b) Enriched performance measure approach for reliability-based design optimization. AIAA J 43(4):874–884
Zhou M, Luo Z, Yi P, Cheng GD (2018) A two-phase approach based on sequential approximation for reliability-based design optimization. Struct Multidiscip Optim 57(2):489–508
Zou T, Mahadevan S (2006) A direct decoupling approach for efficient reliability-based design optimization. Struct Multidiscip Optim 31(3):190–200
Acknowledgments
This study is supported by the National Natural Science Foundation of China (Grant Nos. 51478086 and 11772079) and the National Key Research Development Program of China (Grant No. 2016YFB0201601).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Responsible Editor: Nam Ho Kim
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, X., Meng, Z., Chen, G. et al. A hybrid self-adjusted single-loop approach for reliability-based design optimization. Struct Multidisc Optim 60, 1867–1885 (2019). https://doi.org/10.1007/s00158-019-02291-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-019-02291-x