
Abstract
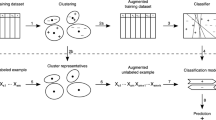
In this study we investigate how to identify hidden contexts from the data in classification tasks. Contexts are artifacts in the data, which do not predict the class label directly. For instance, in speech recognition task speakers might have different accents, which do not directly discriminate between the spoken words. Identifying hidden contexts is considered as data preprocessing task, which can help to build more accurate classifiers, tailored for particular contexts and give an insight into the data structure. We present three techniques to identify hidden contexts, which hide class label information from the input data and partition it using clustering techniques. We form a collection of performance measures to ensure that the resulting contexts are valid. We evaluate the performance of the proposed techniques on thirty real datasets. We present a case study illustrating how the identified contexts can be used to build specialized more accurate classifiers.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Beyer, K.S., Goldstein, J., Ramakrishnan, R., Shaft, U.: When is nearest neighbor meaningful? In: Beeri, C., Bruneman, P. (eds.) ICDT 1999. LNCS, vol. 1540, pp. 217–235. Springer, Heidelberg (1998)
Brézillon, P.: Context in problem solving: a survey. Knowledge Engineering Review 14(1), 47–80 (1999)
Dara, R.A., Makrehchi, M., Kamel, M.S.: Filter-based data partitioning for training multiple classifier systems. IEEE Trans. on Knowledge and Data Engineering 22(4), 508–522 (2010)
Duda, R.O., Hart, P.E., Stork, D.G.: Pattern Classification. Wiley-Interscience Publication, Hoboken (2000)
Frosyniotis, D., Stafylopatis, A., Likas, A.: A divide-and-conquer method for multi-net classifiers. Pattern Analysis and Applications 6(1), 32–40 (2003)
Harries, M.: Splice-2 comparative evaluation: Electricity pricing. Technical report, U. New South Wales (1999)
Harries, M., Sammut, C., Horn, K.: Extracting hidden context. Machine Learning 32(2), 101–126 (1998)
Hastie, T., Tibshirani, R., Friedman, J.: The elements of statistical learning: data mining, inference and prediction. Springer, Heidelberg (2005)
Katakis, I., Tsoumakas, G., Vlahavas, I.: Tracking recurring contexts using ensemble classifiers: an application to email filtering. Knowledge Information Systems 22(3), 371–391 (2010)
Lim, M., Sohn, S.: Cluster-based dynamic scoring model. Expert Systems with Appl. 32(2), 427–431 (2007)
Liu, R., Yuan, B.: Multiple classifiers combination by clustering and selection. Information Fusion 2(3), 163–168 (2001)
Ren, J., Shi, X., Fan, W., Yu, P.S.: Type-independent correction of sample selection bias via structural discovery and re-balancing. In: Proc. of the SIAM Int. Conf. on Data Mining (SDM 2008), pp. 565–576 (2008)
Roth, V., Lange, T., Braun, M., Buhmann, J.: A resampling approach to cluster validation. In: Proc. of Int. Conf. on Computational Statistics, pp. 123–128 (2002)
Strang, T., Linnhoff-Popien, C.: A context modeling survey. In: Workshop on Advanced Context Modelling, Reasoning and Management at the 6th Int. Conf. on Ubiquitous Computing (UbiComp 2004) (2004)
Turney, P.: The identification of context-sensitive features: A formal definition of context for concept learning. In: Proc. of the ICML 1996 Workshop on Learning in Context-Sensitive Domains, pp. 53–59 (1996)
Turney, P.: The management of context-sensitive features: A review of strategies. In: Proc. of the ICML 1996 Workshop on Learning in Context-Sensitive Domains, pp. 60–65 (1996)
Widmer, G., Kubat, M.: Learning in the presence of concept drift and hidden contexts. Machine Learning 23(1), 69–101 (1996)
Wu, M., Scholkopf, B.: A local learning approach for clustering. In: Advances Neural Information Processing Systems (NIPS 2006) (2006)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2011 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Žliobaitė, I. (2011). Identifying Hidden Contexts in Classification. In: Huang, J.Z., Cao, L., Srivastava, J. (eds) Advances in Knowledge Discovery and Data Mining. PAKDD 2011. Lecture Notes in Computer Science(), vol 6634. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-20841-6_23
Download citation
DOI: https://doi.org/10.1007/978-3-642-20841-6_23
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-20840-9
Online ISBN: 978-3-642-20841-6
eBook Packages: Computer ScienceComputer Science (R0)