
Abstract
An apple is one of the most cultivated and consumed fruits in the world and continuously being praised as a delicious and miracle food. It is a rich source of Vitamin A, Vitamin B1, Vitamin B2, Vitamin B6, Vitamin C, and folic acid etc, whereas the rotten fruits affect the health of human being as well as cause big economical loss in agriculture sectors and industries. Therefore, identification of rotten fruits has become a prominent research area. This paper focuses on the classification of rotten and good apple. For classification, first extract the texture features of apples such as discrete wavelet feature, histogram of oriented gradients (HOG), Law’s Texture Energy (LTE), Gray level co-occurrence matrix (GLCM) and Tamura features. After that, classify the rotten and good apples by applying various classifiers such as SVM, k-NN, logistic regression, and Linear Discriminant. The performance of proposed approach by using SVM classifier is 98.9%, which is found better with respect to the other classifiers.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
The degradation in quality and quantity of the fruits and vegetables is the consequence of the disease present in the fruits. This results in great loss for economy of agriculture sectors and industries. Considering the example of soybean rust (rust is fungal disease in soybean plant), it is reported that by removing the disease in plant by just 20%, the profit of 11 million- dollar was incurred [1]. The infections or disease in tree leads to defect in tree’s fruits, branches, leaves and even the twigs. If the illness in fruits is inspected at initial stage, the dispersion of the disease to other parts can be reduced or even it can be eliminated. The reduction in infection in fruits will directly increase the economy of the agriculture industries.
The disease present in plant evaluates the stability, quality and quantity in yield of fruits. Till date as per our best knowledge, no such techniques or sensor is developed which differentiate between the healthy and defected fruits. Only the traditional method for distinguishing the images are used, these are bare-eyes observation and scouting method [2]. Scouting method is the adaptive approach which is man driven, consumes lots of time and implementation is costly.
The method proposed in these papers can be implemented for developing an automated system for the detection of healthy and defected apples. There are n-number of application for image processing in agriculture industries. These include color scanners and cameras for taking images as input and then process it for getting the desired result. In our work, we have tried to elaborate the image processing and analyzing them through machine learning techniques [3].
In this paper, we have taken apple dataset for implementing the approach and thus verifying it. Common disease in apples fruits is caused due to infection or fungal activity; these diseases are apple rot, apple scab, apple blotch, dagger nematode etc.
In our work, we have given an analytical approach and verified the approach for the apple classification. This classification is performed by using the various features of images. Like we are using color and texture features. The approach goes like, the defected portion of the apple images is identified with k-means clustering segmentation technique, and then, features are computed over the segmented images on the color and texture features. Once the feature is extracted, we apply fivefold and hold-out validation technique. And in last by implementing various classifiers, we compute the accuracy [2].
Rest of the paper is organized as follows: Sect. 2 contains a deep literature survey. Section 3 explains the proposed method in detail. Section 4 contains the experimental results and discussion. Finally, the conclusion of the proposed work is given in Sect. 5.
2 Literature Survey
In this section, we have reviewed work done by various authors in feature extraction and classification. The authors have used the different features extraction technique and classifiers for attaining the maximum accuracy in result. Table 1 shows work done by the researchers in field of apple classification using different classifiers and feature extraction techniques [4].
3 The Proposed Method
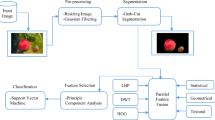
Image classification depends on integration of spatial, structure and statistical method [5]. In our research, we have used statistical approach for texture-based feature for classification of defected and healthy images. Statistical model evaluates the image on basis of entropy, energy, wavelet etc. Structural method evaluates the image on basis of the appearance of object like shape, spots etc., on the image. At last, spectral method uses spectral space representation like Fourier spectrum [5]. The proposed approach contains four main steps, namely the preprocessing, feature extraction, feature selection, and classification step as mentioned in Fig. 1.

Proposed approach
3.1 Preprocessing of Images
Preprocessing of image involves refining the images. This refinement involves resizing the images and enhancing the image quality in terms of pixel brightness. The main objective behind preprocessing of image is to remove the unnecessary distortion and enhance the quality of images.
In a preprocessing step of proposed approach, first convert the color image into grayscale image by using PCA-based color-to-grayscale conversion method because it preserves both color discriminability and the texture by using simple linear computations in subspaces with low computational complexity [6, 7] and then applying contrast limited adaptive histogram equalization (CLAHE) because CLAHE enhanced the quality of image and helpful for further image processing steps such as segmentation, feature extraction, restoration, registration etc. [6,7,8].
3.2 Feature Extraction and Selection
Feature extraction is a process of transforming the input data into set of features [9]. In our propose approach, texture features are extracted from the all healthy and defected apple images. Texture refers to the repetition of basic texture element known as “TEXEL” which contains several pixels that are placed randomly, periodic or quasi-periodic [9]. There are various feature descriptors for texture feature such as GLCM, Tamura, HOG, Wavelet transformation, Local-Binary pattern (LBP), Completed Local Binary Pattern (CLBP) and many more. In the proposed approach, we have taken the feature descriptor as GLCM, Wavelet transformation, Tamura, HOG and LTE for extracting the texture feature.
Gray Level Co-occurrence Matrix (GLCM): GLCM also known as co-occurrence distribution. This is second order statistical method for the analysis of texture feature of the image. The image is composed of pixels and they are associated with a specific Gray level, that is, intensity and the frequency of combination of different gray levels co-occurrence is tabulated. This tabulation is known as GLCM. GLCM tabulation is used for the calculation of texture feature. It gives the measure of fluctuation in intensity of pixels.
Discrete Wavelet Transform (DWT): DWT is a decomposition technique of any continuous signal with respect to time such as image in frequency domain. Several applications such as data compression, removing noise and features detection are based on this technique. In this technique, an image is first decomposed into series of wavelet coefficient corresponding to its four frequency sub-bands Low-Low, Low-High, High-Low, High-High. Most of the image energy/information is concentrated at its Low-Low frequency sub-band.
Histogram of Oriented Gradients (HOG): HOG is used to detect and extract the orientation features of an image. This technique is used to extract the distribution of gradient direction (orientated gradients). Gradients mean the X and Y derivatives of an image. The following flow is used to extract the HOG features.
Tamura’s Features: These features are based on three fundamental texture features, contrast, directionality and coarseness. Variety of the texture pattern is the measurement of Contrast. The difference in luminance that’s make an object is the Contrast. In an image direction of gray level values are measurement of Directionality and granularity of an image is the measurement of Coarseness.
Law’s Texture Energy: Law’s determined some masks which were used to discriminate the different texture. In this method, texture energy transformation is applied to the image to calculate the energy within the pass region of filters. The masks of technique are derived from 1D vectors of five pixel length. By convolving one vertical vector with one horizontal vector, a 2D filter was generated. All the 2D filters are convolved over the image to extract the features.
After extracting total 108 features, various machine learning-based classifiers such as support vector machine (SVM), k-nearest neighbors (k-NN), Logistic Regression, Linear Discriminant analysis are used for the classification of healthy and defected apple image. Short discussion about the various used machine learning-based classifiers is as follows:
Support Vector Machine: Support Vector Machine (SVM) is a supervised learning model. This algorithm is used to analyze the data for both classification and regression. It is a discriminative classifier defined by a separating hyperplane. The algorithm creates the optimal hyperplane as an output for the labeled training dataset. This hyperplane divides the dataset in two parts; these two parts are none other than the two different classes. The SVM does the separation of classes.
k- Nearest Neighbor: It is a supervised and non-parametric algorithm (does not perform any pre-assumption regarding the distribution) which is deployed for both classification and regression. The main principle behind the algorithm is to find an existing number of training dataset which is nearest in distance to the new point and then classifies these training datasets in various classes. The neighbors are determined by calculating the Euclidian and Hamming distance. The algorithm classifies the data input through the class membership of its k-neighbors and most of the neighbors represent the data classified as output.
Logistic Regression: It is used to analyze the relationship between a categorical dependent variable and categorical independent variables. It combines the independent variables to estimate the probability for the happening of event, that is, the object will belong to which class.
Linear Discriminant: Linear Discriminant Analysis (LDA) is a supervised learning model. LDA is used to reduce the dimensionality in the preprocessing for the classification. The main aim of implementing LDA is to avoid the problem of overfitting that is “curse of dimensionality”. The output of LDA represents the feature space of dataset of dimensions n into the smaller subspace k, where k <= (n − 1), by maintaining the difference in classes. It is a statistical tool that is required to figure out the dependent variable in various categories. It helps in analysis of accuracy of a classification.
4 Experimental Results and Discussion
For evaluating and validating our proposed approach for classification of healthy and rotten apple, we have collected the images of both rotten and healthy images. These images are collected from various sources [5, 10]. Some images are taken manually with the help of mobile phone camera while some are downloaded from Google Images [5, 10]. These are downloaded by entering the keywords “healthy apple dataset” for normal apple and “apple + disease name” for defected apple image on Google Images. We have taken 42 healthy apple images and 52 rotten apple images; total 94 images are present in dataset. Figures 2 and 3 show the sample images for the healthy and defected apple. After downloading the images, resize them because some of the downloaded image are in different sizes.


The proposed approach has been implemented on all 94 different apple images taken from the various sources [5, 10]. For experimental analysis, total 108 features are extracted from each 94 images. These 108 features are collection of 22 GLCM features, 15 LTE Features, 32 Wavelet features, 03 Tamura features, and 36 HOG Features. After extracting the features, apply the various machine learning-based approaches together with k-fold cross-validation technique and found that the performance of the proposed approach is better with respect to other existing approaches in the literature. The performance of proposed approach is measured by evaluating an accuracy (ACC) using Eq. (1) as given below:
where TP, TN, FP, and FN represent true positive, true negative, false positive, and false negative values of confusion matrix, respectively.
The performance of classifiers is evaluated by applying two different scenarios. In first scenario, evaluate the performance of classifiers by selecting all extracted features and then apply k-fold validation by using thee different values of k such as fivefold, 10-fold, and 15-fold. The results are mentioned in Table 2. In second scenario, evaluate the performance of classifiers by selecting some suitable features by applying PCA-based feature selection technique and then apply k-fold validation by using thee different values of k such as fivefold, 10-fold, and 15-fold. The results are mentioned in Table 3.
5 Conclusion
An apple is a rich source of important antioxidants, flavonoids, and dietary fiber and helps to reduce the risk of developing cancer, hypertension, diabetes, and heart disease, whereas the rotten fruits affect the human health as well as cause big economical loss in agriculture sectors. Therefore, identification of rotten fruits had become an important issue for research. This paper focuses on the classification of rotten and healthy apple by extracting the features and then classifying the rotten and healthy apples by applying various classifiers. Based on experimental observation, it was found that the performance of proposed approach by using SVM classifier is 98.9%, which was much better with respect to the other classifiers.
References
Roberts, M. J., Schimmelpfennig, D. E., Ashley, E., Livingston, M. J., Ash, M. S., Vasavada, U., et al. (2006). The value of plant disease early warning systems: a case study of usda’s soybean rust coordinated framework. Technical report, United States Department of Agriculture, Economic Research Service.
Dubey, S. R., & Jalal, A. S. (2016). Apple disease classification using color, texture and shape features from images. Signal, Image and Video Processing, 10(5), 819–826.
Dubey, S. R., & Jalal, A. S. (2014). Adapted approach for fruit disease identification using images. arXiv:1405.4930.
Sindhi, K., Pandya, J., & Vegad, S. (2016). Quality evaluation of apple fruit: A survey. International Journal of Computer Applications (0975–8887), 136(1).
Healthy Apples Image. Retrieved January 15, 2018, from https://www.google.co.in/search?tbm=isch&q=apple+images&chips=q:apple+images,g_1:red,g_10:real&sa=X&ved=0ahUKEwiy3KXN55zXAhWMpY8KHTIzBbcQ4lYIOSgA&biw=1366&bih=588&dpr=1.
Singh, N. P., Srivastava, R. (2016). Segmentation of retinal blood vessels by using a matched filter based on second derivative of gaussian. International Journal of Biomedical Engineering and Technology, 21(3), 229–246.
Seo, J. W., & Kim, S. D. (2013). Novel pca-based color-to-gray image conversion. In 2013 20th IEEE International Conference on Image Processing (ICIP), pp. 2279–2283. IEEE.
Singh Rajeev, N. P. (2018). Extraction of retinal blood vessels by using an extended matched filter based on second derivative of gaussian. In Proceedings of the National Academy of Sciences, India Section A: Physical Sciences 2016.
Jain, A. K. (1989). Fundamentals of digital image processing. In Prentice-Hall information and system sciences series. Prentice-Hall.
Ivars, D. J. B., & Garca, D. S. C. (2018). Image database: Apple golden’. Retrieved January 15, 2018, from http://www.cofilab.com/portfolio/goldendb/.
Leemans, V., Destain, M.-F. (2004). A real-time grading method of apples based on features extracted from defects. Journal of Food Engineering, 61(1), 83–89.
Unay, D., & Gosselin, B. (2005). Artificial neural network-based segmentation and apple grading by machine vision. In 2005. IEEE International Conference on Image Processing, ICIP, (Vol. 2, p. II–630). IEEE.
Zhu, B., Jiang, L., Luo, Y., & Tao, Y. (2007). Gabor feature-based apple quality inspection using kernel principal component analysis. Journal of Food Engineering, 81(4), 741–749.
Wang, J.-J., Zhao, D., Ji, W., Tu, J., & Zhang, Y. (2009). Application of support vector machine to apple recognition using in apple harvesting robot. In 2009 ICIA’09 International Conference on Information and Automation (pp. 1110–1115). IEEE.
Unay, D., Gosselin, B., Kleynen, O., Leemans, V., Destain, M.-F., & Debeir, O. (2011). Automatic grading of bi-colored apples by multi-spectral machine vision. Computers and Electronics in Agriculture, 75(1), 204–212.
Arlimatti, S. R. (2012). Window based method for automatic classi_cation of apple fruit. International Journal of Engineering Research and Applications, 2(4), 1010–1013.
Dubey, S. R., & Jalal, A. S. (2012). Detection and classification of apple fruit diseases using complete local binary patterns. In 2012 Third International Conference on Computer and Communication Technology (ICCCT), (pp. 346–351). IEEE.
Jhuria, M., Kumar, A., & Borse, R. (2013). Image processing for smart farming: Detection of disease and fruit grading. In 2013 IEEE Second International Conference onImage Information Processing(ICIIP), (pp. 521–526). IEEE.
Ashok, V., & Vinod, D. S. (2014). Automatic quality evaluation of fruits using probabilistic neural network approach. In 2014 International Conference on Contemporary Computing and Informatics (IC3I), (pp. 308–311). IEEE.
Gonzalez, R. C., & Woods, R. E. (2002). Digital image processing (2nd ed.). Prentice Hall.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Singh, S., Singh, N.P. (2019). Machine Learning-Based Classification of Good and Rotten Apple. In: Khare, A., Tiwary, U., Sethi, I., Singh, N. (eds) Recent Trends in Communication, Computing, and Electronics. Lecture Notes in Electrical Engineering, vol 524. Springer, Singapore. https://doi.org/10.1007/978-981-13-2685-1_36
Download citation
DOI: https://doi.org/10.1007/978-981-13-2685-1_36
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-2684-4
Online ISBN: 978-981-13-2685-1
eBook Packages: EngineeringEngineering (R0)