
Abstract
The May 12, 2008, Wenchuan M S 8.0/M w 7.9 earthquake occurred in the middle part of the north–south seismic zone in central west China, being one of the greatest thrust events on land in recent years. To explore whether there were some indications of the increase of strong earthquake probabilities before the Wenchuan earthquake, we conducted a retrospective forecast test applying the Pattern Informatics (PI) algorithm to the earthquakes in the Sichuan-Yunnan region since 1992. A regional earthquake catalogue complete to M L 3.0 from 01/01/1977 to 15/06/2008 was used. A 15-year long ‘sliding time window’ was used in the PI calculation, with ‘anomaly training time window’ and ‘forecast time window’ both set to 5 years. With a forecast target magnitude of M S 5.5, the ROC test shows that the PI forecast outperforms not only random guess but also the simple number-counting approach based on the clustering hypothesis of earthquakes (the RI forecast). ‘Hotspots’ can be seen in the region of the northern Longmenshan fault which is responsible for the Wenchuan earthquake. However, when considering bigger grid size and higher cutoff magnitude, such ‘hotspots’ disappear and there is very little indication of an impending great earthquake.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the study of earthquake predictability, the testing of forecast algorithms, even retrospective testing, plays an important role in model development and improvement (Field, 2007). The unexpected occurrence of the May 12, 2008, Wenchuan M S 8.0/M w 7.9 earthquake reminds us of the importance of the retrospective evaluation of predictive models for time-dependent earthquake hazard. In such retrospective investigation, one of the candidates is the Pattern Informatics (PI) algorithm, based on the statistical physics of complex systems. The algorithm has been successfully applied to California (Rundle et al., 2000, 2003; Tiampo et al., 2002), central Japan (Nanjo et al., 2006) and Taiwan (Chen et al., 2005). Our analysis of PI includes two parts. First, a general retrospective forecast test was conducted to explore the performance of the PI forecast. Then we performed a retrospective forecast test that focused on the Wenchuan Earthquake, to investigate whether there was any indication of this great earthquake’s approach.
2 Region under Study and Data Used for Analysis
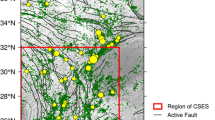
The region investigated in this paper is located between latitudes 20.8°–34.0°N and longitudes 97.2°–107.0°E, including Sichuan and Yunnan Provinces as well as their surrounding regions. The Sichuan-Yunnan diamond and its boundary fault zones form one of the seismically active regions in continental China, with the Xianshuihe, Anninghe, Zemuhe, Xiaojiang, Honghe, Lancangjiang, and Longmenshan fault systems located in this region. These fault systems as well as other neighboring fault systems cut the entire region into different ‘tectonic blocks’ and control the distribution of earthquakes (Xu and Deng, 1996). Yi et al. (2002) and Xu et al. (2005) observed that strong earthquakes in this region have a significant component of stochastic clustering, with a recurrence process that does not demonstrate simple periodicity and does not seem to be well described by the time-predictable model or magnitude-predictable model. Intense seismicity, spatial–temporal heterogeneity, and complicated recurrence behavior motivate the application of the PI algorithm which seeks to identify both seismic activation and quiescence. Figure 1 shows the location of this region, together with the epicenter of the Wenchuan main shock and its aftershocks. Jiang and Wu (2008) conducted a retrospective test of PI algorithm for a smaller region than used in this study. In their study only part of the Longmenshan fault was included (see Fig. 2), and this ironic result indicated that the great Wenchuan earthquake had not been predicted.

a Earthquakes larger than MS 5.5 since 1970 in the Sichuan-Yunnan region, with tectonic faults shown by gray lines. White star and white dots indicate the epicenters of the Wenchuan main shock and its aftershocks, respectively. The region under study is shown in the indexing figure to the bottom right, in which the Wenchuan earthquake is shown by the white star. b Frequency–magnitude distribution showing the selection of the magnitude of completeness. c Temporal distribution, with the three vertical dash lines to the right representing t1 the starting time of the ‘anomaly training window’, t2 the ending time of the ‘anomaly training window’ and the starting time of the ‘forecast window’, and t3 the ending time of the ‘forecast window’. For the sliding window considered in this example, the catalogue is selected to start from t0. See text for details

Retrospective test of the PI algorithm: Sichuan-Yunnan region, period of 01/01/1992 to 01/01/1997. a Hotspot map of the PI algorithm. Color-coded hotspots highlight the relative probability increase for earthquakes above M S 5.5, with spatial grid size 0.2°. Blue circles stand for the earthquakes above M S 5.5 occurring within the ‘forecast window’, while gray reverse triangles show the earthquakes above M S 5.5 occurring within the ‘anomaly training window’. Dashed lines delimitate the region studied by Jiang and Wu (2008). b ROC diagram. Thick solid line represents the ROC result for the PI forecast, thin solid line the ROC result for the RI forecast, and black dashed line the result for random forecast. Gray dashed line shows the difference between the ‘hit rate’ of the PI algorithm and that of the RI algorithm. H hit rate, F false alarm rate, G difference between the hit rate of the PI and that of the RI
For the present study we used the Monthly Earthquake Catalogue from 01/01/1970 to 15/06/2008 provided by the China Earthquake Networks Center (CENC), a composite of catalogues provided by regional/local seismic networks, with magnitude unified as M L. Su et al. (2003) studied the regional earthquake catalogues of Sichuan and Yunnan from 1970 to 2001 and concluded that since the early time of earthquake monitoring in the 1970s, the earthquake catalogues of the Sichuan-Yunnan region have been complete to magnitude M L 3.0. The PI algorithm requires that the catalogue magnitude of completeness be at least two magnitude units smaller than the ‘target earthquake’ (Holliday et al., 2006). In this study, based on previous results (Su et al., 2003) and the Gutenberg-Richter frequency–magnitude statistics as shown in Fig. 1b, the cutoff magnitude M c is set as M L 3.0. This means that anomalies related to earthquakes with magnitudes larger than M S 5.5 should be detected and can be reflected by the PI algorithm. Surface-wave magnitude is used for the definition of ‘target earthquake’ to avoid the bias caused by the difference between different local magnitudes. For this purpose, the ‘target earthquakes’ are selected from the catalogue of the China National Seismograph Network (http://www.csndmc.ac.cn/newweb/data.htm#). Figure 1 also displays the spatial–temporal distribution of these earthquakes. In this figure, the ‘anomaly training window’ and the ‘forecast window’ are also indicated.
3 The PI Algorithm
The PI algorithm applies the concepts of statistical physics of complex systems to the analysis of seismic activity, assuming that seismogenetic dynamics can be regarded as a ‘threshold system’ driven by persistent forces or currents. By analyzing the fluctuations of seismicity, the PI algorithm estimates the increase of the probability of earthquakes at an intermediate-term time scale. Details of the PI algorithm are given by Rundle et al. (2002). The code used for the calculations in this test is the modified Matlab version of the PI algorithm provided by the Rundle group. Simply speaking, the input data for the PI calculation are regional earthquake catalogues. The output of the PI calculation is the relative increase of the probability of earthquakes, or the distribution of ‘hotspots’, described by the top 30% of the normalized probability increase. The PI algorithm is applicable mainly for seismically active regions such as California and Japan. The Sichuan-Yunnan region also possesses the characteristics of high seismicity, and thus is appropriate for using the PI algorithm.
To select proper parameters of predictive models is one of the critical issues in statistical seismology. The PI algorithm suffers from the same difficulty and complexity. Previous works provided clues for the selection of PI parameters. Nanjo et al. (2006) used a 35-year catalogue, 27-year ‘anomaly training window’ and more than 9-year ‘forecasting window’ to forecast the M ≥ 5 target events by setting the box size as 0.1° × 0.1°. For earthquake forecasting verification of the PI method, Holliday et al. (2005) used a 68-year catalogue and took the ‘anomaly training window’ and the ‘forecast window’ to be both 10 years, forecasting the M ≥ 5 target events of southern California and central Japan by setting box size as 0.1° × 0.1°, and for worldwide application with magnitudes <7.0 by setting the box size as 1.0° × 1.0°. To detect the precursory seismic activity preceding the 1999 Chi-Chi, Taiwan, earthquake by using PI analysis, Chen et al. (2005) used a near 12-year catalogue, and an approximately 6-year ‘anomaly training window’. Holliday et al. (2006) applied the modified PI method to a 5-year term forecast, and partitioned the area by using square bins with edge length 0.1°, corresponding to the linear size of a magnitude 6 earthquake. As a contributed forecasting model for RELM testing of Southern California M ≥ 5 target events forecasting, Holliday et al. (2007) used a catalogue of more than 55 years, took the ‘anomaly training window’ and the ‘forecast window’ to be more than 20 and 5 years, respectively, and the research area was divided into 0.1° × 0.1° pixels. Wu et al. (2008) discuss the migration of PI hotspots of the December 26, 2006, Pingtung doublets by setting the box size as 0.1° × 0.1°, and using a 13-year catalogue. In their work t 2 was fixed, with t 1 shifting from 5 to 2 years before t 2 using the sliding step of 3 months. Jiang and Wu (2008) conducted retrospective forecast tests of the PI algorithm for earthquakes in the Sichuan-Yunnan region, to investigate the stability of the algorithm against the selection of model parameters. They adjusted the parameters systematically and investigated the effect of such parameter variation. As a result, optimizing parameters were selected for the ‘target magnitude’ of M S 5.5: A 15-year long ‘sliding time window’; the ‘anomaly training time window’ and ‘forecast time window’ both being 5 years, and the spatial grid taken as D = 0.2°. Considering these previous works, in this paper, the spatial grid is taken as D = 0.2°. Due to the uncertainty of hypocenter location and also following previous work (Keilis-Borok and Rotwain, 1990; Holliday et al., 2007; Jiang and Wu, 2008), in this study only shallow earthquakes with depths ranging from 0 to 70 km are considered.
In Fig. 1c, the period of 01/01/1992 to 01/01/1997 is a seismically active period for earthquakes larger than M S 5.5. As an example of the retrospective test, the ‘forecast window’ is taken as 5 years. Accordingly, the ‘anomaly training window’ is selected as 01/01/1987 to 01/01/1992, with the starting time of the catalogue t 0 = 01/01/1977, i.e., 15 years before the starting time of the ‘forecast window’. In the ‘anomaly training window’, 17 earthquakes occurred larger than M S 5.5, with the November 6, 1988 Lancang-Gengma earthquakes with M S 7.4 and M S 7.2 being the largest. In the ‘forecast window’, there were 15 earthquakes with magnitude larger than M S 5.5, including the July 12, 1995 China-Burma border earthquake with M S 7.3 and the February 3, 1996 Lijiang, Yunnan earthquake with M S 7.0. Figure 1c shows the positions of t 1, t 2 and t 3. Figure 2a depicts the PI ‘hotspots’, using logarithm amplitudes log(ΔP/ΔP max) to represent the relative probability increase for strong earthquakes. Following Chen et al. (2005), only the top 30% values are considered as the ‘hotspots’ and shown in the PI map.
4 The ROC Test
As Rundle et al. (2000, 2003) and Tiampo et al. (2002) did in the evaluation of the performance of forecasts, a receiver operating characteristic (ROC) test (Swets, 1973; Molchan, 1997) was conducted by systematically changing the ‘alarm threshold’ of the ‘forecast region’ and counting the ‘hit rate’ and ‘false alarm rate’ relative to real earthquake activity. Here ‘hit rate’ means the number of ‘forecasted’ events divided by the total number of ‘target’ events. ‘Hit’ or ‘forecasted’ is defined as the case in which the ‘target event’ occurs within any ‘alarmed cell’ or one of the nearest neighbors. In Fig. 2b, the PI forecast is compared with a random guess. It is well known that the larger the area under the ROC curve when compared to the area of the triangle for random forecast, the better the performance of the forecast. From the ROC diagram in Fig. 2b, it may be seen that for the testing period 01/01/1992 to 01/01/1997, the PI forecast significantly outperforms the random forecast.
Similar to Chen et al. (2005) and Holliday et al. (2006), we also compared the PI forecast with the ‘relative intensity’ (RI) forecast. Here the ‘relative intensity’ forecast is used as a null hypothesis to test the necessity of using the PI algorithm. In the RI algorithm, it is assumed that strong earthquakes will occur in the regions where earthquakes occurred before, being similar to the ‘clustering’ argument (Kagan and Jackson, 2000). Here, the RI index is computed simply by the box-counting of the number of events. Similar to the PI algorithm, the RI statistics were normalized, and the ‘alarm threshold’ was determined by the relative value of the RI statistics ranging from 0 to 1. For visual comparison with the PI forecast, only the top 30% of the RI increases is regarded as ‘hotspots’ and is shown on the map. Figure 2b also shows the ROC curve of the RI forecast. It may be seen that the PI algorithm outperforms not only the random guess but also the RI forecast. The reason why the PI algorithm has a better performance than the RI can be understood, to a great extent, from Fig. 2a: In the period under consideration, some ‘target earthquakes’, as shown by the blue circles, did not occur in the regions near the earthquakes occurring in the ‘anomaly training time window’, as shown by the gray reverse triangles. That is, the PI algorithm describes not only seismic activation but also seismic quiescence, while the RI algorithm describes only the former.
5 Retrospective Test for the Sichuan-Yunnan Region: 1992–2007
Figure 3 shows the ergodicity test results for the Sichuan-Yunnan region, indicating that the PI algorithm is valid for this region and for the time period under consideration. The ergodicity test is conducted following Tiampo et al. (2004, 2007) by plotting the Thirumalai-Mountain (TM) metric (Thirumalai et al., 1989) versus time, as shown in Fig. 3. For different grid sizes and different cutoff magnitude values, the TM metric plots show that since 1978 seismicity in Sichuan-Yunnan region has had a strong ergodicity, and the PI algorithm has been able to be used for the estimation of time-dependent earthquake rates.

Plots of the inverse TM metric for the Sichuan-Yunnan region from 01/01/1971 to 15/06/2008. In each subplot D is the spatial grid size, and M c is the cutoff magnitude
To systematically investigate the performance of the PI algorithm, we consider the ‘anomaly training window’ and the ‘forecast window’ to be 5 years, with a ‘sliding window’ of 15 years, and sliding t 2 from 01/01/1992 to 01/01/2003, with the sliding step being 0.5 year. Figure 4a gives the ROC test result, in which the gray zone delimits the range of all the ROC curves, showing the overall performance of the PI forecast. From the figure, it can be seen that despite the variation of the performance with time, generally the PI forecast seems considerably better than a random guess. Figure 4b compares the forecasts of the PI algorithm and the RI algorithm. It can be seen that PI also outperforms RI. For a smaller region, Jiang and Wu (2008) systematically changed the parameter settings to test the robustness of the forecast against the variation of parameters, which shows that the parameter setup as shown in Fig. 2 is stable under the variation of parameter values, and meanwhile seems to be optimal for the Sichuan-Yunnan region.

ROC test of the PI algorithm. ‘Anomaly training window’ and ‘forecast window’ are taken both as 5 years. The sliding window is taken as 15 years. ‘Forecast window’ slides from t 2 = 01/01/1992 to t 2 = 01/01/2003, with sliding step being 0.5 year. a ROC curve for the PI forecasts. Gray zone delimits the range of all the ROC curves, with the gray line and black line representing the results of the first and the last sliding, respectively. b Difference between the hit rate of the PI algorithm and the RI algorithm. The gray line and black line represent the results of the first and the last sliding, respectively. The color bar indicates the stacking of the areas encompassed by the G curves and the horizontal zero-line
6 ‘Forecast’ Performance for the Wenchuan Earthquake
The Wenchuan earthquake occurred on May 12, 2008 at 14:28 p.m. local time, with magnitudes M S 8.0 and M w 7.9, having a thrust-dominated focal mechanism with its aftershock belt being 330 km long, and causing fatalities that reached 69,227 and approaching 18,000 missing (by September 25, 2008, from the Ministry of Civil Affairs of China). The earthquake was one of the largest in China in recent decades and caused considerable attention not only within the scientific community but also in the public (Zhang et al., 2008). After the earthquake, there was a debate on whether the earthquake could have been ‘forecast’ if observational data were carefully examined. This question is important not only for this earthquake but also for the study of future earthquake predictability.
To explore the answer to this tricky question we investigated whether the PI algorithm, which performances well for the Sichuan-Yunnan region, could have provided clues to the approach of the Wenchuan earthquake. Figure 5 shows the ‘forward forecast’ for different time ranges from t 2 = 01/01/2004 to t 2 = 01/01/2008 with a 1-year step, covering the time of the Wenchuan earthquake. In the figure we mark the segment of the Longmenshan fault which accommodated the main rupture and epicenter (or, initiation point) of the Wenchuan earthquake. This area also covers the aftershock zone. From the figure it may be seen that hotspots exist in the ‘forecast time window’, and the ‘hotspot’ cluster spanned the entire rupture area. Note that the original objective of the PI algorithm was to forecast the position of the epicenter of earthquakes, rather than the rupture area. On the other hand, however, this earthquake is too large to be treated as a ‘point source’, and such a correlation between ‘hotspots’ and the rupture area may make sense in the physics of earthquakes.

Hotspot maps of the PI algorithm for different ‘forecasting time windows’. a t 2 = 01/01/2004; b t 2 = 01/01/2005; c t 2 = 01/01/2006; d t 2 = 01/01/2007; e t 2 = 01/01/2008. ‘Forecast time window’ t 3–t 2 = 5 years. Green box delimits the northern segment of the Longmenshan fault which accommodated the Wenchuan earthquake. Star shows the epicenter (or, nucleation point) of the great earthquake
7 Conclusions and Discussion
We tested PI for the Sichuan-Yunnan region, which is to a great extent based on our previous work (Jiang and Wu, 2008) and has been reactivated by the recent Wenchuan earthquake. In the retrospective test, we used the PI algorithm for forecasting the earthquakes with magnitudes larger than M S 5.5. The result shows that the identical algorithm and parameter setup of Holliday et al. (2006) leads to the forecast results outperforming both random guess and RI forecast.
For the Wenchuan earthquake, we examined the PI ‘hotspot’ map in a different ‘forecast time window’ covering the time of this great thrust event. Because the epicenter of this earthquake occurs in one of ‘hotspot clusters’, the PI forecast likely contains information pertaining to about the approaching Wenchuan earthquake. Moreover, the ‘hotspots’ span the entire rupture area, forming a cluster striking north-eastward along the northern Longmenshan fault zone. One problem is, relative to the hotspot distribution in the whole region, it is difficult to make a clear forecast of the Wenchuan earthquake based on the present mapping. In the same figure, there are many ‘hotspots’ existing in this region, with most of them substantially more ‘intense’ than the Longmenshan ‘hotspot cluster’. Another problem might be the selection of the grid size: A larger grid size may be more appropriate for forecasting larger events, as pointed out by Kossobokov and Soloviev (2008) for the 2004 Sumatra earthquake. To explore the possibility of this case, Figs. 6 and 7 show the pictures in which the increases of grid size and cutoff magnitude cause the ‘hotspots’ near the northern Longmenshan fault to disappear. Anomalies are seen 150 km from the rupture zone, but are not seen in the epicentral region. These results are consistent with those of Holliday et al. (2005), which were published prospectively (i.e., before the earthquake occurred) using a 1°-grid size. In that paper, a prominent PI anomaly is located at about 101°E, 30°N, roughly about 200 km distant. This may be indicative that, in dealing with inland earthquakes, the convention that the cutoff magnitude be two units less than that of the ‘target earthquake’ is problematic. Physically, it implies that the population of small events may contain information about the increase in probability of strong earthquakes. If only larger events and larger grids are used, then other patterns, such as the migration of PI ‘hotspots’ (Wu et al., 2008), must be considered. For example, it seems that there is a ‘migration pattern’ of PI hotspots with the approach of the earthquake in Figs. 6 and 7, which is similar to the observation of Wu et al. (2008). Related to this problem, using longer time windows may lead to the ‘cleaning up’ of the ‘hotspot’ picture. However, in the debate regarding whether the Wenchuan earthquake could be forecast, the more important time scales are basically 1 to 5 years. Last but not least, it is important to point out that this work is only a retrospective case study, and has limited significance in the statistical analysis of the PI method.

Hotspot maps of the PI algorithm for different ‘forecasting time windows’ with grid size 1.0° and cutoff magnitude M L 3.0. a t 2 = 01/01/2004; b t 2 = 01/01/2005; c t 2 = 01/01/2006; d t 2 = 01/01/2007; e t 2 = 01/01/2008. ‘Forecast time window’ t 3–t 2 = 5 years. Green box delimits the northern segment of the Longmenshan fault which accommodated the Wenchuan earthquake. Star shows the epicenter (or, nucleation point) of the great earthquake

Hotspot maps of the PI algorithm for different ‘forecasting time windows’ with grid size 1.0° and cutoff magnitude M L 4.0. a t 2 = 01/01/2004; b t 2 = 01/01/2005; c t 2 = 01/01/2006; d t 2 = 01/01/2007; e t 2 = 01/01/2008. ‘Forecast time window’ t 3–t 2 = 5 years. Green box delimits the northern segment of the Longmenshan fault which accommodated the Wenchuan earthquake. Star shows the epicenter (or, nucleation point) of the great earthquake
References
Chen, C. C., Rundle, J. B., Holliday, J. R., Nanjo, K. Z., Turcotte, D. L., Li, S. C., and Tiampo, K. F. (2005), The 1999 Chi-Chi, Taiwan, earthquake as a typical example of seismic activation and quiescence, Geophys. Res. Lett. 32, L22315, doi:10.1029/2005GL023991.
Field, E. D. ed. (2007), Special Issue—Regional Earthquake Likelihood Models, Seism. Res. Lett. 78, 1–140.
Holliday, J. R., Chen, C. C., Tiampo, K. F., Rundle, J. B., and Turcotte, D. L. (2007), A RELM earthquake forecast based on pattern informatics, Seism. Res. Lett. 78, 87–93.
Holliday, J. R., Nanjo, K. Z., Tiampo, K. F., Rundle, J. B., and Turcotte, D. L. (2005). Earthquake forecasting and its verification, Nonlinear Process. Geophys. 12, 965–977.
Holliday, J. R., Rundle, J. B., Tiampo, K. F., Klein, W., and Donnellan, A. (2006), Modification of the pattern informatics method for forecasting large earthquake events using complex eigenfactors, Tectonophysics 413, 87–91.
Jiang, C. S. and Wu, Z. L. (2008), Retrospective forecasting test of a statistical physics model for earthquakes in Sichuan-Yunnan region, Sci. China Ser. D Earth Sci. 51, 1401–1410.
Kagan, Y. Y. and Jackson, D. D. (2000), Probabilistic forecasting of earthquakes, Geophys. J. Int. 143, 438–453.
Keilis-Borok, V. I. and Rotwain, I. M. (1990), Diagnosis of time of increased probability of strong earthquakes in diferent regions of the world, Phys. Earth Planet Inter. 61, 57–72.
Kossobokov V. G. and Soloviev, A. A. (2008), Prediction of extreme events: Fundamentals and prerequisites of verification, Russ. J. Earth Sci. 10, ES2005, doi:10.2205/2007ES000251.
Molchan, G. M. (1997), Earthquake prediction as a decision-making problem, Pure Appl. Geophys. 149, 233–247.
Nanjo, K. Z., Rundle, J. B., Holliday, J. R., and Turcotte, D. L. (2006), Pattern informatics and its application for optimal forecasting of large earthquakes in Japan, Pure Appl. Geophys. 163, 2417–2432.
Rundle, J. B., Klein, W., Turcotte, D. L., and Malamud, B. D. (2000). Precursory seismic activation and critical-point phenomena, Pure Appl. Geophys. 157, 2165–2182.
Rundle, J. B., Tiampo, K. F., Klein, W., and Martins, J. S. A. (2002), Self-organization in leaky threshold systems: The influence of near mean field dynamics and its implications for earthquakes, neurobiology, and forecasting, Proc. Natl. Acad. Sci. USA 99(Suppl. 1), 2514–2521.
Rundle, J. B., Turcotte, D. L., Shcherbakov, R., Klein, W., and Sammis, C. (2003), Statistical physics approach to understanding the multiscale dynamics of earthquake fault systems, Rev. Geophys. 41(4), 1019, doi:10.1029/2003RG000135.
Su, Y. J., Li, Y. L., and Li, Z. H. (2003). Analysis of minimum complete magnitude of earthquake catalogue in Sichuan-Yunnan region, J. Seismol. Res. (in Chinese with English Abstract) 26(Suppl), 10–16.
Swets, J. A. (1973), The relative operating characteristic in psychology, Science 182, 990–1000.
Thirumalai, D., Mountain, R. D. and Kirkpatrick, T. R. (1989). Ergodic behavior in supercooled liquids and in glasses, Phys. Rev. A. 39, 3563–3574.
Tiampo, K. F., Rundle, J. B., Klein, W. and Martins, J. S. Sá. (2004). Ergodicity in natural fault systems, Pure Appl. Geophys. 161, 1957–1968, doi:10.1007/s00024-004-2542-1.
Tiampo, K. F., Rundle, J. B., Klein, W., Holliday, J., Martins, J. S. Sá, and Ferguson, C. D. (2007), Ergodicity in natural earthquake fault networks, Phys. Rev. E. 75, 066107, doi:10.1103/PhysRevE.75.066107.
Tiampo, K. F., Rundle, J. B., McGinnis, S., Gross, S. J., and Klein, W. (2002), Mean-field threshold systems and phase dynamics: An application to earthquake fault systems, Europhys. Lett. 60, 481–487.
Xu, X. W. and Deng, Q. D. (1996), Nonlinear characteristics of paleoseismicity in China, J. Geophys. Res. 101, 6209–6231.
Xu, X. W., Zhang, P. Z., Wen, X. Z. (2005), Features of active tectonics and recurrence behaviors of strong earthquake in the western Sichuan Province and its adjacent regions, Seismol. Geol. (in Chinese with English abstract) 27, 446–461.
Yi, G. X., Wen, X. Z., and Xu, X. W. (2002), Study on recurrence behaviors of strong earthquakes for several entireties of active fault zones in Sichuan-Yunnan region, Earthq. Res. China (in Chinese with English abstract) 18, 267–276.
Zhang, P. Z., Xu, X, W., Wen, X. Z., and Ran, Y. K. (2008), Slip rate and recurrence intervals of the Longmen Shan active fault zone, and tectonic implications for the mechanism of the May 12 Wenchuan earthquake, 2008, Sichuan, China, Chin. J. Geophys. (in Chinese with English abstract) 51, 1066–1073.
Wu, Y.-H., Chen, C., and Rundle, J. B. (2008), Detecting precursory earthquake migration patterns using the pattern informatics method, Geophys. Res. Lett. 35, L19304, doi:10.1029/2008GL035215.
Acknowledgments
Appreciation to MOST for financial support (contract No.2004CB418406), and also thanks to Professor J. B. Rundle for guidance in PI algorithm, to Dr. C. Chen for providing the Matlab code, and Dr. Peng Hanshu for assistance during the work. Authors are also grateful to Dr. Jeremy Zechar, Dr. Matt Gerstenberger and an anonymous referee for their constructive comments and suggestions, which enhanced our work.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Jiang, C., Wu, Z. PI Forecast for the Sichuan-Yunnan Region: Retrospective Test after the May 12, 2008, Wenchuan Earthquake. Pure Appl. Geophys. 167, 751–761 (2010). https://doi.org/10.1007/s00024-010-0070-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-010-0070-8