
Abstract
Five large earthquakes of M ≥ 7.0 (based on the magnitude scale of the China Earthquake Networks Center) occurred in and near the Tibetan Plateau during 2008–2014, including the Wenchuan M8.0 earthquake on May 12, 2008 (BJT). In this paper, the Tibetan Plateau was chosen to be the study region, and calculating parameters of pattern informatics (PI) method with grid of 1° × 1° and forecasting time interval of 8 years were employed for the retrospective study according to the previous studies for M7 earthquake forecasting. The sliding step of forecasting interval was 1 year, and the hotspot diagrams of each forecasting interval since 2008 were obtained year by year. The relationships among the hotspots and the M ≥ 7.0 earthquakes that occurred during the forecast intervals were studied. The predictability of PI method was tested by verification of receiver-operating characteristic curve (ROC) and R score. The results show that the successive obvious hotspots occurred during the sliding forecasting intervals before four of the five earthquakes, while hotspots only occurred in one forecasted interval without successive evolution process before one of the five earthquakes, which indicates that four of the five large earthquakes could be forecasted well by PI method. Test results of the predictability of PI method by ROC and R score show that positive prospect of PI method could be expected for long-term earthquake forecast.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
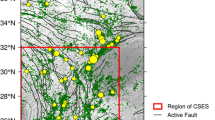
From 2008, five M ≥ 7.0 earthquakes attacked the West Continental China successively. They are Yutian M7.3 earthquake (35.6°N, 81.6°E) (based on the catalogue from China Seismic Network, same in the following) on March 21, 2008 (BJT, same in the following); Wenchuan M8.0 earthquake (31.0°N, 103.4°E) on May 12, 2008; Yushu M7.1 earthquake (33.2°N, 96.6°E) on April 14, 2010; Lushan M7.0 earthquake (30.3°N, 103.0°E) on April 20, 2013; and Yutian M7.3 earthquake (31.0°N, 103.4°E) on Feb 12, 2014. All these five large earthquakes occurred in and near the Tibetan Plateau (Fig. 1). This provides an opportunity to test the predictability of the pattern informatics (PI) method (Rundle et al. 2000a, b, 2002, 2003; Tiampo et al. 2002a, b; Holliday et al. 2005, 2006a) to all these five large earthquakes in this region.

Geographic map of the Tibetan Plateau and its recent large earthquakes during 2008–2014
PI method has proven to be an efficacious approach to earthquake forecasting in medium-term time scale (several years to 10 years) in different tectonic regions, such as California region (Rundle et al. 2002; Tiampo et al. 2002b, Holliday et al. 2005), Japan region (Nanjo et al. 2006a, b; Kawamura et al. 2013, 2014), Taiwan region (Chen et al. 2005, 2006; Wu et al. 2008a, b; Chang et al. 2013), China mainland (Jiang and Wu 2008; Zhang et al. 2009, 2013; Zhang et al. 2014; Xia et al. 2014), and the worldwide region (Holliday et al. 2005). The results of ROC test show that the PI method outperforms not only the random guess method but also the simple number-counting approach based on the clustering hypothesis of earthquakes (the RI forecast) (Rundle et al. 2000a, b, 2002, 2003; Tiampo et al. 2002a, b; Holliday et al. 2005, 2006a). The forecasting efficacy of PI method has also been tested through the investigation of the parameters and conditions, including time spans, for optimizing seismicity-based forecasts by ensuring that the mean activity rate remains constant (Tiampo et al. 2010; Migan and Tiampo 2010; Jiang and Wu 2011; Tiampo and Shcherbakov 2013; Tiampo et al. 2013; Zhang et al. 2013). Tiampo et al. (2010) found that the ergodicity defined by magnitude and time period provides more reliable forecasts of future events in both natural and synthetic catalogues by PI method. Tiampo and Shcherbakov (2012) applied the TM metric and threshold optimization for forecasting parameter estimation to the PI method, and the combined application of these techniques is found successful in forecasting those large events that occurred in Haiti, Chile, and California in 2010 on both global and regional scales. However, when Mignan and Tiampo (2010) tested the PI index by synthetic catalogues where a realistic spatiotemporal clustering has been added on top of the theoretical precursory seismicity, they found that the PI index is found successful in identifying the precursory quiescent signal, but fails in identifying precursory accelerating seismicity directly, because of being more sensitive to aftershock sequences of background events than to the activation-like behavior of the acceleration. Jiang and Wu (2011) also found that the PI forecasts seem to be affected by the aftershock sequence included in the “anomaly identifying interval,” and the PI forecast approach using “background events” seems to display a better performance when they de-clustered the catalogue of the Sichuan-Yunnan region of southwest China by the epidemic-type aftershock sequences (ETAS) model and investigated the effects of de-clustering on the PI forecasts. Cho and Tiampo (2013) studied the effects of locational errors in PI by generating a series of perturbed catalogues by adding different levels of noise to epicenter locations based on the Southern Californian dataset. Their results showed that the maximum performance of the PI technique with respect to both skill scores did not decrease systematically for any of the noise levels used, indicating that the PI performance is not sensitive to the locational errors for catalogues with large numbers of events as a result of their dependence on seismic clustering for its forecasting skill. Zhang et al. (2013) studied the forecasting effects of the calculating parameters on the PI method by varying the calculating parameters of the grid size and the reference time scale, and the results showed that the forecasting efficacy could be improved by choosing approximate parameters after a systematic retrospective study on Wenchuan M8.0 and Yutian M7.3 earthquakes that occurred in 2008.
In fact, five large earthquakes of M ≥ 7.0 occurred in and near the Tibetan Plateau during 2008–2014, including Wenchuan M8.0 and Yutian M7.3 earthquakes in 2008; Yushu M7.1 earthquake in 2010; Lushan M7.0 earthquake in 2013; and Yutian M7.3 earthquake in 2014. This supplies the samples to test if the optimal calculating parameters from Zhang et al. (2013) are effective to the subsequent earthquakes. In this paper, the Tibetan Plateau was chosen to be the study region, and calculating parameters of PI method with grid of 1° × 1° and forecasting time interval of 8 years were employed for the retrospective study for M7 earthquake forecasting. The sliding step of forecasting interval was 1 year, and the snapshots of hotspot map of each forecasting interval since 2008 were obtained on yearly basis. Based on the results, the relationships among the hotspots and the M ≥ 7.0 earthquakes that occurred during the forecast intervals were studied, and the predictability of PI method was tested by verification of receiver-operating characteristic curve (ROC) and R score.
2 The PI Method
PI method was invented by Rundle et al. (2000a, b, 2002, 2003) and developed by Tiampo et al. (2002a, b, c) and Holliday et al. (2005, 2006b). It is an earthquake-forecasting method for quantifying the temporal variations in seismicity based on the statistical mechanics of complex systems. The result is a map of areas with high probability of earthquake potential (hotspots) where earthquakes are likely to occur during a specified period in the future. Rundle et al. (2002) published a forecast map of hotspots of M ≥ 5 earthquakes for California during the period of 2000–2010 (http://quakesim.jpl.nasa.gov/scorecard.html). The testing results show that 17 out of the 19 earthquakes that have occurred between the beginning date of this forecast (January 2000) and September 2006 were coincident with the forecast anomalies within the ±11 km margin of error that is the coarse-graining box size (Tiampo et al. 2008). Nanjo et al. (2006a, b) modified the PI method for use with the Japanese catalogues, and their retrospective study showed that the M = 6.8 Niigata earthquake that occurred on October 23, 2004 could be successfully forecasted. Chen et al. (2005) modified the PI method for use with Taiwan catalogues and found the Chi–Chi Ms7.6 earthquake located in the hotspot area. In this paper, we applied the algorithm of PI method described by Holliday et al. (2005) and realized by Zhang et al. (2009).
Following Holliday et al. (2005), the algorithm of PI method is performed as follows:
(1) First, we divide the region of interest into \(N_{B}\) grids with linear dimension \(\Delta x\). Grids are identified by a subscript \(i\) and are centered at \(x_{i}\). For each grid, the number of earthquakes per unit time at time t larger than the lower cutoff magnitude \(M_{c}\) constructs the time series \(N_{i} (t)\), The time series in grid \(i\) is defined between a base time \(t_{b}\) and the present time \(t\).
(2) All earthquakes in the region of interest with magnitudes greater than \(M_{c}\) are included, and \(M_{c}\) is specified in order to ensure completeness of the data through time, from an initial time \(t_{0}\) to a final time \(t_{2}\).
(3). A reference time interval from \(t_{b}\) to \(t_{1}\) (\(t_{b}\) lies between \(t_{0}\) and \(t_{1}\)), a change time interval from \(t_{1}\) to \(t_{2}\) (\(t_{2}\) > \(t_{1}\)), and a forecast time interval from \(t_{2}\) to \(t_{3}\) are defined. The objective is to quantify anomalous seismic activity in the change interval from \(t_{1}\) to \(t_{2}\) relative to the reference interval \(t_{b}\) to \(t_{1}\), and the forecast time intervals from \(t_{2}\) to \(t_{3}\) are defined. The change and forecast time intervals are taken to have the same length.
(4) \(I_{i} (t_{b} ,t) = \frac{1}{{t - t_{b} }}\sum\nolimits_{{t^{'} = t_{b}^{{}} }}^{t} {N_{i} } (t^{'} )\) is the seismic intensity in grid \(i\), between the two times \(t_{b}\) < \(t\), which means the average number of earthquakes with magnitudes greater than M c occur in the grid per unit time during the specified time interval from \(t_{b}\) to \(t\).
(5) The statistically normalized seismic intensity of grid i during the time interval from \(t_{b}\) to \(t\) is then defined as \(\mathop {I_{i} }\limits^{ \wedge } (t_{b} ,t) = \frac{{I_{i} (t_{b} ,t) - < I_{i} (t_{b} ,t) > }}{{\sigma (t_{b} ,t)}}\), where \(< I_{i} (t_{b} ,t) >\) is the mean intensity averaged over all the grids, and \(\sigma (t_{b} ,t)\) is the standard deviation of intensity over all the grids.
(6) The measure of anomalous seismicity in grid \(i\) is the difference between the two normalized seismic intensities: \(\Delta I_{i} (t_{b} ,t_{1} ,t_{2} ) = \mathop {I_{i} }\limits^{ \wedge } (t_{b} ,t_{2} ) - \mathop {I_{i} }\limits^{ \wedge } (t_{b} ,t_{1} )\).
(7) To reduce the relative importance of random fluctuations (noise) in seismic activity, the average change in intensity (\(\overline{{\Delta I_{i} (t_{0} ,t_{1} ,t_{2} )}}\)) over all possible pairs of normalized intensity maps is defined to have the same change interval: \(\overline{{\Delta I_{i} (t_{0} ,t_{1} ,t_{2} )}} = \frac{1}{{t_{1} - t_{0} }}\sum\nolimits_{{t_{b} = t_{0} }}^{{t_{1} }} {\Delta I_{i} } (t_{b} ,t_{1} ,t_{2} )\), where the sum is performed over increments of the time series, which here are considered as days.
(8) The probability of a future earthquake in grid \(i\), \(P_{i} (t_{0} ,t_{1} ,t_{2} )\), is defined as the square of the average intensity change: \(P_{i} (t_{0} ,t_{1} ,t_{2} ) = \overline{{\Delta I_{i} (t_{0} ,t_{1} ,t_{2} )}}^{2}\).
(9) The change in the probability in grid \(i\) , relative to the background mean probability over all grids, is \(\Delta P_{i} (t_{0} ,t_{1} ,t_{2} ) = P_{i} (t_{0} ,t{}_{1},t_{2} ) - < P_{i} (t_{0} ,t_{1} ,t_{2} ) >\), where \(< P_{i} (t_{0} ,t_{1} ,t_{2} ) >\) is the background probability for a large earthquake.
Hotspots are initially defined to be the regions where \(\Delta P_{i} (t_{0} ,t_{1} ,t_{2} )\) is positive. In these regions, \(P_{i} (t_{0} ,t_{1} ,t_{2} )\) is larger than the average value for all grids (the background level). In order to get the normalized hotspot map and reduce the number of hotspots for reduction of false alarm rate, we calculate the value of \(\log \Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )\), and set a threshold of \(\log \Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )\) to get the final hotspot map. The number of hotspots depends on the threshold of \(\log \Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )\). Since the intensities are squared in defining probabilities, the hotspots may be due to either increases of seismic activity during the change time interval (activation) or due to decreases (quiescence).
There exists a common hypothesis in seismicity-based earthquake-forecasting techniques that future large earthquakes tend to occur in the locations where the activity of small events changed abnormally, such as AMR, LURR, PI, M8, b-value, RTL, RI, etc. (Tiampo and Shcherbakov 2012). For example, Bufe et al. (1993) regarded that before a major earthquake (\(M_{f}\)) occurs, the seismicity of smaller earthquakes with magnitude of \(M_{f} - 2\) often show abnormal acceleration or decrease; Jaume et al. (1999) concluded that the seismicity of smaller earthquakes with magnitude from \(M_{f} - 2\) to \(M_{f} - 3\) often show activity of abnormal acceleration or decrease before a major earthquake (\(M_{f}\)). Kossobokov et al. (1999) employed smaller earthquakes, ~M4, to calculate the “Time of Increased Probability,” or TIP, for the forecasting of a larger event of approximately M6.5–8; Papazachos et al. (2005) determined that the seismicity events of smaller earthquakes with magnitude from \(M_{f} - 1.5\) to \(M_{f} - 2.0\) often show activity of abnormal acceleration or decrease before a major earthquake (\(M_{f}\)). In our study, we hypothesize that earthquakes with magnitudes larger than \(M_{c}\) +2.0 will occur preferentially in hotspots during the forecast time interval from \(t_{2}\)–\(t_{3}\) the same as that Hollidays et al. (2005).
3 The Tibetan Plateau and the Its Seismicity
3.1 Location of the Tibetan Plateau and Its Recent Large Earthquakes during 2008–2014
The Tibetan Plateau is chosen to be the study region. This region includes most part of western China and some parts of Bhutan, Nepal, India, Pakistan, Afghanistan, etc. (Fig. 1). The plateau is bordered to the south by the inner Himalayan range, to the north by the Kunlun Range which separates it from the Tarim Basin, and to the northeast by the Qilian Range which separates the plateau from the Hexi Corridor and Gobi Desert. To the east and southeast, the plateau gives way to the forested gorge and ridge geography of the mountainous headwaters of the Salween, Mekong, and Yangtze rivers in western Sichuan (the Hengduan Mountains) and southwest Qinghai. In the west, the curve of the rugged Karakoram range of northern Kashmir embraces it. It is bounded on the north by a broad escarpment where the altitude drops from around 5000 to 1500 m in less than 150 km. Along the escarpment is a range of mountains. In the west, the Kunlun Mountains separate the plateau from the Tarim Basin. About half way across the Tarim, the bounding range becomes the Altyn-Tagh, and the Kunluns, by convention, continue somewhat to the south. In the ‘V’ formed by this split lies the western part of the Qaidam Basin. To the west are short ranges called the Danghe, Yema, Shule, and Tulai Nanshans. The easternmost range is the Qilian Mountains. The line of mountains continues further east of the plateau as the Qin Mountains which separate the Ordos Region from Sichuan (Li 1987; Zhang et al. 2002).
Five large earthquakes of M ≥ 7.0 occurred in and near the Tibetan Plateau during 2008–2014 (Fig. 1), including the serious deadly Wenchuan M8.0 earthquake. The focal mechanisms of these five earthquakes are listed in Table 1.
3.2 Earthquakes Above M7.0 in and Near the Tibetan Plateau Since 1900
Due to the strong collision between the Indian Plate and Eurasian Plate, a number of active tectonic blocks including Tibetan active block have formed since the Cenozoic era (Zhang et al. 1999), and hence the complex tectonics and high seismicity in this region (e.g., Xu et al. 2005). We select a square region of (21.0°–41.0°N, 74.0°–106.0°E) including the Tibetan Plateau for the study of the predictability of PI method to recent large earthquakes that occurred in this region. According to the earthquake catalogue supplied by China Earthquake Administration (http://10.5.202.22/bianmu), 83 large earthquakes of M ≥ 7.0 occurred in the selected region during 1900–2014, including 10 tremendous earthquakes with magnitude above M8.0 (Fig. 2), and the largest one is Chayu, Tibet (28.4°N, 96.7°E) M8.6 earthquake that occurred on August 15, 1950 (BJT).

Large earthquakes with M ≥ 7.0 that occurred in and near the Tibetan Plateau during 1900–2014
The year of 1970 is a milestone for Chinese micro-earthquake catalogue. Nationwide earthquake catalogues have been produced by the constantly improved Chinese seismic network since 1970. Hence, those large earthquakes covered by the seismic monitoring network could be employed to study the predictability of PI method. As shown in Fig. 2, there were a total of 83 large earthquakes with M7.0 and higher during the period of 1900–2014. 29 out of these 83 earthquakes occurred after 1970 in the selected region, and 21 out of the 29 quakes occurred in the Chinese territory boundary. The algorithm of PI requires a reference time interval from \(t_{b}\) to \(t_{1}\) (initial time \(t_{0}\) = 1970 in our study, and \(t_{b}\) lies between \(t_{0}\) and \(t_{1}\)), and a change interval from \(t_{1}\) to \(t_{2}\) (\(t_{2}\) > \(t_{1}\)). The forecasting interval is from \(t_{2}\) to \(t_{3}\), where \(t_{3}\) should be the year 2014 or before in our retrospective study. Therefore, the earthquakes that occurred during the interval from \(t_{1}\) to \(t_{2}\) could be used for the retrospective study, and those that occurred during the interval from \(t_{2}\) to \(t_{3}\) could be used for the test of the predictability of PI forecasting method. For example, if the forecasting interval from \(t_{2}\) to \(t_{3}\) is 10 years, then those large earthquakes that occurred during 2005–2014 could be employed for the test. In general, \(t_{1}\)–\(t_{0}\) should be much longer than \(t_{2}\)–\(t_{1}\) to retain the higher robustness of the results. According to China Earthquake Networks Center (CENC), there were five M ≥ 7.0 earthquakes that occurred in the selected region during 2005–2014 as shown in Fig. 2 and listed in Table 2.
3.3 The Monitoring Ability and Completeness of Earthquake Catalogue in and near the Tibetan Plateau
In 1970s and 1980s, earthquakes less than M L4.5 could not be recorded completely in the western Continental China when evaluated by Gutenburg-Richter law, which was mainly caused by the lower monitoring ability in the Tibetan Plateau at that time (Zhang et al. 2013). With the gradual advancement in China Seismic Network, the lower cutoff of complete earthquake catalogue in this region reached to M L4.0 since (Zhang et al. 2013). By now, the advanced China Digital Seismic Network is able to record all earthquakes larger than M L3.0 in and near the Tibetan PlateauFootnote 1 (Fig. 3). In our study, we need to employ the earthquake catalogue of the selected region over the entire time duration from 1970 (the initial time \(t_{0}\)) to 2014, so the lower cutoff magnitude \(M_{c}\) of the complete earthquake catalogue in and near the Tibetan Plateau should be M L4.5.

Map of seismic monitoring ability in and near Continental China (Provided by the Department of China Seismic Network, CENC. Contact: huangzhibin@seis.ac.cn)
Figure 4 shows the distribution map of earthquakes larger than M L4.5 recorded by China Seismic Network during the period from 1970 to 2014. From this figure, we can see that the recorded earthquakes cover the territory belonging to China and its neighborhood. The complete earthquake catalogue with lower cutoff of M L4.5 could meet the requirement of the retrospective study to test the predictability of PI method for the recent large earthquakes in this region covered by the recorded earthquakes. From Fig. 4, we see that some of the earthquakes outside the Chinese territory boundary could not be covered by the complete earthquake catalogue recorded by Chinese Seismic Network; these earthquakes could not be employed as the target earthquakes for the test in our study due to lack of data or incomplete catalogue.

Earthquake distribution map in and near the Tibetan Plateau recorded by China Seismic Network. (The earthquake catalogue is from the CENC, with all recorded earthquakes larger than M L4.5 during the period of 1970–2014.)
4 The Computing Parameters for the Test
Computing parameters of PI algorithm include (1) the scale of the grid in the selected region, say the length \(\Delta x\) of the grid, and the number \(N_{B}\) of the grids; (2) the time nodes for determining the beginning time \(t_{b}\), the reference time interval from \(t_{b}\) to \(t_{1}\), change time interval from \(t_{1}\) to \(t_{2}\), and the forecast time interval from \(t_{2}\) to \(t_{3}\); (3) lower cutoff magnitude \(M_{c}\) of the complete earthquake catalogue; and (4) the threshold of \(\log \Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )\). Although the results of ROC test show that the PI method outperforms not only the random guess method but also the simple number-counting approach based on the clustering hypothesis of earthquakes (the RI forecast) (Rundle et al. 2000a, b, 2002, 2003; Tiampo et al. 2002a, b; Holliday et al. 2005, 2006a), the proper parameters will improve the efficacy of the hotspot map in earthquake forecasting. Zhang et al. (2013) tested the forecasting efficacy of the PI method applied to the Wenchuan M8.0 and Yutian M7.3 earthquakes in West Continental China in 2008 by fixing \(t_{b}\)(June 1, 1970) and \(t_{3}\)(June 1, 2008) under different values of \(t_{1}\), \(t_{2}\), and \(\Delta x\), and the results of the ROC test and R score test show that the models with forecasting intervals of 8–10 years under grid size of \(\Delta x\) = 1° and those with forecasting intervals of 7–10 years under grid size of \(\Delta x\) = 2° are better. In order to test if the these parameters also work well for the succeeding earthquakes during 2009–2014 in western China mainland after Wenchuan M8.0 earthquake, all actually occurring in the Tibetan Plateau, we select the square region of (21.0°–41.0°N, 74.0°–106.0°E) including the Tibetan Plateau for the study. The grid size of \(\Delta x\) = 1.° This means the total number of grids is 640. The forecasting interval from \(t_{3}\)–\(t_{2}\) = 8 years. \(t_{b}\) is fixed to January 1, 1970. In order to keep the target earthquakes during 2008–2014 in the forecasting interval \(t_{3}\)–\(t_{2}\), \(t_{3}\) changes from January 1, 2008 to December 31, 2021 with the moving step of 12 months, and \(t_{2}\) changes from January 1, 2001 to December 31, 2008 with the moving step of 12 months. According to the hypothesis of \(t_{3}\)–\(t_{2}\) = \(t_{2}\)–\(t_{1}\)(Holliday et al. 2005), \(t_{1}\) changes from January 1, 1993 to January 1, 2001. According to our hypothesis that earthquakes with magnitudes larger than \(M_{c}\) +2.0 will occur preferentially in hotspots during the forecast time interval \(t_{2}\) to \(t_{3}\), the cutoff magnitude \(M_{c}\) is chosen to be 5.0 to forecast the future M7.0 and above earthquakes. The threshold of \(\log \Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )\) is chosen to be −0.6 to determine the number of hotspots according to the previous work (Zhang et al. 2013).
5 Results of Retrospective Tests for the Predictability of PI Method
5.1 PI Patterns and the Target Earthquakes
Base on the above computing parameters, the forecasting hotspot maps with forecasting interval of 8 years and moving time step of 12 months were obtained. Figure 5 shows 14 PI hotspot maps. The first one is with the forecasting interval \(t_{2}\) = Jan 1, 2001 to \(t_{3}\) = Dec 31, 2008, and the last one is with the forecasting interval from \(t_{2}\) = Jan 1, 2014 to \(t_{3}\) = Dec 31, 2021. Earthquakes that occurred during each forecasting interval were also dotted in the maps.


Hotspot maps of each forecasting interval with the threshold possibility of \(\log_{10} (\Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )) = - 0.6\). The blue circles denote the positions of target earthquakes that occurred during the forecasting intervals
-
1.
Yutian M7.3 and Wenchuan M8.0 earthquakes in 2008.
These two earthquakes were covered by eight PI forecasting intervals, as shown in Fig. 5a–h. For Yutian M7.3 earthquake, it occurred in the intersection of Altyn-Tagh and the Kunluns, northwestern boundary of the Tibetan Plateau (Fig. 1). Yutian M7.3 earthquake dropped in a hotspot or its Moore neighborhood grids (the eight grids surrounding the hotspot grid are defined as the Moore neighborhood (Moore 1962)) in each succeeding forecasting interval (Fig. 5a–h). This means that Yutian M7.3 could be forecasted by PI method. For Whenchuan M8.0 earthquake, it occurred in the Longmenshan Faults, at the eastern boundary of the Tibetan Plateau (Fig. 1). Hotspot only existed in the epicenter grid during the forecasting interval from January 1, 2008 to December, 2015 (Fig. 5h). That is to say that Wenchuan M8.0 could be forecasted in only one forecasting interval among the total of eight such ones.
-
2.
Yushu M7.1 earthquake in 2010.
Yushu M7.1 earthquake occurred in the central area of the Tibetan Plateau (Fig. 1). This earthquake was covered by eight forecasting intervals, as shown in Fig. 5c–j. Hotspots existed in the epicenter grid in three forecasting intervals as shown in Fig. 5d–f, and existed in the Moore neighborhood grids in the forecasting interval as shown in Fig. 5j. Therefore, this earthquake could also be forecasted by the PI method.
-
3.
Lushan M7.0 earthquake in 2013.
Lushan M7.0 earthquake also occurred in the Longmenshan Faults, eastern boundary of the Tibetan Plateau (Fig. 1). It is located about 80 km southwest from the Wenchuan M8.0 earthquake. This earthquake was covered by eight forecasting intervals, as shown in Fig. 5f–m. Hotspots existed in the epicenter grid or the Moore neighborhood grids in four forecasting intervals as shown in Fig. 5h, j, k, m. Therefore, this earthquake could also be forecasted by the PI method.
-
4.
Yutian M7.3 earthquake in 2014.
This earthquake occurred about 100 km northeast from the Yutian M7.3 earthquake in 2008 (Fig. 1). This earthquake was covered by eight forecasting intervals, as shown in Fig. 5g–n. Hotspots existed in the epicenter grid or the Moore neighborhood grids in seven forecasting intervals as shown in Fig. 5g, h, j–n. Therefore, this earthquake could also be well forecasted by the PI method.
From Fig. 5, we see that, following Zhang’s tested computing parameters (Zhang et al. 2013), all of these five large earthquakes could be forecasted by the PI method in different degrees. The Yutian M7.3 earthquake could be forecasted very well with the consistent appearance of the hotspot in the epicentral grid or the Moore Neighbor grids in the succeeding time forecasting intervals. However, the Wenchuan M8.0 earthquake could be forecasted in only one forecasting interval.
From Fig. 5, we also see that there are many hotspots without large earthquakes; theses are false alarms. Further some earthquakes did not occur in the hotspot grid or in the Moore neighborhood grids. Therefore, we need to evaluate the efficacy of the PI method by some kind of quantitative test. Here, we employ the Receiver Operating Characteristic-ROC (Swets 1973; Molchan 1997) test as Rundle et al. (2000c, 2003), Tiampo et al. (2002c) and Holliday et al. (2005) did. We also employ the R score evaluation method proposed by Xu et al. (1989) and Shi et al. (2000). The evaluation results are as follows.
5.2 Retrospective Evaluation for the Predictability of PI Method by ROC Test
ROC test is conducted by systematically changing the ‘alarm threshold’ of the ‘forecast region’ and counting the ‘hit rate’ and ‘false alarm rate’ compared with real earthquake activity. The ‘alarm threshold’ here is the cutoff value of \(\log_{10} (\Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} ))\). Following Rundle et al. (2000c, 2003), Tiampo et al. (2002) and Holliday et al. (2005), we define that: during the forecast interval from \(t_{2}\) to \(t_{3}\), if an earthquake larger than M7.0 occurs in a hotspot grid or within the Moore neighborhood of the grid, this is a success. If no earthquake occurs in a non-hotspot grid, this is also a success; If no earthquake occurs in a hotspot grid or within the Moore neighborhood of the hotspot grid, this is a false alarm; If earthquake occurs in a grid, which is not hotspot grid or the Moore neighborhood of the hotspot grid, this is a failure to forecast.
According to the above definitions, we can obtain the values a (Forecast = yes, Observed = yes), b (Forecast = yes, Observed = no), c (Forecast = no, Observed = yes), and d (Forecast = no, Observed = no), respectively, for the hotspot maps. The fraction of colored grids, also called the probability of forecast of occurrence, is \(r = (a + b)/N\), where the total number of grids is \(N = a + b + c + d\). The hit rate is \(H = a/(a + c)\) and is the fraction of large earthquakes that occur on a hotspot. The false alarm rate is \(F = b/(b + d)\) and is the fraction of non-observed earthquakes that are incorrectly forecast.
For each forecasting interval, we obtain the PI hotspot maps under different thresholds of \(\log_{10} (\Delta P_{i} (t_{0} ,t_{1} ,t_{2} )/\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} ))\); here \(\Delta P_{i} (t_{0} ,t_{1} ,t_{2} )\) is from 0 to \(\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )\). Then we calculate the hit rate and false rate of each hotspot map under different thresholds according to the above-mentioned method.
For example, Fig. 6 shows the diagrams of ROC test for forecasting interval from Jan 1, 2004 to Dec 31, 2011. This figure shows that no matter how the threshold changes, Hit rate is always greater than False alarm rate. That means PI method outperforms the random forecast definitely.

ROC test for forecasting interval from Jan 1, 2004 to Dec 31, 2011. Hit rates and false rates are calculated by changing the threshold possibility \(\Delta P_{i} (t_{0} ,t_{1} ,t_{2} )\) from 0 to \(\Delta P_{\hbox{max} } (t_{0} ,t_{1} ,t_{2} )\)
In order to evaluate the degree of forecast efficacy of each forecasting interval quantitatively, we define a parameter \(E_{f}\) as follows (Zhang et al. 2013):
where \(H_{i}\) denotes the hit rate associated with the false alarm rate \(F_{i}\). The essence of \(E_{f}\) is the area surrounded by the curve of \(H(F)\), the line of H = 0, and the line of F = F max. Here F max is the false alarm rate under the threshold of \(\Delta P_{i} (t_{0} ,t_{1} ,t_{2} ) = 0\). If the hit rate is bigger under the same False alarm rate, the parameter \(E_{f}\) is bigger; hence, the forecast efficacy could be determined by \(E_{f}\). The bigger value of \(E_{f}\) means higher forecast efficacy.
We only test the forecasting maps of Fig. 5a, b, c, d, e, f, g because the ending time of the forecasting intervals shown in Fig. 5i, j, k, l, m has yet to reach completion. Although the ending time of the forecasting interval in Fig. 5h has reached completion, we did not perform the test because the Nepal M8.1 earthquake (28.3°N, 84.7°E) that occurred on April 25, 2015 was very near the Chinese territory boundary, and we need to do further study to verify if this quake could be taken as a target earthquake.
According to the definition of \(E_{f}\), when \(E_{f}\) − 0.5 is positive, the forecasting of PI method will outperform the random guess method. The values of the \(E_{f}\) − 0.5 corresponding to the seven forecasting intervals shown in Fig. 5a–g are listed in Table 2, respectively. All these values are positive, which means PI forecasting efficacy under the selected parameters is stable during different forecasting intervals.
5.3 Retrospective Evaluation for the Predictability of PI Method by R Score Test
Xu et al. (1989) developed an evaluation method for the efficacy of earthquake forecast method in China, the so-called R score. Shi et al. (2000) developed the algorithm of R score for testing the annual potential seismic hazard regions forecasted by China Earthquake Administration (CEA). Compared with the ROC test, “the Moore neighborhood” is not considered in the R score test, that is to say that, during \(t_{2}\)–\(t_{3}\), if an earthquake lager than M7.0 occurs in a hotspot grid, this is considered a success; If no earthquake occurs in a non-hotspot grid, this is also considered a success; If no earthquake occurs in a hotspot grid, this is considered a false alarm; If earthquake occurs in a grid, which is not hotspot grid, this is considered a failure to forecast. So R score test is more rigorous than ROC test.
According to the above definitions, values a (Forecast = yes, Observed = yes), b (Forecast = yes, Observed = no), c (Forecast = no, Observed = yes), and d (Forecast = no, Observed = no) are obtained for the hotspot map. The hit rate is \(H = a/(a + c)\). The false alarm rate is \(F = b/(b + d)\). R score = H − F.
The R scores corresponding to the seven forecasting intervals (Fig. 5a–g) are listed in Table 3, respectively. The average value of R scores in the seven forecasting intervals is about 0.36. Positive R score means the forecasting efficacy outperforms the random guess method (Shi et al. 2000). The results in Table 3 show that the PI method outperforms the random guess method.
6 Discussions
6.1 Are the Computing Parameters Reasonable?
The computing parameters in this study were selected from the previous work on Wenchuan M8.0 and Yutian M7.3 earthquakes (Zhang et al. 2013). Based on the systematic verification of different models with different forecasting intervals and different grid scales by ROC and R score tests, Zhang et al. (2013) regarded that the forecasting intervals of 8–10 years under grid size \(\Delta x\) = 1° and those with forecasting intervals of 7–10 years under grid size \(\Delta x\) = 2° are better. Our retrospective study verifies that these parameters also work very well for the succeeding Yushu M7.1, 2010; Lushan M7.0, 2013, and Yutian M7.3, 2014 earthquakes. So the computing parameters in this study are reasonable for all these five large earthquakes. However, the relationship between the grid size of PI and the critical seismogenic size (e.g., Bufe and Varnes 1993) or the rupture scale (e.g., Kanamori and Anderson 1975) is an issue that needs to be studied in the future. More earthquake cases need to be studied to achieve a solid conclusion.
6.2 What else will Affect the Hotspot Pattern?
In addition to the computing parameters we considered in this study, the selected range for study might be a factor to affect the hotspot pattern. The Tibetan Plateau is included in the western China Mainland. We compared the hotspot patterns under the same computing parameters in Tibetan Plateau region and Western China Mainland region (Zhang et al. 2013), and found that the patterns are different for Wenchuan M8.0 earthquake. This is caused by the algorithm of PI method that all grids are considered for calculation. Further study needs to be carried out to include the effects by the range of the selected region.
6.3 Need we Use the Original Earthquake Catalogue or De-clustered Catalogue for Forecasting Map?
Aftershocks occupy a significant proportion of the total number of earthquakes, especially during the period with large earthquake sequences. Jiang and Wu (2011) de-clustered the catalogue of the Sichuan-Yunnan region of southwest China by the epidemic-type aftershock sequences (ETAS) model and investigated the effects of de-clustering on the PI forecasts. Their results showed that PI forecasts seem to be affected by the aftershock sequence included in the “anomaly identifying interval,” and the PI forecast using “background events” seems to have a better performance. Further study regarding the influence of the aftershock sequences on the PI forecasting map needs to be conducted in the future.
7 Conclusions and Prospects
In this paper, the Tibetan Plateau (included in the region of 21°–41°N, 74°–106°E) was taken as the study region to verify the predictability of the PI method by the receiver-operating characteristic (ROC) test and R Score test. The results show that
-
1.
Successive obvious hotspots occurred in the sliding forecasting intervals before four of the five earthquakes, while hotspots only occurred in one forecasted interval without successive evolution process before one of the five earthquake, which indicates four of the five large earthquakes could be forecasted well by PI method;
-
2.
Test results of the Predictability of PI method by ROC and R score show that positive prospect of PI method could be expected for long-term earthquake forecast.
The effects of changeable selected regions, grid sizes, and de-clustering of catalogue were not considered in our current study, and they will be examined in the future. The future study is suggested to work out the proper parameters to keep the PI pattern stable and make the forecasting map the most optical.
Notes
Provided by the Department of China Digital Seismic Network, CENC. Contact: huangzhibin@seis.ac.cn.
References
Bufe, C. G., & Varnes, D. J. (1993). Predictive modeling of the seismic cycle of the greater San Francisco Bay region. Journal of Geophysical Research, 98, 9871–9883.
Chang, L., Chen, C., & Wu, Y. (2013). A study on the pattern informatics and its application to earthquake prediction in Taiwan[C]//AGU Fall. Meeting Abstracts, 1, 2341.
Chen, C. C., Rundle, J. B., Holliday, J. R., Nanjo, K. Z., Turcotte, D. L., Li, S. C., et al. (2005). The 1999 Chi-chi, Taiwan, earthquake as a typical example of seismic activation and quiescence. Geophysical Research Letters, 32, L22315.
Chen, C. C., Rundle, J. B., Li, H. C., et al. (2006). From tornadoes to earthquakes: forecast verification for binary events applied to the 1999 Chi-Chi, Taiwan, earthquake. Terrestrial Atmospheric and Oceanic Sciences, 17(3), 503–516.
Cho, N. F., & TIAMPO, K. F. (2013). Effects of location errors in pattern informatics[J]. Pure Applied Geophysics, 170(1–2), 185–196.
Holliday, J. R., Nanjo, K. Z., Tiampo, K. F., Rundle, J. B., & Turcotte, D. L. (2005). Earthquake forecasting and its verification. Nonlinear Processes in Geophysics, 12, 965–977.
Holliday, J. R., Rundle, J. B., Tiampo, K. F., Klein, W., & Donnellan, A. (2006a). Modification of the pattern informatics method for forecasting large earthquake events using complex eigenfactors. Tectonophysics, 413, 87–91.
Holliday, J. R., Rundle, J. B., Tiampo, K. F., Klein, W., & Donnellan, A. (2006b). Systematic procedural and sensitivity analysis of the pattern informatics method for forecasting large (M ≥ 5) earthquake events in southern California. Pure Applied Geophysics, 163, 2433–2454.
Jaume, S. C., & Sykes, L. R. (1999). Evolving towards a critical point: a review of accelerating seismic moment/energy release prior to large and great earthquakes. Pure and Applied Geophysics, 155, 279–306.
Jiang, C. S., & Wu, Z. L. (2008). Retrospective forecasting test of a statistical physics model for earthquakes in Sichuan-Yunnan region. Science in China, Series D: Earth Sciences, 51(10), 1401–1410. doi:10.1007/s11430-008-0112-6.
Jiang, C. S. & Wu, Z. L.(2011). PI forecast with or without de-clustering: an experiment for the Sichuan-Yunnan region. Natural Hazards and Earth System Sciences, 11, 697–706. doi:10.5194/nhess-11-697-2011. www.nat-hazards-earth-syst-sci.net/11/697/2011/
Kanamori, H., & Anderson, D. L. (1975). Theoretical basis of some empirical relations in seismology. Bulletin of the Seismological Society of America, 65(5), 1073–1095.
Kawamura, M., Wu, Y. H., Kudo, T., & Chen, C. C. (2013). Precursory migration of anomalous seismic activity revealed by the pattern informatics method: a case study of the 2011 Tohoku earthquake, Japan. Bulletin of the Seismological Society of America, 103(2B), 1171–1180.
Kawamura, M., Wu, Y. H., Kudo, T., & Chen, C. C. (2014). A statistical feature of anomalous seismic activity prior to large shallow earthquakes in Japan revealed by the pattern informatics method. Natural Hazards and Earth System Sciences, 14(4), 849.
Kossobokov, V. G., Romashkova, L. L., & Keilis-Borok, V. I. (1999). Testing earthquake prediction algorithms: statistically significant advance prediction of the largest earthquakes in the Circum-Pacific, 1992–1997. Physics of the Earth and Planetary Interiors, 111, 187–196.
Li, B. Y. (1987). On the Extent of the Qinghai-Xizang (Tibet) Plateau. Geographical Research (in Chinese with English abstract), 6(3), 57–64.
Migan, A., & Tiampo, K. F. (2010). Testing the pattern informatics index on synthetic seismicity catalogues based on the non-critical PAST. Tectonophysics, 483, 255–268. doi:10.1016/j.tecto.2009.10.023.
Molchang, M. (1997). Earthquake prediction as a decision-making problem. Pure and Applied Geophysics, 149, 233–247.
Moore, E. F. (1962). Machine models of self reproduction. In Proceedings of the fourteenth symposium on applied mathematics (pp. 17–33). American Mathematical Society.
Nanjo, K. Z., Holliday, J. R., Chen, C. C., Rundle, J. B., & Turcotte, D. L. (2006a). Application of a modified pattern informatics method to forecasting the locations of future large earthquakes in the central Japan. Tectonophysics, 424, 351–366.
Nanjo, K. Z., Rundle, J. B., Holliday, J. R., et al. (2006b). Pattern informatics and its application for optimal forecasting of large earthquakes in Japan. Pure and Applied Geophysics, 163(11–12), 2417–2432.
Papazachos, C. B., Karakaisis, G. F., Scordilis, E. M., & Papazachos, B. C. (2005). Global observational properties of the critical earthquake model. Bulletin of the Seismological Society of America, 95, 1841–1855.
Rundle, J. B., Klein, W., Gross, S. J., & Tiampo, K. F. (2000a). Dynamics of seismicity patterns in systems of earthquake faults. In J. B. Rundle, D. L. Turcotte, & W. Klein (Eds.) Geo-complexity and the Physics of Earthquakes, vol. 120 of Geophysics Monograph Series (pp. 127–146). Washington, D. C: AGU.
Rundle, J. B., Klein, W., Tiampo, K. F., & Gross, S. J. (2000b). Linear pattern dynamics in nonlinear threshold systems. Physical Review E, 61, 2418–2432.
Rundle, J. B., Klein, W., Turcotte, D. L., et al. (2000c). Precursory seismic activation and critical-point phenomena. Pure and Applied Geophysics, 157, 2165–2182.
Rundle, J. B., Tiampo, K. F., Klein, W., & Martins, J. S. S. (2002) Self-organization in leaky threshold systems: The influence of near-mean field dynamics and its implications for earthquakes, neurobiology, and forecasting. Proceedings of the National Academy of Sciences of the United States of America, 99(Suppl. 1), 2514–2521.
Rundle, J. B., Turcotte, D. L., Shcherbakov, R., Klein, W., & Sammis, C. (2003). Statistical physics approach to understanding the multiscale dynamics of earthquake fault systems. Reviews of Geophysics, 41, 1019–1038.
Shi, Y. L., Liu, J., & Zhang, G. M. (2000). The evaluation of Chinese annual earthquake prediction in the 90s. J Graduate School Academia Sin (in Chinese with English abstract), 17, 63–69.
Swets, J. A. (1973). The relative operating characteristic in psychology. Science, 182, 990–1000.
Tiampo, K. F., Bowman, D. D., Colella, H. & Rundle, J. B. (2008). The stress accumulation method and the pattern informatics index: Complementary approaches to earthquake forecasting. Pure Applied. Geophysics, 165, 693–709, 0033–4553/08/030693–17. doi:10.1007/s00024-008-0329-5.
Tiampo, K. F., Klein, W., Li, H.-C., Migan, A., Toya, Y., Kohen-Kadosh, S. L. Z., et al. (2010). Ergodicity and earthquake catalogs: forecast testing and resulting implications. Pure and Applied Geophysics, 167, 763–782. doi:10.1007/s00024-010-0076-2.
Tiampo, K. F., Rundle, J. B., McGinnis, S., Gross, S. J., & Klein, W. (2002a). Eigenpatterns in southern California seismicity. Journal of Geophysical Research, 107, 2354.
Tiampo, K. F., Rundle, J. B., McGinnis, S., & Klein, W. (2002b). Pattern dynamics and forecast methods in seismically active regions. Pure Applied Geophysics, 159, 2429–2467.
Tiampo, K. F., Rundle, J. B., McGinniss, S., et al. (2002c). Mean-field threshold systems and phase dynamics: an application to earthquake fault systems. Europhysics Letters, 60, 481–487.
Tiampo, K. F., & Shcherbakov, R. (2012). Seismicity-based earthquake forecasting techniques: ten years of progress. Tectonophysics, 522–523, 89–121. doi:10.1016/j.tecto.2011.08.019.
Tiampo, K. F., & Shcherbakov, R. (2013). Optimization of seismicity-based forecasts. Pure and Applied Geophysics, 170, 139–154. doi:10.1007/s00024-012-0457-9.
Wu, Y. H., Chen, C. C. & Rundle, J. B. (2008a) Detecting precursory earthquake migration patterns using the pattern informatics method. Geophysical Research Letters 35 (19) (Art. No. L19304).
Wu, Y. H., Chen, C. C., & Rundle, J. B. (2008b). Precursory Seismic Activation of the Pingtung (Taiwan) Offshore Doublet Earthquakes on 26 December 2006: A Pattern Informatics Analysis. Terrestrial Atmospheric And Oceanic Sciences, 19(6): 743–749.
Xia, C. Y., Zhang, Y. X., Zhang, X. T., & Wu, Y. J. (2014). Test of the predictability of PI method by two Ms7.3 earthquakes in Yutian County, Xinjiang Uygur Autonomous Region. Journal of Seismologica Sinica (In Chinese with English abstract), 37(1), 192–201.
Xu, S. X. (1989). Mark evaluation for earthquake prediction efficacy. In: Department of Science and Technology Monitoring, State Seismological Bureau (Ed.) Collected Papers of Research on Practical Methods of Earthquake Prediction (Volume of Seismology) (in Chinese) (pp. 586–590). Beijing: Academic Books and Periodical Press.
Xu, X. W., Zhang, P. Z., Wen, X. Z., Qin, Z. L., Chen, G. H., & Zhu, A. L. (2005). Features of active tectonics and recurrence behaviours of strong earthquakes in the western Sichuan Province and its adjacent regions[J]. Seismology and Geology, 27(3), 446–461. (in Chinese with English abstract).
Zhang, P. Z. (1999). Late quaternary tectonic deformation and earthquake hazard in continental China[J]. Quaternary Sciences, 19(5), 404–413 (in Chinese with English abstract).
Zhang, Y. L., Li, B. Y., & Zheng, D. (2002). A discussion on the boundary and area of the Tibetan Plateau in China. Geographical Research (in Chinese with English abstract), 21(1), 1–8.
Zhang, Y. X., Zhang, X. T., Wu, Y. J., & Yin, X. C. (2013). Retrospective study on the predictability of pattern informatics to the Wenchuan M8.0 and Yutian M7.3 earthquakes. Pure and Applied Geophysics, 170((1-2)), 197–208. doi:10.1007/s00024-011-0444-6. (Published online 2012).
Zhang, X. T., Zhang, Y. X, Xia, C. Y., Wu, Y. J., & Yu H. Z. (2014). A study on the PI anomaly before the Lushan M7.0 earthquake in the Sichuan-Yunnan region and neighboring areas. Journal of Seismologica Sinica (In Chinese with English abstract), 36(5), 780–789.
Zhang, Y. X., Zhang, X. T., Yin, X. C. & Wu, Y. J. (2009). Study on the forecast effects of PI method to the North and Southwest China, Currency and Computation: Practice and Experience. New York: Wiley. doi:10.1002/cpe.1515 (http://www.interscience.wiley.com) (Published online).
Acknowledgements
The authors gratefully acknowledge the support from the Chinese Ministry of Science and Technology under Grants No. 2010DFB20190 and No. 2012BAK19B02-05. The authors also thank Prof. J.B. Rundle for certain valuable comments on PI methods and the anonymous reviewers for their constructive comments on the paper. The authors also offer their thanks to CENC (China Earthquake Networks Center) for the earthquake catalogue.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, Y., Xia, C., Song, C. et al. Test of the Predictability of the PI Method for Recent Large Earthquakes in and near Tibetan Plateau. Pure Appl. Geophys. 174, 2411–2426 (2017). https://doi.org/10.1007/s00024-017-1551-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-017-1551-9