
Abstract
Prediction and validation of Compound factors for prioritization of watersheds are an essential application using machine learning (ML) techniques in water resource engineering. The current paper proposes a methodology to derive 14 morphometric and 3 topo-hydrological parameters using remote sensing (RS) and geographical information systems (GIS). Compound factor (CF) values are calculated using weighted sum analysis (WSA), ReliefF, and the Pearson correlation coefficient, and the important parameters are identified. Two machine learning models, multilayer perceptron (MLP) and support vector machine (SVM), are utilized to predict CF values. Predication accuracy of ML models is evaluated with three parameters, mean absolute error (MAE), Pearson correlation coefficient (PCC), and root mean square error (RMSE). It is observed that the maximum value of PCC equal to 1 is achieved through ReliefF and SVM, whereas minimum MAE and RMSE are observed with ReliefF and SVM when Tenfold cross-validation is applied. Since ReliefF shows better results, CF values are calculated and applied to create the watershed. The proposed methodology is helpful for accurately predicting CF values and advantageous to allocating the proper watershed, which will be useful for decision-making and implementation of conservation techniques for soil and water.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Watershed prioritization is crucial for developing watershed management planning and better land management. It is essential to determine the watershed priority in the semi-arid and arid regions as it helps manage water in ungauged rivers. Spatial prioritization and watershed health help to understand watershed conditions, and it also helps derive better management strategies in the data-scarce region (Alilou et al. 2019).
Remote sensing (RS) and geographical information systems (GIS) are promising tools for extracting crucial parametrical information from watersheds. The RS and GIS technique helps establish interrelationship with parameters and decide the priority of watershed using the WSA technique (Malik et al. 2019). Many researchers have attempted to prioritize watersheds (Thakkar and Dhiman 2007; Patel et al. 2012, 2015; Samal et al. 2015; Kadam et al. 2017; Memon et al. 2020; Kulimushi et al. 2021a; Sengupta et al. 2021) and utilized different analysis techniques for watershed prioritization such as multicriteria decision analysis (MCDA) (Chowdary et al. 2013; Jaiswal et al. 2015; Samal et al. 2015; Vulević and Dragović 2017), Sediment Yield Index (Khan et al. 2001), Weighted Sum Analysis (WSA) (Aher et al. 2014; Memon et al. 2020), and Principal Component Analysis (PCA) (Farhan et al. 2017; Meshram and Sharma 2017). (Patel et al. 2022) has utilized AHP- and TOPSIS-based subwatershed prioritization to facilitate soil erosion susceptibility analysis of the Ami river basin. Furthermore, (Yadav et al. 2018) has prioritized subwatersheds for potential groundwater zone using topographic sheet and CARTOSAT data to ameliorate the flash flood and droughts, and (Kulimushi et al. 2021b) has utilized compound parameter index (Ci) and Erosion Hazard Rate Index (EHRI) derived from Analytical Hierarchy Process (AHP) for watershed priority assessment. Out of all prioritization, the WSA technique is the most familiar and prominent method for prioritizing the watersheds in the present era; however, the recent development of ML techniques helps to classify, predict, and forecast the laboratory and computer-simulated data for decision-making. Artificial Neural Network (ANN), support vector machine (SVM), and Random Forest are ML models applied in various engineering applications.
ML is a probabilistic model frequently applied for pattern recognition applications. It has been used for applications like fault diagnosis (Kankar et al. 2011), motor current signature analysis (Singh et al. 2014), compressive strength prediction (Sonebi et al. 2016), EEG (Upadhyay et al. 2016), surface roughness prediction (Patel et al. 2020), fault severity analysis (Akhenia et al. 2021), tool wear rate prediction (Shah et al. 2022), and many more applications, regardless of field.
For evaluating any type of ML model and for knowing how well the model predicts without biasedness, cross-validation is used. In k-fold cross-validation, the data is partitioned randomly into the k number of approximately equal sets, from which the model is trained on k-1 sets and tested on the remaining set. The procedure repeated k number of times, and the final result is the average of all the results obtained by repetition. The main benefit of applying this strategy is that each sample is used for training k-1 times and one time for testing, and the average results are obtained. The regression model is used to develop a mathematical function based on the experimental data in which parameters act as features. It is observed that in a feature vector, prediction capability can be improved with identifications of relevant and irrelevant features. To discard irrelevant features, a feature selection strategy can be used to determine the utility of individual features in a feature vector (Vakharia et al. 2015a, b). Other feature ranking techniques like mutual information (Dave et al. 2020), information gain (Naseriparsa et al. 2014), and ReliefF (Kononenko 1994) are also used to improve the accuracy and prediction of classification and regression problems.
With the availability of data, artificial intelligence techniques have been applied in a variety of civil engineering applications. According to literature research, it is found that machine learning strategies are extremely helpful in predicting and validating the experimental results. Furthermore, for decision-making, a particular algorithm may not be suitable; therefore, in such situations, detailed investigations are needed to assess the utility of ML algorithms for particular applications (Vakharia et al. 2022).
In the present paper, RS and GIS techniques are utilized to derive morphometric parameters and topo-hydrological parameters. Initially, the values and ranks to all 14 morphometric and 3 topo-hydrological parameters are assigned, and the CF values are calculated using well-known WSA techniques. After that, two feature ranking techniques, ReliefF and Pearson correlation coefficient, are applied to determine the weightage of morphometric and topological parameters. The weightage obtained from WSA, ReliefF, and PCC will be used to calculate the CF values. Two well-known ML models, SVM and MLP, with Tenfold cross-validations, are applied to identify the best CF values. The accuracy of ML models is examined with mean absolute error (MAE), correlation coefficient (Cr), and root mean square error (RMSE). Based on better prediction capability, decision-making is done for suitable watershed prioritization. As per the literature survey, most authors applied various techniques like parameter averaging, WSA, AHP, MCDM, and TOPSIS. To the authors’ best knowledge, decision-making for watershed prioritization using feature ranking and ML techniques is not explored till now. Therefore, to fill the gap, a novel approach for identifying relevant morphometric parameters and consequently the CF values for watersheds prioritization for the decision-making is executed in the present research. The methodology proposed will be helpful in providing an integrated solution to the decision-maker to restore the watersheds against any uncertain critical conditions. Figure 1 shows the watershed prioritization methodology based on feature ranking and ML.

Proposed methodology for watershed prioritization
Prediction using machine learning
In recent years, much attention has been focused on machine learning. One of the key causes that are driving its significance is the fact that machine learning provides a unified framework for introducing intelligent decision-making into many research areas. This is one of the primary driving forces behind its popularity in the industry as well as academics. Machine learning models can learn patterns in data whether the learning is supervised or unsupervised. The model is developed based on input data, which will be further used to predict unseen data.
Support vector machine
Support vector machine, more commonly referred to as SVMs, is an intelligent computational model developed for performing classification and regression analysis. In regression analysis, underlying relationships between the dependent variable Y (CF) and the independent variable X (morphological parameters) are determined. The relationship is generally mapped by using a kernel function, which described how the estimated Y deviates from the calculated values. Let the training data be represented as
where χ represent the space for input patterns. If the kernel function is assumed to be linear, it can be expressed as
SVM is formulated as a convex optimization problem as
Here, w represents the hyperplane orientation, and b is a scalar quantity known as intercept. When margin is considered Eqs. 3, 4, and 5 can be further modified as (Vapnik 1995)
ξi,ξi* represents the slack variables which are introduced to deal with infeasible constraints. In present study, the penalty parameter “C” is chosen as 10 and radial basis kernel function is used to effectively map the nonlinearity in morphological parameters (Fig. 2a).

Prediction using a support vector machine and b multilayer perceptron
Multilayer perceptron (MLP)
Multilayer perceptron (MLP) is another type of ANN architecture which consists of several layers and functions as a global approximator for nonlinear input–output mapping. MLPs are composed of neurons called perceptron. In our model, morphological features which is represented as {g = g1, g2, g3, ⋯, gn) become an input to perceptron. The input morphological features are passed through a function u which computes the weighted sum of input features as follows:
The output of the perceptron is calculated by an activation function f, which is represented as
The equation w1g1 + w2g2 + ⋯ + wngn − θ = 0 represents the equation of hyperplane. Output = 1 reflects that input morphological parameters lies above the hyperplane, and Output = 0 reflects that input morphological parameters lie below the hyperplane. Hence for output, it gives a set of continuous values and mean square error as a loss function. (Fig. 2b) shows the architecture of MLP with one hidden layer. In the present study, authors have used only one hidden layer based on prior experience.
Parameter estimations through GIS and remote sensing
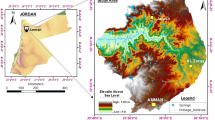
To determine the CF for any catchment area of the River, a Rel-River catchment situated in Banaskantha district of Gujarat, India, is considered in the present study as shown in (Fig. 3a). Basin lies between 24° 50′ N to 24° 75′ N latitude and 72° 00′ E to 72° 45′ E longitude and has an area of 431 km2 (Memon et al. 2020; Darji et al. 2021). The basin area is partitioned into 51 microwatersheds, and Cartosat DEM 10 m resolution is used to calculate slope and watershed boundary. ArcHydro toolset is used for calculating and deriving the boundary of the watershed. Drainage boundaries are derived using Survey of India (SOI) toposheets (42D02, 42D03, 42D06), and the ordering of the drainages is given according to the proposed technique by (Strahler 1964) (Fig. 3b). ArcGIS 10.5 software was used to generate the boundary of watersheds, digitize drainages, and derive different morphometric parameters. Morphometric parameters such as linear aspects, areal aspects, and relief aspects (Horton 1932, 1945; Miller 1953; Schumm 1956; Melton 1957; Faniran 1968; Strahler 1997; Nooka Ratnam et al. 2005) and topo-hydrological parameters such as Stream Power Index (SPI) (Whipple and Tucker 1999), Sediment Transport Index (STI) (Moore and Burch 1986), and Topographic Wetness Index (TWI) (Beven and Kirkby 1979) are considered for the prioritization of watersheds (Table 1). The ranking of the watersheds is calculated based on the WSA technique established by (Aher et al. 2014). Every microwatershed has different and unique characteristics, and watershed priority is carried out to identify the vulnerable areas for erosion. The weights have been calculated based on the correlation between parameters and their values. Its relation does a ranking of the parameters to soil erosion. Based on the literature, the linear factor showed a positive correlation with soil erosion, so maximum priority is given to the higher value, i.e., rank 1. In contrast, shape factors negatively correlated with soil erosion, and the ranking for these parameters was given in reverse order.

Study area. a Rel river basin map. b Rel river drainage map
The final ranking and prioritization of watersheds have been done using CF values. The CF values are calculated with the help of morphological parameters weightage obtained from WSA, ReliefF, and Pearson correlation coefficient methods.
WSA techniques
The WSA is a statistical approach applied to calculate CF values. The CF values are estimated using cross-correction analysis by morphometric parameters and the assigned weightage. The statistical expression for CF is written as follows (Aher et al. 2014):
where CF (WSA) represents compound factor, RMP represents the rank (preliminary priority) estimated from morphometric and topo-hydrological parameters, and WMP represents the weight of morphometric and topo-hydrological parameters obtained using a cross-correlation study (Table 2, 3, and 4). Weights are estimated with a ratio of morphometric and topo-hydrological parameters with a sum of the correlation coefficient value of each parameter (Table 5). Based on the weightage of parameters, a model is constructed for sorting watershed prioritization, which is computed as follows:
As observed in Table 7 and Eq. 11, the highest CF value is 51.13, and it is for watershed 49, the second-highest value is 47.48, and it is for watershed 48, and so on for other watersheds, as shown in (Fig. 4a).

Watershed prioritized maps using a CF (WSA), b CF (RF), and c CF (PCC)
ReliefF
ReliefF is a feature ranking method for selecting important features for classification and regression problems. In this method, predictors that give different values for the same response values are penalized, and predictors that give different values for different response values are rewarded. Final predictor weights are computed using intermediate weights.
where n is several instances, WRP is weighted with different response values and different values for predictor, WR is weighted with different values for response R, and PR is weights with different values for predictor p (Robnik-Šikonja et al. 1997).
The ReliefF method is used to assign the ranks to the morphometric parameters. If ranked first with the weightage of 0.058, whereas Fu is ranked second with the weightage of 0.056. Other subsequent values, ranks, and weights are mentioned in Table 6. The final equation of compound factor obtained using the ReliefF method is as follows:
As observed in Table 7 and Eq. 13, the highest CF value is 14.37, corresponding to watershed 51, and the second-highest value is 12.78, corresponding to watershed 50; likewise, other subsequent CF values are calculated, which are shown in Table 7 and Fig. 4b.
Pearson correlation coefficient (PCC)
The Pearson correlation coefficient (Cr) is generally used to measure and rank the relationship between the calculated and predicted values. A value near + 1 indicates a perfect correlation from the model output, whereas the value of − 1 indicates negative correlations. If a value is closer to 0, it means that there is no direct correlation between the calculated and predicted parameters (Gibbons 2014).
Here, \({\mathrm{PCC}}_{\left(p,q\right)}\) gives the value of the Pearson linear correlation coefficient, m is the length of parameters, and \(\overline{{X }_{p}}\) and \(\overline{{Y }_{q}}\) give the values of a mean of each parameter.
The Pearson correlation coefficient method was used to assign the ranks to the morphometric parameters. If is assigned rank 1 with a weightage of 0.93, whereas Fu is assigned rank 2 with a weightage of 0.9197. Other subsequent values, ranks, and weights are cited in Table 6. The equation of compound factor based on the weightage of correlation coefficient ranked features is as follows:
As observed in Table 7 and Eq. 16, the highest CF value is 405.67, and it is for watershed 51, the second-highest value is 375.3, and it is for watershed 49. The watershed map constructed is shown in Fig. 4c.
Results and discussion
The present paper calculates and derives the basic morphometric parameters using RS and GIS techniques. Various parameters are mentioned in Tables 2 and 3, and the ranks are assigned based on the relation of parameters with soil erodibility, which is shown in Table 4. In the present study, the prioritization of the watershed was decided based on CF values calculated through WSA, ReliefF, and the Pearson correlation coefficient method. Validation and comparison of CF values have been done using MLP and SVM models.
Watershed priority based on CF values
The watershed CF values are calculated using WSA, ReliefF, and the correlation coefficient method. For prioritization, the lowest value of CF is given the priority rank 1, the next lower value is given the priority rank of 2, and so on for all the 51 microwatersheds; CF values are calculated through the three methods mentioned above. Furthermore, the prioritized watersheds are categorized into five categories, i.e., very high, high, moderate, low, and very low. Finally, the categories of watershed maps are utilized for the decision-making system.
As observed in Table 7, the lowest CF values based on WSA are 1.34, hence, it is assigned rank 1, and the same ranking is assigned, which will be useful for prioritizing the watersheds (Table 7). The CF values calculated and the prioritized watersheds based on WSA, ReliefF, and Pearson correlation coefficient are shown. For CF values obtained through ReliefF, all the 51 microwatersheds of the Rel River catchment are classified into five priority categories such as (i) very high (− 1.355 to ≤ 1.789), (ii) high (1.789 to ≤ 4.933), (iii) medium (4.933 to ≤ 8.078), (iv) low (8.078 to ≤ 11.223), and (v) very low (> 11.223) as given in Table 8. It is observed through Table 8 that the 8 microwatersheds belong to very high category (WS no. 1, 3, 4, 5, 7, 8, 9, and 11), 8 microwatersheds under a high category (WS no. 2, 6, 10, 12, 14, 15, 17, and 19), 14 microwatersheds under medium (WS no. 16, 18, 20, 21, 23, 26, 30, 34, 35, 39, 41, 42, 44, and 45), 12 microwatersheds under a low category (WS no. 22, 24, 25, 27, 31, 32, 33, 38, 40, 46, 47, and 51), and 9 microwatershed under the very low category (WS no. 13, 28, 29, 36, 37, 43, 48, 49, and 50). The CF values obtained from Eqs. 11, 13, and 16 watershed are constructed, shown in Fig. 4a–c.
ML model predictions
Two ML algorithms, MLP and SVM, have been utilized to predict the CF values for the prioritization of watersheds. The training and Tenfold cross-validation are performed on all the 51 microwatersheds, and the derived parameters are normalized in the range [− 1 to + 1] to minimize the biasing error. Results of the prediction are shown in Fig. 5a–f. The CF (WSA) values predicted through SVM and MLP are shown in Fig. 5a, b. It is observed that SVM accurately predicts the CF values with a very less average error of 0.04 whereas there is a slight deviation in prediction results with MLP with an average error of 0.90 for all the watershed values considered. Similarly when CF (RF) is predicted, then, an average error of 0.02 and 0.28 is observed from SVM and MLP, respectively, as shown in Fig. 5c, d. Further, the average error of 0.36 and 7.65 is observed when CF (PCC) is predicted, as shown in Fig. 5e, f. The results can infer that the best CF values for watershed prioritization should be obtained from ReliefF Eq. 13 as there are very few mean errors observed from both SVM and MLP. Moreover, to evaluate the suitability of ML algorithms, three performance metrics: mean absolute error, correlation coefficient, and root mean square error, are calculated, and the results are discussed below.

a–f Tenfold cross validation prediction results using SVM and ANN
Correlation coefficient
The correlation coefficient (R) is calculated to find the relationship between the dependent and independent variables. When R is observed as + 1, it indicates a perfect correlation between the two variables, while − 1 indicates a negative correlation between two variables. The \(\eta\) shows the total number of observations, \(\sum a\) shows the mean value of all the first variables in the data set, and \(\sum b\) represents the mean value of all the second variables in the data set. It is mathematically calculated by
Mean absolute error
Mean absolute error (MAE) has been used to analyze the performance of the ML model. The difference between the predicted value and the actual value is calculated by
Here, ◉i shows the predicted value by the machine learning model, and ◉ shows the actual value from experiments.
Root mean square error
Root mean square error (RMSE) represents the standard deviation of the residuals. RMSE is commonly used in hydrology, forecasting, and regression analysis to verify experimental results.
where i is variable, n represents data points, ◉i represent actual observations, and ◉ represents predicted observation.
Tables 9 and 10 show the results of SVM Tenfold and MLP Tenfold for CF (WSA), CF (RF), and CF (CC) values. The prediction of ML models is compared with three performance metrics correlation coefficient, MAE, and RMSE values. Initially, the performance of the ML model is evaluated through a correlation coefficient. It is observed that there is no significant deviation in performance metrics from both the SVM and MLP models. The correlation coefficient was observed as 1, which signifies a very good correlation between the calculated and predicted values.
Figure 6a, b shows the SVM Tenfold and MLP Tenfold results to compare the prediction of CF values using MAE and RMSE. From Fig. 6, it is clear that the minimum MAE is 0.0236 for CF (RF) using the SVM Tenfold model compared to the minimum MAE of 0.2856 for CF (RF) using the MLP Tenfold model. Furthermore, the minimum RMSE is 0.032 for CF (RF) using the SVM Tenfold model compared to the minimum RMSE of 0.440 for CF (RF) using the MLP Tenfold model. The maximum MAE is 0.3684 for CF (CC) using an SVM Tenfold compared to the maximum MAE of 7.6514 for CF (CC) using MLP Tenfold. Also, the maximum RMSE observed is 0.4361 for CF (CC) using SVM Tenfold, compared to the maximum RMSE of 12.26 for CF (RF) using the MLP Tenfold model. Results show that the SVM Tenfold gives better prediction capability as compared to MLP Tenfold for the prediction of CF values with CF (RF), followed by CF (WSA) and CF (PCC), respectively.

Tenfold cross validation prediction results using a SVM and b ANN
Figure 7a–c shows the variation in MAE and RMSE for the CF (RF), CF (WSA), and CF (PCC) predicted using the SVM Tenfold and MLP Tenfold models. The minimum MAE observed is 0.0236 with CF (RF), whereas the minimum MAE is 0.3684 for CF (PCC) from SVM Tenfold. The maximum MAE is 0.2856 with CF (RF) compared to 7.6514 with CF (CC) from MLP Tenfold. Furthermore, the minimum RMSE for predicting CF (RF) is 0.032 compared to 0.4361 in CF (CC) using SVM Tenfold. The maximum RMSE for predicting CF (RF) is 0.4402 compared to 12.2689 in CF (CC) using MLP Tenfold. It is observed that CF values calculated from ReliefF exhibit a higher correlation coefficient as well as very low MAE and RMSE values with both SVM and ANN models (Tables 9 and 10); therefore, CF values calculated from ReliefF are used for constructing watershed prioritization. The final watershed priority category map of 51 microwatersheds is shown in Fig. 8. It is observed that the percentage area of microwatersheds under the very high category is 13.45%, for a high category, it is 15.72%, for medium category is 30.24%, low category is 18.81%, and for very low category, it is 21.78%. This information is beneficial in implementing water management strategies regarding soil and water conservation measures. The result also shows its vulnerability to erosion and runoff potential. This watershed is mainly situated in the upstream part of the catchment or basin and high slopes and elongated basins.

MAE and RMSE variations with SVM and MLP for a CF (RF) and b CF (WSA) and CF (CC)

Watershed priority map based on CF (RF) values
Conclusion
In the methodology proposed, the utility of feature ranking is initially explored in detail for estimating the weightage of various morphological and topological parameters. Afterward, the CF values for various watersheds are calculated from WSA, ReliefF, and Pearson correlation coefficient, obtained from the assigned weightage of various morphological and topological parameters. To determine the best CF values, ML algorithms are explored in detail. Finally, the performance of models is estimated after comparing the three parameters, i.e., mean absolute error, correlation coefficient, and root mean square error. The findings are mentioned below:
-
1.
The SVM model gives better results for predicting various watersheds as compared to MLP model.
-
2.
The comparison of MAE and RMSE for predicting CF (RF), CF (WSA), and CF (CC) reveals that CF (RF) is the best model for the prediction of CF values as compared to other calculations; hence, it is utilized for prioritization of watersheds.
-
3.
It is suggested that watersheds 1, 3, 4, 5, 7, 8, 9, and 11 have a very high vulnerability to soil erosion, followed by the rest of the watersheds in the study region. Hence, appropriate soil and water conservation measures should be adopted to protect against degradation.
Based on a study conducted, the integrated framework of RS, GIS, feature ranking, and machine learning seems to be an efficient water resource management technique for watershed ranking and prioritization. Tenfold cross-validation and feature ranking is a novel approach for accurately predicting CF for watershed ranking and prioritization. The proposed methodology should be extended to investigate the influence of more RS and GIS techniques as well as exploration of more morphometric and topological parameters and analyze its effect on constructing various watersheds for soil and water conservation. It should be noted that the performance of ML models for prediction is dependent on the calculated or extracted parameters.
Data availability
The data required for watershed parameter delineation and prioritization were supported by SAC-ISRO.
Code availability
MATLAB code is utilized for the preparation of ML models.
References
Aher PD, Adinarayana J, Gorantiwar SD (2014) Quantification of morphometric characterization and prioritization for management planning in semi-arid tropics of India: a remote sensing and GIS approach. J Hydrol 511:850–860. https://doi.org/10.1016/J.JHYDROL.2014.02.028
Akhenia P, Bhavsar K, Panchal J, Vakharia V (2021) Fault severity classification of ball bearing using SinGAN and deep convolutional neural network. Proc Inst Mech Eng Part C J Mech Eng Sci 095440622110431. https://doi.org/10.1177/09544062211043132
Alilou H, Rahmati O, Singh VP et al (2019) Evaluation of watershed health using Fuzzy-ANP approach considering geo-environmental and topo-hydrological criteria. J Environ Manage 232:22–36. https://doi.org/10.1016/J.JENVMAN.2018.11.019
Beven KJ, Kirkby MJ (1979) A physically based, variable contributing area model of basin hydrology. Hydrol Sci Bull 24:43–69. https://doi.org/10.1080/02626667909491834
Chowdary VM, Chakraborthy D, Jeyaram A et al (2013) Multi-criteria decision making approach for watershed prioritization using analytic hierarchy process technique and GIS. Water Resour Manag 27:3555–3571. https://doi.org/10.1007/S11269-013-0364-6
Darji K, Patel D, Dubey AK, et al (2021) An approach of satellite and UAS based mosaicked DEM for hydrodynamic modelling -a case of flood assessment of Dhanera City, Gujarat, India. J geomatics 247–257
Dave V, Singh S, Vakharia V (2020) Diagnosis of bearing faults using multi fusion signal processing techniques and mutual information. Indian J Eng Mater Sci 27:878–888
Faniran A (1968) The index of drainage intensity: a provisional new drainage factor. Aust J Sci 31:326–330
Farhan Y, Anbar A, Al-Shaikh N, Mousa R (2017) Prioritization of semi-arid agricultural watershed using morphometric and principal component analysis, remote sensing, and GIS techniques, the Zerqa River Watershed, Northern Jordan. Agric Sci 08:113–148. https://doi.org/10.4236/AS.2017.81009
Gibbons JD CS (2014) Nonparametric statistical inference, Fourth Edition. Nonparametric Stat Inference, Fourth Ed. https://doi.org/10.4324/9780203911563
Horton RE (1932) Drainage-basin characteristics. Eos, Trans Am Geophys Union 13:350–361. https://doi.org/10.1029/TR013I001P00350
Horton RE (1945) Erosional development of streams and their drainage basins; hydrophysical approach to quantitative morphology. Geol Soc Am Bull 56(3):275–370
Jaiswal RK, Ghosh NC, Galkate RV, Thomas T (2015) Multi criteria decision analysis (MCDA) for watershed prioritization. Aquat Procedia 4:1553–1560. https://doi.org/10.1016/J.AQPRO.2015.02.201
Kadam AK, Jaweed TH, Umrikar BN et al (2017) Morphometric prioritization of semi-arid watershed for plant growth potential using GIS technique. Model Earth Syst Environ 3:1663–1673. https://doi.org/10.1007/S40808-017-0386-9
Kankar PK, Sharma SC, Harsha SP (2011) Rolling element bearing fault diagnosis using autocorrelation and continuous wavelet transform. Jvc/J Vib Control 17:2081–2094. https://doi.org/10.1177/1077546310395970
Khan MA, Gupta VP, Moharana PC (2001) Watershed prioritization using remote sensing and geographical information system: a case study from Guhiya, India. J Arid Environ 49:465–475. https://doi.org/10.1006/JARE.2001.0797
Kononenko I (1994) Estimating attributes: analysis and extensions of RELIEF. Lect Notes Comput Sci (including Subser Lect Notes Artif Intell Lect Notes Bioinformatics) 784 LNCS:171–182. https://doi.org/10.1007/3-540-57868-4_57
Kulimushi LC, Bashagaluke JB, Choudhari P, et al (2021a) Novel combination of analytical hierarchy process and weighted sum analysis for watersheds prioritization. A study of Ulindi catchment, Congo River Basin. Geocarto Int 1–39. https://doi.org/10.1080/10106049.2021.2002426
Kulimushi LC, Choudhari P, Maniragaba A et al (2021b) Erosion risk assessment through prioritization of sub-watersheds in Nyabarongo river catchment. Rwanda Environ Challenges 5:100260. https://doi.org/10.1016/j.envc.2021.100260
Malik A, Kumar A, Kandpal H (2019) Morphometric analysis and prioritization of sub-watersheds in a hilly watershed using weighted sum approach. Arab J Geosci 12https://doi.org/10.1007/S12517-019-4310-7
Melton MA (1957) An analysis of the relations among elements of climate, surface properties, and geomorphology. Columbia Univ New York
Memon N, Patel DP, Bhatt N, Patel SB (2020) Integrated framework for flood relief package (FRP) allocation in semiarid region: a case of Rel River flood, Gujarat, India. Nat Hazards 100:279–311. https://doi.org/10.1007/S11069-019-03812-Z
Meshram SG, Sharma SK (2017) Prioritization of watershed through morphometric parameters: a PCA-based approach. Appl Water Sci 7:1505–1519. https://doi.org/10.1007/S13201-015-0332-9
Miller VC (1953) A quantitative geomorphic study of drainage basin characteristics in the clinch mountain area Virginia and Tennessee. Columbia Univ New York
Moore ID, Burch GJ (1986) Sediment transport capacity of sheet and rill flow: application of unit stream power theory. Water Resour Res 22:1350–1360. https://doi.org/10.1029/WR022I008P01350
Naseriparsa M, Bidgoli A-M, Varaee T (2014) A hybrid feature selection method to improve performance of a group of classification algorithms. Int J Comput Appl 69:975–8887. https://doi.org/10.5120/12065-8172
Nooka Ratnam K, Srivastava YK, Venkateswara Rao V et al (2005) Check Dam positioning by prioritization micro-watersheds using SYI model and morphometric analysis - remote sensing and GIS perspective. J Indian Soc Remote Sens 33:25–38. https://doi.org/10.1007/BF02989988
Patel A, Singh MM, Singh SK et al (2022) AHP and TOPSIS based sub-watershed prioritization and tectonic analysis of Ami River Basin, Uttar Pradesh. J Geol Soc India 98:423–430. https://doi.org/10.1007/s12594-022-1995-0
Patel D, Srivastava P, Gupta M (2015) Decision support system integrated with geographic information system to target restoration actions in watersheds of arid environment: a case study of Hathmati. J Earth Syst Sci 124:71–86. https://doi.org/10.1007/s12040-014-0515-z
Patel DR, Kiran MB, Vakharia V (2020) Modeling and prediction of surface roughness using multiple regressions: A noncontact approach. Eng R 2(2):e12119. https://doi.org/10.1002/eng2.12119
Patel DP, Dholakia MB, Naresh N, Srivastava PK (2012) Water harvesting structure positioning by using geo-visualization concept and prioritization of mini-watersheds through morphometric analysis in the Lower Tapi Basin. J Indian Soc Remote Sens 40:299–312. https://doi.org/10.1007/s12524-011-0147-6
Robnik-Šikonja M, Kononenko I, Marko (1997) An adaptation of Relief for attribute estimation in regression. Mach Learn Proc Fourteenth Int Conf 5:296–304
Samal DR, Gedam SS, Nagarajan R (2015) GIS based drainage morphometry and its influence on hydrology in parts of Western Ghats region, Maharashtra, India. Geocarto Int 30:755–778. https://doi.org/10.1080/10106049.2014.978903
Schumm SA (1956) Evolution of drainage systems and slopes in badlands at Perth Amboy, New Jersey. Geol Soc Am Bull 67:597–646
Sengupta S, Mohinuddin S, Arif M (2021) Sub-watershed prioritization for soil erosion potentiality estimation in tenughat catchment, India. Geocarto Int 1–30. https://doi.org/10.1080/10106049.2021.2017008
Shah M, Vakharia V, Chaudhari R et al (2022) Tool wear prediction in face milling of stainless steel using singular generative adversarial network and LSTM deep learning models. Int J Adv Manuf Technol 121:723–736. https://doi.org/10.1007/s00170-022-09356-0
Singh S, Kumar A, Kumar N (2014) Motor current signature analysis for bearing fault detection in mechanical systems. Procedia Mater Sci 6:171–177. https://doi.org/10.1016/j.mspro.2014.07.021
Sonebi M, Cevik A, Grünewald S, Walraven J (2016) Modelling the fresh properties of self-compacting concrete using support vector machine approach. Constr Build Mater 106:55–64. https://doi.org/10.1016/J.CONBUILDMAT.2015.12.035
Strahler AN (1964) Quantitative geomorphology of drainage basin and channel networks. Handbook of applied hydrology
Strahler A (1997) Quantitative geomorphology. Geomorphol. Springer Berlin Heidelberg, Berlin, Heidelb
Thakkar AK, Dhiman SD (2007) Morphometric analysis and prioritization of miniwatersheds in Mohr watershed, Gujarat using remote sensing and GIS techniques. J Indian Soc Remote Sens 35:313–321. https://doi.org/10.1007/BF02990787
Upadhyay R, Padhy PK, Kankar PK (2016) Application of S-transform for automated detection of vigilance level using EEG signals. J Biol Syst 24:1–27. https://doi.org/10.1142/S0218339016500017
Vakharia V, Castelli IE, Bhavsar K, Solanki A (2022) Bandgap prediction of metal halide perovskites using regression machine learning models. Phys Lett A 422:127800. https://doi.org/10.1016/J.PHYSLETA.2021.127800
Vakharia V, Gupta VK, Kumar KP (2015a) Application of chi square feature ranking technique and random forest classifier for fault classification of bearing faults. In Proceedings of the 22th International Congress on Sound and Vibration, Florence, Italy, p 12–16
Vakharia V, Gupta VK, Kankar PK (2015b) Ball bearing fault diagnosis using supervised and unsupervised machine learning methods. Int J Acoust Vib 20 (4):244–250. https://doi.org/10.20855/ijav.2015.20.4387
Vapnik VN (1995) The nature of statistical learning theory. Nat Stat Learn Theory. https://doi.org/10.1007/978-1-4757-2440-0
Vulević T, Dragović N (2017) Multi-criteria decision analysis for sub-watersheds ranking via the PROMETHEE method. Int Soil Water Conserv Res 5:50–55. https://doi.org/10.1016/J.ISWCR.2017.01.003
Whipple KX, Tucker GE (1999) Dynamics of the stream-power river incision model: Implications for height limits of mountain ranges, landscape response timescales, and research needs. J Geophys Res Solid Earth 104:17661–17674. https://doi.org/10.1029/1999JB900120
Yadav SK, Dubey A, Szilard S, Singh SK (2018) Prioritisation of sub-watersheds based on earth observation data of agricultural dominated northern river basin of India. Geocarto Int 33:339–356. https://doi.org/10.1080/10106049.2016.1265592
Acknowledgements
The authors would like to thank various government agencies and SAC-ISRO for providing valuable data for research. The authors are also grateful to PDEU Gandhinagar for providing the infrastructure to conduct this study.
Funding
The corresponding author is thankful to the ORSP (PDPU) and SAC-ISRO for providing the financial support for providing the research grant (ORSP/R&D/SRP/2019–20/1408/51; SAC/EPSA/GHCAG/LHD/SARITA/01/19.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Responsible Editor: Amjad Kallel
Supplementary information
Semiautomated tool and manual
https://drive.google.com/file/d/157VA65tjU_UdPglafaRToKh3HaoAM2RA/view?usp=sharing
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Darji, K., Patel, D., Vakharia, V. et al. Watershed prioritization and decision-making based on weighted sum analysis, feature ranking, and machine learning techniques. Arab J Geosci 16, 71 (2023). https://doi.org/10.1007/s12517-022-11054-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-022-11054-w