
Abstract
This paper presents a novel approach for texture classification using Shearlet Transform. The Shearlet Transform is a recently developed tool, which have the multiscale framework which allows to efficiently encode anisotropic features in multivariate problem classes. Shearlets are a newly developed extension of wavelets that are better suited to image characterization. In addition the degree of computational complexity of many proposed texture measures are very high. In this paper, a novel texture classification method that models the adjacent shearlet subband dependences. In this paper the classification efficiencies of Minimum Distance classifier was compared with SVM classifier efficiency. For texture classification, the energy features are used to represent each shearlet subband. Comprehensive validation experiments performed on different datasets proves that this research work outperforms the current methods due to efficient multiscale directional representation of Shearlet Transform.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Texture is defined as the measure of variation of intensity of the surface determining properties such as roughness, smoothness, repeated, etc. Texture is generally classified into two types namely Surface texture and Visual texture. Surface texture is the primary visual cue observed in natural images. Visual textures are synthetically generated and has an isolated perceptual quality, simplified for study purpose only. Textures are the properties that appear on the surface of the objects, such as a person’s fingerprint, repeated patterns on clothes, etc. The properties of the textures are very important that are visualized by humans and used in their daily life. These important features has caused that textures are inevitable and are involved in physical life applications, such as biomedical image processing, remote sensing, document processing, etc. Despite the lack of a universally agreed definition for texture, all researchers agree on two points. Texture analysis has several significant challenges due to the complexity of textural patterns and different lighting conditions that must be considered. It provide appropriate feature for subsequent studies, such as Image retrieval, pattern recognition, and image segmentation. Texture analysis consists of four major techniques namely Classification, Segmentation, Synthesis and Shape from texture [1]. In texture classification process, the map for classification is drawn between the textures where each textured region is acknowledged with the texture class to which category it belongs. It is also said that, the goal of texture classification is to allocate an unidentified texture image to one of the set of identified texture class. The two main classification methods are supervised and unsupervised classification methods [2]. The supervised classification method is performed by using the trained set of textures to learn the behavior for each texture class. The unsupervised classification automatically discovers different classes from input textures that does not require any prior knowledge about the textures. Another classification method is semi-supervised, in which only limited preceding knowledge is present regarding the textures. These classification methods represented above consist of two stage process. Feature extraction is the first stage, where the description of each texture class in terms of features is measured. Identification and selection of different features that produces exact output are very important because they are invariant to inappropriate transformation of the image, such as translation, scaling, and rotation. The computable measures of certain values of features must be similar to the texture already stored in the database but it is difficult to design an universally acceptable feature extractor since most of the existing techniques depends on some predefined problems and it needs the basic knowledge about the working domain. The next stage is the classification phase, in which the features extracted from the training set are compared with the testing texture and the best fit is found. Texture classification process in general consists of two major phases:
-
A.
Learning Phase:
Learning phase is the initial step in texture classification. The major objective of this phase is to create a model for texture content of every texture class stored in the database which is considered as the training set. The training dataset in general consist of texture images of known classes along with their labels. These texture contents stored for the training images undergo certain texture analysis methods. These analysis methods are used to extract the detailed information regarding the texture images which are denoted as features. These features obtained can be in the form of numbers or discrete histograms that are used to characterize the properties of the texture images. Some of the textural properties of the textures are contrast, smoothness, roughness, orientation, brightness, etc.
-
B.
Recognition Phase:
Recognition phase is the major step in the process of texture classification where the textural features of the unidentified sample are defined with the same texture analysis method as that of learning phase. After obtaining the textural features of the training and testing samples, the features of training samples are compared with the features of testing samples by using the predefined classification algorithm. The comparison results provides the best match and if the match found is not good, the texture is said to be misclassified.
Texture analysis is the technique to obtain the detailed information of the textures and it is done by the following processes such as synthesis, classification, segmentation and shape from texture. Some of the applications of texture analysis techniques are identifying surface defects, medical diagnosis, ground classification and rain forecasting, text analysis, face recognition and fabric classification [3]. Textures are used to explain about the statistical and structural relationship between the pixels, and also it describes on the properties of the textures. Statistical method is mostly used for the natural textures that contains irregular surface patterns, for example grass, sand, bark surfaces. It is the measure of intensity arranged in the specified region. Likewise the structured method is used for the natural or artificially generated textures that contains repeated or regular surface patterns. Since feature extraction plays the major role in texture classification there exist various methods for feature extraction based on the use of filters and signal processing.
This paper is structured as follows. Literature survey is described in Sect. 2. Section 3 deals with the description of Shearlet Transform and the Sect. 4 deal with the feature extraction. Experimental study is explained in Sect. 5. The results are concluded in Sect. 6 and finally References.
2 Literature Survey
Texture analysis is broadly classified into three categories: Pixel based method, local feature based method and Region based method. Pixel based method uses gray level co-occurrence matrices, difference histogram and energy measurements and Local Binary Patterns (LBP). Local feature based method uses edges of local features and generalization of co-occurrence matrices. Region based method uses region growing and topographic models [4].
The spatial distributions of gray values are obtained by calculating the image features at each point and then developing a set of measurements from the distributions of the local texture features. Statistical approaches are the one which are use for natural images that are mostly irregular and in some cases they are repeated. It provides descriptions of textures as fine, rough, smooth, coarse, etc. Thus the experimental measures of texture are based on the original size, which could be the average area of the primitives of reasonably constant gray level [5].
Kaiser have explained about statistical method which examines the spatial distribution of gray values by computing the local features at each point in an image, and extracting a set of statistics from the distribution of local features [6]. This method is also used for examining the regularity and roughness of texture including autocorrelation function. Haralick et al. [7] proposed the equivalent procedure to identify the spatial uniformity of shapes called structural elements in a binary image. When these element themselves are single resolution cells, the autocorrelation function of the binary image is given. The size of co-occurrence matrix obtained will be same as that of the number of threshold levels. The most widely used geometric methods are the use of co-occurrence features and gray level differences which have stimulated a variety of modifications further. The process also includes the signed differences [8] and the LBP (Local Binary Pattern) operator [9]. Other statistical approaches which are already present are autocorrelation function that is used for examining the properties of the texture, and gray level run lengths. The above methods produce low classification efficiency.
Texture classification is an essential process for computer vision and image recognition applications. Texture classification is achieved by four methods such as structural, statistical, model-based and multiscale transform based methods. Multiscale methods are most widely used, since the multiresolution and directional representations of the transforms are possible with the human observation of the textured images. Some of the multiscale transforms that are most commonly used are the Gabor transform [10], the Wavelet transform [11], the Ridgelet transform [12], Curvelet transform and the Contourlet transform [13]. The results of this research work was compared with recent method results like BP-MD DONG et al. (2015), MCC-KNN Dong et al. and DST-ED Kanchana et al. (2013).
3 Shearlet Transform
Shearlets are the multiscale framework which allows to efficiently encode anisotropic features in multivariate problem classes [14]. Shearlets are considered as the sloping waveforms, with directions organized by the shear parameters, and they become gradually thin at adequate scales (for the value such as p → 0). One of the most important properties of shearlet is the fact that they provide optimally sparse approximation for cartoon-like functions. The shearlet transform is not like the traditional wavelet transform which are only good at representing point singularities and do not have the ability to detect lines and curves. But the shearlet transform contains two parameters namely, the scaling parameter ‘a’ and the translation parameter‘t’ that are used for analyzing the directions [15]. The shearlet transform was developed next to contourlet to overcome the limitations present in wavelets and contourlets. By using shearlet transform, the image textures are represented as a simple but accurate mathematical framework which is also considered as the useful tool for the geometrical representation of multidimensional information, and this process is more usual for execution of the different applications.
The shearlet transform decomposes the input image into number of subband images containing the high rate of recurrence subband images and low rate of recurrence subband images. The magnitude of each and every shearlet subband has the same magnitude as that of the initial image [16]. The decomposition is highly redundant. In general, two different types of shearlet systems are utilized today: Band-limited shearlet systems and compactly supported shearlet systems. Regarding those from an algorithmic viewpoint, both have their particular advantages and disadvantages: Algorithmic realizations of the band limited shearlet transform on the one hand has the higher calculation difficulty. However, on the other hand, the process of handling the seismic data requires high localization [17]. The compactly supported shearlet transform are much faster and have the advantage of achieving a high accuracy in spatial domain.
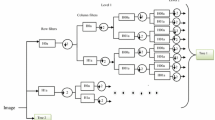
The Fig. 1 represents the two level multiscale, shift invariant and multidirectional image decomposition. During first level decomposition it will give one approximation and n directional detailed bands. The first level approximation is given for further level decomposion. Though the Shearlet Transform consist of necessary properties of shift invariance, features were extracted from the texture images by using these properties.

Filter bank structure of Shearlet transform
4 Proposed System
In many texture classification system the image cannot be efficiently analyzed at various scales and directions. Therefore, an efficient way to obtain a multi-resolution and multi-direction representation of texture images based on shearlet transform is proposed. The proposed method for texture classification system based on shearlet transform is shown in Fig. 2. In general, a typical classification system mainly consists of two phases; feature extraction phase and classification phase.

Feature extraction stage of Shearlet transform
Feature Extraction Phase.
In this phase, the texture images are decomposed into two, namely the approximation (low frequency) component and the detailed (high frequency) components of various subbands by the Shearlet transform at different resolution levels.
Since the number of decomposition level is chosen as 4, we obtain 16 subbands in each level in addition to one approximation subband. Each sub-band represents the components of the original image at specific directions and resolutions with the actual size of original texture. From these sub-bands, the statistical information which characterizes the texture can be extracted to complete the feature extraction.
Features are the functions of original measurement variables that are useful for classification and pattern recognition. Feature extraction is the process of describing a set of features or image characteristics, which will most efficiently represent the information that are important for examination and classification. The subband energies are the features that are used to represent each shearlet subband. The most widely-used energy features are, norm-1, norm-2 energy features and the entropy that are used to represent each shearlet subband. The L-level decomposition of shearlet transform on a given texture is first performed and one low-pass shearlet subband and M directional subbands at each scale were obtained. Then each shearlet subband are denoted as
The norm-1 energy and norm-2 energy features are defined as
and,
respectively. From a statistical point of view, the norm-1 energy is the sample mean of the moduli of coefficients in S, while the norm-2 energy measures the sample standard deviation [18]. In this way, these two energy features can be used to capture the visual information of the shearlet subband S, whether from a signal energy demonstration or from a statistical perspective. The third feature is entropy that provides the statistical measure of randomness to characterize the texture of the input image. Entropy is calculated as
In the above expression, Pj is the probability that the difference between two neighboring pixels is equal to j. In this way, the energy feature can be used to capture the visual information of the shearlet subband S, whether from a signal energy demonstration or from a statistical perspective.
-
A.
Classification phase
In the classification phase, the same kind of features are extracted and compared with the database obtained in the feature extraction stage. The features of all the subbands are fused together to form the feature vector of the related texture image. Similarly, the proposed features are extracted for all training texture samples and stored in the database for classification. Figure 3 show the classification stage of the proposed system. The nearest neighbor classifier and SVM classifier are designed to classify the unknown texture image into known texture class.

Classification stage of Shearlet Transform
The texture image to be classified is decomposed by means of Shearlet Transform and the feature vector is extracted as in the training phase. It should be noted that the number of decomposition level, number of directions and block size should be similar in both the phases to avoid failure of classifier. The classification is done by using minimum distance measure and SVM classification. The City Block distance measure is used in the proposed method. The performance measure of the proposed texture classification system is the classification accuracy which is measured as the percentage of test images classified into the exact texture. The classification rate is based on the number of correctly classified test textures (Fig. 4).

Brodatz images used in experiments
The Minimum Distance between the test image to training image can be calculated by using the following equation:
The classification rate is calculated as
where M is the number of correctly classified images and N is the total number of images present in the database.
5 Experimental Study
In this section, the performance of the proposed texture classification algorithm based on Shearlet Transform is described. Brodatz texture images are used to estimate the performance of the proposed system. The size of the Brodatz texture images used are 512 × 512 and 640 × 640 pixels and the images are gray scale images. The databases consist of different classes which are divided based on the basic character of the pictures. The Brodatz database [19] consisting of 112 texture images of different class. Every image is divided into multiple patches from which some patches are used as training samples and others as tesing samples. The Shearlet Transform features are obtained and stored. The textures were classified by calculating the distance using Minimum distance classifier and SVM classifier. The classification results were obtained using the two classifiers and compared for Brodatz album. The classification rate is based on the number of correctly classified test textures.
The experiments were conducted with 12 basic textures of Brodatz dataset and with 40 texture images of Brodatz dataset. Each texture image is sub divided into sixteen sub images and features such as mean, standard deviation and entropy were used for classification.
In Table 1, C1 and C2 represents the experiment with 16 sub images for training and testing using minimum distance classifier and SVM classifier. C3 and C4 represents the experiment with 12 sub images for training and 4 sub images for testing using minimum distance classifier and SVM classifier. C5 and C6 represents the experiment with 8 sub images for training and 8 sub images for testing using minimum distance classifier and SVM classifier.
In Table 2. For 40 Brodatz textures F1 represents the experiment with 16 sub images for training testing, F2 represents the experiment with 12 sub images for training and 4 sub images for testing and F3 represents the experiment with 8 sub images for training and 8 sub images for testing (Fig. 5).

Comparison result for minimum distance and SVM classifier using 40 Brodatz textures
-
1
– Experiment with 16 sub images for training and testing for all 40 texture images.
-
2
– Experiment with 12 sub images for training and 4 sub images for testing for all 40 texture images.
-
3
– Experiment with 8 sub images for training and 8 sub images for testing for all 40 texture images.
In Table 3. the comparative analysis of the proposed system with other techniques in the literature in terms of classification accuracy is provided. It is observed that the proposed system outperforms all other methods in terms of average classification accuracy.
6 Conclusion
From the experimental analysis it is inferred that the proposed feature set produces good classification rate. This method is done with natural Brodatz texture images. The success rate obtained for Shearlet Transform is improved when compared with other transforms. In order to overcome the inherent complexity of the Shearlet coefficients, we extract energy features such as mean, standard deviation and entropy from the Shearlet subbands and model their dependences using the Minimum Distance Classifier and the SVM classifier. It is proved that Shearlets exhibit high directional sensitivity. The high directional sensitivity of the Shearlet transform and its optimal approximation properties will lead to the enhancement of many image processing applications. Thus overcoming the disadvantages of the Contourlet transform, that there are no restrictions on the number of directions for the shearing. It is inferred that the proposed feature set produces good classification rate for SVM classifier.
References
Liu, L., Fieguth, P.W.: Texture classification from random features. IEEE Trans. Pattern Anal. Mach. Intell. 34(3), 574–586 (2012)
Raghu, P.P., Poongodi, R., Yegnanarayana, B.: Unsupervised texture classification using vector quantization and deterministic relaxation neural network. IEEE Trans. Image Process. 6(10), 1376–1387 (1997)
Salem, Y.B., Nasri, S.: Texture classification of woven fabric based on a GLCM method and using multiclass support vector machine. In: SSD, pp. 1–8 (2009)
Dixit, A., Hedge, N.P.: Image texture analysis techniques-survey. In: 2013 Third International Conference on Advanced Computing & Communication Technologies, ©2013. IEEE (2013)
Yo-Ping, H., Tsun-Wei, C.: Retrieving interesting images using fuzzy image segmentation and fuzzy data mining model. In: Proceedings of IEEE Annual Meeting of the Fuzzy Information, vol. 2, pp. 623–628, June 2004
Srinivasan, G.N., Shobha, G.: Statistical texture analysis. In: Proceedings of World Academy of Science, Engineering and Technology, vol. 36, December 2008. ISSN 2070-3740
Haralick, R.M., Shanmugan, K., Dinstein, I.: Texture features for image classification. IEEE Trans. Syst. Man Cybern. 3(6), 610–621 (1973)
Kaizer, H.: A Quantification of Texture on Aerial Photographs. Boston University Technical Laboratory, Boston (1995)
Pitikainen, M., Ojala, T., Maenpaa, T.: Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. PAMI 24(7), 971–987 (2002)
Liao, S., Law, M.W.K., Chung, A.C.S.: Dominant local binary patterns for texture classification. IEEE Trans. Image Process. 18(5), 1107–1118 (2009)
Unser, M.: Texture classification and segmentaion using wavelet frames. IEEE Trans. Image Process. 4(11), 1549–1560 (1995)
Arivazhagan, S., Ganesan, L., Subash Kumar, T.G.: Texture classification using ridgelet transform. Pattern Recogn. Lett. 27(16), 1875–1883 (2006)
Po, D.D.-Y., Do, M.N.: Directional multiscale modeling of images using the contourlet transform. IEEE Trans. Image Process. 15(6), 1610–1620 (2006)
Guo, K., Labate, D.: Optimally sparse multidimensional representation using shearlets. SIAM J. Math. Anal. 39(1), 298–318 (2007)
Robson, W., Ricardo, S., da Silva, D., Davis, L.S., Pedrini, H.: A novel feature descriptor based on the shearlet transform. In: 2011 18th IEEE International Conference on Image Processing (2011)
Dong, Y., Tao, D., Li, X., Ma, J., Pu, J.: Texture classification and retrieval using shearlets and linear regression. IEEE Trans. Cybern. 45(3), 358–369 (2015)
Easley, G., Labate, D., Lim, W.-Q.: Sparse directional image representations using the discrete shearlet transform. Appl. Comput. Harmon. Anal. 25(1), 25–46 (2008)
Kanchana, M., Varalakshmi, P.: Texture classification using discrete shearlet transform. Int. J. Sci. Res. June 2013. ISSN No 2277-8179
The Brodatz Texture database with 112 images. http://www.ux.uis.no/tranden/brodatz.html
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Nature Singapore Pte Ltd.
About this paper
Cite this paper
Gopala Krishnan, K., Vanathi, P.T., Abinaya, R. (2016). Texture Classification Using Shearlet Transform Energy Features. In: Subramanian, S., Nadarajan, R., Rao, S., Sheen, S. (eds) Digital Connectivity – Social Impact. CSI 2016. Communications in Computer and Information Science, vol 679. Springer, Singapore. https://doi.org/10.1007/978-981-10-3274-5_1
Download citation
DOI: https://doi.org/10.1007/978-981-10-3274-5_1
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-3273-8
Online ISBN: 978-981-10-3274-5
eBook Packages: Computer ScienceComputer Science (R0)