
Abstract
In this paper, a Heuristic-Crossover Enhanced Evolutionary Algorithm for Cluster Head Selection is proposed. The algorithm uses a novel heuristic crossover operator to combine two different solutions in order to achieve a high quality solution that distributes the energy load evenly among the sensor nodes and enhances the distribution of cluster head nodes in a network. Additionally, we propose the Stochastic Selection of Inactive Nodes, a mechanism inspired by the Boltzmann Selection process in genetic algorithms. This mechanism stochastically considers coverage effect in the selection of nodes that are required to go into sleep mode in order to conserve energy of sensor nodes. The proposed selection of inactive node mechanisms and cluster head selections protocol are performed sequentially at every round and are part of the main algorithm proposed, namely the Heuristic Algorithm for Clustering Hierarchy (HACH). The main goal of HACH is to extend network lifetime of wireless sensor networks by reducing and balancing the energy consumption among sensor nodes during communication processes. Our protocol shows improved performance compared with state-of-the-art protocols like LEACH, TCAC and SEECH in terms of improved network lifetime for wireless sensor networks deployments.
S. Dudley—Member of the Institute of Electrical and Electronics Engineers(MIEEE).
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
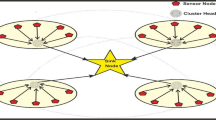
Recent advances in Micro-Electro-Mechanical Systems (MEMS) have led to the development of autonomous and self-configurable wireless sensor nodes that are densely deployed throughout a spatial region [1]. These sensor nodes have the capability to sense any event or abnormal environmental conditions such as motion, moisture, heat, smoke, pressure etc. in form of data. A large number of these sensors can be networked and deployed in remote and inaccessible areas, hence providing a wireless sensor network (WSN) connectivity. WSNs are usually composed of small, inexpensive and battery-powered wireless sensor nodes. In fact, WSNs have contributed tremendously to a number of military and civil applications such as target field imaging, event detection, weather monitoring, security and tactical surveillance. However, sensor nodes are constrained by energy supply and bandwidth. Such constraints combined with a typical deployment of large number of sensor nodes pose many challenges to the design and management of WSNs and necessitate energy-awareness at all layers of the networking protocol stack [2]. Thus, innovative techniques that eliminate energy inefficiencies that would shorten the lifetime of the network are required. In this work, we present a solution that balances the consuming energy among sensor nodes in order to prolong the network lifetime. The energy balance is done using two mechanisms; firstly, a genetic algorithm (GA) for cluster heads (CHs) selection was used to ensure that well distributed nodes with higher energy will be selected as CHs. Secondly, a mechanism inspired by Boltzmann selection was utilized to select nodes to send into sleep mode without causing an adverse effect on the coverage.
Most existing routing protocols designed to tackle the above challenges are broadly classified into two classes, namely flat and hierarchical. Flat protocols include the old-fashion Direct Transmission (DT) and Minimum Transmission Energy (MTE), which cannot promise a balanced energy distribution among sensors in a WSN. The drawback of the MTE is that a remote sensor uses a relay sensor for data transmission to the sink and this makes the relay sensor the first to die. In the DT, sensors communicate directly with the sink and this causes the remote sensor to die first. Therefore designing energy-efficient clustering protocols becomes a major factor for sensor lifetime extension. Generally, clustering protocols can outperform flat protocols in balancing energy consumption and network lifetime prolongation by adopting data aggregation mechanisms [3, 4]. Theoretically, there are three types of nodes: the cluster-head (CH), member node (MN) and sink node (SN). The member node is responsible for sensing the raw data and employs Time Domain Multiple Access (TDMA) scheduling to send the raw data to the cluster head. The main role of the CH is to aggregate data received from MN and thereby forwards the aggregated data to the SN through single-hop or multi-hop. CHs selection can either be done by the sensors themselves, by the SN or pre-determined by the wireless network designer. In this paper, CH selection is done by the SN because the SN has enough energy and can perform complex calculations. The CH selection problem can be viewed as an optimisation problem where the methods have used GA to solve. From that end, we define an objective function to access the individual solution and propose a novel heuristic crossover that is enhanced by the knowledge of our problem.
In this paper, a Heuristic Algorithm for Clustering Hierarchy (HACH) protocol has been developed and it has two mechanisms namely the Heuristic-Crossover Enhanced Evolutionary Algorithm for Cluster Head Selection (HEECHS) and Stochastic Selection of Inactive Nodes (SSIN) mechanisms. HEECHS exploits our knowledge of the problem to develop an effective heuristic crossover that combines genetic material in a unique way to produce improved CHs configuration. This process bears some similarity to a form of optimisation algorithm called Memetic Algorithms (MAs). MAs are a class of stochastic global search heuristics in which Evolutionary Algorithms-based approaches are combined with local search techniques to improve the quality of the solutions created by evolutions [5]. The (SSIN), a mechanism inspired by Boltzmann selection process in GA was used to reduces the number of active nodes in each round by sending some nodes to sleep or inactive mode to conserve energy and extend the network lifetime without adversely affecting coverage. These two mechanisms work collaboratively to maximize network lifetime by balancing energy consumption amongst sensor nodes during the communication process. The balance in energy consumption is achieved by selecting spatially distributed nodes with higher energy as CHs and also sending some nodes into sleep mode without causing an adverse effect on coverage. Protocol presented is a more energy efficient protocol compared with other protocols that employ GA in the sense that it integrates knowledge of the problem into the GA crossover operator.
The remainder of this study is organised as follows. Section 2 discusses related work on the application of genetic algorithms in energy-efficient wireless sensor networks. Section 3 describes the network and radio model underlying the protocol presented. In Sect. 4 we describe our proposed algorithm under three major stages namely the proposed selection mechanism, clustering algorithm and the energy consumption calculation. Section 5 presents our experimental settings, performance measures, result and discussion. Finally, a conclusion is provided in Sect. 6.
2 Related Work
Recently, research interests in the area of energy-efficient wireless sensor network has tends towards energy efficient clustering protocols [6–9]. The Low-Energy Adaptive Clustering Hierarchy (LEACH) assumes that the energy of each sensor node is the same at the time of CH selection and non-CH selection. The selection process is carried out probabilistically. The role of the CH is to aggregate data received from its members within its cluster and pass the aggregated data directly to the sink. Problems with this protocol are that the location of the selected CH might be far away from the sink, so it consumes more energy when transmitting to the sink and this can lead to CH nodes to dying faster than other nodes [4]. A two-level LEACH (TL-LEACH) proposed in [10], adds another level to the cluster whereas LEACH that has only one level. This extra level reduces energy consumption most especially for CH far away from the sink. The hybrid energy efficient distributive (HEED) protocol [11] selects CHs using residual energy and the least amount of energy dissipated for communication between the CHs and non-CHs. Data are sent to the sink using a multi-hop communication approach.
In Topology-Controlled Adaptive Clustering (TCAC) protocol [12], a large number of nodes consider themselves candidates for CH nodes and inform other nodes. Each of the candidate CH nodes checks whether the other candidate CH nodes have a higher residual energy level or not. If there are none with higher residual energy, the highest announces itself as the CH. Non-CH nodes select the CH that has the minimum cost distance between itself and the CH to the sink. The TCAC balances the size of the cluster and send the data directly to the sink from the CH. In the scalable energy efficient clustering hierarchy (SEECH) protocol [13], the network nodes are divided into three layers namely the member nodes, CH nodes and relays. Clusters are formed based on centrality of the CH node with minimum intra-cluster energy distribution. A closer node to the sink in a cluster is often selected as the relay node. The relay node helps the CH node to transmit aggregated data to the sink through hop or multi-hop communication.
In [14] a genetic algorithm based energy efficient cluster (GABEEC) protocol that uses static clustering with dynamic CH selection was described. At the end of each round, an associate member node becomes a CH and this decision is based on the residual energy of the current CHs and the average energy of all members in the cluster. A Genetic algorithm approach was used to minimize the communication distance and maximize the lifetime of the network. In [15], a centralized energy-aware cluster-based protocol was discussed to extend the sensor network lifetime by using Optimization (PSO) algorithms. A new cost function that simultaneously takes into account the maximum distance between the non-CH node and its CH, and the remaining energy of CH candidates in the CH selection algorithm was defined.
3 Network and Radio Model
In the proposed HACH protocol, the following assumptions of the network model are assumed:
-
The data sink is a stationary and resource-rich device that is placed far away from the sensing field.
-
All sensor nodes are homogeneous in terms of energy and are stationary after deployment.
-
All sensors have GPS or other location determination devices
-
Nodes located close to each other have correlated data.
-
Nodes are capable of acting in inactive mode or a low power sleeping mode.
-
The communication channel is symmetric (i.e., the energy required to transmit a message from sensor node s1 to sensor node s2 is the same as energy required to transmit a message from node s2 to node s1 for a given signal to noise ratio).
For fair comparison with previous protocols [4, 16, 17], we assume the simple model shown in Fig. 1 for the radio hardware energy dissipation where the transmitter dissipates energy \(E_{Tx}(k,d)\) to run the radio electronics and the power amplifier, and the receiver dissipates energy \(E_{Rx}(k)\) to run the radio electronics. For the experiments described here, both the free space (\(d^2\) power loss) and the multipath fading (\(d^4\) power loss) channel models were used, depending on the distance (d) between the transmitter and receiver. The power amplifier is appropriately set in such a way that if the distance is less than a threshold distance, the free space (fs) model is used; otherwise, the multipath (mp) model is used. Thus, to transmit a k-bit message at distance d, the radio expends:
And to receive k-bit message, the radio expends:
where \(d_{0}\)=\(\sqrt{\varepsilon _{fs}/\varepsilon _{mp}}\) denotes the threshold distance and the electronics energy, \(E_{elect}\) depends on factors such as the digital coding, modulation, filtering, and spreading of the signal, whereas the amplifier energy, \(\varepsilon _{mp}\) or \(\varepsilon _{fs}\) depends on the distance to the receiver and the acceptable bit-error rate.

Radio Energy Dissipation Model
4 The Proposed Protocol: HACH

This protocol performs three sequential operations: sending nodes to sleep, clustering and network operations. At the set-up phase of the algorithm, the sink transmits control packets in order to receive node information in terms of the nodes ID, location and energy. The proposed SSIN protocol helps to dynamically select which nodes to send to sleep by initially generating a candidate list. The candidates list is populated with nodes that have energy smaller than the average energy of all nodes. Using a stochastic process, only a small number of nodes is sent into sleep mode in the candidate list without causing an adverse on the coverage. CH selection using HEECHS is then performed on the nodes that are kept active. In this work, the authors formulated clustering as an optimisation problem that is best addressed using GA. The genetic operators used in this approach are the tournament selection, heuristic crossover and mutation operator. The best CH configuration that ensures balanced energy consumption across the networks is selected at every network operation round. At the end of each round, the residual energy of each node is computed. This value is then used to compute the average energy for the next round and this cycle continues until all nodes are dead as shown in Algorithm 1.

Illustration of nodes to sleep on coverage area
4.1 Inactive Node Selection Using SSIN
The SSIN makes decisions on which nodes to send into inactive mode at the beginning of each network operation round. The candidate list of sleeping nodes is built up by checking the residual energy of nodes that are less than the computed average energy. This inactive node selection mechanism is synonymous to the Boltzmann selection process whereby a method is adopted for controlling the selection pressure [18]. In Boltzmann selection, the temperature parameter is varied in order to control the selection pressure. In this work, the maximum coverage effect, \(Max_{eff}\) is used to control the effect of putting nodes to sleep on the WSNs, which is defined as:
where \(R_s\) is the sensing range of a sensor node (taking the coverage area as a circle with radius \(R_s\)), \((pi\times R_s^2)\) signifies the coverage of one node and the value \('2'\) represents coverage of two nodes.
The effect of putting a node to sleep based on the coverage is defined by the coverage effect \(C_{eff}\) as shown in Fig. 2. The total coverage effect is calculated by invoking a matrix called the Coverage Matrix. The coverage matrix captures the overlapped areas of nodes coverage which allows the identification of nodes that can be sent into sleep mode without affecting coverage as there will be other nodes covering part of the selected node’s area. The accumulated Coverage effect \(Acc_{eff}\) is defined as the total effect on the coverage as a result of allowing some nodes to sleep. Our algorithm is designed in such a way that the \(Acc_{eff}\) value is expected to be less than the \(Max_{eff}\) for optimum coverage (\(Acc_{eff}<Max_{eff}\)). The probability that a node will be added to the sleeping node list can be computed using:
A randomly generated number is compared with the computed probability, P. A candidate list of inactive node is created if the random number is less than the probability, P. The accumulated frequency \(Acc_{eff}\) is computed by adding its current value to coverage effect \(C_{eff}\) value. The operations of SSIN continues until the \(Acc_{eff}\) is greater than the maximum acceptable coverage effect, \(Max_{eff}\) as shown in Algorithm 2.

4.2 Cluster Heads Selection Using HEECHS
Our clustering algorithm involves the task of CH selection and membership association. The proposed HEECHS protocol is developed for the CH selection task using a heuristic-based GA. Similar to conventional GA, it runs through a cycle of tasks such as the creation of population strings, evaluation of each string, selection of the best strings and reproduction to create a new population. The significant difference is that it uses a problem-dependent knowledge-based heuristic crossover to find the best CH configuration with the optimum number of well distributed CH nodes. The population, P(t) comprises of individuals with binary representation of 0 s or 1s. This represents CH individuals with size \(p_{s}\) and each individual CH has length \(N_{s}\) that is evaluated by computing the fitness value using Eq. 6. Individual CHs with the best fitness value are selected from two randomly selected parent population, \(P_{x}(t)\) and \(P_{y}(t)\) and this continues until the mating pool is filled. Our proposed heuristic crossover is applied to mate the individuals in the pool and subsequently produce a new population of \(P(t+1)\). Again, the fitness value of each individual in this new population is computed using Eq. 6 and the whole cycle continues until the stopping criterion is achieved. Stopping criterion is achieved when the average fitness of the population does not change further.
Proposed Heuristic Crossover. The core component of the proposed HEECHS is the heuristic crossover and this term simply means a unique form of crossover that uses the knowledge of a problem to combine two candidate solution in order to produce an offspring. A heuristic crossover operator was proposed by Lixin Tang [19] as an operator which utilizes the parents implicit information to produce offspring. In a conventional GA, the selected members of a population are paired, and some two parents undergo crossover to produces pairs of offspring that tends to substitute the parents. Heuristic crossover operator produces only one child from two or more parents, which differs from the canonical approach. Also in the canonical approach, there is no guarantee that an offspring produced would be better than the mating parent [20].
The proposed crossover produces individuals with CH configurations that are well distributed across the sensing field and favors the ones with higher energy. We can see from the Algorithm 3 that the proposed crossover does not allow two CHs to be selected within the same region and gives selection priority to the CH with higher energy. Two individuals are selected from the parent pool and the position of CH genes inside each individual is computed. Each individual has its own array set of CH positions, which is denoted by \(CH_{1}\) and \(CH_{2}\). We choose to define the threshold distance between any two neighbouring CH position as \(\frac{\sqrt{(x_{max}-x_{min})^2+(y_{max}-y_{min})^2}}{n\times 0.04}\), where the (\(x_{min},y_{min}\)) and (\(x_{max},y_{max}\)) are minimum and maximum xy-coordinates of the sensor fields respectively, (\(n\times 0.04\)) represent 4 % of the total sensor nodes. The union of \(CH_{1}\) and \(CH_{2}\) is represented by \(CH_{all}=CH_{1}\cup CH_{2}\). By default, the first CH position \(CH_{all}(1)\) in the set \(CH_{all}\) is transferred to a newly created set \(CH_{new}\). Each subsequent CHs position in the \(CH_{all}\) is compared with the \(CH_{new}\) array set in order to ensure decisions based on distance between the CHs and their residual energy (E) as shown in Algorithm 3.

Proposed Objective Functions. In order to solve the CH selection problem, there is a need to develop objective functions because CH selection is dealt with as an optimisation problem. This objective function returns a fitness value which is used to access the quality of a candidate solution. The objective functions is derived by considering the parameters such as the energy of all sensor nodes and the Risk penalty R. The reason for considering the energy parameter of sensor nodes is to ensure that nodes with greater energy are given higher priority in CHs selection.
The Risk penalty, R for the CH selection is defined as:
where Lower and Upper are calculated as the 4 % and 6 % of total number all sensor nodes in the field (n) respectively. R imposes restrictions on the number of CHs (L).
Therefore, the objective function is computed as:
Where \(w_1\) and \(w_2\) are the weighting factors; the average energy of non-CHs and CHs is given by \(AvgENCH=\dfrac{\sum _{i{\varepsilon }NCH}E_{i}}{n-L}\) and \(AvgECH=\dfrac{\sum _{i{\varepsilon }CH}E_{i}}{L}\) respectively. The ratio \(\dfrac{AvgENCH}{AvgECH}\) is assigned a higher weighting factor (\(w_{1}\)=0.9) than the Risk penalty, R (\(w_{2}\)=0.1) because much emphasis is placed upon it. (Note: CH and NCH represent the set of all CHs and non-CHs respectively).
Other Operators. Crossover and mutation provide exploration, compared with the exploitation provided by selection. The effectiveness of GA depends on the trade-off between exploitation and exploration [21, 22].
The tournament selection operator is used to randomly choose a group of individuals from the current population, and the one with the best fitness is selected. The tournament size determines the extent of selection pressure. In this work, a tournament size of two is used in order to reduce the selection pressure. This process is repeated as often as desired (usually until the mating pool is filled).
The mutation operator alters one individual (parent), to produce a single new individual (child) with a probability of mutation (\(p_{m}\)).
The initial population pool (parents) and offspring individuals that was generated in the previous step are sorted in ascending order based on the objective function values. Then the first CH chromosomes with minimum objective function values are selected to form the population pool for the next generation.
The stopping criterion is met when the objective function value of the population does not change further.
4.3 Network Operations and Energy Consumption Computation
Energy consumption at each round can be explained with regards to the two phases in the algorithm such as the set-up phase and the steady state phase.
Set-up Phase. The set-up phase involves the transmission and reception of control packets \(k_{CP}\) from the sink to all nodes to initialise inter- and intra-communication. In the set-up phase, the sink sends a control packet which contains a short message to wake up and request IDs, positions and energy levels of all sensor nodes in the sensor field. As in Eq. 2, the energy \(E_{Rx}(k_{CP})\) is dissipated when control packets are received from the sink. All sensors report their IDs, positions and energy levels back to the sink. Also, as in Eq. 1, energy \(E_{Tx}(k_{CP},d)\) is consumed when transmitting control packets \(k_{CP}\) to the sink. The control packets received from all sensor nodes is processed by the sink in order to make the following vital decision; which nodes to keep active, CH selection, and the associated CH membership. Energy \(E_{Rx}(k_{CP})\) is also dissipated for receiving the membership status information from the sink. The energy required for all CHs to transmit the TDMA schedules to their members can be computed using:
Also the energy spent by each member node to receive the TDMA schedule from the CH can also be computed using Eq. 2.
Steady Phase. During the steady phase, the active sensor nodes start sending data packets k. Each node sends the sensed data to its CH according to the TDMA schedule received. The CH nodes receiver must always be ready to receive packets from its node within its cluster. Data aggregation is performed on all received data at the CH and data are converted into a single data stream. This aggregated data is transmitted from the CH to the sink. During the process the sensor node transceiver consumes energy calculated by Eq. 9. The total amount of energy spent by all member nodes to transmit to their respective CHs is computed using:
Where \(m_{i}\) denotes the member nodes, which ranges from \(i=1,2,3,...,n-L\). Also, the energy dissipated by the CH for aggregating data received from all its members and itself can be calculated using:
Finally, the amount of energy spent by the CH node to transmit to the sink is computed using:
Total Energy Dissipated. In our algorithm, the total energy dissipated by all the CHs can be computed using:
And the energy dissipated by the member nodes is computed as:
Therefore, the overall energy dissipated by all nodes is represented by \(E_{TOTAL}=E_{CHs}+E_{Mem}\). (Note: Residual energy \(E_{Res}\) of individual node at each round can be computed by subtracting the energy consumption from the current residual energy.
5 Experimental Results
In this work, we evaluate protocols from an energy efficiency perspective by examining the number of nodes alive versus rounds. With the aid of MATLAB tools, a simulation model was developed to test the proposed algorithm and graph results are generated to evaluate the lifetime of the sensor nodes. The proposed technique is scalable and it may lead to energy efficiency improvements across various network topologies. To assess this claim the performance of HACH is compared to three other protocols LEACH, TCAC and SEECH across three scenarios with different network sizes; small, medium and large. Table 1 describes the parameters of proposed scenes in details.
5.1 Experimental Settings
The common communication parameters used for all three experiments presented in Table 1 below are the electronic energy, \(E_{elect}\) =50 nJ/bit, free space loss \(\varepsilon _{fs}\)=10 pJ/bit/\(m^2\), multipath loss, \(\varepsilon _{mp}\)=0.0013 pJ/bit/\(m^4\), threshold distance, \(d_{0}\)=87m, data aggregation energy \(E_{DA}\)= 5 nJ/ bit/signal, packet size k=4000, and control packet size, \(k_{CP}\)=50. The GA parameters are set as population size, \(p_{s}\)=100 and mutation rate, \(p_{m}\)= 0.05.
5.2 Performance Measures
There are many metrics used to evaluate the performance of clustering protocols [19]. These measures again are used in this paper to evaluate the performance of HACH protocol:
-
1.
First Dead Node (FDN): This is the number of rounds after which the first node dies. It can also refer to the operational lifetime or stability period of the network.
-
2.
Last Dead Node (LDN): This is the number of rounds from the start of network operation until the last node dies.
-
3.
Instability Period Length (IPL): The round difference between the round at which the last node dies and the first node dies. (i.e. \(IPL=LND-FND\)).
-
4.
Average Energy at First Node Dies (AEFND): The average energy of all sensor nodes when the first node dies.
Clearly, the longer the stability period and the shorter the instability period are, the more reliable the clustering process of the wireless sensor network.

Network Lifetime Comparison of HACH with LEACH, SEECH, TCAC
5.3 Results and Discussion
The values presented in this section are the averaged results obtained from 100 simulation runs. In each simulation run, a new set of sensor nodes was distributed to a network area. Experimental results shown in Fig. 3 depicts the number of alive nodes after each round. For a summarized comparison FND, LND, and IPL measures belonging to the graphs are presented in Table 2. Experiment I (100 nodes) shows that the HACH protocol maintains the network operational lifetime of 36, 131 and 338 more than the SEECH, TCAC and LEACH respectively. The energy of the sensor nodes are balanced until the FND times and this is observed on the graph by a sharp decrease in the number of alive nodes for the TCAC, SEECH and HACH.

Average Energy of alive node versus Rounds (refer to Experiment I)
When the FND is achieved or during the IPL, lots of nodes begin to die due to the limited residual energy. The IPL values of various protocols are shown in Table 2 with HACH having a very low IPL values in Experiment II(400 nodes) and III (1000 nodes) except in Experiment I which has 30 rounds more than TCAC. This shows that our algorithm performs better in a dense network. Using our proposed HACH protocol, the AEFND values for Experiments I,II and III are shown in Table 3. It can be observed that the AEFND value for each of the three experiments is approximately zero at the time the first node dies. For example, Fig. 4 shows that at FND time of 1064, the AEFND of sensor nodes is 0.0232J: which means we were able to used almost all of our initial energy till the death of first node.
From the above, it can be deduced that the proposed HACH decrease in energy consumption and energy balancing can increase the network lifetime. At each round, our proposed HACH protocol conserves energy by selectively allowing some nodes to become inactive before network operation. Also, it uses an adaptive heuristic approach to select the best CHs configuration by ensuring that CH are optimally distributed over the sensor field.
6 Conclusion
In this paper, a Heuristic Algorithm for Clustering Hierarchy (HACH) protocol was proposed where the major two operations included sending some nodes into sleep mode and the cluster head selection. We proposed the Heuristic-Crossover Enhanced Evolutionary Algorithm for Cluster Head Selection protocol (HEECHS), a mechanism that employs genetic algorithms for a cluster head selection that balance energy consumption and enhances better distribution of cluster heads. To achieve the selection process, an objective function to access the quality of each solutions was designed. A problem-dependent heuristic crossover to produce a better cluster head configuration was implemented. Also, we employed a new mechanism called Stochastic Selection of Inactive Node (SSIN) inspired by Boltzmann selection process to stochastically select some nodes to send into sleep without causing an adverse effect on coverage. The two proposed mechanisms work collaboratively to reduce and balance energy consumption by selecting distributed nodes with high energy as cluster heads in order to prolong network lifetime. From the three experiments, simulation results demonstrated that our proposed HACH outperforms other protocol in terms of energy consumption, network lifetime and stability period in all the three experiments.
References
Naeimi, S., Ghafghazi, H., Chow, C.-O., Ishii, H.: A survey on the taxonomy of cluster-based routing protocols for homogeneous wireless sensor networks. Sensors 12(6), 7350–7409 (2012)
Chakraborty, A., Mitra, S.K., Naskar, M.K.: Energy efficient routing in wireless sensor networks: A genetic approach. CoRR abs/1105.2090 (2011)
Abbasi, A.A., Younis, M.: A survey on clustering algorithms for wireless sensor networks. Comput. commun. 30(14), 2826–2841 (2007)
Heinzelman, W.B., Chandrakasan, A.P., Balakrishnan, H.: An application-specific protocol architecture for wireless microsensor networks. IEEE Trans. Wirel. Commun. 1(4), 660–670 (2002)
Hart, W.E., Krasnogor, N., Smith, J.E.: Recent Advances in Memetic Algorithms, vol. 166. Springer Science & Business Media, Heidelberg (2005)
Kang, S.H., Nguyen, T.: Distance based thresholds for cluster head selection in wireless sensor networks. IEEE Commun. Lett. 16(9), 1396–1399 (2012)
YeMao, L., Fa, C., Hai, W.: An energy efficient clustering scheme in wireless sensor networks. Ad Hoc & Sensor Wireless Networks (to be published)
Dimokas, N., Katsaros, D., Manolopoulos, Y.: Energy-efficient distributed clustering in wireless sensor networks. J. parallel Distrib. Comput. 70(4), 371–383 (2010)
Lin, S., Zhang, J., Zhou, G., Lin, G., Stankovic, J.A., He, T.: Atpc: adaptive transmission power control for wireless sensor networks. In: Proceedings of the 4th international conference on Embedded networked sensor systems, pp. 223–236 (2006)
Loscri, V., Morabito, G., Marano, S.: A two-levels hierarchy for low-energy adaptive clustering hierarchy (tl-leach). In: IEEE Vehicular Technology Conference, vol. 62, pp. 1809. IEEE; 1999 (2005)
Younis, O., Fahmy, S.: Heed: a hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Trans. Mobile Comput. 3(4), 366–379 (2004)
Dahnil, D.P., Singh, Y.P., Ho, C.K.: Topology-controlled adaptive clustering for uniformity, increased lifetime in wireless sensor networks. IET Wirel. Sens. Syst. 2(4), 318–327 (2012)
Tarhani, M., Kavian, Y.S., Siavoshi, S.: Seech: scalable energy efficient clustering hierarchy protocol in wireless sensor networks. IEEE Sens. J. 14(11), 3944–3954 (2014)
Bayrakli, S., Erdogan, S.Z.: Genetic algorithm based energy efficient clusters (gabeec) in wireless sensor networks. Procedia Comput. Sci. 10, 247–254 (2012)
Latiff, N.M., Tsimenidis, C.C., Sharif, B.S.: Energy-aware clustering for wireless sensor networks using particle swarm optimization. In: Personal, Indoor and Mobile Radio Communications, PIMRC 2007. IEEE 18th International Symposium on, pp. 1–5. IEEE (2007)
Liu, J.-L., Ravishankar, C.V., et al.: Leach-ga: genetic algorithm-based energy-efficient adaptive clustering protocol for wireless sensor networks. Int. J. Mach. Learn. Comput. 1(1), 79–85 (2011)
Go, K.: An amend implementation on leach protocol based on energy hierarchy. Int. J. Curr. Eng. Technol. 2(4), 427–431 (2012)
Dumitrescu, D., Lazzerini, B., Jain, L.C., Dumitrescu, A.: Evolutionary Computation. International Series on Computational Intelligence. Taylor & Francis, New York (2000)
Lixin, T.: Improved genetic algorithms for tsp. J. Northeastern Univ. (Nat. Sci.), p. 01 (1999)
Hasan, B.S., Khamees, M., Mahmoud, A.S.H., et al.: A heuristic genetic algorithm for the single source shortest path problem. In: Computer Systems and Applications, AICCSA 2007. IEEE/ACS International Conference on, pp. 187–194 (2007)
Halke, R., Kulkarni, V.A.: En-leach routing protocol for wireless sensor network. Int. J. Eng. Res. Appl. 2(4), 2099–2102 (2012)
Brunda, J.S., Manjunath, B.S., Savitha, B.R., Ullas, P.: Energy aware threshold based efficient clustering (eatec) for wireless sensor networks. Energy, 2(4) (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Oladimeji, M.O., Turkey, M., Dudley, S. (2016). A Heuristic Crossover Enhanced Evolutionary Algorithm for Clustering Wireless Sensor Network. In: Squillero, G., Burelli, P. (eds) Applications of Evolutionary Computation. EvoApplications 2016. Lecture Notes in Computer Science(), vol 9597. Springer, Cham. https://doi.org/10.1007/978-3-319-31204-0_17
Download citation
DOI: https://doi.org/10.1007/978-3-319-31204-0_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-31203-3
Online ISBN: 978-3-319-31204-0
eBook Packages: Computer ScienceComputer Science (R0)