
Abstract
Fuzzy regression analysis plays an important role in analyzing the correlation between the dependent and explanatory variables in the fuzzy system. This paper put forward the FLS (Fuzzy Least Squares) method for parameter estimating of the fuzzy linear regression model with input, output variables and regression coefficients that are normal fuzzy numbers. Our improved method proves the statistical properties, i.e., linearity and unbiasedness of the fuzzy least square estimators. Residuals, residual sum of squares and coefficient of determination are given to illustrate the fitting degree of the regression model. Finally, the method is validated in both rationality and validity by solving a practical parameter estimation problem.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords

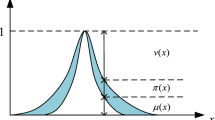
The schematic diagram of fuzzy normal numbers
1 Introduction
The term regression was introduced by Francis Galton. Now, regression analysis is a fundamental analytic tool in many research fields. The method gives a crisp relationship between the dependent and explanatory variables with an estimated variance of measurement errors. Fuzzy regression [1] techniques provide a useful means to model the functional relationships between the dependent variable and independent variables in a fuzzy environment. After the introduction of fuzzy linear regression by Tanaka et al. [2], there has been a great deal of literatures on this topic [3–13]. Diamond [3] defined the distance between two fuzzy numbers and the estimated fuzzy regression parameters by minimizing the sum of the squares of the deviation. Chang [4] summarized three kinds of fuzzy regression methods from existing regression models: minimum fuzzy rule, the rule of least squares fitting and interval regression analysis method. For the purpose of integration of fuzziness and randomness, mixed regression model is put forward in [5]. Chang proposed the triangular fuzzy regression parameters least squares estimation by using the weighted fuzzy arithmetic and least-square fitting criterion. Sakawa and Yano [6] studied the fuzzy linear regression relation between the dependent variable and the fuzzy explanatory variable based on three given linear programming methods. In order to estimate the parameters of fuzzy linear regression model with input, output variables and regression coefficients are LR typed fuzzy numbers, Zhang [7] first represented the observed fuzzy data by using intervals, and then used the left, right point and the midpoint data sets of intervals to derive the corresponding regression coefficients of conventional linear regression models. Zhang [8] discussed the least squares estimation and the error estimate of the fuzzy regression analysis when the coefficient is described by trapezoidal fuzzy numbers depicting the fuzzy concept by using the gaussian membership function corresponding to human mind. To our knowledge, few researches are conducted on fuzzy regression analysis based on normal fuzzy numbers. Therefore, in this paper, we first calculate the least squares estimator of the fuzzy linear regression model, and then discuss statistical properties of the fuzzy least squares (FLS) estimator. Then, we give residuals, residual sum of squares and coefficient of determination and illustrate the fitting degree of the regression model. Last, we also verify the rationality and validity of the parameter estimation method by a numerical example (Fig. 1).
2 Preliminaries
Definition 1
([14]) If fuzzy number \(\tilde{A}\) has the following membership function
where R is a set of real numbers, then \(\tilde{A}\) is called a normal fuzzy number determined by a and \(\sigma ^2\), and thus denoted by \(\tilde{A}=(a,\sigma ^2)\).
Let \(\tilde{A}=(a, \sigma _a^2)\) and \(\tilde{B}=(b, \sigma _b^2)\), then three operations of the normal fuzzy numbers are defined as follows: (1) \(\tilde{A}+\tilde{B}=(a+b, \sigma _a^2+\sigma _b^2)\); (2) \(\lambda \tilde{A}=(\lambda a, \lambda \sigma _a^2)\); (3)\(\frac{1}{\tilde{A}}=(\frac{1}{a}, \frac{1}{\sigma _a^2})\), where \(a\ne 0\).
Definition 2
([15]) The expectation of fuzzy number \(\tilde{A}\) is
where \(\int ^{+\infty }_{-\infty }\tilde{A}(x)dx >0\). The average of \(\tilde{A}\) is denoted by the expectation \(E(\tilde{A})\) of fuzzy number \(\tilde{A}\). In particular, when \(\tilde{A}=(a,\sigma _a^2)\), \(E(\tilde{A})=a\).
Definition 3
([15]) The variance of fuzzy number \(\tilde{A}\) is
where \(\int ^{+\infty }_{-\infty }\tilde{A}(x)dx >0\). The spread of \(\tilde{A}\) is denoted by the variance \(D(\tilde{A}) \) of fuzzy number \(\tilde{A}\). In particular, when \(\tilde{A}=(a,\sigma _a^2)\), \(D(\tilde{A})=\frac{\sigma ^2}{2}\).
Definition 4
([15]) Multiplication between fuzzy numbers \(\tilde{A}\) and \(\tilde{B}\) is defined as:
when \(\tilde{A}=\tilde{B}\), and \(\tilde{A}\otimes \tilde{B}=\tilde{A}\otimes \tilde{A}=[\int _{\infty }^\infty \tilde{A}(x)dx]^2\), \(\tilde{A}\otimes \tilde{A}=||\tilde{A}||^2\) is called the module of \(\tilde{A}\).
Let \(\tilde{A}\) and \(\tilde{B}\) denote the fuzzy numbers \(\tilde{A}=(a, \sigma _a^2)\), and \(\tilde{B}=(b, \sigma _b^2)\) respectively, then
Specifically, when \(\tilde{A}=\tilde{B}\), \(\tilde{A}\otimes \tilde{A}=||\tilde{A}||^2 \).
Definition 5
([16]) Let \(\tilde{A}=(a, \sigma _a^2), \tilde{B}=(b, \sigma _b^2)\), then the distance between \(\tilde{A} \) and \(\tilde{B} \) is defined as:
3 The Least Squares Estimator of Fuzzy Linear Regression Model
The classical linear regression model is as follows:
where Y is explained as variable and \(X_1,X_2,\ldots , X_k\) are explanatory variables, \(\beta _0,\) \(\beta _1,\ldots , \beta _k\) are regression coefficients. Let\(\{(X_i,Y_i):i=1,2,\ldots , n\}\) be a set of sample observations, ordinary least squares estimation is frequently based on the fact that the overall error between the estimated \(\hat{Y}_i\) and the observations \(Y_i\) should be as small as possible. That is, the corresponding Q residual between the estimated \(\hat{Y}_i\) and the observations \(Y_i\) should be as small as possible. Symbolically,
According to the principle of differential and integral calculus, Q will be the minimum value when the first order partial derivative of Q about \(\beta _0,\) \(\beta _1, \ldots , \beta _k\) is equal to zero.
However, in many cases, the fuzzy relations in formula (5) must be considered. In general, there are the following three conditions [9]:
(a) \(\tilde{Y}_i=\beta _0+\beta _1 \tilde{X}_{1i}+\beta _2 \tilde{X}_{2i}+\cdots +\beta _k \tilde{X}_{ki},\beta _0, \beta _1, \ldots , \beta _k\in R, \tilde{X}_1, \ldots , \tilde{X}_k, \tilde{Y}_i \in \widetilde{F}(R), i=1, 2, \ldots , n;\)
(b) \(\tilde{Y}_i=\tilde{\beta }_0+\tilde{\beta }_1 X_{1i}+\tilde{\beta }_2 X_{2i}+\cdots +\tilde{\beta }_k X_{ki},\tilde{\beta }_0, \tilde{\beta }_1, \ldots , \tilde{\beta }_k, \tilde{Y}_i \in \widetilde{F}(R), {X}_1, \ldots , X_k \in R, i=1, 2, \ldots , n; \)
(c) \(\tilde{Y}_i=\tilde{\beta }_0+\tilde{\beta }_1 \tilde{X}_{1i}+\tilde{\beta }_2 \tilde{X}_{2i}+\cdots \tilde{\beta }_k \tilde{X}_{ki}, \tilde{\beta }_0, \tilde{\beta }_1, \ldots , \tilde{\beta }_k,\tilde{X}_1, \ldots , \tilde{X}_k, \tilde{Y}_i\in \widetilde{F}(R), i=1, 2, \ldots , n.\)
In fact, (b) is the most common conditions. For (b), we focus on the fuzzy linear regression model in which dependent variables are the form of real numbers and explanatory variables and the regression coefficients are the form of normal fuzzy numbers.
Theorem 1
Assume the fuzzy multiple linear regression model is as follows:
then
Let \(\varvec{a}=\varvec{X}\varvec{\psi }\), \(\varvec{b}=\varvec{X_1}\varvec{\zeta }\), where
where \(i=1, 2, \ldots , n; \tilde{\beta }_0, \tilde{\beta }_1, \ldots , \tilde{\beta }_k, \tilde{Y}\in \tilde{F}(R); X_{1}, X_{2}, \ldots , X_{k}\in R\). Then, the FLS of \(\tilde{\beta }_0, \tilde{\beta }_1, \ldots , \tilde{\beta }_k\) are defined as:
Proof
Assuming that \(\{(X_i, \tilde{Y}_i), i=1, 2, \ldots , n\}\) are the set of known samples, and \(\tilde{Y}_i=(a_i, \sigma _i^2)\), the sum Q of the squares of the dispersion between the estimated \(\hat{\tilde{Y_i}}\) and the observations \(\tilde{Y}_i\) should be minimized. That is,
should be minimized. \(\tilde{Q}\) will be the minimum value when the first order partial derivatives of Q about \(\hat{\tilde{\beta }}_0,\hat{\tilde{\beta }}_1, \ldots , \hat{\tilde{\beta }}_k\) are equal to zero. In this case, fuzzy ordinary least squares estimator can be calculated.
Then, the above equations can be simplified as
The matrix expression of the normal equations is as follows
And least squares estimator of parameters are as follows
\(\square \)
Corollary 1
Assume that the fuzzy simple linear regression model is as follows
that is
where \({\hat{\tilde{\beta }}_0}=(\hat{a}_{\tilde{\beta }_0}, \hat{\sigma }_{\tilde{\beta }_0}^2)\) and \({\hat{\tilde{\beta }}_1}=(\hat{a}_{\tilde{\beta }_1}, \hat{\sigma }_{\tilde{\beta }_1}^2)\) are respectively the FLS of \(\tilde{\beta }_0\) and \(\tilde{\beta }_1\). then
Proof
Let \({X_i, \tilde{Y_i}, i=1, 2, \ldots , n}\) be a set of sample observations and \(\tilde{Y_i}=(a_i, \sigma _i^2)\), according to Theorem 1, is revised as follows:
Obviously, \(\tilde{Q}\) will be minimized when the first order partial derivatives of \(\tilde{Q}\) about \(\hat{\tilde{\beta _0}}\), \(\hat{\tilde{\beta _1}}\) and are equal to zero. That is, we can solve the question by making the first order partial derivatives of \(\tilde{Q}\) about \(\hat{a}_{\tilde{\beta }_0}\), \(\hat{a}_{\tilde{\beta }_1}\), \(\hat{\sigma }_{\tilde{\beta }_0}^2\), \(\hat{\sigma }_{\tilde{\beta }_1}^2\) respectively equal to zero.
The above equations may be written as
Then, in terms of Cramer’s rule, we can obtain the linear fuzzy least squares estimator of the simple linear regression model by solving the above equations.\(\square \)
4 The Statistical Properties of Fuzzy Least Squares Estimator
Theorem 2
Fuzzy least squares estimator
is a linear estimator.
Proof
Since
where \(\varvec{C}=(\varvec{X}'\varvec{X})^{-1}\varvec{X}',\varvec{D}=(\varvec{X}'\varvec{X})^{-1}\varvec{X}'\) , the parameter estimator is a linear combination of explanatory variables.\(\square \)
In order to know statistic properties of the parameter estimator in simple fuzzy regression mode1, let \(x_i=X_i-\bar{X}\), where \(\bar{X}=\frac{1}{n}\sum \limits _{i=1}^n X_i\). When  , where \(\bar{a}=E(\frac{1}{n}\sum \limits _{i=1}^n \tilde{Y_i})=\frac{1}{n}\sum \limits _{i=1}^n E(\tilde{Y_i})=\frac{1}{n}\sum \limits _{i=1}^n a_i\), \(\bar{\sigma ^2}=Var(\frac{1}{n}\sum \limits _{i=1}^n \tilde{Y_i})=\frac{1}{n^2}\sum \limits _{i=1}^n Var(\tilde{Y_i})=\frac{1}{n^2}\sum \limits _{i=1}^n \sigma _i^2\), then
, where \(\bar{a}=E(\frac{1}{n}\sum \limits _{i=1}^n \tilde{Y_i})=\frac{1}{n}\sum \limits _{i=1}^n E(\tilde{Y_i})=\frac{1}{n}\sum \limits _{i=1}^n a_i\), \(\bar{\sigma ^2}=Var(\frac{1}{n}\sum \limits _{i=1}^n \tilde{Y_i})=\frac{1}{n^2}\sum \limits _{i=1}^n Var(\tilde{Y_i})=\frac{1}{n^2}\sum \limits _{i=1}^n \sigma _i^2\), then
that is
so
Corollary 2
Expectations \(\hat{ a}_{\tilde{\beta }_0}\) and \(\hat{ a}_{\tilde{\beta }_1}\) of fuzzy least squares estimator \(\hat{\tilde{\beta }}_0\,{=} (\hat{a}_{\tilde{\beta }_0},\hat{\sigma }^2_{\tilde{\beta }_0})\) and \(\hat{\tilde{\beta }}_1=(\hat{a}_{\tilde{\beta }_1},\hat{\sigma }^2_{\tilde{\beta }_1})\) are linear estimators.
Proof
where \(k_i=\frac{x_i}{\sum \limits _{i=1}^n x_i^2}\), \(\sum \limits _{i=1}^n x_i=0\);
where \(w_i=\frac{1}{n}-\bar{X}k_i\).\(\square \)
Theorem 3
Fuzzy least squares estimator
are unbiased estimators.
Proof
So fuzzy least squares estimators are unbiased.\(\square \)
Corollary 3
Expectations \(a_{\tilde{\beta }_0}\) and \(a_{\tilde{\beta }_1}\) of fuzzy least squares estimator \(\hat{\tilde{\beta }}_0\,{=}\,(\hat{a}_{\tilde{\beta }_0},\hat{\sigma }^2_{\tilde{\beta }_0})\) and \(\hat{\tilde{\beta }}_1=(\hat{a}_{\tilde{\beta }_1},\hat{\sigma }^2_{\tilde{\beta }_1})\) are unbiased estimators of the parameters \(\tilde{\beta }_0\), \(\tilde{\beta }_1\).
Proof
where \(k_i=\frac{x_i}{\sum \limits _{i=1}^n x_i^2}\), \(\sum \limits _{i=1}^n k_i= \frac{\sum \limits _{i=1}^n x_i}{\sum \limits _{i=1}^n x_i^2}=\frac{\sum \limits _{i=1}^n x_i}{\sum \limits _{i=1}^n x_i^2}=0\)
so \(E(\hat{a}_{\tilde{\beta }_1})=a_{\tilde{\beta }_1}\);
where, \(w_i=\frac{1}{n}-\bar{X}k_i\),\(E\left( \sum \limits _{i=1}^n w_i\right) =E\left( \sum \limits _{i=1}^n \left( \frac{1}{n}-\bar{X}k_i\right) \right) =1 \),
so \(E(\hat{a}_{\tilde{\beta }_0})=a_{\tilde{\beta }_0}\).\(\square \)
5 Assessment on Fuzzy Multiple Linear Regression Model
Regression analysis is a useful statistical method for analyzing quantitative relationships between two or more variables. It is important for the regression analysis to assess the performance of fitting regression model. That is to say, after estimating parameter of fuzzy liner regression model, how far is it from the parameter estimation to the true value? In fuzzy regression analysis, the simplest method evaluating the fuzzy regression model is to take the residual and the Coefficient of Determination as metrics. According to Classical Regression Mode [17], we can calculate the residual and the Coefficient of Determination about Fuzzy Regression Model by using fuzzy calculation rule which listed previously.
Theorem 4 give the module formula of residual \(|\check{e_i}|\) and require that it is as small as possible. The fuzzy total sum of squares(FTSS) and the fuzzy explained sum of squares(FESS) are given in Theorem 5, and we obtain fuzzy coefficient of determination \(\tilde{R}^2\) in Theorem 6, \(\tilde{R}\) is bigger, and more better.
Theorem 4
The residual produced by the fuzzy multiple linear regression model based on normal fuzzy numbers is defined as
Proof
\(\square \)
Corollary 4
The residual produced by the fuzzy simple linear regression model based on normal fuzzy numbers is expressed as
Proof
\(\square \)
Theorem 5
The residual sum of squares produced by the fuzzy multiple linear regression model based on normal fuzzy numbers is defined as
The explained sum of squares produced by the fuzzy multiple linear regression model based on normal fuzzy numbers is defined as
Proof
Corollary 5
The residual produced by the fuzzy simple linear regression model based on normal fuzzy numbers is expressed as
The explained sum of squares produced by fuzzy simple linear regression model based on normal fuzzy numbers is defined as
Proof
\(\square \)
The greater the regression sum of squares, the smaller the sum of squared residuals, and the better the fitting between regression line and the sample points.
Theorem 6
The coefficient of determination of the fuzzy multiple linear regression model based on normal fuzzy numbers is defined as
Proof
It is easy to prove Theorem 6 by using Theorem 5.\(\square \)
Corollary 6
The coefficient of the determination of fuzzy simple linear regression model based on normal fuzzy numbers is expressed as
6 Numerical Example
Assume that the fuzzy linear regression model is as follows:
where, \(\tilde{Y}\) is the dependent variable, \(X_1\) and \(X_2\) the explanatory variables, and \((X_{1i},X_{2i},\tilde{Y_i}), i=1, 2, \ldots , n, X_1, X_2\in R, \tilde{Y}\in \tilde{F}(R)\). Now, our goal is to solve the fuzzy regression and evaluate the model with the observed data shown in Table 1.
Then, the fuzzy regression mode can be obtained by our proposed method.
Residual series of the regression model are shown in Table 2. According to the formulas in Theorem 5, we can calculate the evaluation indexes of the fuzzy model i.e., \(FTSS=7.2531\), \(FESS=6.9836\), and \(\tilde{R}^2=0.9628\). Clearly, the uncertainty of the practical problem is better considered by the fuzzy linear regression analysis. Using fuzzy numbers to represent the observation data makes it more effective to resolve the problem. In this example, the residual sequence of the regression model and the coefficient of determination help to understand how well the regression model can fit the sample points. The coefficient of determination \(96.28\,\%\) implies that the change \(96.28\,\%\) of the explained variable can be explained by the change of explanatory variables.
7 Conclusions
The paper proposes an improved FLS method for parameter estimating of the fuzzy linear regression model when the explanatory variables are precise and the explained variables and regression parameters are normal fuzzy numbers. Specifically, the paper figures out the fuzzy least squares estimation of multivariate linear regression analysis and gets some statistical properties, i.e., linearity and unbiasedness, of the fuzzy least square estimators. Finally, it illustrates the feasibility and effectiveness of the proposed method by the numerical example.
References
Zhang, A.W.: Statistical analysis of fuzzy linear regression model based on centroid method. J. Fuzzy Syst. Math. 5, 172–177 (2012)
Tanaka, H., Uejima, S., Asai, K.: Linear regression analysis with fuzzy model. J. Syst. Man Cyber. 12, 903–907 (1982)
Diamond, P.: Fuzzy least squares. J. Inf. Sci. 46, 141–157 (1988)
Chang, Y.H., Ayyub, B.M.: Fuzzy regression methods–a comparative assessment. J. Fuzzy Sets Syst. 119, 187–203 (2011)
Chang, Y.H.: Hybrid fuzzy least-squares regression analysis and its reliability measures. J. Fuzzy Sets Syst. 119, 225–246 (2011)
Sakawa, M., Yano, H.: Multiobjective fuzzy liear regression analysis for fuzzy input-out data. J. Fuzzy Set Syst. 157, 137–181 (1992)
Zhang, A.W.: Parameter estimation of the fuzzy regressive model with lr typed fuzzy coefficients. J. Fuzzy Syst. Math. 27, 140–147 (2013)
Zhang, A.W.: A least-squares approach to fuzzy regression analysis with trapezoidal fuzzy number. J. Math. Pract. Theory 42, 235–244 (2012)
Parvathi, R., Malathi, C., Akram, M.: Intuitionistic fuzzy linear regression analysis. J. Fuzzy Optim. Decis. Mak. 2, 215–229 (2013)
Xu, R.N., Li, C.L.: Multidimensional least squares fitting with a fuzzy model. J. Fuzzy Sets Syst. 119, 215–223 (2001)
Cope, R., D’Urso, P., Giordani, P., et al.: Least squares estimation of a linear regression model with LR fuzzy response. J. Comput. Stat. Data Anal. 51, 267–286 (2006)
Bisserier, A., Boukezzoula, B., Galichet, S.: Linear Fuzzy Regression Using Trapezoidal Fuzzy Intervals. I PMU, Malaga (2008)
Liang, Y., Wei, L.L.: Fuzzy linear least-squares regression with LR-type fuzzy coefficients. J. Fuzzy Syst. Math. 3, 112–117 (2007)
Peng, Z.Y., Sun, Y.Y.: The Fuzzy Mathematics and Its Application. Wuhan University Press, Wuhan (2007)
Li, A.G., Zhang, Z.H., Meng, Y., et al.: Fuzzy Mathematics and Its Application. Metallurgical Industry Press, Beijing (2005)
Xu, R.N.: Research on time series prediction problem with the normal fuzzy number. J. J. Guangzhou Univ. 12, 82–89 (1988)
Li, Z.N.: Econmetrics. Higher Education Press, Beijing (2012)
Acknowledgments
This work is supported in part by the Science and Technology Department of Henan Province (Grant No. 152300410230) and the Key Scientific Research Projects of Henan Province (Grant No. 17A110040).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing Switzerland
About this paper
Cite this paper
Gu, CL., Wang, W., Wei, HY. (2017). Regression Analysis Model Based on Normal Fuzzy Numbers. In: Fan, TH., Chen, SL., Wang, SM., Li, YM. (eds) Quantitative Logic and Soft Computing 2016. Advances in Intelligent Systems and Computing, vol 510. Springer, Cham. https://doi.org/10.1007/978-3-319-46206-6_46
Download citation
DOI: https://doi.org/10.1007/978-3-319-46206-6_46
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-46205-9
Online ISBN: 978-3-319-46206-6
eBook Packages: EngineeringEngineering (R0)