
Abstract
Evidence now suggests that precision psychiatry is becoming a cornerstone of medical practices by providing the patient of psychiatric disorders with the right medication at the right dose at the right time. In light of recent advances in neuroimaging and multi-omics, more and more biomarkers associated with psychiatric diseases and treatment responses are being discovered in precision psychiatry applications by leveraging machine learning and neural network approaches. In this article, we focus on the most recent developments for research in precision psychiatry using machine learning, deep learning, and neural network algorithms, together with neuroimaging and multi-omics data. First, we describe different machine learning approaches that are employed to assess prediction for diagnosis, prognosis, and treatment in various precision psychiatry studies. We also survey probable biomarkers that have been identified to be involved in psychiatric diseases and treatment responses. Furthermore, we summarize the limitations with respect to the mentioned precision psychiatry studies. Finally, we address a discussion of future directions and challenges.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
Introduction
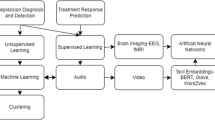
The interdisciplinary fields of precision psychiatry, machine learning, neural network algorithms, and neuroimaging had been making good progress in recent years [1,2,3]. The objective of a machine learning method is to enable a data-driven algorithm that can generally learn from data of the past or present and leverage the learned knowledge to make a predictive decision for an unknown future event or for any unknown data in the future [4,5,6]. In the general terms, the roadmap for a machine learning method is comprised of three steps where we build the model from initial inputs in the first step, evaluate and tune the model in the second step, and then utilize the model for making a predictive decision in the third step [4,5,6]. In the field of precision psychiatry, machine learning approaches integrate multiple data types such as neuroimaging and multi-omics data by using state-of-the-art statistical and data mining algorithms that can automatically learn to perceive complicated patterns based on empirical datasets [1,2,3]. To address the pressing challenges precision psychiatry faces today, there is a tremendous need for the development of machine learning software frameworks that can achieve clinical predictions of a given categorical or quantitative phenotype using next-generation neuroimaging and multi-omics data [1,2,3].
Precision psychiatry, an emerging field of medicine, is growing into a cornerstone of medical practices with prospects of the customization of healthcare for patients with psychiatric disorders, which means that medical practices, decisions, and treatments are tailored to individual patients [7]. More precisely, entire patient populations are subdivided into groups by biomarkers such as neuroimaging and multi-omics data; thereby, medications might be adapted personally to each individual patient with relevant or comparable genetic and imaging characteristics [7]. To date, there are more and more accumulating biomarkers that could affect clinical drug response and disease prognosis for treatment of patients with psychiatric disorders [8]. Furthermore, it has long been acclaimed that selected single nucleotide polymorphisms (SNPs) and gene expression profiles could be used as biomarkers to influence clinical treatment response and adverse drug reactions for antidepressants in patients with major depressive disorder (MDD) [9, 10].
Recent advances in machine learning, especially deep learning, have pointed out its potential and ability to learn and recognize nonlinear and complicated hierarchical patterns based on enormous large-scale empirical datasets [11,12,13,14,15]. Due to new approaches such as the deployment of general-purpose computing on graphics processing units, deep learning has achieved state-of-the-art performances on a wide variety of applications such as precision psychiatry [2, 12,13,14,15]. In general, the goal of deep learning is to construct a machine learning algorithm to facilitate a hierarchical representation of the data by using multiple layers of abstraction such as neural networks [12,13,14,15,16]. In other words, a deep learning algorithm for classification applications such as medical diagnosis in precision psychiatry is a procedure for choosing the best hypothesis using a neural network with multiple layers, instead of using a neural network with only single layer [12,13,14,15,16].
With the advent of technology in neuroimaging and multi-omics sciences, novel diagnostic tools as well as new drugs are exhibiting high growth potentials to address the needs of precision psychiatry for treatment and therapeutic interventions [17]. The use of biomarkers based on machine learning approaches has played a vital role in precision medicine in psychiatry [17]. Recently, there were a number of key emerging diagnostic studies for various diseases and treatments of significance for psychiatry with consideration of machine learning methods [2]. To that end, it would be greatly fascinating to create machine learning models that are able to forecast the probable outcome of disease status and drug treatment for patients with psychiatric disorders [2, 17]. In addressing this need, machine learning approaches might provide invaluable tools to accomplish the promise of precision psychiatry by tailoring treatment based on individual biomarkers [2, 17]. In this article, we present various precision psychiatry studies for assessment of disease status and drug treatment with consideration of machine learning, deep learning, and neural network approaches. In addition, we summarize the limitations in these studies and provide a discussion of future directions and challenges.
Method
Literature Search and Analyses
In this review, we present relevant studies on precision psychiatry and machine learning applications after a comprehensive search of the electronic PubMed database (2015–present). Key words in the search included “machine learning,” “deep learning,” “psychiatry,” “neuroimaging,” “precision psychiatry,” and “neural network.” Furthermore, we employed a manual search procedure of bibliographical cross-referencing. We manually screened the obtained articles and aimed at identifying original papers and reviews with a particular focus on precision psychiatry and machine learning applications. While this article is by no means a comprehensive review of all potential studies reported in the literature, we merely pinpointed various examples for machine learning methods in precision psychiatry.
Machine Learning and Neural Network Applications
Here we describe selective studies that focus on four main arenas including diagnosis prediction, prognosis prediction, treatment prediction, and the detection of potential biomarkers in the context of machine learning and neural network methods in psychiatry. Clinical or biological suggestions from these four main categories could be a decision support aide for future prognosis and optimal treatments in translational psychiatry [18].
While this summary does not provide the entire set of relevant studies reported in the literature, it nonetheless provides a synthesis of those that can markedly influence public and population health-oriented applications in psychiatry and machine learning in the near to midterm future.
Diagnosis Prediction
In recent years, there has been a growing trend in combining machine learning techniques and structural and functional neuroimaging to provide new insights into brain disorders such as Alzheimer’s disease, autism spectrum disorder, and schizophrenia [19]. In particular, we focus on emerging big data methodologies such as deep learning in the following selective studies.
In order to distinguish mild to severe sporadic Alzheimer’s disease from normal aging, Kloppel et al. pioneered a project to utilize a machine learning method, support vector machines (SVMs), using structural magnetic resonance imaging (MRI) and achieved 89% accuracy in their model [20]. In their two-step procedure, SVMs learned the differences between patients with Alzheimer’s disease and healthy controls in the first step, and then the framework was tested on a new brain scan in the second step [20].
In a recent study, Ju et al. proposed a deep learning approach, which consists of auto-encoders and a softmax regression layer, to predict the early diagnosis of Alzheimer’s disease [21]. In general, the auto-encoder is an encoding architecture, which consists of a neural network with the input layer representing the MRI data, multiple hidden layers representing nonlinear transformations from the previous layer, and the output layer representing the reconstructed MRI instances. Compared to widely used single-kernel SVM (accuracy = 84.40%) and multi-kernel SVM (accuracy = 86.42%), their proposed auto-encoder model had a better accuracy (87.76%). Their work highlights that deep learning approaches have an advantage over traditional machine learning methods to predict and prevent Alzheimer’s disease at an early stage [21].
With a belief network-based algorithm, Ortiz et al. employed a deep learning architecture that integrates gray matter images from brain areas and automated anatomical labeling data for identifying Alzheimer’s disease with MRI data [22]. Their model was composed of an ensemble of two deep belief networks with four different voting schemes [22]. The analysis results demonstrated that the proposed deep belief network method provided good performances for differentiating images between healthy controls and Alzheimer’s disease individuals (accuracy = 90%) as well as differentiating images between mild cognitive impairment and Alzheimer’s disease (accuracy = 84%) [22].
In machine learning, a deep belief network is a class of deep neural networks which consist of multiple layers of latent variables and can be viewed as a composition of auto-encoders [23]. Deep belief networks have also been applied to discriminate young children with autism spectrum disorders using functional MRI [23]. In addition, Pinaya et al. utilized a deep belief network model to characterize differences between patients with schizophrenia and healthy controls (accuracy = 73.6%) using MRI data, and the performance was better than the SVM model (accuracy = 68.1%) [24].
Prognosis Prediction
In order to identify course trajectories of MDD, Schmaal et al. proposed a machine learning framework that integrates structural and functional MRI using Gaussian process classifiers [25]. Gaussian process classifiers are one type of multivariate pattern recognition methods, which are similar to SVMs and provide the advantage of predictive probabilities of class membership [25]. Schmaal et al. employed Gaussian process classifiers to evaluate three MDD trajectories (including chronic, gradual improving, and fast remission patients) using prognostic value of MRI and clinical data (such as baseline severity, duration, and comorbidity) [25]. Their analysis showed that their machine learning framework can discriminate chronic patients from remitted patients up to 73% accuracy.
To predict health status and better inform clinical decision-making, Miotto et al. proposed a deep learning framework which constructs a general-purpose patient representation from electronic health records (EHRs) to facilitate clinical predictive modeling [26]. Specifically, the deep learning framework uses a multilayer neural network, which is a three-layer stack of de-noising auto-encoders with sigmoid activation functions to derive hierarchical regularities and dependencies in the dataset of about 700,000 patients [26]. Then, random forest classifiers were implemented to evaluate the probability that patients might develop a certain disease given their current clinical status [26]. In the proposed deep learning framework, de-noising auto-encoders were trained to reconstruct the input from a noisy version of the original data to avoid overfitting [26]. The findings indicated that schizophrenia and attention deficit hyperactivity disorder could be forecasted with high accuracy (area under the receiver operating characteristic curve (AUC) = 0.85) [26]. Moreover, Miotto et al. compared the proposed deep learning framework with well-known conventional machine learning algorithms, including principal component analysis, k-means clustering, Gaussian mixture model, and independent component analysis [26]. The performance metrics of the proposed deep learning framework were superior to those obtained by the conventional machine learning algorithms [26]. The main strength of the proposed approach is that preprocessing EHR data with the deep learning framework can help provide more effective predictions because of nonlinear transformations [26].
Treatment Prediction
The use of machine learning in terms of predicting treatment response in psychiatric drugs is still in its infancy as scant human studies have investigated methods to build prediction models for estimating treatment response. We focus on antidepressant treatment response in this section.
In order to predict patient-specific possible antidepressant treatment outcomes in MDD, Lin et al. carried out a deep learning prediction algorithm and leveraged it to the integrated datasets from several data types (including genetic data such as SNPs, demographic data such as age, sex, and marital status, and clinical data such as baseline Hamilton Rating Scale for Depression score, depressive episodes, and suicide attempt status of MDD patients) [27]. First, they conducted a genome-wide association study (GWAS) to pinpoint potentially significant SNPs of antidepressant treatment response and remission in a hypothesis-free manner [27]. Their deep learning prediction algorithm is called the multilayer feedforward neural network (MFNN) approach, which adapts the back-propagation algorithm. MFNN was employed to calculate the predicted complex relationship between antidepressant treatment response and biomarkers [27]. An advantage of their approach is that these predictive MFNN methods possess the benefits of nonlinear models, fault tolerance, real-time processing, and integrated systems [27]. In their analysis results, Lin et al. identified the MFNN model with three hidden layers (AUC = 0.81; sensitivity = 0.77; specificity = 0.66) for remission and the MFNN model with two hidden layers (AUC = 0.82; sensitivity = 0.75; specificity = 0.69) for antidepressant treatment response [27].
There are several studies that utilized traditional machine learning methods to predict antidepressant treatment response. A study by Kautzky et al. reported that a machine learning prediction model pinpointed 25% of responders correctly for treatment outcome by using clinical and genetic information [28]. Their model was based on the random forests algorithm, which is an ensemble learning method and is constructed as a multitude of decision trees to perform classification tasks [28]. Particularly, Kautzky et al. identified several potential biomarkers including a clinical variable called melancholia as well as three SNPs such as brain-derived neurotrophic factor (BDNF) rs6265, 5-hydroxytryptamine receptor 2A (HTR2A) rs6313, and protein phosphatase 3 catalytic subunit gamma (PPP3CC) rs7430 [28].
Moreover, by leveraging information such as age, structural imaging, and mini-mental status examination scores, the subsequent study by Patel et al. showed that a machine learning model predicted treatment response with 89% accuracy by using an alternating decision tree model, which generalizes decision trees and is related to boosting for primarily reducing bias and variance [29].
Furthermore, another study by Chekroud et al. demonstrated that a machine learning model estimated clinical remission by using 25 variables with 59% accuracy [30]. First, the top 25 predictors were identified by the elastic net, and then a tree-based ensemble method, a gradient boosting machine, was used to combine several weakly predictive models (typically decision trees) to form a final ensemble model [30]. In particular, Chekroud et al. identified the top three potential biomarkers of non-remission such as baseline depression severity, feeling restless during the past 7 days, and reduced energy level during the past 7 days [30]. On the other hand, the top three potential biomarkers of remission were total years of education, currently being employed, and loss of insight into one’s depressive condition [30]. One advantage of their approach is that their model and predictors were externally validated by other independent cohorts [30].
Iniesta et al. also implicated that a machine learning model based on clinical and demographical characteristics can forecast response with clinically meaningful accuracy by using regularized regression models (AUC = 0.72) [31]. They utilized elastic net, an application of regularized regression models, which are general linear models with penalties to provide variable selection from a large number of variables while avoiding overfitting [32].
Finally, a recent study by Maciukiewicz et al. suggested that a machine learning model based on SNPs can predict treatment response with 52% accuracy by using both SVM-based and decision trees-based models [33]. They first conducted a GWAS study to search for genetic susceptibility loci of antidepressant treatment response in a hypothesis-free manner [33]. Then, they performed least absolute shrinkage and selection operator (LASSO) regression to identify potentially significant predictors such as rs2036270 and rs7037011 SNPs [33]. In order to enhance the prediction accuracy, LASSO performs both variable selection and regularization [34].
Detection of Potential Biomarkers
In order to carry out a novel risk factor called Alzheimer’s disease pattern similarity scores, Casanova et al. implemented a high-dimensional machine learning framework which is a regularized logistic regression method with an elastic net to simultaneously accomplish data integration and prediction for Alzheimer’s disease [35]. A regularized logistic regression method with the elastic net, also called the adaptive elastic net, has been successfully applied in high-dimensional data, where the adaptive elastic net uses elastic net estimates as the initial weight in the model [32, 36]. By using MRI data, their approach is based on a coordinate-wise descent technique [37] and is able to discriminate patients with Alzheimer’s disease from healthy controls [35]. Casanova et al. revealed that Alzheimer’s disease pattern similarity scores had strong associations with age, cognitive function, and cognitive status and may be used as an Alzheimer’s disease risk factor [35].
Limitations
The findings as discussed in the previous sections should be interpreted by taking into account some limitations of these studies in psychiatry and machine learning applications. One limitation of the aforementioned studies is that the small size of the sample does not allow for drawing of definite conclusions due to the possibility of overfitting during the training process of machine learning and deep learning algorithms [38]. Second, it is important to replicate their results by comparing comparable data from an independent cohort [2]. However, most of these studies did not provide replication studies because more and larger datasets may not be available to facilitate subsequent studies. Furthermore, these findings may not be generalizable. An open challenge is that the most useful findings will generalize across various testing conditions, broader populations, different ethnic groups, numerous sites, and diverse real-life clinical settings [39].
In addition, variability in data quality such as missing data may make prior selection of predictive variables or driver biomarkers essential; for example, preselecting SNPs from the GWAS data [40]. However, we speculate that this preselection can be expected to impact the overall structure and implementation in the final machine learning model. In future work, large prospective clinical trials are necessary in order to answer whether the relevant biomarkers are reproducibly associated with disease status and drug response in machine learning studies.
While in this article we selected a few studies to exemplify relevant machine learning and deep learning algorithms in the neurobiology of psychiatric disorders, it should be pointed out that psychiatry research could further benefit from combining the advanced machine learning algorithms with multi-omics techniques [17]. Several existing biobanks have been established for multi-omics studies, including the COMBINE Biobank [41], the Korea Healthy Twin Study [42], LifeGene [43], and the Taiwan Biobank [44,45,46,47,48,49,50,51].
Finally, it should be noted that in order to demonstrate the robustness of a single biomarker or even a set of biomarkers, future studies in precision psychiatry and machine learning should assess the overlap or lack of overlap between biomarkers in diverse machine learning analyses by using tools such as Venn diagrams [52]. Current evidence indicates that various machine learning analysis strategies may often yield different biomarkers, even when they were applied to the same type of disease [53].
Perspectives
As suggested by the aforementioned studies, precision psychiatry promises to offer new therapeutic and diagnostic techniques for accurate diagnosis, prognosis, and treatment in a disease-specific and patient-specific manner [7, 8, 54, 55]. In the context of multi-omics and neuroimaging-driven approaches, it is of major importance that potential clinical applications involving machine learning for prediction of drug responses or disease might provide the appropriate solutions to global primary care, and thereby it would have been up-taken by users and governments. Moreover, it is hypothesized that the next generation of psychiatric therapies for disease treatment thus ought to take into consideration the interplay among neuroimaging and multi-omics data. The latest advances in single-cell sequencing and data-intensive life sciences will certainly trigger more novel machine learning software tools for population health in the next decade [56]. Furthermore, it will also increasingly generate application-oriented solutions toward the field of public health in light of the pressing needs of precision psychiatry for innovative diagnostics [57]. Over the next few years, machine learning-based precision psychiatry for the pretreatment prediction may become a reality in patient care after prospective large clinical trials to validate clinical factors and the relevant biomarkers [58].
References
Lin E, Lane HY. Machine learning and systems genomics approaches for multi-omics data. Biomark Res. 2017;5:2.
Bzdok D, Meyer-Lindenberg A. Machine learning for precision psychiatry: opportunities and challenges. Biol Psychiatry Cogn Neurosci Neuroimaging. 2018;3(3):223–30.
Davatzikos C. Machine learning in neuroimaging: progress and challenges. Neuroimage. 2018.
Iniesta R, Stahl D, McGuffin P. Machine learning, statistical learning and the future of biological research in psychiatry. Psychol Med. 2016;46(12):2455–65.
Lane HY, Tsai GE, Lin E. Assessing gene–gene interactions in pharmacogenomics. Mol Diagn Ther. 2012;16(1):15–27.
Lin E, Hwang Y, Liang KH, Chen EY. Pattern-recognition techniques with haplotype analysis in pharmacogenomics. Pharmacogenomics. 2007;8(1):75–83.
Torres EB, Isenhower RW, Nguyen J, Whyatt C, Nurnberger JI, Jose JV, et al. Toward precision psychiatry: statistical platform for the personalized characterization of natural behaviors. Front Neurol. 2016;7:8.
Gandal MJ, Leppa V, Won H, Parikshak NN, Geschwind DH. The road to precision psychiatry: translating genetics into disease mechanisms. Nat Neurosci. 2016;19(11):1397–407.
Lin E, Tsai SJ. Genome-wide microarray analysis of gene expression profiling in major depression and antidepressant therapy. Prog Neuropsychopharmacol Biol Psychiatry. 2016;64:334–40.
Lin E, Lane HY. Genome-wide association studies in pharmacogenomics of antidepressants. Pharmacogenomics. 2015;16(5):555–66.
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, et al. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42:60–88.
Ching T, Himmelstein DS, Beaulieu-Jones BK, Kalinin AA, Do BT, Way GP, et al. Opportunities and obstacles for deep learning in biology and medicine. J R Soc Interface. 2018;15(141).
Dana D, Gadhiya SV, St Surin LG, Li D, Naaz F, Ali Q, et al. Deep learning in drug discovery and medicine; scratching the surface. Molecules. 2018;23(9).
Grapov D, Fahrmann J, Wanichthanarak K, Khoomrung S. Rise of deep learning for genomic, proteomic, and metabolomic data integration in precision medicine. OMICS. 2018.
Zhang S, Hosseini Bamakan SM, Qu Q, Li S. Learning for personalised medicine: a comprehensive review from deep learning perspective. IEEE Rev Biomed Eng. 2018.
Hulshoff Pol H, Bullmore E. Neural networks in psychiatry. Eur Neuropsychopharmacol. 2013;23(1):1–6.
Fernandes BS, Williams LM, Steiner J, Leboyer M, Carvalho AF, Berk M. The new field of ‘precision psychiatry’. BMC Med. 2017;15(1):80.
Dwyer DB, Falkai P, Koutsouleris N. Machine learning approaches for clinical psychology and psychiatry. Annu Rev Clin Psychol. 2018;14:91–118.
Arbabshirani MR, Plis S, Sui J, Calhoun VD. Single subject prediction of brain disorders in neuroimaging: promises and pitfalls. Neuroimage. 2017;145(Pt B):137–65.
Kloppel S, Stonnington CM, Chu C, Draganski B, Scahill RI, Rohrer JD, et al. Automatic classification of MR scans in Alzheimer’s disease. Brain. 2008;131(Pt 3):681–9.
Ju R, Hu C, Zhou P, Li Q. Early diagnosis of Alzheimer’s disease based on resting-state brain networks and deep learning. IEEE/ACM Trans Comput Biol Bioinform. 2017.
Ortiz A, Munilla J, Gorriz JM, Ramirez J. Ensembles of deep learning architectures for the early diagnosis of the Alzheimer’s disease. Int J Neural Syst. 2016;26(7):1650025.
Akhavan Aghdam M, Sharifi A, Pedram MM. Combination of rs-fMRI and sMRI data to discriminate autism spectrum disorders in young children using deep belief network. J Digit Imaging. 2018.
Pinaya WH, Gadelha A, Doyle OM, Noto C, Zugman A, Cordeiro Q, et al. Using deep belief network modelling to characterize differences in brain morphometry in schizophrenia. Sci Rep. 2016;6:38897.
Schmaal L, Marquand AF, Rhebergen D, van Tol MJ, Ruhe HG, van der Wee NJ, et al. Predicting the naturalistic course of major depressive disorder using clinical and multimodal neuroimaging information: a multivariate pattern recognition study. Biol Psychiatry. 2015;78(4):278–86.
Miotto R, Li L, Kidd BA, Dudley JT. Deep patient: an unsupervised representation to predict the future of patients from the electronic health records. Sci Rep. 2016;6:26094.
Lin E, Kuo PH, Liu YL, Yu YW, Yang AC, Tsai SJ. A deep learning approach for predicting antidepressant response in major depression using clinical and genetic biomarkers. Front Psychiatry. 2018;9:290.
Kautzky A, Baldinger P, Souery D, Montgomery S, Mendlewicz J, Zohar J, et al. The combined effect of genetic polymorphisms and clinical parameters on treatment outcome in treatment-resistant depression. Eur Neuropsychopharmacol. 2015;25(4):441–53.
Patel MJ, Andreescu C, Price JC, Edelman KL, Reynolds CF 3rd, Aizenstein HJ. Machine learning approaches for integrating clinical and imaging features in late-life depression classification and response prediction. Int J Geriatr Psychiatry. 2015;30(10):1056–67.
Chekroud AM, Zotti RJ, Shehzad Z, Gueorguieva R, Johnson MK, Trivedi MH, et al. Cross-trial prediction of treatment outcome in depression: a machine learning approach. Lancet Psychiatry. 2016;3(3):243–50.
Iniesta R, Malki K, Maier W, Rietschel M, Mors O, Hauser J, et al. Combining clinical variables to optimize prediction of antidepressant treatment outcomes. J Psychiatr Res. 2016;78:94–102.
Zou H, Zhang HH. On the adaptive elastic-net with a diverging number of parameters. Ann Stat. 2009;37(4):1733–51.
Maciukiewicz M, Marshe VS, Hauschild AC, Foster JA, Rotzinger S, Kennedy JL, et al. GWAS-based machine learning approach to predict duloxetine response in major depressive disorder. J Psychiatr Res. 2018;99:62–8.
Tibshirani R. The lasso method for variable selection in the Cox model. Stat Med. 1997;16(4):385–95.
Casanova R, Barnard RT, Gaussoin SA, Saldana S, Hayden KM, Manson JE, et al. Using high-dimensional machine learning methods to estimate an anatomical risk factor for Alzheimer’s disease across imaging databases. Neuroimage. 2018;183:401–11.
Algamal ZY, Lee MH. Regularized logistic regression with adjusted adaptive elastic net for gene selection in high dimensional cancer classification. Comput Biol Med. 2015;67:136–45.
Friedman J, Hastie T, Tibshirani R. Regularization paths for generalized linear models via coordinate descent. J Stat Softw. 2010;33(1):1–22.
Walter M, Alizadeh S, Jamalabadi H, Lueken U, Dannlowski U, Walter H, et al. Translational machine learning for psychiatric neuroimaging. Prog Neuropsychopharmacol Biol Psychiatry. 2018.
Woo CW, Chang LJ, Lindquist MA, Wager TD. Building better biomarkers: brain models in translational neuroimaging. Nat Neurosci. 2017;20(3):365–77.
Moreno-De-Luca D, Ross ME, Ross DA. Leveraging the power of genetics to bring precision medicine to psychiatry: too little of a good thing? Biol Psychiatry. 2018;83(8):e45–6.
Folkersen L, Brynedal B, Diaz-Gallo LM, Ramskold D, Shchetynsky K, Westerlind H, et al. Integration of known DNA, RNA and protein biomarkers provides prediction of anti-TNF response in rheumatoid arthritis: results from the COMBINE study. Mol Med. 2016;22:322–8.
Gombojav B, Song YM, Lee K, Yang S, Kho M, Hwang YC, et al. The healthy twin study, Korea updates: resources for omics and genome epidemiology studies. Twin Res Hum Genet. 2013;16(1):241–5.
Qvarfordt M, Anderson M, Svartengren M. Quality and learning aspects of the first 9000 spirometries of the Life Gene study. NPJ Prim Care Respir Med. 2018;28(1):6.
Chen CH, Yang JH, Chiang CWK, Hsiung CN, Wu PE, Chang LC, et al. Population structure of Han Chinese in the modern Taiwanese population based on 10,000 participants in the Taiwan Biobank project. Hum Mol Genet. 2016;25(24):5321–31.
Lin JC, Fan CT, Liao CC, Chen YS. Taiwan Biobank: making cross-database convergence possible in the big data era. Gigascience. 2018;7(1):1–4.
Lin E, Kuo PH, Liu YL, Yang AC, Kao CF, Tsai SJ. Association and interaction of APOA5, BUD13, CETP, LIPA and health-related behavior with metabolic syndrome in a Taiwanese population. Sci Rep. 2016;6:36830.
Lin E, Kuo PH, Liu YL, Yang AC, Kao CF, Tsai SJ. Effects of circadian clock genes and environmental factors on cognitive aging in old adults in a Taiwanese population. Oncotarget. 2017;8(15):24088–98.
Lin E, Kuo PH, Liu YL, Yang AC, Kao CF, Tsai SJ. Effects of circadian clock genes and health-related behavior on metabolic syndrome in a Taiwanese population: evidence from association and interaction analysis. PLoS ONE. 2017;12(3):e0173861.
Lin E, Tsai SJ, Kuo PH, Liu YL, Yang AC, Kao CF, et al. The rs1277306 variant of the REST gene confers susceptibility to cognitive aging in an elderly Taiwanese population. Dement Geriatr Cogn Disord. 2017;43(3–4):119–27.
Lin E, Tsai SJ, Kuo PH, Liu YL, Yang AC, Kao CF, et al. The ADAMTS9 gene is associated with cognitive aging in the elderly in a Taiwanese population. PLoS ONE. 2017;12(2):e0172440.
Lin E, Yang AC, Tsai SJ. Association between metabolic syndrome and cognitive function in old adults in a Taiwanese population. Taiwanese J Psychiatry. 2017;31(3):232–40.
Ben-Hamo R, Efroni S. Biomarker robustness reveals the PDGF network as driving disease outcome in ovarian cancer patients in multiple studies. BMC Syst Biol. 2012;6:3.
Tebani A, Afonso C, Marret S, Bekri S. Omics-based strategies in precision medicine: toward a paradigm shift in inborn errors of metabolism investigations. Int J Mol Sci. 2016;17(9).
Dalvie S, Koen N, McGregor N, O’Connell K, Warnich L, Ramesar R, et al. Toward a global roadmap for precision medicine in psychiatry: challenges and opportunities. OMICS. 2016;20(10):557–64.
Williams LM. Precision psychiatry: a neural circuit taxonomy for depression and anxiety. Lancet Psychiatry. 2016;3(5):472–80.
Hu Y, Hase T, Li HP, Prabhakar S, Kitano H, Ng SK, et al. A machine learning approach for the identification of key markers involved in brain development from single-cell transcriptomic data. BMC Genom. 2016;17(Suppl 13):1025.
Serretti A. The present and future of precision medicine in psychiatry: focus on clinical psychopharmacology of antidepressants. Clin Psychopharmacol Neurosci. 2018;16(1):1–6.
Stein MB, Smoller JW. Precision psychiatry-will genomic medicine lead the way? JAMA Psychiatry. 2018;75(7):663–4.
Acknowledgements
This work was supported by grant MOST 107-2634-F-075-002 from Taiwan Ministry of Science and Technology, and grant V105D17-002-MY2-2 from the Taipei Veterans General Hospital. We thank Emily Ting for English editing.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Lin, E., Tsai, SJ. (2019). Machine Learning in Neural Networks. In: Kim, YK. (eds) Frontiers in Psychiatry. Advances in Experimental Medicine and Biology, vol 1192. Springer, Singapore. https://doi.org/10.1007/978-981-32-9721-0_7
Download citation
DOI: https://doi.org/10.1007/978-981-32-9721-0_7
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-32-9720-3
Online ISBN: 978-981-32-9721-0
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)